

Abstract
OBJECTIVE
As people age, they experience reduced temporal processing abilities. This results in poorer ability to understand speech, particularly for degraded input signals. Cochlear implants (CIs) convey speech information via the temporal envelopes of a spectrally degraded input signal. Because there is an increasing number of older CI users, there is a need to understand how temporal processing changes with age. Therefore, the goal of this study was to quantify age-related reduction in temporal processing abilities when attempting to discriminate words based on temporal envelope information from spectrally degraded signals.
DESIGN
Younger normal-hearing (YNH) and older normal-hearing (ONH) participants were presented a continuum of speech tokens that varied in silence duration between phonemes (0 to 60 ms in 10-ms steps), and were asked to identify whether the stimulus was perceived more as the word “Dish” or “Ditch.” Stimuli were vocoded using tonal carriers. The number of channels (1, 2, 4, 8, 16, and unprocessed) and temporal envelope low-pass filter cutoff frequency (50 and 400 Hz) were systematically varied.
RESULTS
For the unprocessed conditions, the YNH participants perceived the word Ditch for smaller silence durations than the ONH participants, indicating that aging affects temporal processing abilities. There was no difference in performance between the unprocessed and 16-channel, 400-Hz vocoded stimuli. Decreasing the number of spectral channels caused decreased ability to distinguish Dish and Ditch. Decreasing the envelope cutoff frequency also caused decreased ability to distinguish Dish and Ditch. Nevertheless, the overall pattern of results revealed that reductions in spectral and temporal information had a relatively larger effect on the ONH participants compared to the YNH participants.
CONCLUSION
Aging reduces the ability to utilize brief temporal cues in speech segments. Reducing spectral information – as occurs in a channel vocoder and in CI speech processing strategies – forces participants to use temporal envelope information; however, older participants are less capable of utilizing this information. These results suggest that providing as much spectral and temporal speech information as possible would benefit older CI users relatively more than younger CI users. In addition, the present findings help set expectations of clinical outcomes for speech understanding performance by adult CI users as a function of age.
INTRODUCTION
There is an increasing number of adults over 65 years old who use cochlear implants (CIs) to partially restore their hearing and understanding of speech. This has occurred because of the continued success of middle-aged CI users who are now aging into the older age range, and because the criteria for implantation have expanded to include older seniors. While CIs in older individuals improve speech understanding and quality of life without undue complications (Chen et al. 2013; Clark et al. 2012; Lin et al. 2012), evidence suggests that that older CI users have poorer speech understanding than younger CI users (Jin et al. 2014; Sladen and Zappler 2014, 2015).
Reduced speech understanding with advancing age has been shown to result from declines in peripheral, central auditory, and cognitive processing (CHABA 1988). Of particular interest for CI users is the well-documented age-related decline in auditory temporal processing across a wide variety of tasks (e.g., Fitzgibbons and Gordon-Salant 1995; Gordon-Salant 2010; Gordon-Salant and Fitzgibbons 2001; Schvartz et al. 2008). For example, it has been shown that aging and hearing loss reduce the ability to identify and discriminate word contrasts that are based on temporal cues (Gordon-Salant et al. 2008; Gordon-Salant et al. 2006). Older participants required longer temporal cue durations for a number of word contrasts such as Dish/Ditch (silence duration), Buy/Pie (voice onset time), Wheat/Weed (vowel duration), and Beat/Wheat (initial consonant transition duration), particularly if the contrasts were embedded in sentences (Gordon-Salant et al. 2008).
To convey speech, CIs present users with electrical pulse trains that are modulated by temporal envelopes using a vocoder-centric approach (Loizou 2006), and it appears that temporal envelope modulation processing impacts speech understanding in CI users (e.g., Fu 2002). Since the spectral resolution of a CI is poor (Friesen et al. 2001), CI users likely rely on temporal information more than normal-hearing (NH) participants (Winn et al. 2012; Winn et al. 2016). Because CI users weight temporal cues more heavily than NH listeners, older CI users with relatively poor temporal processing abilities may be at risk for poor speech perception.
To remove the variability inherent to CI users that results from biological, surgical, and device factors, vocoders have been used as a method to simulate CI sound processing (Shannon et al. 1995). Numerous studies using vocoders have shown that decreasing the number of channels, typically below about 8–10 channels, reduces speech understanding (e.g., Friesen et al. 2001; Goupell et al. 2008; Loizou et al. 1999; Shannon et al. 1995; Stilp and Goupell 2015). The modulations conveyed by the channel envelopes can also be altered by changing the low-pass filter cutoff applied to each of the temporal envelopes. Decreasing envelope cutoff (ECO), typically below about 150 Hz, also reduces speech understanding (Stilp and Goupell 2015; Xu and Pfingst 2008). Some studies have investigated the interaction between the number of channels and envelope cutoff, and found a trade-off in spectral-temporal information (Kim et al. 2015; Stone et al. 2008; Xu and Pfingst 2008; Xu et al. 2005; Xu and Zheng 2007). Such a trade-off has also been observed in actual CI users (Nie et al. 2006).
Older NH individuals are worse at understanding vowels, consonants, and sentences degraded by a vocoder than younger NH individuals (Schvartz et al. 2008; Sheldon et al. 2008a, 2008b). Consistent with the idea that older adults have poorer temporal processing (CHABA 1988; Gordon-Salant 2010), they are also worse at perceiving differences in envelope modulation rate (Schvartz-Leyzac and Chatterjee 2015; Schvartz and Chatterjee 2012; Souza and Boike 2006), seemingly because of decreased temporal processing abilities.
The purpose of this study was to examine the relationship between age-related declines in temporal envelope processing and single word discrimination. To test this relationship, listeners were asked to discriminate the stimulus pair Dish and Ditch, used in a prior investigation (Gordon-Salant et al. 2006), with the intention of clearly drawing the connection between age-related declines in temporal envelope processing to the discrimination of single words based on temporal information. The stimulus pair that showed the largest aging effects in Gordon-Salant (2006) was chosen in the current study to establish that vocoding would alter the magnitude of the age-related temporal processing deficits. YNH and ONH participants completed a phoneme categorization task, in which the silent interval preceding the final sibilant /ʃ/ varied from 0–60 ms, in 10-ms steps, as a cue to the fricative/affricate distinction. That is, the variation in the silent interval changes the listener’s percept from Dish (0-ms silence duration) to Ditch (60-ms silence duration). ONH participants require relatively larger silence durations than YNH participants before unprocessed “Ditch” is perceived, reflecting age-related temporal processing deficits (Gordon-Salant et al. 2006). The novel part of the current study is that the stimuli were also degraded with varied number of spectral channels and varied amount of temporal envelope modulations. We hypothesized that there would be no change from unprocessed to vocoded conditions with relatively high spectral and temporal information, but an age by vocoding interaction would occur for conditions with relatively low spectral information because participants would be forced to rely on temporal cues.
MATERIALS AND METHODS
Participants
Two groups of participants participated in the study: YNH participants (n=19, 18–45 years, mean age and standard deviation = 23.7±6.3) and ONH participants (n=15, 65–78 years, mean age and standard deviation = 70.4±4.1) with normal audiometric hearing, defined as <25 dB HL at octave frequencies from 250 to 4000 Hz. The average thresholds for both groups are shown in Fig. 1. All participants were required to be native speakers of English. Cognitive testing [Montreal Cognitive Assessment (MoCA) Version 7.1 Original Version (Nasreddine et al. 2005)] was used to ensure all participants had normal or near-normal cognitive function, which was defined as scores ≥22.1 The YNH and ONH participants had an average MOCA score of 28.6±1.5 and 27.1±2.7, respectively.
Figure 1.
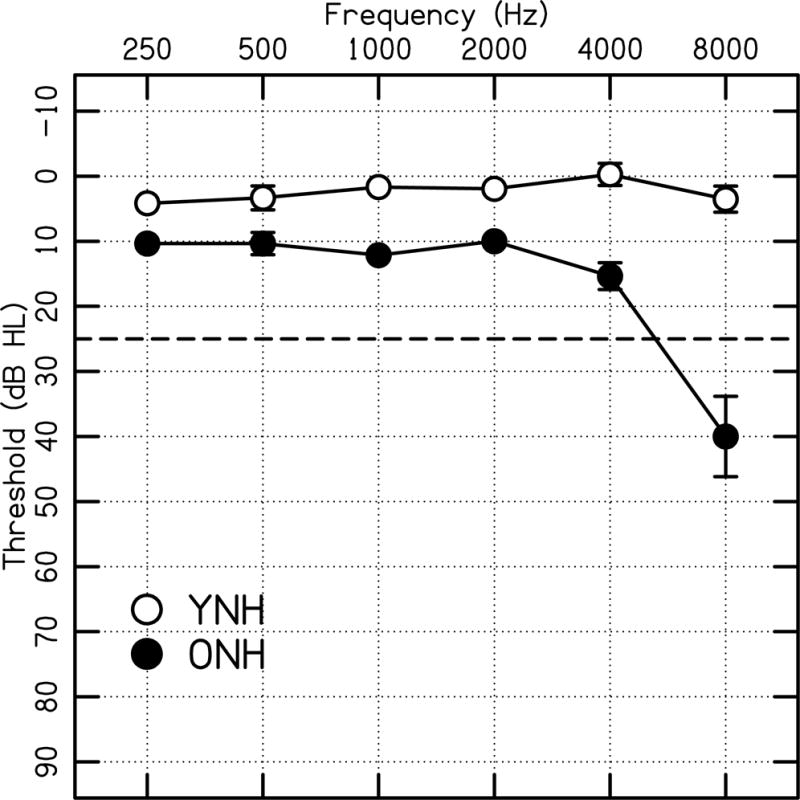
Average pure tone thresholds in dB HL (re: ANSI 2012). Mean thresholds are plotted as open circles for young normal-hearing (YNH) participants and closed circles for older normal-hearing (ONH) participants. Error bars show ±1 standard error.
Equipment
The participants were presented stimuli that were generated on a personal computer running MATLAB (MathWorks, Natick, MA). The stimuli were delivered by a Tucker-Davis Technologies System 3 (RP2.1, PA5, HB7; FL) and a pair of insert earphones (ER2; Etomotyic, Elk Grove Village, IL).
Stimuli
The stimuli were the same speech tokens that were tested in a prior investigation (Gordon-Salant et al. 2006). The test stimuli were created from two natural words, Dish and Ditch, which were recorded in isolation by an adult American male speaker. To create a continuum of speech tokens between Dish and Ditch, the Ditch token was modified to have the burst and frication removed, and replaced with only the frication portion of Dish – this created a hybrid Ditch. Then a seven-step continuum was created by removing 10 ms of segments of the silence duration in the hybrid Ditch. Thus, the final stimulus 1 (Dish) had a silence duration of 0 ms. Stimuli 2–6 had silence durations of 10–50 ms in 10-ms increments, and stimulus 7 (Ditch) had a silence duration of 60 ms. Waveforms and spectrograms of the stimulus continuum endpoints are shown in Figs. 2A and 2B.
Figure 2.
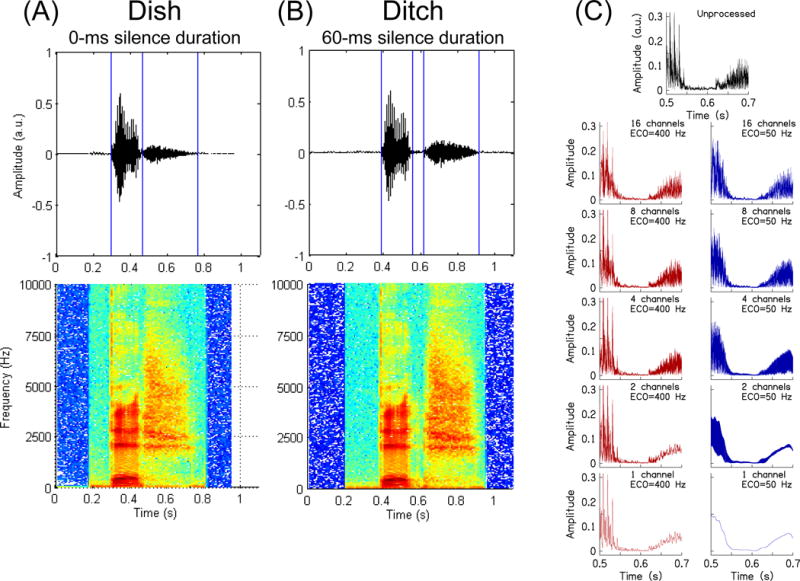
Waveforms (top row) and spectrograms (bottom row) for Dish (0-ms silence duration; column A) and Ditch (60-ms silence duration; column B). Column C shows a 200-ms portion of the Ditch stimulus, centered on the silence duration. Each panel shows the temporal envelope for the unprocessed and vocoded versions of this stimulus.
Once the continuum was constructed, speech segments were vocoded to degrade the speech in a manner similar to the degradation that occurs in CI speech processing. The vocoder bandpass filtered signals into 1, 2, 4, 8, or 16 contiguous channels. The corner frequencies on the bandpass filters were logarithmically spaced from 200 to 8000 Hz. The bandpass filters were 3rd-order Butterworth filters; forward-backward filtering was performed to preserve the timing of the acoustic features of the speech, resulting in a doubling of the filter order and ultimately −36 dB/oct attenuation slope on the filters. The use of forward-backward filtering likely distorted the temporal cues less than one-way filtering and thus minimized such stimulus confounds. The envelope was extracted by calculating the Hilbert envelope and low-pass forward-backward filtering using a 2nd-order Butterworth filter; the low-pass ECO was set to either 50 or 400 Hz. The motivation for using two cutoffs is that a 400-Hz ECO should show large age-related temporal processing differences because the ONH group should not be able to use the higher frequency modulations as well as the YNH group; applying the 50-Hz ECO may reduce the temporal cues to the point that the YNH group might perform similar to the ONH group (i.e., the YNH group will appear older in their temporal processing abilities) (Schvartz-Leyzac and Chatterjee 2015). The extracted envelopes modulated sinusoidal carriers that were at the geometric mean frequency of the channel. The channels were summed and the final vocoded stimulus had the same root-mean-square energy as the unprocessed stimuli. The temporal envelope of the waveform for different conditions is shown in Fig. 2C. This figure shows the smoothing of the temporal envelope as the number of channels and ECO are reduced.
Procedure
MATLAB was used to control the experiment and record the participants’ responses. During testing, a monitor displayed three boxes. One box read “Begin Trial” followed by the presentation of two side-by-side boxes below. The box to the left read “Dish” and the box to the right read “Ditch.” The participant initiated each trial and thus testing was self-paced. The stimuli were presented monaurally over insert earphones in a sound attenuated chamber at 65 dB-A to the better ear of the participant. The better ear was defined as the ear with the better pure tone hearing threshold average between 250 and 4000 Hz. Upon stimulus presentation, the participant identified whether the sound was perceived as Dish or Ditch. If unsure, participants were told to take their best guess. Participants did not receive feedback during the experimental runs.
Prior to testing, each participant performed a training exercise. They were presented with the endpoint stimuli (stimulus 1 – a clear Dish, and stimulus 7 – a clear Ditch). Both of these stimuli were presented in two processing conditions: (1) unprocessed and (2) vocoded with 16 channels and ECO=400 Hz (i.e., the vocoder condition with the most spectral and temporal information tested in this study). Participants heard 10 repetitions of these two “processing” conditions for two separate stimuli (2×2×10 = 40 trials), and received correct-answer feedback after each response. The training task was conducted to verify that the participants’ word recognition performance of Dish and Ditch was above 90 percent correct. A high word recognition score ensured that the participant was able to distinctly identify the difference between the endpoint speech stimuli, thus ensuring participants had a clear perception of the different consonant word pairs. If the participant has trouble identifying the endpoint stimuli of the continuum, theoretically the easiest stimuli to identify, then it can be assumed they will have more trouble during less defined boundaries of speech segments, providing unreliable data for the experiment. The training task also established stable performance for participants because of the correct answer feedback. The participant was given 15 minutes of training to reach the designated word recognition performance level and establish stable performance. All participants achieved near perfect discrimination during the training procedure.
After participants were familiarized with and trained on identifying the endpoint stimuli, they were presented with the entire stimulus continuum. The seven stimuli were unprocessed and vocoded by varying the number of channels (1, 2, 4, 8, or 16) and the low-pass filter envelope cutoff (ECO=50 or 400 Hz). Thus, there were 11 processing conditions. In a run, two trials of each condition were presented in random order for a total of 154 stimulus presentations (7 silence durations × 11 processing conditions × 2 trials/condition). Five runs were completed for a total of 770 stimulus trials. In summary, each of the seven stimuli along the continuum were presented 10 times for each type of the 11 types of processing (unprocessed and vocoded).
Analysis
For each condition, the percentage of Dish responses was calculated. For a given speech contrast and condition, the resulting psychometric function was fit using a logistic regression (psignifit; Wichmann and Hill, 2001). From this fit, the value at which 50% of the responses occurred was found, called the 50% crossover point; this represents the boundary marking a change in stimulus categorization. For several conditions, particularly with 1 or 2 channels, participants did not necessarily distinguish the speech contrast well and there was no crossover point. In such cases, the 50% crossover point was either inferred out to 70 ms from an extrapolation of the curve fit or set to a maximum of 70 ms. Such a decision assumes that larger silence durations are necessary to produce the perception of the word Ditch.
The value of the slope was also calculated. For cases where the participant heard a distinct Dish/Ditch for the endpoints (i.e., they had near 100% and 0% identification for the contrast continuum endpoints), the maximum slope occurred at the 50% crossover point. For conditions where the 50% crossover did not occur within 0–60 ms, the maximum slope of the function between 0 and 60 ms was chosen. The psychometric function slopes computed using psignifit were at times unreasonably steep in cases where the percent of Dish identification went from near 100% to near 0% in a single step, which was a result of the numerical fitting procedure. For the present analyses, the steepest possible slope deemed appropriate was 7.5%/ms.
Inferential statistics, mixed analyses of variance (ANOVAs), were performed. In cases where Mauchly’s test indicated that the assumption of sphericity had been violated, the Greenhouse-Geisser correction was used to adjust the degrees of freedom.
RESULTS
Figure 3 shows the results from the experiment. Figure 3A compares the unprocessed data from this study and those from Gordon-Salant et al. (2006). The curve for the present study is shifted to the right of the previous study, likely a result of using different presentation levels (65 vs 85 dB-A), use of different participants, or because we did not use masking noise for the YNH participants. The unprocessed data are also plotted in the other panels (Figs. 3B–K) to compare the performance for the vocoded conditions.
Figure 3.
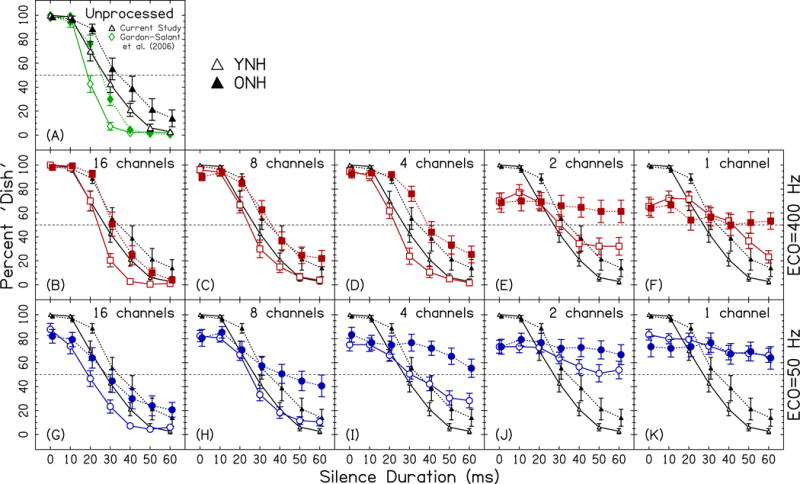
Dish/Ditch response functions. Data points represent the percentage of trials identified as Dish as a function of silence duration, averaged over participants. Error bars show ±1 standard error. Open symbols show data for YNH participants; closed symbols show data for ONH participants. Panel (A) shows the data for the unprocessed conditions from the current study (black upward triangles) and Gordon-Salant et al. (2006; green diamonds). Panels (B–K) show the data for the vocoded conditions (larger symbols), and also the data for the unprocessed conditions (smaller symbols). Red squares show the data for the ECO=400-Hz conditions in panels B–F. Blue circles show the data for the ECO=50-Hz conditions in panels G–K.
Focusing on just the YNH participants, Figs. 3B, 3C, 3G, and 3H show the participants’ performance for the 16- and 8-channel conditions. These vocoded conditions are quite similar to the unprocessed conditions, a notable deviation being less than 100% Dish responses at 0 ms for ECO=50 Hz (Figs. 3G–H). Figures 3D and 3I show the YNH participants’ performance for the 4-channel condition. For this relatively small number of spectral channels, the unprocessed and ECO=400 Hz conditions remain similar; however, the ECO=50 Hz deviates greatly from the unprocessed condition because the curve has become much more shallow. These data are consistent with our hypothesis that temporal cues become more important when there are reduced spectral cues. Figures 3E, 3F, 3J, and 3K show the YNH participants’ performance for the 2- and 1-channel conditions, respectively. For these conditions, slopes also became more shallow, particularly for the ECO=50 Hz condition (Figs. 3J–K).
Now focusing on the data of the ONH participants in Fig. 3, many of the age-related trends occur in several conditions. For example, ONH participants almost always had larger crossover durations and shallower slopes than the YNH participants, the largest differences occurring at 4 channels. For fewer channels, there is a lack of categorical perception, particularly for the ONH participants.
We performed a four-way mixed ANOVA using the dependent variable % of Dish responses with factors age (between-subjects), ECO (within-subjects), number of channels (within-subjects), and silence duration (within-subjects). The results of the analysis are reported in Table I and the level of significance was chosen to be p<0.05. Three main effects were significant (age, channels, and silence duration) and one was not (ECO). Of primary interest for this study was the possible significant interactions with age. The age×channels, age×silence duration, age×channels×silence duration, and age×channels×ECO×silence duration interactions were significant. In addition, the non-age-based interactions channels×ECO, channels×duration, ECO×duration, and channels×ECO×duration were also significant.
Table I.
Results of the four-way mixed ANOVA. df = degrees of freedom.
| Factors | df | F | p |
|
||
|---|---|---|---|---|---|---|
| Between | Within | |||||
| Age | 1.00 | 32.00 | 18.32 | <0.001 | 0.36 | |
| Channels | 2.21 | 70.58 | 15.66 | <0.0001 | 0.33 | |
| ECO | 1.00 | 32.00 | 2.99 | 0.093 | 0.09 | |
| Silence Duration | 2.01 | 64.30 | 196.27 | <0.0001 | 0.86 | |
| Age × Channels | 2.21 | 70.58 | 4.02 | 0.019 | 0.11 | |
| Age × ECO | 1.00 | 32.00 | 0.11 | 0.747 | 0.00 | |
| Age × Silence Duration | 2.01 | 64.30 | 11.63 | <0.0001 | 0.27 | |
| Channels × ECO | 2.60 | 83.02 | 5.56 | 0.003 | 0.15 | |
| Channel × Silence Duration | 7.75 | 248.01 | 44.21 | <0.0001 | 0.58 | |
| ECO × Silence Duration | 3.77 | 120.69 | 33.78 | <0.0001 | 0.51 | |
| Age × Channels × ECO | 2.59 | 83.02 | 0.26 | 0.827 | 0.01 | |
| Age × Channels × Silence Duration | 7.75 | 248.01 | 2.90 | 0.005 | 0.08 | |
| Age × ECO × Silence Duration | 3.77 | 120.69 | 1.54 | 0.198 | 0.05 | |
| Channels × ECO × Silence Duration | 11.50 | 368.12 | 4.00 | <0.0001 | 0.11 | |
| Age × Channels × ECO × Silence Duration | 11.50 | 368.12 | 3.04 | <0.001 | 0.09 | |
In an attempt to better understand the interactions, we calculated slopes and crossover points (see analysis section) to summarize the data and more easily compare the two groups. Figure 4 shows the slopes of the performance functions in Fig. 3, a comparison between the YNH and ONH groups. Figure 4C shows the difference in slopes between the two age groups across conditions, where the YNH participants had slightly steeper slopes than the ONH participants for the unprocessed condition (0.3%/ms) and steeper slopes in all vocoding conditions except for 2 channels, ECO=50 Hz. In other words, using ECO=50 Hz makes the temporal processing of the YNH participants more like the ONH participants. For the vocoded conditions, the data were analyzed with a three-way mixed ANOVA with factors age (between-subjects), channels (within-subjects), and ECO (within-subjects). YNH participants had significantly steeper slopes than ONH participants [F(1,32)=6.65, p=0.015, =0.17], confirming the existence of age-related temporal processing differences. Slopes became shallower with a decreasing number of channels [F(2.6, 83.4)=53.2, p<0.0001, =0.62], indicating that it was more difficult to discriminate Dish and Ditch with less spectral information. Slopes became shallower with a decreasing ECO [F(1,32)=87.4, p<0.0001, =0.73], indicating that it was more difficult to discriminate Dish and Ditch with less temporal information. Most importantly, there was a significant channels×ECO interaction [F(4,128)=12.0, p<0.0001, =0.27] where the difference in slopes between ECO=50 and 400 Hz became smaller with decreasing number of channels. The age×channels [F(2.6,83.4)=1.12, p=0.34, =0.03], age×ECO [F(1,32)=3.55, p=0.069, =0.10], and age×channels×ECO interactions [F(4,128)=0.99, p=0.42, =0.03] were all not significant, indicating the slopes did not significantly change across the two groups depending on the vocoding parameters. This can be seen in the relatively parallel curves in Fig. 4C.
Figure 4.
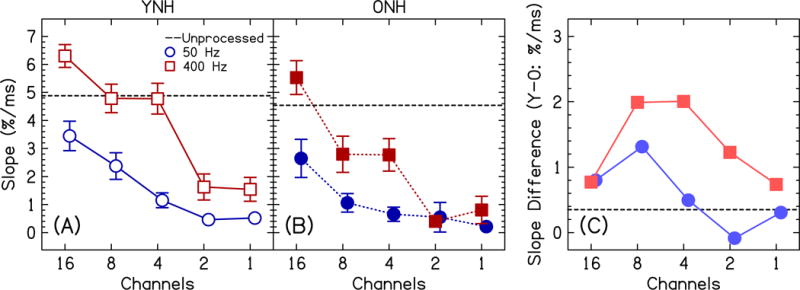
Slope of Dish/Ditch response functions for the YNH group (panel A; open symbols) and the ONH group (panel B; closed symbols) as a function of the number of channels. The slopes for the unprocessed data are shown by the horizontal dashed line in each panel. The vocoded conditions are also plotted for the two ECOs (50 Hz=blue circles; 400 Hz=red squares). Error bars show ±1 standard error. Panel C shows the average difference in slope between the YNH and ONH listeners (positive numbers show larger age-related temporal processing deficits). Panel C uses light red and light blue symbols to signify that it is the difference between the YNH and ONH groups. In panel C, positive numbers show larger age-related temporal processing deficits.
Figure 5 shows the 50% crossover point of the performance functions in Fig. 3, a comparison between the YNH and ONH groups. Figure 5C shows the difference in crossover points across the two age groups, where the ONH participants needed a 9.8-ms longer silence duration than the YNH participants before Ditch was perceived for the unprocessed stimuli. For the vocoded conditions, the data were analyzed with a three-way mixed ANOVA with factors age (between-subjects), channels (within-subjects), and ECO (within-subjects). YNH participants exhibited significantly shorter silence durations to change their percept from Dish to Ditch than ONH participants [F(1,32)=19.5, p<0.001, =0.38], confirming the existence of age-related temporal processing differences. Crossovers were longer with a decreasing number of channels [F(2.8,89.5)=60.7, p<0.0001, =0.66], indicating that longer silence durations were necessary to perceive Ditch when there was less spectral information. Crossovers were longer for a decreasing ECO [F(1,32)=14.2, p=0.001, =0.31], indicating that longer silence durations were necessary to perceive Ditch when there was less temporal information. There was a significant channels×ECO interaction [F(3.1, 100.4)=3.1, p=0.029, =0.09], where listeners needed even longer silence durations to perceive Ditch for ECO=50 Hz compared to 400 Hz, particularly for 4 and 2 channels. This again supports the hypothesis that temporal cues become more necessary in the absence of spectral cues. The interactions with age were not significant [age×channels: F(2.8,89.5)=2.2, p=0.099, =0.06; age×ECO: F(1,32)=13.4, p=0.84, =0.001; age×channels×ECO: F(3.1, 100.4)=0.83, p=0.49, =0.03].
Figure 5.
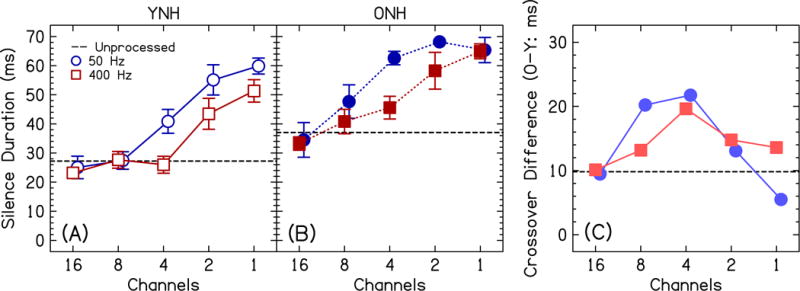
Crossover of response functions for the YNH group (panel A; open symbols) and the ONH group (panel B; closed symbols) as a function of the number of channels. All conventions are the same as in Fig. 4.
The three-way mixed ANOVAs using slope or crossover as the dependent variable did not show significant interactions with age, which is contrary to the significant interactions found in the four-way mixed ANOVA using percentage of Dish responses. This likely occurred for several reasons. First, the slope and crossover are summary metrics and there is much less statistical power when using them. Second, these summary metrics assume well-behaved sigmoidal functions where the endpoints are highly discriminable. Our data, however, do not follow this assumption particularly as the number of channels and ECO were reduced. Third, ceiling and floor effects were much more prevalent with the summary metrics. For example, a ceiling effect on the longest crossover (set to the arbitrarily large value of 70 ms for our analysis) likely contributed to the lack of interactions with age. Finally, these summary metrics do not necessarily capture the information on the endpoints of the silence duration continuum, where some of the largest age-related differences can be seen in Fig. 3. Therefore, our interpretation is that while the summary metrics shown in Figs. 4 and 5 are useful for seeing some of the trends in the age-related changes in temporal processing and also allows for easier comparison with the previous study by Gordon-Salant et al. (2006), the most accurate picture of the data is demonstrated in Fig. 3.
In summary, the experiment showed age-related temporal processing deficits through a main effect of age (Table I; Figs. 3–5) and multiple significant interactions with age (Table I; Fig. 3).
DISCUSSION
The purpose of this study was to better understand how aging, particularly age-related temporal processing deficits, might affect speech understanding in CI users. CI sound processors are vocoder-centric, meaning that temporal envelope information is primarily used to convey speech information (Shannon et al. 1995), a result of CI stimulation patterns having relatively poor spectral resolution compared to the normal ear (Friesen et al. 2001). Testing YNH and ONH participants, we presented vocoded versions of a single word contrast – Dish/Ditch – where the spectral (number of vocoder channels) and temporal information (low-pass filter cutoff applied to the temporal envelope or ECO) were varied. This word contrast has been previously shown to highlight age-related temporal processing deficits when presented as unaltered acoustic signals (i.e., not vocoded; Gordon-Salant et al. 2006). We hypothesized that age-related temporal processing deficits would become more apparent as the spectral information was reduced and participants were forced to utilize the temporal cues to distinguish the words.
Figure 3 shows the results of the experiment for the YNH and ONH participants, respectively. The age-related temporal processing deficits for the unprocessed conditions (Fig. 3A) were replicated from Gordon-Salant et al. (2006). The increase in silence duration needed to cross 50% perceived Dishes was 9.8 ms for the current study, which can be compared to 5.5 ms for the former study. One difference between studies is that both YNH and ONH participant response functions were shifted to longer silence durations in this study compared to the former. These changes in the response patterns between studies were likely because we tested at a lower presentation level than the other study, we tested different participants (potentially more hearing loss in our participants; Fig. 1), and our YNH group was not presented masking noise in an attempt to equate performance between the YNH and ONH groups.
Responses for both listener groups were similar between the unprocessed conditions and conditions with a large (e.g., 16) number of channels and higher ECO (400 Hz). Deviations from the unprocessed condition grew larger as the number of channels and/or ECO were reduced. For example, the words became less discriminable, shown in the slopes that are plotted in Fig. 4. The point at which the word Ditch was perceived occurred at longer silence durations than the unprocessed condition, shown as the duration at which the response functions crossed the 50% point in Fig. 5. These two metrics highlight the importance of examining the entire function, especially perception of stimuli with silence durations in the middle of the speech continuum; however, some of the largest age-related differences in performance occurred near the endpoints of silence duration (Fig. 3), which resulted in multiple interactions with age (Table I).
Such information may also inform the nature of age-related temporal processing deficits. It could be that the age-related differences for the unprocessed stimuli are a result of peripheral or central processing deficits, or a mix of the two (see differences in hearing thresholds in Fig. 1). If there were no age-related central processing deficits, then no interactions with age would have been seen and one could argue a completely peripheral temporal processing deficit. The data from this experiment, however, with its multiple interactions with age that are a result of larger effects in the older participants compared to the younger as spectral and temporal information are reduced (Table I; Fig. 3) argue for some central component to the age-related temporal processing deficits.
Finally, these results suggest that older CI users should also be susceptible to such temporal processing deficits, which should ultimately reduce speech understanding. While previous studies have shown mixed results on whether aging and age-related temporal processing deficits affect speech understanding with a CI, there is mounting evidence that older CI listeners perform worse than their younger peers, particularly when duration of deafness is accounted for in the study (Beyea et al. 2016; Sladen and Zappler 2015). Many studies in this area use sentence recognition as a metric for CI performance. One advantage of the testing paradigm used in this study is that it targets aspects of single words that might be particularly difficult for older CI users to process. The combination of advancing age with spectrally degraded signals – which force participants to rely on temporal cues – should exacerbate the age-related temporal processing deficits that are well known to occur. The results of this study are generally consistent with Winn et al. (2012), who showed that vocoding caused NH participants to rely more on temporal cues when the spectral cues were degraded; however, they did not investigate effects of age. Winn et al. (2012) also tested CI participants and found that the NH and CI participants might be using different sets of cues to discriminate phonemes. Therefore, continuing phoneme discrimination research with both NH and CI participants, and including potential effects of aging is a promising avenue for future research because it will better inform why older CI users are performing worse than their younger peers at perceiving speech. Clearly, testing only one phoneme contrast limits the ability to generalize to other temporally based phoneme contrasts. Nonetheless, the present research highlights the added importance of technological advancement to provide better spectral resolution for older CI users compared to younger for improved clinical outcomes. Clinicians also benefit from this information to help advise older candidates on proper expectations for speech understanding with a CI.
Acknowledgments
We would also like to thank Calli Fodor for help in data collection. This work was supported by NIH Grant R01 AG051603 (M.J.G.), NIH Grant R37 AG09191 (S.G.S.), a seed grant from the University of Maryland-College Park College of Behavioral and Social Sciences, and a seed grant from the University of Maryland-College Park Brain and Behavior Initiative (BBI). We would also like to thank the Student Research Initiative and Maryland Summer Scholars programs at the University of Maryland who funded Casey Gaskins to work on this project.
Footnotes
Normal cognitive functioning is defined as a MOCA score of ≥26; mild cognitive impairment is defined as having a MOCA score 22–25 (Cecato et al. 2016). We included participants with mild cognitive impairment in this study because: (1) requiring participants to have audiometrically normal hearing and a MOCA score ≥26 limits recruiting, (2) the discrimination task is relatively simple such that someone with mild cognitive impairment has no problem performing it, and (3) previous studies have used such a inclusion criterion (Anderson et al. 2012). We found no correlations between performance on the perceptual task and the MOCA, further justifying our choice.
References
- Anderson S, Parbery-Clark A, White-Schwoch T, et al. Aging affects neural precision of speech encoding. J Neurosci. 2012;32:14156–14164. doi: 10.1523/JNEUROSCI.2176-12.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Beyea JA, McMullen KP, Harris MS, et al. Cochlear implants in adults: Effects of age and duration of deafness on speech recognition. Otol Neurotol. 2016;37:1238–1245. doi: 10.1097/MAO.0000000000001162. [DOI] [PubMed] [Google Scholar]
- Cecato JF, Martinelli JE, Izbicki R, et al. A subtest analysis of the Montreal cognitive assessment (MoCA): Which subtests can best discriminate between healthy controls, mild cognitive impairment and Alzheimer’s disease? Int Psychogeriatr. 2016;28:825–832. doi: 10.1017/S1041610215001982. [DOI] [PubMed] [Google Scholar]
- CHABA. Speech understanding and aging. J Acoust Soc Am. 1988;83:859–895. [PubMed] [Google Scholar]
- Chen DS, Clarrett DM, Li L, et al. Cochlear implantation in older adults: Long-term analysis of complications and device survival in a consecutive series. Otol Neurotol. 2013;34:1272–1277. doi: 10.1097/MAO.0b013e3182936bb2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Clark JH, Yeagle J, Arbaje AI, et al. Cochlear implant rehabilitation in older adults: Literature review and proposal of a conceptual framework. J Am Geriatr Soc. 2012;60:1936–1945. doi: 10.1111/j.1532-5415.2012.04150.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fitzgibbons PJ, Gordon-Salant S. Age effects on duration discrimination with simple and complex stimuli. J Acoust Soc Am. 1995;98:3140–3145. doi: 10.1121/1.413803. [DOI] [PubMed] [Google Scholar]
- Friesen LM, Shannon RV, Başkent D, et al. Speech recognition in noise as a function of the number of spectral channels: Comparison of acoustic hearing and cochlear implants. J Acoust Soc Am. 2001;110:1150–1163. doi: 10.1121/1.1381538. [DOI] [PubMed] [Google Scholar]
- Fu QJ. Temporal processing and speech recognition in cochlear implant users. Neuroreport. 2002;13:1635–1639. doi: 10.1097/00001756-200209160-00013. [DOI] [PubMed] [Google Scholar]
- Gordon-Salant S. The Aging Auditory System. New York, NY: Springer; 2010. [Google Scholar]
- Gordon-Salant S, Fitzgibbons PJ. Sources of age-related recognition difficulty for time-compressed speech. J Speech Lang Hear Res. 2001;44:709–719. doi: 10.1044/1092-4388(2001/056). [DOI] [PubMed] [Google Scholar]
- Gordon-Salant S, Yeni-Komshian G, Fitzgibbons P. The role of temporal cues in word identification by younger and older adults: effects of sentence context. J Acoust Soc Am. 2008;124:3249–3260. doi: 10.1121/1.2982409. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gordon-Salant S, Yeni-Komshian GH, Fitzgibbons PJ, et al. Age-related differences in identification and discrimination of temporal cues in speech segments. J Acoust Soc Am. 2006;119:2455–2466. doi: 10.1121/1.2171527. [DOI] [PubMed] [Google Scholar]
- Goupell MJ, Laback B, Majdak P, et al. Effects of upper-frequency boundary and spectral warping on speech intelligibility in electrical stimulation. J Acoust Soc Am. 2008;123:2295–2309. doi: 10.1121/1.2831738. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jin SH, Liu C, Sladen DP. The effects of aging on speech perception in noise: Comparison between normal-hearing and cochlear-implant listeners. J Am Acad Audiol. 2014;25:656–665. doi: 10.3766/jaaa.25.7.4. [DOI] [PubMed] [Google Scholar]
- Kim BJ, Chang SA, Yang J, et al. Relative contributions of spectral and temporal cues to Korean phoneme recognition. PLoS One. 2015;10:e0131807. doi: 10.1371/journal.pone.0131807. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin FR, Chien WW, Li L, et al. Cochlear implantation in older adults. Medicine (Baltimore) 2012;91:229–241. doi: 10.1097/MD.0b013e31826b145a. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Loizou PC. Speech processing in vocoder-centric cochlear implants. In: Moller A, editor. Cochlear and brainstem implants. Basel, Switzerland: Karger; 2006. pp. 109–143. [DOI] [PubMed] [Google Scholar]
- Loizou PC, Dorman M, Tu Z. On the number of channels needed to understand speech. J Acoust Soc Am. 1999;106:2097–2103. doi: 10.1121/1.427954. [DOI] [PubMed] [Google Scholar]
- Nasreddine ZS, Phillips NA, Bédirian V, et al. The Montreal Cognitive Assessment, MoCA: A brief screening tool for mild cognitive impairment. J Am Geriatr Soc. 2005;53:695–699. doi: 10.1111/j.1532-5415.2005.53221.x. [DOI] [PubMed] [Google Scholar]
- Nie K, Barco A, Zeng FG. Spectral and temporal cues in cochlear implant speech perception. Ear Hear. 2006;27:208–217. doi: 10.1097/01.aud.0000202312.31837.25. [DOI] [PubMed] [Google Scholar]
- S3.5–1997, A. American National Standards for Calculation of the Speech Intelligibility Index 2012 [Google Scholar]
- Schvartz-Leyzac KC, Chatterjee M. Fundamental-frequency discrimination using noise-band-vocoded harmonic complexes in older listeners with normal hearing. J Acoust Soc Am. 2015;138:1687–1695. doi: 10.1121/1.4929938. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schvartz KC, Chatterjee M. Gender identification in younger and older adults: Use of spectral and temporal cues in noise-vocoded speech. Ear Hear. 2012;33:411–420. doi: 10.1097/AUD.0b013e31823d78dc. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schvartz KC, Chatterjee M, Gordon-Salant S. Recognition of spectrally degraded phonemes by younger, middle-aged, and older normal-hearing listeners. J Acoust Soc Am. 2008;124:3972–3988. doi: 10.1121/1.2997434. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shannon RV, Zeng FG, Kamath V, et al. Speech recognition with primarily temporal cues. Science. 1995;270:303–304. doi: 10.1126/science.270.5234.303. [DOI] [PubMed] [Google Scholar]
- Sheldon S, Pichora-Fuller MK, Schneider BA. Effect of age, presentation method, and learning on identification of noise-vocoded words. J Acoust Soc Am. 2008a;123:476–488. doi: 10.1121/1.2805676. [DOI] [PubMed] [Google Scholar]
- Sheldon S, Pichora-Fuller MK, Schneider BA. Priming and sentence context support listening to noise-vocoded speech by younger and older adults. J Acoust Soc Am. 2008b;123:489–499. doi: 10.1121/1.2783762. [DOI] [PubMed] [Google Scholar]
- Sladen DP, Zappler A. Older and Younger Adult Cochlear Implant Users: Speech Recognition in Quiet and Noise, Quality of Life, and Music Perception. Am J Audiol. 2014 doi: 10.1044/2014_AJA-13-0066. [DOI] [PubMed] [Google Scholar]
- Sladen DP, Zappler A. Older and younger adult cochlear implant users: Speech recognition in quiet and noise, quality of life, and music perception. Am J Audiol. 2015;24:31–39. doi: 10.1044/2014_AJA-13-0066. [DOI] [PubMed] [Google Scholar]
- Souza PE, Boike KT. Combining temporal-envelope cues across channels: Effects of age and hearing loss. J Speech Lang Hear Res. 2006;49:138–149. doi: 10.1044/1092-4388(2006/011). [DOI] [PubMed] [Google Scholar]
- Stilp CE, Goupell MJ. Spectral and temporal resolutions of information-bearing acoustic changes for understanding vocoded sentences. J Acoust Soc Am. 2015;137:844–855. doi: 10.1121/1.4906179. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stone MA, Fullgrabe C, Moore BC. Benefit of high-rate envelope cues in vocoder processing: Effect of number of channels and spectral region. J Acoust Soc Am. 2008;124:2272–2282. doi: 10.1121/1.2968678. [DOI] [PubMed] [Google Scholar]
- Winn MB, Chatterjee M, Idsardi WJ. The use of acoustic cues for phonetic identification: Effects of spectral degradation and electric hearing. J Acoust Soc Am. 2012;131:1465–1479. doi: 10.1121/1.3672705. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Winn MB, Won JH, Moon IJ. Assessment of spectral and temporal resolution in cochlear implant users using psychoacoustic discrimination and speech cue categorization. Ear Hear. 2016;37:e377–e390. doi: 10.1097/AUD.0000000000000328. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xu L, Pfingst BE. Spectral and temporal cues for speech recognition: implications for auditory prostheses. Hear Res. 2008;242:132–140. doi: 10.1016/j.heares.2007.12.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xu L, Thompson CS, Pfingst BE. Relative contributions of spectral and temporal cues for phoneme recognition. J Acoust Soc Am. 2005;117:3255–3267. doi: 10.1121/1.1886405. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xu L, Zheng Y. Spectral and temporal cues for phoneme recognition in noise. J Acoust Soc Am. 2007;122:1758. doi: 10.1121/1.2767000. [DOI] [PubMed] [Google Scholar]