

Abstract
The Poisson distribution has been widely studied and used for modeling univariate count-valued data. Multivariate generalizations of the Poisson distribution that permit dependencies, however, have been far less popular. Yet, real-world high-dimensional count-valued data found in word counts, genomics, and crime statistics, for example, exhibit rich dependencies, and motivate the need for multivariate distributions that can appropriately model this data. We review multivariate distributions derived from the univariate Poisson, categorizing these models into three main classes: 1) where the marginal distributions are Poisson, 2) where the joint distribution is a mixture of independent multivariate Poisson distributions, and 3) where the node-conditional distributions are derived from the Poisson. We discuss the development of multiple instances of these classes and compare the models in terms of interpretability and theory. Then, we empirically compare multiple models from each class on three real-world datasets that have varying data characteristics from different domains, namely traffic accident data, biological next generation sequencing data, and text data. These empirical experiments develop intuition about the comparative advantages and disadvantages of each class of multivariate distribution that was derived from the Poisson. Finally, we suggest new research directions as explored in the subsequent discussion section.
Keywords: Poisson, Multivariate, Graphical Models, Copulas, High Dimensional
Introduction
Multivariate count-valued data has become increasingly prevalent in modern big data settings. Variables in such data are rarely independent and instead exhibit complex positive and negative dependencies. We highlight three examples of multivariate count-valued data that exhibit rich dependencies: text analysis, genomics, and crime statistics. In text analysis, a standard way to represent documents is to merely count the number of occurrences for each word in the vocabulary and create a word-count vector for each document. This representation is often known as the bag-of-words representation, in which the word order and syntax are ignored. The vocabulary size—i.e. the number of variables in the data—is usually much greater than 1000 unique words, and thus a high-dimensional multivariate distribution is required. Also, words are clearly not independent. For example, if the word “Poisson” appears in a document, then the word “probability” is more likely to also appear signifying a positive dependency. Similarly, if the word “art” appears, then the word “probability” is less likely to also appear signifying a negative dependency. In genomics, RNA-sequencing technologies are used to measure gene and isoform expression levels. These technologies yield counts of reads mapped back to DNA locations, that even after normalization, yield non-negative data that is highly skewed with many exact zeros. This genomics data is both high-dimensional, with the number of genes measuring in the tens-of-thousands, and strongly dependent, as genes work together in pathways and complex systems to produce particular phenotypes. In crime analysis, counts of crimes in different counties are clearly multidimensional, with dependencies between crime counts. For example, the counts of crime in adjacent counties are likely to be correlated with one another, indicating a positive dependency. While positive dependencies are probably more prevalent in crime statistics, negative dependencies might be very interesting. For example, a negative dependency between adjacent counties may suggest that a criminal gang has moved from one county to the other.
These examples motivate the need for a high-dimensional count-valued distribution that permits rich dependencies between variables. In general, a good class of probabilistic models is a fundamental building block for many tasks in data analysis. Estimating such models from data could help answer exploratory questions such as: Which genomic pathways are altered in a disease e.g. by analyzing genomic networks? Or, which county seems to have the strongest effect, with respect to crime, on other counties? A probabilistic model could also be used in Bayesian classification to determine questions such as: Does this Twitter post display positive or negative sentiment about a particular product (fitting one model on positive posts and one model on negative posts)?
The classical model for a count-valued random variable is the univariate Poisson distribution, whose probability mass function for x ∈ {0, 1, 2, …} is:
| (1) |
where λ is the standard mean parameter for the Poisson distribution. A trivial extension of this to a multivariate distribution would be to assume independence between variables, and take the product of node-wise univariate Poisson distributions, but such a model would be ill-suited for many examples of multivariate count-valued data that require rich dependence structures. We review multivariate probability models that are derived from the univariate Poisson distribution and permit non-trivial dependencies between variables. We categorize these models into three main classes based on their primary modeling assumption. The first class assumes that the univariate marginal distributions are derived from the Poisson. The second class is derived as a mixture of independent multivariate Poisson distributions. The third class assumes that the univariate conditional distributions are derived from the Poisson distribution—this last class of models can also be studied in the context of probabilistic graphical models. An illustration of each of these three main model classes can be seen in Fig. 1. While these models might have been classified by primary application area or performance on a particular task, a classification based on modeling assumptions helps emphasize the core abstractions for each model class. In addition, this categorization may help practitioners from different disciplines learn from the models that have worked well in different areas. We discuss multiple instances of these classes in the later sections and highlight the strengths and weaknesses of each class. We then provide a short discussion on the differences between classes in terms of interpretability and theory. Using two different empirical measures, we empirically compare multiple models from each class on three real-world datasets that have varying data characteristics from different domains, namely traffic accident data, biological next generation sequencing data, and text data. These experiments develop intuition about the comparative advantages and disadvantages of the models and suggest new research directions as explored in the subsequent discussion section.
Figure 1.
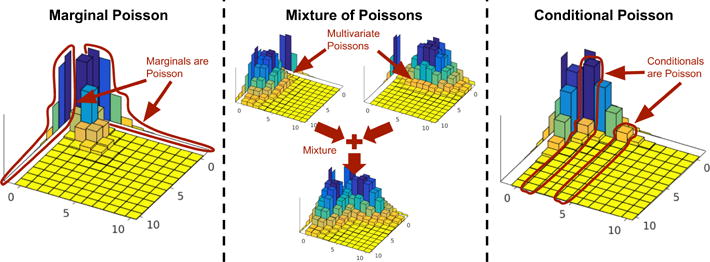
(Left) The first class of Poisson generalizations is based on the assumption that the univariate marginals are derived from the Poisson. (Middle) The second class is based on the idea of mixing independent multivariate Poissons into a joint multivariate distribution. (Right) The third class is based on the assumption that the univariate conditional distributions are derived from the Poisson.
Notation
ℝ denotes the set of real numbers, ℝ+ denotes the nonnegative real numbers, and ℝ++ denotes the positive real numbers. Similarly, denotes the set of integers. Matrices are denoted as capital letters (e.g. X, Φ), vectors are denoted as boldface lowercase letters (e.g. x, ϕ) and scalar values are non-bold lowercase letters (e.g. x, ϕ).
Marginal Poisson Generalizations
The models in this section generalize the univariate Poisson to a multivariate distribution with the property that the marginal distributions of each variable are Poisson. This is analogous to the marginal property of the multivariate Gaussian distribution, since the marginal distributions of a multivariate Gaussian are univariate Gaussian, and thus seems like a natural constraint when extending the univariate Poisson to the multivariate case. Several historical attempts at achieving this marginal property have incidentally developed the same class of models, with different derivations57;12;76;70. This marginal Poisson property can also be achieved via the more general framework of copulas77;62;59.
Multivariate Poisson Distribution
The formulation of the multivariate Poisson1 distribution goes back to M’Kendrick57 where authors use differential equations to derive the bivariate Poisson process. An equivalent but more readable interpretation to arrive at the bivariate Poisson distribution would be to use the summation of independent Poisson variables, as follows12: Let y1, y2 and z be univariate Poisson variables with parameters λ1, λ2 and λ0 respectively. Then by setting x1 = y1 + z and x2 = y2 + z, (x1, x2) follows the bivariate Poisson distribution, and its joint probability mass is defined as:
| (2) |
Since the sum of independent Poissons is also Poisson (whose parameter is the sum of those of two components), the marginal distribution of x1 (similarly x2) is still a Poisson with the rate of λ1 + λ0. It can be easily seen that the covariance of x1 and x2 is λ0 and as a result the correlation coefficient is somewhere between 0 and 29. Independently, Wicksell76 derived the bivariate Poisson as the limit of a bivariate binomial distribution. Campbell12 show that the models in M’Kendrick57 and Wicksell76 can identically be derived from the sums of 3 independent Poisson variables.
This approach to directly extend the Poisson distribution can be generalized further to handle the multivariate case , in which each variable xi is the sum of individual Poisson yi and the common Poisson x0 as before. The joint probability for a Multivariate Poisson is developed in Teicher70 and further considered by other works20;68;75;42:
| (3) |
Several have shown that this formulation of the multivariate Poisson can also be derived as a limiting distribution of a multivariate binomial distribution when the success probabilities are small and the number of trials is large46;47;35. As in the bivariate case, the marginal distribution of xi is Poisson with parameter λi + λ0. Since λ0 controls the covariance between all variables, an extremely limited set of correlations between variables is permitted.
Mahamunulu54 first proposed a more general extension of the multivariate Poisson distribution that permits a full covariance structure. This distribution has been studied further by many50;37;35;38;72. While the form of this general multivariate Poisson distribution is too complicated to spell out for d > 3, its distribution can be specified by a multivariate reduction scheme. Specifically, let yi for i = 1, …, (2d − 1) be independently Poisson distributed with parameter λi. Now, define A = [A1, A2, … Ad] where Ai is a matrix consisting of ones and zeros where each column of Ai has exactly i ones with no duplicate columns. Hence, A1 is the d × d identity matrix and Ad is a column vector of all ones. Then, x = Ay is a d-dimensional multivariate Poisson distributed random vector with a full covariance structure. Note that the simpler multivariate Poisson distribution with constant covariance in Eq. 3 is a special case of this general form where A = [A1, Ad].
The multivariate Poisson distribution has not been widely used for real data applications. This is likely due to two major limitations of this distribution. First, the multivariate Poisson distribution only permits positive dependencies; this can easily be seen as the distribution arises as the sum of independent Poisson random variables and hence covariances are governed by the positive rate parameters λi. The assumption of positive dependencies is likely unrealistic for most real count-valued data examples. Second, computation of probabilities and inference of parameters is especially cumbersome for the multivariate Poisson distribution; these are only computationally tractable for small d and hence not readily applicable in high-dimensional settings. Kano and Kawamura37 proposed multivariate recursion schemes for computing probabilities, but these schemes are only stable and computationally feasible for small d, thus complicating likelihood-based inference procedures. Karlis38 more recently proposed a latent variable based EM algorithm for parameter inference of the general multivariate Poisson distribution. This approach treats every pairwise interaction as a latent variable and conducts inference over both the observed and hidden parameters. While this method is more tractable than recursion schemes, it still requires inference over latent variables and is hence not feasible in high-dimensional settings. Overall, the multivariate Poisson distribution introduced above is appealing in that its marginal distributions are Poisson; yet, there are many modeling drawbacks including severe restriction on the types of dependencies permitted (e.g. only positive relationships), a complicated and intractable form in high-dimensions, and challenging inference procedures.
Copula Approaches
A much more general way to construct valid multivariate Poisson distributions with Poisson marginals is by pairing a copula distribution with Poisson marginal distributions. For continuous multivariate distributions, the use of copula distributions is founded on the celebrated Sklar’s theorem: any continuous joint distribution can be decomposed into a copula and the marginal distributions, and conversely, any combination of a copula and marginal distributions gives a valid continuous joint distribution66. The key advantage of such models for continuous distributions is that copulas fully specify the dependence structure hence separating the modeling of marginal distributions from the modeling of dependencies. While copula distributions paired with continuous marginal distributions enjoy wide popularity (see for example13 in finance applications), copula models paired with discrete marginal distributions, such as the Poisson, are more challenging both for theoretical and computational reasons22;60;61. However, several simplifications and recent advances have attempted to overcome these challenges65;60;61.
Copula Definition and Examples
A copula is defined by a joint cumulative distribution function (CDF), C(u): [0, 1]d → [0, 1] with uniform marginal distributions. As a concrete example, the Gaussian copula (see left subfigure of Fig. 2 for an example) is derived from the multivariate normal distribution and is one of the most popular multivariate copulas because of its flexibility in the multidimensional case; the Gaussian copula is defined simply as:
where H−1(·) denotes the standard normal inverse cumulative distribution function, and HR(·) denotes the joint cumulative distribution function of a random vector, where R is a correlation matrix. A similar multivariate copula can be derived from the multivariate Student’s t distribution if extreme values are important to model18.
Figure 2.
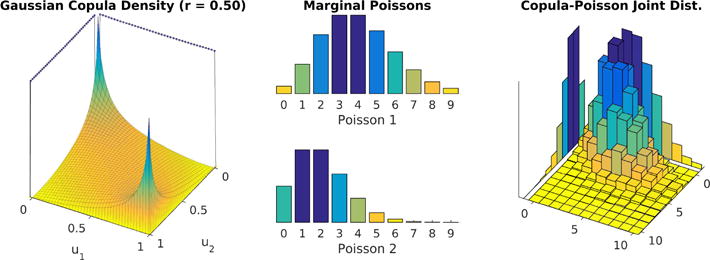
A copula distribution (left)—which is defined over the unit hypercube and has uniform marginal distributions—, paired with univariate Poisson marginal distributions for each variable (middle) defines a valid discrete joint distribution with Poisson marginals (right).
The Archimedean copulas are another family of copulas which have a single parameter that defines the global dependence between all variables71. One property of Archimedean copulas is that they admit an explicit form unlike the Gaussian copula. Unfortunately, the Archimedean copulas do not directly allow for a rich dependence structure like the Gaussian because they only have one dependence parameter rather than a parameter for each pair of variables.
Pair copula constructions (PCCs)1 for copulas, or vine copulas, allow combinations of different bivariate copulas to form a joint multivariate copula. PCCs define multivariate copulas that have an expressive dependency structure like the Gaussian copula but may also model asymmetric or tail dependencies available in Archimedean and t copulas. Pair copulas only use univariate CDFs, conditional CDFs, and bivariate copulas to construct a multivariate copula distribution and hence can use combinations of the Archimedean copulas described previously. The multivariate distributions can be factorized in a variety of ways using bivariate copulas to flexibly model dependencies. Vines, or graphical tree-like structures, denote the possible factorizations that are feasible for PCCs9.
Copula Models for Discrete Data
As per Sklar’s theorem, any copula distribution can be combined with marginal distribution CDFs to create a joint distribution:
If sampling from the given copula is possible, this form admits simple direct sampling from the joint distribution (defined by the CDF G(·)) by first sampling from the copula u ∼ Copula(θ) and then transforming u to the target space using the inverse CDFs of the marginal distributions: .
A valid multivariate discrete joint distribution can be derived by pairing a copula distribution with Poisson marginal distributions. For example, a valid joint CDF with Poisson marginals is given by
where Fi(xi | λi) is the Poisson cumulative distribution function with mean parameter λi, and θ denotes the copula parameters. If we pair a Gaussian copula with Poisson marginal distributions, we create a valid joint distribution that has been widely used for generating samples of multivariate count data77;78;16—an example of the Gaussian copula paired with Poisson marginals to form a discrete joint distribution can be seen in Fig. 2.
Nikoloulopoulos59 present an excellent survey of copulas to be paired with discrete marginals by defining several desired properties of a copula (quoted from59):
Wide range of dependence, allowing both positive and negative dependence.
Flexible dependence, meaning that the number of bivariate marginals is (approximately) equal to the number of dependence parameters.
Computationally feasible cumulative distribution function (CDF) for likelihood estimation.
Closure property under marginalization, meaning that lower-order marginals belong to the same parametric family.
No joint constraints for the dependence parameters, meaning that the use of covariate functions for the dependence parameters is straightforward.
Each copula model satisfies some of these properties but not all of them. For example, Gaussian copulas satisfy properties (1), (2) and (4) but not (3) or (5) because the normal CDF is not known in closed form and the positive definiteness constraint on the correlation matrix. Nikoloulopoulos59 recommend Gaussian copulas for general models and vine copulas if modeling dependence in the tails or asymmetry is needed.
Theoretical Properties of Copulas Derived from Discrete Distributions
From a theoretical perspective, a multivariate discrete distribution can be viewed as a continuous copula distribution paired with discrete marginals but the derived copula distributions are not unique and hence, are unidentifiable22. Note that this is in contrast to continuous multivariate distributions where the derived copulas are uniquely defined67. Because of this non-uniqueness property, Genest and Nešlehová22 caution against performing inference on and interpreting dependencies of copulas derived from discrete distributions. A further consequence of non-uniqueness is that when copula distributions are paired with discrete marginal distributions, the copulas no longer fully specify the dependence structure as with continuous marginals22. In other words, the dependencies of the joint distribution will depend in part on which marginal distributions are employed. In practice, this often means that the range of dependencies permitted with certain copula and discrete marginal distribution pairs is much more limited than the copula distribution would otherwise model. However, several have suggested that this non-uniqueness property does not have major practical ramifications59;39.
We discuss a few common approaches used for the estimation of continuous copulas with discrete marginals.
Continuous Extension for Parameter Estimation
For estimation of continuous copulas from data, a two-stage procedure called Inference Function for Marginals (IFM)34 is commonly used in which the marginal distributions are estimated first and then used to map the data onto the unit hypercube using the CDFs of the inferred marginal distributions. While this is straightforward for continuous marginals, this procedure is less obvious for discrete marginal distributions when using a continuous copula. One idea is to use the continuous extension (CE) of integer variables to the continuous domain19 by forming a new “jitter” continuous random variable :
where u is a random variable defined on the unit interval. It is straightforward to see that this new random variable is continuous and . An obvious choice for the distribution of u is the uniform distribution. With this idea, inference can be performed using a surrogate likelihood by randomly projecting each discrete data point into the continuous domain and averaging over the random projections as done in27;28. Madsen52; Madsen and Fang53 use the CE idea as well but generate multiple jittered samples for each original observation x to estimate the discrete likelihood rather than merely generating one jittered sample for each original observation x as in27;28. Nikoloulopoulos60 find that CE-based methods significantly underestimate the correlation structure because the CE jitter transform operates independently for each variable instead of considering the correlation structure between the variables.
Distributional Transform for Parameter Estimation
In a somewhat different direction, Rüschendorf65 proposed the use of a generalization of the CDF distribution function F (·) for the case with discrete variables, which they term a distributional transform (DT) denoted by :
where v ∼ Uniform(0, 1). Note that in the continuous case, ℙ(X = x) = 0 and thus this reduces to the standard CDF for continuous distributions. One way of thinking of this modified CDF is that the random variable v adds a random jump when there are discontinuities in the original CDF. If the distribution is discrete (or more generally if there are discontinuities in the original CDF), this transformation enables a simple proof of a theorem akin to Sklar’s theorem for discrete distributions65.
Kazianka and Pilz44; Kazianka43 propose using the distributional transform (DT) from65 to develop a simple and intuitive approximation for the likelihood. Essentially, they simply take the expected jump value of (where v ~ Uniform(0, 1)) and thus transform the discrete data to the continuous domain by the following:
which can be seen as simply taking the average of the CDF values at xi −1 and xi. Then, they use a continuous copula such as the Gaussian copula. Note that this is much simpler to compute than the simulated likelihood (SL) method in60 or the continuous extension (CE) methods in27;28;52;53, which require averaging over many different random initializations.
Simulated Likelihood for Parameter Estimation
Finally,60 propose a method to directly approximate the maximum likelihood estimate by estimating a discretized Gaussian copula. Essentially, unlike the CE and DT methods which attempt to transform discrete variables to continuous variables, the MLE for a Gaussian copula with discrete marginal distributions F1, F2, …, Fd can be formulated as estimating multivariate normal rectangular probabilities:
| (4) |
where γ are the marginal distribution parameters, ϕ−1(·) is the univariate standard normal inverse CDF, and ΦR(⋯) is the multivariate normal density with correlation matrix R. Nikoloulopoulos 60 propose to approximate the multivariate normal rectangular probabilities via fast simulation algorithms discussed in23. Because this method directly approximates the MLE via simulated algorithms, this method is called simulated likelihood (SL). Nikoloulopoulos61 compare the DT and SL methods for small sample sizes and find that the DT method tends to overestimate the correlation structure. However, because of the computational simplicity, Nikoloulopoulos61 give some heuristics of when the DT method might work well compared to the more accurate but more computationally expensive SL method.
Vine Copulas for Discrete Distributions
Panagiotelis et al.63 provide conditions under which a multivariate discrete distribution can be decomposed as a vine PCC copula paired with discrete marginals. In addition, Panagiotelis et al.63 show that likelihood computation for vine PCCs with discrete marginals is quadratic as opposed to exponential as would be the case for general multivariate copulas such as the Gaussian copula with discrete marginals. However, computation in truly high-dimensional settings remains a challenge as 2d(d − 1) bivariate copula evaluations are required to calculate the PMF or likelihood of a d-variate PCC using the algorithm proposed by Panagiotelis et al.63. These bivariate copula evaluations, however, can be coupled with some of the previously discussed computational techniques such as continuous extensions, distributional transforms, and simulated likelihoods for further computational improvements. Finally, while vine PCCs offer a very flexible modeling approach, this comes with the added challenge of selecting the vine construction and bivariate copulas17, which has not been well studied for discrete distributions. Overall, Nikoloulopoulos59 recommend using vine PCCs for complex modeling of discrete data with tail dependencies and asymmetric dependencies.
Summary of Marginal Poisson Generalizations
We have reviewed the historical development of the multivariate Poisson which has Poisson marginals and then reviewed many of the recent developments of using the much more general copula framework to derive Poisson generalizations with Poisson marginals. The original multivariate Poisson models based on latent Poisson variables are limited to positive dependencies and require computationally expensive algorithms to fit. However, estimation of copula distributions paired with Poisson marginals—while theoretically has some caveats—can be performed efficiently in practice. Simple approximations such as the expectation under the distributional transformation can provide nearly trivial transformations that move the discrete variables to the continuous domain in which all the tools of continuous copulas can be exploited. More complex transformations such as the simulated likelihood method60 can be used if the sample size is small or high accuracy is needed.
Poisson Mixture Generalizations
Instead of directly extending univariate Poissons to the multivariate case, a separate line of work proposes to indirectly extend the Poisson based on the mixture of independent Poissons. Mixture models are often considered to provide more flexibility by allowing the parameter to vary according to a mixing distribution. One important property of mixture models is that they can model overdispersion. Overdispersion occurs when the variance of the data is larger than the mean of the data—unlike in a Poisson distribution in which the mean and variance are equal. One way of quantifying dispersion is the dispersion index:
| (5) |
If δ > 1, then the distribution is overdispersed whereas if δ < 1, then the distribution is underdispersed. In real world data as will be seen in the experimental section, overdispersion is more common than underdispersion. Mixture models also enable dependencies between the variables as will be described in the following paragraphs.
Suppose that we are modeling univariate random variable x with a density of f(x|θ). Rather than assuming θ is fixed, we let θ itself to be a random variable following some mixing distribution. More formally, a general mixture distribution can be defined as41:
| (6) |
where the parameter θ is assumed to come from the mixing distribution g(θ) and Θ is the domain of θ.
For the Poisson case, let be a d-dimensional vector whose i-th element λi is the parameter of the Poisson distribution for xi. Now, given some mixing distribution g(λ), the family of Poisson mixture distributions is defined as
| (7) |
where the domain of the joint distribution is any count-valued assignment (i.e. xi ∈ ℤ+, ∀i). While the probability density function (Eq. 7) has the complicated form involving a multidimensional integral (a complex, high-dimensional integral when d is large), the mean and variance are known to be expressed succinctly as
| (8) |
| (9) |
Note that Eq. 9 implies that the variance of a mixture is always larger than the variance of a single distribution. The higher order moments of x are also easily represented by those of λ. Besides the moments, other interesting properties (convolutions, identifiability etc.) of Poisson mixture distributions are extensively reviewed and studied in Karlis and Xekalaki41.
One key benefit of Poisson mixtures is that they permit both positive as well as negative dependencies simply by properly defining g(λ). The intuition behind these dependencies can be more clearly understood when we consider the sample generation process. Suppose that we have the distribution g(λ) in two dimensions (i.e. d = 2) with a strong positive dependency between λ1 and λ2. Then, given a sample (λ1, λ2) from g(λ), x1 and x2 are likely to also be positively correlated.
In an early application of the model, Arbous and Kerrich8 constrain the Poisson parameters as the different scales of common gamma variable λ: for i = 1, …, d, the time interval ti is given and λi is set to tiλ. Hence, g(λ) is a univariate gamma distribution specified by λ ∈ ℝ++—which only allows simple dependency structure. Steyn69, as another early attempt, choose the multivariate normal distribution for the mixing distribution g(λ) to provide more flexibility on the correlation structure. However, the normal distribution poses problems because λ must reside in ℝ++ while the the normal distribution is defined on ℝ.
One of the most popular choice for g(λ) is the log-normal distribution thanks to its rich covariance structure and natural positivity constraint2:
| (10) |
The log-normal distribution above is parameterized by μ and Σ, which are the mean and the covariance of (log λ1, log λ2, ⋯, log λd), respectively. Setting the random variable xi to follow the Poisson distribution with parameter λi, we have the multivariate Poisson log-normal distribution3 from Eq. 7:
| (11) |
While the joint distribution (Eq. 11) does not have a closed-form expression and hence as d increases, it becomes computationally cumbersome to work with, its moments are available in closed-form as a special case of Eq. 9:
| (12) |
The correlation and the degree of overdispersion (defined as the variance divided by the mean) of the marginal distributions are strictly coupled by α and σ. Also, the possible Spearman’s ρ correlation values for this distribution are limited if the mean value αi is small. To briefly explore this phenomena, we simulated a two-dimensional Poisson log-normal model with mean zero and covariance matrix:
which corresponds to a mean value of αi per Eq. 12 and the strongest positive and negative correlation possible between the two variables. We simulated one million samples from this distribution and found that when fixing αi = 2, the Spearman’s ρ values are between −0.53 and 0.58. When fixing αi = 10, the Spearman’s ρ values are between −0.73 and 0.81. Thus, for small mean values, the log-normal mixture is limited in modeling strong dependencies but for large mean values the log-normal mixture can model stronger dependencies. Besides the examples provided here, various Poisson mixture models from different mixing distributions are available although limited in the applied statistical literature due to their complexities. See Karlis and Xekalaki41 and the references therein for more examples of Poisson mixtures. Karlis and Xekalaki41 also provide the general properties of mixtures as well as the specific ones of Poisson mixtures such as moments, convolutions, and the posterior.
While this review focuses on modeling multivariate count-valued responses without any extra information, the several extensions of multivariate Poisson log-normal models have been proposed to provide more general correlation structures when covariates are available14;51;64;21;2;83. These works formulate the mean parameter of log-normal mixing distribution, log μi, as a linear model on given covariates in the Bayesian framework.
In order to alleviate the computational burden of using log-normal distributions as an infinite mixing density as above, Karlis and Meligkotsidou40 proposed an EM type estimation for a finite mixture of k > 1 Poisson distributions, which still preserves similar properties such as both positive and negative dependencies, as well as closed form moments. While40 consider mixing multivariate Poissons with positive dependencies, the simplified form where the component distributions are independent Poisson distributions is much simpler to implement using an expectation-maximization (EM) algorithm. This simple finite mixture distribution can be viewed as a middle ground between a single Poisson and a non-parametric estimation method where a Poisson is located at every training point—i.e. the number of mixtures is equal to the number of training data points (k = n).
The gamma distribution is another common mixing distribution for the Poisson because it is the conjugate distribution for the Poisson mean parameter λ. For the univariate case, if the mixing distribution is gamma, then the resulting univariate distribution is the well-known negative binomial distribution. The negative binomial distribution can handle overdispersion in count-valued data when the variance is larger than the mean. Unlike the Poisson log-normal mixture, the univariate gamma-Poisson mixture density—i.e. the negative binomial density—is known in closed form:
As r → ∞, the negative binomial distribution approaches the Poisson distribution. Thus, this can be seen as a generalization of the Poisson distribution. Note that the variance of this distribution is always larger than the Poisson distribution with the same mean value.
In a similar vein to using the gamma distribution, if instead of putting a prior on the Poisson mean parameter λ, we reparametrize the Poisson distribution by the log Poisson mean parameter θ = log(λ), then the log-gamma distribution is conjugate to parameter θ. Bradley et al.11 recently leveraged the log-gamma conjugacy to the Poisson log-mean parameter θ by introducing the Poisson log-gamma hierarchical mixture distribution. In particular, they discuss the multivariate log-gamma distribution that can have flexible dependency structure similar to the multivariate log-normal distribution and illustrate some modeling advantages over the log-normal mixture model.
Summary of Mixture Model Generalizations
Overall, mixture models are particularly helpful if there is overdispersion in the data—which is often the case for real-world data as seen in the experiments section—while also allowing for variable dependencies to be modeled implicitly through the mixing distribution. If the data exhibits overdispersion, then the log-normal or log-gamma distributions11 give somewhat flexible dependency structures. The principal caveat with complex mixture of Poisson distributions is computational; exact inference of the parameters is typically computationally difficult due to the presence of latent mixing variables. However, simpler models such as the finite mixture using simple expectation maximization (EM) may provide good results in practice (see comparison section).
Conditional Poisson Generalizations
While the multivariate Poisson formulation in Eq. 3 as well as the distribution formed by pairing a copula with Poisson marginals assume that univariate marginal distributions are derived from the Poisson, a different line of work generalizes the univariate Poisson by assuming the univariate node-conditional distributions are derived from the Poisson10;79;80;82;31;32. Like the assumption of Poisson marginals in previous sections, this conditional Poisson assumption seems a different yet natural extension of the univariate Poisson distribution. The multivariate Gaussian can be seen to satisfy such a conditional property since the node-conditional distributions of a multivariate Gaussian are univariate Gaussian. One benefit of these conditional models is that they can be seen as undirected graphical models or Markov Random Fields, and they have a simple parametric form. In addition, estimating these models generally reduces to estimating simple node-wise regressions, and some of these estimators have theoretical guarantees on estimating the global graphical model structure even under high-dimensional sampling regimes, where the number of variables (d) is potentially even larger than the number of samples (n).
Background on Exponential Family Distributions
We briefly describe exponential family distributions and graphical models which form the basis for the conditional Poisson models. Many commonly used distributions fall into this family, including Gaussian, Bernoulli, exponential, gamma, and Poisson, among others. The exponential family is specified by a vector of sufficient statistics denoted by T(x) ≡ [T1(x), T2(x), ⋯, Tm(x)], the log base measure B(x) and the domain of the random variable . With this notation, the generic exponential family is defined as:
where η are called the natural or canonical parameters of the distribution, μ is the Lebesgue or counting measure depending on whether is continuous or discrete respectively, and A(η) is called the log partition function or log normalization constant because it normalizes the distribution over the domain . Note that the sufficient statistics can be any arbitrary function of x; for example, Ti(x) = x1x2 could be used to model interaction between x1 and x2. The log partition function A(η) will be a key quantity when discussing the following models: A(η) must be finite for the distribution to be valid, so that the realizable domain of parameters is given by . Thus, for instance, if the realizable domain only allows positive or negative interaction terms, then the set of allowed dependencies would be severely restricted.
Let us now consider the exponential family form of the univariate Poisson:
| (13) |
where η ≡ log(λ) is the natural parameter of the Poisson, T(x) = x is the Poisson sufficient statistic, − log(x!) is the Poisson log base measure and A(η) = exp(η) is the Poisson log partition function. Note that for the general exponential family distribution, the log partition function may not have a closed form.
Background on Graphical Models
The graphical model over x given some graph —a set of nodes and edges—is a set of distributions on x that satisfy the Markov independence assumptions with respect to 48. In particular, an undirected graphical model gives a compact way to represent conditional independence among random variables—the Markov properties of the graph. Conditional independence relaxes the notion of full independence by defining which variables are independent given that other variables are fixed or known.
More formally, let be an undirected graph over d nodes in corresponding d random variables in x where is the set of undirected edges connecting nodes in . By the Hammersley-Clifford theorem15, any such distribution has the following form:
| (14) |
where is a set of cliques (fully-connected subgraphs) of and TC(xC) are the clique-wise sufficient statistics. For example, if , then there would be a term η1,2,3T1,2,3(x1, x2, x3) which involves the first, second and third random variables in x Hence, a graphical model can be understood as an exponential family distribution with the form given in Eq. 14. An important special case—which will be the focus in this paper—is a pairwise graphical model, where consists of merely and —i.e. |C|={1,2}, , so that we have
Since graphical models provide direct interpretations on the Markov independence assumptions, for the Poisson-based graphical models in this section, we can easily investigate the conditional independence relationships between random variables rather than marginal correlations.
As an example, we will consider the Gaussian graphical model formulation of the standard multivariate normal distribution (for simplicity we will assume the mean vector is zero, i.e. μ = 0):
| (15) |
| (16) |
Note how Eq. 16 is related to Eq. 14 by setting ηi = θii, ηij = θij, , Tij(xi, xj) = xixj and — i.e. the edges in the graph correspond to the non-zeros in Θ. In addition, this example shows that the marginal moments—i.e. the covariance matrix Σ—are quite different from the graphical model parameters—i.e. the negative of the inverse covariance matrix . In general, for graphical models such as the Poisson graphical models defined in the next section, the transformation from the covariance to the graphical model parameter (Eq. 15) is not known in closed-form; in fact, this transformation is often very difficult to compute for non-Gaussian models73. For more information about graphical models and exponential families see45;73.
Poisson Graphical Model
The first to consider multivariate extensions constructed by assuming conditional distributions are univariate exponential family distributions, such as and including the Poisson distribution, was Besag10. In particular, suppose all node-conditional distributions—the conditional distribution of a node conditioned on the rest of the nodes—are univariate Poisson. Then, there is a unique joint distribution consistent with these node-conditional distributions under some conditions, and moreover this joint distribution is a graphical model distribution that factors according to a graph specified by the node-conditional distributions. In fact, this approach can be uniformly applicable for any exponential family beyond the Poisson distribution, and can be extended to more general graphical model settings79;82 beyond the pairwise setting in10. The particular instance with the univariate Poisson as the exponential family underlying the node-conditional distributions is called a Poisson graphical model (PGM).3
Specifically, suppose that for every i ∈ {1, ⋯, d}, the node-conditional distribution is specified by univariate Poisson distribution in exponential family form as specified in Eq. 13:
| (17) |
where x−i is the set of all xj except xi, and the function ψ(x−i) is any function that depends on the rest of all random variables except xi. Further suppose that the corresponding joint distribution on x factors according to the set of cliques of a graph . Yang et al.82 then show that such a joint distribution consistent with the above node-conditional distributions exists, and moreover necessarily has the form
| (18) |
where the function A(η) is the log-partition function on all parameters . The pairwise PGM, as a special case, is defined as follows:
| (19) |
where is the set of edges of the graphical model and . For notational simplicity and development of extensions to PGM, we will gather the node parameters ηi into a vector θ = [η1, η2, ⋯, ηd] ∈ ℝd and gather the edge parameters into a ·, symmetric matrix Φ ∈ ℝd×d such that and . Note that for PGM, Φ has zeros along the diagonal. With this notation, the pairwise PGM can be equivalently represented in a compact vectorized form as:
| (20) |
Parameter estimation in a PGM is naturally suggested by its construction: all of the PGM parameters in Eq. 20 can be estimated by considering the node-conditional distributions for each node separately, and solving an ℓ1-regularized Poisson regression for each variable. In contrast to the previous approaches in the sections above, this parameter estimation approach is not only simple, but is also guaranteed to be consistent even under high dimensional sampling regimes, under some other mild conditions including a sparse graph structural assumption (see Yang et al.79,82 for more details on the analysis). As in Poisson log-normal models, the parameters of PGM can be made to depend on covariates to allow for more flexible correlations81.
In spite of its simple parameter estimation method, the major drawback with this vanilla Poisson graphical model distribution is that it only permits negative conditional dependencies between variables:
Proposition 1 (Besag10)
Consider the Poisson graphical model distribution in Eq. 20. Then, for any parameters θ and Φ, APGM(θ, Φ) < +∞ only if the pairwise parameters are non-positive: .
Intuitively, if any entry in Φ, say Φij, is positive, the term Φijxixj in Eq. 20 would grow quadratically, whereas the log base measure terms −log(xi!)− −log(xj!) only decreases as O(xi log xi + xj log xj), so A(θ, Φ) → ∞ as xi,xj → ∞. Thus, even though the Poisson graphical model is a natural extension of the univariate Poisson distribution (from the node-conditional viewpoint), it entails a highly restrictive parameter space, with severely limited applicability. Thus, multiple PGM extensions attempt to relax this negativity restriction to permit positive dependencies as described next.
Extensions of Poisson Graphical Models
To circumvent the severe limitations of the PGM distribution which in particular only permits negative conditional dependencies, several extensions to PGM that permit a richer dependence structure have been proposed.
Truncated PGM
Because the negativity constraint is due in part to the infinite domain of count variable, a natural solution would be to truncate the domain of variables. It was Kaiser and Cressie36 who first introduced an approach to truncate the Poisson distribution in the context of graphical models. Their idea was simply to use a Winsorized Poisson distribution for node-conditional distributions: x is a Winsorized Poisson if , where z′ is Poisson, is an indicator function, and R is a fixed positive constant denoting the truncation level. However, Yang et al.80 showed that Winsorized node-conditional distributions actually does not lead to a consistent joint distribution.
As an alternative way of truncation, Yang et al.80 instead keep the same parametric form as PGM (Eq. 20) but merely truncate the domain to non-negative integers less than or equal to R—i.e. , so that the joint distribution takes the form82:
| (21) |
As they show, the node-conditional distributions of this graphical model distribution belong to an exponential family that is Poisson-like, but with the domain bounded by R. Thus, the key difference from the vanilla Poisson graphical model (Eq. 20) is that the domain is finite, and hence the log partition function ATPGM(·) only involves a finite number of summations. Thus, no restrictions are imposed on the parameters for the normalizability of the distribution.
Yang et al.80 discuss several major drawbacks to TPGM. First, the domain needs to be bounded a priori, so that R should ideally be set larger than any unseen observation. Second, the effective range of parameter space for a non-degenerate distribution is still limited: as the truncation value R increases, the effective values of pairwise parameters become increasingly negative or close to zero—otherwise, the distribution can be degenerate placing most of its probability mass at 0 or R.
Quadratic PGM and Sub-Linear PGM
Yang et al.80 also investigate the possibility of Poisson graphical models that (a) allows both positive and negative dependencies, as well as (b) allow the domain to range over all non-negative integers. As described previously, a key reason for the negative constraint on the pairwise parameters ϕij in Eq. 20 is that the log base measure scales more slowly than the quadratic pairwise term xT Φx where . Yang et al.80 thus propose two possible solutions: increase the base measure or decrease the quadratic pairwise term.
First, if we modify the base measure of Poisson distribution with “Gaussian-esque” quadratic functions (note that for the linear sufficient statistics with positive dependencies, the base measures should be quadratic at the very least80), then the joint distribution, which they call a quadratic PGM, is normalizable while allowing both positive and negative dependencies80:
| (22) |
Essentially, QPGM has the same form as the Gaussian distribution, but where its domain is the set of non-negative integers. The key differences from PGM are that Φ can have negative values along the diagonal, and the Poisson base measure is replaced by the quadratic term . Note that a sufficient condition distribution to be normalizable is given by:
| (23) |
for some constant c > 0, which in turn can be satisfied if Φ is negative definite. One significant drawback of QPGM is that the tail is Gaussian-esque and thin rather than Poisson-esque and thicker as in PGM.
Another possible modification is to use sub linear sufficient statistics in order to preserve the Poisson base measure and possibly heavier tails. Consider the following univariate distribution over count-valued variables:
| (24) |
which has the same base measure log z! as the Poisson, but with the following sub-linear sufficient statistics:
| (25) |
For values of x up to R0, T(x) increases linearly, while after R0 its slope decreases linearly, and finally after R, T(x) becomes constant. The joint graphical model, which they call a sub-linear PGM (SPGM), specified by the node-conditional distributions belonging to the family in Eq. 24, has the following form:
| (26) |
where
| (27) |
and T(x) is the entry-wise application of the function in Eq. 25. SPGM is always normalizable for ϕij ∈ ℝ∀i ≠ j80.
The main difficulty in estimating Poisson graphical model variants above with infinite domain is the lack of closed-form expressions for the log partition function, even just for the node-conditional distributions that are needed for parameter estimation. Yang et al.80 propose an approximate estimation procedure that uses the univariate Poisson and Gaussian log partition functions as upper bounds for the node-conditional log-partition functions for the QPGM and SPGM models respectively.
Poisson Square Root Graphical Model
In the similar vein as SPGM in the earlier section, Inouye et al.32 consider the use of exponential families with square-root sufficient statistics. While they consider general graphical model families, their Poisson graphical model variant can be written as:
| (28) |
where ϕii can be non-zero in contrast to the zero diagonal of the parameter matrix in Eq. 20. As with PGM, when there are no edges (i.e. ϕij = 0 ∀i ≠ j) and θ = 0, this reduces to the independent Poisson model. The node conditionals of this distribution have the form:
| (29) |
where ϕi,−i is the i-th column of Φ with the the i-th entry removed. This can be rewritten in the form of a two parameter exponential family:
| (30) |
where η1 = ϕii, and A(η1, η2) is the log partition function. Note that a key difference with the PGM variants in the previous section is that the diagonal of ΦSQR can be non-zero whereas the diagonal of ΦPGM must be zero. Because the interaction term is asymptotically linear rather than quadratic, the Poisson SQR graphical model does not suffer from the degenerate distributions of TPGM as well as the FLPGM discussed in the next section, while still allowing both positive and negative dependencies.
To show that SQR graphical models can easily be normalized, Inouye et al.32 first define radial-conditional distributions. The radial-conditional distribution assumes the unit direction is fixed but the length of the vector is unknown. The difference between the standard 1D node conditional distributions and the 1D radial-conditional distributions is illustrated in Fig. 3. Suppose we condition on the unit direction of the sufficient statistics but the scaling of this unit direction z = ║x║1 is unknown. With this notation, Inouye et al.32 define the radial-conditional distribution as:
Figure 3.
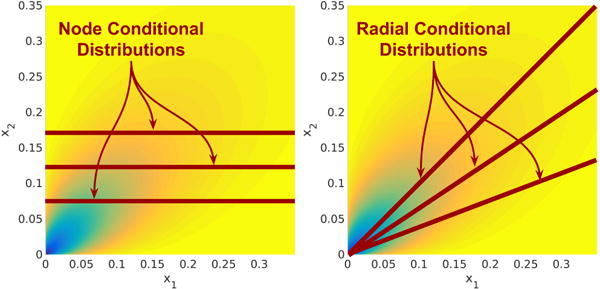
Node-conditional distributions (left) are univariate probability distributions of one variable conditioned on the other variables, while radial-conditional distributions are univariate probability distributions of the vector scaling conditioned on the vector direction. Both conditional distributions are helpful in understanding SQR graphical models. (Illustration from32.)
Similar to the node-conditional distribution, the radial-conditional distribution can be rewritten as a two parameter exponential family:
| (31) |
where , and . The only difference between this exponential family and the node-conditional distribution is the different base measure—i.e. . However, note that the log base measure is still O(−z log(z)) and thus, the base measure will overcome the linear term as z → ∞. Therefore, the radial-conditional distribution is normalizable for any .
With the radial-conditional distributions notation, Inouye et al.32 show that the log partition function for Poisson SQR graphical models is finite by separating the summation into a nested radial direction and scalar summation. Let be the set of unit vectors in the positive orthant. The SQR log partition function ASQR(θ, Φ) can be decomposed into nested summation over the unit direction and the one dimensional radial conditional:
| (32) |
where and are the radial conditional parameters as defined above and . Note that , and thus the inner summation can be replaced by the radial-conditional log partition function. Therefore, because is a bounded set and the radial-conditional log partition function is finite for any and , ASQR < ∞ and the Poisson SQR joint distribution is normalizable.
The main drawback to the Poisson SQR is that for parameter estimation, the log partition function A(η1, η2) of the node conditionals in Eq. 30 is not known in closed form in general. Inouye et al.32 provide a closed-form estimate for the exponential SQR but a closed-form solution for the Poisson SQR model seems unlikely to exist. Inouye et al.32 suggest numerically approximating A(η1, η2), since it only requires a one dimensional summation.
Local PGM
Inspired by the neighborhood selection technique of Meinshausen and Bühlmann55, Allen and Liu4,5 propose to estimate the network structure of count-valued data by fitting a series of ℓ1-regularized Poisson regressions to estimate the node-neighborhoods. Such an estimation method may yield interesting network estimates, but as Allen and Liu5 note, these estimates do not correspond to a consistent joint density. Instead, the underlying model is defined in terms of a series of local models where each variable is conditionally Poisson given its node-neighbors; this approach is thus termed the local Poisson graphical model (LPGM). Note that LPGM does not impose any restrictions on the parameter space or types of dependencies; if the parameter space of each local model was constrained to be non-positive, then the LPGM reduces to the vanilla Poisson graphical model as previously discussed. Hence, the LPGM is less interesting as a candidate multivariate model for count-valued data, but many may still find its simple and interpretable network estimates appealing. Recently, several have proposed to adopt this estimation strategy for alternative network types25;26.
Fixed-Length Poisson MRFs
In a somewhat different direction, Inouye et al.31 propose a distribution that has the same parametric form as the original PGM, but allows positive dependencies by decomposing the joint distribution into two distributions. The first distribution is the marginal distribution over the length of the vector denoted ℙ(L)—i.e. the distribution of the ℓ1-norm of the vector or the total sum of counts. The second distribution, the fixed-length Poisson graphical model (FLPGM), is the conditional distribution of PGM given the fact that the vector length L is known or fixed, denoted ℙFLPGM(x | ║x║1 = L). Note that this allows the marginal distribution on length and the distribution given the length to be specified independently.4 The restriction to negative dependencies is removed because the second distribution given the vector length ℙFLPGM(x | ║x║1 = L) has a finite domain and is thus trivially normalizable—similar to the normalizability of the finite-domain TPGM. More formally, Inouye et al.31 defined the FLPGM as:
| (33) |
| (34) |
where λ is the parameter for the marginal length distribution—which could be Poisson, negative binomial or any other distribution on nonnegative integers. In addition, FLPGM could be used as a replacement for the multinomial distribution because it has the same domain as the multinomial and actually reduces to the multinomial if there are no dependencies. Earlier, Altham and Hankin7 developed an identical model by generalizing an earlier bivariate generalization of the binomial6. However, in7;6, the model assumed that L was constant over all samples, whereas31 allowed for L to vary for each sample according to some distribution ℙ(L).
One significant drawback is that FLPGM is not amenable to the simple node-wise parameter estimation method of the previous PGM models. Nonetheless, in Inouye et al.31, the parameters are heuristically estimated with Poisson regressions similar to PGM, though the theoretical properties of this heuristic estimate are unknown. Another drawback is that while FLPGM allows for positive dependencies, the distribution can yet yield a degenerate distribution for large values of L—similar to the problem of TPGM where the mass is concentrated near 0 or R. Thus, Inouye et al.31 introduce a decreasing weighting function ω(L) that scales the interaction term:
| (35) |
While the log-likelihood is not available in tractable form, Inouye et al.31 approximate the log likelihood using annealed importance sampling58, which might be applicable to the extensions covered previously as well.
Summary of Conditional Poisson Generalizations
The conditional Poisson models benefit from the rich literature in exponential families and undirected graphical models, or Markov Random Fields. In addition, the conditional Poisson models have a simple parametric form. The historical Poisson graphical model—or the auto-Poisson model10)—only allowed negative dependencies between variables. Multiple extensions have sought to overcome this severe limitation by altering the Poisson graphical model so that the log partition function is finite even with positive dependencies. One major drawback to graphical model approach is that computing the likelihood requires approximation of the joint log partition function A(θ, Φ); a related problem is that the distribution moments and marginals are not known in closed-form. Despite these drawbacks, parameter estimation using composite likelihood methods via ℓ1-penalized node-wise regressions (in which the joint likelihood is not computed) has solid theoretical properties under certain conditions.
Model Comparison
We compare models by first discussing two structural aspects of the models: (a) interpretability and (b) the relative stringency and ease of verifying theoretical assumptions and guarantees. We then present and discuss an empirical comparison of the models on three real-world datasets.
Comparison of Model Interpretation
Marginal models can be interpreted as weakly decoupling modeling marginal distributions over individual variables, from modeling the dependency structure over the variables. However, in the discrete case, specifically for distributions based on pairing copulas with Poisson marginals, the dependency structure estimation is also dependent on the marginal estimation, unlike for copulas paired with continuous marginals22. Conditional models or graphical models, on the other hand, can be interpreted as specifying generative models for each variable given the variable’s neighborhood (i.e. the conditional distribution). In addition, dependencies in graphical models can be visualized and interpreted via networks. Here, each variable is a node and the weighted edges in the network structure depict the pair-wise conditional dependencies between variables. The simple network depiction for graphical models may enable domain experts to interpret complex dependency structures more easily compared to other models. Overall, marginal models may be preferred if modeling the statistics of the data, particularly the marginal statistics over individual variables, is of primary importance, while conditional models may be preferred if prediction of some variables given others is of primary importance. Mixture models may be more or less difficult to interpret depending on whether there is an application-specific interpretation of the latent mixing variable. For example, a finite mixture of two Poisson distributions may model the crime statistics of a city that contains downtown and suburban areas. On the other hand, a finite mixture of fifty Poisson distributions or a log-normal Poisson mixture when modeling crash severity counts (as seen in the empirical comparison section) seems more difficult to interpret; even the model empirically well fits the data, the hidden mixture variable might not have an obvious application-specific interpretation.
Comparison of Theoretical Considerations
Estimation of marginal models from data has various theoretical problems, as evidenced by the analysis of copulas paired with discrete marginals in22. The extent to which these theoretical problems cause any significant practical issues remains unclear. In particular, the estimators of the marginal distributions themselves typically have easily checked assumptions since the empirical marginal distributions can be inspected directly. On the other hand, the estimation of conditional models is both computationally tractable, and comes with strong theoretical guarantees even under high-dimensional regimes where n < d82. However the assumptions under which the guarantees of the estimators hold are difficult to check in practice, and could cause problems if they are violated (e.g. outliers caused by unobserved factors). Estimation of mixture models tend to have limited theoretical guarantees. In particular, finite Poisson mixture models have very weak assumptions on the underlying distribution—eventually becoming a non-parametric distribution if k = O(n)—but the estimation problems are likely NP-hard, with very few theoretical guarantees for practical estimators. Yet, empirically as seen in the next section, estimating a finite mixture model using Expectation-Maximization iterations performs well in practice.
Empirical Comparison
In this section, we seek to empirically compare models from the three classes presented to assess how well they fit real-world count data.
Comparison Experimental Setup
We empirically compare models on selected datasets from three diverse domains which have different data characteristics in terms of their mean count values and dispersion indices (Eq. 5) as can be seen in Table 1. The crash severity dataset is a small accident dataset from56 with three different count variables corresponding to crash severity classes: “Property-only”, “Possible Injury”, and “Injury”. The crash severity data exhibits high count values and high overdispersion. We retrieve raw next generation sequencing data for breast cancer (BRCA) using the software TCGA2STAT74 and computed a simple log-count transformation of the raw counts: ⌊log(x + 1)⌋, a common preprocessing technique for RNA-Seq data. The BRCA data exhibits medium counts and medium overdispersion. We collect the word count vectors from the Classic3 text corpus which contains abstracts from aerospace engineering, medical and information sciences journals.5 The Classic3 dataset exhibits low counts—including many zeros—and medium overdispersion. In the supplementary material, we also give results for a crime statistics dataset and the 20 Newsgroup dataset but they have similar characteristics and perform similarly to the the BRCA and Classic3 datasets respectively; thus, we omit them for simplicity. We select variables (e.g. for d = 10 or d = 100) by sorting the variables by mean count value—or sorting by variance in the case of the BRCA dataset as highly variable genes are of more interest in biology.
Table 1.
Dataset Statistics
| Dataset | (Per Variable ⇒) | Means
|
Dispersion Indices
|
Spearman’s ρ
|
|||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| d | n | Min | Med | Max | Min | Med | Max | Min | Med | Max | |
| Crash Severity | 3 | 275 | 3.4 | 3.8 | 9.7 | 6 | 9.3 | 16 | 0.61 | 0.73 | 0.79 |
| BRCA | 10 | 878 | 3.2 | 5 | 7.7 | 1.5 | 2.2 | 3.8 | −0.2 | 0.25 | 0.95 |
| 100 | 878 | 1.1 | 4 | 9 | 0.63 | 1.7 | 4.6 | −0.5 | 0.08 | 0.95 | |
| 1000 | 878 | 0.51 | 3.5 | 11 | 0.26 | 1 | 4.6 | −0.64 | 0.06 | 0.97 | |
| Classic3 | 10 | 3893 | 0.26 | 0.33 | 0.51 | 1.4 | 3.4 | 3.8 | −0.17 | 0.12 | 0.82 |
| 100 | 3893 | 0.09 | 0.14 | 0.51 | 1.1 | 2.1 | 8.3 | −0.17 | 0.02 | 0.82 | |
| 1000 | 3893 | 0.02 | 0.03 | 0.51 | 0.98 | 1.7 | 8.5 | −0.17 | −0 | 0.82 | |
In order to understand how each model might perform under varying data characteristics, we consider the following two questions: (1) How well does the model (i.e. the joint distribution) fit the underlying data distribution? (2) How well does the model capture the dependency structure between variables? To help answer these questions, we evaluate the empirical fit of models using two metrics, which only require samples from the model. The first metric is based on a statistic called maximum mean discrepancy (MMD)24 which estimates the maximum moment difference over all possible moments. The empirical MMD can be approximated as follows from two sets of samples and :
| (36) |
where is the union of the RKHS spaces based on the Gaussian kernel using twenty one σ values log-spaced between 0.01 and 100. In our experiments, we estimate the MMD between the pairwise marginals of model samples and the pairwise marginals of the original observations:
| (37) |
where x(s) is the vector of data for the s-th variable of the true data and is the vector of data for the s-th variable of samples from the estimated model—i.e. x(s) are observations from the true underlying distribution and are samples from the estimated model distribution. In our experiments, we use the fast approximation code for MMD from84 with 26 number of basis vectors for the FastMMD approximation algorithm. The second metric merely computes the absolute difference between the pairwise Spearman’s ρ values of model samples and the Spearman’s ρ values of the original observations:
| (38) |
The MMD metric is of more general interest because it evaluates whether the models actually fit the empirical data distribution while the Spearman metric may be more interesting for practitioners who primarily care about the dependency structure, such as biologists who specifically want to study gene dependencies rather than gene distributions.
We empirically compare the model fits on these real-world data sets for several types of models from the three general classes presented. As a baseline, we estimate an independent Poisson model (“Ind Poisson”). We include Gaussian copulas and vine copulas both paired with Poisson marginals (“Copula Poisson” and “Vine Poisson”) to represent the marginal model class. We estimate the copula-based models via the two-stage Inference Functions for Margins (IFM) method34 via the distributional transform65. For the mixture class, we include both a simple finite mixture of independent Poissons (“Mixture Poiss”) and a log-normal mixture of Poissons (“Log-Normal”). The finite mixture was estimated using a simple expectation-maximization (EM) algorithm; the log-normal mixture model was estimated via MCMC sampling using the code from83. For the conditional model class, we estimate the simple Poisson graphical model (“PGM”), which only allows negative dependencies, and three variants that allow for positive dependencies: the truncated Poisson graphical model (“Truncated PGM”), the Fixed-Length Poisson graphical model with a Poisson distribution on the vector length L = ║x║1 (“FLPGM Poisson”) and the Poisson square root graphical model (“Poisson SQR”). Using composite likelihood methods of penalized ℓ1 node-wise regressions, we estimate these models via code from82,30,33 and the XMRF6 R package. After parameter estimation, we generate 1,000 samples for each method using different types of sampling for each of the model classes.
To avoid overfitting to the data, we employ 3-fold cross-validation and report the average over the three folds. Because the conditional models (PGM, TPGM, FLPGM, and Poisson SQR) can be significantly different depending on the regularization parameter—i.e. the weight for the ℓ1 regularization term in the objective function for these models—, we select the regularization parameter of these models by computing the metrics on a tuning split of the training data. For the mixture model, we similarly tune the number of components k by testing k = {10, 20, 30, ⋯, 100}. For the very high dimensional datasets where d = 1000, we use a regularization parameter near the tuning parameters found when d = 100 and fix k = 50 in order to avoid the extra computation of selecting a parameter. More sampling and implementation details for each model are available in the supplementary material.
Empirical Comparison Results
The full results for both the MMD and Spearman’s ρ metrics for the crash severity, breast cancer RNA-Seq and Classic3 text datasets can be seen in Fig. 4, Fig. 5, and Fig. 6 respectively. The low dimensional results (d ≤ 10) give evidence across all the datasets that three models outperform the others in their classes:7 The Gaussian copula paired with Poisson marginals model (“Copula Poisson”) for the marginal model class, the mixture of Poissons distribution (“Mixture Poiss”) for the mixture model class, and the Poisson SQR distribution (“Poisson SQR”) for the conditional model class. Thus, we only include these representative models along with an independent Poisson baseline in the high-dimensional experiments when d > 10. We discuss the results for specific data characteristics as represented by each dataset.8
Figure 4.
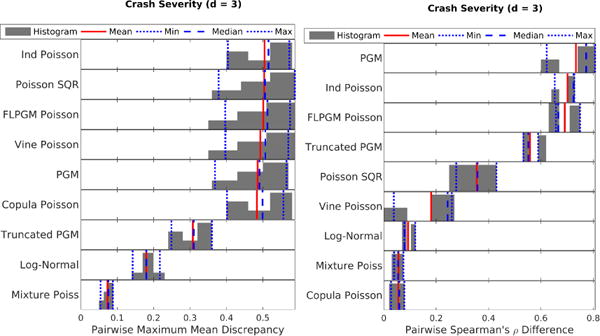
Crash severity dataset (high counts and high overdispersion): MMD (left) and Spearman ρ’s difference (right). As expected, for high overdispersion, mixture models (“Log-Normal” and “Mixture Poiss”) seem to perform the best.
Figure 5.
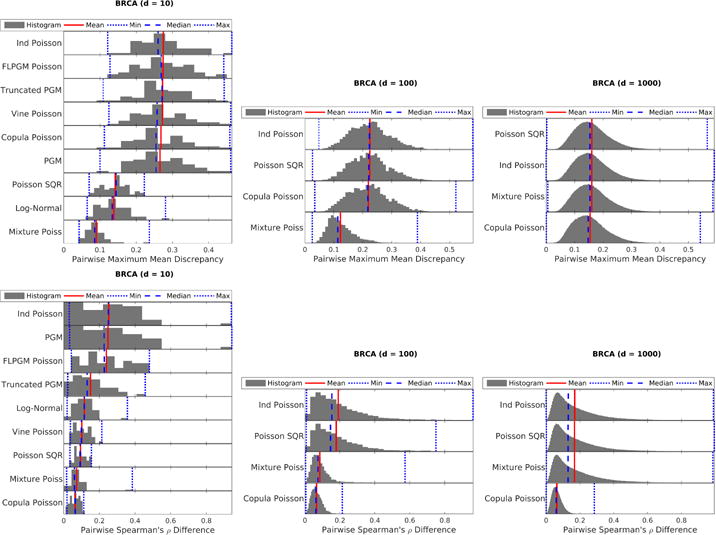
BRCA RNA-Seq dataset (medium counts and medium overdispersion): MMD (top) and Spearman ρ’s difference (bottom) with different number of variables: 10 (left), 100 (middle), 1000 (right). While mixtures (“Log-Normal” and “Mixture Poiss”) perform well in terms of MMD, the Gaussian copula paired with Poisson marginals (“Copula Poisson”) can model dependency structure well as evidenced by the Spearman metric.
Figure 6.
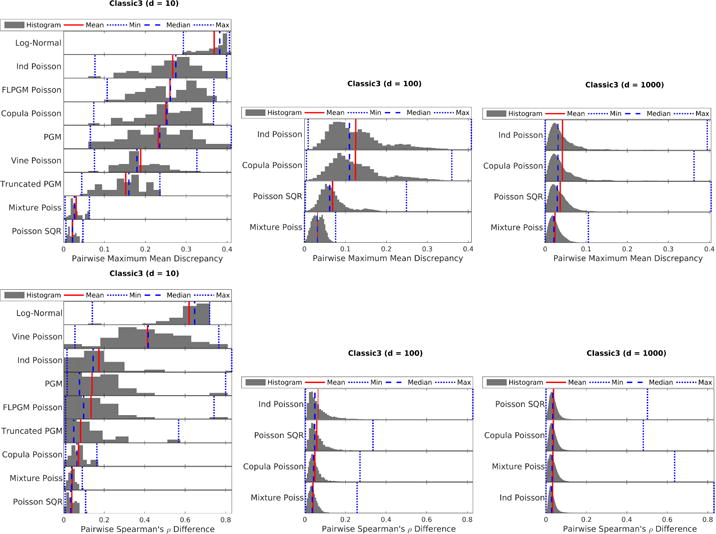
Classic3 text dataset (low counts and medium overdispersion): MMD (top) and Spearman ρ’s difference (bottom) with different number of variables: 10 (left), 100 (middle), 1000 (right). The Poisson SQR model performs better on this low count dataset than in previous settings.
For the crash severity dataset with high counts and high overdispersion (Fig. 4), mixture models (i.e. “Log-Normal” and “Mixture Poiss”) perform the best as expected since they can model overdispersion well. However, if dependency structure is the only object of interest, the Gaussian copula paired with Poisson marginals (“Copula Poisson”) performs well. For the BRCA dataset with medium counts and medium overdispersion (Fig. 5), we note similar trends with two notable exceptions: (1) The Poisson SQR model actually performs reasonably in low dimensions suggesting that it can model moderate overdispersion. (2) The high dimensional (d ≥ 100) Spearman’s ρ difference results show that the Gaussian copula paired with Poisson marginals (“Copula Poisson”) performs significantly better than the mixture model; this result suggests that copulas paired with Poisson marginals are likely better for modeling dependencies than mixture models. Finally, for the Classic3 dataset with low counts and medium overdispersion (Fig. 6), the Poisson SQR model seems to perform well in this low-counts setting especially in low dimensions unlike in previous data settings. While the simple independent mixture of Poisson distributions still performs well, the Poisson log-normal mixture distribution (“Log-Normal”) performs quite poorly in this setting with small counts and many zeros. This poor performance of the Poisson log-normal mixture is somewhat surprising since the dispersion indices are almost all greater than one as seen in Table 1. The differing results between low counts and medium counts with similar overdispersion demonstrate the importance to consider both the overdispersion and the mean count values when characterizing a dataset.
In summary, we note several overall trends. Mixture models are important for overdispersion when counts are medium or high. The Gaussian copula with Poisson marginals joint distribution can estimate dependency structure (per the Spearman metric) for a wide range of data characteristics even when the distribution does not fit the underlying data (per the MMD metric). The Poisson SQR model performs well for low count values with many zeros (i.e. sparse data) and may be able to handle moderate overdispersion.
Discussion
While this review analyzes each model class separately, it would be quite interesting to consider combinations or synergies between the model classes. Because negative binomial distributions can be viewed as a gamma-Poisson mixture model, one simple idea is to consider pairing a copula with negative binomial marginals or developing a negative binomial SQR graphical model. As another example, we could form a finite mixture of copula-based or graphical-model-based models. This might combine the strengths of a mixture in handling multiple modes and overdispersion with the strengths of the copula-based models and graphical models which can explicitly model dependencies.
We may also consider how one type of model informs the other. For example, by the generalized Sklar’s theorem65, each conditional Poisson graphical model actually induces a copula—just as the Gaussian graphical model induces the Gaussian copula. Studying the copulas induced by graphical models seems to be a relatively unexplored area. On the other side, it may be useful to consider fitting a Gaussian copula paired with discrete marginals using the theoretically-grounded techniques from graphical models for sparse dependency structure estimation especially for the small sample regimes in which d > n; this has been studied for the case of continuous marginals in49. Overall, bringing together and comparing these diverse paradigms for probability models opens up the door for many combinations and synergies.
Conclusion
We have reviewed three main approaches to constructing multivariate distributions derived from the Poisson using three different assumptions: 1) the marginal distributions are derived from the Poisson, 2) the joint distribution is a mixture of independent Poisson distributions, and 3) the node-conditional distributions are derived from the Poisson. The first class based on Poisson marginals, and in particular the general approach of pairing copulas with Poisson marginals, provides an elegant way to partially9 decouple the marginals from the dependency structure and gives strong empirical results despite some theoretical issues related to non-uniqueness. While advanced methods to estimate the joint distribution of copulas paired with discrete marginals such as simulated likelihood61 or vine copula constructions provide more accurate or more flexible copula models respectively, our empirical results suggest that a simple Gaussian copula paired with Poisson marginals with the trivial distributional transform (DT) can perform quite well in practice. The second class based on mixture models can be particularly helpful for handling overdispersion that often occurs in real count data with the log-normal-Poisson mixture and a finite mixture of independent Poisson distributions being prime examples. In addition, mixture models have closed-form moments and in the case of a finite mixture, closed-form likelihood calculations—something not generally true for the other classes. The third class based on Poisson conditionals can be represented as graphical models, thus providing both compact and visually appealing representations of joint distributions. Conditional models benefit from strong theoretical guarantees about model recovery given certain modeling assumptions. However, checking conditional modeling assumptions may be impossible and may not always be satisfied for real-world count data. From our empirical experiments, we found that (1) mixture models are important for overdispersion when counts are medium or high, (2) the Gaussian copula with Poisson marginals joint distribution can estimate dependency structure for a wide range of data characteristics even when the distribution does not fit the underlying data, and (3) Poisson SQR models perform well for low count values with many zeros (i.e. sparse data) and can handle moderate overdispersion. Overall, in practice, we would recommend comparing the three best performing methods from each class: namely the Gaussian copula model paired with Poisson marginals, the finite mixture of independent Poisson distributions, and the Poisson SQR model. This initial comparison will likely highlight some interesting properties of a given dataset and suggest which class to pursue in more detail.
This review has highlighted several key strengths and weaknesses of the main approaches to constructing multivariate Poisson distributions. Yet, there remain many open questions. For example, what are the marginal distributions of the Poisson graphical models which are defined in terms of their conditional distributions? Or conversely, what are the conditional distributions of the copula models which are defined in terms of their marginal distributions? Can novel models be created at the intersection of these model classes that could combine the strengths of different classes as suggested in the discussion section? Could certain model classes be developed in an application area that has been largely dominated by another model class? For example, graphical models are well-known in the machine learning literature while copula models are well-known in the financial modeling literature. Overall, multivariate Poisson models are poised to increase in popularity given the wide potential applications to real-world high-dimensional count-valued data in text analysis, genomics, spatial statistics, economics, and epidemiology.
Supplementary Material
Acknowledgments
D.I. and P.R. acknowledge the support of ARO via W911NF-12-1-0390 and NSF via IIS-1149803, IIS-1447574, DMS-1264033, and NIH via R01 GM117594-01 as part of the Joint DMS/NIGMS Initiative to Support Research at the Interface of the Biological and Mathematical Sciences. G.A. acknowledges support from NSF DMS-1264058 and NSF DMS-1554821.
Footnotes
The label “multivariate Poisson” was introduced in the statistics community to refer to the particular model introduced in this section but other generalizations could also be considered multivariate Poisson distributions.
This is because if y ∈ ℝ ∼ Normal, then exp(y) ∈ ℝ++ ∼ LogNormal.
Besag10 originally named these Poisson auto models, focusing on pairwise graphical models, but here we consider the general graphical model setting.
If the marginal distribution on the length is set to be the same as the marginal distribution on length for the PGM—i.e. if , then the PGM distribution is recovered.
For the crash-severity dataset, the truncated Poisson graphical model (“Truncated PGM”) outperforms the Poisson SQR model under the pairwise MMD metric. After inspection, however, we realized that the Truncated PGM model performed better merely because outlier values were truncated to the 99th percentile as described in the supplementary material. This reduced the overfitting of outlier values caused by the crash severity dataset’s high overdispersion.
These basic trends are also corroborated by the two datasets in the supplementary material.
In the discrete case, the dependency structure cannot be perfectly decoupled from the marginal distributions unlike in the continuous case where the dependency structure and marginals can be perfectly decoupled.
Contributor Information
David Inouye, University of Texas at Austin.
Eunho Yang, Korea Advanced Institute of Science and Technology.
Genevera Allen, Rice University & Baylor College of Medicine.
Pradeep Ravikumar, Carnegie Mellon University.
References
- 1.Aas K, Czado C, Frigessi A, Bakken H. Pair-copula constructions of multiple dependence. Insurance: Mathematics and economics. 2009;44(2):182–198. [Google Scholar]
- 2.Aguero-Valverde J, Jovanis PP. Bayesian multivariate Poisson lognormal models for crash severity modeling and site ranking. Transportation Research Record: Journal of the Transportation Research Board. 2009;2136(1):82–91. [Google Scholar]
- 3.Aitchison J, Ho C. The multivariate Poisson-log normal distribution. Biometrika. 1989;76(4):643–653. [Google Scholar]
- 4.Allen GI, Liu Z. Bioinformatics and Biomedicine, 2012 IEEE International Conference on. IEEE; 2012. A log-linear graphical model for inferring genetic networks from high-throughput sequencing data; pp. 1–6. [Google Scholar]
- 5.Allen GI, Liu Z. A local Poisson graphical model for inferring networks from sequencing data. NanoBioscience, IEEE Transactions on. 2013;12(3):189–198. doi: 10.1109/TNB.2013.2263838. [DOI] [PubMed] [Google Scholar]
- 6.Altham PME. Two generalizations of the binomial distribution. Journal of the Royal Statistical Society Series C (Applied Statistics) 1978;27(2):162–167. [Google Scholar]
- 7.Altham PME, Hankin RKS. Multivariate generalizations of the multiplicative binomial distribution: Introducing the mm package. Journal of Statistical Software. 2012;46(12):1–23. doi: http://dx.doi.org/10.18637/jss.v046.i12. URL http://cran.cnr.berkeley.edu/web/packages/MM/vignettes/Gianfranco.pdf. [Google Scholar]
- 8.Arbous AG, Kerrich J. Accident statistics and the concept of accident-proneness. Biometrics. 1951;7(4):340–432. [Google Scholar]
- 9.Bedford T, Cooke RM. Vines: A new graphical model for dependent random variables. Annals of Statistics. 2002:1031–1068. [Google Scholar]
- 10.Besag J. Spatial interaction and the statistical analysis of lattice systems. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 1974;36:192–236. [Google Scholar]
- 11.Bradley JR, Holan SH, Wikle CK. Computationally efficient distribution theory for Bayesian inference of high-dimensional dependent count-valued data. arXiv preprint arXiv: 1512.07273. 2015 [Google Scholar]
- 12.Campbell J. The Poisson correlation function. Proceedings of the Edinburgh Mathematical Society. 1934;4(01):18–26. [Google Scholar]
- 13.Cherubini U, Luciano E, Vecchiato W. Copula Methods in Finance. John Wiley and Sons; 2004. [Google Scholar]
- 14.Chib S, Winkelmann R. Markov chain Monte Carlo analysis of correlated count data. Journal of Business & Economic Statistics. 2001;19(4):428–435. [Google Scholar]
- 15.Clifford P. Disorder in physical systems. Oxford Science Publications; 1990. Markov random fields in statistics. [Google Scholar]
- 16.Cook RJ, Lawless JF, Lee KA. A copula-based mixed Poisson model for bivariate recurrent events under event-dependent censoring. Statistics in Medicine. 2010;29(6):694–707. doi: 10.1002/sim.3830. [DOI] [PubMed] [Google Scholar]
- 17.Czado C, Brechmann EC, Gruber L. Copulae in Mathematical and Quantitative Finance. Springer; 2013. Selection of vine copulas; pp. 17–37. [Google Scholar]
- 18.Demarta S, McNeil AJ. The t copula and related copulas. International Statistical Review. 2005;73(1):111–129. [Google Scholar]
- 19.Denuit M, Lambert P. Constraints on concordance measures in bivariate discrete data. Journal of Multivariate Analysis. 2005;93(1):40–57. [Google Scholar]
- 20.Dwass M, Teicher H. On infinitely divisible random vectors. Annals of Mathematical Statistics. 1957:461–470. [Google Scholar]
- 21.El-Basyouny K, Sayed T. Collision prediction models using multivariate Poisson-lognormal regression. Accident Analysis & Prevention. 2009;41(4):820–828. doi: 10.1016/j.aap.2009.04.005. [DOI] [PubMed] [Google Scholar]
- 22.Genest C, Nešlehová J. A primer on copulas for count data. Astin Bulletin. 2007;37(02):475–515. [Google Scholar]
- 23.Genz A, Bretz F. Computation of Multivariate Normal and t Probabilities. Vol. 195. Springer; 2009. [Google Scholar]
- 24.Gretton A. A kernel two-sample test. Journal of Machine Learning Research. 2012;13:723–773. [Google Scholar]
- 25.Hadiji F, Molina A, Natarajan S, Kersting K. Poisson dependency networks: Gradient boosted models for multivariate count data. Machine Learning. 2015;100(2–3):477–507. [Google Scholar]
- 26.Han SW, Zhong H. Estimation of sparse directed acyclic graphs for multivariate counts data. Biometrics. 2016 doi: 10.1111/biom.12467. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Heinen A, Rengifo E. Multivariate autoregressive modeling of time series count data using copulas. Journal of Empirical Finance. 2007;14(4):564–583. [Google Scholar]
- 28.Heinen A, Rengifo E. Multivariate reduced rank regression in non-Gaussian contexts, using copulas. Computational Statistics and Data Analysis. 2008;52(6):2931–2944. [Google Scholar]
- 29.Holgate P. Estimation for the bivariate Poisson distribution. Biometrika. 1964;51(1–2):241–287. [Google Scholar]
- 30.Inouye DI, Ravikumar P, Dhillon IS. Admixtures of Poisson MRFs: A topic model with word dependencies. International Conference on Machine Learning. 2014;31 [Google Scholar]
- 31.Inouye DI, Ravikumar P, Dhillon IS. Fixed-length Poisson MRF: Adding dependencies to the multinomial. Neural Information Processing Systems. 2015;28 [Google Scholar]
- 32.Inouye DI, Ravikumar P, Dhillon IS. Square root graphical models: Multivariate generalizations of univariate exponential families that permit positive dependencies. International Conference on Machine Learning. 2016 [PMC free article] [PubMed] [Google Scholar]
- 33.Inouye DI, Ravikumar P, Dhillon IS. Generalized root models: Beyond pairwise graphical models for univariate exponential families. arXiv preprint arXiv: 1606.00813. 2016 [Google Scholar]
- 34.Joe H, Xu JJ. The Estimation Method of Inference Functions for Margins for Multivariate Models. The University of British Columbia; Vancouver, Canada: 1996. (Technical report 166). [Google Scholar]
- 35.Johnson NL, Kotz S, Balakrishnan N. Discrete multivariate distributions. Vol. 165. Wiley; New York: 1997. [Google Scholar]
- 36.Kaiser MS, Cressie N. Modeling Poisson variables with positive spatial dependence. Statistics & Probability Letters. 1997;35(4):423–432. [Google Scholar]
- 37.Kano K, Kawamura K. On recurrence relations for the probability function of multivariate generalized Poisson distribution. Communications in statistics-theory and methods. 1991;20(1):165–178. [Google Scholar]
- 38.Karlis D. An em algorithm for multivariate Poisson distribution and related models. Journal of Applied Statistics. 2003;30(1):63–77. [Google Scholar]
- 39.Karlis D. Models for multivariate count time series. In: Davis RA, Holan SH, Lund R, Ravishanker N, editors. Handbook of Discrete-Valued Time Series. CRC Press; 2016. pp. 407–424. chapter 19. [Google Scholar]
- 40.Karlis D, Meligkotsidou L. Finite mixtures of multivariate Poisson distributions with application. Journal of statistical Planning and Inference. 2007;137(6):1942–1960. [Google Scholar]
- 41.Karlis D, Xekalaki E. Mixed Poisson distributions. International Statistical Review. 2005;73(1):35–58. [Google Scholar]
- 42.Kawamura K. The structure of multivariate Poisson distribution. Kodai Mathematical Journal. 1979;2(3):337–345. [Google Scholar]
- 43.Kazianka H. Approximate copula-based estimation and prediction of discrete spatial data. Stochastic Environmental Research and Risk Assessment. 2013;27(8):2015–2026. [Google Scholar]
- 44.Kazianka H, Pilz J. Copula-based geostatistical modeling of continuous and discrete data including covariates. Stochastic Environmental Research and Risk Assessment. 2010;24(5):661–673. [Google Scholar]
- 45.Koller D, Friedman N. Probabilistic graphical models: principles and techniques. MIT press; 2009. [Google Scholar]
- 46.Krishnamoorthy A. Multivariate binomial and Poisson distributions. Sankhyā: the Indian Journal of Statistics. 1951:117–124. [Google Scholar]
- 47.Krummenauer F. Limit theorems for multivariate discrete distributions. Metrika. 1998;47(1):47–69. [Google Scholar]
- 48.Lauritzen SL. Graphical models. Oxford University Press; USA: 1996. [Google Scholar]
- 49.Liu H, Han F, Yuan M, Lafferty J, Wasserman L. High dimensional semiparametric Gaussian copula graphical models. The Annals of Statistics. 2012;40(4):34. doi: 10.1214/12-AOS1037. URL http://projecteuclid.org/euclid.aos/1358951383$\delimiter”026E30F$nhttp://arxiv.org/a. [DOI] [Google Scholar]
- 50.Loukas S, Kemp C. On computer sampling from trivariate and multivariate discrete distributions: Multivariate discrete distributions. Journal of Statistical Computation and Simulation. 1983;17(2):113–123. [Google Scholar]
- 51.Ma J, Kockelman KM, Damien P. A multivariate Poisson-lognormal regression model for prediction of crash counts by severity, using Bayesian methods. Accident Analysis & Prevention. 2008;40(3):964–975. doi: 10.1016/j.aap.2007.11.002. [DOI] [PubMed] [Google Scholar]
- 52.Madsen L. Maximum likelihood estimation of regression parameters with spatially dependent discrete data. Journal of Agricultural, Biological, and Environmental Statistics. 2009;14(4):375–391. [Google Scholar]
- 53.Madsen L, Fang Y. Joint regression analysis for discrete longitudinal data. Biometrics. 2011;67(3):1171–1175. doi: 10.1111/j.1541-0420.2010.01494.x. [DOI] [PubMed] [Google Scholar]
- 54.Mahamunulu D. A note on regression in the multivariate Poisson distribution. Journal of the American Statistical Association. 1967;62(317):251–258. [Google Scholar]
- 55.Meinshausen N, Bühlmann P. High-dimensional graphs and variable selection with the lasso. Annals of Statistics. 2006:1436–1462. [Google Scholar]
- 56.Milton JC, Shankar VN, Mannering FL. Highway accident severities and the mixed logit model: An exploratory empirical analysis. Accident Analysis and Prevention. 2008;40:260–266. doi: 10.1016/j.aap.2007.06.006. [DOI] [PubMed] [Google Scholar]
- 57.M’Kendrick A. Applications of mathematics to medical problems. Proceedings of the Edinburgh Mathematical Society. 1925;44:98–130. [Google Scholar]
- 58.Neal RM. Annealed importance sampling. Statistics and Computing. 2001;11(2):125–139. [Google Scholar]
- 59.Nikoloulopoulos AK. Copula-based models for multivariate discrete response data. In: Jaworski P, Durante F, Härdle W, editors. Copulae in Mathematical and Quantitative Finance. Jul, 2013. number. [Google Scholar]
- 60.Nikoloulopoulos AK. On the estimation of normal copula discrete regression models using the continuous extension and simulated likelihood. Journal of Statistical Planning and Inference. 2013;143(11):1923–1937. [Google Scholar]
- 61.Nikoloulopoulos AK. Efficient estimation of high-dimensional multivariate normal copula models with discrete spatial responses. Stochastic Environmental Research and Risk Assessment. 2016;30(2):493–505. [Google Scholar]
- 62.Nikoloulopoulos AK, Karlis D. Modeling multivariate count data using copulas. Communications in Statistics-Simulation and Computation. 2009;39(1):172–187. [Google Scholar]
- 63.Panagiotelis A, Czado C, Joe H. Pair copula constructions for multivariate discrete data. Journal of the American Statistical Association. 2012;107(499):1063–1072. [Google Scholar]
- 64.Park E, Lord D. Multivariate Poisson-lognormal models for jointly modeling crash frequency by severity. Transportation Research Record: Journal of the Transportation Research Board. 2007;(2019):1–6. [Google Scholar]
- 65.Rüschendorf L. Mathematical Risk Analysis. Springer-Verlag Berlin Heidelberg; 2013. Copulas, Sklar’s theorem, and distributional transform; pp. 3–34. chapter 1. [Google Scholar]
- 66.Sklar A. Fonctions de repartition à n dimensions et leurs marges. Publ Inst Statist Univ Paris. 1959;8:229–231. [Google Scholar]
- 67.Sklar A. Random variables, joint distribution functions, and copulas. Kybernetika. 1973;9(6):449–460. [Google Scholar]
- 68.Srivastava R, Srivastava A. On a characterization of Poisson distribution. Journal of Applied Probability. 1970;7(2):497–501. [Google Scholar]
- 69.Steyn H. On the multivariate Poisson normal distribution. Journal of the American Statistical Association. 1976;71(353):233–236. [Google Scholar]
- 70.Teicher H. On the multivariate Poisson distribution. Scandinavian Actuarial Journal. 1954;1954(1):1–9. [Google Scholar]
- 71.Trivedi PK, Zimmer DM. Copula Modeling: An Introduction for Practitioners. 2005;1 [Google Scholar]
- 72.Tsiamyrtzis P, Karlis D. Strategies for efficient computation of multivariate Poisson probabilities. Communications in Statistics-Simulation and Computation. 2004;33(2):271–292. [Google Scholar]
- 73.Wainwright MJ, Jordan MI. Graphical models, exponential families, and variational inference. Foundations and Trends ® in Machine Learning. 2008;1(1–2):1–305. [Google Scholar]
- 74.Wan YW, Allen GI, Liu Z. TCGA2STAT: simple TCGA data access for integrated statistical analysis in R. Bioinformatics. 2016;32(6):952–954. doi: 10.1093/bioinformatics/btv677. [DOI] [PubMed] [Google Scholar]
- 75.Wang Y. Characterizations of certain multivariate distributions. Mathematical Proceedings of the Cambridge Philosophical Society. 1974;75(02):219–234. [Google Scholar]
- 76.Wicksell SD. Some Theorems in the Theory of Probability, with Special Reference to Their Importance in the Theory of Homograde Correlation. 1916 [Google Scholar]
- 77.Xue-Kun Song P. Multivariate dispersion models generated from gaussian copula. Scandinavian Journal of Statistics. 2000;27(2):305–320. [Google Scholar]
- 78.Yahav I, Shmueli G. On generating multivariate Poisson data in management science applications. Applied Stochastic Models in Business and Industry. 2012;28(1):91–102. [Google Scholar]
- 79.Yang E, Ravikumar P, Allen G, Liu Z. Graphical models via generalized linear models. Neural Information Processing Systems. 2012;25 [Google Scholar]
- 80.Yang E, Ravikumar P, Allen G, Liu Z. On Poisson graphical models. Neural Information Processing Systems. 2013;26 [Google Scholar]
- 81.Yang E, Ravikumar P, Allen G, Liu Z. Conditional random fields via univariate exponential families. Neural Information Processing Systems. 2013;26 [Google Scholar]
- 82.Yang E, Ravikumar P, Allen G, Liu Z. Graphical models via univariate exponential family distribution. Journal of Machine Learning Research. 2015;16:3813–3847. [PMC free article] [PubMed] [Google Scholar]
- 83.Zhan X, Abdul Aziz HM, Ukkusuri SV. An efficient parallel sampling technique for multivariate Poisson-lognormal model: Analysis with two crash count datasets. Analytic Methods in Accident Research. 2015;8:45–60. [Google Scholar]
- 84.Zhao J, Meng D. FastMMD: Ensemble of circular discrepancy for efficient two-sample test. Neural computation. 2015;27:1345–1372. doi: 10.1162/NECO_a_00732. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.