

Abstract
Deleterious alleles have long been proposed to play an important role in patterning phenotypic variation and are central to commonly held ideas explaining the hybrid vigor observed in the offspring of a cross between two inbred parents. We test these ideas using evolutionary measures of sequence conservation to ask whether incorporating information about putatively deleterious alleles can inform genomic selection (GS) models and improve phenotypic prediction. We measured a number of agronomic traits in both the inbred parents and hybrids of an elite maize partial diallel population and re-sequenced the parents of the population. Inbred elite maize lines vary for more than 350,000 putatively deleterious sites, but show a lower burden of such sites than a comparable set of traditional landraces. Our modeling reveals widespread evidence for incomplete dominance at these loci, and supports theoretical models that more damaging variants are usually more recessive. We identify haplotype blocks using an identity-by-decent (IBD) analysis and perform genomic prediction analyses in which we weigh blocks on the basis of complementation for segregating putatively deleterious variants. Cross-validation results show that incorporating sequence conservation in genomic selection improves prediction accuracy for grain yield and other fitness-related traits as well as heterosis for those traits. Our results provide empirical support for an important role for incomplete dominance of deleterious alleles in explaining heterosis and demonstrate the utility of incorporating functional annotation in phenotypic prediction and plant breeding.
Author summary
A key long-term goal of biology is understanding the genetic basis of phenotypic variation. Although most new mutations are likely disadvantageous, their prevalence and importance in explaining patterns of phenotypic variation is controversial and not well understood. In this study we combine whole genome-sequencing and field evaluation of a maize mapping population to investigate the contribution of deleterious mutations to phenotype. We show that a priori prediction of deleterious alleles correlates well with effect sizes for grain yield and that variants predicted to be more damaging are on average more recessive. We develop a simple model allowing for variation in the heterozygous effects of deleterious mutations and demonstrate its improved ability to predict both phenotypes and hybrid vigor. Our results help reconcile alternative explanations for hybrid vigor and highlight the use of leveraging evolutionary history to facilitate breeding for crop improvement.
Introduction
Understanding the genetic basis of phenotypic variation is critical to many biological endeavors from human health to conservation and agriculture. Although most new mutations are likely deleterious [1], their importance in patterning phenotypic variation is controversial and not well understood [2]. Empirical work suggests that, although the long-term burden of deleterious variants is relatively insensitive to demography [3], population bottlenecks and expansion may lead to an increased abundance of deleterious alleles over shorter time scales such as those associated with domestication [4], postglacial colonization [5] or recent human migration [6]. Even when the impacts on total load are minimal, demographic change may have important consequences for the contribution of deleterious variants to phenotypic variation [3, 7–9]. Together, these considerations point to a potentially important role for deleterious variants in determining patterns of phenotypic variation, especially for traits closely related to fitness.
In addition to its global agricultural importance, maize has long been an important genetic model system [10] and central to debates about the basis of hybrid vigor and the role of deleterious alleles [11, 12]. The maize domestication bottleneck has lead to an increased burden of deleterious alleles in maize compared to its wild ancestor teosinte [13], and rapid expansion following domestication likely lead to an increase in new mutations and stronger purifying selection [4]. More recently, modern maize breeding has lead to dramatic reductions in effective population size [14], but inbreeding during the development of modern inbred lines may have decreased load by purging recessive deleterious alleles [15]. Nonetheless, substantial evidence suggests an abundance of deleterious alleles present in modern germplasm, from the observed maintenance of heterozygosity during the processes of inbreeding [16, 17] and selection [18] to genome-wide association results that reveal an excess of associations with genes segregating for damaging protein-coding variants [19].
Modern maize agriculture takes advantage of hybrid maize plants that result from the cross between two parental inbred lines [12]. These crosses result in a phenomenon known as hybrid vigor or heterosis, in which the hybrid plant shows improved agronomic qualities compared to its parents. Heterosis cannot be easily predicted from parental phenotype alone, and the genetic underpinnings of heterosis remain largely unknown. The most straightforward explanation for heterosis has been simple complementation of recessive deleterious alleles that are homozygous in one of the inbred parents [20, 21]. While this model is supported by considerable empirical evidence [22, 23], it fails in its simplest form to explain a number of observations such as heterosis and inbreeding depression in polyploid plants [11, 24, 25]. Other explanations, such as single-gene heterozygote advantage, clearly may play an important role in some cases [26], [27], but mapping studies suggest such models are not easily generalizable [28].
In this study, we set out to investigate the contribution of deleterious alleles to phenotypic variation and hybrid vigor in maize. We created a partial diallel population from 12 maize inbred lines which together represent much of the ancestry of present-day commercial U.S. corn hybrids [29, 30]. We measured a number of agronomically relevant phenotypes in both parents and hybrids, including flowering time (days to 50% pollen shed, DTP; days to 50% silking, DTS; anthesis-silking interval, ASI), plant size (plant height, PHT; height of primary ear, EHT), grain quality (test weight which is a measure of grain density, TW), and grain yield (GY). We conducted whole genome sequencing of the parental lines and characterized genome-wide deleterious variants using genomic evolutionary rate profiling (GERP) [31]. We then test models of additivity and dominance for each phenotype using putatively deleterious variants and investigate the relationship between dominance and phenotypic effect size and the long-term fitness consequences of a mutation as measured by GERP. Finally, we take advantage of a Bayesian genomic selection framework [32] approach to explicitly test the utility of including GERP scores in phenotypic prediction for hybrid traits and heterosis.
Materials and methods
Plant materials and phenotypic data
We formed a partial diallel population from the F1 progeny of 12 inbred maize lines (S1 Table, S1 Fig). Field performance of the 66 F1 hybrids and 12 inbred parents were evaluated along with two current commercial check hybrids in Urbana, IL over three years (2009-2011) in a resolvable incomplete block design with three replicates. To avoid competition effects, inbreds and hybrids were grown in different blocks within the field. Plots consisted of four rows (5.3 m long with row spacing of 0.76 m at a plant density of 74,000 plants ha−1), with all observations taken from the inside two rows to minimize effects of shading and maturity differences from adjacent plots. We measured plant height (PHT, in cm), height of primary ear (EHT, in cm), days to 50% pollen shed (DTP), days to 50% silking (DTS), anthesis-silking interval (ASI, in days), grain yield adjusted to 15.5% moisture (GY, in bu/A), and test weight (TW, weight of 1 bushel of grain in pounds).
We estimated Best Linear Unbiased Estimates (BLUEs) of the genetic effects in ASReml-R (VSN International) with the following linear mixed model:
where Yijkl is the phenotypic value of the lth genotype evaluated in the kth block of the jth replicate within the ith year; μ, the overall mean; ςi, the fixed effect of the ith year; δij, the random effect of the jth replicate nested within the ith year; βkij, the random effect of the kth block nested within the ith year and jth replicate; αl, the fixed genetic effect of the lth individual; ςi · αl, the random interaction effect of the lth individual with the ith year; and ε, the model residuals. We calculated the broad sense heritability (H2) of traits based on the analysis of all individuals (inbred parents, hybrid progeny, and checks) following the equation:
where i = 3 (number of years) and j = 3 (number of replicates per year).
The BLUE values for each cross can be found in S1 Table; values across all hybrids were relatively normally distributed for all traits (Shapiro-Wilk normality tests P values >0.05, S1 Fig), though some traits were highly correlated (e.g. Spearman correlation r = 0.98 for DTS and DTP, S2 Fig).
We estimated mid-parent heterosis (MPH) as:
where , and are the BLUE values of the hybrid and its two parents i and j. Note that for ASI, lower trait values are considered superior. General combining ability (GCA) was estimated following Falconer and Mackay [33], and the estimated values can be found in S2 Table.
Sequencing and genotyping
We extracted DNA from the 12 inbred lines following [34] and sheared the DNA on a Covaris (Woburn, Massachusetts) for library preparation. Libraries were prepared using an Illumina paired-end protocol with 180 bp fragments and sequenced using 100 bp paired-end reads on a HiSeq 2000. Raw sequencing data are available at NCBI SRA (PRJNA381642).
We trimmed raw sequence reads for adapter contamination with Scythe (https://github.com/vsbuffalo/scythe) and for quality and sequence length (≥20 nucleotides) with Sickle (https://github.com/najoshi/sickle). We mapped filtered reads to the maize B73 reference genome (AGPv2) with bwa-mem [35], keeping reads with mapping quality higher than 10 and with a best alignment score higher than the second best one for further analyses.
We called single nucleotide polymorphisms (SNPs) using the mpileup function from samtools [36]. To deal with known issues with paralogy in maize [15], SNPs were filtered to be heterozygous in fewer than 3 inbred lines, have a mean minor allele depth of at least 4, have a mean depth across all individuals less than 30 and have missing alleles in fewer than 6 inbred lines. Data on the total number of SNPs called and the rate of missing data per line are shown in S3 Table. We estimated the allelic error rate using three independent data sets: for all individuals using 41,292 overlapping SNPs from the maize SNP50k bead chip [14]; for all individuals using 180,313 overlapping SNPs identified through genotyping-by-sequencing (GBS) [37]; and for B73 and Mo17 using 10,426,715 SNP from the HapMap2 project [15]. Alignments and genotypes for each of the 12 inbreds are available at CyVerse (https://doi.org/10.7946/P2WS60). Because these parents are highly inbred, knowing their homozygous genotype also allows us to know the genotype of the F1 derived from any two of the parents.
To test whether alignment to the B73 reference introduces a bias in relatedness estimation, we computed kinship matrices using both our SNP data as well as genotyping-by-sequencing data (version AllZeaGBSv2.7 downloaded from (www.panzea.org)) obtained from alignments to a set of sequencing reads ascertained from a broad germplasm base [38]. The two matrices were nearly identical (Pearson’s correlation coefficient r = 0.995), suggesting the degree of relatedness among lines is not sensitive to using B73 as the reference genome.
Identifying putatively deleterious alleles
We used genomic evolutionary rate profiling (GERP) [39] estimated from a multi-species whole-genome alignment of 13 plant genomes [40] including Zea mays, Coelorachis tuberculosa, Vossia cuspidata, Sorghum bicolor, Oryza sativa, Setaria italica, Brachypodium distachyon, Hordeum vulgare, Musa acuminata, Populus trichocarpa, Vitis vinifera, Arabidopsis thaliana, and Panicum virgatum; the alignment and estimated GERP scores are available at CyVerse (https://doi.org/10.7946/P2WS60). We define “GERP-SNPs” as the subset of SNPs with GERP score >0, and at each SNP we assign the minor allele in the multi-species alignment as the likely deleterious allele. Finally, we predicted the functional consequences of GERP-SNPs based on genome annotation information obtained from SnpEff [41]. The multi-species alignment made use of the B73 AGPv3 assembly, and to ensure consistent coordinates, we ported our SNP coordinates from AGPv2 to AGPv3 using the Gramene assembly converter (http://ensembl.gramene.org/Zea_mays/Tools/AssemblyConverter?db=core).
To compare GERP scores (for all SNPs with GERP > 0) to recombination rate and allele frequencies, we obtained the NAM genetic map [42] from the Panzea website (http://www.panzea.org/) and allele frequencies from the > 1,200 maize lines sequenced as part of HapMap3.2 [43]. To compare the burden of deleterious alleles in modern inbred lines to landraces, we extracted genotypic data of 23 specially-inbred traditional landrace cultivars (see [15] for more details) from HapMap3.2. For each line, we calculated burden as the count of minor alleles present across all GERP-SNPs divided by the total number of non-missing sites. We separated sites into fixed (present in all individuals of a group) and segregating for landrace and modern maize samples separately.
Estimating effect sizes and dominance of GERP-SNPs
We estimated the additive and dominant effects of individual GERP-SNPs using a GBLUP model [44] implemented in GVCBLUP [45]:
where Yi is the BLUE value of the ith hybrid, μ is the average genotypic value, αj is the allele substitution effect of the jth GERP-SNP, dj is the dominant effect of the jth GERP-SNP, Xij = {2p, 2p − 1, 2p − 2}, ε is the model residuals, and Wij = {−2p2, 2p(1 − p), −2(1 − p)2} are the genotype encodings for genotypes A1 A1, A1 A2, and A2 A2 in the ith hybrid for the jth GERP-SNP with p of the A1 allele.
The additive and dominance SNP encoding ensures that the effects are independent for a given GERP-SNP. We extracted additive (a = α − 2p(1 − p)d) and dominant (d) effects from the GVCBLUP output file (see supplemantary file of Da et al., [44] for more details). We first estimated the total variance explained under models of complete additivity (d = 0) or complete dominance (α = 0). Then, to assess correlations between SNP effects and GERP scores, we calculated the degree of dominance (k = d/a) [46] for SNPs that each explained greater than the genome-wide mean per-SNP variance (total variance explained divided by total number of GERP-SNPs). Because this approach can lead to very large absolute values of k, we truncated GERP-SNPs with |k = d/a|>2 for all further analyses.
To compare the variance explained by our model to that explained by random SNPs, we used a 2-dimensional sampling approach to create 10 equal-sized datasets of randomly sampled SNPs (including SNPs with GERP score < = 0) matched for allele frequency (in bins of 10%) and recombination rate (in quartiles of cM/Mb). For each dataset we fit the above model separately and estimated SNP effects and phenotypic variance explained by each SNP.
To test the relationship between GERP score and dominance under a simple model of mutation-selection equilibrium, we estimated the selection coefficient s by assuming that yield is a measure of fitness. We assigned the yield-increasing allele at each GERP-SNP a random dominance value in the range of 0 ≥ k ≥ 1 and calculated its equilibrium allele frequency p under mutation-selection balance using for values of k > 0.98 and for k ≤ 0.98. We then simulated datasets using binomial sampling to choose SNPs in a sample of size n = 12 inbreds.
Haplotype analysis
We imputed missing data and identified regions of identity by descent (IBD) between the 12 inbred lines using the fastIBD method implemented in BEAGLE [47]. We then defined haplotype blocks as contiguous regions within which there were no IBD break points across all pairwise comparisons of the parental lines (S3 Fig). Haplotype blocks at least 1 Kb in size were kept for further analyses.
Because there is no recombination in an inbred parent, this allows us to project the diploid genotype of each F1 based on the haplotypes of the two parents. In the projected diploid genotype of each F1, haplotype blocks were weighted by the summed GERP scores of all GERP-SNPs (python script ‘gerpIBD.py’ available at https://github.com/yangjl/zmSNPtools); blocks with no SNPs with positive GERP scores were excluded from further analysis. For a particular SNP with a GERP score g, the homozygote for the conserved (major) allele was assigned a value of 0, the homozygote for the putatively deleterious allele a value of 2g, and the heterozygote a value of (1 + k) × g, where k is the dominance estimated from the GBLUP model above.
Genomic selection
We used the BayesC option from GenSel4 [32] for genomic selection model training with 41,000 iterations. We removed the first 1,000 iterations as burn-in. We used the model
where Yi is the BLUE value of the ith hybrid, rj is the regression coefficient for the jth haplotype block, and Iij is the sum of GERP scores under an additive, dominance or incomplete dominance model for the ith hybrid in the jth haplotype block.
We used a 5-fold cross-validation method to conduct prediction, dividing the diallel population randomly into training (80%) and validation sets (20%) 100 times. After model training, we obtained prediction accuracies by comparing the predicted breeding values with the observed BLUE values in the corresponding validation sets. For comparison, we permuted GERP scores using 50k SNP (≈ 100Mb or larger) windows which were circularly shuffled 10 times to estimate a null conservation score for each IBD block. We conducted permutations on all GERP-SNPs as well as on a restricted set of GERP-SNPs only in genic regions to control for GERP differences between genic (N = 221,960) and intergenic regions (N = 123,216). We conducted permutation cross-validation experiments using the same training and validation sets.
We estimated the posterior phenotypic variance explained using all of the data to derive correlations between breeding values estimated from the prediction model and observed BLUE values. Note that the correlation used here is different from the prediction accuracy (r) used for the cross-validation experiments, where the latter is defined as the correlation between real and estimated values; the two statistics will converge to the same value when there is no error in SNP/haplotype effect estimation [48].
Finally, to compare our genomic prediction model to a classical model of general combining ability, we used the following equations:
where Yij is the BLUE value of the hybrid of the ith and jth inbreds, μ is the overall mean, GCAi and GCAj are the general combining abilities of the ith and jth inbreds, Gij is the breeding value of the hybrid of the ith and jth inbreds as estimated by our genomic prediction model, and ε the model residuals.
Data and code accessibility
Sequencing data have been deposited in NCBI SRA (SRP103329) database, and code for all analyses are available in the public GitHub repository (https://github.com/yangjl/GERP-diallel).
Results
Heterosis in a partial diallel population
We created a partial diallel population from 12 maize inbred lines which together represent much of the ancestry of present-day commercial U.S. corn hybrids (S1 Table) [29, 30]. We measured a number of agronomically relevant phenotypes in both parents and hybrids, including flowering time (days to 50% pollen shed, DTP; days to 50% silking, DTS; anthesis-silking interval, ASI), plant size (plant height, PHT; height of primary ear, EHT), test weight (TW; a measure of quality based on grain density), and grain yield (GY). In an agronomic setting GY—a measure of seed production per unit area—is the primary trait selected by breeders and thus analogous to fitness. Plant height and ear height, both common measures of plant health or viability, were significantly correlated to GY (S2 Fig).
For each genotype we derived best linear unbiased estimators (BLUEs) of its phenotype from mixed linear models (S1 Table) to control for spatial and environmental variation (see Methods). We estimated mid-parent heterosis (MPH, Fig 1a) for each trait as the percent difference between the hybrid compared to the mean value of its two parents (see Methods, S1 Table). Consistent with previous work [28], we find that grain yield (GY) showed the highest level of heterosis (MPH of 182% ± 60%). While flowering time (DTS and DTP) is an important adaptive phenotype globally [49], it showed relatively little heterosis in this study, likely due to the relatively narrow geographic range represented by the parental lines.
Fig 1. Heterosis and deleterious variants.

(a) Boxplots (median and interquartile range) of percent mid-parent heterosis (MPH). (b) Proportion of deleterious alleles in landraces (LR, green) and elite maize (MZ, blue) lines. (c) The allele frequency of the minor alleles in the multi-species alignment in bins of 0.01 GERP score (including GERP < = 0 sites). (d) The mean GERP score for putatively deleterious sites (GERP >0). Each point represents a 1 Mb window. In (c) and (d) the solid blue and dashed black lines define the best-fit regression line and its 95% confidence interval.
Annotation of deleterious alleles
We resequenced the 12 inbred parents to an average depth of ≈ 10×, resulting in a filtered set of 13.8M SNPs. Compared to corresponding SNPs identified by previous studies (see Methods), we observed a mean genotypic concordance rate of 99.1%. In order to quantify the deleterious consequences of variants a priori, we made use of Genomic Evolutionary Rate Profiling (GERP) [39] scores of the maize genome [50]. GERP scores provide a quantitative measure of the evolutionary conservation of a site across a phylogeny that allows characterization of the long-term fitness consequences of both coding and noncoding positions in the genome [51]. Sites with more positive GERP scores are inferred to be under stronger purifying selection, and SNPs observed at such sites are thus inferred to be more deleterious. At each site with GERP scores > 0 (hereafter called GERP-SNPs), we designated the minor allele from the multispecies alignment as putatively deleterious. Of the 350k total segregating GERP-SNPs in our parental lines, 14% are detected in coding regions, equally split between synonymous (N = 64,439) and non-synonymous (N = 65,376) sites (S4 Table). Each line carries, on average, 139k potential deleterious SNPs, 19k of which are in coding regions (S5 Table). The reference genome B73 contains only ≈ 1/3 of the deleterious SNPs of the other parents, likely due to reference bias in identifying deleterious variants. The F1 hybrids of the diallel each contain an average of ≈ 56,000 homozygous deleterious SNPs, ranging from 47,219 (PH207 x PHG35) to 77,210 (PHG84 x PHZ51) (S6 Table).
To compare the burden of deleterious variants between our elite maize lines and traditionally cultivated landraces, we used genotypes from the maize HapMap3.2 [43] for our diallel parents and 23 specially-inbred landrace lines [15] (S5 Table). Compared to landraces, the parents of our diallel exhibited a greater burden of fixed (allele frequency of 1) deleterious variants but a much smaller burden of segregating SNPs, resulting in a slightly lower overall proportion of deleterious sites (mean of 1.3M deleterious alleles out of 6.5M total sites vs. 0.6/3.3M; Fig 1b).
Population genetic theory predicts that deleterious variants should be at low overall frequencies, and that such variants should be enriched in regions of the genome with extremely low recombination [52]. Using data from more than 1,200 lines in maize HapMap3.2 [43], we find that allele frequency of the minor alleles in the multi-species alignment shows a strong negative correlation with GERP score (Fig 1c). This negative correlation holds using allele frequency derived from our 12 parental lines (S4 Fig), though as expected is less significant given the smaller sample size. SNPs found in regions of the genome with low recombination also show higher overall GERP scores (Fig 1d), a trend particularly noticeable around centromeres (S5 Fig). These results match previous empirical findings in maize that deleterious alleles are rare [19] and most abundant in the lowest recombination regions [17, 40, 53], and support the use of GERP scores as a quantitative measure of the long-term fitness effects of an observed variant.
Phenotypic effects of deleterious SNPs
We first investigate the impacts of deleterious variants on phenotype using simple linear regressions. Across all hybrids, the number of homozygote GERP-SNPs was negatively correlated with grain yield, plant height, and ear-height per se (see S6 Table for complementation data and S7 Table for correlations with all traits).
We next applied a genomic best linear unbiased prediction (GBLUP) [44] modeling approach to estimate the effect sizes and variance explained by GERP-SNPs for each of the phenotypes per se across our diallel (see Methods). GERP-SNPs had larger average effects and explained more phenotypic variance than the same number of randomly sampled SNPs (including SNPs with GERP score < = 0) matched for allele frequency and recombination (Fig 2a). We found the cumulative proportion of dominance variance explained by GERP-SNPs was higher for traits showing high heterosis (Spearman correlation P value < 0.01, r = 0.9), from ≈ 0 for flowering time traits to as much as 24% for grain yield (S6 Fig). Distributions of per-SNP dominance (see Methods) across traits were consistent with the cumulative partitioning of variance components (Fig 2b) and matched well with expectations from previous studies showing a predominantly additive basis for flowering time [54] and plant height [55] but meaningful contributions of dominance to test weight and grain yield [28, 30]. Although our diallel population is relatively small, our estimated values explain as much (for traits with low dominance variance like flowering time) or more variance (for traits with substantial dominance variance like grain yield) than sets of data with randomly shuffled values of dominance (n = 10 randomizations of k per trait; S7 Fig).
Fig 2. Variance explained and degree of dominance (k) of GERP-SNPs for traits per se.

(a) Total per-SNP variance explained for grain yield trait per se by GERP-SNPs (red lines) and randomly sampled SNPs (grey beanplots). (b) Density plots of the degree of dominance (k). Extreme values of k were truncated at 2 and -2. (c-e) Linear regressions of additive effects (c), dominance effects (d), and degree of dominance (e) of seven traits per se against SNP GERP scores. Solid and dashed lines represent significant and nonsignificant linear regressions, with grey bands representing 95% confidence intervals. Data are only shown for SNPs that explain more than the mean genome-wide per-SNP variance (see Methods for details).
We then evaluated the relationship between GERP score and SNP effect size, dominance, and contribution to phenotypic variance. We found weak or negligible correlations between effect size and GERP score for flowering time and grain quality, but a strong positive correlation for fitness-related traits (Fig 2c and 2d). The variance explained by individual SNPs, however, was largely independent of GERP score (S8 Fig), likely due to the observed negative correlation between allele frequency and GERP score (Fig 1c). Finally, we observed a positive relationship between GERP score and the degree of dominance (k) for grain yield (Fig 2e), such that the putatively deleterious allele at SNPs with higher GERP scores are also estimated to be more recessive for their phenotypic effects on grain yield (larger k for the major allele).
We investigated a number of possible caveats to the results presented in Fig 2. First, to control for the potential inflation of SNP effect sizes in regions of high linkage disequilibrium, we removed SNPs from regions of the genome in the lowest quartile of recombination. While some individual correlations changed significance, our overall results appear robust to the removal of low recombination regions (S9 Fig). Second, we tested the impact of reference bias caused by inclusion of the B73 genome in the multi-species alignment used to estimate GERP scores. To do so, we removed the 11 hybrids which include as one parent the reference genome line B73 and repeated the above analyses. Doing so dramatically reduces the size of our dataset, but we nonetheless find significant correlations between complementation and phenotype (S7 Table), that GERP-SNPs explain a greater proportion of overall variation than randomly sampled SNPs (S10a Fig), and that the relative pattern of dominance among traits remains the same (S10b Fig). While most of the correlations between effect size and GERP score lose significance (S10c and S10d Fig), likely due to the decreased sample size, the positive correlation between dominance and GERP score remains significant even in the absence of B73-derived hybrids (S10e Fig). Finally, because natural selection will maintain dominant deleterious alleles at lower frequencies than their recessive counterparts, we investigated whether the ascertainment bias against rare alleles present in our small sample would lead to the observed correlation between GERP and dominance. Simulations of SNPs with random dominance at mutation-selection balance (see Methods), however, failed to find any relationship between dominance and GERP score (S11 Fig), though we caution that the dramatic demographic shifts involved in the recent history of maize [4] make such a simulation approximate at best.
Genomic prediction by incoporating GERP information
To explicitly test the informativeness of alleles identified a priori as putatively deleterious, we implemented a genomic prediction model that evaluates complementation at the haplotype level by incorporating GERP scores of individual SNPs as weights (see Methods). We explored the explanatory power with several different models and found that a model which incorporates both GERP scores and dominance (k) estimated from our GBLUP model explained a greater amount of the posterior phenotypic variance for most traits per se (Fig 3a) and heterosis (MPH) (Fig 3b). A simple additive model showed superior explanatory power for flowering time, however, consistent with previous association mapping results that flowering time traits are predominantly controlled by a large number of additive effect loci [54].
Fig 3. Genomic prediction models incorporating GERP.

(a-b) Total phenotypic variance explained for traits per se (a) and heterosis (MPH) (b) under models of additivity (red), dominance (green), and incomplete dominance (blue). (c-d) Beanplots represent prediction accuracy estimated from cross-validation experiments for traits per se (c) and heterosis (MPH) (d) under a model of incomplete dominance. Prediction accuracy using estimated values for each GERP-SNP under an incomplete dominance model is shown on the left (red) and permutated values on the right (grey). Horizontal bars indicate mean accuracy for each trait and the grey dashed lines indicate the overall mean accuracy. Stars above the beans indicate prediction accuracies significantly (FDR < 0.05) higher than permutations. Results for pure additive and dominance models are shown in S13 Fig.
To explicitly test the utility of incorporating GERP information in prediction models, we compared cross-validation prediction accuracies of the observed GERP scores to those from datasets in which GERP scores were circularly shuffled along the genome (see Methods). Models incorporating our observed GERP scores out-performed permutations (Fig 3c and 3d), even when considering only SNPs in genes (S12 Fig). Our model improved prediction accuracy of grain yield by more than 4.3%, and improvements were also seen for plant height (0.8%) and testing weight (3.3%). While our model showed no improvement in predicting heterosis for traits showing low levels of heterosis (Fig 1a), including GERP scores significantly improved prediction accuracy for heterosis of grain yield (by 1%). Finally, our approach also significantly improved model fit for phenotypes of all traits per se as well as heterosis for GY and PHT compared to traditional models of genomic selection that use general combining ability (see Methods, S2 Table) calculated directly from the pedigree of the hybrid population [56] (ANOVA FDR <0.01 and difference in AIC < 0, S8 Table).
Discussion
We combine a priori prediction of deleterious alleles from whole genome sequence data with multi-year field evaluation of important agronomic phenotypes to test the role of incomplete dominance in determining hybrid phenotypes and heterosis in maize.
We first show that GERP scores are meaningful quantitative estimates of the fitness consequences of individual alleles, as SNPs with higher GERP scores are found at lower allele frequencies (Fig 1c), enriched in regions of low recombination (Fig 1d), and associated with larger effect sizes on grain yield (Fig 2c and 2d). Although a number of other methods exist to identify deleterious alleles from sequence data, GERP scores include both coding and noncoding sequence, do not require additional functional annotation, and show higher sensitivity and specificity than other related approaches [51]. While the GERP scores used here reflect conservation across relatively deep phylogenetic time, future efforts may be able to increase power by incorporating information from within-species polymorphism data [57, 58] as well as other types of annotations that have been shown to contribute substantially to phenotypic variation (e.g. Wallace et al., [59] and Rodgers-Melnick et al., [50]).
Using GERP scores as a proxy for deleterious alleles, we then ask whether our elite maize inbreds show an increased burden of deleterious alleles compared to a set of traditional landrace varieties. We find that modern inbreds are characterized by an increase in the proportion of deleterious variants fixed within the population (Fig 1b), consistent with the strong impact of drift associated with rapid decreases in effective population size during modern breeding [14]. In contrast, modern maize inbreds exhibit a much smaller proportion of segregating deleterious variants than landraces. This latter result is likely due to increased inbreeding in smaller populations, an effect exacerbated by the transition from traditional open-pollinated maize to the intentional formation of inbred lines. Inbreeding facilitates purging of deleterious variants, as evidenced by the striking inbreeding depression exhibited by open-pollinated maize [60]. Domestication and modern breeding have been predicted to result in decreased genetic load in elite cultivars compared to landraces, but increased load in domesticates compared to their wild progenitors [61]. Our results, combined with those of Wang et al. [13], support these general predictions, but do not suggest an important role for positive selection. Wang et al. find no evidence for hitch-hiking associated with selective sweeps during domestication, and the differences we observe in the burden of deleterious variants closely mimic results from simulations of partially recessive deleterious alleles in populations that have recently undergone demographic bottlenecks, but no additional selection [3].
We next use the set of SNPs with GERP > 0 scores (or GERP-SNPs) to investigate the phenotypic effects of deleterious variants. Across phenotypes, our results largely mirror previous work, finding that dominance contributes substantially to grain yield [28] while traits such as flowering time appear to be largely additive [54]. At the level of individual SNPs, we find correlations between GERP score and phenotypic effect size for yield and ear height, suggesting that long-term evolutionary constraint as measured by GERP is a useful predictor of the phenotypic effects of variants on traits related to fitness. These results are consistent with the idea that deleterious variants may contribute substantially to variation in fitness-related quantitative traits, especially in species like maize that have undergone recent demographic expansion [7–9]. Both yield and ear height are well explained by a model allowing for incomplete dominance (Fig 3a), as is plant height, which shows a positive but not significant correlation between effect size and GERP score. Though our population size is small, our partial diallel crossing design and genomic selection model circumvent some of the problems with standard genome-wide association analyses, including genome-wide multiple testing thresholds and difficulties in assessing the effects of rare alleles due to limited replication. While there is likely substantial error in our individual SNP estimates, permutation analyses show that overall our approach nonetheless are produces meaningful results (Fig 2a, S7 Fig).
We also find that more strongly deleterious alleles (those with higher GERP score and a larger negative effect on yield) are more likely to be recessive for grain yield. Such a genome-wide relationship between dominance and fitness has not been well demonstrated in other multicellular organisms, but supports previous empirical evidence from gene knockouts in yeast [62, 63]. This relationship has been predicted based on models of metabolic pathways [64], though other models may also generate such a relationship [65] and recent work suggests incorporating information on gene expression may better fit empirical patterns [66].
After showing that GERP-SNPs explain a substantial portion of the observed phenotypic variation when combined with our estimates of dominance and effect size, we more rigorously test the direct utility of GERP scores using cross-validation prediction methods. We show that for both plant height and grain yield, our GERP-enabled prediction model has significantly improved accuracy compared to randomized data, even when only considering SNPs within genes (S12 Fig). As genotyping costs continue to decline, genomic prediction models are increasing in popularity [67]. Most previous work on genomic prediction, however, focuses exclusively on the statistical properties of models, ignoring potentially useful biological information (but see Edwards et al., [68] for a recent example). Identifying deleterious alleles may prove a useful tool for crop breeding [69], and our results suggest that incorporating additional annotations—in particular information on evolutionary constraint—can provide additional, inexpensive benefits to existing genomic prediction frameworks.
Finally, our results also have implications for understanding the genetic basis of heterosis. We observed substantial heterosis for a number of traits in our diallel (Fig 1), including high levels of heterosis for grain yield consistent with reports in other maize diallel populations [70]. Heterosis has been observed across many species, from yeast [71] to plants [72] and vertebrates [73], and a number of hypotheses have been put forth to explain the phenomenon [11, 21]. Of all these explanations, complementation of recessive deleterious alleles [12, 21] remains the simplest genetic explanation and is supported by considerable empirical evidence [22, 23, 74]. It remains controversial, however, because complementation of completely recessive mutations cannot fully explain a number of empirical observations including unexpected differences in heterosis and inbreeding depression among polyploids [11, 75]. For example, a model of simple complementation of purely recessive alleles is unable to explain differing levels of heterosis between triploid hybrids with different numbers of parental genomes (e.g. AAB vs ABB) [24] or why the cross of two tetraploid F1 hybrids shows greater heterosis than the original F1 [25]. Our results, however, indicate although the degree of complementation appears to correlate with hybrid yield (S7 Table), most deleterious SNPs show incomplete dominance (Fig 2b) for traits with high levels of heterosis, and our genomic prediction models find improvement in predictions of heterosis when incorporating GERP scores under such a model (Fig 3d). These results are in line with other empirical evidence suggesting that new mutations tend to be partially recessive [76] and that GWAS hits exhibit incomplete dominance for phenotypes per se among hybrids [27]. We argue that allowing for incomplete dominance effectively unifies models of simple complementation with those of gene dosage [24]. Combined with observations that deleterious SNPs are enriched in low-recombination pericentromeric regions [40] (Fig 1d), such a model can satisfactorily explain changes in heterozygosity during breeding [18, 53], enrichment of yield QTL and apparent overdominance in centromeric regions [28], and even observed patterns of heterosis in polyploids (S14 Fig). It is unlikely of course that any single explanation is sufficient for a phenomenon as complex as heterosis, and other processes such as overdominance likely make important contributions (e.g. Guo et al., [77] and Huang et al., [27]), but we argue here that a simple model of incompletely dominant deleterious alleles may provide substantial explanatory power not only for fitness-related phenotypic traits but for hybrid vigor as well.
Conclusion
In this study, we use genomic and phenotypic data from a partial diallel population of maize to show that an incomplete dominance model of deleterious mutation both fits predictions of population genetic theory and explains phenotypic variation for fitness-related phenotypes and hybrid vigor. We find genome-wide support for hypotheses predicting that more damaging variants are more recessive. Finally, we show that leveraging evolutionary annotation information in silico enables us to predict grain yield and other traits, including heterosis, with greater accuracy. Together, these results help reconcile alternative explanations for hybrid vigor and point to the utility of leveraging evolutionary history to facilitate breeding for crop improvement.
Supporting information
(a) Twelve maize inbred lines were selected and crossed in a half-diallel fashion. Each inbred lines was used as both male and female and the resulting F1 seed was bulked. (b) Density plots of normalized BLUE values for the seven phenotypic traits. We used the “scale” function in R to normalize the BLUE values by first centering on zero and then dividing the numbers by their standard deviation. The seven phenotypic traits are plant height (PHT), height of primary ear (EHT), days to 50% pollen shed (DTP), days to 50% silking (DTS), anthesis-silking interval (ASI), grain yield adjusted to 15.5% moisture (GY), and test weight (TW).
(PDF)
The upper right panels show the scatter plots of all possible pairwise comparisons of two traits. The red line is a fitted loess curve. In the lower left panels, the numbers are the Spearman correlation coefficients (r) and the asterisks (*) indicate the correlation coefficients are statistically significant (Spearman correlation test P value < 0.05). Units for various traits are plant height (PHT, in cm), height of primary ear (EHT, in cm), days to 50% pollen shed (DTP), days to 50% silking (DTS), anthesis-silking interval (ASI, in days), grain yield adjusted to 15.5% moisture (GY, in bu/A), and test weight (TW, weight of 1 bushel of grain in pounds).
(PDF)
In the upper panel, regions in red are IBD blocks identified by pairwise comparison of the two parental lines of a hybrid. The vertical dashed lines define haplotype blocks. In the lower panel, hybrid genotypes in each block are coded as heterozygotes (0) or homozygotes (1).
(PDF)
Red solid and grey dashed lines define the best-fit regression line and its 95% confidence interval.
(PDF)
ots indicate mean GERP scores of putatively deleterious SNPs (GERP scores > 0) carried by the 12 parental maize lines (bin size = 1 cM). Vertical red lines indicate centromeres.
(PDF)
Additive and dominance effects are indicated by red and blue colors respectively.
(PDF)
Histograms show the results for the randomly shuffled (10 times) degrees of dominance (k) in each trait. Red lines show the phenotypic variance explained using the observed k.
(PDF)
Solid and dashed lines represent significant and non-significant linear regressions, with grey bands representing 95% confidence intervals. Data are only shown for SNPs which explain more phenotypic variance than the genome-wide mean.
(PDF)
Solid and dashed lines represent significant and non-significant linear regressions, with grey bands representing 95% confidence intervals. Data are only shown for GERP-SNPs which explain more variance than the genome-wide mean and found in regions above the first quantile of the recombination rate (cM/Mb).
(PDF)
(a) Total per-SNP variance explained for grain yield per se by deleterious (red lines) and randomly sampled SNPs (grey beanplots). (b) Density plots of the degree of dominance (k). Extreme values of k were truncated at 2 and -2 for visualization. (c-e) Linear regressions of additive effects (c), dominance effects (d), and degree of dominance (e) of seven traits per se against SNP GERP scores. Colors in (c-e) are the same as the legend for (b). Solid and dashed lines represent significant and nonsignificant linear regressions, with grey bands representing 95% confidence intervals. Data are only shown for deleterious alleles that explain more variance than the genome-wide mean.
(PDF)
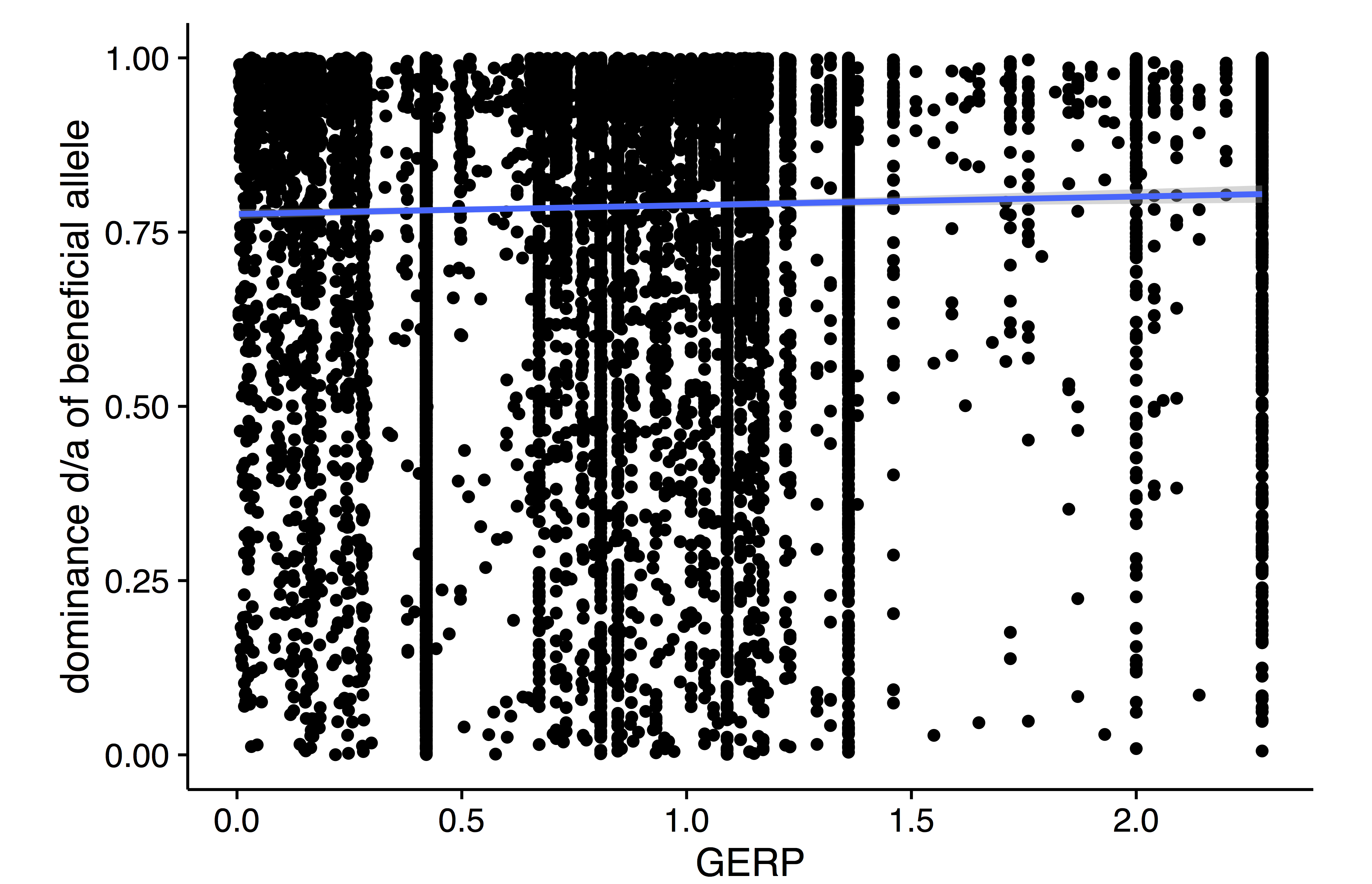
The solid blue line indicates the regression line fitted to data simulated under mutation-selection balance (see Methods for details).
(PNG)
{kind=link}
Beanplots represent prediction accuracy estimated from cross-validation experiments for traits per se (a, b, c) and heterosis (d, e, f) under additive (a, d), dominance (b, e), and incomplete dominance (c, f) models. Prediction accuracy using real data is shown on the left (green) and permutation results on the right (grey). Horizontal bars indicate mean accuracy and the grey dashed lines indicate the overall mean accuracy. Stars indicate real data having significantly (t-test P value < 0.05) higher cross-validation accuracy than permuted data.
(PDF)
Beanplots represent prediction accuracy estimated from cross-validation experiments for traits per se (a, b) and heterosis (c, d) under additive (a, c) and dominance (b, d) models. Prediction accuracy using real data is shown on the left (red) and permutation results on the right (grey). Horizontal bars indicate mean accuracy of each trait and the grey dashed lines indicate the mean accuracy of all traits. Stars indicate real data having significantly (t-test P value < 0.05) higher cross-validation accuracy than permuted data.
(PDF)
Each line represents the posterior breeding values of a diploid hybrid (red circle), its best parent (black diamond), and predicted breeding values of simulated AAB triploid (blue square) and ABB triploid (green triangle) plants based on estimated effect sizes and dominance values for each SNP.
(PDF)
Abbreviations for phenotypic traits are plant height (PHT, in cm), height of primary ear (EHT, in cm), days to 50% pollen shed (DTP), days to 50% silking (DTS), anthesis-silking interval (ASI, in days), grain yield adjusted to 15.5% moisture (GY, in bu/A), and test weight (TW, weight of 1 bushel of grain in pounds).
(CSV)
(CSV)
(CSV)
(XLSX)
(CSV)
(CSV)
(CSV)
(CSV)
Acknowledgments
We would like to thank Tim Beissinger, Graham Coop, James Holland, Matthew Hufford, Emily Josephs, Peter Morrell, Michelle C. Stitzer, Kevin Thornton, and Stephen Wright for helpful discussion.
Data Availability
Sequencing data have been deposited in NCBI SRA (SRP103329) database, and code for all analyses are available in the public GitHub repository (https://github.com/yangjl/GERP-diallel).
Funding Statement
Financial support for this work came from NSF (grants IOS-0820619 and IOS-1238014), USDA (grant 2009-65300-05668 and Hatch projects CA-D-PLS-2066-H and ILLU-802-354), DuPont Pioneer, Kellogg Company, and Mars Incorporated. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1. Eyre-Walker A, Keightley PD. The distribution of fitness effects of new mutations. Nature Reviews Genetics. 2007;8(8):610–618. 10.1038/nrg2146 [DOI] [PubMed] [Google Scholar]
- 2. Mitchell-Olds T, Willis JH, Goldstein DB. Which evolutionary processes influence natural genetic variation for phenotypic traits? Nature Reviews Genetics. 2007;8(11):845–856. [DOI] [PubMed] [Google Scholar]
- 3. Simons YB, Turchin MC, Pritchard JK, Sella G. The deleterious mutation load is insensitive to recent population history. Nature genetics. 2014;46(3):220 10.1038/ng.2896 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Beissinger TM, Wang L, Crosby K, Durvasula A, Hufford MB, Ross-Ibarra J. Recent demography drives changes in linked selection across the maize genome. Nature Plants. 2016;2(7):16084 10.1038/nplants.2016.84 [DOI] [PubMed] [Google Scholar]
- 5.Laenen B, Tedder A, Nowak MD, Toräng P, Wunder J, Wötzel S, et al. Demography And Mating System Shape The Genome-Wide Impact Of Purifying Selection In Arabis alpina. bioRxiv. 2017; p. 127209. [DOI] [PMC free article] [PubMed]
- 6.Peischl S, Dupanloup I, Foucal A, Jomphe M, Bruat V, Grenier JC, et al. Relaxed selection during a recent human expansion. bioRxiv. 2016; p. 064691. [DOI] [PMC free article] [PubMed]
- 7. Lohmueller KE. The impact of population demography and selection on the genetic architecture of complex traits. PLoS Genet. 2014;10(5):e1004379 10.1371/journal.pgen.1004379 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Uricchio LH, Zaitlen NA, Ye CJ, Witte JS, Hernandez RD. Selection and explosive growth alter genetic architecture and hamper the detection of causal rare variants. Genome research. 2016;26:863–873. 10.1101/gr.202440.115 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Sanjak J, Long AD, Thornton KR. The Genetic Architecture of a Complex Trait is more Sensitive to Genetic Model than Population Growth. bioRxiv. 2016;
- 10. Nannas NJ, Dawe RK. Genetic and genomic toolbox of Zea mays. Genetics. 2015;199(3):655–669. 10.1534/genetics.114.165183 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Birchler JA, Auger DL, Riddle NC. In search of the molecular basis of heterosis. The Plant Cell. 2003;15(10):2236–2239. 10.1105/tpc.151030 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Crow JF. 90 years ago: the beginning of hybrid maize. Genetics. 1998;148(3):923–928. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Wang L, Beissinger TM, Lorant A, Ross-Ibarra C, Ross-Ibarra J, Hufford M. The interplay of demography and selection during maize domestication and expansion. bioRxiv. 2017; p. 114579. [DOI] [PMC free article] [PubMed]
- 14. van Heerwaarden J, Hufford MB, Ross-Ibarra J. Historical genomics of North American maize. Proceedings of the National Academy of Sciences. 2012;109(31):12420–12425. 10.1073/pnas.1209275109 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15. Chia JM, Song C, Bradbury PJ, Costich D, de Leon N, Doebley J, et al. Maize HapMap2 identifies extant variation from a genome in flux. Nat Genet. 2012;44(7):803–7. 10.1038/ng.2313 [DOI] [PubMed] [Google Scholar]
- 16. McMullen MD, Kresovich S, Villeda HS, Bradbury P, Li H, Sun Q, et al. Genetic properties of the maize nested association mapping population. Science. 2009;325(5941):737–740. 10.1126/science.1174320 [DOI] [PubMed] [Google Scholar]
- 17. Gore Ma, Chia JM, Elshire RJ, Sun Q, Ersoz ES, Hurwitz BL, et al. A first-generation haplotype map of maize. Science (New York, NY). 2009;326(5956):1115–7. 10.1126/science.1177837 [DOI] [PubMed] [Google Scholar]
- 18. Gerke JP, Edwards JW, Guill KE, Ross-Ibarra J, McMullen MD. The genomic impacts of drift and selection for hybrid performance in maize. Genetics. 2015;201(3):1201–1211. 10.1534/genetics.115.182410 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Mezmouk S, Ross-Ibarra J. The pattern and distribution of deleterious mutations in maize. G3 (Bethesda, Md). 2014;4(January):163–71. 10.1534/g3.113.008870 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Crow JF. 90 years ago: the beginning of hybrid maize. Genetics. 1998;148(3):923–928. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Charlesworth D, Willis JH. The genetics of inbreeding depression. Nature reviews Genetics. 2009;10(11):783–96. 10.1038/nrg2664 [DOI] [PubMed] [Google Scholar]
- 22. Garcia AAF, Wang S, Melchinger AE, Zeng ZB. Quantitative trait loci mapping and the genetic basis of heterosis in maize and rice. Genetics. 2008;180(3):1707–1724. 10.1534/genetics.107.082867 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Xiao J, Li J, Yuan L, Tanksley SD. Dominance is the major genetic basis of heterosis in rice as revealed by QTL analysis using molecular markers. Genetics. 1995;140(2):745–754. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Yao H, Gray AD, Auger DL, Birchler JA. Genomic dosage effects on heterosis in triploid maize. Proceedings of the National Academy of Sciences. 2013;110(7):2665–2669. 10.1073/pnas.1221966110 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Birchler JA, Yao H, Chudalayandi S, Vaiman D, Veitia RA. Heterosis. The Plant Cell. 2010;22(7):2105–2112. 10.1105/tpc.110.076133 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Krieger U, Lippman ZB, Zamir D. The flowering gene SINGLE FLOWER TRUSS drives heterosis for yield in tomato. Nature genetics. 2010;42(5):459–463. 10.1038/ng.550 [DOI] [PubMed] [Google Scholar]
- 27. Huang X, Yang S, Gong J, Zhao Q, Feng Q, Zhan Q, et al. Genomic architecture of heterosis for yield traits in rice. Nature. 2016;537(7622):629–633. 10.1038/nature19760 [DOI] [PubMed] [Google Scholar]
- 28. Larièpe a, Mangin B, Jasson S, Combes V, Dumas F, Jamin P, et al. The genetic basis of heterosis: multiparental quantitative trait loci mapping reveals contrasted levels of apparent overdominance among traits of agronomical interest in maize (Zea mays L.). Genetics. 2012;190(2):795–811. 10.1534/genetics.111.133447 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Mikel MA, Dudley JW. Evolution of North American dent corn from public to proprietary germplasm. Crop science. 2006;46(3):1193–1205. 10.2135/cropsci2005.10-0371 [DOI] [Google Scholar]
- 30. Macke JA, Bohn MO, Rausch KD, Mumm RH. Genetic Factors Underlying Dry-Milling Efficiency and Flaking-Grit Yield Examined in US Maize Germplasm. Crop Science. 2016;56(5):2516–2526. 10.2135/cropsci2016.01.0024 [DOI] [Google Scholar]
- 31. Cooper GM, Stone Ea, Asimenos G, Green ED, Batzoglou S, Sidow A. Distribution and intensity of constraint in mammalian genomic sequence. Genome research. 2005;15(7):901–13. 10.1101/gr.3577405 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Habier D, Fernando RL, Kizilkaya K, Garrick DJ. Extension of the Bayesian alphabet for genomic selection. BMC bioinformatics. 2011;12(1):186 10.1186/1471-2105-12-186 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Falconer DS, Mackay TFC. Introduction to Quantitative Genetics. Longman; 1996. Available from: http://books.google.de/books?id=7ASZNAEACAAJ. [Google Scholar]
- 34. Doyle J, Doyle J. Genomic plant DNA preparation from fresh tissue-CTAB method. Phytochem Bull. 1987;19(11):11–15. [Google Scholar]
- 35. Li H, Durbin R. Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics. 2009;25(14):1754–60. 10.1093/bioinformatics/btp324 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36. Li H, Handsaker B, Wysoker A, Fennell T, Ruan J, Homer N, et al. The Sequence Alignment/Map format and SAMtools. Bioinformatics. 2009;25(16):2078–9. 10.1093/bioinformatics/btp352 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Romay MC, Millard MJ, Glaubitz JC, Peiffer JA, Swarts KL, Casstevens TM, et al. Comprehensive genotyping of the USA national maize inbred seed bank. Genome Biol. 2013;14(6):R55 10.1186/gb-2013-14-6-r55 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38. Glaubitz JC, Casstevens TM, Lu F, Harriman J, Elshire RJ, Sun Q, et al. TASSEL-GBS: a high capacity genotyping by sequencing analysis pipeline. PloS one. 2014;9(2):e90346 10.1371/journal.pone.0090346 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39. Davydov EV, Goode DL, Sirota M, Cooper GM, Sidow A, Batzoglou S. Identifying a high fraction of the human genome to be under selective constraint using GERP++. PLoS computational biology. 2010;6(12):e1001025 10.1371/journal.pcbi.1001025 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40. Rodgers-Melnick E, Bradbury PJ, Elshire RJ, Glaubitz JC, Acharya CB, Mitchell SE, et al. Recombination in diverse maize is stable, predictable, and associated with genetic load. Proceedings of the National Academy of Sciences. 2015;112(12):3823–3828. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41. Cingolani P, Platts A, Coon M, Nguyen T, Wang L, Land SJ, et al. A program for annotating and predicting the effects of single nucleotide polymorphisms, SnpEff: SNPs in the genome of Drosophila melanogaster strain w1118; iso-2; iso-3. Fly. 2012;6(2):80–92. 10.4161/fly.19695 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42. Ogut F, Bian Y, Bradbury PJ, Holland JB. Joint-multiple family linkage analysis predicts within-family variation better than single-family analysis of the maize nested association mapping population. Heredity. 2015;114(6):552 10.1038/hdy.2014.123 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Bukowski R, Guo X, Lu Y, Zou C, He B, Rong Z, et al. Construction of the third generation Zea mays haplotype map. bioRxiv. 2015; p. 026963. [DOI] [PMC free article] [PubMed]
- 44. Da Y, Wang C, Wang S, Hu G. Mixed model methods for genomic prediction and variance component estimation of additive and dominance effects using SNP markers. PloS one. 2014;9(1). 10.1371/journal.pone.0087666 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45. Wang C, Prakapenka D, Wang S, Pulugurta S, Runesha HB, Da Y. GVCBLUP: a computer package for genomic prediction and variance component estimation of additive and dominance effects. BMC Bioinformatics. 2014;15(1):1–9. 10.1186/1471-2105-15-270 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46. Lynch M, Walsh B, et al. Genetics and analysis of quantitative traits. vol. 1 Sinauer; Sunderland, MA; 1998. [Google Scholar]
- 47. Browning BL, Browning SR. A unified approach to genotype imputation and haplotype-phase inference for large data sets of trios and unrelated individuals. Am J Hum Genet. 2009;84(2):210–23. 10.1016/j.ajhg.2009.01.005 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48. Wray NR, Yang J, Hayes BJ, Price AL, Goddard ME, Visscher PM. Pitfalls of predicting complex traits from SNPs. Nature Reviews Genetics. 2013;14(7):507–515. 10.1038/nrg3457 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49. Navarro JAR, Willcox M, Burgueño J, Romay C, Swarts K, Trachsel S, et al. A study of allelic diversity underlying flowering-time adaptation in maize landraces. Nature genetics. 2017;49(3):476–480. 10.1038/ng.3784 [DOI] [PubMed] [Google Scholar]
- 50. Rodgers-Melnick E, Vera DL, Bass HW, Buckler ES. Open chromatin reveals the functional maize genome. Proceedings of the National Academy of Sciences. 2016;113(22):E3177–E3184. 10.1073/pnas.1525244113 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51. Kircher M, Witten DM, Jain P, O’roak BJ, Cooper GM, Shendure J. A general framework for estimating the relative pathogenicity of human genetic variants. Nature genetics. 2014;46(3):310–315. 10.1038/ng.2892 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52. Haddrill PR, Halligan DL, Tomaras D, Charlesworth B. Reduced efficacy of selection in regions of the Drosophila genome that lack crossing over. Genome biology. 2007;8(2):R18 10.1186/gb-2007-8-2-r18 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53. McMullen MD, Kresovich S, Villeda HS, Bradbury P, Li H, Sun Q, et al. Genetic properties of the maize nested association mapping population. Science (New York, NY). 2009;325(5941):737–40. 10.1126/science.1174320 [DOI] [PubMed] [Google Scholar]
- 54. Buckler ES, Holland JB, Bradbury PJ, Acharya CB, Brown PJ, Browne C, et al. The genetic architecture of maize flowering time. Science. 2009;325(5941):714–718. 10.1126/science.1174276 [DOI] [PubMed] [Google Scholar]
- 55. Peiffer JA, Romay MC, Gore MA, Flint-Garcia SA, Zhang Z, Millard MJ, et al. The genetic architecture of maize height. Genetics. 2014;196(4):1337–1356. 10.1534/genetics.113.159152 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56. Greenberg AJ, Hackett SR, Harshman LG, Clark AG. A hierarchical Bayesian model for a novel sparse partial diallel crossing design. Genetics. 2010;185(1):361–373. 10.1534/genetics.110.115055 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57. Joly-Lopez Z, Flowers JM, Purugganan MD. Developing maps of fitness consequences for plant genomes. Current opinion in plant biology. 2016;30:101–107. 10.1016/j.pbi.2016.02.008 [DOI] [PubMed] [Google Scholar]
- 58. Huang Y, Gulko B, Siepel A. Fast, scalable prediction of deleterious noncoding variants from functional and population genomic data. Nature gGenetics. 2017;49(4):618 10.1038/ng.3810 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59. Wallace JG, Bradbury PJ, Zhang N, Gibon Y, Stitt M, Buckler ES. Association mapping across numerous traits reveals patterns of functional variation in maize. PLoS Genet. 2014;10(12):e1004845 10.1371/journal.pgen.1004845 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60. East EM. Inbreeding in corn. Rep Conn Agric Exp Stn. 1908;1907:419–428. [Google Scholar]
- 61. Gaut BS, Díez CM, Morrell PL. Genomics and the contrasting dynamics of annual and perennial domestication. Trends in genetics. 2015;31(12):709–719. 10.1016/j.tig.2015.10.002 [DOI] [PubMed] [Google Scholar]
- 62. Phadnis N, Fry JD. Widespread correlations between dominance and homozygous effects of mutations: implications for theories of dominance. Genetics. 2005;171(1):385–392. 10.1534/genetics.104.039016 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63. Agrawal AF, Whitlock MC. Inferences about the distribution of dominance drawn from yeast gene knockout data. Genetics. 2011;187(2):553–566. 10.1534/genetics.110.124560 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64. Kacser H, Burns JA. The molecular basis of dominance. Genetics. 1981;97(3-4):639–666. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65. Manna F, Martin G, Lenormand T. Fitness landscapes: an alternative theory for the dominance of mutation. Genetics. 2011;189(3):923–937. 10.1534/genetics.111.132944 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Huber CD, Durvasula A, Hancock AM, Lohmueller KE. Gene expression drives the evolution of dominance. bioRxiv. 2017; p. 182865. [DOI] [PMC free article] [PubMed]
- 67. Desta ZA, Ortiz R. Genomic selection: genome-wide prediction in plant improvement. Trends in plant science. 2014;19(9):592–601. 10.1016/j.tplants.2014.05.006 [DOI] [PubMed] [Google Scholar]
- 68. Edwards SM, Sørensen IF, Sarup P, Mackay TF, Sørensen P. Genomic Prediction for Quantitative Traits Is Improved by Mapping Variants to Gene Ontology Categories in Drosophila melanogaster. Genetics. 2016; p. 110–116. 10.1534/genetics.116.187161 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Kono TJ, Fu F, Mohammadi M, Hoffman PJ, Liu C, Stupar RM, et al. The role of deleterious substitutions in crop genomes. bioRxiv. 2016; p. 033175. [DOI] [PMC free article] [PubMed]
- 70. Melchinger A, Lee M, Lamkey K, Hallauer A, Woodman W. Genetic diversity for restriction fragment length polymorphisms and heterosis for two diallel sets of maize inbreds. TAG Theoretical and Applied Genetics. 1990;80(4):488–496. 10.1007/BF00226750 [DOI] [PubMed] [Google Scholar]
- 71. Shapira R, Levy T, Shaked S, Fridman E, David L. Extensive heterosis in growth of yeast hybrids is explained by a combination of genetic models. Heredity. 2014;113(4):1–11. 10.1038/hdy.2014.33 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72. Shull GH. The composition of a field of maize. Journal of Heredity. 1908;1(1):296–301. 10.1093/jhered/os-4.1.296 [DOI] [Google Scholar]
- 73. Gama LT, Bressan MC, Rodrigues EC, Rossato LV, Moreira OC, Alves SP, et al. Heterosis for meat quality and fatty acid profiles in crosses among Bos indicus and Bos taurus finished on pasture or grain. Meat Science. 2013;93(1):98–104. 10.1016/j.meatsci.2012.08.005 [DOI] [PubMed] [Google Scholar]
- 74. Wang L, Greaves IK, Groszmann M, Wu LM, Dennis ES, Peacock WJ. Hybrid mimics and hybrid vigor in Arabidopsis. Proceedings of the National Academy of Sciences. 2015;112(35):E4959–E4967. 10.1073/pnas.1514190112 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75. Li Z, Li B, Tong Y. The contribution of distant hybridization with decaploid Agropyron elongatum to wheat improvement in China. Journal of Genetics and Genomics. 2008;35(8):451–456. 10.1016/S1673-8527(08)60062-4 [DOI] [PubMed] [Google Scholar]
- 76. Halligan DL, Keightley PD. Spontaneous mutation accumulation studies in evolutionary genetics. Annual Review of Ecology, Evolution, and Systematics. 2009;40:151–172. 10.1146/annurev.ecolsys.39.110707.173437 [DOI] [Google Scholar]
- 77. Guo M, Rupe MA, Wei J, Winkler C, Goncalves-Butruille M, Weers BP, et al. Maize ARGOS1 (ZAR1) transgenic alleles increase hybrid maize yield. Journal of experimental botany. 2014;65(1):249–260. 10.1093/jxb/ert370 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
(a) Twelve maize inbred lines were selected and crossed in a half-diallel fashion. Each inbred lines was used as both male and female and the resulting F1 seed was bulked. (b) Density plots of normalized BLUE values for the seven phenotypic traits. We used the “scale” function in R to normalize the BLUE values by first centering on zero and then dividing the numbers by their standard deviation. The seven phenotypic traits are plant height (PHT), height of primary ear (EHT), days to 50% pollen shed (DTP), days to 50% silking (DTS), anthesis-silking interval (ASI), grain yield adjusted to 15.5% moisture (GY), and test weight (TW).
(PDF)
The upper right panels show the scatter plots of all possible pairwise comparisons of two traits. The red line is a fitted loess curve. In the lower left panels, the numbers are the Spearman correlation coefficients (r) and the asterisks (*) indicate the correlation coefficients are statistically significant (Spearman correlation test P value < 0.05). Units for various traits are plant height (PHT, in cm), height of primary ear (EHT, in cm), days to 50% pollen shed (DTP), days to 50% silking (DTS), anthesis-silking interval (ASI, in days), grain yield adjusted to 15.5% moisture (GY, in bu/A), and test weight (TW, weight of 1 bushel of grain in pounds).
(PDF)
In the upper panel, regions in red are IBD blocks identified by pairwise comparison of the two parental lines of a hybrid. The vertical dashed lines define haplotype blocks. In the lower panel, hybrid genotypes in each block are coded as heterozygotes (0) or homozygotes (1).
(PDF)
Red solid and grey dashed lines define the best-fit regression line and its 95% confidence interval.
(PDF)
ots indicate mean GERP scores of putatively deleterious SNPs (GERP scores > 0) carried by the 12 parental maize lines (bin size = 1 cM). Vertical red lines indicate centromeres.
(PDF)
Additive and dominance effects are indicated by red and blue colors respectively.
(PDF)
Histograms show the results for the randomly shuffled (10 times) degrees of dominance (k) in each trait. Red lines show the phenotypic variance explained using the observed k.
(PDF)
Solid and dashed lines represent significant and non-significant linear regressions, with grey bands representing 95% confidence intervals. Data are only shown for SNPs which explain more phenotypic variance than the genome-wide mean.
(PDF)
Solid and dashed lines represent significant and non-significant linear regressions, with grey bands representing 95% confidence intervals. Data are only shown for GERP-SNPs which explain more variance than the genome-wide mean and found in regions above the first quantile of the recombination rate (cM/Mb).
(PDF)
(a) Total per-SNP variance explained for grain yield per se by deleterious (red lines) and randomly sampled SNPs (grey beanplots). (b) Density plots of the degree of dominance (k). Extreme values of k were truncated at 2 and -2 for visualization. (c-e) Linear regressions of additive effects (c), dominance effects (d), and degree of dominance (e) of seven traits per se against SNP GERP scores. Colors in (c-e) are the same as the legend for (b). Solid and dashed lines represent significant and nonsignificant linear regressions, with grey bands representing 95% confidence intervals. Data are only shown for deleterious alleles that explain more variance than the genome-wide mean.
(PDF)
The solid blue line indicates the regression line fitted to data simulated under mutation-selection balance (see Methods for details).
(PNG)
Beanplots represent prediction accuracy estimated from cross-validation experiments for traits per se (a, b, c) and heterosis (d, e, f) under additive (a, d), dominance (b, e), and incomplete dominance (c, f) models. Prediction accuracy using real data is shown on the left (green) and permutation results on the right (grey). Horizontal bars indicate mean accuracy and the grey dashed lines indicate the overall mean accuracy. Stars indicate real data having significantly (t-test P value < 0.05) higher cross-validation accuracy than permuted data.
(PDF)
Beanplots represent prediction accuracy estimated from cross-validation experiments for traits per se (a, b) and heterosis (c, d) under additive (a, c) and dominance (b, d) models. Prediction accuracy using real data is shown on the left (red) and permutation results on the right (grey). Horizontal bars indicate mean accuracy of each trait and the grey dashed lines indicate the mean accuracy of all traits. Stars indicate real data having significantly (t-test P value < 0.05) higher cross-validation accuracy than permuted data.
(PDF)
Each line represents the posterior breeding values of a diploid hybrid (red circle), its best parent (black diamond), and predicted breeding values of simulated AAB triploid (blue square) and ABB triploid (green triangle) plants based on estimated effect sizes and dominance values for each SNP.
(PDF)
Abbreviations for phenotypic traits are plant height (PHT, in cm), height of primary ear (EHT, in cm), days to 50% pollen shed (DTP), days to 50% silking (DTS), anthesis-silking interval (ASI, in days), grain yield adjusted to 15.5% moisture (GY, in bu/A), and test weight (TW, weight of 1 bushel of grain in pounds).
(CSV)
(CSV)
(CSV)
(XLSX)
(CSV)
(CSV)
(CSV)
(CSV)
Data Availability Statement
Sequencing data have been deposited in NCBI SRA (SRP103329) database, and code for all analyses are available in the public GitHub repository (https://github.com/yangjl/GERP-diallel).