

Abstract
In the classical biased sampling problem, we have k densities π1(·), …, πk(·), each known up to a normalizing constant, i.e. for l = 1, …, k, πl(·) = νl(·)/ml, where νl(·) is a known function and ml is an unknown constant. For each l, we have an iid sample from πl,·and the problem is to estimate the ratios ml/ms for all l and all s. This problem arises frequently in several situations in both frequentist and Bayesian inference. An estimate of the ratios was developed and studied by Vardi and his co-workers over two decades ago, and there has been much subsequent work on this problem from many different perspectives. In spite of this, there are no rigorous results in the literature on how to estimate the standard error of the estimate. We present a class of estimates of the ratios of normalizing constants that are appropriate for the case where the samples from the πl’s are not necessarily iid sequences, but are Markov chains. We also develop an approach based on regenerative simulation for obtaining standard errors for the estimates of ratios of normalizing constants. These standard error estimates are valid for both the iid case and the Markov chain case.
phrases: Geometric ergodicity, importance sampling, Markov chain Monte Carlo, ratios of normalizing constants, regenerative simulation, standard errors
1 Introduction
The problem of estimating ratios of normalizing constants of unnormalized densities arises frequently in statistical inference. Here we mention three instances of this problem. In missing data (or latent variable) models, suppose that the data is Xobs, and the likelihood of the data is difficult to write down but Xobs can be augmented with a part Xmis in such a way that the likelihood for (Xmis, Xobs) is easy to write. In this case (using generic notation) we have pθ(Xmis | Xobs) = pθ(Xmis, Xobs)/pθ(Xobs). The denominator, i.e. the likelihood of the observed data at parameter value θ, is precisely a normalizing constant. For the purpose of carrying out likelihood inference, if θ1 is some reference value, knowledge of is equivalent to knowledge of log(pθ(Xobs)): for these two functions the maximum occurs at the same point, and the negative second derivative at the maximum (i.e. the observed Fisher information) is the same.
A second example arises when the likelihood has the form pθ(x) = gθ(x)/zθ, where gθ is a known function. This situation arises in exponential family problems, and except for the usual textbook examples, the normalizing constant is analytically intractable. If for some arbitrary point θ1 we know the ratio , then we would know pθ(x) up to a multiplicative constant and, as before, this would be equivalent to knowing pθ(x) itself. A third example arises in certain hyperparameter selection problems in Bayesian analysis. Suppose that we wish to choose a prior from the family , where the πh’s are densities with respect to a dominating measure μ. For any h ∈ , the marginal likelihood of the data X when the prior is πh is given by mh(X) = ∫ pθ(X)πh(θ) μ(dθ), i.e. it is the normalizing constant in the statement “the posterior is proportional to the likelihood times the prior.” The empirical Bayes choice of h is by definition argmaxh mh(X). Suppose that h1 is some arbitrary point in . As in the previous two examples, for the purpose of finding the empirical Bayes choice of h, knowing is equivalent to knowing mh(X). (One may also be interested in the closely related problem of estimating the posterior expectation of a function f(θ) when the hyperparameter is h, which is given by Eh(f(θ) | X) = (∫ f(θ)pθ(X)πh(θ) μ(dθ))/mh(X). Estimating Eh(f(θ) | X) as h varies is relevant in Bayesian sensitivity analysis. The scheme for doing this used in Buta and Doss (2011) does not involve estimating mh(X) itself and requires only estimating for some fixed .)
Now, estimation of a normalizing constant is generally a difficult problem; for example, the so-called harmonic mean estimator proposed by Newton and Raftery (1994) typically converges at a rate that is much slower than (Wolpert and Schmidler, 2011). On the other hand, estimating a ratio of normalizing constants typically can be done with a -consistent estimator. To illustrate this fact, consider the second of the problems described above, and let μ be the measure with respect to which the pθ’s are densities. Suppose that X1, X2, … are a “sample” from (iid sample or ergodic Markov chain output). For the simple and well-known estimator we have
| (1.1) |
and under certain moment conditions on the ratio and mixing conditions on the chain, the estimate on the left of (1.1) also satisfies a central limit theorem (CLT). In fact, in all the problems mentioned above, it is not necessary to estimate the normalizing constants themselves, and it is sufficient to estimate ratios of normalizing constants.
If θ is not close to θ1, or more precisely, if gθ and are not close over the region where the Xi’s are likely to be, the ratio has high variance, so the estimator above does not work well. It is better to choose θ1, …, θk appropriately spread out in the parameter space Θ, and on the left side of (1.1) replace with , where ws > 0, s = 1, …, k. The hope is that gθ will be close to at least one of the ’s, and so preclude having large variances. To implement this, suppose we know all the ratios , s, t ∈ {1, …, k}, or equivalently, we know , s ∈ {1, …, k}. In this case, if for each l = 1, …, k there is available a sample , …, from , then letting and al = nl/n, we have
| (1.2) |
When compared with the estimate on the left side of (1.1), the estimate on the left side of (1.2) is accurate over a much bigger range of θ’s. But to use it, it is necessary to be able to estimate the ratios , s ∈ {1, …, k}, and it is this problem that is the focus of this paper.
We now state explicitly the version of this problem that we will deal with here, and we change to the notation that we will use for the rest of the paper. We have k densities π1, …, πk with respect to the measure μ, which are known except for normalizing constants, i.e. we have πl = νl/ml, where the νl’s are known functions and the ml’s are unknown constants. For each l we have a Markov chain with invariant density πl, the k chains are independent, and the objective is to estimate all possible ratios mi/mj, i ≠ j or, equivalently, the vector
When the samples are iid sequences, this is the biased sampling problem introduced by Vardi (1985), which contains examples that differ in character quite a bit from those considered here.
Suppose we are in the iid case, and consider the pooled sample . Let x ∈ S, and suppose that x came from the lth sample. If we pretend that the only thing we know about x is its value, then the probability that x came from the lth sample is
| (1.3) |
where m = (m1, …, mk). Geyer (1994) proposed to treat the vector m as an unknown parameter and to estimate it by maximizing the quasi-likelihood function
| (1.4) |
with respect to m. Actually, there is a non-identifiability issue regarding Ln: for any constant c > 0, Ln(m) and Ln(cm) are the same. So we can estimate m only up to an overall multiplicative constant, i.e. we can estimate only d. Accordingly, Geyer (1994) proposed to estimate d by maximizing Ln(m) subject to the constraint m1 = 1. (A more detailed discussion of the quasi-likelihood function (1.4) is given in Section 3.) In fact, the resulting estimate, , was originally proposed by Vardi (1985), and studied further by Gill, Vardi and Wellner (1988), who showed that it is consistent and asymptotically normal, and established its optimality properties, all under the assumption that for each l = 1, …, k, , …, is an iid sequence. Geyer (1994) extended the consistency and asymptotic normality result to the case where the k sequences , …, are Markov chains satisfying certain mixing conditions. The estimate was rederived in Meng and Wong (1996), Kong et al. (2003), and Tan (2004) from completely different perspectives, all under the iid assumption.
As mentioned earlier, for the kinds of problems we have in mind the distributions πl are analytically intractable, and the estimate on the left side of (1.1) or (1.2) are applicable to a much larger class of problems if we are willing to use Markov chain samples instead of iid samples. The variances of these estimates have a complex form which is difficult to estimate consistently. The variance matrix of is much harder to estimate since is not given in closed form, but is given only implicitly as the solution to a constrained optimization problem.
The present paper deals with two issues. First, none of the authors cited above give consistent estimators of the variance matrix of , even in the iid case. (For the iid case, Kong et al. (2003) give an estimate that involves the inverse of a certain Fisher information matrix, but this formal calculation does not establish consistency of the estimate, or even the necessary CLT, nor do the authors make such claims.) As mentioned earlier, the problem of estimating the variance is far more challenging when the samples are Markov chains as opposed to iid sequences. In this paper we give a CLT for the vector based on regenerative simulation. The main benefit of this result is that it gives, essentially as a free by-product, a simple consistent estimate of the variance matrix in the Markov chain setting. Second, the estimate of d obtained by the afore-mentioned authors is optimal in the case where the samples are iid. When the samples are Markov chains, the estimate is no longer optimal. We present a method for forming estimators which are suitable in the Markov chain setting. The regeneration-based CLT and estimate of the variance matrix both apply to the class of estimators that we propose.
The rest of this paper is organized as follows. In Section 2 we extend the quasi-likelihood function used by Geyer (1994) to a class of quasi-likelihood functions, each of which gives rise to an estimator of d. The main theoretical developments of this paper are in Section 3, where we use ideas from regenerative simulation to develop CLTs for any of these estimators, and we show that variance estimates emerge as by-products. There are two reasons why we need to be able to estimate the variance of an estimate of d. One is the standard rule that a point estimate should always be accompanied by a measure of uncertainty, an important rule that applies to any context. The other is that when the samples are Markov chains, as opposed to iid samples, the quasi-likelihood function (1.4) gives rise to a non-optimal estimator. So in Section 4 we consider the other quasi-likelihood functions presented in Section 2 and we develop a method for choosing the one which gives rise to the estimator with the smallest variance. It is precisely our ability to estimate the variance that makes this possible. In Section 5 we present a small study that illustrates the gains obtained from using an estimate of d designed for Markov chains, and we illustrate our methodology by showing how it can be used to estimate certain quantities of interest in the Ising model of statistical mechanics. The Appendix provides proofs of the three assertions made by the theorem in Section 3, namely strong consistency of our estimates of d, the CLT for the estimates, and strong consistency of the estimates of the variance matrix.
2 Estimation of the Ratios of Normalizing Constants in the Markov Chain Setting
We begin by considering more carefully the quasi-likelihood function for m given by (1.4), and for the technical development it is much more convenient to work on the log scale. So define the vector ζ by
| (2.1) |
and rewrite (1.3) as
| (2.2) |
Clearly, ζ determines and is determined by (m1, …, mk), and the log quasi-likelihood function for ζ is
| (2.3) |
In (2.1), (m1, …, mk) is an arbitrary vector with strictly positive components, i.e. ml need not correspond to the normalizing constant for νl. We will use ζ(t) to denote the true value of ζ, i.e. the value it takes when the ml’s are the normalizing constants for the νl’s. The non-identifiability issue now is that for any constant c ∈ ℝ, ln(ζ) and ln(ζ +c1k) are the same (here, 1k is the vector of k 1’s), so we can estimate ζ(t) only up to an additive constant. Accordingly, with ζ0 ∈ ℝk defined by , Geyer (1994) proposed to estimate ζ0 by , the maximizer of ln subject to the linear constraint ζ⊤1k = 0, and thus obtain an estimate of d.
The term pl(x, ζ) in (2.2) has the appearance of a likelihood ratio, and for the denominator, in the term , the probability measure νs/ms is given weight proportional to the length of the chain Φs. Now Gill et al’s. (1988) optimality result does not apply to the Markov chain case, in which, among other things, the chains Φ1, …, Φk mix at possibly different rates, and the as’s should in some sense reflect the vague notion of “effective sample sizes” of the different chains. The optimal choice of the vector a = (a1, …, ak) is very difficult to determine theoretically, and in Section 4 we describe an empirical method for choosing a. Accordingly in (2.1) and henceforth, a will not necessarily be given by al = nl/n, but will be an arbitrary probability vector satisfying the condition that al > 0 for l = 1, …, k.
A Quasi-Likelihood Function Designed for the Markov Chain Setting
As mentioned earlier, Geyer (1994) showed that when we take aj = nj/n, the maximizer of the log quasi-likelihood function defined by (2.3) (subject to the constraint ζ⊤1k = 0) is a consistent estimate of the true value ζ0, and also satisfies a CLT, even when the k sequences , l = 1, …, k are Markov chains. But when the k sequences are Markov chains, the choice aj = nj/n is no longer optimal, and for other choices of a, the (constrained) maximizer of (2.3) is not necessarily even consistent. We will present a new log quasi-likelihood function which does yield consistent asymptotically normal estimates, and before doing this, we give a brief motivating argument.
Suppose that we are in the simple case where we have a parametric family {pθ, θ ∈ Θ} and we observe data Y1, …, , for some θ0 ∈ Θ. Let ly(θ) = log(pθ(y)), and let . The fact that argmaxθ Q(θ) = θ0 is well known (and easy to see via a short argument involving Jensen’s inequality). The log likelihood function based on Y1, …, Yn is . By the strong law of large numbers,
| (2.4) |
and assuming sufficient regularity conditions, , i.e. the maximum likelihood estimator is consistent.
We now return to the present situation, in which for l = 1, …, k, is a Markov chain with invariant density πl. Suppose we use ln(ζ) given by (2.3), with a an arbitrary probability vector (i.e. a is not necessarily given by aj = nj/n), and let . The key condition
| (2.5) |
need not hold, and the constrained maximizer of ln(ζ) may converge, but not to the true value.
With this in mind, suppose that a is an arbitrary probability vector with non-zero entries and define w ∈ ℝk by
| (2.6) |
The log quasi-likelihood function we will use is
| (2.7) |
instead of ln given by (2.3) [note the slight change of notation from l to ℓ]. As will emerge in our proofs of consistency and asymptotic normality of the constrained maximizer of ℓn(ζ), for this log quasi-likelihood function, the stochastic process (in ζ) n−1 ℓn(ζ) converges almost surely to a function of ζ which is maximized at ζ0, a condition that plays the role of (2.4) and (2.5). Note that if al = nl/n, then wl = 1 and (2.7) reduces to (2.3).
3 A Regeneration-Based CLT and Estimate of the Variance Matrix
Here we discuss estimation of the variance matrix of the estimator developed in Section 2. Estimation of the variance matrix is complicated by the fact that is based on several Markov chains and that it is given only implicitly as the solution of a constrained maximization problem. Before describing our approach for estimating the variance matrix of , we first review what is available in a much simpler setting.
3.1 Estimation of the Variance of the Sample Mean in the Single Markov Chain Setting
Suppose we have a single Markov chain X1, X2, … on the measurable space , with invariant distribution π, f : X → ℝ is a function whose expectation μ = Eπ(f(X)) we estimate via , and we are interested in estimating the variance of . Here we describe the commonly used approaches for the simple case, namely those based on batching, regeneration, and spectral methods. We explain how regeneration may be used for the case of the statistic in Section 3.2 (see also the Appendix), and in Section 6 we explain how batching and spectral methods can be implemented for the case of the statistic using the theoretical development in Section 3. We then compare and contrast the three methods of estimating the variance matrix and argue that, when it can be carried out, regeneration is the method of choice, but point out that unfortunately regeneration-based methods are not always feasible.
Batching
This method involves breaking up into M non-overlapping segments of equal length called batches. For m = 1, …, M, batch m is used to produce an estimate in the obvious way. If we have a CLT that states , then we can conclude that for fixed M, for each m. If the batch length is large enough relative to the “mixing time” of the chain, then these estimators are approximately independent. If the independence assumption was exactly true rather than approximately true, then the sample variance of the would be a valid estimator of (M/n)κ2. The batch means estimate of κ2 is simply n/M times this sample variance. Under regularity conditions that include M → ∞ at a certain rate, the batch means estimate of κ2 is strongly consistent; see Jones et al. (2006), and also Flegal, Haran and Jones (2008). The method of batching has the advantage that it is trivial to program, although some authors caution that it can be outperformed by spectral methods in terms of mean squared error; see, e.g., Geyer (1992).
Regenerative Simulation
A regeneration is a random time at which a stochastic process probabilistically restarts itself. The “tours” made by the chain in between such random times are iid, and this fact makes it much easier to analyze the asymptotic behavior of averages, and of statistics which are functions of several averages. In the discrete state space setting, if x ∈ X is any point to which the chain returns infinitely often, then the times of return to x form a sequence of regenerations. For most of the Markov chains used in MCMC algorithms, the state space is continuous, and there is no point to which the chain returns infinitely often with probability one. Even when the state space is discrete, regenerations based on returns to a point x, as described above, are often not useful, because if x has very small probability under the stationary distribution, then on average it will take a very long time to return to x. Fortunately, Mykland, Tierney and Yu (1995) provided a general technique for identifying a sequence of regeneration times 1 = τ0 < τ1 < τ2 < ⋯ that is based on the construction of a minorization condition. This construction will be reviewed shortly, but we now briefly sketch how having a regeneration sequence enables us to construct a simple estimate of the standard error of . Define
and note that the pairs (Yt, Tt) form an iid sequence. If we run the chain for ρ regenerations, then the total number of cycles, starting at τ0, is given by . We may write as
| (3.1) |
Equation (3.1) expresses as a ratio of two averages of iid quantities, and this representation enables us to use the delta method to obtain both a CLT for and a simple standard error estimate for .
An outline of the argument is as follows. From (3.1) we see that as ρ → ∞ (which implies that n → ∞) we have
| (3.2) |
where the convergence statement on the left follows from the ergodic theorem, and the convergence statement on the right follows from two applications of the strong law of large numbers. (In (3.2) the subscript π to the expectation indicates that X ∼ π.) From (3.2) we obtain E(Y1) = Eπ(f(X))E(T1). Now the bivariate CLT gives
| (3.3) |
where Σf = Cov ((Y1, T1)⊤). The delta method applied to the function h(y, t) = y/t gives the CLT
where (and ∇h is evaluated at the vector of means in (3.3)). Moreover, it is straightforward to check that for the variance estimator
| (3.4) |
we have . The regularity conditions needed to make this argument rigorous are spelled out when we discuss the case of the more complicated estimator (Section 3.2 and the Appendix).
The argument above hinges on being able to arrive at a sequence of regeneration times, and whether these are useful depends on whether the sequence has the property that the length of the tours between regenerations is not very large. We now describe the minorization condition that can sometimes be used to construct useful regeneration sequences. Let Kx(A) be the Markov transition function. The construction described in Mykland et al. (1995) requires the existence of a function s: X → [0, 1), whose expectation with respect to π is strictly positive, and a probability measure Q, such that K satisfies
| (3.5) |
This is called a minorization condition and, as we describe below, it can be used to introduce regenerations into the Markov chain driven by K. Define the Markov transition function R by
Note that for fixed x ∈ X, Rx is a probability measure. We may therefore write
which gives a representation of Kx as a mixture of two probability measures, Q and Rx. This provides an alternative method of simulating from K. Suppose that the current state of the chain is Xn. We generate δn ∼ Bernoulli(s(Xn)). If δn = 1, we draw Xn+1 ~ Q; otherwise, we draw . Note that if δn = 1, the next state of the chain is drawn from Q, which does not depend on the current state. Hence the chain “forgets” the current state and we have a regeneration. To be more specific, suppose we start the Markov chain with
| (3.6) |
and then use the method described above to simulate the chain. Each time δn = 1, we have Xn+1 ∼ Q and the process stochastically restarts itself; that is, the process regenerates.
In practice, simulating from R can be extremely difficult. Fortunately, Mykland et al. (1995), following Nummelin (1984, p. 62), noticed a clever way of circumventing the need to draw from R. Instead of making a draw from the conditional distribution of δn given xn and then generating xn+1 given (δn, xn), which would result in a draw from the joint distribution of (δn, xn+1) given xn, we simply draw from the conditional distribution of xn+1 given xn in the usual way (i.e. using K), and then draw δn given (xn, xn+1). This alternative sampling mechanism yields a draw from the same joint distribution, but avoids having to draw from R. Moreover, given (xn, xn+1), δn has a Bernoulli distribution with success probability given simply by
where is the Radon-Nikodym derivative of s(x′)Q with respect to Kx′, whose existence is implied by (3.5).
We note that both batching and regenerative simulation involve breaking up the Markov chain into segments. In batching, the segments are only approximately independent, but they are of equal lengths; in regenerative simulation, the segments are exactly independent, but they are not of equal lengths, and in fact the lengths are random.
Spectral Methods
The asymptotic variance, σ2, of (when it exists) is the infinite series
where γj = Cov(f(X1), f(X1+j)) is calculated under the assumption that X1 has the stationary distribution. Spectral methods involve truncating the series after Mn terms and estimating the truncated series. In more detail, we consider the sum , where wn is a decreasing function on [0, 1] satisfying wn(0) = 1 and wn(1) = 0, and is called the lag window. We estimate σ2 via , where are estimates of γj. To ensure consistency, we must have Mn → ∞, but Mn must increase slowly with n; precise conditions on the truncation point Mn and the window wn are given in Flegal and Jones (2010).
3.2 A CLT for the Estimate of d Designed for Markov Chains
We assume that for l = 1, …, k, chain l has Markov transition function which satisfies the minorization condition
| (3.7) |
for some probability measure Ql and function sl : X → [0, 1) with , and that the chain has been run for ρl regenerations. Let denote the regeneration times of the lth chain, and let be the length of the tth tour of the lth chain. So the length of the lth chain, , is random. We will assume that ρ1, …, ρk → ∞ in such a way that ρl/ρ1 → cl ∈ (0, ∞), for l = 1, …, k. We will allow the vector a to depend on ρ = (ρ1, …, ρk), i.e. a = a(ρ) (although we will suppress this dependence in the notation except when this dependence matters), and we will make the minimal assumption that a(ρ) → α as ρ1, …, ρk → ∞, where α is a probability vector with strictly positive entries. The extra generality is needed if we wish to choose a in a data-driven way (cf. Remark 3 of Section 4). The definitions of ζ and pl(x, ζ) given by (2.1) and (2.2), respectively, are still in force, ζ0 is still the centered version of the true value of ζ, but now is the constrained maximizer of the new log quasi-likelihood function (2.7). We will show that is a consistent asymptotically normal estimate of ζ0, and since ζ0 determines and is determined by d, this will produce a corresponding estimate of d. Before proceeding, we mention the fact that difficulties arise if the supports of the distributions π1, …, πk differ (the difficulties are pervasive: for the case where we have a continuum of distributions {πθ, θ ∈ Θ}, the simple estimate (1.1) is not even defined if πθ is not absolutely continuous with respect to ). So for the rest of this paper, we will assume that the k distributions π1, …, πk are mutually absolutely continuous. We do not really need to make an assumption this strong, but the assumption is satisfied for all the classes of problems we are considering, and making it eliminates some technical issues.
In order to state our CLT for the vector , we need to define the quantities that go into the expression for the asymptotic variance matrix. We first consider the vector , whose variance matrix is singular (since this vector sums to 0). The asymptotic distribution of involves the matrices B and Ω defined below. Let ζα be the vector whose components are [ζα]l = −log(ml) + log(αl), and let B be the k × k matrix given by
| (3.8) |
We will be using the natural estimate defined by
| (3.9) |
Let
| (3.10) |
and note that both and have mean 0. Define
| (3.11) |
Let Ω be the k × k matrix defined by
| (3.12) |
To obtain an estimate , we let
and define by
| (3.13) |
The function g : ℝk → ℝk−1 that maps ζ0 into d is
| (3.14) |
and its gradient at ζ0 (in terms of d) is
| (3.15) |
We have d = g(ζ0), and by definition .
The theorem below has three parts, pertaining to the strong consistency of , asymptotic normality of , and a consistent estimate of the asymptotic variance matrix of . For consistency we need only minimal assumptions on the Markov chains Φ1, …, Φk, namely the so-called basic regularity conditions (irreducibility, aperiodicity and Harris recurrence) that are needed for the ergodic theorem (Meyn and Tweedie, 1993, Chapter 17). CLTs and associated results always require a stronger condition, and the one that is most commonly used is geometric ergodicity. The theorem refers to the following conditions, which pertain to each l = 1, …, k.
A1 The Markov chain satisfies the basic regularity conditions.
A2 The Markov chain is geometrically ergodic.
A3 The Markov transition function K(l) satisfies the minorization condition (3.7).
For a square matrix C, C† will denote the Moore-Penrose inverse of C.
Theorem 1
Suppose that for each l = 1, …, k, the Markov chain has invariant distribution πl.
Under A1, the log quasi-likelihood function (2.7) has a unique maximizer subject to the constraint ζ⊤1k = 0. Let denote this maximizer, and let . Then as ρ1 → ∞, .
- Under A1 and A2, as ρ1 → ∞,
(3.16) Assume A1–A3. Let be the matrix D in (3.15) with in place of d, and let and be defined by (3.9) and (3.13), respectively. Then, is a strongly consistent estimator of W.
4 Choice of the Vector a
As mentioned earlier, the log quasi-likelihood that has been proposed and studied in the literature involves the functions pl(x, ζ) given by (2.2), which have the form
| (4.1) |
where in the denominator of (4.1), the probability density νs(x)/ms is given weight proportional to the length of the sth chain. Intuitively, one would want to replace ns with the “effective sample size” for chain s, so that if chain s mixes slowly, the weight that is given to νs(x)/ms is small. Unfortunately, there is really no such thing as an effective sample size because the effect of slow mixing varies quite a bit with the function whose mean is being estimated. Therefore, it is better to take a direct approach that involves replacing the vector (n1/n, …, nk/n) by a probability vector a, and choose a to minimize the variance of the resulting estimator. (It should be emphasized that the estimator is a complicated function of k chains.)
In more detail, we do the following. Let be the k-dimensional simplex. For each a ∈ , in (4.1) replace ns/n by as and form the corresponding log quasi-likelihood function (see equation (2.7)), call it . We let be the constrained maximizer of , and let be the corresponding estimate of d. Let Wa be the variance matrix of given by Part 2 of Theorem 1, and let be its estimate. We choose a to minimize (this corresponds to the classical “A-optimal design”). It should be noted that we are able to carry out this optimization scheme precisely because Theorem 1 enables us to estimate Wa.
Remarks
-
It is natural to ask whether in the Markov chain case our procedure gives rise to an optimal estimate of d, and we now address this question. To keep the discussion as simple as possible, we consider the case k = 2. Let be the set of all “bridge functions” β : X → ℝ satisfying the conditions that 0 < | ∫ β(x)π1(x)π2(x) μ(dx)| < ∞ and β(x) = 0 when either π1(x) = 0 or π2(x) = 0. It is easy to see that when the two sequences , l = 1, 2 are each iid, for any β ∈ , the estimate
is a consistent and asymptotically normal estimate of d2. Meng and Wong (1996) show that within , the function for which the asymptotic variance is minimized is
where sj = nj/n, j = 1, 2. Because this function involves the unknown d2, Meng and Wong (1996) propose an iterative scheme in which we start with, say, , and at stage m, we from
They show that exists and is exactly equal to the estimate considered by Geyer (1994), and so established an equivalence between the iterative bridge estimator and the estimate based on maximization of the log quasi-likelihood function.When the sequences , l = 1, 2 are Markov chains, the optimal bridge function has the form βopt,mcmc(x) = β∗(x)βopt,iid(x), where the correction factor, β∗(x), is the solution to a complicated Fredholm integral equation (Romero, 2003) and reflects the dependence structure of the two chains. In particular, for the case of Markov chains, the optimal bridge function need not have the form
for any t1, t2. Unfortunately, β∗ is very hard to identify, let alone estimate. To conclude, since our procedure is, effectively, searching within the class (4.2), it will not yield an optimal estimate in general, and instead should be viewed as a method for yielding estimates which are practically useful, even if not optimal.(4.2) A crude way to find is to calculate as a varies over a grid in and then find the minimizing a. This is inefficient and unnecessary, as there exist efficient algorithms for minimizing real-valued functions of several variables; see, e.g., Robert and Casella (2004, Chapter 5).
The vector can be calculated from a small pilot experiment, after which new chains are run and used to form the log quasi-likelihood function , from which we obtain (and hence ).
If for each l, is an iid sequence, then a regeneration occurs at each step. In this case, there is no need to estimate a, since the optimal value is known to be aj = nl/n (Meng and Wong, 1996). The wl’s in (2.6) reduce to 1, and the log quasi-likelihood function (2.7) reduces to exactly the log quasi-likelihood function used by Geyer (1994), so our estimate is exactly the estimate introduced by Vardi (1985), who worked in the iid setting.
5 Illustrations
Here we have two goals. In Section 5.1 we provide a simulation study to show the gains in efficiency that are possible if we use the method for choosing the weight vector a described in Section 4. Our illustration involves toy problems. The purpose of Section 5.2 is to demonstrate the applicability of our methodology, and we return to the second of the three classes of problems we discussed in Section 1, where we have a family of probability densities of the form pθ(x) =gθ(x)/zθ, which are intractable because the normalizing constant zθ cannot be computed in closed form. Our focus here is a bit different, in that we are not interested in estimating the family zθ, θ ∈ Θ; rather, we are now interested in estimating a family of expectations of the form Eθ(U(X)), θ ∈ Θ, where U is a function, as well as estimating functions of these expectations. Our illustration is in the context of the Ising model of statistical physics, and we show how to estimate the internal energy and specific heat of the system as a function of temperature.
5.1 Gains in Efficiency When Using the Optimal Weight Vector a
Recall that is calculated from a small pilot experiment. Let be the corresponding estimate of d. Also, let denote the estimate of d obtained when we use the conventional choice aj = nj/n. In this section we demonstrate through a simulation study that significant gains in efficiency are possible if we use instead of in situations where the Markov chains mix at different rates. We consider a very simple situation where k = 2, so that d is just d2. We take π1 and π2 to be two t distributions, specifically π1 = t5,1 and π2 = t5,0, where tr,μ denotes the t distribution with r degrees of freedom, centered at μ. The representation πl = νl/ml is taken to be trivial: νl = πl and ml = 1 for l = 1, 2. So d2 = m2/m1 is known to be 1, but we proceed to estimate it as if we didn’t know that fact.
In our simulations, chain 1 is an iid sequence from π1. Chain 2 is an independence Metropolis-Hastings (IMH) chain with proposal density t5,μ. That is, if the current state of the chain is x, a proposal Y ~ t5,μ is generated; the chain moves to Y with acceptance probability min {[t5,0(Y)t5,μ (x)]/[t5,0(x)t5,μ(Y)], 1} and stays at x with the remaining probability. We will let μ range over a fine grid in (−3, 3). Note that when μ = 0, the proposal is always accepted, and the chain is an iid sequence from t5,0, but as μ moves away from 0 in either direction, proposals are less likely to be accepted, and the mixing rate of the chain is slower. It is simple to check that infx (t5,μ(x)/t5,0(x)) > 0, which implies that the IMH algorithm is uniformly ergodic (Mengersen and Tweedie, 1996, Theorem 2.1) and hence geometrically ergodic. Moreover, Mykland et al. (1995, Section 4.1) have shown that for IMH chains there is always a scheme for producing minorization conditions and regeneration sequences, and here we use the scheme they described.
Our simulation study is carried out as follows. For each value of μ, we conduct a pilot study to calculate , using the method described in Section 4. The pilot study is based on 1000 iid draws from π1 and a number of regenerations of the IMH Markov chain for π2 that gives a sample of approximately the same size. Then we run the main study, in which we form (where is obtained in the pilot study), and also form . The main study is 10 times as large as the pilot study. For each μ, the above is replicated 1000 times, and from these replicates we calculate the average squared distance between the ’s and 1, the average squared distance between the ’s and 1, and form the ratio, which we take as a measure of the efficiency of vs. .
Figure 1 gives a plot of the ratio of these estimated mean squared errors as μ varies over (−3, 3), along with 95% confidence bands, valid pointwise (the bands are constructed via the delta method applied to the function f(o, c) = o/c). From the figure we see that, as expected, the efficiency is about 1 when μ is near 0. But it grows rapidly as μ moves away from 0 in either direction, reaching about 15 when μ is 3 or −3, and it is reasonable to believe that the efficiency is unbounded as μ → ∞ or μ→ −∞. Figure 2 provides a graphical description of the explanation. The figure gives a plot of , the first component of , as μ varies over (−3, 3). When μ = 0, the two chains are each iid sequences, and , so that . But when μ moves away from 0 in either direction, chain 2 mixes more slowly, and increases towards 1, so that in the term (2.2) in our quasi-likelihood function, less weight is given to chain 2, which is why is more efficient than is .
Figure 1.
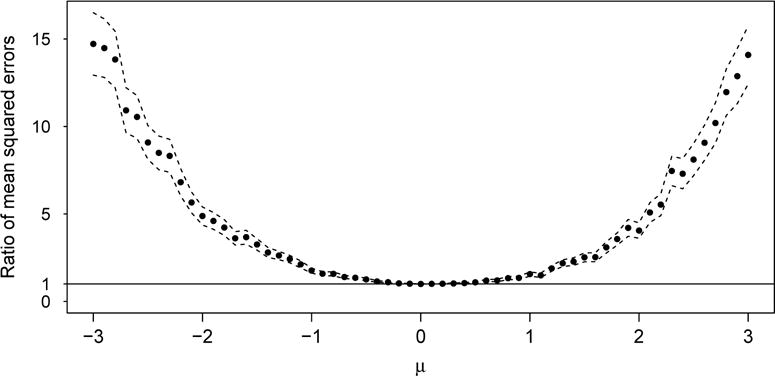
Estimated relative efficiency of vs. , together with 95% confidence bands. As μ moves away from 0, the mixing rate of chain 2 slows, and the efficiency of vs. increases. The horizontal line at height 1 serves a reference line.
Figure 2.
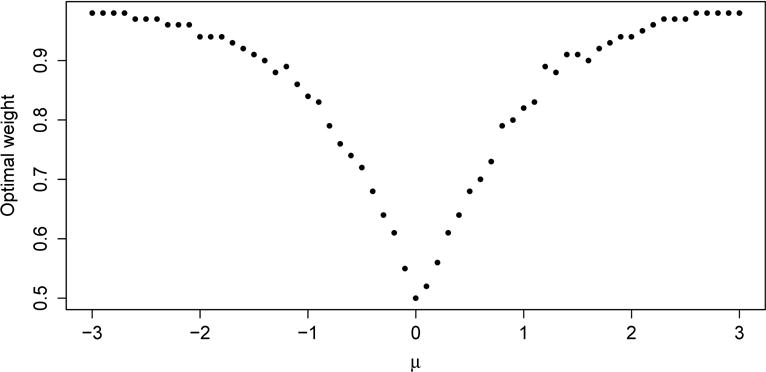
The points are the medians of the first component of , i.e. the weight assigned to sample 1 in the term (2.2) in our quasi-likelihood function, over the 1000 replications at each μ. As μ moves away from 0, the weight given to the second (slower mixing) chain decreases to 0.
Of course, because the calculation of requires a pilot study, the comparison above could be viewed as unfair. However, for to perform well all that is required, both in theory and in practice, is that consistently estimate , and for this to occur all that is required is that the size of the pilot study increase to infinity. That is, the size of the pilot study can increase to infinity arbitrarily slowly when compared to the size of the main study so, asymptotically, the amount of time required to compute and is the same.
Since ultimately our estimates and the standard error estimates given by Theorem 1 are to be used to produce confidence intervals for d2 (more generally confidence regions for d), we checked the coverage probability of these intervals. Figure 3 gives a graphical display of the observed coverage rates of the nominal 95% confidence intervals over the 1000 repetitions, as μ ranges from −3 to 3. The figure shows that these hover neatly around .95, with no systematic deviation from .95, and no deviation from .95 that is not accounted for in an experiment involving only 1000 repetitions.
Figure 3.
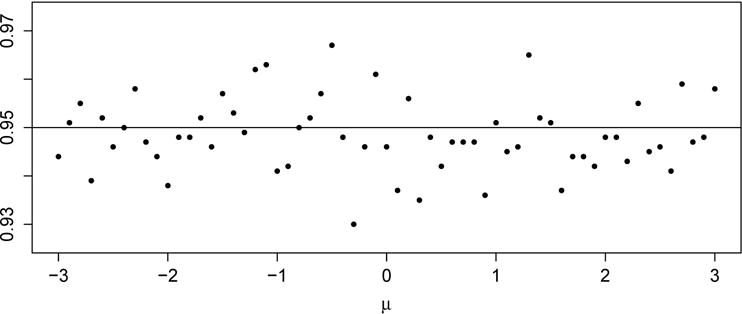
Observed coverage rate of confidence intervals based on and the standard error estimates given by Theorem 1.
5.2 Estimation of the Internal Energy and Specific Heat as Functions of Temperature in the Ising Model
We consider the Ising model on a c × c square lattice with periodic boundary conditions. That is, we have a graph (V, E) where V denotes the set of c2 vertices of the lattice, and E denotes the set of 2c2 edges that connect nearest neighbors on the lattice. Vertices in the first and last rows are also considered neighbors, as are vertices in the first and last columns, so the graph resides on the torus. For each vertex i ∈ V, we have a random variable Xi taking on the values 1 and −1. The random vector X = {Xi, I ∈ V} gives the state of the system, and the state space S contains states. For x ∈ S, let , where the notation i ~ j signifies that i and j are nearest neighbors. For each θ ∈ Θ := [0, ∞), define a probability distribution pθ on S by
where is the normalizing constant, called the partition function in the physics literature, and θ = 1/(κT), where T is the temperature and κ is the Boltzmann constant. See, e.g., Newman and Barkema (1999, sec. 1.2) for an overview.
Important to physicists are the internal energy of the system, defined by
and the specific heat, which is the derivative of the internal energy with respect to temperature, or equivalently,
and interest is focused on how these quantities vary with θ. Because the size of the state space increases very rapidly as c increases, except for the case c ≤ 5, the quantities above cannot be evaluated, and MCMC must be used. It is simple to implement a Metropolis-Hastings algorithm that randomly chooses a site, proposes to flip its spin, and accepts this proposal with the Metropolis-Hastings probability; however this algorithm converges very slowly. Swendsen and Wang (1987) proposed a data augmentation algorithm in which bond variables are introduced: if i and j are nearest neighbors and Xi = Xj, then with probability 1 − exp(−θ) an edge is placed between vertices i and j. This partitions the state space into connected components, and entire components are flipped. This algorithm converges far more rapidly than the single-site updating algorithm, and it is the algorithm we use here. Mykland et al. (1995, sec. 5.3) developed a simple minorization condition for the Swendsen-Wang algorithm, and we use it here to produce the regenerative chains that are needed to estimate the families {Iθ, θ ∈ Θ} and {Cθ, θ ∈ Θ} via the methods of this paper.
We now consider the problem of estimating the families {Iθ, θ ∈ Θ} and {Cθ, θ ∈ Θ}, and as we will see, the issue of obtaining standard errors for our estimates is quite important. We are in the framework of the second of the three classes of problems mentioned in Section 1, and the two-step procedure given there, described in the present context, is as follows:
Step 1 We choose points θ1, …, θk appropriately spread out in the region of Θ of interest, and for l = 1, …, k, we run a Swendsen-Wang chain with invariant distribution for ρl regenerations. Using these k chains, we form , the estimate of the vector d, where , l = 2, …, k.
Step 2 For each l = 1, …, k, we generate a new Swendsen-Wang chain with invariant distribution for Rl regenerations, and we use these new chains, together with the estimate produced in Step 1, to estimate Iθ and Cθ.
We now describe the details involved in Step 2. Denote the lth sample (in Step 2) by . For each θ ∈ Θ, define gθ(x) = exp[−θH(x)] for x ∈ S. Let
and let
(These quantities depend on θ, but this dependence is temporarily suppressed in the notation.) Using El to denote expectation with respect to , we have
as ρl → ∞ and Rl → ∞ for l = 1, …, k, where the convergence statement follows from ergodicity of the Swendsen-Wang chains and the fact that . Similarly, we have
Furthermore, Theorem 2 of Tan, Doss and Hobert (2012) deals precisely with the asymptotic distribution of estimates of the form and , in the framework of regenerative Markov chains. This theorem, which relies on Theorem 1 of the present paper, states that if (i) both Stage 1 and Stage 2 chains satisfy A1–A3 of the present paper, (ii) for l = 1, …, k, Rl/R1 and ρl/ρ1 converge to positive finite constants, and (iii) R1/ρ1 converges to a nonnegative finite constant, then and have asymptotically normal distributions, and the theorem also provides regeneration-based consistent estimates of the asymptotic variances. These are the estimates we use in this section.
We will apply the approach described above in two situations. The first involves the Ising model on a square lattice small enough so that exact calculations can be done. This enables us to check the performance of our estimators and confidence intervals. The second involves the Ising model on a larger lattice, where calculations can be done only through Monte Carlo methods.
We first consider the Ising model on a 5 × 5 lattice, and we focus on the problem of estimating Cθ, the specific heat. Figure 4 was created using our methods. The left panel gives a plot of , together with 95% confidence bands (valid pointwise), and a plot of the exact values. The right panel gives the standard error estimates for .To create the figure, we used the approach described above, with k = 5 and (θ1, …, θ5) = (.3, .4, .5, .6, .7). For each l = 1, …, 5, regenerative Swendsen-Wang chains of (approximate) length 10,000 were run for θl, based on which and from Theorem 1 were calculated. We then ran independent chains for the same five θ values, for as many iterations, to form estimates on a fine grid of θ values that range from .2 to 1 in increments of .01. The plot in the right panel was obtained from the formula in Theorem 2 of Tan et al. (2012) and the exact values of Cθ were obtained using closed-form expressions from the physics literature.
Figure 4.
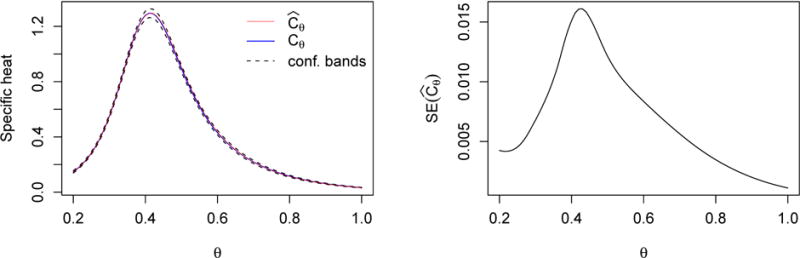
Estimation of the specific heat for the Ising model on a 5 × 5 lattice. Left panel gives a plot of the point estimates and a plot of the exact values, as θ varies. The two plots are visually indistinguishable. Also provided are 95% confidence bands. Right panel gives standard errors for .
We mention that Newman and Barkema (1999, sec. 3.7) also considered the problem of estimating the specific heat for the Ising model on a 5 × 5 lattice. They have a plot very similar to ours, but they produced it by running a separate Swendsen-Wang chain for each θ value on a fine grid, and each chain is used solely for the θ value under which it was generated. In contrast, our method requires only k Swendsen-Wang chains, where k is fairly small, and all chains are used to estimate Cθ for every θ. Here, we have considered a simple instance of the Ising model, the so-called one-parameter case. It is common to also consider the situation where there is an external magnetic field, in which case θ has dimension 2, and . Running a separate Swendsen-Wang chain for each θ in a fine subgrid in dimension 2 becomes extremely time consuming, whereas our approach is easily still workable.
In our second example, we consider the Ising model on a 30 × 30 lattice, for which exact calculations of physical quantities are prohibitively expensive, and our interest is now on estimating the internal energy. The left panel of Figure 5 shows a plot of vs. θ as θ ranges from .35 to 1.5 in increments of .01. To form the plot we carried out the two-step procedure discussed earlier, with k = 5 and reference points (θ1, …, θ5) = (.65, .75, .85, .95, 1.05), and a sample size of 100,000 for each chain in both steps. The left panel also shows 95% bands, valid pointwise, and the right panel shows the estimated standard errors. From the plot, we can see that the standard errors are much larger when θ < θ1 = .65 than they are when θ ≥ θ1. The importance sampling estimates are not stable when we try to extrapolate below the lowest reference θ value, but we can go well above the highest reference value and still get accurate estimates. It is our ability to estimate SE’s through regeneration that makes it possible for us to determine the range of θ’s for which we have reliable estimates. In fact, this range depends in a complicated way on the reference points and the sample sizes, and even for the relatively simple case where k = 1, the range is not simply an interval centered at θ1.
Figure 5.
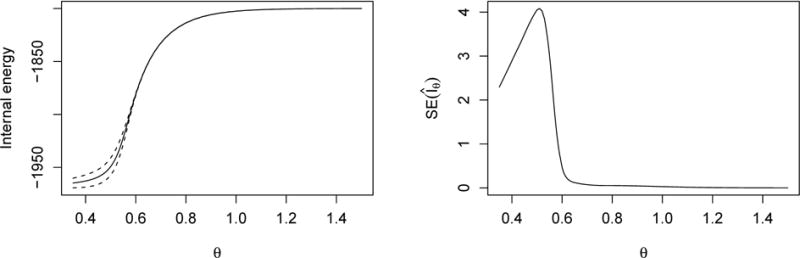
Estimation of the internal energy for the Ising model on a 30 × 30 lattice. Left panel gives estimated values, together with 95% confidence bands. Right panel gives the corresponding standard error estimates.
6 Discussion
The main contributions of this paper are the development of estimators of the vector d which are appropriate for the Markov chain setting, and of consistent standard errors for these estimators. Although we have discussed only estimating variances via regenerative simulation, both batching and spectral methods can also be used (and we believe that a rigorous asymptotic theory can be developed for each of these two methods, although we do not attempt to do so here).
There are two ways to do batching. One is trivial, and is described as follows. Suppose we have some method for estimating d, and let be the estimate produced by this method when we use the sequences . We break up each of the k chains into M non-overlapping segments of equal length, and we let be the estimate produced from the first segment of each chain, i.e. is produced from the sequences (we ignore the problem that the nj’s may not be divisible by M). Similarly define . Assuming we have established that , we have, for m = 1, …, M, the corresponding result . Denoting the average by , we may estimate the variance matrix V by , or what is slightly better, This method requires essentially no programming effort and gives ball-park estimates of the variance matrix.
The crude estimates obtained by the method above are badly outperformed by the regeneration-based estimates developed in this paper (this is illustrated by Figure 6 below, which we will discuss shortly). To obtain better batching-based variance estimates, we must make use of the structure of the problem. We now outline the approach for doing this. Notably, the approach applies equally well to spectral methods. As mentioned earlier, and d = g(ζ0), where g is given by (3.14). So asymptotic normality of follows from asymptotic normality of by the delta method. As we will see in the Appendix, the proof of asymptotic normality of , or that of , is based on representing each component of this vector as a linear combination of standardized averages of functions of the k Markov chains, plus a vanishingly small term. This will be made clear in Appendix A.2; see in particular (A.16) and (A.9). We express this generically as
where fr1, …, frk are real-valued functions for which , and cr1, …, crk are constants. For each r and j, the variance of can be estimated by batching in the usual way, or via spectral methods, and since the k Markov chains are independent, this leads to an estimate of the variance of , r = 1, …, k. The covariances , r, s = 1, …, k, are handled in a similar way.
Figure 6.
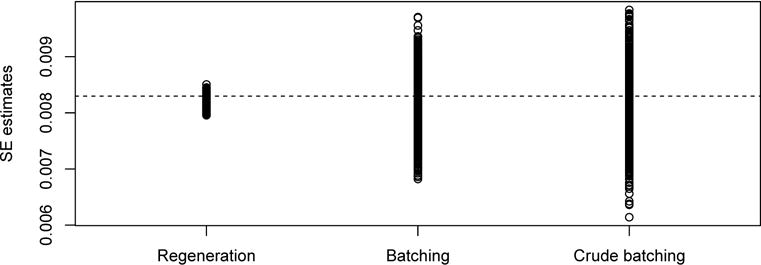
Dotplots of 1000 estimates of standard error of in the setting of Section 5.1 with μ = 1, for three methods: regenerative simulation, structure-based batching, and crude batching. The height of the horizontal dotted line is the true value of the standard error.
Figure 6 compares the distributions of the estimates of standard deviation of the statistic based on regeneration, structure-based batching, and the crude method of batching, for the toy example of Section 5.1 with μ = 1. The length of the chains is n = 10,000 (approximately) and the number of batches is bn ≈ n1/2, as recommended in Flegal and Jones (2010). Here we do not know the true value of the standard deviation of , so we estimate this quantity via the sample standard deviation based on 1000 independent replications. The horizontal dotted line is positioned at this empirical estimate. The figure gives a dotplot of the 1000 values for each of the three methods. It shows that structure-based batching outperforms crude batching, and both are outperformed by the regeneration-based method developed in this paper, at least in this particular scenario. When we change the parameter values the ordering is maintained, although the magnitude of the differences varies. (We do not display results for the spectral-based estimate because its performance varies quite a bit with the choice of of window and truncation point; however we can say that in almost all cases it is outperformed by the regeneration-based methods.)
Flegal and Jones (2010) provide a thorough analysis and comparison of confidence intervals produced by regeneration, batching, and spectral methods, for the case where the statistic is an average, They studied confidence intervals of the form , and they report that when tuning parameters are chosen in a suitable manner all three methods produce acceptable results. The significant differences in performance we report above are not inconsistent with the results in Flegal and Jones (2010)—all that is needed for confidence intervals to be asymptotically valid is convergence of to σ in probability.
We now mention some of the advantages of regenerative simulation for our problem.
Batching is generally acknowledged to be outperformed in terms of accuracy by spectral methods (Geyer, 1992), but estimation by spectral methods is computationally expensive. Typically, the truncation point Mn is of the order nη for some η ∈ (0, 1), and for each j estimation of γj requires O(n) operations, so the number of operations needed to estimate the variance by spectral methods is O(n1+η). By contrast, the number of operations needed to calculate the variance estimate (3.4) is of the order O(n). Consider now the estimate constructed in Section 4, whose calculation requires us to repeatedly compute trace for a in , in order to obtain . Once we have constructed the k regeneration sequences , l = 1, …, k, these same sequences may be used in the computation of for all a ∈ . But the analogous minimization procedure applied to spectral methods would come at a significantly greater computational cost.
Regeneration does not require us to specify tuning parameters such as the batch size for the case of batching or the truncation point and window for the case of spectral methods.
By (3.6) we start each chain at a regeneration point. Therefore, the issue of burn-in does not even exist.
We now discuss the general applicability of the three methods. Regeneration has been applied successfully to a number of problems in recent years; see for example Mykland et al. (1995), Sahu and Zhigljavsky (2003), Roy and Hobert (2007), Tan and Hobert (2009), and Flegal, Jones and Neath (2012). We believe that, when feasible, regenerative simulation is the method of choice. Unfortunately, its successful implementation is problem-specific, i.e. it cannot be routinely applied (the general-purpose method developed by Mykland et al. (1995) applies only to independence Metropolis-Hastings chains). To use regenerative simulation, one must come up with a minorization condition which gives rise to regeneration times that are not too long, and there does not exist a generic procedure for doing this. In most of the published examples, the successful minorization condition is obtained only after some trial and error.
Acknowledgments
We are grateful to two referees and an associate editor, whose constructive criticism improved the paper. This work was supported by NSF Grants DMS-08-05860 and DMS-11-06395 and NIH Grant P30 AG028740.
Appendix: Proof of Theorem 1
A.1 Proof of Consistency of
We first work in the ζ domain, and at the very end switch to the d domain. As mentioned earlier, in the standard textbook situation in which we have X1, …, where θ0 ∈ Θ, ln(θ) is the log likelihood and , the classical proof of consistency (Wald, 1949) is based on the observation that Q(θ) is maximized at θ = θ0, and that for each fixed θ, . The, convergence may be non-uniform, and care needs to be exercised in showing that the maximizer of ln(θ) converges to the maximizer of Q(θ). The present situation is simpler in that the log likelihood and its expected value are twice differentiable and concave, but is more complicated in that we have multiple sequences, they are not iid, and we have a non-identifiability issue, so that maximization is carried out subject to a constraint.
We will write ℓρ instead of ℓn to remind ourselves that the ρl’s are given and the nl’s are determined by these ρl’s. Also, we will write ℓρ(X, ζ) instead of ℓρ(ζ) when we need to note the dependence of ℓρ(ζ) on X, where . We define the (scaled) expected log quasi-likelihood by
As ρl → ∞, we have nl → ∞, so , and so
The structure of our proof is similar to that of Theorem 1 of Geyer (1994), and the outline of our proof is as follows. First, define S = {ζ : ζ⊤1k = 0}, and recall that is defined to be a maximizer of ℓρ(X, ζ) satisfying .
We will show that for every X, ℓρ(X, ζ) is everywhere twice differentiable and concave in ζ.
We will show that λ(ζ) is finite, everywhere twice differentiable, and concave. We further show that its Hessian matrix is semi-negative definite, and that its only null eigenvector is 1k.
We will show that ∇λ(ζ0) = 0.
We will note that the two steps above imply that ζ0 is the unique maximizer of λ subject to the condition ζ0 ∈ S.
We will argue that with probability one, for every ζ, ∇2ℓρ(X, ζ) is semi-negative definite, and 1k is its only null eigenvector. This will show that is the unique maximizer of ℓρ(X, ζ) subject to .
We will conclude that the convergence of ℓρ(X, ζ) to λ(ζ) implies convergence of their maximizers that reside in S, that is, .
We now provide the details.
- The differentiability is immediate from the definition of ℓρ (see (2.7)). To show concavity, it is sufficient to show that for every x, log(pl(x, ζ)) is concave in ζ. Now
where p = (p1(x, ζ), …, pk(x, ζ))⊤. The matrix inside the parentheses on the right side of (A.1) is the variance matrix for the multinomial distribution with parameter p, so this matrix is positive semi-definite.(A.1) -
First, λ(ζ) is finite because λ(ζ) ≤ 0, and
We now obtain the first and second derivatives of λ. By a standard argument involving the dominated convergence theorem, we can interchange the order of differentiation and integration. (If v is the vector of length k with a 1 in the rth position and 0’s everywhere else, then for any x, any ζ, and any l ∈ {1, …, k}, [log(pl(x, ζ + υ/m)) − log(pl(x, ζ))]m = ∂ log(pl(x, ζ∗))/∂ζr, where ζ∗ is between ζ + υ/m and ζ, and this partial derivative is uniformly bounded between −1 and 1.) So for r = 1, …, k, we have
Consider the integrand on the right side of (A.2), i.e. pr(X, ζ). Its gradient is given by and ∂pr/∂ζl = −prpl for l ≠ r, and these derivatives are uniformly bounded in absolute value by 1. Hence again by the dominated convergence theorem, we can interchange the order of differentiation and integration, and doing this gives(A.2)
Define the expectation operator . From (A.3) we have −∇2λ(ζ) = EP(J), where J = diag(p) − pp⊤, and as before p = (p1(X, ζ), …, pk(X, ζ))⊤. As before, J is the covariance of the multinomial, so is positive semi-definite, and therefore so is EP (J).(A.3) We now determine the null eigenvectors of ∇2λ(ζ) (which is −EP (J)). If ∇2λ(ζ)u = 0, then u⊤[∇2λ(ζ)]u = 0, so EP(u⊤Ju) = 0. Since J is positive semi-definite, it has a square root, J1/2. Hence EP (‖J1/2u‖2) = 0, which implies Ju = 0 [P]-a.e. The condition Ju = 0 [P]-a.e. is expressed as
and under our assumption that ν1, …, νk are mutually absolutely continuous, (A.4) implies that for r = 1, …, k. So u1 = ⋯ = uk, i.e. u ∝ 1k.(A.4) - To show that ∇λ(ζ0) = 0, we write
- For any ζ satisfying ζ⊤1k = 0, we may write
where ζ∗ is between ζ and ζ0. If ζ ≠ ζ0, i.e. ζ − ζ0 ≠ 0, then since (ζ − ζ0)⊤ 1k = 0, ζ − ζ0 cannot be a scalar multiple of 1k. Hence by Step 2, (ζ − ζ0)⊤∇2λ(ζ∗)(ζ − ζ0) < 0. Clearly . The proof that (i) ∇2ℓρ(X, ζ) is semi-negative definite, (ii) the only null eigenvector of ∇2ℓρ(X, ζ) is 1k, and (iii) is the unique maximizer of ℓρ(X, ζ) subject to the constraint ζ ∈ S, is essentially identical to the proof of these assertions for λ(ζ).
Since for each ζ, a.s. convergence occurs on a dense subset of S. Also, the functions involved are all concave in the entire space of ζ’s, hence are concave in S. Therefore, we have a.s. uniform convergence of to λ(ζ) on compact subsets of S. Under concavity, this is enough to imply , i.e. .
Finally, to see that , we write , where ζ∗ is between and ζ0. The function g actually depends on a(ρ), so depends on ρ, but the gradient ∇g(ζ∗) is bounded for large ρ because and α(ρ) → α. Therefore .
A.2 Proof of Regeneration-Based CLT for
We begin by considering . As in the classical proof of asymptotic normality of maximum likelihood estimators, we expand ∇ℓρ at around ζ0, and using the appropriate scaling factor, we get
| (A.5) |
where ζ∗ is between and ζ0. Consider the left side of (A.5), which is just , since . There are several nontrivial components to the proof, so we first give an outline.
We show that each element of the vector n−1∇ℓρ(ζ0) can be represented as a linear combination of mean 0 averages of functions of the k chains plus a vanishingly small term.
Using Step 1 above, we obtain a regeneration-based CLT for the scaled score vector, via a considerably more involved version of the method we used in Section 3.1: we show that , where Ω is given by (3.12).
We argue that and that , where B is defined in (3.8), using ideas in Geyer (1994).
We conclude that .
We note the relationships d = g(ζ0) and , where g was define by (3.14), and apply the delta method to obtain the desired result.
We now provide the details.
-
We start by considering n−1∇ℓρ(ζ0). For r = 1, …, k, we have
where(A.6) (A.7) We claim that e = 0. To see this, note that from (A.7) we have(A.8) The last equality in (A.8) holds becauseTherefore, using the fact that wlnlar/al = wrnr, we getWe summarize: Because e = 0, (A.6) can be used to view n−1∂ℓρ(ζ0)/∂ζr as a linear combination of mean 0 averages of functions of the k chains. To express these averages in terms of iid quantities, we first recall the definitions of , , , and given in (3.10) and (3.11), and multiplying by the scaling factor , we rewrite (A.6) as(A.9a) (A.9b) (A.9c) (A.9d) (A.9e) -
We now apply a more complex and more rigorous version of the argument we used in Section 3.1. We note the following: (i) the k chains are geometrically ergodic by Assumption A2; (ii) since pr(x, ζ) ∈ (0, 1) for all x and all ζ, for some ε > 0 (in fact for any ε > 0); and (iii) by (3.10) the mean of is 0. The usual CLT for iid sequences does not apply to the sequence , …, because a = a(ρ) is allowed to change with ρ, so the distribution of changes with ρ. Since r and l are now fixed and play no important role, while the dependence of a on ρ now needs to be noted we will write yi(a(ρ)) instead of , Yt(a(ρ)) instead of , etc. We really have a triangular array of random variables, and we will apply the Lindeberg-Feller version of the CLT.
We first need to show that . (This condition is nontrivial because Yt(a(ρ)) is the sum of a random number of terms.) Note that since pr(x, ζ) ∈ (0, 1), |yi(a(ρ))| ≤ 1, and therefore,(A.10) Theorem 2 of Hobert, Jones, Presnell and Rosenthal (2002) states that under geometric ergodicity. So E([Yt(a(ρ))]2) < ∞, and we may form the triangular array whose row consists of the variables U1(a(ρ)), …, whereClearly, E[Ut(a(ρ))] = 0 and .
The Lindeberg Condition is that for every η > 0,
and this is equivalent to the condition(A.11) To see (A.11) note that as ρl → ∞, by the assumption that a(ρ) → α where all the components of α are strictly positive and dominated convergence, we haveBy (A.10), we have , and by Theorem 2 of Hobert et al. (2002). Therefore, E([Yt(a(ρ))]2) → E([Yt(α)]2) by (A.10) and dominated convergence, and we also have E[Yt(a(ρ))] → E[Yt(α)], so that Var[Yt(a(ρ))] → Var[Yt(α)]. Since I[|Y1(a(ρ))| > (ρl Var[Y1(a(ρ))])1/2η] = 0 for large ρ, (A.11) follows by dominated convergence.
The Lindeberg-Feller theorem (together with the fact that )) now states that the term in the second set of brackets in (A.9e) has an asymptotic normal distribution, with mean 0, and variance . The term in the first set of brackets converges to Since the k chains are independent, we conclude that
where Ω was defined in (3.12). But by the Cramér-Wold Theorem, we obtain the more general statement involving the asymptotic distribution of the entire gradient vector. The argument is standard and gives -
Now, referring to (A.5), denote the matrix −n−1∇2ℓρ(ζ∗) by Bρ. We have
and for later use also define by(A.12) (A.13) Hence(A.15) Now from (A.14) and the spectral decomposition of the symmetric matrix Bρ, we have , so (A.15) becomes(A.16) We now study the asymptotic behavior of . From (A.13), the fact that wl = aln/nl by definition, and ergodicity, we haveThe first part of Theorem 1 states that as ρ1 → ∞. Now since partial derivatives (with respect to ζ) of terms of the form pr(x, ζ) (1 − pr(x, ζ)) or pr(x, ζ)ps(x, ζ) are uniformly bounded by 1 in absolute value, we see that a.s. for all r and s, and conclude that . (Here, ‖υ‖1 denotes the L1 norm of a vector .) Similarly, a.s. for all r and s, so . Furthermore, the spectral decomposition of Bρ and B, and the fact that Bρ1k = 0 and B1k = 0, we have
showing that .(A.17) The convergence statement now follows immediately.
Finally, we write , where ζ∗ is between and ζ0. Since , the desired result (3.16) now follows.
A.3 Proof of Consistency of the Estimate of the Asymptotic Variance Matrix
In the proof of the first part of Theorem 1, we showed that and . Hence, . In the proof of the second part of Theorem 1 we showed that . Using the spectral representation of and of B (see (A.17)), we see that this entails .
To complete the proof, we need to show that . Consider the expressions for Ω and given by (3.12) and (3.13), respectively. Since a → α and , to show that , we need only show that
| (A.18) |
Now, the left side of (A.18) is an average of quantities that involve and , which themselves are a sum and an average, respectively, of a function that involves the random quantity . At the risk of making the notation more cumbersome, we will now write instead of and instead of . Our plan is to introduce , a version of in which is replaced by the non-random quantity ζα, and show that (i) and (ii) . To this end, let
and note that by definition
Define the k × k matrices Ψ, , and by
Note that Ψrs is simply the right side of (A.18). Here, Ψrs is the population-level quantity (which we wish to estimate), is the empirical estimate of this quantity, and is an “intermediate” or bridging quantity, used only in our proof. We will show that (i) and (ii) .
To show that , we first express as a sum of four averages. That the four averages converge to their respective population counterparts follows from the ergodic theorem, together with the fact that .
To show that , we express as the sum of four differences of averages, and show that each of these converges almost surely to 0. Consider the first difference, which is
| (A.19) |
The expression inside the brackets in (A.19) is equal to
| (A.20) |
and because all partial derivatives with respect to ζ of functions of the form pr(x, ζ)ps(y, ζ) are uniformly bounded by 1 in absolute value, the expression inside the brackets in (A.20) is bounded by . Since there are summands in the double sum in (A.20), , and from the fact that we now see that .
The second difference is
| (A.21) |
The expression inside the brackets in (A.21)
and reasoning as we did for the case of the first difference, we have , which implies that . The third difference is handled in a similar way.
The fourth difference
| (A.22) |
The expression inside the brackets in (A.22) is
and we have , from which we conclude that .
References
- Buta E, Doss H. Computational approaches for empirical Bayes methods and Bayesian sensitivity analysis. Annals of Statistics. 2011;39:2658–2685. [Google Scholar]
- Flegal JM, Haran M, Jones GL. Markov chain Monte Carlo: Can we trust the third significant figure? Statistical Science. 2008;23:250–260. [Google Scholar]
- Flegal JM, Jones GL. Batch means and spectral variance estimators in Markov chain Monte Carlo. The Annals of Statistics. 2010;38:1034–1070. [Google Scholar]
- Flegal JM, Jones GL, Neath RC. Markov chain Monte Carlo estimation of quantiles. arXiv preprint arXiv:1207.6432 2012 [Google Scholar]
- Geyer CJ. Practical Markov chain Monte Carlo (with discussion) Statistical Science. 1992;7:473–511. [Google Scholar]
- Geyer CJ. Tech Rep 568r. Department of Statistics, University of Minnesota; 1994. Estimating normalizing constants and reweighting mixtures in Markov chain Monte Carlo. [Google Scholar]
- Gill RD, Vardi Y, Wellner JA. Large sample theory of empirical distributions in biased sampling models. The Annals of Statistics. 1988;16:1069–1112. [Google Scholar]
- Hobert JP, Jones GL, Presnell B, Rosenthal JS. On the applicability of regenerative simulation in Markov chain Monte Carlo. Biometrika. 2002;89:731–743. [Google Scholar]
- Jones GL, Haran M, Caffo BS, Neath R. Fixed-width output analysis for Markov chain Monte Carlo. Journal of the American Statistical Association. 2006;101:1537–1547. [Google Scholar]
- Kong A, McCullagh P, Meng XL, Nicolae D, Tan Z. A theory of statistical models for Monte Carlo integration (with discussion) (Series B).Journal of the Royal Statistical Society. 2003;65:585–618. [Google Scholar]
- Meng XL, Wong WH. Simulating ratios of normalizing constants via a simple identity: A theoretical exploration. Statistica Sinica. 1996;6:831–860. [Google Scholar]
- Mengersen KL, Tweedie RL. Rates of convergence of the Hastings and Metropolis algorithms. The Annals of Statistics. 1996;24:101–121. [Google Scholar]
- Meyn SP, Tweedie RL. Markov Chains and Stochastic Stability. Springer-Verlag; New York, London: 1993. [Google Scholar]
- Mykland P, Tierney L, Yu B. Regeneration in Markov chain samplers. Journal of the American Statistical Association. 1995;90:233–241. [Google Scholar]
- Newman M, Barkema G. Monte Carlo Methods in Statistical Physics. Oxford University Press; 1999. [Google Scholar]
- Newton M, Raftery A. Approximate Bayesian inference with the weighted likelihood bootstrap (with discussion) (Series B).Journal of the Royal Statistical Society. 1994;56:3–48. [Google Scholar]
- Nummelin E. General Irreducible Markov Chains and Non-negative Operators. Cambridge University Press; London: 1984. [Google Scholar]
- Robert CP, Casella G. Monte Carlo Statistical Methods. Second. Springer-Verlag; New York: 2004. [Google Scholar]
- Romero M. Ph D thesis. University of Chicago; 2003. On Two Topics with no Bridge: Bridge Sampling with Dependent Draws and Bias of the Multiple Imputation Variance Estimator. [Google Scholar]
- Roy V, Hobert JP. Convergence rates and asymptotic standard errors for MCMC algorithms for Bayesian probit regression. (Series B).Journal of the Royal Statistical Society. 2007;69:607–623. [Google Scholar]
- Sahu SK, Zhigljavsky AA. Self-regenerative Markov chain Monte Carlo with adaptation. Bernoulli. 2003;9:395–422. [Google Scholar]
- Swendsen R, Wang J. Nonuniversal critical dynamics in Monte Carlo simulations. Physical Review Letters. 1987;58:86–88. doi: 10.1103/PhysRevLett.58.86. [DOI] [PubMed] [Google Scholar]
- Tan A, Doss H, Hobert JP. Tech rep. Department of Statistics, University of Florida; 2012. Honest importance sampling with multiple Markov chains. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tan A, Hobert JP. Block Gibbs sampling for Bayesian random effects models with improper priors: convergence and regeneration. Journal of Computational and Graphical Statistics. 2009;18:861–878. [Google Scholar]
- Tan Z. On a likelihood approach for Monte Carlo integration. Journal of the American Statistical Association. 2004;99:1027–1036. [Google Scholar]
- Vardi Y. Empirical distributions in selection bias models. The Annals of Statistics. 1985;13:178–203. [Google Scholar]
- Wald A. Note on the consistency of the maximum likelihood estimate. Annals of Mathematical Statistics. 1949;20:595–601. [Google Scholar]
- Wolpert RL, Schmidler SC. α-stable limit laws for harmonic mean estimators of marginal likelihoods. Statistica Sinica. 2011 (in press) preprint at http://ftp.stat.duke.edu/WorkingPapers/10-19.html.