

Abstract
Energy demand is an important economic index, and demand forecasting has played a significant role in drawing up energy development plans for cities or countries. As the use of large datasets and statistical assumptions is often impractical to forecast energy demand, the GM(1,1) model is commonly used because of its simplicity and ability to characterize an unknown system by using a limited number of data points to construct a time series model. This paper proposes a genetic-algorithm-based remnant GM(1,1) (GARGM(1,1)) with sign estimation to further improve the forecasting accuracy of the original GM(1,1) model. The distinctive feature of GARGM(1,1) is that it simultaneously optimizes the parameter specifications of the original and its residual models by using the GA. The results of experiments pertaining to a real case of energy demand in China showed that the proposed GARGM(1,1) outperforms other remnant GM(1,1) variants.
Introduction
Energy is necessary for the sustainable development and economic prosperity of a country [1], and this is evidenced by the fact that energy demand has emerged as an important economic index in recent years. With the rapid pace of industrialization, the global demand for energy has increased exponentially in the past decade. Worldwide energy consumption is expected to increase by over 50% before 2030 if the current pattern of global energy consumption continues [2]. Moreover, high energy consumption has a significant and deleterious impact on the environment. This means that the environmental impact of energy consumption will play a crucial role in guiding energy development policies for cities and countries in the future [1]. An important issue in this context is the ability to accurately predict energy demand.
Traditional methods of demand forecasting, including artificial intelligence techniques, multivariate regression, and time series analysis, have been frequently applied to predict energy demand [3–8]. However, a large sample size is usually required to achieve reasonable forecasting accuracy for these methods [9–12]. Furthermore, statistical methods usually require that the data conform to statistical assumptions such as following a particular distribution. However, using large sample sizes or conforming to statistical assumptions is often impractical [13]. Hence, a forecasting method is needed that can work with small samples without making statistical assumptions to construct an energy demand prediction model [10, 11].
Grey prediction [14] has emerged as a popular technique in the past decade, and is suitable for forecasting energy demand because of its simplicity and ability to characterize an unknown system using a limited number of data points [1]. Grey prediction consists of several forecasting models, of which the GM(1, 1) is commonly used for time series forecasting [15]. The GM(1, 1) model needs only four recent sample data points to achieve reliable and acceptable prediction accuracy [16, 17]. Its effectiveness has been verified through application to a wide range of real-world problems, including energy consumption forecasting [10–13, 18–23], technology management [24, 25], engineering problems [26], optimization model development [27, 28], and general management [29–31].
To increase the forecasting accuracy of the original GM(1, 1) model, further development of the residual GM(1,1) model has been recommended [14, 15]. A residual modification model, also called a remnant GM(1,1) model, is commonly constructed by first building the original GM(1,1) model, and then constructing the residual GM(1,1) model to modify the predicted values obtained by the original model. A number of improved remnant GM(1, 1) models focusing on sign estimation for residual modification have been developed. For instance, Hsu and Chen [32] used a multi-layer perceptron (MLP) to estimate the signs of residual modification to forecast power demand; Hsu [33] used Markov-chain-based sign estimation to modify residuals for the global integrated circuit industry, whereas Lee and Tong [13] combined residual modification with residual genetic programming (GP) sign estimation to develop the GPGM(1, 1) model in view of the importance of forecasting energy demand.
Usually, the original and the residual models are set up separately for remnant models. It would be interesting to investigate whether the prediction accuracy of the traditional remnant GM(1,1) model improves when the GM(1,1) and its residual models are constructed simultaneously. This paper develops a grey forecasting model called the genetic-algorithm-based remnant GM(1,1) model (GARGM(1,1)) with sign estimation that delivers high prediction accuracy. Its distinctive feature is that it can simultaneously optimize the parameters required for the original GM(1,1) and its residual models by a powerful search and optimization method [34–36], the genetic algorithm (GA). This grey prediction model is then applied to forecast energy demand.
The remainder of the paper is organized as follows. Sections 2 and 3 introduce the traditional remnant GM(1,1) and the proposed GARGM(1,1) models, respectively. Section 4 examines the forecasting performance of the GARGM(1,1) model using a dataset collected from China Statistical Yearbook 2008. The results show that the GARGM(1,1) model can outperform other variants of the remnant GM(1,1) model. Section 5 contains a discussion and the conclusions of this study.
Remnant GM(1,1) model
This section introduces the traditional remnant GM(1,1) model used to improve the predictive accuracy of the original GM(1,1) model. It consists of two main components: the original GM(1,1) model described in Section 2.1, and the residual GM(1,1) model described in Section 2.2.
Original GM(1,1) model
Let an original data sequence be provided by one system and consist of n samples. A new sequence can then be generated from x(0) by the accumulated generating operation (AGO) [7, 15] as follows:
| (1) |
, ,…, can then be approximated by a first-order differential equation:
| (2) |
where a and b are the developing coefficient and the control variable, respectively. The AGO is used because it can identify potential regularities hidden in the data sequences even if the original data are finite, insufficient, and chaotic.
, the predicted value of , can be obtained by solving the grey difference equation with initial condition :
| (3) |
a and b can be estimated by means of a grey difference equation:
| (4) |
where the background value is formulated as follows:
| (5) |
α is usually specified as 0.5 for convenience, but this is not the optimal setting. By using n–1 grey difference equations (k = 2, 3,…, n), a and b can be obtained by the ordinary least-squares method:
| (6) |
where
| (7) |
| (8) |
Using the inverse AGO, the predicted value, , of can be generated as follows:
| (9) |
Therefore, can be formulated as follows:
| (10) |
Note that .
Residual GM(1,1) model
Let ε(0) = (, ,…, ) denote the sequence of absolute residual values, where
| (11) |
Using the same manner of construction as for the original GM(1,1) model for x(0), a residual model can be constructed for ε(0). The predicted residual, , of can be derived as follows:
| (12) |
where aɛ and bɛ are the developing coefficient and the control variable respectively. In the remnant GM(1,1) model with sign estimation, is modified by adding to, or subtracting from, [37]:
| (13) |
where s(k) denotes the sign (positive or negative) of with respect to the k-th year. Compared to the original remnant GM(1,1) model, the sign of each residual in the improved one is unknown and needs to be estimated.
Genetic-algorithm-based remnant GM(1,1) model
Two main issues need to be addressed in the traditional remnant GM(1,1) model. First, the determination of both the developing coefficient and the control variable, in the original GM(1,1) model and the residual GM(1,1) model, are completely dependent on the background values. However, as the background values cannot be easily determined in advance by decision makers, it is reasonable to try to find developing coefficients and control variables without using background values. The second issues that needs to be addressed is that aɛ and bɛ are determined once a and b in the original GM(1,1) model have been created. However, in addition to sign estimation, to minimize the difference between the predicted and the actual values, it might be worth examining whether simultaneously determining the four crucial parameters (i.e., a, b, aɛ, bɛ) has an effect on the prediction accuracy of the remnant GM(1,1) model.
The objective of our optimization problem is to minimize the mean absolute percentage error (MAPE) of the training patterns:
| (14) |
where TS denotes the training or testing data. As the background values are not involved in the formulation of , the computation of MAPE is completely free of the influence of background values. The absolute percentage error (APE), which was used to compare and with the time series data, was defined as:
| (15) |
A method based on the GA is developed to automatically determine the developing coefficients (i.e., a and aɛ), the control variables (i.e., b and bɛ), and the sign of the k-th year (i.e., sk, k = 2, 3, …, n) for the improved remnant GM(1,1) model (i.e., GARGM(1,1)). Let Pm denote the population generated in generation m (1 ≤ m ≤ nmax). Chromosome u (1 ≤ u ≤ nsize) produced in Pm is represented as ,…, to construct the proposed GARGM(1,1) model, where , , , and are real-valued genes, and is a binary-valued gene for . has a positive sign when it is one and a negative sign when it is zero.
Let nsize and nmax denote the population size and the maximum number of generations, respectively. Using the MAPE for the training data as the fitness function, having evaluated the fitness value of each chromosome in Pm, selection, crossover, and mutation are applied until nsize new chromosomes have been generated for Pm+1. The GA can be executed until nmax generations have been generated. The authors of this study performed these genetic operations as described in detail in [38].
Selection
Using binary tournament selection, two chromosomes from the current population are randomly selected, and the one with the higher fitness is placed in a mating pool. This process is repeated until there are nsize chromosomes in the mating pool. nsize pairs of chromosomes from the pool are then randomly selected for mating. Crossover and mutation operations are applied to a selected parent to reproduce children by altering the chromosomal makeup of the chromosomes of two parents.
Crossover
For chromosomes u ( ,…, ) and v ( ,…, ) (1 ≤ v ≤ nsize), each pair of real-valued genes has a crossover probability Prc. The operations are performed as follows:
where h1, h2, h3, h4, and hk are all random numbers in the interval [0, 1]. In practice, the one-point crossover operation with Prc is used to exchange partial information between binary-valued substrings (i.e., , …, and ,…, ) in the selected pair of chromosomes. The crossover point in a substring is chosen randomly. Two new chromosomes are thus generated, and replace their parents in generation Pm+1.
Mutation
Let Prm denote the probability that mutation is performed for each real-valued parameter in a new chromosome generated by crossover. To avoid excessive perturbation in the gene pool, a low mutation rate should be used. If mutation occurs for a real-valued gene, it is altered by adding a number randomly selected from a specified interval. For each gene of the newly generated binary chromosomes, the mutation operation with Prm is performed on each bit or gene of the string. Each gene in a string can be thus changed either from zero to one or from one to zero with probability Prm.
After crossover and mutation, ndel (0 ≤ ndel ≤ nsize) chromosomes in Pm+1 are randomly removed from the set of new chromosomes (those formed by genetic operations) to make room for additional copies of the chromosome with a maximum fitness value in Pm. Fig 1 shows a flowchart of the construction of the proposed prediction model using the GA.
Fig 1. Flowchart of construction of the proposed prediction model.
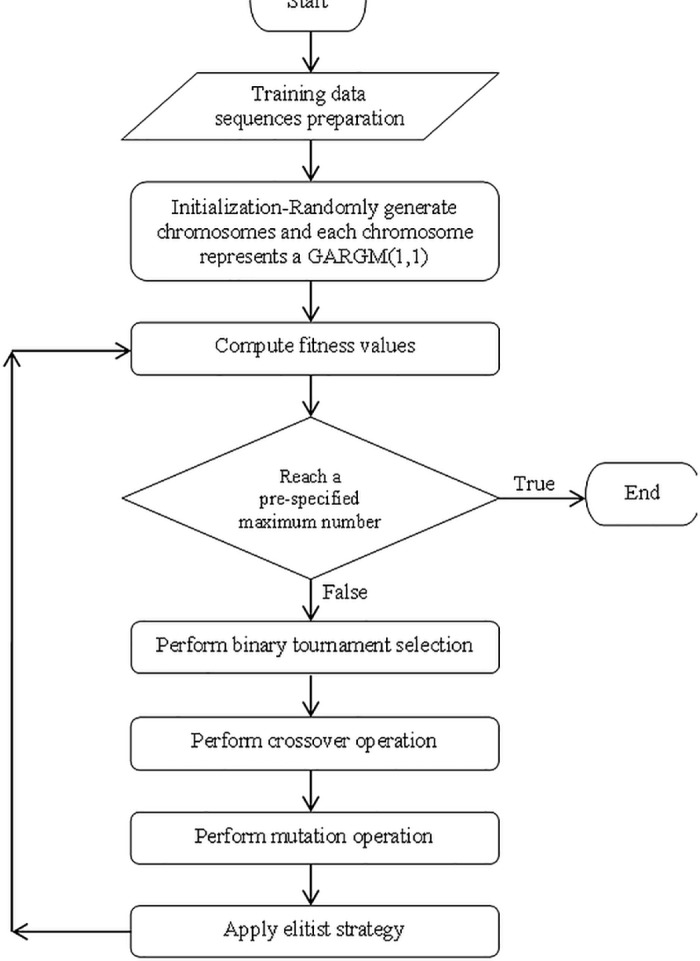
Experimental results
Section 4.1 presents the parameter specifications of the GA-based learning algorithm and Section 4.2 reports the performance of different forecasting methods on a real-world case.
Parameter specifications of GA
A number of factors can influence the performance of the GA, including population size and the probabilities of applying the crossover and mutation operators. As a matter of fact, no optimal GA parameter specifications exist. The principles recommended by Osyczka [35] and Ishibuchi et al. [36] to specify parameters of GA were as follows:
The population size commonly should range from 50 to 500 individuals.
The stopping condition should be specified according to the available computation time.
Only a small number of elite chromosomes were needed.
The crossover probability should be set to a large value because it controls the range of exploration in the solution space.
The mutation probability should be set to a small value to avoid generating excessive perturbations.
Therefore, the parameters in the experiment were specified as: nsize = 200, nmax = 1000, ndel = 2, Prc = 0.9, and Prm = 0.01.
This experiment constructed the proposed GARGM(1,1) without any complex mechanisms to tune its parameters.
Application to total energy demand in China
To examine the forecasting capability of the GARGM(1,1) model, an experiment was conducted to compare its performance with the original GM(1,1), the GPGM(1,1), and the improved grey forecasting model using MLP models (MLPGM(1,1)) on a dataset collected from the China Statistical Yearbook 2008. This dataset made up of historical annual total energy consumption in China was shown in [13]. With its rapid economic development and ongoing industrialization, China has played a vital role with regard to energy production and consumption [39]. Indeed, energy demand forecasting has become an increasingly important issue for China [12].
Data from 1990 to 2003 were used for model fitting and those from 2004 to 2007 for ex-post testing. The forecasting results reported in [13] for the original GM(1,1), the MLPGM(1,1), and the GPGM(1,1) models are summarized in Table 1 and illustrated in Fig 2. Table 1 shows that the MAPE values of the original GM(1,1), the MLPGM(1,1), the GPGM(1,1), and the GARGM(1,1) models for the training data were 4.13%, 3.61%, 2.59%, and 1.50%, respectively. Similarly, for the testing data, the MAPE values were 26.21%, 20.23%, 20.23%, and 17.51%, respectively. These results indicate that the GARGM(1,1) model outperformed the other forecasting methods on both training and testing data. The results of ex-post testing were relatively poor for every prediction model because the total energy consumption drastically went up in 2004, as shown in Table 1.
Table 1. Prediction accuracy obtained by different methods for total energy consumption (unit: 104 tons of SCE).
| Year | Actual | Original GM(1,1) | MLPGM(1,1) | GPGM(1,1) | GARGM(1,1) | ||||
|---|---|---|---|---|---|---|---|---|---|
| Predicted | APE | Predicted | APE | Predicted | APE | Predicted | APE | ||
| 1990 | 98703 | 98703 | 0 | 98703 | 0 | 98703 | 0 | 98703 | 0 |
| 1991 | 103783 | 108706.1 | 4.74 | 103783 | 0 | 103783 | 0 | 101195.7 | 2.49 |
| 1992 | 109170 | 112335.5 | 2.9 | 116225.8 | 6.46 | 108445.2 | 0.66 | 102596.3 | 3.14 |
| 1993 | 115993 | 116086.1 | 0.08 | 111804.1 | 3.61 | 111804.1 | 3.61 | 117195.8 | 1.04 |
| 1994 | 122737 | 119962 | 2.26 | 115248.8 | 6.10 | 124675.1 | 1.58 | 121997.9 | 0.60 |
| 1995 | 131176 | 123967.2 | 5.50 | 129154.8 | 1.54 | 129154.8 | 1.54 | 127012.8 | 3.17 |
| 1996 | 138948 | 128106.2 | 7.80 | 133816.1 | 3.69 | 133816.1 | 3.69 | 132251.6 | 4.82 |
| 1997 | 137798 | 132383.3 | 3.93 | 138668.2 | 0.63 | 138668.2 | 0.63 | 137725.9 | 0.05 |
| 1998 | 132214 | 136803.3 | 3.47 | 143721 | 8.7 | 129885.5 | 1.76 | 129692.7 | 1.91 |
| 1999 | 133831 | 141370.8 | 5.63 | 133756.5 | 0.06 | 133756.5 | 0.06 | 134280.7 | 0.34 |
| 2000 | 138553 | 146090.8 | 5.44 | 137709.8 | 0.61 | 137709.8 | 0.61 | 139002.5 | 0.32 |
| 2001 | 143199 | 150968.4 | 5.43 | 141743.6 | 1.02 | 141743.6 | 1.02 | 143858.7 | 0.46 |
| 2002 | 151797 | 156008.9 | 2.77 | 145855.2 | 3.91 | 145855.2 | 3.91 | 148849.8 | 1.94 |
| 2003 | 174990 | 161217.6 | 7.87 | 150041.6 | 14.26 | 172393.5 | 1.48 | 176275.6 | 0.73 |
| MAPE | 4.13 | 3.61 | 2.59 | 1.50 | |||||
| 2004 | 203227 | 166600.2 | 18.02 | 178901.5 | 11.97 | 178901.5 | 11.97 | 183797.7 | 9.56 |
| 2005 | 224682 | 172162.6 | 23.37 | 185702.4 | 17.35 | 185702.4 | 17.35 | 191681.9 | 14.69 |
| 2006 | 264270 | 177910.7 | 32.68 | 192813.8 | 27.04 | 192813.8 | 27.04 | 199949.4 | 24.34 |
| 2007 | 265583 | 183850.7 | 30.77 | 200254.3 | 24.60 | 200254.3 | 24.60 | 208623.1 | 21.45 |
| MAPE | 26.21 | 20.23 | 20.23 | 17.51 | |||||
Fig 2. Predicted values and actual values from 1990 to 2007.
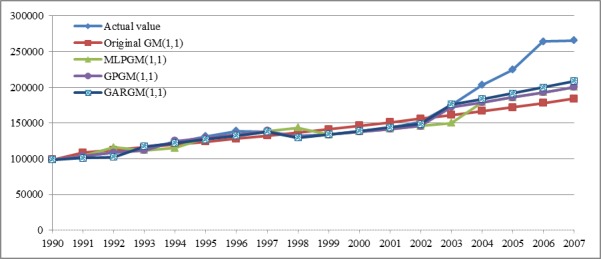
Note that Lewis [40] presented the following MAPE criteria for evaluating a forecasting model: MAPE ≤ 10, 10 < MAPE ≤ 20, 20 < MAPE ≤ 50, and MAPE > 50 correspond to high, good, reasonable and weak forecasting models, respectively. Although the original GM(1,1), the GPGM(1,1), the MLPGM(1,1), and the GARGM(1,1) models all have high forecasting capability on the training data, it is noteworthy that the GARGM(1,1) model exhibited its good forecasting capability, but the original GM(1,1), the GPGM(1,1), and the MLPGM(1,1) models recorded merely reasonable forecasting accuracy values on the testing data. It is hence clear that the GARGM(1, 1) model yielded satisfactory performance compared to the other forecasting methods considered.
Discussion and conclusions
Energy management is crucial for economic prosperity and environmental security [1]. Energy demand forecasting plays an important role in creating energy policy. GM(1,1) is an appropriate approach to predict energy demand because it uses a limited number of samples to construct a prediction model without statistical assumptions. The present study developed the GARGM(1,1) model to forecast energy demand. The proposed model is sufficiently simple to implement as a computer program. Although the parameter specifications are somewhat subjective, the experimental results showed that they are acceptable.
Compared with the MLPGM(1, 1) and the GPGM(1, 1) models, the GARGM(1, 1) model has the advantage of directly determining the developing coefficients and the control variables by the GA without using background values. The required parameters for the RGM are also optimized simultaneously. Experimental results concerning a case of energy demand data from China showed the effectiveness of the proposed forecasting model. In addition to grey prediction models, we examined the prediction performance of two frequently used models, linear regression and the MLP with backpropagation learning. The MLP had an input node, a hidden layer with two neurons, and an output layer with one neuron; it was trained over 10,000 iterations at a learning rate of 0.8. The forecasting results obtained by linear regression and the MLP are summarized in Table 2. It is clear that the prediction accuracy values of linear regression on the training and testing data were 4.20% and 27.76%, respectively [13], whereas those of the MLP on the training and testing data were 3.85% and 18.30%, respectively [20]. Therefore, the proposed GARGM(1,1) outperforms linear regression and the MLP. In case of linear regression, it is reasonable to speculate that the size of the training sample and the statistical assumptions (e.g., homoscedasticity) had a certain impact on the prediction performance of the statistical methods.
Table 2. Prediction accuracy obtained by linear regression and MLP.
| Year | Actual | Linear regression | MLP | GARGM(1,1) | |||
|---|---|---|---|---|---|---|---|
| Predicted | APE | Predicted | APE | Predicted | APE | ||
| 1990 | 98703 | 101756.6 | 3.09 | 93012.6 | 5.77 | 98703 | 0 |
| 1991 | 103783 | 106243.4 | 2.37 | 107674.6 | 3.75 | 101195.7 | 2.49 |
| 1992 | 109170 | 110730.2 | 1.43 | 116921.0 | 7.10 | 102596.3 | 3.14 |
| 1993 | 115993 | 115217.0 | 0.67 | 122130.4 | 5.29 | 117195.8 | 1.04 |
| 1994 | 122737 | 119703.8 | 2.47 | 125034.6 | 1.87 | 121997.9 | 0.60 |
| 1995 | 131176 | 124190.6 | 5.33 | 126861.3 | 3.29 | 127012.8 | 3.17 |
| 1996 | 138948 | 128677.5 | 7.39 | 128373.0 | 7.61 | 132251.6 | 4.82 |
| 1997 | 137798 | 133164.3 | 3.36 | 130080.1 | 5.60 | 137725.9 | 0.05 |
| 1998 | 132214 | 137651.1 | 4.11 | 132407.0 | 0.15 | 129692.7 | 1.91 |
| 1999 | 133831 | 142137.9 | 6.21 | 135788.9 | 1.46 | 134280.7 | 0.34 |
| 2000 | 138553 | 146624.7 | 5.83 | 140696.7 | 1.55 | 139002.5 | 0.32 |
| 2001 | 143199 | 151111.5 | 5.53 | 147565.7 | 3.05 | 143858.7 | 0.46 |
| 2002 | 151797 | 155598.3 | 2.5 | 156595.8 | 3.16 | 148849.8 | 1.94 |
| 2003 | 174990 | 160085.1 | 8.52 | 167469.6 | 4.30 | 176275.6 | 0.73 |
| MAPE | 4.20 | 3.85 | 1.50 | ||||
| 2004 | 203227 | 164572.0 | 19.02 | 179212.1 | 11.82 | 183797.7 | 9.56 |
| 2005 | 224682 | 169058.8 | 24.76 | 190465.4 | 15.23 | 191681.9 | 14.69 |
| 2006 | 264270 | 173545.6 | 34.33 | 200083.0 | 24.29 | 199949.4 | 24.34 |
| 2007 | 265583 | 178032.4 | 32.97 | 207546.2 | 21.85 | 208623.1 | 21.45 |
| MAPE | 27.76 | 18.30 | 17.51 | ||||
Energy demand forecasting can be regarded as a grey system problem [1, 12] because a few factors, such as income and population, influence energy demand. However, how exactly they influence energy demand is unclear. Therefore, based on the superior forecasting performance of the GARGM(1, 1) model in terms of energy demand, the applicability of the proposed forecasting model to other energy forecasting problems, such as electricity consumption in certain developing countries, should be explored. Moreover, sign estimation for the remnant forecasting model should be explored using other artificial intelligence tools such as the functional-link net [41, 42] and other nonadditive neural networks [43–45] could improve prediction accuracy.
Moreover, it has been known that the GA can be time consuming in searching for optimum solutions. Although forecasting energy demand cannot be treated as a kind of large-scale optimization problem, several improved versions, such as the parallel GA [46–50], may be used to expedite the construction of the model or increase its precision for optimum solutions of the proposed GARGM(1,1) model.
Acknowledgments
The author would like to thank the anonymous referees for their valuable comments. This research is supported by the Ministry of Science and Technology, Taiwan under grant MOST 104-2410-H-033-023-MY2 and MOST 106-2410-H-033-006-MY2. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Data Availability
All relevant data are within the paper. The dataset made up of historical annual total energy consumption in China were shown in [13].
Funding Statement
This research is partially supported by the Ministry of Science and Technology, Taiwan under grant MOST 104-2410-H-033-023-MY2 and MOST 106-2410-H-033-006-MY2. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.Suganthi L, Samuel AA. Energy models for demand forecasting-A review. Renewable and Sustainable Energy Reviews. 2012; (16):1223–40. [Google Scholar]
- 2.Smith M, Hargroves K, Stasinopoulos P, Stephens R, Desha C, Hargroves S, et al. Energy Transformed: Sustainable Energy Solutions for Climate Change Mitigation. Australia: The Natural Edge Project, CSIRO, and Griffith University; 2007. [Google Scholar]
- 3.Ediger VS, Akar S. ARIMA forecasting of primary energy demand by fuel in Turke. Energy Policy. 2007; (35):1701–8. [Google Scholar]
- 4.Gonzalez PA, Zamarreno JA. Prediction of hourly energy consumption in buildings based on a feedback artificial neural network. Energy and Buildings. 2005; (37):595–601. [Google Scholar]
- 5.Tutun S, Chou CA, http://0-www.sciencedirect.com.cylis.lib.cycu.edu.tw/science/article/pii/S0360544215014322 - aff2Canıyılmaz E. A new forecasting framework for volatile behavior in net electricity consumption: A case study in Turkey. Energy. 2015; (93):2406–22. [Google Scholar]
- 6.Lauret P, Fock E, Randrianarivony RN, Manicom-Ramasamy JF. Bayesian neural network approach to short time load forecasting. Energy Conversion and Management. 2008; (49):1156–66. [Google Scholar]
- 7.Duran M, Toksari. Estimating the net electricity energy generation and demand using ant colony optimization approach: Case of Turkey. Energy Policy. 2009; (37):1181–7. [Google Scholar]
- 8.Xia C, Wang J, Short McMenemy K. Medium and long term load forecasting model and virtual load forecaster based on radial basis function neural networks. Electrical Power and Energy Systems. 2010; (32):743–50. [Google Scholar]
- 9.Wang CH, Hsu LC. Using genetic algorithms grey theory to forecast high technology industrial output. Applied Mathematics and Computation. 2008; (195):256–63. [Google Scholar]
- 10.Feng SJ, Ma YD, Song ZL, Ying J. Forecasting the energy consumption of China by the grey prediction model. Energy Sources, Part B: Economics, Planning, and Policy. 2012; (7):376–89. [Google Scholar]
- 11.Li DC, Chang CJ, Chen CC, Chen WC. Forecasting short-term electricity consumption using the adaptive grey-based approach-An Asian case. Omega. 2012; (40):767–73. [Google Scholar]
- 12.Pi D, Liu J, Qin X. A grey prediction approach to forecasting energy demand in China. Energy Sources, Part A: Recovery, Utilization, and Environmental Effects. 2010; (32):1517–28. [Google Scholar]
- 13.Lee YS, Tong LI. Forecasting energy consumption using a grey model improved by incorporating genetic programming. Energy Conversion and Management. 2011; (52):147–52. [Google Scholar]
- 14.Deng JL. Control problems of grey systems. Systems and Control Letters. 1982; 1(5):288–94. [Google Scholar]
- 15.Liu S, Lin Y. Grey Information: Theory and Practical Applications London: Springer-Verlag; 2006. [Google Scholar]
- 16.Wen KL. Grey Systems Modeling and Prediction. Tucson: Yang’s Scientific Research Institute; 2004. [Google Scholar]
- 17.Wang CH, Hsu LC. Using genetic algorithms grey theory to forecast high technology industrial output, Applied Mathematics and Computation. 2008; (195):256–63. [Google Scholar]
- 18.Hu YC. Electricity consumption forecasting using a neural-network-based grey prediction approach. Journal of the Operational Research Society. 2016. doi: 10.1057/s41274-016-0150-y [Google Scholar]
- 19.Hu YC, Jiang P. Forecasting energy demand using neural-network-based grey residual modification models. Journal of the Operational Research Society. 2017; 68(5):556–65. [Google Scholar]
- 20.Hu YC. Nonadditive grey prediction using functional-link net for energy demand forecasting. Sustainability. 2017; 9(7). doi: 10.3390/su9071166 [Google Scholar]
- 21.Wang ZX, Hao P. An improved grey multivariable model for predicting industrial energy consumption in China. Applied Mathematical Modelling. 2016; 40(11–12):5745–58. [Google Scholar]
- 22.Xu N, Dang Y, Gong Y. Novel grey prediction model with nonlinear optimized time response method for forecasting of electricity consumption in China. Energy. 2017; (118):473–80. [Google Scholar]
- 23.Sun W, Xu Y. Research on China's energy supply and demand using an improved Grey-Markov chain model based on wavelet transform. Energy. 2017; (118):969–84. [Google Scholar]
- 24.Tsaur RC, Liao YC. Forecasting LCD TV demand using the fuzzy grey model GM(1,1). International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems. 2007; (15):753–67. [Google Scholar]
- 25.Ene S, Öztürk N. Grey modelling based forecasting system for return flow of end-of-life vehicles. Technological Forecasting and Social Change. 2017; (115):155–66. [Google Scholar]
- 26.Chang CJ, Yu L, Jin P. A mega-trend-diffusion grey forecasting model for short-term manufacturing demand. Journal of the Operational Research Society. 2016; 67(12):1439–45. [Google Scholar]
- 27.Cui J, Liu SF, Zeng BN, Xie NM. A novel grey forecasting model and its optimization. Applied Mathematical Modelling. 2013; 37(6):4399–406. [Google Scholar]
- 28.Lu JS, Xie WD, Zhou HB, Zhang AJ. An optimized nonlinear grey Bernoulli model and its applications. Neurocomputing. 2016; (177):206–14. [Google Scholar]
- 29.Mao MZ, Chirwa EC. Application of grey model GM(1,1) to vehicle fatality risk estimation. Technological Forecasting and Social Change. 2006; (73):588–605. [Google Scholar]
- 30.Wei J, Zhou L, Wang F, Wu D. Work safety evaluation in Mainland China using grey theory. Applied Mathematical Modelling. 2015; 39(2):924–33. [Google Scholar]
- 31.Hu YC. Predicting foreign tourists for the tourism industry using soft computing-based Grey–Markov models. Sustainability. 2017; 9(7), doi: 10.3390/su9071228 [Google Scholar]
- 32.Hsu CC, C. Chen Y. Applications of improved grey prediction model for power demand forecasting. Energy Conversion and Management. 2003; (44):2241–9. [Google Scholar]
- 33.Hsu LC. Applying the grey prediction model to the global integrated circuit industry. Technology Forecasting and Social Change. 2003; 70(6):563–74. [Google Scholar]
- 34.Goldberg DE. Genetic Algorithms in Search, Optimization, and Machine Learning. MA: Addison-Wesley; 1989. [Google Scholar]
- 35.Osyczka A. Evolutionary Algorithms for Single and Multicriteria Design Optimization. NY: Physica-Verlag; 2003. [Google Scholar]
- 36.Ishibuchi H, Nakashima T, Nii M. Classification and Modeling with Linguistic Information Granules: Advanced Approaches to Linguistic Data Mining. Heidelberg: Springer; 2004. [Google Scholar]
- 37.Hsu CI, Wen YU. Improved Grey prediction models for trans-Pacific air passenger market. Transportation Planning and Technology. 1998; (22):87–107. [Google Scholar]
- 38.Hu YC. Recommendation using neighborhood methods with preference-relation-based similarity. Information Sciences. 2014; (284):18–30. [Google Scholar]
- 39.Liu ZY. Global Energy Internet. China Electric Power Press; 2015. [Google Scholar]
- 40.Lewis C. Industrial and Business Forecasting Methods. London: Butterworth Scientific; 1982. [Google Scholar]
- 41.Pao YH. Adaptive Pattern Recognition and Neural Networks. Reading: Addison-Wesley; 1989. [Google Scholar]
- 42.Pao YH. Functional-link net computing: Theory, system architecture, and functionalities. Computer. 1992; 25(5):76–9. [Google Scholar]
- 43.Hu YC, Tseng FM. Functional-link net with fuzzy integral for bankruptcy prediction. Neurocomputing. 2007; 70(16–18):2959–68. [Google Scholar]
- 44.Hu YC, Wang JH, Chang CY. Flow-based grey single-layer perceptron with fuzzy integral. Neurocomputing. 2012; (91):86–9. [Google Scholar]
- 45.Chiang JH. Choquet fuzzy integral-based hierarchical networks for decision analysis. IEEE Transactions on Fuzzy Systems. 1999; 7(1):63–71. [Google Scholar]
- 46.Lim DD, Ong YS, Jin YC, Sendho B, Lee BS. Efficient hierarchical parallel genetic algorithms using grid computing. Future Generation Computer Systems. 2007; 23(4):658–70. [Google Scholar]
- 47.Cantu-Paz E, Goldberg DE. Efficient parallel genetic algorithms: theory and practice. Computer Methods in Applied Mechanics and Engineering. 2000; 186(2–4):221–38. [Google Scholar]
- 48.Tsoulos IG, Tzallas A, Tsalikakis D. PDoublePop: An implementation of parallel genetic algorithm for function optimization. Computer Physics Communications. 2016; (209):183–9. [Google Scholar]
- 49.Yu WJ, Li JZ, Chen WN, Zhang J. A parallel double-level multiobjective evolutionary algorithm for robust optimization. Applied Soft Computing. 2017; (59):258–75. [Google Scholar]
- 50.Liu YY, Wang S. A scalable parallel genetic algorithm for the Generalized Assignment Problem. Parallel Computing. 2015; (46):98–119. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
All relevant data are within the paper. The dataset made up of historical annual total energy consumption in China were shown in [13].