

Abstract
Hyperspectral imaging (HSI) technology has increasingly been applied as an analytical tool in fields of agricultural, food, and Traditional Chinese Medicine over the past few years. The HSI spectrum of a sample is typically achieved by a spectroradiometer at hundreds of wavelengths. In recent years, considerable effort has been made towards identifying wavelengths (variables) that contribute useful information. Wavelengths selection is a critical step in data analysis for Raman, NIRS, or HSI spectroscopy. In this study, the performances of 10 different wavelength selection methods for the discrimination of Ophiopogon japonicus of different origin were compared. The wavelength selection algorithms tested include successive projections algorithm (SPA), loading weights (LW), regression coefficients (RC), uninformative variable elimination (UVE), UVE-SPA, competitive adaptive reweighted sampling (CARS), interval partial least squares regression (iPLS), backward iPLS (BiPLS), forward iPLS (FiPLS), and genetic algorithms (GA-PLS). One linear technique (partial least squares-discriminant analysis) was established for the evaluation of identification. And a nonlinear calibration model, support vector machine (SVM), was also provided for comparison. The results indicate that wavelengths selection methods are tools to identify more concise and effective spectral data and play important roles in the multivariate analysis, which can be used for subsequent modeling analysis.
1. Introduction
Ophiopogon japonicus (the tuber of Ophiopogon japonicus Ker-Gawl., Liliaceae) was originally documented in “Shennong materia medica,” in which it was classified as high grade [1]. The herb is sweet, slightly bitter, and slightly cold, enters the heart, lung, and stomach channels, moisturizes lung by nourishing yin, purges heat, promotes the production of body fluids, and so forth. It is one of the most commonly used Chinese medicines, which is widely applied to clinic. Ophiopogon japonicus is mainly planted in Zhejiang and Sichuan province in China, recognized as “Zhemaidong” and “Chuanmaidong” in China, respectively [2]. And there exist great differences in growing and harvesting between them as follows: “Zhemaidong” is three-year cultivated, while “Chuanmaidong” is one-year cultivated. On soil conditions, “Zhemaidong” is planted coastally, while “Chuanmaidong” is planted inland. Therefore, although “Zhemaidong” and “Chuanmaidong” are similar in appearance, they not only differ in quality, but also have a large difference in price. The traditional identification methods of Ophiopogon japonicus of different growing areas include thin layer chromatography, high performance liquid chromatography, gas chromatography, and liquid chromatography-mass spectrometry. These analytical methods are generally complex and time-consuming and require consumption of chemical reagents and higher professional requirements for operators; therefore, it is necessary to develop a rapid and nondestructive identification method of “Zhemaidong” and “Chuanmaidong.”
Hyperspectral imaging (HSI) technology has emerged as an alternative technique that can meet both spatial and spectral requirements and thus has been widely applied in quality evaluation and classification of Traditional Chinese Medicine. Zhang et al. fabricated a visible-near-infrared (Vis-NIR) HSI portable field spectrometer to distinguish sun-dried and sulfur-fumigated Chinese medicine herbs and achieved the results with a sensitivity of 96.4% and a specificity of 98.3% for RPA identification [3]. Tankeu et al. classified Stephania tetrandra and the nephrotoxic Aristolochia fangchi based on hyperspectral imaging. A discrimination model with a coefficient of determination (R2) of 0.9 and a root mean square error of prediction (RMSEP) of 0.23 was created [4]. The potential of short wave infrared (SWIR) hyperspectral imaging and image analysis as a rapid quality control method to distinguish between Illicium anisatum (Japanese star anise) and Illicium verum whole dried fruit was investigated. A classification model with 4 principal components and an R2X_cum of 0.84 and R2Y_cum of 0.81 was developed for the 2 species using partial least squares-discriminant analysis (PLS-DA). The model was subsequently used to accurately predict the identity of I. anisatum (98.42%) and I. verum (97.85%) introduced into the model as an external dataset [5]. Sandasi et al. applied HIS, MIR, and NIR spectroscopy to certify ginseng reference materials and commercial products. And good discrimination models with high R2X and Q2 cum values were developed [6]. These results suggest that hyperspectral imaging is a potential technique to control medicine quality for medical applications.
A HSI spectrum of a sample is typically measured by a spectroradiometer for hundreds of wavelengths. The large number of spectral variables in most spectral datasets often renders the prediction of a dependent variable unreliable. However, the use of appropriate projection or selection techniques, such as principle component analysis or partial least squares regression, may minimize this problem [7]. Recently, considerable efforts have been made on developing and evaluating different programs that identify variables that contribute useful information or eliminate variables that contain redundancy data. The basic principle of the selection method is to select a small number of representative variables from the original set of variables. And the purpose of variable selection is to select a subset of spectral variables that produce the smallest possible errors when used to establish determination or classification models. Variable selection is an important step in multivariate analysis because the removal of redundant variables will produce better prediction results [8].
Two to five wavelengths selection methods were usually compared [9–11], however, which could not fully reflect the effectiveness and importance of wavelength selection methods in multivariate analysis. In the present work, 10 wavelength selection methods were compared in classification of “Zhemaidong” and “Chuanmaidong” to discuss the application of wavelength selection methods in multivariate analysis.
2. Materials and Methods
2.1. Materials
A total of 675 Ophiopogon japonicus samples were collected, of which 315 samples were purchased from different growers of Cixi, Zhejiang province, and 360 samples were derived from different growers of Mianyang, Sichuan province.
2.2. Hyperspectral Imaging System
A hyperspectral imaging system was used in the experiment, which consists of an imaging spectrograph (Imspector V10E, Spectral Imaging Ltd., Oulu, Finland), a CCD camera (C8484-05, Hamamatsu city, Japan), a lens (OLE-23, Specim, Spectral Imaging Ltd., Oulu, Finland), an illuminant source with two quartz tungsten halogen lamps (Fiber-Lite DC950, Dolan Jenner Industries Inc., Boxborough, USA), a conveyer belt controlled by a stepper motor (IRCP0076 Isuzu Optics Corp, Taiwan, China), and a computer. The whole system was assembled in a dark chamber except the computer, as shown in Figure 1.
Figure 1.

The hyperspectral imaging system.
2.3. Acquisition and Calibration of Hyperspectral Images
After repeated tests, the height between the lens and the sample was set as 15 cm, the exposure time of camera was set as 1.35 ms, and the speed of the conveyer was set as 18.7 mm·s−1. The hyperspectral image was acquired by a software (Spectral Image-V10E, Isuzu Optics Corp, Taiwan, China).
The acquired raw hyperspectral images should be calibrated with the white and dark reference according the following equation:
| (1) |
where R was the corrected image, Iraw was the raw hyperspectral image, Iwhite was the white reference with nearly 100% reflectance acquired by the special white Teflon tile, and Iblack was the dark reference image with nearly 0% reflectance obtained by turning off the light source together with covering the camera lens.
2.4. Wavelengths Selection Methods
2.4.1. Successive Projections Algorithm, SPA
Successive projections algorithm (SPA) is an efficient method of spectral feature selection, which could minimize the collinearity between variables [12].
2.4.2. Regression Coefficient Method, RC
Regression coefficient is calculated based on PLS, and sensitive wavelengths are usually selected according to the regression coefficient of the optimal PLS model. Generally, the peaks or bands where the absolute value of RC is greater than threshold are selected as sensitive wavelength or waveband [9].
2.4.3. Loading Weights Method, LW
The loading weights show the importance of corresponding wavelength or bands in the spectral matrix. The peaks or valleys with the maximum absolute loading weights from the first principal factor to the optimal principal factor are selected as sensitive wavelengths [13, 14].
2.4.4. Uninformative Variable Elimination, UVE
Uninformative variable elimination (UVE) is widely applied for variable selection based on analysis of the regression coefficients of the PLS model. It can eliminate noninformative variables and the remaining is useful for the chemical and classification analysis [15, 16].
2.4.5. Competitive Adaptive Reweighted Sampling, CARS
Competitive adaptive reweighted sampling (CARS) is a feature variable selection method combining Monte Carlo sampling with PLS regression coefficient. Adaptive reweighted sampling is employed in CARS, and the variables with larger weight of regression coefficient are applied as a new subset to establish PLS model, and after repeated calculation, the subset with the lowest root mean square error of cross validation (RMSECV) is chosen [17, 18].
2.4.6. Interval PLS, iPLS
In the iPLS method, the data are divided into nonoverlapping sections; each section develops a separate PLS model to identify the most useful variable range [19, 20].
2.4.7. Backward Interval PLS, BiPLS
For the backward iPLS (BiPLS) algorithm, the dataset is split into a given number of intervals; the PLS models are then calculated with each interval left out in a sequence; that is, if n intervals are chosen, then each model is based on n − 1 intervals that exclude one interval at a time. The first omitted interval gives the poorest performing model with respect to RMSECV [21, 22].
2.4.8. Forward Interval PLS, FiPLS
As in the interval PLS model, the dataset is split into a given number of intervals, but the PLS models are then developed based on successively improving intervals with respect to RMSECV; that is, if n intervals are used, then the first model is based on one interval that has the best performance, the second model uses the next interval, and so on [23, 24].
2.4.9. Genetic Algorithm-PLS, GA-PLS
The method combines the advantage of GA and PLS and is the most commonly used method for spectral data analysis. GA applied to PLS have been shown to be very efficient optimization procedures. They have been applied on many spectral datasets and have been proved to provide better results than full-spectrum methods [25, 26].
2.4.10. UVE-SPA Method
In this method, UVE eliminates uninformative variables, and then SPA is employed for variable selection. Fewer variables are selected by a UVE-SPA algorithm compared to UVE.
2.4.11. Model Evaluation and Software
The efficiency of the wavelengths selection method is based on the identification rate and the number of variables. The efficiency equation is as follows:
| (2) |
where E was the efficiency of wavelengths selection method, Ds was the identification rate of prediction set in the model established by variables selected by the wavelengths selection method, and Df was the identification rate of prediction set in the full-spectrum model. Nf was the number of variables of full-spectrum and Ns was the number of variables selected by wavelength selection method.
When E > 0.5, the wavelength extraction method is proved to be highly efficient.
When −0.5 ≤ E ≤ 0.5, the method is proved to be efficient, except when E = 0, (Nf − Ns)/Nf ≥ 0.8; the method is proved to be highly efficient.
When E < −0.5, the method is proved to be of low efficiency.
The spectral data extraction, SPA, UVE, UVE-SPA, iPLS, BiPLS, FiPLS, CARS, GA-PLS, and SVM were conducted on Matlab R 2010b (The Math Works, Natick, MA, USA). LW, RC, and PLS-DA were performed on Unscrambler® 10.1 (CAMO AS, Oslo, Norway).
3. Results and Discussion
3.1. Raw Spectra Reflectance Curves of Ophiopogon japonicus
The spectra of “Zhemaidong” and “Chuanmaidong” were acquired in the range of 380–1030 nm. The raw average spectra of “Zhemaidong” and “Chuanmaidong” were shown in Figure 2. No significant differences were observed in the range of 380~401 nm and 961~1030 nm, while different magnitudes of the spectra reflectance could be found in the range of 402~960 nm. Wavelength selection methods were further employed to identify feature information for better classification of “Zhemaidong” and “Chuanmaidong.”
Figure 2.
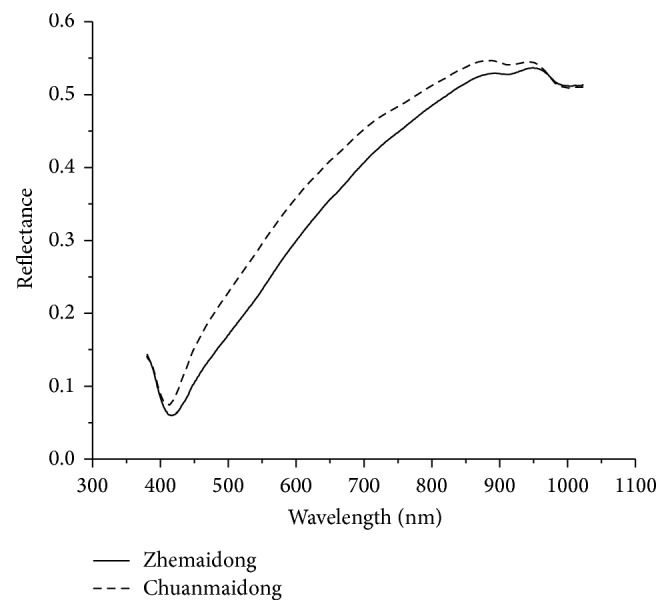
Average raw spectra reflectance curves of Ophiopogon japonicus.
675 Ophiopogon japonicus samples were split into two sets, calibration set and prediction set. “Zhemaidong” samples were labeled as “1,” while “Chuanmaidong” samples were labeled as “2.” Ophiopogon japonicus samples were divided in Table 1.
Table 1.
Class assignment and division of Ophiopogon japonicus samples.
| Zhemaidong | Chuanmaidong | |
|---|---|---|
| Label | 1 | 2 |
| Calibration set | 210 | 240 |
| Prediction set | 105 | 120 |
| Sum up | 315 | 360 |
3.2. Sensitive Wavelengths Selection
Firstly, each wavelengths selection method should be optimized to evaluate the performance of each method better.
3.2.1. SPA
The number of sensitive wavelengths was set as 5~30, and 5 wavelengths (889, 1014, 411, 460, and 407 nm) were selected.
3.2.2. RC
Regression coefficients of PLS model based on full-spectrum were shown in Figure 3. The threshold was set as ±4.5; finally, 7 wavelengths were selected by RC method.
Figure 3.
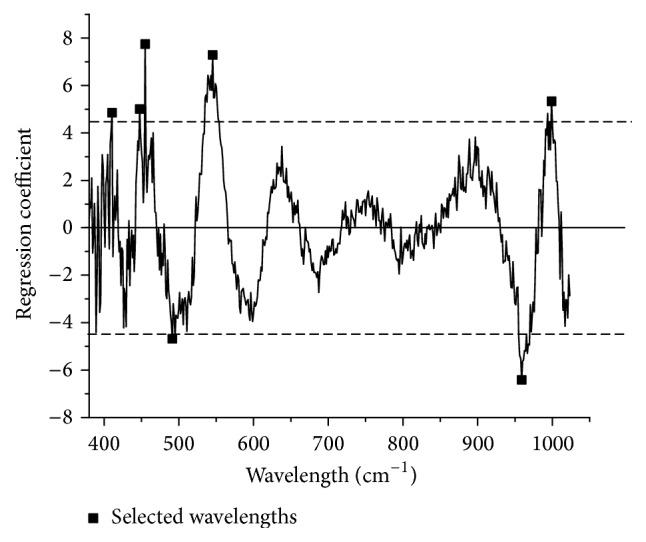
Seven wavelengths were selected by RC method.
3.2.3. UVE
UVE method was applied for full-spectrum data with no pretreatment; the number of principal components was set as 20. The selection criteria of threshold were 99% of the maximum value of variable stability. 291 wavelengths were selected by UVE (as shown in Figure 4), in which columns represent selected wavelengths.
Figure 4.
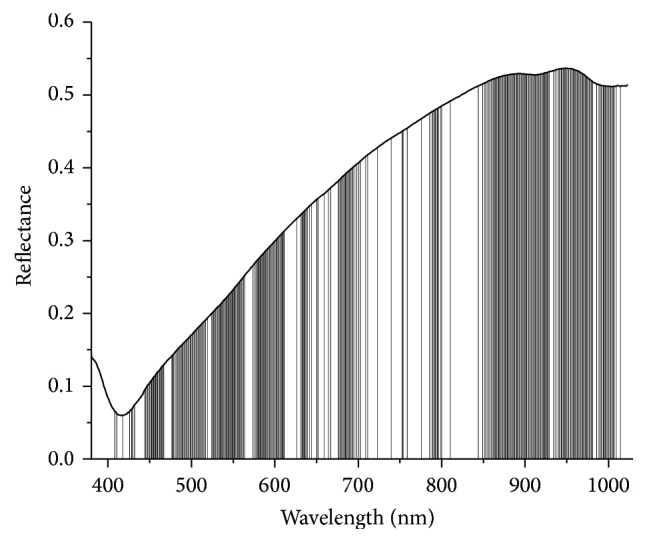
Plot of 291 selected wavelengths by UVE. Columns represent selected wavelengths.
3.2.4. UVE-SPA
291 variables were selected by UVE method; SPA was applied to minimize the number of variables selected by UVE. 12 wavelengths were extracted finally which were shown in Figure 5.
Figure 5.
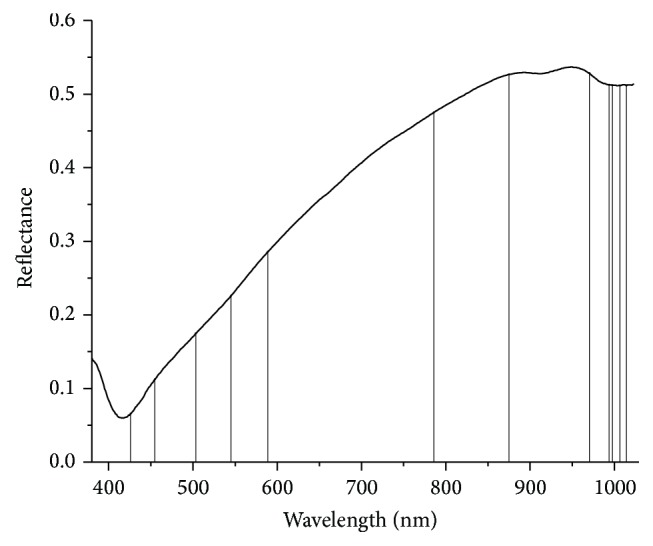
Plot of 12 selected wavelengths by UVE-SPA. Columns represent selected wavelengths.
3.2.5. iPLS
The raw dataset was split to 16–32 intervals, and the optimal interval was selected according to the lowest root-mean-squares error of cross validation (RMSECV). As shown in Figure 6, 16 intervals were the optimum mode. RMSECV of PLS models based on 16 intervals, respectively, were shown in Figure 7; the 15th interval was selected as the sensitive wavelengths range.
Figure 6.
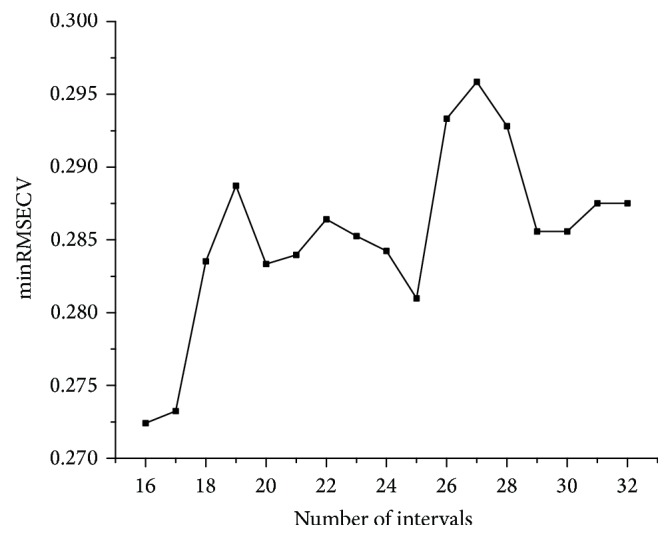
Minimum RMSECV of different number of intervals.
Figure 7.
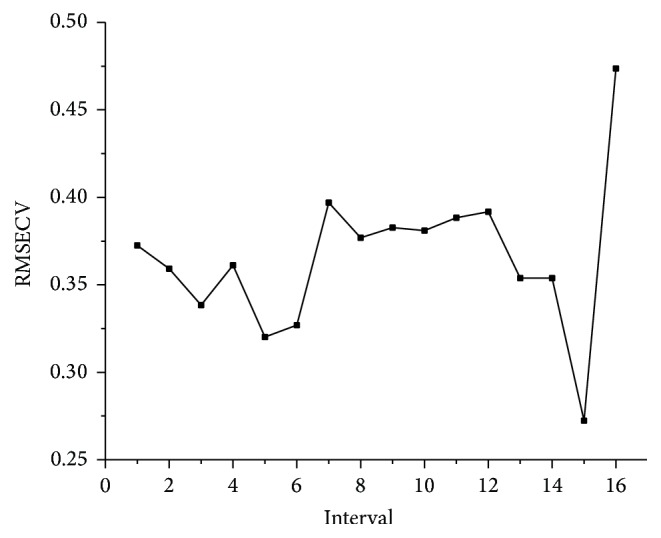
RMSECV of 16 intervals.
3.2.6. BiPLS
The optimal result was achieved when raw dataset was divided into 32 intervals. Finally, seen in Figure 8, 13 intervals were selected as follows, numbers 3, 5, 7, 9~11, 13, 14, 24, 25, and 30~32.
Figure 8.
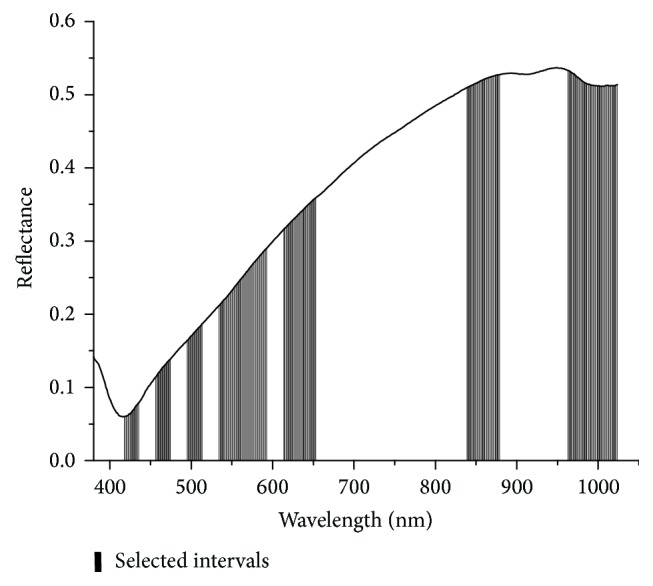
13 intervals selected by BiPLS. Columns represent selected intervals.
3.2.7. GA-PLS
In the GA-PLS method, population size was set as 30, probability of mutation was set as 0.01, probability of cross-over was set as 0.5, and the number of runs was chosen to be 100. 85 wavelengths were selected eventually.
After optimization procedure, wavelengths selected by different methods were shown in Table 2. The number of wavelengths selected by SPA, RC, LW, and UVE-SPA method was under 12, while that by iPLS and GA-PLS method was 32 and 85, respectively, and that by UVE, CARS, and BiPLS method was no more than half of the full-spectrum, whereas FiPLS eliminated only 32 redundant variables.
Table 2.
Effective wavelengths selected by different methods.
| Methods | Number | Wavelengths/nm |
|---|---|---|
| SPA | 5 | 889, 1014, 411, 460, 407 |
| RC | 7 | 409, 448, 455, 491, 545, 959, 999 |
| LW | 8 | 550, 990, 433, 1014, 539, 385, 380, 382 |
| UVE | 291 | 408, 410, 417, 425, 428, 430, 432, 444~467, 477~479, 481~517, 519, 524~564, 574, 576~611, 626, 631~639, 642, 644, 650, 652, 659, 664, 667, 676~695, 697, 700, 703, 709, 711, 723, 740, 752, 759, 776, 786, 788~796, 799, 800, 810, 844, 849, 852, 853, 856, 857, 859~929, 934, 937, 940~981, 986, 990~1007, 1009, 1014 |
| UVE-SPA | 12 | 426, 455, 503, 545, 589, 786, 875, 970, 994, 998, 1007, 1014 |
| CARS | 105 | 418, 426, 431, 437, 443, 457, 466, 475~481, 489, 491~495, 497~500, 507, 511, 516, 519, 533, 535, 539, 540, 543~545, 548~551, 555, 558, 565~569, 571, 573, 576, 582, 584, 594~610, 613~618, 624, 637, 640, 643, 648, 653, 661, 668, 675, 681, 685, 687, 689, 719, 735, 738, 750, 751, 795, 806, 813, 816, 831, 856, 862, 874~877, 881, 888~889, 905, 910, 918, 920, 924, 961~964, 968, 973, 976, 987, 992~996, 1023 |
| iPLS | 32 | 942~982 |
| BiPLS | 208 | 418~436, 456~474, 494~513, 534~592, 614~653, 839~879, 963~1023 |
| FiPLS | 480 | 418~1023 |
| GA-PLS | 85 | 431, 466~469, 472, 473, 479~481, 490~494, 506~509, 512~522, 534~550, 551, 580~584, 685~689, 799~801, 875~877, 888, 956~963, 965~978, 983, 985, 990~1000 |
3.3. Partial Least Squares-Discriminant Analysis (PLS-DA) Model
PLS-DA models were established based on variables selected by different methods and the raw full-spectrum, respectively, and prediction results of different models were compared (shown in Table 3). In UVE-PLS-DA, UVE-SPA-PLS-DA, CARS-PLS-DA, BiPLS-PLS-DA, FiPLS-PLS-DA, and GA-PLS-PLS-DA models, the identification accuracy improved and the number of variables reduced. Seen from Table 3, the identification accuracy of all models was over 88%. Compared with PLS-DA model based on the raw dataset, the identification accuracy of BiPLS-PLS-DA model increased from 95.1% to 99.1%, while the number of variables decreased from 512 to 208, which stated BiPLS was an effective wavelengths selection method. Although the identification accuracy of PLS-DA models based on SPA, RC, LW, and iPLS method was lower than that of full-spectrum, the number of variables greatly decreased. Compared with PLS-DA model based on full-spectrum, the number of variables of SPA-PLS-DA model decreased 99%, from 512 to 5, while the identification accuracy only decreased 1.8%. The number of variables of RC-PLS-DA model was reduced 98.6%, while the identification accuracy only decreased 1.3%. The number of variables of PLS models based on LW and iPLS models decreased 98.4%, while the identification accuracy decreased only 6.7%. According to the efficiency of each wavelengths selection method, SPA, RC, LW, and iPLS were methods of low efficiency, FiPLS was efficient method, and UVE, UVE-SPA, CARS, BiPLS, and GA-PLS were highly efficient methods.
Table 3.
Results of PLS-DA models using different selected wavelengths.
| Methods | Variables | Calibration | Prediction | |||
|---|---|---|---|---|---|---|
| Correct number | Identification accuracy/% | Correct number | Identification accuracy/% | E | ||
| Raw | 512 | 449 | 99.8 | 214 | 95.1 | |
| SPA | 5 | 417 | 92.7 | 210 | 93.3 | −1.78 |
| RC | 7 | 413 | 91.8 | 211 | 93.8 | −1.28 |
| LW | 8 | 402 | 89.3 | 199 | 88.4 | −6.60 |
| UVE | 291 | 449 | 99.8 | 219 | 97.3 | 0.95 |
| UVE-SPA | 12 | 449 | 99.8 | 216 | 96.0 | 0.88 |
| CARS | 105 | 449 | 99.8 | 221 | 98.2 | 2.46 |
| iPLS | 32 | 430 | 95.6 | 199 | 88.4 | −6.28 |
| BiPLS | 208 | 450 | 100 | 223 | 99.1 | 2.38 |
| FiPLS | 480 | 449 | 99.8 | 219 | 97.3 | 0.14 |
| GA-PLS | 85 | 446 | 99.1 | 217 | 96.4 | 1.08 |
3.4. Support Vector Machine (SVM) Models
Support vector machine is suitable for solving small sample, nonlinear, and high dimensional pattern problems. SVM models were developed based on variables selected by different methods and full-spectrum, and the results were compared. Seen from Table 4, the identification accuracy of all models was over 88%. The optimal performance was achieved by GA-PLS-SVM model; the identification accuracy of calibration set and prediction set were 99.6% and 99.1%, respectively. Compared with SVM model established with raw spectra, the performance of UVE-SVM, BiPLS-SVM, and FiPLS-SVM models was better, and the number of variables reduced with different degrees. Although the identification accuracy of UVE-SPA-SVM and CARS-SVM decreased 0.5%, the number of their variables reduced 97.7% and 79.5%, respectively. Similarly, the identification accuracy of SPA-SVM, RC-SVM, LW-SVM, and iPLS-SVM models was worse than that of raw spectra, with a decrease of no more than 8.5%, while the number of variables reduced 99.0%~93.8%. Therefore, wavelengths selection which greatly improves the operation rate and prediction effect is an extraordinary step of modeling analysis. According to the efficiency of each model, SPA, RC, LW, and iPLS were methods of low efficiency, UVE, UVE-SPA, CARS, and FiPLS were efficient method, and BiPLS and GA-PLS were highly efficient methods.
Table 4.
Results of SVM models using different wavelengths.
| Methods | Variables | Calibration | Prediction | |||
|---|---|---|---|---|---|---|
| Correct number | Identification accuracy/% | Correct number | Identification accuracy/% | E | ||
| Raw | 512 | 449 | 99.8 | 218 | 96.9 | |
| SPA | 5 | 431 | 95.8 | 208 | 92.4 | −4.46 |
| RC | 7 | 429 | 95.3 | 210 | 93.3 | −3.55 |
| LW | 8 | 415 | 92.2 | 205 | 91.1 | −5.71 |
| UVE | 291 | 448 | 99.6 | 219 | 97.3 | 0.17 |
| UVE-SPA | 12 | 448 | 99.6 | 217 | 96.4 | −0.49 |
| CARS | 105 | 444 | 98.7 | 217 | 96.4 | −0.40 |
| iPLS | 32 | 442 | 98.2 | 199 | 88.4 | −7.97 |
| BiPLS | 208 | 444 | 98.7 | 221 | 98.2 | 0.77 |
| FiPLS | 480 | 444 | 98.7 | 218 | 96.9 | 0 |
| GA-PLS | 85 | 448 | 99.6 | 223 | 99.1 | 1.83 |
3.5. Comparison of Different Models
According to the discriminant results of SVM and PLS-DA models, BiPLS and GA-PLS were highly efficient methods. SPA, RC, LW, and iPLS were methods of low efficiency, probably because these methods greatly reduce variables but also remove some useful information. The efficiency of UVE, UVE-SPA, and CARS was different in the two models. Above all, in identification of “Zhemaidong” and “Chuanmaidong,” BiPLS and GA-PLS were efficient wavelengths selection methods.
Seen from Tables 3 and 4, the identification accuracy of all models was above 88%. The average identification accuracy of prediction set of PLS-DA models and SVM models based on different selected variables was 94.8% and 95.1%, respectively, which stated the similar performance of PLS-DA models and SVM models in identification of Ophiopogon japonicus. The optimal performance of PLS-DA and SVM models was achieved based on BiPLS and GA-PLS methods, respectively, with the identification accuracy over 99%. The results indicated that using variable selection methods to select sensitive wavelengths was efficient for reduction of spectral data as well as the establishment of classification model, and it was feasible to identify “Zhemaidong” and “Chuanmaidong” by applying near-infrared hyperspectral imaging technology.
4. Conclusions
In this study, in view of hyperspectral data of Ophiopogon japonicus, 10 wavelengths selection methods were chosen to explore the general characteristics of different feature selection methods. UVE, UVE-SPA, CARS, BiPLS, and GA-PLS were highly efficient methods when the selected variables were used to develop PLS-DA models, and CARS achieved the best performance where the number of variables reduced 79.5% and the identification accuracy increased from 95.1% to 98.2%. Of all the SVM models based on different selected variables, BiPLS and GA-PLS were highly efficient methods, and GA-PLS performed the best where the number of variables decreased 83.4% and the identification accuracy increased from 96.9% to 99.1%, which was consistent with the literatures [26, 27]. SPA, RC, LW, and iPLS were methods of low efficiency; the number of variables decreased greatly while the identification accuracy reduced slightly, while Zhang et al. proved that, in the determination of soluble protein content in oilseed rape leaves based on near-infrared hyperspectral imaging, of all the sensitive wavelengths selection method, SPA performed better than GA-PLS and RC [28]. Therefore, the performance of each method could be different according to different spectral data.
The study indicated that the wavelengths selection method could extract a small number of variables containing effective information and eliminating noninformation variables. Variables selection methods were tools to identify more concise and effective spectral data and played important roles in the multivariate analysis, which could be used for subsequent modeling analysis. Meanwhile, the characteristic wavelengths selected could provide a theoretical basis for the development of instruments.
Acknowledgments
This study was supported by the National Natural Science Foundation of China (Grant nos. 61405175 and MOI201702), the National Key Research and Development Program of China (Grant no. 2016YFD0700304), and the National Key Scientific Instrument and Equipment Development Project (Grant no. 2014YQ47037702).
Conflicts of Interest
The authors declare that there are no conflicts of interest.
References
- 1.National pharmacopoeia committee. Pharmacopoeia of People's Republic of China. 2015:p. 155. National pharmacopoeia committee, Pharmacopoeia of People's Republic of China. [Google Scholar]
- 2.Zhang J., Wang Y. Determination of Total Flavonoids and Total Saponins in Ophiopogon japonicu(Thunb.)Ker.Gawl by NIR Spectroscopy. Chinese Journal of Spectroscopy Laboratory. 2012;29(01):551–555. [Google Scholar]
- 3.Zhang H., Wu T., Zhang L., Zhang P. Development of a Portable Field Imaging Spectrometer: Application for the Identification of Sun-Dried and Sulfur-Fumigated Chinese Herbals. Applied Spectroscopy. 2016;70(5):879–887. doi: 10.1177/0003702816638293. [DOI] [PubMed] [Google Scholar]
- 4.Tankeu S., Vermaak I., Chen W., Sandasi M., Viljoen A. Differentiation between two "fang ji" herbal medicines, Stephania tetrandra and the nephrotoxic Aristolochia fangchi, using hyperspectral imaging. Phytochemistry. 2016;122:213–222. doi: 10.1016/j.phytochem.2015.11.008. [DOI] [PubMed] [Google Scholar]
- 5.Vermaak I., Viljoen A., Lindström S. W. Hyperspectral imaging in the quality control of herbal medicines - The case of neurotoxic Japanese star anise. Journal of Pharmaceutical and Biomedical Analysis. 2013;75:207–213. doi: 10.1016/j.jpba.2012.11.039. [DOI] [PubMed] [Google Scholar]
- 6.Sandasi M., Vermaak I., Chen W., Viljoen A. The application of vibrational spectroscopy techniques in the qualitative assessment of material traded as ginseng. Molecules. 2016;21(4, article no. 472) doi: 10.3390/molecules21040472. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Xiaobo Z., Jiewen Z., Povey M. J. W., Holmes M., Hanpin M. Variables selection methods in near-infrared spectroscopy. Analytica Chimica Acta. 2010;667(1-2):14–32. doi: 10.1016/j.aca.2010.03.048. [DOI] [PubMed] [Google Scholar]
- 8.Balabin R. M., Smirnov S. V. Variable selection in near-infrared spectroscopy: Benchmarking of feature selection methods on biodiesel data. Analytica Chimica Acta. 2011;692(1-2):63–72. doi: 10.1016/j.aca.2011.03.006. [DOI] [PubMed] [Google Scholar]
- 9.Chen H. Z., Xia Z. Y. Determination of total flavonoids in propolis based on NIR spectroscopy technology. Chinese Journal of Pharmaceutical Analysis. 2014;34(10):1868–1873. [Google Scholar]
- 10.Nie P., Wu D., Sun D.-W., Cao F., Bao Y., He Y. Potential of visible and near infrared spectroscopy and pattern recognition for rapid quantification of notoginseng powder with adulterants. Sensors (Basel, Switzerland) 2013;13(10):13820–13834. doi: 10.3390/s131013820. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Nie P., Xia Z., Sun D.-W., He Y. Application of visible and near infrared spectroscopy for rapid analysis of chrysin and galangin in Chinese propolis. Sensors (Basel, Switzerland) 2013;13(8):10539–10549. doi: 10.3390/s130810539. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Zhang C., Liu F., Kong W., Zhang H., He Y. Fast identification of watermelon seed variety using near infrared hyperspectral imaging technology. Nongye Gongcheng Xuebao/Transactions of the Chinese Society of Agricultural Engineering. 2013;29(20):270–277. doi: 10.3969/j.issn.1002-6819.2013.20.035. [DOI] [Google Scholar]
- 13.Wang Y., Gao Y., Yu X., Wang Y., Deng S., Gao J.-M. Rapid Determination of Lycium Barbarum Polysaccharide with Effective Wavelength Selection Using Near-Infrared Diffuse Reflectance Spectroscopy. Food Analytical Methods. 2015 doi: 10.1007/s12161-015-0178-7. [DOI] [Google Scholar]
- 14.Shao Y., Xie C., Jiang L., Shi J., Zhu J., He Y. Discrimination of tomatoes bred by spaceflight mutagenesis using visible/near infrared spectroscopy and chemometrics. Spectrochimica Acta - Part A: Molecular and Biomolecular Spectroscopy. 2015;140:431–436. doi: 10.1016/j.saa.2015.01.018. [DOI] [PubMed] [Google Scholar]
- 15.Pan L., Lu R., Zhu Q., Tu K., Cen H. Predict Compositions and Mechanical Properties of Sugar Beet Using Hyperspectral Scattering. Food and Bioprocess Technology. 2016;9(7):1177–1186. doi: 10.1007/s11947-016-1710-5. [DOI] [Google Scholar]
- 16.Dong J., Guo W., Wang Z., Liu D., Zhao F. Nondestructive Determination of Soluble Solids Content of ‘Fuji’ Apples Produced in Different Areas and Bagged with Different Materials During Ripening. Food Analytical Methods. 2016;9(5):1087–1095. doi: 10.1007/s12161-015-0278-4. [DOI] [Google Scholar]
- 17.Fan S., Zhang B., Li J., Huang W., Wang C. Effect of spectrum measurement position variation on the robustness of NIR spectroscopy models for soluble solids content of apple. Biosystems Engineering. 2016;143:9–19. doi: 10.1016/j.biosystemseng.2015.12.012. [DOI] [Google Scholar]
- 18.Deng B.-C., Yun Y.-H., Cao D.-S., et al. A bootstrapping soft shrinkage approach for variable selection in chemical modeling. Analytica Chimica Acta. 2016;908:63–74. doi: 10.1016/j.aca.2016.01.001. [DOI] [PubMed] [Google Scholar]
- 19.Zhao Y., Wang S., Li Z., Cao F., Pei Z. A Novel Interval Integer Genetic Algorithm Used for Simultaneously Selecting Wavelengths and Pre-processing Methods. Chinese Journal of Analytical Chemistry. 2016;44(9):e1609–e1616. doi: 10.1016/S1872-2040(16)60928-3. [DOI] [Google Scholar]
- 20.Chen X. H., Huang J. Wavelength selection algorithm based on iPLS and CARS multi-model fusion technology. Computer Engineering and Application. 2016;52(16):229–232. [Google Scholar]
- 21.Zou X., Zhao J., Li Y. Selection of the efficient wavelength regions in FT-NIR spectroscopy for determination of SSC of 'Fuji' apple based on BiPLS and FiPLS models. Vibrational Spectroscopy. 2007;44(2):220–227. doi: 10.1016/j.vibspec.2006.11.005. [DOI] [Google Scholar]
- 22.Mahanty B., Yoon S.-U., Kim C.-G. Spectroscopic quantitation of tetrazolium formazan in nano-toxicity assay with interval-based partial least squares regression and genetic algorithm. Chemometrics and Intelligent Laboratory Systems. 2016;154:16–22. doi: 10.1016/j.chemolab.2016.03.012. [DOI] [Google Scholar]
- 23.Yang Q., Zhu G. H., Ren P., Long S., Yang J. D. Wavelength Selection for NIR Spectroscopic Analysis of Chemical Oxygen Demand Based on Different Partial Least Squares Models. Journal of Analytical Science. 2016;32(4):485–489. [Google Scholar]
- 24.Qu F., Ren D., Hou J., et al. The Characteristic Spectral Selection Method Based on Forward and Backward Interval Partial Least Squares, Spectroscopy and Spectral Analysis, [PubMed]
- 25.Ding X.-B., Zhang C., Liu F., Song X.-L., Kong W.-W., He Y. Determination of soluble solid content in strawberry using hyperspectral imaging combined with feature extraction methods. Guang Pu Xue Yu Guang Pu Fen Xi/Spectroscopy and Spectral Analysis. 2015;35(4):1020–1024. doi: 10.3964/j.issn.1000-0593(2015)04-1020-05. [DOI] [PubMed] [Google Scholar]
- 26.Zhang C., Xu N., Luo L., et al. Detection of Aspartic Acid in Fermented Cordyceps Powder Using Near Infrared Spectroscopy Based on Variable Selection Algorithms and Multivariate Calibration Methods. Food and Bioprocess Technology. 2014;7(2):598–604. doi: 10.1007/s11947-013-1149-x. [DOI] [Google Scholar]
- 27.Jiao L., Bing S., Zhang X., Wang Y., Li H. Determination of enantiomeric composition of tryptophan by using fluorescence spectroscopy combined with backward interval partial least squares. Analytical Methods. 2015;7(11):4535–4540. doi: 10.1039/c5ay00190k. [DOI] [Google Scholar]
- 28.Zhang C., Liu F., Kong W., He Y. Application of visible and near-infrared hyperspectral imaging to determine soluble protein content in oilseed rape leaves. Sensors (Switzerland) 2015;15(7):16576–16588. doi: 10.3390/s150716576. [DOI] [PMC free article] [PubMed] [Google Scholar]