

Abstract
The recent interest in the dynamics of networks and the advent, across a range of applications, of measuring modalities that operate on different temporal scales have put the spotlight on some significant gaps in the theory of multivariate time series. Fundamental to the description of network dynamics is the direction of interaction between nodes, accompanied by a measure of the strength of such interactions. Granger causality and its associated frequency domain strength measures (GEMs) (due to Geweke) provide a framework for the formulation and analysis of these issues. In pursuing this setup, three significant unresolved issues emerge. First, computing GEMs involves computing submodels of vector time series models, for which reliable methods do not exist. Second, the impact of filtering on GEMs has never been definitively established. Third, the impact of downsampling on GEMs has never been established. In this work, using state-space methods, we resolve all these issues and illustrate the results with some simulations. Our analysis is motivated by some problems in (fMRI) brain imaging, to which we apply it, but it is of general applicability.
1 Introduction
Following the operational development of the notion of (temporal) causality by Granger (1969) and Sims (1972), Granger causality (GC) analysis has become an important part of time series and econometric testing and inference (Hamilton, 1994). It has also been applied in the biosciences (Kaminski & Blinowska, 1991; Bernasconi & Konig, 1999; Ding, Bressler, Yang, & Liang, 2000), climatology (global warming; Suna & Wang, 1996; Kaufmann & Stern, 1997; Triacca, 2005), and, most recently, functional magnetic resonance imaging (fMRI). This last application has stimulated this letter.
Since its introduction into fMRI (Goebel, 2003; Valdes-Sosa, 2004; Roebroeck, Formisano, & Goebel, 2005; Yamashita, Sadato, Okada, & Ozaki, 2005) GC has become the subject of an intense debate: (see Valdes-Sosa, Roebroeck, Daunizeau, & Friston, 2011; Roebroeck, Formisano, & Goebel, 2011) and associated commentary. There are two main issues in that debate that occur more widely in dynamic networks. First is the impact of downsampling on GC. In the fMRI neuroimaging application, causal processes may operate on a timescale on the order of tens of milliseconds, whereas the recorded signals are typically available only on a 1 second timescale, although sampling up to a 100 ms rate is now becoming possible (Feinberg & Yacoub, 2012). So it is natural to wonder if GC analysis on a slower timescale can reveal GC structure (GCS) on a faster timescale. Second is the impact of filtering on GC due to the hemodynamic response function, which relates neural activity to the recorded fMRI signal. Since intuitively GC will be sensitive to time delay, the variability of the hemodynamic response function (HRF), particularly spatially varying delay (called time to onset in the fMRI literature) and time to peak (confusingly sometimes called delay in the fMRI literature) has been suggested as a potential source of problems (Deshpande, Sathian, & Hu, 2010; Handwerker, Gonzalez-Castillo, D’Esposito, & Bandettini, 2012). A referee has, however, pointed out that following David et al. (2008), deconvolution (Glover, 1999) has gained favor (Havlicek, Friston, Jan, Brazdil, & Calhoun, 2011) as a potential means of dealing with this.
An important advance in GC theory and tools was made by Geweke (1982), who provided measures of the strength of causality or influence of one time series on another (henceforth called GEM, for Geweke causality measure), including frequency domain decompositions of them. Subsequently it was pointed out that the GEMs are measures of directional mutual information (Rissannen & Wax, 1987). The GEMs were extended to conditional causality in Geweke (1984). However, GEMs have not found as wide an application as they should have, partly because of some technical difficulties in calculating them, which are discussed further below. But GEMs (and their frequency domain versions) are precisely the tool needed to pursue both GC downsampling and filtering questions.
In the econometric literature, it was appreciated early that downsampling, especially in the presence of aggregation, could cause problems. This was implicit in the work of Sims (1971) and mentioned also in the work of Christiano and Eichenbaum (1987), who gave an example of contradictory causal analysis based on monthly versus quarterly data, and also discussed in Marcet (1991). But precise general conditions under which problems do and do not arise have never been given. We do so in this letter.
Some of the econometric discussion has been framed in terms of sampling of continuous time models (Sims, 1971; Marcet, 1991; Christiano & Eichenbaum, 1987). And authors such as Sims (1971) have suggested that models are best formulated initially in continuous time. While this is a view that I have long shared (and related to the modeling approach advocated by Middleton and Goodwin (1990), we deal with only discrete time models here. To cast our development in terms of continuous time models would require a considerable development of its own without changing our basic message.
The issue at stake, in its simplest form, is the following. Suppose that a pair of (possibly vector) processes exhibit a unidirectional GC relation (a influences b, but b does not influence a), but suppose measurement time series are available only at a slower timescale or as filtered time series or both. Then two questions arise. The first, which we call the forward question, is this: When is the unidirectional GC relation preserved? The second, which we call the reverse question, is harder. Suppose the measurement time series exhibit a unidirectional GC relation. Does that mean the underlying unfiltered faster timescale processes do? The latter question is the more important and so far has received no theoretical attention. The more general form of this issue is to what extent the GC structure (GCS) between two time series is distorted by downsampling and or filtering or both.
In order to resolve these issues, we need to develop some theory and some computational and modeling tools. First, to compute GEMs, one needs to be able to find submodels from a larger model (i.e., one having more time series). Thus, to compute the GEMs between time series xt, yt, Geweke (1982, 1984) attempted to avoid this by fitting submodels separately to xt to yt and then also fitting a joint model to xt, yt. Unfortunately this can generate negative values for some of the frequency domain GEMs (Chen, Bressler, & Ding, 2006). Properly computing submodels will resolve this problem, and previous work has not accomplished this (we discuss the attempts in Dufour & Taamouti, 2010, and Chen et al., 2006, below).
Second, one needs to be able to compute how models transform when they are downsampled. This has been done only in special cases (Pandit & Wu, 1983) or by methods that are not computationally realistic. We provide computationally reliable, state-space-based methods for doing this here.
Third, we need to study the effect of downsampling and filtering on GEMs. We will show how to use the newly developed tools to do this.
To sum up, we can say that previous discussions, including those above, as well as Geweke (1978), Telser (1967), Sims (1971), and Marcet (1991), fail to provide general algorithms for finding submodels or models induced by downsampling. Indeed both these problems have remained open problems in multivariate time series in their own right for several decades, and we resolve them here. Further, there does not seem to have been any theoretical discussion of the effect of filtering on GEMs, and we resolve that here also. To do that, it turns out that state-space models provide the proper framework.
Throughout this work, we deal with the dynamic interaction between two vector time series. It is well known in econometrics that if there is a third vector time series involved in the dynamics but not accounted for, then spurious causality can occur for reasons that have nothing to do with downsampling, a situation discussed by Hsiao (1982) and Geweke (1984). Other causes of spurious causality such as observation noise are also not discussed. Of course, the impact of downsampling in the presence of a third (vector) variable is also of interest but will be pursued elsewhere.
Finally, our whole discussion is carried out in the framework of linear time series models. It is of great interest to pursue nonlinear versions of these issues, but that would be a major separate task.
The remainder of the letter, is organized as follows. In section 2, we review and modify some state-space results important for system identification or model fitting and needed in the following sections. In section 3, we develop state-space methods for computing submodels of innovations state-space models. In section 4, we develop methods for transforming state-space models under downsampling. In section 5, we review GC and GEMs and extend them to a state space-setting. In section 6, we study the effect of filtering on GC via frequency domain GEMs. In section 7, we offer a theory to explain when GC is preserved under downsampling. In section 8, we discuss the reverse GC problem showing how spurious causality can be induced by downsampling. In section 9, we set up the framework for the application of these results to fMRI. This includes discussion of the phase properties of HRFs as well as the impact of deconvolution on the assessment of GC. Conclusions are in section 10. There are three appendixes.
1.1 Acronyms and Notation
GC is Granger causality or Granger causes; GCS is Granger causal structure; dn-gc does not Granger cause; GEM is Geweke causality measure. HRF is hemodynamic response function; SS is state space or state-space model; ISS is innovations state-space model; UC is unit circle; VAR is vector autoregression; VARMA is vector autoregressive moving average process; wp1 is with probability 1. LHS denotes left-hand side. The lag or backshift operator is denoted L or z−1; thus, if xt is a signal, then Lxt = z−1 xt = xt−1. L or z−1 are causal operators since they operate on the past. L−1 or z are noncausal operators since they operate on the future (so L−1xt = zxt = xt+1). The causal filter is sometimes denoted h, and its noncausal reflection is h∗ = h∗(L)= h(L−1).
denotes the values xa, xa+1, …, xb, so . For stationary processes, we have a = −∞. If M, N are positive semidefinite matrices, then M ≥ N means M−N is positive semidefinite. A stable square matrix is one whose eigenvalues all have modulus < 1.
2 State Space
The computational methods we develop rely on state-space techniques and spectral factorization, the latter being intimately related to the steady-state Kalman filter. In this section, we review and modify some basic results in state-space theory, Kalman filtering, and spectral factorization. Our discussion deals with two vector time series, collected as, .
2.1 State-Space Models
We consider a general constant parameter SS model,
| (2.1) |
with positive semidefinite noise covariance, . We refer to this as an SS model with parameters (A, C, [Q, R, S]).
It is common with SS models to take S = 0, but for equivalence between the class of VARMA models and the class of state-space models, it is necessary to allow S ≠ 0.
Now by matrix partitioning, . So we introduce
N: Noise Condition. R is positive definite.
N implies that Qs is positive semidefinite.
2.2 Steady-State Kalman Filter, Innovations State-Space Models, and the Discrete Algebraic Ricatti Equation
We now recall the Kalman filter for mean square estimation of the unobserved state sequence ξt from the observed time series zt. It is given by Kailath, Sayeed, and Hassibi (2000, theorem 9.2.1),
where et is the innovations sequence of variance Vt = R + CPtCT, is the Kalman gain sequence, and Pt is the state error variance matrix generated from the Ricatti equation, .
The Kalman filter is a time-varying filter, but we are interested in its steady state. If there is a steady state (i.e., Pt → P as t → ∞) then the limiting state error variance matrix P will, obey the so-called discrete algebraic Ricatti equation (DARE),
| (2.2) |
where V = R + CPCT and K = (APCT + S)V−1 is the corresponding steady-state Kalman gain. With some clever algebra, (Kailath et al., 2000), the DARE can be rewritten (the Ricatti equation can be similarly rewritten) as
where As = A − SR−1C and Ks = AsPCTV−1.
We now introduce two assumptions.
St: Stabilizability condition: As, is stabilizable (see appendix A)
De: Detectability condition: As, C is detectable.
In appendix A, it is shown De is equivalent to A, C being detectable. Also it holds automatically if A is stable.
The resulting steady-state Kalman filter can be written as
| (2.3) |
where εt is the steady-state innovation process and has variance matrix V and Kalman gain K. This steady-state filter provides a new state-space representation of the data sequence. We refer to it as an innovations state-space (ISS) model with parameters (A, C, K, V). We summarize this:
Result 1
Given the SS model, equation 2.1, with parameters (A, C, [Q, R, S]), then provided N, St, De hold:
The corresponding ISS model, equation 2.3, with parameters (A, C, K, V), can be found by solving the DARE, equation 2.2, which has a unique positive-definite solution P.
V is positive definite, (A, C) is detectable, and A−KC is stable so that (A, K) is controllable.
Proof
See appendix A.
Remarks
Henceforth an ISS model with parameters (A, C, K, V) will be required to have V positive definite, (A, C) detectable, and (A, K) controllable so that A–KC is stable.
It is well known that any VARMA model can be represented as an ISS model and vice versa (Solo, 1986; Hannan & Deistler, 1988).
Note that the ISS model with parameters (A, C, K, V) can also be written as the SS model with parameters (A, C, [KVKT, V, KV]).
The DARE is a quadratic matrix equation, but it can be computed using the (numerically reliable) DARE command in Matlab as follows. Compute: [P, L0, G] = DARE(AT, CT, Q, R, S, I) and then, V = R + CPCT, K = GT.
Note that stationarity is not required for this result.
2.3 Stationarity and Spectral Factorization
Given an ISS model with parameters (A, C, B, Σε), we now introduce
Assumption EV: Eigenvalue stability condition: A has all eigenvalues with modulus < 1, that is, A is a stability matrix.
With this assumption we can obtain an infinite vector moving average (VMA) representation, an infinite vector autoregressive (VAR) representation, and a spectral factorization.
Before stating these results, we need a definition;
Definition. Minimum phase transfer function. A matrix H(L) of causal transfer functions is said to be minimum phase (MP) if its inverse exists and is causal and stable. If H(L) is not minimum phase, it is called nonminimum phase (NMP).
Examples
Causal and stable. H(L) = 1 − aL, |a| < 1 has inverse , which follows from summing the geometric series. Then H_(L) is clearly causal and is stable since its pole has modulus < 1 (i.e., it lies inside the unit circle). Another way to state this is to say that H(L) is MP because its zero zo = a has modulus < 1 (i.e., it lies inside the unit circle, UC).
Causal but not stable. is not minimum phase since is not stable since its pole has modulus > 1. If we rewrite , then . This is stable but not causal since the expansion is in terms of the future. Again we can rephrase this example to say H(L) is NMP because its zero is outside the unit circle.
Not causal but stable. H(L) = L(1 − aL), |a| < 1 is nonminimum phase since is not causal. Note that H_(L) is stable. We can rephrase this as follows. H(L) has two zeros: one is inside the unit circle, and the other is at ∞ (i.e., z = L−1 = ∞ makes H (L) vanish and so is outside the unit circle).
For further discussion of minimum phase filters, see Green (1988) and Solo (1986).
The following result is based on Kailath et al. (2000, theorem 8.3.2) and the surrounding discussion.
Result 2
For the ISS model (A, C, B, Σε) obeying condition Ev we have,
- Infinite VMA or Wold decomposition:
(2.4) - Infinite VAR representation:
(2.5) - Spectral factorization. Put L = exp(− jλ); then zt has positive-definite spectrum with spectral factorization as follows:
(2.6) H(L) is minimum phase.
Proof
Write equation 2.3, in operator form. The series is convergent wp1 and in mean square since A is stable.
Rewrite equation as . Then write this in operator form. The series is convergent wp1 and in mean square since A−KC is stable and zt is stationary.
This follows from standard formulas for spectra of filtered stationary time series applied to (a).
From (a),(b) G(L) = H−1 (L) and by (b) G(L) is causal and stable, and the result follows.
Remarks
Result 2 is a special case of a general result that given a full-rank multivariate spectrum fZ(λ), there exists a unique causal stable minimum phase spectral factor H(L) with H(0) = I and positive-definite innovations variance matrix Σε such that equation 2.6 holds (Hannan & Deistler, 1988; Green, 1988). In general detH(L) may have some roots on the unit circle (Hannan & Poskitt, 1988; Green, 1988), but the assumptions in result 2 rule this case out. Such roots mean that some linear combinations of zt can be perfectly predicted from the past (Hannan & Poskitt, 1988; Green, 1988), something that is not realistic in the fMRI application.
Result 2 is also crucial from a system identification or model-fitting point of view. From that point of view, all we can know (from second-order statistics) is the spectrum, and so if, naturally, we want a unique model, the only model we can obtain is the causal stable minimum phase model: the ISS model. The standard approach to SS model fitting is the so-called state-space subspace method (Deistler, Peternell, & Scherer, 1995; Bauer, 2005), and indeed it delivers an ISS model. The alternative approach of fitting a VARMA model (Hannan & Deistler, 1988; Lutkepohl, 1993) is equivalent to getting an ISS model.
We need result 1, however, since when we form submodels, we do not immediately get an ISS model; rather, we must compute it.
3 Submodels
Our computation of causality measures requires that we compute induced submodels. In this section, we show how to obtain an ISS submodel from the ISS joint model.
We partition zt = (xt, yt)T into subvector signals of interest and partition the state-space model correspondingly: and B = (BX, BY). We first read out an SS submodel for xt from the ISS model for zt. We have simply ξt+1 = Aξt + wt, xt = CXξt + εX,t where, . We need to calculate the covariance matrix: . We find , Q = var(wt) = BΣεBT and . This leads to:
Theorem 1
Given the joint ISS model, equation 2.3 or 2.4, for zt, then under condition Ev, the corresponding ISS submodel for xt, (A, CX, K(X), ΩX) (the bracket notation K(X) is used to avoid confusion with e.g. CX, ΣX,ε which are submatrices), can be found by solving the DARE, equation 2.2, with .
Proof
First, we note by partitioning |Σε| = |ΣX,ε||Σ(Y|X),ε| where so that ΣX,ε and Σ(Y|X),ε are both positive definite. Now we need only check conditions N, St, De of result 1. We need to show that is positive definite, (A, CX) is detectable, and is stabilizable; in fact, we show it is controllable.
The first is already established. The second follows trivially since A is stable. We use the PBH test (see appendix A) to check the third.
Suppose controllability fails. Then by the PBH test, there exists q ≠ 0 with and
since Σ(Y|X)ε, is positive definite. But then,
Thus, (A − BXCX, BY) is not controllable. But this is a contradiction since we can find a matrix, namely CY, so that A − BXCX − BYCY = A − BC is stable.
Remarks
For implementation in Matlab, positive definiteness in constructing Q can be an issue. A simple resolution is to use a Cholesky factorization of and form Bε = BLε and then form .
The P(X) matrix from DARE, obeys and then .
Dufour and Taamouti (2010) discuss a method for obtaining sub-models, but it is flawed. First, it requires computing the inverse of the VAR operator. While this might be feasible (analytically) on a toy example, there is no known numerically reliable way to do this in general (computation of determinants is notoriously ill conditioned). Second, it requires the solution of simultaneous quadratic autocovariance equations to determine VMA parameters for which no algorithm is given. In fact, these are precisely the equations required for a spectral factorization of a VMA process. There are reliable algorithms for doing this, but given the flaw already revealed, we need not discuss this approach any further.
Next we state an important corollary:
Corollary 1
Any submodel is in general a VARMA model, not a VAR. To put it another way, the class of VARMA models is closed under the forming of submodels, whereas the class of VAR models is not.
This means that VAR models are not generic and is a strong argument against their use. Any vector time series can be regarded as a submodel of a larger-dimensional time series and thus must in general obey a VARMA model. This result (which is well known in time series folklore) is significant for econometrics where VAR models are in widespread use.
For the next section we need:
Theorem 2
For the joint ISS model, equation 2.3 or 2.4, for zt with conditions St, De holding and with induced submodel for xt given in theorem 1, we have,
| (3.1) |
4 Downsampling
There are two approaches to the problem of finding the model obeyed by a downsampled process: frequency domain and time domain. While the general formula for the spectrum of a downsampled process has long been known, it is not straightforward to use and has not yielded any general computational approach to finding submodels of parameterized spectra.
The spectral formula, however, has made it very clear that downsampling leads to aliasing, so that higher-frequency information is lost. This strongly suggests that GCS will be affected by downsampling.
The most complete (time domain) work on downsampling seems to be that of Pandit and Wu (1983), although they treat only the first- and second-order scalar cases. There is work in the engineering literature for systems with observed inputs, but that is also limited and in any case not helpful here. We follow an SS route.
We begin with the ISS model, equation 2.3. Suppose we downsample the observed signal zt with sampling multiple m. Let t denote the fine timescale and k the coarse timescale so t = mk. The downsampled signal is . To develop the SS model for , we iterate the SS model above to obtain
Now set t = mk, l = m and denote sampled signals, . Then we find
where . We now use result 1 to find the ISS model corresponding to this SS model.
We first have to calculate the model covariances:
| (4.1) |
| (4.2) |
We now obtain:
Theorem 3
Given the ISS model, equation 2.3, then under condition Ev, for m > 1, the ISS model for the downsampled process is , obtained by solving the DARE with SS model (Am, C, [Qm, R, Sm]) where Qm is given in equation 4.2 and Sm is given in equation 4.1.
Proof
Using result 1, we need to show the following. R is positive definite, (Am,C) is detectable, and (Am − SmR−1C), is stabilizable. In fact, we show controllability. The first holds trivially; the second does as well since A is stable and thus so is Am. For the third, we use the PBH test.
Suppose controllability fails. Then there is a left eigenvector q (possibly complex) with λqT = qT(Am − SmR−1C) = qTAm−1(A − BC) and Since Σε is positive definite, this delivers for r = 0, …, m − 2.
Using this, we now find λ−qT = qTAm−1(A − BC) = qTAm−2(A − BC)2 +qTAm−2BC(A − BC) = qTAm−2(A − BC)2. Iterating this yields λqT − qT(A − BC)m. Thus, if λm is an mth root of λ, then λmqT = qT(A − BC). Since qT B = 0, we thus conclude that (A − BC, B) is not controllable. But this is a contradiction since (A − BC) + BC = A is stable.
Remark
In Matlab, we would compute, , yielding and .
More specifically obeys , where ; ; ; .
5 Granger Causality
In this section, we review and extend some basic results in Granger causality. In particular, we extend GEMs to the state-space setting and show how to compute them reliably.
Since the development of Granger causality, it has become clear (Dufour & Renault, 1998; Dufour & Taamouti, 2010) that in general, one cannot address the causality issue with only one-step-ahead measures as commonly used. One needs to look at causality over all forecast horizons. However one-step measures are sufficient when one is considering only two vector time series as we are (Dufour & Renault, 1998, proposition 2.3).
5.1 Granger Causality Definitions
Our definitions of one-step Granger causality naturally draw on Granger (1963, 1969), Sims (1972), and Solo (1986) but are also influenced by Caines (1976), who, drawing on the work of Pierce and Haugh (1977), distinguished between weak and strong GC, or what Caines calls weak and strong feedback free processes. We introduce:
Condition WSS: The vector time series xt, yt are jointly second-order stationary.
- Definition: Weak Granger causality. Under WSS, we say yt does not weakly Granger-cause (dn-wgc) xt if, for all t,
Otherwise, we say yt weakly Granger causes (wgc) xt. Because of the elementary identity,
the equality of variance matrices in the definition also ensures the equality of predictions: . This definition agrees with Granger (1969); Caines and Chan (1975), who do not use the designator weak; and Caines (1976) and Solo (1986) who do. - Definition: Strong Granger causality. Under WSS, we say yt does not strongly Granger cause (dn-sgc) xt if, for all t,
Otherwise we say yt strongly Granger-causes (sgc) xt. Again, equality of the variance matrices ensures equality of predictions, . This definition agrees with Caines (1976) and Solo (1986). Definition: FBI (feedback interconnected). If xt Granger-causes yt and yt Granger-causes xt, then we say xt, yt are feedback interconnected.
Definition: UGC (unidirectionally Granger causes). If xt Granger-causes yt but yt dn-gc xt we say xt unidirectionally Granger-causes yt.
5.2 Granger Causality for Stationary State-Space Models
Now we partition zt = (xt, yt)T into subvector signals of interest and partition the vector MA or state-space model, equation 2.4, correspondingly:
| (5.1) |
| (5.2) |
Now we recall results of Caines (1976):
Result 3
If obeys a Wold model of the form zt=HZ (L)εt where HZ(L) is a one-sided square summable moving average polynomial with HZ(0)= I, which is partitioned as in equation 5.2, then:
yt dn-wgc xt iff HXY(L) = 0.
yt dn-sgc xt iff HXY(L) = 0 and ΣXY,ε = 0.
We can now state a new SS version of this result:
Theorem 4
For the stationary ISS model, equations 5.1 and 5.2:
yt dn-wgc xt iff CXAr BY = 0, r ≥ 0.
yt dn-sgc xt iff CXAr BY = 0, r ≥ 0 and ΣXY,ε = 0.
Proof
The proof follows immediately from result 3 since .
Remarks
By the Cayley-Hamilton theorem, we can replace part a of theorem 4 with CXArBY = 0, 0 ≤ r ≤ n − 1, n = dim (ξt).
Collecting these equations together gives CX (BY, ABY,…, An−1BY) = 0, which says that the pair (A, BY) is not controllable. Also, we have , which says that the pair (CX, A) is not observable. Thus, the representation of HXY(L) is not minimal.
From a data analysis point of view, we need to embed this result in a well-behaved hypothesis test. The results of Geweke (1982), suitably modified, allow us to do this.
5.3 Geweke Causality Measures for SS Models
Although much of the discussion in Geweke (1982) is in terms of VARs, we can show it applies more generally. We begin as Geweke (1982) did with the following definitions. First, is a measure of the gain in using the past of y to predict x beyond using just the past of x; similarly introduce . Thus, for example, FY→X is a directional measure of the influence of yt on xt. Next, define the instantaneous influence measure: . These are then joined in the fundamental decomposition (Geweke, 1982),
| (5.3) |
where, . Geweke (1982) then proceeds to decompose these measures in the frequency domain. Thus, the frequency domain GEM for the dynamic influence of yt on xt is given by Geweke (1982),
| (5.4) |
and fe(λ) is assembled (following Geweke, 1982) as follows.
Introduce , and note that is uncorrelated with εX,t and has variance . Then rewrite equation 5.2 as
This corresponds to equation 3.3 in Geweke (1982) and yields the following expressions corresponding to those in Geweke (1982):
| (5.5) |
| (5.6) |
Using the SS expressions above, we rewrite HeX(L) in a form more suited to computation as
| (5.7) |
Note that then, using theorem 2,
| (5.8) |
Clearly, with L = exp(−jλ), fX(L) ≥ fe(L) ⇒ FY→X≥0.
Also the instantaneous causality measure is
| (5.9) |
Clearly ΣX,ε ≥ Σ(X|Y),ε so that FY.X ≥ 0.
Introduce the normalized cross-covariance-based matrix, . Then, using a well-known partitioned matrix determinant formula (Magnus & Neudecker, 1999), we find FY.X = ln|I − Γx,y|. This means that the instantaneous causality measure depends only on the canonical correlations (which are the eigenvalues of Γx,y) between εX,t, εY,t (Seber, 1984; Kshirsagar, 1972).
To implement these formulas, we need expressions for ΩX, ΩY, fX(λ). To get them, Geweke (1982) fits separate models to each of xt and yt. But this causes positivity problems with fY→X(λ) (Chen et al., 2006). Instead we obtain the required quantities from the correct submodel obtained in the previous section. We have:
Theorem 5a
The GEMs can be obtained from the joint ISS model, equation 5.1, and the submodel in theorem 2, as follows:
where ΩX is got from the submodel in theorem 3.
The frequency domain GEM fY→X(λ), equation 5.4, can be computed from equations 5.6, 3.1, and 5.7.
ΩY, FX→Y, fX→Y(λ) can be obtained similarly.
Now pulling all this together with the help of result 3, we have an extension of the results of Geweke (1982) to the state-space/VARMA case.
Theorem 5b
For the joint ISS model, equation 5.1:
FY→X ≥ 0, FY.X ≥ 0 and .
yt dn-wgc xt iff, fX(L) = fe(L) which holds iff FY→X=0, that is, iff ΩX = ΣX,ε.
yt dn-sgc xt iff fX(L) = fe(L) and Σ(X|Y),ε = ΣX,ε that is, iff FY→X = 0 and FY.X=0, that is, iff FY→X + FY.X = 0 i.e. iff ΩX = Σ(X|Y),ε.
Remarks
A very nice nested hypothesis testing explanation of the decomposition 5.3 is given by Parzen in the discussion to Geweke (1982).
It is straightforward to see that the GEMs are unaffected by scaling of the variables. This is a problem for other GC measures (Edin, 2010).
- For completeness, we state extensions of the inferential results in Geweke (1982) without proof. Suppose we fit an SS model to data zt, t = 1, …, T using, for example, so-called state-space subspace methods (Deistler et al., 1995; Bauer, 2005) or VARMA methods in, for example, Lutkepohl (1993). Let , , , be the corresponding GEM estimators. If we denote true values with a superscript 0, we find under some regularity conditions:
So to test for strong GC, we put these together:
Together with similar asymptotics for , , we see that the fundamental decomposition, equation 5.3, has a sample version involving a decomposition of a chi-squared into sums of smaller chi-squared statistics. Chen et al. (2006) also attempt to derive FY→X without fitting separate models to xt, yt. However the proposed procedure to compute fX(λ) involves a two-sided filter and is thus in error. The only way to get fX(λ) is by spectral factorization (which produces one-sided or causal filters), as we have done.
Other kinds of causality measures have emerged in the literature (Kaminski & Blinowska, 1991; Baccala & Sameshima, 2001; Takahashi, Baccala, & Sameshima, 2008; Pascual-Marqui et al., 2014), but it is not known whether they obey the properties in theorems 5a and 5b. However these properties are crucial to our subsequent analysis.
6 Effect of Filtering on Granger Causality Measures
Now the import of the frequency domain GEM becomes apparent since it allows us to determine the effect of one-sided (or causal) filtering on GC.
We need to be clear on the situation envisaged here. The unfiltered time series are the underlying series of interest, but we have access only to the filtered time series, so we can only find the GEMs from the spectrum of the filtered time series. What we need to know is when those filtered GEMs are the same as the underlying GEMs. We have:
Theorem 6
Suppose we filter zt with a stable, full-rank, one-sided filter . Then:
If Φ(L) is minimum phase, the GEMs (and so GC) are unaffected by filtering.
If Φ(L) has the form where ψ(L) is a scalar all-pass filter and is stable, minimum phase, then the GEMs (and so GC) are unaffected by filtering.
If Φ(L) is nonminimum phase and case b does not hold, then the GEMs (and so GC) are changed by filtering.
Proof
Denote by result 2a. Then for the frequency domain GEM, we need to find , where L = exp(−jλ). We find trivially that . Finding is much more complicated; we need the minimum phase vector moving average or state-space model corresponding to equation 5.2. Taking Φ(L) to be nonminimum phase, we carry out a spectral factorization, , where is causal, stable, minimum phase with and then, from appendix C, , can be written , , where E(L) is all pass and J, are constant matrices (Cholesky factors). Writing this in partitioned form,
yields , where
Thus, in , the |ΦX(L)| factors cancel giving, . This will reduce to fY→X(λ) iff where K(L−1) is all pass, which occurs iff DXY(L−1) = 0, DYX(L−1)= 0, DXX (L−1) = ψ(L−1)I, DYY (L−1) = ψ(L−1)I where ψ(L−1) is a scalar all-pass filter. Results a, b, and c now follow.
Remark
Result a has also been obtained in the independent work of Seth, Chorley, and Barnett (2013) by different methods.1
We give three examples:
Example 6A
Differential delay. Suppose where εt, νt are independent zero mean white noises with variances 1, σ2, respectively, while . So the two series are white noises that exhibit an instantaneous GC. The filtering delays one series relative to the other. Then we have , and we see that while is stable, causal, and invertible; indeed, . Thus, we see that the differential delay has introduced a spurious dynamic GC relation and the original purely instantaneous GC is lost.
Example 6B
Noncausal filter. We use the same setup as in example 6 A except that now where |θx| < 1, |θy| < 1 and θx ≠ θy. We rewrite this as −L−1Ψ(L) where . Although L−1 is noncausal and so NMP, it is the same for both filters and so by theorem 6b will not affect the GEMS. So we can replace Φ(L) with Ψ(L). Both entries in Ψ(L) are causal but unstable, and so NMP and the GCS will be altered. In fact, we now show this explicitly.
Note, first, how the noncausal filter operates. We have
Future values are needed to compute the filtered signal at the current time.
The process has spectrum where , and similarly for B. It is straightforward to check that this has spectral factorization,
where and a = 1 − θxL, b = 1 − θyL. Note that AA∗ = aa∗ and A∗B = ab∗. This factorization corresponds to the model where εa,t, νb,t are independent white noises of variances , R2, respectively. We see that the NMP filtering has introduced spurious dynamics and reversed the GCS.
Example 6C
Wiener deconvolution. When filtered versions of xt, yt are observed in noise, one can estimate them by using the Wiener fitler (Kailath et al., 2000). The optimal filter uses the joint spectrum, but fMRI practice (Glover, 1999) is to filter each signal separately. This is suboptimal but will still reduce the effect of the noise. Suppose we observe wx,t = hx(L)xt + εt where h(L) is a stable filter and εt is a white noise of variance σ2 independent of xt. The Wiener filter estimate of xt is where (Kailath et al., 2000) where γx = γx(L) is the autocovariance generating function of xt. In fMRI practice (Glover, 1999), γx(L) is set to 1. This is sub-optimal and may lead to performance worse than no filtering. But continuing, we carry out a spectral factorization giving where kx = kx(L) is a causal minimum phase filter with kx(0) = 1. The filter thus becomes . Since kx is minimum phase and causal, then is stable and causal and will not affect the GEMS. We are left with the noncausal filter — for example, in the simple case, hx= 1 − θxL, |θx| < 1, the spectral factorization reduces to solving a quadratic equation and one obtains kx = 1 − αx L, |αx| < 1 Thus, . With a similar deconvolution (where βx ≠ βy) applied to a noisy filtered version of yt, we conclude that deconvolution will distort the GCS since the βx, βy filters are noncausal.
7 Downsampling and Forwards Granger Causality
We now consider to what extent GC is preserved under downsampling.
Using the sampled notation of our discussion above and defining , we have the following result:
Theorem 7
Forwards causality:
If yt dn-sgc xt, then dn-sgc .
If yt dn-wgc xt, then in general wgc .
Remarks
Part a is new, although technically a special case of a result of the author’s established in a non-SS framework.
We might consider taking part b as a formalization of longstanding folklore in econometrics (Christiano & Eichenbaum, 1987; Marcet, 1991) that downsampling can destroy unidirectional Granger causality. However, that same folklore is flawed because it failed to recognize the possibility of part a. The folklore is further flawed because it failed to recognize the more serious reverse problem discussed below.
Proof of Theorem 7, Part a
We use the partitioned expressions in the discussion leading up to result 3. We also refer to the discussion leading up to theorem 6.
This allows us to write two decompositions. First, we write wk=wX,k +wY,k, where
From result 3 and the definition of dn-sgc,
| (7.1) |
The other decomposition is , and
| (7.2) |
Next we note from theorem 4 that
for all p ≥ 0. Thus, we deduce
| (7.3) |
We can now write
| (7.4) |
Based on equation 7.4, we now introduce the ISS model for ,
where νX,k is the innovations sequence. Using this, we introduce the estimator K(X)νX,k of wX,k and the estimation error . Below we show
| (7.5) |
We thus rewrite the model for as
Now we can construct an ISS model for ζk = (I + CY (L−1 I − Am)−1K(Y))νY,k where νY,k is the innovations sequence. In view of equations 7.1, 7.2, and 7.5, νX,k and νY,l are uncorrelated for all k, l. Thus, we have constructed the joint ISS model:
From this we deduce that dn-sgc as required.
Proof of Equation 7.5
Consider then . The second term vanishes for k ≠ l. The first term vanishes for k > l since wX,k is uncorrelated with the past and hence νX,l; for l > k, it vanishes since νX,l is uncorrelated with the past. For k = l, it vanishes by the definition of K(X) (Kailath et al., 2000).
Proof of Theorem 7, Part b
A perusal of the proof of theorem 7, part a, shows that we cannot construct the block lower triangular joint ISS model. In general, we obtain a full block ISS model.
8 Downsampling and Reverse Granger Causality
We now come to the more serious issue of how downsampling might distort GC. To establish distortion, we simply have to exhibit a numerical example, but that is not as simple as one might hope.
8.1 Simulation Design
Designing a procedure to generate a wide class of examples of spurious causality is not as simple as one might hope. We develop such a procedure for a bivariate vector autoregression of order one: a bivariate VAR(1). On the one hand, this is about the simplest example one can consider; on the other hand, it is general enough to generate important behaviors.
The bivariate VAR(1) model is then
Where Σ is the variance matrix of the zero mean white noise and ρ is a correlation.
We note that this model can be written as an ISS model with parameters, A, I, −A, Σ. Hence, all the computations described above are easily carried out.
But the real issue is how to select the parameters. By a straightforward scaling argument, it is easy to see that we may set σa = 1 = σb without loss of generality. Thus, we need to choose only A, ρ.
Some reflection shows that there are two issues. First, we must ensure the process is stationary; for the eigenvalues λ1, λ2 of A, we must have |λ1| < 1, |λ2| < 1. Second, to design a simulation, we need to choose FY→X, FX→Y, but these quantities depend on the parameters A, ρ in a highly nonlinear way, so it is not obvious how to do this. And five parameters are already too many to pursue this by trial and error.
For the first issue, we have trace(A) = λ1 + λ2=ϕx + ϕy and det(A) = λ1λ 2 = ϕxϕy − γxγy. Our approach is to select λ1, λ2 and then find ϕx, ϕy to satisfy ϕx + ϕy = λ1 + λ2, ϕxϕy = λ1λ2 + γxγy. This requires solving a quadratic equation. If we denote the solutions as r+, r−, then we get two cases: (ϕx, ϕy) = (r+, r−) and (ϕy, ϕx) = (r+, r−). This leaves us to select γx, γy.
In appendix B we show that where . Similarly, FX→Y ≥ ln(1 + ξy) where . But we also show that ξx = 0 ⇒ FY→X = 0 and ξy = 0 ⇒ FX→Y = 0, so we select ξx, ξy, thereby setting a lower bounds to FY→X, FX→Y. This seems to be the best one can do, and as we see below, it works quite well. So given ξx, ξy, compute and . This gives four cases and multiplied by the two cases above yields eight cases.
This is not quite the end of the story since the γx, γy values need to be consistent with the ϕx, ϕy values. Specifically the quadratic equation to be solved for ϕx, ϕy must have real roots. Thus, the discriminant must be ≥ 0. So (ϕx + ϕy)2 − 4(ϕxϕy) = (λ1 + λ2)2 − 4(λ1λ2 + γxγy)=(λ1− λ2)2 − 4γxγy ≥ 0. There are four cases: two with real roots and two with complex roots.
If λ1, λ2 are real, then we require . This always holds if sign(γxγy) ≤ 0. If sign(γx γy) > 0, we have a binding constraint that restricts the sizes of ξx, ξy.
If λ1, λ2 are complex conjugates, then (λ1−λ2)2 is negative. If sign(γxγy) ≥ 0, then the condition never holds. If sign(γxγy) < 0, then there is a binding constraint that restricts the sizes of ξx, ξy. In particular, note that if sign(γxγy) = 0, then one cannot have complex roots for A. We now use this design procedure to illustrate reverse causality.
8.2 Computation
We describe the steps used to generate the results below. We assume the state-space model for comes in ISS form. Since standard state-space subspace model-fitting algorithms (Larimore, 1983; van Overschee & de Moor, 1996; Bauer, 2005) generate ISS models, this is a reasonable assumption. Otherwise we use result 1 to generate the corresponding ISS model.
Given a sampling multiple m, we first use theorem 3 to generate the subsampled ISS model and, hence, . To obtain the GEMs, we use theorem 1 to generate the marginal models for xt, yt yielding , . And now , are gotten from formulas 5.8 and 5.9 and the comment following theorem 5a.
8.3 Scenario Studies
We now illustrate the various results above with some bivariate simulations.
Example 1: GEMs Decline Gracefully
Here, for the underlying process, y pushes x much harder than x pushes y. This pattern is roughly preserved with slower sampling, but the relative strengths change as seen in Table 1.
Table 1.
GEMs for Various Sampling Intervals for (λ1, λ2, ξx, ξy, ρ) = (−.95 exp(j × .1), −.95 exp(− j × .1), 1.5, .2, .2) ⇒ .
| m | 1 | 2 | 3 | 4 | 5 | 6 | 10 | 20 | 30 | 40 |
|---|---|---|---|---|---|---|---|---|---|---|
| FY→X | 1.38 | 1.66 | 1.41 | 1.17 | 0.99 | 0.86 | 0.551 | 0.15 | 0.00 | 0.01 |
| FX→Y | 0.20 | 0.25 | 0.29 | 0.31 | 0.32 | 0.32 | 0.29 | 0.11 | 0.00 | 0.01 |
Example 2: GEMs Reverse
In this case, the underlying processes push each other with roughly equal strength. But subsampling yields a false picture with x pushing y much harder than the reverse (see Table 2).
Table 2.
GEMs for Various Sampling Intervals for (λ1, λ2, ξx, ξy, ρ) = (.95 exp(j × .1), .95 exp(− j × .1), 1.5, .2, .2) ⇒ .
| m | 1 | 2 | 3 | 4 | 5 | 6 | 10 | 20 | 30 | 40 |
|---|---|---|---|---|---|---|---|---|---|---|
| FY→X | 0.93 | 0.88 | 0.77 | 0.683 | 0.62 | 0.57 | 0.42 | 0.13 | 0.00 | 0.01 |
| FX→Y | 1.05 | 1.82 | 2.01 | 1.80 | 1.53 | 1.30 | 0.75 | 0.18 | 0.00 | 0.02 |
Example 3: Near Equal Strength Dynamics Becomes Nearly Unidirectional
In this case, the underlying relation is one of near equal strength feedback interconnection. But as Table 3 shows, almost immediately a very unequal relation appears under subsampling which soon decays to a near unidirectional relation.
Table 3.
GEMs for Various Sampling Intervals for (λ1, λ2, ξx, ξy, ρ) = (.995, −.7, 1, .5, .7) ⇒
| m | 1 | 2 | 3 | 4 | 5 | 6 | 10 | 20 | 30 | 40 |
|---|---|---|---|---|---|---|---|---|---|---|
| FY→X | 1.49 | 0.05 | 0.25 | 0.06 | 0.11 | 0.05 | 0.04 | 0.02 | 0.01 | 0.01 |
| FX→Y | 1.69 | 0.17 | 0.64 | 0.26 | 0.47 | 0.29 | 0.29 | 0.21 | 0.16 | 0.13 |
Example 4: Near Unidirectional Dynamics Becomes Near Equal Strength
In this case a near unidirectional dynamic relation immediately becomes one of significant but unequal strengths and then one of near equal strength (see Table 4).
Table 4.
GEMs for Various Sampling Intervals for (λ1, λ2, ξx, ξy, ρ) = (.99 exp(j × .25), .95 exp(− j × .25), .1, 3, −.8) ⇒ .
| m | 1 | 2 | 3 | 4 | 5 | 6 | 10 | 20 | 30 | 40 |
|---|---|---|---|---|---|---|---|---|---|---|
| FY→X | 0.02 | 0.28 | 0.38 | 0.43 | 0.45 | 0.46 | 0.31 | 0.45 | 0.41 | 0.17 |
| FX→Y | 2.93 | 2.38 | 1.62 | 1.24 | 1.02 | 0.86 | 0.37 | 0.53 | 0.45 | 0.18 |
There is nothing pathological about these examples, and using the design procedure developed above, it is easy to generate other similar kinds of examples. They make it emphatically clear that GC cannot be reliably discerned from downsampled data.
In independent work, Seth et al. (2013) have shown simulations where downsampling distorts GC. But their work is purely empirical, and they do not have the theoretical framework developed here to design specific types of distortion as we have done.
9 Application to fMRI
In this section we apply the above results to fMRI, but to do so, we need to describe fMRI data generation schemes (dgs’s); we give three such schemes The following feature is common to all of them.
We suppose there is an underlying neural activity (NA) 2-node circuit operating on a fast timescale of order 50 ms and that it is described by a state-space model. Specifically, the (possibly vector) NA signals at each node are xt, yt, which we collect together into a joint NA vector signal , which is described by a state-space model such as equation 2.1 or 2.3.
- Filter (F). The BOLD signal recorded at a particular voxel is generated as follows. The NA zt is filtered by (a spatially varying) HRF to generate a fast BOLD signal —specifically
Filter then downsample (F-DS). The BOLD signal recorded at a particular voxel is generated in two stages. The first stage is the same as F. In the second stage, the scanner samples this signal delivering a downsampled (or slow) BOLD signal —for example, if the NA timescale is 50 ms and the downsampled time scale is 200 ms, then m = 4.
Downsample then filter (DS-F). Here we suppose the NA zt is down-sampled to a slow timescale giving a slow NA . This is then filtered by (a slow spatially varying) HRF to generate the slow BOLD signal zb,k.
Note that F is the limiting case of F-DS where fMRI is recorded on the same timescale as NA. Clearly F-DS makes physiological sense, whereas DS-F does not. Indeed F-DS is advocated by Deshpande et al. (2010), who provide further physiological references to back it up. However, below we will see that DS-F seems to be behind some of the processing methods used in practice.
The aim now is to try to solve the reverse GC problem; to determine the GCS of fast NA circuit zt from the GCS of either the fast BOLD circuit or the slow BOLD circuit zb,k. To do this, we see from theorem 6, that we need to investigate the phase properties of the HRF.
9.1 HRFs Are Nonminimum Phase
We denote an HRF by hr, r=1, 2,⋯ and its transfer function as . We assume H(z) is bounded input, bounded output stable (Kailath et al., 2000), for which the necessary and sufficient condition is .
In Figure 1 we show plots of canonical HRFs (with default parameter choices) used in SPM and Glover (1999). They exhibit three main features found in practice:
Refractory period: Characterized by a time to onset τo
Overshoot—characterized by a peak time τp
Undershoot
Figure 1.
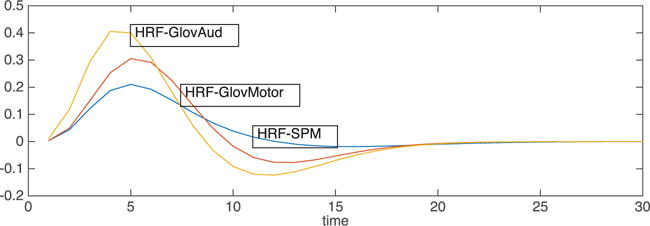
Canonical HRFs.
Also there are persistent reports in the literature of HRFs with an initial small dip immediately following the refractory period (e.g., Miezin, Maccotta, Ollinger, Petersen, & Buckner, 2000).
A number of results in the control engineering literature show how nonminimum phase (NMP) zeros of the transfer function imply overshoot and undershoot of an impulse response (see Damm & Muhirwa, 2014). But none of these works provide converse results, showing what impulse response shape implies about transfer function zeros.
We give a preliminary general result and then two converse results.
Theorem 8a
Any HRF with a refractory period is NMP.
Proof
We can write the transfer function as h(L) = Lτo g(L) where g(L) is a causal transfer function. Even if g(L) is MP, then h(L) is NMP because L−τo is not a causal operator.
Certainly the time to onset can be estimated, and then the BOLD signal can be shifted in time to align the start time with the stimulus start time. This effectively corrects the HRF for the refractory period. But this makes sense only if it is known that the refractory period is due to information transmission delay. If it is due to the GCS, then such alignment, being noncausal, will destroy the GCS.
To continue, we now assume the HRF has been corrected for the refractory period so that the corrected transfer function is .
Theorem 8b
Dip: if h1 < 0 and H(1) > 0, then the HRF is NMP.
Note that . The fact that the overshoot area (far) exceeds the sum of the other two areas (so that H(1) > 0) seems to be a universal property of actual HRFs.
Proof
We prove that Hc(z) has a real zero outside the UC. We can set z = R, which is real. Then consider that . For R ≥ 1, the second term is bounded by and → 0 as R → ∞. Since h1 < 0, then for R large enough, RH(R) < 0 Since 1H(1) > 0, this means there must exist Ro > 1 with RoH(Ro) = 0 as required.
Theorem 8c
No dip: if h1 > 0 and H(−1) > 0, then the HRF is NMP.
Note that and H(−1) > 0 is satisfied by the default canonical HRFs. Further, because HRFs are very smooth, the successive differences h2m − h2m−1 will be very small. H(−1) can be split into four pieces: a positive sum up to the peak time, a negative sum from there to the zero crossing, a positive sum to the trough of the undershoot, and a negative sum from there back up to the the time axis. We thus expect H(−1) to be small.
Proof
We prove Hc(z) has a complex zero outside the UC. Put z = Rejπ = −R. Then consider that . For R ≥ 1, the second term is bounded by , which → 0 as R → ∞ and so since −h1 < 0, then for R large enough, RH(−R) < 0. Since 1H (−1) > 0, there must thus exist Ro > 1 for which RoH(−Ro) = 0 and the result is established.
Since the condition H(−1) > 0 and more generally the possibility of complex zeros outside the UC is so crucial, more flexible modeling of the HRF is called for. Recent approaches include Khalidov, Fadili, Lazeyras, Ville, and Unser (2011), Zafer, Blu, and Ville (2014), Wu et al. (2013), Sreenivasan, Havlicek, and Deshpande (2015) and our approach using Laguerre-polynomials (Cassidy, Long, Rae, & Solo, 2012).
9.2 Deconvolution
As noted in section 1, the current practice is to first apply a deconvolution to the BOLD signals before carrying out a GC analysis. As discussed in section 9.3, this makes sense only for DS-F.
We now see from the deconvolution example 6 C that even if Wiener deconvolution is applied to noise-free data zb,k, it will distort the GCS because it necessarily involves noncausal filtering. This is discussed further in section 9.3.
9.3 Reverse GC Problem
We discuss approaches under F, F-DS, and DS-F.
F
There is only one approach possible here. If the HRF is minimum phase, then the fast filtering will not affect the GCS and the first stage would consist of a GC analysis of the fast BOLD data. That is, fit an SS model to ; find submodels for , using DARE (see theorem 1); and compute the GEMS FY→X, FY.X, FX→Y using the expressions in theorem 5a. This would deliver the GCS of the fast BOLD circuit and, hence, of the NA circuit. But in practice, the BOLD data will be noisy, and an attempt to reduce the impact of the noise by deconvolution will distort the GCS. If the HRF is nonminimum phase, then this GCS would be distorted and nothing can be done to overcome that.
F-DS
Again there is only one approach possible here. If the HRF is minimum phase, then the fast filtering will not affect the GCS and the first stage would consist of a GC analysis of the slow BOLD data—that is, fit an SS model to zb,k; find submodels for xb,k, yb,k using DARE (see theorem 1); and compute the GEMS FY→X, FY.X, FX→Y using the expressions in theorem 5a. This would deliver the GCS of the slow BOLD circuit. The second stage is to try to get the GCS of the fast BOLD circuit. But now we see that it must fail since the results of the reverse GC study in section 8 demonstrate that we cannot use the GCS of the slow BOLD circuit to discern the GCS of the fast BOLD circuit. So we cannot get at the GCS of the fast NA circuit.
Notice that in F-DS there is no role for deconvolution.
If the HRF, is NMP then the GCS will be distorted and there is nothing we can do to overcome this. If we apply deconvolution, then the analysis above shows it must fail since the Wiener filter is NMP.
DS-F
There are two approaches here. The direct approach has two stages. If the HRF is minimum phase, then the slow filtering will not affect the GCS and the first stage would consist of a GC analysis of the slow BOLD data—that is, fit an SS model to zb,k; find submodels for xb,k, yb,k using DARE (see theorem 1); and compute the GEMS FY→X, FY.X, FX→Y using the expressions in theorem 5a. This would deliver the GCS of the slow NA circuit since by theorem 6, the GEMS would be the same as for the slow BOLD data. The second stage is to try to get the GCS of the fast NA circuit. But now we see that it must fail, since the results of the reverse GC study in section 8 demonstrate that we cannot use the GCS of the slow NA circuit to discern the GCS of the fast NA circuit.
The indirect approach has three stages. If the slow HRF is minimum phase, then in the zeroth stage, we could inverse filter (deconvolve) the slow BOLD data to obtain the slow NA. In the first stage, we obtain its GCS using the procedure described in the first stage of the direct approach. But for the second stage, we are in the same situation as in the direct approach and must fail to discern the GCS of the fast NA.
In practice, slow timescale deconvolution has gained favor recently. It is done using a Wiener filter (Glover, 1999) since this deals with possible noise (which we have ignored in our discussion). But as discussed above, this must fail since the Wiener filter is NMP.
We see here that only in DS-F is there a role for slow timescale deconvolution.
In sum we conclude that under any data-generating scheme, GC analysis must fail.
We note that there is an extensive discussion of GC in fMRI in Rodrigues and Andrade (2015). Unfortunately this work relies on the erroneous method of Chen et al. (2006) for computing GEMs (see the remarks following theorem 5b), and so its results are flawed.
10 Conclusion
This letter has given a theoretical and computational analysis of the use of Granger causality (GC) and applied the results to fMRI. There were two main issues: the effect of downsampling and the effect of hemodynamic filtering on Granger causal structure (GCS). To deal with these issues, a number of novel results in multivariate time series and Granger causality were developed via state-space methods as follows:
Computations of submodels via the DARE (see theorems 1 and 4)
Computation of downsampled models via the DARE (see theorem 3)
Reliable computation of GEMs via the DARE (see theorems 5a and 5b)
Effect of filtering on GEMs (see theorem 6)
Theorem 6 showed that nonminimum phase filters distort GCS. Using the results in the first three methods, we were able to develop, in section 8, a framework for generating downsampling-induced spurious Granger causality on demand and provided a number of illustrations.
In section 9 these results were applied to fMRI. To do this we described three data generating processes for fMRI:
F where fMRI time series are filtered neural activity (NA)
F-DS where NA is filtered, then downsampled to give fMRI time series
DS-F where NA is downsampled, then fitered to give fMRI time series
While F-DS has strong physiological justification, DS-F seems to be behind a number of approaches in the literature. We showed that HRFs are non-minimum phase due to a refractory period. If that period can be corrected for, the phase character of the HRF has to be checked on a case-by-case basis. Certainly default canonical HRFs are nonminimum phase, and so more flexible HRF modeling will be needed.
Then we discussed the reverse GC problem under each data-generating process. In each case, we concluded that GC analysis could not work.
All this leads to the conclusion that linear Granger causality analysis of fMRI data cannot be used to discern neuronal level–driving relationships. Not only is the timescale too slow, but even with faster sampling, the non-minimum phase aspect of the HRF and the noise will still compromise the method.
Future work would naturally include an extension of the Granger causality results to handle the presence of a third vector time series and extensions to deal with time-varying Granger causality. Nongaussian versions could mitigate the nonminimum phase problem to some extent, but there does not seem to be any evidence for the nongaussianity of fMRI data. Extensions to nonlinear Granger causality are currently of great interest but need considerable development.
Acknowledgments
In the May 2016 issue of Neural Computation (Volume 28, Number 5, pp. 914–949), the letter “State-Space Analysis of Granger-Geweke Causality Measures with Application to fMRI” by Victor Solo was printed with incomplete acknowledgments.
The published acknowledgment reads:
This work was partially supported by NIH grant P41EB015896.
The complete acknowledgment should read:
This work was partially supported by the NIH grant P41EB015896. The author would first like to thank Martinos Center colleagues Dr. Bruce Rosen and Dr. Robert Weiskoff who raised crucial questions during a joint discussion of Granger causality and fMRI (held in 1998), which ultimately led to this paper. Thanks are also due to Dr. Graham Goodwin who asked a critical question during an IEEE Control Engineering conference presentation that led to the work on the reverse problem. Special thanks are due to a referee who posed a series of critical questions that led to a major expansion of section 9 into its current form. Finally we acknowledge discussions with Martinos Center colleagues Dr. Mark Vangel, Dr. Fa-Hsuan Lin, and Dr. Matti Håmålåinen.
Appendix A: Stabilizability, Detectability, and DARE
In this appendix we restate and modify for our purposes some standard state-space results. We rely mostly on Kailath et al. (2000, appendixes E and C).
We denote an eigenvalue of a matrix by λ and a corresponding eigenvector by q. We say λ is a stable eigenvalue if |λ| < 1; otherwise, λ is an unstable eigenvalue.
A.1 Stabilizability
The pair (A, B) is controllable if there exists a matrix G so that A−BG is stable (i.e., all eigenvalues of A−BG are stable). (A, B) is controllable iff any of the following conditons hold,
Controllability matrix: C = [B, AB, …, An−1B] has rank n.
Rank test: rank[λI − A, B] = n for all eigenvalues λ of A.
PBH test: There is no left eigenvector of A that is orthogonal to B, that is, if qTA = λqT, then qTB ≠ 0.
The pair (A, B) is stabilizable if rank[λI − A, B] = n for all unstable eigen-values of A. Three useful tests for stabilizability are:
PBH test: (A, B) is stabilizable iff there is no left eigenvector of A corresponding to an unstable eigenvalue that is orthogonal to B, that is, if qTA = λqT and |λ| 1, then qTB ≠ 0.
(A, B) is stabilizable if (A, B) is controllable.
(A, B) is stabilizable if A is stable.
A.2 Theorem DARE
See Kailath et al. (2000, theorem E6.1, lemma 14.2.1, section 14.7).
Under conditions N,St,De, the DARE has a unique positive semidefinite solution P, which is stabilizing (i.e., As − KsC is a stable matrix). Further if we initialize P0 = 0, then Pt is nondecreasing and Pt → P as t → ∞.
Remarks
“As − KsC stable” means that A−KC is stable (see below), and this implies that (A, K) is controllable (see below).
Since V ≥ R, then N ⇒ V is positive definite.
Proof of Remark i
We first note (taking limits in) (Kailath et al., 2000, equation 9.5.12) Ks = K − SR−1. We then have As−KsC=A − SR−1C − (K − SR−1)C = A − KC. So As− KsC is stable iff A−KC is stable. But then (A, K) is controllable.
A.3 Detectability
The pair (A,C) is detectable if (AT,CT) is stabilizable.
Remarks
If As is stable (all eigenvalues have modulus < 1), then St De automatically hold.
Condition De can be replaced with the detectability of (A,C) which is the way Kailath et al. (2000) state the result. We show equivalence below (this is also noted in a footnote in Kailath et al., 2000, section 14.7).
Proof of Remark ii
Suppose (As,C) is detectable but (A,C) is not. Then by the PBH test, there is a right eigenvector p of A corresponding to an unstable eigenvalue of A with Ap = λp,Cp = 0. But then Asp = (A − SR−1C)p = Ap = λp while Cp = 0 which contradicts the detectbility of (As,C). The reverse argument is much the same.
Proof of Result 1
Part a follows from the discussion leading to theorem DARE. Part b follows from the remarks after theorem DARE.
Appendix B: GEMs for Bivariate VAR(1)
Applying formula 5.5 and reading off HXX from the VAR(1) model yields
This can clearly be written as an ARMA(2,1) spectrum Equating coefficients gives
where and . We thus have , and using this in the first equation gives, or . This has, of course, two solutions:
Note that if ξx = 0, this delivers .
We must choose the solution that ensures . And so we must choose the + solution. Continuing, we now claim,
This follows if , which holds.
Appendix C: Spectral Factorization
Suppose εt is a white noise sequence with E(εt) = 0, var(εt)= Σ. Let G(L) be a stable causal, possibly nonminimum phase filter. Then has spectrum where L = exp(−jλ). We can then find a unique causal, stable minimum phase spectral factorization . Let V, Vo have Cholesky factorizations V = JJT, and set Gc(L) = G(L)J, Go,c(L) = Go(L)Jo. Then . Since Go,c(L) is minimum phase, we can introduce the causal filter . Such a filter is called an all pass filter (Hannan & Deistler, 1988; Green, 1988). Now, Gc(L) = Go,c(L)E(L) or G(L) = Go(L)JoE(L)J−1 (i.e., a decomposition of a nonminimum phase (matrix) filter into a product of a minimum phase filter and an all-pass filter. We can also write this as showing how the nonminimum phase filter is transformed to yield a spectral factor.
Footnotes
The main parts of this theorem were announced in a research workshop at the 2011 Human Brain Mapping meeting
References
- Baccala L, Sameshima K. Partial directed coherence: A new concept in neural structure determination. Biol Cybernetics. 2001;84:463–474. doi: 10.1007/PL00007990. [DOI] [PubMed] [Google Scholar]
- Bauer D. Estimating linear dynamical systems using subspace. Econometric Theory. 2005;21:181–211. [Google Scholar]
- Bernasconi C, Konig P. On the directionality of cortical interactions studied by structural analysis of electrophysiological recordings. Biol Cyb. 1999;81:199–210. doi: 10.1007/s004220050556. [DOI] [PubMed] [Google Scholar]
- Caines P. Weak and strong feedback free processes. IEEE Trans Autom Contr. 1976;21:737–739. [Google Scholar]
- Caines P, Chan W. Feedback between stationary stochastic processes. IEEE Trans Autom Contr. 1975;20:498–508. [Google Scholar]
- Cassidy B, Long C, Rae C, Solo V. Identifying fMRI model violations with Lagrange multiplier tests. IEEE Trans Medical Imaging. 2012;31:1481–1492. doi: 10.1109/TMI.2012.2195327. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen Y, Bressler S, Ding M. Frequency domain decomposition of conditional Granger causality and application to multivariate neural field potential data. J Neuroscience Methods. 2006;150:228–237. doi: 10.1016/j.jneumeth.2005.06.011. [DOI] [PubMed] [Google Scholar]
- Christiano L, Eichenbaum M. (Technical Report, Federal Reserve Bank of Minnesota).Temporal aggregation and structural inference in macroeconomics. 1987 [Google Scholar]
- Damm T, Muhirwa LN. Zero crossings, overshoot and initial undershoot in the step and impulse responses of linear systems. IEEE Trans Autom Contr. 2014;59:1925–1929. [Google Scholar]
- David O, Guillemain I, Saillet S, Reyt S, Deransart C, Segebarth C, Depaulis A. Identifying neural drivers with functional MRI: An electrophysiological validation. PLOS Biology. 2008;6:2683–2697. doi: 10.1371/journal.pbio.0060315. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deistler M, Peternell K, Scherer W. Consistency and relative efficiency of subspace methods. Automatica. 1995;31:1865–1875. [Google Scholar]
- Deshpande G, Sathian K, Hu X. Effect of hemodynamic variability on Granger causality analysis of fMRI. NeuroImage. 2010;52:884–896. doi: 10.1016/j.neuroimage.2009.11.060. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ding M, Bressler S, Yang W, Liang H. Short-window spectral analysis of cortical event-related potentials by adaptive multivariate autoregressive modeling: Data preprocessing, model validation, and variability assessment. Biol Cyb. 2000;83:35–45. doi: 10.1007/s004229900137. [DOI] [PubMed] [Google Scholar]
- Dufour J, Renault E. Short and long run causality in time series: Theory. Econometrica. 1998;66:1099–1125. [Google Scholar]
- Dufour J, Taamouti A. Short and long run causality measures: Theory and inference. Journal of Econometrics. 2010;154:42–58. [Google Scholar]
- Edin F. Scaling errors in measures of brain activity cause erroneous estimates of effective connectivity. NeuroImage. 2010;49:621–630. doi: 10.1016/j.neuroimage.2009.07.007. [DOI] [PubMed] [Google Scholar]
- Feinberg D, Yacoub E. The rapid development of high speed, resolution and precision in fMRI. NeuroImage. 2012;62:720–725. doi: 10.1016/j.neuroimage.2012.01.049. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Geweke J. Temporal aggregation in the multiple regression model. Econo- metrica. 1978;46:643–661. [Google Scholar]
- Geweke J. The measurement of linear dependence and feedback between multiple time series. J Amer Stat Assoc. 1982;77:304–313. [Google Scholar]
- Geweke J. Measures conditional of linear dependence and feedback between time series. J Amer Stat Assoc. 1984;79:907–915. [Google Scholar]
- Glover G. Deconvolution of impulse response in event-related bold fMRI. NeuroImage. 1999;9:416–429. doi: 10.1006/nimg.1998.0419. [DOI] [PubMed] [Google Scholar]
- Goebel R. Investigating directed cortical interactions in time-resolved fMRI data using vector autoregressive modeling and Granger causality mapping. Magn Reson Imaging. 2003;21:1251–1261. doi: 10.1016/j.mri.2003.08.026. [DOI] [PubMed] [Google Scholar]
- Granger C. Economic processes involving feedback. Information and Control. 1963;6:28–48. [Google Scholar]
- Granger C. Investigating causal relations by econometric models and cross- spectral methods. Econometrica. 1969;37:424–438. [Google Scholar]
- Green M. All-pass matrices, the positive real lemma and unit canonical correlations between future and past. J Multiv Anal. 1988;24:143–154. [Google Scholar]
- Hamilton J. Time series analysis. Princeton, NJ: Princeton University Press; 1994. [Google Scholar]
- Handwerker D, Gonzalez-Castillo J, D’Esposito M, Bandettini P. The continuing challenge of understanding and modeling hemodynamic variation in fMRI. NeuroImage. 2012;62:1017–1023. doi: 10.1016/j.neuroimage.2012.02.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hannan E, Deistler M. Statistical theory of linear systems. New York: Wiley; 1988. [Google Scholar]
- Hannan E, Poskitt D. Unit canonical correlations between future and past. Ann Stat. 1988;16:784–790. [Google Scholar]
- Havlicek M, Friston K, Jan J, Brazdil M, Calhoun VD. Dynamic modeling of neuronal responses in fMRI using cubature Kalman filtering. NeuroImage. 2011;56(4):2109–2128. doi: 10.1016/j.neuroimage.2011.03.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hsiao C. Time series modeling and causal ordering of Canadian money, income and interest rates. In: Anderson OD, editor. Time series analysis: Theory and practice. Amsterdam: North-Holland; 1982. pp. 671–699. [Google Scholar]
- Kailath T, Sayeed A, Hassibi B. Linear estimation. Upper Saddle River, NJ: Prentice Hall; 2000. [Google Scholar]
- Kaminski M, Blinowska K. A new method of the description of the information flow in the brain structures. Biol Cyb. 1991;65:203–210. doi: 10.1007/BF00198091. [DOI] [PubMed] [Google Scholar]
- Kaufmann K, Stern D. Evidence for human influence on climate from hemispheric temperature relations. Nature. 1997;388:39–44. [Google Scholar]
- Khalidov I, Fadili J, Lazeyras F, Ville D, Unser M. Activelets: Wavelets for sparse representation of hemodynamic responses. Signal Processing. 2011;91:2810–2821. [Google Scholar]
- Kshirsagar A. Multivariate analysis. New York: Marcel Dekker; 1972. [Google Scholar]
- Larimore W. Proc American Control Conference. Piscataway, NJ: IEEE; 1983. System identification, reduced order filters and modeling via canonical variate analysis; pp. 445–451. [Google Scholar]
- Lutkepohl H. Introduction to multivariate time series analysis. Berlin: Springer-Verlag; 1993. [Google Scholar]
- Magnus J, Neudecker H. Matrix differential calculus with applications in statistics and econometrics. New York: Wiley; 1999. [Google Scholar]
- Marcet A. Temporal aggregation of economic time series. In: Hanson LP, Sargent TJ, editors. Rational expectations matrix. Boulder, CO: Westview Press; 1991. pp. 237–281. [Google Scholar]
- Middleton R, Goodwin G. Digital control and estimation: A unified approach. Upper Saddle River, NJ: Prentice Hall; 1990. [Google Scholar]
- Miezin FM, Maccotta L, Ollinger JM, Petersen SE, Buckner RL. Characterizing the hemodynamic response: Effects of presentation rate, sampling procedure, and the possibility of ordering brain activity based on relative timing. NeuroImage. 2000;11:735–759. doi: 10.1006/nimg.2000.0568. [DOI] [PubMed] [Google Scholar]
- Pandit S, Wu S. Time series and systems analysis with applications. New York: Wiley; 1983. [Google Scholar]
- Pascual-Marqui R, Biscay R, Bosch-Bayard J, Lehmann D, Kochi K, Yamada N, Sadato N. Isolated effective coherence (ICOH): Causal information flow excluding indirect paths. Zurich: KEY Institute for Brain-Mind Research, University of Zurich; 2014. (Technical Report). arXiv:1402.4887. [Google Scholar]
- Pierce D, Haugh L. Causality in temporal systems characterizations and a survey. Journal of Econometrics. 1977;5:265–293. [Google Scholar]
- Rissannen J, Wax M. Measures of mutual and causal dependence between two time series. IEEE Trans Inf Thy. 1987;33:598–601. [Google Scholar]
- Rodrigues J, Andrade A. Lag-based effective connectivity applied to fMRI: A simulation study highlighting dependence on experimental parameters and formulation. NeuroImage. 2015;89:358–377. doi: 10.1016/j.neuroimage.2013.10.029. [DOI] [PubMed] [Google Scholar]
- Roebroeck A, Formisano E, Goebel R. Mapping directed influence over the brain using Granger causality. NeuroImage. 2005;25:230–242. doi: 10.1016/j.neuroimage.2004.11.017. [DOI] [PubMed] [Google Scholar]
- Roebroeck A, Formisano E, Goebel R. The identification of interacting networks in the brain using fMRI: Model selection, causality and deconvolution. NeuroImage. 2011;58:296–302. doi: 10.1016/j.neuroimage.2009.09.036. [DOI] [PubMed] [Google Scholar]
- Seber G. Multivariate observations. New York: Wiley; 1984. [Google Scholar]
- Seth A, Chorley P, Barnett L. Granger causality analysis of fMRI bold signals is invariant to hemodynamic convolution but not downsampling. NeuroImage. 2013;65:540–555. doi: 10.1016/j.neuroimage.2012.09.049. [DOI] [PubMed] [Google Scholar]
- Sims C. Discrete approximations to continuous time distributed lags in econometrics. Econometrica. 1971;39:545–563. [Google Scholar]
- Sims C. Money, income and causality. Am Econ Rev. 1972;62:540–552. [Google Scholar]
- Solo V. Topics in advanced time series analysis. In: del Pino G, Rebolledo R, editors. Lectures in probability and statistics. Berlin: Springer-Verlag; 1986. pp. 165–328. [Google Scholar]
- Sreenivasan K, Havlicek M, Deshpande G. Nonparametric hemodynamic deconvolution of fMRI using homomorphic filtering. IEEE Trans Medical Imaging. 2015;34:1155–1163. doi: 10.1109/TMI.2014.2379914. [DOI] [PubMed] [Google Scholar]
- Suna L, Wang M. Global warming and global dioxide emission: An empirical study. J Environmental Management. 1996;46(4):327–343. [Google Scholar]
- Takahashi D, Baccala L, Sameshima K. Partial directed coherence asymptotics for VAR processes of infinite order. International Journal of Bioelectromagnetism. 2008;10:31–36. [Google Scholar]
- Telser L. Discrete samples and moving sums in stationary stochastic processes. J Amer Stat Assoc. 1967;62:484–499. [Google Scholar]
- Triacca U. Is Granger causality analysis appropriate to investigate the relationship between atmospheric concentration of carbon dioxide and global surface air temperature? Theoretical and Applied Climatology. 2005;81:133–135. [Google Scholar]
- Valdes-Sosa P. Spatio-temporal autoregressive models defined over brain manifolds. Neuroinformatics. 2004;2:239–250. doi: 10.1385/NI:2:2:239. [DOI] [PubMed] [Google Scholar]
- Valdes-Sosa P, Roebroeck A, Daunizeau J, Friston K. Effective connectivity: Influence, causality and biophysical modeling. NeuroImage. 2011;58:339–361. doi: 10.1016/j.neuroimage.2011.03.058. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van Overschee P, de Moor B. Subspace identification for linear systems. Dordrecht: Kluwer; 1996. [Google Scholar]
- Wu G, Liao W, Stramaglia S, Ding J, Chen H, Marinazzo D. A blind deconvolution approach to recover effective connectivity brain networks from resting state fMRI data. Medical Image Analysis. 2013;17:365–374. doi: 10.1016/j.media.2013.01.003. [DOI] [PubMed] [Google Scholar]
- Yamashita O, Sadato N, Okada T, Ozaki T. Evaluating frequency-wise directed connectivity of bold signals applying relative power contribution with the linear multivariate time-series models. NeuroImage. 2005;25:478–490. doi: 10.1016/j.neuroimage.2004.11.042. [DOI] [PubMed] [Google Scholar]
- Zafer D, Blu T, Ville D. Proc IEEE ISBI. Piscataway, NJ: IEEE; 2014. Detecting spontaneous brain activity in functional magnetic resonance imaging using finite rate of innovation; pp. 1047–1050. [Google Scholar]