

Abstract
Recurrent neural networks (RNNs) process input text sequentially and model the conditional transition between word tokens. In contrast, the advantages of recursive networks include that they explicitly model the compositionality and the recursive structure of natural language. However, the current recursive architecture is limited by its dependence on syntactic tree. In this paper, we introduce a robust syntactic parsing-independent tree structured model, Neural Tree Indexers (NTI) that provides a middle ground between the sequential RNNs and the syntactic tree-based recursive models. NTI constructs a full n-ary tree by processing the input text with its node function in a bottom-up fashion. Attention mechanism can then be applied to both structure and node function. We implemented and evaluated a binary-tree model of NTI, showing the model achieved the state-of-the-art performance on three different NLP tasks: natural language inference, answer sentence selection, and sentence classification, outperforming state-of-the-art recurrent and recursive neural networks 1.
1 Introduction
Recurrent neural networks (RNNs) have been successful for modeling sequence data (Elman, 1990). RNNs equipped with gated hidden units and internal short-term memories, such as long short-term memories (LSTM) (Hochreiter and Schmidhuber, 1997) have achieved a notable success in several NLP tasks including named entity recognition (Lample et al., 2016), constituency parsing (Vinyals et al., 2015), textual entailment recognition (Rocktäschel et al., 2016), question answering (Hermann et al., 2015), and machine translation (Bahdanau et al., 2015). However, most LSTM models explored so far are sequential. It encodes text sequentially from left to right or vice versa and do not naturally support compositionality of language. Sequential LSTM models seem to learn syntactic structure from the natural language however their generalization on unseen text is relatively poor comparing with models that exploit syntactic tree structure (Bowman et al., 2015b).
Unlike sequential models, recursive neural networks compose word phrases over syntactic tree structure and have shown improved performance in sentiment analysis (Socher et al., 2013). However its dependence on a syntactic tree architecture limits practical NLP applications. In this study, we introduce Neural Tree Indexers (NTI), a class of tree structured models for NLP tasks. NTI takes a sequence of tokens and produces its representation by constructing a full n-ary tree in a bottom-up fashion. Each node in NTI is associated with one of the node transformation functions: leaf node mapping and non-leaf node composition functions. Unlike previous recursive models, the tree structure for NTI is relaxed, i.e., NTI does not require the input sequences to be parsed syntactically; and therefore it is flexible and can be directly applied to a wide range of NLP tasks beyond sentence modeling.
Furthermore, we propose different variants of node composition function and attention over tree for our NTI models. When a sequential leaf node transformer such as LSTM is chosen, the NTI network forms a sequence-tree hybrid model taking advantage of both conditional and compositional powers of sequential and recursive models. Figure 1 shows a binary-tree model of NTI. Although the model does not follow the syntactic tree structure, we empirically show that it achieved the state-of-the-art performance on three different NLP applications: natural language inference, answer sentence selection, and sentence classification.
Figure 1.

A binary tree form of Neural Tree Indexers (NTI) in the context of question answering and natural language inference. We insert empty tokens (denoted by –) to the input text to form a full binary tree. (a) NTI produces answer representation at the root node. This representation along with the question is used to find the answer. (b) NTI learns representations for the premise and hypothesis sentences and then attentively combines them for classification. Dotted lines indicate attention over premise-indexed tree.
2 Related Work
2.1 Recurrent Neural Networks and Attention Mechanism
RNNs model input text sequentially by taking a single token at each time step and producing a corresponding hidden state. The hidden state is then passed along through the next time step to provide historical sequence information. Although a great success in a variety of tasks, RNNs have limitations (Bengio et al., 1994; Hochreiter, 1998). Among them, it is not efficient at memorizing long or distant sequence (Sutskever et al., 2014). This is frequently called as information flow bottleneck. Approaches have therefore been developed to overcome the limitations. For example, to mitigate the information flow bottleneck, Bahdanau et al. (2015) extended RNNs with a soft attention mechanism in the context of neural machine translation, leading to improved the results in translating longer sentences.
RNNs are linear chain-structured; this limits its potential for natural language which can be represented by complex structures including syntactic structure. In this study, we propose models to mitigate this limitation.
2.2 Recursive Neural Networks
Unlike RNNs, recursive neural networks explicitly model the compositionality and the recursive structure of natural language over tree. The tree structure can be predefined by a syntactic parser (Socher et al., 2013). Each non-leaf tree node is associated with a node composition function which combines its children nodes and produces its own representation. The model is then trained by back-propagating error through structures (Goller and Kuchler, 1996).
The node composition function can be varied. A single layer network with tanh non-linearity was adopted in recursive auto-associate memories (Pollack, 1990) and recursive autoencoders (Socher et al., 2011). Socher et al. (2012) extended this network with an additional matrix representation for each node to augment the expressive power of the model. Tensor networks have also been used as composition function for sentence-level sentiment analysis task (Socher et al., 2013). Recently, Zhu et al. (2015) introduced S-LSTM which extends LSTM units to compose tree nodes in a recursive fashion.
In this paper, we introduce a novel attentive node composition function that is based on S-LSTM. Our NTI model does not rely on either a parser output or a fine-grained supervision of non-leaf nodes, both required in previous work. In NTI, the supervision from the target labels is provided at the root node. As such, our NTI model is robust and applicable to a wide range of NLP tasks. We introduce attention over tree in NTI to overcome the vanishing/explode gradients challenges as shown in RNNs.
3 Methods
Our training set consists of N examples , where the input Xi is a sequence of word tokens and the output Yi can be either a single target or a sequence. Each input word token wt is represented by its word embedding xt ∈ Rk.
NTI is a full n-ary tree (and the sub-trees can be overlapped). It has two types of transformation function: non-leaf node function fnode(h1, …, hc) and leaf node function fleaf (xt). fleaf (xt) computes a (possibly nonlinear) transformation of the input word embedding xt. fnode(h1, …, hc) is a function of its child nodes representation h1, …, hc, where c is the total number of child nodes of this non-leaf node.
NTI can be implemented with different tree structures. In this study we implemented and evaluated a binary tree form of NTI: a non-leaf node can take in only two direct child nodes (i.e., c = 2). Therefore, the function fnode(hl, hr) composes its left child node hl and right child node hr. Figure 1 illustrates our NTI model that is applied to question answering (a) and natural language inference tasks (b). Note that the node and leaf node functions are neural networks and are the only training parameters in NTI.
We explored two different approaches to compose node representations: an extended LSTM and attentive node composition functions, to be described below.
3.1 Non-Leaf Node Composition Functions
We define two different methods for non-leaf node function fnode(hl, hr).
LSTM-based Non-leaf Node Function (S-LSTM)
We initiate fnode(hl, hr) with LSTM. For non-leaf node, we adopt S-LSTM Zhu et al. (2015), an extension of LSTM to tree structures, to learn a node representation by its children nodes. Let and be vector representations and cell states for the left and right children. An S-LSTM computes a parent node representation and a node cell state as
| (1) |
| (2) |
| (3) |
| (4) |
| (5) |
| (6) |
where and biases (for brevity we eliminated the bias terms) are the training parameters. σ and ⊙ denote the element-wise sigmoid function and the element-wise vector multiplication. Extension of S-LSTM non-leaf node function to compose more children is straightforward. However, the number of parameters increases quadratically in S-LSTM as we add more child nodes.
Attentive Non-leaf Node Function (ANF)
Some NLP applications (e.g., QA and machine translation) would benefit from a dynamic query dependent composition function. We introduce ANF as a new non-leaf node function. Unlike S-LSTM, ANF composes the child nodes attentively in respect to another relevant input vector q ∈ Rk. The input vector q can be a learnable representation from a sequence representation. Given a matrix SANF ∈ Rk×2 resulted by concatenating the child node representations and the third input vector q, ANF is defined as
| (7) |
| (8) |
| (9) |
| (10) |
where is a learnable matrix, m ∈ R2 the attention score and α ∈ R2 the attention weight vector for each child. fscore is an attention scoring function, which can be implemented as a multi-layer perceptron (MLP)
| (11) |
or a matrix-vector product m = q⊤SANF. The matrices and and the vector w ∈ Rk are training parameters. e ∈ R2 is a vector of ones and ⊗ the outer product. We use ReLU function for non-linear transformation.
3.2 Attention Over Tree
Comparing with sequential LSTM models, NTI has less recurrence, which is defined by the tree depth, log(n) for binary tree where n is the length of the input sequence. However, NTI still needs to compress all the input information into a single representation vector of the root. This imposes practical difficulties when processing long sequences. We address this issue with attention mechanism over tree. In addition, the attention mechanism can be used for matching trees (described in Section 4 as Tree matching NTI) that carry different sequence information. We first define a global attention and then introduce a tree attention which considers the parent-child dependency for calculation of the attention weights.
Global Attention
An attention neural network for the global attention takes all node representations as input and produces an attentively blended vector for the whole tree. This neural net is similar to ANF. Particularly, given a matrix SGA ∈ Rk×2n−1 resulted by concatenating the node representations h1, …, h2n−1 and the relevant input representation q, the global attention is defined as
| (12) |
| (13) |
| (14) |
| (15) |
where and are training parameters and α ∈ R2n−1 the attention weight vector for each node. This attention mechanism is robust as it globally normalizes the attention score m with softmax to obtain the weights α. However, it does not consider the tree structure when producing the final representation htree.
Tree Attention
We modify the global attention network to the tree attention mechanism. The resulting tree attention network performs almost the same computation as ANF for each node. It compares the parent and children nodes to produce a new representation assuming that all node representations are constructed. Given a matrix STA ∈ Rk×3 resulted by concatenating the parent node representation , the left child and the right child and the relevant input representation q, every non-leaf node simply updates its own representation by using the following equation in a bottom-up manner.
| (16) |
| (17) |
| (18) |
| (19) |
and this equation is similarity to the global attention. However, now each non-leaf node attentively collects its own and children representations and passes towards the root which finally constructs the attentively blended tree representation. Note that unlike the global attention, the tree attention locally normalizes the attention scores with softmax.
4 Experiments
We describe in this section experiments on three different NLP tasks, natural language inference, question answering and sentence classification to demonstrate the flexibility and the effectiveness of NTI in the different settings.
We trained NTI using Adam (Kingma and Ba, 2014) with hyperparameters selected on development set. The pre-trained 300-D Glove 840B vectors (Pennington et al., 2014) were obtained for the word embeddings2. The word embeddings are fixed during training. The embeddings for out-of-vocabulary words were set to zero vector. We pad the input sequence to form a full binary tree. A padding vector was inserted when padding. We analyzed the effects of the padding size and found out that it has no influence on the performance (see Appendix 5.3). The size of hidden units of the NTI modules were set to 300. The models were regularized by using dropouts and an l2 weight decay.3
4.1 Natural Language Inference
We conducted experiments on the Stanford Natural Language Inference (SNLI) dataset (Bowman et al., 2015a), which consists of 549,367/9,842/9,824 premise-hypothesis pairs for train/dev/test sets and target label indicating their relation. Unless otherwise noted, we follow the setting in the previous work (Mou et al., 2016; Bowman et al., 2016) and use an MLP for classification which takes in NTI outputs and computes the concatenation [ ], absolute difference and elementwise product of the two sentence representations. The MLP has also an input layer with 1024 units with ReLU activation and a softmax output layer. We explored nine different task-oriented NTI models with varying complexity, to be described below. For each model, we set the batch size to 32. The initial learning, the regularization strength and the number of epoch to be trained are varied for each model.
NTI-SLSTM
This model does not rely on fleaf transformer but uses the S-LSTM units for the non-leaf node function. We set the initial learning rate to 1e-3 and l2 regularizer strength to 3e–5, and train the model for 90 epochs. The neural net was regularized by 10% input dropouts and the 20% output dropouts.
NTI-SLSTM-LSTM
We use LSTM for the leaf node function fleaf. Concretely, the LSTM output vectors are given to NTI-SLSTM and the memory cells of the lowest level S-LSTM were initialized with the LSTM memory states. The hyper-parameters are the same as the previous
NTI-SLSTM node-by-node global attention
This model learns inter-sentence relation with the global attention over premise-indexed tree, which is similar to word-by-word attention model of Rocktäschel et al. (2016) in that it attends over the premise tree nodes at every time step of hypothesis encoding. We tie the weight parameters of the two NTI-SLSTMs for premise and hypothesis and no fleaf transformer used. We set the initial learning rate to 3e–4 and l2 regularizer strength to 1e–5, and train the model for 40 epochs. The neural net was regularized by 15% input dropouts and the 15% output dropouts.
NTI-SLSTM node-by-node tree attention
This is a variation of the previous model with the tree attention. The hyper-parameters are the same as the previous model.
NTI-SLSTM-LSTM node-by-node global attention
In this model we include LSTM as the leaf node function fleaf. Here we initialize the memory cell of S-LSTM with LSTM memory and hidden/memory state of hypothesis LSTM with premise LSTM (the later follows the work of (Rocktäschel et al., 2016)). We set the initial learning rate to 3e–4 and l2 regularizer strength to 1e–5, and train the model for 10 epochs. The neural net was regularized by 10% input dropouts and the 15% output dropouts.
NTI-SLSTM-LSTM node-by-node tree attention
This is a variation of the previous model with the tree attention. The hyper-parameters are the same as the previous model.
Tree matching NTI-SLSTM-LSTM global attention
This model first constructs the premise and hypothesis trees simultaneously with the NTI-SLSTM-LSTM model and then computes their matching vector by using the global attention and an additional LSTM. The attention vectors are produced at each hypothesis tree node and then are given to the LSTM model sequentially. The LSTM model compress the attention vectors and outputs a single matching vector, which is passed to an MLP for classification. The MLP for this tree matching setting has an input layer with 1024 units with ReLU activation and a softmax output layer.
Unlike Wang and Jiang (2016)’s matching LSTM model which is specific to matching sequences, we use the standard LSTM units and match trees. We set the initial learning rate to 3e–4 and l2 regularizer strength to 3e–5, and train the model for 20 epochs. The neural net was regularized by 20% input dropouts and the 20% output dropouts.
Tree matching NTI-SLSTM-LSTM tree attention
We replace the global attention with the tree attention. The hyper-parameters are the same as the previous model.
Full tree matching NTI-SLSTM-LSTM global attention
This model produces two sets of the attention vectors, one by attending over the premise tree regarding each hypothesis tree node and another by attending over the hypothesis tree regarding each premise tree node. Each set of the attention vectors is given to a LSTM model to achieve full tree matching. The last hidden states of the two LSTM models (i.e. one for each attention vector set) are concatenated for classification. The training weights are shared among the LSTM models The hyper-parameters are the same as the previous model.4
Table 1 shows the results of our models. For comparison, we include the results from the published state-of-the-art systems. While most of the sentence encoder models rely solely on word embeddings, the dependency tree CNN and the SPINN-PI models make use of sentence parser output; which present strong baseline systems. The last set of methods designs inter-sentence relation with soft attention (Bahdanau et al., 2015). Our best score on this task is 87.3% accuracy obtained with the full tree matching NTI model. The previous best performing model on the task performs phrase matching by using the attention mechanism.
Table 1.
Training and test accuracy on natural language inference task. d is the word embedding size and |θ|M the number of model parameters.
| Model | d | |θ|M | Train | Test |
|---|---|---|---|---|
|
| ||||
| Classifier with handcrafted features (Bowman et al., 2015a) | - | - | 99.7 | 78.2 |
|
| ||||
| LSTMs encoders (Bowman et al., 2015a) | 300 | 3.0M | 83.9 | 80.6 |
| Dependency Tree CNN encoders (Mou et al., 2016) | 300 | 3.5M | 83.3 | 82.1 |
| NTI-SLSTM (Ours) | 300 | 3.3M | 83.9 | 82.4 |
| SPINN-PI encoders (Bowman et al., 2016) | 300 | 3.7M | 89.2 | 83.2 |
| NTI-SLSTM-LSTM (Ours) | 300 | 4.0M | 82.5 | 83.4 |
|
| ||||
| LSTMs attention (Rocktäschel et al., 2016) | 100 | 242K | 85.4 | 82.3 |
| LSTMs word-by-word attention (Rocktäschel et al., 2016) | 100 | 250K | 85.3 | 83.5 |
| NTI-SLSTM node-by-node global attention (Ours) | 300 | 3.5M | 85.0 | 84.2 |
| NTI-SLSTM node-by-node tree attention (Ours) | 300 | 3.5M | 86.0 | 84.3 |
| NTI-SLSTM-LSTM node-by-node tree attention (Ours) | 300 | 4.2M | 88.1 | 85.7 |
| NTI-SLSTM-LSTM node-by-node global attention (Ours) | 300 | 4.2M | 87.6 | 85.9 |
| mLSTM word-by-word attention (Wang and Jiang, 2016) | 300 | 1.9M | 92.0 | 86.1 |
| LSTMN with deep attention fusion (Cheng et al., 2016) | 450 | 3.4M | 88.5 | 86.3 |
| Tree matching NTI-SLSTM-LSTM tree attention (Ours) | 300 | 3.2M | 87.3 | 86.4 |
| Decomposable Attention Model (Parikh et al., 2016) | 200 | 580K | 90.5 | 86.8 |
| Tree matching NTI-SLSTM-LSTM global attention (Ours) | 300 | 3.2M | 87.6 | 87.1 |
| Full tree matching NTI-SLSTM-LSTM global attention (Ours) | 300 | 3.2M | 88.5 | 87.3 |
Our results show that NTI-SLSTM improved the performance of the sequential LSTM encoder by approximately 2%. Not surprisingly, using LSTM as leaf node function helps in learning better representations. Our NTI-SLSTM-LSTM is a hybrid model which encodes a sequence sequentially through its leaf node function and then hierarchically composes the output representations. The node-by-node attention models improve the performance, indicating that modeling inter-sentence interaction is an important element in NLI. Aggregating matching vector between trees or sequences with a separate LSTM model is effective. The global attention seems to be robust on this task. The tree attention were not helpful as it normalizes the attention scores locally in parent-child relationship.
4.2 Answer Sentence Selection
For this task, a model is trained to identify the correct sentences that answer a factual question, from a set of candidate sentences. We experiment on WikiQA dataset constructed from Wikipedia (Yang et al., 2015). The dataset contains 20,360/2,733/6,165 QA pairs for train/dev/test sets.
We used the same setup in the language inference task except that we replace the softmax layer with a sigmoid layer and model the following conditional probability distribution.
| (20) |
where and are the question and the answer encoded vectors and oQA denotes the output of the hidden layer of the MLP. For this task, we use NTI-SLSTM-LSTM to encode answer candidate sentences and NTI-ANF-LSTM to encode the question sentences. Note that NTI-ANF-LSTM is relied on ANF as the non-leaf node function. q vector for NTI-ANF-LSTM is the answer representation produced by the answer encoding NTI-SLSTM-LSTM model. We set the batch size to 4 and the initial learning rate to 1e–3, and train the model for 10 epochs. We used 20% input dropouts and no l2 weight decay. Following previous work, we adopt MAP and MRR as the evaluation metrics for this task.5
Table 2 presents the results of our model and the previous models for the task.6 The classifier with handcrafted features is a SVM model trained with a set of features. The Bigram-CNN model is a simple convolutional neural net. The Deep LSTM and LSTM attention models outperform the previous best result by a large margin, nearly 5–6%. NASM improves the result further and sets a strong baseline by combining variational autoencoder (Kingma and Welling, 2014) with the soft attention. In NASM, they adopt a deep three-layer LSTM and introduced a latent stochastic attention mechanism over the answer sentence. Our NTI model exceeds NASM by approximately 0.4% on MAP for this task.
Table 2.
Test set performance on answer sentence selection.
| Model | MAP | MRR |
|---|---|---|
|
| ||
| Classifier with features (2013) | 0.5993 | 0.6068 |
|
| ||
| Paragraph Vector (2014) | 0.5110 | 0.5160 |
| Bigram-CNN (2014) | 0.6190 | 0.6281 |
| 3-layer LSTM (2016) | 0.6552 | 0.6747 |
| 3-layer LSTM attention (2016) | 0.6639 | 0.6828 |
| NASM (2016) | 0.6705 | 0.6914 |
| NTI (Ours) | 0.6742 | 0.6884 |
4.3 Sentence Classification
Lastly, we evaluated NTI on the Stanford Sentiment Treebank (SST) (Socher et al., 2013). This dataset comes with standard train/dev/test sets and two subtasks: binary sentence classification or fine-grained classification of five classes. We trained our model on the text spans corresponding to labeled phrases in the training set and evaluated the model on the full sentences.
We use NTI-SLSTM and NTI-SLSTM-LSTM models to learn sentence representations for the task. The sentence representations were passed to a two-layer MLP for classification. We set the batch size to 64, the initial learning rate to 1e–3 and l2 regularizer strength to 3e–5, and train each model for 10 epochs. The NTI-SLSTM model was regularized by 10%/20% of input/output and 20%/30% of input/output dropouts and the NTI-SLSTM-LSTM model 20% of input and 20%/30% of input/output dropouts for binary and fine-grained settings.
NTI-SLSTM-LSTM (as shown in Table 5) set the state-of-the-art results on both subtasks. Our NTI-SLSTM model performed slightly worse than its constituency tree-based counter part, CT-LSTM model. The CT-LSTM model composes phrases according to the output of a sentence parser and uses a node composition function similar to S-LSTM. After we transformed the input with the LSTM leaf node function, we achieved the best performance on this task.
Table 5.
Nearest-neighbor sentences based on cosine similarity between learned representations.
| A dog mouth holds a retrieved ball. | A cat nurses puppies. | A dog sells a woman a hat. |
|---|---|---|
|
| ||
| A brown and white dog holds a tennis ball in his mouth. | A golden retriever nurses some other dogs puppies. | The dog is a labrador retriever. |
| The dog has a ball. | A golden retriever nurses puppies. | A girl is petting her dog. |
| The dogs are chasing a ball. | A mother dog checking up on her baby puppy. | The dog is a shitzu. |
| A small dog runs to catch a ball. | A girl is petting her dog. | A husband and wife making pizza. |
| The puppy is chasing a ball. | The hat wearing girl is petting a cat. | The dog is a chihuahua. |
5 Qualitative Analysis
5.1 Attention and Compositionality
To help analyzing the results, we output attention weights by our NTI-SLSTM node-by-node global attention model. Figure 2 shows the attention heatmaps for two sentences in the SNLI test set. It shows that our model semantically aligns single or multiword expressions (“little child” and “toddler”; “rock wall” and “stone”). In addition, our model is able to re-orient its attention over different parts of the hypothesis when the expression is more complex. For example, for (c) “rock wall in autumn”, NTI mostly focuses on the nodes in depth 1, 2 and 3 representing contexts related to “a stone”, “leaves.” and “a stone wall surrounded”. Surprisingly, attention degree for the single word expression like “stone”, “wall” and “leaves” is lower to compare with multiword phrases. Sequence models lack this property as they have no explicit composition module to produce such mutiword phrases.
Figure 2.

Node-by-node attention visualizations. The phrases shown on the top are nodes from hypothesis-indexed tree and the premise tokens are listed along the x-axis. The adjacent cells are composed in the top cell representing a binary tree and resulting a longer attention span.
Finally, the most interesting pattern is that the model attends over higher level (low depth) tree nodes with rich semantics when considering a (c) longer phrase or (d) full sentence. As shown in (d), the NTI model aligns the root node representing the whole hypothesis sentence to the higher level tree nodes covering larger sub-trees in the premise. It certainly ignores the lower level single word expressions and only starts to attend when the words are collectively to form rich semantics.
5.2 Learned Representations of Phrases and Sentences
Using cosine similarity between their representations produced by the NTI-SLSTM model, we show that NTI is able to capture paraphrases on SNLI test data. As shown in Table 4, NTI seems to distinguish plural from singular forms (similar phrases to “a person”). In addition, NTI captures non-surface knowledge. For example, the phrases similar to “park for fun” tend to align to the semantic content of fun and park, including “people play frisbee outdoors”. The NTI model was able to relate “Santa Claus” to christmas and snow. Interestingly, the learned representations were also able to connect implicit semantics. For example, NTI found that “sad, depressed, and hatred” is close to the phrases like “an Obama supporter is upset”. Overall the NTI model is robust to the length of the phrases being matched. Given a short phrase, NTI can retrieve longer yet semantically coherent sequences from the SNLI test set.
Table 4.
Nearest-neighbor phrases based on cosine similarity between learned representations.
| a person | park for fun | Santa Claus | sad, depressed, and hatred |
|---|---|---|---|
|
| |||
| single person | an outdoor concert at the park | a snowmobile in a blizzard | an Obama supporter is upset |
| a woman | kids playing at a park outside | a Skier ski - jumping | but doesn’t have any money |
| a young person | a mom takes a break in a park | A skier preparing a trick | crying because he didn’t get cake |
| a guy | people play frisbee outdoors | a child is playing on christmas | trying his hardest to not fall off |
| a single human | takes his lunch break in the park | two men play with a snowman | is upset and crying on the ground |
In Table 5, we show nearest-neighbor sentences from SNLI test set. Note that the sentences listed in the first two columns sound semantically coherent but not the ones in the last column. The query sentence “A dog sells a women a hat” does not actually represent a common-sense knowledge and this sentence now seem to confuse the NTI model. As a result, the retrieved sentence are arbitrary and not coherent.
5.3 Effects of Padding Size
We introduced a special padding character in order to construct full binary tree. Does this padding character influence the performance of the NTI models? In Figure 3, we show relationship between the padding size and the accuracy on Stanford sentiment analysis data. Each sentence was padded to form a full binary tree. The x-axis represents the number of padding characters introduced. When the padding size is less (up to 10), the NTI-SLSTM-LSTM model performs better. However, this model tends to perform poorly or equally when the padding size is large. Overall we do not observe any significant performance drop for both models as the padding size increases. This suggests that NTI learns to ignore the special padding character while processing padded sentences. The same scenario was also observed while analyzing attention weights. The attention over the padded nodes was nearly zero.
Figure 3.
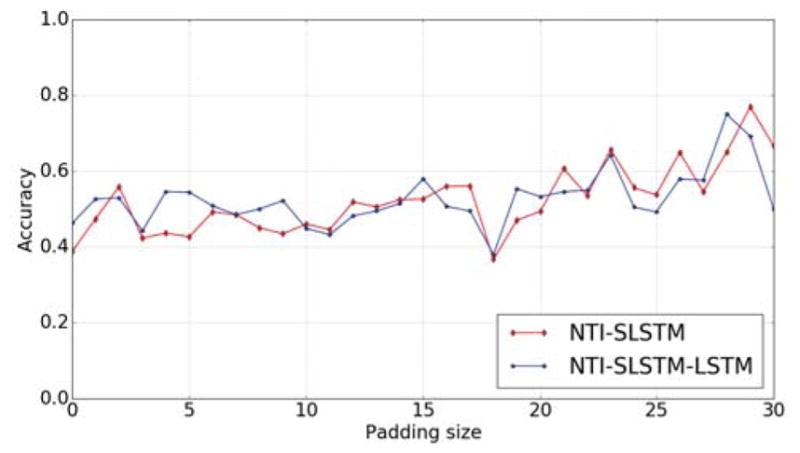
Fine-grained sentiment classification accuracy vs. padding size on test set of SST data.
6 Discussion and Conclusion
We introduced Neural Tree Indexers, a class of tree structured recursive neural network. The NTI models achieved state-of-the-art performance on different NLP tasks. Most of the NTI models form deep neural networks and we think this is one reason that NTI works well even if it lacks direct linguistic motivations followed by other syntactic-tree-structured recursive models (Socher et al., 2013).
CNN and NTI are topologically related (Kalchbrenner and Blunsom, 2013). Both NTI and CNNs are hierarchical. However, current implementation of NTI only operates on non-overlapping sub-trees while CNNs can slide over the input to produce higher-level representations. NTI is flexible in selecting the node function and the attention mechanism. Like CNN, the computation in the same tree-depth can be parallelized effectively; and therefore NTI is scalable and suitable for large-scale sequence processing. Note that NTI can be seen as a generalization of LSTM. If we construct left-branching trees in a bottom-up fashion, the model acts just like sequential LSTM. Different branching factors for the underlying tree structure have yet to be explored. NTI can be extended so it learns to select and compose dynamic number of nodes for efficiency, essentially discovering intrinsic hierarchical structure in the input.
Table 3.
Test accuracy for sentence classification. Bin: binary, FG: fine-grained 5 classes.
| Model | Bin | FG |
|---|---|---|
|
| ||
| RNTN (Socher et al., 2013) | 85.4 | 45.7 |
| CNN-MC (Kim, 2014) | 88.1 | 47.4 |
| DRNN (Irsoy and Cardie, 2015) | 86.6 | 49.8 |
| 2-layer LSTM (Tai et al., 2015) | 86.3 | 46.0 |
| Bi-LSTM (Tai et al., 2015) | 87.5 | 49.1 |
| NTI-SLSTM (Ours) | 87.8 | 50.5 |
| CT-LSTM (Tai et al., 2015) | 88.0 | 51.0 |
| DMN (Kumar et al., 2016) | 88.6 | 52.1 |
| NTI-SLSTM-LSTM (Ours) | 89.3 | 53.1 |
Acknowledgments
We would like to thank the anonymous reviewers for their insightful comments and suggestions. This work was supported in part by the grant HL125089 from the National Institutes of Health (NIH). Any opinions, findings and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect those of the sponsor.
Footnotes
Code for the experiments and NTI is available at https://bitbucket.org/tsendeemts/nti
More detail on hyper-parameters can be found in code. model.
Computational constraint prevented us from experimenting the tree attention variant of this model
We used trec eval script to calculate the evaluation metrics
Inclusion of simple word count feature improves the performance by around 0.15–0.3 across the board
References
- Bahdanau Dzmitry, Cho Kyunghyun, Bengio Yoshua. Neural machine translation by jointly learning to align and translate. ICLR 2015 2015 [Google Scholar]
- Bengio Yoshua, Simard Patrice, Frasconi Paolo. Learning long-term dependencies with gradient descent is difficult. Neural Networks, IEEE Transactions on. 1994;5(2):157–166. doi: 10.1109/72.279181. [DOI] [PubMed] [Google Scholar]
- Bowman Samuel R, Angeli Gabor, Potts Christopher, Manning Christopher D. A large annotated corpus for learning natural language inference. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing; Lisbon, Portugal. September; Association for Computational Linguistics; 2015a. pp. 632–642. [Google Scholar]
- Bowman Samuel R, Manning Christopher D, Potts Christopher. Tree-structured composition in neural networks without tree-structured architectures. Proceedings of the 2015 NIPS Workshop on Cognitive Computation: Integrating Neural and Symbolic Approaches-Volume 1583; 2015b. pp. 37–42. [Google Scholar]
- Bowman Samuel R, Gauthier Jon, Rastogi Abhinav, Gupta Raghav, Manning Christopher D, Potts Christopher. A fast unified model for parsing and sentence understanding. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Berlin, Germany. August; Association for Computational Linguistics; 2016. pp. 1466–1477. [Google Scholar]
- Cheng Jianpeng, Dong Li, Lapata Mirella. Long short-term memory-networks for machine reading. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing; Austin, Texas. November; Association for Computational Linguistics; 2016. pp. 551–561. [Google Scholar]
- Elman Jeffrey L. Finding structure in time. Cognitive science. 1990;14(2):179–211. [Google Scholar]
- Goller Christoph, Kuchler Andreas. Learning task-dependent distributed representations by backpropagation through structure. Neural Networks, 1996., IEEE International Conference on; IEEE; 1996. pp. 347–352. [Google Scholar]
- Hermann Karl Moritz, Kocisky Tomas, Grefenstette Edward, Espeholt Lasse, Kay Will, Suleyman Mustafa, Blunsom Phil. Teaching machines to read and comprehend. NIPS 2015 2015 [Google Scholar]
- Hochreiter Sepp, Schmidhuber Jürgen. Long short-term memory. Neural computation. 1997;9(8):1735–1780. doi: 10.1162/neco.1997.9.8.1735. [DOI] [PubMed] [Google Scholar]
- Hochreiter Sepp. The vanishing gradient problem during learning recurrent neural nets and problem solutions. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems. 1998;6(02):107–116. [Google Scholar]
- Irsoy Ozan, Cardie Claire. Modeling compositionality with multiplicative recurrent neural networks. ICLR 2015 2015 [Google Scholar]
- Kalchbrenner Nal, Blunsom Phil. Recurrent continuous translation models. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics; 2013. pp. 1700–1709. [Google Scholar]
- Kim Yoon. Convolutional neural networks for sentence classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP); Doha, Qatar. October; Association for Computational Linguistics; 2014. pp. 1746–1751. [Google Scholar]
- Kingma Diederik, Ba Jimmy. Adam: A method for stochastic optimization. ICLR 2014 2014 [Google Scholar]
- Kingma Diederik P, Welling Max. Autoencoding variational bayes. ICLR 2014 2014 [Google Scholar]
- Kumar Ankit, Irsoy Ozan, Su Jonathan, Bradbury James, English Robert, Pierce Brian, Ondruska Peter, Gulrajani Ishaan, Socher Richard. Ask me anything: Dynamic memory networks for natural language processing. Proceedings of The 33rd International Conference on Machine Learning (ICML 2016); New York, NY, USA. June.2016. pp. 1378–1387. [Google Scholar]
- Lample Guillaume, Ballesteros Miguel, Subramanian Sandeep, Kawakami Kazuya, Dyer Chris. Neural architectures for named entity recognition. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; San Diego, California. June; Association for Computational Linguistics; 2016. pp. 260–270. [Google Scholar]
- Le Quoc V, Mikolov Tomas. Distributed representations of sentences and documents. ICML 2014. 2014;14:1188–1196. [Google Scholar]
- Miao Yishu, Yu Lei, Blunsom Phil. Neural variational inference for text processing. ICLR 2016 2016 [Google Scholar]
- Mou Lili, Men Rui, Li Ge, Xu Yan, Zhang Lu, Yan Rui, Jin Zhi. Natural language inference by tree-based convolution and heuristic matching. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers); Berlin, Germany. August; Association for Computational Linguistics; 2016. pp. 130–136. [Google Scholar]
- Parikh Ankur, Täckström Oscar, Das Dipanjan, Uszkoreit Jakob. A decomposable attention model for natural language inference. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing; Austin, Texas. November; Association for Computational Linguistics; 2016. pp. 2249–2255. [Google Scholar]
- Pennington Jeffrey, Socher Richard, Manning Christopher. Glove: Global vectors for word representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP); Doha, Qatar. October; Association for Computational Linguistics; 2014. pp. 1532–1543. [Google Scholar]
- Pollack Jordan B. Recursive distributed representations. Artificial Intelligence. 1990;46(1):77–105. [Google Scholar]
- Rocktäschel Tim, Grefenstette Edward, Hermann Karl Moritz, Kočiský Tomáš, Blunsom Phil. Reasoning about entailment with neural attention. ICLR 2016 2016 [Google Scholar]
- Socher Richard, Pennington Jeffrey, Huang Eric H, Ng Andrew Y, Manning Christopher D. Semi-supervised recursive autoencoders for predicting sentiment distributions; Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing; Edinburgh, Scotland, UK. July; Association for Computational Linguistics; 2011. pp. 151–161. [Google Scholar]
- Socher Richard, Huval Brody, Manning Christopher D, Ng Andrew Y. Semantic compositionality through recursive matrix-vector spaces. Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning; Jeju Island, Korea. July; Association for Computational Linguistics; 2012. pp. 1201–1211. [Google Scholar]
- Socher Richard, Perelygin Alex, Wu Jean, Chuang Jason, Manning Christopher D, Ng Andrew, Potts Christopher. Recursive deep models for semantic compositionality over a sentiment treebank. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing; Seattle, Washington, USA. October; Association for Computational Linguistics; 2013. pp. 1631–1642. [Google Scholar]
- Sutskever Ilya, Vinyals Oriol, Le Quoc V. Sequence to sequence learning with neural networks. NIPS. 2014:3104–3112. [Google Scholar]
- Tai Kai Sheng, Socher Richard, Manning Christopher D. Improved semantic representations from tree-structured long short-term memory networks. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Beijing, China. July; Association for Computational Linguistics; 2015. pp. 1556–1566. [Google Scholar]
- Vinyals Oriol, Kaiser Łukasz, Koo Terry, Petrov Slav, Sutskever Ilya, Hinton Geoffrey. Grammar as a foreign language. NIPS 2015 2015 [Google Scholar]
- Wang Shuohang, Jiang Jing. Learning natural language inference with lstm. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; San Diego, California. June; Association for Computational Linguistics; 2016. pp. 1442–1451. [Google Scholar]
- Yang Yi, Yih Wen-tau, Meek Christopher. Wikiqa: A challenge dataset for open-domain question answering. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing; Lisbon, Portugal. September; Association for Computational Linguistics; 2015. pp. 2013–2018. [Google Scholar]
- Yih Wen-tau, Chang Ming-Wei, Meek Christopher, Pastusiak Andrzej. Question answering using enhanced lexical semantic models. Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Sofia, Bulgaria. August; Association for Computational Linguistics; 2013. pp. 1744–1753. [Google Scholar]
- Yu Lei, Hermann Karl Moritz, Blunsom Phil, Pulman Stephen. Deep learning for answer sentence selection. NIPS Deep Learning Workshop; 2014.2014. [Google Scholar]
- Zhu Xiao-Dan, Sobhani Parinaz, Guo Hongyu. Long short-term memory over recursive structures. ICML, pages. 2015:1604–1612. [Google Scholar]