

Abstract
The prevalence, which is the average fraction of infected nodes, has been studied to evaluate the robustness of a network subject to the spread of epidemics. We explore the vulnerability (infection probability) of each node in the metastable state with a given effective infection rate τ. Specifically, we investigate the ranking of the nodal vulnerability subject to a susceptible-infected-susceptible epidemic, motivated by the fact that the ranking can be crucial for a network operator to assess which nodes are more vulnerable. Via both theoretical and numerical approaches, we unveil that the ranking of nodal vulnerability tends to change more significantly as τ varies when τ is smaller or in Barabási-Albert than Erdős-Rényi random graphs.
Introduction
The continuous outbreaks of epidemic diseases in a population and viruses in computer networks1–4 motivate the study of epidemic spreading on a network. The Susceptible-Infected-Susceptible (SIS) epidemic process5–12 has been widely studied as a model of virus spread on a network. In the SIS model, a node is either infected or susceptible at any time t. Each infected node infects each of its susceptible neighbors with an infection rate β. Each infected node recovers with a recovery rate δ. Both infection and recovery processes are independent Poisson processes and the ratio τ = β/δ is the effective infection rate. There is an epidemic threshold τ c and above the threshold τ > τ c a nonzero fraction of nodes is infected in the metastable state. The infection probability v k∞(τ) of a node k in the metastable state at a given effective infection rate τ indicates the vulnerability of node k to the virus, and the prevalence, which equals the average fraction y ∞(τ) of infected nodes reflects the global vulnerability of the network.
Researchers have mainly concentrated on the average fraction y ∞ of infected nodes in the metastable state to estimate the vulnerability of a network against a certain epidemic or virus. Great effort has been devoted to understand how the network topology influences the vulnerability and the epidemic threshold6, 13–15, when the effective infection rate is just above the epidemic threshold [ref. 16, p. 469]. In this case, it is found [ref. 16, p. 469] that, the metastable-state infection probability vector (), obtained by the N-Intertwined Mean-Field Approximation (NIMFA) of SIS model is proportional to the principal eigenvector x 1 of the adjacency matrix A. In this work, we aim to explore the nodal infection probability in a systematic way, in different network topologies and when the effective infection rate τ varies. As a starting point, we investigate the ranking of nodal infection probabilities, which crucially informs a network operator which nodes are more vulnerable or require protection. Interestingly, we find that the ranking of the nodal infection probability changes as the effective infection rate τ varies. The observation points out that we cannot find a topological feature of a node i to represent the vulnerability of node i to an SIS epidemic, because the rankings in vulnerability of nodes in a network may be different when the effective infection rate τ varies, whereas a topological feature of node i remains the same. Our observation explains the finding of Hebert-Dufresne et al.17 that different nodal features (such as degree, betweenness, etc.) should be used to select the nodes to immunize in different scenarios (based on different infection rates, link densities, etc.), i.e. different nodes should be immunized at different infection rates. In this paper, we explore two questions: (I) which network topology changes the ranking of nodal infection probabilities more significantly and (II) in which effective infection rate range, does the increment of the effective infection rate lead to a more significant change in the ranking for a given network topology?
We first assume that, for an arbitrary pair of nodes, the trajectory v k∞(τ) and v m∞(τ) as a function of the effective infection rate τ cross at most once in any interval (τ 0, τ 1). We call this assumption the one-crossing assumption and Section “Discussion about the one-crossing assumption” of the supplementary information shows that the assumption is reasonably good. Then the rankings of the vulnerabilities v k∞(τ) and v m∞(τ) change or equivalently the trajectories v k∞(τ) and v m∞(τ) cross if (v k∞(τ 0) − v m∞(τ 0) (v k∞(τ 1) − v m∞(τ 1) < 0, when the effective infection rate τ changes from τ 0 to τ 1. To estimate the maximal change in the ranking of nodal infection probabilities in a network, we consider the total number of crossings between the trajectories of the infection probabilities of all the nodes in a network, when the effective infection rate τ changes from just above the epidemic threshold to a large value, above which the ranking remains the same. The total number of crossings is a simple and straightforward measure of the changes in the ranking of nodal infection probabilities. (We also briefly discuss how the correlation of the ranking of nodal infection probabilities changes as the effective infection rate increases in Section “The Spearman rank correlation ρ as a function of α” of the supplementary information.) A higher total number of crossings may lead to a more complicated protection policy for a network operator. Given a network, we find a lower bound of the total number of crossings, which can be computed from the topology properties, in particular, from the degree vector and the principal eigenvector of the adjacency matrix. The lower bound is roughly proportional to, thus an accurate indicator of, the total number of crossings for an arbitrary network. Hence, these two topological features (i.e. the degree vector and the principal eigenvector of the adjacency matrix) could indeed characterize to what extent the ranking of nodal vulnerabilities would change on a network. Since the lower bound is computationally simple, it can be used to compare the total number of crossings for different network topologies. This result explains why the total number of crossings tends to be larger in networks with a smaller average degree if the degree distribution is given or with a larger degree variance if the average degree is given. Regarding to Question (II), we analytically derive the number of crossings when the effective infection rate τ 0 increases with a small value ε, given the infection probability vector V ∞(τ 0) at the effective infection rate τ 0. This theoretical result, validated by numerical results, explains the reason why the crossings are more likely to occur when the effective infection rate τ is smaller.
Results
We first introduce in detail how to count or quantify the changes of the nodal ranking of the infection probability. Afterwards, we investigate the changes in the ranking (I) in different topologies when the effective infection rate τ increases from just above the epidemic threshold to a large value, above which the ranking remains the same, and (II) when the effective infection rate varies in different ranges.
The counting of the nodal ranking changes
To explore the changes of the nodal ranking of the infection probability, we investigate in a given network how many crossings, denoted by χ, between the trajectory v k∞(τ) and v m∞(τ) for all pairs of nodes can occur in the effective infection rate interval (τ 0, τ 1), where , and where (λ 1 is the largest eigenvalue of the adjacency matrix) is the NIMFA epidemic threshold: the epidemic dies out if the effective infection rate . (More details on are introduced in Section “Methods”). In Fig. 1, we illustrate the trajectories v k∞(τ) of 10 nodes, randomly selected from a real-world network called Roget (N = 994 nodes, average degree E [D] = 7.32 and detailed in Section “Real-world graphs” of the supplementary information). For example, the vulnerability of the node corresponding to the red dash line in Fig. 1 changes dramatically from the medium vulnerability when τ = 0.12 to the high vulnerability when τ = 0.24. Network operators should be alert to such a change of nodal vulnerabilities. The trajectories v k∞(τ) of other groups of nodes in Roget are shown and discussed in the first section of the supplementary information.
Figure 1.
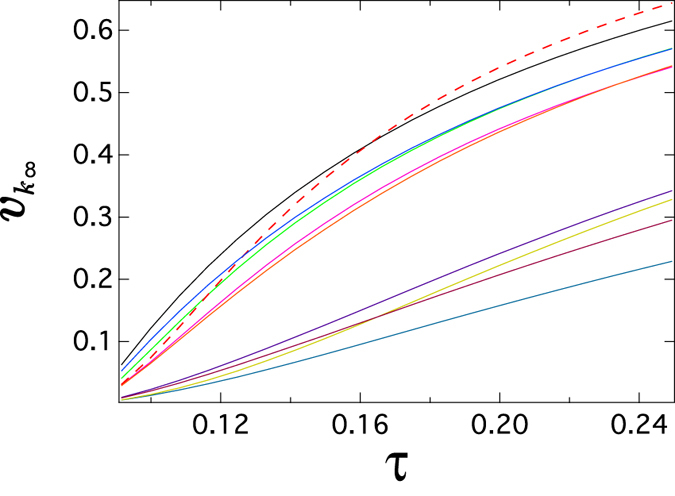
The meta-stable infection probabilit v k∞ as a function of the effective infection rate τ for 10 random nodes in a real-world network called Roget (details in Section “Real-world graph” of the supplementary information). The meta-stable infection probability v k∞ is obtained by solving (11).
For a graph with N nodes, the maximum possible number of crossings is under the one-crossing assumption. To count the number of crossings in the interval (τ 0, τ 1), we define an N × N matrix F with elements f ij:
Since f ii = 0, the matrix F has a zero diagonal just as the adjacency matrix A. A negative matrix element f ij < 0 means that there is a crossing between the trajectory v i∞(τ) and v j∞(τ) in the interval (τ 0, τ 1). The number of crossings in the interval (τ 0, τ 1) of the effective infection rate then equals
| 1 |
where 1{x} is the indicator function: 1{x} = 1 if the event or condition {x} is true, else 1{x} = 0. Specifically, if all nodal degrees are the same in a random graph, the nodal ranking in any interval of τ does not change, since the infection probability of every node6 equals the average fraction of infected nodes for any effective infection rate τ. In this work, we focus on the NIMFA nodal infection probability in the meta-stable state which is obtained by solving (11), hence the initial conditions (such as how many nodes are initially infected) are not necessary.
We can compute the SIS metastable viral infection probability v k∞ of any node k both by the N-Intertwined Mean-Field Approximation (NIMFA)6, 18 and by simulations8 of the SIS continuous-time Markov process. We then further compare the number of crossings χ as a function of the increment in the effective infection rate τ over different ranges, obtained by NIMFA and the continuous-time simulations of the SIS model. As shown in Section “The comparison between NIFMA and the continuous-time simulation” of the supplementary information, the number of crossings obtained from NIMFA is relatively close to that from the simulations, so we compute the number χ of crossings mainly by NIMFA due to its computational efficiency. However, NIMFA may not be accurate when the effective infection rate is close to the epidemic threshold8. Hence, the number of crossings obtained by NIMFA and simulations may be different from each other when the effective infection rate is close to the epidemic threshold as shown in Section “The comparison between NIFMA and the continuous-time simulation” of the supplementary information.
The total number of crossings in different topologies
We explore the total number of crossings in different graph topologies when the effective infection rate τ changes from just above the epidemic threshold, i.e. , to a large value τ u, above which the ranking of the nodal infection probability hardly changes. In Section “Methods – The derivation of the lower bound χ l”, we prove that there exists a value of τ, above which the ranking of the nodal infection probabilities does not change. We derive a lower bound of the total number of crossings and show that the lower bound is actually an accurate indicator of the total number of crossings in different types of graphs.
As shown in Section “Methods”, we derive a lower bound χ l of the total number of crossings in a given graph:
| 2 |
where x 1 is the principal eigenvector of the adjacency matrix A, belonging to the largest eigenvalue λ 1 and d is the degree vector of the given graph.
With the one-crossing assumption, we can compute from the infection probability vector and V ∞(τ u). However, we have to select a proper value of τ u which is large enough and practical. We set the value of τ u as the minimum infection rate such that the average fraction of infected nodes y ∞(τ u) ≥ 0.9, since we find for most Erdös-Rényi (ER), Barabási-Albert (BA) random graphs and the aforementioned real-world network, that the rankings of the nodal degree and the infection probability are almost the same when the average fraction of infected nodes y ∞ ≥ 0.9. We discuss how we select the value of τ u in Section “The value of τ u” of the supplementary information. The scatter plot of the lower bound χ l vs versus is shown in Fig. 2 for different graphs including ER random graphs, BA random graphs and six graphs constructed from real-world datasets (as described in Section “Real-world graphs” of the supplementary information), and the dash line in Fig. 2 is , equivalent to
| 3 |
We employ the average degree E [D] = 8, 10, 12, 14, 16, 18, 20, 40, 60, 80 for ER random graphs and E [D] = 4, 6, 8, 10, 12, 14, 16, 18, 20 for BA random graphs. Both ER and BA random graphs have the same size N = 1000. We confine ourselves to the connected graphs in this work. Hence, we employ the link density of ER random graphs, which is larger than the critical link density (equivalently the average degree E [D] > 7), to ensure the connectivity. Figure 2 and Equation (3) show that the lower bound χ l is indeed always smaller than and approximately proportional to . Hence, the lower bound χ l is a computationally simple indication of the total number of changes in the ranking of the metastable state infection probability in a graph. Moreover, we find that for graphs generated by the same random graph model (ER or BA model), a graph with a small average degree tends to have a large number of crossings; given the average degree, a graph with a large degree variance tends to have more crossings. We can understand this observation as follows. The principal eigenvector component of any node i obeys the eigenvalue equation . The principal eigenvector is positively correlated with the degree vector19. Such correlation weakens if the principal eigenvector has a large variance, leading to a large χ l. When the degree variance is large, the variance of the principal eigenvector tends to be large as well, contributing to a large χ l. As more links are added to a network, the network becomes more homogeneous and the variance of the principal eigenvector decreases, resulting in a smaller χ l, or equivalently less crossings.
Figure 2.
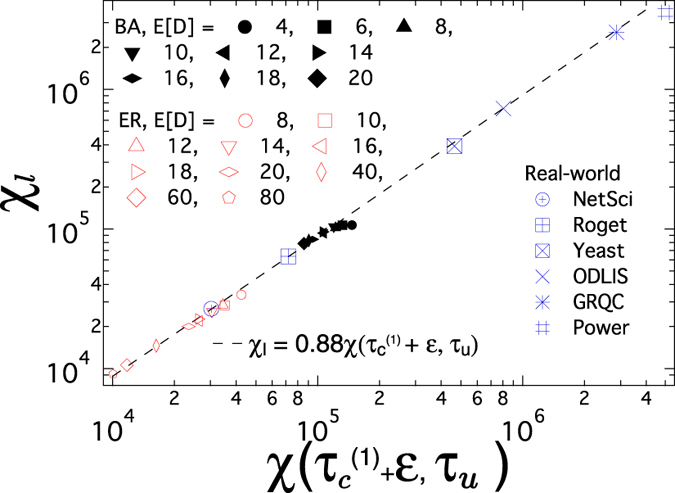
The lower bound χ l versus the total number of crossings in ER random graphs (with the size N = 1000), BA random graphs (with the size N = 1000) and real-world networks (details in Section “Real-world graphs” of the supplementary information).
The number of crossings in different intervals of τ
As shown in (1), we can compute the number χ(τ 0, τ 1) of crossings in the given interval (τ 0, τ 1) based on the knowledge of the infection probability vectors V ∞(τ 0) and V ∞(τ 1) only. Here, we show that we can theoretically derive the number of crossings in a small interval (τ 0, τ 0 + Δτ) with the only knowledge of V ∞(τ 0). Afterwards, we will validate this theory by numerical results, and illustrate in which ranges of the effective infection rate the number of crossings tends to be larger.
The crossings close to a given τ
For sufficiently small ε = Δτ > 0, the Taylor expansion of the steady-state NIMFA infection probability v k∞ for any node k is
| 4 |
explicit up to order 2. In Section “Derivatives of v i∞ with respect to τ” of the supplementary information, we show the procedure to determine the m-th order derivative v i∞(τ) with respect to the effective infection rate τ for any node k.
If v k∞(τ) − v m∞(τ) > 0 and , then v k∞(τ + ε) − v m∞(τ + ε) > 0 for sufficiently small ε > 0 and the ranking at τ + ε and at τ is unchanged. On the other hand, if v k∞(τ + ε) − v m∞(τ + ε) = 0, which implies, for sufficiently small ε > 0 (so that we can ignore the higher order terms in ε m for m > 1 in (4)), that
In other words, given v k∞(τ) of all nodes at τ, then there can be a zero or crossing at τ + ε km, where
| 5 |
if ε km is small compared to τ. This approach is actually known as the Newton-Raphson method and corresponds with the first term in the Lagrange series for the inverse function (see ref. 20 in Page 304). A second order approximation, by ignoring terms of order O(ε 3) in (4), equating v k∞(τ + ε) − v m∞(τ + ε) = 0 and solving for ε, yields
| 6 |
which is expected to be more accurate, in spite of the higher computational complexity since now also the set of second order derivatives needs to be solved. We rewrite (6) as
Using the generalized binomial expansion , valid for any |z| < 1, up to first order yields
After only retaining the root with the minus sign, we arrive again at (5), illustrating that (5) is accurate when (5) is as small as possible (so that higher order evaluations are not needed). The discriminant must be positive in order to obtain feasible ε km. A positive discriminant is a condition for the existence of crossing in the interval (τ, τ + ε). Hence, given an effective infection rate τ 0 and the corresponding infection probability vector V ∞(τ 0), there is a crossing close to τ 0 between the trajectory v k∞(τ) and the trajectory v m∞(τ) at τ + ε km if ε km computed by (5) is positive and small enough.
Numerical results
In the following, we propose to normalize the effective infection rate by the NIMFA epidemic threshold: , so that we can compare the number χ of crossings in different intervals of α in the same range (1, α max) for different network topologies, i.e. different average degrees and different degree distributions. We explore the crossings of the infection probability trajectories when the effective infection rate varies over the range (1, α max). We divide the range (1, α max) into intervals (α j−1, α j) where j = 1, 2, …, n is the index and α n = α max.
We aim to explore in which interval of the normalized effective infection rate α the crossings are more likely to appear. Hence, instead of directly exploring the number of crossings between the trajectory of every node in the whole interval (1, α max) of the effective infection rate α, we investigate the number χ(α j−1, α j) of crossings in (1) in each small interval (α j−1, α j). We denote α 0 = 1 (since the effective infection rate below the epidemic threshold corresponds to the all-healthy state), α n = α max and α j = α 0 + jΔα, where Δα = (α max − 1)/n is the length of each interval. We will study how the number of crossings changes at different regions of the effective infection rate τ or scaled α. The infection probability v k∞(α) at any given value of the normalized effective infection rate α is computed by solving the NIMFA equation (11). On one hand, we can further compute the number χ(α j−1, α j) of crossings between all node pairs within any interval (α j−1, α j) by employing our theoretical result (5). On the other hand, we can also numerically compute the number χ(α j−1, α j) by (1). We first compare the theoretical (5) and numerical (1) when the normalized effective infection rate α is not close to 1, i.e. when the effective infection rate τ is not close to the epidemic threshold τ c; specifically, we start from α 0 = 2 and α j = α 0 + jΔα, where Δα = 1. The main figures in Fig. 3 demonstrate that, for both ER and BA graphs, our theoretical result (5) agrees well with the numerical result (1) except for BA graphs in the interval (2, 3). The lower accuracy of our theoretical result for small α can be explained as follows. Compared to , a small value of is required for the accuracy of the theoretical results (5), since ε in (5) is required to be small with respect to the given effective infection rate τ. Hence, when α j is smaller, a smaller value of is needed for (5) to be accurate.
Figure 3.
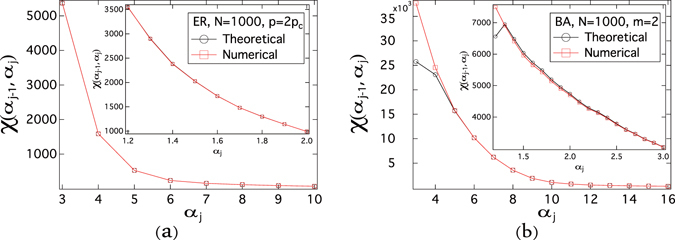
The number χ(α j−1, α j) of crossings as a function of the normalized effective infection rate α j. For ER graphs, we employ the link density p = 2p c, thus the average degree E [D] = 14, the size N = 1000 and the NIMFA epidemic threshold . For BA graphs, we employ the number of newly added links in each step m = 2, thus the average degree E [D] = 4, the size N = 1000, and the NIMFA epidemic threshold . The meta-stable infection probability v k∞ is obtained by solving (11) and the number χ(α j−1, α j) of crossings is obtained by (1). The results are averaged over 10 realizations.
We further plot the number χ(α j−1, α j) of crossings in the interval (α j−1, α j) as a function of α j, when the normalized effective infection rate α is close to 1 and the length of the interval is reduced to Δα = 0.1. When the length of the interval, i.e. Δα, is smaller, the theoretical (5) results are more consistent with the numerical (1) results for BA random graphs in the range of α ∈ (2, 3) in the inset than in the main figure of Fig. 3(b). For both ER and BA graphs, the two methods agree with each other well when the intervals of α are small, even when the normalized effective infection rate α is close to 1 as shown in the insets of Fig. 3.
Physical explanation
Figure 3 shows that more crossings appear when the effective infection rate is smaller. In this section, we give a physical explanation of that observation.
At an effective infection rate τ or a normalized effective infection rate α, Equation (14) shows that the comparison of the infection probabilities v k∞(α) and v m∞(α) is actually equivalent to the comparison of the sum of the infection probabilities of their neighbors, i.e. and . Without loss of generality, we assume that the degree d k of node k is larger than the degree d m of node m, i.e. d k > d m. As discussed in Section “Methods”, the infection probability v k∞(α) > v m∞(α) if the effective infection rate is large enough. If there exists a value of α 1 at which while d k > d m, there must be a crossing between v k∞(α) and v m∞(α) in the interval (α 1,∞). If the infection probabilities v j∞(α) (where j = 1, 2, …, N) of all nodes vary in a larger range with respect to the average infection probability , i.e. the average fraction y ∞ of infected nodes, then there may be a higher probability that and thus more crossings could be expected when the effective infection rate τ exceeds α 1. This hypothesis further motivates us to study the normalized standard deviation of the nodal infection probability:
| 7 |
(where we define ) and explore whether a larger difference of σ* would imply more crossings in the interval (α j−1 , α j).
The number χ(α j−1, α j) of crossings as a function of the difference σ*(α j−1) − σ*(α j) is shown in Fig. 4(a) for ER random graphs and in Fig. 4(b) for BA random graphs. For both ER and BA random graphs, the number χ(α j−1, α j) of crossings are positively correlated with the difference σ*(α j−1) − σ*(α j) in the interval (α j−1, α j). We observe the same in ER and BA random graphs with various average degrees though not shown here. The numerical results support that more crossings tend to appear in an interval where the variable σ* changes more.
Figure 4.
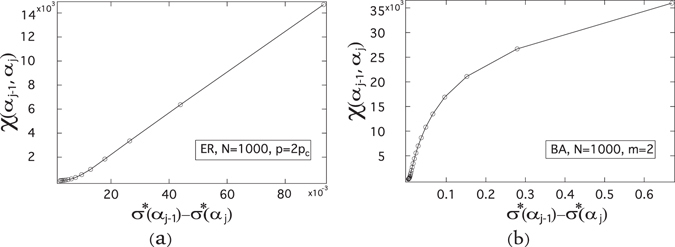
The number χ(α j−1, α j) of crossings as a function of the difference σ*(α j−1) − σ*(α j) of the normalized standard deviation of the metastable infection probability. For ER graphs, we employ the link density p = 2p c, thus the average degree E [D] = 14, and the size N = 1000 (the NIMFA epidemic threshold ). For BA graphs, we employ the minimum degree m = 2, thus the average degree E [D] = 4, and the size N = 1000 (the NIMFA epidemic threshold ). The meta-stable infection probability v k∞ is obtained by solving (11), the number χ(α j−1, α j) of crossings is obtained by (1) and the value of σ*(α) is obtained by (7). The results are averaged over 10 realizations.
We then further explore how the value of the variable σ*(α) changes with the normalized effective infection rate α. We plot the variable σ* as a function of the normalized effective infection rate α in Fig. 5(a) for ER random graphs and in Fig. 5(b) for BA random graphs with N = 1000 and various average degrees, and find that for both types of random graphs the curves can be fitted by a power law function, i.e. σ* is proportional to α −γ, especially when the average degree is not small. More figures and the curve fittings are shown in the last section of the supplementary information for both ER and BA random graphs.
Figure 5.
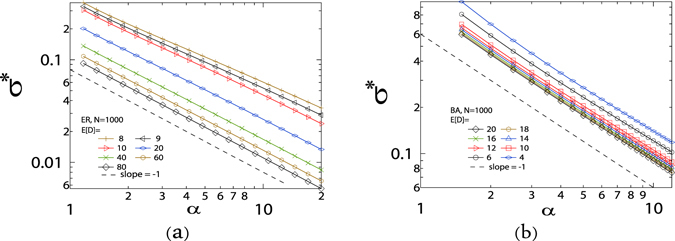
The normalized standard deviation σ* of infection probabilities of all nodes as a function of α in (a) ER and (b) BA random graphs. The dash line is a power-law curve with the exponent γ = −1. The sizes of all random graphs are 1000 and the average degree E [D] is shown in the figures. The meta-stable infection probability v k∞(α) is obtained by solving (11) and the value of σ*(α) is obtained by (7). The NIMFA epidemic threshold , 0.0993, 0.0902, 0.0476, 0.0244, 0.0164 and 0.0124 for ER random graphs with the average degree E [D] = 8, 9, 10, 20, 40, 60 and 80 respectively, and , 0.0698, 0.0479, 0.0416, 0.0368, 0.0329, 0.0300 and 0.0274 for BA random graphs with the average degree E [D] = 4, 6, 10, 12, 15, 16, 18 and 20 respectively. The results are averaged over 10 realizations.
Figure 5 illustrates that the power law exponent γ of the fitting curves is close to 1 as the average degree E [D] increases for ER random graphs, and that is always approximately 1 for BA random graphs even though the average degree E [D] is small. Furthermore, the relationship between the variable σ* and the normalized effective infection rate α follows a power law when the effective infection rate is much larger, as shown in Section “σ* as a function of τ” of the supplementary information.
When α is large, we can theoretically prove the power-law relationship between the variable σ* and the normalized effective infection rate α. By (12) and assuming a large enough effective infection rate, we obtain for node i and consequently , so that (7) becomes
| 8 |
In a finite graph, Var and E are finite, hence σ* is proportional to τ −1. The NIMFA epidemic threshold is a constant for a given graph, and with , we obtain that σ* is proportional to α −1. Although the power-law relationship between σ* and α can be clearly observed in Fig. 5, the effective infection rate τ corresponding to the variable α in this figure may be smaller than 1 and the theoretical proof is only valid when the effective infection rate . Our result (8) is based on connected graphs, because the terms E and Var are undefined in unconnected graphs with isolated nodes.
The power-law decay of the variable σ* with the effective infection rate τ explains why there are more crossings when the effective infection rate is smaller.
Validation on a real-world network
Finally, we validate our previous findings on the real-world network – Roget, detailed in Section “Real-world graphs” of the supplementary information. As shown in Fig. 6(a), the number χ(α j−1, α j) of crossings at normalized effective infection rate α interval obtained by theoretical and numerical methods are consistent with each other. The number of crossings decreases fast as α increases, similar to ER and BA models. The main figure of Fig. 6(b) shows that the number χ(α j−1, α j) of crossings increases with the difference σ*(α j−1) − σ*(α j) in the interval (α j−1, α j). In the inset of Fig. 6(b), we observe the power-law relationship between the variable σ* and the normalized effective infection rate α. All these findings are well in line with previous results on ER and BA random graphs.
Figure 6.
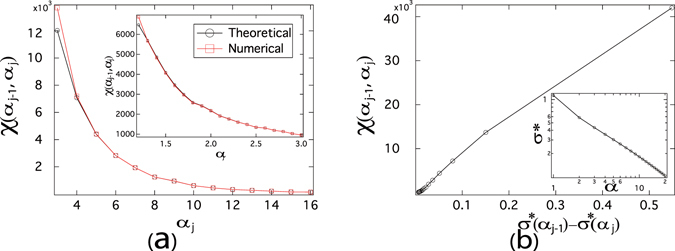
(a) The number χ(α j−1, α j) of crossings as a function of the normalized effective infection rate α j. (b) Main figure: the number χ(α j−1, α j) of crossings as a function of the difference σ*(α j−1) − σ*(α j) of the normalized standard deviation of the metastable infection probability; Inset: the normalized standard deviation σ* of infection probabilities of all nodes as a function of α. The real-world network – Roget, detailed in Section “Real-world graphs” of the supplementary information, is employed. The meta-stable infection probability v k∞ is obtained by solving (11), the number χ(α j−1, α j) of crossings is obtained by (1) and the value of σ*(α) is obtained by (7). The NIMFA epidemic threshold .
Discussion
In the SIS model, the infection probability trajectory v k∞(τ) of node k and the infection probability trajectory v m∞(τ) of node m may cross if (v k∞(τ 0) − v m∞(τ 0))(v k∞(τ 1) − v m∞(τ 1)) < 0, when the effective infection rate τ varies from τ 0 to τ 1. The number χ(τ 0, τ 1) of crossings of all node pairs within an interval (τ 0, τ 1) of the effective infection rate measures the change in the ranking of the nodal vulnerabilities when the effective infection rate changes from τ 0 to τ 1. We explore in what types of network topologies and in what ranges of the effective infection rates the crossings are more likely to appear. Theoretically, we find a lower bound χ l in (2) of the total number of crossings in a graph. The lower bound χ l only depends on topological features, i.e. the degree vector and principal eigenvector of the adjacency matrix. That lower bound χ l is also shown to reflect the total number of crossings for a given graph. Moreover, we analytically predict the crossings close to an effective infection rate τ 0, given the infection probabilities of all nodes at the effective infection rate τ 0. This theory can be used to estimate the changes of the ranking of the nodal vulnerabilities if the effective infection rate τ slightly increases from its current value τ 0. We find that more crossings tend to appear when the effective infection rate is smaller. Our findings may help network operators to estimate how significant the ranking of nodal vulnerabilities may change for a given change of the effective infection rate on a given network.
This work inspires interesting further questions. For example, how much is the change in the value of the nodal infection probabilities when the trajectories of the nodal infection probability crossing? Can we use the changes in the ranking of nodal infection probabilities to more effectively select the nodes to immunize?
Methods
Network construction
The Erdös-Rényi (ER) random graph21 is one of the most widely-used and well-studied models. In an ER random graph G p(N) with N nodes, each pair of nodes is connected with probability p independent from every other pair. The distribution of the degree of a random node is binomial: and the average degree E [D] = (N − 1)p. For large N and constant E [D], the degree distribution tends16 to a Poisson distribution: Pr [D = k] = exp(−E [D]) (E [D])k/k! Moreover, if the link density for large N, the graph G p(N) is almost surely connected. We employ ER graphs with p = 2p c (the average degree is approximately E [D] = 14) and N = 1000 as an example in some discussions, but consider the ER graphs with various average degrees when needed.
Besides the ER random graph, the scale-free model is often used to capture the scale-free degree distribution of the real-world networks such as the Internet22 and World Wide Web23. In this work, we consider the Barabási-Albert (BA) model24, which begins with an initial connected network of m 0 nodes. At each step, a new node is connected to m ≤ m 0 existing nodes. The probability that an existing node is chosen to be connected is proportional to the degree of the existing node. The degree distribution of BA random graphs16 is Pr [D = k] = ck −3 for sufficiently large N, where . The minimum degree of BA graphs is m, and we set m 0 = m + 1 to generate a BA graph with N = 1000 nodes. Hence, the number of links is and the average degree is E , thus approximately equals to 2m. We employ the BA random graphs with m = 2 (the average degree E [D] = 4) as an example in discussions and consider more average degrees when needed.
The N-Intertwined Mean-Field Approximation of the SIS model
The N-Intertwined Mean-Field Approximation (NIMFA) is one of the most accurate approximation of the SIS model that takes into account the influence of the network topology6. The single governing equation for a node i in the NIMFA is
| 9 |
where v i(t) is the infection probability of node i at time t, and the adjacency matrix element a ij = 1 or 0 denotes if there is a link or not between node i and node j. With , the matrix evolution equation of NIFMA is
| 10 |
where A is the N × N adjacency matrix of the network, I is the N × N identity matrix and diag (v i(t)) is the diagonal matrix with elements . In the steady state, defined by , or equivalently and , we have
| 11 |
Given the network and the effective infection rate τ, we can numerically compute the infection probability v i∞ as a function of the effective infection rate τ for each node i by solving (11). The trivial, i.e. all-zero, solution indicates the absorbing state where all nodes are susceptible. The non-zero solution of V ∞ in (11), if exists, points to the existence of a metastable state with a non-zero fraction of infected nodes. Or else, the metastable state can be figured as 0 or not existing. In this paper, we are interested in actually the metastable state.
Furthermore, the NIMFA epidemic threshold , where λ 1 is the largest eigenvalue of the adjacency matrix A, is a lower bound of the exact epidemic threshold τ c, i.e. . The epidemic dies out if the effective infection rate . Since the NIMFA is the main approach in this work, we also employ the NIMFA epidemic threshold . The Laurent series of the steady-state infection probability is given by refs 16 and 25
| 12 |
possesses the coefficients and
| 13 |
and for m ≥ 2, the coefficients obey the recursion
The derivation of the lower bound χl
As shown in [ref. 16, p. 469] when the effective infection rate is just above the NIMFA epidemic threshold , the vector V ∞ with the NIMFA metastable-state infection probabilities is proportional to the principal eigenvector x 1 of the adjacency matrix A. In particular, v k∞ = ε(x 1)k, where ε > 0 and (x 1)k is the k-th component corresponding to node k of the principal eigenvector x 1 of the adjacency matrix A, belonging to the largest eigenvalue λ 1. The Perron-Frobenius Theorem20 states that all vector components of x 1 are non-negative, and even positive if the graph G is connected. Hence, when the effective infection rate is just above the epidemic threshold, the ranking of the infection probability is the same as the ranking of the component of the principal eigenvector (x 1)i, i.e. for any k and m.
On the other hand, the NIMFA steady-state infection probability for node k is given by ref. 18, [ref. 16, p. 464] and expressed as
| 14 |
from which we obtain
The sign of v k∞(τ) − v m∞(τ) thus equals to the sign of . Common neighbors of node m and k do not play a role in the sign change of v k∞(τ) − v m∞(τ). (The common neighbors of node m and k are the set of nodes ). Moreover, if the number of non-common neighbors is 1 (or 0), then there is no change in the sign of v k∞(τ) − v m∞(τ) while the effective infection rate τ varies. Since the minimum infection probability v min(τ) > 0 for as shown in [ref. 16, Lemma 17.4.2 on p. 464], the following bounds apply
where v max(τ) and v min(τ) are the maximum and minimum infection probability respectively and d k is the degree of node k, so that the condition v k∞(τ) − v m∞(τ) > 0 at τ is surely satisfied if . Using and in [ref. 16, p. 464–465], we arrive at the conservative bound for the condition v k∞(τ) − v m∞(τ) > 0 at τ,
Hence, for large τ, the comparison between v k∞(τ) and v m∞(τ) reduces to a comparison in the nodal degree: if d k > d m, then v k∞(τ) > v m∞(τ). This conclusion implies that there exists an effective infection rate τ u, above which the ranking of the metastable-state infection probability is the same as the ranking of the nodal degree, i.e. f km(V ∞(τ), d) = 0 for any k and m (where d is the degree vector), if τ ≥ τ u.
The above discussion suggests that the number of crossings in the interval is the total number of crossings which a graph can possess. With the one-crossing assumption, we have
| 15 |
Since only the crossings between two nodes with different degrees are considered in , we obtain a lower bound of the total number of crossings. In order to simplify the notation, we denote the lower bound of the total number of crossings by .
Electronic supplementary material
Acknowledgements
This work was partly supported by the National Natural Science Foundation of China (No. 61603097) and Natural Science Foundation of Shanghai (No. 16ZR1446400).
Author Contributions
P.V.M., B.Q., C.L. and H.W. planned the study; P.V.M., B.Q. and H.W. did the theoretical derivation; B.Q., C.L. and H.W. performed the experiments, analyzed the data and prepared the figures; All authors wrote the manuscript.
Competing Interests
The authors declare that they have no competing interests.
Footnotes
Electronic supplementary material
Supplementary information accompanies this paper at doi:10.1038/s41598-017-08611-9
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Albert R, Jeong H, Barabási A-L. Error and attack tolerance of complex networks. Nature. 2000;406:378–382. doi: 10.1038/35019019. [DOI] [PubMed] [Google Scholar]
- 2.Kephart, J. O. & White, S. R. Directed-graph epidemiological models of computer viruses. In Research in Security and Privacy, 1991. Proceedings., 1991 IEEE Computer Society Symposium on, 343–359 (IEEE, 1991).
- 3.Garetto, M., Gong, W. & Towsley, D. Modeling malware spreading dynamics. In INFOCOM 2003. Twenty-Second Annual Joint Conference of the IEEE Computer and Communications. IEEE Societies, vol. 3, 1869–1879 (IEEE, 2003).
- 4.Ganesh, A., Massoulié, L. & Towsley, D. The effect of network topology on the spread of epidemics. In INFOCOM 2005. 24th Annual Joint Conference of the IEEE Computer and Communications Societies. Proceedings IEEE, vol. 2, 1455–1466 (IEEE, 2005).
- 5.Daley, D. J., Gani, J. & Gani, J. M. Epidemic modelling: an introduction, vol. 15 (Cambridge University Press, 2001).
- 6.Van Mieghem P. The N-intertwined SIS epidemic network model. Computing. 2011;93:147–169. doi: 10.1007/s00607-011-0155-y. [DOI] [Google Scholar]
- 7.Cator E, Van Mieghem P. Susceptible-infected-susceptible epidemics on the complete graph and the star graph: Exact analysis. Phys. Rev. E. 2013;87 doi: 10.1103/PhysRevE.87.012811. [DOI] [PubMed] [Google Scholar]
- 8.Li C, van de Bovenkamp R, Van Mieghem P. Susceptible-infected-susceptible model: A comparison of n-intertwined and heterogeneous mean-field approximations. Phys. Rev. E. 2012;86 doi: 10.1103/PhysRevE.86.026116. [DOI] [PubMed] [Google Scholar]
- 9.Boccara N, Cheong K. Critical behaviour of a probabilistic automata network SIS model for the spread of an infectious disease in a population of moving individuals. J Phys A-Math Gen. 1993;26 doi: 10.1088/0305-4470/26/15/020. [DOI] [Google Scholar]
- 10.Shi H, Duan Z, Chen G. An SIS model with infective medium on complex networks. Physica A. 2008;387:2133–2144. doi: 10.1016/j.physa.2007.11.048. [DOI] [Google Scholar]
- 11.Wang H, et al. Effect of the interconnected network structure on the epidemic threshold. Physical Review E. 2013;88 doi: 10.1103/PhysRevE.88.022801. [DOI] [PubMed] [Google Scholar]
- 12.Li, D., Qin, P., Wang, H., Liu, C. & Jiang, Y. Epidemics on interconnected lattices. EPL (Europhysics Letters) 105, 68004, http://stacks.iop.org/0295-5075/105/i=6/a=68004 (2014).
- 13.Li C, Wang H, Van Mieghem P. Epidemic threshold in directed networks. Physical Review E. 2013;88 doi: 10.1103/PhysRevE.88.062802. [DOI] [PubMed] [Google Scholar]
- 14.Pastor-Satorras, R., Castellano, C., Van Mieghem, P. & Vespignani, A. Epidemic processes in complex networks. arXiv preprint arXiv:1408.2701 (2014).
- 15.Yang Z, Zhou T. Epidemic spreading in weighted networks: an edge-based mean-field solution. Physical Review E. 2012;85 doi: 10.1103/PhysRevE.85.056106. [DOI] [PubMed] [Google Scholar]
- 16.Van Mieghem, P. Performance analysis of communications networks and systems (Cambridge University Press, 2014).
- 17.Hébert-Dufresne, L., Allard, A., Young, J.-G. & Dubé, L. J. Global efficiency of local immunization on complex networks. Scientific Reports3 (2013). [DOI] [PMC free article] [PubMed]
- 18.Van Mieghem P, Omic J, Kooij R. Virus spread in networks. Networking, IEEE/ACM Transactions on. 2009;17:1–14. doi: 10.1109/TNET.2008.925623. [DOI] [Google Scholar]
- 19.Li C, Li Q, Van Mieghem P, Stanley HE, Wang H. Correlation between centrality metrics and their application to the opinion model. The European Physical Journal B. 2015;88:1–13. [Google Scholar]
- 20.Van Mieghem, P. Graph spectra for complex networks (Cambridge University Press, 2010).
- 21.Erdös P, Rényi A. On random graphs i. Publ. Math. Debrecen. 1959;6:290–297. [Google Scholar]
- 22.Caldarelli G, Marchetti R, Pietronero L. The fractal properties of internet. EPL (Europhysics Letters) 2000;52 doi: 10.1209/epl/i2000-00450-8. [DOI] [Google Scholar]
- 23.Albert R, Jeong H, Barabási A-L. Internet: Diameter of the world-wide web. Nature. 1999;401:130–131. doi: 10.1038/43601. [DOI] [Google Scholar]
- 24.Barabási A-L, Albert R, Jeong H. Scale-free characteristics of random networks: the topology of the world-wide web. Physica A. 2000;281:69–77. doi: 10.1016/S0378-4371(00)00018-2. [DOI] [Google Scholar]
- 25.Van Mieghem P. The viral conductance of a network. Computer Communications. 2012;35:1494–1506. doi: 10.1016/j.comcom.2012.04.015. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.