

Abstract
Background
Uptake of medicinal drugs (preventive or treatment) is among the approaches used to control disease outbreaks, and therefore, it is of vital importance to be aware of the counts or frequencies of most commonly used drugs and trending topics about these drugs from consumers for successful implementation of control measures. Traditional survey methods would have accomplished this study, but they are too costly in terms of resources needed, and they are subject to social desirability bias for topics discovery. Hence, there is a need to use alternative efficient means such as Twitter data and machine learning (ML) techniques.
Objective
Using Twitter data, the aim of the study was to (1) provide a methodological extension for efficiently extracting widely consumed drugs during seasonal influenza and (2) extract topics from the tweets of these drugs and to infer how the insights provided by these topics can enhance seasonal influenza surveillance.
Methods
From tweets collected during the 2012-13 flu season, we first identified tweets with mentions of drugs and then constructed an ML classifier using dependency words as features. The classifier was used to extract tweets that evidenced consumption of drugs, out of which we identified the mostly consumed drugs. Finally, we extracted trending topics from each of these widely used drugs’ tweets using latent Dirichlet allocation (LDA).
Results
Our proposed classifier obtained an F1 score of 0.82, which significantly outperformed the two benchmark classifiers (ie, P<.001 with the lexicon-based and P=.048 with the 1-gram term frequency [TF]). The classifier extracted 40,428 tweets that evidenced consumption of drugs out of 50,828 tweets with mentions of drugs. The most widely consumed drugs were influenza virus vaccines that had around 76.95% (31,111/40,428) share of the total; other notable drugs were Theraflu, DayQuil, NyQuil, vitamins, acetaminophen, and oseltamivir. The topics of each of these drugs exhibited common themes or experiences from people who have consumed these drugs. Among these were the enabling and deterrent factors to influenza drugs uptake, which are keys to mitigating the severity of seasonal influenza outbreaks.
Conclusions
The study results showed the feasibility of using tweets of widely consumed drugs to enhance seasonal influenza surveillance in lieu of the traditional or conventional surveillance approaches. Public health officials and other stakeholders can benefit from the findings of this study, especially in enhancing strategies for mitigating the severity of seasonal influenza outbreaks. The proposed methods can be extended to the outbreaks of other diseases.
Keywords: machine learning, Twitter messaging, social media, disease outbreaks, influenza, public health surveillance, natural language processing, influenza vaccines
Introduction
Background
Public health surveillance involves the systematic collection, management, analysis, and interpretation of health-related data, followed by the dissemination of these data to public health programs to enhance public health actions [1,2]. This process comes in handy during periods of severe health concerns such as disease outbreaks that need preventive and control interventions.
Among these disease outbreaks is influenza-like illness (ILI) or flu, which is a respiratory illness caused by viruses that can cause severe illness and even death for some people [3]. Common influenza types include seasonal, avian, swine, variant, and pandemic. Due to its recurring nature, we focused on seasonal influenza in this study.
To control disease outbreaks of seasonal influenza, one widely adopted measure is the proper use of medicinal drugs (ie, drugs which treat, prevent, or alleviate symptoms of diseases) [4]. When outbreaks occur, it is vitally important to know and analyze feedback data related to drugs that are widely consumed by people so that control measures to fight these outbreaks can be enhanced and implemented in the future.
Our work is built on the knowledge that seasonal influenza outbreaks affect a large number of people and are spread over large geographical areas. These facts pose challenges in gathering and analyzing useful feedback data related to the consumption of medicinal drugs by using traditional or conventional surveillance methods, which are limited by a small sample size, cost, and timeliness in reporting [5-7].
Therefore, this research study intended to extract relevant topics from tweets mentioning widely consumed drugs during seasonal influenza outbreaks and to use those topics to enhance seasonal influenza surveillance.
With the fast development of Web 2.0 technology, we considered using social media because of its ability to collect vast amounts of health-related data. Twitter, which was established in 2006, is among the most famous social media platforms and is currently the leading microblogging service for people to send and receive messages (tweets) of up to 140 characters. Twitter has a volume of 313 million monthly active users, 1 billion unique monthly visits, and 500 million tweets per day [8]. The communication forms in Twitter can be chats, conversations, news reporting, and information sharing [9]. People discuss their health conditions and statuses on Twitter [10], which makes it a new potential data source for health-related studies examining the prevalence of health issues, drug consumption, and health topics or categories [11-19].
To follow the use of influenza drugs in this study, we could have followed sales of over-the-counter and prescription drugs [5,20], or we could have used search engine queries and Web data [6,7,21,22]. However, prescription drug sales would not allow us to obtain topics or feedback from consumers, and access to these data is limited, even for researchers. As Web data and search engines also have limited access to researchers, we chose to use Twitter data.
However, selecting tweets that could be associated with actual uptake of drugs to determine which drugs are widely used and to derive insight from corresponding tweet topics is still a challenge.
Related Work
Medical Entity Estimates From Twitter
To obtain widely used drugs (or any other medical entity) from tweets, one needs to count the tweets with mentions of drugs (medical entities) and rank their frequencies. In previous studies, Twitter has been used to estimate the extent to which medical entities (drugs, diseases, symptoms) mentioned in tweets have been experienced or will be experienced by aggregating counts and then finding correlations with official surveillance data. For example, flu epidemics have been predicted in previous studies [11,23]. Correlations between flu or disease mentions in Twitter data and official flu case data have been found as well [12,18,19]. With regard to drugs, Twitter has been effectively leveraged to study prescription drug abuse [13], to track usage of illicit drugs [14], and to find a correlation between flu vaccine sentiment tweets and official vaccination rates according to geography [24].
The presence of medical entities in tweets does not necessarily signify that people have the illness, are using the pharmacological substances (drugs), or are exhibiting certain symptoms. Therefore, to obtain frequency of drug use from tweets, it is best to first identify which tweets indicate that tweeters have consumed the drugs mentioned in their tweets.
Several previous studies have paid attention to the identification of actual experiences of medical entities from other mentions. This includes work by Aslam et al [25] and Ji et al [26] who sought first to differentiate between valid and invalid tweets that expressed experiences with the flu before proceeding with further analyses. Weeg et al [27] found that the correlation between population disease prevalence and disease mentions in tweets increased from .113 to .208 (P<.001) when only disease name mentions that refer to actual diseases were taken into consideration. Using a somewhat similar approach, Alvaro et al [28] identified tweets that described firsthand experiences of prescription drugs, which were then used to gather evidence about adverse drug reactions.
Due to the large volumes of Twitter data, an effective way to separate the class of tweeters with experience with medical entities from the nonexperience class is by using machine learning (ML) techniques. However, researchers are still striving to improve the performance of the ML classifiers used for classifying tweets into those respective classes.
Topic Extraction From Twitter
To obtain insight from tweeters who have consumed these drugs, we sought to extract categories or topics from their respective tweets. Twitter data have been used in previous studies to extract categories or topics about health-related issues for various purposes. We have seen Twitter being used to investigate topics surrounding antibiotic prescription drugs [15] to find emerging trends for tweets related to electronic cigarettes [16], to detect topics at the peak of a disease related to official reports [29], and to find trending topics from preselected health-related keywords [17].
However, most of these studies conducted their topic analysis by classifying their tweets into predefined health categories [15,16] instead of obtaining these categories automatically. Those approaches miss opportunities to discover hidden and new topics. Additionally, the discovered topics were extracted from all the tweets that mentioned the medical entities [29]. However, only the tweets that expressed experiences with medical entities should be included in the topic extraction [17].
Influenza Drug Uptake Surveys
Uptake of drugs to treat or prevent influenza infections is an effective measure to mitigate the impact of influenza outbreaks. Consequently, there is a need to understand which factors contribute to the increase or decrease of drug uptake. With that information, public health agencies can take appropriate action against factors that may decrease drug uptake and promote factors that may increase drugs uptake.
Among the factors that deter uptake of influenza drugs (especially vaccines) are fear of needles, pain, and distress resulting from vaccination [30-32].
The logistics of vaccination processes that include the locations of vaccination centers and waiting time are among the factors that influence people to receive an influenza vaccine [32-34]. Some people tend to prefer traditional vaccination locations (hospitals, clinics, and doctor’s office) [32], whereas others prefer nontraditional locations (pharmacies, workplaces, and schools) [33,34]. Short line-ups and wait times help facilitate influenza vaccine uptake [34].
There have been concerns about the safety of the influenza drugs with respect to people with allergies [35] and pregnant women [36-39], which negatively affect the uptake of drugs.
Demographic factors, including age and level of education have been found to contribute to the uptake of influenza vaccines in which younger and less-educated adults are more hesitant to take drugs than other groups [40].
Public health agencies and pharmaceutical companies, as well as doctors or medical professionals [41,42] and parents [42] are also positive influences on drug uptake.
It has also been observed that some people prefer natural remedies to conventional drugs for influenza treatment or prevention [22]. However, natural remedies should be used to supplement and not replace tested influenza drugs.
The findings of these studies provide useful public health information for controlling the severity of seasonal influenza outbreaks through drug uptake. However, the methods for data collection used in most of these studies, that is, face-to-face interviews [30-32,37,41], written questionnaires [34,38], telephone surveys [33,42], secondary data databases [36], and Web page hits [22] have many drawbacks that may adversely affect the quality of the findings.
The cost for conducting these survey studies is one of the limitations. For example, a typical clinic-based survey (interview) for one participant in the United States costs US $23.51 compared with US $14.63 for a social media survey [43]. In another study [44], the cost of a telephone survey per sample (US $3.98) was higher compared with Web-based surveys (US $0.71). These high costs may hinder collection of data from large sample populations.
For public health agencies to take immediate and effective action, the findings of these studies should be released as soon as possible. However, these conventional methods are subject to delays with regard to data collection and may provide results later than they are needed to make informed decisions [45].
To employ effective strategies against seasonal influenza outbreaks, research results that reflect the actual situation in the population being studied should be used. However, because of the nature of the interactions between researchers and respondents in conventional or traditional methods, these studies are affected by social desirability bias in which respondents tend to provide responses that seem favorable [46]. This trend may lead to incorrect analysis results and ultimately cause public health agencies to fail to take appropriate action in locations where it is required.
Additionally, the size of study populations, which are often scattered in disparate geographical regions, can limit coverage in these studies. It is very costly to conduct studies with a population size that can be generalized to larger populations such as regions and countries.
In summary, existing approaches have two main limitations. First, the performance of ML classifiers used for identifying experience or personal tweets need improvements. These approaches mainly used n-gram bag-of-words or characters as ML features. These features suffer from the curse of dimensionality because the total dimension of each tweet’s text is equal to the vocabulary size, which can overfit the models. Additionally, these features do not consider semantic relations between words, which can result in poor performances in some cases.
Second, traditional surveys for finding insights about influenza drugs suffer from limitations associated with cost, timelessness in reporting, coverage, and bias.
Objectives
To achieve our research aim, we set the following objectives as our guidelines:
The first objective was to provide a methodological extension for efficiently extracting more widely used drugs during seasonal influenza using tweets with evidence for consumption of drugs. We focused on providing an improved ML classifier that could identify tweets indicating uptake of drugs from others. We hypothesized that using a dependency words structure (introduced in the Methods section) of the tweets as our features would improve performance in classification.
Our second objective was to extract topics from tweets mentioning each of the widely consumed drugs and to infer how the insights provided by these topics can enhance seasonal influenza surveillance in lieu of relying on traditional surveillance. From this perspective, we focused on automatically (without predefined categories) finding fine-tuned topics (extracted separately from tweets about each drug). We hypothesized that topics of widely consumed drugs could be used to enhance surveillance of seasonal influenza. Additionally, the tweets from these topics were the ones that signified actual consumption of drugs.
The contribution or significance of the research is two-fold in the following ways:
First, we proposed a new enhanced classification method to identify whether a tweet indicates someone has consumed or intended to consume a drug or not. This enhanced classification method guarantees results that reflect the actual situation in the population being studied when searching for widely used drugs and in subsequent analyses (topic extraction).
Second, a topic extraction–based method was applied to analyze the hot topics in tweets that can help public health stakeholders enhance seasonal influenza surveillance and intervention measures in terms of drug administration and consumption. Instead of using traditional or conventional survey methods, the topic extraction–based method can directly extract topics from tweets of people who have consumed these drugs. This sort of approach guarantees cost-effective, fast, and high coverage results for public health stakeholders to take action if needed.
To the best of our knowledge, this paper is the first to use a topic extraction–based method to retrieve insights about seasonal influenza drugs using Twitter data. The retrieved topics can highlight enabling and deterrent factors to drug uptake.
We evaluated our ML classifier by comparing it with a 1-gram term frequency (TF)–based classifier and a clue (keyword or lexicon)-based classifier. These benchmarks were chosen because they have been extensively used for separating tweets of individuals with actual experience (personal or valid) from tweets made by others [25,26,28,47-50]. For the extracted topics, we examined how the findings support the results of previous studies that used conventional or traditional surveillance methods.
Methods
Overview
The overview of the proposed method is summarized in Figure 1. The tweets are first preprocessed and filtered to obtain tweets with drug mentions only. Then, a random sample of these tweets is manually annotated as relevant or irrelevant with respect to actual drug uptake evidence. Next, features to be used by our classifier are generated. The classifier is trained, evaluated, and applied to the whole dataset to identify tweets indicative of the consumption of drugs (relevant tweets). From these tweets, we derive (1) a ranked list of widely used drugs and (2) topics from tweets mentioning each of these widely used drugs. A detailed description and implementation of these steps are provided in the following sections.
Figure 1.
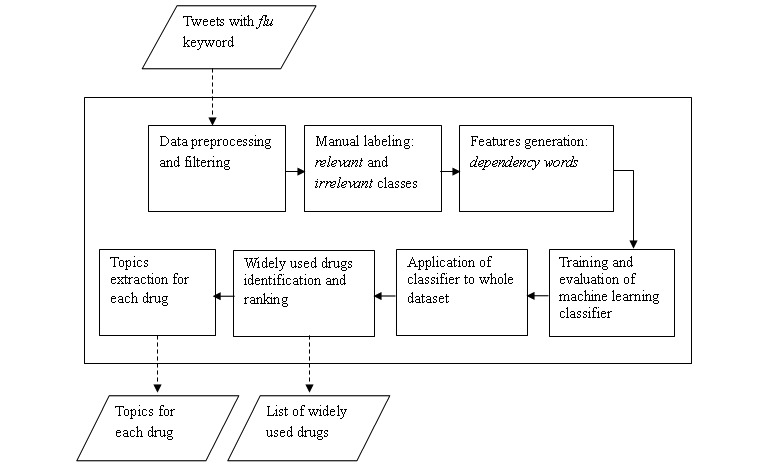
An overview of the proposed method.
Data
We used historical Twitter data for the 2012-2013 influenza season collected from August 31, 2012 to March 04, 2013 within 30 cities in the United States using the Twitter application programming interface (API) and the keyword flu. This approach ensured that the analyzed drugs were related to seasonal flu outbreaks. Only tweets written in the English language were considered, and in total there were 459,043 tweets included in the analysis.
Post collection filtering was done to remove tweets that contained the keyword flu but were unrelated to the flu disease. For example, some tweets contained the phrase stomach flu, which implies an intestinal infection. Additionally, tweets that had the keyword flu as part of the Twitter username or handle or Twitter hashtag (such as @this_is_flu or #flu_camp, respectively) were also removed from our dataset. Because the majority of retweets and tweets with URLs do not usually express actual experiences of health-related issues [25], they were also removed from the dataset.
To identify the tweets that mentioned drugs, the unified medical language system (UMLS)-MetaMap [51] developed at the US National Library of Medicine was used. The semantic type of each token or word in a tweet was first identified by the UMLS-MetaMap. If the word was classified into one of the following three UMLS semantic types: immunological factor, clinical drug, or pharmacological substance (which are the semantic types for preventive or treatment drugs), then the corresponding tweet was kept for subsequent analyses.
Manual Annotation of Tweets
Since we wanted to train an ML classifier that could identify tweets indicating uptake of drugs, we first manually labeled a random sample of the tweets in two classes, including the relevant class if a tweet indicated actual consumption of drugs and the irrelevant class for other topics. These manually labeled data were later used to train and test the classifier. Table 1 has some examples of relevant and irrelevant tweet labeling.
Table 1.
Samples of relevant and irrelevant tweets with mentions of drugs (drugs italicized).
| Category | Tweet text |
| Relevant | Nyquil cold&Flu thanks for my life back! |
| Got my flu shot. Ughhh. | |
| I got the flu vaccine that means I am gunna get sicky. | |
| Irrelevant | We have flu shots In! Make Your Appointment Today 642-### |
| He got a song about some damn Thera flu lol | |
| So I either have the flu or a mild case west nile virus! FML!! |
Two annotators were tasked with categorizing 5000 tweets into the two classes (relevant and irrelevant). The interrater agreement between the 2 annotators measured using Cohen kappa [52] was .91. A third annotator was recruited to decide on the disagreements between the 2 annotators through majority votes.
Machine Learning Classifier Features
The proposed classifier used dependency words as features that were obtained as follows: We parsed each tweet to obtain the dependency structure of words, and then we identified which words in the tweet had dependency relations with a drug mentioned in the tweet; we only used these words as our features. Our approach was peculiar in the sense that we did not use the dependency grammar categories (eg, nsbuj, dobj, and conj) of the words in the tweets as features. We named this feature dependency words.
TF-inverse document frequency (IDF) basically represents each text document (in this case, a tweet’s dependency words) as a vector of terms or words with each component of the vector corresponding to each term in the corpus and has a weight or count associated with it [52]. The TF part measures how frequently a term occurs in a document, whereas the IDF part weights the most frequent terms while scaling up the rare ones. For corpus terms that are not in the document, their weights are zero. The terms can have any n-gram (n=1, 2...) size. However, Cole-Lewis et al [16] determined that using 1-gram instead of other n-grams to classify tweets into relevant and irrelevant categories led to the best performance. Since we intended to implement our model with a support vector machine (SVM) algorithm that also scales the terms, we used TF only. Thus, a 1-gram TF of dependency words was adopted in this study to categorize tweets into relevant or irrelevant types.
The Stanford parser (Stanford University) [53] was used to find dependency words, whereas during TF feature construction, we used the Stanford CoreNLP [54] to reduce the dependency words into their lemma forms.
The following example shows the dependency words extracted from a sentence in a tweet:
| Original sentence: Just got my Nyquil, ready for bed. |
| Results: my, got, and ready |
From the example, the drug mentioned in the tweet is Nyquil, which has grammatical dependency relations with the words my, got, and ready.
Classifier Training, Evaluation, and Application
We used the SVM with a linear kernel function as the ML algorithm, which was implemented using LIBSVM from the National Taiwan University [55]. To obtain a trained SVM model that can provide optimum classification results, there are two parameters that must be tuned, namely C and gamma. We applied a grid search method on C and gamma using 10-fold cross validation to test several pairs of C and gamma, and the pair that provided the best 10-fold cross-validation performance for the training set was chosen. With these parameters, the classifier was then trained with 3400 labeled data, and its performance was evaluated using 1600 test data in terms of precision, recall, and F1 score. To ascertain the classifier’s ability to avoid overfitting, the classifier was tested by evaluating its performance on the test dataset that was not used for training. This test dataset was assumed to approximate the typical unseen data the classifier would encounter in the future.
Our training set had a total of 701 features (dependency words). We tested whether we could achieve the same or better performance with fewer features through feature selection (20%, 40%, 60%, and 80%), but we could not get better performance with less than 100% of the features. Therefore, all of the features were used.
To evaluate the performance of our proposed ML classifier, we compared it with two benchmark classifiers, including a 1-gram TF-based classifier used in prior studies [25,28,47-49] and a lexicon (keyword or clue)-based classifier as used in another previous study [26]. The 1-gram TF classifier was constructed by using all of the words in each tweet after removing all of the named entities (eg, person, location, organization, numerical, and temporal) and stop words, which are considered to have little or no contribution to document classification. The lexicon-based classifier was constructed by considering the presence of subjectivity words, news keywords, and profanity words. A tweet was considered to indicate drug experience (relevant) if it contained at least 3 strong subjective words and 3 weak subjective words. In contrast, a tweet was considered to be irrelevant if it contained news keywords, and there were no profane words.
The optimum-trained model was then applied to the whole corpus of tweets to find all relevant tweets, that is, tweets indicating consumption of drugs. We counted the drugs mentioned in these tweets and ranked them to identify widely consumed drugs.
Topic Extraction for Tweets Mentioning Drugs
Topic models are based on a concept that documents are mixtures of topics in which a topic is a probability distribution for words [56] . In other words, a topic refers to a group of words that frequently occur together and can form meaningful and interpretable themes. Latent Dirichlet allocation (LDA) is one of the simplest topic models and is widely used in Web text mining.
LDA is a generative model for topic modeling that can automatically discover hidden topics from a collection of text documents represented as a bag-of-words [57]. Each document is regarded as a mixture of several topics, and a topic is a distribution of words. For a collection of text documents, the LDA model can generate a certain number of topics. By understanding the topic distributions among text documents and the word distributions among topics, unknown or hidden information in the text can be retrieved.
The goal of topic modeling was to separately discover hidden topics from a collection of relevant tweets for each widely used drug. For the tweets of each drug, we applied the LDA topic modeling method to find topics. The LDA method was implemented by MALLET (University of Massachusetts Amherst) [58].
The number of topics retrieved for tweets about each drug was varied using an optimum topic number test as suggested by a previous method [59]. We applied the LDA topic model to the documents (tweets) with a randomly specified number of topics and observed the per-document topic distributions results. If the per-document topic distributions of all documents were dominated by a few topics, then the number of topics was increased and vice versa, until an optimal balance was found. The only parameter or value we specified was the number of topics. Other LDA parameters were tuned automatically from their default values (alpha=5.0 and beta=.01) based on the specified number of topics and based on the number of words in the tweets. Detailed information on our implementation of the LDA-based topic model for tweets of widely consumed drugs is provided in Multimedia Appendix 1.
The results of this LDA topic model included per-document topic distributions, a set of topics, and word-to-topic assignments for each word in the corpus. However, the data that were most interesting to us were the extracted topics.
Results
Relevant Tweets With Drug Mentions
After the initial preprocessing and filtering of tweets to remove retweets, as well tweets with URLs and tweets with the keyword flu that did not imply the flu disease, we had 220,375 tweets remaining. The number of tweets with drug mentions was 50,828 after filtering with MetaMap software. The number of relevant tweets that indicated actual uptake of drugs after applying our classifier was 40,428. These 40,428 tweets produced 6232-word vocabulary size (ie, number of dependency words).
Classifier Performance Evaluation
The performance of our SVM classifier, when applied to the test set measured in terms of precision, recall, and the F1 score is shown in Table 2. The gamma and C parameter values for the SVM classifier that provide the optimum performance were .008 and 8, respectively, after a thorough grid search. Our proposed model, which was 1-gram TF of dependency words, outperformed the model constructed using 1-gram TF and the lexicon-based model as depicted in Table 2.
Table 2.
Performance of the classifiers using lexicon-based, 1-gram term frequency (TF), and dependency word features.
| Classifier features | Precision | Recall | F1 score |
| Lexicon-based (benchmark 1) | 0.52 | 0.91 | 0.66 |
| 1-gram TFa (benchmark 2) | 0.73 | 0.88 | 0.79 |
| Dependency words (our approach) | 0.77 | 0.90 | 0.82 |
aTF: term frequency.
The test dataset was divided into 30 parts, and a statistical significance test of our classifier over the two benchmark classifiers was conducted to check whether the proposed method outperformed the two baseline methods significantly. The results showed that the differences in the F1 score between our classifier and the two benchmarks were statistically significant (ie, P<.001 with the lexicon-based model and P=.048 with the 1-gram TF model).
Widely Used Drugs
Table 3 shows the counts for the selected widely used drugs and their percentages. We only considered drugs with tweet count percentages that were at least 0.20%. We excluded some drugs that the MetaMap software identified as drugs, but the tweets did not imply drug use. We did a manual analysis of these drugs by going through some of the tweets they came from. For example, RID in many of the tweets was used to mean to clear or to free, but it was identified as a drug because it could also mean pyrethrins or piperonyl in other contexts. This outcome occurred because the syntactic structure of tweets with these drugs was similar to tweets with mentions of true drugs, which made it difficult for the classifier to detect this ambiguity automatically.
Table 3.
Widely used drugs retrieved from relevant tweets (N=40,428).
| Drugs | Tweets count, n (%) |
| Influenza virus vaccines | 31,111 (76.95) |
| Theraflu | 1267 (3.13) |
| Vitamins | 439 (1.09) |
| NyQuil | 354 (0.88) |
| Acetaminophen | 270 (0.67) |
| Oseltamivir | 162 (0.40) |
| DayQuil | 75 (0.20) |
Since we wanted to obtain frequencies or counts of drug uptake only, we did not include water and disinfectant products in the table, which were also identified as widely used drugs.
Although some drugs were identified separately by the MetaMap software, they are actually the same. Therefore, we grouped these drugs into one category for the sake of simplicity. For example, flu shots, flu vaccines, flu vaccine, vaccines, and vaccine were combined and presented as one category or class called influenza virus vaccines, and vitamins and vitamin C were grouped into vitamins.
Topics for Drugs-Mentioning Tweets
The optimum number of topics retrieved for each relevant drug was as follows: Influenza virus vaccines (10), Theraflu (5), DayQuil and NyQuil (5), vitamins (5), acetaminophen (3), and oseltamivir (3).
Table 4 shows topics of tweets with influenza virus vaccine mentions. Multimedia Appendix 2 has the full results of topic extraction for all drugs, which includes the number of topics, topic compositions, and LDA parameters.
Table 4.
Relevant topics retrieved from tweets mentioning influenza virus vaccines (only interpretable topic compositions are listed).
| Topic numbera | Topic compositions |
| 1 | mom, today, needles, doctor, nurse, gave, give, told, dad, baby, big, shot, giving, making, wanted, lady, sh*t, f*ck |
| 2 | reaction, hoping, sick, kids, allergic, eggs, made, egg, chicken, allergy, medicine, tea |
| 3 | flu, season, people, year, virus, immune, system, shot, epidemic, strain, stay, healthy, spreading, protect, remember |
| 4 | influenza, pregnant, risk, vaccination, national, recommend, women, immunity, free, safe |
| 5 | arm, sore, today, hurts, hurt, yesterday, damn, left, feels, side, bad, feel, stupid, throat, pain, ouch, killing, feeling, hurting |
| 6 | waiting, cvs, line, walgreens, pharmacy, free, wait, office, give, long, gave, spray, clinic, nasal, giving, people |
| 7 | sick, hate, shots, f*ck, sh*t, flu, needles, damn, today, nervous |
| 8 | work, office, day, today, free, morning, tomorrow, doctors, doctor, shot, good, school |
aCorresponding interpretations of these topics are in Table 5.
In Table 5, we presented interpretations of the topics (clusters of frequently occurring words) for the drugs listed in Table 3. These interpretations express the meanings that the topics convey.
Table 5.
Interpretations of topics retrieved for each drug.
| Drugs | Topic interpretations |
| Influenza virus vaccinesa | Vaccination proponents, vaccination allergic reaction, vaccination reminders, vaccination pregnancy risk, vaccination pain and distress, vaccination queues concerns, vaccination fear, vaccination places |
| Theraflu | Natural flu remedies uptake (chicken soup, hot drinks) |
| DayQuil or NyQuil | Drug uptake time (morning, night) |
| Vitamins | Flu preparedness through vitamins intake |
| Acetaminophen | Symptoms; Natural flu remedies uptake (soup, tea, orange juice) |
| Oseltamivir | Prescription of drug |
aCorrespond to topic numbers in Table 4.
Discussion
Principal Findings and Comparison With Previous Studies
The Classification Method
When compared with the two benchmarks, our proposed method showed performance (F1 score) improvement for classifying tweets with mentions of drugs into relevant and irrelevant categories. This improvement was significant compared with both the 1-gram TF classifier (P=.048) and the lexicon-based classifier (P<.001).
The ML classification intention was designed to find which tweets indicate that a tweeter has consumed or intends to consume the drugs mentioned in their tweets. We used dependency parsing to first find which words in the tweets were involved in the binary grammatical relations with the drugs mentioned in the tweets, and then by using these words as our ML classifier features, we achieved better performance. This result occurred because these words (features) are closely related or aligned to the drugs and serve as better distinguishing features than using all words (1-gram TF) or even had much better results than using lexicon-based methods. Additionally, as dependency words were used only as features, the approach is not affected by dimensionality, and there is no possibility of model overfitting.
The two benchmarks were chosen because of the fact that they have been extensively used to identify valid or relevant or personal and invalid or irrelevant or nonpersonal tweets regarding flu experience, which is similar to the procedures used in prior studies [25,26,28,47-50].
Widely Used Drugs and Corresponding Topics
In this study, we defined relevant tweets as the ones that were composed by people who express their or another person’s consumption of drugs. Out of 50,828 tweets that mentioned drugs, 40,428 (79.54%) were relevant tweets. This result implied that people discuss health-related conditions and actions on Twitter for both themselves and other people. This outcome is consistent with the work of Yin et al [10] who investigated whether Twitter users disclose health statuses (either their status or the status of other people).
The research estimated the proportions of different drugs used during the flu season. The results showed that widely used drugs included influenza virus vaccines 76.95% (31,111/40,428). Previous studies also investigated the uptake of influenza drugs, especially vaccines [60,61]. However, these studies mostly relied on surveys or interviews that were prone to social desirability bias, delays, and were very costly. Our approach leveraged tweets to obtain these proportions quickly and at a low cost, which can efficiently reflect the actual drug uptake.
Furthermore, in this research, we found that the topics of tweets mentioning the drugs varied depending on the types of drugs that were discussed. These topics could not be easily and accurately found using normal search queries [15] or traditional survey methods because of their limited scope. Combining mentions of widely used drugs together with trending topics can be beneficial to various public health stakeholders for controlling flu epidemics.
Regarding influenza virus vaccines, we observed that during flu seasons, people who were vaccinated tended to remind others to do the same to protect themselves from the flu and stay healthy (Table 4, topic 3: flu, season, people, year, virus, immune, system, shot, epidemic, strain, stay, healthy, spreading, protect, remember). This is a positive sign because lack of reminders has been found to be one of the barriers to vaccination among adults [62]. The following tweet shows how people who get vaccinated urge others to do so:
Guys protect yourself this flu season. Just got my mandatory flu shot. #HealthyPeople
Additionally, apart from medical personnel, we noticed that people got their flu vaccines because of the persuasion or presence of their parents (Table 4, topic 1: mom, today, doctor, nurse, gave, give, told, dad, baby, big, shot, giving, making, wanted, lady, sh*t, f*ck). The presence of curse words and needle indicates pain resulting from vaccine injections, whereas the words doctors, nurse, moms, and dads indicate that vaccines were given or offered in the presence of these people or these people influenced the vaccination process. This result provides information on which cohort to target for sensitization campaigns to have a more positive impact on flu medication uptake, especially preventive drugs such as flu vaccines or shots. According to Giese et al [63], individuals are likely to be vaccinated if their doctors or medical staff have recommended the vaccine. Our topics analysis has discovered another potential group (parents) that can also facilitate convincing more people to get vaccinated because they were involved in the vaccination process. We expected parents to make vaccination decisions for young children only [64,65]. However, as Twitter users are mainly adults, it appears that parents can influence adults too:
...my moms making me get the flu shot ):
Moms making me get the flu shot. I f****ng hate needles.
Idk my dad wants me to get a flu shot he knows I hate needles.
Additionally, the extracted topics indicated that people got or had intended to get their vaccines at places where they were spending most of their time during the day and where the drugs were offered or given for free (Table 4, topic 8: work, office, day, today, free, morning, tomorrow, doctors, doctor, shot, good, school). The presence of topic words such as work, office, school, and free means that vaccines were given at those places (mostly for free). The finding can imply that offering drugs at these places can be an effective decision because of the peer pressure effect, rather than offering these drugs at health facilities only. This result correlated with the finding that people who receive vaccines are individuals who are in contact with many others during their daily activities [66]:
My office is giving out free flu shots I think I will go, last year my insurance did not cover my flu shot.
The topic analysis also showed that people who got or had intended to get their vaccines were concerned with waiting for a long time in vaccination queues (Table 4, topic 6: waiting, cvs, line, walgreens, pharmacy, free, wait, office, give, long, gave, spray, clinic, nasal, giving, people). The words line, long, and waiting meant that waiting lines were long, or people waited for a long time in lines. The words cvs, walgreens, pharmacy, office, and clinic are vaccination locations. These results imply that time spent waiting on long lines at vaccination centers was a concern for many people, and measures need to be taken to address that concern:
2 hours in line at cvs for a flu shot #sickofthissh*t.
Additionally, the aftermath of pain and distress from vaccines were among the concerns of many people (Table 4, topic 5: arm, sore, today, hurts, hurt, yesterday, damn, left, feels, side, bad, feel, stupid, throat, pain, ouch, killing, feeling, hurting). The presence of words such as hurts, hurt, hurting, sore, damn, ouch, and pain indicates pain, whereas the words arm and left indicate the body part affected by the pain. This finding can help health administration to design better strategies for offering these drugs and to avoid discouraging intended recipients in the future. For example, the 5P (procedural, physical, pharmacologic, psychological, and process) pain management intervention strategies [67,68] can be employed to ease pain and distress from drugs. The following tweets indicate the pain and distress users tend to associate with vaccine use:
I got the flu shot today and my arm STILL HURTS I’m all sore.
This FLU SHOT after effect is KILLING ME. My arm so sore and in pain OMG.
Vaccination needle fear was also among the themes that emerged from the tweeters (Table 4, topic 7: sick, hate, shots, f*ck, sh*t, flu, needles, damn, today, nervous). This means sensitization needs to be conducted to ensure that more people overcome their fear and partake in vaccination. The following tweet indicates the fear of needles:
Getting a flu shot. So nervous. Hate shots.
Tweeters with egg or chicken allergies raised concerns about whether the vaccines would cause an allergic reaction (Table 4, topic 2: reaction, hoping, sick, kids, allergic, eggs, made, egg, chicken, allergy, medicine, tea). This outcome implies proper education should be given to avoid scaring away people with egg or chicken allergies or other allergies:
@Twitterhandle That’s good to know. Both me and my little girl have egg allergy and got no ill effects from the flu shots.
There were also themes showing concerns about the risk of vaccination to pregnant women (Table 4, topic 4: influenza, pregnant, risk, vaccination, national, recommend, women, immunity, free, safe). This finding means people were concerned with the efficacy and safety of the vaccines, which is similar to the findings of another study [69] and suggests there should be strategies to improve vaccination uptake among pregnant women.
1st getting my flu shot. Is it safe to get a flu shot during pregnancy? Yes. Better safe than sorry.
Some topics for Theraflu and acetaminophen were related to how people who consumed these drugs also tended to use natural or home flu remedies (Multimedia Appendix 2, table MA3, topic 1: soup, chicken, noodle, juice, orange, care, flu, work, sleepy, warm, easier, food, drinkin, spicy, vodka) and (Multimedia Appendix 2, table MA5: fever, throat, juice, recommend, drowsy, soup, temp, symptom, strep, spray, orange, tea). However, there is a need to provide awareness to people so that they use these home remedies only as early interventions or in conjunction with clinically prescribed drugs for effective treatment of the flu [70]. The following tweets indicate that some people use drugs such as Theraflu and acetaminophen in conjunction with home remedies:
Chicken noodle soup and thera flu for dinner...mmm.
@Twitterhandle drink some green tea and chicken soup and take theraflu and get rest#lets earn two.
For the other drugs (except for influenza vaccines, Theraflu, and acetaminophen), the observable interpretable topics were related to preparedness against flu, symptoms, and prescriptions, as well as the use of the drugs to prevent or combat the flu.
Overall, in this research, we went the extra mile by ensuring that the topics about drugs reflected actual experiences of medical entities or drugs and that not all mentions of drugs were included, as they were in prior studies [17,29]. Additionally, these topics were supported by findings from several studies that are related to influenza surveillance but used traditional survey methods.
Limitations and Future Work
The study succeeded in improving the performance of the classifier when compared with the benchmarks and managed to find important themes about the consumed drugs. However, the study was limited by challenges such as misspellings, abbreviations, and slang language, which are common issues facing researchers attempting to analyze social media text. As most tweets were composed by individuals with no medical backgrounds, the tweets had lots of misspellings when mentioning drugs. Additionally, because of space restrictions and the informal nature of Twitter conversations, people often opted to use abbreviations and slang when exchanging messages. In this study, we automatically extracted treatment drugs using MetaMap software, which recognized only standard medical names and left out some tweets with drug mentions. This might have caused the number of tweets with a specific drug to be reduced and made it hard to find all of the meaningful topics. To overcome these challenges, future research studies should consider using MetaMap software combined with appropriate misspelling identification and correction methods. Additionally, abbreviations and slang should be expanded to their full forms and interpreted using appropriate lexica.
Additionally, we did not explore correlations of the uptake of the drugs between tweets and official statistics. We also did not conduct analyses in smaller, more specific geographical locations (such as cities). Instead, we considered the country as a whole. Future research studies can conduct analyses at the city level and find correlations between results from tweets and official data.
Conclusions
As the number of users and the sharing of health information on Twitter increase, Twitter has turned out to be a potential data source for public health research. It can help to investigate the uptake of various drugs and perceptions of users toward those drugs during seasonal flu outbreaks. Analyzing these massive datasets requires efficient methods that can identify emerging trends in the uptake and administration of drugs. Using ML techniques, this study proposed a methodological extension for efficiently extracting more widely used drugs during seasonal influenza using tweets confirming the consumption of drugs during seasonal flu outbreaks from a pool of tweets with mentions of drugs. Emerging topics of each confirmed tweet about drugs were extracted, which provided hidden information conveyed by people who have consumed these drugs. Mainly, these insights included encouraging or discouraging factors for influenza drug uptake. This information was obtained automatically rather than being obtained by conventional methods that have many shortcomings. Therefore, public health entities and other stakeholders can make full use of this efficiently obtained information to devise efficient and effective strategies for influenza epidemic surveillance.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (Award #:71572013, 71272057, 71521002) and Joint Development Program of Beijing Municipal Commission of Education. Findings, opinions, conclusions, or recommendations expressed in this research are those of the authors and do not necessarily reflect the views of the National Natural Science Foundation of China and Beijing Municipal Commission of Education.
The authors would like to extend their gratitude to Professor Ming-Hsiang Tsou from Geography Department, San Diego State University for sharing raw Twitter data used in this study.
Abbreviations
- API
application programming interface
- ILI
influenza-like illness
- LDA
latent Dirichlet allocation
- ML
machine learning
- SVM
support vector machine
- TF
term frequency
- TF-IDF
term frequency-inverse document frequency
- UMLS
unified medical language system
Latent Dirichlet allocation (LDA) topic model and implementation.
Topics for tweets with drug mentions.
Footnotes
Conflicts of Interest: None declared.
References
- 1.Porta M, Greenland S, Silva IdS, Last JM. A dictionary of epidemiology. New York: Oxford University Press; 2014. [Google Scholar]
- 2.Lee LM, Teutsch SM, Thacker SB, St Louis ME. Principles & practice of public health surveillance, 3rd edition. Oxford: Oxford University Press; 2010. [Google Scholar]
- 3.CDC. 2017. [2017-08-19]. Seasonal influenza (flu): about flu https://www.cdc.gov/flu/about/index.html .
- 4.CDC. 2016. [2016-11-16]. CDC says “Take 3” actions to fight the flu http://www.cdc.gov/flu/protect/preventing.htm .
- 5.Sugawara T, Ohkusa Y, Ibuka Y, Kawanohara H, Taniguchi K, Okabe N. Real-time prescription surveillance and its application to monitoring seasonal influenza activity in Japan. J Med Internet Res. 2012 Jan 16;14(1):e14. doi: 10.2196/jmir.1881. http://www.jmir.org/2012/1/e14/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Seo D, Jo M, Sohn CH, Shin S, Lee J, Yu M, Kim WY, Lim KS, Lee S. Cumulative query method for influenza surveillance using search engine data. J Med Internet Res. 2014 Dec 16;16(12):e289. doi: 10.2196/jmir.3680. http://www.jmir.org/2014/12/e289/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Sharpe JD, Hopkins RS, Cook RL, Striley CW. Evaluating google, twitter, and wikipedia as tools for influenza surveillance using bayesian change point analysis: a comparative analysis. JMIR Public Health Surveill. 2016 Oct 20;2(2):e161. doi: 10.2196/publichealth.5901. http://publichealth.jmir.org/2016/2/e161/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Twitter. 2016. [2016-11-15]. Twitter usage/company facts https://about.twitter.com/company .
- 9.Java A, Song X, Finin T, Tseng B. Why we twitter: understanding microblogging usage and communities. Proceedings of the 9th WebKDD and 1st SNA-KDD 2007 Workshop on Web mining and Social Network Analysis; WebKDD/SNA-KDD '07; August 12, 2017; San Jose, CA. ACM; 2007. pp. 56–65. [DOI] [Google Scholar]
- 10.Yin Z, Fabbri D, Rosenbloom ST, Malin B. A scalable framework to detect personal health mentions on twitter. J Med Internet Res. 2015;17(6):e138. doi: 10.2196/jmir.4305. http://www.jmir.org/2015/6/e138/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Aramaki E, Maskawa S, Morita M. Twitter catches the flu: detecting influenza epidemics using twitter. Proceedings of the Conference on Empirical Methods in Natural Language Processing; EMNLP 2011; July 27-31, 2011; Edinburgh. 2011. pp. 1568–76. [Google Scholar]
- 12.Paul M, Dredze M. You are what you tweet: analyzing twitter for public health. Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media; ICWSM-11; July 17–21, 2011; Barcelona. AAAI Press; 2011. pp. 265–72. https://www.aaai.org/ocs/index.php/ICWSM/ICWSM11/paper/view/2880/3264. [Google Scholar]
- 13.Hanson CL, Burton SH, Giraud-Carrier C, West JH, Barnes MD, Hansen B. Tweaking and tweeting: exploring Twitter for nonmedical use of a psychostimulant drug (Adderall) among college students. J Med Internet Res. 2013;15(4):e62. doi: 10.2196/jmir.2503. http://www.jmir.org/2013/4/e62/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Daniulaityte R, Nahhas RW, Wijeratne S, Carlson RG, Lamy FR, Martins SS, Boyer EW, Smith GA, Sheth A. “Time for dabs”: analyzing twitter data on marijuana concentrates across the U.S. Drug Alcohol Depend. 2015 Oct 1;155:307–11. doi: 10.1016/j.drugalcdep.2015.07.1199. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Kendra RL, Karki S, Eickholt JL, Gandy L. Characterizing the discussion of antibiotics in the twittersphere: what is the bigger picture? J Med Internet Res. 2015;17(6):e154. doi: 10.2196/jmir.4220. http://www.jmir.org/2015/6/e154/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Cole-Lewis H, Varghese A, Sanders A, Schwarz M, Pugatch J, Augustson E. Assessing electronic cigarette-related tweets for sentiment and content using supervised machine learning. J Med Internet Res. 2015;17(8):e208. doi: 10.2196/jmir.4392. http://www.jmir.org/2015/8/e208/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Yepes A, MacKinlay A, Han B. Investigating public health surveillance using twitter. Proceedings of the 2015 Workshop on Biomedical Natural Language Processing (BioNLP 2015); ACL-IJCNLP 2015; July 30, 2015; Beijing. 2015. pp. 164–70. [DOI] [Google Scholar]
- 18.Gesualdo F, Stilo G, Agricola E, Gonfiantini MV, Pandolfi E, Velardi P, Tozzi AE. Influenza-like illness surveillance on twitter through automated learning of naïve language. PLoS One. 2013;8(12):e82489. doi: 10.1371/journal.pone.0082489. http://dx.plos.org/10.1371/journal.pone.0082489. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Broniatowski DA, Paul MJ, Dredze M. National and local influenza surveillance through twitter: an analysis of the 2012-2013 influenza epidemic. PLoS One. 2013;8(12):e83672. doi: 10.1371/journal.pone.0083672. http://dx.plos.org/10.1371/journal.pone.0083672. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Pivette M, Mueller JE, Crépey P, Bar-Hen A. Drug sales data analysis for outbreak detection of infectious diseases: a systematic literature review. BMC Infect Dis. 2014 Nov 18;14:604. doi: 10.1186/s12879-014-0604-2. https://bmcinfectdis.biomedcentral.com/articles/10.1186/s12879-014-0604-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Woo H, Cho Y, Shim E, Lee J, Lee C, Kim SH. Estimating influenza outbreaks using both search engine query data and social media data in South Korea. J Med Internet Res. 2016;18(7):e177. doi: 10.2196/jmir.4955. http://www.jmir.org/2016/7/e177/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Hill S, Mao J, Ungar L, Hennessy S, Leonard CE, Holmes J. Natural supplements for H1N1 influenza: retrospective observational infodemiology study of information and search activity on the Internet. J Med Internet Res. 2011 May 10;13(2):e36. doi: 10.2196/jmir.1722. http://www.jmir.org/2011/2/e36/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Signorini A, Segre AM, Polgreen PM. The use of twitter to track levels of disease activity and public concern in the U.S. during the influenza A H1N1 pandemic. PLoS One. 2011;6(5):e19467. doi: 10.1371/journal.pone.0019467. http://dx.plos.org/10.1371/journal.pone.0019467. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Salathé M, Khandelwal S. Assessing vaccination sentiments with online social media: implications for infectious disease dynamics and control. PLoS Comput Biol. 2011 Oct;7(10):e1002199. doi: 10.1371/journal.pcbi.1002199. http://dx.plos.org/10.1371/journal.pcbi.1002199. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Aslam AA, Tsou M, Spitzberg BH, An L, Gawron JM, Gupta DK, Peddecord KM, Nagel AC, Allen C, Yang J, Lindsay S. The reliability of tweets as a supplementary method of seasonal influenza surveillance. J Med Internet Res. 2014;16(11):e250. doi: 10.2196/jmir.3532. http://www.jmir.org/2014/11/e250/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Ji X, Chun SA, Wei Z, Geller J. Twitter sentiment classification for measuring public health concerns. Soc Netw Anal Min. 2015 May 12;5(1):13. doi: 10.1007/s13278-015-0253-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Weeg C, Schwartz HA, Hill S, Merchant RM, Arango C, Ungar L. Using twitter to measure public discussion of diseases: a case study. JMIR Public Health Surveill. 2015;1(1):e6. doi: 10.2196/publichealth.3953. http://publichealth.jmir.org/2015/1/e6/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Alvaro N, Conway M, Doan S, Lofi C, Overington J, Collier N. Crowdsourcing twitter annotations to identify first-hand experiences of prescription drug use. J Biomed Inform. 2015 Dec;58:280–7. doi: 10.1016/j.jbi.2015.11.004. http://linkinghub.elsevier.com/retrieve/pii/S1532-0464(15)00241-5. [DOI] [PubMed] [Google Scholar]
- 29.Robertson C, Yee L. Avian influenza risk surveillance in North America with online media. PLoS One. 2016;11(11):e0165688. doi: 10.1371/journal.pone.0165688. http://dx.plos.org/10.1371/journal.pone.0165688. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Taddio A, Ipp M, Thivakaran S, Jamal A, Parikh C, Smart S, Sovran J, Stephens D, Katz J. Survey of the prevalence of immunization non-compliance due to needle fears in children and adults. Vaccine. 2012 Jul 06;30(32):4807–12. doi: 10.1016/j.vaccine.2012.05.011. [DOI] [PubMed] [Google Scholar]
- 31.Wheelock A, Parand A, Rigole B, Thomson A, Miraldo M, Vincent C, Sevdalis Nick. Socio-psychological factors driving adult vaccination: a qualitative study. PLoS One. 2014;9(12):e113503. doi: 10.1371/journal.pone.0113503. http://dx.plos.org/10.1371/journal.pone.0113503. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Rossmann BE, Rench MA, Montesinos DP, Healy CM. Acceptability of immunization in adult contacts of infants: possibility of expanding platforms to increase adult vaccine uptake. Vaccine. 2014 May 07;32(22):2540–5. doi: 10.1016/j.vaccine.2014.03.056. [DOI] [PubMed] [Google Scholar]
- 33.Kim N, Mountain TP. Role of non-traditional locations for seasonal flu vaccination: empirical evidence and evaluation. Vaccine. 2017 May 19;35(22):2943–8. doi: 10.1016/j.vaccine.2017.04.023. [DOI] [PubMed] [Google Scholar]
- 34.Prematunge C, Corace K, McCarthy A, Nair RC, Roth V, Suh KN, Garber G. Qualitative motivators and barriers to pandemic vs. seasonal influenza vaccination among healthcare workers: a content analysis. Vaccine. 2014 Dec 12;32(52):7128–34. doi: 10.1016/j.vaccine.2014.10.023. [DOI] [PubMed] [Google Scholar]
- 35.Kelso JM. Influenza vaccine and egg allergy: nearing the end of an evidence-based journey. J Allergy Clin Immunol Pract. 2015;3(1):140–1. doi: 10.1016/j.jaip.2014.08.011. [DOI] [PubMed] [Google Scholar]
- 36.Zerbo O, Qian Y, Yoshida C, Fireman BH, Klein NP, Croen LA. Association between influenza infection and vaccination during pregnancy and risk of autism spectrum disorder. JAMA Pediatr. 2017 Jan 02;171(1):e163609. doi: 10.1001/jamapediatrics.2016.3609. [DOI] [PubMed] [Google Scholar]
- 37.Maher L, Dawson A, Wiley K, Hope K, Torvaldsen S, Lawrence G, Conaty S. Influenza vaccination during pregnancy: a qualitative study of the knowledge, attitudes, beliefs, and practices of general practitioners in Central and South-Western Sydney. BMC Fam Pract. 2014 May 23;15:102. doi: 10.1186/1471-2296-15-102. https://bmcfampract.biomedcentral.com/articles/10.1186/1471-2296-15-102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Chamberlain A, Seib K, Ault K, Orenstein W, Frew P, Malik F, Cortés M, Cota P, Whitney EA, Flowers LC, Berkelman RL, Omer SB. Factors associated with intention to receive influenza and tetanus, diphtheria, and acellular pertussis (Tdap) vaccines during pregnancy: a focus on vaccine hesitancy and perceptions of disease severity and vaccine safety. PLoS Curr. 2015 Feb 25;7:-. doi: 10.1371/currents.outbreaks.d37b61bceebae5a7a06d40a301cfa819. doi: 10.1371/currents.outbreaks.d37b61bceebae5a7a06d40a301cfa819. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Bettinger JA, Greyson D, Money D. Attitudes and beliefs of pregnant women and new mothers regarding influenza vaccination in British Columbia. J Obstet Gynaecol Can. 2016 Nov;38(11):1045–52. doi: 10.1016/j.jogc.2016.08.004. [DOI] [PubMed] [Google Scholar]
- 40.Lau JT, Au DW, Tsui HY, Choi KC. Prevalence and determinants of influenza vaccination in the Hong Kong Chinese adult population. Am J Infect Control. 2012 Sep;40(7):e225–7. doi: 10.1016/j.ajic.2012.01.036. [DOI] [PubMed] [Google Scholar]
- 41.Lv M, Fang R, Wu J, Pang X, Deng Y, Lei T, Xie Z. The free vaccination policy of influenza in Beijing, China: The vaccine coverage and its associated factors. Vaccine. 2016 Apr 19;34(18):2135–40. doi: 10.1016/j.vaccine.2016.02.032. [DOI] [PubMed] [Google Scholar]
- 42.Gargano L, Underwood N, Sales J, Seib K, Morfaw C, Murray D, DiClemente RJ, Hughes JM. Influence of sources of information about influenza vaccine on parental attitudes and adolescent vaccine receipt. Hum Vaccin Immunother. 2015;11(7):1641–7. doi: 10.1080/21645515.2015.1038445. http://europepmc.org/abstract/MED/25996686. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Admon L, Haefner JK, Kolenic GE, Chang T, Davis MM, Moniz MH. Recruiting pregnant patients for survey research: a head to head comparison of social media-based versus clinic-based approaches. J Med Internet Res. 2016 Dec 21;18(12):e326. doi: 10.2196/jmir.6593. http://www.jmir.org/2016/12/e326/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Yang M, Tan EC. Web-based and telephone surveys to assess public perception toward the national health insurance in taiwan: a comparison of cost and results. Interact J Med Res. 2015 Apr 17;4(2):e9. doi: 10.2196/ijmr.4090. http://www.i-jmr.org/2015/2/e9/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Santillana M, Nguyen AT, Dredze M, Paul MJ, Nsoesie EO, Brownstein JS. Combining search, social media, and traditional data sources to improve influenza surveillance. PLoS Comput Biol. 2015 Oct;11(10):e1004513. doi: 10.1371/journal.pcbi.1004513. http://dx.plos.org/10.1371/journal.pcbi.1004513. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Guthmann J, Fonteneau L, Bonmarin I, Lévy-Bruhl D. Influenza vaccination coverage one year after the A(H1N1) influenza pandemic, France, 2010-2011. Vaccine. 2012 Feb 01;30(6):995–7. doi: 10.1016/j.vaccine.2011.12.011. [DOI] [PubMed] [Google Scholar]
- 47.Allen C, Tsou M, Aslam A, Nagel A, Gawron J. Applying GIS and machine learning methods to Twitter data for multiscale surveillance of influenza. PLoS One. 2016;11(7):e0157734. doi: 10.1371/journal.pone.0157734. http://dx.plos.org/10.1371/journal.pone.0157734. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Tuarob S, Tucker C, Salathe M, Ram N. Discovering health-related knowledge in social media using ensembles of heterogeneous features. Proceedings of the 22nd ACM International Conference on Information and Knowledge Management (CIKM 2013); CIKM 2013; October 27 - November 01, 2013; San Francisco. New York: ACM; 2013. pp. 1685–90. [DOI] [Google Scholar]
- 49.Jain VK, Kumar S. An effective approach to track levels of influenza-A (H1N1) pandemic in India using twitter. Procedia Computer Science. 2015;70:801–7. doi: 10.1016/j.procs.2015.10.120. [DOI] [Google Scholar]
- 50.Prieto VM, Matos S, Álvarez M, Cacheda F, Oliveira JL. Twitter: a good place to detect health conditions. PLoS One. 2014;9(1):e86191. doi: 10.1371/journal.pone.0086191. http://dx.plos.org/10.1371/journal.pone.0086191. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Aronson A. Effective mapping of biomedical text to the UMLS Metathesaurus: the MetaMap program. Proc AMIA Symp. 2001:17–21. http://europepmc.org/abstract/MED/11825149. [PMC free article] [PubMed] [Google Scholar]
- 52.Cohen J. A coefficient of agreement for nominal scales. Educ Psychol Meas. 2016 Jul 02;20(1):37–46. doi: 10.1177/001316446002000104. [DOI] [Google Scholar]
- 53.De Marnefe M-C, Manning CD. Stanford University. [2017-08-18]. Stanford typed dependencies manual https://nlp.stanford.edu/software/dependencies_manual.pdf .
- 54.Manning C, Surdeanu M, Bauer J, Finkel J, Bethard S, McClosky D. The Stanford coreNLP natural language processing toolkit. Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics; System Demonstrations; June 23-24, 2014; Baltimore. ACL; 2014. pp. 55–60. http://www.aclweb.org/anthology/P/P14/P14-5010. [DOI] [Google Scholar]
- 55.Chang C, Lin C. LIBSVM. ACM Trans Intell Syst Technol. 2011 Apr 01;2(3):1–27. doi: 10.1145/1961189.1961199. [DOI] [Google Scholar]
- 56.Blei DM. Probabilistic topic models. Commun ACM. 2012 Apr 01;55(4):77. doi: 10.1145/2133806.2133826. [DOI] [Google Scholar]
- 57.Blei D, Ng A, Jordan M. Latent dirichlet allocation. J Mach Learn Res. 2003;3(Jan):993–1022. [Google Scholar]
- 58.Mallet. 2002. [2016-11-16]. MALLET: a machine learning for language toolkit http://mallet.cs.umass.edu/
- 59.Graham S, Weingart S, Milligan I. The Programming Historian. 2012. [2017-08-18]. Getting started with topic modeling and MALLET https://programminghistorian.org/lessons/topic-modeling-and-mallet .
- 60.Han YK, Michie S, Potts HW, Rubin GJ. Predictors of influenza vaccine uptake during the 2009/10 influenza A H1N1v ('swine flu') pandemic: results from five national surveys in the United Kingdom. Prev Med. 2016 Mar;84:57–61. doi: 10.1016/j.ypmed.2015.12.018. https://linkinghub.elsevier.com/retrieve/pii/S0091-7435(15)00391-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Bíró A. Determinants of H1N1 vaccination uptake in England. Prev Med. 2013 Aug;57(2):140–2. doi: 10.1016/j.ypmed.2013.04.017. [DOI] [PubMed] [Google Scholar]
- 62.Johnson DR, Nichol KL, Lipczynski K. Barriers to adult immunization. Am J Med. 2008 Jul;121(7 Suppl 2):S28–35. doi: 10.1016/j.amjmed.2008.05.005. [DOI] [PubMed] [Google Scholar]
- 63.Giese C, Mereckiene J, Danis K, O'Donnell J, O'Flanagan D, Cotter S. Low vaccination coverage for seasonal influenza and pneumococcal disease among adults at-risk and health care workers in Ireland, 2013: The key role of GPs in recommending vaccination. Vaccine. 2016 Jul 12;34(32):3657–62. doi: 10.1016/j.vaccine.2016.05.028. [DOI] [PubMed] [Google Scholar]
- 64.Campbell H, Edwards A, Letley L, Bedford H, Ramsay M, Yarwood J. Changing attitudes to childhood immunisation in English parents. Vaccine. 2017 May 19;35(22):2979–85. doi: 10.1016/j.vaccine.2017.03.089. [DOI] [PubMed] [Google Scholar]
- 65.He L, Liao Q, Huang Y, Feng S, Zhuang X. Parents' perception and their decision on their children's vaccination against seasonal influenza in Guangzhou. Chin Med J (Engl) 2015 Feb 05;128(3):327–41. doi: 10.4103/0366-6999.150099. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Chan T, Fu Y, Wang D, Chuang J. Determinants of receiving the pandemic (H1N1) 2009 vaccine and intention to receive the seasonal influenza vaccine in Taiwan. PLoS One. 2014;9(6):e101083. doi: 10.1371/journal.pone.0101083. http://dx.plos.org/10.1371/journal.pone.0101083. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Taddio A, McMurtry CM, Shah V, Riddell RP, Chambers CT, Noel M, MacDonald NE, Rogers J, Bucci LM, Mousmanis P, Lang E, Halperin SA, Bowles S, Halpert C, Ipp M, Asmundson GJ, Rieder MJ, Robson K, Uleryk E, Antony MM, Dubey V, Hanrahan A, Lockett D, Scott J, Votta BE, HELPinKids&Adults Reducing pain during vaccine injections: clinical practice guideline. CMAJ. 2015 Sep 22;187(13):975–82. doi: 10.1503/cmaj.150391. http://www.cmaj.ca/cgi/pmidlookup?view=long&pmid=26303247. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Taddio A, McMurtry CM, Shah V, Yoon EW, Uleryk E, Pillai RR, Lang E, Chambers CT, Noel M, MacDonald NE, HELPinKids&Adults Team Methodology for knowledge synthesis of the management of vaccination pain and needle fear. Clin J Pain. 2015 Oct;31(10 Suppl):S12–9. doi: 10.1097/AJP.0000000000000263. http://europepmc.org/abstract/MED/26352917. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Eppes C, Wu A, You W, Cameron KA, Garcia P, Grobman W. Barriers to influenza vaccination among pregnant women. Vaccine. 2013 Jun 12;31(27):2874–8. doi: 10.1016/j.vaccine.2013.04.031. [DOI] [PubMed] [Google Scholar]
- 70.Evanovich LL, Scott TM. Facilitating PBIS implementation: an administrator's guide to presenting the logic and steps to faculty and staff. Beyond Behavior. 2016 Apr;25(1):4–8. doi: 10.1177/107429561602500102. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Latent Dirichlet allocation (LDA) topic model and implementation.
Topics for tweets with drug mentions.