

Summary
Continuous treatments (e.g., doses) arise often in practice, but many available causal effect estimators are limited by either requiring parametric models for the effect curve, or by not allowing doubly robust covariate adjustment. We develop a novel kernel smoothing approach that requires only mild smoothness assumptions on the effect curve, and still allows for misspecification of either the treatment density or outcome regression. We derive asymptotic properties and give a procedure for data-driven bandwidth selection. The methods are illustrated via simulation and in a study of the effect of nurse staffing on hospital readmissions penalties.
Keywords: causal inference, dose-response, efficient influence function, kernel smoothing, semiparametric estimation
1. Introduction
Continuous treatments or exposures (such as dose, duration, and frequency) arise very often in practice, especially in observational studies. Importantly, such treatments lead to effects that are naturally described by curves (e.g., dose-response curves) rather than scalars, as might be the case for binary treatments. Two major methodological challenges in continuous treatment settings are (1) to allow for flexible estimation of the dose-response curve (for example to discover underlying structure without imposing a priori shape restrictions), and (2) to properly adjust for high-dimensional confounders (i.e., pre-treatment covariates related to treatment assignment and outcome).
Consider a recent example involving the Hospital Readmissions Reduction Program, instituted by the Centers for Medicare & Medicaid Services in 2012, which aimed to reduce preventable hospital readmissions by penalizing hospitals with excess readmissions. McHugh et al. (2013) were interested in whether nurse staffing (measured in nurse hours per patient day) affected hospitals’ risk of excess readmissions penalty. The left panel of Figure 1 shows data for 2976 hospitals, with nurse staffing (the ‘treatment’) on the x-axis, whether each hospital was penalized (the outcome) on the y-axis, and a loess curve fit to the data (without any adjustment). One way to characterize effects is to imagine setting all hospitals’ nurse staffing to the same level, and seeing if changes in this level yield changes in excess readmissions risk. Such questions cannot be answered by simply comparing hospitals’ risk of penalty across levels of nurse staffing, since hospitals differ in many important ways that could be related to both nurse staffing and excess readmissions (e.g., size, location, teaching status, among many other factors). The right panel of Figure 1 displays the extent of these hospital differences, showing for example that hospitals with more nurse staffing are also more likely to be high-technology hospitals and see patients with higher socioeconomic status. To correctly estimate the effect curve, and fairly compare the risk of readmissions penalty at different nurse staffing levels, one must adjust for hospital characteristics appropriately.
Fig. 1.
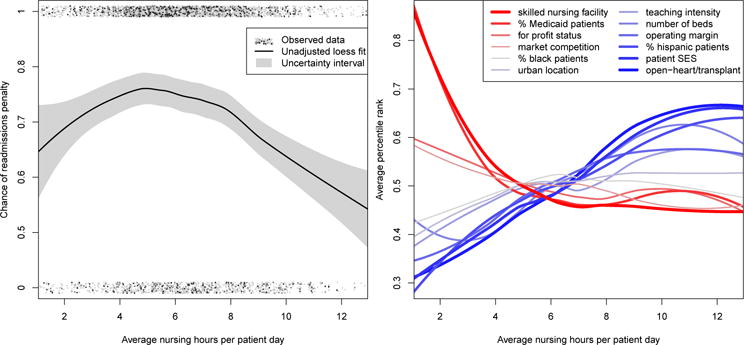
Left panel: Observed treatment and outcome data with unadjusted loess fit. Right panel: Average covariate value as a function of exposure, after transforming to percentiles to display on common scale.
In practice, the most common approach for estimating continuous treatment effects is based on regression modeling of how the outcome relates to covariates and treatment (e.g., Imbens (2004), Hill (2011)). However, this approach relies entirely on correct specification of the outcome model, does not incorporate available information about the treatment mechanism, and is sensitive to the curse of dimensionality by inheriting the rate of convergence of the outcome regression estimator. Hirano and Imbens (2004), Imai and van Dyk (2004), and Galvao and Wang (2015) adapted propensity score-based approaches to the continuous treatment setting, but these similarly rely on correct specification of at least a model for treatment (e.g., the conditional treatment density).
In contrast, semiparametric doubly robust estimators (Robins and Rotnitzky, 2001; van der Laan and Robins, 2003) are based on modeling both the treatment and outcome processes and, remarkably, give consistent estimates of effects as long as one of these two nuisance processes is modeled well enough (not necessarily both). Beyond giving two independent chances at consistent estimation, doubly robust methods can also attain faster rates of convergence than their nuisance (i.e., outcome and treatment process) estimators when both models are consistently estimated; this makes them less sensitive to the curse of dimensionality and can allow for inference even after using flexible machine learning-based adjustment. However, standard semiparametric doubly robust methods for dose-response estimation rely on parametric models for the effect curve, either by explicitly assuming a parametric dose-response curve (Robins, 2000; van der Laan and Robins, 2003), or else by projecting the true curve onto a parametric working model (Neugebauer and van der Laan, 2007). Unfortunately, the first approach can lead to substantial bias under model misspecification, and the second can be of limited practical use if the working model is far away from the truth.
Recent work has extended semiparametric doubly robust methods to more complicated nonparametric and high-dimensional settings. In a foundational paper, van der Laan and Dudoit (2003) proposed a powerful cross-validation framework for estimator selection in general censored data and causal inference problems. Their empirical risk minimization approach allows for global nonparametric modeling in general semiparametric settings involving complex nuisance parameters. For example, Díaz and van der Laan (2013) considered global modeling in the dose-response curve setting, and developed a doubly robust substitution estimator of risk. In nonparameric problems it is also important to consider non-global learning methods, e.g., via local and penalized modeling (Györfi et al., 2002). Rubin and van der Laan (2005, 2006a,b) proposed extensions to such paradigms in numerous important problems, but the former considered weighted averages of dose-response curves and the latter did not consider doubly robust estimation.
In this paper we present a new approach for causal dose-response estimation that is doubly robust without requiring parametric assumptions, and which can naturally incorporate general machine learning methods. The approach is motivated by semiparametric theory for a particular stochastic intervention effect and a corresponding doubly robust mapping. Our method has a simple two-stage implementation that is fast and easy to use with standard software: in the first stage a pseudo-outcome is constructed based on the doubly robust mapping, and in the second stage the pseudo-outcome is regressed on treatment via off-the-shelf non-parametric regression and machine learning tools. We provide asymptotic results for a kernel version of our approach under weak assumptions, which only require mild smoothness conditions on the effect curve and allow for flexible data-adaptive estimation of relevant nuisance functions. We also discuss a simple method for bandwidth selection based on cross-validation. The methods are illustrated via simulation, and in the study discussed earlier about the effect of hospital nurse staffing on excess readmission penalties.
2. Background
2.1. Data and notation
Suppose we observe an independent and identically distributed sample (Z1, …, Zn) where Z = (L, A, Y) has support . Here L denotes a vector of covariates, A a continuous treatment or exposure, and Y some outcome of interest. We characterize causal effects using potential outcome notation (Rubin, 1974), and so let Ya denote the potential outcome that would have been observed under treatment level a.
We denote the distribution of Z by P, with density p(z) = p(y | l, a)p(a | l)p(l) with respect to some dominating measure. We let ℙn denote the empirical measure so that empirical averages can be written as ℙn {f(Z)} = ∫ f(z)dℙn(z). To simplify the presentation we denote the mean outcome given covariates and treatment with , denote the conditional treatment density given covariates with , and denote the marginal treatment density with . Finally, we use ‖f‖ = {∫ f(z)2dP (z)}1/2 to denote the L2(P) norm, and we use to denote the uniform norm of a generic function f over .
2.2. Identification
In this paper our goal is to estimate the effect curve . Since this quantity is defined in terms of potential outcomes that are not directly observed, we must consider assumptions under which it can be expressed in terms of observed data. A full treatment of identification in the presence of continuous random variables was given by Gill and Robins (2001); we refer the reader there for details. The assumptions most commonly employed for identification are as follows (the following must hold for any at which θ(a) is to be identified).
Assumption 1. Consistency: A = a implies Y = Ya.
Assumption 2. Positivity: π(a | l) ≥ πmin > 0 for all l ∈ ℒ.
Assumption 3. Ignorability: .
Assumptions 1–3 can all be satisfied by design in randomized trials, but in observational studies they may be violated and are generally untestable. The consistency assumption ensures that potential outcomes are defined uniquely by a subject’s own treatment level and not others’ levels (i.e., no interference), and also not by the way treatment is administered (i.e., no different versions of treatment). Positivity says that treatment is not assigned deterministically, in the sense that every subject has some chance of receiving treatment level a, regardless of covariates; this can be a particularly strong assumption with continuous treatments. Ignorability says that the mean potential outcome under level a is the same across treatment levels once we condition on covariates (i.e., treatment assignment is unrelated to potential outcomes within strata of covariates), and requires sufficiently many relevant covariates to be collected. Using the same logic as with discrete treatments, it is straightforward to show that under Assumptions 1–3 the effect curve θ(a) can be identified with observed data as
| (1) |
Even if we are not willing to rely on Assumptions 1 and 3, it may often still be of interest to estimate θ(a) as an adjusted measure of association, defined purely in terms of observed data.
3. Main results
In this section we develop doubly robust estimators of the effect curve θ(a) without relying on parametric models. First we describe the logic behind our proposed approach, which is based on finding a doubly robust mapping whose conditional expectation given treatment equals the effect curve of interest, as long as one of two nuisance parameters is correctly specified. To find this mapping, we derive a novel efficient influence function for a stochastic intervention parameter. Our proposed method is based on regressing this doubly robust mapping on treatment using off-the-shelf nonparametric regression and machine learning methods. We derive asymptotic properties for a particular version of this approach based on local-linear kernel smoothing. Specifically, we give conditions for consistency and asymptotic normality, and describe how to use cross-validation to select the bandwidth parameter in practice.
3.1. Setup and doubly robust mapping
If θ(a) is assumed known up to a finite-dimensional parameter, for example θ(a) = ψ0 + ψ1a for (ψ0, ψ1) ∈ ℝ2, then standard semiparametric theory can be used to derive the efficient influence function, from which one can obtain the efficiency bound and an efficient estimator (Bickel et al., 1993; van der Laan and Robins, 2003; Tsiatis, 2006). However, such theory is not directly available if we only assume, for example, mild smoothness conditions on θ(a) (e.g., differentiability). This is due to the fact that without parametric assumptions θ(a) is not pathwise differentiable, and root-n consistent estimators do not exist (Bickel et al., 1993; Díaz and van der Laan, 2013). In this case there is no developed efficiency theory.
To derive doubly robust estimators for θ(a) without relying on parametric models, we adapt semiparametric theory in a novel way similar to the approach of Rubin and van der Laan (2005, 2006a). Our goal is to find a function ξ(Z; π, μ) of the observed data Z and nuisance functions (π, μ) such that
if either or (not necessarily both). Given such a mapping, off-the-shelf nonparametric regression and machine learning methods could be used to estimate θ(a) by regressing on treatment A, based on estimates and .
This doubly robust mapping is intimately related to semiparametric theory and especially the efficient influence function for a particular parameter. Specifically, if then it follows that for
| (2) |
This indicates that a natural candidate for the unknown mapping ξ(Z; π, μ) would be a component of the efficient influence function for the parameter ψ, since for regular parameters such as ψ in semi- or non-parametric models, the efficient influence function ϕ(Z; π, μ) will be doubly robust in the sense that , if either or (Robins and Rotnitzky, 2001; van der Laan and Robins, 2003). This implies so that if either or . This kind of logic was first used by Rubin and van der Laan (2005, 2006a) for full data parameters that are functions of covariates rather than treatment (i.e., censoring) variables.
The parameter ψ is also of interest in its own right. In particular, it represents the average outcome under an intervention that randomly assigns treatment based on the density ϖ (i.e., a randomized trial). Thus comparing the value of this parameter to the average observed outcome provides a test of treatment effect; if the values differ significantly, then there is evidence that the observational treatment mechanism impacts outcomes for at least some units. Stochastic interventions were discussed by Díaz and van der Laan (2012), for example, but the efficient influence function for ψ has not been given before under a nonparametric model. Thus in Theorem 1 below we give the efficient influence function for this parameter respecting the fact that the marginal density ϖ is unknown.
Theorem 1
Under a nonparametric model, the efficient influence function for ψ defined in (2) is , where
A proof of Theorem 1 is given in the Appendix (Section 2). Importantly, we also prove that the function ξ(Z; π, μ) satisfies its desired double robustness property, i.e., that if either or . As mentioned earlier, this motivates estimating the effect curve θ(a) by estimating the nuisance functions (π, μ), and then regressing the estimated pseudo-outcome
on treatment A using off-the-shelf nonparametric regression or machine learning methods. In the next subsection we describe our proposed approach in more detail, and analyze the properties of an estimator based on kernel estimation.
3.2. Proposed approach
In the previous subsection we derived a doubly robust mapping ξ(Z; π, μ) for which as long as either or . This indicates that doubly robust nonparametric estimation of θ(a) can proceed with a simple two-step procedure, where both steps can be accomplished with flexible machine learning. To summarize, our proposed method is:
Estimate nuisance functions (π, μ) and obtain predicted values.
Construct pseudo-outcome and regress on treatment variable A.
We give sample code implementing the above in the Appendix (Section 9).
In what follows we present results for an estimator that uses kernel smoothing in Step 2. Such an approach is related to kernel approximation of a full-data parameter in censored data settings. Robins and Rotnitzky (2001) gave general discussion and considered density estimation with missing data, while van der Laan and Robins (1998), van der Laan and Yu (2001), and van der Vaart and van der Laan (2006) used the approach for current status survival analysis; Wang et al. (2010) used it implicitly for nonparametric regression with missing outcomes.
As indicated above, however, a wide variety of flexible methods could be used in our Step 2, including local partitioning or nearest neighbor estimation, global series or spline methods with complexity penalties, or cross-validation-based combinations of methods, e.g., Super Learner (van der Laan et al., 2007). In general we expect the results we report in this paper to hold for many such methods. To see why, let denote the proposed estimator described above (based on some initial nuisance estimators and a particular regression method in Step 2), and let denote an estimator based on an oracle version of the pseudo-outcome where are the unknown limits to which the estimators converge. Then , where the second term on the right can be analyzed with standard theory since is a regression of a simple fixed function on A, and the first term will be small depending on the convergence rates of and . A similar point was discussed by Rubin and van der Laan (2005, 2006a).
The local linear kernel version of our estimator is , where and
| (3) |
for Kha(t) = h−1K{(t−a)/h} with K a standard kernel function (e.g., a symmetric probability density) and h a scalar bandwidth parameter. This is a standard local linear kernel regression of on A. For overviews of kernel smoothing see, e.g., Fan and Gijbels (1996), Wasserman (2006), and Li and Racine (2007). Under near-violations of positivity, the above estimator could potentially lie outside the range of possible values for θ(a) (e.g., if Y is binary); thus we present a targeted minimum loss-based estimator (TMLE) in the Appendix (Section 4), which does not have this problem. Alternatively one could project onto a logistic model in (3).
3.3. Consistency of kernel estimator
In Theorem 2 below we give conditions under which the proposed kernel estimator is consistent for θ(a), and also give the corresponding rate of convergence. In general this result follows if the bandwidth decreases with sample size slowly enough, and if either of the nuisance functions π or μ is estimated well enough (not necessarily both). The rate of convergence is a sum of two rates: one from standard nonparametric regression problems (depending on the bandwidth h), and another coming from estimation of the nuisance functions π and μ.
Theorem 2
Let and denote fixed functions to which and converge in the sense that and , and let denote a point in the interior of the compact support of A. Along with Assumption 2 (Positivity), assume the following:
-
(a)
Either or .
-
(b)
The bandwidth h = hn satisfies h → 0 and nh3 → ∞ as n → ∞.
-
(c)
K is a continuous symmetric probability density with support [−1, 1].
-
(d)
θ(a) is twice continuously differentiable, and both ϖ(a) and the conditional density of given A = a are continuous as functions of a.
-
(e)
The estimators and their limits are contained in uniformly bounded function classes with finite uniform entropy integrals (as defined in Section 5 of the Appendix), with and also uniformly bounded.
Then
where
are the ‘local’ rates of convergence of and near A = a.
A proof of Theorem 2 is given in the Appendix (Section 6). The required conditions are all quite weak. Condition (a) is arguably the most important of the conditions, and says that at least one of the estimators or must be consistent for the true π or μ in terms of the uniform norm. Since only one of the nuisance estimators is required to be consistent (not both), Theorem 2 shows the double robustness of the proposed estimator . Conditions (b), (c), and (d) are all common in standard nonparametric regression problems, while condition (e) involves the complexity of the estimators and (and their limits), and is a usual minimal regularity condition for problems involving nuisance functions.
Condition (b) says that the bandwidth parameter h decreases with sample size but not too quickly (so that nh3 → ∞). This is a standard requirement in local linear kernel smoothing (Fan and Gijbels, 1996; Wasserman, 2006; Li and Racine, 2007). Note that since nh = nh3/h2, it is implied that nh → ∞; thus one can view nh as a kind of effective or local sample size. Roughly speaking, the bandwidth h needs to go to zero in order to control bias, while the local sample size nh (and nh3) needs to go to infinity in order to control variance. We postpone more detailed discussion of the bandwidth parameter until a later subsection, where we detail how it can be chosen in practice using cross-validation. Condition (c) puts some minimal restrictions on the kernel function. It is clearly satisfied for most common kernels, including the uniform kernel K(u) = I(|u| ≤ 1)/2, the Epanechnikov kernel K(u) = (3/4)(1 − u2)I(|u| ≤ 1), and a truncated version of the Gaussian kernel K(u) = I(|u| ≤ 1)ϕ(u)/{2Φ(1) − 1} with ϕ and Φ the density and distribution functions for a standard normal random variable. Condition (d) restricts the smoothness of the effect curve θ(a), the density of ϖ(a), and the conditional density given A = a of the limiting pseudo-outcome . These are standard smoothness conditions imposed in nonparametric regression problems. By assuming more smoothness of θ(a), bias-reducing (higher-order) kernels could achieve faster rates of convergence and even approach the parametric root-n rate (see for example Fan and Gijbels (1996), Wasserman (2006), and others).
Condition (e) puts a mild restriction on how flexible the nuisance estimators (and their corresponding limits) can be, although such uniform entropy conditions still allow for a wide array of data-adaptive estimators and, importantly, do not require the use of parametric models. Andrews (1994) (Section 4), van der Vaart and Wellner (1996) (Sections 2.6–2.7), and van der Vaart (2000) (Examples 19.6–19.12) discuss a wide variety of function classes with finite uniform entropy integrals. Examples include standard parametric classes of functions indexed by Euclidean parameters (e.g., parametric functions satisfying a Lipschitz condition), smooth functions with uniformly bounded partial derivatives, Sobolev classes of functions, as well as convex combinations or Lipschitz transformations of any such sets of functions. The uniform entropy restriction in condition (e) is therefore not a very strong restriction in practice; however, it could be further weakened via sample splitting techniques (see Chapter 27 of van der Laan and Rose (2011)).
The convergence rate given in the result of Theorem 2 is a sum of two components. The first, , is the rate achieved in standard nonparametric regression problems without nuisance functions. Note that if h tends to zero slowly, then will tend to zero quickly but h2 will tend to zero more slowly; similarly if h tends to zero quickly, then h2 will as well, but will tend to zero more slowly. Balancing these two terms requires h ~ n−1/5 so that . This is the optimal pointwise rate of convergence for standard nonparametric regression on a single covariate, for a twice continuously differentiable regression function.
The second component, rn(a)sn(a), is the product of the local rates of convergence (around A = a) of the nuisance estimators and towards their targets π and μ. Thus if the nuisance function estimates converge slowly (due to the curse of dimensionality), then the convergence rate of will also be slow. However, since the term is a product, we have two chances at obtaining fast convergence rates, showing the bias-reducing benefit of doubly robust estimators. The usual explanation of double robustness is that, even if is misspecified so that sn(a) = O(1), then as long as is consistent, i.e., rn(a) = o(1), we will still have consistency since rn(a)sn(a) = o(1). But this idea also extends to settings when both and are consistent. For example suppose h ~ n−1/5 so that , and suppose and are locally consistent with rates rn(a) = n−2/5 and sn(a) = n−1/10. Then the product is rn(a)sn(a) = O(n−1/2) = o(n−2/5) and the contribution from the nuisance functions is asymptotically negligible, in the sense that the proposed estimator has the same convergence rate as an infeasible estimator with known nuisance functions. Contrast this with non-doubly-robust plug-in estimators whose convergence rate generally matches that of the nuisance function estimator, rather than being faster (van der Vaart, 2014).
In Section 8 of the Appendix we give some discussion of uniform consistency, which, along with weak convergence, will be pursued in more detail in future work.
3.4. Asymptotic normality of kernel estimator
In the next theorem we show that if one or both of the nuisance functions are estimated at fast enough rates, then the proposed estimator is asymptotically normal after appropriate scaling.
Theorem 3
Consider the same setting as Theorem 2. Along with Assumption 2 (Positivity) and conditions (a)–(e) from Theorem 2, also assume that:
-
(f)
The local convergence rates satisfy
Then
where bh(a) = θ″ (a)(h2/2) ∫ u2K(u) du + o(h2), and
for τ2(l, a) = var(Y | L = l, A = a), , .
The proof of Theorem 3 is given in the Appendix (Section 7). Conditions (a)–(e) are the same as in Theorem 2 and were discussed earlier. Condition (f) puts a restriction on the local convergence rates of the nuisance estimators. This will in general require at least some semiparametric modeling of the nuisance functions. Truly nonparametric estimators of π and μ will typically converge at slow rates due to the curse of dimensionality, and will generally not satisfy the rate requirement in the presence of multiple continuous covariates. Condition (f) basically ensures that estimation of the nuisance functions is irrelevant asymptotically; depending on the specific nuisance estimators used, it could be possible to give weaker but more complicated conditions that allow for a non-negligible asymptotic contribution while still yielding asymptotic normality.
Importantly, the rate of convergence required by condition (g) of Theorem 3 is slower than the root-n rate typically required in standard semiparametric settings where the parameter of interest is finite-dimensional and Euclidean. For example, in a standard setting where the support is finite, a sufficient condition for yielding the requisite asymptotic negligibility for attaining efficiency is rn(a) = sn(a) = o(n−1/4); however in our setting the weaker condition rn(a) = sn (a) = o(n−1/5) would be sufficient if h ~ n−1/5. Similarly, if one nuisance estimator or is computed with a correctly specified generalized additive model, then the other nuisance estimator would ony need to be consistent (without a rate condition). This is because, under regularity conditions and with optimal smoothing, a generalized additive model estimator converges at rate Op (n−2/5) (Horowitz, 2009), so that if the other nuisance estimator is merely consistent we have rn (a)sn (a) = O(n−2/5)o(1) = o(n−2/5), which satisfies condition (f) as long as h ~ n−1/5. In standard settings such flexible nuisance estimation would make a non-negligible contribution to the limiting behavior of the estimator, preventing asymptotic normality and root-n consistency.
Under the assumptions of Theorem 3, the proposed estimator is asymptotically normal after appropriate scaling and centering. However, the scaling is by the square root of the local sample size rather than the usual parametric rate . This slower convergence rate is a cost of making fewer assumptions (equivalently, the cost of better efficiency would be less robustness); thus we have a typical bias-variance trade-off. As in standard nonparametric regression, the estimator is consistent but not quite centered at θ(a); there is a bias term of order O(h2), denoted bh(a). In fact the estimator is centered at a smoothed version of the effect curve . This phenomenon is ubiquitous in nonparametric regression, and complicates the process of computing confidence bands. It is sometimes assumed that the bias term is and thus asymptotically negligible (e.g., by assuming h = o(n−1/5) so that nh5 → 0); this is called undersmoothing and technically allows for the construction of valid confidence bands around θ(a). However, there is little guidance about how to actually undersmooth in practice, so it is mostly a technical device. We follow Wasserman (2006) and others by expressing uncertainty about the estimator using confidence intervals centered at the smoothed data-dependent parameter . For example, under the conditions of Theorem 3, pointwise Wald 95% confidence intervals can be constructed with , where is the (1, 1) element of the sandwich variance estimate based on the estimated efficient influence function for βh(a) given by
for .
3.5. Data-driven bandwidth selection
The choice of smoothing parameter is critical for any nonparametric method; too much smoothing yields large biases and too little yields excessive variance. In this subsection we discuss how to use cross-validation to choose the relevant bandwidth parameter h. In general the method we propose parallels those used in standard nonparametric regression settings, and can give similar optimality properties.
We can exploit the fact that our method can be cast as a non-standard nonparametric regression problem, and borrow from the wealth of literature on bandwidth selection there. Specifically, the logic behind Theorem 3 (i.e., that nuisance function estimation can be asymptotically irrelevant) can be adapted to the bandwidth selection setting, by treating the pseudo-outcome as known and using for example the bandwidth selection framework from Härdle et al. (1988). These authors proposed a unified selection approach that includes generalized cross-validation, Akaike’s information criterion, and leave-one-out cross-validation as special cases, and showed the asymptotic equivalence and optimality of such approaches. In our setting, leave-one-out cross-validation is attractive because of its computational ease. The simplest analog of leave-one-out cross-validation for our problem would be to select the optimal bandwidth from some set with
where is the ith diagonal of the so-called smoothing or hat matrix. The properties of this approach can be derived using logic similar to that in Theorem 3, e.g., by adapting results from Li and Racine (2004). Alternatively one could split the sample, estimate the nuisance functions in one half, and then do leave-one-out cross-validation in the other half, treating the pseudo-outcomes estimated in the other half as known. We expect these approaches to be asymptotically equivalent to an oracle selector.
An alternative option would be to use the k-fold cross-validation approach of van der Laan and Dudoit (2003) or Díaz and van der Laan (2013). This would entail randomly splitting the data into k parts, estimating the nuisance functions and the effect curve on (k − 1) training folds, using these estimates to compute measures of risk on the kth test fold, and then repeating across all k folds and averaging the risk estimates. One would then repeat this process for each bandwidth value h in some set , and pick that which minimized the estimated cross-validated risk. van der Laan and Dudoit (2003) gave finite-sample and asymptotic results showing that the resulting estimator behaves similarly to an oracle estimator that minimizes the true unknown cross-validated risk. Unfortunately this cross-validation process can be more computationally intensive than the above leave-one-out method, especially if the nuisance functions are estimated with flexible computation-heavy methods. However this approach will be crucial when incorporating general machine learning and moving beyond linear kernel smoothers.
4. Simulation study
We used simulation to examine the finite-sample properties of our proposed methods. Specifically we simulated from a model with normally distributed covariates
Beta distributed exposure
and a binary outcome
The above setup roughly matches the data example from the next section. Figure 2 shows a plot of the effect curve induced by the simulation setup, along with treatment versus outcome data for one simulated dataset (with n = 1000).
Fig. 2.
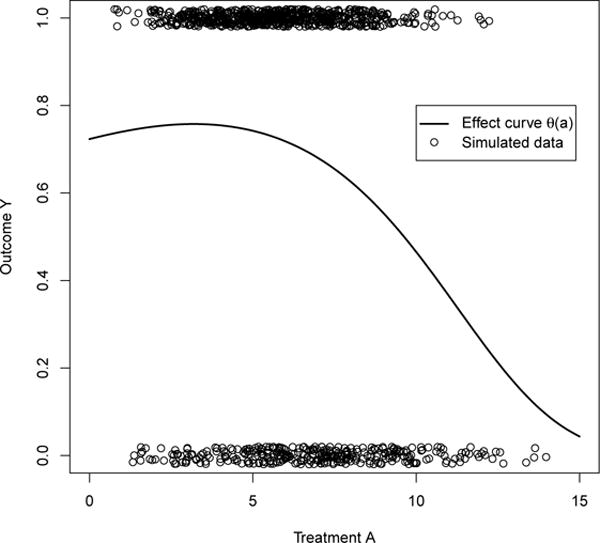
Plot of effect curve induced by simulation setup, with treatment and outcome data from one simulated dataset with n = 1000.
To analyze the simulated data we used three different estimators: a marginalized regression (plug-in) estimator , and two different versions of the proposed local linear kernel estimator. Specifically we used an inverse-probability-weighted approach first developed by Rubin and van der Laan (2006b), which relies solely on a treatment model estimator (equivalent to setting ), and the standard doubly robust version that used both estimators and . To model the conditional treatment density π we used logistic regression to estimate the parameters of the mean function λ(l); we separately considered correctly specifying this mean function, and then also misspecifying the mean function by transforming the covariates with the same covariate transformations as in Kang and Schafer (2007). To estimate the outcome model μ we again used logistic regression, considering a correctly specified model and then a misspecified model that used the same transformed covariates as with π and also left out the cubic term in a (but kept all other interactions). To select the bandwidth we used the leave-one-out approach proposed in Section 3.5, which treats the pseudo-outcomes as known. For comparison we also considered an oracle approach that picked the bandwidth by minimizing the oracle risk . In both cases we found the minimum bandwidth value in the range using numerical optimization.
We generated 500 simulated datasets for each of three sample sizes, n = 100, 1000, and 10000. To assess the quality of the estimates across simulations we calculated empirical bias and root mean squared error at each point, and integrated across the function with respect to the density of A. Specifically, letting denote the estimated curve at point a in simulation s (s = 1, …, S with S = 500), we estimated the integrated absolute mean bias and root mean squared error with
In the above denotes a trimmed version of the support of A, excluding 10% of mass at the boundaries. Note that the above integrands (except for the density) correspond to the usual definitions of absolute mean bias and root mean squared error for estimation of a single scalar parameter (e.g., the curve at a single point).
The simulation results are given in Table 1 (both the integrated bias and root mean squared error are multiplied by 100 for easier interpretation). Estimators with stars (e.g., IPW*) denote those with bandwidths selected using the oracle risk. When both and were misspecified, all estimators gave substantial integrated bias and mean squared error (although the doubly robust estimator consistently performed better than the other estimators in this setting). Similarly, all estimators had relatively large mean squared error in the small sample size setting (n = 100) due to lack of precision, although differences in bias were similar to those at moderate and small sample sizes (n = 1000, 10000). Specifically the regression estimator gave small bias when was correct and large bias when was misspecified, while the inverse-probability-weighted estimator gave small bias when was correct and large bias when was misspecified. However, the doubly robust estimator gave small bias as long as either or was correctly specified, even if one was misspecified.
Table 1.
Integrated bias and root mean squared error (500 simulations)
| Bias (RMSE) when correct model is: | |||||
|---|---|---|---|---|---|
| n | Method | Neither | Treatment | Outcome | Both |
| 100 | Reg | 2.67 (5.54) | 2.67 (5.54) | 0.62 (5.25) | 0.62 (5.25) |
| IPW | 2.26 (8.49) | 1.64 (8.57) | 2.26 (8.49) | 1.64 (8.57) | |
| IPW* | 2.26 (7.36) | 1.58 (7.37) | 2.26 (7.36) | 1.58 (7.37) | |
| DR | 2.23 (6.27) | 1.01 (6.28) | 1.12 (5.92) | 1.10 (6.50) | |
| DR* | 2.12 (5.48) | 1.00 (5.36) | 1.03 (5.08) | 1.02 (5.65) | |
| 1000 | Reg | 2.62 (3.07) | 2.62 (3.07) | 0.06 (1.53) | 0.06 (1.53) |
| IPW | 2.38 (3.97) | 0.86 (2.94) | 2.38 (3.97) | 0.86 (2.94) | |
| IPW* | 2.11 (3.44) | 0.70 (2.34) | 2.11 (3.44) | 0.70 (2.34) | |
| DR | 2.03 (3.11) | 0.75 (2.39) | 0.74 (2.53) | 0.68 (2.25) | |
| DR* | 1.84 (2.67) | 0.64 (1.88) | 0.61 (1.78) | 0.58 (1.78) | |
| 10000 | Reg | 2.65 (2.70) | 2.65 (2.70) | 0.02 (0.47) | 0.02 (0.47) |
| IPW | 2.36 (3.42) | 0.33 (1.09) | 2.36 (3.42) | 0.33 (1.09) | |
| IPW* | 2.24 (3.28) | 0.35 (0.85) | 2.24 (3.28) | 0.35 (0.85) | |
| DR | 1.81 (2.35) | 0.26 (0.86) | 0.20 (1.21) | 0.25 (0.78) | |
| DR* | 1.76 (2.27) | 0.31 (0.68) | 0.24 (1.10) | 0.29 (0.64) | |
Notes: Bias / RMSE = integrated mean bias / root mean squared error; IPW = inverse probability weighted; Reg = regression; DR = doubly robust;
= uses oracle bandwidth.
The inverse-probability-weighted estimator was least precise, although it had smaller mean squared error than the misspecified regression estimator for moderate and large sample sizes. The doubly robust estimator was roughly similar to the inverse-probability-weighted estimator when the treatment model was correct, but gave less bias and was more precise, and was similar to the regression estimator when the outcome model was correct (but slightly more biased and less precise). In general the estimators based on the oracle-selected bandwidth were similar to those using the simple leave-one-out approach, but gave marginally less bias and mean squared error for small and moderate sample sizes. The benefits of the oracle bandwidth were relatively diminished with larger sample sizes.
5. Application
In this section we apply the proposed methodology to estimate the effect of nurse staffing on hospital readmissions penalties, as discussed in the Introduction. In the original paper, McHugh et al. (2013) used a matching approach to control for hospital differences, and found that hospitals with more nurse staffing were less likely to be penalized; this suggests increasing nurse staffing to help curb excess readmissions. However, their analysis only considered the effect of higher nurse staffing versus lower nurse staffing, and did not explore the full effect curve; it also relied solely on matching for covariate adjustment, i.e., was not doubly robust.
In this analysis we use the proposed kernel smoothing approach to estimate the full effect curve flexibly, while also allowing for doubly robust covariate adjustment. We use the same data on 2976 acute care hospitals as in McHugh et al. (2013); full details are given in the original paper. The covariates L include hospital size, teaching intensity, not-for-profit status, urban versus rural location, patient race proportions, proportion of patients on Medicaid, average socioeconomic status, operating margins, a measure of market competition, and whether open heart or organ transplant surgery is performed. The treatment A is nurse staffing hours, measured as the ratio of registered nurse hours to adjusted patient days, and the outcome Y indicates whether the hospital was penalized due to excess readmissions. Excess readmissions are calculated by the Centers for Medicare & Medicaid Services and aim to adjust for the fact that different hospitals see different patient populations. Without unmeasured confounding, the quantity θ(a) represents the proportion of hospitals that would have been penalized had all hospitals changed their nurse staffing hours to level a. Otherwise θ(a) can be viewed as an adjusted measure of the relationship between nurse staffing and readmissions penalties.
For the conditional density π(a | l) we assumed a model A = λ(L) + γ(L)ε, where ε has mean zero and unit variance given the covariates, but otherwise has an unspecified density. We flexibly estimated the conditional mean function and variance function γ(l) = var(A | L = l) by combining linear regression, multivariate adaptive regression splines, generalized additive models, Lasso, and boosting, using the cross-validation-based Super Learner algorithm (van der Laan et al., 2007), in order to reduce chances of model misspecification. A standard kernel approach was used to estimate the density of ε.
For the outcome regression μ(l, a) we again used the Super Learner approach, combining logistic regression, multivariate adaptive regression splines, generalized additive models, Lasso, and boosting. To select the bandwidth parameter h we used the leave-one-out approach discussed in Section 3.5. We considered regression, inverse-probability-weighted, and doubly robust estimators, as in the simulation study in Section 4. The two hospitals (<0.1%) with smallest inverse-probability weights were removed as outliers. For the doubly robust estimator we also computed pointwise uncertainty intervals (i.e., confidence intervals around the smoothed parameter ; see Section 3.4) using a Wald approach based on the empirical variance of the estimating function values.
A plot showing the results from the three estimators (with uncertainty intervals for the proposed doubly robust estimator) is given in Figure 3. In general the three estimators were very similar. For less than 5 average nurse staffing hours the adjusted chance of penalization was estimated to be roughly constant, around 73%, but at 5 hours chances of penalization began decreasing, reaching approximately 60% when nurse staffing reached 11 hours. This suggests that adding nurse staffing hours may be particularly beneficial in the 5–10 hour range, in terms of reducing risk of readmissions penalization; most hospitals (65%) lie in this range in our data.
Fig. 3.
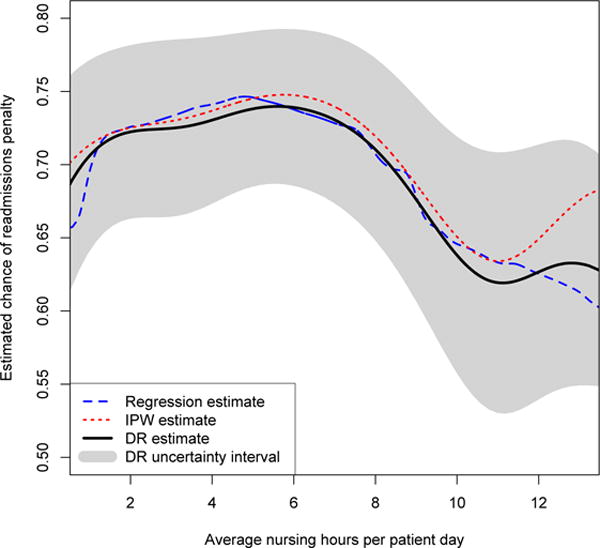
Estimated effects of nurse staffing on readmissions penalties.
6. Discussion
In this paper we developed a novel approach for estimating the average effect of a continuous treatment; importantly the approach allows for flexible doubly robust covariate adjustment without requiring any parametric assumptions about the form of the effect curve, and can incorporate general machine learning and non-parametric regression methods. We presented a novel efficient influence function for a stochastic intervention parameter defined within a nonparametric model; this influence function motivated the proposed approach, but may also be useful to estimate on its own. In addition we provided asymptotic results (including rates of convergence and asymptotic normality) for a particular kernel estimation version of our method, which only require the effect curve to be twice continuously differentiable, and allows for flexible data-adaptive estimation of nuisance functions. These results show the double robustness of the proposed approach, since either a conditional treatment density or outcome regression model can be misspecified and the proposed estimator will still be consistent as long as one such nuisance function is correctly specified. We also showed how double robustness can result in smaller second-order bias even when both nuisance functions are consistently estimated. Finally, we proposed a simple and fast data-driven cross-validation approach for bandwidth selection, found favorable finite sample properties of our proposed approach in a simulation study, and applied the kernel estimator to examine the effects of hospital nurse staffing on excess readmissions penalty.
This paper integrates semiparametric (doubly robust) causal inference with non-parametric function estimation and machine learning, helping to bridge the “huge gap between classical semiparametric models and the model in which nothing is assumed” (van der Vaart, 2014). In particular our work extends standard nonparametric regression by allowing for complex covariate adjustment and doubly robust estimation, and extends standard doubly robust causal inference methods by allowing for nonparametric smoothing. Many interesting problems arise in this gap between standard nonparametric and semiparametric inference, leading to many opportunities for important future work, especially for complex non-regular target parameters that are not pathwise differentiable. In the context of this paper, in future work it will be useful to study uniform distributional properties of our proposed estimator (e.g., weak convergence), as well as its role in testing and inference (e.g., for constructing tests that have power to detect a wide array of deviations from the null hypothesis of no effect of a continuous treatment).
Acknowledgments
Edward Kennedy was supported by NIH grant R01-DK090385, Zongming Ma by NSF CAREER award DMS-1352060, and Dylan Small by NSF grant SES-1260782. The authors thank Marshall Joffe and Alexander Luedtke for helpful discussions, and two referees for very insightful comments and suggestions.
References
- Andrews DW. Empirical process methods in econometrics. Handbook of Econometrics. 1994;4:2247–2294. [Google Scholar]
- Bickel PJ, Klaassen CA, Ritov Y, Wellner JA. Efficient and Adaptive Estimation for Semiparametric Models. Johns Hopkins University Press; 1993. [Google Scholar]
- Díaz I, van der Laan MJ. Population intervention causal effects based on stochastic interventions. Biometrics. 2012;68:541–549. doi: 10.1111/j.1541-0420.2011.01685.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Díaz I, van der Laan MJ. Targeted data adaptive estimation of the causal dose-response curve. Journal of Causal Inference. 2013;1:171–192. [Google Scholar]
- Fan J, Gijbels I. Local Polynomial Modelling and Its Applications: Monographs on Statistics and Applied Probability. Vol. 66. CRC Press; 1996. [Google Scholar]
- Galvao AF, Wang L. Uniformly semiparametric efficient estimation of treatment effects with a continuous treatment. Journal of the American Statistical Association 2015 [Google Scholar]
- Gill RD, Robins JM. Causal inference for complex longitudinal data: the continuous case. The Annals of Statistics. 2001;29:1785–1811. [Google Scholar]
- Györfi L, Kohler M, Krzykaz A, Walk H. A Distribution-Free Theory of Nonparametric Regression. Springer; 2002. [Google Scholar]
- Härdle W, Hall P, Marron JS. How far are automatically chosen regression smoothing parameters from their optimum? Journal of the American Statistical Association. 1988;83:86–95. [Google Scholar]
- Hill JL. Bayesian nonparametric modeling for causal inference. Journal of Computational and Graphical Statistics. 2011;20 [Google Scholar]
- Hirano K, Imbens GW. Applied Bayesian Modeling and Causal Inference from Incomplete-Data Perspectives. Vol. 226164. New York: Wiley; 2004. The propensity score with continuous treatments; pp. 73–84. [Google Scholar]
- Horowitz JL. Semiparametric and Nonparametric Methods in Econometrics. Springer; 2009. [Google Scholar]
- Imai K, van Dyk DA. Causal inference with general treatment regimes. Journal of the American Statistical Association. 2004;99:854–866. [Google Scholar]
- Imbens GW. Nonparametric estimation of average treatment effects under exogeneity: A review. Review of Economics and Statistics. 2004;86:4–29. [Google Scholar]
- Kang JD, Schafer JL. Demystifying double robustness: A comparison of alternative strategies for estimating a population mean from incomplete data. Statistical Science. 2007;22:523–539. doi: 10.1214/07-STS227. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li Q, Racine JS. Cross-validated local linear nonparametric regression. Statistica Sinica. 2004;14:485–512. [Google Scholar]
- Li Q, Racine JS. Nonparametric Econometrics: Theory and Practice. Princeton University Press; 2007. [Google Scholar]
- McHugh MD, Berez J, Small DS. Hospitals with higher nurse staffing had lower odds of readmissions penalties than hospitals with lower staffing. Health Affairs. 2013;32:1740–1747. doi: 10.1377/hlthaff.2013.0613. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Neugebauer R, van der Laan MJ. Nonparametric causal effects based on marginal structural models. Journal of Statistical Planning and Inference. 2007;137:419–434. [Google Scholar]
- Robins JM. Statistical Models in Epidemiology, the Environment, and Clinical Trials. Springer; 2000. Marginal structural models versus structural nested models as tools for causal inference; pp. 95–133. [Google Scholar]
- Robins JM, Rotnitzky A. Comments on inference for semiparametric models: Some questions and an answer. Statistica Sinica. 2001;11:920–936. [Google Scholar]
- Rubin DB. Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology. 1974;66:688–701. [Google Scholar]
- Rubin DB, van der Laan MJ. A general imputation methodology for nonparametric regression with censored data. UC Berkeley Division of Biostatistics Working Paper Series. 2005 Paper 194. [Google Scholar]
- Rubin DB, van der Laan MJ. Doubly robust censoring unbiased transformations. UC Berkeley Division of Biostatistics Working Paper Series. 2006a doi: 10.2202/1557-4679.1052. Paper 208. [DOI] [PubMed] [Google Scholar]
- Rubin DB, van der Laan MJ. Extending marginal structural models through local, penalized, and additive learning. UC Berkeley Division of Biostatistics Working Paper Series. 2006b Paper 212. [Google Scholar]
- Tsiatis AA. Semiparametric Theory and Missing Data. Springer; 2006. [Google Scholar]
- van der Laan MJ, Dudoit S. Unified cross-validation methodology for selection among estimators and a general cross-validated adaptive epsilon-net estimator: Finite sample oracle inequalities and examples. UC Berkeley Division of Biostatistics Working Paper Series. 2003 Paper 130. [Google Scholar]
- van der Laan MJ, Polley EC, Hubbard AE. Super learner. Statistical Applications in Genetics and Molecular Biology. 2007;6 doi: 10.2202/1544-6115.1309. [DOI] [PubMed] [Google Scholar]
- van der Laan MJ, Robins JM. Locally efficient estimation with current status data and time-dependent covariates. Journal of the American Statistical Association. 1998;93:693–701. [Google Scholar]
- van der Laan MJ, Robins JM. Unified Methods for Censored Longitudinal Data and Causality. Springer; 2003. [Google Scholar]
- van der Laan MJ, Rose S. Targeted Learning: Causal Inference for Observational and Experimental Data. Springer; 2011. [Google Scholar]
- van der Laan MJ, Yu Z. Comments on inference for semiparametric models: Some questions and an answer. Statistica Sinica. 2001;11:910–917. [Google Scholar]
- van der Vaart AW. Asymptotic Statistics. Cambridge University Press; 2000. [Google Scholar]
- van der Vaart AW. Higher order tangent spaces and influence functions. Statistical Science. 2014;29:679–686. [Google Scholar]
- van der Vaart AW, van der Laan MJ. Estimating a survival distribution with current status data and high-dimensional covariates. The International Journal of Biostatistics. 2006;2:1–40. [Google Scholar]
- van der Vaart AW, Wellner JA. Weak Convergence and Empirical Processes. Springer; 1996. [Google Scholar]
- Wang L, Rotnitzky A, Lin X. Nonparametric regression with missing outcomes using weighted kernel estimating equations. Journal of the American Statistical Association. 2010;105:1135–1146. doi: 10.1198/jasa.2010.tm08463. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wasserman L. All of Nonparametric Statistics. Springer; 2006. [Google Scholar]