

Abstract
The exact density distribution of the nonlinear least squares estimator in the one-parameter regression model is derived in closed form and expressed through the cumulative distribution function of the standard normal variable. Several proposals to generalize this result are discussed. The exact density is extended to the estimating equation (EE) approach and the nonlinear regression with an arbitrary number of linear parameters and one intrinsically nonlinear parameter. For a very special nonlinear regression model, the derived density coincides with the distribution of the ratio of two normally distributed random variables previously obtained by Fieller (1932), unlike other approximations previously suggested by other authors. Approximations to the density of the EE estimators are discussed in the multivariate case. Numerical complications associated with the nonlinear least squares are illustrated, such as nonexistence and/or multiple solutions, as major factors contributing to poor density approximation. The nonlinear Markov-Gauss theorem is formulated based on the near exact EE density approximation.
Keywords: Edgeworth approximation, exact statistical inference, Markov theorem, Michaelis-Menten model, saddlepoint approximation, small-sample property, partial least squares
1. Introduction
According to the JSTOR database, the search for “nonlinear regression” returns 47,988 published items (on December 6, 2016) with the first article published by G.U. Yule in 1909. Since then, nonlinear regression has been studied along four lines of research: (1) Development of nonlinear least squares optimization algorithms. It is worthwhile to mention that the algorithm developed by Levenberg (1944) & Marquardt (1963) till now is the dominant method for sum of squares minimization and is widely used in modern numerical packages. (2) Developing curvature measures as a characterization of the model nonlinearity, starting from the pioneering 1961 paper by Beale and then continued by Bates & Watts (1980). (3) Connection of the curvature measures to criteria for existence and uniqueness of the nonlinear least squares estimate studied in the work by Demidenko (1989, 2000, 2006). (4) Derivation of the density of the nonlinear least squares estimator in small samples, mostly developed in the mid-eighties. The present paper continues the quest for the exact probability density distribution of the NLS estimate as continuation of the work by Pazman (1984), Hougaard (1985) and Skovgaard (1985). Needless to say how important the exact distribution of any estimator might be: it can be used as the benchmark for other approximations, to construct accurate confidence intervals and to test hypotheses with the exact type I error.
Studying statistical properties of nonlinear models in small samples is the most formidable problem of statistics. Although several general techniques are available, such as the saddlepoint and Edgeworth approximations (Goutis & Casella, 1999; Barndorf-Nielsen & Cox, 1979) they are still approximations in scope. To illustrate, consider the popular Lugannani & Rice (1980) and Fraser et al. (1999) saddle point approximation of order O(n−3/2) for the cumulative distribution function (cdf) of the standardized maximum likelihood estimator with the sample size n used in the recent survey paper by Brazzale & Davison (2008)
where Φ and ϕ are the cdf and density of the standard normal distribution, and qn is a positive function of the Fisher information (we do not present the exact formula for brevity). However the cdf Fn(b) is not an increasing function of b which means that the density may become negative. In fact, many density approximations of the NLS estimator suggested by the previous authors may become negative as we learn from the next section. To the contrary, our exact density is always positive although derived under somewhat stringent conditions.
The study of the small-sample properties of nonlinear estimation tangles with numerical issues as nonexistence of the least squares solution and the presence of multiple solutions. Understandably, the previous authors who studied the distribution approximation for finite n even do not mention the possibility of the estimate nonexistence or multiplicity because their occurrence vanishes with n → ∞.
Several authors recognized the possibility of existence multiple local minima of the sum of squares in nonlinear regression and more generally multiple solutions of the estimating equation (M-estimator) leading to the concept of the intensity as a substitute of the density function (Skovgaard, 1990). This approach has been further developed in the following up work by Jensen & Wood (1998) and Almudevar et al. (2000). In contrast to that line of research, we aim at derivation of the explicit expression of the density distribution with applications to confidence interval and hypothesis testing in mind. Our method of derivation is different from those used by other authors: we use the fact that the estimating equation is linear in observations and derive the density by integrating out the multivariate density upon transformation.
For many years, it was believed that the distribution of the nonlinear least squares estimator, even if its unique, cannot be derived in closed form for a general model. We have derived this distribution and shown that it matches the distribution of a special case derived by Fieller (1932) more than 80 years ago. First, the exact distribution is derived for a nonlinear regression model with one parameter and then extended to models with an arbitrary number of linear parameters and a coefficient (partial linear least squares). Second, the exact density is generalized to the estimating equation approach with fixed sample size.
In short, unlike extensive research on the approximation of the distribution from the asymptotic point of view we derived the distribution directly for fixed n. We outline how this derivation can be extended to incorporate the possibilities of nonexistence of the NLS estimate and multiple solutions of the normal equation.
The Gauss-Markov theorem is the landmark result of statistical science (Casella & Berger, 1990; Schervish, 1995). The classic optimal estimation results with fixed n, such as uniformly minimum variance unbiased estimation, hold for the narrow exponential family of distributions (Bickel & Doksum, 2007) and therefore cannot be applied to nonlinear regression. Novel, non-quadratic loss function approaches are needed to expand the optimality theory to more complicated nonexponential distribution statistical models, such as nonlinear regression. As an example, we illustrate the application of the density of the M-estimator by showing that the nonlinear least squares is optimal in the local sense.
The organization of the paper is as follows. The exact density distribution and its comparison with density approximations in the univariate case are presented in Section 2. In that section, we generalize the density to weighted nonlinear least squares and apply the result to a nonlinear regression with a linear part. In Section 3, we generalize our derivation to the estimating equation approach and apply the exact density to a regression with unknown coefficient. Numerical complications arising in nonlinear optimization or the solution of the normal equation and its effect on the density are discussed in Section 4. Section 5 contains results for the multivariate density approximation for nonlinear regression and the estimating equation approach. The formulation of the nonlinear Gauss-Markov theorem and the local optimality of the nonlinear least squares is found in Section 6. In the final section, we outline open problems for exact statistical inference in nonlinear statistical problems with small sample.
2. One intrinsically nonlinear parameter
In this section, we consider nonlinear regression with one intrinsically nonlinear parameter. First, we derive the exact density for the Nonlinear Least Squares (NLS) estimator. Second, we compare the exact density with the near exact density developed previously. Third, we generalize our derivation to the weighted NLS with a known weight matrix. Fourth, we apply the weighted NLS to a regression with one intrinsically nonlinear parameter and an arbitrary number of linear parameters.
With only one nonlinear parameter, β, the nonlinear regression is written as
| (1) |
where yi is the ith observation of the dependent variable, fi(β) is the nonlinear regression function, and {εi} are iid normally distributed errors with zero mean and variance σ2. In many applications, the original regression function is written in the form f(β; xi), where xi is the explanatory (covariate) variable; we prefer the notation, fi(β) = f(β; xi), simply for brevity. Regarding regression functions {fi(β)}, we assume them to have continuous derivatives up to the second order on a fixed interval, β ∈ (a, b); typically a = −∞ and b = +∞ (we refer to a and b as to the lower and upper domain parameters). Also, to comply with identifiability condition, we assume that two different parameter values cannot produce the same function values. That is, fi(b1) = fi(b2) for at least one i implies b1 = b2.
The NLS estimate, , minimizes the sum of squared residuals,
| (2) |
One more comment regarding the notation: While denotes the estimator, b denotes a value it takes (it will also act as a dummy argument of functions). The NLS estimate can be found from the solution of the normal equation,
| (3) |
where the dot over the function means the derivative, dfi/dβ = fi, because symbol ′ is reserved for vector/matrix transposition. If the normal equation has a unique solution then the solution is the NLS estimate, otherwise, it may yield spurious solutions. Throughout the paper, we use the vector/matrix notation, y = (y1, …, yn)′ and f(β) = (f1(β), …, fn(β))′, so that , . In this notation, the normal equation takes the form
| (4) |
The normal equation may have no solution. To avoid this complication, we may restrict our attention to regression with infinite tails: ||f(b)|| → ∞ when |b| → ∞. As was shown by Demidenko (2000), this assumption guarantees that equation (4) has at least one solution for each y.
Before formulating the main result, we introduce relevant quantities and functions:
As is seen from the following theorem, the exact density distribution of the NLS estimator is expressed through the standard normal cumulative distribution function (cdf), Φ and its density ϕ.
Theorem 1
Let the solution of the normal equation, the NLS estimate, uniquely exist for each y. Let εi be iid and for at least one i. Then the exact density of the NLS estimator is given by
| (5) |
with the adjustment coefficient
| (6) |
The proof is found in the Appendix and proceeds as follows. First, without loss of generality, we can assume that . Expressing the first observation (i = 1) through b and the other n − 1 observations, a well-known theorem for the density upon nonlinear transformation is applied. Second, we derive the mean absolute value of a linear function of a normally distributed vector in closed form. Third, we express the function value and its derivatives for i = 1 through the full component vectors.
We make a few remarks regarding the exact density, pEX. First, we note that AE−C2 ≥ 0 due to the Cauchy inequality, so the square root function appearing in the adjustment coefficient is well defined. Second, the adjustment coefficient, aEX(b; β, σ) ≥ 0, so that the density cannot be negative. To prove that we rewrite the first term in (6) as
| (7) |
where Since x(2Φ (x) − 1) ≥ 0 for all x, we have aEX(b; β, σ) ≥ 0.
2.1. Comparison with the near exact density and other approximations
Early authors, including Pazman (1984), Hougaard (1985), and Skovgaard (1985), developed the so-called Near Exact (NE) density of the NLS estimator. This density coincides with (5) but has a different (simplified) adjustment coefficient,
| (8) |
A nice feature of the NE density is that the cdf of the NLS estimator can be expressed through the standard normal cdf as
| (9) |
which follows from straightforward differentiation. Equivalently, one can write, , where is the NLS estimate. However, in order for (9) to be a real b cdf, three conditions must be met: (1) the argument of Φ must be an increasing function of b for each β, (2) the argument must approach −∞ when b approaches its lower parameter domain and (2) the argument must approach +∞ when b approaches its upper parameter domain.
There are two important distinctions between the EX and NE densities: (1) There is a presence of Φ in the former density, (2) the exact adjustment coefficient contains σ but the NE does not. When σ → 0, the argument of Φ in (6) approaches +∞, implying that Φ → 1. The second adjustment coefficient vanishes when σ → 0, so that
In another extreme situation, when σ → ∞, we have Φ → 1/2, so that
This observation suggests that the NE density approximation can be called “a small-variance approximation” because it coincides with the exact one when σ2 approaches zero.
Skovgaard (1985, formula (3.6)) suggested another expression for the density of the NLS estimator. As in the case of previous authors, the formula differs by the adjustment coefficients. More specifically, it has the same argument Q at functions Φ and ϕ, but different coefficients on these functions:
| (10) |
The difference between this and our aEX (6) is in the coefficient at the first term. Clearly, the two expressions will be close when Q is large. It is possible to prove that the Skovgaard density is always positive because aSK > 0.
A nonlinear model that can be reduced to a linear model has the form f(β) = g(β)x, where g is a strictly monotonic function. In the terminology of Pazman (1993), this model is an Intrinsically Linear (IL) model. For an IL model, AB − CD = 0 and AE − C2 = 0, so we can approximate the density with a1 = 1 and a2 = 0, which leads to the IL approximation of ,
| (11) |
All three densities, (5), (8), and (11), are the same for an intrinsically linear nonlinear regression.
A further way to simplify the approximation of the density is to replace the derivative, , with the derivative evaluated at the true parameter value β:
| (12) |
This approximation will be called the Intrinsically Linear-Linear (ILL) approximation. This approximation is satisfactory in close proximity to the true value and reduces to the standard normal density upon transformation under the assumption that is a monotonic function of b for each β. However, the area under the curve (12) is less than 1 if the range of z does not cover the entire line.
Finally, as follows from the standard asymptotic results (e.g. Gallant 1987), when n → ∞ the distribution of approaches the normal distribution with zero mean and varianc , which implies the normal approximation,
| (13) |
routinely used in nonlinear regression analysis.
The problem with approximations (8), (11) and (12) is that the area under the “density” is not 1. The fact that the area under the curve specified by the near exact density is not 1 has been mentioned by other authors, including Hougaard (1988), but perhaps the most discouraging feature of the NE density approximation is that it may become negative. For example, for an exponential regression f(β) = eβx, where x =(x1, x2, …, xn)′, the adjustment coefficient evaluated at b = 0 is proportional to
Assuming that max x > 0, some algebra shows that this quantity becomes negative when β → ∞. Although negative values of the density usually appear at the tails, it may lead to infinite confidence intervals with large σ; the same problem may arise when the area under the density is greater than one.
Example
Five density approximations, (8), (10), (11), (12) and (13), are compared with the exact density (5) for exponential regression, , where xi = i with i = 1, …, n = 6 and the true value, β = 0 and σ = 2.5. The results are depicted in Figure 1. The area under the four curves is evaluated numerically by integration over the interval (−4, 0.5) using function integrate in R with 107 subdivisions (R Core Team, 2014). As seen from this figure, the problem with the NE density approximation starts when the NLS estimate takes values below −0.5, resulting in a considerable deviation of the area under the “density” from 1. The negative density is due to the negative values of the adjustment coefficient which falls below zero starting from b = −0.5. The IL and ILL approximations are close to each other and to the EX/NE densities. From a statistical prospective, the NLS estimator has a long left tail which is less visible in the NE approximation. The NE density deviates from the true one because the curvature of the exponential model is unbounded (Pazman, 1984).
Figure 1.
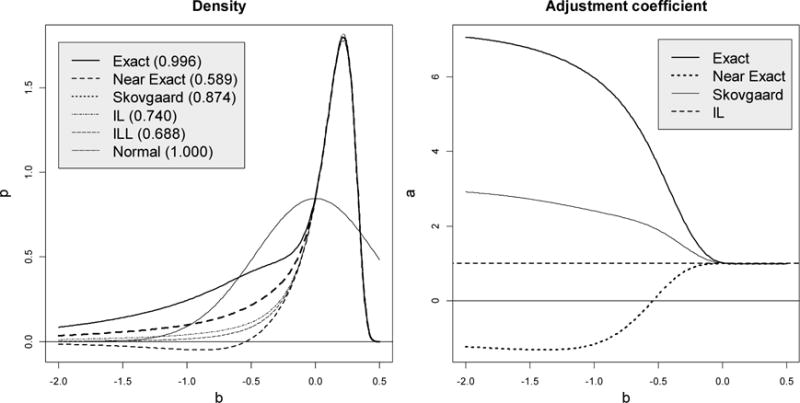
Exact and four density approximations for the exponential regression fi(β) = eiβ with i = 1, 2, …, 6, σ = 2.5 and the true β = 0. The figure in the parentheses shows the area under the curve (must be 1).
An obvious remedy for possible negative values of the adjustment coefficient (and the density) in the NE approximation is to take the absolute value, |aNE(b; β)| or set it zero. This suggestion can be justified by the fact that function x (2Φ (x) − 1) in (7) can be well approximated by |x|. After ignoring the second adjustment coefficient in aEX, we arrive at |aNE(b; β)|.
2.2. Nonlinear regression with linear parameters
A nonlinear regression with m additive linear parameters takes the form
| (14) |
where it is assumed that the n × (m + 1) matrix, [X,h(b)], has full rank for all b. We can reduce this regression to a univariate linear regression by fixing β and applying least squares for γ, yielding and f(b) = Wh(b), where W = I − P and P = X(X′X)−1X′ is the projection matrix, so that W1/2 = W. Sometimes, this procedure is called the partially linear least squares, or the Golub-Pereyra algorithm by the name of the original authors, Golub & Pereyra (2003). The reduced sum of squares can be rewritten as
where γ may be taken as the true parameter because WX = 0. Formally, the nonlinear regression is f(b) = Xγ − h(b), but since and WX = 0, it is sufficient to use f(b) = h(b) with matrix W = I − X(X′X)−1X′. Consequently, the distribution of does not depend on linear parameters γ. To obtain the joint density, (a) write the density of conditional on ,
| (15) |
then (b) the joint density for and is the product of pEX and this normal conditional density.
2.3. Possible improvements of Theorem 1
The exact density of the NLS estimator is derived under a stringent assumption on the uniqueness of the solution of the normal equation. If this assumption does not hold the area under pEX may be different from 1, below is a motivating example.
Example (provided by a referee)
Define the circle nonlinear regression as f(β) = (cos β, sin β) on β ∈ (−π, π], n = 2. The normal equation has two solutions, and . One solution is the NLS estimate as the minimizer of the residual sum of squares (2) and another is the maximizer, the spurious solution. The conditions of Theorem 1 are violated and it is not difficult to find that the area under pEX density is 2. This example, gives rise to the following improvement of Theorem 1.
Find the density of the NLS estimator under condition that the second derivative of the residual sum of squares is positive: this condition eliminates the spurious solution of the estimating equation corresponding to the maximum of the criterion function.
An advantage of the proof of Theorem 1 is that we can easily incorporate the condition on the positiveness of the second derivatives because it is expressed as a linear function of observations. Indeed, in the notation of the proof from the Appendix, let in addition to the normal equation we define the condition of the positiveness of the second derivative as
where z = σ−1(y − f(β)) are normalized observations and g(b) = σ−1(f(b) − f(β)), and u < 0. The joint density of (b, u) can be derived by integrating out y2, …, yn following the line of the proof. Finally, to obtain the marginal distribution of b we condition on u > 0 by integration the bivariate density over (−∞, 0). For example, for the circle regression the density of the NLS (with the spurious solution eliminated) is proportional to
This integral has been evaluated in closed form using a technique presented in the proof based on the formula . Remarkably, the circle regression gives rise to a new family of distributions on the circle (Mardia & Jupp, 2000). In Figure 2 we depict the empirical (using 100,000 simulations) and theoretical densities of the NLS estimator in the circle regression, wrapped around the unit circle, under two scenarios of true parameters: the densities match perfectly. The density has a peak, the distance from the unit circle, at the true β, and the density with σ = 2 is more “uniform.”
Figure 2.
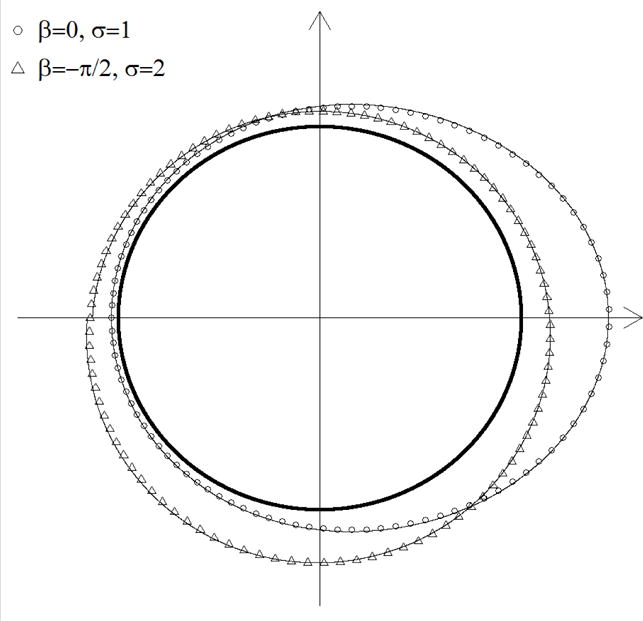
The theoretical and empirical densities of the NLS estimate in circle regression wrapped around the unit circle under two scenarious (symbols represent simulations and curves represent the analytic density).
Another possible improvement of Theorem 1 is to incorporate the criterion on the global minimum into the derivation of the density. Indeed, the global criterion is usually formulated as follows: if b is a local minimizer such that ║y − f(b)║2 < ║y − f(b0)║2, where b0 is known, then b is the global minimizer of the sum of squared residuals (Demidenko, 2006, 2008). Express the above inequality as ║y − f(b0)║2 −║y − f(b)║2 = 2u where u > 0, or equivalently as y′(f(b)−f(b0)) = u−(║f(b) ║2−║f(b0)║2)/2. Since this equation is linear in y we can derive the joint density of b and u and then find the marginal density of b by integrating out u. The same method can be utilized to incorporate an existence criterion into density derivation which is also expressed as the difference of the sums of squared residuals (Demidenko, 1989, 2000).
3. Extension to the estimating equation approach
Theorem 1 can also be generalized to the case when any function, say r, is used instead of ḟ in the normal equation (4). This leads to the estimating equation (EE) approach:
| (16) |
where r(b) is a nonnull vector function such that r′(b)ḟ(b) ≠ 0 for all b and, as before, {yi − fi(β)} are iid . The solution of this equation is usually referred to as the M-estimator, or the EE estimator. Here we assume that the solution of (16) exists and is unique for each y (the discussion on the alternative intensity function is deferred to Section 5.2). Without loss of generality, one can assume r′(b)ḟ(b) > 0. It is well known that the EE approach yields a consistent M-estimator of β under mild conditions (Huber, 1981; Schervish, 1995). In particular, the estimating equation approach appears in the framework of the quasi (pseudo) -likelihood and the generalized estimating equation approach (Godambe, 1960; Gong & Samaniego, 1981; Zeger et al., 1988, Pawitan, 2001), robust statistics, and the instrumental variable approach in connection with the measurement error problem (Fuller, 1987).
Theorem 2
The exact density of the M-estimator, , defined by estimating equation (16), is given by
| (17) |
with adjustment coefficients computed by the same formulas as in Theorem 1, but
The Near Exact and IL approximations have adjustment coefficients
The proof is a slight modification of that for Theorem 1 and is found in the Appendix. Basically, we replace with r and with and repeat the three steps of the proof outlined in the preceding section. Note that we use the absolute value in G, so may be negative.
As in the case of the NE distribution for the NLS estimator, it is straightforward to check that the EE estimator has the cdf given by
| (18) |
Similar to our previous comment, in order for this function to be a cdf, FEE as a function of b must satisfy three conditions.
Linear instrumental variable check: Let f(β) = βx and r(β) = (r1, r2, …, rn)′ be a fixed vector such that r′x > 0, so that the estimating equation takes the form (y−βx)′r = 0. This estimator emerges as the instrumental variable approach (Fuller, 1987). As follows from linear theory, . But from Theorem 2, B = C = E = 0 and a1 = G/A = (r′x) ║r║2, a2 = 0, which yields
the same density as follows from the linear theory. All three densities, NE, IL and ILL, coincide for linear regression.
3.1. Nonlinear regression with an unknown coefficient
In this section, we apply the theory of the estimating equation to regression with one intrinsically nonlinear parameter and an unknown coefficient at the nonlinear function,
| (19) |
assuming that the n × 2 matrix [h(b), h(b)] has a full rank for all b, and ν ≠ 0. After eliminating ν through linear least squares, we arrive at the estimating equation for β,
which is equivalent to
where ν is the true value. Thus, letting
Theorem 2 applies (the argument, b, is omitted for brevity). The required condition, follows from the Cauchy inequality,
since matrix has full rank. The exact and near exact densities require the derivative vector, , which is straightforward to obtain in terms of derivatives of h,
Fieller (1932) example. In this example, we test (17) through a distribution derived almost one hundred years in a very special case. Namely, we apply the estimating equation theory to the nonlinear regression
| (20) |
In previous notation we have h(b) = 1+bx, r(b) = x − (1+bx)′x(1+bx) ║1+bx║−2. For this model the exact distribution of the NLS estimator of β reduces to the distribution of the ratio of two normally distributed random variables. Indeed, the NLS estimator of β is
| (21) |
where and are the least squares slope and intercept, respectively. They have a bivariate normal distribution with marginal distributions and , respectively, and correlation coefficient . Fieller (1932) initially derived and Hinkley (1969) extended the distribution of the ratio of two normally distributed random variables, Z = X1/X2 with means μi, variances , and correlation coefficient ρ. Thus the Fieller result applies with μ1 = νβ, and μ2 = ν, and as the benchmark testing of our EE distribution specified in Theorem 2. After some algebra, one can show that our density pEX and the density of the ratio are identical while other known density approximations, such as NE or Skovgaard do not coincide with the density of the ratio.
3.1.1. Example: Michaelis-Menten model
The Michaelis-Menten model is a popular model in many application fields, especially in chemistry (Seber & Wild, 1989; Hadeler et al. 2007). It has a hyperbolic shape and describes the data with the right asymptote,
| (22) |
We use Puromycin data on the velocity of a chemical reaction from the example provided in Bates & Watts (1988, p. 269), n = 12 with the true parameter values β = 0.064 and ν = 212.7 estimated from the data, where x is the substrate concentration and y is the velocity of the enzymatic reaction. The estimated residual standard error was σ = 10.9; we use σ = 40 here to amplify the difference between the densities. Four densities of the NLS estimator with the associated 75% density limits are depicted in Figure 3 (we use the 75% confidence level, not 95%, for the illustrative purpose).
Figure 3.
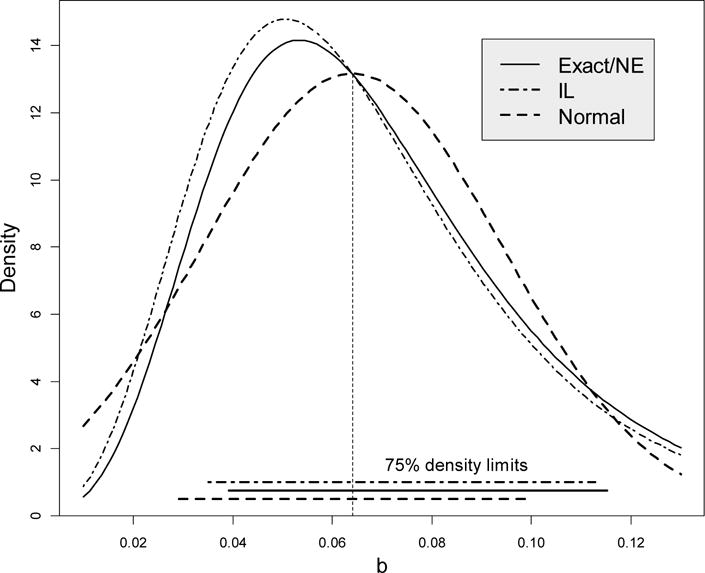
Four densities of the NLS estimator of β = 0.064 in the Puromycin example (σ = 40) with the 75% density limits. The exact and near exact densities practically coincide.
The exact and near exact densities practically coincide; that is why only three curves are seen. The IL density deviates only slightly from the exact/NE densities. The normal approximation is adequate only in a close proximity to the true value, but deviates from the exact density elsewhere due to the implied symmetry. Consequently, the normal density limits are narrow and symmetric around β. The Exact/NR and IL limits are wider and shifted to the right due to skewness of the estimates. The same conclusions, on average, can be drawn regarding confidence intervals for β.
In Figure 4, the exact expected value of and its MSE are computed using the function integrate in R based on the exact density as a function of the standard error of residuals. For σ larger than 40, the negative bias becomes considerable (left plot). For σ > 30 the normal approximation variance, routinely used in existing statistical packages, considerably exceeds the exact value and inflates the p-value as follows from the right plot.
Figure 4.
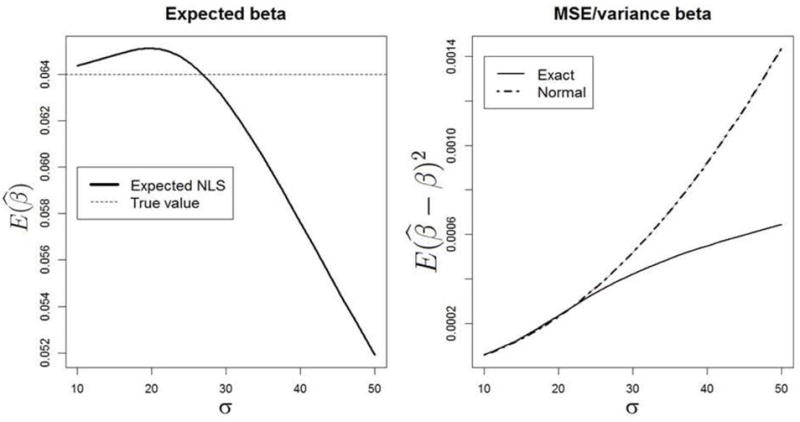
Computation of the expected value and the MSE of the NLS estimator using the numerical integration of the exact density.
The NLS estimate in the Michaelis-Menten model may not exist especially for large σ; complications associated with nonexistence are discussed below in Section 4. Criteria for the NLS existence for this model are developed in Hadeler et al. (2007). A simple criterion based on the concept of the existence level (Demidenko, 2000, 2004), is as follows. Denote and ; if there is a starting value for ν and β with the sum of squares less than min(S1, S 2), the NLS estimate exists.
Now we derive the joint distribution of the estimator for two parameters, the linear coefficient, and , where . As in (15), we note that the distribution of conditional on is normal with mean νh′(β)h(b)/h′(b)h(b) and variance σ2/h′(b)h(b). Therefore, the joint distribution is the product of this conditional normal distribution and the marginal density, pEX(b; β, σ2).
3.2. Nonlinear regression with an unknown coefficient and linear parameters
The regression with one intrinsically nonlinear parameter, a linear part and an unknown coefficient takes the form
| (23) |
where γ is an m-dimensional parameter vector and ν and β are scalars. It is assumed that the n × (m + 2) matrix, [X, h(β), h(β)], has full rank for all β. This regression is an obvious combination of (14) and (19) with applications arising from two-compartment modeling as the solution to ordinary differential equations. For example, Gallant (1987) uses model (23) with h(β) = eβz.
After elimination of the linear parameters, γ, we come to a one-parameter nonlinear least squares problem with coefficient ν treated as in the above section. Thus, the same formula for the density of applies with f = νh and h replaced with f = νWh and Wh, as in Section 2.2.
4. Numerical complications
The goal of this section is to examine how numerical complications arising when minimizing the sum of squares or solving the normal equation affect the density of the NLS estimator distribution. Apparently, two kinds of complications are possible: the solution does not exist and there are multiple solutions.
4.1. What happens when the NLS estimator does not exist
In the traditional asymptotic approach, nonexistence of the NLS estimate is not an issue because according to the classical maximum likelihood theory this probability vanishes when n → ∞. However, in practice the probability that the NLS estimate does not exist cannot be ignored, see an example below. Only a handful of papers discuss the nonexistence of the NLS estimate either in terms of sufficient criteria Demidenko (1989, 2000, 2008) or necessary and sufficient conditions for specific nonlinear regression models Hadeler et al. (2007), Jukíc & Markovic (2010), and Jukíc (2014), to name a few. The purpose of this section is to illustrate how the probability of nonexistence affects the density distribution using simplistic examples of nonlinear regression where this probability is tractable.
The NLS estimate does not exist for some observations y1, …, yn when σ2 is large and the regression curve has finite tails, namely, when ║f(b)║ does not go to infinity when |b| → ∞. To illustrate, let us consider an exponential regression with two observations (n = 2). For simplicity, we assume that x1 = 1 and x2 = 2, implying that the regression curve is a half parabola in the observation space R2. The normal equation turns into a cubic polynomial 2θ3 + (1 − 2y2)θ − y1 = 0 where θ = eb. Although the cubic equation has at least one real root, there may be no positive roots which means that the NLS estimate does not exist.
Using some algebra on the cubic equation similar to Demidenko (2000), one can show that there are no positive roots for θ if y1 ≤ 0 and y2 < 1.2 |y1|2/3 + 0.5. These explicit conditions allow computation of the probability that the NLS estimate does not exist for given β and σ expressed as an integral,
| (24) |
These probabilities as functions of σ are depicted in Figure 5 for β = ln 0.5 and β = 0. The closer the true point is on the regression curve to zero or the larger σ, the greater the probability. For example, in regression with the true value β = ln 0.5 = −0.7 and the standard deviation, σ = 1, a quarter of all iterations would diverge to −∞ if standard nonlinear regression software such as nls in R were used.
Figure 5.
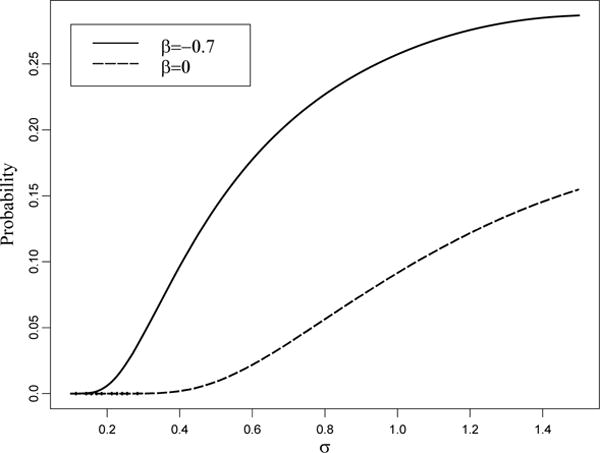
Probabilities that the NLS estimate does not exist in the exponential regression with two observations (n = 2) computed as the integral (24). The smaller the value of β the greater the probability.
Now we investigate the effect of nonexistence on the density of the NLS estimator. Two exact densities with the true value β = 0 and σ = 0.5, σ = 1 computed by formula (5) are depicted in Figure 6. Both densities have a long left tail, especially for σ = 1. The areas under the densities evaluated by numerical integration are shown in the upper-left corner. While for σ = 0.5 this area is 1, as it supposed to be, the area under the density for σ = 1 is less than 1 which reflects the fact that in approximately 20% of cases the NLS estimate does not exist. In general, numerical evaluation of the area under the density is a good test that points out to a nonignorable nonexistence of the NLS estimate.
Figure 6.
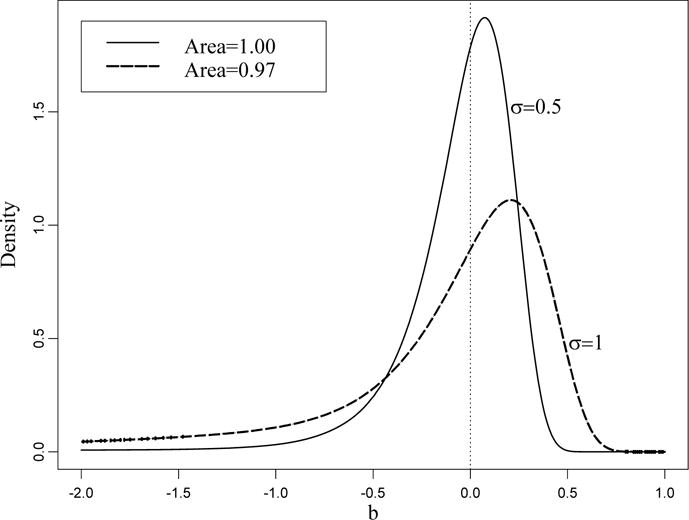
Two densities for an exponential regression with β = 0 and different σ. For σ = 0.5, there is a tiny probability that the NLS estimate does not exist. For σ = 1 this probability is about 0.1, as follows from the previous figure.
4.2. What happens when the normal equation has multiple roots
In this section, we analyze the effect of violation of another assumption under which the exact and near exact densities were derived, namely, when the normal equation has multiple roots. Lehmann & Casella (1998, p. 451) and Skovgaard (1990) presented the analysis of multiple solutions in general terms by showing that the maximum likelihood estimator lacks consistency. Here, we illustrate the consequences with an example similar to that from the previous section, the parabolic regression, f1(b) = b and f2(b) = b2, −∞ < b < ∞ (n = 2), see Figure 7. Then the normal equation reduces to a cubic equation which admits a closed-form solution. As was shown in Demidenko (2000), the sum of squares (y1 −b)2 + (y2−b2) has two local minima if y2 > 3/41/3 |y1|2/3 +1/2. In the figure, the data point y leads to two local minima as the distance to the parabolic curve; the positive value is the true NLS estimate and the negative value is the false NLS estimate. For given β and σ, one can compute the probability of two local minima as the integral
| (25) |
For example, for β = 0.5 and σ = 0.5 the probability that the sum of squares has two local minima is 0.026. In Figure 7, the circle around (0.5, 0.52) shows the 95% confidence region of (y1, y2). Probability (25) equals the density-weighted area of the intersection of this circle with the shaded area.
Figure 7.
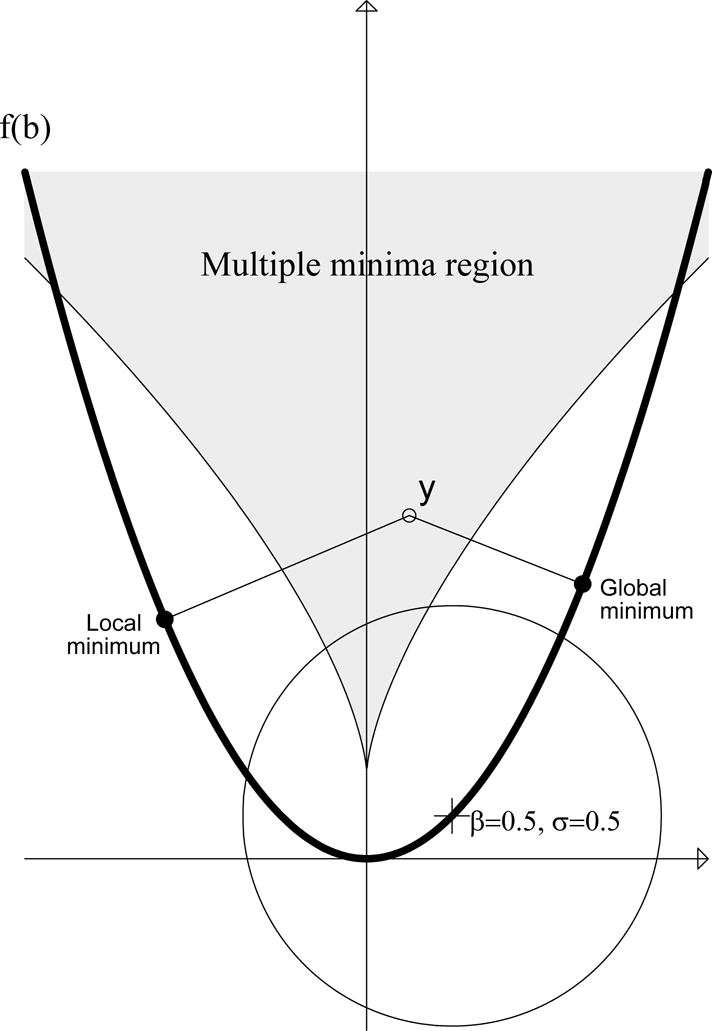
Parabolic regression on the plane (n = 2). If y = (y1, y2) is from the shaded region the sum of squares, (y1 − b)2 + (y2 − b2)2, has two local minima.
Now we turn our attention to how multiple roots (local minima) affect the densities. Although the NLS estimate should yield the absolute minimum of the sum of squares it may not hold in practice where a possibility of local minimum is a reality. In Figure 8, five densities are shown for β = 0.5 and σ = 0.5. The first two densities are theoretical and the last three densities are empirical, estimated with the Gaussian kernel based on 100,000 simulations. Three strategies for handling multiple roots are studied through simulations: The “Global minimum” strategy is when the global minimum is taken, which leads to the true NLS estimate. The “False minimum” is when the wrong local minimizer is taken as the false NLS estimate. The “50/50” strategy is when the true or the false estimate is randomly chosen with equal probability. We notice that the NE density has a prominent dip and differs from the EX density in the interval (−0.5, 0.25). The probability of the false NLS estimate computed by formula (25) is 0.026. The left bump around −0.5 in the densities reflects the possibility of the false estimate. In fact, when y is close to the center of the multiple minima region (b = 0), the roots of the normal equation have the same magnitude but different signs. The existence of multiple roots makes the area under the EX density larger than 1; for this example, it is 1.10. As in the case of the NLS nonexistence, the deviation of the area under the density from 1 is indicative of the nonuniqueness of the NLS estimate.
Figure 8.
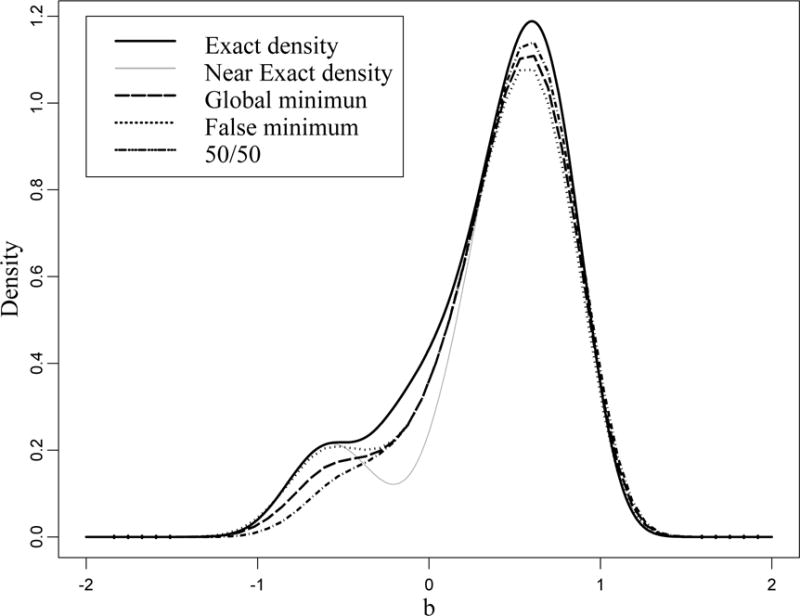
Two theoretical and three empirical densities from simulations (N = 100,000) estimated with the Gaussian kernel for parabolic regression, β = 0.5, σ = 0.5. The left bump reflects the existence of the false NLS estimate. The probability that the sum of squares has two local minima, computed by formula (25), is 0.026.
5. Multivariate case
In multivariate nonlinear regression, parameter β is an m-dimensional vector, so we use boldface now,
The NLS estimator, , is the solution to the vector normal equation
| (26) |
where F(b) =∂f/∂b is the n × m derivative (Jacobian) matrix assuming det(F′(b)F(b)) ≠0 for all b and that f(b1) = f(b2) implies b1 = b2 to ensure the identifiability. As in the univariate case, we assume that the solution of (26) uniquely exists for each y ∈Rn. The exact density for a multivariate nonlinear regression model cannot be derived in closed form, so we deal with approximations.
5.1. Density approximations for the NLS estimator
The NE density for the multivariate case was derived by Pazman (1984, 1993) using a geometric approach,
| (27) |
where H(b) is a (nm) × m stack matrix with the ith m × m block as the Hessian matrix of fi, namely, Hi = ∂2fi/∂b2, and P(b) = F(b)(F′(b)F(b))−1F′(b) is the n × n projection matrix. Notation ⊥ is used to indicate the row distance vector to the plane spanned by vector columns of matrix F(b), namely, (f(b) − f(β))⊥ = (f(b) − f(β))′(In − P(b)). Skovgaard (1985), Hougaard (1985) and Pazman (1999) derived expression (27) using the saddlepoint approximation.
We make several comments on density (27). First, the Kronecker product in (27) can be expressed explicitly as
| (28) |
Second, for m = 1, after some algebra, we arrive at the previous expression (5) with adjustment coefficient (8). Third, density (27) is equivalent to saying that
| (29) |
The IL approximation can be used as a simplification of pNE by omitting term (28),
Again, one can prove that this density is exact for the intrinsically linear regression model, the nonlinear model that can be reduced to linear after reparametrization. The ILL approximation is a further simplification when matrices are evaluated at the true value:
The complications outlined in Section 4 apply to these densities as well. Namely, (27) can be negative and the volume under the densities may be not 1. Pazman (1984) expressed the deviation of (27) from the true density in terms of the minimum radius of intrinsic curvature as a part of the nonoverlapping assumption. The problem is that, in most nonlinear regression models, this minimum reaches zero if parameter space is not restricted, so that the nonoverlapping assumption does not hold. For example, the radius of intrinsic curvature approaches zero when β → −∞ in the exponential model with 0 < x1 < … < xn. Of course, one can restrict the parameter space, say, β > 0, but that restriction would become questionable.
5.2. Density approximations for the estimating equation approach
In the multivariate EE approach, the M-estimator is found from the vector equation
| (30) |
where R(b) is a n × m matrix such that matrix R′(b)F(b) is positive definite. In a special case when R = F, the estimating equation approach reduces to NLS. Following the line of the proof in the univariate case, we obtain the NE approximation of the density of the M-estimator,
| (31) |
where E(b) is a (nm) × m stack matrix, with the ith m × m block, Ei = ∂ri/∂b and ri = ri(b), being the ith row vector of matrix R(b), and the projection matrix is given by
Simple algebra shows that (31) reduces to (17) when m = 1. The IL approximation is an obvious simplification,
The saddlepoint approximation to the density in more general settings expressed in terms of the cumulant generating function were developed by Field (1982) and Strawderman et al. (1996), among others (see a nicely written paper by Goutis & Casella (1999) as a general introduction to the saddlepoint approximation). One can show that the saddlepoint approximation yields pIL. There is a bulk of work on the distribution of the M-estimator in a less idealistic situation when there are several solutions of the EE with the density counterpart termed the intensity function derived in a general form. For example, Almudevar et al. (2000) provide an explicit solution for the density only for a linear Huber’s robust regression.
The multivariate version of the EE densities can be applied to nonlinear regressions with linear part and unknown coefficients, such as Xγ+ν1f1(β1) + ν2f(β2), similar to regression with one intrinsically nonlinear parameter.
5.3. Possible improvements of multivariate density derivation
We have indicated that our derivation of the univariate density may be improved by brushing off spurious solutions or by accounting for nonexistence of the estimate. Many previous derivations of the multivariate density relied on the saddle point approximation. We provide an outline of an alternative derivation of the density as a generalization of the univariate case in the Appendix. As before, we assert that this derivation is flexible enough to incorporate conditions on positive definiteness of the Hessian, or at least positiveness of the diagonal elements, and existence criteria once they are expressed as linear functions of observations.
6. Gauss-Markov theorem for nonlinear regression
The aim of this section is to show how the density results can be used to study methods of optimal parameter estimation. Classic quadratic loss function criteria for optimality do not work in this setting because (a) the moments may not exist, such as in Fieller problem, and therefore the concept of unbiasedeness is invalid, and (b) the distribution is highly asymmetric.
Gauss-Markov theorem is the landmark result of linear regression with normally distributed variables: if y = Xβ + ε, where components of error vector ε are iid normally distributed with zero mean and matrix X has full rank, then the maximum likelihood (least squares) estimators of the beta-coefficients are unbiased and have minimum variance for any finite n. This result holds for the NLS estimator in nonlinear regression in large sample (n → ∞). The paramount question: does it hold for finite n? One can guess that this question was on the mind of statisticians since the Gauss-Markov theorem was proved for linear regression. Two challenging questions should be answered before even formulating the problem:
What family of competitive estimators should be considered?
How to define the most precise estimator with a known cdf which may have infinite mean or variance like in the Fieller test example when the traditional mean square error loss function does not work?
To answer the first question we suggest to consider the EE approach with the family of estimators defined by equation (30). To motivate our choice we refer to linear regression restricting to linear estimators that reduces to equation R′(y − Xβ) = 0, where matrix R has full rank and matrix R′X is nonsingular (‘linear’ means that matrix R does not depend on β). The EE estimator is unbiased with the covariance matrix , as the Gauss-Markov theorem says (the last inequality follows from the fact that matrix I − X(X′X)−1X′ is nonnegative definite). Restriction on unbiased estimators is crucial—the EE approach defined by (30) can be viewed as the unbiasedeness counterpart.
To answer the second question, we invoke the concept of the confidence interval (CI) termed here as inverse cdf (see Casella & Berger, 1990, pp. 417–418). Hereafter in this section we consider the one-parameter statistical estimation problem. Let the cdf of an estimator be defined as F(b; β) such that F(b; β) is a strictly decreasing function of β for every fixed b and limβ→−∞ F(b; β) = 1, limβ→∞ F(b; β) = 0. If α is the significance level, say, α = 0.05 and is the EE estimator, the lower and the upper limits of the CI for β are the solutions to the equations F( ; β) = 1 − α/2 and F( ; β) = α, respectively. The solutions exist and unique as follows from the assumptions on cdf F, although the existence of the limiting values for F are not crucial— if the the solution does not exist the CI limit is set to ∞.
Definition 3
Let the cdfs of two estimators of the true β be F1(b; β) and F2(b; β). We say that the first estimator is more precise if its inverse cdf CI is a subinterval of the second for every α > 0.
It is easy to see that the two estimators are unbiased and normally distributed with cdfs Φ((b − β)/σ1) and Φ((b − β)/σ2) the first estimator is more precise if and only if σ1 ≤ σ2.
Now we turn our attention to formulation of the extended Gauss-Markov theorem; as mentioned before one intrinsically nonlinear parameter nonlinear regression with known σ is discussed here. Also we restrict ourselves with near exact approximation of the density distribution since the cdfs for the NLS and EE estimators admit a closed-form expression via Φ defined by (9) and (18). The family of nonlinear regressions has to be constrained as well to comply with the uniqueness of the cdf solutions in inverse cdf CI. We adopt the following definition of the unidirected regression (Demidenko, 2006):
Definition 4
A nonlinear regression is called unidirected if the vector derivatives constitute a sharp angle for any pair of parameter values, i.e. ḟ′(β1)ḟ(β2) > 0 for every β1 and β2.
It is easy to see that for a unidirected regression the inverse cdf CI based on the cdf (9) is unique for any α. Indeed, if is the NLS estimator the lower and upper limits of the CI are the solutions to the equation H.(β; ) = σΦ−1(1 − α/2), where
But for the unidirected function H is a strictly increasing function of β for any fixed b, including b = so that the solutions are unique.
Now we turn our attention to the EE estimator as the solution to (16) defined by function r. In general terms, the Gauss-Markov theorem for nonlinear regression proves that r(b) = ḟ(b) yields a more precise EE estimator than any other choice of function r(b). The expression for cdf (18) is crucial here.
Theorem 5. Local near-exact Gauss-Markov theorem for nonlinear regression
Let (1) be a unidirected nonlinear regression and r(b) be such that r′(b)ḟ(β) > 0 for every b and β. Denote
Then (a) the EE estimator with r = r∗ is the most precise if Hr(β; b) ≤ Hr∗(β; b) for all β and b. (b) The NLS/ML estimator is locally precise meaning that
for any function r = r(b).
Proof
As follows from (18) the inverse cdf (1−α)100% CI can defined as the interval Ir = {β: Hr(β; b) ≤ σΦ−1(1−α/2)}. If r∗ is such that then the interval is a subinterval of Ir.
- For the NLS/MLE estimator we have
For the EE estimator with any r = r(b) we have
due to Cauchy-Schwarz inequality, end of proof.
We make a few comments regarding this theorem: (a) function H provides a criterion for search of the most precise EE estimator through the vector function r(b). (b) the Gauss-Markov theorem holds in the local sense, for tight CI.
7. Future work
The present work on the density distribution for the estimating equation approach can be extended in several theoretical research directions. First, the density distribution of the variance estimate, should be derived and the confidence intervals for the parameters should be corrected based on this density. We believe that this knowledge may show the way to find a better estimator of σ2.
Second, the extension to the estimating equation approach developed in this paper opens the possibility of studying the small-sample properties of the weighted nonlinear regression (Carroll & Ruppert, 1988), and the quasi/pseudo-likelihood approach (Gong & Samaniego, 1981; Zeger et al. 1988) with a normally distributed response variable. In the former approach, which is sometimes called generalized nonlinear least squares, the weight matrix is a function of the regression parameters and the estimating equation takes the form
where W(b) is the weight matrix, which turns into estimating equation (30) by letting R(b) = W(b)F(b).
Third, following the line of our density derivation, one may study the small-sample properties of the Generalized Estimating Equation (GEE) approach, often applied to the analysis of longitudinal and cluster data (Fitzmaurice & Molenberghs, 2009), with estimating equation and the weight matrix , where Rk is the correlation matrix and Dk(b) is the diagonal matrix of standard deviations.
Fourth, the exact (or improved) statistical inference can be extended to statistical models when variance-covariance matrices are subject to estimation using the estimating equation approach (Paige & Trindade, 2009).
Fifth, the normal approximation density can be improved for multivariate nonlinear regression (Vonesh et al., 2001) and, more generally, nonlinear mixed models (Demidenko, 2013).
Sixth, the near exact density approximation of estimating equation approach allows formulation of the nonlinear Gauss-Markov theorem. We have derived a local version of the theorem; more work has to be done in this direction, intriguing from the theoretical and important from practical perspective. In particular, the question whether NLS/ML estimator remains precise in the global sense is open and awaiting the solution. It is possible that for a concrete regression function one may find a better estimator.
Seventh, the idea finding the exact distribution conditional on the difference of residual sum of squares in Section 2.3 may be applied to adjust for nonexistence of the NLS, frequently forgotten in the literature of higher order asymptotics, because the criteria of existence usually have the form where β0 is a fixed parameter value (Demidenko 1989, 2008).
On the practical side, as was mentioned above, the existing commercial statistical packages, such as SAS and STATA, or freely available R rely on the normal approximation which yields symmetric Wald confidence intervals. Arguments against computationally intensive confidence intervals in nonlinear models were adequate several decades ago, but not today. In addition to Wald confidence intervals and p-values, software offering nonlinear regression should be augmented with more precise numerical and statistical features, such as testing whether the found minimum of the sum of squares is global and improved asymmetric profile-confidence intervals and associated p-values such as implemented in the recent R package nlreg (Brazzale et al., 2007, Brazzale & Davison, 2008).
Acknowledgments
I thank two referees for their helpful and enlightening comments and especially for providing the circle regression example. In part, this work was supported by the following grants from the National Institutes of Health (NIH): R01 LM012012A, 8 P20 GM103534, 1U01CA196386, P30 CA23108-37, and 1UL1TR001086.
Appendix
A. Proof of Theorem 1
The following lemma is an obvious reformulation of a textbook result on the density of the multivariate distribution under a nonlinear transformation.
Lemma 6
Let random vector y = (y1, y2, …, yn) have density py(y1, y2, …, yn) and random variable b be a unique solution to a nonlinear equation,
| (32) |
where g is a nonlinear function such that . Moreover, let y1 be expressed from (32) via inverse function, y1 = h(b, y2, …, yn). Then the density of b is given by
Since the normal equation does not depend on σ, we can assume that σ is fixed and known. Moreover, we can normalize the normal equation by replacing the observations and the regression function with yi/σ and fi(β)/σ, respectively, so that observations will have unit variance. Also, without loss of generality, we can assume that for all b. The proof has three steps.
#1. Express y1 through the NLS estimator b and y2, …., yn. as
and apply Lemma 3 to obtain the density of the NLS estimator as an integral:
| (33) |
The needed derivative is obtained using elementary calculus, , where and
Introducing the (n − 1) × 1 vectors z, q and g with the ith components zi, qi and , respectively, rewrite integral (33) in a compact form as
| (34) |
where .
#2. Express integral (34) as an expectation of |R + q′z| over a normally distributed vector using cdf Φ. Using an elementary fact (a > 0),
which follows from equality where ϕ = Φ′. After some algebra, we obtain
| (35) |
We apply this formula to (34) letting X = R + q′z and expressing the integrand through a density of a (n − 1) dimensional normal variable. Using the formula
we represent
where μ=−p(I + gg′)−1 g = −p(1 + ||g||2)−1 g. Using this result, we can rewrite the exponential part as
But det (I + gg′) = 1 + ||g||2, so finally the distribution of R + q′z is a constant times the normal distribution, or symbolically,
Combining this result with formula (35) and letting X = R + q′z with
we obtain the following result. Let , p and R be scalar and g and q be vectors. Then
| (36) |
where
| (37) |
| (38) |
Note that without the absolute value, we obtain an easier expression,
| (39) |
where
| (40) |
#3. Express the density through the n-dimensional vector f and its derivatives and simplify. Letting
for brevity, some tedious algebra yields
and
Plugging these expressions back into (36), we obtain the exact density of the NLS estimator (5) with the adjustment coefficients, which follow from (37) and (38). Note that the NE density approximation with adjustment coefficient (8) follows from (39). Thus, this approximation is obtained from density (33) by ignoring the absolute value of the derivative/Jacobian.
B. Proof of Theorem 2
This proof follows the proof of Theorem 1 closely. Express y1 through the NLS estimator b and y2, …., yn. as
and find the derivative , where
Introducing the (n − 1) × 1 vectors z, q and g with the ith components zi, qi and gi = ri(b)/r1(b), respectively, and p = [(f(b) − f(β))′r(b)]/r1(b). We notice that the derivative appears only in the expression of R; in the rest of the expressions, ri acts as and subsequently acts as . Thus, we need to work on the terms containing R,
Thus, we come to the formula for density in Theorem 2 by replacing with r(b) and with .
C. Outline of the multivariate density derivation
Partition the Jacobian matrix F(b), the data vector y and the regression function f(b) as follows:
assuming that the square matrix F1(b) is nonsingular for every b. Using the normal equation express y1 through the NLS estimator b and z2 = y2 − f2(β),
and apply the multivariate version of Lemma 6 to obtain the density of the NLS estimator as an integral over Rn−m,
where and H2i = ∂2fi2/∂2b. Approximate
using the Jacobi’s formula and proceed as in the univariate case since the right-hand side may be treated as a normally distributed random variable and as such exact density can be derived beyond this point. Note that if the absolute value of the determinant in pNLS expression is approximated as det(R) we obtain the NE density.
References
- Almudevar A, Field C, Robinson J. The density of multivariate M-estimators. Annals of Statistics. 2000;28:275–297. [Google Scholar]
- Barndorf-Nielsen OE, Cox DR. Edgeworth and saddlepoint approximations with statistical applications. Journal of the Royal Statistical Society, ser B. 1979;41:279–312. [Google Scholar]
- Bates DM, Watts DG. Relative curvature measures of nonlinearity (with discussion) Journal of the Royal Statistical Society, ser B. 1980;42:1–25. [Google Scholar]
- Bates DM, Watts DG. Nonlinear regression analysis and its applications. Wiley; New York: 1988. [Google Scholar]
- Brazzale AR, Davison AC, Reid N. Applied asymptotics: Case studies in small-sample statistics. Cambridge University Press; Cambridge, UK: 2007. [Google Scholar]
- Brazzale AR, Davison AC. Accurate parametric inference for small samples. Statistical Science. 2008;23:465–484. [Google Scholar]
- Beale EML. Confidence regions in nonlinear estimation (with discussion) Journal of the Royal Statistical Society, ser B. 1961;22:41–88. [Google Scholar]
- Bickel PJ, Doksum KA. Mathematical statistics Basic ideas and selected topics. 2nd. Vol. 1. Upper Saddle River; NJ: 2007. [Google Scholar]
- Carroll RJ, Ruppert D. Transformation and weighting in regression. Chapman and Hall; New York: 1988. [Google Scholar]
- Casella G, Berger RL. Statistical inference. Duxbury Press; Belmont, CA: 1990. [Google Scholar]
- Demidenko E. Optimization and regression. Nauka (in Russian); Moscow: 1989. [Google Scholar]
- Demidenko E. Is this the least squares estimate? Biometrika. 2000;87:437–452. [Google Scholar]
- Demidenko E. Mixed models: Theory and applications with R. 2nd. Wiley, Hoboken; New Jersey: 2013. [Google Scholar]
- Demidenko E. Criteria for global minimum of sum of squares in nonlinear regression. Computational Statistics and Data Analysis. 2006;53:1739–1753. [Google Scholar]
- Demidenko E. Criteria for unconstrained global optimization. Journal of Optimization Theory and Applications. 2008;136:375–395. [Google Scholar]
- Field CA. Small sample asymptotic expansions for multivariate M-estimates. Annals of Statistics. 1982;10:672–689. [Google Scholar]
- Fieller EC. The distribution of the index in a normal bivariate population. Biometrika. 1932;24:428–440. [Google Scholar]
- Fitzmaurice G, Molenberghs M. Advances in longitudinal data analysis: An historical perspective. In: Fitzmaurice G, Davidian M, Verbeke G, Molenberghs G, editors. Longitudinal Data Analysis. CRC Press; Boca Raton, FL: 2009. [Google Scholar]
- Fraser DAS, Reid N, Wu J. A simple general formula for tail probabilities for frequentist and Bayesian inference. Biometrika. 1999;86:249–264. [Google Scholar]
- Fuller WA. Measurement error models. Wiley; New York: 1987. [Google Scholar]
- Gallant AR. Nonlinear statistical models. Wiley; New York: 1987. [Google Scholar]
- Godambe VP. An optimum property of regular maximum likelihood estimation. Annals of Mathematical Statistics. 1960;31:1208–1211. [Google Scholar]
- Golub GH, Pereyra V. Separable nonlinear least squares: the variable projection method and its applications. Inverse Problems. 2003;19:1–126. [Google Scholar]
- Gong G, Samaniego FJ. Pseudo maximum likelihood estimation: Theory and applications. Annals of Statistics. 1981;9:861–869. [Google Scholar]
- Goutis C, Casella G. Explaining the saddlepoint approximation. The American Statistician. 1999;53:216–224. [Google Scholar]
- Hadeler KP, Jukic D, Sabo K. Least-squares problems for Michaelis–Menten kinetics. Mathematical Methods in Applied Sciences. 2007;30:1231–1241. [Google Scholar]
- Hinkley DV. On the ratio of two correlated normal random variables. Biometrika. 1969;56:635–639. [Google Scholar]
- Hougaard P. Saddlepoint approximations for curved exponential families. Statistical and Probability Letters. 1985;3:161–166. [Google Scholar]
- Huber PJ. Robust statistics. Wiley; New York: 1981. [Google Scholar]
- Jensen JL, Wood TA. Large deviation and other results for minimum contrast estimators. Ann Inst Statist Math. 1998;50:673–685. [Google Scholar]
- Jukíc D. A simple proof of the existence of the best estimator in a quasilinear regression model. Journal of Optimization Theory and Applications. 2014;162:293–302. [Google Scholar]
- Jukíc D, Markovic D. Nonlinear weighted least squares estimation of a three-parameter Weibull density with a nonparametric start. Applied Mathematics and Computations. 2010;215:3599–3609. [Google Scholar]
- Lehmann EL, Casella G. Theory of point estimation. 2nd. Springer; New York: 1998. [Google Scholar]
- Levenberg K. A method for the solution of certain problems in least squares. Quarterly of Applied Mathematics. 1944;2:164–168. [Google Scholar]
- Lugannani R, Rice S. Saddle point approximation for the distribution of the sum of independent random variables. Advances in Applied Probability. 1980;12:475–490. [Google Scholar]
- Mardia KV, Jupp PE. Directional statistics. Wiley; New York: 2000. [Google Scholar]
- Marquardt DW. An algorithm for least-squares estimation of nonlinear parameters. SIAM Journal for Applied Mathematics. 1963;11:431–441. [Google Scholar]
- Paige RL, Trindade AA. Saddlepoint-based bootstrap inference for quadratic estimating equations. Scandinavian Journal of Statistics. 2009;36:98–111. [Google Scholar]
- Pawitan Y. In all likelihood: Statistical modelling and inference using likelihood. Oxford: Clarendon Press; 2001. [Google Scholar]
- Pazman A. Probability distribution of the multivariate nonlinear least squares estimates. Kibernetika. 1984;20:209–230. [Google Scholar]
- Pazman A. Nonlinear statistical models. Dordrecht: Kluwer; 1993. [Google Scholar]
- Pazman A. Some properties and improvements of the saddlepoint approximation in nonlinear regression. Annals of the Institute of Statistical Mathematics. 1999;51:463–478. [Google Scholar]
- R Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing; Vienna, Austria: 2014. URL http://www.R-project.org. [Google Scholar]
- Seber GSF, Wild CJ. Nonlinear regression. New York: Wiley; 1989. [Google Scholar]
- Skovgaard IM. Large deviation approximations for maximum likelihood estimators. Probability and Mathematical Statistics. 1985;6:89–107. [Google Scholar]
- Skovgaard IM. On the density of minimum contrast estimators. The Annals of Statistics. 1990;18:779–789. [Google Scholar]
- Schervish MJ. Theory of statistics. New York: Springer-Verlag; 1995. [Google Scholar]
- Strawderman RL, Casella G, Wells MT. Practical small-sample asymptotics for regression problems. Journal of American Statistical Association. 1996;91:643–654. [Google Scholar]
- Vonesh EF, Wag H, Majumdar D. Generalized least squares, Taylor series linearization, and Fisher’s scoring in multivariate nonlinear regression. Journal of American Statistical Association. 2001;96:282–291. [Google Scholar]
- Yule GU. The applications of the method of correlation to social and economic statistics. Journal of the Royal Statistical Society. 1909;72:721–730. [Google Scholar]
- Zeger SL, Liang KY, Albert PS. Models for longitudinal data: A generalized estimating equation approach. Biometrics. 1988;44:1049–1060. [PubMed] [Google Scholar]