

Abstract
Binaural hearing helps normal-hearing listeners localize sound sources and understand speech in noise. However, it is not fully understood how far this is the case for bilateral cochlear implant (CI) users. To determine the potential benefits of bilateral over unilateral CIs, speech comprehension thresholds (SCTs) were measured in seven Japanese bilateral CI recipients using Helen test sentences (translated into Japanese) in a two-talker speech interferer presented from the front (co-located with the target speech), ipsilateral to the first-implanted ear (at +90° or −90°), and spatially symmetric at ±90°. Spatial release from masking was calculated as the difference between co-located and spatially separated SCTs. Localization was assessed in the horizontal plane by presenting either male or female speech or both simultaneously. All measurements were performed bilaterally and unilaterally (with the first implanted ear) inside a loudspeaker array. Both SCTs and spatial release from masking were improved with bilateral CIs, demonstrating mean bilateral benefits of 7.5 dB in spatially asymmetric and 3 dB in spatially symmetric speech mixture. Localization performance varied strongly between subjects but was clearly improved with bilateral over unilateral CIs with the mean localization error reduced by 27°. Surprisingly, adding a second talker had only a negligible effect on localization.
Keywords: spatial release from masking, better-ear glimpsing, localization, cochlear implants, bilateral benefit
Introduction
Listening to speech in the presence of noise is an integral part of our daily lives. In noisy situations, individuals with normal hearing take advantage of listening with two ears (rather than with only one ear), a phenomenon known as binaural hearing. Binaural hearing plays an important role in localizing sounds as well as in segregating target speech from distracting speech or noise (e.g., Bronkhorst, 2000; Cherry, 1953). When a distractor is located on one side of the head and is spatially separated from the target signal then the head shadow will typically improve the signal-to-noise ratio (SNR) in one ear (termed the better ear) and thereby improve speech intelligibility. However, the situation becomes more challenging when there is more than one distracting source. In such complex “cocktail-party” scenarios, the auditory system takes advantage of interaural time differences (ITDs) as well as interaural level differences (ILDs) to improve the “effective” SNR as well as to spatially attend to the signal of interest and to suppress interfering signals (Bronkhorst & Plomp, 1988; Glyde, Buchholz, Dillon, Cameron, & Hickson, 2013). For spectrotemporally fluctuating interferers, such as speech, the head shadow typically results in an SNR that continuously changes over time, frequency, and between the ears. The auditory system can take advantage of these SNR variations either by glimpsing (Cooke, 2006) within each ear separately or by a process termed better-ear glimpsing (Brungart & Iyer, 2012). Additionally, the auditory system can utilize ITDs to improve the effective SNR by a process similar to the equalization-cancelation theory (Durlach, 1963). Independent of the mechanism involved, the improvement in effective SNR is commonly attributed to a spatial release from energetic masking, whereas the benefit related to spatial attention and stream segregation is commonly attributed to a spatial release from informational masking or a “perceived” (spatial) segregation of target and interferer signals, respectively (e.g., Freyman, Helfer, McCall, & Clifton, 1999; Kidd, Mason, Richards, Gallun, & Durlach, 2007; Shinn-Cunningham, 2008). Spatial release from masking (SRM) in general is decreased in individuals with hearing loss as well as increased age, leading to difficulty in understanding speech in noise (e.g., Best, Mason, Kidd, Iyer, & Brungart, 2015; Glyde, Cameron, Dillon, Hickson, & Seeto, 2013).
The most common treatment for hearing loss is either a hearing aid or a cochlear implant (CI) depending on the severity of the hearing loss. SRM has been studied in hearing aid users (e.g., Glyde, Buchholz, Dillon, Best, et al., 2013; Glyde, Cameron, et al., 2013) as well as in CI users (e.g., van Hoesel, 2012; van Hoesel & Tyler, 2003), utilizing single as well as multiple interferers. For a frontal target, in the case that a single interferer is moved from the front to the side of the listener, a substantial SRM can be observed in bilateral CI users (Buss et al., 2008; Laszig et al., 2004; Müller, Schon, & Helms, 2002; Tyler et al., 2002; van Hoesel & Tyler, 2003). However, as mentioned above, this spatial benefit is mainly due to the better-ear effect and does not involve any sophisticated binaural processes. Nevertheless, two CIs are generally required to take full advantage of this effect in the real world.
In contrast to this spatially asymmetric masker condition, which has been extensively studied in CI users, very little is known about the SRM in spatially symmetric conditions with fluctuating (speech) interferers (e.g., Schön, Müller, & Helmsön, 2002). As mentioned earlier, in these conditions, neither ear provides a consistent SNR advantage, but ITD as well as ILD cues can provide a SRM. Since ITD cues are typically not available to CI users (e.g., van Hoesel, 2012), they are also not expected to provide any contribution to SRM in these spatially symmetric speech mixtures. However, ILDs are reasonably well preserved in the implanted ear and provide the main cue for localization in bilateral CI users (Aronoff, Freed, Fisher, Pal, & Soli, 2012; Grantham, Ashmead, Ricketts, Haynes, & Labadie, 2008; Seeber & Fastl, 2008). Hence, they may also provide SRM in these conditions, either by utilizing within-ear or across-ear (i.e., better-ear) glimpsing or by perceptually segregating the target from the interfering talkers and thereby providing a spatial release from IM. Either way, in comparison to the healthy auditory system, it is expected that the achieved SRM will be limited by the reduced spectral and temporal resolution of the implanted ear, mismatch in tonotopicity and loudness between ears, the limited dynamic range that is available in the implanted ear, and the distortion of the ILDs created by the wide-dynamic range compressors (and other adaptive processes) that operate independently at the left and right ear (e.g., Dillon, 2012, pp. 170–193; Kelvasa & Dietz, 2015). Moreover, it should be noted that any SRM that is achieved with bilateral CIs may be offset by an overall reduction in performance due to adding a second CI to a poor-performing ear; a phenomenon known as “binaural interference” that at least in hearing aid users can result in a negligible bilateral benefit or even in a detrimental effect (e.g., Mussoi & Bentler, 2017; Reiss, Eggleston, Walker, & Oh, 2016; Walden & Walden, 2005). This study investigated the SRM and the bilateral benefit achieved by CI users in a spatially symmetric as well as in a spatially asymmetric condition using an ongoing two-talker interferer. Whereas the spatially symmetric condition was of main interest here, the spatially asymmetric condition was included as a reference “best-case” condition that also allowed a more direct comparison with results reported in the literature. To derive the SRM, speech comprehension was measured in a co-located condition and compared with that in the two spatially separated conditions. To estimate the bilateral benefit, the performance achieved with a single CI fitted to the first implanted ear was compared with the performance achieved with both CIs.
ITDs and ILDs do not only provide a spatial advantage for understanding speech in noise, they are also the basic cues for localizing sounds. Thereby, the localization of sounds is not only important for identifying the direction of a sound source but also for participating in (multitalker) conversations, being aware of the surroundings, and for protecting from dangerous situations such as road accidents. Generally, adults with CIs on both the ears perform better in localization tasks than adults with a single CI (Dunn, Tyler, Oakley, Gantz, & Noble, 2008; Mosnier et al., 2008; Tyler, Dunn, Witt, & Noble, 2007). However, most studies have only investigated the localization of single sound sources, even though in real life a listener is often surrounded by multiple sound sources or wants to participate in (or attend to) a conversation with more than one partner. In such cases, listeners need to segregate as well as to localize the different sound sources. Therefore, in the present study, the ability to localize a single talker as well as two spatially separated simultaneous talkers of different gender was evaluated in bilateral CI users and compared with the performance achieved in a unilateral condition. It was assumed that the localization performance in the two-talker condition was not only affected by the listening mode (i.e., bilateral versus unilateral listening) but also by the participant’s ability to segregate the two talkers. The first aspect is mainly affected by the availability and utilization of binaural (mainly ILD) cues. The latter aspect will also depend on the ability to analyze and utilize pitch cues as well as other talker difference cues.
In summary, the overall aims of this study were to (a) investigate the extent to which SRM can be observed in bilateral CI users in spatially symmetric speech mixtures, (b) investigate the extent to which localization performance is affected in CI users when a more realistic source-segregation task is included, and (c) measure the benefit of providing two CIs over a single CI on the considered sound localization as well as speech comprehension tasks.
Methods
Participants
Seven adults (mean age of 62.9 years) with post-lingual deafness were recruited. All participants except of one had at least 6 months experience with their bilateral cochlear implants and had no more than eight years of severe to profound hearing loss prior to bilateral cochlear implantation (Table 1). They all used both CIs regularly, scored more than 60% at +10 dB SNR in the CI-2004: Adult Everyday Sentence Test (Megumi, Fumiai, Kozo, Kumiko, & Hidehiko, 2011) and spoke Japanese as their first language. None of the participants reported any cognitive impairment that would prevent or restrict participation in the audiological evaluations. This was confirmed for all subjects by administering a Japanese version of the Montreal cognitive assessment (MOCA) screening test (Nasreddine et al., 2005). The mean and standard deviation of the scores obtained in the MOCA test was 25 ± 2.4. All participants were implanted with devices from Cochlear Limited and travelled from Japan to Sydney for testing. Biographical details of all participants are given in Table 1. Written consent was obtained from all participants and ethical clearance was received from the Macquarie University Human Research Ethics Committees (Reference No: 5201401150).
Table 1.
Biographical Details of All Seven Participants.
| Subject code | Age (yr) | Sex | Age of first CI surgery (yr.mo) | Implant type | Speech processor | Age of second CI surgery (yr.mo) | Implant type | Speech processor | Cause of hearing loss |
|---|---|---|---|---|---|---|---|---|---|
| S1 | 34 | F | 31.10 | CI422 | CP 900 | 32.1 | CI422 | CP 900 | Unknown |
| S2 | 68 | M | 61.10 | CI24RE (CA) | CP 900 | 65.11 | CI24RE (CA) | CP 900 | Unknown |
| S3 | 62 | M | 47.11 | CI24M | SPrint | 60.3 | CI422 | CP 900 | Unknown |
| S4 | 71 | M | 63 | CI24R (CS) | CP 900 | 69.4 | CI422 | CP 900 | Genetic |
| S5 | 78 | M | 74.11 | CI422 | CP 900 | 77.2 | CI422 | CP 900 | Unknown |
| S6 | 60 | F | 58.5 | CI422 | CP 900 | 58.8 | CI422 | CP 900 | Unknown |
| S7 | 67 | F | 63.10 | CI24RE (CA) | N5 CP 800 | 64.8 | CI422 | N5 CP 800 | Meniere’s disease |
Note. Numbers in bold represent the preferred ear; yr = year; mo = months; CI = cochlear implant; F = female; M = male.
Speech Comprehension in Noise
Stimuli
Speech comprehension thresholds (SCTs) were measured by asking the participants to answer brief questions in the presence of various background noises. The questions were taken from the English Helen sentence test (Ludvigsen, 1974) and were extended for this study. The resulting test contained eight categories (colors, numbers, opposites, days of the week, addition and subtraction, multiplication and division, size comparison, and how many) of 20 to 51 questions each, providing 227 questions in total. The questions were all brief and easy to answer and included nonbibliographical questions from the above-mentioned categories, such as: “what color is a polar bear?” “what day comes after Monday?” or “what is two plus five?” A speech comprehension task was applied here instead of a more common sentence (or word) recall task because it was assumed to provide a more realistic performance measure (see Best, Keidser, Buchholz, & Freeston, 2016). This is because the task involves extraction of meaning as well as the formulation of a reply, which is very different from a simple word recall task, and may address higher level auditory functions that are relevant for communication in daily life (Kiessling et al., 2003). Additionally, it was particularly important for the spatially symmetric noise condition that the performance measure involved a substantial amount of glimpses, which is not really the case in a word test.
The Helen questions were translated into Japanese and were spoken by a native Japanese female speaker with a mean fundamental frequency (±1 standard deviation) of 226 (±49) Hz. The questions contained between five and seven words and had a mean duration (±1 standard deviation) of 1.9 (±0.3) s. The recording took place in a double-walled audiological test booth using a Rhode NT-1 A microphone connected to a desktop computer via a RME QuadMic microphone preamplifier and a RME Fireface USB soundcard. The questions were recorded and edited using Adobe Audition 5.5 software. All sentences were root-mean-square (RMS) level normalized in MATLAB.
The speech comprehension test was administered inside a double-walled, acoustically treated audiological test booth containing an array of 16 Genelec 8020C loudspeakers that were used to present the different stimuli via a purpose-built MATLAB interface. All loudspeakers were placed equidistantly on a circle with a radius of 1 m and connected to a desktop computer inside a control room via two RME ADI-8 DS analog-to-digital converters and a RME fireface USB sound card. The participants were wearing a lapel microphone connected to a high-quality intercom to communicate with the experimenter inside the control room. The participants were seated in the center of the loudspeaker array facing the frontal (0°) loudspeaker with their ears at the height of the loudspeakers. The target questions were always presented from the frontal loudspeaker.
Three different noise conditions were created: (a) two speech discourses presented from the loudspeaker in front of the listener (the co-located condition), (b) two speech discourses presented from the side of the first-implanted ear (loudspeaker either at −90° or +90°), that is, the ear with the unilateral CI (the spatially asymmetric condition), and (c) one speech discourse presented from the left side (loudspeaker at −90°) and one from the right side (loudspeaker at +90°) of the listener (the spatially symmetric condition). The two speech discourses were realized by a male and a female native Japanese talker reading different 5-min-long popular children stories. The mean fundamental frequency (±1 standard deviation) was 108 (±21) Hz for the male talker and 239 (±41) Hz for the female talker; both talkers spoke with a rather slow speech rate of about 3.5 Hz, as calculated by the main maximum of their speech modulation spectrum. The discourses were recorded, processed, and RMS level normalized in the same way as the Helen questions described earlier. In every noise condition, two SCTs were measured and averaged. Within the spatially symmetric noise condition, the first SCT was measured with the female distractor on the left and the male distractor on the right side of the listener and the second SCT with interchanged distractor locations. The different noise conditions are illustrated in Figure 1.
Figure 1.
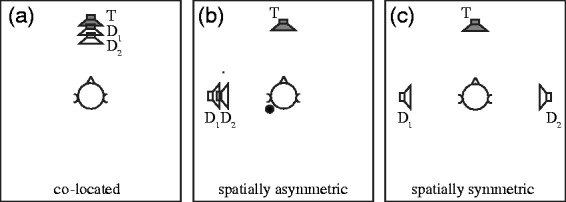
(a to c) The three different noise conditions applied in the speech comprehension test. The target source is indicated by the gray-filled loudspeakers and noise sources are indicated by the open loudspeakers. Note that the spatially asymmetric condition shown in panel (b) represents the case when the left ear is tested in the unilateral condition (as indicated by the dot) and needs to be mirrored for the right ear. T = Target speech; D = speech distractor.
Procedure
SCTs were adaptively measured with a one-up one-down procedure using up to 32 questions in the presence of the three different background noises described earlier. The questions were organized in four successive blocks of eight questions each, with the order of the questions in each block randomized. Each block was generated by randomly selecting one question from each of the eight categories. The different background noises were presented continuously at a constant intensity of 60 dB SPL for all participants except one. Participant S4 could not tolerate 60 dB SPL and hence the intensity was reduced to 50 dB SPL in 5 dB steps until the participant reported it to be comfortable.
Participants were instructed to first repeat the question before providing the answer verbally, but only the answers were considered in the adaptive procedure. The repetition of the question was mainly to monitor if subjects had problems with answering even though they repeated the question correctly. This could have indicated a cognitive problem and would have disqualified the listener from this study. For all listeners, these errors were extremely rare. The SCT was defined as the SNR at which the listener could answer the questions correctly at least 50% of the time. To obtain SCTs, the adaptive track started with an SNR of 10 dB and the target level was varied with a step-size of 4 dB. When at least five questions were answered and an upward reversal occurred, the measurement phase started wherein the step-size was reduced to 2 dB. The SCT was then calculated as the mean value of all SNRs that were tested during the measurement phase. An adaptive track finished when all 32 questions were presented or when the standard error was below 1 dB and at least 17 questions were presented during the measurement phase. Each SCT was repeated once and the average was calculated as well as the test–retest accuracy. If the two SCTs differed by more than 4 dB, a third SCT was measured and the closest two SCTs were averaged. All the responses given by the subjects were translated by a Japanese translator and were scored by the experimenter.
All measurements were done with CIs in both ears (bilateral condition) as well as with only one CI in the first implanted ear (unilateral condition). For all subjects except S1, the first implanted ear was also the preferred ear. The speech comprehension testing was conducted over two consecutive days and each subject took about 1 to 1.5 hours/day. All conditions were measured once on the first day and repeated on the second day. On each day, measurements were done in two blocks with bilateral conditions first and unilateral conditions after an extensive break. Within each block, the order of the conditions was randomized. Before any testing started, the procedures were explained to the participants and practiced until they felt comfortable with it. Also, prior to any testing, loudness balancing was done for each participant to ensure that the perceived loudness was equal across the two ears. This was achieved by changing the volume and sensitivity control of the CIs. Since the study focused on measuring the spatial benefit provided by the auditory system, any adaptive noise suppression or directional features such as SCAN were turned off.
Sound Localization
Stimuli
The subject’s ability to localize speech was tested using 15 s long segments of speech, which were extracted from the original 5 min of discourse used in the speech comprehension test and recorded with a male and a female native Japanese talker. The male and female talkers were either presented individually (one-talker condition) or simultaneously (two-talker condition) in randomized order at a constant level of 60 dB SPL. Two different genders were applied here to provide a unique identification of the two sources within the localization task. However, this inherently assessed also the accuracy of the subjects to identify the individual talkers (or voice genders).
The participants were seated in the center of a three-dimensional (spherical) loudspeaker array with a radius of 1.85 m located inside the anechoic chamber of the Australian Hearing Hub. The array consisted of 41 Tannoy V8 loudspeakers that were controlled by a desktop computer with an RME MADI PCI sound card located outside the anechoic chamber. The loudspeakers were connected to the sound card via two RME M-32 digital-to-analog converters and 11 Yamaha XM4180 amplifiers. Only 13 loudspeakers were used in this study (see highlighted buttons in Figure 2): nine loudspeakers in the frontal horizontal plane (at azimuth angles from −90° to +90° with an angular spacing of 22.5°), three loudspeakers in the horizontal plane behind the subject (at −135°, +135°, and 180°), and one loudspeaker directly above the subject at an elevation angle of 90°.
Figure 2.

Graphical user interface for the localization and voice gender identification experiment provided to the subjects on a handheld touch screen (iPad). The highlighted loudspeaker and listener buttons indicate the 13 source directions that were tested.
Procedure
The participants were seated such that the head was in the centre of the loudspeaker array and facing the frontal loudspeaker (0°). They were asked to wear a small lapel microphone in order to be heard clearly by the experimenter who was seated outside the chamber with headphones on. The experimenter monitored participants via a webcam to ensure they maintained a fixed-head position and could talk to them via an intercom when required. All subjects were aware that they may hear either one or two talkers, but within each trial, no information on the number of presented talkers was provided. The participant’s task was to indicate both the direction and gender of the talker(s) on a handheld touch screen (iPad) with the user interface shown in Figure 2.
Touching any of the 16 loudspeaker buttons or the subject button (to indicate the elevated loudspeaker) once turned the button red to indicate a female talker from the corresponding loudspeaker direction. Touching the button twice turned it blue to indicate a male talker. Touching the button 3 times turned the button half blue and half red to indicate a male and female talker from the same direction. Touching the button 4 times reset the button. The participants were able to respond as soon as they heard the stimuli and had additional 5 s before the next stimulus was presented. At any time, they could move to the next condition by touching the start button.
The number of trials completed was shown by a counter in the left part of the user interface. The user interface was programmed in MATLAB and controlled from the computer outside the anechoic chamber, which was connected to the iPad via WiFi and the Splashtop software. The interface was either controlled by fingers or a stylus pen as preferred by the participant. The experimental procedure was described to the participants at the beginning of the experiment by a written information sheet as well as by verbal communication with the experimenter and interpreter.
Prior to commencing the experiment, each participant performed a number of familiarization trials until they and the experimenter were both confident that they understood the task. Each of the 13 possible directions (i.e., the loudspeaker locations described above and highlighted in Figure 2) was tested 5 times in the single-talker condition and 10 times in the two-talker condition, resulting in 130 two-talker items (65 male and 65 female) and 65 single-talker items (33 male and 32 female). Therefore, for each direction, this resulted in two to three trials per gender in the single-talker condition and five trials per gender in the two-talker condition. Within the two-talker condition, the talker directions were randomly combined, which resulted in five trials in which the two talkers were presented from the same (randomly chosen) loudspeaker. All 130 trials were randomized and measured in both a bilateral condition as well as in a unilateral condition.
Results
Speech Comprehension in Noise
Figure 3 shows the individual SCTs obtained for all seven participants across the three different noise configurations in the unilateral (left panel) and bilateral (right panel) conditions. Since the SCTs of Subject 4 (left-pointing triangles), in particular in the bilateral conditions, were largely affected by fatigue effects, the corresponding data were considered unreliable and were therefore excluded (as indicated by the round brackets) from the mean values shown in Figure 3 (filled circles) as well as the subsequent speech comprehension data analysis. Many of the adaptive tracks of this subject showed variations of more than 20 dB which did not necessarily improve after taking extensive breaks.
Figure 3.

Mean and individual SCTs obtained in the three different background noise configurations in the unilateral (left panel) and bilateral (right panel) condition. The data of Subject 4 (left-pointing triangles in round brackets) is neither considered in the mean value (solid circles) nor in the subsequent statistical analysis. Col = co-located; SA = spatially asymmetric; SS = spatially symmetric.
As described in the Methods section, the individual SCTs shown in Figure 3 were averaged over two measurements. Additionally, test–retest variability was calculated by subtracting the second from the first SCT measurement and the resulting mean and intrasubject standard deviations are summarized in Table 2. Mean values were within ±1 dB and a paired t-test revealed no significant differences (p > .05) for all conditions. The intrasubject standard deviation was less than 1.5 dB for the bilateral conditions and increased to up to 3 dB for the unilateral conditions. The intrasubject standard deviation in the bilateral conditions was very similar to the one of more common sentence tests, as for instance reported by Keidser, Dillon, Mejia, and Nguyen (2013) for the BKB sentence test, indicating a sufficient test–retest reliability of the applied speech comprehension test.
Table 2.
Mean Differences Between the First and Second SCT Measurement and Corresponding Intrasubject Standard Deviation (STD).
| CIs | Co-located | Spatially asymmetric | Spatially symmetric | |
|---|---|---|---|---|
| Mean difference | Unilateral | −0.13 dB | 0.52 dB | 0.52 dB |
| Bilateral | 0.56 dB | 0.97 dB | 0.8 dB | |
| Intrasubject STD | Unilateral | 3.03 dB | 2.73 dB | 1.22 dB |
| Bilateral | 0.90 dB | 1.48 Db | 1.36 dB |
CI = cochlear implant; SCT = speech comprehension threshold.
A two-way, repeated measures analysis of variance with noise configuration and listening mode as independent variables revealed a significant main effect of listening mode, F(1, 5) = 44.82, p = .001, but not of noise configuration, F(2, 10) = 0.72, p = .51. A significant interaction between noise configuration and listening mode was also observed, F(2, 10) = 21.18, p < .01. Within the unilateral mode, a paired t-test with adjusted p-values (Holm, 1979) revealed a significant difference between the co-located and spatially asymmetric SCTs (p < .001), but neither between the co-located and spatially symmetric SCTs (p = .82) nor between the spatially symmetric and spatially asymmetric SCTs (p = .06). Within the bilateral mode, no significant differences were found for any of the three SCT comparisons (p > .05).
To investigate if the relative performance between subjects was consistent across all noise conditions, an interclass correlation analysis in terms of consistency was applied using a two-way model (McGraw & Wong, 1996). The resulting intraclass correlation coefficient (ICC) indicated a consistent subject effect, with ICC = 0.87 for the unilateral conditions, ICC = 0.91 for the bilateral conditions, and ICC = 0.94 for the unilateral and bilateral conditions combined. Hence, subjects performed either consistently well or consistently poorly across all conditions.
In Figure 4, a number of performance measures are shown that were derived from the individual SCT data shown in Figure 3. The left panel shows the spatial benefit (or SRM) that is achieved when the two distracting talkers are spatially separated from the target speech; this measure is derived by subtracting the individual SCTs measured in the spatially separated condition(s) (Figure 1(b) and (c)) from the individual SCTs measured in the co-located condition (Figure 1(a)). To analyze the significance of the SRM observed in the different conditions, a paired t-test with adjusted p-values (Holm, 1979) was applied to compare the SCTs in the co-located and spatially separated conditions. For the spatially asymmetric noise, a significant negative SRM (i.e., a disadvantage) of, on average, −4 dB was found in the unilateral condition (p < .001). In the bilateral condition, the observed SRM of, on average, 2.7 dB was not significant (p = .03). For the spatially symmetric noise, the SRM was neither significant in the unilateral nor in the bilateral condition (p > .05).
Figure 4.
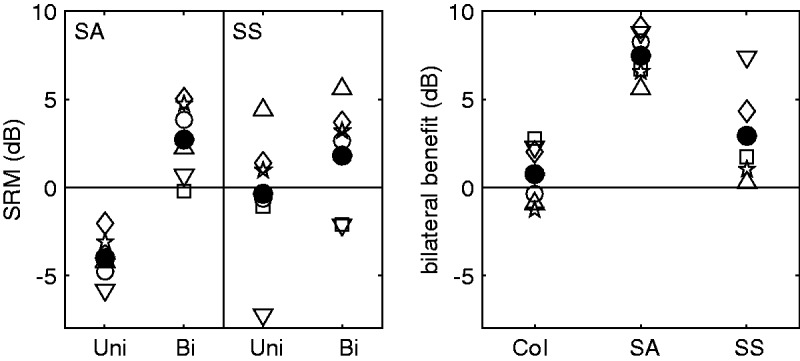
Mean and individual SRM (left panel) as well as the bilateral benefit obtained in the three different background noise configurations (right panel). Data of Subject 4 are not considered here. Col = co-located; SA = spatially asymmetric; SS = spatially symmetric; Uni = unilateral CIs; Bi = bilateral CIs.
The right panel of Figure 4 shows the bilateral benefit for all three noise conditions, which was calculated by subtracting the individual SCTs measured in the bilateral conditions from the corresponding SCTs measured in the unilateral conditions. The bilateral benefit directly quantifies the advantage in speech comprehension that is provided by two CIs over one CI. To analyze the significance of the bilateral benefit, a paired t-test with adjusted p-values (Holm, 1979) was applied to compare bilateral with unilateral SCTs. A significant bilateral benefit of, on average, 7.5 dB was found for the spatially asymmetric noise condition (p < .01). Neither the bilateral benefit in the spatially symmetric noise condition of, on average, 3 dB nor the bilateral benefit in the co-located condition of, on average, 0.8 dB was significant (p > .01).
Sound Localization
Most subjects were very accurate in identifying the number of talkers (i.e., one or two) that were presented within each trial (error rate < 1%). Only Subjects s2, s3, and s5 wrongly estimated the number of talkers in the beginning of their first experiment (bilateral condition), which was most likely due to initial problems with handling the user interface. These trials were disregarded in the following analysis. The gender of the talker(s) was correctly identified by all subjects in at least 98.5% of the trials, confirming that all subjects were able to utilize the voice-gender identity within the two-talker localization task. In the unilateral condition, all subjects except Subject s1 (with 10.9 s) spent the entire available time of 20 s to provide their responses. In the bilateral condition, Subject s1, s3, and s6 had significantly shorter average response times than in their unilateral condition with 6.5, 10.6, and 13.3 s. This indicates that at least for these three subjects, providing a second CI made the localization task easier. Only Subject s1 and s7 managed to correctly identify when a talker was presented from the elevated loudspeaker with a sufficient reliability, that is, achieving sensitivity values between d ′ = 1.3 and d ′ = 2.5. However, they were only able to do that in the bilateral condition.
Horizontal localization performance varied strongly between subjects but always improved when a second CI was applied, indicating a clear bilateral benefit in localization. Example response patterns for two subjects (s1 and s7) are shown in Figure 5 for the unilateral (left panels) as well as the bilateral (right panels) condition. Response directions are plotted against the presentation directions for each of the 130 trials indicated by a circle. To avoid circles masking each other due to the discretization of the presented and responded directions (the angular resolution was 22.5°), the presented directions were shifted horizontally in Figure 5 within the white-and-gray shaded areas. In the unilateral condition, Subject s1 showed a rather large variation in the responses but somehow managed to utilize the entire horizontal plane. In contrast, Subject s7 localized all the presented sources in the direction of the left ear where the unilateral CI was fitted. Localization performance clearly improved in both subjects when a second CI was fitted. However, the response pattern across the horizontal plane was very different between subjects. Whereas Subject s1 still showed rather poor localization performance for directions to the side and back, Subject s7 was rather accurate across the entire horizontal plane. The data of the other subjects followed either type of pattern and are not shown here due to space limitations.
Figure 5.

Horizontal localization performance for two example subjects (s1 and s7) for the unilateral (left panels) as well as the bilateral condition (right panels). The circles indicate individual trials and are shifted horizontally within the gray-and-white shaded area for clarity.
Even though front-back confusions were apparent in all subjects’ responses (see responses around the dashed diagonal lines in Figure 5), the large overall RMS error observed in particular in the unilateral conditions made it impossible to reliably segregate front-back confusions from actual localization errors. Hence, front-back confusions were not further considered here. To quantify the localization performance in the horizontal plane, the RMS localization error was therefore applied as given by
| (1) |
where N is the total number of considered items (i.e., individual talker directions), ηi is the presented azimuth angle in radians of item i, and φi is the corresponding responded azimuth angle. The number of the considered items (or scoring units) N depended on whether one or two simultaneous talkers were presented and whether male and female talkers were evaluated separately or together. The RMS error disregards front-back confusions by “folding” the directions behind the participants to the front. The individual RMS errors are shown in Figure 6 averaged across the male and female talker but separately for the one-talker and two-talker condition. The unilateral results are indicated by open symbols and the bilateral results by filled symbols.
Figure 6.

Individual RMS localization errors are shown for the unilateral (open symbols) and the bilateral (filled symbols) condition, with the data for the single-talker condition plotted on the left and for the two-talker condition on the right of the dashed lines. In each condition, the RMS errors were averaged across the male and female voices.
The average RMS error (±1 standard deviation) was 4.2° (±8.5°) lower for the one-talker than for the two-talker condition and, even though not shown here, 4.2° (±8.5°) lower for the male than for the female talker. However, a paired t-test neither found the effect of the number of talkers significant nor the effect of their gender (p > .05). Hence, in the following analysis, the RMS error was combined across the male and female talker as well as across the one-talker and two-talker condition.
The RMS error is improved by, on average, 27° when a second implant is fitted, but this improvement (or bilateral benefit) varied strongly between subjects, that is, between 9° for Subject s3 and 68° for Subject s7. The variation of the localization performance between subjects was significantly smaller in the bilateral condition than in the unilateral condition, with an intersubject standard deviation of 9.4° in the unilateral and 19° in the bilateral condition. This was largely due to Subjects s1, s6, and s7, who received a much larger bilateral benefit than the other four subjects.
To get an indication whether the individual performances in the speech comprehension and localization tasks are limited by similar processes within the implanted ear, the individual RMS localization errors were correlated with the individual SCTs measured in the spatially separated noise conditions. However, none of the correlations were significant (p > .05). This result was a bit surprising, because it was expected that by adding a source segregation component into the localization task (i.e., by introducing a second, spatially separated talker), the addressed auditory processes would become more similar to the ones involved in the speech-in-noise task, in particular for the spatially symmetric masker. However, the nonsignificant correlation may be explained by the rather small number of subjects.
Discussion
Speech Comprehension in Noise
The performance in speech comprehension varied strongly between subjects with an average intersubject standard deviation of about 5.3 dB in the bilateral and 4.7 dB in the unilateral condition (see Figure 3). In contrast, the intrasubject standard deviation between repeated measures was on average only 1.3 dB in the bilateral conditions and 2.3 dB in the unilateral conditions. Hence, the differences between subjects were strongly influenced by the differences in individual performance. As a consequence, the intersubject standard deviation of the performance measures that were based on within-subject differences were strongly reduced (see Figure 4), with an average intersubject standard deviation of 2.6 dB in SRM and 3.3 dB in bilateral benefit. This was further confirmed by the intraclass correlation analysis described in the Results section, which revealed that the large intersubject variability was due to a consistent subject effect, that is, subjects performed either consistently well or consistently poorly across all noise conditions as well as listening modes (i.e., unilateral vs. bilateral).
The differences in SCTs between the co-located and spatially separated conditions (i.e., the SRM) as well as the differences between the bilateral and unilateral conditions (i.e., the bilateral benefit) are discussed in the following sections.
Spatial release from masking
SRM is defined here as the individual SCTs measured in the co-located two-talker noise conditions minus the SCTs measured in either of the two spatially separated two-talker noise conditions. In the case that the two-talker noise was presented only from the side of the listener with the first-implanted ear, that is, the spatially asymmetric condition (Figure 1(b)), a nonsignificant SRM of, on average, 2.7 dB was observed in the bilateral condition and a significant (negative) SRM, on average, of −4 dB in the unilateral condition. The SRM observed in the bilateral condition was due to head shadow improving the SNR at the ear contralateral to the interferer, that is, the “better ear.” In the unilateral condition, the CI was fitted only to the ear ipsilateral to the interferer, that is, the ear with the poorer SNR. The (nonsignificant) SRM of 2.7 dB that was observed in the bilateral condition was much smaller than the SRM of about 7 to 9 dB that is typically observed in such spatially asymmetric conditions in normal-hearing listeners, which to some extent, depends on the type of masker that is applied (e.g., Misurelli & Litovsky, 2012; Hawley, Litovsky, & Culling, 2004; Arbogast, Mason, & Kidd, 2002). However, the observed spatial benefit is in agreement with studies that investigated SRM in similar asymmetric conditions in bilateral adult CI users. Loizou et al. (2009) found an SRM of about 4 dB when a three-talker interferer is used, van Hoesel and Tyler (2003) found an SRM of about 4 dB when a speech-shaped noise masker is used, and Kokkinakis and Pak (2013) found an SRM of about 2 to 4 dB when a four-talker babble is used.
In the case that one distracting talker was presented from the left and one from the right side of the listener, that is, the spatially symmetric condition (Figure 1(c)), an average SRM of 1.8 dB was observed in the bilateral condition and −0.4 dB in the unilateral condition. However, both effects were not significant (p > .05). Considering the small number of subjects that were tested and the rather large spread of the individual SRM data both in the unilateral (i.e., from −7.2 dB to 4.4 dB) and bilateral condition (i.e., from −2.1 dB to 5.6 dB), it may still be that at least some bilateral CI users were able to take advantage of the fluctuating SNR, either by within-ear glimpsing or better-ear glimpsing (i.e., providing a release from energetic masking), or by utilizing ILDs to perceptually segregate the target talker from the interfering talkers (i.e., providing a release from IM). Either way, the resulting SRM is much smaller than the SRM of more than 7 dB that is observed in normal-hearing listeners in similar conditions (e.g., Brungart & Iyer, 2012; Glyde, Buchholz, Dillon, Best, et al., 2013). To the best knowledge of the authors, SRM in a spatially symmetric two-talker noise has not been investigated before in bilateral adult CI users. However, there are a few relevant studies in children, which also did not find any significant SRM but showed smaller average values than observed here of between −2 and 1 dB (Misurelli & Litovsky, 2012, 2015). However, these results cannot be directly compared with the present study, because the detailed procedures and stimuli were very different and moreover, the SRM that is observed in, at least, normal-hearing children is generally smaller than in adults (Cameron, Glyde, & Dillon, 2011). Since bilateral CI recipients in the spatially symmetric condition need to integrate information across ears, this condition may be particularly sensitive to differences in both the loudness matching and the frequency mapping between ears (due to differences in electrode placement) as well as the distortion of the relevant ILD cues by the nonlinear and independently operating devices. These differences may at least partly explain the large intersubject variability of the SRM observed in the spatially symmetric noise condition. Future studies should therefore investigate how these (and other) factors influence SRM in speech mixtures and find solutions to maximize it.
Bilateral benefit
The bilateral benefit was calculated here as the individual SCTs measured in the unilateral condition minus the SCTs measured in the corresponding bilateral condition, which was separately derived for all three background noises (see Figure 4, right panel). A significant bilateral benefit of, on average, 7.5 dB was observed in the spatially asymmetric noise condition and a nonsignificant bilateral benefit of, on average, 3 dB in the spatially symmetric noise condition. The small bilateral benefit seen in the co-located condition of about 0.8 dB was also not significant. The large bilateral benefit of around 7.5 dB seen in the spatially asymmetric condition is in general agreement with other studies with bilateral CI users, who, dependent on the type of masker, reported bilateral benefits of 5 to 7 dB (e.g., Kokkinakis & Pak, 2013; Litovsky, Parkinson, Arcaroli, & Sammeth, 2006; Schleich, Nopp, & D'Haese, 2004). The observed benefit mainly reflects the SNR difference between the ear ipsilateral to the masker (the “poor ear”) and the ear contralateral to the masker (the “better ear”). In the unilateral condition, the CI users had only access to the “poor ear,” whereas in the bilateral condition, the CI users had also access to the “better ear.”
The mean bilateral benefit of 3 dB that was observed in the spatially symmetric two-talker noise condition was either due to the increased availability of glimpses (within ear or between ear) or due to improved perceptual segregation of the target talker and the interfering talkers. Even though this effect was nonsignificant (p > .01), the individual data showed a substantial range of benefits from 0 to 7 dB. Although the underlying auditory mechanisms are not fully understood, the present results therefore suggest that at least some CI users can receive a substantial bilateral benefit in spatially symmetric speech mixtures where neither ear provides a consistent SNR advantage. Future studies should therefore further investigate the underlying auditory mechanisms and find solutions that optimize the resulting benefit in bilateral CI users.
The small but not significant bilateral benefit of about 0.8 dB that was observed in the co-located two-talker noise condition is consistent with other CI studies that compared bilateral with unilateral performance in the preferred ear (e.g., Laske et al., 2009; Loizou et al., 2009; van Hoesel & Tyler, 2003) as well as with studies with normal-hearing listeners (Bronkhorst & Plomp, 1989; Hawley et al., 2004; MacKeith & Coles, 1971).
Sound Localization
The main novelty of the applied localization test was the inclusion of a two-talker localization task, which was expected to improve the ecological validity of the results. In this regard, it was surprising that the subjects’ localization performance in the two-talker condition was only slightly (on average 4.2°) worse than in the one-talker condition. Since the subjects in the two-talker condition had not only to localize but also to segregate the two simultaneous talkers, it was expected that the performance would be substantially worse than in the single-talker condition. However, the observed similarity in the RMS errors highlights the fact that none of the subjects had difficulties in segregating the two simultaneous talkers, which may be an interesting observation on its own. However, the similarity in performance may have been due to the rather long speech segments of 15 s that were provided in this task, which may have allowed the subjects to localize one talker at a time. The results may have been different if shorter speech stimuli were applied, such as the sentences used in the speech comprehension task. Moreover, the rather large angular separation of 22.5° of the applied loudspeakers may have further contributed to the negligible differences in performance. Given the nonsignificant effect of number of talkers (as well as the gender of the talker), only the RMS error averaged over number and gender of talkers was further analyzed.
Localization performance in the horizontal plane was found to be consistently poor for all subjects in the unilateral condition with a mean RMS error of 68° and an intersubject standard deviation of 9.4°. Considering other studies that utilized the entire horizontal plane in the localization experiment, that is, that applied a loudspeaker array span of 360°, the observed RMS error is much lower than commonly reported with mean values of around 90° (e.g., Laszig et al., 2004; Neuman, Haravon, Sislian, & Waltzman, 2007). Similar low RMS errors of around 50° to 70° have only been reported for loudspeaker array spans that are 180° or less (e.g., van Hoesel, 2012). The difference may be due to the possible benefit of slight head movements, the rather long speech signals of up to 15 s duration that were applied here, which gave the listeners much more time to make their decisions than given in previous studies, or the rather wide loudspeaker spacing of 22.5°. Considering the example localization pattern shown in Figure 6 (left panels), which were representative for most subjects, it can be deduced that the large RMS errors seen in the unilateral condition were either from subjects providing rather random localization responses (a) or from subjects mainly localizing sources at their unilateral ear (c).
The overall performance for all subjects improved substantially in the bilateral condition with a resulting mean RMS error of 40.7° and a mean bilateral benefit of 27.7°. However, at the same time, the intersubject standard deviation increased from 9.4° to 19°, indicating that some subjects received larger bilateral benefits than others. Considering the individual RMS errors shown in Figure 6 (left panel), it can be deduced that the increased intersubject variation in the bilateral condition was mainly due to three subjects (s1, s6, and s7) that received a much larger bilateral benefit of, on average, 46.3° than the other four subjects with 12.9°. The resulting mean RMS errors for these two groups were 21° and 55.5°. The RMS error and the individual differences are in good agreement with Laszig et al. (2004), who found for a loudspeaker array span of 360° an average RMS error of about 50°. However, the first group showed RMS errors that have only been reported for loudspeaker array spans of less than 90° (e.g., van Hoesel, 2012). Nevertheless, the present study is in general agreement with the existing literature, in that horizontal localization performance is substantially improved when a second CI is provided. Considering the example localization pattern shown in Figure 5 (right panels), some subjects were able to equally well localize sound sources over the entire horizontal plane (panel d) and others showed rather good performance in the front of the listener that then deteriorated towards the side of the listener (panel b). The behaviour seen in Figure 5(b) can most likely be explained by the broadband ILD function, which exhibits larger changes with direction for frontal sources than for lateral sources (van Hoesel, 2004). The behavior seen in Figure 5(d) may suggest that subjects are able to utilize frequency-specific ILD cues for localization (e.g., van Hoesel, 2012).
Even though it was not the main goal of this study, the applied localization task also showed that subjects were able to reliably determine the number of talkers, with an error rate of less than 1%, and also to identify their gender, with an error rate of less than 1.5%. Existing studies on gender identification typically found by far higher error rates in CI users of between 5% and 56% (e.g., Fu, Chinchilla, & Galvin, 2004; Kovacic & Balaban, 2009; Massida et al., 2013). However, the applied listening tasks were very different, stimuli durations were much shorter, the talker differences (e.g., fundamental frequency, formant frequencies, spectrum) were smaller and often manipulated using speech transformation software, and the number of options (i.e., talkers) was larger. In particular, the fact that only two different talkers were applied here may have allowed the CI users to utilize cues that are not directly related to talker gender identification.
Finally, it should be mentioned that in the bilateral condition two out of the seven subjects were able to rather reliably detect when speech was presented from the (elevated) loudspeaker above the subject. Since the spectral cues that are relevant for elevation perception are very subtle (e.g., Blauert, 1997), it is rather unlikely that these subjects were actually able to localize the elevated source. It is more likely that the subjects interpreted the ambiguous ILD cues together with some (learned) broad spectral or level cues as an indicator that the source could not come from the horizontal plane, leaving the loudspeaker above the only remaining option. The latter is in general agreement with Majdak, Goupell, and Laback (2011) who found that, within the vertical plane, CI users were only able to identify the correct hemifield (and not localize within a hemifield) which was mainly achieved by using level rather than spectral cues. Additionally, small head movements may have helped localizing the elevated loudspeaker.
Conclusions
The present study confirmed that a second CI provides a clear (bilateral) benefit over only one device for the understanding of speech in noise as well as the localization of sounds. The largest bilateral advantage in speech intelligibility of about 7.5 dB was observed when a two-talker distractor was presented from the side of the listener that was ipsilateral to the unilateral CI and target speech was presented from the front. In this case, the bilateral benefit was mainly due to the better (long term) SNR provided by head shadow at the contralateral ear, and is in good agreement with existing literature. On the one hand, this agreement confirms the validity of the applied comprehension task, which is different from the more commonly applied sentence/word recall task, but on the other hand, it suggests that the realism added by the comprehension task did not affect the outcomes. However, this may be different for other noise conditions or for other types of comprehension measures (e.g., Best, Keidser, et al., 2016), which should be further evaluated in the future.
A novel finding was the bilateral advantage (of, on average, 3 dB) that was seen with a spatially symmetric two-talker interferer, where one talker was presented from the left and another talker from the right side of the listener. Even though the effect was not significant, some subjects showed a bilateral benefit of up to 7 dB. Since the long-term SNR at the two ears was identical in this condition, the benefit provided by the second CI was either due to glimpsing (within or across ears) or ILD cues providing a perceived (spatial) separation of the different talkers. Moreover, a clear bilateral benefit was also observed in the localization of a single talker as well as of two simultaneous talkers. Thereby, the localization performance in the two-talker condition was only slightly (and not significantly) poorer than in the single-talker condition, suggesting that the stream segregation processes that were inherently involved in the two-talker condition did not play a major role. This rather surprising result may have been due to some methodical details that should be improved in future studies.
Even though the performance in localization as well as speech intelligibility in noise was improved by a second CI, the overall performance, as well as the benefit provided by the second device, was still significantly poorer than generally observed in normal-hearing listeners. There are a number of well-known reasons for this discrepancy, including differences in the spectral maps between the left and right ear (due to differences in electrode placement), loudness differences between ears, limited temporal and spectral resolution, insufficient temporal fine-structure coding of ITDs as well as pitch, and independently operating devices. Even though these issues may be largely resolved by adequate technologies, implantation techniques, and fitting procedures, the subsequent neural auditory pathway may also be different between ears and further disrupt binaural processing, which may be improved by adequate training procedures.
Future studies should further investigate the SRM observed in spatially symmetric speech-on-speech masking and develop methods that maximize its benefit in CI users. Moreover, it is unclear how far the current findings, as well as the findings reported in the existing literature, reflect the performance experienced in real life. Therefore, future measures of localization and speech intelligibility need to consider more realistic environments, including room reverberation, background noise, and multiple talkers at different distances and head orientations. Moreover, the applied tasks need to be more realistic, address more cognitive processes, and provide visual cues as well as context information. For instance, speech comprehension may be measured by asking subjects to answer questions while listening to monologues or dialogues in a noisy environment (e.g., Best, Streeter, Roverud, Mason, & Kidd, 2016); and localization in quiet may be replaced by measures of auditory spatial awareness (e.g., Brungart, Cohen, Cord, Zion, & Kalluri, 2014; Weller, Buchholz, & Best, 2016). Finally, to draw stronger conclusions about the investigated processes within the implanted ears, the statistical power needs to be improved by applying more subjects.
Author's Note
Aspects of this work were presented at the 5th Joint Meeting, Acoustical Society of America and Acoustical Society of Japan (Honolulu, Hawaii, 2016). The National Acoustics Laboratories and Cochlear Ltd. are part of the Australian Hearing Hub, an initiative of Macquarie University that brings together Australia’s leading hearing and healthcare organizations to collaborate on research projects.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors acknowledge the financial support of Macquarie University through an international research excellence (iMQRES) scholarship and the Australian National Health and Medical Research Council (NHMRC) via grant APP1056332.
References
- Arbogast T. L., Mason C. R., Kidd G., Jr. (2002) The effect of spatial separation on informational and energetic masking of speech. The Journal of the Acoustical Society of America 112(5): 2086–2098. [DOI] [PubMed] [Google Scholar]
- Aronoff J. M., Freed D. J., Fisher L. M., Pal I., Soli S. D. (2012) Cochlear implant patients’ localization using interaural level differences exceeds that of untrained normal hearing listeners. The Journal of the Acoustical Society of America 131(5): EL382–EL387. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Best V., Mason C. R., Kidd G., Jr., Iyer N., Brungart D. S. (2015) Better-ear glimpsing in hearing-impaired listeners. The Journal of the Acoustical Society of America 137(2): EL213–EL219. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Best V., Streeter T., Roverud E., Mason C. R., Kidd G., Jr. (2016. a) A flexible question-and-answer task for measuring speech understanding. Trends in Hearing 20 . doi:10.1177/2331216516678706. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Best V., Keidser G., Buchholz J. M., Freeston K. (2016. b) Development and preliminary evaluation of a new test of ongoing speech comprehension. International Journal of Audiology 55(1): 45–52. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blauert J. (1997) Spatial hearing: The psychoacoustics of human sound localization (revised edition), Cambridge: The MIT Press. [Google Scholar]
- Bronkhorst A. W., Plomp R. (1988) The effect of head-induced interaural time and level differences on speech intelligibility in noise. The Journal of the Acoustical Society of America 83(4): 1508–1516. [DOI] [PubMed] [Google Scholar]
- Bronkhorst A. W., Plomp R. (1989) Binaural speech intelligibility in noise for hearing-impaired listeners. The Journal of the Acoustical Society of America 86(4): 1374–1383. [DOI] [PubMed] [Google Scholar]
- Bronkhorst A. W. (2000) The cocktail party phenomenon: A review of research on speech intelligibility in multiple-talker conditions. Acta Acustica United With Acustica 86: 117–128. [Google Scholar]
- Brungart D. S., Iyer N. (2012) Better-ear glimpsing efficiency with symmetrically-placed interfering talkers. The Journal of the Acoustical Society of America 132(4): 2545–2556. [DOI] [PubMed] [Google Scholar]
- Brungart D. S., Cohen J., Cord M., Zion D., Kalluri S. (2014) Assessment of auditory spatial awareness in complex listening environments. The Journal of the Acoustical Society of America 136: 1808–1820. [DOI] [PubMed] [Google Scholar]
- Buss E., Pillsbury H. C., Buchman C. A., Pillsbury C. H., Clark M. S., Haynes D. S., Novak M. A. (2008) Multicenter US bilateral MED-EL cochlear implantation study: Speech perception over the first year of use. Ear and Hearing 29(1): 20–32. [DOI] [PubMed] [Google Scholar]
- Cameron S., Glyde H., Dillon H. (2011) Listening in spatialized noise—Sentences test (LISN-S): Normative data and retest reliability data for adolescents and Adults up to 60 years of age. The Journal of the American Academy of Audiology 22: 697–709. [DOI] [PubMed] [Google Scholar]
- Cherry E. C. (1953) Some experiments on the recognition of speech, with one and with two ears. The Journal of the Acoustical Society of America 25(5): 975–979. [Google Scholar]
- Cooke M. (2006) A glimpsing model of speech perception in noise. The Journal of the Acoustical Society of America 119: 1562–1573. [DOI] [PubMed] [Google Scholar]
- Dillon H. (2012) Hearing aids, 2nd ed Sydney, Australia: Boomerang Press. [Google Scholar]
- Dunn C. C., Tyler R. S., Oakley S., Gantz B. J., Noble W. (2008) Comparison of speech recognition and localization performance in bilateral and unilateral cochlear implant users matched on duration of deafness and age at implantation. Ear and Hearing 29(3): 352. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Durlach N. I. (1963) Equalization and cancellation theory of binaural masking-level differences. The Journal of the Acoustical Society of America 35: 1206–1218. [Google Scholar]
- Freyman R. L., Helfer K. S., McCall D. D., Clifton R. K. (1999) The role of perceived spatial separation in the unmasking of speech. The Journal of the Acoustical Society of America 106(6): 3578–3588. [DOI] [PubMed] [Google Scholar]
- Fu Q. J., Chinchilla S., Galvin J. J. (2004) The role of spectral and temporal cues in voice gender discrimination by normal-hearing listeners and cochlear implant users. Journal of the Association for Research in Otolaryngology 5(3): 253–260. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Glyde H., Cameron S., Dillon H., Hickson L., Seeto M. (2013. a) The effects of hearing impairment and aging on spatial processing. Ear and Hearing 34(1): 15–28. [DOI] [PubMed] [Google Scholar]
- Glyde H., Buchholz J., Dillon H., Best V., Hickson L., Cameron S. (2013. b) The effect of better-ear glimpsing on spatial release from masking. The Journal of the Acoustical Society of America 134(4): 2937–2945. [DOI] [PubMed] [Google Scholar]
- Glyde H., Buchholz J. M., Dillon H., Cameron S., Hickson L. (2013. c) The importance of interaural time differences and level differences in spatial release from masking. The Journal of the Acoustical Society of America 134(2): EL147–EL152. [DOI] [PubMed] [Google Scholar]
- Grantham D. W., Ashmead D. H., Ricketts T. A., Haynes D. S., Labadie R. F. (2008) Interaural time and level difference thresholds for acoustically presented signals in post-lingually deafened adults fitted with bilateral cochlear implants using CIS+processing. Ear and Hearing 29: 33–44. [DOI] [PubMed] [Google Scholar]
- Hawley M. L., Litovsky R. Y., Culling J. F. (2004) The benefit of binaural hearing in a cocktail party: Effect of location and type of interferer. The Journal of the Acoustical Society of America 115(2): 833–843. [DOI] [PubMed] [Google Scholar]
- Holm S. (1979) A simple sequentially rejective multiple test procedure. Scandinavian Journal of Statistics 6(2): 65–70. [Google Scholar]
- Keidser G., Dillon H., Mejia J., Nguyen C. V. (2013) An algorithms that administers adaptive speech-in-noise testing to a specified reliability at selectable points on the psychometric function. International Journal of Audiology 52(11): 795–800. [DOI] [PubMed] [Google Scholar]
- Kelvasa D., Dietz M. (2015) Auditory model-based sound direction estimation with bilateral cochlear implants. Trends in Hearing 19: 1–16. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kidd G., Mason C. R., Richards V. M., Gallun F. J., Durlach N. I. (2007) Informational masking. In: Yost W. A., Popper A. N., Fay R. R. (eds) Auditory perception of sound sources, New York, NY: Springer, pp. 143–189. [Google Scholar]
- Kiessling J., Pichora-Fuller M. K., Gatehouse S., Stephens D., Arlinger S., Chisolm T., von Wedel H. (2003) Candidature for and delivery of audiological services: Special needs of older people. International Journal of Audiology 42(Suppl. 2): S92–S101. [PubMed] [Google Scholar]
- Kokkinakis K., Pak N. (2013) Binaural advantages in users of bimodal and bilateral cochlear implant devices. The Journal of the Acoustical Society of America 135(1): EL47–EL53. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kovacic D., Balaban E. (2009) Voice gender perception by cochlear implanteesa). The Journal of the Acoustical Society of America 126(2): 762–775. [DOI] [PubMed] [Google Scholar]
- Laske R. D., Veraguth D., Dillier N., Binkert A., Holzmann D., Huber A. M. (2009) Subjective and objective results after bilateral cochlear implantation in adults. Otology & Neurotology 30(3): 313–318. [DOI] [PubMed] [Google Scholar]
- Laszig R., Aschendorff A., Stecker M., Müller-Deile J., Maune S., Dillier N., Battmer R. D. (2004) Benefits of bilateral electrical stimulation with the nucleus cochlear implant in adults: 6-month postoperative results. Otology and Neurotology 25(6): 958–968. [DOI] [PubMed] [Google Scholar]
- Litovsky R., Parkinson A., Arcaroli J., Sammeth C. (2006) Simultaneous bilateral cochlear implantation in adults: A multicenter clinical study. Ear and Hearing 27(6): 714. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Loizou P. C., Hu Y., Litovsky R., Yu G., Peters R., Lake J., Roland P. (2009) Speech recognition by bilateral cochlear implant users in a cocktail-party setting. The Journal of the Acoustical Society of America 125(1): 372–383. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ludvigsen C. (1974) Construction and evaluation of an audio-visual test, the Helentest. Scandinavian Audiology Supplementum 3: 67–75. [Google Scholar]
- MacKeith N. W., Coles R. R. A. (1971) Binaural advantages in hearing of speech. The Journal of Laryngology and Otology 85(03): 213–232. [DOI] [PubMed] [Google Scholar]
- Majdak P., Goupell M. J., Laback B. (2011) Two-dimensional localization of virtual sound sources in cochlear-implant recipients. Ear and Hearing 32: 198–208. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Massida Z., Marx M., Belin P., James C., Fraysse B., Barone P., Deguine O. (2013) Gender categorization in cochlear implant users. Journal of Speech, Language, and Hearing Research 56(5): 1389–1401. [DOI] [PubMed] [Google Scholar]
- McGraw K. O., Wong S. P. (1996) Forming inference about some intraclass correlation coefficients. Psychological Methods 1: 30–46. [Google Scholar]
- Megumi I., Fumiai K., Kozo K., Kumiko S., Hidehiko T. (2011) Evaluation of speech perception for cochlear implant users using the Japanese speech recognition test battery “CI-2004.”. Audiology Japan 54(4): 277–284. [Google Scholar]
- Misurelli, S. M., & Litovsky, R. Y. (2012). Spatial release from masking in children with normal hearing and with bilateral cochlear implants: Effect of interferer asymmetry. The Journal of the Acoustical Society of America, 132(1), 380–391. [DOI] [PMC free article] [PubMed]
- Mosnier I., Sterkers O., Bebear J.-P., Godey B., Robier A., Deguine O., Fraysse B. (2008) Speech performance and sound localization in a complex noisy environment in bilaterally implanted adult patients. Audiology and Neurotology 14(2): 106–114. [DOI] [PubMed] [Google Scholar]
- Müller J., Schon F., Helms J. (2002) Speech understanding in quiet and noise in bilateral users of the MED-EL COMBI 40/40+ cochlear implant system. Ear and Hearing 23(3): 198–206. [DOI] [PubMed] [Google Scholar]
- Mussoi B. S., Bentler R. A. (2017) Binaural interference and the effects of age and hearing loss. Journal of the American Academy of Audiology 28(1): 5–13. [DOI] [PubMed] [Google Scholar]
- Nasreddine Z. S., Phillips N. A., Bédirian V., Charbonneau S., Whitehead V., Collin I., Chertkow H. (2005) The Montreal Cognitive Assessment, MoCA: A brief screening tool for mild cognitive impairment. Journal of the American Geriatrics Society 53(4): 695–699. [DOI] [PubMed] [Google Scholar]
- Neuman A. C., Haravon A., Sislian N., Waltzman S. B. (2007) Sound-direction identification with bilateral cochlear implants. Ear and Hearing 28(1): 73–82. [DOI] [PubMed] [Google Scholar]
- Reiss L. A., Eggleston J. L., Walker E. P., Oh Y. (2016) Two ears are not always better than one: Mandatory vowel fusion across spectrally mismatched ears in hearing-impaired listeners. Journal of the Association for Research in Otolaryngology 17(4): 341–356. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schleich P., Nopp P., D'Haese P. (2004) Head shadow, squelch, and summation effects in bilateral users of the MED-EL COMBI 40/40+ cochlear implant. Ear and Hearing 25(3): 197–204. [DOI] [PubMed] [Google Scholar]
- Schön F., Müller J., Helms J. (2002) Speech reception thresholds obtained in a symmetrical four-loudspeaker arrangement from bilateral users of MED-EL cochlear implants. Otology and Neurotology 23(5): 710–714. [DOI] [PubMed] [Google Scholar]
- Seeber B. U., Fastl H. (2008) Localization cues with bilateral cochlear implants. The Journal of the Acoustical Society of America 123: 1030–1042. [DOI] [PubMed] [Google Scholar]
- Shinn-Cunningham B. G. (2008) Object-based auditory and visual attention. Trends in Cognitive Sciences 12: 182–186. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tyler R. S., Gantz B. J., Rubinstein J. T., Wilson B. S., Parkinson A. J., Wolaver A., Lowder M. W. (2002) Three-month results with bilateral cochlear implants. Ear and Hearing 23(1): 80S–89S. [DOI] [PubMed] [Google Scholar]
- Tyler R. S., Dunn C. C., Witt S. A., Noble W. G. (2007) Speech perception and localization with adults with bilateral sequential cochlear implants. Ear and Hearing 28(2): 86S–90S. [DOI] [PubMed] [Google Scholar]
- Van Hoesel R. J. M., Tyler R. S. (2003) Speech perception, localization, and lateralization with bilateral cochlear implants. The Journal of the Acoustical Society of America 113(3): 1617–1630. [DOI] [PubMed] [Google Scholar]
- Van Hoesel R. J. M. (2004) Exploring the benefits of bilateral cochlear implants. Audiology and Neurotology 9: 234–246. [DOI] [PubMed] [Google Scholar]
- Van Hoesel R. J. M. (2012) Contrasting benefits from contralateral implants and hearing aids in cochlear implant users. Hearing Research 288: 300–314. [DOI] [PubMed] [Google Scholar]
- Walden T. C., Walden B. E. (2005) Unilateral versus bilateral amplification for adults with impaired hearing. Journal of the American Academy of Audiology 16(8): 574–584. [DOI] [PubMed] [Google Scholar]
- Weller T., Buchholz J. M., Best V. (2016) A method for assessing auditory spatial analysis in reverberant multi-talker environments. Journal of the American Academy of Audiology 27: 601–611. [DOI] [PubMed] [Google Scholar]