

Abstract
Randomly connected networks of neurons exhibit a transition from fixed-point to chaotic activity as the variance of their synaptic connection strengths is increased. In this study, we analytically evaluate how well a small external input can be reconstructed from a sparse linear readout of network activity. At the transition point, known as the edge of chaos, networks display a number of desirable features, including large gains and integration times. Away from this edge, in the nonchaotic regime that has been the focus of most models and studies, gains and integration times fall off dramatically, which implies that parameters must be fine tuned with considerable precision if high performance is required. Here we show that, near the edge, decoding performance is characterized by a critical exponent that takes a different value on the two sides. As a result, when the network units have an odd saturating nonlinear response function, the falloff in gains and integration times is much slower on the chaotic side of the transition. This means that, under appropriate conditions, good performance can be achieved with less fine tuning beyond the edge, within the chaotic regime.
The dynamic state of a network of neurons influences its information processing capabilities [1]. A network of recurrently connected neurons generates complex dynamics that have been utilized for various computational purposes [2–4]. Large networks of this type exhibit a sharp transition from nonchaotic to chaotic dynamics [5,6], and performance has been characterized as optimal at the edge of this transition [4,7–9]. The location of the transition depends on properties of the inputs to the network [10,11], so maintaining a network right at the edge of chaos would require finely tuning parameters for each input, which is impractical. Therefore, it is important to determine how performance degrades away from this optimal transition point. Here, using a model that is amenable to analytic calculation, we find that, under many circumstances, performance degrades more slowly on the chaotic side of the transition than on the nonchaotic side, showing that it is advantageous to work in the chaotic regime when fine tuning to the edge of chaos cannot be achieved.
Our study is based on a dynamic mean-field calculation applied to randomly connected networks. We compute the signal-to-noise ratio for reconstructing a small external input from a sparse linear readout, a standard network task. This ratio bounds decoding accuracy for both static [12] and dynamic [13] stimuli. To quantify the behavior of the signal-to-noise ratio near the transition point, we evaluate its critical exponents. The analytic expression for the signal-to-noise ratio provides an intuitive picture of the tradeoff between increasing the signal through a larger gain and increasing chaotic noise. The presence of observation noise emphasizes the importance of increasing the signal over decreasing the internally generated noise, providing an advantage to the chaotic state. As outlined above, in the presence of observation noise, the signal-to-noise ratio is maximized at the edge of chaos, where the network time constant shows a critical slowing and small inputs are highly amplified. In addition, at a given distance from the transition point, the chaotic state is often more informative than the nonchaotic state and provides longer-lasting memory.
I. MODEL AND METHOD
We use the dynamic mean-field method [5,10,11,14]to analyze responses of randomly connected networks to external input. For simplicity, we study a discrete-time model with N units. The dynamics of the recurrent input to unit i on trial a (where each trial starts from a different initial condition; what we call trials are also known as replicas) is described by
| (1) |
where Jij is the coupling strength from unit j to unit i,
| (2) |
is an abbreviation used for a saturating response nonlinearity, ϕ, and θ(t) is a spatially uniform external input. Our goal is to determine how accurately and over what time period θ(t) can be decoded from a linear readout of network activity [15,16]. Each coupling strength is independently and randomly drawn from a distribution with zero mean and standard deviation . For the purposes of calculation, we use a Gaussian distribution, but distributions that include a δ function at zero, corresponding to sparse connections, or that have discrete support, corresponding to a finite number of possible connection strengths, give the same results in the limit of large N.
We introduce a mean-field distribution for the set of state variables through a Dirac delta function constraint,
| (3) |
with [·]J denoting an average over random Gaussian couplings. In the following, we make use of two other averages: E[·| J], which is an average over trials with a fixed {Jij}, and E[·] ≡ [E[·| J ]]J. In other words, to compute E[·| J], we average over h using the distribution inside the brackets in Eq. (3), removing the average over {Jij}. To compute E[·], we average over h weighted by the full J-averaged distribution of Eq. (3).
Calculations using the dynamic mean-field method [10,14], in the limit of large N, give the moment-generating function for h (see Appendix A),
| (4) |
where is the parameter of the generating function, f is the free energy, and the order parameters q = {qab(t,s)} and are determined self consistently by the saddle-point equations
| (5) |
In principle, all the moments of h can be obtained by evaluating the derivatives of the generating function. In particular, the average is and the correlation is
| (6) |
All higher-order cumulants above the second order are O(1/N).
When the input is constant in time, the system converges to a stationary state. In this case, the self-consistent solution for the order parameter is determined by only two parameters,
| (7) |
satisfying, self consistenly,
| (8) |
with
| (9) |
For θ = 0, using a hyperbolic tangent nonlinearity ϕ(x) = tanh(x), q = 0 is a stable solution, so the order parameter simplifies to
| (10) |
with q0 increasing from zero in the chaotic region, g>1 [Fig. 1(a)].
FIG. 1.
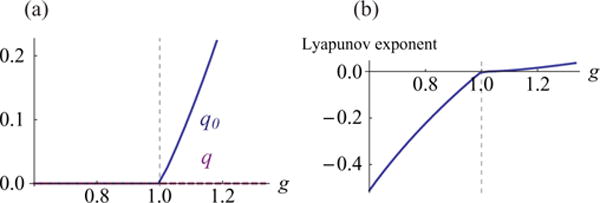
(Color online) The self-consistent solution for the order parameters, q0 and q (which is 0), in the stationary state (a), and the Lyapunov exponent (b) plotted as a function of the synaptic variability, g. The dotted line at g =1 indicates the edge of chaos.
The chaotic state is characterized by a Lyapunov exponent given in Ref. [10]
| (11) |
which increases more rapidly below the transition to chaos (g<1) than above the transition [g>1; Fig. 1(b)]. This difference foreshadows the asymmetric behavior of the signal detection and integration properties analyzed below, but it is important to point out that our later results do not follow directly from this feature of the Lyapunov exponent. The Lyapunov exponent, which determines how two trajectories starting from nearby initial conditions diverge, and the parameter we use to characterize signal detection and integration measure different things and, depending on the nonlinearity used, can take dissimilar values.
II. SIGNAL-TO-NOISE RATIO
We now evaluate the signal-to-noise ratio for sparse linear decoders designed to optimally read out a dynamic input θ(t) from a fixed subset of K(≪N) units. We assume that the measurement of the total input to network unit i on trial a, , is corrupted by Gaussian measurement noise, σobsη, of mean zero and variance , so that the actual measured value is
| (12) |
We limit our analysis to odd nonlinear functions, ϕ(x)= −ϕ(−x), because this simplifies the analysis. To evaluate the signal-to-noise ratio, we consider a small deviation of the external input from θ = 0 occurring at time t0. We could alternatively consider decoding information from the nonlinear function of the total input, ϕ(θ + h)+σobsη, but the result is unaltered to the leading order for finite σobs around the edge of chaos because ϕ(θ + h) ≈ θ + h there.
The average (over networks) signal-to-noise ratio for an optimal linear decoder reading out this perturbation after a measurement period lasting from t0 to T is [12]
| (13) |
where
| (14) |
and the sums over i and j are restricted to the values of the K units being used in the readout. The quantities in R(t)are all evaluated at θ = 0. The matrix D ≡ C−1 is the inverse of the trial-averaged covariance of the observed K units for a given network (i.e., for a specific {Jij}), whose elements are described by
| (15) |
It is important for what follows that this covariance matrix has dimensions K×K, not N×N, and that D is the inverse of this K×K matrix.
The memory curve for an optimal linear decoder, which is sometimes used to quantify the ability of networks to buffer past input [15,16], is identical to Eq. (13) for small input. Equation (13) characterizes the accuracy of a readout based on the trial-mean μ. Generally, information could also be readout from higher-order statistics by using nonlinear decoders [12,17,18]. In this sense, Eq. (13) is a lower bound on the information available from more general nonlinear decoders. Note that the optimal linear readout weights depend on the specific {Jij}, so it is necessary to adjust the decoder for each network.
From the mean-field analysis, we find that each element of the covariance matrix converges to its averaged value in the limit of large N (see Appendix B), i.e.,
| (16) |
with
| (17) |
evaluated at θ = 0. The O(N−1/2) term in Eq. (16) introduces corrections of order into R [Eq. (13)]. To avoid these corrections, we restrict our analysis to the case . This assures that the O (N−1/2), J-specific residuals in Eq. (16) do not contribute to R for large N, and we find
| (18) |
with
| (19) |
for a ≠ b. This means that, to evaluate R, we need to evaluate the second derivative of the order parameter, q. This calculation simplifies for an odd nonlinear response function (see Appendix C), and we obtain
| (20) |
with
| (21) |
which corresponds to g times the effective gain (slope) of the response nonlinearity.
Equation (20) tells us that, at any particular time during the measurement period, R receives a contribution from the past input being detected that decays exponentially in time. The decay constant γ therefore determines the memory lifetime of the network, which is −1/ln(γ), and γ near 1 indicates a long memory lifetime. The denominator in Eq. (20) sums two sources of noise, the measurement noise and internal network noise quantified by q0. The best strategy for increasing R is to minimize the internally generated noise, q0, and to make γ as close to 1 as possible to allow long-time integration of the signal. In the presence of large observation noise σobs ≫q0, the value of R is dominated by how close γ is to 1.
The lifetime variable reaches its maximum value γ = 1 at the edge of chaos and, importantly, it decreases more slowly in the chaotic regime than in the nonchaotic regime (Fig. 2). This indicates that, although optimal performance occurs at the edge of chaos and requires fine tuning of g to 1, for a given magnitude of detuning from this value (i.e., a given |g −1|), γ is closer to 1 in the chaotic regime (g> 1; Fig. 2).
FIG. 2.
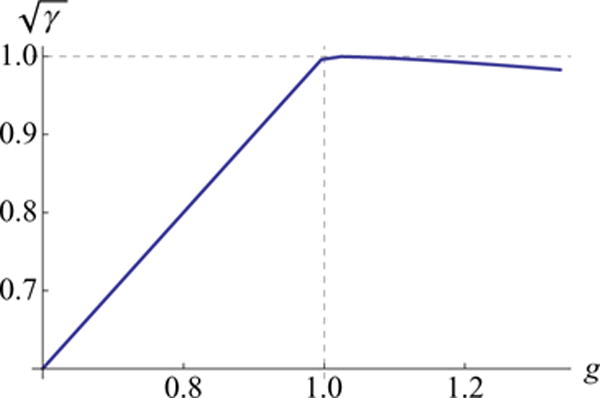
(Color online) The factor plotted for ϕ(x) = tanh(x) as a function of the synaptic variability, g. takes the maximum value of 1 at the edge of chaos (g = 1; dotted line) and falls off more slowly in the chaotic regime (g>1) than for g<1.
Assuming an infinitely long observation period,
| (22) |
which is plotted as a function of g in Fig. 3 for some σobs. When the decay constant γ approaches 1, which happens at the edge of chaos, R diverges because any input perturbations cause perpetually lasting changes in network activity. These analytic results agree well with simulation results (Fig. 4).
FIG. 3.
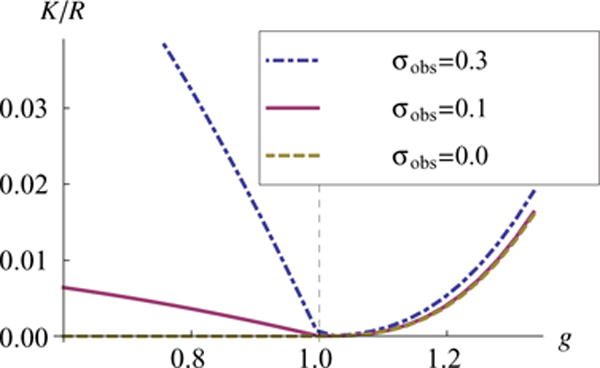
(Color online) The factor K/R plotted for ϕ(x) = tanh(x) as a function of the synaptic variability, g. In the presence of observation noise, R is maximized at the edge of chaos and falls off more slowly in the chaotic regime (g > 1) than for g< 1 reflecting γ shown in Fig. 2.
FIG. 4.
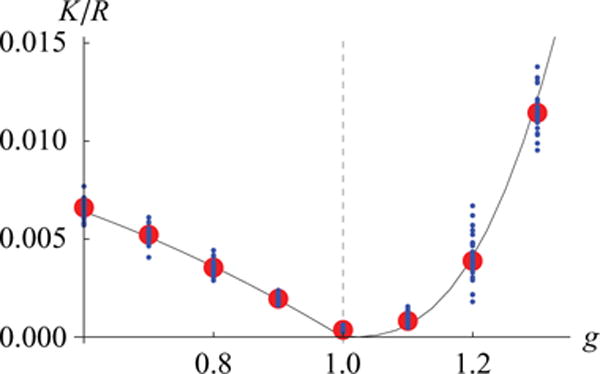
(Color online) Numerical calculation of Eq. (13)(circles) with σobs = 0.1. compared with the analytic result of Eq. (22) (solid line). The numerical result was obtained by linearly decoding a simulated network with N = 3000 and K = 20. The small circles describe performances of each network and the large circles describe the average performance across different networks. The analytic results matched well with the numerical results.
III. CRITICAL BEHAVIOR NEAR THE EDGE OF CHAOS
We next analyze the critical behavior of the system near the edge of chaos. By definition, the derivative of ϕ at 0 is 1, so we can expand any odd, monotonically increasing ϕ as
| (23) |
The Landau expansion of Eq. (8) for small q0 yields that the sign of α3 determines the nature of the phase transition around q0 = 0. The system shows a first-order transition if the nonlinearity is accelerating (α3 > 0). In this case, q0 jumps discontinuously from zero to a positive value at g = 1 as g increases. The transition is second order if the nonlinearity is saturating (α3 < 0). In this case, q0 increases from zero continuously at g = 1 as g increases. The analysis of the critical behavior is much easier for the second-order transition (α3 < 0), the case we examine.
We analyze the critical behavior of R near the edge of chaos, that is, for small Δg≡g −1, using Eqs. (20) and (21). In the nonchaotic regime (Δg < 0), q0 = 0 so the decay factor is γ = g2. From Eq. (22), we find that
| (24) |
In the chaotic regime (Δg > 0), we expand Eq. (8) for small q0 and find that the order parameter is
| (25) |
Based on this expression, the effective gain is to leading order. Hence, to leading order,
| (26) |
near the edge but on the chaotic side. Interestingly, the dependencies of and R on ϕ (such as α3 and α5) disappear up to this order. In contrast to the nonchaotic regime with R ~ Δg−1, the divergence is stronger in the chaotic regime with R ~ Δg−2, yielding larger R at an equal distance, |Δg|, away from the edge (Fig. 5).
FIG. 5.
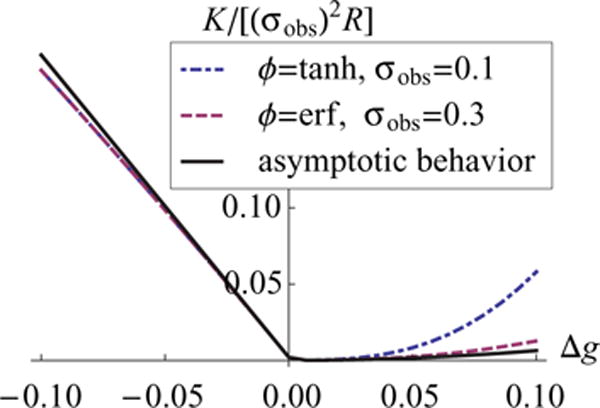
(Color online) The critical behavior of R does not depend on details of the nonlinearity or on the noise level. For any saturating odd nonlinear response function, R diverges linearly on the nonchaotic and quadratically on the chaotic side of the edge or transition. The solid line describes the asymptotic behavior; the dash-dotted line describes ϕ(x) = tanh(x) and σobs = 0.1; and the dashed line describes and σobs = 0.3.
We have determined analytically that the signal-to-noise ratio of large randomly connected networks diverges at the edge of chaos, and the memory lifetime of the network also diverges. Observation noise is an important element for this property. Without observation noise, any network without internally generated noise yields an infinite R. On the other hand, addition of observation noise emphasizes the benefit of increasing signal over increasing internally generated noise. Hence, if a deterministic network performs sensory or memory processing and if a receiver of its output has limited observational resolution, it is advantageous to increase the signal by increasing the network gain. Generally, setting network parameters right at the edge of chaos requires fine tuning. We have shown that at the same small distance away from the edge, R is larger in the chaotic regime than in the nonchaotic regime for any saturating odd nonlinear function.
Although, we have concentrated on a rather special situation in this paper for mathematical simplicity, several lines of generalization are possible without losing analytic tractability. First, we have neglected internal stochastic noise within the network. Although neurons behave irregularly in networks, they respond reliably in isolation. This observation has lead to a speculation that the dominant apparent stochasticity of cortical circuits is generated by the chaotic dynamics of, individually, essentially deterministic neurons [6]. The mean-field analysis with system noise has been studied previously [10]. With an addition of small system noise, R is peaked (but does not diverge) near the edge of chaos on the nonchaotic side. Second, we have concentrated on a class of odd nonlinear response functions. This assumption is a mathematical convenience that simplifies the final expression of R. For a general response nonlinearity, R depends not only on γ and q0 but on other factors as well. Third, although we considered discrete temporal dynamics, it is possible to analyze a continuous-time model in a similar way [5,11]. We believe that qualitative aspects of the signal-to-noise ratio are common in the two models. Fourth, although we consider unstructured networks in this paper, it would be interesting to study how structured connections change chaotic dynamics [19] and influence signal extraction and integration [20].
Acknowledgments
We thank X. Pitkow, M. Tsodyks, K. Kang, and S. Amari for discussions. T.T. was supported by the Patterson Trust and the Special Postdoctoral Research Program at RIKEN. L.F.A. was supported by the National Institutes of Health (NIH) Director’s Pioneer program, part of the NIH Roadmap for Medical Research, through Grant No. 5-DP1-OD114-02, the Gatsby and Swartz Foundations, and the Kavli Institute for Brain Science at Columbia University.
APPENDIX A: MEAN-FIELD CALCULATION
In this appendix, we calculate the moment-generating function of Eq. (4). We denote and . In this section, we follow the convention that summation is implied when the same index appear twice in an expression (e.g., ). A calculation of the moment-generating function (as a function of ξ) yields
| (A1) |
where ,
| (A2) |
and
| (A3) |
Next, we use the saddle-point method to evaluate Z(ξ). To leading order, the integrals of q and are approximated by the saddle-point value, i.e.,
| (A4) |
and the saddle-point, [q(ξ), ], is determined self consistently by solving
| (A5) |
with the average, 〈·〉ℒ, defined as
| (A6) |
Equation (A5) is especially easy to solve when ξ = 0 because is a self-consistent solution of Eq. (A5). To confirm this, we define , and find that
| (A7) |
Hence, when ξ = 0, a solution of the saddle-point condition is
| (A8) |
Note that, in the above expression, describes a Gaussian average of h with mean zero and covariance . The possibility of a solution is not within the scope of this paper (see Ref. [14], for example). Thus, we concentrate on the solution Eq. (A8) in the following.
In principal, we can obtain all higher-order cumulants of h by differentiating the cumulant-generating function ln Z(ξ) = Nf (ξ,q(ξ), by ξ and, then, setting ξ = 0. From the normalization constraint, ln Z(0) = 0. The first derivative is
| (A9) |
because ∂f/∂q = 0 and at the saddle-point Eq. (A5). Hence, the first-order cumulant is
| (A10) |
The calculation of high-order cumulants becomes easier if we neglect O(1/N) factors. First, for n ⩾ 1 at ξ = 0. Moreover, the nth (n ⩾ 1) derivatives of the order parameters are and at ξ = 0 from Eq. (A5). This means that perturbations to a single unit contribute only ~1/N to the mean-field variables, which are defined by averaging over N units. Hence, terms that contain derivatives of order parameters contribute only to O (1 /N) terms. Thus, for the calculation of higher-order cumulants, the full derivatives of ξ can be approximated by its partial derivatives, d/dξ ≈ ∂/∂ξ, and the order parameters can be approximated, using their ξ = 0 values as q(ξ) ≈ q(0) and . Neglecting O(1/N) terms, we find
| (A11) |
This shows that the mean-field distribution P(h) is a Gaussian distribution for independent units with mean zero and covariance up to O(1/N) terms. Hence, to this precision, the two averages E[·] and are indistinguishable.
APPENDIX B: NETWORK SPECIFIC STATISTICS
In this appendix, we evaluate statistics of the state variable, h, for given {Jij}. The trial-mean of a quantity A(h) is written as E[A(h)| J], where each trial has different initial conditions at t→ −∞. When the system is ergodic this trial average does not depend on a specific set of initial conditions. From this definition and Eq. (A11), to the leading order, we can derive the following:
| (B1) |
where a ≠ b, and and . Now we define the network specific covariance as Γij;ts ≡ Cov[hit,hjs|J] and evaluate how Γ is different from one realization of {Jij} to another. The variance of Γ across networks is, from Eq. (A11),
| (B2) |
where a,b,c,d are all different. Therefore, each component of Γ converges to its network average as
| (B3) |
APPENDIX C: PERTURBATION EXPANSION OF THE ORDER PARAMETER
In this appendix, we evaluate the signal component of Eq. (19) by calculating the responses of the order parameter, , to perturbations in the external input, . Dynamic evolution of the order parameter is described by the saddle-point Eq. (A8), which we repeat here for convenience
where . To simplify expressions, we omit the temporal index so that and in the following, and find that, for general smooth functions ϕ and ѱ, the Gaussian integral is expressed as
| (C1) |
with . Note that this expression implies that ha and hb have variances of qaa and qbb, respectively, and covariance qab under the average, . The first derivative of this average is
| (C2) |
with vectors and .
In the second line of Eq. (C2), we used the following relations
| (C3) |
| (C4) |
obtained from integration by parts. Similarly, using Eq. (C2) repeatedly, the second derivative is
| (C5) |
where, applying Eq. (C2) once again to each component of , we find with
| (C6) |
Although we had to distinguish ϕ and ψ to derive Eq. (C5), we only have to consider the derivatives of in the following, so we can replace ψ by ϕ. When the external input is constant in time, the order parameter takes only two distinctive values, in the stationary state [see Eq. (7)]. Moreover, when the response nonlinearity is an odd function and the input is zero, θ = 0, we know that q = 0 is a stable solution. Hence, in this case, it is easy to check that
| (C7) |
for all integers m and n, where ϕ(n) is the nth derivative of ϕ. When θ = 0, the order parameter qab = 0 for a ≠ b, meaning that ha and hb are independent Gaussian random variables of mean zero. In this case, Eq. (C7) results because either ϕ(m) or ϕ(n) (with an even m or n) is an odd function. When a = b, on the other hand, ϕ(m)(ha)ϕ(n)(ha) is an odd function of a Gaussian random variable, ha with zero mean. Using Eq. (C7), Eq. (C2) can be simplified to
| (C8) |
Because , we obtain the self-consistent update equations
| (C9) |
when a = b, and
| (C10) |
when a ≠ b, respectively. We can see from Eq. (C9) and Eq. (C10) that the stability condition of the order parameter is and . Under this stability condition, both dqaa and dqab should converge to zero in time.
Next, we evaluate the quantity of interest: for a ≠ b in Eq. (19). By using a simplified notation for partial derivatives (i.e., ) we find , , and . Furthermore, because ∂qab → 0for large t from Eq. (C9) and Eq. (C10), we can use , , and for sufficiently large t. Hence, from Eq. (C5), the dynamics of the second derivative of the order parameter is
| (C11) |
where Θ(x) is the step function, which is one for x ⩾ 0 and zero otherwise.
References
- 1.Rabinovich MI, Varona P, Selverston AI, Abarbanel HDI. Rev Mod Phys. 2006;78:1213. [Google Scholar]
- 2.Jaeger H, Haas H. Science. 2004;304:78. doi: 10.1126/science.1091277. [DOI] [PubMed] [Google Scholar]
- 3.Maass W, Natschlager T, Markram H. Neural Comput. 2002;14:2531. doi: 10.1162/089976602760407955. [DOI] [PubMed] [Google Scholar]
- 4.Sussillo D, Abbott LF. Neuron. 2009;63:544. doi: 10.1016/j.neuron.2009.07.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Sompolinsky H, Crisanti A, Sommers HJ. Phys Rev Lett. 1988;61:259. doi: 10.1103/PhysRevLett.61.259. [DOI] [PubMed] [Google Scholar]
- 6.van Vreeswijk C, Sompolinsky H. Science. 1996;274:1724. doi: 10.1126/science.274.5293.1724. [DOI] [PubMed] [Google Scholar]
- 7.Bertschinger N, Natschlager T. Neural Comput. 2004;16:1413. doi: 10.1162/089976604323057443. [DOI] [PubMed] [Google Scholar]
- 8.Büsing L, Schrauwen B, Legenstein R. Neural Comput. 2010;22:1272. doi: 10.1162/neco.2009.01-09-947. [DOI] [PubMed] [Google Scholar]
- 9.Schweighofer N, Doya K, Fukai H, Chiron JV, Furukawa T, Kawato M. Proc Natl Acad Sci USA. 2004;101:4655. doi: 10.1073/pnas.0305966101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Molgedey L, Schuchhardt J, Schuster HG. Phys Rev Lett. 1992;69:3717. doi: 10.1103/PhysRevLett.69.3717. [DOI] [PubMed] [Google Scholar]
- 11.Rajan K, Abbott LF, Sompolinsky H. Phys Rev E. 2010;82:011903. doi: 10.1103/PhysRevE.82.011903. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Pouget A, Zhang K, Deneve S, Latham PE. Neural Comput. 1998;10:373. doi: 10.1162/089976698300017809. [DOI] [PubMed] [Google Scholar]
- 13.Rieke F, Warland D, de Ruyter van Steveninck R, Bialek W. Spikes: Exploring the Neural Code. MIT Press; Cambridge: 1996. [Google Scholar]
- 14.Sompolinsky H, Zippelius A. Phys Rev B. 1982;25:6860. [Google Scholar]
- 15.White OL, Lee DD, Sompolinsky H. Phys Rev Lett. 2004;92:148102. doi: 10.1103/PhysRevLett.92.148102. [DOI] [PubMed] [Google Scholar]
- 16.Ganguli S, Huh D, Sompolinsky H. Proc Natl Acad Sci USA. 2008;105:18970. doi: 10.1073/pnas.0804451105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Latham PE, Deneve S, Pouget A. J Physiol Paris. 2003;97:683. doi: 10.1016/j.jphysparis.2004.01.022. [DOI] [PubMed] [Google Scholar]
- 18.Shamir M, Sompolinsky H. Neural Comput. 2004;16:1105. doi: 10.1162/089976604773717559. [DOI] [PubMed] [Google Scholar]
- 19.Tirozzi B, Tsodyks M. Europhys Lett. 1991;14:727. [Google Scholar]
- 20.Barrett DGT, Latham PE. COSYNE. 2010 [Google Scholar]