

SUMMARY
Influenza vaccination is the most practical means available for preventing influenza virus infection and is widely used in many countries. Because vaccine components and circulating strains frequently change, it is important to continually monitor vaccine effectiveness (VE). The test-negative design is frequently used to estimate VE. In this design, patients meeting the same clinical case definition are recruited and tested for influenza; those who test positive are the cases and those who test negative form the comparison group. When determining VE in these studies, the typical approach has been to use logistic regression, adjusting for potential confounders. Because vaccine coverage and influenza incidence change throughout the season, time is included among these confounders. While most studies use unconditional logistic regression, adjusting for time, an alternative approach is to use conditional logistic regression, matching on time. Here, we used simulation data to examine the potential for both regression approaches to permit accurate and robust estimates of VE. In situations where vaccine coverage changed during the influenza season, the conditional model and unconditional models adjusting for categorical week and using a spline function for week provided more accurate estimates. We illustrated the two approaches on data from a test-negative study of influenza VE against hospitalization in children in Hong Kong which resulted in the conditional logistic regression model providing the best fit to the data.
Key words: Epidemiology, influenza, influenza vaccines, statistics
INTRODUCTION
Influenza vaccines are unique in requiring annual vaccination for continued protection. The reasons for this are twofold. First, their composition is frequently updated to keep pace with antigenic drift; and second, vaccine-induced immunity rapidly wanes [1]. Moreover, the dominant strain, timing and severity of seasons vary. As a result, the influenza vaccine's effectiveness (VE) may not be constant across seasons and therefore there may be a need for re-estimation each season.
While randomized controlled trials provide the most robust estimates of the efficacy of influenza vaccines, they are not feasible on an annual basis. In contrast, observational studies can easily provide ongoing estimates of influenza VE. Commonly, this is done using data collected through routine surveillance and analysed as a test-negative design study [2]. Using this design, the odds of influenza positivity among the vaccinated are compared to the odds of positivity among the unvaccinated to estimate VE [3].
Although vaccination campaigns are typically timed to precede the start of the influenza season, in some instances the timing of vaccine receipt has overlapped with enrolment; e.g. during the 2009 influenza A(H1N1) pandemic [4]. Thus, both vaccination coverage and influenza incidence can change throughout a season, so time acts as a confounder and should be adjusted for in VE estimation. This is typically achieved by including it as a covariate in a multivariable logistic regression model fitted using unconditional maximum likelihood. The specification of time can vary and it has been included as a continuous variable, a categorical variable or spline function, and the unit of time has also varied [2]. An alternative approach is to use time as a matching variable, which is equivalent to stratification over time, and fit the model using conditional maximum likelihood.
The objective of this paper was to evaluate the validity of the unconditional and conditional maximum-likelihood estimates when applied to data from test-negative studies under different scenarios of influenza vaccination coverage within a season. In the following sections, we provide a detailed description of the test-negative design and the regression approaches considered, and we then present a comparison of approaches using a simulation study and empirical data from a test-negative study conducted in Hong Kong.
Test-negative design
The test-negative design was first used for the estimation of influenza VE in 2005 [5] and has since been used in over 100 papers reporting VE estimates [2]. It is popular because it can take advantage of routine surveillance systems that are already in place in many settings. In these studies, participants meeting a clinical case definition for influenza-like illness or acute respiratory illness are enrolled in a clinical setting, such as an outpatient clinic or a hospital. For example, such a study might recruit patients presenting to their general practitioner (GP) with fever and cough. A respiratory specimen is collected from each participant and tested for influenza virus. Participants meeting the clinical case definition and testing positive for influenza are the cases, while those meeting the clinical case definition and testing negative for influenza are the comparison group. Information on the vaccination status and important confounders is recorded. VE is estimated by comparing the odds of positivity between the vaccinated and unvaccinated; i.e. VE = (1 – ORadj) × 100, where ORadj is the odds ratio with correction for potential bias caused by confounding [2, 3, 6].
In contrast to traditional case-control studies, the participant's status (test-positive vs. test-negative) is not known at enrolment, so no sampling frame is used to select participants. Furthermore, all patients are seeking care for the same complaint. This approach is said to avoid the validity issues identified in more traditional case-control studies of influenza VE, which are threatened by bias associated with underlying differences in health status [7] and healthcare-seeking behaviour [3] between vaccinated and unvaccinated patients. By enrolling all patients from the same population, presenting with the same complaint and therefore believed to have similar health status and healthcare-seeking behaviours, this type of bias should be reduced.
A number of assumptions are required for the test-negative design to provide accurate estimates of influenza VE. First, the occurrence of influenza-like illnesses due to non-influenza causes cannot be affected by receipt of influenza vaccine. Second, the test used to determine influenza status must be highly specific, although this is true for any study where the exposure is uncommon [8]. Recruitment should also be restricted to the period during which influenza is circulating.
Motivating example
In a test-negative study of influenza VE, our effect of interest is vaccination on influenza infection. This effect may be confounded by age because both vaccination coverage and risk of infection commonly vary by age. Calendar time might also confound the effect because of its association with the timing of vaccination and the varying probability of infection due to influenza circulation following the seasonal pattern of increase, peak and decline. To account for the potential confounding caused by calendar time, most influenza VE studies include it as a covariate (e.g. week of presentation) in their logistic regression models [2]. However, it is unclear whether simply including a variable in a maximum-likelihood model can sufficiently account for the bias that arises if the vaccination coverage changes over the season. Control for the effects of time may be better handled by using time as a matching variable and estimating VE by conditional maximum likelihood. In such a study, patients are selected for the study by matching cases and controls on time (risk-set sampling). In case-control studies, matching alone does not remove the confounding bias and induces selection bias [9, 10]. To overcome this bias, adjustment for the matching variable is required, which can be achieved by sparse data methods, such as conditional logistic regression [9, 10].
METHODS
Maximum-likelihood estimation of VE in the test-negative design
Adjusted odds ratios to estimate VE are typically calculated using a logistic regression model, which is generally defined by:
| 1 |
where Y is the outcome status of the patients, α is the parameter for the intercept, β is a vector of parameters (β1, β2, …, βp) for the covariates, and x is a vector of covariates. In a study of influenza VE, Y would be the patients' influenza status and the covariates might include vaccination status, age and time.
The parameters in the logistic regression model are estimated by maximum-likelihood estimation, which involves finding the set of parameters for which the probability of the observed data is greatest. Formal likelihood theory is explained in detail in Breslow & Day [11]. Briefly, there are two options: unconditional and conditional.
The unconditional maximum likelihood is described by:
 |
2 |
where N is the total number of individuals.
The conditional maximum likelihood is described by:
 |
3 |
where subjects 1 to n1 correspond to the cases and n0 is the number of controls. The sum in the denominator ranges over the  choices of n1 integers from the set {1, 2, …, n} [11] for each of k strata.
choices of n1 integers from the set {1, 2, …, n} [11] for each of k strata.
The conditional likelihood for each stratum is obtained as the probability of the observed data conditional on the stratum total and the number of cases observed:
| 4 |
where αk represents the contribution of all constant terms, including the matching variables, within the kth stratum [12].
The two maximum-likelihood estimates differ in some important ways. The conditional estimate does not equal the unconditional estimate and has no explicit formula [12]. Nevertheless, the interpretation of the regression coefficients is the same. Moreover, the conditional estimate is always closer to the null and tends to be less biased than the unconditional estimate [11, 10]. However, when samples are large, the two likelihood estimates and their standard errors will be asymptotically identical [13].
For the test-negative design study, where time is a covariate, the logistic regression model corresponds to:
| 5 |
where v represents vaccination, a age and c calendar time. Conversely, when patients are matched on time, the model is:
| 6 |
where there are k = 1, 2, …, n strata of calendar time.
Simulation study
To begin the investigation a simple discrete time simulation using three vaccination scenarios was performed: (1) all vaccinations administered before the epidemic; (2) vaccinations administered before and during the epidemic; (3) vaccinations administered throughout the peak period of the epidemic at a constant rate. (The period of 13 weeks was chosen as the peak period based on sentinel surveillance data from Australia, which indicated that the epidemic period was approximately 13 weeks) [14, 15]. The three scenarios are illustrated in Figure 1.
Fig. 1.

Plots showing the epidemic curve and the number of vaccinated patients using the three different vaccination scenarios. Solid black lines show the infected susceptibles, dashed black lines show the infections among vaccinated persons and the grey lines show the total vaccine coverage. We assume vaccines become effective 2 weeks after vaccination.
The simulated population size was 1 million people. VE was set at 60%, based on a recent meta-analysis [16]. The proportion vaccinated π was set to 0·3 based on the prevalence of vaccination among test-negative subjects in some recent outpatient studies [17–20]. The proportion infected with influenza ψ was set to 0·05 [21]. The rate of infection for other respiratory viruses γ was set to 0·3 [22]. Additionally, the proportions of those infected with influenza which were selected to be in the test-negative dataset ψS and other viruses selected to be in the test-negative dataset γS were arbitrarily set to 0·005. These parameters are summarized in Table 1. The simulation model assumes restricted age to avoid incorporating a statistical adjustment for age.
Table 1.
Parameters used in the simulation
| Parameter | Value |
|---|---|
| VE | 0·6 |
| π | 0·3 |
| ψ | 0·05 |
| γ | 0·3 |
| ψS | 0·005 |
| γS | 0·005 |
| N | 1 000 000 |
Epidemic curves were produced using a binomial (25, 0·5) infection pattern (P) to populate the numbers of infected susceptibles (SI=1), infected vaccinees (VI=1), susceptibles infected with other, non-influenza viruses (SO=1) and vaccinees infected with non-influenza viruses (VO=1) using the following equations:
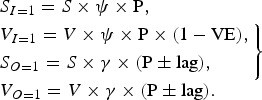 |
7 |
Susceptibles and vaccinees infected with non-influenza viruses followed the same epidemic curve as those with influenza. However, the peak of the epidemic curve was varied to occur 2 or 6 weeks before and 2 or 6 weeks after the peak of the influenza epidemic. The main analysis here shows the case in which the non-influenza viruses occur 2 weeks before. The model was restricted to run only during the epidemic period, defined as the weeks in which there were ⩾1 patients testing positive for influenza, as this is a commonly used criterion [2]. Sensitivity analyses were carried out to assess: the sensitivity of parameter inputs to the simulation results by varying the expected VE, proportion vaccinated and proportion testing positive; the effect of running the model outside of the epidemic period (i.e. not restricting to the data to weeks with cases); and the effect of differing the onset time of the non-influenza viruses epidemic.
Each simulation was run 1000 times. Five regression models were assessed: (1) crude logistic regression (L); (2) logistic regression with week as a continuous variable (LW); (3) logistic regression with week as a categorical variable (LC); (4) logistic regression with week as a restricted cubic spline function with four knots (LS); (5) conditional logistic regression, stratified by week (CL).
Application to test-negative data from Hong Kong
The use of conditional logistic regression was compared with ordinary logistic regression using data from a test-negative study conducted in Hong Kong [23]. Children were enrolled on a specified day each week from the paediatric inpatient wards of two large public hospitals on Hong Kong island – Queen Mary Hospital and Pamela Youde Nethersole Eastern Hospital. Inclusion criteria were: (1) resident of Hong Kong island; (2) aged 2–5 years; (3) meeting the case definition of a febrile acute respiratory infection, defined as fever ⩾38 °C with any respiratory symptom such as cough, runny nose, or sore throat. Respiratory specimens were collected from all enrolled children and tested for influenza by immunofluorescence, culture, and/or reverse transcription–polymerase chain reaction. Influenza vaccination history within 6 months of hospitalization was elicited from the parents or legal guardians of enrolled patients using a standardized questionnaire administered by research staff. The methods have been described in detail previously [6]. VE was estimated using the same regression models described for the simulation study, excluding the crude logistic regression model as we a priori believe that time should be adjusted. Age was restricted to avoid including it in the regression models.
RESULTS
Simulation study
For the simulation study, results for VE using the previously mentioned models are shown in Table 2. These results suggest that when all vaccinations are administered before the epidemic, adjusting a regression model for time is not necessary as the crude model gives a VE estimate close to our set parameter value of 60%. The results show slight bias in the crude model for scenario 2 where all vaccinations are given before and during the epidemic. Larger biases were observed in the crude model for scenario 3 where vaccinations are given at a constant rate during the epidemic. These simulation results therefore suggest that if modelling a situation in which vaccinations are being administered during an epidemic adjusting for time in a regression model is necessary. How this adjustment is made, however, seems to have little effect on the results.
Table 2.
Vaccine effectiveness (VE) and 95% sampling intervals obtained from simulated results using conditional and unconditional maximum-likelihood models under three vaccination scenarios
| Logistic regression model | Scenario 1: VE (95% SI) | Scenario 2: VE (95% SI) | Scenario 3: VE (95% SI) |
|---|---|---|---|
| 1. L | 59·66 (42·86–76·45) | 55·71 (37·15–74·27) | 45·91 (19·35–72·47) |
| 2. LW | 59·70 (42·90–76·50) | 60·13 (42·86–77·41) | 59·46 (38·75–80·17) |
| 3. LC | 60·03 (43·10–76·96) | 60·41 (42·99–77·82) | 59·91 (38·95–80·88) |
| 4. LS | 59·83 (42·99–76·66) | 60·15 (42·83–77·46) | 59·59 (38·75–80·42) |
| 5. CL | 59·71 (42·80–76·63) | 60·04 (42·66–77·43) | 59·49 (38·58–80·40) |
SI, Sampling interval; L, crude model; LW, adjusting for week as a continuous variable; LC, adjusting for week as a categorical variable; LS, adjusting for week with a spline term; CL, conditional logistic model matching on week.
Sensitivity analysis was also carried out to inspect the sensitivity of the simulation towards parameter values. Figure 2 shows the differences when we restrict the model to only run during the influenza season (⩾1 positive case each week) and when we allow the model to run on all data. We expected there to be bias when using the entire surveillance period vs. just the weeks with cases because this is what has been seen in practice [24]. However, the two panels in Figure 2 show minimal differences. Such variability is probably a product of sample size, such that in a study with a small overall sample, changing the definition of the study period can have a severe impact on VE estimates. In contrast, our simulated datasets included between 1000 and 2000 patients, which may have been sufficient to overcome sampling problems.
Fig. 2.

Plots showing results of the sensitivity analysis comparing calculated vaccine effectiveness estimates when data are restricted to the influenza epidemic period vs. using entire surveillance period. Data shown are point estimates and sampling intervals for each model.
The effect of varying parameter values is shown in Figure 3. These adjustments have little effect on the calculated VE estimate, except when the probability of infection (PI) is increased in which case the sampling intervals for the estimate narrow. Again, there is evidence of bias towards the null in the crude estimate obtained from scenarios 2 and 3.
Fig. 3.

Plots showing the sensitivity analysis performed using different combinations of parameter values. VE, Vaccine effectiveness; PV, proportion vaccinated; PI, proportion infected. Data shown are point estimates and sampling intervals for each model.
We also conducted a sensitivity analysis, examining the effect of varying the onset of the epidemic curves for non-influenza viruses. This was done by implementing the non-influenza viruses' curves with a 2- and 6-week lag and a 2- and 6-week lead/advance. The infection pattern for both influenza and non-influenza viruses were the same throughout the analysis [binomial (25, 0·5)]. The results are shown in Table 3. We can see that when the two epidemic curves are significantly separated, i.e. 6 weeks lag and 6 weeks lead, the bias shown for the crude model in scenarios 2 and 3 is large. This analysis also shows that when the non-influenza epidemic occurs before the influenza epidemic the crude model underestimates VE and, conversely, when this occurs after the influenza epidemic the crude model overestimates VE. This highlights the need for time adjustment in a model where the vaccination is given during the influenza epidemic especially when the non-influenza virus activity occurs before or after the influenza epidemic. We can also see slight bias in all models when the difference between the influenza and other virus' epidemics are greatest.
Table 3.
Sensitivity analysis showing the effects of differing the epidemic period for non-influenza viruses. Values shown in table are VE (%) with 95% sampling intervals
| 6 weeks before | 2 weeks before (main analysis) | 2 weeks after | 6 weeks after | |
|---|---|---|---|---|
| Scenario 1 | ||||
| 1. L | 59·90 (43·28–76·52) | 59·66 (42·86–76·45) | 59·80 (43·82–75·78) | 59·35 (42·77–75·93) |
| 2. LW | 59·40 (37·97–80·82) | 59·70 (42·90–76·50) | 59·78 (43·46–76·09) | 58·52 (34·21–82·83) |
| 3. LC | 59·78 (35·94–83·62) | 60·03 (43·10–76·96) | 60·12 (43·60–73·64) | 59·01 (33·99–84·04) |
| 4. LS | 59·63 (36·37–82·90) | 59·83 (42·99–76·66) | 59·88 (43·50–76·25) | 58·80 (34·12–83·49) |
| 5. CL | 59·27 (35·54–83·00) | 59·71 (42·80–76·63) | 59·75 (43·25–76·26) | 58·50 (33·61–83·40) |
| Scenario 2 | ||||
| 1. L | 36·26 (8·31–64·21) | 55·71 (37·15–74·27) | 61·65 (45·79–76·98) | 62·11 (45·42–78·80) |
| 2. LW | 58·78 (34·65–82·91) | 60·13 (42·86–77·41) | 59·51 (42·70–76·32) | 58·85 (34·49–83·51) |
| 3. LC | 59·28 (34·48–84·08) | 60·41 (42·99–77·82) | 59·70 (42·81–76·58) | 59·35 (34·62–84·07) |
| 4. LS | 58·93 (34·23–83·63) | 60·15 (42·83–77·46) | 59·49 (42·64–76·33) | 59·11 (34·48–83·75) |
| 5. CL | 58·85 (34·07–83·42) | 60·04 (42·66–77·43) | 59·38 (42·52–76·25) | 58·85 (34·24–83·44) |
| Scenario 3 | ||||
| 1. L | 33·48 (-4·03–70·99) | 45·91 (19·35–72·47) | 68·23 (53·35–83·12) | 75·38 (63·46–87·29) |
| 2. LW | 56·87 (23·48–90·26) | 59·46 (38·75–80·17) | 59·62 (40·22–79·01) | 57·95 (30·44–85·47) |
| 3. LC | 57·77 (23·27–92·26) | 59·91 (38·95–80·88) | 59·80 (40·36–79·24) | 58·28 (30·31–86·26) |
| 4. LS | 57·37 (23·24–91·50) | 59·59 (38·75–80·42) | 59·63 (40·17–79·08) | 58·10 (30·20–85·99) |
| 5. CL | 57·22 (22·96–91·47) | 59·49 (38·58–80·40) | 59·55 (40·12–78·98) | 57·84 (30·00–85·68) |
L, crude model; LW, adjusting for week as a continuous variable; LC, adjusting for week as a categorical variable; LS, adjusting for week with a spline term; CL, conditional logistic model matching on week.
Overall, considering all simulation results, including the sensitivity analyses, it is shown that when vaccinations are distributed during an epidemic the models producing the most accurate results are the logistic model adjusting for time as a categorical variable or using a spline function, and the conditional logistic regression model matching on time.
Application to test-negative data from Hong Kong
Between 1 October 2009 and 30 September 2013, 2467 children were recruited from the inpatient departments of two hospitals, of whom 241 (9·8%) tested positive for influenza A virus and 82 (3·3%) tested positive for influenza B virus. The timeline of recruitment of patients is shown in Figure 4. The upper panel shows that influenza virus infections in Hong Kong occurred throughout the year, with occasional peaks and troughs in incidence. Elsewhere we have shown that peaks in influenza virus activity tend to occur in winter (February–March) and summer (June–July) in subtropical Hong Kong although the seasonal pattern can vary from year to year [6, 25].
Fig. 4.

Enrolment of patients and vaccination coverage over calendar time in Hong Kong. (a) Number of enrolled children each week, by laboratory test result. The dark grey bars show the test-negative patients and the light grey bars show the test-positive patients. (b) Vaccine coverage among cases testing negative for influenza virus, smoothed using the Daniel 1 kernel [26].
The lower panel of Figure 4 shows the influenza vaccination coverage among the test-negative patients, which reflects vaccination coverage in the population, varied throughout each year, with highest coverage between January and March each year. Hong Kong uses the Northern Hemisphere influenza vaccine and vaccination campaigns typically run from October to January prior to the winter influenza season, although vaccines are also administered at other times of the year and are available throughout the year.
From analysis of the hospital data we found among the test-negative patients, 245/(1899 + 245) (11·4%) reported receipt of influenza vaccination in the preceding 6 months, compared to 18/(305 + 18) (5·6%) of patients that tested positive for influenza A or B virus. Estimates of the VE adjusted for different time indicators were estimated from fitting conditional and unconditional maximum-likelihood models (Table 4).
Table 4.
Estimated vaccine effectiveness (VE) under alternative regression models
| Time indicator (weeks) | Sample size* | VE (%) | (95% CI) | AIC | |
|---|---|---|---|---|---|
| 1. LW | 1 | 2467 | 55·10 | (28·32–73·56) | 1908·72 |
| 2. LW | 2 | 2467 | 55·10 | (28·32–73·56) | 1908·72 |
| 3. LW | 4 | 2467 | 55·11 | (28·34–73·57) | 1908·71 |
| 4. LW | 12 | 2467 | 55·02 | (28·19–73·51) | 1908·85 |
| 5. LC | 1 | 1603 | 65·41 | (39·71–80·17) | 1679·42 |
| 6. LC | 2 | 2027 | 62·82 | (38·06–78·88) | 1718·12 |
| 7. LC | 4 | 2305 | 62·64 | (38·29–78·62) | 1721·85 |
| 8. LC | 12 | 2467 | 60·99 | (36·64–77·35) | 1774·21 |
| 9. LS | 1 | 2467 | 62·40 | (38·97–78·16) | 1759·47 |
| 10. LS | 2 | 2467 | 62·64 | (39·06–78·16) | 1764·82 |
| 11. LS | 4 | 2467 | 62·44 | (39·06–78·16) | 1764·82 |
| 12. LS | 12 | 2467 | 60·34 | (35·71–76·93) | 1773·77 |
| 13. CL | 1 | 1603 | 62·66 | (36·06–78·19) | 1117·57 |
| 14. CL | 2 | 2027 | 61·53 | (34·60–77·30) | 1323·44 |
| 15. CL | 4 | 2305 | 61·99 | (35·84–77·48) | 1469·67 |
| 16. CL | 12 | 2467 | 60·78 | (34·66–76·45) | 1660·62 |
CI, Confidence interval; AIC, Akaike's Information Criterion; LW, adjusting for week as a continuous variable; LC, adjusting for week as a categorical variable; LS, adjusting for week with a spline term; CL, conditional logistic model matching on week.
* Weeks without a case and a non-case were dropped from models 2 and 4.
Table 4 shows the results from the unconditional logistic regression models adjusting for time in the previously described ways and the conditional logistic model using matched time variables. Among the unconditional models, Akaike's Information Criterion (AIC) values indicated that the model including a categorical variable for week was the preferred model; however, the model including a spline function for week provided similar estimates and AIC values. However, the AIC value for the conditional model was lower, suggesting this approach fit the data best. The models were run using differing units of time (i.e. week, month, 12-week period). When the unit of time was 12 weeks no weeks were dropped in the conditional regression or the model with categorical time, and therefore the sample size included in the conditional regression was the same as the sample included in all the unconditional models allowing for a fair comparison of AIC values. This comparison still shows the AIC to be the lowest in the conditional model. Regardless of the unit of time, the conditional model shows the lowest AIC, concluding that this model fitted the data the best. Each model, with the exception of the continuous unconditional model (which stayed consistent across all time indicators), provided a better fit with the smaller unit of time (week).
DISCUSSION
Based on the analysis presented here, the need to adjust for time depends on which scenario best fits the data under study. Scenario 1 may best represent a typical, temperate season, where the majority have been vaccinated prior to the start of the epidemic. On the other hand, scenario 2 may be more realistic in seasons where the epidemic starts early, or where seasons closely follow or even coincide with vaccine availability, which may occur in some regions [27–30] or during pandemics [4]. However, we conservatively recommend that either the conditional logistic model, or an unconditional model in which week is included either as a categorical variable or using a spline function may be the most appropriate models to use for a test-negative data set. As well as producing accurate estimates for the simulation data under a range of scenarios, these models also permitted reliable estimation of VE in the Hong Kong hospital data. Although not seen in the simulation or Hong Kong application here, the conditional logistic model has been shown to produce slightly larger standard errors than the logistic model due to a higher number of parameters needed for the conditional logistic regression model resulting in greater uncertainty [11]. However, the reduced bias may be preferable to reduced precision.
One limitation of our approach is that we did not consider the impact of potential confounding variables on the estimation of VE. An important confounder of this relationship is age, which we attempted to control the effects of by restricting the analysis to children aged 2–5 years. However, we did not explore how adjustment for this variable might influence estimates. This would be one area for further work, perhaps with an agent-based simulation model. Further to this, we did not explore effect modification across levels of this confounder. However, we note that in practice most published datasets may have insufficient sample to adequately explore effect modification. Gains in understanding how an effect varies across levels of covariates must be weighed against other potential biases. For example, inclusion of product terms can overparameterize the model and lead to sparse data bias, the severity of which may be greater than confounding bias [31–33]. Second, for the application to clinical data, the true VE is unknown and we cannot be sure that the regression models we used were able to account sufficiently for confounding. In practice, matching on calendar time may be more useful in tropical regions, like Hong Kong, where there may be multiple influenza seasons within a year; conversely in temperate climates where the influenza season typically follows a neat epidemic curve and where most patients will have been vaccinated prior to the epidemic, the need to control for time may be reduced.
ACKNOWLEDGEMENTS
We thank Dr S. S. Chiu, Department of Paediatrics and Adolescent Medicine, Hong Kong Special Administrative Region, for providing the data used in this analysis. This work has received financial support from the Area of Excellence Scheme of the Hong Kong University Grants Committee (grant no. AoE/M-12/06) and the Harvard Centre for Communicable Disease Dynamics from the National Institute of General Medical Sciences (grant no. U54 GM088558). The WHO Collaborating Centre for Reference and Research on Influenza is funded by the Australian Government Department of Health. The funding bodies were not involved in the collection, analysis, and interpretation of data, the writing of the article, or the decision to submit it for publication.
DECLARATION OF INTEREST
B.J.C. has received research funding from MedImmune Inc. and Sanofi Pasteur, and consults for Crucell NV.
REFERENCES
- 1.Barr IG, et al. Epidemiological, antigenic and genetic characteristics of seasonal influenza A (H1N1), A (H3N2) and B influenza viruses: basis for the WHO recommendation on the composition of influenza vaccines for use in the 2009–2010 Northern Hemisphere season. Vaccine 2009; 5: 1156–1167. [DOI] [PubMed] [Google Scholar]
- 2.Sullivan SG, Feng S, Cowling BJ. Potential of the test-negative design for measuring influenza vaccine effectiveness: a systematic review. Expert Review of Vaccines 2014. (in press). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Jackson ML, Nelson JC. The test-negative design for estimating influenza vaccine effectiveness. Vaccine 2013; 17: 2165–2168. [DOI] [PubMed] [Google Scholar]
- 4.Griffin MR, et al. Effectiveness of non-adjuvanted pandemic influenza A vaccines for preventing pandemic influenza acute respiratory illness visits in 4 U.S. communities. PLoS ONE 2011; 6: e23085. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Skowronski DM, Gilbert M, Tweed SA. Effectiveness of vaccine against medical consultation due to laboratory-confirmed influenza: results from a sentinel physician pilot project in British Columbia, 2004–2005. Canada Communicable Disease Report 2005, 18: 181–191. [PubMed] [Google Scholar]
- 6.Cowling BJ, et al. Incidence of influenza virus infections in children in Hong Kong in a three year randomised placebo-controlled vaccine study, 2009–12. Clinical Infectious Diseases 2014, 4: 517–524. [DOI] [PubMed] [Google Scholar]
- 7.Jackson LA, et al. Evidence of bias in estimates of influenza vaccine effectiveness in seniors. International Journal of Epidemiology 2006, 5: 337–344. [DOI] [PubMed] [Google Scholar]
- 8.Jurek AM, et al. Proper interpretation of non-differential misclassification effects: expectations vs observations. International Journal of Epidemiology 2005, 34: 680–687. [DOI] [PubMed] [Google Scholar]
- 9.Mansournia MA, Hernan MA, Greenland S. Matched designs and causal diagrams. International Journal of Epidemiology 2013; 42: 860–869. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Rothman KJ, Greenland S, Lash TL. Design Strategies to Improve Study Accuracy. Philadelphia: Williams & Wilkins, 2008. [Google Scholar]
- 11.Breslow NE, Day NE. Statistical methods in Cancer research. International Agency for Research in Cancer 1980; 1: 249–250. [Google Scholar]
- 12.Hosmer DW, Lemeshow S. Applied Logistic Regression, 2nd edn. Hoboken, NJ, USA: John Wiley & Sons Inc., 2000. [Google Scholar]
- 13.Efron B. Logistic regression, survival analysis and the Kaplan-Meier curve. Journal of the American Statistical Association 1988; 8: 414–425. [Google Scholar]
- 14.Tay EL, et al. Exploring a proposed WHO method to determine thresholds for seasonal influenza surveillance. PLoS ONE 2013; 8: e77244. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Kissling E, et al. I-MOVE multi-centre case control study 2010–11: overall and stratified estimates of influenza vaccine effectiveness in Europe. PLoS ONE 2011; 6: e27622. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Osterholm MT, et al. Efficacy and effectiveness of influenza vaccines: a systematic review and meta-analysis. Lancet Infectious Diseases 2011; 12: 36–44. [DOI] [PubMed] [Google Scholar]
- 17.Andrews N, et al. Effectiveness of trivalent seasonal influenza vaccine in preventing laboratory-confirmed influenza in primary care in the United Kingdom: 2012/13 end of season results. Eurosurveillance 2014; 19: 5–13. [PubMed] [Google Scholar]
- 18.Carville KS, et al. Understanding influenza vaccine protection in the community: an assessment of the 2013 influenza season in Victoria, Australia. Vaccine 2015; 33: 341–345. [DOI] [PubMed] [Google Scholar]
- 19.McLean HQ, Meece JK, Belongia EA. Influenza vaccination and risk of hospitalization among adults with laboratory confirmed influenza illness. Vaccine 2014; 32: 453–457. [DOI] [PubMed] [Google Scholar]
- 20.Skowronski DM, et al. Influenza A/subtype and B/lineage effectiveness estimates for the 2011–2012 trivalent vaccine: cross-season and cross-lineage protection with unchanged vaccine. Journal of Infectious Diseases 2014; 210: 126–137. [DOI] [PubMed] [Google Scholar]
- 21.McDonald SA, et al. An evidence synthesis approach to estimating the incidence of seasonal influenza in the netherlands. Influenza and Other Respiratory Viruses 2013; 8: 33–41. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Orenstein EW, et al. Methodological issues regarding the use of three observational study designs to assess influenza vaccine effectiveness. International Journal of Epidemiology 2007; 3: 623–631. [DOI] [PubMed] [Google Scholar]
- 23.Cowling BJ, et al. The effectiveness of influenza vaccination in preventing hospitalizations in children in Hong Kong, 2009–2013. Vaccine 2014; 41: 5278–5284. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Sullivan SG, Tay EL, Kelly H. Variable definitions of the influenza season and their impact on vaccine effectiveness estimates. Vaccine 2013; 31: 4280–4283. [DOI] [PubMed] [Google Scholar]
- 25.Wu P, et al. Excess mortality associated with influenza A and B virus in Hong Kong, 1998–2009. Journal of Infectious Diseases 2012; 206: 1862–1871. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Brockwell PJ, Davis RA. Time Series: Theory and Methods. Springer, New York, 1991. [Google Scholar]
- 27.de Mello WA, et al. The dilemma of influenza vaccine recommendations when applied to the tropics: the Brazilian case examined under alternative scenarios. PLoS ONE 2009; 4: e5095. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Koul PA, et al. Differences in influenza seasonality by latitude, Northern India. Emerging Infections Diseases 2014; 20: 1723–1726. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Saha S, et al. Influenza seasonality and vaccination timing in tropical and subtropical areas of southern and south-eastern Asia. Bulletin of the World Health Organization 2014; 92: 318–330. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Yu H, et al. Characterization of regional influenza seasonality patterns in China and implications for vaccination strategies: spatio-temporal modeling of surveillance data. PLoS Medicine 2013; 10: e1001552. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Rothman KJ, Mosquin PL. Sparse-data bias accompanying overly fine stratification in an analysis of beryllium exposure and lung cancer risk. Annals of Epidemiology 2013; 23: 43–48. [DOI] [PubMed] [Google Scholar]
- 32.Greenland S, Schwartzbaum JA, Finkle WD. Problems due to small samples and sparse data in conditional logistic regression analysis. American Journal of Epidemiology 2000; 151: 531–539. [DOI] [PubMed] [Google Scholar]
- 33.Greenland S. Bayesian perspectives for epidemiological research. II. Regression analysis. International Journal of Epidemiology 2007; 36: 195–202. [DOI] [PubMed] [Google Scholar]