

Abstract
The use of mobile health applications (apps) especially in the area of lifestyle behaviors has increased, thus providing unprecedented opportunities to develop health programs that can engage people in real-time and in the real-world. Yet, relatively little is known about which factors relate to the engagement of commercially available apps for health behaviors. This exploratory study examined behavioral engagement with a weight loss app, Lose It! and characterized higher versus lower engaged groups. Cross-sectional, anonymized data from Lose It! were analyzed (n = 12,427,196). This dataset was randomly split into 24 subsamples and three were used for this study (total n = 1,011,008). Classification and regression tree methods were used to identify subgroups of user engagement with one subsample, and descriptive analyses were conducted to examine other group characteristics associated with engagement. Data mining validation methods were conducted with two separate subsamples. On average, users engaged with the app for 29 days. Six unique subgroups were identified, and engagement for each subgroup varied, ranging from 3.5 to 172 days. Highly engaged subgroups were primarily distinguished by the customization of diet and exercise. Those less engaged were distinguished by weigh-ins and the customization of diet. Results were replicated in further analyses. Commercially-developed apps can reach large segments of the population, and data from these apps can provide insights into important app features that may aid in user engagement. Getting users to engage with a mobile health app is critical to the success of apps and interventions that are focused on health behavior change.
Keywords: Mobile health application, Mobile health technology, Smartphone app, Data mining, Big data, User engagement, Classification and regression tree
Introduction
Americans are increasingly relying on mobile technology and the internet for health-related information and resources [1]. The proliferation of smartphone ownership among US adults, particularly among traditionally underserved populations (e.g., low-income, racial/ethnic minorities), has expanded the potential reach of healthy eating, physical activity, and weight loss programs. From 2011 to 2015, the percentage of US adults owning a smartphone increased from 35 to 68% [2], and low income and racial/ethnic populations were more likely to be “smartphone” dependent, thus relying primarily on their phone for health information [3].
In general, the development of health and wellness smartphone applications (apps) has outpaced empirical investigations of these apps [4, 5]. Fortunately, data mining approaches can be used to explore patterns in health app data as well as confirm the reliability of the findings in a relatively rapid fashion. For example, classification and regression tree (CART) analyses have been used to identify different classifications of weight loss among those using a health app, and these exploratory findings were quickly confirmed in independent samples taken randomly from the same dataset [6]. These rapid and sequential exploratory and confirmatory analyses can provide preliminary, empirically-based insights into who uses health apps, thus providing more scientific rigor than anecdotal findings or exploratory only investigations.
While smartphones now provide unprecedented opportunities to develop health programs that can engage people in real-time and in the real-world, lack of user engagement with existing health apps is a concern [7, 8]. Often individuals download a health app and never use it again, with only about 16% of users willing to give apps a third chance [9]. Identifying specific app features that encourage users to stay actively engaged with an app may help increase the dose of information users receive. Sama and colleagues [10], in their analysis of 400 health and wellness apps available in the Apple iTunes Store, found that self-monitoring was the most commonly used engagement technique (at 74.8%). Yet, there may be distinct groups who are more likely to engage with a particular health app [11] that may not be captured by just focusing on the engagement strategies used for app users in general.
Prior exploratory research notes that app user engagement (e.g., food days logged) was a key factor in distinguishing between those who were more and less successful at weight loss [6]. In addition, greater customization of the app was associated with more likelihood of weight loss success. Based on these results, the questions that arise are (1) what features of the app differentiate those who are more versus less engaged with this weight loss app? and (2) what are the characteristics of high versus low user engagement groups? We explore these subsequent questions using the “Lose It!” database, a commercial weight loss app that has served over 24 million users since its inception in 2008 with an average of three million active users each month (http://www.loseit.com/about/). Specifically, the purposes of this study are to explore the features of a weight loss app that are related to behavioral engagement and to characterize higher versus lower engaged groups.
Methods
Sample
Researchers at the National Cancer Institute forged a relationship with Lose It! and a formal collaboration was agreed upon. Data were made available for research purposes only, and cross-sectional, anonymized data (n = 12,427,196) were provided by Lose It! The study was reviewed by HHS/NIH Office for Human Research Protections and given approval/exemption because secondary data analyses were conducted with de-identified data.
The application Lose It! (hereafter, known as the app) is available through the iOS and Android markets, as well as the web. The app provides users with several tools to assist them with weight loss; for example, food tracking with the aid of barcode scanners, the ability to sync the app with other devices and applications (e.g., Fitbit, Nike+), motivation and support by finding and connecting with friends on the app, and options for nutrition feedback (e.g., app-generated reports that compare a user’s food log with the US Department of Agriculture’s MyPlate recommendations). A user can create an app account and a weight loss plan based on his/her height, weight, exercise level, target weight goal, and desired weekly weight loss. The plan consists of logging in weight via self-report or a synced device (e.g., Wi-Fi enabled devices), and logging in diet and exercise. In addition, the app provides tools that allow users to identify friends and share progress and information with them.
Data from users who had Lose It! accounts during 2008 to 2014 were analyzed. The data provided were from the metadata reporting database, which is used to power the app and provides a general summary of user activity. Data included the following information: gender, age at the start of the account; height; body weight (3 values: start, minimum, and maximum); body mass index (BMI); desired target weight; desired weekly weight loss; number of days logged in for food and exercise; number of exercise calories burned; number of calories consumed; number of times weighed in; number of days active (logged) on the app; date of last activity; devices and applications connected to a user’s account; type of operating system used; number of friends and groups on app; number of challenges users participated in; number of customized goals, foods, recipes, and exercises created; and app-specific options (e.g., has a picture, uses reminders). Weight and health behavior data were self-reported, while technical-related data (e.g., operating system used, app-specific options) were from the system’s database. More time-intensive longitudinal data were not readily available at the time of analyses.
Data preparation
Prior to analyses, duplicate records were removed, and codes were created distinguishing between missing and invalid data; valid ranges for each variable were implemented. For example, records that contained exactly the same information for all variables were removed, and one record for that user was kept. There were 63,641 duplicate records that were deleted, leaving a total sample of 12,363,555. However, this dataset was too large to handle on a single computer. For computing management and efficiency reasons, the dataset was randomly split into 24 subsamples, each with a sample size of approximately 500,000.
The current study used three subsamples. The following exclusions were applied to each subsample: (a) users who were not active or had zero days of activity, (b) users who were less than 18 years old or greater than 70 years old at the start of the account (older adults, 65 and older, are less likely to use health-related smartphone apps [1]); this was a conservative strategy as it is unlikely that anyone greater than 70 years old would be using this system), (c) participants who reported to being younger than 18 at the date of last activity, and (d) participants with weight loss values that were out of range; for example, minimum weight values that exceeded start weight values were considered as out of range. Regarding this last criterion, if a user is new to the app, then the minimum weight should theoretically equal the start weight because no other weight has been recorded. If minimum weight is greater (e.g., 160) than start weight (e.g., 150), then the data are suspect given that minimum weight should be the lower value. Applying these exclusions resulted in the following analytic samples: n 1 = 336,968; n 2 = 337,262; and n 3 = 336,778 (data flow chart shown in Fig. 1). The outcome of interest was user engagement, which was operationalized as app use, that is, the number of days users logged in on the app. The predictors included demographics and app features.
Fig. 1.
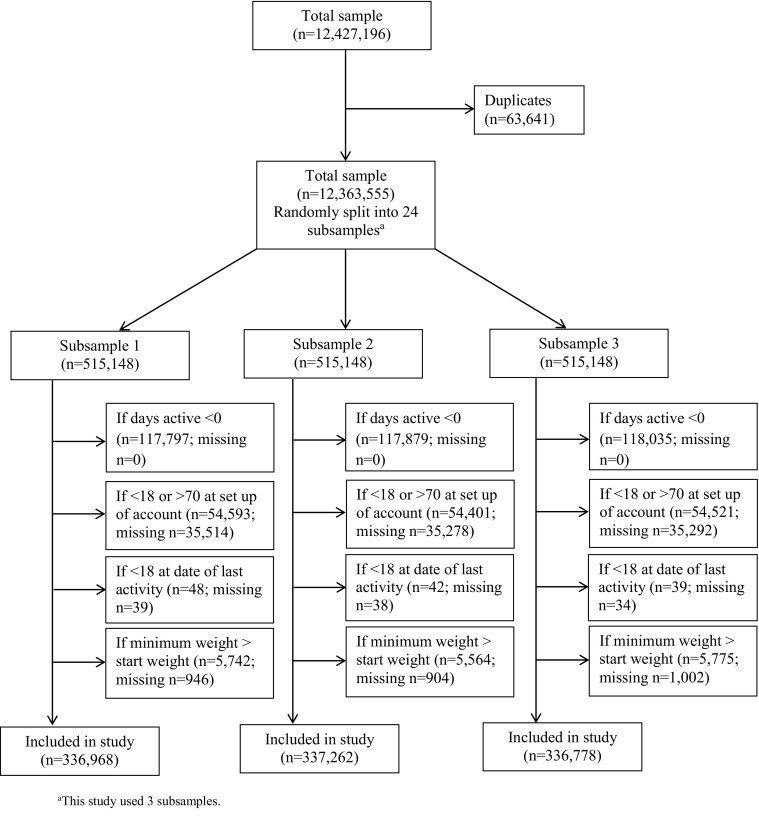
Data flow chart
Exploratory data mining approach
Data mining methods via CART analysis were used. CART analysis, also called recursive partitioning, is a tree-building technique that uses the data to predict a response [12–16]. CART is a non-parametric approach that identifies mutually exclusive and exhaustive subgroups of individuals sharing common attributes that influence the outcome of interest. For classification, the CART procedure uses a splitting criterion to assess all possible predictors and chooses a splitting variable that separates individuals into binary groups that are the most different with respect to the outcome [17]. For regression, the splitting criterion is made in accordance with the ANOVA method and chooses the split that maximizes the between-groups sum of squares [17].
Although CART methods have been available for some time, only now have they been increasingly applied to health behavior research [12, 13, 18–20]. CART methods have several advantages over more traditional techniques, such as logistic regression, used in health behavior research. Because CART methods are non-parametric, no assumptions are made about the underlying distribution of the data, making it well suited for highly skewed distributions or even extreme scores or outliers [12, 13, 16]. Missing data are also handled differently. If data are missing at a specific split point, surrogate variables with similar information to the primary splitter are used [17], an important consideration given to the missing data often observed with commercial health app data.
Statistical analysis
The CART analysis was conducted in R (version 3.1.3), using the package rpart [17]. The default settings in rpart were used, with the exception of the minimum number of observations in a node to compute a split as well as the terminal node, which were both set to 3000 (1% of the sample) versus the default of 20 and 7, respectively. These settings were used to achieve a more parsimonious and interpretable model. Specific details about this R package can be found elsewhere [17]. The CART analysis identified mutually exclusive subgroups in subsample 1 (hereafter, known as the training sample), which were then used to conduct comparative analyses to examine additional factors that may further distinguish the various subgroups. Due to the large sample size, significance in the additional analyses was determined by the unique variance explained by the predictor variables (using R 2 or Cramer’s V) rather than p values. As a rule-of-thumb, the predictor variable had to account for at least 1% of the variance [6]. These additional analyses were conducted in SAS (version 9.3; SAS Institute, Inc.).
To examine the robustness of the CART model identified in the training sample, the model predictions were evaluated with subsample 2 (hereafter, known as data mining validation sample 1). Conversely, the training sample was used to train the model/regression tree, and this tree was used to test data mining validation sample 1 [21]. The root mean squared error (RMSE) was calculated to measure the differences between the predicted values obtained with the training sample and the actual values observed in the data mining validation sample. An additional evaluation was conducted with subsample 3 (hereafter, known as data mining validation sample 2) to assess how well the model performed on another independent subsample. The RMSE was also obtained with data mining validation sample 2. For the purposes of obtaining the lowest RMSE and comparing it with the one originally obtained, the CART analysis was re-run with the training sample, varying the complexity parameter (i.e., a criterion that takes into account the consequences of misclassification) to 0.001 (versus 0.01) and applying the same minimum number of observations in the node and terminal node. For additional exploratory purposes, a CART analysis was conducted with data mining validation sample 2, and the second model was obtained and compared with our first model.
Results
The CART model, including the best predictors that formed the splits and the identified subgroups, is displayed in Fig. 2. As shown in Fig. 2, the average number of days users logged on the app in the training sample was 29. Six unique subgroups were identified according to the split variables that best distinguished them.
Fig. 2.
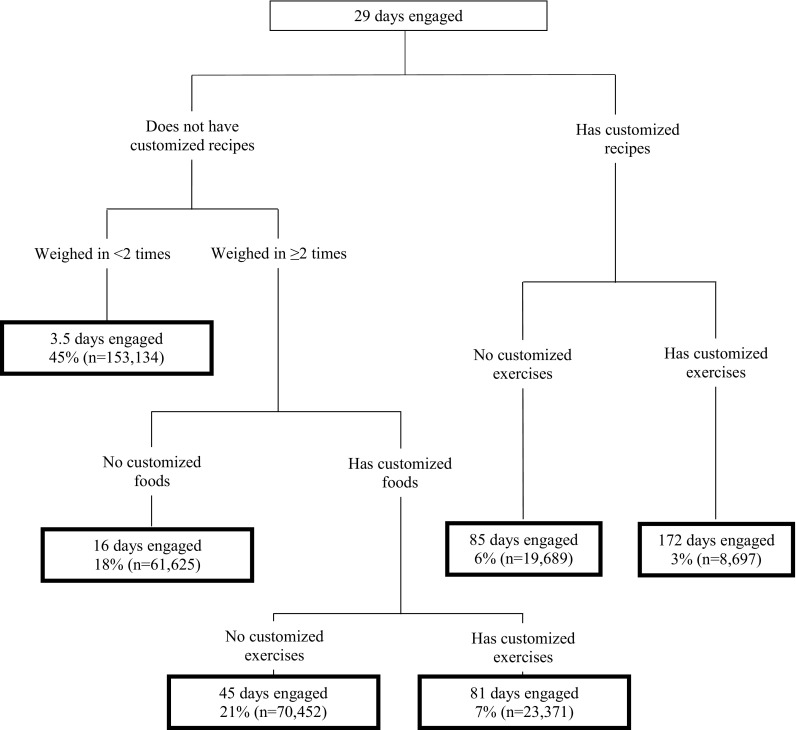
Regression tree for identifying subgroups of user engagement with the training sample (n = 336,968)
The subgroup that had the lowest app use logged on the app had an average of 3.5 days, and these users did not create customized recipes and they reported their weight only once or never at all. Next, was the subgroup of individuals who logged on for an average of 16 days; these individuals did not create customized recipes nor any customized foods, but reported their weight at least two or more times. The next two subgroups had no customized recipes, logged in weight at least two or more times, and logged in customized foods. However, what differentiated these next two subgroups from each other was whether users had created at least one customized exercise. Users who did not create a customized exercise used the app an average of 45 days, and those who had customized exercises used the app an average of 81 days. The two subgroups who used the app the most, both had customized recipes, but users were further divided by whether they generated customized exercises. Recipes without customized exercises equaled to 85 days of engagement, but with customized exercises, engagement equaled to 172 days.
Additional characteristics to help describe the subgroups are presented in Table 1. The majority of app users were females. The most active group (172 days) logged in their weight the most, logged in a higher number of exercise days, had a higher percentage of iPhone users versus Android or web, had one or more devices linked, had more friends on the app, were part of a group, had administered a challenge, and had customized the app more (e.g., had a picture).
Table 1.
Additional characteristics of identified engagement subgroups with the training sample (n = 336,968)
| Group 1a | Group 2b | Group 3c | Group 4d | Group 5e | Group 6f | Cramer’s V | R 2 | p value | |
|---|---|---|---|---|---|---|---|---|---|
| % or mean (SD) | % or mean (SD) | % or mean (SD) | % or mean (SD) | % or mean (SD) | % or mean (SD) | ||||
| Demographics | |||||||||
| Female | 76.6% | 74.7% | 74.2% | 78.9% | 71.3% | 75.8% | 0.0395 | p < 0.0001 | |
| Age (at set up of account) | 34.3 (12.7) | 35.1 (12.2) | 37.1 (12.5) | 36.5 (12.3) | 36.7 (11.9) | 36.8 (11.7) | 0.0089 | p < 0.0001 | |
| Start weight | 186.5 (51.1) | 192.8 (51.0) | 193.2 (50.3) | 184.5 (46.8) | 194.2 (51.3) | 187.3 (47.6) | 0.0047 | p < 0.0001 | |
| Start BMI | 30.0 (7.3) | 30.8 (7.2) | 30.8 (7.1) | 29.7 (6.6) | 30.6 (7.2) | 29.8 (6.7) | 0.0032 | p < 0.0001 | |
| Health Behaviors | |||||||||
| Weigh ins | 1.0 (0.1) | 6.7 (19.7) | 15.2 (39.4) | 25.7 (61.7) | 28.0 (69.7) | 54.9 (111.3) | 0.0950 | p < 0.0001 | |
| Exercise days logged | 1.3 (4.6) | 7.1 (22.6) | 19.4 (48.0) | 44.7 (87.5) | 37.8 (80.9) | 95.7 (152.0) | 0.1463 | p < 0.0001 | |
| Exercise calories logged | 3,265,704.7 (571,411,776.0) | 22,721,100.8 (5,252,250,786.6) |
2,858,480.4 (532,810,339.2) |
34,250,810.9 (2,068,288,681.2) |
15,591.7 (44,785.4) | 34,540,405.2 (1,857,059,497.7) |
0.0000 | p = 0.1967 | |
| Food calories logged | 2,016,766.4 (442,884,965.9) | 19,697.9 (60,550.4) | 7,330,980.0 (843,277,111.2) | 60,275,627.6 (6,735,867,555.2) |
5,202,694.7 (712,670,413.3) |
252,564.1 (393,709.7) | 0.0001 | p = 0.0006 | |
| Goal weight | 152.3 (34.1) | 155.7 (34.3) | 156.5 (33.6) | 151.7 (31.9) | 158.0 (34.1) | 153.9 (32.2) | 0.0040 | p < 0.0001 | |
| Goal plan | 1.6 (0.5) | 1.6 (0.5) | 1.6 (0.5) | 1.6 (0.5) | 1.5 (0.5) | 1.5 (0.6) | 0.0060 | p < 0.0001 | |
| App Behaviors | |||||||||
| iPhone users (% yes) | 59.4% | 63.3% | 68.5% | 70.9% | 81.6% | 84.4% | 0.1406 | p < 0.0001 | |
| Android users (% yes) | 29.0% | 34.1% | 30.2% | 29.3% | 22.1% | 23.6% | 0.0627 | p < 0.0001 | |
| Web users (% yes) | 12.1% | 6.0% | 6.7% | 6.7% | 2.9% | 2.6% | 0.1150 | p < 0.0001 | |
| One or more devices linked with app (e.g., Fitbit) (% yes) | 0.9% | 2.9% | 5.3% | 8.0% | 10.6% | 17.7% | 0.1941 | p < 0.0001 | |
| Has friends on the app (% yes) | 5.7% | 13.0% | 23.0% | 30.9% | 34.0% | 47.3% | 0.3042 | p < 0.0001 | |
| Number of friends on the app | 0.1 (0.5) | 0.2 (1.5) | 0.5 (2.2) | 1.1 (6.2) | 0.9 (4.9) | 3.8 (24.4) | 0.0188 | p < 0.0001 | |
| Is part of a group on the app (% yes) | 0.5% | 2.0% | 2.2% | 3.6% | 4.0% | 7.4% | 0.1126 | p < 0.0001 | |
| Number of groups on the app | 0.0 (0.1) | 0.0 (0.3) | 0.0 (0.3) | 0.1 (0.6) | 0.1 (0.6) | 0.3 (1.9) | 0.0119 | p < 0.0001 | |
| Has been an administrator of a challenge (% yes) | 0.0% | 0.0% | 0.0% | 0.1% | 0.2% | 0.6% | 0.0471 | p < 0.0001 | |
| Number of challenges participated in | 0.0 (0.0) | 0.0 (0.1) | 0.0 (0.0) | 0.0 (0.1) | 0.0 (0.2) | 0.0 (0.4) | 0.0012 | p < 0.0001 | |
| Number of customized goals entered | 0.0 (0.1) | 0.0 (0.4) | 0.1 (0.6) | 0.1 (0.8) | 0.2 (1.2) | 0.5 (1.8) | 0.0223 | p < 0.0001 | |
| Number of customized foods entered | 0.8 (3.7) | 0.0 (0.0) | 12.5 (29.2) | 33.0 (68.2) | 18.1 (41.3) | 53.0 (91.5) | 0.1463 | p < 0.0001 | |
| Number of customized recipes entered | 0.0 (0.0) | 0.0 (0.0) | 0.0 (0.0) | 0.0 (0.0) | 6.6 (13.4) | 11.7 (21.4) | 0.2005 | p < 0.0001 | |
| Number of customized exercises entered | 0.1 (0.6) | 0.1 (0.9) | 0.0 (0.0) | 5.0 (17.2) | 0.0 (0.0) | 6.9 (29.1) | 0.0579 | p < 0.0001 | |
| Uses app reminders (% yes) | 0.9% | 3.1% | 6.1% | 8.6% | 9.8% | 16.4% | 0.1865 | p < 0.0001 | |
| Has a picture (% yes) | 2.3% | 7.4% | 11.3% | 18.2% | 17.0% | 30.1% | 0.2410 | p < 0.0001 | |
| Uses email reports (% yes) | 0.2% | 0.7% | 1.9% | 3.3% | 3.6% | 6.8% | 0.1301 | p < 0.0001 | |
a3.5 days active (n = 153,134)
b16 days active (n = 61,625)
c45 days active (n = 70,452)
d81 days active (n = 23,371)
e85 days active (n = 9689)
f172 days active (n = 8697).
Interestingly, certain subgroups had similar characteristics but different engagement levels, while other subgroups had similar engagement levels but rather different characteristics. Subgroups 2 and 3 had similar characteristics but differed primarily on whether users created customized foods—if a user had customized foods (but no customized exercises), they were active for 45 days versus 16 days. Subgroups 4 and 5 had similar engagement levels (81 days versus 85 days of activity), but differed from each other on whether users generate customized recipes, with users in subgroup 4 being identified as weighing in more than two times and having customized foods and exercises. Users in subgroups 4 and 6 both had customized exercises, but differed from each other based on customized recipes; having customized recipes and exercises resulted in more than double the engagement, 172 days of app use. Additional analyses indicated that subgroup 6 also had the highest percentage of iPhone users and the highest use of customized app features of all the subgroups. Subgroups 2 and 3 had about the same percentage of females whereas subgroup 4 had a higher percentage of females than subgroups 5 or 6.
The RMSE obtained with data mining validation sample 1, using the CART model from the training sample, was 73.16. The RMSE obtained with data mining validation sample 2, using the same CART model predictions, was 73.77. Varying the complexity parameter to produce a separate CART model with the training sample produced an RMSE of 71.85, which is only slightly better than the RMSE obtained with the original model. Thus, the original CART model (Fig. 2) was retained. A secondary model was obtained with data mining validation sample 2 to compare with the original model. The splits for this model were identical to the original model, and the subgroups identified were almost identical as well.
Discussion
Commercially-developed mHealth apps can reach large segments of the population, and data from these apps can provide insights into important app features that aid in user engagement. This study identified subgroups of user engagement, and descriptive analyses further characterized these subgroups. Results showed that particular subgroups emerged when focusing on behavioral engagement, and these subgroups were primarily distinguished by the customization of diet and exercise among high engagement subgroups and by weigh-ins and the customization of diet among low engagement subgroups.
Findings are consistent with prior research that has focused on defining and characterizing weight loss subgroups among app users in that customization of an app is important [6]. Yet, while prior research suggests that general app customization (i.e., the overall number of features a user customizes) is associated with weight loss success, the present study finds that customization patterns of diet (i.e., food and recipes) and exercise, in particular, are keys to the classification of app users when it comes to behavioral engagement. As these data are cross-sectional, causal relationships cannot be established. Moreover, the available behavioral engagement variable being defined as number of food days logged precludes the evaluation of exercise alone as a behavioral outcome. Nonetheless, distinct behavioral engagement subgroups defined by customized diet, customized exercise, and weigh-ins suggest that users may have different reasons or strategies (e.g., diet only, diet and exercise, curiosity) for using weight loss apps.
Findings further suggest that encouraging users who only customize their food entries to add customized recipes may be a helpful strategy for increasing user engagement. In addition, subgroups that customize exercise in addition to diet were engaged twice as long as subgroups that customized diet alone. While the highest engagement subgroup customized many more app features than the other subgroups, focusing on ways to tailor motivational messages to the reasons or strategies for using the app (e.g., diet only, diet, and exercise) for the low- and middle-range engagement subgroups may help increase app use. Future longitudinal research is needed to explore this possibility.
But how does customization of an app lead to greater engagement? Studies suggest that customization provides users with a sense of identity and sense of control or agency [22, 23], which implies that a user must feel that he/she is in control in order to be engaged. In this case, it is possible that users may need to feel a sense of control over the technology in order to be engaged in achieving the health outcome desired, that is, weight loss. This hypothesis should be further explored. Others have suggested several behavioral techniques that may aid in mHealth user engagement [10], but customization was not one of them. Incorporating more customizable features in mobile health applications, targeting key subgroups, may help to facilitate longer use, and thus better health outcomes. Those involved in mHealth interventions should take this into consideration.
Limitations
There were limitations associated with this study. This study analyzed data from a commercial app; therefore, the app sample may not be representative of a national population. To examine this, the entire app sample was compared with a weighted-nationally representative sample. Data from the National Health Information Survey (NHIS) during the years 2008–2014 were assessed. After restricting both samples to include those only 18–70 years old (the app: n = 10,444,981; NHIS: n = 186,134 with final sample weights), the app sample had a higher percentage of women (75%) than the NHIS sample (51%) and had slightly younger (35.5 years) respondents than the NHIS sample (42.6 years). Also, the data analyzed were metadata and summary data, so specific longitudinal patterns of engagement were not assessed. In addition, this study operationalized user engagement as the number of days users were active (i.e., logged at least one food) on the app. Others have proposed different definitions of user engagement [24, 25], and there is currently no consensus on the definition and operationalization of user engagement.
Apart from objective information obtained from a synced device, data were mainly self-reported. Thus, there is no way to ensure the accuracy of the data or the validity of the findings since the quality of the data is based on how accurately users reported their information. Although our analytical approach (i.e., CART analyses) allowed for skewed and missing data, it has no control over the quality of the data. In addition, the results of this study are based on data from users of Lose It! It is unknown to what extent this population of users is like other users of a similar app. Therefore, the results obtained in this study may not be generalizable to other weight loss apps. Despite these limitations, this study was able to provide some insight into app features that are associated with user engagement in a commercial health app that has wide reach, which may help to inform the development of future smartphone apps aimed at improving health.
Conclusions
This study used exploratory data mining methods to identify different subgroups of user engagement with data from a weight loss app. A strength of this study is that data mining validation methods were used to confirm the stability of the initial results. Results revealed that the most engaged subgroup customized their recipes and exercises and utilized more custom features of the app, revealing the importance of customization for behavioral engagement. Moreover, for weight loss apps, defining key motivations of distinct subgroups may be helpful in sustaining user engagement. Future longitudinal and experimental research is warranted to further explore which groups engage in weight loss apps, which factors best characterize these groups, and what methods and strategies increase and/or sustain their utilization of these apps.
Acknowledgements
The authors thank FitNow Inc., the makers of Lose It! for providing this anonymized dataset for analysis.
Compliance with ethical standards
Funding source
This work is a secondary data analysis and was not funded by a grant.
Conflicts of interest
The authors declare that they have no conflicts of interest.
Human rights and welfare of animals
The Office of Human Subjects Research Protections at the National Institutes of Health has determined that federal regulations for the protection of human subjects do not apply to this research activity. No animals were used in this research study.
Informed consent
This work is a secondary data analysis of commercial application data, and data given were de-identified. No consent was needed.
Footnotes
Implications Practice: Identifying behavioral factors associated with engagement of a mobile health app may be helpful in sustaining user engagement for mobile health interventions.
Policy: Behavioral researchers can use exploratory data mining and validation methods with big data to increase confidence in the results that are obtained.
Research: Future longitudinal and experimental research is needed to further explore what type of groups engage in weight loss apps, which factors best characterize these groups, and what methods and strategies increase and/or sustain their utilization of these apps.
This manuscript represents original work that has not been published elsewhere. All authors had full access to and participated in all aspects of the research, including the data analysis and writing process. Because the data that were analyzed and reported in this paper were proprietary, only researchers at the National Cancer Institute and approved consultants were allowed access to the data.
References
- 1.Fox, S., & Duggan, M. (2012). Mobile health 2012. Retrieved from http://www.pewinternet.org/2012/11/08/mobile-health-2012/. Accessed 6 Oct 2016.
- 2.Anderson, M. (2015). Technology device ownership: 2015. Retrieved from http://www.pewinternet.org/2015/10/29/technology-device-ownership-2015/. Accessed 6 Oct 2016.
- 3.Smith, A. (2015). U.S. smartphone use in 2015. Retrieved from http://www.pewinternet.org/2015/04/01/us-smartphone-use-in-2015/. Accessed 6 Oct 2016.
- 4.Atienza AA, Patrick K. Mobile health: the killer app for cyberinfrastructure and consumer health. American Journal of Preventive Medicine. 2011;40(5 Suppl 2):S151–S153. doi: 10.1016/j.amepre.2011.01.008. [DOI] [PubMed] [Google Scholar]
- 5.Patrick K, Griswold WG, Raab F, Intille SS. Health and the mobile phone. American Journal of Preventive Medicine. 2008;35(2):177–181. doi: 10.1016/j.amepre.2008.05.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Serrano KJ, Yu M, Coa KI, Collins LM, Atienza AA. Mining health app data to find more and less successful weight loss subgroups. Journal of Medical Internet Research. 2016;18(6) doi: 10.2196/jmir.5473. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Becker S, Miron-Shatz T, Schumacher N, Krocza J, Diamantidis C, Albrecht UV. mHealth 2.0: experiences, possibilities, and perspectives. JMIR mHealth and uHealth. 2014;2(2):e24. doi: 10.2196/mhealth.3328. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Laing BY, Mangione CM, Tseng CH, et al. Effectiveness of a smartphone application for weight loss compared with usual care in overweight primary care patients: a randomized, controlled trial. Annals of Internal Medicine. 2014;161(10 Suppl):S5–12. doi: 10.7326/M13-3005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Pramis, J. (2013). Are you a rarity? Only 16 percent of people will try out an app more than twice. Retrieved from http://www.digitaltrends.com/mobile/16-percent-of-mobile-userstry-out-a-buggy-app-more-than-twice/. Accessed 6 Oct 2016.
- 10.Sama PR, Eapen ZJ, Weinfurt KP, Shah BR, Schulman KA. An evaluation of mobile health application tools. JMIR mHealth and uHealth. 2014;2(2) doi: 10.2196/mhealth.3088. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Yang CH, Maher JP, Conroy DE. Acceptability of mobile health interventions to reduce inactivity-related health risk in central Pennsylvania adults. Preventive Medicine Reports. 2015;2:669–672. doi: 10.1016/j.pmedr.2015.08.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Lemon SC, Roy J, Clark MA, Friedmann PD, Rakowski W. Classification and regression tree analysis in public health: methodological review and comparison with logistic regression. Annals of Behavioral Medicine. 2003;26(3):172–181. doi: 10.1207/S15324796ABM2603_02. [DOI] [PubMed] [Google Scholar]
- 13.McArdle, J. J. (2012). Exploratory data mining using CART in the behavioral sciences. In Cooper, H., Camic, P. M., Long, D. L., Panter, A. T., Rindskopf, D., & Sher, K. J. (Eds.), APA handbook of research methods in psychology, vol 3: Data analysis and research publication (pp. 405-421). Washington, DC: APA Books.
- 14.Loh WY. Classification and regression trees. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery. 2011;1(1):14–23. doi: 10.1002/widm.14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Breiman L, Friedman JH, Olshen RA, Stone CJ. Classification and regression trees. New York: Chapman & Hall; 1984. [Google Scholar]
- 16.Kraemer HC. Evaluating medical tests: Objective and quantitative guidelines. Newbury Park: Sage publications; 1992. [Google Scholar]
- 17.Therneau, T. M, & Atkinson, E. J. (2015). An introduction to recursive partitioning using the rpart routines. Retrieved from http://www.webcitation.org/6dwgz2E6v.
- 18.Atienza AA, Yaroch AL, Masse LC, Moser RP, Hesse BW, King AC. Identifying sedentary subgroups: the National Cancer Institute’s Health Information National Trends Survey. American Journal of Preventive Medicine. 2006;31(5):383–390. doi: 10.1016/j.amepre.2006.07.024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Dunton GF, Atienza AA, Tscherne J, Rodriguez D. Identifying combinations of risk and protective factors predicting physical activity change in high school students. Pediatric Exercise Science. 2011;23(1):106–121. doi: 10.1123/pes.23.1.106. [DOI] [PubMed] [Google Scholar]
- 20.King AC, Goldberg JH, Salmon J, et al. Identifying subgroups of U.S. adults at risk for prolonged television viewing to inform program development. American Journal of Preventive Medicine. 2010;38(1):17–26. doi: 10.1016/j.amepre.2009.08.032. [DOI] [PubMed] [Google Scholar]
- 21.Hastie T, Tibshirani R, Friedman J. The elements of statistical learning; data mining, inference and prediction. New York: Springer; 2008. [Google Scholar]
- 22.Sundar SS, Marathe SS. Personalization versus customization: The importance of agency, privacy, and power usage. Human Communication Research. 2010;36(3):298–322. doi: 10.1111/j.1468-2958.2010.01377.x. [DOI] [Google Scholar]
- 23.Marathe, S., & Sundar, S.S. (2011). What drives customization? Control or identity? Proceedings of the SIGCHI conference on human factors in computing systems. New York, NY: ACM.
- 24.O'Brien HL, Toms EG. What is user engagement? A conceptual framework for defining user engagement with technology. Journal of the American Society for Information Science and Technology. 2008;59(6):938–955. doi: 10.1002/asi.20801. [DOI] [Google Scholar]
- 25.Kim YH, Kim DJ, Wachter K. A study of mobile user engagement (MoEN): Engagement motivations, perceived value, satisfaction, and continued engagement intention. Decision Support Systems. 2013;56:361–370. doi: 10.1016/j.dss.2013.07.002. [DOI] [Google Scholar]