

Abstract
The National Institutes of Health Clinical Center (NIH CC) is the largest hospital in the United States devoted entirely to clinical research, with a highly diverse spectrum of patients. Patient safety and clinical quality is a major goal of the hospital, and therapy is often complicated by multiple cotherapies and comorbidities. To this end, we implemented a pharmacogenomics program in two phases. In the first phase, we implemented genotyping for HLA-A and HLA-B gene variations with clinical decision support (CDS) for abacavir, carbamazepine, and allopurinol. In the second phase, we implemented genotyping for drug metabolizing enzymes and transporters (DMET): SLCO1B1 for CDS of simvastatin and TPMT for CDS of mercaptopurine, azathioprine, and thioguanine. The purpose of this review is to describe the implementation process, which involves clinical, laboratory, informatics, and policy decisions pertinent to the NIH CC.
Keywords: Pharmacogenomics, implementation, precision medicine, translation
INTRODUCTION
The National Institutes of Health Clinical Center (NIH CC) has 200 inpatient beds, 11 operating rooms and 93 day-hospital wards. All patients at the CC consent to participate in research studies, are treated without charge, and must have a medical condition that is under study by an NIH Institute or Center to be eligible for treatment. There are currently over 1,600 clinical research studies underway led by approximately 500 principal investigators. These cover a wide range of illnesses: cancer, infectious diseases, blood disorders, heart disease, lung disease, alcoholism, and drug abuse. Of these protocols, 48% are intervention clinical trials (261 phase 1 trials, 462 phase 2 trials, 39 phase 3 trials, and 11 phase 4). Over the years more than 500,000 patients have participated in clinical research at the NIH CC. Annually, 5,600 patients are admitted to the NIH CC, 10,000 new patients are seen at the NIH, and approximately 100,000 outpatient visits occur. However, the NIH is not a full hospital conducting standard of care; therefore, new prescriptions are administered less often than those of other clinics. Due to the large and highly heterogeneous patient population seen at the NIH CC, often consisting of individuals with rare or orphan diseases, drug-disease and drug-drug interactions are of major concern and require careful management of medications in many cases. For this reason, we began the NIH CC effort to implement pharmacogenomics for clinical decision support (CDS) pertaining to certain medications. The purpose of this review is to highlight the clinical, laboratory, informatics, and policy procedures relevant to the implementation of germline pharmacogenomics testing for patients undergoing therapy at the NIH CC.
GENE-DRUG INTERACTIONS WITH CLINICAL GUIDELINES
Generally, the NIH CC uses the recommendations of the Clinical Pharmacogenetics Implementation Consortium (CPIC), an international group of individuals from government, academia, and industry that peer reviews and updates freely-available clinical practice guidelines based on evidence-based methods (https://www.pharmgkb.org/view/dosing-guidelines.do?source=CPIC). Currently, thirty-six medications from a wide variety of therapeutic classes have CPIC guidelines (see Table 1). The high representation of anticancer agents, antiinfectives, and antidepressants reflects the usefulness of pharmacogenomics when medications have a narrow therapeutic index with high risk of inefficacy and/or toxicity.1 Many of these therapies are specifically associated with the risk of severe immune adverse reactions (iADRs; e.g., carbamazepine, allopurinol, abacavir, etc.), which reflects the significance of that toxicity and the high predictive value of 4 distinct genotypes encoding certain human leukocyte antigens (HLAs), which are HLA-A*31:01, HLA-B*15:02, HLA-B*57:01, and HLA-B*57:02.2
Table 1.
Abbreviated Summary of CPIC Guidelines*
| Medication | Relevant Gene(s) | Reason |
|---|---|---|
| Analgesics | ||
| Codeine | CYP2D6 | Lack of analgesia |
| Anticancer Agents | ||
| Capecitabine | DPYD | Risk of fatal toxicity/dose selection |
| Fluorouracil | DPYD | Risk of fatal toxicity/dose selection |
| 6-mercaptopurine | TPMT | Inefficacy and risk of fatal toxicity |
| Tegafur | DPYD | Risk of fatal toxicity/dose selection |
| Thioguanine | TPMT | Inefficacy and risk of fatal toxicity |
| Anticoagulant | ||
| Warfarin | CYP2C19, CYP2D6 | Inefficacy and starting dose selection |
| Antidepressants | ||
| Amitriptyline | CYP2C19, CYP2D6 | Dose and therapy selection |
| Citalopram | CYP2C19 | Dose and therapy selection |
| Clomipramine | CYP2C19, CYP2D6 | Dose and therapy selection |
| Desipramine | CYP2D6 | Dose and therapy selection |
| Doxepin | CYP2C19, CYP2D6 | Dose and therapy selection |
| Escitalopram | CYP2C19 | Dose and therapy selection |
| Fluvoxamine | CYP2D6 | Dose and therapy selection |
| Imipramine | CYP2C19, CYP2D6 | Dose and therapy selection |
| Nortriptyline | CYP2D6 | Dose and therapy selection |
| Paroxitine | CYP2D6 | Dose and therapy selection |
| Sertraline | CYP2C19 | Dose and therapy selection |
| Trimipramine | CYP2C19, CYP2D6 | Dose and therapy selection |
| Antiemetics | ||
| Ondansetron | CYP2D6 | Therapy selection |
| Tropisetron | CYP2D6 | Therapy selection |
| Antifungal | ||
| Vorconazole | CYP2C19 | Therapy selection |
| Antiplatelet | ||
| Clopidogrel | CYP2C19 | Dose and therapy selection |
| Antiseizure | ||
| Carbamazepine | HLA-B | SCAR |
| Phenytoin | CYP2C9, HLA-B | Starting dose selection |
| Cystic Fibrosis | ||
| Transporter Potentiator | ||
| Ivacaftor | CFTR | Therapy selection |
| Xanthane Oxidase Inhibitor | ||
| Allopurinol | HLA-B | Risk of SCAR |
| Antivirals | ||
| Ribavirin | IFNL3 | Poor response rates |
| Peginterferon-α2a | IFNL3 | Poor response rates |
| Peginterferon-α2b | IFNL3 | Poor response rates |
| Antiretrovirals | ||
| Abacavir | HLA-B | SCAR |
| Atazanavir | UGT1A1 | Bilirubin-related discontinuation |
| Immunosuppressants | ||
| Azathioprine | TPMT | Risk of fatal toxicity |
| Tacrolimus | CYP3A5 | Dose selection |
| Statin | ||
| Simvastatin | SLCO1B1 | Dose or alternative statin selection |
| Uric Acid Metabolizer | ||
| Rasburicase | G6PD | Risk of hemolytic anemia |
All data available on Pharmgkb.org
Genes with variants that result in a high degree of variation in the expression and function are highly represented in the CPIC guidelines. For instance, twelve of 36 of the CPIC guidelines relate to variation in CYP2D6, a gene that has numerous known functional polymorphisms and copy number variations that affect its enzymatic turnover such that metabolic phenotype ranges from poor to ultra-rapid.3 Many other genes represented in the CPIC guidelines have variants with high degrees of inter-individual variation in phenotypes (see Table 1). The NIH CC effort to implement pharmacogenomics for clinical care has therefore focused on therapeutics that have severe side effects and highly predictive genotypes. Implementation is also guided by the existing information technology at the NIH CC. We chose to initially focus on gene-drug pairs in which knowledge of genotype or phenotype will improve drug therapy outcomes or reduce toxicity for those medications that are commonly initiated at the NIH CC. In addition, pharmacogenomic efforts are commonly incorporated into clinical research protocols as part of the research objectives.
PHARMACOGENETICS TESTING IMPLEMENTATION COMMITTEE (PGTIC) AND THE PHAMACOGENETICS (PG) SUBCOMMITTEE
For successful CDS design,4 a multidisciplinary team is necessary to ensure a high quality clinical framework and precise/accurate laboratory test methods. Therefore, the PGTIC consisted of pharmacologists, pharmacists, nurses, informaticists, laboratory experts, and geneticists. The team was responsible for selecting the drug-gene pairs, designing the messages to prescribers, and constructing and testing the CDS algorithm. During implementation of the first phase, the PGTIC became the Pharmacogenetics (PG) Subcommittee of the Pharmacy and Therapeutics Committee (P&T Committee). The PG Subcommittee recommends the drug-gene pairs and the corresponding clinical recommendations to incorporate into the CDS. P&T Committee approval indicates that there is sufficient evidence that a preemptive assessment of the genotype and/or phenotype should be considered an integral part of clinical care. The NIH CC institutional process is diagramed in Figure 1.
FIGURE 1.

Diagram of the NIH CC institutional process.
TECHNICAL IMPLEMENTATION
Ordering
The NIH CC utilizes Allscripts Sunrise Clinical Manager 15.3 as the central component of the electronic health record referred to as the Clinical Research Information System (CRIS).5, 6 With guidance from the PG Subcommittee, a pharmacogenomics CDS program that is completely integrated into the natural medication order pathway was implemented within the EHR.7 The current program is based on our previous experience with immune adverse drug reactions (iADRs) corresponding to abacavir, allopurinol and carbamazepine therapies, as discussed in Goldspiel, et al.8 We have recently expanded this program to include genotyping drug metabolizing and transporting (DMET) genes, using the Affymetrix DMET™ Plus array that tests 1936 genetic variants in 235 pharmacogenes. There are six steps for processing the medication orders to incorporate CDS using the DMET platform that ultimately result in a clinical recommendation to the prescriber:
As medications are added to the Pharmacogenomics DMET Program, the order, order set and the pharmacogenomics DMET program control table are configured by the informatics team. The pharmacogenomics DMET control table is used by the Medication Logic Module (MLM) to manage the execution of the MLM when the pharmacogenomics order is placed. The pharmacogenomics DMET control table is populated with the name of the medication, values for expected results, acceptable override flags and warning messages.
Physicians order the medications (azathioprine, mercaptopurine, simvastatin, thioguanine) included in the pharmacogenomics program through an order set from CRIS (Figure 2A–C).
When the order set form opens, a CDS process executes within CRIS. The process was developed using Medical Logic Modules (MLMs) with the Arden Syntax programming language. The status of the order and results of the Pharmacogenomics Multigene Test are evaluated. Results are used to guide the user through the ordering process if results exist (see Table 2). If no results are present, the Pharmacogenomics Multigene Test is pre-selected and available for submission.
An electronic order for the Pharmacogenomics Multigene Test is made available to the external laboratory through a secured and encrypted file share process.
The external laboratory performs the test and provides a report in PDF and tab-delimited file formats containing the results of the test through a secured and encrypted file share process.
The report is sent to CRIS in PDF format and is made available to users of the electronic health record.
Gene results specific to the CDS are stored in a table external to CRIS. The comprehensive report is stored in BTRIS, NIH’s data repository. This report is provided to patients upon request.
FIGURE 2.
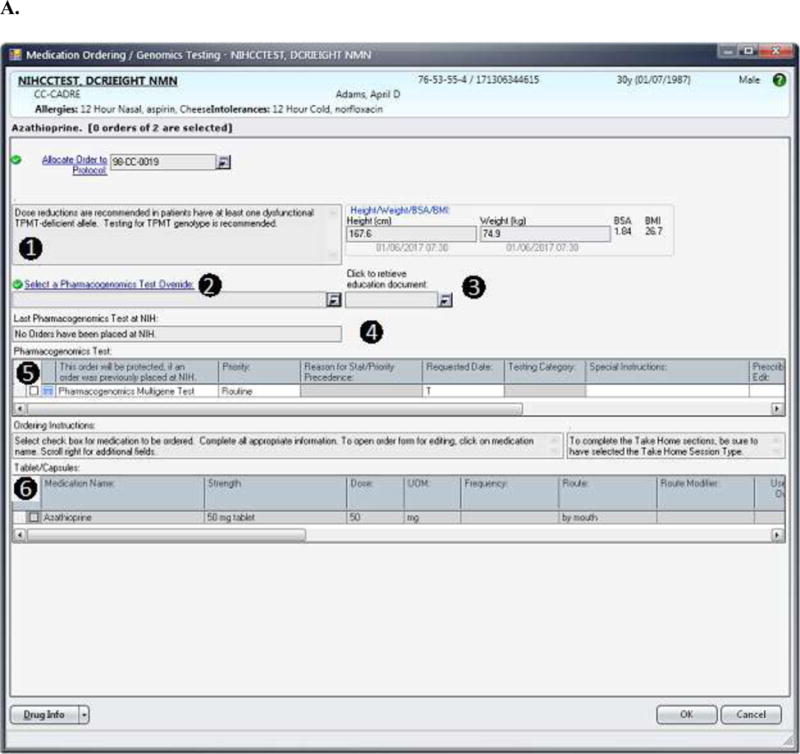
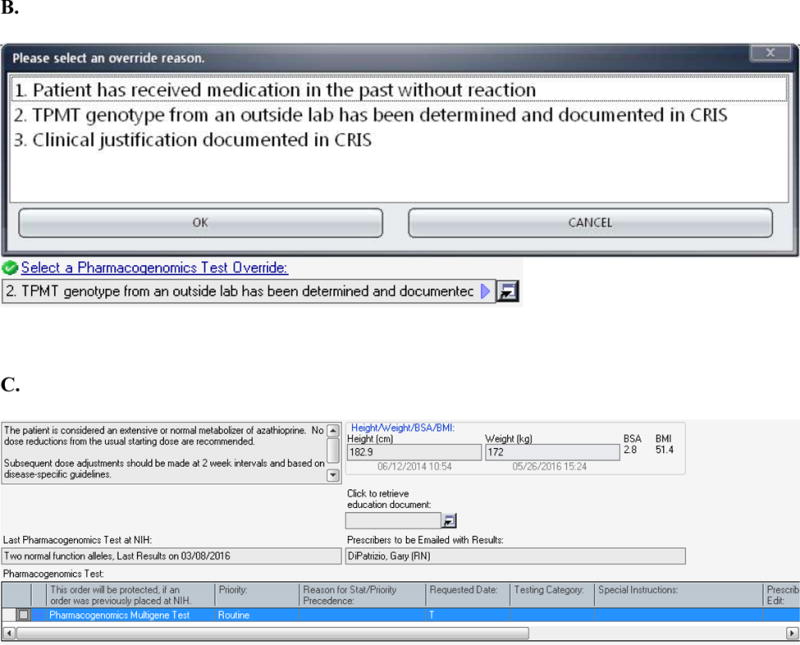
(A) The design for the order set form for drugs included in the pharmacogenomics DMET program is shown. In this case, the information displayed to the prescriber is based on the case where the Pharmacogenomics Multigene Test has not yet been ordered. The displayed messages and order actions are determined by the control table. The standard design for the order set form includes (1) a message box where the clinical information message is displayed, and (2) a message box where over-ride reasons are displayed (the ‘over-ride reason number’ field becomes a required entry if an over-ride reason is allowed), (3) a link to the Education Document to provide to the patient, (4) a message box where pharmacogenomics test information and when appropriate result information is displayed, (5) a grid where the Pharmacogenomics Multigene Test can be ordered or are automatically preselected depending on the case, and (6) a grid where medications can be ordered through the Clinical Research Information System. (B) The top image shows the modal window showing the override options. The bottom image shows how override reason 2 will display when selected. (C) The image shows information related to the actual result of the Pharmacogenomics Multigene Test. The MLMs uses a control table to process clinical rules for medication orders. The control table allows the management of the process through logic defined in the MLM and also allows the user to add new medications or add or modify rules for test results as needed to refine the logic. Each medication within the pharmacogenomics DMET program will have entries in the control table as seen in Table 1. This report is a sample and does not refer to an actual patient.
Table 2.
Results table.
| Mercaptopurine (MP) | Azathioprine | Thioguanine (TG) | |
|---|---|---|---|
|
| |||
| Result | |||
| Case 1: DMET test has not been ordered. | |||
| What message do we provide to the user? | Dose reductions are recommended in patients who have at least one dysfunctional TPMT-deficient allele. Testing for TPMT genotype is recommended. | Dose reductions are recommended in patients have at least one dysfunctional TPMT-deficient allele. Testing for TPMT genotype is recommended. | Dose reductions are recommended in patients who have at least one dysfunctional TPMT-deficient allele. Testing for TPMT genotype is recommended. |
| Do we allow medication to be ordered? (override reason required for “Yes”) |
Yes | Yes | Yes |
| What are the override reasons? | Override reasons
|
Override reasons
|
Override reasons
|
| Do we automatically pre-check the box for the DMET genotype test? | Yes – if not overridden | Yes – if not overridden | Yes – if not overridden |
| Case 2: DMET has been ordered but result has not been provided. | |||
| What message do we provide to the user? | A TPMT genotype test has been ordered but not yet resulted. | A TPMT genotype test has been ordered but not yet resulted. | A TPMT genotype test has been ordered but not yet resulted. |
| Do we allow medication to be ordered? (over-ride reason required for “Yes”) |
Yes | Yes | Yes |
| What are the override reasons? | 1. Clinical justification documented in CRIS | 1. Clinical justification documented in CRIS | 1. Clinical justification documented in CRIS |
|
| |||
| Case 3: DMET has been ordered and results are available | See message to prescriber in table below. | See message to prescriber in table below. | See message to prescriber in table below. |
Genotyping
Following the order, whole blood samples requiring HLA genotyping are sent to the Department of Transfusion Medicine (DTM), where HLA testing is conducted using HLA-A and HLA-B allele SEQR Typing Kits (Atria Genetics, Hayward, California, USA) on a 3730xL DNA analyzer (Applied Biosystems, Carlsbad, California, USA).8 If the order requires typing of ADME genes, whole blood samples are sent to a core facility that conducts genotyping using the Affymetrix DMET™ Plus array in a CLIA-certified setting. The DMET array tests 1936 variants in 235 genes involved in absorption, distribution, metabolism, and/or elimination. This platform ascertains appropriate genotypes for the vast majority of gene-drug pairs covered by the CPIC guidelines. The DMET array also genotypes a multitude of other allelic variants that may be found useful as the landscape of pharmacogenomics testing expands.
Processing results
We use a separate process to receive and store the genetics data generated by the laboratory.7, 8 The laboratory providing the pharmacogenomic results places the PDF result and a tab delimited file to a secured NIH share drive. A script runs every five minutes checking for the availability of the files and then completes the steps below:
The script parses the order identifier and patient identifier from the filename of the PDF file and sends it to the CRIS electronic health record via an HL7 result message. The PDF is stored on a Clinical PDF File Server while a link is stored in the CRIS electronic health record pointing to this PDF file. An example of the PDF Report is shown in Figure 3 and Table 3.
Send the order identifier, patient identifier, gene, medication, phenotype call, and known call to a stored procedure. This information is stored in a structured results table which is called by the Medication Logic Module (MLM) during the ordering process. The MLM also calls a stored procedure that does the analysis of the clinical result against the control table.
Notify the prescribers identified on the order as well as the pharmacy point of contact of the receipt of test results. The email contains only the order number, which is used to access the results and patient information.
Log all events. All information is stored and tracked in the electronic health record with the defined messages including email notifications and to whom they were sent.
FIGURE 3.
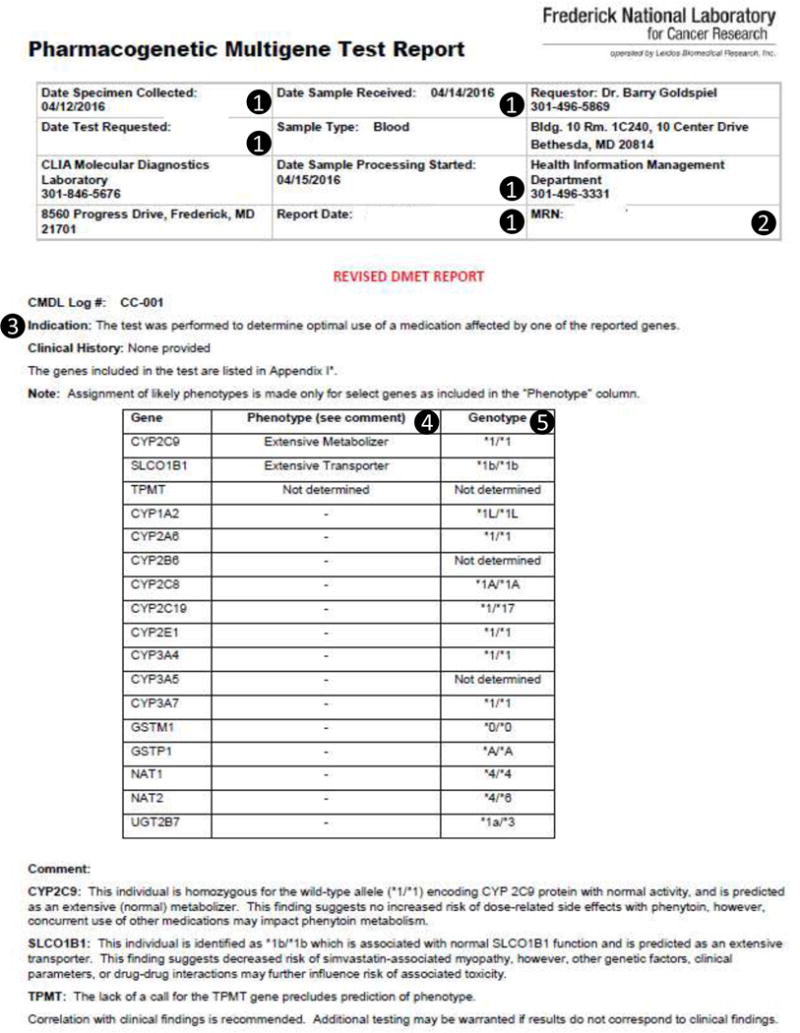
Example PDF Report containing (1) dates (laboratory test requested date, results received date, and date added to table), (2) identification numbers for the patient, (3) table logic parameters (medication name, laboratory test name, allele information), (4) a textual description of the results value, (5) the result for the variant. Fields with example data stored with in the DMET Results table are shown in Table 2. This report is a sample and does not refer to an actual patient.
Table 3.
Recommendations to the prescribing physician for mercaptopurines
| Table. Message to prescriber based on phenotype call | |||
|---|---|---|---|
| Phenotype | Mercaptopurine | Azathioprine | Thioguanine |
| Extensive Metabolizer | The patient is considered an extensive or normal metabolizer of mercaptorpurine. No dose reductions from the usual starting dose are recommended. Subsequent dose adjustments should be made at 2 week intervals and based on disease-specific guidelines. For myelosuppression, no special emphasis on reducing MP doses is necessary. |
The patient is considered an extensive or normal metabolizer of azathioprine. No dose reductions from the usual starting dose are recommended. Subsequent dose adjustments should be made at 2 week intervals and based on disease-specific guidelines. |
The patient is considered an extensive or normal metabolizer of thioguanine. No dose reductions from the usual starting dose are recommended. Subsequent dose adjustments should be made at 2 week intervals and based on disease-specific guidelines. For myelosuppression, no special emphasis on reducing TG doses is necessary. |
| Intermediate Metabolizer | The patient is considered an intermediate metabolizer for mercaptopurine. Initiate therapy at 30 to 70% of the usual starting dose. Subsequent dose adjustments should be made at 2 – 4 week intervals and based on disease-specific guidelines. If myelosuppression occurs, reducing the MP dose should be considered before reducing the doses of other myelosuppresive agents. |
The patient is considered an intermediate metabolizer for azathioprine. Consider initiating therapy at 30 to 70% of the usual starting dose. Subsequent dose adjustments should be made at 2 – 4 week intervals and based on disease-specific guidelines. |
The patient is considered an intermediate metabolizer for thioguanine. Consider initiating therapy at 50 to 70% of the usual starting dose. Subsequent dose adjustments should be made at 2 – 4 week intervals and based on disease-specific guidelines. If myelosuppression occurs, reducing the TG dose should be considered before reducing the doses of other myelosuppresive agents. |
| Poor Metabolizer | The patient is considered a poor metabolizer for mercaptopurine. When used for cancer treatment: Significant, dose adjustments are required. Initiate therapy at 10% of the usual starting dose and decrease the frequency to three times per week. Subsequent dose adjustments should be made at 4 – 6 week intervals and based on disease-specific guidelines. If myelosuppression occurs, reducing the MP dose should be considered before reducing the doses of other myelosuppresive agents. When used for non-malignant conditions: Consider alternative therapy before using MP. |
The patient is considered a poor metabolizer for azathioprine. Consider alternative therapy. If azathioprine must be used, significant dose adjustments are required. Initiate therapy at 10% of the usual starting dose and decrease the frequency to three times per week. Subsequent dose adjustments should be made at 4 – 6 week intervals and based on disease-specific guidelines. |
The patient is considered a poor metabolizer for thioguanine. Consider alternative therapy. If TG must be used, significant dose adjustments are required. Initiate therapy at 10% of the usual starting dose and decrease the frequency to three times per week. Subsequent dose adjustments should be made at 4 – 6 week intervals and based on disease-specific guidelines. If myelosuppression occurs, reducing the TG dose should be considered before reducing the doses of other myelosuppresive agents |
| Not Determined | A DMET test result has been found in the patient’s record; however, the patient’s TPMT genotype or phenotype was not defined. Routine clinical criteria should be used to determine the patient’s starting dose. Dose reductions are recommended in patients who have at least one dysfunctional TPMT-deficient allele. The DMET results report can be found under the RESULTS Tab -> OUTSIDE RESULTS. Please consult your clinical pharmacy specialist or the Drug Information Center (301-496-2407) for assistance with dosing. |
A DMET test result has been found in the patient’s record; however, the patient’s TPMT genotype or phenotype was not defined. Routine clinical criteria should be used to determine the patient’s starting dose. Dose reductions are recommended in patients who have at least one dysfunctional TPMT-deficient allele. The DMET results report can be found under the RESULTS Tab -> OUTSIDE RESULTS. Please consult your clinical pharmacy specialist or the Drug Information Center (301-496-2407) for assistance with dosing. |
A DMET test result has been found in the patient’s record; however, the patient’s TPMT genotype or phenotype was not defined. Routine clinical criteria should be used to determine the patient’s starting dose. Dose reductions are recommended in patients who have at least one dysfunctional TPMT-deficient allele. The DMET results report can be found under the RESULTS Tab -> OUTSIDE RESULTS. Please consult your clinical pharmacy specialist or the Drug Information Center (301-496-2407) for assistance with dosing. |
| Not Poor Metabolizer | The patient’s phenotype could not be determined to a single phenotype; however, the patient is NOT a poor metabolizer. Use routine clinical and patient-specific factors to determine dose. Dose reductions are recommended in patients who have at least one dysfunctional TPMT-deficient allele. The DMET results report can be found under the RESULTS Tab -> OUTSIDE RESULTS. Please consult your clinical pharmacy specialist or the Drug Information Center (301-496-2407) for assistance with dosing. |
The patient’s phenotype could not be determined to a single phenotype; however, the patient is NOT a poor metabolizer. Use routine clinical and patient-specific factors to determine dose. Dose reductions are recommended in patients who have at least one dysfunctional TPMT-deficient allele. The DMET results report can be found under the RESULTS Tab -> OUTSIDE RESULTS. Please consult your clinical pharmacy specialist or the Drug Information Center (301-496-2407) for assistance with dosing. |
The patient’s phenotype could not be determined to a single phenotype; however, the patient is NOT a poor metabolizer. Use routine clinical and patient-specific factors to determine dose. Dose reductions are recommended in patients who have at least one dysfunctional TPMT-deficient allele. The DMET results report can be found under the RESULTS Tab -> OUTSIDE RESULTS. Please consult your clinical pharmacy specialist or the Drug Information Center (301-496-2407) for assistance with dosing. |
Testing and Quality Assurance
Unit, function, integration and user acceptance testing was performed to address all scenarios. Unit testing is performed to ensure that each medication in the Pharmacogenomics DMET Program has an order set that contains the Pharmacogenomics Multigene order, the appropriate medication order grid, entries in the pharmacogenomics DMET control table, and MLMs executed without error. Function testing ensures that, upon order set open, the messages show that no Pharmacogenomics Multigene order is placed and defaulted the selection of the order and that MLMs execute without error. Integration testing is used to ensure end to end testing from order to result. Integration testing includes pre-checking of the Pharmacogenomics Multigene order, genomics results matching each entry in CRIS, and the email notification sent to the appropriate staff.
As part of the quality assurance process, upon order entry, an email notification is also sent to two members of the PG Subcommittee to monitor the process. Upon results being received by CRIS, the pharmacy PG Subcommittee member and the provider entering the medication order receive an email that results are within CRIS for the Pharmacogenomics Multigene order. An identification number within the email message allows the user to login to CRIS and retrieve the results for the patient. The prescriber can then proceed in ordering the medication if appropriate.
EDUCATION
Implementation of the pharmacogenomics CDS program affects all members of the healthcare team: clinicians, pharmacists, nurses, laboratory medicine staff, and patients. The pharmacy department therefore initiated an education program for hospital staff that included information pertaining to pharmacogenomics guidelines, the availability of the lab test, and the order entry process. To reach all clinicians, a variety of methods were utilized including Clinical Alert flyers, in-service training programs, and email communication to targeted clinicians. Additionally, warning messages, instructions, labels, and information for the medication and genomic tests are provided to prescribers (see Table 3). In-service training programs are also provided to pharmacy, nursing, and laboratory staff as part of the initial implementation.
As part of the continuous learning program, nurses also developed a Genetics and Genomics in Healthcare course and competency to provide nursing with a broader understanding of how genomics interplays with patient care and medication administration. The Genetics and Genomics course is available to all healthcare providers within the NIH and has two sections – Introduction and Intermediate. The Introduction Course, a one day course, is required of all nursing staff, who must complete a competency requirement. The Intermediate Course is a 2 day program (syllabus included in Figure S1).
Educational materials were created for the patient (Figure S2). This information is available in the medical order in the electronic health record to allow clinicians ready access to a document for use in discussion with the patient. It is also available on the interanal access page of the pharmacy department. As more gene-drug pairs are introduced at NIH, educational information will be provided/presented to staff to appropriately care for patients. Educational materials will be developed on the new drugs for patients and will be available through current processes.
CURRENT STATUS OF IMPLEMENTATION
The clinical pharmacogenomics program was implemented in two phases. The first phase included drug-gene pairs in which HLA variations were ascertained for prediction of potential dermatologic reactions following abacavir (HLA-B*57:01), allopurinol (HLA-B*58:01), and carbamazepine (HLA-A*31:01, and HLA-B*15:02) treatment.8 The second phase included genetic variants in ADME genes that are associated with the dose or toxicity of a medication.
HLA genotyping was implemented first because the DTM had already developed assays for the high-resolution HLA gene sequencing and such therapies are frequently ordered at our institution. Therefore, implementation only involved controlling the test name to trigger the CDS and was utilized by prescribing physicians shortly thereafter. The results to date are similar to our previous conclusions:8 prescribers order the gene test frequently because of the construct of the order form. A CDS algorithm was recently approved for genotyping HLA-B*15:02 prior to phenytoin therapy; however, we have not yet implemented this algorithm.
DMET testing involves ascertaining genotypes of 235 different pharmacogenes and determining the genotype-predicted phenotype of a subset of these genes. Therefore, implementing the second phase was more challenging since it involved both the development of a CLIA-certified Affymetrix DMET-Plus array test and the ability to securely and automatically transmit the results for use in CDS. We have algorithms approved for genotyping several gene-drug pairs: Solute carrier organic anion transporter family member 1B1 (SLCO1B1) and simvastatin; Thiopurine methyltransferase (TPMT) and azathioprine, mercaptopurine, and thioguanine; CYP2C9 and phenytoin (implementation is pending).9
Initially, we reported all phenotypes that were determined by the Affymetrix software. Only the approved drug-gene pairs are programmed for CDS. The additional phenotypes could be used by the clinician if they felt that the information could contribute to better medication therapy. Although we had completed testing on the algorithms, we soon discovered that the phenotype report produced multiple phenotype results when a single genotype could not be determined. This is a result of the software making all possible calls when a single call can’t be made. We then decided to have human interpretation for the three approved drug-gene pairs and report just the software-generated genotypes for the other genes on the chip. This unexpected result has reduced our ability to provide comprehensive pre-emptive testing and will require us to backfill reports as new drug-gene pairs are approved. We have since updated all the patient results in the system.
MODELS AT OTHER INSTITUTIONS
Many institutions have integrated genotyping for pharmacogenomics testing into standard clinical care programs.10 Heterogeneity exists among several aspects of how these programs are structured and implemented. Firstly, some institutions concentrate these initiatives in specialized clinics or pharmacogenomics consult services. In contrast, the NIH CC model is one in which testing is intended to be available to all clinicians; therefore, results and recommendations are relayed to clinicians in the form of CDS imbedded into the electronic health record. Secondly, institutions vary greatly in which drug-gene pairs are included in these initiatives and which regulatory bodies are required for approval. The most common structure is creation of a pharmacogenomics-subcommittee of the P&T committee to evaluate the evidence and present recommendations prior to approval by the P&T. Alternatively, some institutions rely on consensus from external guidelines and/or internal consensus among clinicians utilizing affected drugs in their services, e.g. the University of North Carolina Chapel Hill Inpatient Cardiology Service program for Clopidigrel/CYP2C19 testing.7 Efforts to standardize approaches to evaluate evidence in literature and incorporating pharmacogenomics results into clinical guidance are being provided by organizations, such as the Clinical Pharmacogenetics Implementation Consortium and the Pharmacogenomics Knowledgebase (PharmGKB). Both organizations use an evidence-based, tiered system of grading pharmacogenetic associations.11
Perhaps the largest difference in institutional use of pharmacogenomics testing for clinical care involves the use of pre-emptive or reactive testing. A majority of initiatives are currently designed for reactive testing, in which pharmacogenomics testing is ordered at the time of ordering a drug for which an approved drug-gene pair has been established at the institution. For this model to be successful, however, the turnaround time for results is a crucial component. St. Jude Children’s Research Hospital’s PG4KDS Protocol is the largest program currently to offer preemptive pharmacogenomics testing to all patients treated at the institution: over 3000 patients were preemptively genotyped. While this is a highly unique and specialized institution, other institutions with broader patient populations, such as the Mayo Clinic, have also successfully piloted large-scale preemptive pharmacogenomics testing programs. Such programs highlight the potential for the successful transition from reactive testing to preemptive pharmacogenomics testing as the standard of care.12 The preemptive testing approach offers the opportunity for clinician researchers to access all SNP array test results for exploratory analyses of new pharmacogenomic associations and for future clinical utility.
Each institution must determine the approach that will allow for ease of use and long term sustainability of the pharmacogenomics program. Ultimately, no matter which approach is selected, the priority should be focused on ensuring the institution is providing actionable data to healthcare practitioners, and easy access utilization of these data in their practice, thus achieving the end goal of providing precision medicine.
DISCUSSION
The current NIH CC pharmacogenomics testing approach is designed to minimize adverse drug reactions and maximize therapeutic efficacy by preemptively informing the selection of therapy at the right dose. The strategy we have employed is expected to cover all CPIC guidelines irrespective of race within the next 5 years and is adaptable to the changing landscape of the pharmacogenomics literature. Moreover, we have designed the program to allow multiple NIH physicians and clinics to access genomic data from a central source, the electronic health record. We also provide patients with their genotype data so that local physicians can use the information when patients return to their local community. However, as the NIH is solely a research hospital, our pharmacogenomics effort has been implemented more slowly and on a smaller scale than many other institutions.
Broad clinical pharmacogenomics implementation in hospitals is a rather recent event, with widely-accepted clinical guidelines for important gene-drug interactions only occurring in the past 6 years.13, 14 These guidelines are useful to standardize CDS across multiple hospitals. However, decisions such as the regulatory framework to implement CDS, which testing platforms to use, how to include CDS data in the medical record, and physician/patient education programs involve decisions that depend on factors specific to individual hospitals. The NIH CC has implemented the above guidelines because we service a large, diverse, highly-specialized, and multidisciplinary institution with over 1,600 clinical studies, involving patients with severe and complex disorders on short-term but intensive care regimens.
Since the NIH CC already had CDS support for HLA-A and HLA-B haplotypes in place, we chose to implement testing prior to abacavir, allopurinol, and carbamazepine medication first and added other tests in a second phase once we developed CLIA support for the DMET array. The DMET array was chosen because multiple variants in many genes that are not currently ascertained in the CPIC guidelines are included, and we have banked these “extra” data in case additional variants are needed in the future. Our choice of gene-drug pairs to implement first in the second phase depended on the prevalent use of these drugs in many clinics throughout the NIH CC (i.e., simvastatin, and phenytoin) or the highly-predictive value of genotyping patients receiving mercaptopurine and its analogues. Therapies that are guided by somatic mutations are implemented by the NIH pathology department and are therefore beyond the scope of this review.15
The implementation has involved several challenges that have warranted a slower implementation process at the NIH CC for a variety of reasons. First, the NIH CC is a pure research hospital, and clinical protocols are very often written to provide the necessary pharmacogenomics coverage when applicable to experimental therapies. Second, as a pure research hospital, NIH is not providing standard of care. Most patients who are referred to NIH are already taking prescribed medications with pharmacogenomics indications at local clinics and require preemptive genotyping much more rarely than patients in other hospitals. We have also developed a mechanism to transmit pharmacogenomics information back to the local physician, which has also been challenging. Next, the NIH is a very large and highly multidisciplinary; this aspect of the NIH CC requires careful implementation and broad communication between the PGTIC and various clinics on the NIH campus. Such communication has been a necessary component of implementation since many clinics have developed local methods to determine which alleles require genotyping before therapy. The PGTIC has therefore partnered with clinics that frequently use pharmacogenetics testing to add value to existing CDS infrastructure while still providing a central CDS resource that is available to all NIH physicians. Fourth, in spite of careful quality control, the DMET array does not always return all 1936 genotypes that are probed, and we have therefore had to develop means to determine whether DMET testing can still provide actionable information in such contingencies. Finally, we have intentionally introduced implementation in a stepwise fashion so that CDS can be “beta-tested” without introducing undue burden on NIH research and patient care. Future efforts will focus on introducing additional gene-drug pairs into clinical implementation and increasing the adaptability of the pharmacogenomics program as new studies are published in genes in which we do not currently ascertain genotype.
Supplementary Material
Acknowledgments
Financial Support
This work was supported by the Intramural Research Program of the NIH.
Footnotes
Disclaimer
The content of this publication does not necessarily reflect the views or policies of the Department of Health and Human Services, nor does mention of trade names, commercial products, or organizations imply endorsement by the U.S. Government.
References
- 1.Relling MV, Evans WE. Pharmacogenomics in the clinic. Nature. 2015;526(7573):343–350. doi: 10.1038/nature15817. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Kaniwa N, Saito Y. Pharmacogenomics of severe cutaneous adverse reactions and drug-induced liver injury. J Hum Genet. 2013;58(6):317–326. doi: 10.1038/jhg.2013.37. [DOI] [PubMed] [Google Scholar]
- 3.Teh LK, Bertilsson L. Pharmacogenomics of CYP2D6: molecular genetics, interethnic differences and clinical importance. Drug Metab Pharmacokinet. 2012;27(1):55–67. doi: 10.2133/dmpk.dmpk-11-rv-121. [DOI] [PubMed] [Google Scholar]
- 4.Khorasani R, Hentel K, Darer J, et al. Ten commandments for effective clinical decision support for imaging: enabling evidence-based practice to improve quality and reduce waste. AJR Am J Roentgenol. 2014;203(5):945–951. doi: 10.2214/AJR.14.13134. [DOI] [PubMed] [Google Scholar]
- 5.Cimino JJ, Ayres EJ, Remennik L, et al. The National Institutes of Health’s Biomedical Translational Research Information System (BTRIS): design, contents, functionality and experience to date. J Biomed Inform. 2014;52:11–27. doi: 10.1016/j.jbi.2013.11.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Haerian K, McKeeby J, Dipatrizio G, Cimino JJ. Use of clinical alerting to improve the collection of clinical research data. AMIA Annu Symp Proc. 2009;2009:218–222. [PMC free article] [PubMed] [Google Scholar]
- 7.Cavallari LH, Lee CR, Duarte JD, et al. Implementation of inpatient models of pharmacogenetics programs. Am J Health Syst Pharm. 2016;73(23):1944–1954. doi: 10.2146/ajhp150946. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Goldspiel BR, Flegel WA, DiPatrizio G, et al. Integrating pharmacogenetic information and clinical decision support into the electronic health record. J Am Med Inform Assoc. 2014;21(3):522–528. doi: 10.1136/amiajnl-2013-001873. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Caudle KE, Rettie AE, Whirl-Carrillo M, et al. Clinical pharmacogenetics implementation consortium guidelines for CYP2C9 and HLA-B genotypes and phenytoin dosing. Clin Pharmacol Ther. 2014;96(5):542–548. doi: 10.1038/clpt.2014.159. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Dunnenberger HM, Crews KR, Hoffman JM, et al. Preemptive clinical pharmacogenetics implementation: current programs in five US medical centers. Annu Rev Pharmacol Toxicol. 2015;55:89–106. doi: 10.1146/annurev-pharmtox-010814-124835. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Caudle KE, Gammal RS, Whirl-Carrillo M, Hoffman JM, Relling MV, Klein TE. Evidence and resources to implement pharmacogenetic knowledge for precision medicine. Am J Health Syst Pharm. 2016;73(23):1977–1985. doi: 10.2146/ajhp150977. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Ji Y, Skierka JM, Blommel JH, et al. Preemptive Pharmacogenomic Testing for Precision Medicine: A Comprehensive Analysis of Five Actionable Pharmacogenomic Genes Using Next-Generation DNA Sequencing and a Customized CYP2D6 Genotyping Cascade. J Mol Diagn. 2016;18(3):438–445. doi: 10.1016/j.jmoldx.2016.01.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Relling MV, Klein TE. CPIC: Clinical Pharmacogenetics Implementation Consortium of the Pharmacogenomics Research Network. Clin Pharmacol Ther. 2011;89(3):464–467. doi: 10.1038/clpt.2010.279. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Swen JJ, Nijenhuis M, de Boer A, et al. Pharmacogenetics: from bench to byte–an update of guidelines. Clin Pharmacol Ther. 2011;89(5):662–673. doi: 10.1038/clpt.2011.34. [DOI] [PubMed] [Google Scholar]
- 15.Gagan J, Van Allen EM. Next-generation sequencing to guide cancer therapy. Genome Med. 2015;7(1):80. doi: 10.1186/s13073-015-0203-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.