

Abstract
This paper examines the association between income, income inequalities and health inequalities in Europe. The contribution of this paper is to study different hypotheses linking self-perceived health status and income, allowing for the identification of different mechanisms in income-related health inequalities. Using data from the Survey of Health, Ageing and Retirement in Europe (15 countries), we take the advantage of the cross-sectional and longitudinal nature of this rich database to make robust results. The analyses (coefficient estimates as well as average marginal effects) strongly support two hypotheses by showing that (i) income has a positive and concave effect on health (Absolute Income Hypothesis); (ii) income inequalities in a country affect all members in a society (strong version of the Income Inequality Hypothesis). However, our study suggests that, when considering the position of the individual in the income distribution, as well as the interaction between income inequalities and these rankings, one cannot identify individuals the most affected by income inequalities (which should be the least well-off in a society according to the weak version of the Income Inequality Hypothesis). Finally, the robustness of this study is emphasized when implementing a generalized ordered probit to consider the subjective nature of the self-perceived health status to avoid the traps encountered in previous studies.
Keywords: Health inequalities, Income inequalities, Self-reported health, Europe
Background
The last few years have seen unprecedented attention to an attempt by policy makers, policy advisers and international institutions to reduce health inequalities. To do so, they usually focus on the access to healthcare, given that such policies allow to improve the health of lower income groups [28, 34]. Improving equality of access to healthcare is however not the sole public policy which can favor health equality. In particular, it has been widely said that income and income inequalities are associated to health status; thus, any public policy which influences income and/or income inequalities might influence health. In this way, studying the relationship between income, income inequalities and health is interesting per se. With these elements in mind, this paper confronts on an empirical basis three hypotheses. The first one, called the Absolute Income Hypothesis, was initially introduced by Preston [29] and states that there is a positive and concave relationship between income and health.1 Higher incomes can provide means for purchasing a better health status. The second one is the strong version of the Income Inequality Hypothesis and it asserts that the health status is determined by income inequalities within a society. Thus, the health of all individuals is affected by an increase or a decrease in income inequalities. The last one, a weak version of the Income Inequality Hypothesis, says that income inequalities are a threat to individuals placed at the lower end of the income distribution. This last hypothesis implies that income inequalities do not impact low income people and high income people in the same magnitude.
Various authors have studied the Absolute Income Hypothesis mainly in the United States, using different health measures, like self-perceived measures [26], life expectancy [10] and other health outcomes [8, 12]. Fiscella and Franks [13], Kennedy et al. [20], Van Doorslaer et al. [32], Wagstaff et al. [33] focus on the strong version of the Income Inequality Hypothesis and show that income inequalities in a society also matter in order to explain the average health status measured by self-perceived measures (mostly in the United States). Concerning the weak version of the Income Inequality Hypothesis, there are few empirical studies which investigate it, with the exception of Mellor and Milyo [27] in the United States, Li and Zhu [21] in China or Hildebrand and Van Kerm [15] in Europe. Importantly, the strong version of Income Inequality Hypothesis and the weak version of Income Inequality Hypothesis are non-nested given that the weak version considers the rank of individuals and an interaction term between the rank and the income inequalities index whereas the strong version does not. Thus, both versions can be valid when income inequalities in a society are negatively associated to the health of all individuals, and more particularly the health of people ranked at the lower end of the income distribution. However, the authors previously mentioned focus mainly on one of the versions in the best case (mainly on data from the United States), without comparing them. This paper aims at filling these gaps by looking at the three hypotheses, using the same European data, in order to give more insight about efficient public policies which should be implemented in Europe. Finally, studying these three hypotheses at the same time allows to highlight different mechanisms between health and income.
In this paper, we test the three above hypotheses with the Survey of Health, Ageing, and Retirement in Europe (SHARE), using mainly the fifth wave of this survey (2015 release), as well as the pooled version of the survey in robustness. We use self-perceived health status as our health outcome. This type of subjective measure is sometimes criticized but it is similar to the ones used by Mackenbach et al. [26], Fiscella and Franks [13] and Hildebrand and Van Kerm [15]. Furthermore, some authors show that these subjective measures are not biased [1]. Lastly, even if this type of measure can be criticized because of interpersonal comparison issues, authors prove that some econometric models tackle these problems [22] (see “Robustness checks” subsection for some robustness checks in which we explicitly consider this issue).
The paper is organized as follows. “Literature review: the relationship between income inequalities and health” section presents formally the three hypotheses that we will test empirically. “Method” section describes the SHARE dataset as well as the baseline econometric specification. In “Results” section we present the results and some robustness checks. “Conclusion” section concludes the paper.
Literature review: the relationship between income inequalities and health
Inequalities in health refer to the close relationship between health and membership in a group characterized by incomes, where income is an individual social determinant. This section formally presents the three hypotheses mentioned in the introduction, as well as some related literature. We should mention that, in this literature review, we transcribe terminology employed by authors which reflects causal relationships even if cross-sectional databases are used or some endogeneity might be at play.
The Absolute Income Hypothesis
From an early stage in the debate, the Absolute Income Hypothesis states that the relationship between health and income is positive and concave [29], meaning that people with higher incomes have better health outcomes, but income inequalities have no direct effect on health. As a result, the concavity of the relationship between individual income and health status is a necessary condition to assess the efficiency of redistributive policies, in which transferring a given amount of money from rich people to poor people will result in an improvement of the average health.
The individual-level relation between income and health is specified as follows:
| 1 |
where h i represents the health status of individual i (objective or subjective measures); x i is the income of individual i; Z i is a set of individual specific control variables2; and ε i is the error term coming from differences in individual health. The concavity effect is legitimized if β 1 is positive, β 2 is negative, and .
A strong link between health and income has been demonstrated in a large number of empirical studies, and a concave relationship between the two is found. Preston [29] explains that the impact of additional income on mortality is greater among the poor than richer people. Ettner [12], using three US surveys, finds that increases in income improve mental and physical health but also increase alcohol consumption. Then, Mackenbach et al. [26] show that a higher income is associated with better self-assessed health in Europe. Using mortality rates, Cutler et al. [10] conclude the same thing in the United States. Theodossiou and Zangelidis [31], using data on individuals aged between 50 and 65 from six European countries, find a positive but small effect of income on health. More recently, Carrieri and Jones [8] analyze the effect of income on blood-based biomarkers and find a positive and concave effect of income on health.
The strong version of Income Inequality Hypothesis
Some researchers affirm that income inequalities in a society are equally important in determining individual health status. The key difference between the Absolute Income Hypothesis and the strong version of Income Inequality Hypothesis stems from the fact that the latter explicitly considers the effect of income inequalities on health while the former only takes into account the concavity assumption between health and income. Mellor and Milyo [27] specifically define two versions of this hypothesis: the strong version and the weak version. The strong version of the Income Inequality Hypothesis implies that, whatever the level of income, the health of all individuals in a society is equivalently affected by income inequalities in this society. In this way, both the well-off and poor people are impacted by income inequalities. These may be a public bad for all members in a society since income inequalities are a threat to the health of all individuals. We can thus identify an individual effect (a micro part) which is assimilated to the Absolute Income Hypothesis and an aggregate effect (a macro part) which corresponds to the relationship between individual health and income inequalities in a society. Theoretically, the strong version of the Income Inequality Hypothesis is specified as follows:
| 2 |
which is an expansion of Eq. (1) with the introduction of II j as a measure of income inequalities in a society j (corresponding to the macro part explained above); where h ij represents the health status of individual i in a society j.
This hypothesis has been empirically tested mainly on data from developed countries (principally in the United States). Tests have been conducted at both the individual level and the aggregate level. At the aggregate level, a number of studies try to demonstrate an association between income inequalities and public health and the results are contrasted [17, 25, 30]. At the individual level, Kawachi et al. [19], Kennedy et al. [20], and Fiscella and Franks [13] all find a negative association between income inequalities and self-perceived health. However, Van Doorslaer et al. [32] find no effect of income inequalities on an objective health measure, the McMaster health utility index, derived from the self-perceived health status. Finally, other authors test the impact of income inequalities on malnutrition [33] or health service use [23] and find contrasted results.
The strong version focuses on the direct ties between health and income inequalities. There are several potential pathways through which income inequalities might be negatively related to an individual’s health. Kawachi and Kennedy [18] summarize three plausible mechanisms linking income inequalities to health. The first one is that disinvestment in human capital is linked to income inequalities. In states with high income inequalities, educational outcomes are negatively impacted when a smaller proportion of the state budget is spent on education which creates differences in education and thus in income. High income disparities may translate into lower social spending because interests of richer persons begin to diverge from other people in societies where inequalities rise. Thus, reducing social spending turns into a decrease in life opportunities for poorer people and thus an increase in inequalities (see also [14]). The second mechanism is that income inequalities lead to the erosion of the “features of social organization that facilitate cooperation for mutual benefit”. In other words, Kawachi and Kennedy [18] interpret this mechanism as the erosion of the “social capital”, corresponding to the set of collective resources an individual can put together. This may be the access to public services, the feeling of security, the characteristics of the relatives or the community solidarity (Grignon et al.: Mesurer l’impact des déterminants non médicaux des inégalités sociales de santé, unpublished). Here we focus on the solidarity argument. This one is important for the maintenance of population health. Kawachi and Kennedy [18] made a study using the General Social Survey where each indicator of social capital (like the degree of mistrust or levels of perceived reciprocity) was correlated with lower mortality rates. An increasing level of mistrust between the members of a society was due to the development of the distance between the well-off’s expectation and the ones of poorer people. Unfortunately this result implies a growth of a latent social conflict. As a result, when health is associated to the erosion of social capital, this seems to be towards the transition of social policies which are detrimental to poor people, implying unequal political participation. A lower turnout at elections is perceived among states with low levels of interpersonal trust. These states are less likely to invest in policies that ensure the security of poorer people in a society. Finally less generous states are likely to provide less hospitable environments for these individuals. The last mechanism is that income inequalities are correlated to unhealthiness through stressful social comparisons. In this case, a technique in anthropology called “cultural consensus analysis” is used to take into account the psychosocial effects of social comparisons. Indeed, many communities have a common cultural model of the standard of living. This technique involves interviewing people and observing if individuals succeed in achieving the cultural model of lifestyle. This aspect can be seen as the satisfaction individuals have with their life. However, it should be noticed and not forgiven that a possible endogeneity issue can appear with this mechanism connected to the life satisfaction of individuals.
The weak version of Income Inequality Hypothesis
The second version of the Income Inequality Hypothesis is the weak one. According to this hypothesis, people who are more likely to have poorer health are the ones who feel more economically disadvantaged than their peers in a reference group. As a result, it specifically suggests that only the least well-off are hurt by income inequalities in a society. The damaging effect of these inequalities on health decreases with a person’s income rank. Indeed, for an individual, stress and depression leading to illness may be linked to the fact of having a low relative income when compared to another person [9]. The main concern is thus on the difficulties that an individual may face when he is situated at the bottom of the social ladder. Theoretically, the weak version of the Income Inequality Hypothesis is specified as follows:
| 3 |
which is an expansion of Eq. (2) where we introduce R ij as a person’s rank, and the interaction between inequalities and a person’s rank (R ij∗II j) to allow the effects of income inequalities to vary by the relative income level in a society. The interaction term allows us to know how income inequalities are related to people with lower levels of income, compared to other people. Therefore, this hypothesis suggests that the breadth of the difference between rich people and poor ones accounts for the health. When testing this equation, δ underlines the strong version of the Income Inequality Hypothesis whereas θ and η specifically refer to the weak version. Thus, if the three previous coefficients are significant and have the right signs, then both the strong and the weak version are correct, meaning that everybody’s health is associated to income inequalities, and in particular people who are at the lower end of the income distribution. On the other hand, whether only δ (or θ and η respectively) is significant implies that only the strong version (resp. the weak version) is satisfied.
As explained in the introduction, only few researches focus on this hypothesis. Mellor and Milyo [27] use data from the Current Population Survey and find no consistent association between income inequalities and individual health. On the other hand, Li and Zhu [21], using data from China, find that income inequalities are detrimental for people who are at the lower end of the income hierarchy. Finally, Hildebrand and Van Kerm [15] also test the hypothesis that income inequalities may affect only the least well-off in a society using the European Community Household Panel but find no evidence supporting it.
Method
The data
The survey
The Survey of Health, Ageing and Retirement in Europe (SHARE) is a multidisciplinary and cross-national panel database of micro data on health, socio-economic status and social and family networks of more than 123,000 individuals aged 50 and over from many European countries and Israel [7]. Since 2004, SHARE asks questions throughout Europe to a sample of households with at least one member who is 50 and older. These households are re-interviewed every two years in the panel. SHARE is part of a context of an ageing population. It is the European Commission which has identified the need for scientific knowledge about ageing people in Europe.3 In fact, people of the European Innovation Partnership on Active and Health Ageing project estimate that in 2050, one in three Europeans will be over 60 years old and one in ten will be over 85 years old. The SHARE survey was then constructed in the different European countries under the leadership of Professor Axel Börsch-Supan. In addition, SHARE is harmonized with the Health and Retirement Study (in the United States - HRS) and the English Longitudinal Study of Ageing (UK - ELSA).
The first wave (2004-2005, 27,014 individuals) and the second one (2006-2007, 34,393 individuals) were used to collect data on health status, medical consumption, socio-economic status and living conditions. The 2008-2009 survey (Wave 3 - “SHARELIFE”) was extended to life stories by collecting information on the history of the respondents. The number of participants increased from 12 countries in wave 1, to 15 (+ Ireland, Israel, Poland and Czech Republic) in wave 2, and the third wave contains information about 14 countries. The fourth wave (2010-2011), is a return to the initial questionnaire of the first two waves. It collects data from 56,675 individuals in 16 European countries. Finally, the fieldwork of the fifth wave of this survey was completed in 2013. The following countries are included in the scientific release of 2015: Austria, Belgium, Switzerland, Czech Republic, Germany, Denmark, Estonia, Spain, France, Israel, Italy, Luxembourg, Netherlands, Sweden, and Slovenia. This wave contains the responses of 63,626 individuals. We focus on the fifth wave [3] in order to have a great number of individuals who come from different countries. Moreover, in order to test and compare the three hypotheses linking health and income, one has to use the same set of observations (e.g. the fifth wave of the SHARE survey). We do not make our analysis using directly the pooled database since all the control explanatory variables are not available in each waves, which is a limitation of this database. Moreover, we also focus on the pooled database (waves 1, 2, 4 [4–6] and 5) in order to make our results more robust (the third wave is not considered in the pooled database since it does not contain the same information as the other ones).
The advantage of the SHARE database is that it has many individual variables on health, socioeconomic status and income to perform this research. However, researchers should be also aware of the potential disadvantage of this database. Indeed, Börsch-Supan et al. [7] explain that in some waves there are a relative low response rates and moderate levels of attrition (even though the overall response rate is high compared to other European and US surveys4) which are due to the economic crisis faced by some countries, implying a decrease in the participation rates. Due to this attrition, we thus focus on the fifth wave of this survey instead of the pooled database. Nonetheless, we present the results using the pooled database as a robustness test.
Indexes for the measurement of income inequalities
In this study, we want to underline the effects of income inequalities on health and this is why we need a measurement of income inequalities. The Gini coefficient, as well as the Theil index are two well-known indexes which can be used.
Algebraically, the Gini coefficient is defined as half of the arithmetic average of the absolute differences between all pairs of incomes in a population, and then the total is normalized on mean income. If incomes in a population are distributed completely equally, the Gini value is zero, and if one person has all the incomes in a society, the Gini is one. The Gini coefficient can be illustrated through the Lorenz curve. However, the Gini coefficient does not take into account the income distribution since different Lorenz curves may correspond to the same Gini index.5 In other words, it does not distinguish between inequalities in low income group and high income ones. Formally, the Gini coefficient is:
| 4 |
with y i representing the income of the population sorted and ranked, from the lowest decile group to the top decile group, and N representing the total population.
As a result, one of the solution is to use the Theil index which measures income inequalities. The Theil index is:
| 5 |
where is the mean income per person (or expenditure per capita). In order to normalize the Theil index to vary between zero and one, we divide it by ln(N).6 It measures a “distance” of the real population and the “ideal” egalitarian state where everyone have the same income.
Since the Gini coefficient does not take into account the income distribution, most of the following tables of results will be displayed using the Theil index.
Descriptive statistics - an overview
In this paper, the data used are from the fifth wave of the SHARE survey. This wave includes responses from 63,626 respondents aged 50 and over, living in 15 different countries. Thus, this survey aims to provide information on health, income, activities and other features of the elderly. In one hand, the variable of interest is the health which is defined in the database as the self-perceived health status. Individuals are asked to classify their health using ordered qualitative labels from “poor” to “excellent. The Fig. 1 characterizes the distribution of the health variable among individuals aged 50 and older by gender for all countries. As we can see the majority of inhabitants reports being in a good health. In the other hand, one of our main determinant of health is the income. This variable can be seen as a proxy for well-being, that is to say a factor which allows individuals to improve the living standards. In the database, it corresponds to the sum of individual imputed income for all household components. Figure 2 shows the distribution of income of people aged 50 and over in the fifth wave where the mean is about 36,000€. Moreover, the income inequality hypothesis includes an indicator for the measurement of income inequalities (see Fig. 3). In this paper, we use either the Gini index or the Theil index. The mean of the Gini index in Europe is 0.39 which corresponds to a rather egalitarian society. The mean of the Theil index in Europe is 0.33 which is also rather egalitarian. In our analysis we include others variables such as the age, the marital status, the education, the job situation, dummies for the countries and the gender, and the GDP of the countries (see Tables 2, 3, 4 and 5 in the Appendix for further information). Finally, the pooled data (waves 1, 2, 4 and 5) contains 181,708 observations, where each individual is present on average 2.9 years in the panel.
Fig. 1.
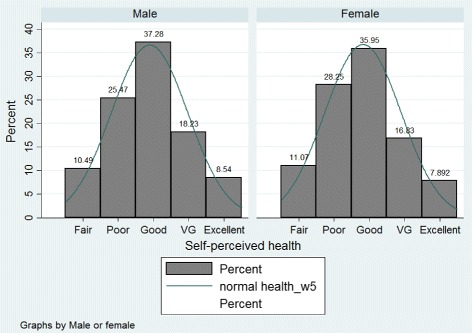
Self-perceived health in Europe
Fig. 2.
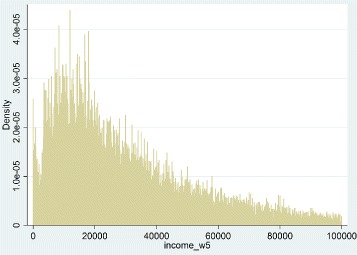
Distribution of income in Europe
Fig. 3.
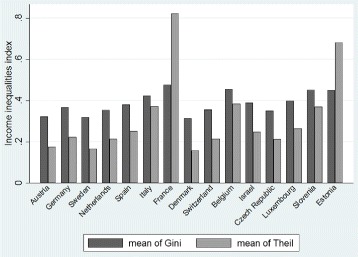
Income inequalities indexes in Europe
The ordered probit model
To model the association between self-perceived health and other socioeconomic status and test the hypotheses, we use an ordered probit specification. When the self-perceived health status outcome is denoted as h i, the model can be stated as:
| 6 |
The latent variable specification of the model that we estimate can be written as:
| 7 |
where is a latent variable which underlies the self-reported health status7; x i is a set of observed socioeconomic variables; and ε i is an individual-specific error term, which is assumed to be normally distributed.
In this data, the latent outcome is not observed. Instead, we observe an indicator of the category in which the latent indicator falls. As a result the observed variable is equal to 1, 2, 3, 4 or 5 for “poor”, “fair”, “good”, “very good” or “excellent” with this probability:
| 8 |
The interval decision rule is:
h i=1 if ;
h i=2 if ;
h i=3 if ;
h i=4 if ;
h i=5 if .
In this model, the threshold values (μ 1,μ 2,μ 3,μ 4) are unknown. We do not know the value of the index necessary to shift from very good to excellent. In theory, the threshold values are different for everyone.
Results
Economic results and discussion
Table 1 reports coefficient estimates for all estimated ordered probit models when income inequalities are measured using the Theil index.8 The fifth wave gives us access to 63,626 observations and we also display results of the pooled database for sake of robustness (see Table 6 in the Appendix section). Results in the first column reports the estimated coefficients for the absolute income hypothesis while results in columns two and three provide tests of both the strong version and the weak version of the income inequality hypothesis.
Table 1.
Results of the ordered probit regressions for Wave 5
| Variables | Absolute income | IIH | |
|---|---|---|---|
| Hypothesis | Strong version | Weak version | |
| Income | |||
| Income squared | |||
| Quintiles of income: Reference - Q5 | |||
| Quintile 1 | |||
| Quintile 2 | |||
| Quintile 3 | |||
| Quintile 4 | |||
| Index of inequalities (II) - Theil | |||
| Interaction quintile 1 and II | |||
| Interaction quintile 2 and II | |||
| Interaction quintile 3 and II | |||
| Interaction quintile 4 and II | |||
| GDP | |||
| Age | |||
| Age squared | |||
| Years of education | |||
| Gender =1 if women | |||
| Marital Status: Reference - Married | |||
| Registered partnership | |||
| Married, not living with spouse | |||
| Never married | |||
| Divorced | |||
| Widowed | |||
| Job Situation: Reference Retired | |||
| Employed | |||
| Unemployed | |||
| Permanently sick | |||
| Home-maker | |||
| Other | |||
| Mechanisms IIHs: | |||
| 1 st: % Health expenditure in GDP | |||
| 2 nd: Received help from others | |||
| 2 nd bis: Given help from others | |||
| 3 rd: Life satisfaction | |||
| Cut-point μ 1 | |||
| Cut-point μ 2 | |||
| Cut-point μ 3 | |||
| Cut-point μ 4 | |||
| ME at mean of absolute income on: | |||
| Pr(Poor health) | |||
| Pr(Fair health) | |||
| Pr(Good health) | |||
| Pr(Very good health) | |||
| Pr(Excellent health) | |||
For AIH, dummies for countries are included but not reported, and available upon request
***: 1% significant; **: 5% significant; *: 10% significant. Standard deviations are in parentheses, below the coefficients.
Coefficients of individual income and income squared provide support for all the hypotheses that there is a positive and concave relationship between income and self-perceived health status. Indeed, coefficients associated to the income variable are all positive and significant and coefficients associated to the income squared variable are all negative and significant. This implies that higher income is related to a better health outcome. As a result, the absolute income hypothesis is verified. Concerning income inequalities, coefficients on the Theil index in columns two and three are negative and significantly different from zero. This supports evidence of the strong version of income inequality hypothesis stating that an increase in income inequalities is detrimental to all members of a society, i.e. income inequalities and health are negatively related. Indeed concerning this index, zero represents an egalitarian state, thus the negative relationship between self-perceived health and the indicator of income inequalities is in line with health being better if the index is low. However, results in column three do not give support to the weak version of income inequality hypothesis which states that inequalities are more detrimental to the least well-off in a society. Indeed, we introduce individual rank (by country) and an interaction term between the rank and the index of income inequalities to allow a variation between income level and the effect of income inequalities. In the specification, we choose to follow the framework of Mellor and Milyo [27] who introduced interaction terms between the measurement of income inequalities and dummies variables based on quintiles of income (1 for the lowest income group and 5 for the highest, which is a proxy for the rank). In other words, interaction terms indicate the effect of aggregate income inequalities (at the country level) on self-perceived health status between individuals situated at different levels of the income distribution. Concerning the first two interaction terms (II j∗Q1 and II j∗Q2), these indicate the effect of aggregate income inequalities (at the country level) on self-perceived health status between the poorest individuals (situated at the lower end of the income distribution) and the richest ones (reference category corresponding to individuals situated at the top of the income distribution). These coefficients are positive and statistically significant, meaning that for the poorest individuals (compared to more well-off individuals), an increase in income inequalities in their country increases self-perceived health status, which is in contradiction with the weak version of the income inequality hypothesis. Concerning the two other interaction terms (third and fourth quintiles, representing people at the middle and almost top of the income distribution), coefficients are not statistically significant meaning that middle and higher income people are not affected at all by an increase in income inequalities. This claim does not support the weak version because this hypothesis states that people at the lower end are the most affected by an increase in income inequalities compared to people at the top of the income distribution. As a result, higher income people should also be affected by income inequalities (at a lower rate). Our qualitative results suggest that for low-income individuals, an increase in income inequalities in their country is positively related to report a better health status. Furthermore, for higher income individuals, an increase in income inequalities in their country is not related to report neither a better nor a lower health status. To conclude, our results do not support the weak version of income inequality hypothesis, but it further invalidates this weak version because our qualitative results quite claim the opposite.
Regarding the mechanisms of Kawachi and Kennedy [18] (Table 1, column two), the disinvestment in human capital (first mechanism) is characterized by the percentage of health expenditure in the GDP.9 The coefficient associated is positively correlated to health meaning that when governments increase health spending, this has a positive effect on individual health. For the second mechanism, we want to illustrate the interaction between individuals to represent the erosion of social capital. As a result, we choose a variable from the SHARE survey: “received help from others”. The coefficient associated to this variable is negative and significant. We can explain this negative association by saying that people who are in bad health are the ones who receive help. In order, to legitimize this explanation, we also do the estimation with the “reverse variable”: “given help to others”. In this case, the coefficient is positive and significant proving that people in good health offer their help. Then, the last mechanism is about social comparisons. The coefficient associated to this variable (“life satisfaction”) is positively linked to health which implies that when individuals are satisfied with their life, they also report having a good health.
In sum, our baseline specifications provide evidence of a statistically significant association between income, income inequalities and health since results are robust to model specifications.
Robustness checks
As a sake of robustness, we also make our entire analysis using the pooled database (see Table 6 in the Appendix section) and the results are very similar to the ones obtained with the fifth wave of the survey.
To give more support to the concavity assumption, we compute, for all three hypotheses, the marginal effects at mean10 of income on the five outcomes. Results, reported at the end of Table 1, are all significant. On one hand, for the first two outcomes, income has a negative effect on the probability to report either a poor health or a fair health status. On the other hand, there is a positive effect of income on the probability to report being in a good, very good and excellent health (outcomes three to five). These results are obtained following the ordered probit regressions of the three hypotheses, where the quadratic effect of income is investigated (see Eqs. 1, 2 and 3). These results do not validate the concavity assumption but they do show the increasing effect of income on self-perceived health status. We also plot the average marginal effect of income on each outcome for all individuals with a confidence interval, in order to give more support to the concavity effect in the three hypotheses (see Fig. 4). We restrict ourselves to individuals who earn less than 200,000€ per year (which corresponds to more than 99% of the distribution, see Table 4 in the Appendix section for further information on the distribution of income). The following graphs (Fig. 4) concern the absolute income hypothesis.11 Graph 4a gives the impact of income on the probability to report a poor health. This impact is negative (y-axis is negative), meaning that when income raises, the probability decreases. In addition, the negative impact is stronger for the majority of the population than for individuals who earn very high incomes. In other words, for low incomes, in absolute terms, an additional increase in income has a larger impact on the probability of reporting a poor health than for very high income. This is a low support for the concavity assumption. Graph 4b gives the impact of income on the probability of reporting a fair health status. Conclusion are similar to the ones of graph 4a since the effect is negative. The slight decreases of the curve at the beginning does not impact the conclusion and can be related to large confidence intervals. Graph 4c gives the impact of income on the probability to report a good health status. For almost all the distribution, when income raises, the probability increases. Then, graphs 4d and 4e are more conclusive. Indeed, graph 4d gives the impact of income on the probability to have a very good health. For more than 99% of the income distribution, this impact is positive and decreasing, which might support the concavity assumption. Finally, graph 4e gives the impact of income on the probability of reporting an excellent health status. As previously, when income increases, the probability to have an excellent health increases. However, when we look at people with very high incomes12, this impact is greater than for the majority of individuals.
Fig. 4.
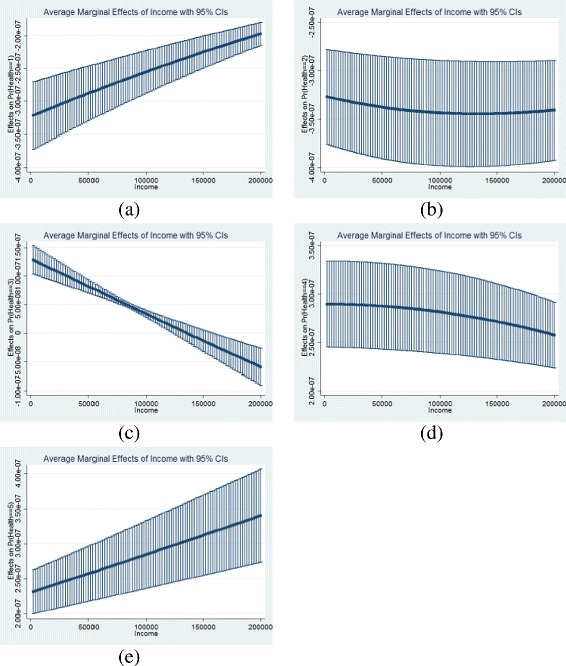
Average marginal effects of income on health - Absolute Income Hypothesis. a Probability to report a poor health; b Probability to report a fair health; c Probability to report a good health; d Probability to report a very good health; e Probability to report an excellent health
Finally, it is important to investigate the robustness of our results by taking into account the subjective nature of the self-perceived health status. Indeed, our baseline specification depends on a dependent variable which is subjective. Self-reported measures give a good amount of information about individual health since people summarize all the health information they have from their practitioners (general practitioners and specialists) and from what they feel [1]. The use of this measure in our specification raises the problem of interpersonal comparisons between people aged 50 and over (“Is the way I consider “good health” the same as you consider this health commodity?”. Empirical studies on the relationship between health, income and income inequalities commonly use ordered probit models where the thresholds are constant by assumption. However, one limit is that it restricts the marginal probability effects. In fact the distributional effects are restricted by the specific structure. Then, another limit is that additional individual heterogeneity between individual realizations is not allowed by the distributional assumption. Thus, Boes and Winkelmann [2] and Jones and Schurer [16] both give a solution to these issues with the use of the generalized ordered probit model since it is based on a latent threshold where the thresholds themselves are linear function of the explanatory variables. In other words, previous thresholds of Eq. 8 are now computed by selecting individual characteristics so that they depend on covariates:
| 9 |
where γ j is a vector of response specific parameters. We have:
| 10 |
where C j is the class. With this model, the probabilities are:
| 11 |
Now, the effects of covariates on the log-odds are category-specific and this model allows to have more heterogeneity across individuals. Results concerning the generalized ordered probit model are similar to those obtained from the ordered probit model. All the effects are estimated around each four cut-points (from poor to fair, from fair to good, from good to very good, and from very good to excellent). For all the hypotheses (absolute income hypothesis - Appendix: Table 7, income inequality hypothesis, both versions - Tables 8 and 9 in the Appendix part), the coefficients associated to the variables of interest (income and income squared) do not change significantly in comparison to the results with the ordered probit model. Results are consistent (either with the Theil index or the Gini coefficient for the income inequality hypothesis) as this is proved in previous study [22]. In fact, in the four cut-points, the results legitimize the concavity assumption of income since the coefficients are statistically significant. Moreover, the index of income inequalities is negative and significant which is in line with the strong version of the income inequality hypothesis. Then, concerning the interaction terms, these are not significant for all quintile groups which do not justify the weak version of income inequality hypothesis. Finally, adding some heterogeneity in this model and taking into account the issues of interpersonal comparisons do not modify our previous results.
Conclusion
In this study we underline the hypotheses through which health is associated to income and income inequalities. The aim of this paper is to empirically investigate the evidence for the absolute income hypothesis and both the strong and the weak versions of the income inequality hypothesis for people aged 50 and over in Europe, using data from the SHARE survey. Indeed, we review the relationship on income-related health inequalities where we mention the literature as well as the theoretical and statistical tools needed to carry out this research. Then we present the data used and some descriptive statistics. Finally we show the model specification, the results of the three hypotheses and some robustness tests. This whole work, both the literature study and the establishment of various models led us to estimate different assumptions on the relationship between health and income. This study is one of the first analyzing this relationship through different hypotheses at the same time using the SHARE survey which is a rich database, containing a lot of information on elderly people and countries simultaneously.
We find evidence supporting the absolute income hypothesis which states that people with higher incomes have better health outcomes. We also find evidence supporting the strong version of income inequality hypothesis which argues that inequality affects all members in a society equivalently. In this hypothesis, we find that when there are high income inequalities in a country, people aged 50 and over feel less healthy. However, we do not find evidence supporting the weak version of income inequality hypothesis which states that only the least well-off are hurt by income inequalities in a society. This hypothesis underlines the fact that income inequalities are more detrimental for the health of people with low incomes. Our qualitative results suggest that for low-income individuals, an increase in income inequalities in their country is positively related to report a better health status. Furthermore, for higher income individuals, an increase in income inequalities in their country is not related to report either a better or a lower health status. One limitation is the used of cross-sectional data without investigating possible endogeneity issues. Thus our results highlight statistical associations rather than causal effects. Finally, by implementing the generalized ordered probit, we control for potential problems of interpersonal comparisons and the results are very similar to those found with the ordered probit model.
Results concerning the hypotheses are consistent with the concavity assumption of income on health. Extension would be to highlight causal effects, using other methods, in order to support some political implication. In fact, what is important in determining the health status is more how income is distributed in a society and less the overall health of this society. As a result, the more equally income is distributed, the better the overall health in this society. Concerning political implication, one way to improve health might be to take measures using the redistribution of incomes as a lever. In fact, Lynch et al. [24] argue that, redistributive fiscal and tax policies will help the governments to achieve better population health. Deaton [11] explains that if income inequalities affect health, transfer policies that affect the distribution of incomes would have good effects through individual levels of health. There will be like a virtuous circle in which incomes influence the health status (improving the production possibilities of the economy can be achieved by improving the health) which in turn affects the income.
Endnotes
1 In this way, redistributing income from rich people to poor people will have an important and positive impact on the health of the poorer people, whereas the richer ones will experience a small decrease in their health.
2 Such as age, gender, number of years of education, marital status and the job situation. It can also contain countries dummies variables.
3 See http://ec.europa.eu/ for an explanation of the European Innovation Partnership on Active and Healthy Ageing - A Europe 2020 initiative.
4 After wave four was completed, the average retention rate over the year was 81%.
5 For instance, if 50 percent of the population has no income and the other half has the same income, the Gini index is 0.5. The same result can be found with the following analysis which is less unequal. On one hand, 25 percent of total income is shared in the same way by 75 percent of the population, and on he other hand, the remaining 25 percent of the total income is divided by the remaining 25 percent of the population.
6 It is this normalized index that we use hereafter and that we name the Theil index.
7 Once crosses a certain value you report fair, then poor, then good, then very good, then excellent health.
8 Results associated to the Gini coefficient are not provided here but they are very similar and available upon request.
9 Source: OECD website.
10 We look at the average individual of the database and compute the marginal effects.
11 We do not include the ones for the income inequality hypothesis (both versions) since the results are very similar and do not change the main conclusion, but these are available upon request.
12 In this case, people with very high incomes are individuals who earn more than 150,000€ per year, corresponding to less than 2% of the sample.
Table 2.
Descriptive statistics of the variables
| Variables | Mean | Standard deviation | Minimum | Maximum |
|---|---|---|---|---|
| Health | ||||
| Self-perceived health status (N=63626) | 2.85 | 1.09 | 1 | 5 |
| Inequalities | ||||
| Gini per country | 0.39 | 0.05 | 0.31 | 0.48 |
| Theil per country | 0.33 | 0.19 | 0.16 | 0.82 |
| Other Variables | ||||
| Income | 36,621.21 | 71,863.78 | 2 | 1.00e+07 |
| GDP per country (2013 - Dollar US/capita) | 39,726.43 | 11,543.57 | 26,160.08 | 92,781.41 |
| Education | 11.12 | 4.28 | 1 | 25 |
| Age | 67.12 | 10.06 | 50 | 103 |
Table 3.
Detailed descriptive statistics for the health
| Health | Percentage of people |
|---|---|
| Poor (1) | 10.81% |
| Fair (2) | 27.01% |
| Good (3) | 36.52% |
| Very Good (4) | 17.58% |
| Excellent (5) | 8.18% |
Table 4.
Detailed descriptive statistics for income
| Distribution | Income |
|---|---|
| 5% | 3,828.99 |
| 25% | 12,446 |
| 50% | 24,659.55 |
| 75% | 46,200 |
| 95% | 103,897.2 |
Table 5.
Detailed descriptive statistics for the countries
| Country | Percentage of people* | GDP - 2013** | Indexes of inequality*** | |
|---|---|---|---|---|
| Theil index | Gini index | |||
| Austria | 6.54% | 45 132.54 | 0.1762 | 0.3222 |
| Germany | 8.71% | 43 282.31 | 0.2234 | 0.3672 |
| Sweden | 7.06% | 44 585.87 | 0.1672 | 0.3183 |
| Netherlands | 6.42% | 46 749.31 | 0.2152 | 0.3543 |
| Spain | 9.75% | 33 111.45 | 0.2521 | 0.3813 |
| Italy | 6.88% | 34 836.43 | 0.373 | 0.4239 |
| France | 6.86% | 37 617.06 | 0.8224 | 0.4772 |
| Denmark | 6.37% | 43797.23 | 0.1578 | 0.3138 |
| Switzerland | 4.62% | 56 896.91 | 0.2144 | 0.3554 |
| Belgium | 8.66% | 41 863.94 | 0.3849 | 0.4545 |
| Czech Republic | 8.7% | 28 962.64 | 0.2123 | 0.3512 |
| Luxembourg | 2.5% | 92 781.4 | 0.2649 | 0.3979 |
| Israel | 3.56% | 32 504.72 | 0.2475 | 0.3906 |
| Slovenia | 4.51% | 28 675.43 | 0.3696 | 0.451 |
| Estonia | 8.88% | 26 160.08 | 0.6816 | 0.4497 |
*: From each country in the full sample
**: Gross Domestic Product, Total dollar US/capita
***: Values
Appendix
Descriptive Statistics
Additional Econometric Results
Table 6.
Results of the ordered probit regressions for the pooled database
| Variables | Absolute Income | IIH | |
|---|---|---|---|
| Hypothesis | Strong Version | Weak Version | |
| Income | |||
| Income squared | |||
| Quintiles of income: Reference - Q5 | |||
| Quintile 1 | |||
| Quintile 2 | |||
| Quintile 3 | |||
| Quintile 4 | |||
| Index of inequalities (II) - Theil | |||
| Interaction quintile 1 and II | |||
| Interaction quintile 2 and II | |||
| Interaction quintile 3 and II | |||
| Interaction quintile 4 and II | |||
| Interaction quintile 5 and II | Reference | ||
| GDP | |||
| Age | |||
| Age squared | |||
| Years of education | |||
| Gender =1 if women | |||
| Marital Status: Reference - Married | |||
| Registered partnership | |||
| Married, not living with spouse | |||
| Never married | |||
| Divorced | |||
| Widowed | |||
| Waves: Reference - Wave 5 | |||
| Wave 1 | |||
| Wave 2 | |||
| Wave 4 | |||
| Cut-point μ 1 | |||
| Cut-point μ 2 | |||
| Cut-point μ 3 | |||
| Cut-point μ 4 | |||
For AIH, dummies for countries are included but not reported, and available upon request
***: 1% significant; **: 5% significant; *: 10% significant. Standard deviations are in parentheses, below the coefficients
Table 7.
Absolute Income Hypothesis - Generalized ordered probit (Wave 5)
| Variables | Health commodities | |||
|---|---|---|---|---|
| 1 to 2 | 2 to 3 | 3 to 4 | 4 to 5 | |
| Income | 1.99e-06 *** | 2.25e-06 *** | 3.68e-06 *** | 3.81e-06 *** |
| (2.76e-07) | (2.00e-07) | (2.44e-07) | (4.44e-07) | |
| Income squared | -2.11e-13 *** | -7.96e-13 *** | -3.26e-13 *** | -5.41e-12 *** |
| (2.90e-14) | (1.17e-13) | (4.71e-13) | (1.55e-12) | |
| Age | 0.037 *** | 0.037 *** | 0.026 *** | 0.029 *** |
| (0.01) | (0.008) | (0.009) | (0.012) | |
| Age squared | -0.0004 *** | -0.0004 *** | -0.0004 *** | -0.0003 *** |
| (0.0001) | (0.0001) | (0.0001) | (0.0001) | |
| Years of education | 0.031 *** | 0.038 *** | 0.036 *** | 0.024 *** |
| (0.002) | (0.001) | (0.001) | (0.002) | |
| Gender =1 if women | 0.066 *** | -0.014 | -0.005 | -0.002 ** |
| (0.016) | (0.012) | (0.012) | (0.016) | |
| Marital Status: | ||||
| Married, living with spouse | Reference group | |||
| Registered partnership | -0.063 | -0.093 ** | 0.029 | -0.027 |
| (0.069) | (0.046) | (0.045) | (0.057) | |
| Married, not living with spouse | -0.251 *** | -0.112 ** | -0.0001 | 0.118 * |
| (0.062) | (0.049) | (0.053) | (0.069) | |
| Never married | -0.048 | -0.068 *** | -0.038 | -0.065 * |
| (0.032) | (0.024) | (0.026) | (0.035) | |
| Divorced | -0.157 *** | -0.059 *** | 0.05 *** | 0.06 ** |
| (0.026) | (0.019) | (0.021) | (0.027) | |
| Widowed | -0.017 | -0.026 | 0.002 | -0.015 |
| (0.021) | (0.017) | (0.02) | (0.029) | |
| Job Situation: | ||||
| Retired | Reference group | |||
| Employed | 0.398 *** | 0.312 *** | 0.203 *** | 0.174 *** |
| (0.029) | (0.019) | (0.019) | (0.025) | |
| Unemployed | -0.222 *** | -0.191 *** | -0.233 *** | -0.126 ** |
| (0.047) | (0.035) | (0.038) | (0.053) | |
| Permanently sick | -1.196 *** | -1.268 *** | -1.307 *** | -0.963 *** |
| (0.033) | (0.038) | (0.054) | (0.076) | |
| Home-maker | -0.088 *** | -0.052 ** | -0.047 * | -0.006 |
| (0.029) | (0.022) | (0.025) | (0.035) | |
| Other | -0.354 *** | -0.173 *** | -0.145 *** | -0.017 |
| (0.041) | (0.037) | (0.046) | (0.064) | |
Dummies for countries are included but not reported, and available upon request
***: 1% significant; **: 5% significant; *: 10% significant
1 to 2: Poor to Fair; 2 to 3: Fair to Good; 3 to 4: Good to VG; 4 to 5: VG to Excellent
Table 8.
IIH, strong version - Generalized ordered probit (Wave 5)
| Variables | Health commodities | |||
|---|---|---|---|---|
| 1 to 2 | 2 to 3 | 3 to 4 | 4 to 5 | |
| Income | 1.75e-06 *** | 2.34e-06 *** | 3.89e-06 *** | 3.20e-06 *** |
| (2.69e-07) | (1.97e-07) | (2.38e-07) | (4.42e-07) | |
| Income squared | -1.89e-13 *** | -8.28e-13 *** | -3.75e-12 *** | -5.18e-12 *** |
| (2.82e-14) | (1.18e-13) | (4.72e-13) | (1.60e-12) | |
| Index of inequalities (Theil) | -0.095 ** | -0.369 *** | -0.7389 *** | -0.4746 *** |
| (0.041) | (0.031) | (0.035) | (0.048) | |
| Mechanisms: | ||||
| 1st: % Health exp. in the GDP | 0.059 *** | 0.087 *** | 0.073 *** | 0.082 *** |
| (0.005) | (0.004) | (0.004) | (0.006) | |
| 2nd: Received help from others | -0.214 *** | -0.193 *** | -0.134 *** | -0.089 *** |
| (0.009) | (0.008) | (0.009) | (0.013) | |
| 2nb bis: Given help to others | 0.001 *** | 0.001 *** | 0.001 *** | 0.001 *** |
| (0.0001) | (0.0001) | (0.0001) | (0.0001) | |
| 3rd: Life satisfaction | 0.195 *** | 0.215 *** | 0.239 *** | 0.238 *** |
| (0.004) | (0.003) | (0.004) | (0.006) | |
| GDP | 2.52e-06 *** | 1.41e-06 ** | -4.87e-07 | 5.94e-07 |
| (8.66e-07) | (6.04e-07) | (6.36e-07) | (8.72e-07) | |
| Age | 0.019 * | 0.004 | 0.013 | 0.019 * |
| (0.01) | (0.008) | (0.009) | (0.012) | |
| Age squared | -0.0003 *** | -0.0002 *** | -0.0003 *** | -0.0003 *** |
| (0.0001) | (0.0001) | (0.0001) | (0.0001) | |
| Years of education | 0.025 *** | 0.029 *** | 0.028 *** | 0.021 *** |
| (0.002) | (0.001) | (0.0014) | (0.0018) | |
| Gender =1 if women | 0.069 *** | -0.018 | -0.003 | -0.0004 |
| (0.016) | (0.012) | (0.012) | (0.016) | |
| Marital Status: | ||||
| Married, living with spouse | Reference group | |||
| Registered partnership | -0.023 | -0.053 | 0.034 | 0.014 |
| (0.071) | (0.047) | (0.045) | (0.058) | |
| Married, not living with spouse | -0.131 ** | 0.005 | 0.091 * | 0.122 * |
| (0.065) | (0.051) | (0.054) | (0.072) | |
| Never married | 0.033 | 0.023 | 0.064 ** | 0.001 |
| (0.034) | (0.025) | (0.027) | (0.036) | |
| Divorced | -0.046 * | 0.062 *** | 0.166 *** | 0.122 *** |
| (0.028) | (0.021) | (0.022) | (0.028) | |
| Widowed | 0.053 ** | 0.069 *** | 0.076 *** | 0.022 |
| (0.023) | (0.018) | (0.022) | (0.031) | |
| Job Situation: | ||||
| Retired | Reference group | |||
| Employed | 0.344 *** | 0.225 *** | 0.177 *** | 0.176 *** |
| (0.03) | (0.019) | (0.019) | (0.025) | |
| Unemployed | -0.141 *** | -0.097 *** | -0.11 *** | 0.012 |
| (0.048) | (0.035) | (0.039) | (0.054) | |
| Permanently sick | -1.016 *** | -1.121 *** | -1.098 *** | -0.744 *** |
| (0.034) | (0.034) | (0.056) | (0.084) | |
| Home-maker | -0.074 *** | -0.033 | -0.076 *** | -0.044 |
| (0.029) | (0.022) | (0.025) | (0.035) | |
| Other | -0.299 *** | -0.114 *** | -0.09 * | 0.048 |
| (0.043) | (0.038) | (0.048) | (0.067) | |
***: 1% significant; **: 5% significant; *: 10% significant
1 to 2: Poor to Fair; 2 to 3: Fair to Good; 3 to 4: Good to VG; 4 to 5: VG to Excellent
Table 9.
IIH, weak version - Generalized ordered probit (Wave 5)
| Variables | Health commodities | |||
|---|---|---|---|---|
| 1 to 2 | 2 to 3 | 3 to 4 | 4 to 5 | |
| Income | 1.97e-06 *** | 3.03e-06 *** | 5.92e-06 *** | 7.65e-06 *** |
| (3.06e-07) | (2.43e-07) | (3.15e-07) | (6.10e-07) | |
| Income squared | -2.09e-13 *** | -1.14e-12 *** | -6.03e-12 *** | -1.60e-11 *** |
| (3.17e-14) | (1.25e-13) | (5.21e-13) | (1.92e-12) | |
| Index of inequalities (Theil) | -0.319 *** | -0.79 *** | -1.077 *** | -0.899 *** |
| (0.101) | (0.065) | (0.065) | (0.084) | |
| Quintile 1 | -0.145 *** | -0.195 *** | -0.003 | 0.07 |
| (0.055) | (0.039) | (0.043) | (0.059) | |
| Quintile 2 | -0.099 * | -0.159 *** | -0.014 | 0.079 |
| (0.054) | (0.038) | (0.039) | (0.059) | |
| Quintile 3 | -0.061 | -0.043 | 0.018 | 0.025 |
| (0.054) | (0.037) | (0.037) | (0.047) | |
| Quintile 4 | -0.012 | -0.02 | 0.055 | 0.023 |
| (0.056) | (0.036) | (0.034) | (0.043) | |
| Quintile 5 | Reference group | |||
| Interaction quintile 1 and II | -0.204 * | 0.079 | -0.039 | 0.084 |
| (0.12) | (0.088) | (0.107) | (0.147) | |
| Interaction quintile 2 and II | -0.162 | 0.097 | 0.048 | 0.029 |
| (0.123) | (0.087) | (0.101) | (0.138) | |
| Interaction quintile 3 and II | -0.163 | -0.048 | -0.013 | 0.144 |
| (0.125) | (0.088) | (0.098) | (0.129) | |
| Interaction quintile 4 and II | -0.058 | 0.066 | 0.001 | 0.098 |
| (0.132) | (0.088) | (0.093) | (0.124) | |
| Interaction quintile 5 and II | Reference group | |||
| GDP | 0.0001 *** | 9.96e-06 *** | 3.83e-06 *** | 2.17e-06 *** |
| (8.30e-07) | (6.31e-07) | (6.99e-07) | (9.91e-07) | |
| Age | 0.034 *** | 0.023 *** | 0.029 *** | 0.034 ** |
| (0.01) | (0.008) | (0.008) | (0.011) | |
| Age squared | -0.0004 *** | -0.0003 *** | -0.0004 *** | -0.0004 *** |
| (0.0001) | (0.0001) | (0.0001) | (0.0001) | |
| Years of education | 0.025 *** | 0.029 *** | 0.028 *** | 0.022 *** |
| (0.002) | (0.001) | (0.001) | (0.002) | |
| Gender =1 if women | 0.066 *** | -0.016 | 0.0004 | 0.007 |
| (0.015) | (0.011) | (0.012) | (0.016) | |
| Marital Status: | ||||
| Married, living with spouse | Reference group | |||
| Registered partnership | 0.053 | 0.023 | 0.075 * | 0.049 |
| (0.067) | (0.045) | (0.044) | (0.056) | |
| Married, not living with spouse | -0.203 *** | -0.091 * | -0.014 | 0.052 |
| (0.061) | (0.049) | (0.052) | (0.068) | |
| Never married | 0.034 | 0.014 | 0.042 | -0.008 |
| (0.033) | (0.024) | (0.026) | (0.035) | |
| Divorced | -0.079 *** | 0.009 | 0.107 *** | 0.085 *** |
| (0.027) | (0.02) | (0.021) | (0.027) | |
| Widowed | 0.024 | 0.015 | 0.019 | -0.015 |
| (0.022) | (0.018) | (0.021) | (0.029) | |
| Job Situation: | ||||
| Retired | Reference group | |||
| Employed | 0.374 *** | 0.251 *** | 0.206 *** | 0.188 *** |
| (0.029) | (0.019) | (0.018) | (0.024) | |
| Unemployed | -0.188 *** | -0.169 *** | -0.221 *** | -0.128 ** |
| (0.046) | (0.034) | (0.038) | (0.053) | |
| Permanently sick | -1.162 *** | -1.262 *** | -1.245 *** | -0.923 *** |
| (0.032) | (0.033) | (0.054) | (0.08) | |
| Home-maker | -0.062 ** | -0.021 | -0.081 *** | -0.069 ** |
| (0.027) | (0.021) | (0.024) | (0.034) | |
| Other | -0.317 *** | -0.152 *** | -0.148 *** | -0.017 |
| (0.041) | (0.037) | (0.046) | (0.064) | |
***: 1% significant; **: 5% significant; *: 10% significant
1 to 2: Poor to Fair; 2 to 3: Fair to Good; 3 to 4: Good to VG; 4 to 5: VG to Excellent
Acknowledgements
“This paper uses data from SHARE Waves 1, 2, 4 and 5 (DOIs: 10.6103/SHARE.w1.260, 10.6103/SHARE.w2.260, 10.6103/SHARE.w4.111, 10.6103/SHARE.w5.100). The SHARE data collection has been primarily funded by the European Commission through FP5 (QLK6-CT-2001- 00360), FP6 (SHARE-I3: RII-CT-2006-062193, COMPARE: CIT5-CT-2005-028857, SHARELIFE: CIT4-CT-2006- 028812) and FP7 (SHARE-PREP: N 211909, SHARE-LEAP: N 227822, SHARE M4: N 261982). Additional funding from the German Ministry of Education and Research, the U.S. National Institute on Ageing (U01 AG09740-13S2, P01 AG005842, P01 AG08291, P30 AG12815, R21 AG025169, Y1-AG-4553-01, IAG BSR06-11, OGHA 04-064) and from various national funding sources is gratefully acknowledged (see www.share-project.org).”
We thank participants of the 5th SHARE User’s Conference, the EuHEA conference and the third EuHEA PhD student and supervisor conference, Fabian Gouret and Toni Mora for their helpful comments, as well as Richard Moussa for technical support. We also want to thank two anonymous referees who made very interesting comments.
Authors’ contributions
The authors did the research jointly. Both authors read and approved the final manuscript.
Competing interests
Authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Amélie Adeline, Email: amelie.adeline@u-cergy.fr.
Eric Delattre, Email: eric.delattre@u-cergy.fr.
References
- 1.Benitez-Silva H, Buchinsky M, Man Chan H, Cheidvasser S, Rust J. How large is the bias in self-reported disability? J Appl Econom. 2004;19(6):649–670. doi: 10.1002/jae.797. [DOI] [Google Scholar]
- 2.Boes S, Winkelmann R. Ordered response models. In: Modern Econometric Analysis. Springer. Allgemeines Statistiches Archiv. 2006; 90(1):167–91.
- 3.Börsch-Supan A. Survey of Health, Ageing and Retirement in Europe (SHARE) Wave 5. Release version: 5.0.0. SHARE-ERIC Data set.2016a. doi:10.6103/SHARE.w5.500..
- 4.Börsch-Supan A. Survey of Health, Ageing and Retirement in Europe (SHARE) Wave 1. Release version: 5.0.0. SHARE-ERIC. Data set.2016b. doi:10.6103/SHARE.w1.500.
- 5.Börsch-Supan A. Survey of Health, Ageing and Retirement in Europe (SHARE) Wave 2. Release version: 5.0.0. SHARE-ERIC. Data set.2016c. doi:10.6103/SHARE.w2.500.
- 6.Börsch-Supan A. Survey of Health, Ageing and Retirement in Europe (SHARE) Wave 4. Release version: 5.0.0. SHARE-ERIC. Data set.2016d. doi:10.6103/SHARE.w4.500.
- 7.Börsch-Supan A, Brandt M, Hunkler C, Kneip T, Korbmacher J, Malter F, Schaan B, Stuck S, Zuber S. Data Resource Profile: the Survey of Health, Ageing and Retirement in Europe (SHARE) Int J Epidemiol. 2013;42(4):992–1001. doi: 10.1093/ije/dyt088. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Carrieri V, Jones AM. The income-health relationship “beyond the mean”: New evidence from biomarkers. Health Econ. 2017;26(7):937–56. doi: 10.1002/hec.3372. [DOI] [PubMed] [Google Scholar]
- 9.Cohen S, Line S, Manuck SB, Rabin BS, Heise ER, Kaplan JR. Chronic social stress, social status, and susceptibility to upper respiratory infections in nonhuman primates. Psychosom Med. 1997;59(3):213–21. doi: 10.1097/00006842-199705000-00001. [DOI] [PubMed] [Google Scholar]
- 10.Cutler D, Deaton A, Lleras-Muney A. The determinants of mortality. J Econ Perspect. 2006;20(3):97–120. doi: 10.1257/jep.20.3.97. [DOI] [Google Scholar]
- 11.Deaton A. Health, inequality, and economic development. J Econ Lit. 2003;41(1):113–58. doi: 10.1257/jel.41.1.113. [DOI] [Google Scholar]
- 12.Ettner SL. New evidence on the relationship between income and health. J Health Econ. 1996;15(1):67–85. doi: 10.1016/0167-6296(95)00032-1. [DOI] [PubMed] [Google Scholar]
- 13.Fiscella K, Franks P. Individual income, income inequality, health, and mortality: what are the relationships? Health Serv Res. 2000;35:307–18. [PMC free article] [PubMed] [Google Scholar]
- 14.Grossman M. The relationship between health and schooling: What’s new?Tech. rep. National Bureau of Economic Research. 2015.
- 15.Hildebrand V, Van Kerm P. Income inequality and self-rated health status: evidence from the European Community Household Panel. Demography. 2009;46(4):805–25. doi: 10.1353/dem.0.0071. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Jones AM, Schurer S. How does heterogeneity shape the socioeconomic gradient in health satisfaction? J Appl Econom. 2011;26(4):549–79. doi: 10.1002/jae.1134. [DOI] [Google Scholar]
- 17.Kaplan GA, Pamuk ER, Lynch JW, Cohen RD, Balfour JL. Inequality in income and mortality in the United States: analysis of mortality and potential pathways. Brit Med J. 1996;312(7037):999–1003. doi: 10.1136/bmj.312.7037.999. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Kawachi I, Kennedy BP. Income inequality and health: pathways and mechanisms. Health Serv Res. 1999;34(1):215. [PMC free article] [PubMed] [Google Scholar]
- 19.Kawachi I, Kennedy BP, Lochner K. Prothrow-Stith. Social capital, income inequality, and mortality. Am J Public Health. 1997;87(9):1491–98. doi: 10.2105/AJPH.87.9.1491. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Kennedy BP, Kawachi I, Glass R, Prothrow-Stith D, et al. Income distribution, socioeconomic status, and self rated health in the United States: a multilevel analysis. Brit Med J. 1998;317(7163):917–21. doi: 10.1136/bmj.317.7163.917. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Li H, Zhu Y. Income, income inequality and health: Evidence from china. J Comp Econ. 2006;34(4):668–93. doi: 10.1016/j.jce.2006.08.005. [DOI] [Google Scholar]
- 22.Lindeboom M, Van Doorslaer E. Cut-point shift and index shift in self-reported health. J Health Econ. 2004;23(6):1083–99. doi: 10.1016/j.jhealeco.2004.01.002. [DOI] [PubMed] [Google Scholar]
- 23.Lindelow M. Sometimes more equal than others: how health inequalities depend on the choice of welfare indicator. Health Econ. 2006;15(3):263–279. doi: 10.1002/hec.1058. [DOI] [PubMed] [Google Scholar]
- 24.Lynch J, Smith GD, Harper S, Hillemeier M, Ross N, Kaplan GA, Wolfson M. Is income inequality a determinant of population health? part 1 - A systematic review. Milbank Q. 2004;82(1):5–99. doi: 10.1111/j.0887-378X.2004.00302.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Lynch JW, Kaplan GA, Pamuk ER, Cohen RD, Heck KE, Balfour JL, Yen IH. Income inequality and mortality in metropolitan areas of the united states. Am J Public Health. 1998;88(7):1074–80. doi: 10.2105/AJPH.88.7.1074. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Mackenbach JP. Martikainen P, Looman CW, Dalstra JA, Kunst AE, Lahelma E, Group SW, et al. The shape of the relationship between income and self-assessed health: an international study. Int J Epidemiol. 2005;34(2):286–93. doi: 10.1093/ije/dyh338. [DOI] [PubMed] [Google Scholar]
- 27.Mellor JM, Milyo J. Income inequality and health status in the United States: evidence from the current population survey. J Hum Resour. 2002;37(3):510–39. doi: 10.2307/3069680. [DOI] [Google Scholar]
- 28.Potvin L, Moquet MJ, Jones C. Réduire les inégalités sociales en santé: INPES - coll. Santé en Actions (French national institute on health prevention and education).2010. p. 380.
- 29.Preston SH. The changing relation between mortality and level of economic development. Pop Stud. 1975;29(2):231–48. doi: 10.1080/00324728.1975.10410201. [DOI] [PubMed] [Google Scholar]
- 30.Subramanian S, Kawachi I. Income inequality and health: what have we learned so far? Epidemiol Rev. 2004;26(1):78–91. doi: 10.1093/epirev/mxh003. [DOI] [PubMed] [Google Scholar]
- 31.Theodossiou I, Zangelidis A. The social gradient in health: The effect of absolute income and subjective social status assessment on the individual’s health in Europe. Econ Hum Biol. 2009;7(2):229–237. doi: 10.1016/j.ehb.2009.05.001. [DOI] [PubMed] [Google Scholar]
- 32.Van Doorslaer E, Koolman X, Jones AM. Explaining income-related inequalities in doctor utilisation in Europe. Health Econ. 2004;13(7):629–47. doi: 10.1002/hec.919. [DOI] [PubMed] [Google Scholar]
- 33.Wagstaff A, Van Doorslaer E, Watanabe N. On decomposing the causes of health sector inequalities with an application to malnutrition inequalities in Vietnam. J Econometrics. 2003;112(1):207–23. doi: 10.1016/S0304-4076(02)00161-6. [DOI] [Google Scholar]
- 34.World Health Organization. WHO: Commission on Social Determinants of Health: final report. 2009.