

Abstract
Background
Mammographic percentage density is an established and important risk factor for breast cancer. In this paper, we investigate the role of the spatial organisation of (dense vs. fatty) regions of the breast defined from mammographic images in terms of breast cancer risk.
Methods
We present a novel approach that provides a thorough description of the spatial organisation of different types of tissue in the breast. Each mammogram is first segmented into four regions (fatty, semi-fatty, semi-dense and dense tissue). The spatial relations between each pair of regions is described using so-called forces histograms (FHs) and summarised using functional principal component analysis. In our main analysis, association with case–control status is assessed using a Swedish population-based case–control study (1,170 cases and 1283 controls), for which digitised mammograms were available. We also carried out a small validation study based on digital images.
Results
For our main analysis, we obtained a global p value of 2×10−7 indicating a significant association between the spatial relations of the four segmented regions and breast cancer status after adjustment for percentage density and other important breast cancer risk factors. Our (spatial relations) score had a per standard deviation odds ratio 1.29, after accounting for overfitting (percentage density had a per standard deviation odds ratio of 1.34). The spatial relations between the fatty and semi-fatty tissue and the spatial relations between the fatty and dense tissue were the most significant. The spatial relations between the fatty and semi-fatty tissue were associated with parity and age at first birth (p=6×10−4). Using digital images, we were able to verify that the same characteristics of tissue organisation can be identified and we validated the association for the spatial relations between the fatty and semi-fatty tissue.
Conclusions
Our findings are consistent with the notion that fibroglandular and adipose tissue plays a role in breast cancer risk and, more specifically, they suggest that fatty tissue in the lower quadrants and the absence of density in the retromammary space, as shown in mediolateral oblique images, are protective against breast cancer.
Keywords: Mammography, Spatial organisation, Breast cancer risk, Adipose distribution
Background
Recent years have seen intensive efforts put into searching for relevant information from mammograms to assist the prediction of breast cancer risk. Mammographic breast density, which represents the amount of fibroglandular tissue in the breast, is the only strongly established image-based risk factor for breast cancer [1]. It is measured quantitatively either as the total dense area or the percentage of dense area on the mammogram (percentage density or PD). Women exhibiting a high PD, e.g. over 75%, have an approximately sixfold increased risk of breast cancer compared to women with a low PD (< 5%) [1]. However, the underlying mechanisms of this association are still unclear. Although PD aims at measuring the amount of dense tissue in the breast, it indirectly reflects the quantity of fat. The role of non-dense tissue in cancer development has been investigated by several researchers with contrasting outcomes [2, 3].
Mammograms present a two-dimensional projection of the breast, superimposing several layers of tissue into a single image. Hence, some researchers argue that measures of dense mammographic volume should be more accurate for classifying risk than measures of dense mammographic area [4]. These measures have still not been studied as extensively as area-based methods and Keller et al. [5] suggest that volumetric and areal density measures may be complementary for breast cancer risk assessment.
Aside from mammographic breast density, additional relevant information can be extracted from mammograms. Numerous studies have investigated the relations between cancer risk and the heterogeneity of the mammographic parenchymal pattern using quantitative texture descriptors. These particular features have been extracted on different scales, from the entire breast region [6, 7] to specific regions of interest such as the retroareolar area [8] and the central area of the breast [9].
Another type of information present in mammograms, though seldom measured, is the spatial organisation (relations) of the different types of tissue in the breast. Whilst mammographic breast density summarises the relative amounts of dense and fatty tissue in the breast and different texture features measure the local interactions between pixel intensities, spatial relations quantitatively capture the global layout of dense and fatty tissue. It has been previously suspected that the relative distribution of adipose and fibroglandular tissue is involved in breast cancer development [10]. Figure 1 shows three different mammograms to illustrate different types of distributions of fatty and dense tissue inside the breast. Such differences could be identified by, for instance, applying basic shape descriptors on the segmented dense tissue and by measuring the distance from its centroid to the skin line [5]. However, measuring only a specific spatial relation is rarely sufficient to describe fully the possibly complex relationships between two objects. In this article, we use a novel approach that provides a more complete description of the spatial organisation of different types of tissue in the breast. We use the so-called forces histograms (FHs), which represent quantitative fuzzy spatial relation descriptors of the pairwise relations of different regions of interest. A single FH takes into account both the directional and distance relationships as well as the shapes of two objects [11]. FHs have been used in other fields of medical image analysis [12, 13] and we recently described how they can be applied to analyse mammograms [14]. In [14], we also carried out a pilot case–control study on 500 mammographic images.
Fig. 1.
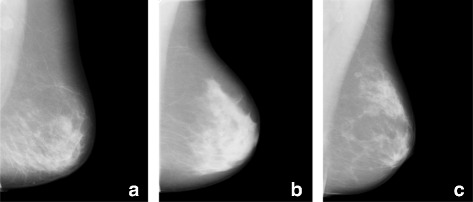
Examples of mammograms exhibiting different distributions of fatty and dense tissue. a The dense tissue is mainly located on the lower part of the breast. b The bulk of the dense tissue is concentrated in the retroareolar area. c The dense tissue is scattered but falls into two clusters, one next to the nipple and the other in the upper part of the breast
In our main analysis based on digitised mammograms, we show, using 1170 cases and 1283 controls, that spatial relation FHs hold important information for discriminating between breast cancer cases and controls, after taking into account PD and other important breast cancer risk factors. We present additional analyses that shed light on the biological information captured by the FHs that are most strongly associated with breast cancer risk. We also present a small validation study based on 300 digital mammograms (69 cases and 231 controls).
Methods
Materials
Our main analysis is based on CAHRES (Cancer and Hormone Replacement Study), a population-based post-menopausal breast cancer case–control study of Swedish residents born in Sweden and aged 50 to 74 years, between 1 October 1993 and 31 March 1995. The study includes approximately 6000 women (3000 cases and 3000 age group matched controls) from which area-based PD measurements of digitised mammograms are available [15]. Body mass index (BMI) was recorded at entrance to the study, whereas age, in this study, was assessed according to date of mammography. All cases had primary invasive breast cancer. We used the mediolateral oblique (MLO) view since it offers the best opportunity to visualise the maximum amount of breast tissue in a single image. Mammograms were digitised with an Array 2905HD Laser Film Digitizer.1 Density resolution was set at 12 bits, spatial resolution at 5.0 mm and optical density at 0–4.7. The size of the images was 4770 × 3580 pixels with 0.05 mm per pixel. For the present study, we used 2453 mammograms (1170 cases and 1283 controls) for which data on PD, age, BMI, hormone replacement therapy (HRT) status, parity and age at first birth (AFB) were available for all women included. Of these, 500 (250 cases and 250 controls) were previously included in our pilot study [14].
We carried out a small validation study using digital mammograms from the Karolinska Mammography cohort (KARMA) study (http://karmastudy.org/), which is a prospective cohort study that was initiated in January 2011. Recruitment ended in March 2013. It comprises women attending mammography screening or clinical mammography at four hospitals in Sweden [16]. Participants answered a comprehensive web-based questionnaire, allowed storage of mammograms and accepted linkage to national breast cancer registers. Identification of KARMA participants as cases or controls for the present study was based on linkage with the Swedish Cancer Registry (last updated 31 December 2013). Here, we included 69 incident cases (59 with primary invasive cancer and 10 with ductal carcinoma in situ) with full field digital mammography images (raw MLO images) from GE Medical Systems, model Senographe Essential version ADS 53.40. We selected an additional 231 healthy controls with images taken with the same machine (so that, in total, our validation study was based on 300 post-menopausal women). The size of the images was 3062 × 2394 pixels with 0.1 mm per pixel. Information on age, BMI, HRT status and reproductive history was collected via a web-based questionnaire at study entry.
In both studies, for cases, all mammograms were taken less than 3 years before diagnosis (and at latest, at date of diagnosis). For cases, we used the mammogram contralateral to the tumour to ensure that image measurements were not affected by the tumours, whereas for controls an image of a single side was selected at random. This is common practice in case–control studies using mammographic images [17, 18]. For KARMA controls, all mammograms were taken at questionnaire date and, therefore, had a confirmed negative follow-up of at least 9 months. For CAHRES, mammograms of the controls were taken within 3 years of questionnaire date (the majority of mammograms were from before questionnaire date, but some were from several months after) and were all from before the diagnosis date of the last incident case, so that they were free from a breast cancer diagnosis.
Percentage density measurement used in this study
For CAHRES, an area-based PD for each image was measured using the user-assisted approach of Cumulus [19]. Cumulus is the most widely used software for measurement of mammographic density in analogue images. The user first needs to trace and remove the pectoral muscle manually. Then, they use sliders to perform global (breast region) and then local (dense region) interactive thresholding. A trained user (LE) carried out the Cumulus measurements blinded to case–control status. KARMA images were not read by Cumulus. For these images, we used an automated measure of area PD, which has been shown to perform in line with other established density measures in terms of breast cancer risk association [20].
Spatial relations measurements
Image preprocessing
The main aim of the preprocessing step is to separate the breast from other objects in the mammogram (i.e. labels, tags and screening artefacts) with a minimum loss of breast tissue. In general, two independent steps are performed. The first aims to segment the breast region, while the second separates the pectoral muscle from the rest of the breast area. The pectoral muscles were removed from both digital and digitised images using the texture gradient-based approach proposed by Bora et al. [21].
Digitised mammograms were rescaled to have pixel values between 0 and 1 and denoised using pixelwise adaptive Wiener filtering. The strong signal-to-noise ratio of the digital images allowed us to segment the breast region by applying a simple thresholding to the image. To segment the breast profile, the contrast of the image first needed to be enhanced to brighten the low-intensity pixels close to the skin line. This was achieved using a logarithmic transformation of the image. The image was then segmented into three classes according to Otsu’s multi-thresholding method. The two brightest classes were kept since they correspond to the breast region and the other objects in the mammogram, while the darkest corresponds to the background. The breast mask was finally extracted as the largest group of connected components and smoothed using morphological filtering.
Partition of breast images
After breast region segmentation, pectoral muscle removal and contrast enhancement for raw digital images, breast regions representing different types of tissue need to be defined. In the literature, there is no standard for the number of regions that can be defined from an X-ray image of the breast, and the number used has varied from two to 13 [22], often depending on the purpose of the study. In our work, we defined four different regions in the breast. The choice of four regions is common in the literature and corresponds to the number of original parenchymal patterns defined by Wolfe [23], who categorised images according to both the extent of densities and their characteristics (prominence of ducts and dysplasia). Also, four regions representing very dense tissue (both fibrotic stromal and glandular tissue), the fatty background of the mammogram and the fatty breast edge have been used for extracting textural descriptions [24]. Here, we used a fully automated segmentation method, the fuzzy C-Means clustering, to divide the breast into four regions loosely representing the fatty, semi-fatty, semi-dense and dense tissue.
Forces histogram
The FH method is applied to describe comprehensively the relative positions of the different regions of tissue. Since the FH encapsulates in a single histogram the directional and the distance relationships between the regions considered as well as their shapes, we construct an exhaustive description of the spatial organisation of tissue in a mammogram by computing the FH between all pairs of regions.
Figure 2 illustrates the principle of the computation of the FH between two sets of pixels, in this example comparing pixels within a region A (in green) with pixels within a region B (in orange). The value of the FH for a specific angle θ is obtained using the following algorithm. First, a series of parallel lines sweeping across the image in direction θ is defined. Then, for each line, a weight is calculated as the sum of the inverted squared Euclidean distances between all pairs of pixels, such that the first pixel belongs to object A and the other to B. Finally, the weights of all the lines are summed to generate the value of the FH along this particular direction, which corresponds to a single bin of the histogram. This procedure is repeated for a series of angles evenly distributed between 0° and 360°. The number of angles considered defines the length of the histogram and its angular precision, hence shorter descriptions are less accurate.
Fig. 2.
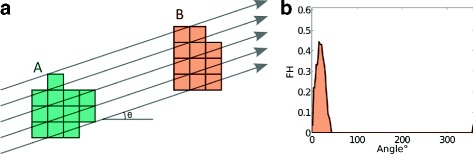
Illustration of the computation of FHs between two objects A (green) and B (orange). a Both objects and the parallel lines sweeping across the image oriented by a specific angle θ°. b The final FH (with angles between 0° and 360°) describing the spatial relationships between A and B. In this example, the maximum value of the FH is obtained for an angle of approximately 18° and is empty for values between 50° and 350°, since no line meets both objects A and B along these orientations. FH forces histogram
Each image of the breast, segmented into four regions, is then described by a set of six FHs (4 choose 2) measuring the relative positions of the different pairs of regions. We use FHij to denote the FH that measures the relative positions of regions i and j. FH descriptions for an example mammographic image are shown as part of Fig. 3 (which is an overview of the complete strategy for our main analysis, which we continue to describe in ‘Statistical methods’). The computation of the FH follows a complexity of , where n is the number of pixels in the image and a is the number of angles considered. To reduce the computation time while retaining the overall spatial organisation of the tissue, each image was rescaled to 0.25 mm per pixel and we set the number of angles to 180 (a step of 2°). For more details, see [14].
Fig. 3.
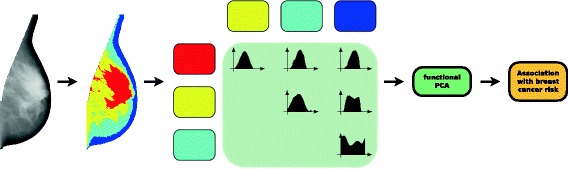
Overview of main analyses. A given breast image is first segmented into four regions: dense (red), semi-dense (yellow), semi-fatty (light blue) and fatty (dark blue) tissue. The spatial relations between each pair of regions is described by a forces histogram. The information captured by each forces histogram is compressed into a small number of variables using a functional principal component analysis and then the association between these variables (representing the spatial organisation of the regions) and breast cancer status is evaluated through a statistical test. PCA principal component analysis
Statistical methods
Prior to testing for association with breast cancer status, for each study, we compressed the key information gathered in our six FHs (described by, in total, 6×180 FH variables) into a small number of variables. Each FH can be viewed as a function of the angle θ. To summarise the information contained in each FH, we apply approaches that are suitable for analysing data. These provide information about phenomena varying over a continuum (i.e. curves). Specifically, we chose to extract the dominant modes of variations included in each FH by carrying out a functional principal component (fPC) analysis [25]. We used the method described in [26], which is implemented in PACE,2 a MATLAB package for functional data analysis. This approach transforms the FH data to K-dimensional multivariate data consisting of the first K(fPC) scores, which account for a cumulative variance of 85%. In CAHRES, for all FHs, we retained two fPCs per FH except for the one relating regions 2 and 4, for which we retained three fPCs (13 fPCs, in total). Exactly the same number of fPCs (for all FHs) was retained when analysing the KARMA images (again 13 fPCs, in total). We will denote the kth fPC for the FH that measures the relative positions of regions i and j by . For CAHRES, we carried out our main association analysis by describing breast tissue organisation using all 13 fPC variables. This step of the analysis is represented by the box ‘functional PCA’ in Fig. 3.
We evaluated the association between the fPCs and case–control status in CAHRES by fitting logistic regression models treating case–control status as a dependent variable and the fPCs as independent variables. All fPCs were standardised to zero mean and unit variation prior to being included in logistic regression models. We included age, BMI, PD, HRT, parity and AFB (the variables parity and AFB were combined into a single categorical variable with five categories; see Table 1) in all logistic regression models as adjustment variables. In our main analysis, we chose to transform PD by taking its square root prior to including it as an adjustment variable, although we also repeated our analysis with PD on its original scale as well as categorised into five groups ([0,5[, [5,10[, [10,20[, [20,40[ and [40,100]). In our data, the overall model fit was best using square root PD. To evaluate whether our selected features (fPCs) were, overall, associated with breast cancer status (after adjustment for potential confounding variables), we carried out a likelihood ratio test. This step of the analysis is represented by the box ‘Association with breast cancer risk’ in Fig. 3.
Table 1.
Key characteristics of individuals (CAHRES)
| Characteristic | Cases | Controls | P value |
|---|---|---|---|
| Number | 1,170 | 1,283 | |
| HRT use | 2×10−9 | ||
| Never | 791 (68%) | 998 (78%) | |
| Past | 98 (8%) | 40 (3%) | |
| Current | 281 (24%) | 245 (19%) | |
| Parity and AFB | 7×10−7 | ||
| Nulliparous | 157 (13%) | 129 (10%) | |
| Parity ≤2 and AFB ≤25 | 349 (30%) | 354 (28%) | |
| Parity ≤2 and AFB >25 | 372 (32%) | 351 (27%) | |
| Parity >2 and AFB ≤25 | 214 (18%) | 351 (27%) | |
| Parity >2 and AFB >25 | 78 (7%) | 98 (8%) | |
| Age | 62.6 (±6.5) | 63.6 (±6.4) | 8×10−5 |
| BMI | 25.2 (±3.6) | 25.0 (±3.8) | 0.26 |
| PD | 18.7 (±14.6) | 14.8 (±13.2) | 4×10−12 |
| 3.9 (±1.7) | 3.5 (±1.7) | 6×10−14 |
Means (with standard deviations in parentheses) are given for continuous variables and counts (with percentages in parentheses) are given for categorical variables. P values are obtained using likelihood ratio tests based on fitting logistic regression models without adjustment for additional covariates
AFB age at first birth, BMI body mass index, HRT hormone replacement therapy, PD percentage density
We estimated an effect size for a risk score constructed from the fPC variables of the spatial relations. If a single dataset is used naively both to train a score and to evaluate its effect size, the effect size will be overestimated (which we will refer to as an apparent estimate). We, therefore, used a bootstrapping procedure that provides a nearly unbiased (honest) estimate of the effect size (the procedure is, in fact, slightly biased in the direction of underestimating the effect); see Harrell et al. [27]. We also estimated area under the receiver operating characteristic curve (AUC) values (honest values were calculated using the bootstrap procedure) and used Delong’s test [28] for comparing apparent AUC values.
After carrying out our global test of association and estimating AUC values and an effect size for a spatial relation score, to interpret our results, we identified the most important fPCs using a stepwise selection procedure (using the step function in R). Two fPCs were selected. For these two fPCs, to identify the angle(s) (in their corresponding FHs) for which they predominantly capture variability, we visualised plots of modes of variations [29] and eigenfunctions (see Figure 6 in the Appendix). To understand the fPCs better, we studied their association with risk factors considered in our case–control analysis. Since (both) selected fPCs were approximately normally distributed, we did this by fitting linear regression models with normal error distributions.
For our validation study (KARMA), we retained only the two fPCs that were selected in our analysis based on CAHRES data. We verified that the fPCs extracted from CAHRES and KARMA carried corresponding information (using plots of modes of variations and eigenfunctions; see Figure 7 in the Appendix). Associational analysis in KARMA was also based on logistic regression analysis.
Results
Main analysis
For CAHRES, key characteristics of cases and controls included in our analyses are described in Table 1. We refer to the four density regions segmented inside the breast as 1, 2, 3 and 4, corresponding to the fatty, semi-fatty, semi-dense and dense tissue, respectively. The 13 fPCs, which describe breast tissue organisation (see ‘Statistical methods’), were used as covariates in the logistic regression model to investigate the association of tissue organisation with breast cancer status.
Parameter estimates of the logistic regression with all covariates (fPCs) and adjustment variables are shown in Table 2. We obtained a global p value of 2×10−7 from a likelihood ratio test on 13 degrees of freedom, indicating significant association between the spatial relations of the four segmented regions and breast cancer status. To ensure that this association is independent of breast size (it is possible that the FHs, to some extent, capture breast size), we also adjusted for the breast mammographic area; the p value was then 1×10−7. We also noted that the global p value was largely unchanged when PD was on its original scale (p=5×10−8), or when it was coded as a categorical variable (p=7×10−7). For an independent validation of our pilot study result, we removed the 500 images that had been included in [14]. When doing so, we obtained a p value of 8×10−5.
Table 2.
Logistic regression results with age, BMI, , parity and AFB, HRT and fPCs as covariates (CAHRES)
| Covariate | Estimated | Standard | P value |
|---|---|---|---|
| coefficient | error | ||
| Intercept | −1.828 | 0.667 | 0.006 |
| Age | −0.008 | 0.007 | 0.259 |
| BMI | 0.066 | 0.015 | 2×10−5 |
| 0.199 | 0.040 | 6×10−7 | |
| Parity and AFB | |||
| Nulliparous | |||
| Parity ≤2 and AFB ≤25 | −0.186 | 0.149 | 0.213 |
| Parity ≤2 and AFB >25 | −0.139 | 0.147 | 0.346 |
| Parity >2 and AFB ≤25 | −0.666 | 0.156 | 2×10−5 |
| Parity >2 and AFB >25 | −0.393 | 0.201 | 0.051 |
| HRT use | |||
| Never | |||
| Past | 0.737 | 0.201 | 2×10−4 |
| Current | 0.270 | 0.108 | 0.013 |
| Spatial relations fPCs a | |||
| −0.150 | 0.130 | 0.250 | |
| −0.395 | 0.100 | 8×10−5 | |
| 0.004 | 0.098 | 0.967 | |
| 0.144 | 0.092 | 0.118 | |
| −0.208 | 0.091 | 0.023 | |
| 0.039 | 0.066 | 0.554 | |
| 0.148 | 0.121 | 0.219 | |
| 0.097 | 0.091 | 0.283 | |
| −0.022 | 0.093 | 0.812 | |
| 0.158 | 0.078 | 0.042 | |
| 0.006 | 0.066 | 0.926 | |
| 0.118 | 0.065 | 0.069 | |
| 0.081 | 0.066 | 0.217 |
AFB age at first birth, BMI body mass index, HRT hormone replacement therapy, PD percentage density a p=2×10−7
We next constructed a spatial relations score, as a sum of the fPC values weighted by the estimated coefficients (for the fPCs), as shown in Table 2. From fitting a logistic regression model with this score (instead of the 13 fPC variables), along with PD and the other breast cancer risk factors, and multiplying the standard deviation of the score by its regression coefficient, we obtained a naive (biased) per standard deviation effect size estimate of 0.33 (the per standard deviation odds ratio was 1.39) and an apparent AUC value of 0.654. Delong’s test gave a p value of 6.46×10−4 when comparing this model to one that excluded our score (which had an apparent AUC of 0.630). Using a bootstrapping procedure (based on 1000 bootstrap samples), we obtained an honest estimate of 1.29 for the per standard deviation odds ratio for the fPC-based score, and an honest estimate of 0.637 for the AUC for the full model (the honest estimate of AUC for the model excluding our score was 0.621). We note that from fitting a model that excluded all spatial relations variables, we estimated the per standard deviation odds ratio for PD to be 1.34 (the per standard deviation odds ratio for PD actually increased, to 1.40, when the fPCs of the spatial relations were included as covariates in the model).
The main features of the fPCs have to be identified to gain insight into the biological reasons for the association of the fPCs with breast cancer status. Due to the organisation of the segmented regions, it is expected that different fPCs carry overlapping information. Based on the full model (Table 2), it appears that the fPCs describing the relative position of the different regions to the fatty breast edge (region 1) are most important. After using stepwise selection, we retained and . When fitting a logistic regression model with these two variables as covariates and with all the considered confounders, the corresponding estimated coefficients for and were −0.124 with a p value of 0.006, and −0.201 with a p value of 3×10−5, respectively. The combined p value for these two fPCs was 7×10−8. These two fPCs were moderately correlated (r=0.3) and both were approximately normally distributed.
To visualise the variation in FHs between regions 1 and 2, captured by , we plotted the second mode of variation, along with its FH data and eigenfunction; see Figure 6 (a to c) in the Appendix. From the mode of variation and the corresponding eigenfunction it can be seen that captures variability at angles of 54°, 152° and 268°. We note that we obtained a multiple R 2 value of 0.99 based on fitting a linear regression model to with FH12(54°), FH12(152°) and FH12(268°) included as covariates. FH12(54°) and FH12(268°) are positively associated with whereas FH12(152°) is negatively associated with .
We next selected images with high and low values of ; four images are shown in Fig. 4. These images (a to d) have PD values of 53, 9, 35 and 9, and standardised values of 2.5, 3.0, −1.9 and −1.9, respectively. Histograms for FH12(54°), FH12(152°) and FH12(268°) are included above each image, with the specific FH value of an image marked as a vertical red line. From scrutinising the images and their FH values, it seems that low values are linked to regular distributions of both fatty and semi-fatty tissue along the skin line of the breast, whereas high values are related to thinning regions near the retroareolar area and irregular spreading of semi-fatty tissue in the lower part of the breast (fatty and semi-fatty tissue are collected in the lower quadrants of the images).
Fig. 4.
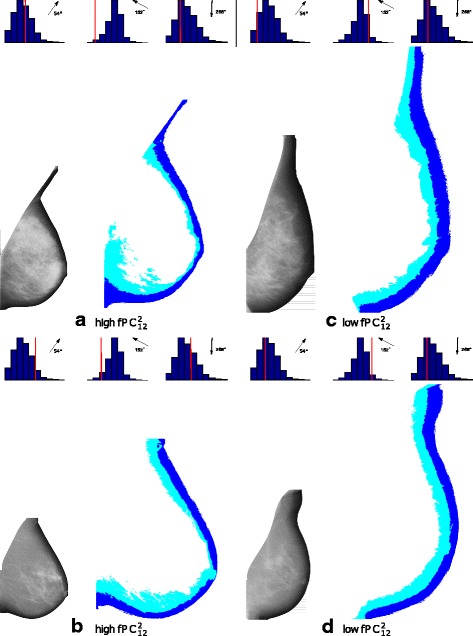
Examples of mammograms with high ((a) and (b)) and low ((c) and (d)) values of . Original mammograms are shown next to their segmented regions 1 (dark blue) and 2 (light blue). Histograms of FH 12 values at angles of 54°, 152°and 268°are included above each image with the value for the specific image marked as a vertical red line. A low value, after adjustment for PD and other covariates, is associated with increased risk of breast cancer
From the first mode of variation and its corresponding eigenfunction for the FHs between regions 1 and 4, it can be seen that captures variability at an angle of 192°; see Figure 6 (d to f) in the Appendix. FH14(192°) is positively associated with and we obtained an R 2 value of 0.93 based on fitting a linear regression model to with FH4(192°) as a covariate. Four images selected for having high or low values of are shown in Fig. 5. These images (a to d) have PD values of 39, 3, 19 and 3, and standardised values of 4.4, 3.3, −1,9 and −1.6, respectively. The value of FH14(192°) for each image is marked with a vertical red line on the histogram of the values of FH14(192°) for all images (shown above the corresponding image). provides information about the location of dense tissue in relation to the fatty region. From viewing images (a) and (c), two images with moderately high PD, it appears that low values of this fPC can be synonymous with the dense region being located in the retromammary space of the image (high values capture an absence of dense tissue in the retromammary space). From viewing the images (b) and (d), it may be plausible that, in low PD images, a low value of is synonymous with a more heterogeneous distribution of dense tissue (i.e. it is more scattered).
Fig. 5.
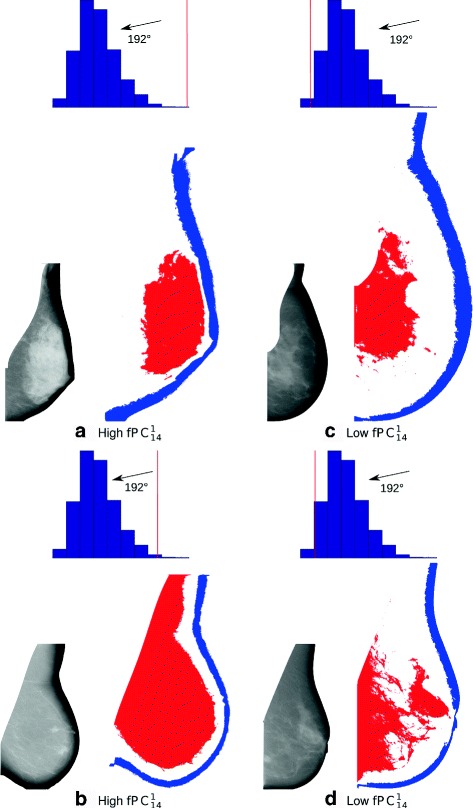
Examples of mammograms with high ((a) and (b)) and low ((c) and (d)) values of . Original mammograms are shown next to their segmented regions 1 (dark blue) and 4 (red). The histograms of FH 14 at an angle of 192° are included above each image with the value for the specific image marked as a vertical red line. A low value, after adjustment for PD and other covariates, is associated with increased risk of breast cancer. PD percentage density
To trace any potential determinants of (key characteristics of the spatial distribution of adipose tissue) and (position of dense tissue relative to fatty tissue), we fitted linear regression models with, in turn, and as dependent variables, and the risk factors considered in the earlier models as independent variables. PD, parity and AFB, and BMI are all positively associated with . Parameter estimates for the model for are shown in Table 3. For , only BMI and PD have statistically significant coefficients; see Table 4.
Table 3.
Linear regression model for with breast cancer risk factor covariates (CAHRES)
| Covariate | Estimated | Standard | P value | |
|---|---|---|---|---|
| coefficient | error | |||
| Intercept | −1.332 | 0.272 | 1×10−6 | |
| Age | 0.003 | 0.003 | 0.373 | |
| BMI | 0.025 | 0.006 | 8×10−6 | |
| PD | 0.022 | 0.002 | < 2×10−16 | |
| Parity and AFB a | ||||
| Nulliparous | ||||
| Parity ≤2 and AFB ≤25 | 0.252 | 0.069 | 2×10−4 | |
| Parity ≤2 and AFB >25 | 0.100 | 0.068 | 0.142 | |
| Parity >2 and AFB ≤25 | 0.229 | 0.071 | 0.001 | |
| Parity >2 and AFB >25 | 0.108 | 0.093 | 0.243 | |
| HRT use | ||||
| Never | ||||
| Past | −0.121 | 0.089 | 0.175 | |
| Current | −0.074 | 0.050 | 0.140 |
Pearson product–moment correlation coefficients between and variables age, BMI and PD are −0.04 (p=0.05), −0.01 (p=0.82) and 0.25 (p<2×10−16), respectively
AFB age at first birth, BMI body mass index, HRT hormone replacement therapy, PD percentage density a p=6×10−4
Table 4.
Linear regression model for with breast cancer risk factor covariates (CAHRES)
| Covariate | Estimated | Standard | P value |
|---|---|---|---|
| coefficient | error | ||
| Intercept | −2.24 | 0.260 | < 2×10−16 |
| Age | −0.003 | 0.003 | 0.224 |
| BMI | 0.078 | 0.005 | < 2×10−16 |
| PD | 0.028 | 0.001 | < 2×10−16 |
| Parity and AFB | |||
| Nulliparous | |||
| Parity ≤2 and AFB ≤25 | 0.052 | 0.066 | 0.420 |
| Parity ≤2 and AFB >25 | 0.086 | 0.065 | 0.188 |
| Parity >2 and AFB ≤25 | 0.015 | 0.068 | 0.826 |
| Parity >2 and AFB >25 | 0.004 | 0.089 | 0.959 |
| HRT use | |||
| Never | |||
| Past | −0.005 | 0.085 | 0.953 |
| Current | 0.016 | 0.048 | 0.732 |
Pearson product–moment correlation coefficients between and variables age, BMI and PD are −0.10 (p=8×10−7), 0.15 (p=7×10−14) and 0.29 (p<2×10−16) respectively
AFB age at first birth, BMI body mass index, HRT hormone replacement therapy, PD percentage density
In the main association analysis (Table 2), we concentrated on looking for the main effects of fPCs. It is, of course, possible that particular features are important within narrow ranges of PD. However, when dividing the samples into three groups defined by PD ([0,7[, [7,25[ and [25,100]; the number of images per group being respectively 717, 1,176 and 560), and were jointly significantly associated with breast cancer status in all groups (with p values of 0.009, 8×10−4 and 0.006) and the signs of the coefficients were consistent across all groups.
We note that, with the exception of breastfeeding, we believe that we adjusted for the potentially most important confounders in our main analysis (Table 2). Because information on breastfeeding was missing for a substantial number of individuals (451), we did not include breastfeeding as a covariate in the main analysis. We did, however, carry out a sub-analysis. When we re-performed our analysis on a reduced data set (2002 individuals and images) with complete information on breastfeeding (yes or no), and including breastfeeding, along with the other covariates, the p value for association between the 13 fPCs and breast cancer risk was 2×10−6, which was unchanged when breastfeeding was excluded from the model. Based on fitting linear regression models with fPCs as outcome variables, breastfeeding was not significantly associated with either or after adjustment for other covariates (e.g. parity and AFB).
Validation
A major purpose of our validation study was to check that we can identify the same characteristics of breast tissue organisation from digital images as we can from digitised analogue images. That we have a relatively small number of cases with digital images means that we have relatively low power to validate case–control associations. Key characteristics of cases and controls selected from KARMA are displayed in Table 5 in Appendix. For KARMA, as in CAHRES, 13 fPCs were retained that describe breast tissue organisation.
For further validation, we considered the two fPCs that were retained using stepwise selection in CAHRES ( and ).
After constructing and examining mode of variations and eigenfunction plots (see Figure 7 in Appendix), we could confirm that these fPCs identified the same features in the KARMA digital images as they did in CAHRES analogue images. The angles capturing maximum variability in in KARMA were 56°, 156° and 270°, which were very close to the angles captured by in CAHRES. Similarly, the angle of maximum variability was almost the same over the two studies for . When fitting a logistic regression model to case–control status, with and as covariates along with the considered confounders, the corresponding estimated coefficients for and were −0.344 with a p value of 0.031, and 0.243 with a p value of 0.128, respectively (Table 6 in Appendix). That is, despite the small number of cases, we were able to validate the association with . This association had a p value that was lower than that for the association between case–control status and PD in this dataset. The apparent and honest AUCs for the model with no fPCs were 0.687 and 0.634, respectively, whilst for the model with the selected fPCs, the apparent and honest AUCs were 0.703 and 0.643, respectively. Delong’s test (based on the apparent AUCs) gave a p value of 0.386.
Discussion
In this paper, we investigated the role of the spatial organisation of different regions comprising the breast, on mammograms, in terms of the risk of developing breast cancer. The results of our main analysis showed that the spatial relations between the fatty and semi-fatty tissue along with the spatial relations between the fatty and dense tissue are associated with breast cancer risk after adjustment for PD and other possible confounders. These findings are consistent with the idea that fibroglandular and adipose tissue play a role in breast cancer risk.
Several studies have already explored the role of breast fatty tissue, but have reported conflicting results [2, 3]. However, it has been noted that studies reporting a negative association between adipose tissue area and breast cancer risk based their measurements on the craniocaudal view, whereas those reporting a positive association used the mediolateral view. Our results show that the location of adipose tissue (both our fatty and semi-fatty regions) has an impact on breast cancer risk and provides additional information to explain these contrasting studies and may help in understanding the role of the fatty tissue. To define better estimates for breast cancer risk, it will likely be important to clarify the biological mechanisms regulating the spatial distribution of adipose tissue inside the breast.
In our validation study, we were able to verify that it is possible to identify the same characteristics of breast tissue organisation in digital images as in analogue images. Moreover, despite the small sample size of our validation study, we were able to validate the association between risk and our measure of the spatial relations between the fatty and semi-fatty tissue. It would, though, be valuable to study the association between the two specific FH variables identified here (or related measures developed to capture directly the important spatial features identified here) with breast cancer status using larger digital external datasets and to investigate their use in breast cancer risk prediction.
Fig. 6.
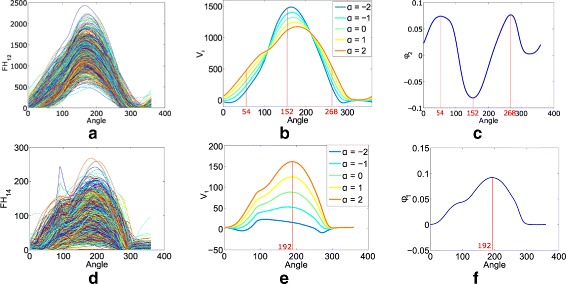
Visualisation of variability in and in CAHRES (analogue images). a and d show FH12 and FH14 for all images. The second mode of variation of FH12 and its eigenfunction are displayed in b and c, respectively. The red lines at angles 54°, 152° and 268° indicate the locations of the maxima of variations in the set of all the FH12. The first mode of variation of FH14 and its eigenfunction are displayed in e and f, respectively. The red line at angle 192° indicates the maximum of variation in the set of all the FH14
Fig. 7.
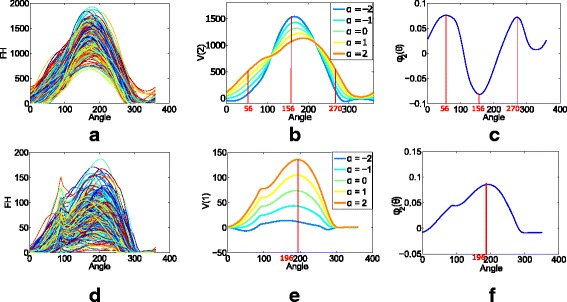
Visualisation of variability in and in KARMA (digital images). a and d show FH12 and FH14 for all images. The second mode of variation of FH12 and its eigenfunction are displayed in b and c, respectively. The red lines at angles 56°, 156° and 270° indicate the locations of the maxima of variations in the set of all the FH12. The first mode of variation of FH14 and its eigenfunction are displayed in e and f, respectively. The red line at angle 196° indicates the maximum of variation in the set of all the FH14
We have adopted one approach for segmenting the images prior to carrying out statistical analyses. Other approaches could be employed. Moreover, the segmentation method used in this study will always divide the breast into four regions, even for a very low-density mammogram. Since the proposed features are unavoidably influenced by the choice of the segmentation method, an adaptive approach taking into consideration the quantity of dense tissue in the breast might yield more precise descriptors, which could be easier to interpret.
Our approach could also be used on other types of images. In this study, we included only MLO mammograms. It would be interesting to investigate the spatial organisation by including craniocaudal views to give a more precise and more exhaustive description of the spatial relations of regions of density inside the breast. It would also be interesting to extend the method described here to digital breast tomosynthesis images, which provide a detailed three-dimensional view of the breast where patterns of fibroglandular tissue are not subject to overlapping tissue. Finally, we point out that the approach we described here, for capturing relevant patterns in the organisation of breast tissue, may be useful in numerous contexts, for example, in studying in detail the role of tissue density in screening sensitivity.
Conclusions
Much attention has been paid to the dense and non-dense areas of the breast and the role of their sizes as breast cancer risk factors. In this study, we go further and find an association between the spatial organisation of breast tissue and breast cancer risk that is independent of (overall) mammographic density and a number of other established risk factors for breast cancer. The concentration of adipose tissue in the lower quadrants (which is associated with high parity and young age at first birth) and the absence of dense tissue in the retromammary space can be protective against breast cancer. These findings are completely novel and may provide a basis for more detailed biological hypotheses concerning the role of breast tissue in breast cancer.
Endnotes
1 Array Corporation, Hampton, NH, USA
Appendix
Modes of variation plots
For a particular fPC, of a particular FH, the set of functions (defined across a range of values of α) viewed on the modes of variations plots were calculated as
where μ(θ) is the mean function of the considered FH, λ is the corresponding eigenvalue and ϕ(θ) is the corresponding eigenfunction.
Validation study (KARMA)
Table 5.
Key characteristics of individuals (KARMA)
| Characteristic | Cases | Controls | P value |
|---|---|---|---|
| Number | 69 | 231 | |
| HRT use | 0.179 | ||
| Never | 42 (61%) | 125 (54%) | |
| Past | 18 (26%) | 86 (37%) | |
| Current | 9 13%) | 20 (9%) | |
| Parity and AFB | 0.192 | ||
| Nulliparous | 9 (13%) | 26 (11%) | |
| Parity ≤2 and AFB ≤25 | 19 (27%) | 75 (33%) | |
| Parity ≤2 and AFB >25 | 24 (35%) | 66 (29%) | |
| Parity >2 and AFB ≤25 | 15 (22%) | 40 (17%) | |
| Parity >2 and AFB >25 | 2 (3%) | 24 (10%) | |
| Age | 63.06 (±6.05) | 60.95 (±6.71) | 0.021 |
| BMI | 25.93 (±4.48) | 25.37 (±3.65) | 0.283 |
| PD | 20.156 (±7.268) | 18.908 (±8.252) | 0.258 |
| 4.410 (±0.8481) | 4.238 (±.976) | 0.187 |
Means (with standard deviations in parentheses) are given for continuous variables and counts (with percentages in parentheses) are given for categorical variables. P values are obtained using likelihood ratio tests based on fitting logistic regression models without adjustment for additional covariates
AFB age at first birth, BMI body mass index, HRT hormone replacement therapy, PD percentage density
Table 6.
Logistic regression results with age, BMI, , Parity and AFB, HRT and fPCs as covariates (KARMA)
| Covariate | Estimated | Standard | P value |
|---|---|---|---|
| coefficient | error | ||
| Intercept | −8.680 | 2.300 | 2×10−04 |
| Age | 0.072 | 0.024 | 0.002 |
| BMI | 0.070 | 0.046 | 0.128 |
| 0.388 | 0.186 | 0.037 | |
| Parity and AFB | |||
| Nulliparous | |||
| Parity ≤2 and AFB ≤25 | −0.490 | 0.502 | 0.330 |
| Parity ≤2 and AFB >25 | −0.022 | 0.485 | 0.963 |
| Parity >2 and AFB ≤25 | −0.125 | 0.528 | 0.816 |
| Parity >2 and AFB >25 | −1.331 | 0.857 | 0.121 |
| HRT use | |||
| Never | |||
| Past | −0.772 | 0.347 | 0.026 |
| Current | 0.246 | 0.476 | 0.605 |
| Spatial relations fPCs | |||
| −0.344 | 0.160 | 0.031 | |
| 0.243 | 0.160 | 0.128 |
AFB age at first birth, BMI body mass index, fPC Functional principal component, HRT hormone replacement therapy, PD percentage density
Acknowledgments
Funding
This research was supported by the Swedish Cancer Society (grant CAN 2014/472), the Swedish Research Council (2016-01245), the Cancer Health Risk Prediction Centre (CRISP; www.crispcenter.org) and a Linneus Centre (contract ID 70867902) financed by the Swedish Research Council.
Availability of data and materials
Subject to participants’ consent and legal requirements, data can be made available upon request to the primary department of the corresponding author.
Ethical approval and consent to participate
All participants in the studies had provided written informed consent, and the studies had the approval of the ethics review board at Karolinska Institutet, Stockholm, Sweden.
Abbreviations
- AFB
Age at first birth
- AUC
Area under the receiver operating characteristic curve
- BMI
Body mass index
- FH
Forces histogram
- FHxy(θ)
Forces histogram between regions x and y at angle 𝜃
- fPC
Functional principal component
Functional principal component number z from the forces histogram between regions x and y
- HRT
Hormone replacement therapy
- MLO
Mediolateral oblique
- PCA
Principal component analysis
- PD
Percentage density
Authors’ contributions
MAA and KH were involved in the development and application of the methodology, were responsible for interpreting the results, and drafting and revising the manuscript. LE helped in interpreting the results, and in revising the manuscript. KC and PH helped in collection and assembly of data and in revising the manuscript. All authors read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Maya Alsheh Ali, Email: maya.alsheh.ali@ki.se.
Kamila Czene, Email: Kamila.Czene@ki.se.
Louise Eriksson, Email: louise.eriksson@ki.se.
Per Hall, Email: Per.Hall@ki.se.
Keith Humphreys, Email: Keith.Humphreys@ki.se.
References
- 1.Boyd NF, Guo H, Martin LJ, Sun L, Stone J, Fishell E, et al. Mammographic density and the risk and detection of breast cancer. N Engl J Med. 2007;356(3):227–36. doi: 10.1056/NEJMoa062790. [DOI] [PubMed] [Google Scholar]
- 2.Lokate M, Peeters PH, Peelen LM, Haars G, Veldhuis WrB, van Gils CH. Mammographic density and breast cancer risk: the role of the fat surrounding the fibroglandular tissue. Breast Cancer Res. 2011;13(5):1–8. doi: 10.1186/bcr3044. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Pettersson A, Hankinson SE, Willett WC, Lagiou P, Trichopoulos D, Tamimi RM. Nondense mammographic area and risk of breast cancer. Breast Cancer Res. 2011;13(5):1–10. doi: 10.1186/bcr3041. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Shepherd JA, Kerlikowske K, Ma L, Duewer F, Fan B, Wang J, et al. Volume of mammographic density and risk of breast cancer. Cancer Epidemiol Biomarkers Prev. 2011;20(7):1473–82. doi: 10.1158/1055-9965.EPI-10-1150. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Keller BM, Conant EF, Oh H, Kontos D. Breast imaging: 11th International Workshop. Berlin Heidelberg: Springer; 2012. Breast cancer risk prediction via area and volumetric estimates of breast density. [Google Scholar]
- 6.Nielsen M, Vachon CM, Scott CG, Chernoff K, Karemore G, Karssemeijer N, et al. Mammographic texture resemblance generalizes as an independent risk factor for breast cancer. Breast Cancer Res. 2014;16:R37. doi: 10.1186/bcr3641. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Haberle L, Wagner F, Fasching PA, Jud SM, Heusinger K, Loehberg CR, et al. Characterizing mammographic images by using generic texture features. Breast Cancer Res. 2012;14(2):R59. doi: 10.1186/bcr3163. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Wei J, Chan HP, Wu YT, Zhou C, Helvie MA, Tsodikov A, et al. Association of computerized mammographic parenchymal pattern measure with breast cancer risk: a pilot case–control study. Radiology. 2011;260(1):42–9. doi: 10.1148/radiol.11101266. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Manduca A, Carston MJ, Heine JJ, Scott CG, Pankratz VS, Brandt KR, et al. Texture features from mammographic images and risk of breast cancer. Cancer Epidemiol Biomarkers Prev. 2009;18(3):837–45. doi: 10.1158/1055-9965.EPI-08-0631. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Pereira SMP, McCormack VA, Moss SM, dos Santos Silva I. The spatial distribution of radiodense breast tissue: a longitudinal study. Breast Cancer Res. 2009;11(3):1–12. doi: 10.1186/bcr2318. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Matsakis P. Understanding the spatial organization of image regions by means of force histograms: a guided tour. In: Matsakis S, editor. Applying soft computing in defining spatial relations. Heidelberg: Springer. Physica-Verlag; 2002. [Google Scholar]
- 12.Shyu CR, Matsakis P. Spatial lesion indexing for medical image databases using force histograms. In: Computer vision and pattern recognition IEEE, vol. 2. IEEE: 2001. p. 603–608.
- 13.Garnier M, Alsheh Ali M, Seguin J, Mignet N, Hurtut T, Wendling L. International conference image analysis and recognition. Portugal: Springer; 2014. Grading cancer from liver histology images using inter and intra region spatial relations. [Google Scholar]
- 14.Alsheh Ali M, Garnier M, Humphreys K. Spatial relations of mammographic density regions and their association with breast cancer risk. Procedia Comput Sci. 2016;90:169–74. doi: 10.1016/j.procs.2016.07.019. [DOI] [Google Scholar]
- 15.Eriksson L, Czene K, Rosenberg L, Humphreys K, Hall P. The influence of mammographic density on breast tumor characteristics. Breast Cancer Res Treat. 2012;134(2):859–66. doi: 10.1007/s10549-012-2127-0. [DOI] [PubMed] [Google Scholar]
- 16.Gabrielson M, Eriksson M, Hammarström M, Borgquist S, Leifland K, Czene K, et al. Cohort profile: The Karolinska Mammography Project for Risk Prediction of Breast Cancer (KARMA). Int J Epidemiol. 2017. doi:10.1093/ije/dyw357. [DOI] [PMC free article] [PubMed]
- 17.Bertrand KA, Tamimi RM, Scott CG, Jensen MR, Pankratz VS, Visscher D, et al. Mammographic density and risk of breast cancer by age and tumor characteristics. Breast Cancer Res. 2013;15(6):R104. doi: 10.1186/bcr3570. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Aitken Z, McCormack VA, Highnam RP, Martin L, Gunasekara A, Melnichouk O, et al. Screen-film mammographic density and breast cancer risk: a comparison of the volumetric standard mammogram form and the interactive threshold measurement methods. Cancer Epidemiol Biomarkers Prev. 2010;19(2):418–28. doi: 10.1158/1055-9965.EPI-09-1059. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Byng JW, Boyd N, Fishell E, Jong R, Yaffe MJ. The quantitative analysis of mammographic densities. Phys Med Biol. 1994;39(10):1629. doi: 10.1088/0031-9155/39/10/008. [DOI] [PubMed] [Google Scholar]
- 20.Cheddad A, Czene K, Eriksson Ml, Li J, Easton D, Hall P, et al. Area and volumetric density estimation in processed full-field digital mammograms for risk assessment of breast cancer. PloS ONE. 2014;9(10):e110690. doi: 10.1371/journal.pone.0110690. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Bora VB, Kothari AG, Keskar AG. Robust automatic pectoral muscle segmentation from mammograms using texture gradient and Euclidean distance regression. J Digit Imaging. 2016;29(1):115–25. doi: 10.1007/s10278-015-9813-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.He W, Juette A, Denton ERE, Oliver A, Martí R, Zwiggelaar R. A review on automatic mammographic density and parenchymal segmentation. Int J Breast cancer. 2015;2015. doi:http://dx.doi.org/10.1155/2015/276217. [DOI] [PMC free article] [PubMed]
- 23.Wolfe JN. Breast patterns as an index of risk for developing breast cancer. Am J Roentgenol. 1976;126(6):1130–7. doi: 10.2214/ajr.126.6.1130. [DOI] [PubMed] [Google Scholar]
- 24.Gong YC, Brady M, Petroudi S. Digital mammography: 8th International Workshop. Berlin Heidelberg: Springer; 2006. Texture based mammogram classification and segmentation. [Google Scholar]
- 25.Shang HL. A survey of functional principal component analysis. AStA Adv Stat Anal. 2014;98(2):121–42. doi: 10.1007/s10182-013-0213-1. [DOI] [Google Scholar]
- 26.Yao F, Müller HG, Wang JL. Functional data analysis for sparse longitudinal data. J Am Stat Assoc. 2005;100(470):577–90. doi: 10.1198/016214504000001745. [DOI] [Google Scholar]
- 27.Harrell FE, Lee KL, Mark DB. Tutorial in biostatistics multivariable prognostic models: issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Stat Med. 1996;15:361–87. doi: 10.1002/(SICI)1097-0258(19960229)15:4<361::AID-SIM168>3.0.CO;2-4. [DOI] [PubMed] [Google Scholar]
- 28.DeLong ER, DeLong DM. Clarke-Pearson DL. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics. 1988;44:837–45. doi: 10.2307/2531595. [DOI] [PubMed] [Google Scholar]
- 29.Jones MC, Rice JA. Displaying the important features of large collections of similar curves. Am Stat. 1992;46(2):140–5. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Subject to participants’ consent and legal requirements, data can be made available upon request to the primary department of the corresponding author.