

Abstract
Objectives
It is well known from previous research that when listeners are told what they are about to hear before a degraded or partially masked auditory signal is presented, the speech signal “pops out” of the background and becomes considerably more intelligible. The goal of this research was to explore whether this priming effect is as strong in older adults as in younger adults.
Design
Fifty-six adults – 28 older and 28 younger – listened to “nonsense” sentences spoken by a female talker in the presence of a two-talker speech masker (also female) or a fluctuating speech-like noise masker at five signal-to-noise ratios. Just prior to, or just after, the auditory signal was presented, a typed caption was displayed on a computer screen. The caption sentence was either identical to the auditory sentence or differed by one key word. The subjects’ task was to decide whether the caption and auditory messages were the same or different. Discrimination performance was reported in d′. The strength of the pop-out perception was inferred from the improvement in performance that was expected from the caption-before order of presentation. A subset of 12 subjects from each group made confidence judgments as they gave their responses, and also completed several cognitive tests.
Results
Data showed a clear order effect for both subject groups and both maskers, with better same-different discrimination performance for the caption-before condition than the caption-after condition. However, for the two-talker masker, the younger adults obtained a larger and more consistent benefit from the caption-before order than the older adults across signal-to-noise ratios. Especially at the poorer signal-to-noise ratios, older subjects showed little evidence that they experienced the pop-out effect that is presumed to make the discrimination task easier. On average, older subjects also appeared to approach the task differently, being more reluctant than younger subjects to report that the captions and auditory sentences were same. Correlation analyses indicated a significant negative association between age and priming benefit in the two-talker masker and non-significant associations between priming benefit in this masker and either high-frequency hearing loss or performance on the cognitive tasks.
Conclusions
Previous studies have shown that older adults are at least as good, if not better, at exploiting context in speech recognition, as compared to younger adults. The current results are not in disagreement with those findings but suggest that, under some conditions, the automatic priming process that may contribute to context benefits is not as strong in older as in younger adults.
INTRODUCTION
An abundance of previous research has shown that listeners can take advantage of various forms of context in order to improve performance in speech perception tasks. Words that can be predicted from sentence context are more accurately recognized than unpredictable words (e.g., Kalikow et al., 1977). Sentences are more accurately recognized when the topic of the sentence is known than when it is not (Helfer & Freyman, 2008). Recognition for sentences improves when subjects have seen words related to the sentence that will be presented a few seconds later (Zekveld et al., 2011, 2012, 2013). Listeners’ ability to exploit this type of context is especially useful under the most adverse listening conditions (e.g., Zekveld et al., 2011).
As a result of the well-documented auditory communication difficulties experienced by older adults, it is important for this population of listeners to be able to take advantage of various forms of linguistic context effectively. The general finding across studies is that older adults are at least as good and sometimes better at exploiting sentence context as younger adults (Perry & Wingfield, 1994; Wingfield et al., 1994; Pichora-Fuller et al., 1995: Frisina & Frisina, 1997; Gordon-Salant & Fitzgibbons, 1997; Sommers & Danielson, 1999; Dubno et al., 2000; Wingfield et al., 2005; Helfer & Freyman, 2008; Sheldon et al., 2008; Benichov et al., 2012; Woods et al., 2012; Lash et al., 2013).
Less well studied, and the topic of the current paper, is the effect of aging on automatic “priming” processes that occur when message content is mostly or completely known ahead of time. An example of benefit from priming is that highly degraded acoustic signals derived from speech, such as sentences processed with noise vocoding, can appear remarkably clear if a listener has prior knowledge of the message content (e.g., Davis et al., 2005; Sheldon et al., 2008; Wild et al., 2012; Sohoglu et al., 2014). Providing this type of preview of a message could be considered an extreme form of context. However, this priming effect can be observed with “nonsense” sentences where there is little semantic predictability of upcoming words (e.g., Jones & Freyman, 2012).
The increased clarity observed in priming tasks appears to be automatic and may be tied to the concept of implicit memory (e.g., Meyer & Schvaneveldt, 1971; Rodiger, 1990; Schacter & Church, 1992). A meta-analysis of numerous studies on implicit priming suggests that the effects of aging are rather small (La Voie & Light, 1994). However, the experimental paradigms in the studies reviewed do not generally include conditions that allow the measurement of how a prime that is identical to and immediately precedes a test stimulus affects recognition of that stimulus. It is not straightforward to measure the enhanced intelligibility in such conditions because, after exposure to a priming message immediately in advance of a test message (or simultaneously with it), a subject could simply remember the prime and report what is remembered even if the acoustic message is poorly perceived. Therefore, studies of this phenomenon have sometimes used subjective judgments of increased clarity or perceived noisiness of the background (e.g., Jacoby et al., 1988; Rankovic & Levy, 1997; Wild et al., 2012; Sohoglu et al., 2014).
There have been attempts to measure priming effects on intelligibility objectively. If all but the last key word of a masked nonsense sentence is presented ahead of the stimulus, that primed portion of the message pops out of the background, which can lead to increased intelligibility of the last (unprimed and unpredictable) word in the non-meaningful sentence (Freyman et al., 2004). The effect is much greater for (same sex) speech maskers than noise maskers, presumably because the benefit of the perceptual pop out of the target continues even for the unprimed last key word through processes related to auditory streaming, which could be important for overcoming the informational type of masking. Using this task, two studies found that older subjects benefited as much or more from priming as younger subjects (Sheldon et al., 2008 with noise vocoding, and Ezzatian et al., 2011 in a competing speech task). These results are also generally consistent with the findings of Getzmann et al. (2014), who showed that a linguistic prime had similar benefits for older and younger adults in a discrimination task. However, that study found evidence of age-group differences in the processing of the cues, as revealed by event-related potential (ERP) data. Also, the results of a study very similar to Ezzatian et al. (2011) with Chinese nonsense sentences (Wu et al., 2012) showed reduced effects of priming in older subjects. An explanation for the differences in results was not obvious (Wu et al., 2012). As noted above, because the last (test) word was never primed, its intelligibility may depend on other processes besides the pop-out effect, such as the continuity of the auditory sentence stream as it progresses from primed to unprimed words. It is possible that the particular stimulus conditions used by Wu et al. (2012), which included synthetically created sentences rather than recorded sentences, caused older adults to have difficulty with this streaming process.
The current effort to study priming used an alternative method of objective quantification. Specifically, we used the same/different paradigm from Jones & Freyman (2012). On half the trials the entire nonsense sentence is primed with a written caption. On the other half one key word in the sentence is replaced with a foil. The subject’s task is to determine whether the caption matches the acoustic sentence via a same-different judgment. The foil trials allowed for the measurement of performance in d’. Subjects’ performance when the caption is presented before the auditory message was compared to when the caption is presented after the auditory message. The reasoning behind the approach is that in the caption-before condition the clarity of the auditory message should increase due to priming. The comparison with the caption should therefore be easier in that condition than when the caption follows the auditory signal. Jones & Freyman (2012) showed significant improvements in the caption-before order relative to the caption-after order in the presence of both speech and noise maskers. Sohoglu et al. (2014) demonstrated a similar order effect using noise vocoded speech. In Freyman et al. (2015), priming effects using the same-different task were demonstrated for nonsense sentences presented in a two-talker babble presented spatially, non-spatially, and time-reversed, and for vocoded speech in continuous noise.
The current study compared younger and older adults’ performance on this same-different task, in particular on the difference in performance between caption-before and caption-after orders of presentation. Although use of context in speech perception has been shown to be undiminished or even enhanced with aging, it is less clear whether the automatic pop-out effect (where the prime is providing context) that is so strong in younger listeners is similarly strong in older listeners. Based on data obtained from different paradigms than the one used here (Sheldon et al., 2008; Ezzatian et al., 2011), it could be predicted that priming measured this way will be unaffected or even improved in older listeners. However, the task in the current study is quite different. As mentioned above, priming effects are observed with this paradigm for both noise and speech maskers (Jones & Freyman, 2012) while the benefit from priming with the earlier paradigm (Freyman et al., 2004, Sheldon et al., 2008; Ezzatian et al., 2011) is much larger in the presence of competing speech. It is important to determine the potential benefit of priming in the presence of different types of maskers because older adults have been found to be disproportionately affected by competing speech masking, as compared to than younger subjects (e.g., Tun et al., 2002; Rossi-Katz & Arehart, 2009; Helfer et al., 2010). The current study also investigated the influence of cognitive factors on priming, as a body of evidence suggests that age-related changes in cognition influence speech understanding in the presence of competing speech (e.g., Tun et al., 2002; Humes, Lee, & Coughlin, 2006; Helfer & Freyman, 2008, 2014; Helfer & Vargo, 2009; Rossi-Katz & Arehart, 2009; Koelweijn et al., 2012, 2014; Lee & Humes, 2012; Jesse & Janse, 2012; Woods et al., 2013; Anderson et al., 2013; Souza & Arehart, 2015; Fullgrabe et al., 2015; Helfer & Jesse, 2015).
MATERIALS AND METHODS
Subjects
A total of 56 listeners, all native English speakers, participated in this study. Half were older adults, ranging in age from 60 to 91 years, with a negative history of otological or neurological disorders. The other half were young adults age 19 to 31. All the younger subjects passed a hearing screening at 25 dB HL in both ears at octave frequencies from 250 Hz to 8000 Hz. Older subjects were restricted to have no more than a moderate hearing loss at any frequency. The mean pure-tone thresholds and standard deviations from the older listeners are shown in Fig. 1. Otoscopy and tympanometry were normal bilaterally. All subjects signed written consent forms for this project, which was approved by the University of Massachusetts Institutional Review Board.
Fig. 1.

Audiometric thresholds in dB HL for the 28 older subjects averaged across left and right ears and across listeners. Error bars reflect +/− one standard deviation.
General Sequence
This study was run in two stages. Initially 16 subjects were tested in each group, using the same-different task described by Jones & Freyman (2012). Results showed substantially reduced effects of priming in the older subjects relative to the younger subjects in the two-talker masker, one of the two masking conditions tested (see below). Because this appeared to be a different overall result from that obtained by Sheldon et al. (2008) and Ezzatian et al. (2011), who used a different (partial priming) methodology, it was decided to collect data on an additional 12 subjects per group to build the data set and strengthen the ability to make definitive conclusions. While collecting the second set of data, we used the opportunity to learn more about the cognitive functioning of the 12 additional older adults to determine whether cognitive abilities could explain variance in overall performance above and beyond age and pure-tone thresholds. We also tested whether and how the older adults approached the same-different task differently from younger adults by requesting confidence judgments about subjects’ same-different decisions.
Stimuli
Target stimuli were nonsense sentences identical to those used by Jones & Freyman (2012) and Freyman et al. (2015). The corpus from which the sentences were drawn consisted of 320 non-meaningful sentences developed by Helfer (1997) and recorded by an adult female talker of Standard American English. An example sentence is “The clay would surprise my glove”, with the three key words underlined. Two types of maskers were used, the same as those in Jones & Freyman (2012): (1) A 35-second stream of a mixture of two female talkers (two-talker babble, TTB) reciting nonsense sentences similar to the target. This masker appears to include a large informational-masking component when combined with the female target talker used in this study (Freyman et al., 2007). (2) A modulated speech-spectrum noise that follows the spectro-temporal fluctuation of the speech masker (dynamic speech noise or DSN, see Jones & Freyman, 2012). Older adults have been found to be disproportionately affected by intelligible competing speech (e.g., Rossi-Katz & Arehart, 2009; Helfer et al., 2010), and we anticipated that there might be some differences in priming effects between these two types of maskers in older adults.
Conditions
A total of 240 nonsense sentences, drawn randomly for each subject from the original corpus, were presented to each participant under four blocked conditions. In Condition A, 60 sentences were presented in the TTB masker, with a caption preceding the sentences. Condition B was the same but with the DSN masker. In Condition C, 60 sentences were presented with the TTB masker, with caption occurring after the acoustic sentence presentation. Condition D was the same as C, but with the DSN masker. The order of these conditions was counterbalanced across subjects. Prior to data collection a practice block was completed, consisting of five sentences, differing from the sentences used in the experiment, presented at each of five SNRs in each of the four conditions.
Data were collected in each of these conditions at five signal-to-noise ratios (12 sentences for each SNR). The SNRs were selected in order to span a range of performance that would permit comparisons between the two groups. The SNRs used for the younger adults were −14, −10, −6, −2, and 2 dB, as in Jones & Freyman (2012). The SNRs used for the older adults were −10, −6, −2, 2, and 6 dB, shifted by 4 dB relative to the younger subjects in order to account for anticipated performance differences between subject groups. The target stimuli were presented at 52 dBA (rms), while the masking stimuli were varied in level to achieve the specified signal-to-noise ratios. For each SNR, half of the trials (six) were foil trials, in which one of the key words in the visual display was different from the auditory presentation of the sentence. For example, when the auditory sentence was “The worm cost the form”, the foil sentence was “The beach cost the form”. More details are provided in Jones & Freyman (2012).
For the six foil trials at each SNR, two trials had the foil word for the first key word, two for the second, and two for the third. Subjects were told that they would see a visual display of a non-meaningful sentence and also hear a non-meaningful sentence that was partially obscured by masking, and were instructed to respond whether the printed and auditory sentences were the same. They were told that when the sentences were different, there would be one changed word that may be in the beginning, middle, or end of the sentence. The first 16 subjects in each group were asked to indicate if the caption was the same as the target sentence by clicking on “Yes” or “No” displayed on the computer monitor. The latter 12 subjects per group were given the modified instruction to select “Sure Same”, “Probably Same”, “Maybe Same”, “Maybe Different”, “Probably Different”, or “Sure Different”. Also, these latter subjects were not explicitly instructed that 50% of trials would be same and 50% different, while the first groups of subjects (16/group) were given this information.
On each trial, a random segment of the 35-s masker was selected and was digitally mixed with the target at the required SNR, with the masker leading the target by 0.5 s and both ending simultaneously. The mixture was outputted through a computer’s sound card at 22.05 kHz, amplified (TDT HBUF5), power amplified (TOA P75D), and delivered to a Realistic Minimus 7 loudspeaker at average ear height in a sound treated room, where the listener was seated at a distance of 1.2 meters from the loudspeaker. Nonsense sentence text (the caption) was presented on a computer screen positioned well below the loudspeaker height for 3 seconds either immediately before (conditions A and B), or immediately following (conditions C and D) the auditory presentation. Subjects were then prompted to enter their responses, as described above. No correct-answer feedback was provided.
Cognitive tests
Each participant in the latter two groups of 12 subjects completed a battery of cognitive tasks. Specific tasks were selected based upon previous studies demonstrating associations between certain cognitive skills and speech understanding in complex listening situations. Participants in the current study completed tests of working memory (SICSPAN: Sörqvist et al., 2010); inhibitory ability (a computerized Stroop task: Jesse & Janse, 2012); processing speed (Connections test: Salthouse et al., 2000); and attention switching/executive function (Visual Elevator task from the Test of Everyday Attention: Robertson et al., 1996). A complete description of each task can be found in our previous publications (Helfer & Freyman, 2014; Helfer & Jesse, 2015). Table 1 reports the means and ranges of these measures for the 24 participants in the second cohort of subjects, who completed these cognitive tasks.
Table 1.
Means (and ranges) for each cognitive measure for younger and older participants. Stroop = the difference in response time between congruent and incongruent trials (in msec); larger numbers suggest better inhibitory ability. Connections = the average number of items connected; larger numbers suggest better executive function. Visual Elevator = the time needed to complete each trial divided by the number of direction switches, in seconds; smaller numbers suggest better executive function. SICSPAN = number of items correctly recalled; larger numbers suggest better working memory.
| Younger | Older | |
|---|---|---|
| Stroop | 10.02 (3.64–29.31) | 4.14 (−32.02–38.87) |
| Connections Test | 26.20 (13.00–39.88) | 18.21 (10.13–24.63) |
| Visual Elevator task | 3.04 (2.22–3.86) | 4.28 (2.60–7.96) |
| SICSPAN | 29.08 (18.00–36.00) | 20.92 (7.00–32.00) |
RESULTS
Data are displayed in Fig. 2 for each subject group and condition as performance in d’ as a function of signal-to-noise ratio. For the purposes of calculating this metric, the experiment was analyzed as a simple Yes/No task under the assumption that reading the caption produced no sensory variability (Macmillan & Creelman, 2005, p. 215). “No” responses (to the question of whether the sentences were the same) for different (foil) trials were considered hits, and “No” responses for same trials were considered false alarms. This assignment is in keeping with the examples in Macmillan & Creelman (2005, p. 215). For the last 12 subjects in each group who reported confidence judgments on each trial, the level of confidence was ignored for the purpose of calculating d’. Each of the means and standard errors in the different panels of the figure was based on the average of 28 d’ values, one for each subject, with each of these calculated from 12 trials (six same and six different trials). Thus, each of the plotted values was based on a total of 336 trials. Because d’ was sometimes undefined (that is, when hits or false alarms proportions were 1 or 0), corrections recommended by Macmillan & Creelman (2005, p. 8) were employed, where 0 was transformed to 1/2N (.0833), and 1 was transformed to 1-1/2N (.9167), where N = 6.
Fig. 2.

Average performance in d’ (and +/− 1 standard error) on the same/different task as a function of signal-to-noise ratio for the four conditions across all 28 subjects in the two listener groups. Left panel: two-talker masker; right panel: fluctuating speech-spectrum noise. Prime conditions refer to the caption-before order.
We averaged the d’ values across all conditions for each subject in order to compare performance between the initial and follow-up subject cohorts. ANOVA with these averaged scores as the within-subjects variable and study (that is, first set of subjects versus second set of subjects) as the between-subjects variable verified that performance between these two cohorts was not significantly different (F (1,54) = 3.34, p = .07). More importantly, we repeated this analysis for the difference scores between caption-after and caption-before conditions for these same two subject cohorts and found that this group difference was also non-significant (F (1,54) = 0.20, p = .68). Therefore, most of the remaining analyses were conducted with data aggregated among all participants.
A repeated-measures ANOVA was conducted with masker type (noise versus TTB), prime condition (caption-before versus caption-after), and SNR (using data from the four common SNRs) as within-subject variables and subject age group as the between-subject variable. Results showed significant main effects for all four factors (each with p < .001) as well as several significant interactions: prime × age group (F[1,54] = 4.20, p = .045); masker × SNR (F[1,54] = 9.05, p < .001); prime × SNR (F[1,54] = 13.03, p < .001); and masker × prime × SNR (F(1,54) = 4.97, p = .004).
The data in Fig. 2, left panel, show robust order (priming) effects for the younger subjects across SNR for the two-talker masker. That is, substantially better performance was obtained for the condition in which the caption preceded the auditory message than when the caption followed the auditory message, consistent with Jones & Freyman (2012) and Freyman et al. (2015). These trends are observed in the data from older subjects as well, but the effect was generally smaller and less consistent across SNRs. The absence of differences at the lowest and highest SNRs in the older subjects has the appearance of being influenced by floor and ceiling effects. However, it is noteworthy that at both −14 and −10 dB SNR, performance was essentially chance for the younger subjects in the caption-after condition, but a substantial priming benefit was nevertheless observed at both SNRs.
Benefits of priming were also observed when the stimuli were presented with the DSN masker (right panel). The size of the effect varied with SNR to a greater extent in the older than in the younger subjects, but unlike with the TTB masker, there did not appear to be a consistent advantage for younger subjects relative to older subjects in the size of the priming effect.
To further analyze these results the data were collapsed across SNRs in three different manners, either all five SNRs for each subject group, the four SNRs that were in common between the two subject groups, and, to minimize potential floor and ceiling effects, the three central SNRs for each of the groups. The differences between caption-before and caption-after conditions were averaged across listeners for each of the three different methods of collapsing across SNR. The results for the two-talker masker, shown in Fig. 3 (left panel), show priming benefits in younger subjects of about 0.7 to 0.9 d’ units, depending on the range of SNRs included in the average, with considerably smaller benefits observed for older than for younger subjects. The difference was tested statistically for the average across the four common SNRs, and was significant [F(1,54) = 5.22, p = .026.] In contrast, the benefits of priming for the DSN masker were between about 0.4 and 0.6 d’ units for both groups of subjects and group differences were not statistically significant [F(1,54) = .08, p = .780].
Fig. 3.

Difference in d’ between caption-before and caption-after conditions averaged across signal-to-noise ratios. Averages across three different groupings of signal-to-noise ratios are displayed. Error bars represent +/− one standard error.
The significant group differences observed for the TTB masker were broken down further by plotting hits and false alarms separately for both age groups, as shown in Fig. 4. Caution is warranted in interpreting these figures because the effect of differences in hits and false alarms on d’ is more substantial near the extremes of 0% and 100% than in the middle range. A few aspects of the results are noteworthy. First, in general, the effect of condition, either SNR or priming, was smaller for hits than for false alarms. Hits were obtained when different trials were correctly identified. Recall that during different trials, not all of the key words were identical between text and auditory stimuli. The presumed absence of a pop-out effect for those keywords could potentially explain why the caption-before order was not as beneficial for these trials. Nevertheless it is surprising that higher signal-to-noise ratios, where the stimuli were more audible, did not universally lead to a better ability to correctly identify different trials across subject groups and conditions. Second, whereas older subjects showed a reduction in false alarms due to priming (better identification of same trials) in a middle range of SNRs, they did not show a substantial reduction at -10 dB SNR. The younger subjects showed substantially reduced false alarms due to priming at both -10 and -14 dB. Third, the older subjects seemed to approach the task differently, particularly at low SNRs. That is, they were much more likely to respond with “different” than younger subjects, leading to high percentages of both hits and false alarms. They seemed reluctant to report that the caption and auditory stimuli were the same when the SNR was low (that is, when audibility was less assured). Across all conditions and SNRs, 49% of responses from younger subjects were “different” responses, while 56% of responses from older subjects were “different”. It did not appear to be very important whether the older participants came from the first group of 16 who were explicitly instructed that 50% of trials would be different (57.2% “different” responses), or from the second group of 12 who were not (55.4% “different” responses). Thus, it is not clear that subjects paid attention to or used that particular detail within the longer list of instructions when deciding how to respond.
Fig. 4.

Hit and false alarm rates in the two-talker masker condition as a function of signal-to-noise ratio for older subjects (left panel) and younger subjects (right panel). Error bars represent +/− one standard error.
The apparent difference in approach of older and younger subjects was reinforced by an analysis of the confidence judgments obtained from the second cohort of subjects. The responses and confidence judgments summed across all conditions are shown in Fig. 5, and reveal the tendency for older subjects to be considerably more confident in “different” responses than in “same” responses, while younger subjects were more confident in “same” responses.
Fig. 5.
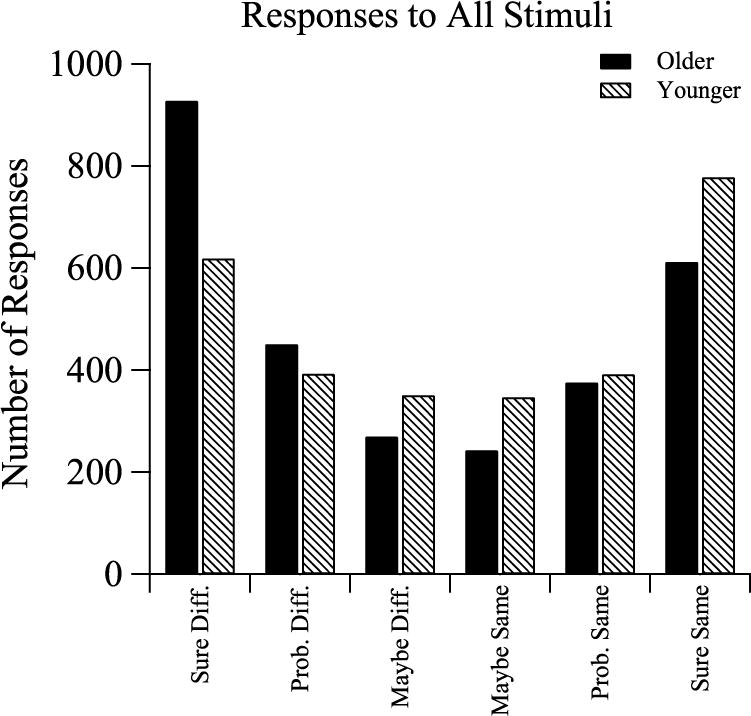
Number of responses reported across all conditions for the 24 older and younger subjects (12 per group) who made confidence judgments on each trial.
Receiver Operating Characteristics (ROCs) were also constructed from the confidence judgments using the procedures of Macmillan & Creelman (2005, page 55), and the statistic da, which uses the area under the ROC curve to estimate sensitivity (Macmillan & Creelman (2005, page 61), was computed from the aggregate ROCs from each group. Because they were computed from the combined data, the ROCs and the resulting da statistic were unaffected by the earlier-mentioned corrections required when 100% or 0% hits or false alarms arose for individual subjects. Like the d’ data shown in Fig. 3, the da values varied slightly across the 5-SNR, 4-SNR, and 3-SNR averaging ranges. The advantage in priming effect for younger subjects relative to the older subjects for the two-talker masker ranged from .31 to .34 da units, depending on the SNRs being averaged. The advantage for younger subjects in priming effect for the DSN masking condition was much smaller, ranging from .03 to .11 da units. Thus the major trends seen in Fig. 3 for the d’ data were also observed for this smaller group of subjects and when the whole ROC was analyzed.
For the 24 listeners who completed the cognitive test battery, we explored the influence of age, high-frequency hearing loss (average of thresholds at 2 k, 3 k, 4 k, and 6 kHz), and the measured cognitive abilities. A Pearson r correlation analysis was completed using the above variables along with the priming effect averaged across all SNRs for each type of masker. Results of this analysis, shown in Table 2, indicate that age was negatively associated with the size of the priming effect in the two-talker masker, but was not associated significantly with this metric in noise. Degree of high-frequency hearing loss was not significantly associated with either of these measures, although the correlation with the priming effect in two-talker babble just missed statistical significance (p = .057). The only cognitive variable that was associated with the priming effect was performance on the Connections task, which was significantly related to the priming effect in noise.
DISCUSSION
When nonsense sentences were presented in either a two-talker masker or fluctuating noise masker, the task of making same-different judgments between captions and auditory presentations of the sentences was influenced substantially by order of presentation, with the caption-before order (prime condition) producing much better performance than caption-after order for both younger and older subjects. However, in the case of the two-talker masker, younger subjects derived greater benefit from priming than did older subjects, with respect to both size of the order effect and the consistency across SNR. As Jones & Freyman (2012) presumed, the advantage of presenting the caption first may be that it can dramatically enhance the perception of the degraded auditory presentation, causing it to “pop out” of the background (Davis et al., 2005). The enhanced perception of the auditory signal would make it easier to determine whether the acoustic sentence matched the caption, relative to when the priming or pop-out effect did not occur, i.e., if the auditory signal was presented first. If this is indeed the explanation for the caption order effect, then the additional indication that follows is that older subjects did not experience as much pop out across SNRs as younger subjects for speech presented within a two-talker masker. The finding of reduced priming effects in older listeners is in agreement, at least qualitatively, with the results of Wu et al. (2012) for Chinese speech.
Despite the difference observed between the age groups in this study, it is nevertheless the case that older subjects did indeed show significant improvements in performance due to priming, especially at -6 dB SNR for both maskers (Fig. 2), and to a lesser extent at some other SNRs. If the priming effect reflects an enhanced perception of the auditory signal following the reading of the captions, then older subjects clearly experienced this phenomenon. However, as noted above, the effect was not as large and not as consistent across SNRs for the two-talker masker for older subjects relative to younger subjects. At the lowest SNR of -14 dB for example, younger subjects performed fairly well in the primed condition, while the older subjects were near chance even at −10 dB. In the primed condition, older adults required a −6 dB SNR to exceed younger subjects’ performance at −14 dB, a shift of almost 8 dB for equivalent performance. Such a large deficit is not observed for the un-primed (caption-after) conditions.
The pop-out perception that occurs with the caption-before order may be related to implicit memory tasks, where an item presented in an earlier phase of an experiment (the “study phase”) affects perception of the same stimulus in a later test phase, even when a subject is not asked to explicitly remember the stimulus. The same-different task itself requires some short-term explicit memory, since one must compare the auditory stimulus with the caption and remember both. However, explicit memory is required in both orders tested. Therefore, the specific reduction in benefit in older listeners from the caption-before temporal order for the TTB masker seems more logically related to implicit memory. Studies of implicit memory have generally revealed relatively intact processing by older subjects (Pilotti & Beyer, 2002; Fleischman, 2007; Pitarque et al., 2014). The current findings with the noise masker showing similar priming effects in younger and older subjects is consistent with these earlier results. However, the reduced priming effect in older subjects with the two-talker masker may demonstrate an effect of age on implicit priming of sentences presented in this masker beyond what has been observed in most studies. The possibility should be considered that the change in modality, from reading text to hearing, is an important factor in the current experiment, as Pilotti & Beyer (2002) and other previous studies (e.g., Light et al., 1992) have observed. However, since in the current study the modality difference was also present for the noise masker, where there was no clear effect of age on priming, the explanation based on modality difference, while it cannot be completely ruled out, is not easily supported for the current two-talker masker data. The simplest, though still cautious, interpretation of the current data is that in some conditions the older subjects did not experience the same level of perceptual pop-out effect as younger subjects.
If indeed the preceding caption caused a less dramatic perception of pop out in the older subjects than in the younger subjects for the two-talker masker, then this may also help explain the reduced priming effects in older listeners observed by Wu et al. (2012). However this explanation must also be viewed in light of the priming studies of Ezzatian et al. (2011), which showed equal effects of priming in younger and older listeners in a two-talker masker, and of Sheldon et al. (2008), which showed equal or increased effects of priming in older listeners, depending on how the difference was quantified. Methodological differences between the current study and those earlier studies may be partially responsible for the different outcomes. In both the Sheldon et al. and Ezzatian et al. studies (as well as Wu et al., 2012), priming was measured as the increase in key word recognition for a nonsense sentence following a prime that consisted of the earlier part of the sentence, whereas in the current study, for same trials, all three keywords in the nonsense sentence were primed and presumably were enhanced by the caption.
It is tempting to assume that some aspect of this task difference accounts for the difference seen in the effects of aging on priming benefit between the current study and those earlier studies. On the other hand, it is possible that the two different tasks may be tapping into the same pop-out perception, and the difference could be due to stimulus factors or the specific aspects of the data that are being analyzed. The Sheldon et al. (2008) study was focused solely on the effect of priming on the perception of noise vocoded sentences. Vocoding was not studied in the current experiment, and reductions in priming were specific to the two-talker masker, as opposed to noise-masker conditions. It is possible that no age-related reductions in caption order effects would have been observed for noise-vocoded sentences with the current same-different task. Regarding Ezzatian et al. (2011), differences in results are unlikely to be related to the basic stimuli themselves, because their stimuli were borrowed from our lab. However, a few points are worth noting. First, reductions in priming benefit for older listeners in the current study are largest at the lowest SNR of -10 dB. Ezzatian et al. (2011) did not test older listeners below -8 dB SNR, and at that SNR there was clearly a trend, whether statistically significant or not, for older listeners to have smaller priming benefits than younger listeners. That trend toward reduced benefit may have been even greater at -10 dB where the current study showed the largest reductions in priming benefit in older listeners. Second, like the earlier study, the current study does show considerable priming benefit in older listeners over a middle range of SNRs. This is seen in the overall performance results in Fig. 2 and in the large reductions in false alarm rates at -6 and -2 dB SNR in older listeners (Fig. 4). Thus, while there may be some effects of task differences, the details of the across-study differences in stimuli and results do not lead clearly to an interpretation in that direction. Indeed there are quite a few qualitative similarities in the results between studies, and the age-related differences in the current study are greatest in conditions not tested in Ezzatian et al. (2011).
As discussed in the Introduction, older subjects have been shown to be at least as good, if not better, than younger subjects at taking advantage of context in predicting what they will hear next. The current results do not disagree with those findings, but suggest the possibility that under some circumstances of speech-on-speech masking older subjects may receive less of the pop-out effect that occurs so dramatically in younger subjects when they are told what they are going to hear ahead of time. This does not appear to be simply a function of increased high-frequency thresholds in older individuals, as correlation results showed a significant association between age (but not high-frequency hearing loss) and extent of priming benefit in the two-talker masker. Moreover, the results did not indicate significant associations between performance on our cognitive measures and priming benefit in the two-talker masker. At this point, we are uncertain what aspects of aging lead to the observed reduction in priming benefit.
One expects this type of pop-out perception to be helpful when older people read closed captions while watching television or movies. Captions may be helpful in a variety of conditions where, for example, the sound system is poor, there are foreign accents, there is interfering speech or noise, or the viewer’s speech perception is affected by hearing loss. Both older and younger individuals modulate their emphasis on captions versus spoken speech depending on a variety of factors, including the SNR of the acoustic signal and the accuracy of the caption (Krull & Humes, 2016). Assuming an accurate caption, one can learn the content of the spoken message simply by reading the caption text. But we assume that the overall experience is improved (and, perhaps, listening is less effortful) if reading the caption leads to enhanced perception of the auditory message. Our previous research with younger listeners (Freyman et al., 2015) suggests that the timing of captions should be slightly ahead of the auditory message (rather than fully simultaneous) in order for the largest indications of pop-out to be observed, about 500 milliseconds for the conditions tested in that study. It may be useful to evaluate these same temporal dependencies in older listeners as well, and with a wider range of test stimuli. An additional topic that may be worthy of further exploration is the apparent difference in approach to the same/different task between the two age groups. The confidence judgment task employed with the second set of subjects enhanced the ability to see differences in bias patterns between older and younger individuals. This type of paradigm may prove useful in future studies on age-related changes in priming and context effects.
While captions are potentially important under the circumstances mentioned above, the majority of communication obviously takes place without such a direct preview or confirmation of what one is hearing. However, as suggested in the Introduction, automatic priming processes may also be involved in the everyday use of sentence context. The results of the current study confirm that immediate priming effects are clearly present in older listeners but suggest that they may be reduced under some circumstances. To the extent that priming is a factor in facilitating benefit from context, this could attenuate the ability of listeners in this age group to take advantage of context under these same circumstances.
Table 2.
Results of Pearson r correlation analysis. Variables in this analysis were age; high-frequency better-ear pure-tone average (HFPTA); scores on each of the cognitive measures (Stroop task, Connections task (Connx), Visual Elevator task (VisEl), and SICSPAN); and priming effect (performance in caption-before conditions minus performance in caption-after conditions, averaged across all SNRs) for noise (PE-Noise) and two-talker (PE-TT) maskers.
| Age | HFPTA | Stroop | Connx | VisEl | SICSPAN | PE-TT | PE-Noise | |
|---|---|---|---|---|---|---|---|---|
| Age | — | .84** | −.21 | −.64** | .54** | −.57** | −.44* | −.18 |
| HFPTA | — | .03 | −.66** | .64** | −.61** | −.39 | −.16 | |
| Stroop | — | −.01 | .43* | −.35 | −.06 | .01 | ||
| Connx | — | −.78** | .73** | .28 | .44* | |||
| VisEl | — | −.72** | .29 | −.41 | ||||
| SICSPAN | — | .21 | .35 | |||||
| PE-TT | — | .01 | ||||||
| PE-Noise | — |
= significant at the .05 level;
= significant at the .01 level
Acknowledgments
The authors would like to thank Derina Boothroyd, Decia DeMaio, and Gabrielle Merchant for their assistance. This research was supported by The National Institute on Deafness and Other Communication Disorders DC-01625 and DC-012057.
Financial Disclosures:
This research was funded by the National Institute on Deafness and Other Communication Disorders DC01625 and DC012057.
References
- Anderson S, White-Schwoch T, Parbery-Clark A, Kraus N. A dynamic auditory-cognitive system supports speech-in-noise perception in older adults. Hear Res. 2013;300:18–32. doi: 10.1016/j.heares.2013.03.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Benichov J, Cox LC, Tun PA, et al. Word recognition within a linguistic context: Effects of age, hearing acuity, verbal ability and cognitive function. Ear Hear. 2012;32:250–256. doi: 10.1097/AUD.0b013e31822f680f. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Davis MH, Johnsrude IS, Hervais-Adelman A, et al. Lexical Information drives perceptual learning of distorted speech: Evidence from the comprehension of noise-vocoded sentences. J Ex Psychol Gen. 2005;134:222–241. doi: 10.1037/0096-3445.134.2.222. [DOI] [PubMed] [Google Scholar]
- Dubno JR, Ahlstrom JB, Horwitz AR. Use of context by young and aged adults with normal hearing. J Acoust Soc Am. 2000;107:538–546. doi: 10.1121/1.428322. [DOI] [PubMed] [Google Scholar]
- Ezzatian P, Li L, Pichora-Fuller K, et al. The effect of priming on release from informational masking is equivalent for younger and older adults. Ear Hear. 2011;32:84–96. doi: 10.1097/AUD.0b013e3181ee6b8a. [DOI] [PubMed] [Google Scholar]
- Fleischman DA. Repetition priming in aging and Alzheimer’s disease: an integrative review and future directions. Cortex. 2007;43:889–897. doi: 10.1016/s0010-9452(08)70688-9. [DOI] [PubMed] [Google Scholar]
- Freyman RL, Balakrishnan U, Helfer KS. Spatial release from informational masking in speech recognition. J Acoust Soc Am. 2001;109:2112–2122. doi: 10.1121/1.1354984. [DOI] [PubMed] [Google Scholar]
- Freyman RL, Balakrishnan U, Helfer KS. Effect of number of masking talkers and auditory priming on informational masking in speech recognition. J Acoust Soc Am. 2004;115:2246–2256. doi: 10.1121/1.1689343. [DOI] [PubMed] [Google Scholar]
- Freyman RL, Griffin AM, Macmillan NA. Priming of lowpass-filtered speech affects response bias, not sensitivity, in a bandwidth discrimination task. J Acoust Soc Am. 2013;134:1183–1192. doi: 10.1121/1.4807824. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Freyman RL, Helfer KS, Balakrishnan U. Variability and uncertainty in masking by competing speech. J Acoust Soc Am. 2007;121:1040–1046. doi: 10.1121/1.2427117. [DOI] [PubMed] [Google Scholar]
- Freyman RL, Morse-Fortier C, Griffin AM. Temporal effects in priming of masked and degraded speech. J Acoust Soc Am. 2015;138:1418–1427. doi: 10.1121/1.4927490. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Frisina DR, Frisina RD. Speech recognition in noise and presbycusis: relations to possible neural mechanisms. Hear Res. 1997;106:95–104. doi: 10.1016/s0378-5955(97)00006-3. [DOI] [PubMed] [Google Scholar]
- Fullgrabe C, Moore BCJ, Stone MA. Age-group differences in speech identification despite matched audiometrically normal hearing: contributions from auditory temporal processing and cognition. Front Aging Neurosci. 2015;6:347. doi: 10.3389/fnagi.2014.00347. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Getzmann S, Lewald J, Falkenstein M. Using auditory pre-information to solve the cocktail-party problem: electrophysiological evidence for age-specific differences. Frontiers in neuroscience. 2014;8:413. doi: 10.3389/fnins.2014.00413. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gordon-Salant S, Fitzgibbons PJ. Selected cognitive factors and speech recognition performance among young and elderly listeners. J Speech Lang Hear Res. 1997;40:423–431. doi: 10.1044/jslhr.4002.423. [DOI] [PubMed] [Google Scholar]
- Helfer KS. Auditory and auditory-visual perception of clear and conversational speech. J Speech Lang Hear Res. 1997;40:432–443. doi: 10.1044/jslhr.4002.432. [DOI] [PubMed] [Google Scholar]
- Helfer KS, Chevalier J, Freyman RL. Aging, spatial cues, and single-versus dual-task performance in competing speech perception. J Acoust Soc Am. 2010;128:3625–3633. doi: 10.1121/1.3502462. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Helfer KS, Freyman RL. Aging and speech-on-speech masking. Ear Hear. 2008;29:87–98. doi: 10.1097/AUD.0b013e31815d638b. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Helfer KS, Freyman RL. Stimulus and listener factors affecting age-related changes in competing speech perception. J Acoust Soc Am. 2014;136:748–759. doi: 10.1121/1.4887463. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Helfer KS, Jesse A. Lexical influences on competing speech perception in younger, middle-aged, and older adults. J Acoust Soc Am. 2015;138:363–376. doi: 10.1121/1.4923155. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Helfer KS, Vargo M. Speech recognition and temporal processing in middle-aged women. Journal of the American Academy of Audiology. 2009;20:264–271. doi: 10.3766/jaaa.20.4.6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Humes LE, Lee JH, Coughlin MP. Auditory measures of selective and divided attention in young and older adults using single-talker competition. J Acoust Soc Am. 2006;120:2926–2937. doi: 10.1121/1.2354070. [DOI] [PubMed] [Google Scholar]
- Jacoby LL, Allan LG, Collins JC, et al. Memory influences subjective experience: Noise judgments. J Exp Psychol Learn Mem Cogn. 1988;14:240–247. [Google Scholar]
- Jesse A, Janse E. Audiovisual benefit for recognition of speech presented with single-talker noise in older listeners. Lang Cogn Process. 2012;27:1167–1191. [Google Scholar]
- Jones JA, Freyman RL. Effect of priming on energetic and informational masking in a same-different task. Ear Hear. 2012;33:124–133. doi: 10.1097/AUD.0b013e31822b5bee. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kalikow DN, Stevens KN, Elliott LL. Development of a test of speech intelligibility in noise using sentence materials with controlled word predictability. J Acoust Soc Am. 1977;61:1337–1351. doi: 10.1121/1.381436. [DOI] [PubMed] [Google Scholar]
- Koelweijn T, Zekveld AA, Festen JM, Kramer K. “Pupil dilation uncovers extra listening effort in the presence of single-talker masker,” Ear Hear. 2012;33:291–300. doi: 10.1097/AUD.0b013e3182310019. [DOI] [PubMed] [Google Scholar]
- Koelweijn T, Zekveld AA, Festen JM, Kramer K. The influence of informational masking on speech perception and pupil response in adults with hearing impairment. J Acoust Soc Am. 2014;135:1596–1606. doi: 10.1121/1.4863198. [DOI] [PubMed] [Google Scholar]
- Krull V, Humes LE. Text as a Supplement to Speech in Young and Older Adults. Ear Hear. 2016;37:164–176. doi: 10.1097/AUD.0000000000000234. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lash A, Rogers CS, Zoller A, et al. Expectation and entropy in spoken word recognition: Effects of age and hearing acuity. Exp Aging Res. 2013;39:235–253. doi: 10.1080/0361073X.2013.779175. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee JH, Humes LE. Effect of fundamental-frequency and sentence-onset differences on speech-identification performance of young and older adults in a competing-talker background. J Acoust Soc Am. 2012;132:1700–1717. doi: 10.1121/1.4740482. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Macmillan NA, Creelman CD. Detection Theory: A User’s Guide. 2nd. Erlbaum; Mahwah, NJ: 2005. [Google Scholar]
- Meyer DE, Schvaneveldt RW. Facilitation in recognizing pairs of words: evidence of a dependence between retrieval operations. J Exp Psychol. 1971;90:227–234. doi: 10.1037/h0031564. [DOI] [PubMed] [Google Scholar]
- La Voie D, Light LL. Adult age differences in repetition priming: A meta-analysis. Psychol Aging. 1994;9:539–553. doi: 10.1037//0882-7974.9.4.539. [DOI] [PubMed] [Google Scholar]
- Light LL, LaVoie D, Valencia-Laver D, et al. Direct and indirect measures of memory for modality in young and older adults. J Exp Psychol Learn Mem Cogn. 1992;18:1284–1297. doi: 10.1037//0278-7393.18.6.1284. [DOI] [PubMed] [Google Scholar]
- Pitarque A, Sales A, Melendez JC, et al. Repetition increases false recollection in older people. Scand J Psychol. 2014;56:38–44. doi: 10.1111/sjop.12168. [DOI] [PubMed] [Google Scholar]
- Pilotti M, Beyer T. Perceptual and lexical components of auditory repetition priming in young and older adults. Mem Cognit. 2002;30:226–236. doi: 10.3758/bf03195283. [DOI] [PubMed] [Google Scholar]
- Perry AR, Wingfield A. Contextual encoding by young and elderly adults as revealed by cued and free recall. Aging and Cognition. 1994;1:120–139. [Google Scholar]
- Pichora-Fuller MK, Schneider BA, Daneman M. How young and old adults listen to and remember speech in noise. J Acoust Soc Am. 1995;97:593–608. doi: 10.1121/1.412282. [DOI] [PubMed] [Google Scholar]
- Rankovic CM, Levy RM. Estimating articulation scores. J Acoust Soc Am. 1997;102:3754–3761. doi: 10.1121/1.420138. [DOI] [PubMed] [Google Scholar]
- Roediger HL. Implicit memory: Retention without remembering. Am Psychol. 1990;45:1043–1056. doi: 10.1037//0003-066x.45.9.1043. [DOI] [PubMed] [Google Scholar]
- Rossi-Katz J, Arehart KH. Message and talker identification in older adults: Effects of task, distinctiveness of the talker’s voices, and meaningfulness of the competing message. J Speech Lang Hear Res. 2009;52:435–453. doi: 10.1044/1092-4388(2008/07-0243). [DOI] [PubMed] [Google Scholar]
- Robertson IH, Ward T, Ridgeway V, et al. The structure of normal human attention: The Test of Everyday Attention. J Int Neuropsychol Soc. 1996;2:525–534. doi: 10.1017/s1355617700001697. [DOI] [PubMed] [Google Scholar]
- Salthouse TA, Toth J, Daniels K, et al. Effects of aging on efficiency of task switching in a variant of the trail making test. Neuropsychology. 2000;14:102–111. [PubMed] [Google Scholar]
- Schacter DL, Church BA. Auditory priming: implicit and explicit memory for words and voices. J Exp Psychol Learn Mem Cogn. 1992;18:915–930. doi: 10.1037//0278-7393.18.5.915. [DOI] [PubMed] [Google Scholar]
- Sheldon S, Pichora-Fuller MK, Schneider BA. Priming and sentence context support listening to noise-vocoded speech by younger and older adults. J Acoust Soc Am. 2008;123:489–499. doi: 10.1121/1.2783762. [DOI] [PubMed] [Google Scholar]
- Sohoglu E, Peelle JE, Carlyon RP, et al. Top-down influences of written text on perceived clarity of degraded speech. J Exp Psychol Hum Percept Perform. 2014;40:186–199. doi: 10.1037/a0033206. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sommers MS, Danielson SM. Inhibitory processes and spoken word recognition in young and older adults: The interaction of lexical competition and semantic context. Psychol Aging. 1999;14:458–472. doi: 10.1037//0882-7974.14.3.458. [DOI] [PubMed] [Google Scholar]
- Sörqvist P, Ljungberg JK, Ljung R. A sub-process view of working memory capacity: Evidence from effects of speech on prose memory. Memory. 2010;18:310–326. doi: 10.1080/09658211003601530. [DOI] [PubMed] [Google Scholar]
- Tun PA, O’Kane G, Wingfield A. Distraction by competing speech in young and older adult listeners. Psychology and aging. 202;17:453–457. doi: 10.1037//0882-7974.17.3.453. [DOI] [PubMed] [Google Scholar]
- Wild CJ, Davis MH, Johnsrude IS. Human auditory cortex is sensitive to the perceived clarity of speech. Neuroimage. 2012;60:1490–1502. doi: 10.1016/j.neuroimage.2012.01.035. [DOI] [PubMed] [Google Scholar]
- Wingfield A, Tun PA, McCoy SL. Hearing loss in older adulthood what it is and how it interacts with cognitive performance. Curr Dir Psychol Sci. 2005;14:144–148. [Google Scholar]
- Wingfield A, Alexander AH, Cavigelli S. Does memory constrain utilization of top-down information in spoken word recognition? Evidence from normal aging. Language and Speech. 1994;37:221–235. doi: 10.1177/002383099403700301. [DOI] [PubMed] [Google Scholar]
- Woods DL, Doss Z, Herron TJ, et al. Age-related changes in consonant and sentence processing. J Rehabil Res Dev. 2012;49:1277–1292. doi: 10.1682/jrrd.2011.08.0150. [DOI] [PubMed] [Google Scholar]
- Wu M, Li H, Hong Z, et al. Effects of aging on the ability to benefit from prior knowledge of message content in masked speech recognition. Speech Commun. 2012;54:529–542. [Google Scholar]
- Zekveld AA, Rudner M, Johnsrude IS, et al. The influence of semantically related and unrelated text cues on the intelligibility of sentences in noise. Ear Hear. 2011;32(6):e16–e25. doi: 10.1097/AUD.0b013e318228036a. [DOI] [PubMed] [Google Scholar]
- Zekveld AA, Rudner M, Johnsrude IS, et al. Behavioral and fMRI evidence that cognitive ability modulates the effect of semantic context on speech intelligibility. Brain Lang. 2012;122:103–113. doi: 10.1016/j.bandl.2012.05.006. [DOI] [PubMed] [Google Scholar]
- Zekveld AA, Rudner M, Johnsrude IS, et al. The effects of working memory capacity and semantic cues on the intelligibility of speech in noise. J Acoust Soc Am. 2013;134:2225–2234. doi: 10.1121/1.4817926. [DOI] [PubMed] [Google Scholar]