

Abstract
Humans stand out among animals for their unique capacities in domains such as language, culture and imitation, yet it has been difficult to identify cognitive elements that are specifically human. Most research has focused on how information is processed after it is acquired, e.g. in problem solving or ‘insight’ tasks, but we may also look for species differences in the initial acquisition and coding of information. Here, we show that non-human species have only a limited capacity to discriminate ordered sequences of stimuli. Collating data from 108 experiments on stimulus sequence discrimination (1540 data points from 14 bird and mammal species), we demonstrate pervasive and systematic errors, such as confusing a red–green sequence of lights with green–red and green–green sequences. These errors can persist after thousands of learning trials in tasks that humans learn to near perfection within tens of trials. To elucidate the causes of such poor performance, we formulate and test a mathematical model of non-human sequence discrimination, assuming that animals represent sequences as unstructured collections of memory traces. This representation carries only approximate information about stimulus duration, recency, order and frequency, yet our model predicts non-human performance with a 5.9% mean absolute error across 68 datasets. Because human-level cognition requires more accurate encoding of sequential information than afforded by memory traces, we conclude that improved coding of sequential information is a key cognitive element that may set humans apart from other animals.
Keywords: stimulus sequences, working memory, animal cognition, human uniqueness
1. Introduction
Human achievements such as complex societies, art and science are ultimately grounded in cognitive abilities that other species lack. Paradoxically, however, researchers have struggled to identify cognitive elements that are uniquely human. Overall, the search for uniquely human cognition has focused on how different species process information [1], but less on how information is initially encoded or represented [2–5]. Here, we focus on the encoding of sequential information, showing that available evidence supports the hypothesis that non-human animals do not faithfully encode the succession of stimuli they experience.
Even a cursory survey of cognitive domains in which humans excel (table 1) reveals that correct representation and processing of sequential information is crucial to human cognition [3,6]. For example, whale killerand killer whale have different meaning in English, and indeed all languages use word order to convey information [7]. Language, as well as the imitation of action sequences, also requires correct encoding and recall of sequential information. Both are daunting tasks for non-human animals [8–10]. Remarkably, human sequence processing is not restricted to a specific context, set of stimuli or sensory modality. For instance, languages can be spoken, written, signed, embossed as Braille and even whistled [11]. Although here we are primarily concerned with sequences of stimuli, it is noteworthy that sequential structure is also critical to our mental life, e.g. in recollecting histories of events, in problem solving and in planning for the future.
Table 1.
Role of sequential information in human abilities. The examples are not meant to be mutually exclusive. For example, episodic memory may be involved in planning, theory of mind and so on. The goal of these examples is to illustrate the pervasive importance of accurate sequential information.
| ability | role of sequential information | example |
|---|---|---|
| episodic memory | enables ordering of events | I arrived first ≠ You arrived first |
| causal learning | enables attribution of cause and effect | Noise causes prey to escape ≠ Prey escaping causes noise |
| planning | plans are ordered sequences of actions | Turn door handle, then push ≠ Push door, then turn handle |
| imitation | order of actions must be perceived and remembered | She peeled the banana, then ate it ≠ She ate the banana, then peeled it |
| language | contributes to meaning | Killer whale ≠ whale killer |
| social intelligence (theory of mind) | enables attribution of beliefs and knowledge to individuals | You spoke to her before me ≠ You spoke to me before her |
| cooperation | order of actions must be agreed upon and remembered | I count to three, then we lift ≠ We lift, then I count to three |
| music | order determines aesthetic qualities, e.g. melody | CDEC ≠ CECD |
| mathematics | order of operations influences results | 3−5≠5−3 |
At first sight, the claim that animals encode sequential information poorly seems to clash with many observations. For example, hearing a bell before receiving food will lead a dog to salivate to the bell, but hearing the bell after receiving the food will not. However, this discrimination (and similar ones in associative learning) only requires remembering what happens before a biologically salient event (food), rather than the representation of arbitrary sequential information. Other behaviours, such as echolocation in bats [12] and song learning in birds [13], involve genuinely complex sequence processing, but are also likely to rely on task-specific adaptations. Here, we are concerned with studies in which animals have been trained to discriminate sequences of stimuli for which they have no specific biological adaptation. For example, animals may be trained to respond to a sequence AB (stimulus A followed by stimulus B) while ignoring B alone, or to respond to AB while ignoring AA, BA and BB.
To avoid confusing difficulties in sequence processing with perceptual or procedural difficulties, we chose to include only studies that meet two requirements. First, the stimuli used to compose sequences should be readily identifiable by the animals. Selected studies fulfil this requirement in either of two ways: either the stimuli come from the animals’ natural repertoire (e.g. own species vocalizations), or the stimuli are known to be readily identifiable from previous research. For example, rats and pigeons do not have dedicated adaptations for processing such stimuli as monochromatic lights, white noise or pure tones, yet research shows that they identify these stimuli and associate them with experimental outcomes.
We also required studies to employ experimental paradigms known to be readily mastered when single stimuli are used, rather than sequences of stimuli. For example, pigeons readily learn to obtain food by pecking or not pecking in response to single stimuli, hence we have included studies training pigeons to peck or not peck in response to sequences of stimuli. In summary, by imposing these requirements on stimuli and experimental procedures, we are reasonably sure that, whenever an animal fails to solve a discrimination, the reason should be sought in the sequential nature of the task rather than in a poor choice of stimuli or task.
2. Stimulus sequence discrimination across species
Figure 1 shows representative learning curves from sequence discrimination studies. A first, evident conclusion is that sequence discriminations are much harder than discriminations between single stimuli. Rats, for example, can discriminate perfectly between two stimuli in 10–50 trials (provided the stimuli are not too similar), but can require thousands of trials to discriminate between two sequences (figure 1a). Figure 2 shows a summary of all reviewed studies in terms of the amount of training required to reach a given level of performance. A linear mixed model of discrimination performance, with study as random effect to control for task differences, reveals a significant effect of trials (χ2(1)=34.2, p<10−8) but no effect of species (χ2(5)=7.23, p=0.20) and no interaction between species and trials (χ2(3)=0.95, p=0.81), suggesting no large species differences in the speed of sequence discrimination learning (see electronic supplementary material, S1 for data sources).
Figure 1.

Sequence discrimination in humans and non-human animals. Labels of the form ‘X versus Y ’ identify as X the rewarded sequences and as Y the unrewarded ones. The vertical axis (% correct) gives the fraction of responses emitted to rewarded sequences. (a) Acquisition of a discrimination between two acoustic sequences in rats (AB versus BA, each repeated five times, two experiments [14,15]); also shown is the much faster acquisition of two A versus B discriminations (go left versus right, choose black versus white [16]). (b) Acquisition, in rats, of three discriminations formed using sequences in the set AAB, ABA, ABB, BAA, BAB, BBA [17]. (c) Discrimination in dogs between two rewarded acoustic sequences, AB and BA, and two unrewarded sequences AA and BB [18]. (d) Comparison of performance on the same task in pigeons (light blue [19]) and humans (magenta, electronic supplementary material, S3). (e) Discrimination in pigeons between three-stimulus visual sequences [20]. (f) Acoustic sequence discrimination in starlings: 16 AABB versus 16 ABBA sequences [21]. (g) Discriminations between acoustic sequences in a dolphin [22]. (h) Discrimination between song syllable sequences in zebra finches [23]. Open diamonds give responding to untrained sequences tested after training. For these sequences, ‘50% correct’ means responding equal to that of trained sequences; ‘100% correct’ means no responding.
Figure 2.

Eventual performance versus amount of training in all reviewed studies (electronic supplementary material, S1). Colour indicates species; point shape indicates length of sequences to which a response was trained. Shaded areas show the range of values spanned by data for the most studied species. Numbers in parenthesis refer to the number of experiments for each species. Chickadee 1 indicates black-capped chickadee; chickadee 2 indicates mountain chickadee. Total number of studied individuals varies from more than 100 pigeons and rats to a single dolphin.
The discriminations in the reviewed studies are trivial for humans and are seldom studied. Human studies, in fact, typically employ sequences of 5–10 elements, often presented just one or a few times [24,25]. However, some studies do compare humans and other species on the same task. In two studies comparing Bengalese finches [26] and zebra finches [27] to humans, the birds required 300–800 trials/sequence to achieve 80–90% accuracy on discriminations that took humans 6–8 trials/sequence to learn to 90–98% accuracy, even when the sequences were composed of Bengalese or zebra finch song syllables unfamiliar to humans. In another study [28], humans took 30 trials/sequence to reach 90% correct on a discrimination that took macaques 400 trials/sequence to learn to 70% accuracy. Lastly, we replicated a study [19] that trained pigeons to discriminate between a sequence AB (reinforced) and sequences AA, BB and BA (figure 1d; electronic supplementary material, S3). In our replication, humans reached over 95% accuracy within 25 trials/sequence, while in the original study pigeons took 1000 trials/sequence to learn to 85% accuracy.
Comparing human and non-human data may harbour several potential confounds. First, the stimuli used may be more easily discriminated by humans than by the animals. This seems unlikely in the reviewed studies, which used bird song syllables [26,27], distinctly coloured lights [19] (pigeons’ colour vision is superior to humans’), or simple tones [28] differing by ∼50 Hz in a frequency range in which the subject species (rhesus macaques) can discriminates differences of ∼5 Hz [29]. Second, humans may benefit from verbal instruction. Animals, however, generally receive extensive pre-training with the apparatus, which itself consists of hundreds or thousands of training trials (which have not been included in our analysis of learning times). At the start of a discrimination task, therefore, animals are very familiar with the experimental apparatus. Task instructions, moreover, typically deal with the mechanics of the task, i.e. that it is possible to produce a response and get feedback about its correctness. They do not reveal what the correct response is. In the reviewed studies, the only exception is a comparison of humans and macaques [28], in which humans were instructed to press a button upon hearing tone sequences falling in pitch. The monkeys, however, were already familiar with a similar task in which they had to discriminate tone sequences differing in pitch pattern [30].
Figure 2 shows large variation in performance for a given number of learning trials, even within species. We have investigated the sources of this variation using linear mixed models to relate discrimination performance to structural and temporal aspects of sequences (table 2). We found that discrimination is more difficult between sequences that end with the same stimulus (figure 1d,e), and even more difficult when the last two stimuli are the same (figure 1e). Additionally, we confirmed observations in the literature that lengthening blank intervals between stimuli or at the end of sequences has detrimental effects on performance. Conversely, lengthening the duration of stimuli and inter-trial intervals improves performance.
Table 2.
Effect of sequence structure and temporal parameters on discrimination performance. Effect is measured as estimated change in the percentage of correct responses. Significance is assessed by analysis of deviance of linear mixed models (χ2 statistic with one degree of freedom). The first two lines refer to a linear mixed model with % correct responses as the dependent variable, two-fixed effects variables (identity of the last stimulus in the to-be-discriminated sequences, and identity of the last two stimuli) and experiment as a random effect to control for differences in experimental tasks. The analysis is restricted to studies employing sequences of two or three stimuli. The following lines estimate the effect of temporal parameters. These effects refer to a 1 s increase in the independent variable. For example, an increase in stimulus duration of 1 s is estimated as improving correct responses by 2%. All models are linear mixed models restricted to studies in which the variable of interest was varied, with experiment as a random effect.
| effect | χ2(1) | p< | |
|---|---|---|---|
| sequence content: | |||
| same last stimulus | −8% | 43.4 | 10−9 |
| same last two stimuli | −18% | 83.7 | 10−9 |
| duration of: | |||
| stimuli | 2% | 26.0 | 10−6 |
| interval between trials | 0.2% | 7.7 | 0.01 |
| gap between stimuli | −1% | 162.4 | 10−9 |
| gap between end of sequence and response opportunity | −2% | 14.9 | 0.001 |
Our results do not negate that animals are capable of sophisticated processing of sequences for which specific adaptations have evolved [12,13]. Rather, they show that non-human animals have a limited ability, compared with humans, to discriminate arbitrary stimulus sequences. This conclusion is strengthened by the following observations, some of which have been anticipated above. The studies we reviewed trained simple instrumental discriminations that are readily mastered when they involve single stimuli rather than sequences (figure 1a). The stimuli used are themselves readily discriminable (high- and low-pitch tones, dark versus light, etc.). Some studies, indeed, used naturalistic stimuli which animals should be well equipped to process, such as conspecific vocalizations [23,26,27]. Crucially, animals may solve readily some discriminations while having great difficulty with others, even within the same experiment. For example, in the experiment in figure 1e pigeons discriminated BAB from AAA to 95% accuracy in about 300 trials, while showing almost no improvement in discriminating BAB from AAB for about 2000 trials. In these cases, the difficulty clearly lies in the temporal structure of sequences, rather than in a poor choice of task or stimuli.
3. Model of non-human sequence memory
Several authors have suggested that non-human sequence discrimination may rely on simple memory traces, that is, on ‘impressions’ of stimuli that fade progressively after stimulus removal [31,32]. For example, AB and BA could be distinguished based on the fact that the first sequence results in a stronger trace of B and a weaker trace of A. Here, we formulate a mathematical model based on this intuition, and we evaluate it quantitatively. We define the trace of stimulus S at time t as a single number, mS(t). When S is present, mS(t) increases towards a maximum value of 1, while when S is absent mS(t) decreases towards a value of 0. We assume that mS(t) follows these differential equations:
| 3.1 |
where m′S(t) is the time derivative of mS(t), and rup and rdown are the rates of memory increase and decrease, respectively. Equation (3.1) can be readily solved (electronic supplementary material, S2), enabling us to calculate the memory trace of any sequence of stimuli. Example memory traces are shown in figure 3a for four sequences of two stimuli of equal duration, i.e. AA, AB, BA and BB. The figure also shows how the sequences are mapped onto four representative points in a two-dimensional memory space with the trace strength of A and B as coordinates. That is, the representation at time t of a sequence of A and B is the pair (mA(t),mB(t)) of the memory traces of A and B at t. The points in figure 3a correspond to the time at which the sequences end.
Figure 3.

Representation of stimulus sequences through memory traces. (a) Representation of sequences of two stimuli of equal duration (AA and BB indicate the repetition of the same stimulus). Graphs on the left show the dynamics of memory traces. Blue lines represent the memory of A, red lines of B. Shaded areas indicate when each stimulus is present. The right panel shows how the traces map into a two-dimensional memory space. We hypothesize that the difficulty of a discrimination is inversely proportional to distance in this space. (b) Comparison of a trace memory with a toy model of memory with a strict notion of order (see text for details). (c) Representation of AB and BA sequences in which the first stimulus is much longer than the second. The memory traces are closer than in (a), assumed to correspond to a more difficult discrimination. (d) Comparison of a trace memory and an order memory relative to the discrimination of the sequences in (c).
The main idea behind our model is that the discriminability of two stimulus sequences depends on how far the sequence representations are at the time the decision is made, i.e. at the time animals are required to choose between responding or not responding. For example, the relative distances of AA, BB and BA from AB in figure 3b suggest that discriminating AB from BB should be difficult, because these two sequences are represented close to each other. AB versus BA should be an easier discrimination, and AB versus AA should be even easier. Empirical data show precisely this ordering (figure 1c) [19,33]. Note that not all memory representations would lead to the same conclusion. For example, figure 3b also shows distances between memories in a toy model of a memory with a strict representation of order. We refer to this model as the ‘order memory’. This memory has four bits. Bits one and two encode the presence (1) or absence (0) of A and B, respectively, in the first position in the sequence; bits three and four encode the presence or absence of A and B in the second position. Thus AB is represented as {1,0,0,1}, while AA as {1,0,1,0}. As shown in figure 3b, in the order memory the sequences AA, BB, AB and BA are represented further apart, hence, according to our hypothesis, discriminations should be easier than in the trace memory. Figure 3c,d shows how the two memories are affected if the first stimulus is much longer than the second; the difficulty of discriminations increases in the trace memory, but not in the order memory. (Although the order memory is intended primarily as an illustration of how memory representation may affect the difficulty of discriminations, we also note that it is a better match than the trace model to the human data in figure 1d, which show no great difference in learning speed across discriminations.)
Equation (3.1) is the core of our sequence discrimination model. To compare the model to data, however, we also need assumptions on how memory representations are used in decision-making, which we keep as simple as possible. Consider a discrimination between one rewarded sequence, p, and one non-rewarded sequence n, and let d(p,n) be the Euclidean distance between their representations at the time the decision is made. Intuitively, the discrimination should be easier the larger d(p,n) is. If R(p) and R(n) indicate the strength of responding to p and n after a period of training, we can formalize this intuition by writing
| 3.2 |
where the left-hand side is the proportion of correct responses (the quantity graphed in figure 1 as a percentage) and c is a positive parameter. According to equation (3.2), discrimination performance is at chance level ( or 50% correct) for sequences that are represented as identical (d(n,p)=0), and increases with distance between representations. (We assume that a value of equation (3.2) equal to or greater than one corresponds to perfect discrimination.) When there are multiple rewarded and non-rewarded sequences, equation (3.2) is not sufficient, but can be generalized by writing the response R(x) to a generic sequence x as
| 3.3 |
where g and h are constants, and 〈d(x,n)〉 and 〈d(x,p)〉 are the average distances of x from all non-rewarded and rewarded sequences. Equation (3.3) reflects the simple assumption that responding is an increasing function of proximity to rewarded sequences, and of distance from non-rewarded sequences. If only one rewarded sequence and one unrewarded sequence are considered, equation (3.3) yields, taking into account that d(p,p)=d(n,n)=0 and d(p,n)=d(n,p),
from which equation (3.2) is recovered with c=h/2g.
We evaluate the model given in equations (3.1) and (3.3) by fitting the memory parameters rup and rdown to maximize the correlation between observed discrimination performance and model predictions (g and h are also fit, but this merely serves to bring R(x), which is based on arbitrary units of distance, within the range [0,1], as is necessary to model discrimination performance (see electronic supplementary material, S2). We use the same rup and rdown for all stimuli in an experiment. That is, although it is conceivable that the memories of different stimuli build up and decay at different rates, we adopt here the assumption that these rates are the same for all stimuli used in an experiment. Across experiments, we fit different values of rup and rdown to account for differences in experimental details that are known to influence animal working memory [34]. Additionally, we use a third parameter, rblank≤rdown, during inter-stimulus and inter-trial intervals, based on the assumption that memory decay is slower when external stimulation is minimized. We found 68 datasets providing information sufficient to evaluate the relative difficulty of a set of discriminations (figure 4). These data are representative of all the effects reported in table 2, and include variation in stimulus duration (range: 0.1–12 s), in inter-trial intervals (5–60 s), in gaps between stimuli (0–50 s), and in gaps between sequence end and the opportunity to respond (0–50 s). The fit between the trace model and the data is impressive, with a mean Pearson’s correlation between predicted and observed responding of 0.88 and a mean absolute error per dataset of 5.9% (figure 5).
Figure 4.

Prediction of sequence discrimination performance with the memory trace model (figure 3). We fitted individual data when available, otherwise mean group data (l) displays mean group data for legibility, but individual fits are similar (see electronic supplementary material, S1 for study information). In (i), chance performance was 16% correct rather than 50%. Study species: (a–i), pigeons; (j), rhesus macaques; (k–m), zebra finches; (m) budgerigars. Panels (k–m) include test stimuli to which a response was not explicitly trained (cf. figure 1h).
Figure 5.
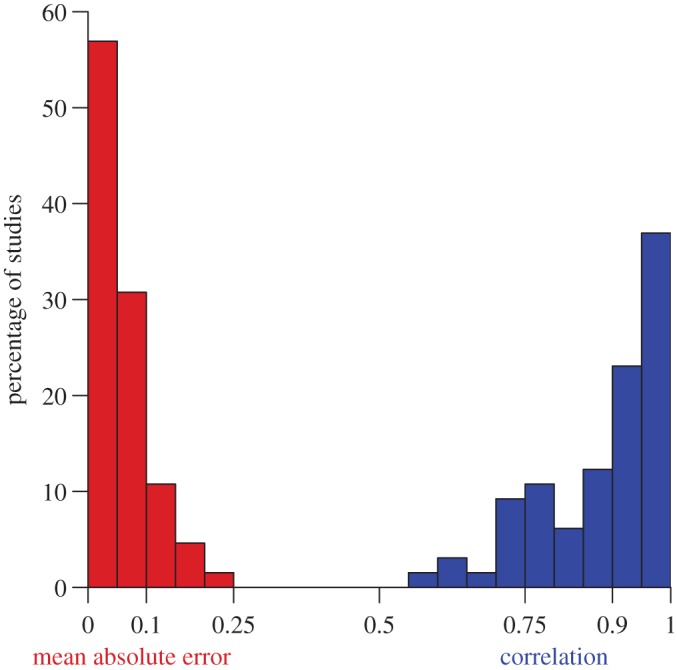
Distribution of mean absolute errors (MAEs, red) and Pearson’s correlations (blue) between predicted and observed performance across the 68 fitted datasets in figure 4. MAEs refer to the average, per dataset, of |R(xi)−Ri|, where xis are tested stimulus sequences, Ri is the observed response to xi and R(xi) is the response predicted by a fitted memory trace model (see electronic supplementary material, S2). Responding is normalized in the interval [0,1], so that an MEA of 0.1 signifies a 10% average error.
Crucially, the trace model successfully reproduces effects of sequence structure that would not be expected if sequential information were faithfully encoded. For example, the discrimination between AB and BA is predicted to be more difficult when the first stimulus is much longer than the second than when the stimuli have the same duration (figure 3). Indeed, MacDonald [32] found ∼50% accuracy after ∼7000 training trials with stimuli of equal duration, and only ∼25% accuracy after ∼9000 trials with the first stimulus eight times as long as the second (in this study, chance level was 16% (see electronic supplementary material, S1 and S2). The trace model also accounts for complex discriminations that are often analysed in terms of symbolic rules or grammars [17,21,23]. For example, zebra finch performance after training to respond to ABA and BAB but not to AAB, ABB, BAA or BBA (figure 1h) is accurately predicted by the trace model (figure 4j). Remarkably, the model also predicts correctly responding to untrained test sequences. For example, BBAA was treated like BAA (little responding), while BABA was treated like ABA (strong responding). This result is poorly explained in terms of rule or grammar learning [23], but follows naturally from the fact that the trace of sequence X1X2X3X4, where each Xi is either A or B, is bound to be similar to the trace of X2X3X4, because the memory of X1 in the first sequence is either overwritten, if the same stimulus reappears later in the sequence, or it is erased by the passage of time.
4. Discussion
Our results suggest that studying the ability to represent and process sequential information is important to understand cognitive differences between humans and other species. The hypothesis that sequential memory is more developed in humans seems supported by available evidence, but more work is needed to evaluate it conclusively. In particular, sequence discrimination experiments should be conducted with more species, as we discuss next.
Our sample (eight bird and five mammal species, including two primates) is sufficiently diverse to suggest widespread difficulties in sequence discrimination learning, but it does have gaps. Notably, we did not find experiments with apes. Endress et al. [35] found some differences between chimpanzees and humans in a habituation–dishabituation task with sound sequences, but the significance of this finding is unclear because the task did not require subjects to make a discrimination (that is, there was no consequence to responding or not responding to any of the sequences; this observation applies also to other habituation studies [36]). Apes perform similarly to other mammals in delayed match-to-sample experiments [34], but studies with other experimental paradigms have suggested good working memory at least for short intervals [37]. The latter studies, however, did not require the apes to remember sequences of stimuli, but rather arrays of simultaneously presented stimuli. In summary, much remains to be ascertained about the sequence-processing abilities of apes. Songbirds are another group that may have sequence representation abilities more advanced than a trace memory, although possibly restricted to song or other auditory stimuli. In most songbirds, juveniles learn to sing with the help of a template memory that is updated by listening to the song of adult birds [13,38]. How the template operates to guide song learning varies across species [13,39], but at least in some cases it seems capable of encoding accurate temporal information [40,41].
While our results suggests that humans have improved memory for sequential information, they do not show directly how human memory overcomes the limitations of non-human memory. One obvious possibility is that human memory is aided by language [42,43]. For example, language may enable the formation of explicit verbal strategies such as ‘Respond only when the first colour is blue and the second is yellow’. Although this possibility has intuitive appeal, it is also the case that language itself seems to require encoding and representation of sequential information. In other words, if we could not form concepts such as ‘first’, ‘second’, ‘before’ or ‘after’, we would not have words for them. It is also possible that neither language nor a faithful sequential memory are wholly primitive, and that they bootstrap each other during development. Indeed, research shows that sequence processing and language abilities are deeply intertwined [44–47]. Further studies charting the development of sequence discrimination abilities in pre-verbal and young children would be illuminating.
The accurate fit of a trace memory model to sequence discrimination data raises several issues for future research. The trace model is purely ‘retrospective’, i.e. decisions are taken at the time of responding based on ‘looking at the past’ through the (imperfect) lens of working memory. ‘Prospective’ accounts of animal working memory have also been proposed, in which decisions are taken (when logically possible) at the time stimuli are experienced, and are then remembered until it is time to respond [48,49]. Retrospective models have been sometimes rejected based on verbal arguments [48,49], but it may be worthwhile to re-evaluate the issue using computational models. Similar remarks can be offered with respect to other aspects of sequence information processing. For example, it has been suggested [50,51] that animals may form more sophisticated stimulus representations by grouping together sets of stimuli (‘chunking’; see [24]), or by representing stimuli in terms of abstract rules or grammars [17,23,52]. The fact that a trace model accounts well for many sequence discrimination tasks, including some that were originally devised as grammatical decision tasks [23,27], raises the possibility that a trace memory may also account for features of chunking, grammar learning, and possibly other paradigms. At the very least, a trace model can serve, in its simplicity, as a useful baseline to assess whether data warrant the assumption of more sophisticated forms of processing.
Our findings stand out among attempts to identify cognitive differences between humans and other animals: if non-human animals lack the capacity to faithfully represent sequential information, the difference between humans and animals may be more fundamental than it is often suggested. Current research, in fact, is focused on specific aspects of cognition such as planning [53,54], social learning [55–57], rule learning [17,58,59] or grammar learning [21,27,36,51,52]. Humans, however, excel in all these activities. Moreover, these activities all presuppose accurate encoding and representation of sequential information (table 1). Thus, a taxonomic gap in sequence encoding and representation would contribute significantly to explaining the cognitive divide between humans and other animals. If humans depended on simple memory traces for sequence processing, there would likely be no language, music, complex culture or mathematics on this planet.
Supplementary Material
Acknowledgements
We thank Carel ten Cate, Robin Murphy and Timothy Gentner for sharing data; Kimmo Eriksson, Pontus Strimling, Carel ten Cate and Ofer Tchernichovski for comments; Dorie-Mae Nicolas, Ruzana Safonova and Justin Varughese for collecting the human data in figure 1d. Silhouettes in figure 1 are by permission of www.psdgraphics.com (humans), www.pd4pic.com (starling) and www.animal-silhouettes.com (others).
Ethics
The research did not involve animal subjects. The experiment with human subjects reported in figure 1d and in the electronic supplementary material was authorized by the CUNY IRB with code 412807.
Data accessibility
Data and code for model fitting are publicly available at https://doi.org/10.6084/m9.figshare.3179239.v1.
Authors' contributions
S.G., J.L. and M.E. conceived the research. S.G., J.L. and M.E. collected and analysed data. S.G. performed model fitting. S.G., J.L. and M.E. wrote the manuscript. All authors gave their final approval for publication.
Competing interests
The authors declare no competing interests.
Funding
S.G., J.L. and M.E. have been supported by grant no. 2015.0005 from the Knut and Alice Wallenberg Foundation. S.G. was additionally supported by a CUNY Graduate Center fellowship from the Committee for Interdisciplinary Studies.
References
- 1.Thalgard P. 2014. Cognitive science. In The Stanford Encyclopedia of Philosophy (ed. EN Zalta). Fall 2014 edn. Stanford, CA: The Metaphysics Research Lab, Center for the Study of Language and Information, Stanford University. [Google Scholar]
- 2.Coolidge FL, Wynn T. 2005. Working memory, its executive functions, and the emergence of modern thinking. Camb. Archaeol. J. 15, 5–26. (doi:10.1017/S0959774305000016) [Google Scholar]
- 3.Dehaene S, Mayniel F, Wacongne C, Wang L, Pallier C. 2015. The neural representation of sequenes: from transition probabilities to algebraic patterns and linguistic trees. Neuron 88, 2–19. (doi:10.1016/j.neuron.2015.09.019) [DOI] [PubMed] [Google Scholar]
- 4.D’Amato MR. 1988. A search for tonal pattern perception in cebus monkeys: why monkeys can’t hum a tune. Music Percept. 5, 453–480. (doi:10.2307/40285410) [Google Scholar]
- 5.Penn DC, Holyoak KJ, Povinelli DJ. 2008. Darwin’s mistake: explaining the discontinuity between human and nonhuman minds. Behav. Brain Sci. 31, 109–130. (doi:10.1017/S0140525X08003543) [DOI] [PubMed] [Google Scholar]
- 6.Lashley KS. 1951. The problem of serial order in behavior. In Cerebral mechanisms in behavior; the Hixon Symp. (ed. LA Jeffress), pp. 112–146. Oxford, UK: Wiley. [Google Scholar]
- 7.Dryer MS, Haspelmath M (eds). 2013. The world atlas of language structures online. Leipzig, Germany: Max Planck Institute for Evolutionary Anthropology; Available online at http://wals.info. [Google Scholar]
- 8.Terrace HS. 1985. On the nature of animal thinking. Neurosci. Biobehav. Rev. 9, 643–652. (doi:10.1016/0149-7634(85)90011-9) [DOI] [PubMed] [Google Scholar]
- 9.Tomasello M, Call J. 1997. Primate cognition. Oxford, UK: Oxford University Press. [Google Scholar]
- 10.Heyes C. 2001. Causes and consequences of imitation. Trends Cogn. Sci. 5, 253–261. (doi:10.1016/S1364-6613(00)01661-2) [DOI] [PubMed] [Google Scholar]
- 11.Busnel RG, Classe A. 1976. Whistled languages. New York, NY: Springer. [Google Scholar]
- 12.Moss CF, Surlykke A. 2001. Auditory scene analysis by echolocation in bats. J. Acoust. Soc. Am. 110, 2207–2226. (doi:10.1121/1.1398051) [DOI] [PubMed] [Google Scholar]
- 13.Catchpole CK, Slater PJ. 2008. Bird song: biological themes and variations, 2nd edn Cambridge, UK: Cambridge University Press. [Google Scholar]
- 14.Kudoh M, Seki K, Shibuki K. 2004. Sound sequence discrimination learning is dependent on cholinergic inputs to the rat auditory cortex. Neurosci. Res. 50, 113–123. (doi:10.1016/j.neures.2004.06.007) [DOI] [PubMed] [Google Scholar]
- 15.Kudoh M, Shibuki K. 2006. Sound sequence discrimination learning motivated by reward requires dopaminergic D2 receptor activation in the rat auditory cortex. Learn. Mem. 13, 690–698. (doi:10.1101/lm.390506) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Mackintosh NJ. 1974. The psychology of animal learning. London, UK: Academic Press. [Google Scholar]
- 17.Murphy RA, Mondragón E, Murphy VA. 2008. Rule learning by rats. Science 319, 1849–1851. (doi:10.1126/science.1151564) [DOI] [PubMed] [Google Scholar]
- 18.Brown BL, Sołtysik S. 1971. Four-pair same-different differentiation and transient memory in dogs. Acta Neurobiol. Exp. 31, 87–100. [PubMed] [Google Scholar]
- 19.Weisman R, Wasserman E, Dodd P, Larew MB. 1980. Representation and retention of two-event sequences in pigeons. J. Exp. Psychol. Anim. Behav. Process. 6, 312 (doi:10.1037/0097-7403.6.4.312) [Google Scholar]
- 20.Weisman RG, Duder C, von Konigslow R. 1985. Representation and retention of three-event sequences in pigeons. Learn. Motiv. 16, 239–258. (doi:10.1016/0023-9690(85)90014-1) [Google Scholar]
- 21.Gentner TQ, Fenn KM, Margoliash D, Nusbaum HC. 2006. Recursive syntactic pattern learning by songbirds. Nature 440, 1204–1207. (doi:10.1038/nature04675) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Thompson RKR. 1976. Performance of the bottlenose dolphin (Tursiops truncatus) on delayed auditory sequences and delayed auditory successive discriminations. Honolulu, HI: University of Hawaii. [Google Scholar]
- 23.van Heijningen CAA, Chen J, van Laatum I, van der Hulst B, ten Cate C. 2013. Rule learning by zebra finches in an artificial grammar learning task: which rule? Anim. Cogn. 16, 165–175. (doi:10.1007/s10071-012-0559-x) [DOI] [PubMed] [Google Scholar]
- 24.Miller GA. 1956. The magical number seven, plus or minus two: some limits on our capacity for processing information. Psychol. Rev. 63, 81–97. (doi:10.1037/h0043158) [PubMed] [Google Scholar]
- 25.Bower GH. (ed.) 1982. Psychology of learning and motivation. New York, NY: Academic Press. [Google Scholar]
- 26.Seki Y, Suzuki K, Osawa AM, Okanoya K. 2013. Songbirds and humans apply different strategies in a sound sequence discrimination task. Front. Psychol. 4, 447 (doi:10.3389/fpsyg.2013.00447) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Chen J, van Rossum D, ten Cate C. 2015. Artificial grammar learning in zebra finches and human adults: XYX versus XXY. Anim. Cogn. 18, 151–164. (doi:10.1007/s10071-014-0786-4) [DOI] [PubMed] [Google Scholar]
- 28.Izumi A. 2003. Effect of temporal separation on tone-sequence discrimination in monkeys. Hear. Res. 175, 75–81. (doi:10.1016/S0378-5955(02)00712-8) [DOI] [PubMed] [Google Scholar]
- 29.Massopust LC, Wolin LR, Meder R, Frost V. 1967. Changes in auditory frequency discrimination thresholds after temporal cortex ablations. Exp. Neurol. 19, 245–255. (doi:10.1016/0014-4886(67)90022-2) [DOI] [PubMed] [Google Scholar]
- 30.Izumi A. 2002. Auditory stream segregation in Japanese monkeys. Cognition 82, B113–B122. (doi:10.1016/S0010-0277(01)00161-5) [DOI] [PubMed] [Google Scholar]
- 31.Roberts WA, Grant DS. 1976. Studies of short-term memory in the pigeon using the delayed matching to sample procedure. In Processes of animal memory (eds DL Medin, WA Roberts, RT Davis), pp. 79–112. Hillsdale, NJ: Erlbaum.
- 32.MacDonald SE. 1993. Delayed matching-to-successive-samples in pigeons: short term memory for item and order information. Anim. Learn. Behav. 21, 59–67. (doi:10.3758/BF03197977) [Google Scholar]
- 33.Brown BL, Sołtysik S. 1971. Further findings on the same-different differentiation with acoustic stimuli in dogs. Acta Neurobiol. Exp. 31, 69–85. [PubMed] [Google Scholar]
- 34.Lind J, Ghirlanda S, Enquist M. 2015. Animal memory: a review of delayed match-to-sample data from 25 species. Behav. Process. 117, 52–58. (doi:10.1016/j.beproc.2014.11.019) [DOI] [PubMed] [Google Scholar]
- 35.Endress AD, Carden S, Versace E, Hauser MD. 2010. The apes’ edge: positional learning in chimpanzees and humans. Anim. Cogn. 13, 483–495. (doi:10.1007/s10071-009-0299-8) [DOI] [PubMed] [Google Scholar]
- 36.Ravignani A, Sonnweber RS, Stobbe N, Fitch WT. 2013. Action at a distance: dependency sensitivity in a New World primate. Biol. Lett. 9, 20130852 (doi:10.1098/rsbl.2013.0852) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Inoue S, Matsuzawa T. 2007. Working memory of numerals in chimpanzees. Curr. Biol. 17, R1004–R1005. (doi:10.1016/j.cub.2007.10.027) [DOI] [PubMed] [Google Scholar]
- 38.Soha J. 2017. The auditory template hypothesis: a review and comparative perspective. Anim. Behav. 124, 247–254. (doi:10.1016/j.anbehav.2016.09.016) [Google Scholar]
- 39.Feher O, Wang H, Saar S, Mitra PP, Tchernichovski O. 2009. De novo establishment of wild-type song culture in the zebra finch. Nature 459, 564–568. (doi:10.1038/nature07994) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Hultsch H, Todt D. 1989. Memorization and reproduction of songs in nightingales (Luscinia megarhynchos): evidence for package formation. J. Comp. Physiol. A165, 197–203. (doi:10.1007/BF00619194) [Google Scholar]
- 41.Babtista LF, Morton ML. 1981. Interspecific song acquisition by a white-crowned sparrow. Auk 98, 383–385. [Google Scholar]
- 42.Dean LG, Kendal RL, Schapiro SJ, Thierry B, Laland KN. 2012. Identification of the social and cognitive processes underlying human cumulative culture. Science 335, 1114–1118. (doi:10.1126/science.1213969) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Morgan TJH, et al. 2015. Experimental evidence for the co-evolution of hominin tool-making teaching and language. Nat. Commun. 6, 6029 (doi:10.1038/ncomms7029) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Merzenich MM, Jenkins WM, Johnston P, Schreiner C, Miller SL, Tallal P. 1996. Temporal processing deficits of language-learning impaired children ameliorated by training. Science 271, 77–81. (doi:10.1126/science.271.5245.77) [DOI] [PubMed] [Google Scholar]
- 45.Ullman MT. 2004. Contributions of memory circuits to language: the declarative/procedural model. Cognition 92, 231–270. (doi:10.1016/j.cognition.2003.10.008) [DOI] [PubMed] [Google Scholar]
- 46.Dominey PF, Hoen M, Blanc JM, Lelekov-Boissard T. 2003. Neurological basis of language and sequential cognition: evidence from simulation, aphasia, and ERP studies. Brain Lang. 86, 207–225. (doi:10.1016/S0093-934X(02)00529-1) [DOI] [PubMed] [Google Scholar]
- 47.Hoen M, Dominey PF. 2000. ERP analysis of cognitive sequencing: a left anterior negativity related to structural transformation processing. Neuroreport 11, 3187–3191. (doi:10.1097/00001756-200009280-00028) [DOI] [PubMed] [Google Scholar]
- 48.Kendrick DF, Rilling ME, Denny MR (eds). 1986. Theories of animal memory. Hillsdale, NJ: Lawrence Eribaum Associates. [Google Scholar]
- 49.Honig WK, Thompson RKR. 1982. Retrospective and prospective processing in animal working memory. In Psychology of learning and motivation (ed. GH Bower). New York, NY: Academic Press. [Google Scholar]
- 50.Terrace H. 2001. Chunking and serially organized behavior in pigeons, monkeys and humans. In Avian visual cognition (ed. RG Cook). Medford, MA, USA: Comparative Cognition Press. [Google Scholar]
- 51.Herbranson WT, Shimp CP. 2008. Artificial grammar learning in pigeons. Learn. Behav. 36, 116–137. (doi:10.3758/LB.36.2.116) [DOI] [PubMed] [Google Scholar]
- 52.Fitch WT, Friederici AD. 2012. Artificial grammar learning meets formal language theory: an overview. Phil. Trans. R. Soc. B 367, 1933–1955. (doi:10.1098/rstb.2012.0103) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Raby CR, Alexis DM, Dickinson A, Clayton NS. 2007. Planning for the future by western scrub-jays. Nature 445, 919–921. (doi:10.1038/nature05575) [DOI] [PubMed] [Google Scholar]
- 54.Osvath M, Osvath H. 2008. Chimpanzee (Pan troglodytes) and orangutan (Pongo abelii) forethought: self-control and pre-experience in the face of future tool use. Anim. Cogn. 11, 661–674. (doi:10.1007/s10071-008-0157-0) [DOI] [PubMed] [Google Scholar]
- 55.Call J, Carpenter M, Tomasello M. 2005. Copying results and copying actions in the process of social learning: chimpanzees (Pan troglodytes) and human children (Homo sapiens). Anim. Cogn. 8, 151–163. (doi:10.1007/s10071-004-0237-8) [DOI] [PubMed] [Google Scholar]
- 56.Tomasello M. 1999. The cultural origins of human cognition. London, UK: Harvard University Press. [Google Scholar]
- 57.Tomasello M. 2001. Cultural transmission: a view from chimpanzees and human infants. J. Cross Cult. Psychol. 32, 135–146. (doi:10.1177/0022022101032002002) [Google Scholar]
- 58.Catania C. 1985. Rule governed behaviour and the origins of language. In Behaviour analysis and contemporary psychology (eds CF Lowe, M Richelle, CK Catchpole), pp. 135–156. London, UK: Erlbaum. [Google Scholar]
- 59.Fountain SB. 2008. Pattern structure and rule induction in sequential learning. Comp. Cogn. Behav. Rev. 3, 66–85. (doi:10.3819/ccbr.2008.30004) [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Data and code for model fitting are publicly available at https://doi.org/10.6084/m9.figshare.3179239.v1.