

Abstract
We examine the effects of multiple sources of noise in risky decision making. Noise in the parameters that characterize an individual’s preferences can combine with noise in the response process to distort observed choice proportions. Thus, underlying preferences that conform to expected value maximization can appear to show systematic risk aversion or risk seeking. Similarly, core preferences that are consistent with expected utility theory, when perturbed by such noise, can appear to display nonlinear probability weighting. For this reason, modal choices cannot be used simplistically to infer underlying preferences. Quantitative model fits that do not allow for both sorts of noise can lead to wrong conclusions.
Keywords: decision making, noise, risky choice, prospect theory
Research on risky choice has relied heavily on the use of deterministic utility maximization models, such as expected utility theory (EUT; Von Neumann & Morgenstern, 2007) and cumulative prospect theory (CPT; Kahneman & Tversky, 1979; Tversky & Kahneman, 1992). When their functional forms are specified and parameterized, these models make precise quantitative predictions. However, they fail to capture an important aspect of actual choice behavior: namely that choice is stochastic, so that decision makers may respond differently when given exactly the same choice problem on more than one occasion within a short space of time (see Mosteller and Nogee, 1951, for early evidence; and Luce and Suppes, 1965, for a discussion; Rieskamp, Busemeyer, and Mellers, 2006; Wilcox, 2008; and Marley and Regenwetter, 2016, provide more recent reviews of key issues).
There are two main ways in which stochasticity in choice has been accommodated. One approach involves allowing for some error in selecting the utility-maximizing option, with the overall choice probabilities being determined by the relative utilities of the gambles in consideration (e.g., Luce, 1959; McFadden, 1973; Thurstone, 1927). An alternative approach allows the parameters of an individual’s utility function to vary from one moment to another, with choice probabilities being determined by the likelihood of one gamble having a higher utility than the other at a particular moment (e.g., Becker, DeGroot, & Marschak, 1963; Loomes & Sugden, 1995). The first approach can be interpreted as involving response noise: that is, noise that applies after the utilities for the gambles have been determined according to some model and compared. In contrast, the second approach involves noise in the utility generation process itself: that is, variability in the decision maker’s underlying preferences. This note warns that unless the analysis of risky choice data considers both forms of noise, false conclusions may be drawn about people’s underlying preferences.
Risky Decision Models
We can write two-outcome risky gambles as X = (x1, p1; x2, p2), so that X offers payoffs x1 and x2 with probabilities p1 and p2, with p1 + p2 = 1. Using a power function formulation for the value of any payoff x and Prelec’s (1998) one-parameter probability weighting function, the EUT or CPT utility of X can be written as1:
| 1 |
where x1 ≥ x2 ≥ 0 and π(p1) = and where we restrict α > 0 and γ > 0. CPT allows both α and γ to vary. When γ = 1, we have EUT as a special case of CPT. We obtain expected value when both α = 1 and γ = 1. When α < 1, concave value functions produce risk averse choices under EUT, whereas α > 1 corresponds with risk seeking. When γ < 1, we have overweighting (underweighting) of small (large) probabilities, with γ > 1 producing the opposite.
Aside from error, EUT and CPT models assume that X is always chosen over Y if U(X|α, γ) > U(Y|α, γ). To accommodate probabilistic choice data, some variability must be incorporated. One approach has been to assume that there is some error in the response such that the probability of selecting gamble X over Y is given by some increasing function of U(X|α, γ) – U(Y|α, γ). In many studies, this is implemented either by the logit model (Luce, 1959; McFadden, 1973) or by the probit model (Thurstone, 1927). In the binary choice case, both models can also be interpreted as involving an additive error ε, with E[ε] = 0, so that the probability of choosing X is the probability that U(X|α, γ) – U(Y|α, γ) + ε > 0 (Yellott, 1977).2 We refer to variability added to the core utilities as ‘response noise.’
A second way of modeling stochastic choice involves allowing the parameters of decision makers to fluctuate (Becker et al., 1963; Loomes & Sugden, 1995). For example, suppose α = α* + ηα and γ = γ* + ηγ, where ηα and ηγ are symmetric random variables with E[ηα] = E[ηγ] = 0. ηα and ηγ, and thus α and γ, vary from trial to trial (but not between options in a given trial). Because the expected values of α and γ are E[α] = α* and E[γ] = γ*, α* and γ* characterize the central tendency of a decision maker’s underlying preferences.3 We refer to such variability in model parameters as ‘preference noise.’
Preference noise and response noise can coexist. For example, if we assume that response noise is given by the logit model, the choice probability of X generated by a particular realization of ηα and ηγ, and subsequently α = α* + ηα and γ = γ* + ηγ is:
| 2 |
Note that ηα and ηγ are random variables so that the overall choice probability of X over Y in any given trial can be obtained by calculating the expectation of Pr[X chosen], given the distribution of ηα and ηγ. θ is a parameter that is inversely proportional to the degree of response noise in the choice process.
Theoretically there are many reasons to assume both preference noise and response noise. Preferences (and in turn, the parameters that characterize these preferences) can fluctuate, reflecting variations in attitudes, noise in the process of deliberation, or changes in affective states. Additionally, there may be numerous factors (e.g., computational mistakes, inattention to some elements of the decision) that potentially overturn the decision maker’s underlying preference, with the frequency of such response errors depending on the relative desirability of the utility maximizing option.
Empirically the assumption of both preference noise and response noise can offer a more adequate account of choice data than each of these assumptions alone. For example, allowing for only response noise in the above framework generates much higher frequencies of violations of transparent dominance than are generally observed, whereas allowing for only preference noise leads to the prediction that dominance is never violated at all, contrary to the evidence (Loomes & Sugden, 1998; also see Butler, Isoni, & Loomes, 2012 and Busemeyer & Townsend, 1993 for a related effect). Likewise, EUT and CPT have been fit to choices elicited at different points in time (Glöckner & Pachur, 2012; Zeisberger, Vrecko, & Langer, 2012). The fits assume only response noise, but the best-fit parameters also exhibit variability, with decision makers’ estimated preferences at one point in time being correlated with, but not identical to, their estimated preferences at a different point in time. Related work has fit EUT and CPT models, permitting both response and preference noise, and has found that both types of noise are necessary for the best quantitative fits (Blavatskyy & Pogrebna, 2010; Loomes, Moffatt, & Sugden, 2002).
Qualitative Inferences
Noisy Risk Attitudes
It might be thought that if both types of noise are unsystematic (symmetrically distributed around zero), modal choices can be used to make inferences about underlying preferences. This section tests that intuition and shows that it is incorrect.
Consider the choice between a risky gamble X offering a 50% chance of obtaining $10 and a 50% chance of obtaining $0, and its safe expected value equivalent Y offering $5 with certainty. Assume that a decision maker’s central tendency is described by the power form of EUT (i.e., γ = 1 in Equation 1) and that choices display both preference and response noise as specified in Equation 2. Suppose also that response noise involves θ = 1 and that preference noise involves ηα distributed uniformly in the interval [−0.5, 0.5]. Let α* = 0.9 so that modal underlying preferences are risk averse. However, when response noise is added, Pr[X chosen] = 0.53 > 0.5. Thus, despite underlying preferences predominantly favoring Y, the decision maker chooses the riskier X more frequently than Y.
This mismatch between underlying preferences and observed choices happens because of the nonlinearity of utility differences in α. The probability of choosing X is an increasing function of U(X|α, 1) – U(Y|α, 1) = 0.5 · 10α – 5α. For the range of α, we are considering, E[U(X|α, 1) – U(Y|α, 1)] > 0, resulting in a higher choice probability of X, despite the fact that α* < 1 and that U(X|α*, 1) – U(Y|α*, 1) < 0.
The point is expanded upon in Figure 1. We plot the probability of choosing X = ($10, 0.5; $0, 0.5) over Y = ($5, 1) according to power function EUT with only response noise (implemented via a logit function with θ = 1), and we compare that with the case in which preference noise (with ηα distributed uniformly in the interval [−0.5, 0.5]) is combined with the same specification of response noise. The first model entails Pr[X chosen] less than, equal to, or greater than 0.5 according to whether α* is less than, equal to, or greater than 1, as shown by the solid line in Figure 1. However, in the case when α is variable—shown by the broken line in Figure 1—there is a range of values of α* between 0.87 and 1 where Pr[X chosen] > 0.5. Over this range, the decision maker’s expected modal choice suggests risk seeking, whereas the central tendency of underlying preferences, represented by α*, suggests risk aversion or risk neutrality. In short, when both preference noise and response noise are present simultaneously, we cannot use modal choices to make reliable inferences about the decision maker’s risk attitude.4
Figure 1.
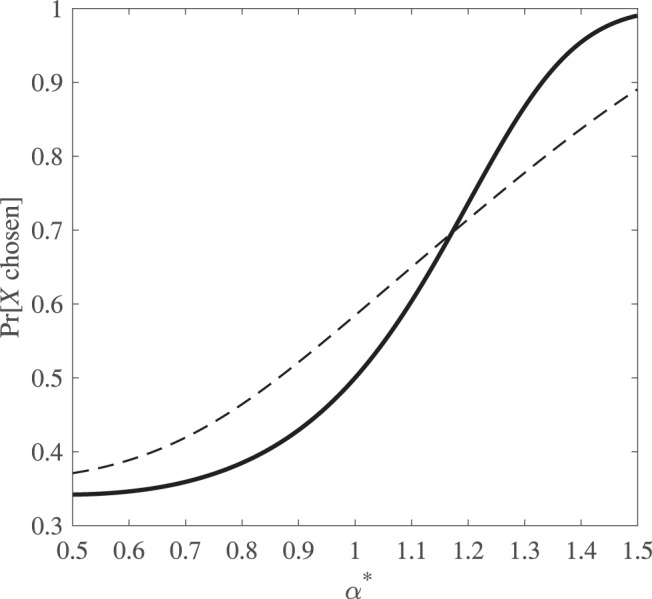
The probability of choosing a risky gamble X over its expected value Y for varying values of α*, plotted with only response noise (solid line) and with both response and preference noise (dashed line). Here we can observe a higher choice probability of X over Y for some values of α* < 1 in the presence of preference noise.
Noisy Probability Weighting: The 4-Fold Pattern
We now turn to cases in which probabilities may be transformed nonlinearly. We use the single parameter Prelec (1998) formulation outlined in Equation 1, but other transformation functions (Gonzalez & Wu, 1999; Tversky & Kahneman, 1992) could be used without altering the essential conclusions. When γ < 1, this function overweights low probabilities and underweights high probabilities. Such an inverse-S function is crucial to Tversky and Kahneman’s (1992) account of the 4-fold pattern of risky choice.
In the positive domain considered here,5 the 4-fold pattern entails a risky gamble being chosen over its expected value when the probability of the higher payoff in the risky gamble is small but the opposite pattern when the probability of the higher payoff in the risky gamble is large. Thus, in the choice between a risky gamble XI offering a 1% chance of obtaining $10 and a 99% chance of obtaining $0 and its safe expected value equivalent YI offering $0.10 with certainty, decision makers typically choose XI. In contrast, in the choice between a risky gamble XII offering a 99% chance of obtaining $10 and a 1% chance of obtaining $0, and its safe expected value equivalent YII offering $9.90 with certainty, decision makers typically choose YII.
Consider a setting with both response and preference noise. Let α = 1 so that the value function is linear, and allow noise only in the γ parameter, with ηγ being distributed uniformly in the interval [−0.5, 0.5]. For response noise, use the logit function with θ = 1 as in the previous section. Figure 2a shows the probability of choosing XI over YI and Figure 2b shows the probability of choosing XII over YII. As shown by the solid line, a model with response noise only and with γ* = 1 entails for both pairs a 0.5 chance of choosing each option. For all γ* < 1, the risky option is the modal choice in Figure 2a, whereas the sure amount is the modal choice in Figure 2b. However, when γ exhibits preference noise, the effect—as shown by the broken line—is to shift the path up in Figure 2a and down in Figure 2b: the combination of preference and response noise increases the choice probability of XI over YI and of YII over XII for all γ* considered.
Figure 2.

a and b. The probability of choosing a low-probability risky gamble XI over its expected value YI (left panel) and the probability of choosing a high-probability risky gamble XII over its expected value YII (right panel) for varying values of γ*. These figures are plotted with only response noise (solid line) and with both response and preference noise (dashed line).
At the point at which α = 1 and γ* = 1—that is, in the case in which the underlying preference entails a risk-neutral expected utility maximizer—the modal choices exhibit the mixed attitude to risk typical of CPT with γ < 1. Indeed, there is a range of γ* between 1 and 1.15 for which the decision maker’s expected modal choices generate a preference for XI over YI and for YII over XII, a behavioral pattern associated with the overweighting of small probabilities, whereas that range of γ* represents an underweighting of small probabilities. Again, we cannot use modal choices to infer probability weighting if preference and response noise are present simultaneously.6
Noisy Probability Weighting: The Common Ratio Effect
The probability weighting transformation assumed by CPT also enables it to account for the common ratio effect (Kahneman & Tversky, 1979). The classic common-ratio case involves choices between two pairs of lotteries. One pair offers a gamble XIII = (x, p; 0, 1 − p) versus YIII = (y, 1), where p is typically around 0.8 and where y is near the expected value of XIII. In the example we consider, our scaled-up pair is a choice between a gamble XIII offering an 80% chance of obtaining $10 and a 20% chance of obtaining $0 and its expected value equivalent YIII offering $8 with certainty. For such a pair, decision makers typically choose the sure option YIII.
The second pair involves scaling down the probabilities of the positive payoffs in the first pair by some factor λ and correspondingly increasing the probabilities of 0 in both options to give a choice between XIV = (x, λp; 0, 1 − λp) and YIV = (y, λ; 0, 1 − λ). Letting λ = 0.25 gives XIV offering a 20% chance of obtaining $10 and an 80% chance of $0 versus YIV offering a 25% chance of obtaining $8 and a 75% chance of $0. In such scaled-down pairs, decision makers choose the riskier option XIV much more frequently. This is inconsistent with EUT, which assumes that preferences are linear in probabilities. In a deterministic world of EUT maximizers, whatever proportion of the sample chooses XIII in the first pair should also choose XIV in the second pair.
The change in modal choices often found in the data can be accommodated by CPT with γ < 1. This is illustrated by the solid lines in Figures 3a and 3b in which we fix α = 1, assume a logit noise term (with θ = 1) and let γ* range between 0.5 and 1.5. Over the range γ* < 1, a model with only response noise entails that YIII is the modal choice in Figure 3a, whereas XIV is the modal choice in Figure 3b.
Figure 3.

a and b. The probability of choosing a scaled-up risky gamble XIII over its expected value YIII (left panel) and the probability of choosing a scaled-down risky gamble XIV over its expected value equivalent safe gamble YVI (right panel) for varying values of γ*. These probabilities are plotted with only response noise (solid line) and with both response and preference noise (dashed line).
Now allow response and preference noise to coexist and let ηγ be distributed uniformly in the interval [−0.5, 0.5]. This produces a shift in the choice probabilities, with an increase in the choice probability of YIII over XIII and of XIV over YIV for γ* in the neighborhood of 1. Thus, even when α = 1 and γ* = 1, the modal choices exhibit the reversal observed in many experiments, with a preference for YIII in the scaled-up pair but a preference for XIV in the scaled-down pair. Here, too, modal choices cannot be used to infer the underlying preference of decision makers: the common ratio effect can be generated by risk neutral expected utility maximizers.7
Quantitative Inferences
Recovering Risk Preferences
In this section, we explore the effects on quantitative model fits if preference noise is neglected. Particularly, we simulate the choices of decision makers when the two forms of noise are present simultaneously and then examine what happens if we attempt to recover best-fit parameters with only response noise modeled.
We begin with EUT, considering only variability in the parameter α (i.e., restricting γ = 1). We perform two sets of simulations: one in which α is deterministic, with α = α*, and another in which α is probabilistic, with α = α* + ηα and ηα distributed uniformly in the interval [−0.5, 0.5]. We vary α* in the range [0.5, 1.5], and for each value of α*, we simulate the corresponding EUT model on Stott’s (2006) gamble pairs.8 The best-fit values of α for the choices generated by the deterministic α simulation and probabilistic α simulation are then recovered. Our first recovery involves α generated by the probabilistic α simulation, under the (incorrect) assumption that α is deterministic. This recovery can help us establish the degree to which parameter recovery is biased when the data-generating model involves both sources of noise but the fitted model involves only response noise. The second recovery involves α for the choices generated by the probabilistic α simulation under the (correct) assumption that α is probabilistic.9 The third recovery involves α for the choices generated by the deterministic α simulation under the (correct) assumption that α is deterministic. These latter recoveries help us evaluate the efficacy of parameter estimates when the underlying model is correctly specified.10
Figure 4a displays the median recovered α, from now on referred to as αfit, for each value of α* for each of the three parameter recoveries. It shows that αfit is very close to the corresponding α* when the fitted model is correctly specified. In contrast, αfit differs quite significantly from α* for the first recovery in which the fitted model incorrectly assumes deterministic α when α is in fact probabilistic. In that case, the recovered parameter values are systematically biased. Particularly, αfit > α* when α* is small but αfit < α* when α* is large. Thus, highly risk averse decision makers appear less risk averse than they actually are, whereas risk-neutral (α* = 1) and some risk-seeking (α* = 1.1, 1.2) decision makers actually appear to be risk averse.
Figure 4.

a and b. Median recovered values of α, αfit, plotted against α* (left panel) and median recovered values of γ, γfit, plotted against γ* (right panel). The first parameter recovery (dotted-dashed line) involves a data-generating model with both response and preference noise and a misspecified fitted model which assumes only response noise. The second parameter recovery (dashed line) involves a data-generating model and correctly specified fitted model with both response and preference noise. The third parameter recovery (solid line) involves a data-generating model and correctly specified fitted model with only response noise.
Recovering Probability Weighting Parameters
To examine probability weighting biases, we perform two sets of simulations: one in which γ is deterministic, with γ = γ*, with only response noise; and another in which γ is also probabilistic, with γ = γ* + ηγ and ηγ distributed uniformly in the interval [−0.5, 0.5]. For both sets of simulations, we take γ* values in the range [0.5, 1.5]. To focus on probability weighting biases, we fix α at 1. All other aspects of our parameter recovery exercise are identical to those in the previous section.
Figure 4b displays the median recovered γ, from now on referred to as γfit, for each value of γ* for all three sets of recovered parameters. Again, the fitted value is very close to γ* in the second and third recoveries, when the fitted models are correctly specified. In contrast, γfit differs quite significantly from γ* for the first (misspecified) recovery. Moreover, the recovered parameter values are systematically biased, with γfit < γ* for all the values of γ that we consider, for the first recovery. Decision makers without any central tendency disposition to transform probabilities (γ* = 1) appear to overweight small probabilities (with γfit < 1) if their choices are fit with the assumption that there is no parameter variability.
The supplemental materials (http://dx.doi.org/10.1037/rev0000073.supp) show that these parameter recovery biases also emerge when both α and γ are recovered together.
Correlates of Risk Preference
If it can be unsafe to infer an individual’s underlying preferences from modal choice patterns or from quantitative fits of models that only allow for response noise, it may also be unsafe to infer differences in preferences between different groups of individuals or between individuals in different experimental conditions.
Between them, the disciplines of psychology, neuroscience, and economics have produced a large number of studies examining the relationship between risk preference and a wide variety of social, biological, cultural, cognitive, emotional, and neural variables. Much of this work makes the implicit or explicit assumption that differences in modal choice probabilities between different experimental or demographic groups reflect differences in underlying value functions and/or probability weighting preferences.
For example, based on choice proportions, men are considered to be more risk seeking than women (Charness & Gneezy, 2012), a tendency that is amplified by contextual factors such as stereotype threat (Carr & Steele, 2010); Chinese are considered more risk seeking than Americans (Hsee & Weber, 1999); the nucleus accumbens is seen as influencing risk-seeking choices, whereas the anterior insula is seen as influencing riskless choices (Kuhnen & Knutson, 2005); high incentives are associated with more risk aversion than low incentives (Holt & Laury, 2005); and decision makers under high time pressure are seen as being more risk averse than decision makers under low time pressure (Zur & Breznitz, 1981). Likewise, stress is seen as affecting the amount of probability weighting in gains and losses (Porcelli & Delgado, 2009); the degree of striatal activity is assumed to influence the overweighting of small probabilities (Hsu, Krajbich, Zhao, & Camerer, 2009); framing the decision as involving precaution is assumed to lead to the overweighting of small and medium-sized probabilities (Kusev, van Schaik, Ayton, Dent, & Chater, 2009); age has been argued to generate more optimistic decision weights in gains (Pachur, Mata, & Hertwig, 2017); and decision feedback is considered to lead to linear probability weighting (Jessup, Bishara, & Busemeyer, 2008). Finally, it is often assumed that decision makers tend to weigh probabilities differently when gamble payoffs and probabilities are described compared with when these payoffs and probabilities are experienced (Hertwig, Barron, Weber, & Erev, 2004).
However, as we have shown, differences in modal choice proportions may be due to differences in the amount of variability in underlying parameters rather than to differences in central tendency parameter values. To illustrate, let us return to Figure 1. The horizontal axis shows a range of α*, and the vertical axis shows the choice probability for the risky gamble X corresponding with those different values of α*. The two lines reflect different levels of preference noise.
Now suppose we observe a male decision maker choosing X with frequency 0.53, whereas a female decision maker chooses X with frequency 0.47. If we were considering only the raw choice data, we might conclude that the male is somewhat risk seeking and the female is somewhat risk averse. If we allow for preference noise but suppose that the degree of such noise is the same for both individuals, we could still attribute the gap to different values of α*, with the male identified as being less risk averse. But if the male’s underlying preferences involve more preference noise (the dotted line) than the female’s (the solid line), we cannot draw that conclusion. Mapping from Pr[X chosen] = 0.53 via the dotted line gives the male’s α* as about 0.9, whereas mapping from Pr[X chosen] = 0.47 via the solid line gives the female’s α* as approximately 0.95, meaning that the male is, in terms of underlying preferences, actually more risk averse than the female.
The same point may hold for differences in best-fitting parameters across demographic groups or experimental conditions. If decision makers display both preference and response noise, but if the fitted model allows for only response noise, differences in the degree of preference noise across groups could be incorrectly interpreted as differences in underlying parameters. It is hard to say, in general, just how substantial any such effect might be: one could imagine it being stronger in some instances and weaker or insignificant in others. Our point is not to reject out of hand all of the differences reported in the studies cited earlier but rather to alert researchers to the possibility that the combination of parameter and response noise may in some cases lead to misestimates of the degree (and occasionally even the direction) of such differences.
Nonlinearity in Parameters
In many ways, the above sections serve as an existence proof, showing how a combination of some types of preference and response noise can systematically distort choice probabilities. However, such effects are not limited to the particular functional forms of EUT and CPT or to the specifications of response and preference noise used in this paper. They are liable to apply whenever there is a nonlinear relationship between the parameters that describe preference and the utilities used to determine choice. In these circumstances, the means of the utility differences between options are liable to diverge from the utility differences generated by central tendency parameter values.
The supplemental materials examine various settings in considerable detail. However, to illustrate, we consider a different domain: intertemporal choice. Here the exponential discounting model (Frederick, Loewenstein, & O’Donoghue, 2002; Samuelson, 1937) is commonly used to model choices between rewards occurring at differing periods of time. One criticism of this model is that it cannot account for an increased preference for a proximate reward over a delayed reward because the lengths of the delay diminish by some common amount. For example, this model predicts that decision makers cannot prefer $10 in 3 months and 1 week to $5 in 3 months but also prefer $5 immediately to $10 1 week from now. Yet such present-biased choice patterns have often been reported, and they have been explained by alternative discount functions (see Frederick et al., 2002 for an overview). However, one could also explain such patterns using exponential discounting with preference noise. Indeed, if we use the exponential discounting model with a discount factor of δ = δ* + ηδ, with δ* = 0.75, E[ηδ] = 0 and ηδ uniform in [−0.25, 0.25] and if we assume (for simplicity) deterministic linear utility and a logistic response rule with θ = 1, we find that the probability of choosing $5 immediately over $10 in 1 week is 79% but that the probability of choosing $5 in 3 months over $10 in 3 months and 1 week is 48%. If we fail to allow for the role played by preference noise, this shift in modal choice may mislead us about the underlying time preferences of decision makers. Likewise, observed differences in intertemporal choice patterns that have been ascribed to differences in demographic, biological, neural, cognitive, emotion, social, and task-based factors may not exclusively reflect the impact of those factors on discount rates but might (to some extent, at least) reflect differences in the effects of noise.
Appropriate Analysis
We have seen how the combination of preference and response noise can bias parameter estimates if model fits assume that underlying preferences are deterministic when in reality they are not.11 However, this does not mean that models such as EUT and CPT are unidentifiable in the statistical sense: parameters can be recovered accurately so long as the model is correctly specified.
Unlike current approaches to applying models like EUT and CPT (see, e.g., Broomell & Bhatia, 2014; Glöckner & Pachur, 2012; Harless & Camerer, 1994; Hey & Orme, 1994; Rieskamp, 2008; Stott, 2006), an appropriate analysis would assume a distribution over underlying parameter values. Such a hierarchical approach has been shown to be desirable for capturing group-level variability in the parameters of cognitive models of choice (Lee & Newell, 2011; Wetzels, Vandekerckhove, Tuerlinckx, & Wagenmakers, 2010; also see mixture logit models as in Train, 2009). Indeed, a recent study, using hierarchical Bayesian estimation (Nilsson, Rieskamp, & Wagenmakers, 2011; also Scheibehenne & Pachur, 2015), showed how this technique could be used to model prospect theory preferences without bias in settings with heterogeneous decision makers. Even though this work did not consider within-person preference noise, the statistical structure they proposed is essentially equivalent to the structure assumed in this paper, suggesting that hierarchical Bayesian estimation could be used to recover the parameters of CPT and EUT more accurately in the presence of preference noise at the individual level.
Of course, determining the correct model specification is not trivial. In this paper we have assumed a logistic model for response noise as well as an additive error model for preference noise. However, in reality this may not be the case. Indeed, other more sophisticated ways of modeling error have already been proposed (see Marley & Regenwetter, 2016 or Wilcox, 2008 for an overview), and many of these have desirable properties not possessed by the logit model. Currently we are unable to correctly diagnose the underlying noise specification based solely on data, and much more work needs to be done to identify appropriate error theories for modeling response and preference noise.
Another way to avoid the choice biases documented in this paper might involve the QTest method, which shows how choice proportions could be used to infer the underlying preferences of decision makers (Regenwetter et al., 2014; see also Regenwetter & Davis-Stober, 2012). This method attempts to characterize deterministic models with various stochastic assumptions in terms of the points on a multiple dimensional choice space that their choice predictions occupy. Currently this work appears to be applied either to deterministic models under the influence of response noise or else to random parameter specifications without response noise. However, we understand that the proponents of the QTest method are currently investigating the feasibility of combining these two sources of noise: if this is computationally tractable, it might provide a useful way to conceptualize the issues discussed in this paper.
A somewhat different line of development might build upon the true and error model (Birnbaum, 2013; Birnbaum & Bahara, 2012; Birnbaum & Diecidue, 2015). This approach assumes that decision makers have true preference orderings that are perturbed by errors but does not impose the kinds of functional restrictions assumed in our paper. Particularly, when presented with a number of choices within some block of questions in an experiment, an individual’s preferences are assumed to be consistent with some core (deterministic) theory throughout that block. However, the observed choices within that block may depart from that theory because of response error. In variants of this approach, it is also allowed that if the same choices are repeated in different blocks, the individual’s true preference might change from one block to another.
It may be possible to control for some of the effects outlined in this paper using the true and error framework and additionally use insights from this framework to identify necessary extensions and modifications of our own approach. For example, the experiments in Birnbaum (2013) suggest that preference noise is not independent and identically distributed, as assumed in this paper. Instead, there are cross-temporal correlations inherent in preferences. Indeed, one approach to modeling these correlations within a functional parametric structure has already been proposed by Birnbaum (2013, Appendix B), who suggests that parameters in utility functions can be seen to evolve according to a random walk process.
Beyond Deterministic Models
We have used EUT and CPT to motivate and illustrate our arguments, but the issues we have discussed apply much more broadly. Although it has been known for more than half a century that human decision making is probabilistic (Mosteller & Nogee, 1951; Luce & Suppes, 1965), the evolution of modern decision theory has primarily involved the production of scores of deterministic models, whose developers have left the question of stochasticity in abeyance. When experimenters have tried to test these models, the most common strategy has been to add on some analytically convenient—but often rather arbitrary—error specification. However, it has become clear that the relationship between these deterministic models and their stochastic implementations is such that it is possible to drastically change inferences made using these models by altering assumptions regarding the nature of the variability in the data.
This problem is endemic to deterministic models of choice and cannot be fully remedied by the application of more rigorous methodological tools, even though the more recent techniques discussed in the previous section may represent improvements on simple logit specifications. We would argue that theoretical research on decision making should attempt to incorporate variability as part of the fabric of models rather than as ad hoc ways of giving a deterministic model a probabilistic appearance. There have already been a number of advances in modeling the cognitive basis of the stochastic choice process (Bhatia, 2013, 2014; Bogacz, Usher, Zhang, & McClelland, 2007; Busemeyer & Townsend, 1993; Diederich, 1997; Krajbich, Armel, & Rangel, 2010; Rangel & Hare, 2010; Roe, Busemeyer, & Townsend, 2001; Trueblood, Brown, & Heathcote, 2014; Tsetsos, Chater, & Usher, 2012; Usher & McClelland, 2004; see also Rieskamp et al., 2006 and Oppenheimer & Kelso, 2015 for useful discussions). Cognitive models of stochastic choice make explicit assumptions about how noise enters into deliberation and how it interacts with preference, choice, decision time, and confidence. In allowing stochasticity to play a central role in choice, these models are naturally able to capture a large range of behavioral effects that currently lie outside the descriptive scope of deterministic models. Indeed, some of these models even try to explain key decision-making anomalies using only unsystematic noise rather than specific restrictions on value functions or probability weighting (Bhatia, 2014; Navarro-Martinez, Loomes, Isoni, & Butler, 2014; also see, e.g., Ratcliff & Rouder, 1998). Moreover, experimental work has shown that these types of models outperform many of the deterministic utility models in terms of quantitative fit (Rieskamp, 2008). Future research should consider using these types of psychologically grounded choice models to understand the behavior of decision makers.
Conclusion
We have shown that the coexistence of both preference noise and response noise—in each case modeled as zero-mean, symmetric, and independent—can systematically distort choice patterns. Thus, decision makers whose preferences are, on average, risk neutral, can display modal choice patterns that might be mistaken as evidence of risk aversion or risk seeking. Likewise, underlying preferences may be linear in probabilities but choice patterns may appear supportive of nonlinear probability transformations. In fact, a number of common and seemingly systematic decision anomalies can be generated by expected value maximizers with some degree of response and preference noise.
Our analysis suggests the need for care when trying to elicit the underlying preferences of decision makers. The presence of both preference and response noise can bias quantitative model fits if these fits do not make appropriate allowance for both sources of noise. Likewise, differences in choice proportions between various categories of decision makers may be due, at least to some extent, to different degrees of noise rather than being entirely attributable to intrinsic differences in preferences. In short, caution is needed when trying to infer the preferences of decision makers or when trying to identify the effects of psychological, biological, economic, and demographic variables on those preferences.
Supplementary Material
Footnotes
Numerous other functional forms are possible. Our conclusions do not depend on the particular choices of functional form, as we illustrate in the supplemental materials. Also note that evidence suggests that both EUT and CPT have some descriptive limitations (Birnbaum, 2008; Starmer, 2000). However, our primary purpose is not to defend or advocate either theory; we simply take them as two examples of risky utility maximization models and explore the difficulties of inferring their parameters and distinguishing their predictions in the presence of both preference and response noise.
Although we present Luce’s and Thusrtone’s approach as being closely related, they do have diverging interpretations. Choice in Thurstone’s theory is often seen as involving the comparison of random variables or discriminable processes. In case 5 of this theory, these random variables involve scale values (such as U(X|α,γ) and U(Y|α, γ)) combined with additive errors (such as ε). In contrast, Luce derives his theory from axiomatic restrictions on choice probabilities (see Marley & Regenwetter, 2016, or Wilcox, 2008, for an overview). There are also other related approaches that depart from the assumption that response noise is a function of only the utility differences (Carroll, 1980; Restle, 1961; Wilcox, 2011). For simplicity, we will not be explicitly examining the predictions of these approaches in this paper, although we do discuss them briefly in the supplemental materials.
This approach is closely related to models of stochastic ordering (Block & Marschak, 1960; Regenwetter, Dana, & Davis-Stober, 2011; Regenwetter & Marley, 2001). These models involve relational preferences, which are drawn at random, so that a decision maker chooses X or Y based on whether X ≻ Y or Y ≻ X is sampled in any given trial (typically without any additional response noise or error). If variability in parameters were the only source of noise in the decision, then our above specification could be represented in terms of a random ordering.
In the supplemental materials, we provide additional analysis demonstrating corresponding distortions for a variety of different gambles.
The other two aspects of the 4-fold pattern pertain to the loss domain, in which the mirror-image pattern is generated by the interaction between the probability weighting function and a loss function, which exhibits diminishing sensitivity.
The supplemental materials examine the robustness of this result, including the implications for Tversky and Kahneman’s (1992) 4-fold pattern gambles.
In the supplemental materials, we show that this effect also emerges for Kahneman and Tversky’s (1979) classic common ratio gambles.
Specifically, we take α* values in the set (0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2, 1.3, 1.4, 1.5), which implies that α varies between 0 and 2 in the simulations. Response noise in utilities is generated by a logit choice function with θ = 1. For each value of α*, the corresponding EUT model is simulated 1,000 times on Stott’s 90 gamble pairs. For each gamble in each simulation, the model’s choice is sampled according to the choice probability in Equation 2. Again note that the same sampled value of α is used for both options within a choice, but α varies across choices.
In this recovery, we approximate the continuous uniform distribution over parameter values present in data-generating model (i.e., η uniform in [−0.5, 0.5]) with a discrete uniform distribution (η uniform over the set [0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2, 1.3, 1.4, 1.5]). This is done for computational tractability. However, it does mean that our data-generating model is not perfectly identical to the fitted model. Ultimately, the mean squared error for the fits obtained as part of this recovery is an upper bound for the MSE that could be expected if the fitted model was perfectly specified. Also note that this recovery assumes that the variance in parameters (i.e., ηα distributed uniformly in the interval [−0.5, 0.5]) is known. A more complex recovery that also estimates parameter variance should also be able to recover true parameters as already shown by Nilsson et al. (2011) and others.
Model fits are performed by maximizing log likelihood and are implemented in MATLAB using the simplex routine, with starting points for each of the fits set at αstart = α* and θstart = 1. The use of these starting points ensures that any divergence between the true underlying parameters and the recovered parameters is not due to our fits converging on suboptimal local maxima.
Note that the alternative type of misspecification also leads to incorrect inferences. If decision makers have both preference and response noise but it is (incorrectly) assumed that they have only preference noise, inferences made using either modal choices or model fits can be biased.
References
- Andersen S., Harrison G., Lau M., & Rutstrom E. (2008). Eliciting risk and time preferences. Econometrica, 76, 583–618. 10.1111/j.1468-0262.2008.00848.x [DOI] [Google Scholar]
- Becker G. M., DeGroot M. H., & Marschak J. (1963). Stochastic models of choice behavior. Behavioral Science, 8, 41–55. 10.1002/bs.3830080106 [DOI] [Google Scholar]
- Bhatia S. (2013). Associations and the accumulation of preference. Psychological Review, 120, 522–543. 10.1037/a0032457 [DOI] [PubMed] [Google Scholar]
- Bhatia S. (2014). Sequential sampling and paradoxes of risky choice. Psychonomic Bulletin & Review, 21, 1095–1111. 10.3758/s13423-014-0650-1 [DOI] [PubMed] [Google Scholar]
- Birnbaum M. H. (2008). New paradoxes of risky decision making. Psychological Review, 115, 463–501. 10.1037/0033-295X.115.2.463 [DOI] [PubMed] [Google Scholar]
- Birnbaum M. H. (2013). True-and-error models violate independence and yet they are testable. Judgment and Decision Making, 8, 717–737. [Google Scholar]
- Birnbaum M. H., & Bahra J. P. (2012). Separating response variability from structural inconsistency to test models of risky decision making. Judgment and Decision Making, 7, 402–426. [Google Scholar]
- Birnbaum M. H., & Diecidue E. (2015). Testing a class of models that includes majority rule and regret theories: Transitivity, recycling, and restricted branch independence. Decision, 2, 145–190. 10.1037/dec0000031 [DOI] [Google Scholar]
- Blavatskyy P. R., & Pogrebna G. (2010). Models of stochastic choice and decision theories: Why both are important for analyzing decisions. Journal of Applied Econometrics, 25, 963–986. 10.1002/jae.1116 [DOI] [Google Scholar]
- Block H. D., & Marschak J. (1960). Random orderings and stochastic theories of responses In Olkin I., Ghurye S. G., Hoeffding W., Madow W. G., & Mann H. B. (Eds.), Contributions to probability and statistics: Essays in honor of harold hotelling (pp. 97–132). Stanford, CA: Stanford University Press. [Google Scholar]
- Bogacz R., Usher M., Zhang J., & McClelland J. L. (2007). Extending a biologically inspired model of choice: Multi-alternatives, nonlinearity and value-based multidimensional choice. Philosophical Transactions of the Royal Society of London, Series B: Biological Sciences, 362, 1655–1670. 10.1098/rstb.2007.2059 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Broomell S., & Bhatia S. (2014). Parameter recovery for decision modeling using choice data. Decision, 1, 252–274. 10.1037/dec0000020 [DOI] [Google Scholar]
- Busemeyer J. R., & Townsend J. T. (1993). Decision field theory: A dynamic-cognitive approach to decision making in an uncertain environment. Psychological Review, 100, 432–459. 10.1037/0033-295X.100.3.432 [DOI] [PubMed] [Google Scholar]
- Butler D., Isoni A., & Loomes G. (2012). Testing the ‘standard’ model of stochastic choice under risk. Journal of Risk and Uncertainty, 45, 191–213. 10.1007/s11166-012-9154-4 [DOI] [Google Scholar]
- Carr P. B., & Steele C. M. (2010). Stereotype threat affects financial decision making. Psychological Science, 21, 1411–1416. 10.1177/0956797610384146 [DOI] [PubMed] [Google Scholar]
- Carroll J. D. (1980). Models and methods for multidimensional analysis of preferential choice (or other dominance) data In Lantermann E. D. & Feger H. (Eds.), Similarity and Choice (pp. 234–289). Bern, Switzerland: Huber. [Google Scholar]
- Charness G., & Gneezy U. (2012). Strong evidence for gender differences in risk taking. Journal of Economic Behavior & Organization, 83, 50–58. 10.1016/j.jebo.2011.06.007 [DOI] [Google Scholar]
- Diederich A. (1997). Dynamic stochastic models for decision making under time constraints. Journal of Mathematical Psychology, 41, 260–274. 10.1006/jmps.1997.1167 [DOI] [PubMed] [Google Scholar]
- Frederick S., Loewenstein G., & O’Donoghue T. (2002). Time discounting and time preference: A critical review. Journal of Economic Literature, 40, 351–401. 10.1257/jel.40.2.351 [DOI] [Google Scholar]
- Glöckner A., & Pachur T. (2012). Cognitive models of risky choice: Parameter stability and predictive accuracy of prospect theory. Cognition, 123, 21–32. 10.1016/j.cognition.2011.12.002 [DOI] [PubMed] [Google Scholar]
- Gonzalez R., & Wu G. (1999). On the shape of the probability weighting function. Cognitive Psychology, 38, 129–166. 10.1006/cogp.1998.0710 [DOI] [PubMed] [Google Scholar]
- Harless D. W., & Camerer C. F. (1994). The predictive utility of generalized expected utility theories. Econometrica, 62, 1251–1289. 10.2307/2951749 [DOI] [Google Scholar]
- Hertwig R., Barron G., Weber E. U., & Erev I. (2004). Decisions from experience and the effect of rare events in risky choice. Psychological Science, 15, 534–539. 10.1111/j.0956-7976.2004.00715.x [DOI] [PubMed] [Google Scholar]
- Hey J. D., & Orme C. (1994). Investigating generalizations of expected utility theory using experimental data. Econometrica, 62, 1291–1326. 10.2307/2951750 [DOI] [Google Scholar]
- Holt C. A., & Laury S. K. (2005). Risk aversion and incentive effects: New data without order effects. American Economic Review, 95, 902–904. 10.1257/0002828054201459 [DOI] [Google Scholar]
- Hsee C. K., & Weber E. U. (1999). Cross-national differences in risk preference and lay predictions. Journal of Behavioral Decision Making, 12, 165–180. [DOI] [Google Scholar]
- Hsu M., Krajbich I., Zhao C., & Camerer C. F. (2009). Neural response to reward anticipation under risk is nonlinear in probabilities. Journal of Neuroscience, 29, 2231–2237. 10.1523/JNEUROSCI.5296-08.2009 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jessup R. K., Bishara A. J., & Busemeyer J. R. (2008). Feedback produces divergence from prospect theory in descriptive choice. Psychological Science, 19, 1015–1022. 10.1111/j.1467-9280.2008.02193.x [DOI] [PubMed] [Google Scholar]
- Kahneman D., & Tversky A. (1979). Prospect theory: An analysis of decision under risk. Econometrica, 47, 263–291. 10.2307/1914185 [DOI] [Google Scholar]
- Krajbich I., Armel C., & Rangel A. (2010). Visual fixations and the computation and comparison of value in simple choice. Nature Neuroscience, 13, 1292–1298. 10.1038/nn.2635 [DOI] [PubMed] [Google Scholar]
- Kuhnen C. M., & Knutson B. (2005). The neural basis of financial risk taking. Neuron, 47, 763–770. 10.1016/j.neuron.2005.08.008 [DOI] [PubMed] [Google Scholar]
- Kusev P., van Schaik P., Ayton P., Dent J., & Chater N. (2009). Exaggerated risk: Prospect theory and probability weighting in risky choice. Journal of Experimental Psychology: Learning, Memory, and Cognition, 35, 1487–1505. 10.1037/a0017039 [DOI] [PubMed] [Google Scholar]
- Lee M. D., & Newell B. R. (2011). Using hierarchical Bayesian methods to examine the tools of decision-making. Judgment and Decision Making, 6, 832–840. [Google Scholar]
- Loomes G., Moffatt P. G., & Sugden R. (2002). A microeconometric test of alternative stochastic theories of risky choice. Journal of Risk and Uncertainty, 24, 103–130. 10.1023/A:1014094209265 [DOI] [Google Scholar]
- Loomes G., & Sugden R. (1995). Incorporating a stochastic element into decision theories. European Economic Review, 39, 641–648. 10.1016/0014-2921(94)00071-7 [DOI] [Google Scholar]
- Loomes G., & Sugden R. (1998). Testing different stochastic specifications of risky choice. Economica, 65, 581–598. 10.1111/1468-0335.00147 [DOI] [Google Scholar]
- Luce R. D. (1959). Individual Choice Behavior. New York, NY: Wiley and Sons. [Google Scholar]
- Luce R. D., & Suppes P. (1965). Preference, utility, and subjective probability In Luce R. D., Bush R. R., & Galanter E. (Eds.), Handbook of Mathematical Psychology (Vol. III). New York, NY: Wiley and Sons. [Google Scholar]
- Marley A. A. J., & Regenwetter M. (2016). Choice, preference, and utility: Probabilistic and deterministic representations In Batchelder W., Colonius H., Dzhafarov E., & Myung J. (Eds.), New handbook of mathematical psychology (Vol. 1, pp. 374–453). New York, NY: Cambridge University Press. [Google Scholar]
- McFadden D. (1973). Conditional logit analysis of qualitative choice behavior In Zarembka P. (Ed.), Frontiers in Econometrics (pp. 105–142). New York, NY: Academic Press. [Google Scholar]
- Mosteller F., & Nogee P. (1951). An experimental measure of utility. Journal of Political Economy, 59, 371–404. 10.1086/257106 [DOI] [Google Scholar]
- Navarro-Martinez D., Loomes G., Isoni A., & Butler D. (2014). “Boundedly rational expected utility theory”. University of Warwick working paper. [DOI] [PMC free article] [PubMed]
- Nilsson H., Rieskamp J., & Wagenmakers E. J. (2011). Hierarchical Bayesian parameter estimation for cumulative prospect theory. Journal of Mathematical Psychology, 55, 84–93. 10.1016/j.jmp.2010.08.006 [DOI] [Google Scholar]
- Oppenheimer D. M., & Kelso E. (2015). Information processing as a paradigm for decision making. Annual Review of Psychology, 66, 277–294. 10.1146/annurev-psych-010814-015148 [DOI] [PubMed] [Google Scholar]
- Pachur T., Mata R., & Hertwig R. (2017). Who dares, who errs? Disentangling cognitive and motivational roots of age differences in decisions under risk. Psychological Science, 28, 504–518. [DOI] [PubMed] [Google Scholar]
- Porcelli A. J., & Delgado M. R. (2009). Acute stress modulates risk taking in financial decision making. Psychological Science, 20, 278–283. 10.1111/j.1467-9280.2009.02288.x [DOI] [PMC free article] [PubMed] [Google Scholar]
- Prelec D. (1998). The probability weighting function. Econometrica, 66, 497–527. 10.2307/2998573 [DOI] [Google Scholar]
- Rangel A., & Hare T. (2010). Neural computations associated with goal-directed choice. Current Opinion in Neurobiology, 20, 262–270. 10.1016/j.conb.2010.03.001 [DOI] [PubMed] [Google Scholar]
- Ratcliff R., & Rouder J. N. (1998). Modeling response times for two-choice decisions. Psychological Science, 9, 347–356. 10.1111/1467-9280.00067 [DOI] [Google Scholar]
- Regenwetter M., Dana J., & Davis-Stober C. P. (2011). Transitivity of preferences. Psychological Review, 118, 42–56. 10.1037/a0021150 [DOI] [PubMed] [Google Scholar]
- Regenwetter M., & Davis-Stober C. P. (2012). Behavioral variability of choices versus structural inconsistency of preferences. Psychological Review, 119, 408–416. 10.1037/a0027372 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Regenwetter M., Davis-Stober C. P., Lim S. H., Guo Y., Popova A., Zwilling C., et al. Messner W. (2014). QTest: Quantitative testing of theories of binary choice. Decision, 1, 2–34. 10.1037/dec0000007 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Regenwetter M., & Marley A. A. J. (2001). Random relations, random utilities, and random functions. Journal of Mathematical Psychology, 45, 864–912. 10.1006/jmps.2000.1357 [DOI] [Google Scholar]
- Restle F. (1961). Psychology of Judgment and Choice. New York, NY: Wiley. [Google Scholar]
- Rieskamp J. (2008). The probabilistic nature of preferential choice. Journal of Experimental Psychology: Learning, Memory, and Cognition, 34, 1446–1465. 10.1037/a0013646 [DOI] [PubMed] [Google Scholar]
- Rieskamp J., Busemeyer J., & Mellers B. (2006). Extending the bounds of rationality: Evidence and theories of preferential choice. Journal of Economic Literature, 44, 631–661. 10.1257/jel.44.3.631 [DOI] [Google Scholar]
- Roe R. M., Busemeyer J. R., & Townsend J. T. (2001). Multialternative decision field theory: A dynamic connectionist model of decision making. Psychological Review, 108, 370–392. 10.1037/0033-295X.108.2.370 [DOI] [PubMed] [Google Scholar]
- Samuelson P. A. (1937). A note on measurement of utility. Review of Economic Studies, 4, 155–161. 10.2307/2967612 [DOI] [Google Scholar]
- Scheibehenne B., & Pachur T. (2015). Using Bayesian hierarchical parameter estimation to assess the generalizability of cognitive models of choice. Psychonomic Bulletin & Review, 22, 391–407. 10.3758/s13423-014-0684-4 [DOI] [PubMed] [Google Scholar]
- Starmer C. (2000). Developments in non-expected utility theory: The hunt for a descriptive theory of choice under risk. Journal of Economic Literature, 38, 332–382. 10.1257/jel.38.2.332 [DOI] [Google Scholar]
- Stott H. P. (2006). Cumulative prospect theory’s functional menagerie. Journal of Risk and Uncertainty, 32, 101–130. 10.1007/s11166-006-8289-6 [DOI] [Google Scholar]
- Thurstone L. L. (1927). The measurement of values. Chicago, IL: University of Chicago Press. [Google Scholar]
- Train K. E. (2009). Discrete choice methods with simulation. New York, NY: Cambridge University Press. [Google Scholar]
- Trueblood J. S., Brown S. D., & Heathcote A. (2014). The multiattribute linear ballistic accumulator model of context effects in multialternative choice. Psychological Review, 121, 179–205. 10.1037/a0036137 [DOI] [PubMed] [Google Scholar]
- Tsetsos K., Chater N., & Usher M. (2012). Salience driven value integration explains decision biases and preference reversal. Proceedings of the National Academy of Sciences, United States of America, 109, 9659–9664. 10.1073/pnas.1119569109 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tversky A., & Kahneman D. (1992). Advances in prospect theory: Cumulative representation of uncertainty. Journal of Risk and Uncertainty, 5, 297–323. 10.1007/BF00122574 [DOI] [Google Scholar]
- Usher M., & McClelland J. L. (2004). Loss aversion and inhibition in dynamical models of multialternative choice. Psychological Review, 111, 757–769. 10.1037/0033-295X.111.3.757 [DOI] [PubMed] [Google Scholar]
- Von Neumann J., & Morgenstern O. (2007). Theory of Games and Economic Behavior. Princeton, NJ: Princeton University Press. [Google Scholar]
- Wetzels R., Vandekerckhove J., Tuerlinckx F., & Wagenmakers E. J. (2010). Bayesian parameter estimation in the Expectancy Valence model of the Iowa gambling task. Journal of Mathematical Psychology, 54, 14–27. 10.1016/j.jmp.2008.12.001 [DOI] [Google Scholar]
- Wilcox N. T. (2008). Stochastic models for binary discrete choice under risk: A critical primer and econometric comparison In Cox J. C., & Harrison G. W. (Eds.), Research in Experimental Economics: Vol. 12 Risk Aversion in Experiments (pp. 197–292). Bingley, UK: Emerald Group Publishing Limited. [Google Scholar]
- Wilcox N. T. (2011). Stochastically more risk averse: A contextual theory of stochastic discrete choice under risk. Journal of Econometrics, 162, 89–104. 10.1016/j.jeconom.2009.10.012 [DOI] [Google Scholar]
- Yellott J. I., Jr. (1977). The relationship between Luce’s choice axiom, Thurstone’s theory of comparative judgment, and the double exponential distribution. Journal of Mathematical Psychology, 15, 109–144. 10.1016/0022-2496(77)90026-8 [DOI] [Google Scholar]
- Zeisberger S., Vrecko D., & Langer T. (2012). Measuring the time stability of prospect theory preferences. Theory and Decision, 72, 359–386. 10.1007/s11238-010-9234-3 [DOI] [Google Scholar]
- Zur H. B., & Breznitz S. J. (1981). The effect of time pressure on risky choice behavior. Acta Psychologica, 47, 89–104. 10.1016/0001-6918(81)90001-9 [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.