

Abstract
We examined sequential learning in individuals with agrammatic aphasia (n = 12) and healthy age-matched participants (n = 12) using an artificial grammar. Artificial grammar acquisition, 24-hour retention, and the potential benefits of additional training were examined by administering an artificial grammar judgment test (1) immediately following auditory exposure-based training, (2) one day after training, and (3) after a second training session on the second day. An untrained control group (n = 12 healthy age-matched participants) completed the tests on the same time schedule. The trained healthy and aphasic groups showed greater sensitivity to the detection of grammatical items than the control group. No significant correlations between sequential learning and language abilities were observed among the aphasic participants. The results suggest that individuals with agrammatic aphasia show sequential learning, but the underlying processes involved in this learning may be different than for healthy adults.
Keywords: Agrammatic aphasia, sequential learning, artificial grammar, retention
Introduction
Sequential learning is a process of discovering structure based on regularities in sequentially ordered stimuli, which is thought to play an important role in language learning and language processing. It has been proposed that syntactic processing is subserved by the same domain-general mechanisms that underlie sequential learning (Christiansen & Chater, 2015; Christiansen, Conway, & Onnis, 2012; Dominey, Hoen, Blanc, & Lelekov-Boissard, 2003). Accordingly, it has been suggested that the syntactic impairments observed in stroke-induced agrammatic aphasia result from damage to these domain-general mechanisms (Christiansen, Kelly, Shillcock, & Greenfield, 2010). Thus, deficits in sequential learning would be expected to co-occur with the syntactic deficits of agrammatic aphasia, such as difficulty producing grammatically correct sentences and particular difficulty producing and comprehending syntactically complex sentences (Caplan & Futter, 1986; Grodzinsky, 1986, 1995; Schwartz, Saffran, & Marin, 1980). In contrast, if the mechanisms underlying sequential learning are separate from those underlying syntactic processing, then dissociations between these abilities would be expected to occur after brain injury. The present study addresses this question by testing sequential learning in individuals with agrammatic aphasia.
Behavioural and neuroimaging evidence suggests a strong relationship between sequential learning and language processing in healthy adults. Better performance in sequential learning tasks is associated with better speech perception under degraded listening conditions (Conway, Bauernschmidt, Huang, & Pisoni, 2010; Conway, Karpicke, & Pisoni, 2007), online processing of sentences with long-distance dependencies (Misyak, Christiansen, & Tomblin, 2010), offline comprehension of complex sentences (Misyak & Christiansen, 2012), and reading abilities (Arciuli & Simpson, 2012). In addition, neuroimaging evidence indicates that sequential learning and language processing share common neural substrates. Structural incongruencies in recently learned sequences and syntactic violations in natural language both elicit the P600 event-related potential (Christiansen et al., 2012), and sequential learning is associated with activation of Broca's area, a region known to be crucial for language (Forkstam, Hagoort, Fernandez, Ingvar, & Petersson, 2006; Karuza et al., 2013; Petersson, Folia, & Hagoort, 2012; Petersson, Forkstam, & Ingvar, 2004). These studies suggest that either sequential learning itself is involved in language processing, or sequential learning and language processing share common underlying mechanisms.
In line with these ideas, it has been suggested that brain damage resulting in syntactic impairments also impairs sequential learning abilities; hence, individuals with agrammatic aphasia are expected to exhibit deficits in sequential learning tasks (Christiansen et al., 2010). However, studies examining sequential learning in people with agrammatic aphasia have shown mixed results. Several studies using serial reaction time (SRT) tasks, in which participants respond to a repeating sequence of stimuli, have shown evidence of sequential learning (Dominey et al., 2003; Goschke, Friederici, Kotz, & van Kampen, 2001; Schuchard, Nerantzini, & Thompson, 2017; Schuchard & Thompson, 2014). In contrast, artificial grammar learning studies, in which participants make judgments after exposure to multiple sequences of stimuli that follow an underlying rule structure, have shown abnormal learning ability in agrammatic aphasia (Christiansen et al., 2010; Zimmerer, Cowell, & Varley, 2014). There has also been conflicting evidence regarding the domain-generality of sequential learning abilities in aphasia. Goschke et al. (2001) found sequential learning deficits specific to the linguistic domain (i.e. when learning phoneme sequences as opposed to visuomotor sequences), whereas Schuchard and Thompson (2014) found normal patterns of verbal sequence learning in people with agrammatic aphasia, possibly as a result of the larger sample size in the latter study.
Potential explanations for these inconsistent findings include variability in the tasks that were administered as well as the participants included in the studies. Although SRT and artificial grammar tasks are both thought to recruit sequential learning abilities, the more complex structures of artificial grammars may reveal impairments to a greater extent than the relatively simple repeating sequences in SRT tasks. In addition, individuals classified as “agrammatic” vary in their symptom profiles and severity of impairment. It is possible that some individuals have sequential learning impairments and others do not, and it is important to determine whether such impairments are associated with specific linguistic deficits.
In addition to theoretical implications, a better understanding of the ability of people with aphasia to extract sequential patterns through exposure may inform language rehabilitation. One strategy for aphasia treatment involves repeated exposure to linguistic stimuli to maximise correct responding during training (Fillingham, Hodgson, Sage, & Lambon Ralph, 2003), but purely exposure-based training is not always efficacious for relearning sequential linguistic stimuli, such as complex sentence structures (Schuchard et al., 2017). Knowledge of aphasia symptom profiles that are associated with exposure-based sequential learning abilities may help identify individuals who will benefit from this type of language training.
In the present study, the experimental tasks and inclusionary criteria for participants were selected to (1) test the hypothesis that common mechanisms subserve sequential learning and syntactic processing, and (2) test aspects of learning relevant to language training in aphasia. Because we were interested in the implications of this study for language training, we used an artificial grammar in the verbal domain designed to include the kinds of dependencies found in natural languages (Saffran, 2002), and we tested the extent to which sequential learning is retained across days and improved with additional exposure. Unlike previous artificial grammar learning studies, we administered an artificial grammar judgment test immediately following training of the artificial grammar, one day after training, and after a second training session on the second day with agrammatic and neurologically intact adults. If sequential learning and syntactic abilities rely on shared mechanisms, agrammatic participants should perform poorly on the artificial grammar tests, and variability in these scores should be associated with performance on tests of syntactic processing. Hence, we also tested the correlations of the artificial grammar test scores with measures of syntactic impairment.
For artificial grammar learning paradigms, it is important to consider that people with aphasia may differ from neurologically intact adults in the specific cognitive processes or strategies involved in the experimental task. Artificial grammar tasks may involve implicit learning that occurs largely outside of conscious awareness or more intentional, explicit processes (Pothos, 2007), and people with aphasia may differ from healthy adults in sequential learning tasks under explicit learning conditions (Schuchard & Thompson, 2014). In addition, participants may make judgments about an artificial grammar based on the underlying rules, similarity between test items and trained items, or frequencies of co-occurring elements in the stimuli (Pothos, 2007). In studies that delineated the acquisition of specific regularities of an artificial grammar, some individuals with aphasia differed from healthy controls in their sensitivity to certain structures, suggesting qualitatively different approaches to sequential learning (Zimmerer et al., 2014; Zimmerer & Varley, 2015). To shed light on factors that may influence participants' learning, we included analyses to test the effects of anchor strength and associative chunk strength, two measures of co-occurring elements in the stimuli that contribute to how familiar the test items seem to participants given exposure to the trained items (Knowlton & Squire, 1994), in addition to the grammaticality of the items. We also examined whether participants' learning was restricted to trained items, which would suggest a strategy based on remembering specific items, or generalised to untrained items.
To summarise, the aim of the present study was to test the sequential learning abilities of individuals with agrammatic aphasia using an artificial grammar task administered on two consecutive days. If sequential learning and syntactic processing rely on shared underlying mechansims, we would expect (1) poor performance across the three administrations of the artificial grammar judgment test for agrammatic compared to healthy participants and (2) significant correlations between artificial grammar learning scores and syntactic test scores for agrammatic participants. In addition, if aphasic individuals are impaired in retaining sequential learning or in accumulating learning across multiple training sessions, we would expect them to exhibit different changes in performance between the test administrations compared to healthy adults.
Methods
Participants
Participants included 12 adults with chronic agrammatic aphasia resulting from a single left hemisphere stroke (10 male; age 35–81, M = 54) and 24 neurologically intact adults who were not significantly different from the aphasic participants in age or years of education (11 male; age 32–77, M = 57). All participants reported having normal or corrected-to-normal vision and hearing and no history of learning disorders or language disorders other than aphasia. Participants were monolingual English speakers, with the exception of one aphasic participant who spoke both English and Spanish as a child but primarily English as an adult. Aphasic participants were at least 11 months post-stroke (range 0.9–22 years, M = 6 years). All provided written informed consent approved by the Northwestern University Institutional Review Board.
Language testing
The aphasic participants completed assessments of language production and comprehension abilities. Language testing included the Western Aphasia Battery-Revised (WAB-R; Kertesz, 2007), which provides a measure of overall aphasia severity (Aphasia Quotient) in addition to subtest scores, and the Northwestern Assessment of Verbs and Sentences (NAVS; Thompson, 2011), which includes measures of canonical and noncanonical sentence production and comprehension. Because the experimental stimuli in this study used pseudowords, participants' ability to process pseudowords was tested using the Nonword Discrimination and Auditory Lexical Decision subtests of the Psycholinguistic Assessments of Language Processing in Aphasia (PALPA; Kay, Lesser, & Coltheart, 1992). In addition, narrative speech samples were collected by asking participants to tell the story of Cinderella. These speech samples were recorded, transcribed, and analysed to provide measures of speech production, including the percentage of grammatically correct sentences and average words per minute. Inclusionary criteria for aphasic participants in this study included (1) a score of at least 7/10 on the Auditory Verbal Comprehension subtest of the WAB-R to indicate that participants would be able to understand spoken instructions, (2) scores of at least 80% on the PALPA subtests to demonstrate the ability to process pseudowords, and (3) symptoms consistent with agrammatism. Symptoms consistent with agrammatism included (1) indications of nonfluent speech in the narrative speech sample, such as speaking at a rate of less than 60 words per minute or less than 70% grammatical sentences and (2) lower accuracy for noncanonical sentence structures compared to canonical sentence structures in the Sentence Production or Sentence Comprehension subtests of the NAVS. Table 1 displays summaries of language testing for the aphasic participants.
Table 1.
Language testing data for aphasic participants.
| Assessment | P1 | P2 | P3 | P4 | P5 | P6 | P7 | P8 | P9 | P10 | P11 | P12 | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Western Aphasia Battery-Revised | |||||||||||||
| Aphasia Quotient (severity measure) | 71.7 | 77.0 | 82.5 | 78.0 | 77.2 | 76.6 | 83.8 | 65.1 | 88.6 | 71.3 | 59.0 | 88.0 | 76.6 |
| Auditory Verbal Comprehension | 8.5 | 8.4 | 7.6 | 7.9 | 8.3 | 8.8 | 9.3 | 8.8 | 9.9 | 8.6 | 8.3 | 9.8 | 8.7 |
| Northwestern Assessment of Verbs and Sentences | |||||||||||||
| Sentence Production Test | |||||||||||||
| Canonical sentences | 33.3 | 53.3 | 80.0 | 46.7 | 46.7 | 80.0 | 100.0 | 60.0 | 73.3 | 13.3 | n/a | 100.0 | 62.4 |
| Noncanonical sentences | 0.0 | 26.7 | 46.7 | 20.0 | 0.0 | 66.7 | 60.0 | 33.3 | 26.7 | 0.0 | n/a | 60.0 | 30.9 |
| Sentence Comprehension Test | |||||||||||||
| Canonical sentences | 86.7 | 73.3 | 66.7 | 60.0 | 80.0 | 86.7 | 100.0 | 86.7 | 86.7 | 46.7 | 66.7 | 80.0 | 76.7 |
| Noncanonical sentences | 80.0 | 93.3 | 73.3 | 73.3 | 26.7 | 46.7 | 80.0 | 53.3 | 66.7 | 46.7 | 40.0 | 46.7 | 60.6 |
| Psycholinguistic Assessments of Language Processing in Aphasia | |||||||||||||
| Nonword Discrimination | 88.9 | 97.2 | 88.9 | 94.4 | 93.1 | 97.2 | 97.2 | 97.2 | 98.6 | 80.6 | 88.9 | 94.4 | 93.1 |
| Auditory Lexical Decision | 93.1 | 91.3 | 96.9 | 91.9 | 96.3 | 87.5 | 96.9 | 95.6 | 97.5 | 92.5 | 93.1 | 88.8 | 93.4 |
| Cinderella narrative speech sample | |||||||||||||
| Percent grammatical sentences | 18.8 | 12.1 | 93.3 | 47.5 | 0.0 | 30.0 | 53.7 | 0.0 | 65.6 | 0.0 | 34.5 | 64.3 | 35.0 |
| Words per minute | 73.5 | 42.8 | 54.4 | 81.7 | 32.2 | 26.0 | 22.7 | 33.8 | 120.0 | 64.0 | 68.7 | 37.6 | 54.8 |
Notes: The highest possible Western Aphasia Battery (WAB) Aphasia Quotient is 100 (with neurologically intact adults scoring an average of 98.4 (Kertesz, 2007)); the highest possible score for the Auditory Verbal Comprehension subtest is 10. Scores on the Northwestern Assessment of Verbs and Sentences and the Psycholinguistic Assessments of Language Processing in Aphasia represent percent correct.
Memory testing
A series of memory tests was administered to screen for participants with memory impairments that could interfere with learning in the experimental task (due to time constraints, one aphasic participant (P12) did not complete the memory tests). Non-linguistic assessments were selected so that the linguistic deficits of the aphasic participants would not prevent them from successfully completing the tests. The test scores did not indicate severe memory impairment in any of the participants, and average scores were similar for the aphasic and healthy age-matched adults (see Table 2).
Table 2.
Memory testing data.
| Participants | Corsi Block Task | Doors and People Test | |||
|---|---|---|---|---|---|
|
|
|
||||
| Forward | Backward | Doors Test | Shapes Test | Delayed Recall | |
| Control (mean; range) | 7.8; 5–12 | 7.8; 4–11 | 16.4; 10–22 | 31.3; 19–36 | 10.6; 4–12 |
| Aphasia (mean; range) | 7.5; 6–11 | 6.5; 4–9 | 17.8; 10–22 | 29.4; 12–36 | 10.7; 6–12 |
A computerised version of the Corsi Block-Tapping Task was administered to test working memory (PEBL Psychological Test Battery; http://pebl.sourceforge.net/battery.html). In the Corsi forward span test, a display of nine blue squares appeared on the computer monitor. A series of the squares turned yellow one at a time, and after this presentation the participant used the mouse to click on the squares in the same order in which they had turned yellow. The series of squares increased in length, beginning with two squares at level 1. Two trials were administered at each level until the participant answered incorrectly on both trials of a given level, at which point the test was discontinued. The score consisted of the total number of trials answered correctly. The same procedures were followed in the Corsi backward span test, with the exception that the participant was instructed to click on the squares in the opposite order that they had turned yellow.
The Doors Test and the Shapes Test from the Doors and People Test (Baddeley, Emslie, & Nimmo-Smith, 1994) were also administered. The Doors Test is a test of recognition memory. Participants were instructed to look at 12 photographs of doors, presented one at a time for three seconds each. Each of the 12 photographs was then presented alongside three new photographs of doors, and participants were asked to point to the door that they had seen before. These procedures were repeated with a second set of 12 doors, for a total possible score of 24. The Shapes Test is a test of recall memory. Participants were shown four simple cross shapes and asked to draw each one on a sheet of paper. The experimenter then asked the participant to draw the shapes from memory. If the participant did not draw all four shapes correctly, he or she was given two more attempts to study and then draw the shapes. Approximately 15 minutes after this initial test, a Delayed Recall Test was administered, in which the participant was asked to draw the four shapes once more. Drawings were scored according to the presence of three specific features of each shape, with a total possible score of 36 in the initial Shapes Test and 12 in the Delayed Recall Test.
Stimuli
The artificial grammar in the present study was adapted from the “Language P” used by Saffran (2002). In this language, monosyllabic pseudowords are assigned to one of five lexical categories and arranged according to the rules of a hierarchical phrase structure grammar (see Figure 1), although the language can also be processed as a Markov finite-state grammar (see Zimmerer, 2010). All sentence stimuli in the present experiment were three to five pseudowords in length. Fifty grammatical sentences were constructed for the training sessions (see Appendix 1). Fourteen grammatical and 14 ungrammatical sentences were used for the artificial grammar judgment test (see Appendix 2), similar to the number of test items used in Saffran (2002). Half of the grammatical test items were also included in the training stimuli (“trained” sentences), and the other half were not (“untrained” sentences). Grammatical and ungrammatical test stimuli were designed to match each other and the training stimuli in sentence length and the relative frequency of each pseudoword, which was calculated by dividing the number of sentences that included a particular pseudoword by the total number of sentences in the set of stimuli.
Figure 1.

Artificial grammar. The rules of the artificial grammar (1a) and the pseudowords assigned to the five lexical categories (1b) were adapted from Saffran (2002). S = Sentence; AP, BP, CP = Phrases; A, C, D, F, G = Lexical categories.
Both grammatical and ungrammatical test items varied in associative chunk strength and anchor strength (see Appendix 2). Associative chunk strength is defined as the average frequency with which the chunks (here, the component word pairs and word triplets) in a test item occur in the training items. Anchor strength is defined as the average frequency with which the initial and final chunks in a test item occur as the initial and final chunks, respectively, of the trained items. These two measures are based on co-occurring elements of the stimuli rather than underlying grammatical rules. However, these measures were not completely independent of grammaticality in this study because grammatical test items had higher values of associative chunk strength and anchor strength compared to ungrammatical items. All sentences were recorded by the same female speaker at a rate of approximately 1.5 words per second with uniformly descending prosody across each sentence and normalised to 70 dB SPL. Stimuli were presented using SuperLab software (Cedrus, Phoenix, Arizona).
Procedures
Design
Neurologically intact participants were randomly assigned to a trained group (hereafter, “trained controls”) or to an untrained control group (hereafter, “untrained controls”), whereas all aphasic participants received training in the artificial grammar (hereafter, “aphasic group”). Participants in the trained control and aphasic groups were exposed to the artificial grammar on two consecutive days. On the first day, participants listened to grammatical sentences for approximately 30 minutes. Immediately after this training session, participants completed the 28-item judgment test (Test 1). To assess retention, participants returned the next day and again completed the same test (Test 2). Participants then received a second training session identical to the first and completed the test a third time immediately after the session (Test 3). Participants in the untrained control group completed the test three times on the same time schedule but did not receive training in the grammar. See Figure 2 for a visual depiction of the overall design.
Figure 2.
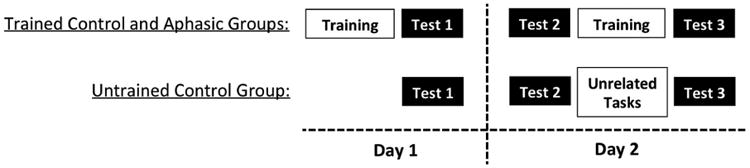
Study design. Training consisted of exposure to auditory grammatical sentences in the artificial grammar. The test that was administered three times required judgments for grammatical and ungrammatical sentences.
Artificial grammar training
General instructions administered prior to the first training session informed participants that they would hear sentences in a made-up language consisting of 10 words that have no associated meaning. Participants were told that they would be asked to answer questions about the made-up language, but they did not know which aspects of the language would be tested until after the first training session was completed. In each of the 2 training sessions, participants listened to the set of 50 grammatical sentences in the artificial grammar repeated 8 times for a total of 400 sentence exposures lasting approximately 30 minutes. During this time, participants also watched a muted nature video. This concurrent task was included to keep participants alert throughout the training session without requiring any linguistic or motor skills that may be impaired in participants with aphasia.
Artificial grammar testing
To promote comprehension of the judgment task, detailed instructions, examples, and practice items were administered prior to the first administration of the test. Pre-recorded instructions explained that “good” sentences should sound more like the sentences heard in training than “bad” sentences, and that the order of the words does not follow the rules of the language in the “bad” sentences. One example of a good sentence and one example of a bad sentence were provided, and four practice trials were administered. The same pre-recorded instructions were administered to trained and control participants, but because the control participants had not received exposure to the training stimuli, they were also told that they could answer based on which items sounded better or more pleasing to them. Participants were encouraged to ask questions prior to beginning the test if they were uncertain about the task.
In the test, participants were instructed to decide whether each item was a “good” or “bad” sentence in the language. In each trial, a fixation cross was displayed for 500 ms as a ready signal prior to the auditory presentation of a test item. Immediately following presentation of the sentence, participants were prompted to respond with a visual display of the number “1” underneath the word “Good” and a smiling face and the number “2” underneath the word “Bad” and a frowning face. Participants pressed the key on the computer keyboard corresponding to their response, and a blank screen was presented for 2000 ms before the next trial began. The same 28 items were administered in a different random order at each test time.
Data analysis
Test data were analysed with model comparisons using mixed effects regression models to account for individual differences in the context of models of overall group performance (see Baayen, Davidson, & Bates, 2008). Analyses were carried out in R version 3.1.2 using the lme4 package (R Core Team, 2014). Because models did not converge using a maximal random effects structure, random effects on the intercept only were included. Improvements in model fit were evaluated using −2 times the change in log-likelihood, which is distributed as chi-squared with degrees of freedom equal to the number of parameters added. p-Values for parameter estimates were estimated using the normal approximation for the t-values (linear models) or z-values (logistic models) with alpha = 0.05.
Test performance was analysed using the sensitivity index d′, which separates sensitivity to the stimuli from response bias (in this case, a bias towards responding either “good” or “bad” during the judgment tests). This measure was calculated as d′ = z-score (hits) – z-score (false alarms) for each participant from the number of hits (correct identification of grammatical items) and the number of false alarms (incorrect identification of ungrammatical items as being grammatical). One aphasic participant (P12) did not complete Test 2; consequently, Test 2 data are based on a sample size of 11 aphasic participants.
The d′ scores were entered as the dependent variable in linear mixed effects models with random effects of participants on the intercept and fixed effects of test (Test 1, Test 2, and Test 3) and participant group (trained control, aphasic group, and untrained control). Each fixed effect and the interaction term was added individually, and their effects on model fit were evaluated as detailed above.
To examine associations between sequential learning and linguistic abilities for the participants with aphasia, a series of correlations was performed. Percent accuracy on the Sentence Comprehension Test of the NAVS was used as a measure of syntactic abilities in comprehension. This test consists of a sentence-picture matching task with auditory presentation of semantically reversible sentences with simple and complex syntactic structures. The percentage of grammatical sentences in the narration of the Cinderella story was used as a measure of syntactic abilities in production. In addition, the WAB-R Aphasia Quotient was used as a measure of overall aphasia severity. Correlations were performed between each of these language measures and aphasic participants'd′ scores (averaged across the three tests).
A separate set of regression models was used to examine how well grammatical rule violations and other properties of the test items predicted participants' judgments, with data collapsed across all three tests. For each participant group, a logistic mixed effects model was constructed with the judgment (accept/reject) for each item as the binary dependent variable. Fixed effects of anchor strength, associative chunk strength, and a three-level factor of item type (trained grammatical, untrained grammatical, and ungrammatical) were entered with random effects of participants and items on the intercept. The independent variables were entered simultaneously, such that the order of the variables in the model did not affect the results.
Results
Artificial grammar judgment accuracy and sensitivity
Table 3 reports average percent accuracy and d′ scores for each participant group subdivided by test time, and Table 4 reports average percent accuracy by item type, collapsing across all test times. Figure 3 displays individual d′ scores overlaid on the group averages. The details of all regression model analyses are reported in Appendix 3. The effect of test on d′ did not improve model fit, χ2 (2) = 1.62, p = .44, but the effect of group did, χ2 (2) = 12.64, p < .01. The trained control and aphasic groups each obtained higher d′ scores compared to the untrained control group, trained control vs. untrained control: Estimate = 0.555, SE = 0.14, p < .001, aphasic group vs. untrained control: Estimate = 0.314, SE = 0.14, p = .03. The trained control and aphasic groups did not differ from each other, Estimate = 0.241, SE = 0.14, p = .09. The interaction between test and group had a marginally significant effect on model fit, χ2 (4) = 8.98, p = .06. The difference between Test 2 and Test 3 for the trained control group differed from the untrained control group, Estimate = 0.862, SE = 0.286, p < .01, whereas no other differences between tests were significantly different between the participant groups, p > .05.
Table 3.
Artificial grammar judgment test accuracy and sensitivity.
| Mean % accuracy (SD) | |||
| Group | Test 1 | Test 2 | Test 3 |
| Trained control | 61.3 (12.4) | 57.7 (9.5) | 65.2 (8.4) |
| Aphasic group | 58.9 (9.1) | 57.1 (9.7) | 56.8 (8.1) |
| Untrained control | 52.1 (7.4) | 55.4 (9.9) | 50.6 (7.7) |
| Mean d′ (SD) | |||
| Group | Test 1 | Test 2 | Test 3 |
| Trained control | 0.64 (0.71) | 0.42 (0.51) | 1.04 (0.71) |
| Aphasic group | 0.49 (0.48) | 0.40 (0.61) | 0.49 (0.59) |
| Untrained control | 0.11 (0.39) | 0.29 (0.53) | 0.04 (0.42) |
Table 4.
Artificial grammar judgment test accuracy by item type.
| Group | Mean % accuracy (SD) | Ungrammatical | |
|---|---|---|---|
|
| |||
| Trained grammatical | Untrained grammatical | ||
| Trained control | 72.6 (9.3) | 72.2 (16.3) | 50.4 (11.7) |
| Aphasic group | 65.3 (15.6) | 69.0 (18.1) | 48.2 (12.2) |
| Untrained control | 56.3 (8.6) | 54.0 (13.2) | 50.2 (11.2) |
Figure 3.
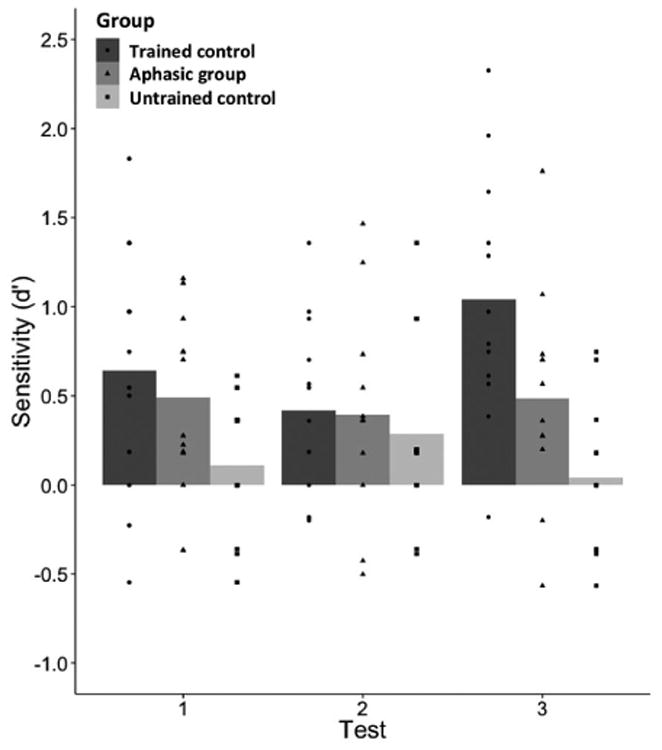
Artificial grammar judgment sensitivity. Individual d′ scores are shown overlaid on bars representing the average d′ scores for each participant group at Test 1 (day 1 after training), Test 2 (day 2 before training), and Test 3 (day 2 after second training). Higher d′ scores indicate greater sensitivity to the detection of grammatical items.
Sequential learning and language abilities
Figure 4 displays associations between d′ scores and three measures of language abilities for the participants with aphasia. No significant correlations were found between the Sentence Comprehension Test accuracy and d′ scores, r = .07, p = .83, between the percent production of grammatical sentences and d′ scores, r = −.45, p = .15, or between the WAB-R Aphasia Quotient and d′ scores, r = −.33, p = .30. However, it is important to note that post-hoc power analyses indicated that the sample size of 12 individuals resulted in relatively low power for the correlations. For example, the power achieved for the effect size r = −.45 was 0.35.
Figure 4.
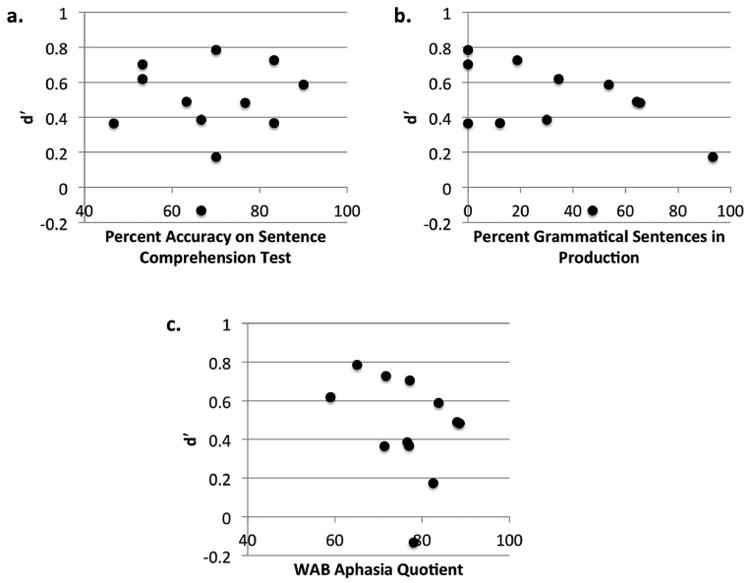
Associations between linguistic and sequential learning abilities. Graphs display the associations between aphasic participants'd′ scores across the three artificial grammar judgment tests and their scores on tests of syntactic abilities in comprehension (4a), syntactic abilities in production (4b), and severity of aphasia (4c). No significant correlations between linguistic and sequential learning abilities were observed.
Predictors of artificial grammar judgments
A significant predictor of artificial grammar judgments was found for the trained controls, but not for the aphasic group or untrained controls (see Appendix 3). Specifically, the significant effect of item type indicated that grammaticality of the items had an effect on the trained controls' judgments, trained grammatical vs. ungrammatical: Estimate = 1.24, SE = 0.48, p = .01, untrained grammatical vs. ungrammatical: Estimate = 1.09, SE = 0.41, p = .01. Item type was not a significant predictor of judgments in the other participant groups, and anchor strength and associative chunk strength were not significant predictors for any group, all p > .05. Importantly, no significant difference was found between trained grammatical and untrained grammatical items for the trained controls, Estimate = −0.15, SE = 0.36, p = .67, or the aphasic group, Estimate = 0.25, SE = 0.26, p = .34.
Discussion
Artificial grammar judgment accuracy and sensitivity
This study provides evidence of exposure-based sequential learning in the verbal domain in people with agrammatic aphasia as well as neurologically intact adults. After exposure to auditory sentences in an artificial grammar, participants' knowledge was assessed using an artificial grammar judgment test administered three times on two consecutive days. Mixed effects regression models indicated that the group of trained healthy adults and the group of trained adults with agrammatic aphasia showed greater sensitivity to the detection of grammatical items than the untrained control group.
This finding is in line with previous evidence that individuals with stroke-induced syntactic impairments can learn sequential regularities through exposure, although learning abilities in this population are highly variable across individuals and across tasks. Individuals with agrammatic aphasia show sequential learning in SRT tasks (Dominey et al., 2003; Goschke et al., 2001; Schuchard et al., 2017; Schuchard & Thompson, 2014), although they may be impaired in learning certain types of sequences (Goschke et al., 2001) or in learning the abstract underlying structures of sequences (Dominey et al., 2003). In contrast, Christiansen et al. (2010) found no evidence of sequential learning in a group of seven agrammatic individuals who were exposed to an artificial grammar composed of visual shapes. However, Zimmerer et al. (2014), who analysed visual artificial grammar learning data at an individual level, found that some aphasic individuals showed impairments, and others scored within a range of normal performance. Some of the inconsistencies in findings across studies may be attributed to variability in the inclusion criteria for aphasic participants, the heterogeneity of impairments among individuals classified as agrammatic, and/or the inclusion of more severely aphasic participants in certain studies (e.g. Zimmerer et al., 2014). Further research will be necessary to identify factors underlying the individual differences in sequential learning abilities among people with aphasia.
With regard to changes across the three tests, the average d′ scores of the trained control and aphasic groups decreased slightly after a 24-hour retention interval (Test 1 to Test 2) and then increased after the second training session (Test 2 to Test 3). However, only the trained control group demonstrated an increase between Test 2 and Test 3 that was significantly different from the performance of the untrained control group. Aphasic participants showed little improvement following the second training session. Although the average scores for all groups were well below the ceiling of 100% accuracy, it is possible that aphasic participants did not benefit from additional training because they reached a ceiling of performance after the first training session, which may suggest an impairment in sequential learning compared to healthy adults. It is also possible that after being exposed to the test format in Tests 1 and 2, trained controls were better able to explicitly search for regularities during the second training session and thereby perform better on Test 3. This interpretation is consistent with evidence that healthy individuals perform better than aphasic individuals in sequential learning tasks under explicit, intentional learning conditions (Schuchard & Thompson, 2014). However, further research would be necessary to determine the extent to which learning in this paradigm is implicit or explicit. Future studies should also examine whether the accumulation of exposure-based learning across days is impaired in the context of language treatment for aphasia.
Sequential learning and language abilities
Contrary to the idea that sequential learning abilities are closely associated with linguistic abilities in aphasia, the results of the present study did not reveal correlations between performance on the tests of artificial grammar learning and measures of syntactic abilities in sentence comprehension, syntactic abilities in speech production, or aphasia severity. Although non-significant, the correlations of artificial grammar learning with grammatical production and with aphasia severity were negative, suggesting that more linguistically impaired individuals do not necessarily perform worse on sequential learning tasks than less impaired individuals. These results should be interpreted with caution, particularly considering that the correlation analyses were underpowered. Nevertheless, the results are in line with a previous study in which the artificial grammar learning abilities of syntactically impaired individuals could not be predicted by their performance on tests of grammatical ability, including sentence comprehension and grammaticality judgment tasks (Zimmerer et al., 2014). In contrast, Dominey et al. (2003) found a significant correlation between syntactic comprehension and performance on a task in which agrammatic participants were explicitly instructed to learn the underlying structure of letter sequences, and Hoen et al. (2003) found that agrammatic adults who were explicitly trained on a sequential structure with non-linguistic stimuli improved in comprehending sentences that involved a similar underlying structure. Together with evidence of explicit sequential learning deficits in aphasia (Schuchard & Thompson, 2014), these findings suggest that explicit, intentional sequential learning may be more impaired and more strongly associated with syntactic abilities than exposure-based sequential learning without explicit instruction in people with agrammatic aphasia.
Predictors of artificial grammar judgments
The results of this study suggest both similarities and differences between agrammatic and healthy adults in the aspects of the artificial grammar that were learned. Inspection of percent accuracy by item type indicates that learning effects in both the trained control and aphasic groups were primarily due to higher acceptance of grammatical items than the untrained controls, whereas accuracy for ungrammatical items was at chance for all groups (see Table 4). Similar results for trained controls are reported in Christiansen et al. (2010), suggesting that participants can more easily learn to accept grammatical sequences than reject grammatical violations, or that participants are biased towards accepting test items as grammatical. In the item-level analyses of the present study, grammaticality of the items was found to be a significant predictor of artificial grammar judgments in the trained control but not the aphasic group, which may indicate that participants with aphasia were sensitive to features of the stimuli other than grammatical rule violations. However, there was no significant difference for trained compared to untrained grammatical items in any participant group, suggesting that participants did not simply recall specific items to which they were exposed. In addition, measures of co-occurring elements in the stimuli (i.e. anchor strength and associative chunk strength) were not found to have significant effects on judgments in any group.
When considering these results, it is important to keep in mind that this study was designed to test the ability of people with aphasia to extract sequential patterns through exposure, and not to determine the particular knowledge obtained. Grammatical items had higher values of anchor strength and associative chunk strength compared to ungrammatical items, which complicates the interpretation of individual predictors of performance. In contrast, other studies have used stimuli designed to test the acquisition of specific structural properties (Zimmerer, Cowell, & Varley, 2011; Zimmerer et al., 2014; Zimmerer & Varley, 2015). Evidence from these studies suggests individual variability in the criteria on which participants make artificial grammar judgments. It is possible that measures that characterise these differences may be associated with linguistic abilities to a greater extent than measures of overall performance like d′.
Conclusions
The results of this study have implications for theories of sequential learning and language as well as for language relearning in aphasia. A number of studies have shown associations between language processing and sequential learning in healthy adults (Arciuli & Simpson, 2012; Conway et al., 2007; Conway et al., 2010; Misyak et al., 2010; Misyak & Christiansen, 2012), and electrophysiological evidence suggests that these processes share common neural mechanisms (Christiansen et al., 2012). However, the present study and previous research with aphasic adults suggests that after neural mechanisms underlying syntactic abilities are damaged, sequential learning is not always significantly impaired, and the severity of language deficits may not be strongly associated with the severity of sequential learning deficits. One explanation for these results is that agrammatic aphasia primarily arises from damage to neural mechanisms of language that are separate from those underlying sequential learning. Alternatively, if agrammatic aphasia arises from damage to neural mechanisms underlying both language and sequential learning, sequential learning abilities may be recovered relatively quickly. In any case, the relationship between language and learning abilities is likely more variable among individuals with brain injuries compared to neurologically intact adults, and a better understanding of the factors that contribute to this variability will be important for elucidating the underlying mechanisms of learning and language. In addition, these factors may inform language rehabilitation by identifying aphasic individuals who are likely to demonstrate learning, and importantly retention of learning, via exposure to sequential regularities in language.
Acknowledgments
The authors would like to thank Dr. Vitor Zimmerer and an anonymous reviewer for comments provided during the review of this paper.
Funding: This work was supported by the National Institute On Deafness and Other Communication Disorders of the National Institutes of Health under Award Numbers F31DC013204 (Schuchard), R01DC001948 (Thompson), and P50DC012283 (Thompson) and by the Graduate Research Grant from Northwestern University (Schuchard). The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Appendix 1
Training stimuli.
| Hep lum loke. |
| Biff lum loke. |
| Hep cav dupp. |
| Hep cav loke. |
| Biff cav loke. |
| Biff lum dupp. |
| Hep lum dupp. |
| Biff vot cav dupp. |
| Biff vot lum loke. |
| Hep pell cav loke. |
| Biff vot cav loke. |
| Biff vot lum dupp. |
| Hep pell lum dupp. |
| Hep pell cav dupp. |
| Hep pell lum loke cav. |
| Hep vot cav dupp lum. |
| Hep vot cav loke lum. |
| Biff vot lum dupp cav. |
| Hep pell lum dupp cav. |
| Biff cav tiz dupp. |
| Hep lum mib loke. |
| Biff lum tiz loke. |
| Hep cav mib loke. |
| Biff lum tiz dupp. |
| Hep cav mib dupp. |
| Biff cav mib dupp. |
| Biff pell cav tiz loke. |
| Hep pell lum mib loke. |
| Biff vot lum mib loke. |
| Biff pell cav mib loke. |
| Biff pell lum tiz dupp. |
| Hep vot lum mib dupp. |
| Biff cav dupp lum. |
| Hep lum loke cav. |
| Hep cav dupp lum. |
| Hep cav loke lum. |
| Biff lum dupp cav. |
| Hep lum dupp cav. |
| Biff lum loke cav. |
| Biff cav mib dupp lum. |
| Hep lum tiz loke cav. |
| Biff lum tiz loke cav. |
| Hep cav tiz loke lum. |
| Biff cav mib loke lum. |
| Hep lum tiz dupp cav. |
| Biff cav dupp lum tiz. |
| Hep lum loke cav mib. |
| Biff lum loke cav tiz. |
| Biff lum dupp cav tiz. |
| Hep lum dupp cav mib. |
Appendix 2
Test stimuli.
| Test item | Grammaticality | ACS | AS |
|---|---|---|---|
| Hep lum dupp. | Grammatical (T) | 7.3 | 4.3 |
| Hep lum dupp cav. | Grammatical (T) | 7.0 | 5.3 |
| Hep lum loke cav mib. | Grammatical (T) | 5.9 | 3.8 |
| Biff lum tiz loke. | Grammatical (T) | 5.4 | 3.8 |
| Biff vot cav loke. | Grammatical (T) | 4.0 | 3.3 |
| Hep vot cav loke lum. | Grammatical (T) | 3.3 | 2.8 |
| Biff pell lum tiz dupp. | Grammatical (T) | 3.4 | 2.3 |
| Biff cav dupp. | Grammatical (U) | 5.3 | 3.0 |
| Biff cav loke lum. | Grammatical (U) | 4.0 | 3.5 |
| Hep lum mib dupp. | Grammatical (U) | 3.8 | 3.5 |
| Biff lum mib dupp cav. | Grammatical (U) | 3.6 | 3.5 |
| Hep pell lum loke. | Grammatical (U) | 4.8 | 3.3 |
| Biff pell lum loke cav. | Grammatical (U) | 4.3 | 3.0 |
| Hep vot cav tiz loke. | Grammatical (U) | 3.0 | 2.0 |
| Average | Grammatical | 4.7 | 3.4 |
| Standard deviation | Grammatical | 1.4 | 0.8 |
| Biff hep lum loke cav. | Ungrammatical | 4.6 | 2.0 |
| Biff cav vot lum. | Ungrammatical | 2.4 | 1.8 |
| Hep lum pell cav mib. | Ungrammatical | 3.1 | 2.8 |
| Hep lum mib cav. | Ungrammatical | 2.8 | 2.5 |
| Hep vot dupp tiz loke. | Ungrammatical | 1.1 | 1.3 |
| Biff pell tiz loke. | Ungrammatical | 1.6 | 1.3 |
| Biff tiz dupp. | Ungrammatical | 1.3 | 0.8 |
| Hep dupp lum. | Ungrammatical | 1.7 | 1.0 |
| Hep loke cav lum vot. | Ungrammatical | 1.0 | 0.0 |
| Loke vot biff cav. | Ungrammatical | 1.4 | 0.0 |
| Biff mib lum cav dupp. | Ungrammatical | 1.0 | 0.8 |
| Hep dupp cav lum. | Ungrammatical | 1.4 | 0.0 |
| Pell biff tiz dupp lum. | Ungrammatical | 1.3 | 1.0 |
| Hep loke lum pell. | Ungrammatical | 0.8 | 0.0 |
| Average | Ungrammatical | 1.8 | 1.1 |
| Standard deviation | Ungrammatical | 1.1 | 0.9 |
Note: ACS = associative chunk strength; AS = anchor strength; Grammatical (T) = trained; Grammatical (U) = untrained.
Appendix 3
Regression models
Artificial grammar judgment sensitivity
Base model: d prime ∼ 1 + (1|Participant)
Model 1: d prime ∼ Test + (1|Participant)
Model 2: d prime ∼ Test + Group + (1|Participant)
Model 3: d prime ∼ Test * Group + (1|Participant)
| Model | logLik | deviance | Chisq | df | p-value |
|---|---|---|---|---|---|
| Base model | −95.50 | 191.00 | |||
| Model 1 | −94.69 | 189.38 | 1.62 | 2 | 0.44 |
| Model 2 | −88.37 | 176.74 | 12.64 | 2 | <0.01* |
| Model 3 | −83.88 | 167.76 | 8.98 | 4 | 0.06 |
Note: The base model includes the intercept and random effects on the intercept represented as (1|Participant). The subsequent comparison models show the individually added fixed effects, with “*” representing the complete set of main effects and interactions.
Item-level analyses
Accept ∼ Anchor strength + Associative chunk strength + Item type + (1|Participant) + (1|Item)
| Group | Fixed effect | Estimate | SE | z value | p - value * |
|---|---|---|---|---|---|
| Trained control | Intercept | 1.36 | 0.63 | 2.17 | .03 |
| Anchor strength | 0.15 | 0.22 | 0.67 | .51 | |
| Associative chunk strength | −0.16 | 0.16 | −0.98 | .33 | |
| Trained grammatical vs. ungrammatical | 1.24 | 0.48 | 2.57 | .01* | |
| Untrained grammatical vs. ungrammatical | 1.09 | 0.41 | 2.67 | .01* | |
| Untrained grammatical vs. trained grammatical | −0.15 | 0.36 | −0.43 | .67 | |
| Aphasic group | Intercept | 0.10 | 0.48 | 0.21 | .83 |
| Anchor strength | 0.21 | 0.17 | 1.24 | .22 | |
| Associative chunk strength | −0.03 | 0.12 | −0.23 | .82 | |
| Trained grammatical vs. ungrammatical | 0.18 | 0.35 | 0.50 | .61 | |
| Untrained grammatical vs. ungrammatical | 0.43 | 0.31 | 1.40 | .16 | |
| Untrained grammatical vs. trained grammatical | 0.25 | 0.26 | 0.95 | .34 | |
| Untrained control | Intercept | −0.04 | 0.39 | −0.10 | .92 |
| Anchor strength | 0.13 | 0.14 | 0.92 | .36 | |
| Associative chunk strength | −0.03 | 0.10 | −0.31 | .76 | |
| Trained grammatical vs. ungrammatical | 0.05 | 0.30 | 0.17 | 87 | |
| Untrained grammatical vs. ungrammatical | −0.02 | 0.25 | −0.07 | .95 | |
| Untrained grammatical vs. trained grammatical | −0.07 | 0.22 | −0.31 | .76 |
Notes: The model includes the intercept and random effects on the intercept represented as (1|Participant) and (1|Item). Accept = the participant's artificial grammar judgment (accept an item as “good” or not). Item type = trained grammatical, untrained grammatical, or ungrammatical.
Footnotes
Disclosure statement: No potential conflict of interest was reported by the authors.
References
- Arciuli J, Simpson IC. Statistical learning is related to reading ability in children and adults. Cognitive Science. 2012;36(2):286–304. doi: 10.1111/j.1551-6709.2011.01200.x. [DOI] [PubMed] [Google Scholar]
- Baayen RH, Davidson DJ, Bates DM. Mixed-effects modeling with crossed random effects for subjects and items. Journal of Memory and Language. 2008;59(4):390–412. [Google Scholar]
- Baddeley AD, Emslie H, Nimmo-Smith I. The doors and people test: A test of visual and verbal recall and recognition. Bury St Edmunds: Thames Valley Test Company; 1994. [Google Scholar]
- Caplan D, Futter C. Assignment of thematic roles to nouns in sentence comprehension by an agrammatic patient. Brain and Language. 1986;27(1):117–134. doi: 10.1016/0093-934x(86)90008-8. [DOI] [PubMed] [Google Scholar]
- Christiansen MH, Chater N. The language faculty that wasn't: A usage-based account of natural language recursion. Frontiers in Psychology. 2015;6(1182):1–18. doi: 10.3389/fpsyg.2015.01182. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Christiansen MH, Conway CM, Onnis L. Similar neural correlates for language and sequential learning: Evidence from event-related brain potentials. Language and Cognitive Processes. 2012;27(2):231–256. doi: 10.1080/01690965.2011.606666. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Christiansen MH, Kelly ML, Shillcock RC, Greenfield K. Impaired artificial grammar learning in agrammatism. Cognition. 2010;116(3):382–393. doi: 10.1016/j.cognition.2010.05.015. [DOI] [PubMed] [Google Scholar]
- Conway CM, Bauernschmidt A, Huang S, Pisoni DB. Implicit statistical learning in language processing: Word predictability is the key? Cognition. 2010;114(3):356–371. doi: 10.1016/j.cognition.2009.10.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Conway CM, Karpicke J, Pisoni DB. Contribution of implicit sequence learning to spoken language processing: Some preliminary findings with hearing adults. Journal of Deaf Studies and Deaf Education. 2007;12(3):317–334. doi: 10.1093/deafed/enm019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dominey PF, Hoen M, Blanc J, Lelekov-Boissard T. Neurological basis of language and sequential cognition: Evidence from simulation, aphasia, and ERP studies. Brain and Language. 2003;86(2):207–225. doi: 10.1016/s0093-934x(02)00529-1. [DOI] [PubMed] [Google Scholar]
- Fillingham JK, Hodgson C, Sage K, Lambon Ralph MA. The application of errorless learning to aphasic disorders: A review of theory and practice. Neuropsychological Rehabilitation. 2003;13(3):337–363. doi: 10.1080/09602010343000020. [DOI] [PubMed] [Google Scholar]
- Forkstam C, Hagoort P, Fernandez G, Ingvar M, Petersson KM. Neural correlates of artificial syntactic structure classification. NeuroImage. 2006;32(2):956–967. doi: 10.1016/j.neuroimage.2006.03.057. [DOI] [PubMed] [Google Scholar]
- Goschke T, Friederici AD, Kotz SA, van Kampen A. Procedural learning in Broca's aphasia: Dissociation between the implicit acquisition of spatio-motor and phoneme sequences. Journal of Cognitive Neuroscience. 2001;13(3):370–388. doi: 10.1162/08989290151137412. [DOI] [PubMed] [Google Scholar]
- Grodzinsky Y. Language deficits and the theory of syntax. Brain and Language. 1986;27(1):135–159. doi: 10.1016/0093-934x(86)90009-x. [DOI] [PubMed] [Google Scholar]
- Grodzinsky Y. Trace deletion, Θ-roles, and cognitive strategies. Brain and Language. 1995;51(3):469–497. doi: 10.1006/brln.1995.1072. [DOI] [PubMed] [Google Scholar]
- Hoen M, Golembiowski M, Guyot E, Deprez V, Caplan D, Dominey PF. Training with cognitive sequences improves syntactic comprehension in agrammatic aphasics. Cognitive Neuroscience and Neuropsychology. 2003;14(3):495–499. doi: 10.1097/00001756-200303030-00040. [DOI] [PubMed] [Google Scholar]
- Karuza EA, Newport EL, Aslin RN, Starling SJ, Tivarus ME, Bavelier D. The neural correlates of statistical learning in a word segmentation task: An fMRI study. Brain and Language. 2013;127(1):46–54. doi: 10.1016/j.bandl.2012.11.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kay J, Lesser R, Coltheart M. Psycholinguistic assessments of language processing in aphasia. Hove: Lawrence Erlbaum Associates; 1992. [Google Scholar]
- Kertesz A. Western aphasia battery-revised. San Antonio, TX: PsychCorp; 2007. [Google Scholar]
- Knowlton BJ, Squire LR. The information acquired during artificial grammar learning. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1994;20(1):79–91. doi: 10.1037//0278-7393.20.1.79. [DOI] [PubMed] [Google Scholar]
- Misyak JB, Christiansen MH. Statistical learning and language: An individual differences study. Language Learning. 2012;62(1):302–331. [Google Scholar]
- Misyak JB, Christiansen MH, Tomblin JB. Sequential expectations: The role of prediction-based learning in language. Topics in Cognitive Science. 2010;2(1):138–153. doi: 10.1111/j.1756-8765.2009.01072.x. [DOI] [PubMed] [Google Scholar]
- Petersson KM, Folia V, Hagoort P. What artificial grammar learning reveals about the neurobiology of syntax. Brain and Language. 2012;120(2):83–95. doi: 10.1016/j.bandl.2010.08.003. [DOI] [PubMed] [Google Scholar]
- Petersson KM, Forkstam C, Ingvar M. Artificial syntactic violations activate Broca's region. Cognitive Science. 2004;28(3):383–407. [Google Scholar]
- Pothos EM. Theories of artificial grammar learning. Psychological Bulletin. 2007;133(2):227–244. doi: 10.1037/0033-2909.133.2.227. [DOI] [PubMed] [Google Scholar]
- R Core Team. R: A language and environment for statistical computing. Vienna: R Foundation for Statistical Computing; 2014. Retrieved from http://www.r-project.org/ [Google Scholar]
- Saffran JR. Constraints on statistical language learning. Journal of Memory and Language. 2002;47(1):172–196. [Google Scholar]
- Schuchard J, Nerantzini M, Thompson CK. Implicit learning and implicit treatment outcomes in individuals with aphasia. Aphasiology. 2017;31(1):25–48. doi: 10.1080/02687038.2016.1147526. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schuchard J, Thompson CK. Implicit and explicit learning in individuals with agrammatic aphasia. Journal of Psycholinguistic Research. 2014;43(3):209–224. doi: 10.1007/s10936-013-9248-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schwartz MF, Saffran EM, Marin OSM. The word order problem in agrammatism: I. Comprehension. Brain and Language. 1980;10(2):249–262. doi: 10.1016/0093-934x(80)90055-3. [DOI] [PubMed] [Google Scholar]
- Thompson CK. Northwestern assessment of verbs and sentences. Evanston, IL: Northwestern University; 2011. [Google Scholar]
- Zimmerer VC. Ph D Dissertation. University of Sheffield; 2010. Intact and impaired fundamentals of syntax: Artificial grammar learning in healthy speakers and people with aphasia. [Google Scholar]
- Zimmerer VC, Cowell PE, Varley RA. Individual behavior in learning of an artificial grammar. Memory & Cognition. 2011;39:491–501. doi: 10.3758/s13421-010-0039-y. [DOI] [PubMed] [Google Scholar]
- Zimmerer VC, Cowell PE, Varley RA. Artificial grammar learning in individuals with severe aphasia. Neuropsychologia. 2014;53:25–38. doi: 10.1016/j.neuropsychologia.2013.10.014. [DOI] [PubMed] [Google Scholar]
- Zimmerer VC, Varley RA. A case of “order insensitivity”? Natural and artificial language processing in a man with primary progressive aphasia. Cortex. 2015;69:212–219. doi: 10.1016/j.cortex.2015.05.006. [DOI] [PubMed] [Google Scholar]