

Abstract
We present a novel framework for characterizing paired brain networks using techniques in hyper-networks, sparse learning and persistent homology. The framework is general enough for dealing with any type of paired images such as twins, multimodal and longitudinal images. The exact nonparametric statistical inference procedure is derived on testing monotonic graph theory features that do not rely on time consuming permutation tests. The proposed method computes the exact probability in quadratic time while the permutation tests require exponential time. As illustrations, we apply the method to simulated networks and a twin fMRI study. In case of the latter, we determine the statistical significance of the heritability index of the large-scale reward network where every voxel is a network node.
1 Introduction
There are many studies related to paired images: longitudinal studies with two repeat scans [7], multimodal imaging study involving PET and MRI [13] and twin imaging studies [15]. The paired images are usually analyzed by relating voxel measurements that match across two images in a mass univariate fashion at each voxel. Compared to the paired image setting, paired brain networks have not been often analyzed possibly due to the lack of problem awareness and analysis frameworks.
In this paper, we present a new unified statistical framework that can integrate paired networks in a holistic fashion by pairing every possible combination of voxels across two images. This is achieved using a hyper-network that connects multiple smaller networks into a larger network. Although hyper-networks are frequently used in machine learning [16], the concept has not been often used in medical imaging. Jie et al. used the hyper-network framework from the resting-state fMRI in classifying MCI from AD in a machine learning framework [9]. Bezerianos et al. constructed the hyper-network from the coupling of EEG activity of pilots and copilots operating an aircraft albeit using ad-hoc procedures without an explicit model specification [1]. Motivated particularly by the science of [1], we rigorously formulate the problem of characterizing paired networks as a single hyper-network with physically nonexistent hyper-edges connecting between two existing networks.
Graph theory is often used framework for analyzing brain networks mainly due to easier accessibility and interpretation. Since we do not know the exact statistical distribution of many graph theory features, resampling techniques such as the permutation tests have been mainly used in estimating the null distribution and computing p-values. The availability of inexpensive and fast computers made the permutation tests a natural choice for computing p-values when underlying distributions are unknown. However, even with fast computers, permutation test is still extremely slow even for small-scale problems. There is a strong need for fast inference procedures. We propose a new exact inference procedure for graphs and networks. The method speeds up the computation by counting the number of permutations combinatorially instead of empirically computing them by numerically generating large number of permutations.
Our main contributions are as follows.
The new formulation of the hyper-network approach for paired images. We show that hyper-networks can be effectively used as a baseline model for paired twin fMRI. The proposed holistic framework is applied to a twin fMRI study in determining the statistical significance of the brain network differences and the heritability of the reward network.
Showing that the topological structure of the sparse hyper-network has a monotonic nestedness. This is used to define monotonic graph features and subsequently in computing topologically aware distance between networks.
The derivation of the probability distribution of the combinatorial test procedure on graph theory feature vectors that do not rely on resampling techniques such as the permutation tests. While the permutation tests require exponential run time, our exact combinatorial approach requires quadratic run time.
2 Sparse hyper-network
Consider a collection of n paired images
We assume xk and yk are related either genetically (twin or sibling images), scan-wise (multimodal images of the same subject) or longitudinally. We further assume (xk, yk) are independently but identically distributed for different i. Let x = (x1, …, xn)⊤ and y = (y1, …, yn)⊤ be the vectors of images. We set up a hyper-network by relating the paired vectors at different voxels υi and υj:
| (1) |
for some zero-mean noise vector e (Fig. 1). The parameters β = (βij) are the weights of the hyper-edges between voxels υi and υj that have to be estimated. We are constructing a physically nonexistent artificial network across different images. For fMRI, (1) requires estimating over billions of connections, which is computationally challenging. In practice however, each application will likely to force β to have a specific structure that may reduce the computational burden. For this study, we will consider a reduced model relevant to our genetic imaging application:
Fig. 1.
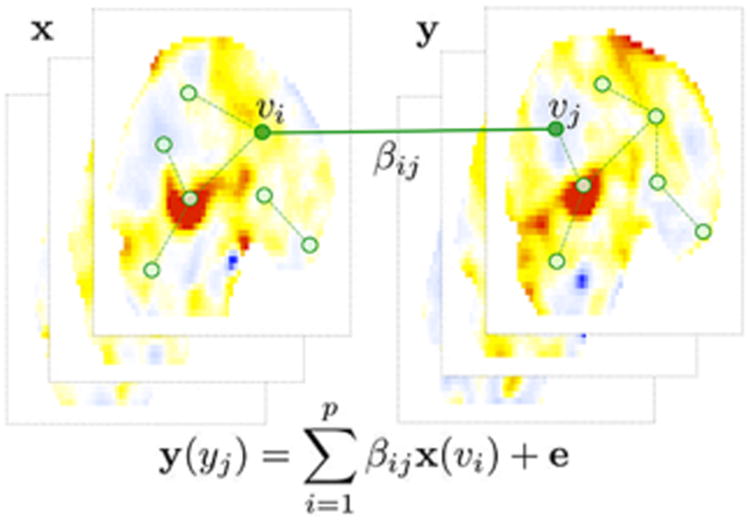
The schematic of hyper-network construction on paired image vectors x and y. The image vectors y at voxel υj is modeled as a linear combination of the first image vector x at all other voxels. The estimated parameters βij give the hyper-edge weights.
| (2) |
The scientific motivation for using the reduced model will be explained in section 6. Without loss of generality, we can center and scale x and y such that
| (3) |
for all voxels υi.
In many applications, we have significantly more number of voxels (p) than the number of images (n), so model (2) is an under-determined system and belongs to the small-n large-p problem [5]. It is necessary to regularize the model using a sparse penalty:
| (4) |
where sparse parameter λ ≥ 0 modulates the sparsity of the hyper-edges. The estimation β̂ is a function of λ. When λ = 0, (4) is a least-squares problem and we obtain β̂ij(0) = x⊤(υi)y(υj), which is referred to as the cross-correlation. The cross-correlation is invariant under the centering and scaling.
3 Distance between networks
To study the topological characteristic of the hyper-network, the estimated edge weights β̂ij(λ) are binarized by assigning value 1 to any nonzero weight and 0 otherwise. Let Gλ be the resulting binary graph, i.e., unweighted graph, with adjacency matrix Aλ = (aij(λ)):
| (5) |
As λ increases, Gλ becomes smaller and nested in a sense that every edge weight gets smaller. This is not true for the binarization of other sparse network models. Our sparse hyper-network has this extra layer of additional structure that guarantees the nestedness.
Theorem 1
The binary graph Gλ obtained from sparse model (4) satisfies
| (6) |
for any 0 ≤ λ1 ≤ λ2 ≤ … ≤ λq ≤ 1.
Proof
By solving dβ̂(λ)/dλ = 0 for λ ≠ 0 and considering β̂(0) separately it can be algebraically shown that the solution of the optimization problem (2) is given by [5]
| (7) |
From (3) and the Cauchy-Schwarz inequality we have |x⊤(υi)y(υj)| ≤ 1. Thus, if λ > 1, β̂(λ) = 0. To avoid the trivial case of zero edge weights everywhere, we need 0 ≤ λ ≤ 1. From (7), we have |β̂ij(λj)| ≥ |β̂ij(λj+1)| for 0 ≤ λj ≤ λj+1 ≤ 1. Subsequently, from (5), aij(λj) ≥ aij(λj+1). Therefore, we have Gλj ⊃ Gλj+1.
The sequence of nested multi-scale graph structure (6) is called the graph filtration in persistent homology [11]. The graph filtration can be quantified using monotonic function B satisfying
| (8) |
The number of connected components, which is the zero-th Betti number β0 and the most often used topological invariant in persistent homology, satisfies this condition. The size of the largest connected component satisfies a similar but opposite relation of monotonic decrease.
Given two different graph filtrations and , define the distance between them as
which can be discretely approximated as
If we choose enough number of q such that λj are all the sorted edge weights, then D(G1, G2) = Dq. This is possible since there are only up to p(p – 1)/2 number of unique edge weights in a graph with p nodes and and increase discretely. In practice, ρj = j/q is chosen uniformly in [0, 1] or a divide-and-conquer strategy can be used to do adaptively grid the unit interval.
D satisfies all the axioms of a metric except identity. D(G1, G2) = 0 does not imply G1 = G2. Thus, D is not a metric. However, it will be shown in section 4 that probability P(D(G1, G2) = 0) = 0 showing such event rarely happens in practice. Thus, D can be treated as a metric-like in applications without much harm.
4 Exact topological inference
We are interested in testing the null hypothesis H0 of the equivalence of two monotonic graph feature functions:
As a test statistic, we propose to use Dq. The test statistic takes care of the multiple comparisons by the use of supremum. Under the null hypothesis, we can derive the probability distribution of Dq combinatorially without numerically permuting images.
Theorem 2
where Au,υ satisfies Au,υ = Au–1,υ + Au,υ–1 with the boundary condition A0,q = Aq,0 = 1 within band |u – υ| < d.
Proof
The proof is similar to the combinatorial construction of Kolmogorov-Smirnov (KS) test [2,5,8]. Combine two monotonically increasing vectors
and arrange them in increasing order. Represent and as ↑ and → respectively. For example, ↑↑→↑→→ …. There are exactly q number of ↑ and q number of → in the sequence. Treat the sequence as walks on a Cartesian grid. → indicates one step to the right and ↑ indicates one step up. Thus the walk starts at (0, 0) and ends at (q, q) (Fig. 2). There are total possible number of paths, which forms the sample space. This is also the total number of possible permutations between the elements of the two vectors. The null assumption is that the two vectors are identical and there is no preference to one vector element to another. Thus, each walk is equally likely to happen in the sample space.
Fig. 2.
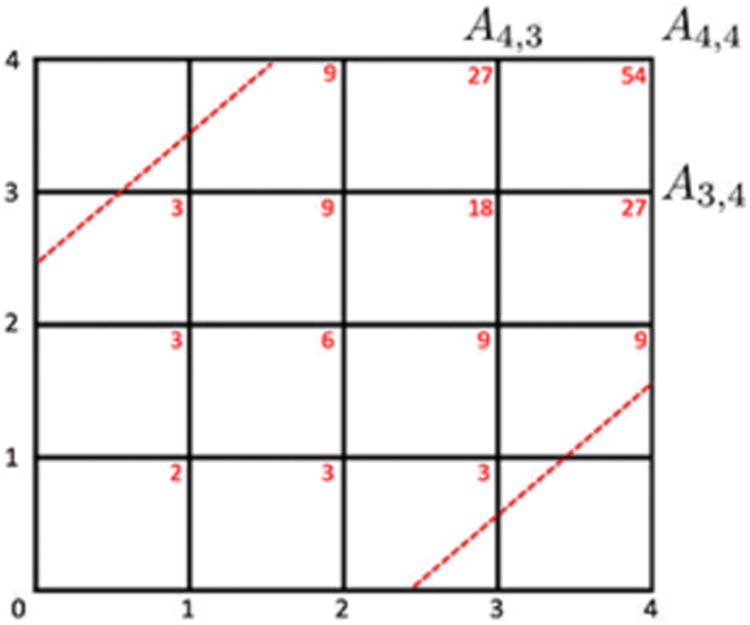
Au,υ are computed within the boundary (dotted red line). The red numbers are the number of paths from (0, 0).
The values of B(G1ρj) and B(G2ρj) satisfying the condition supj |B(G1ρj) – B(G2ρj)| < d are the integer coordinates of (u, υ) on the path satisfying |u – υ| < d. These are integer grid points within the boundary υ = u ± d (dotted red lines in Fig. 2). Thus the probability can be written as
| (9) |
where Au,υ be the total number of passible paths from (0, 0) to (u, υ) within the boundary. Since there are only two paths (either ↑ or →), Au,υ can be computed recursively as
within the boundary. On the boundary A0,q = Aq,0 = 1 since there is only one path.
Theorem 2 provides the exact probability computation for any number of nodes p. For instance, probability P(D4 ≥ 2.5) is computed iteratively as follows. We start with computing A1,1 = A0,1 + A1,0 = 2, A2,1 = A1,1 + A1,0 = 3, …, A4,4 = A4,3 + A3,4 = 27 + 27 = 54 (red numbers in Fig. 2). Thus the probability is . Few other examples that can be computed easily are
Computing Aq,q iteratively requires at most q2 operations while permuting two samples consisting of q elements each requires perations. Thus, our method can compute the p-value exactly substantially faster than the permutation test that is approximate and exponentially slow.
The asymptotic probability distribution of Dq can be also determined for sufficiently large q without computing iteratively as Theorem 2.
Theorem 3
The proof is not given here but the result follows from [8,14]. From Theorem 3, p-value under H0 is computed as
where do is the least integer greater than in the data (Fig. 3-left). For any large observed value d0 ≥ 2, the second term is in the order of 10−14 and insignificant. Even for small observed d0, the expansion converges quickly and 5 terms are sufficient.
Fig. 3.
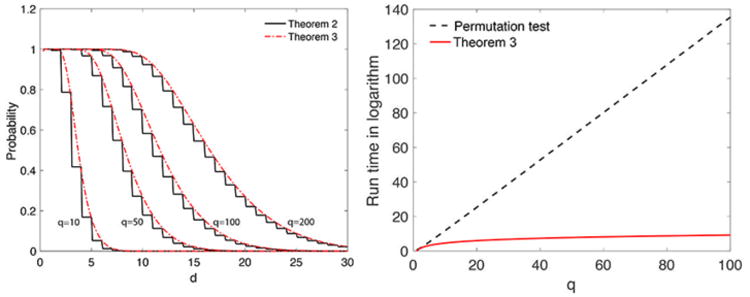
Left: Convergence of Theorem 2 to Theorem 3 for q = 10, 50, 100, 200. Right: Run time of permutation test (dotted black line) vs. the combinational method in Theorem 2 (solid red line) in logarithmic scale.
5 Validation and comparison
The proposed method was validated and compared in two simulation studies against Gromov-Hausdorff (GH) distance. GH-distance was originally used to measure distance between two metric spaces. It was later adapted to measure distances in persistent homology, dendrograms [3] and brain networks [11]. Following [11], the computation of GH-distance is done done on graphs with1-correlation as edge weights. GH-distance is the difference in the L∞-norm of corresponding single linkage matrices.
No network difference
The simulations were performed 1000 times and the average results were reported. There are three groups and the sample size is n = 5 in each group and the number of nodes are p = 40. In Groups I and II, data xk(υi) at each node υi was simulated as standard normal, i.e., xk(υi) ∼ N(0, 1). The paired data was simulated as yk(υi) = xk(υi) + N(0, 0.022) for all the nodes (Fig. 4). Using the proposed combinatorial method, we obtained the p-values of 0.6568 ± 0.3367 and 0.2830 ± 0.3636 for β0 and the size of the largest connected component demonstrating that the method did not detect network differences as expected.
Fig. 4.
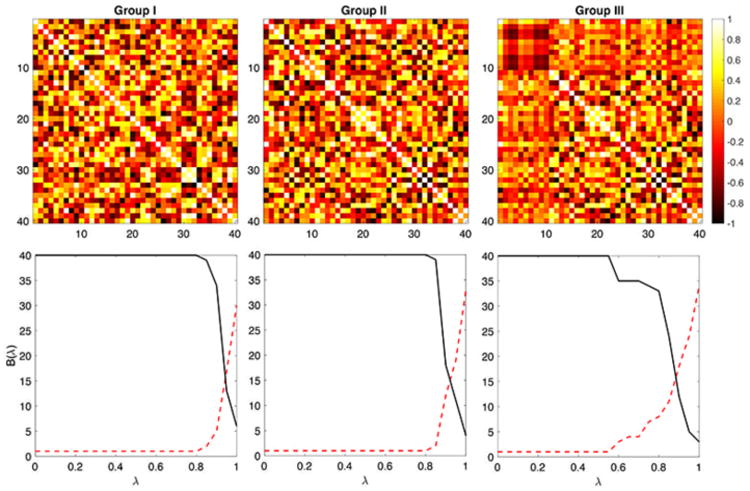
Simulation studies. Group I and Group II are generated independently and identically. The resulting B(λ) plots are similar. The dotted red line is β0 and the solid black line is the size of the largest connected component. No statistically significant differences can be found between Groups I and II. Group III is generated independently but identically as Group I but additional dependency is added for the first 10 nodes (square on the top left corner). The resulting B(λ) plots are statistically different between Groups I and II.
Using GH-distance, we obtained the p-value of 0.4938 ± 0.2919. The p-value was computed using the permutation test. Since there are 5 samples in each group, the total number of permutation is making the permutation test exact and the comparison fair. Both methods seem to perform reasonably well. However, GH-distance method took about 950 seconds (16 minutes) while the combinatorial method took about 20 seconds in a computer.
Network difference
Group III was generated identically and independently like Group I but additional dependency was added by letting yk(υj) = xk(υ1)/2 for ten nodes indexed by j = 1, 2, …, 10. This dependency gives high connectivity differences between Groups I and III (Fig. 4). Using the proposed combinatorial method, we obtained the p-values of 0.0422 ± 0.0908 and 0.0375 ± 0.1056 for β0 and the size of the largest connected component. On the other hand, we obtained 0.1145 ± 0.1376 for GH-distance. The proposed method seems to perform better in the presence of signal. The MATLAB codes for performing these simulations is given in http://www.cs.wisc.edu/∼mchung/twins.
6 Twin fMRI study
The study consists of 11 monozygotic (MZ) and 9 same-sex dizygotic (DZ) twin pairs of 3T functional magnetic resonance images (fMRI) acquired in Intera-Achiava Phillips MRI scanners with a 32 channel SENSE head coil. Subjects completed monetary incentive delay task of 3 runs of 40 trials [10]. A total 120 trials consisting of 40 $0, 40 $1 and 40 $5 rewards were pseudo randomly split into 3 runs.
fMRI data went through spatial normalization to the template following the standard SPM pipeline. The fMRI dimensions after preprocessing are 53 × 63 × 46 and the voxel size is 3mm cube. There are a total of p = 25972 voxels in the template. After fitting a general linear model at each voxel, we obtained the contrast maps testing the significance of activity in the delay period for $5 trials relative to the control condition of $0 reward (Fig. 1). The paired contrast maps were then used as the initial images vectors x and y in the starting model (2).
We are interested in knowing the extent of the genetic influence on the functional brain network of these participants while anticipating the high reward as measured by activity during the delay that occurs between the reward cue and the target, and its statistical significance. The hyper-network approach is applied in extending the voxel-level univariate genetic feature called heritability index (HI) into a network-level multivariate feature. HI determines the amount of variation (in terms of percentage) due to genetic influence in a population. HI is often estimated using Falconer's formula [6] as a baseline. MZ-twins share 100% of genes while DZ-twins share 50% of genes. Thus, the additive genetic factor A, the common environmental factor C for each twin type are related as
| (10) |
| (11) |
where ρMZ and ρDZ are the pairwise correlation between MZ- and and same-sex DZ-twins at voxel υi. Solving (10) and (11), we obtain the additive genetic factor, i.e., HI given by
HI is a univariate feature measured at each voxel and does not quantify how the changes in one voxel is related to other voxels. We can determine HI across voxels υi and υj as
ϱMZ and ϱDZ are the symmetrized cross-correlations between voxels υi and υj for MZ- and DZ-twin pairs:
and are the estimated cross-correlations from model (4). Note that
In Fig. 5-left and -middle, the nodes are ρMZ(υi) and ρDZ(υi) while the edges are ϱMZ(υi, υj) and ϱDZ(υi, υj) for λ = 0.5, 0.8. In Fig. 5-right, we have ℋ(υi) = ℋ(υi, υi). The network visualization shows high HI values for almost everywhere along the edges. We are interested in testing the statistical significance of the estimated HI for all edges. Testing for ℋ(υi, υj) = 0 is equivalent to testing ϱMZ(υi, υj) = ϱDZ(υi, υj). Thus, we test for hyper-network differences between twins using the test statistic Dq (q = 100 is used) (Fig. 6). For β0 and the size of the largest connected component p-values are less than 0.00002 and 0.00001 respectively indicating very strong significance of MZ- and DZ- network difference and HI of the whole brain network.
Fig. 5.
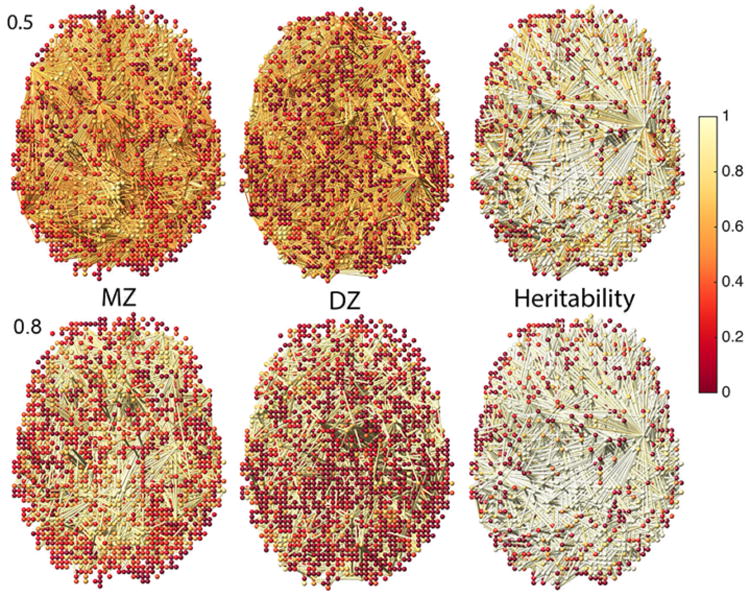
Left, middle: Node colors are correlations of MZ- and DZ-twins. Edge colors are sparse cross-correlations at sparsity λ = 0.5, 0.8. Right: Heritability index (HI) at nodes and edges. MZ-twins show higher correlations compared to DZ-twins. Some low HI nodes show high HI edges. Using only the voxel-level HI feature, we may fail to detect such high-order genetic effects on the functional network.
Fig. 6.
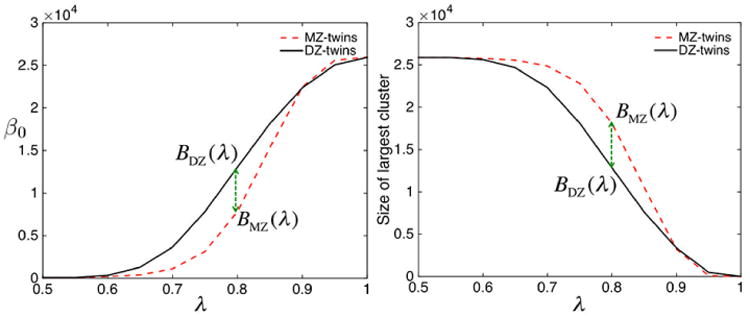
The result of graph filtrations on twin fMRI data. The number of connected components (left) and the size of the largest connected component (right) are plotted over the sparse parameter λ. For each λ, MZ-twins tend to have smaller number of connected components but larger connected component. The dotted green arrow (Dq) where the maximum group separation occurs.
7 Discussion
Hyper-network
In this paper, we presented a unified statistical framework for for analyzing paired images using a hyper-network. Although we applied the framework in twin fMRI, the method can be easily applied to other paired image settings such as longitudinal and multimodal studies. The method can be further extended to triple images. Then we should start with the following hyper-network model
| (12) |
Since we usually have more number of nodes p than the number of images n, it is necessary to introduce two separate sparse parameters in (12). Then, instead of building graph filtration over 1D, we need to build it over 2D sparse parameter space. This is related to multidimensional persistent homology [4,12]. Extending the proposed method to triple image setting is left as a future study.
Exact topological inference
We presented a combinatorial method for computing the probability that avoids time consuming permutation tests. Theorem 2 is the exact nonparametric procedure and does not assume any statistical distribution on graph features other than that they has to be monotonic. The technique is very general and applicable to any monotonic graph features such as node degree. Based on Stirling's formula, , the total number of permutations in permuting two vectors of size q each is . This is substantially larger than the quadratic run time q2 needed in our method (Fig. 3). Even for small q = 10, more than tens of thousands permutations are needed for the accurate estimation the p-value. On the other hand, only up to 100 iterations are needed in our combinatorial method.
Acknowledgments
This work was supported by NIH grants 5 R01 MH098098 04 and EB022856 and NRF grant from Korea (NRF-2016R1D1A1B03935463). We thank Yoonsuck Choe of Texas A&M University and and Daniel Rowe of Marquette University for valuable discussions on permutation tests. We wish to thank anonymous reviewers for valuable comments that improved the revision.
References
- 1.Bezerianos A, Sun Y, Chen Y, Woong KF, Taya F, Arico P, Borghini G, Babiloni F, Thakor N. Cooperation driven coherence: Brains working hard together. 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) 2015:4696–4699. doi: 10.1109/EMBC.2015.7319442. [DOI] [PubMed] [Google Scholar]
- 2.Böhm W, Hornik K. A Kolmogorov-Smirnov test for r samples. Institute for Statistics and Mathematics. 2010;105 Research Report Series:Report. [Google Scholar]
- 3.Carlsson G, Memoli F. Persistent clustering and a theorem of J. Kleinberg. arXiv preprint arXiv:0808.2241. 2008 [Google Scholar]
- 4.Carlsson G, Singh G, Zomorodian A. Computing multidimensional persistence. International Symposium on Algorithms and Computation. 2009:730–739. [Google Scholar]
- 5.Chung MK, Hanson JL, Ye J, Davidson RJ, Pollak SD. Persistent homology in sparse regression and its application to brain morphometry. IEEE Transactions on Medical Imaging. 2015;34:1928–1939. doi: 10.1109/TMI.2015.2416271. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Falconer D, Mackay T. Introduction to Quantitative Genetics, 4th ed. Longman; 1995. [Google Scholar]
- 7.Freeborough PA, Fox NC. Modeling brain deformations in Alzheimer disease by fluid registration of serial 3D MR images. Journal of Computer Assisted Tomography. 1998;22:838–843. doi: 10.1097/00004728-199809000-00031. [DOI] [PubMed] [Google Scholar]
- 8.Gibbons JD, Chakraborti S. Nonparametric Statistical Inference. Chapman & Hall/CRC Press; 2011. [Google Scholar]
- 9.Jie B, Shen D, Zhang D. Brain connectivity hyper-network for MCI classification; International Conference on Medical Image Computing and Computer-Assisted Intervention; 2014. pp. 724–732. [DOI] [PubMed] [Google Scholar]
- 10.Knutson B, Adams CM, Fong GW, Hommer D. Anticipation of increasing monetary reward selectively recruits nucleus accumbens. Journal of Neuroscience. 2001;21:RC159. doi: 10.1523/JNEUROSCI.21-16-j0002.2001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Lee H, Chung MK, Kang H, Kim BN, Lee DS. Computing the shape of brain networks using graph filtration and Gromov-Hausdorff metric. MICCAI, Lecture Notes in Computer Science. 2011;6892:302–309. doi: 10.1007/978-3-642-23629-7_37. [DOI] [PubMed] [Google Scholar]
- 12.Lee H, Kang H, Chung MK, Lim S, Kim BN, Lee DS. Integrated multimodal network approach to PET and MRI based on multidimensional persistent homology. Human Brain Mapping. 2017;38:1387–1402. doi: 10.1002/hbm.23461. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Pichler Bernd J, Kolb Armin, Nägele Thomas, Schlemmer HeinzPeter. Pet/mri: paving the way for the next generation of clinical multimodality imaging applications. Journal of Nuclear Medicine. 51:333–336. doi: 10.2967/jnumed.109.061853. [DOI] [PubMed] [Google Scholar]
- 14.Smirnov NV. Estimate of deviation between empirical distribution functions in two independent samples. Bulletin of Moscow University. 1939;2:3–16. [Google Scholar]
- 15.Thompson PM, Cannon TD, Narr KL, van Erp T, Poutanen VP, Huttunen M, Lonnqvist J, Standertskjold-Nordenstam CG, Kaprio J, Khaledy M. Genetic influences on brain structure. Nature Neuroscience. 2001;4:1253–1258. doi: 10.1038/nn758. [DOI] [PubMed] [Google Scholar]
- 16.Zhang BT. Hypernetworks: A molecular evolutionary architecture for cognitive learning and memory. IEEE Computational Intelligence Magazine. 2008;3:49–63. [Google Scholar]