

Abstract
Identifying important biomarkers that are predictive for cancer patients’ prognosis is key in gaining better insights into the biological influences on the disease and has become a critical component of precision medicine. The emergence of large-scale biomedical survival studies, which typically involve excessive number of biomarkers, has brought high demand in designing efficient screening tools for selecting predictive biomarkers. The vast amount of biomarkers defies any existing variable selection methods via regularization. The recently developed variable screening methods, though powerful in many practical setting, fail to incorporate prior information on the importance of each biomarker and are less powerful in detecting marginally weak while jointly important signals. We propose a new conditional screening method for survival outcome data by computing the marginal contribution of each biomarker given priorily known biological information. This is based on the premise that some biomarkers are known to be associated with disease outcomes a priori. Our method possesses sure screening properties and a vanishing false selection rate. The utility of the proposal is further confirmed with extensive simulation studies and analysis of a diffuse large B-cell lymphoma dataset. We are pleased to dedicate this work to Jack Kalbfleisch, who has made instrumental contributions to the development of modern methods of analyzing survival data.
Keywords: Conditional screening, Cox model, Diffuse large B-cell lymphoma, High-dimensional variable screening
1 Introduction
Despite much progress made in the past two decades, many cancers do not have a proven means of prevention or effective treatments. Precision medicine that takes into account individual susceptibility has become a valid approach to gaining better insights into the biological influences on cancers, which is expected to benefit millions of cancer patients. A critical component of precision medicine lies in detecting and identifying important biomarkers that are predictive for cancer patients’ prognosis. The emergence of large-scale biomedical survival studies, which typically involve excessive number of biomarkers, has brought high demand in designing efficient screening tools for selecting predictive biomarkers. The presented work is motivated by a genomic study of diffuse large B-cell lymphoma (DLBCL) (Rosenwald et al. 2002), with the goal of identifying gene signatures out of 7399 genes for predicting survival among 240 DLBCL patients. The results may address whether the DLBCL patients’ survival after chemotherapy could be regulated by the molecular features.
The recently developed variable screening methods, such as the sure independence screening proposed by Fan and Lv (2008), have emerged as a powerful tool to solve this problem, but their validity often hinges upon the partial faithfulness assumption, that is, the jointly important variables are also marginally important. Consequently, they will fail to identify the hidden variables that are jointly important but have weak marginal associations with the outcome, resulting in poor understanding of the molecular mechanism underlying or regulating the disease. To alleviate this problem, Fan and Lv (2008) further suggested an iterative procedure (ISIS) by repeatedly using the residuals from the previous iterations, which has gained much popularity. However, the required iterations have increased the computational burden, and the statistical properties are elusive.
On the other hand, intensive biomedical research has generated a large body of biological knowledge. For example, several studies have confirmed AA805575, a germinal-center B-cell signature gene, is relevant to DLBCL survival (Gui and Li 2005; Liu et al. 2013). Including such prior knowledge for improved accuracy in variable selection has drawn much interest. Barut et al. (2016) proposed a conditional screening (CS) approach in the framework of a generalized linear model (GLM) when some prior knowledge on feature selection is known, and showed that the CS approach provides a useful means to identify jointly informative but marginally weak associations, and Hong et al. (2016) further proposed to integrate prior information using data-driven approaches.
Development of high dimensional screening tools with survival outcome has been fruitful. Some related work includes an (iterative) sure screening procedure for Cox’s proportional hazards model (Fan et al. 2010), a marginal maximum partial likelihood estimator (MPLE) based screening procedure (Zhao and Li 2012), a censored rank independence screening method which is robust to outliers and applicable to a general class of survival models (Song et al. 2014). But to the best of our knowledge, all these methods essentially posit the partial faithfulness assumption and do not incorporate the known prior biological information. As a result, they will be likely to suffer the inability to identify marginally weak but jointly important signals.
To fill the gap, we propose a new CS method for the Cox proportional hazards model by computing the marginal contribution of each covariate given priorily known information. We refer to it as Cox conditional screening (CoxCS). As opposed to the conventional marginal screening methods, our method is more likely to detect marginally weak but jointly important signals, which will have important biological applications as shown in the data example section. Moreover, in contrast with most screening methods that usually employ subjective thresholds for screening, we also propose a principled cut-off to govern the screening and control the false positives in light of Zhao and Li (2012). This will be especially important in the presence of hidden variables.
To demonstrate the utility of CoxCS in recovering important hidden variables, we briefly discuss using Example 1 in Sect. 4. By design, variable 6 is the hidden variable in that example as it is only weakly correlated with the survival time marginally. Let denote the screening statistics by the CoxCS approach (defined in Sect. 2), where indexes variables that are pre-included into the model. When , the CoxCS is equivalent to the marginal screening approach for the Cox proportional hazards model. Figure 1 summarizes the densities of the screening statistics for the hidden variable 6 and noisy variables 10–1000 for different sets of conditional variables based on 400 simulated datasets. The results show that with a high probability the marginal screening statistic for hidden variable 6 is much smaller than those of noisy variables. When the conditioning set includes one truly active variable, the density plots show a clear separation between the hidden variables and the noisy variables. When we include more truly active variables, this separation becomes larger. Interestingly, when conditional on noisy variables that are correlated with both active and hidden variables in the model, the chance of identifying the hidden variable using CoxCS is still higher than the marginal screening. A similar phenomenon was observed in the GLM setting (Barut et al. 2016). This is because when such “noisy” variables are correlated with both marginally important variables and hidden variables, they may effectively function as surrogates for the active variables and conditioning on them can help detect hidden variables.
Fig. 1.
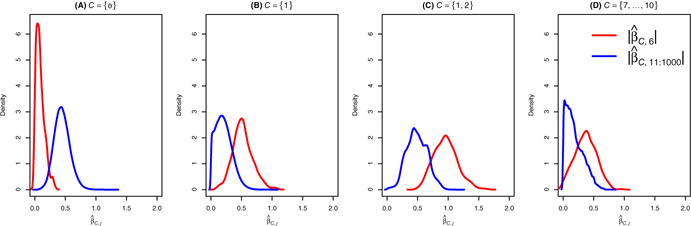
Density of the screening statistics (red) for the hidden variable compared with a mixture of densities of screening statistics (blue) for the noise variables with different conditioning sets: a which is equivalent to marginal screening; b one truly active variables; c two truly active variables; d four noisy variables (Color figure online)
The theory of CS for GLM has been established by Barut et al. (2016). But its extension to the survival context is challenging and elusive, calling for new techniques. To this end, we propose two new functional operators on random variables to characterize their linear associations given other random variables: the conditional linear expectation and the conditional linear covariance. Both are critical to formulate the regularity conditions for the population level properties of CoxCS with statistically meaningful interpretations, and facilitate the development of theory for CS approaches in general settings. A similar concept of the conditional linear covariance has been introduced by Barut et al. (2016), but it can not be used for the survival outcome data. In summary, the proposed method is computationally efficient, adapts to sparse and weak signals, enjoys the good theoretical properties under weak regularity conditions, and works robustly in a variety of settings to identify hidden variables.
The remaining of this paper is organized as follows. In Sect. 2, we review the Cox proportional hazards model and present CoxCS approach with some alternatives. In Sect. 3, we list the regularity conditions and establish the sure screening properties. In Sect. 4, we further conduct simulation studies to compare our method with the major competing methods under under a number of scenarios. In Sect. 4, we apply our method to study the DLBCL data. We conclude with a brief discussion on the future work in Sect. 5.
2 Model
2.1 The Cox proportional hazards model
Suppose we have n observations with p covariates. Let i and j be respectively index subjects and covariates. Denote by Zi,j covariate j for subject i, write Zi = (Zi,1,…, Zi,p)T. Let Ti be the underlying survival time and Ci be the censoring time. We observe and, where I(·) is the indicator function. Assume that there exists τ > 0, such that P(Xi > τ|Zi) > 0 and assume that the event time Ti and the censoring time Ci are independent given Zi. Suppose Ti follows a Cox proportional hazards model
| (1) |
where is an-unspecified baseline hazard and is the true-coefficient. Let be the baseline cumulative hazard function. Suppose there is a set of covariates that are known a priori to be related to the survival outcome. Denote by the indices of these covariates. Let q = | | be the number of covariates in . Write , , and .Note that in our problem, is known but both and are unknown. Then the true hazard function in (1) is equivalent to
| (2) |
To estimate and , we introduce the independent counting process and the at-risk process . When p is small, we can obtain the partial likelihood estimator by solving the estimation equation U(α) = 0p with U(α) = (U1(α),…,Up(α)) and
| (3) |
with
| (4) |
for When p > n, it is computationally and theoretically infeasible to directly solve Eq. (3). By imposing sparsity on the coefficients, one may maximize the penalized partial likelihood to obtain solutions. However, when , we need to employ a variable screening procedure first before performing regularized regression. We propose a new CS procedure in the next section.
2.2 Cox conditional screening
We fit the marginal Cox regression by including the known covariates in . Specifically, for , we have the following marginal Cox regression model
| (5) |
from which the maximum partial likelihood estimation equation can be obtained. It is given by the solution of the following equation:
| (6) |
with
| (7) |
and
| (8) |
for and . For a given threshold γ > 0. The selected index set in addition to set is given by
| (9) |
Namely, we recruit variables with large additional contribution given . We refer to this method as Cox conditional screening (CoxCS).
3 Theoretical results
We establish the theoretical properties of the proposed methods by introducing a few new definitions along with the basic properties.
3.1 Definitions and basic properties
Let ( ) be the probability space for all random variables introduced in this paper, where is the sample space, is the σ-algebra as the set of events and P is the probability measure.
For any d ≥ 1, any random variable and any operator A, denote by A[•|ξ] conditional A of • given ξ. For any vector , let be the subvector where all its elements are indexed in . Let be the L-d norm for any vector . For a sequence of random variables indexed by if and only if for any ε1 > 0 and ε2 > 0, there exists N such that for any .
For simplicity, let T, C, X, Y (t), Zj, Z and δ represent Ti, Ci, Xi, Yi (t), Zi,j, Zi and δi respectively, by removing the subject index i. Let and represent the survival functions for the event time T and censored time C. Let .
Definition 1
Let and be the true set of non-zero coefficients and its cardinality in model (1), aside from the important predictors known a priori.
To study the asymptotic property of , define the population level quantity as follows:
Definition 2
Let be the solution of the following equations
| (10) |
with
| (11) |
where and
Definition 3
Let be the solution of the following equations
| (12) |
To understand the intuition of the population level properties for the CoxCS, we need to define a conditional linear expectation. A similar concept has been used to study the conditional sure independence screening (CSIS) in the GLM setting by Barut et al. (2016). We provide a formal definition here.
Definition 4
For two random variables and . The conditional linear expectation of ζ given ξ is defined as
| (13) |
where . Also, define notation .
Definition 5
For any random variables and . The conditional linear covariance between ζ1 and ζ2 given ξ is defined as
| (14) |
Definition 6
Define
where vector such that .
We list all the properties of the conditional linear expectation and the conditional linear covariance in Propositions 1 and 2 in Appendix. They are quite useful for the theoretical developments of the sure screening property. Also, combining Propositions 1, 4 and Lemma 1 in Appendix, we show the uniqueness of the solution to score equations in Definitions 3 and 6.
3.2 Regularity conditions
We list all conditions for the theoretical results.
Condition 1
For each and , there exists a neighborhood of , which is defined as
such that for each τ < ∞.
- For m = 0, 1,
in probability as . - There exists a constant L > 0 such that
Of note, does not depend on k. Let .
Condition 2
The covariates Zj’s satisfy the following conditions.
For and there exists a constant K0 such that .
Zj is a time constant variable, for all j.
All Zj’s, are independent of all Zk’s, given .
- For constant c1 > 0 and κ <1/2,
Condition 3
There exists a constant K1 such that
for all p > 0.
Condition 4
For all , there exists a constant M > 0 such that
where .
To study the sure screening property of our proposed method, we first link βj in a joint model to its counterpart in a marginal model. Thus we first understand its properties on the population as well as the sample level.
3.3 Properties on population level
Theorem 1
Suppose Condition 2 holds, βj = 0 if and only if αj.= 0 for all
To identify covariate needs to be at least O (n−1/2). The following Theorem 2 specifies the signal strength .
Theorem 2
Suppose Condition 2 holds. There exist constants c2 > 0 and κ < 1/2 such that
3.4 Properties on sample level
Theorem 3 proves the uniform convergence of the proposed estimator and the sure screening property of the procedure.
Theorem 3
Suppose Conditions 1–4 hold. For any ε1 > 0 and any ε2 > 0, there exits positive constants c3, c4 and integer N such that for any n > N,
- For any 0 < κ < 1/2,
where w is the size of , q is the size of and c2 is the same value in Theorem 2 and c3 does not dependent on ε1, ε2 and κ, but N depends on ε1 and ε2. - If , where κ is the same number in Condition 2, then
where c4 does not depend on ε1, ε2 and κ, thus(15) (16)
3.5 Alternative methods
In this section we introduce two alternative methods for controlling the false discovery rate.
Define the information matrix
| (17) |
which is of q + 1 dimension. Denote be the variance estimate of . For a given threshold γ > 0, we can have a different way to select the index which is given by
| (18) |
We refer to (18) as “CS-Wald”.) suggested that where f is the number of false positive that one is willing to tolerate and Φ(·) is the standard normal cumulative distribution function. Another alternative to construct the screening statistics, which is also scale free, is to utilize the partial log likelihood ratio statistic. Specifically,
| (19) |
Suppose maximizes (19) for a given j. Then, for a given threshold γ > 0, the index set can be chosen by considering the following likelihood ratio statistic.
| (20) |
where maximizes . Hereafter (20) will be referred to as “CS-PLIK”.
4 Simulation studies
The utility of the proposed methods was evaluated via extensive simulations. Denote by CS-MPLE, a version of CoxCS that is based on the criteria of (9). For completeness, we considered two other variations of CoxCS, namely, CS-PLIK and CS-Wald. The finite sample performance of the proposed methods was compared with the following marginal screening methods designed for the survival data.
-
–
CRIS: censored rank independence screening proposed by Song et al. (2014).
-
–
CORS: correlation screening, which is an extension of sure independence screening to the censored outcome data by using inverse probability weighting; see Song et al. (2014).
-
–
PSIS-Wald: Wald test based on the marginal Cox model fitted on each covariate; see Zhao and Li (2012).
-
–
PSIS-PLIK: partial likelihood ratio test based on the marginal Cox model fitted on each covariate, which is asymptotically equivalent to Zhao and Li (2012).
We illustrated our methods and compared them with the competing methods on data simulated as below.
Example 1 The survival time was generated from a Cox model with baseline hazards function being set to be 1, i.e.,
where Z were generated from the standard normal distribution with equal correlation 0.5 and .
Example 2 The survival time was generated from a Cox model with baseline hazards function being set to be exp(−1), i.e.,
where and all covariates were generated from the independent standard normal distribution.
Example 3 The same as Example 2 except that the first p – 1 covariates were generated from the multivariate standard normal distribution with an equal correlation of 0.9.
Example 4 The same as Example 1 except that the magnitude of the active variables were reduced to half, i.e., .
The simulated data examples were designed in such a way that variables Z6 in Example 1 and Zp in Example 3 possess marginally weak but conditionally strong signals, which makes marginal screening approaches not ideal for identifying them. Example 4 exhibits a scenario with smaller signal-to-noise ratios, compared with Examples 1–3. For the GLM, Barut et al. (2016) provided a similar simulation design in the context of non-censored regression. Figure 2 depicts the distribution of the absolute correlation between the survival time and the covariate variables, where uncensored data were used to compute the marginal correlation between the event time and the covariate using an inverse probability weighting (Song et al. 2014). In Examples 1–3, the magnitude of the marginal correlation between the survival and inactive variables are sometimes even larger than that of between the survival and active variables. Therefore, it is expected that the competing methods such as CORS which relies on the marginal correlation between the survival and covariates would be difficult to identify active variables. Clearly, in Example 1 the marginal signal strength of Z6 is weaker than most noisy (inactive) variables (Z7 – Z1000), while the marginal signal strength of Z1000 in Examples 2 and 3 is similar or even lower than most noisy variables. The marginal correlation between the survival time and each variable is getting weaker with heavier censoring.
Fig. 2.
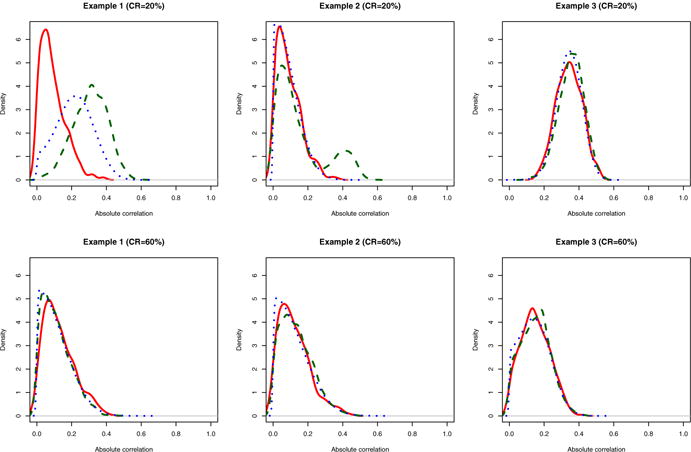
Absolute correlation of the survival time and the covariate variables. The blue short-dashed lines (……) represents the distribution of the inactive variables; the green long-dashed lines (– – –) for the active variables with relatively strong signals; the red solid lines (— —) for the hidden active variable (Color figure online)
In all these examples, the censoring times Ci were independently generated from a uniform distribution U [0, c], with c chosen to give approximately 20% and 60% of censoring proportions. We set n = 100 and varied p from 1000 (high-dimensional) to 10, 000 (ultrahigh-dimensional). For each configuration, a total of 400 simulated datasets were generated.
We considered two metrics to compare the performance between different methods: the minimum model size (MMS) which is the minimum number of variables that need to be selected in order to include all active variables, and the true positive rate (TPR) which is the proportion of active variables that are included in the first n selected variables. Hence, a method with small MMS and large TPR can be more efficient to discover true signals. For a fair comparison, we added the number of conditioning variable in our examples to MMS for the proposed methods (CS-MPLE, CS-Wald and CS-PLIK). In practice, identifying conditional sets normally requires some prior biological information. In our simulations, we simply chose the covariate Z1 as the conditioning variable. In practice, we propose to choose the variable with the highest marginal signal strength as the conditioning variable, which can be a practical solution in the absence of prior biological knowledge. In Examples 1–4, we considered two sets of conditioning sets. The first choice was since the signal of the first variable is strong enough to be easily picked by other marginal screening methods. Our second choice was that consists of one active variable (the first variable in our examples) and 4 noisy variables. The purpose was to assess the robustness of the proposed method when the conditioning set is dominated by noisy variables.
Tables 1 and 2 demonstrate the advantages of our proposed methods under the difficult scenarios as reflected in Examples 1–4. Although the performance of the proposed methods deteriorates a bit in Example 4 due to small signal-to-noise ratios, in all examples (including Example 4) the proposed methods outperform the marginal approaches by largely reducing MMS. Moreover, all the marginal screening methods have had some difficulties in identifying Z6 in Example 1 and Example 4 and Z1000 in Examples 2 and 3. Indeed, these variables have the lowest priorities to be included by using the marginal methods. Moreover, the results with demonstrate that conditioning can be beneficial even if the conditioning set is dominated by noisy variables.
Table 1.
Median minimum model size (MMS) and median true positive rates (TPR) along with their corresponding IQRs (in the parentheses) based on 400 simulated data sets
| Method | (n,
p) = (100, 1000) |
(n,
p) = (100, 10000) |
|||
|---|---|---|---|---|---|
| MMS | TPR | MMS | TPR | ||
| CRIS | 1000.0 (3.0) | 0.50 (0.17) | 9995.0 (37.0) | 0.17 (0.17) | |
| CORS | 944.0 (168.2) | 0.33 (0.33) | 9466.0 (1101.8) | 0.00 (0.17) | |
| Example 1 CR ≈ 20% | PSIS-PLIK | 1000.0 (0.0) | 0.67 (0.17) | 10000.0 (2.2) | 0.33 (0.17) |
| PSIS-Wald | 1000.0 (0.0) | 0.67 (0.17) | 10000.0 (2.2) | 0.33 (0.17) | |
| CS-PLIK ( ) | 152.5 (272.2) | 0.83 (0.17) | 1322.0 (2253.8) | 0.67 (0.17) | |
| CS-Wald ( ) | 154.5 (274.5) | 0.83 (0.17) | 1286.5 (2287.0) | 0.67 (0.17) | |
| CS-MPLE ( ) | 143.0 (249.0) | 0.83 (0.17) | 1321.0 (2305.8) | 0.50 (0.17) | |
| CS-PLIK ( ) | 109.5 (212.0) | 0.83 (0.17) | 1012.5 (1906.5) | 0.67 (0.33) | |
| CS-Wald ( ) | 111.0 (206.8) | 0.83 (0.17) | 1021.0 (1906.0) | 0.67 (0.33) | |
| CS-MPLE ( ) | 110.0 (199.8) | 0.83 (0.17) | 1070.0 (1892.8) | 0.67 (0.17) | |
| CRIS | 926.5 (151.8) | 0.33 (0.17) | 9429.0 (1405.0) | 0.00 (0.17) | |
| CORS | 898.0 (152.2) | 0.00 (0.17) | 8976.0 (1610.0) | 0.00 (0.00) | |
| Example 1 CR ≈ 60% | PSIS-PLIK | 1000.0 (2.0) | 0.67 (0.17) | 9999.0 (17.0) | 0.33 (0.17) |
| PSIS-Wald | 1000.0 (2.0) | 0.67 (0.17) | 9999.0 (17.0) | 0.33 (0.17) | |
| CS-PLIK ( ) | 227.0 (351.2) | 0.83 (0.17) | 2383.5 (3331.5) | 0.50 (0.33) | |
| CS-Wald ( ) | 227.5 (348.2) | 0.83 (0.17) | 2403.5 (3233.2) | 0.50 (0.33) | |
| CS-MPLE ( ) | 228.5 (320.5) | 0.83 (0.17) | 2229.5 (3046.8) | 0.50 (0.17) | |
| CS-PLIK ( ) | 206.0 (279.2) | 0.83 (0.17) | 1012.5 (1906.5) | 0.67 (0.33) | |
| CS-Wald ( ) | 207.0 (278.0) | 0.83 (0.17) | 1021.0 (1906.0) | 0.67 (0.33) | |
| CS-MPLE ( ) | 207.5 (267.2) | 0.83 (0.17) | 1070.0 (1892.8) | 0.67 (0.17) | |
| CRIS | 262.5 (401.8) | 0.50 (0.00) | 2871.0 (4314.0) | 0.50 (0.00) | |
| CORS | 490.5 (510.8) | 0.50 (0.00) | 4878.5 (5099.8) | 0.50 (0.00) | |
| Example 2 CR ≈ 20% | PSIS-PLIK | 318.0 (492.8) | 0.50 (0.00) | 3777.0 (5690.8) | 0.50 (0.00) |
| PSIS-Wald | 318.5 (494.2) | 0.50 (0.00) | 3786.5 (5707.8) | 0.50 (0.00) | |
| CS-PLIK ( ) | 2.0 (0.0) | 1.00 (0.00) | 2.0 (0.0) | 1.00 (0.00) | |
| CS-Wald ( ) | 2.0 (0.0) | 1.00 (0.00) | 2.0 (0.0) | 1.00 (0.00) | |
| CS-MPLE ( ) | 2.0 (0.0) | 1.00 (0.00) | 2.0 (0.0) | 1.00 (0.00) | |
| CS-PLIK ( ) | 6.0 (0.0) | 1.00 (0.00) | 6.0 (0.0) | 1.00 (0.00) | |
| CS-Wald ( ) | 6.0 (0.0) | 1.00 (0.00) | 6.0 (0.0) | 1.00 (0.00) | |
| CS-MPLE ( ) | 6.0 (0.0) | 1.00 (0.00) | 6.0 (0.0) | 1.00 (0.00) | |
| CRIS | 399.5 (478.0) | 0.50 (0.00) | 3601.0 (4894.2) | 0.50 (0.00) | |
| CORS | 603.5 (390.5) | 0.00 (0.00) | 5988.0 (4353.0) | 0.00 (0.00) | |
| Example 2 CR ≈ 60% | PSIS-PLIK | 325.0 (498.5) | 0.50 (0.00) | 3942.5 (5679.5) | 0.50 (0.00) |
| PSIS-Wald | 322.0 (501.0) | 0.50 (0.00) | 3915.5 (5679.5) | 0.50 (0.00) | |
| CS-PLIK ( ) | 2.0 (0.0) | 1.00 (0.00) | 2.0 (1.0) | 1.00 (0.00) | |
| CS-Wald ( ) | 2.0 (0.0) | 1.00 (0.00) | 2.0 (2.0) | 1.00 (0.00) | |
| CS-MPLE ( ) | 2.0 (0.0) | 1.00 (0.00) | 2.0 (4.0) | 1.00 (0.00) | |
| CS-PLIK ( ) | 6.0 (0.0) | 1.00 (0.00) | 6.0 (4.0) | 1.00 (0.00) | |
| CS-Wald ( ) | 6.0 (0.0) | 1.00 (0.00) | 6.0 (5.0) | 1.00 (0.00) | |
| CS-MPLE ( ) | 6.0 (0.0) | 1.00 (0.00) | 7.0 (7.2) | 1.00 (0.00) | |
| CRIS | 1000.0 (0.0) | 0.50 (0.00) | 10000.0 (0.0) | 0.50 (0.00) | |
| CORS | 1000.0 (0.0) | 0.50 (0.50) | 10000.0 (0.0) | 0.00 (0.00) | |
| Example 3 CR ≈ 20% | PSIS-PLIK | 1000.0 (0.0) | 0.50 (0.00) | 10000.0 (0.0) | 0.50 (0.00) |
| PSIS-Wald | 1000.0 (0.0) | 0.50 (0.50) | 10000.0 (0.0) | 0.00 (0.50) | |
| CS-PLIK ( ) | 2.0 (0.0) | 1.00 (0.00) | 2.0 (0.0) | 1.00 (0.00) | |
| CS-Wald ( ) | 2.0 (0.0) | 1.00 (0.00) | 2.0 (0.0) | 1.00 (0.00) | |
| CS-MPLE ( ) | 3.0 (4.0) | 1.00 (0.00) | 7.5 (33.0) | 1.00 (0.00) | |
| CS-PLIK ( ) | 6.0 (0.0) | 1.00 (0.00) | 6.0 (0.0) | 1.00 (0.00) | |
| CS-Wald ( ) | 6.0 (0.0) | 1.00 (0.00) | 6.0 (0.0) | 1.00 (0.00) | |
| CS-MPLE ( ) | 24.0 (29.0) | 1.00 (0.00) | 168.5 (266.8) | 0.50 (0.50) | |
| CRIS | 1000.0 (0.0) | 0.50 (0.00) | 10000.0 (0.0) | 0.50 (0.00) | |
| CORS | 783.0 (463.8) | 0.00 (0.50) | 7967.0 (4972.2) | 0.00 (0.00) | |
| Example 3 CR ≈ 60% | PSIS-PLIK | 1000.0 (0.0) | 0.50 (0.00) | 10000.0 (0.0) | 0.50 (0.00) |
| PSIS-Wald | 1000.0 (0.0) | 0.00 (0.00) | 10000.0 (0.0) | 0.00 (0.00) | |
| CS-PLIK ( ) | 2.0 (0.0) | 1.00 (0.00) | 2.0 (0.0) | 1.00 (0.00) | |
| CS-Wald ( ) | 2.0 (0.0) | 1.00 (0.00) | 2.0 (0.0) | 1.00 (0.00) | |
| CS-MPLE ( ) | 20.0 (55.2) | 1.00 (0.00) | 161.5 (553.5) | 0.50 (0.50) | |
| CS-PLIK ( ) | 6.0 (0.0) | 1.00 (0.00) | 6.0 (2.0) | 1.00 (0.00) | |
| CS-Wald ( ) | 6.0 (0.0) | 1.00 (0.00) | 6.0 (3.0) | 1.00 (0.00) | |
| CS-MPLE ( ) | 105.0 (127.5) | 0.50 (0.50) | 973.5 (1303.2) | 0.50 (0.00) | |
Table 2.
Median minimum model size (MMS) and median true positive rates (TPR) along with their corresponding IQRs (in the parentheses) based on 400 simulated data sets
| Method | (n,
p) = (100, 1000) |
(n,
p) = (100, 10000) |
|||
|---|---|---|---|---|---|
| MMS | TPR | MMS | TPR | ||
| CRIS | 997.0 (17.0) | 0.33 (0.17) | 9954.5 (205.0) | 0.17 (0.17) | |
| CORS | 947.5 (180.5) | 0.33 (0.33) | 9566.0 (1618.2) | 0.00 (0.17) | |
| Example 4 CR ≈ 20% | PSIS-PLIK | 1000.0 (4.0) | 0.67 (0.17) | 9997.0 (47.2) | 0.33 (0.17) |
| PSIS-Wald | 1000.0 (4.0) | 0.67 (0.17) | 9997.0 (47.2) | 0.33(0.17) | |
| CS-PLIK ( ) | 252.0 (383.0) | 0.83 (0.17) | 2428.0 (3387.2) | 0.50 (0.33) | |
| CS-Wald ( ) | 253.0 (385.2) | 0.83 (0.17) | 2451.0 (3394.0) | 0.50 (0.33) | |
| CS-MPLE ( ) | 250.0 (349.5) | 0.83 (0.17) | 2320.5 (3354.5) | 0.50 (0.17) | |
| CS-PLIK ( ) | 237.5 (387.0) | 0.83 (0.17) | 2248.5 (3610.2) | 0.50 (0.17) | |
| CS-Wald ( ) | 241.0 (388.8) | 0.83 (0.17) | 2258.0 (3629.2) | 0.50 (0.17) | |
| CS-MPLE ( ) | 232.0 (366.5) | 0.83 (0.17) | 2139.0 (3554.8) | 0.50 (0.33) | |
| CRIS | 918.0 (144.2) | 0.17 (0.33) | 9137.0 (1529.2) | 0.00 (0.00) | |
| CORS | 895.0 (155.0) | 0.00 (0.17) | 8876.5 (1514.2) | 0.00 (0.00) | |
| Example 4 CR ≈ 60% | PSIS-PLIK | 998.0 (26.0) | 0.50 (0.33) | 9972.5 (206.0) | 0.17 (0.17) |
| PSIS-Wald | 998.0 (26.0) | 0.50 (0.33) | 9972.5 (212.2) | 0.17(0.17) | |
| CS-PLIK ( ) | 387.0 (418.8) | 0.67 (0.33) | 4082.5 (4522.8) | 0.33 (0.17) | |
| CS-Wald ( ) | 389.0 (423.5) | 0.67 (0.33) | 4076.5 (4553.5) | 0.33 (0.17) | |
| CS-MPLE ( ) | 365.5 (377.2) | 0.67 (0.33) | 3906.5 (4356.5) | 0.33 (0.33) | |
| CS-PLIK ( ) | 375.5 (472.2) | 0.67 (0.33) | 4298.5 (4557.8) | 0.33 (0.17) | |
| CS-Wald ( ) | 373.0 (471.5) | 0.67 (0.33) | 4283.5 (4585.5) | 0.33 (0.17) | |
| CS-MPLE ( ) | 373.0 (448.2) | 0.67 (0.33) | 4151.5 (4479.5) | 0.33 (0.17) | |
The performance by CS-MPLE, CS-Wald and CS-PLIK are quite similar in all the cases in Examples 1, 2, and 4. In Example 3, there is a very high correlation among the covariate variables, CS-MPLE has a slightly larger MMS compared to the CS-Wald and CS-PLIK which well control the false discover rate in this cases.
Figure 3 shows that the proposed methods with efficiently identify all active variables by including much fewer variables than the other methods. Specifically, in Example 1 the proposed methods are capable of achieving a 100% TPR by choosing at most one fifth of the variables. In contrast, other competing methods have to include almost all the variables in order to discover all active variables. In Examples 2 and 3 the proposed methods quickly detect the remaining active variable (Zp) conditioning on the active variable (Z1), as opposed to the marginal screening approaches that have to include far more variables to ensure a 100% TPR.
Fig. 3.
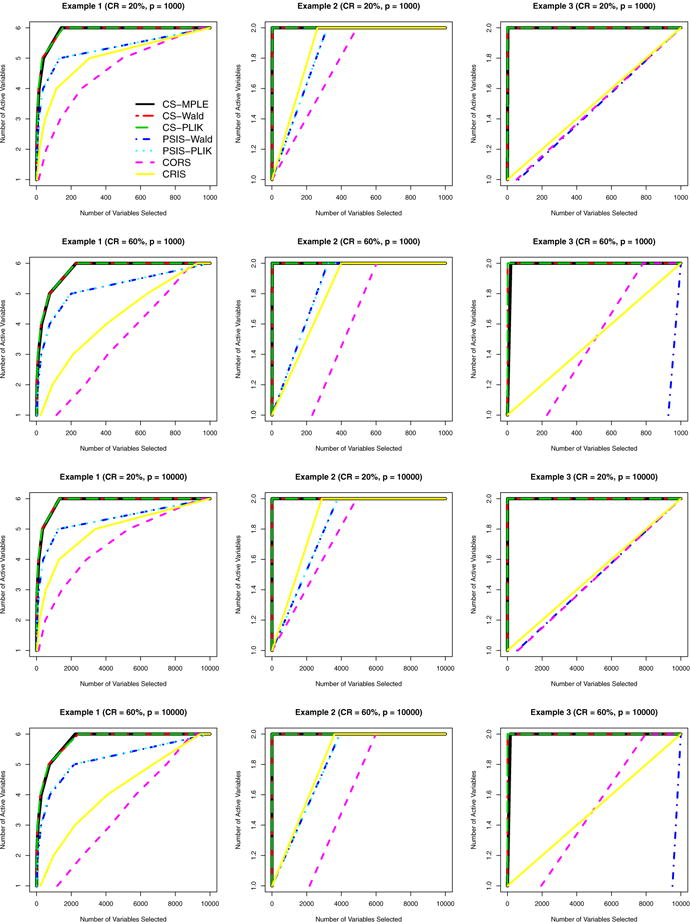
Median number of active variables that are included in the model with different thresholds by different methods
5 Application
We illustrated the practical utility of the proposed method by applying it to analyze the DLBCL dataset of Rosenwald et al. (2002). The dataset, which was originally collected for identifying gene signatures relevant to the patient survival from time of chemotherapy, included a total of 240 DLBCL patients with 138 deaths observed during the followup and a median survival time of 2.8 years. Along with the clinical outcomes, the expression levels of 7399 genes were available for analysis. In our subsequent analysis, each gene expression was standardized to have mean zero and variance 1.
To facilitate the use of our method, we identified the conditional set by resorting to the medical literature. As gene AA805575, a Germinal-center B-cell signature gene, has been known to be predictive to DCBCL patients’ survival in the literature (see Liu et al. 2013; Gui and Li 2005), we used it as the conditional variable in our proposed procedure. For comparisons, we also analyzed the same data using various competing methods introduced in the simulation section and computed the corresponding concordance statistics (C-statistics) (Uno et al. 2011).
Specifically, we randomly assigned 160 patients to the training set and 80 patients to the testing set, while maintaining the censoring proportion roughly the same in each set. For each split, we applied each method to select top 31(= 160/ log(160)) variables as suggested by Fan and Lv (2008) using the training set. LASSO was performed subsequently for refined modeling, with the tuning parameter selected by the 10-fold cross-validation. The risk score for each subject was obtained by using the final model selected by LASSO in the training dataset and the C-statistics was obtained in the testing dataset. A total of 100 splits were made and the average C-statistics and the model size (MS) were reported in Table 3. By the criterion of C-statistics, the proposed method seemed to have more predictive power.
Table 3.
Summary of C-statistics and the model size for different methods
| CRIS | CORS | PSIS-PLIK | PSIS-Wald | |
|---|---|---|---|---|
| C-statistics | 0.54 (0.21) | 0.58 (0.20) | 0.58 (0.19) | 0.55 (0.20) |
| Model size | 14.41 (3.00) | 6.83 (3.70) | 15.22 (2.93) | 15.65 (2.89) |
|
| ||||
| CS-MPLE | CS-PLIK | CS-Wald | ||
|
| ||||
| C-statistics | 0.63 (0.18) | 0.63 (0.18) | 0.62 (0.19) | |
| Model size | 16.74 (3.26) | 15.90 (3.01) | 16.28 (3.41) | |
Our further scientific investigation focused on identifying the relevant genes by utilizing the full dataset. Applying our proposed method, we selected top 240/ log(240) = 44 genes before using LASSO to reach the final list. It follows that CS-MPLE, CS-PLIK and CS-Wald selected 20, 16 and 16 genes, respectively. Among the 22 uniquely selected genes by either of them, 14 genes were overlapped and were reported in Table 4. Twelve genes among these 22 genes belong to lymph-node signature group, proliferation signature group, and germinal-center B-cell group defined by Rosenwald et al. (2002). We observed that 13 of these 22 genes were chosen by at least one of CRIS, CORS, PSIS-PLIK, and PSIS-Wald. On the other hand, gene AB007866, Z50115, S78085, U00238, AL050283, J03040, U50196, and AA830781, and M81695 were only identified by using our methods.
Table 4.
A comparison of genes that are selected by CS-MPLE, CS-PLIK and CS-Wald
| GenBank ID | Signature | Description | CS-MPEE | CS-PLIK | CS-Wald |
|---|---|---|---|---|---|
| LC_25054 | ✓ | ✓ | ✓ | ||
| X77743 | Proliferation | Cyclin-dependent kinase 7 | ✓ | ✓ | ✓ |
| U15552 | Acidic 82 kDa protein mRNA | ✓ | ✓ | ✓ | |
| AB007866 | KIAA0406 gene product | ✓ | |||
| BC012161 | Proliferation | Septin 1 | ✓ | ✓ | ✓ |
| AF134159 | Proliferation | Vhromosome 14 open reading frame 1 | ✓ | ✓ | ✓ |
| Z50115 | Proliferation | Thimet oligopeptidase 1 | ✓ | ||
| S78085 | Proliferation | Programmed cell death 2 | ✓ | ||
| M29536 | Proliferation | Eukaryotic translation initiation factor 2 | ✓ | ✓ | ✓ |
| U00238 | Proliferation | Phosphoribosyl pyrophosphate amidotransferase | ✓ | ||
| AL050283 | Proliferation | Sentrin/SUMO-specific protease 3 | ✓ | ||
| BF129543 | Germinal-center-B-cell | ESTs, Weakly similar to A47224 thyroxine-binding globulin precursor | ✓ | ✓ | ✓ |
| M81695 | integrin, alpha X | ✓ | ✓ | ✓ | |
| D13666 | Lymph node | Osteoblast specific factor 2 (fasciclin I-like) | ✓ | ✓ | ✓ |
| J03040 | Lymph node | Secreted protein | ✓ | ✓ | |
| U50196 | Adenosine kinase | ✓ | ✓ | ✓ | |
| U28918 | Proliferation | Suppression of tumorigenicity 13 | ✓ | ✓ | |
| AA721746 | ESTs | ✓ | ✓ | ✓ | |
| AA830781 | ✓ | ✓ | ✓ | ||
| AF127481 | Lymphoid blast crisis oncogene | ✓ | |||
| M61906 | Phosphoinositide-3-kinase | ✓ | ✓ | ✓ | |
| D42043 | KIAA0084 protein | ✓ | ✓ | ✓ |
In fact, only a few studies have suggested an important role of M81695 (Deb and Reddy 2003; Chow et al. 2001; Mikovits et al. 2001; Stewart and Schuh 2000) or AA830781 (Li and Luan 2005; Binder and Schumacher 2009; Schifano et al. 2010) in predicting DLBCL survival. As the marginal correlation between M81695 and the survival time and between AA830781 and the survival time are markedly low at 0.008 and 0.097, respectively, these two genes are highly likely to be missed by using the conventional marginal screening approaches. Indeed, AA830781 was identified by Schifano et al. (2010) only because of its co-expression or correlation with other relevant genes. A more detailed investigation of the functions of the identified genes in the context of a broader class of blood cancers, including lymphoma, may shed light on preventing, treating and controlling the lethal blood cancers.
6 Discussion
In this paper, we have proposed a new conditional variable screening approach for the Cox proportional hazards model with ultra-high dimensional covariates. The proposed partial likelihood based CS approaches are computationally efficient, with a solid theoretical foundation. Our method and theory are extensions of the conditional sure independence screening (CSIS) (Barut et al. 2016), which is designed for the GLM. In the development of theory, we introduce the new concept of the conditional linear covariance for the first time, which is useful to specify the regularity conditions for the model identifiability and the sure screening property. This also provides a building block for a general theoretical framework of conditional variable screening in the context of other semi-parametric models, such as the partially linear single-index model.
We have mainly focused on studying the theoretical properties of CS-MPLE, which extends the work of Barut et al. (2016) in the GLM setting, though development of the inference procedures for the two variants of the proposed method, namely, CS-PLIK and CS-Wald, will be more involved and out of scope of this paper. However, as indicated by the simulation studies, these two variants may induce substantial improvement especially when the variables are highly correlated. More research is warranted.
Our work also enlightens a few directions that are worth ensuing effort. First, as our proposal requires the prior information to be known and informative, it remains statistically challenging to develop efficient screening methods in the absence of such information. Recently, in the context of GLM, Hong et al. (2016) has proposed a data-driven alternative when a pre-selected set of variables is unknown. It is thus of substantial interest to develop a data-driven CS for the survival model. Second, even with prior knowledge, an open question often lies in how to balance it with the information extracted from the given data. There has been some recent work on how to incorporate prior information. For example, Wang et al. (2013) developed a LASSO method by assigning different prior distributions to each subset according to a modified Bayesian information criterion that incorporates prior knowledge on both the network structure and the pathway information, and Jiang et al. (2015) proposed “prior lasso” (plasso) to balance between the prior information and the data. A natural extension of the current work is to develop a variable screening approach that incorporates more complex prior knowledge, such as the network structure or the spatial information of the covariates. We will report the progress elsewhere.
Acknowledgments
This research was partially supported by a grant from NSA (H98230-15-1-0260, Hong), an NIH grant (R01MH105561, Kang) and Chinese Natural Science Foundation (11528102, Li).
Appendix
The basic properties of the conditional linear expectation are listed in the following proposition.
Proposition 1
if and only if , for all .
The proof is straightforward based on Definitions 2 and 3.
Proposition 2
Let and be any four random variables in the probability space The following properties hold for the conditional linear expectation given :
Closed form: .
Stability: .
Linearity: , where A1 and A2 are two matrices that are compatible with the equation.
Law of total expectation: .
Remark 1 In general, . Also, ζ and ξ are independent does not imply , unless ζ and ξ are jointly normally distributed.
Remark 2 By Proposition 2, we can easily verify the following properties.
Proposition 3
The conditional linear covariance defined in Definition 5 has the following properties:
- Linear independence and linear zero correlation:
- Expectation of conditional linear covariance:
- Sign: for any increasing function and random variable , then
Combining Propositions 1–3 and based on Definition 6 we have the following property.
Proposition 4
if and only if .
Lemma 1
The solution of and the solution of are both unique, for any .
Proof of Theorem 1
Proof First we make the connection between βj to the expected conditional linear covariance between Zj and given , that is
then by Condition 2, we relate it to . For any and , it is straightforward to see that
| (21) |
and
| (22) |
for m = 0, 1. Then
| (23) |
where
By Proposition 2,
By Definition 6,
where
and
By Definition 2, ,
When , then by Condition 2.3. Thus . Also, by Propositions 1 and 2, , then . By uniqueness in Lemma 1, βj = 0.
When α j ≠ 0, by Condition 2, we have
This implies that and are both nonzero and have the same signs since they are equal. Next we show for any and have the opposite signs unless they are equal to zero. This fact implies that βj ≠ 0. Specifically, note that P(δ = 1| Z) is the probability of occurring the event and represents the probability at risk at time t. Based on Model (1), for any t,
By Proposition 3, and have the opposite signs unless they are zero. This further implies that for any ,
and have opposite signs unless they are equal to zero. Therefore, βj ≠ 0.
Proof of Theorem 2
Proof For any , we have βj ≠ 0 by Theorem 1, by mean value theorem, for some ,
Next we show that is bounded. For given any , consider as a function of β, Then
where
By Condition 2.1, P(|Z| < K0) = 1, then Thus,
By the proof in Theorem 1, and have the opposite signs, and by Condition 2,
Taking , . This completes the proof.□
Proof of Theorem 3
Proof For any and , by Lin and Wei (1989), we have
where En [·] denotes the empirical measure, which is defined as for any random variables , and are independent over i, and write with
Note that given any i, j, k, with probability one are uniformly bounded. Specifically, by Conditions 1.2, 2.1 and 3, with probability one, for all , ,
and
Thus, with probability one,
where . By the fact that ,
By Lemma 2.2.9 (Bernsterin’s inequality) of Vaart and Wellner (1996), for any t > 0, for all j, k, and β, we have
Note that the above inequality holds for every and By Bonferroni inequality,
Since,
Then for any ε1 > 0 and ε2 > 0, there exits N1, such that for any n > N1,
where M is the same value in Condition 4. By Triangle inequality and Bonferroni inequality, we have
When , take on both side of the inequality, where c2 is the same value in Theorem 2, we have
Take N = max{⌈(K2/3)1/κ⌉,N1}, then for any n > N, n−κ< 3/K2, and
Note that the above inequality holds for all , particularly for . Also, we have .By Condition 4, we have
Taking and by Bonferroni completes the proof for part 1.
For part 2, by Theorem 2,
Note that, for any , event
Take with c4 = c2/4,
Thus,
Let we have for any ,
Note that the left side of the above equation does not depends on n any more. Taking completes proof.
References
- Barut E, Fan J, Verhasselt A. Conditional sure independence screening. J Am Stat Assoc. 2016;116:544–557. doi: 10.1080/01621459.2015.1092974. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Binder H, Schumacher M. Incorporating pathway information into boosting estimation of highdimensional risk prediction models. BMC Bioinform. 2009;10:18. doi: 10.1186/1471-2105-10-18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chow ML, Moler EJ, Mian IS. Identifying marker genes intranscriptionprofiling data using a mixture of feature relevance experts. Physiol Genomics. 2001;5:99–111. doi: 10.1152/physiolgenomics.2001.5.2.99. [DOI] [PubMed] [Google Scholar]
- Deb K, Reddy AR. Reliable classification of two-class cancer data using evolutionary algorithms. BioSystems. 2003;72:111–129. doi: 10.1016/s0303-2647(03)00138-2. [DOI] [PubMed] [Google Scholar]
- Fan J, Lv J. Sure independence screening for ultrahigh dimensional feature space (with discussion) J R Stat Soc B. 2008;70:849–911. doi: 10.1111/j.1467-9868.2008.00674.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan J, Feng Y, Wu Y. IMS collections borrowing strength: theory powering applications—A Festschrift for Lawrence D Brown. Vol. 6. Institute of Mathematical Statistics; Beachwood: 2010. High-dimensional variable selection for Cox’s proportional hazards model; pp. 70–86. [Google Scholar]
- Gui J, Li H. Penalized Cox regression analysis in the high-dimensional and low-sample size settings, with applications to microarray gene expression data. Bioinformatics. 2005;21(13):3001–3008. doi: 10.1093/bioinformatics/bti422. [DOI] [PubMed] [Google Scholar]
- Hong H, Wang L, He X. A data-driven approach to conditional screening of high dimensional variables. Stat. 2016;5(1):200–212. [Google Scholar]
- Jiang Y, He Y, Zhang H. Variable selection with prior information for generalized linear models via the prior Lasso method. J Am Stat Assoc. 2015;111(513):355–376. doi: 10.1080/01621459.2015.1008363. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li H, Luan Y. Boosting proportional hazards models using smoothing splines, with applications to high-dimensional microarray data. Bioinformatics. 2005;21(10):2403–2409. doi: 10.1093/bioinformatics/bti324. [DOI] [PubMed] [Google Scholar]
- Lin DY, Wei LJ. The robust inference for the Cox proportional hazards model. J Am Stat Assoc. 1989;84(408):1074–1078. [Google Scholar]
- Liu XY, Liang Y, Xu ZB, Zhang H, Leung KS. Adaptive shooting regularization method for survival analysis using gene expression data. Sci World J. 2013;2013:475702. doi: 10.1155/2013/475702. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mikovits J, Ruscetti F, Zhu W, Bagni R, Dorjsuren D, Shoemaker R. Potential cellular signatures of viral infections in human hematopoietic cells. Dis Markers. 2001;17(3):173–178. doi: 10.1155/2001/896953. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rosenwald A, Wright G, Chan W, Connors J, Campo E, et al. The use of molecular profiling to predict survival after chemotherapy for diffuse large-b-cell lymphoma. N Engl J Med. 2002;346(25):1937–1947. doi: 10.1056/NEJMoa012914. [DOI] [PubMed] [Google Scholar]
- Schifano ED, Strawderman RL, Wells MT. Mm algorithms for minimizing nonsmoothly penalized objective functions. Electron J Stat. 2010;4:1258–1299. [Google Scholar]
- Song R, Lu W, Ma S, Jeng XJ. Censored rankindependence screening for high-dimensional survival data. Biometrika. 2014;101(4):799–814. doi: 10.1093/biomet/asu047. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stewart AK, Schuh AC. White cells 2: impact of understanding the molecular basis of haematological malignant disorders on clinical practice. Lancet. 2000;355(9213):1447–1453. doi: 10.1016/s0140-6736(00)02150-4. [DOI] [PubMed] [Google Scholar]
- Uno H, Cai T, Pencina MJ, D’Agostino RB, Wei LJ. On the c-statistics for evaluating overall adequacy of risk prediction procedures with censored survival data. Stat Med. 2011;30(10):1105–1117. doi: 10.1002/sim.4154. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van Der Vaart AW, Wellner JA. Weak convergence. Springer; New York: 1996. [Google Scholar]
- Wang Z, Xu W, San Lucas F, Liu Y. Incorporating prior knowledge into gene network study. Bioinformatics. 2013;29:2633–2640. doi: 10.1093/bioinformatics/btt443. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao SD, Li Y. Principled sure independence screening for Cox models with ultra-high-dimensional covariates. J Multivar Anal. 2012;105(1):397–411. doi: 10.1016/j.jmva.2011.08.002. [DOI] [PMC free article] [PubMed] [Google Scholar]