

Abstract
In this article, sample size calculations are developed for use when the main interest is in the differences between the cure rates of two groups. Following the work of Ewell and Ibrahim, the asymptotic distribution of the weighted log-rank test is derived under the local alternative. The optimal log-rank test under the proportional distributions alternative is discussed, and sample size formulae for the optimal and standard log-rank tests are derived. Simulation results show that the proposed formulae provide adequate sample size estimation for trial designs and that the optimal log-rank test is more efficient than the standard log-rank test, particularly when both cure rates and percentages of censoring are small.
Keywords: clinical trial, cure model, log-rank test, optimal test, sample size
1 Introduction
When survival data include a portion of cured patients or long-term survivors, cure models are useful for analyzing the data and designing clinical trials. Recently, various parametric and semiparametric cure models have been proposed by Farewell (1982), Peng et al. (1998), and Kuk and Chen (1992). A maximum-likelihood expectation-maximization (EM) algorithm for parametric and semiparametric cure models has been proposed by Peng and Dear (2000) and Sy and Taylor (2000). A SAS macro PSPMCM, developed by Corbiere and Joly (2007), is available to fit both parametric and semiparametric cure models. Thus, survival data in which a portion of patients are cured can be analyzed using these methods for the purpose of designing clinical trials using the selected cure models.
In a cancer clinical trial in which a portion of patients experience long-term survival, the main interest is often in the differences between cure rates. Examples from the Children’s Cancer Group trials are given by Lee and Sather (1995). To develop an appropriate test for testing the differences between cure rates in a two-arm randomized trial, Gray and Tsiatis (1989) proposed a family of cure models with a proportional distributions alternative. The optimal log-rank test was discussed under the proportional distributions alternative, which has the form of a Gρ test where ρ = −1 (Harrington and Fleming, 1982), and its efficacy relative to that of the standard log-rank test was also investigated. Ewell and Ibrahim (1997) extended the work of Gray and Tsiatis by deriving the large sample distribution of the weighted log-rank test under a more general sequence of local alternatives that allows for treatment effects on both short- and long-term survival. They also derived a power calculation for the weighted log-rank test assuming exponential failure times.
In this article, we focus on the situation where the main interest is in the differences between the cure rates of two groups. Following the work of Ewell and Ibrahim, sample size formulae are derived for both the standard log-rank test and the optimal weighted log-rank test. The relative efficacy of the two tests is also discussed.
The rest of the paper is organized as follows. A mixture cure model is introduced in Section 2. The sample size formula for the weighted log-rank test is derived in Section 3. The optimal log-rank test and its sample size formula are obtained in Section 4. In section 5, comparisons of the efficiency and robustness of the two tests are presented, and simulations are conducted to study the performance of the proposed sample size formulae. Section 6 illustrates clinical trial design using the proposed methods. Conclusions are presented in section 7.
2 Cure Models
The failure time, T∗, is assumed to be vT +(1−v)∞, where v is an indicator of whether a subject will eventually (v = 1) or never (v = 0) experience treatment failure, and T denotes the failure time if the subject is not cured, with a survival distribution S(t), which is the conditional distribution for patients who will experience treatment failure and is often called the latency distribution. Thus, the unconditional survival distribution of T∗ is a mixture model of a cure rate π = P(v = 0) and a latency distribution S(t) given by
Let λ∗(t) and λ(t) be the hazard functions of T∗ and T, respectively. We then have the following relation between the two hazard functions:
For a two-arm randomized survival trial, let and Cij denote the survival and censoring times, respectively, of patient i in the jth group, where j = 1, 2 (1 for the control group and 2 for the treatment group). The observed data then consist of {Xij; Δij; i = 1, …, nj, j = 1, 2}, where and . It is commonly assumed that are independent and identically distributed samples of (Tj, Cj) for control (j = 1) and treatment (j = 2) and that Tij is independent of Cij. Let denote the unconditional survival distribution and let denote its hazard function for the jth group. When the main interest is in testing for differences between cure rates, it is reasonable to assume that the conditional survival distributions are the same for the two groups and are denoted by S(t), with the hazard function and cumulative hazard function being denoted by λ(t) and Λ(t), respectively. The cure rate for the jth group is defined by πj, where 0 ≤ πj < 1. Then, the survival distribution of the mixture cure model for the jth group is given by
| (1) |
and the hazard function for the jth group is given by
We are interested in testing the following hypothesis:
| (2) |
Furthermore, we define the parameters γ and π0 as follows:
where γ is the half-log ratio of the failure rates, and π0 is the proportion of cured patients under the null hypothesis. Then, hypothesis (2) is equivalent to the following hypothesis:
| (3) |
The mixture cure model (1) can be written as
| (4) |
and the corresponding hazard function is given by
| (5) |
This alternative implies that the unconditional failure distributions for two groups are proportional; it is called a proportional distributions alternative by Gray and Tsiatis (1989).
To test hypothesis (2) or (3), or the difference in the unconditional failure distributions, a weighted score test can be used, which is given by
where n = n1 + n2 is the total sample size of two groups, W(t) is a weight function that converges in probability to w(t), Nj(t) is the number of observed failures by time t, Yj(t) is the number of subjects at risk just prior to t in groups j = 1, 2, and Y (t) = Y1(t) + Y2(t). By the martingale central limit theorem (Fleming and Harrington, 1991), under the null hypothesis, Uw converges in distribution to a normal variable with a mean of zero and variance
| (6) |
where p = limn→∞ n1/n, and G(t) is the common survival distribution of the censoring time of two groups (see appendix). The variance in (6) can be estimated by
where N(t) = N1(t) + N2(t). Therefore, under the null hypothesis, the weighted log-rank test is asymptotically standard normal distributed. Thus, given a significance level α, we reject the null hypothesis if |Lw| > z1−α/2, where z1−α/2 is the 100(1 − α/2)th percentile of the standard normal distribution.
3 Sample Size Formula
To derive the sample size formula, we need to know the asymptotic distribution of the weighted log-rank test under the alternative hypothesis. Consider a sequence of local alternatives
where n1/2γn = γa. Under the local alternatives, as shown in the appendix, the weighted log-rank test converges in distribution to a normal variable with unit variance and mean μ(w, γa)/σw, where is given by (6), and
| (7) |
for which .
Therefore, on the basis of the limiting distribution of Lw under the local alternative, given a type I error of α, to achieve a power of 1 − β, the total sample size n of two groups must approximately satisfy the following equation:
For a local alternative γ, we replace γa by n1/2γ. Then, the sample size required to detect a local alternative γ can be determined by
| (8) |
Substituting equations (6) and (7) into (8), the total sample size for the weighted log-rank test can be calculated by
| (9) |
4 Optimal Log-rank Test
It is well known that the log-rank test is optimal against the proportional hazards model. However, the cure model (1) does not satisfy the proportional hazards assumption; thus, the log-rank test is not an optimal test, and a study design based on the log-rank test is not fully efficient. Therefore, it is desirable to find an optimal test for the cure model (1) under the local proportional distributions alternative. As the mean of the weighted log-rank test is proportional to
where h(t) = G(t)S(t)λ(t), by using the Cauchy-Schwartz inequality, we obtain the following inequality:
with equality if only if w(t) is proportional to . That is, the optimal weight function w(t) is proportional to , which minimizes the sample size given by formula (9). Thus, taking the weight function W (t) = {K(t−)}−1, where K(t−) is the left-continuous version of the Kaplan-Meier estimate computed from the pooled sample of two groups, gives the asymptotically optimal test for the proportional distributions alternative. Hence, by substituting into formula (9), the sample size for the optimal log-rank test LK is given by
| (10) |
and by substituting w(t) = 1 into formula (9), the sample size for the standard log-rank test L is given by
| (11) |
The asymptotic relative efficiency ρ = n/nK (Randales and Wolfe, 1979) of the optimal test compared to the standard log-rank test is given by
| (12) |
In the special case when there is no censoring, that is, when G(t) = 1, the asymptotic relative efficiency ρ in (12) is reduced to
5 Comparison
We investigated three important issues. First, we studied the relative efficiency of the optimal log-rank test versus the standard log-rank test. Second, we evaluated the robustness of the optimal and standard log-rank tests when the hazard parameter was misspecified in the trial design. Third, we investigated the performance of the two sample size formulae under various design scenarios.
The relative efficiency ρ given in equation (12) was calculated for selected cure rates under the exponential cure model with an uncured hazard parameter λ = 1. Assume a uniform accrual over [0, τ] and no follow-up period, where τ is determined by the percentage of censoring ranging from 0% to 50%. The results (Table 1) showed that when the cure rate π0 was at most 10% and there was no censoring, the gain in efficiency of the optimal log-rank test versus the standard log-rank test was more than 50%, whereas if the cure rate π0 was at least 50%, the gain in efficiency was less than 5%. If the percentage of censoring was more than 50%, then the gain in efficiency was less than 10%, regardless of the cure rate. We also investigated the relative efficiency through the sample size calculations. Under the same assumptions, sample sizes were calculated under various combinations of the cure rates of two groups. Similarly, the largest gain in efficiency was achieved when both the cure rate and percentage of censoring were small (Table 2).
Table 1.
The relative efficiency ρ of the optimal log-rank test compared to the standard log-rank test under the exponential model with a hazard parameter λ = 1 and a uniform accrual over the interval [0, τ], where τ is determined by the percentage of censoring.
| Cure rate π0 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||
| Cens | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 |
| None | 1.528 | 1.235 | 1.127 | 1.072 | 1.041 | 1.022 | 1.011 | 1.004 | 1.001 |
| 10% | 1.490 | 1.221 | 1.120 | 1.068 | 1.039 | 1.021 | 1.010 | 1.004 | 1.001 |
| 20% | 1.399 | 1.190 | 1.105 | 1.061 | 1.035 | 1.019 | 1.009 | 1.004 | 1.001 |
| 30% | 1.272 | 1.144 | 1.084 | 1.050 | 1.029 | 1.016 | 1.008 | 1.003 | 1.001 |
| 40% | 1.166 | 1.099 | 1.061 | 1.037 | 1.022 | 1.012 | 1.006 | 1.002 | 1.001 |
| 50% | 1.095 | 1.061 | 1.040 | 1.026 | 1.016 | 1.009 | 1.005 | 1.002 | 1.000 |
Censoring time was uniformly distributed over [0, τ], with the value of τ being chosen so that the probability of the failure time being censored for a subject who was not cured was the specified censoring percentage. Abbreviation: Cens: censoring.
Table 2.
Sample sizes for the optimal and standard log-rank tests for various cure rates in two groups with a nominal type I error of 5% and power of 90%. Here, sample sizes were calculated under the exponential model, with a hazard parameter λ = 1 and a uniform accrual over the interval [0, τ], where τ is determined by the percentage of censoring.
| Cure rate (π1, π2) | ||||||||
|---|---|---|---|---|---|---|---|---|
|
| ||||||||
| (.05, .15) | (.05, .2) | (.1, .2) | (.1, .3) | (.2, .4) | (.3, .5) | (.4, .6) | ||
|
| ||||||||
| Test | Cens | Sample size | ||||||
| L | None | 598 | 301 | 738 | 217 | 257 | 279 | 281 |
| 10% | 766 | 379 | 916 | 263 | 304 | 323 | 321 | |
| 20% | 1067 | 513 | 1218 | 338 | 375 | 388 | 379 | |
| 30% | 1566 | 730 | 1697 | 453 | 481 | 483 | 460 | |
| 40% | 2323 | 1058 | 2415 | 623 | 632 | 616 | 573 | |
| 50% | 3479 | 1577 | 3509 | 881 | 860 | 813 | 740 | |
|
| ||||||||
| LK | None | 394 | 215 | 554 | 177 | 230 | 261 | 270 |
| 10% | 517 | 275 | 698 | 217 | 272 | 303 | 310 | |
| 20% | 766 | 391 | 964 | 286 | 341 | 367 | 367 | |
| 30% | 1233 | 597 | 1423 | 398 | 445 | 461 | 448 | |
| 40% | 1993 | 926 | 2144 | 569 | 597 | 594 | 562 | |
| 50% | 3180 | 1437 | 3262 | 831 | 828 | 794 | 729 | |
Censoring time was uniformly distributed over [0, τ], with the value of τ being chosen so that the probability of the failure time being censored for a subject who was not cured was the specified censoring percentage. Abbreviations: Cens: censoring; L: standard log-rank test; LK: optimal log-rank test.
To evaluate the robustness of the two tests, sample sizes (n) were calculated under exponential models with hazard parameters λ = 0.1 and 1. Cure rates were set to π1 = 0.1 and , where γ0 ranged from 1.5 to 2.0, accrual time ta = 1, and follow-up time tf = 2. Sample sizes (n∗) were also calculated under misspecification of the hazard parameter within a range of λ±20%λ. The %diff = 100(n∗−n)/n was calculated for the evaluation of robustness. The results showed that both tests were sensitive to the misspecification of the hazard parameter. However, the %diff was similar for both tests, and the optimal test was slightly more sensitive than the standard log-rank test (Table 3).
Table 3.
Sample sizes for the exponential cure models under misspecification of the hazard parameter λ, with cure rates π1 = 0.1 and π2 = π1eγ0/(1−π1 + π1eγ0), uniform accrual with accrual time ta = 1 and follow-up time tf = 2, and nominal type I error of 5% and power of 90%.
| True λ | Misspecified λ | |||||
|---|---|---|---|---|---|---|
|
| ||||||
| λ = 0.1 | λ = 0.08 | λ = 0.12 | ||||
|
| ||||||
| Test | γ0 | n | n∗ | %diff | n∗ | %diff |
| L | 1.5 | 2282 | 2885 | 26.4 | 1880 | −17.6 |
| 1.6 | 1873 | 2367 | 26.4 | 1545 | −17.5 | |
| 1.7 | 1554 | 1963 | 26.3 | 1283 | −17.4 | |
| 1.8 | 1302 | 1643 | 26.2 | 1075 | −17.4 | |
| 1.9 | 1100 | 1387 | 26.1 | 909 | −17.4 | |
| 2.0 | 938 | 1181 | 25.9 | 776 | −17.3 | |
|
| ||||||
| LK | 1.5 | 2274 | 2879 | 26.6 | 1872 | −17.7 |
| 1.6 | 1868 | 2363 | 26.5 | 1538 | −17.7 | |
| 1.7 | 1550 | 1959 | 26.4 | 1278 | −17.5 | |
| 1.8 | 1298 | 1640 | 26.3 | 1071 | −17.5 | |
| 1.9 | 1097 | 1385 | 26.3 | 906 | −17.4 | |
| 2.0 | 935 | 1179 | 26.1 | 773 | −17.3 | |
| λ = 1 | λ = 0.8 | λ = 1.2 | ||||
|---|---|---|---|---|---|---|
|
| ||||||
| Test | γ0 | n | n∗ | %diff | n∗ | %diff |
| L | 1.5 | 219 | 259 | 18.3 | 197 | −10.0 |
| 1.6 | 185 | 218 | 17.8 | 167 | −9.7 | |
| 1.7 | 158 | 185 | 17.1 | 144 | −8.9 | |
| 1.8 | 137 | 159 | 16.1 | 124 | −9.5 | |
| 1.9 | 119 | 138 | 16.0 | 109 | −8.4 | |
| 2.0 | 105 | 121 | 15.2 | 96 | −8.6 | |
|
| ||||||
| LK | 1.5 | 193 | 233 | 20.7 | 170 | −11.9 |
| 1.6 | 164 | 198 | 20.7 | 146 | −11.0 | |
| 1.7 | 142 | 169 | 19.0 | 127 | −10.6 | |
| 1.8 | 123 | 146 | 18.7 | 111 | −9.8 | |
| 1.9 | 108 | 128 | 18.5 | 98 | −9.3 | |
| 2.0 | 96 | 112 | 16.7 | 87 | −9.4 | |
%diff: change in sample size through misspecified hazard parameter λ, i.e., %diff =100 × (n∗ − n)/n, where n is the sample size calculated under the true λ and n∗ is the sample size calculated under the misspecified λ. Abbreviations: L: standard log-rank test; LK: optimal log-rank test.
To investigate the performance of the sample size formulae for the optimal and standard log-rank tests, we calculated sample sizes under the cure model (1), where cure rates were set as in Table 3, and the conditional survival distribution was Weibull, , or log-logistic, . The scale parameter λ was set to 0.4, and the shape parameter κ was set to 0.5, 1, or 2, reflecting a decreasing, constant, and increasing hazard function, respectively, for the Weibull distribution; and a decreasing and single-mode hazard function for the log-logistic distribution. We assumed that subjects were recruited with a uniform distribution over the accrual period ta = 1, with a follow-up period tf = 2. We further assumed that no subject was lost to follow-up during the study. Then, the censoring time was uniformly distributed over the interval [tf, ta + tf], that is, the censoring survival distribution G(t) = 1 if t ≤ tf; = (ta + tf − t)/ta if tf ≤ t ≤ ta + tf; = 0 otherwise. Therefore, given a two-sided nominal significance level of 0.05 and power of 90%, the required sample sizes were calculated for each design scenario under each distribution. The empirical type I errors and powers of the corresponding designs were simulated based on 100,000 runs. The simulation results presented in Table 4 can be summarized as follows. First, the empirical powers of both the optimal and standard log-rank tests were close to the nominal level of 90%. Thus, the sample sizes were adequately estimated. Second, the empirical type I errors of both tests were close to the nominal level of 5%. Thus, both tests preserved type I error well. Third, the sample sizes calculated from the optimal test were smaller than those calculated for the standard log-rank test.
Table 4.
Sample sizes (n) and corresponding simulated empirical type I errors and powers for the optimal and standard log-rank tests under the Weibull and log-logistic distributions, with a scale parameter λ = 0.4, cure rates π1 = 0.1 and , nominal type I error of 0.05, power of 90%, and uniform accrual with accrual time ta = 1 and follow-up time tf = 2.
| κ = 0.5 | κ=1 | κ = 2 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||||||||||
| Dist | Test | γ0 | n |
|
|
n |
|
|
n |
|
|
||||||
| WB | L | 1.5 | 841 | .048 | .905 | 510 | .053 | .905 | 222 | .052 | .914 | ||||||
| 1.6 | 695 | .049 | .900 | 424 | .050 | .899 | 188 | .052 | .914 | ||||||||
| 1.7 | 580 | .051 | .901 | 355 | .045 | .906 | 161 | .050 | .922 | ||||||||
| 1.8 | 488 | .050 | .903 | 301 | .050 | .906 | 139 | .051 | .924 | ||||||||
| 1.9 | 415 | .049 | .905 | 258 | .048 | .907 | 121 | .052 | .921 | ||||||||
| 2.0 | 356 | .051 | .907 | 222 | .053 | .906 | 106 | .050 | .925 | ||||||||
|
|
|||||||||||||||||
| LK | 1.5 | 827 | .049 | .901 | 490 | .053 | .904 | 195 | .051 | .919 | |||||||
| 1.6 | 683 | .045 | .901 | 408 | .048 | .910 | 166 | .055 | .919 | ||||||||
| 1.7 | 571 | .051 | .902 | 343 | .051 | .902 | 143 | .048 | .925 | ||||||||
| 1.8 | 481 | .049 | .905 | 291 | .050 | .906 | 125 | .052 | .928 | ||||||||
| 1.9 | 410 | .053 | .904 | 250 | .052 | .909 | 110 | .052 | .926 | ||||||||
| 2.0 | 351 | .052 | .906 | 216 | .047 | .910 | 97 | .052 | .932 | ||||||||
|
| |||||||||||||||||
| LG | L | 1.5 | 1112 | .048 | .900 | 762 | .052 | .908 | 404 | .048 | .906 | ||||||
| 1.6 | 916 | .050 | .907 | 630 | .049 | .903 | 337 | .049 | .908 | ||||||||
| 1.7 | 763 | .047 | .908 | 526 | .053 | .904 | 284 | .051 | .908 | ||||||||
| 1.8 | 641 | .047 | .905 | 443 | .050 | .907 | 241 | .050 | .916 | ||||||||
| 1.9 | 544 | .049 | .903 | 377 | .050 | .907 | 207 | .049 | .915 | ||||||||
| 2.0 | 465 | .048 | .900 | 324 | .054 | .907 | 180 | .050 | .912 | ||||||||
|
|
|||||||||||||||||
| LK | 1.5 | 1100 | .048 | .902 | 746 | .051 | .903 | 382 | .053 | .907 | |||||||
| 1.6 | 907 | .049 | .906 | 617 | .045 | .897 | 319 | .053 | .909 | ||||||||
| 1.7 | 755 | .050 | .908 | 516 | .052 | .898 | 270 | .051 | .914 | ||||||||
| 1.8 | 635 | .048 | .903 | 436 | .051 | .906 | 230 | .050 | .911 | ||||||||
| 1.9 | 539 | .049 | .908 | 371 | .056 | .903 | 198 | .051 | .910 | ||||||||
| 2.0 | 461 | .053 | .904 | 319 | .049 | .910 | 172 | .050 | .916 | ||||||||
Abbreviations: Cens: censoring; Dist: distribution; WB: Weibull; LG: log-logistic; L: standard log-rank test; LK: optimal log-rank test.
Overall, the results showed that the derived sample size formulae provide adequate sample size estimation for trial design if the main interest is to detect the differences between the cure rates of two groups and that the optimal test is more efficient than the standard log-rank test, particular when both cure rates and percentage censoring are small.
6 Example
We illustrate study design under a parametric cure model by using the data from the Eastern Cooperative Oncology Group (ECOG) trial e1684. The ECOG trial e1684 was a two-arm phase III clinical trial to compare the relapse-free survival (RFS) of patients with melanoma who were treated with high-dose interferon alpha-2b or placebo as postoperative adjuvant therapy. The trial accrued patients between 1984 and 1990 and remained blinded under analysis until 1993 (Kirkwood, et al., 1996). Researchers have studied this dataset extensively using cure models (Corbiere and Joly, 2007). There were 92 deaths among the 146 patients in the treatment group. The SAS macro PSPMCM was applied to this data to fit the treatment arm data under the Weibull cure model (Figure 1), with an estimated shape parameter κ of 1.018, scale parameter λ of 0.836, and a cure rate of 35%. Suppose we wish to design a two-arm randomized phase III trial to detect a 20% difference between the cure rate in the arm that receives the new treatment and that in the control arm that receives the same therapy as the treatment arm of the ECOG trial, with a two-sided type I error of 0.05, power of 90% at the alternative, a uniform accrual with a 5-year accrual period and 5-year of follow-up, no loss to follow-up, and equal allocation between the two groups. Then, the required sample sizes calculated using formulae (10) and (11) under the Weibull cure model are 266 and 280 patients, respectively. The corresponding simulated empirical type I error and power are 0.05 and 91.4% for the optimal log-rank test, and 0.05 and 90.7% for the standard log-rank test. As the cure rate is relatively high, the gain in efficiency is only approximately 5% in this example.
Figure 1.
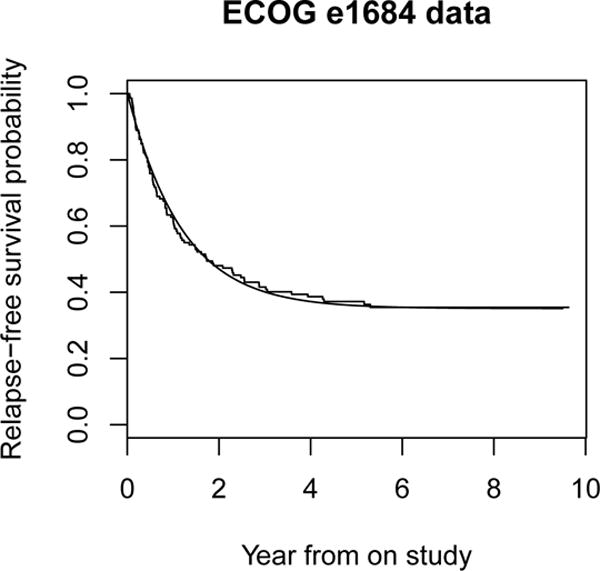
Relapse-free survival for ECOG e1864 data. The step function is the Kaplan-Meier survival curve. The solid curve is the fitted Weibull cure model.
7 Conclusion
For cancer clinical trials in which a portion of patients are cured, the main interest is in demonstrating the differences between the cure rates in the two treatment groups. In this article, sample size formulae are derived for both the optimal and standard log-rank tests. Because the proposed cure model is not a proportional hazards model, the standard log-rank test is not fully efficient. Thus, a sample size calculation derived under the optimal test can ensure the efficacy of the study design. The optimal log-rank test is implemented in the standard statistical software R by using the survdiff function with the option rho = −1. The simulation results demonstrated that the sample size formula for the optimal test provides adequate sample size estimation and is more efficient than the formula for the standard log-rank test. Finally, if trials are planned to include interim analyses to enable them to be halted early if futility or efficacy is demonstrated, then the group sequential methods developed by Lee and Sather (1995) can be used.
Acknowledgments
The author acknowledges an anonymous reviewer for his/her valuable comments that improved an earlier version of the paper. This work was supported in part by the National Cancer Institute support grant CA21765 and ALSAC.
Appendix: Derivation of the asymptotic distribution of the weighted log-rank test
The weighted score test is given by
where n = n1 + n2 is the total sample size of two groups, W (t) is a weight function that converges in probability to w(t), Nj(t) is the number of observed failures by time t, Yj(t) is the number of subjects at risk just prior to t in groups j = 1, 2, and Y (t) = Y1(t) + Y2(t). If we define martingale processes such that , j = 1, 2, where is given in equation (5), then the weighted score test can be written as
Under the null hypothesis H0 : γ = 0, we have , where
Hence, by the martingale property, the mean of Uw is 0 and the variance of Uw is given by
where . As
where and π(t) = pπ1(t) + (1 − p)π2(t). Thus, by the martingale central limit theorem (Fleming and Harrington, 1991), , where
for which and G(t) is the common survival distribution of the censoring time of the two groups. By noting that , we have
| (13) |
The variance can be estimated by
where and N(t) = N1(t) + N2(t). Therefore, the weighted log-rank test is asymptotically standard normal distributed under the null hypothesis.
To derive the asymptotic distribution of the weighted log-rank test under the alternative, consider a sequence of local alternatives , or
where n1/2γn = γa < ∞, and define martingale processes as . Then, Uw = U1w+U1w+U2w, where
and
As γn → 0, and, , and by the martingale central limiting theorem, U1w converges to a normal variable with mean EU1w = 0 and variance
By Taylor’s expansion of at γn = 0, we have
It then follows that
By substituting this into U2w, we have shown that U2w converges in probability to μ(w, γa), where
Thus, under the local alternatives , the weighted log-rank test is asymptotically normal distributed with mean μw/σw and unit variance, that is,
References
- Corbiere F, Joly P. A SAS macro for parametric and semiparametric mixture cure models. Computer Methods and Programs in Biomedicine. 2007;85:173–180. doi: 10.1016/j.cmpb.2006.10.008. [DOI] [PubMed] [Google Scholar]
- Ewell M, Ibrahim JG. The large sample distribution of the weighted log rank statistic under general local alternatives. Lifetime Data Analysis. 1997;3:5–12. doi: 10.1023/a:1009690200504. [DOI] [PubMed] [Google Scholar]
- Farewell VT. The use of mixture models for the analysis of survival data with long-term survivors. Biometrics. 1982;38:1041–1046. [PubMed] [Google Scholar]
- Fleming TR, Harrington DP. Counting processes and survival analysis. John Wiley and Sons; New York: 1991. [Google Scholar]
- Gray RJ, Tsiatis AA. A linear rank test for use when the main interest is in differences in cure rates. Biometrics. 1989;45:899–904. [PubMed] [Google Scholar]
- Harrington DP, Fleming TR. A class of rank test procedures for censored survival data. Biometrika. 1982;69:553–566. [Google Scholar]
- Kirkwood JM, Straderman MH, Ernstoff MS, Smith TJ, Borden EC, Blum RH. Interferon alfa-2b adjuvant therapy of high-risk resected cutaneous melanoma: the Eastern Cooperative Oncology Group Trial EST 1684. Journal of Clinical Oncology. 1996;14:7–17. doi: 10.1200/JCO.1996.14.1.7. [DOI] [PubMed] [Google Scholar]
- Kuk AYC, Chen CH. A mixture model combining logistic regression with proportional hazards regression. Biometrika. 1992;79:531–541. [Google Scholar]
- Lee JW, Sather HN. Group sequential methods for comparison of cure rates in clinical trials. Biometrics. 1995;51:756–763. [PubMed] [Google Scholar]
- Peng Y, Dear KBG. A nonparametric mixture model for cure rate estimation. Biometrics. 2000;56:237–243. doi: 10.1111/j.0006-341x.2000.00237.x. [DOI] [PubMed] [Google Scholar]
- Peng Y, Dear KBG, Denham JW. A generalized F mixture model for cure rate estimation. Statistics in Medicine. 1998;17:813–830. doi: 10.1002/(sici)1097-0258(19980430)17:8<813::aid-sim775>3.0.co;2-#. [DOI] [PubMed] [Google Scholar]
- Randales RH, Wolfe DA. Introduction to the theory of nonparametric statistics. John Wiley & Sons; New York: 1979. [Google Scholar]
- Sy JP, Taylor JMG. Estimation in a Cox proportional hazards cure model. Biometrics. 2000;56:227–236. doi: 10.1111/j.0006-341x.2000.00227.x. [DOI] [PubMed] [Google Scholar]