

“The expression ‘barbarians at the gate’ was … used by the Romans to describe foreign attacks against their empire.”1 “[It] is often used in contemporary English within a sarcastic, or ironic context, when speaking about a perceived threat from a rival group of people, often deemed to be less capable or somehow ‘primitive.’”2
INTRODUCTION
Citizen science has a mixed reputation. It includes well-organized, crowd-sourced efforts like the 1830s British great tidal experiment that enlisted members of the public to monitor tides at 650 coastal locations, but it also includes less rigorous dabbling by amateurs.3 Successful citizen science projects often engage laypeople, supervised by professional scientists, to collect and analyze data or even to assist in creating the finished scholarly works4—in other words, the citizens are a source of labor. This article explores an alternative model—citizen research sponsorship—in which citizens supply essential capital assets to support research. The assets could be monetary (research funding, for example), although this article focuses on a different kind of capital: data resources, which are a critical input for twenty-first century biomedical research.5
The citizen research sponsorship model flips the traditional control relationship of citizen science. Instead of laypeople laboring under the supervision of professional scientists, the professional scientists work at the instigation of citizen groups, using the people’s data for projects the people endorse. Citizen groups that control an essential research input, such as data or biospecimens, sometimes succeed in leveraging their asset to enlist qualified scientists to generate desired knowledge. This sponsorship model was exemplified late in the 1980s when a group of Canavan-disease-affected families developed a disease registry and biospecimen bank and leveraged these resources to spur discovery of associated genetic variants and development of a diagnostic test.6 Their sponsorship took the form of supplying data and biospecimens for the research, as opposed to providing funding. This revealed a new dynamic in the era of informational research7 that mines preexisting health records and data derived from biospecimens: money will follow a good data resource, instead of data resources following (and having to be generated by) those who hold money. Data resources are a central currency of twenty-first-century science, and the question is, “Who will control them?”
The Canavan families’ scientific success was later marred by litigation when their chosen investigator elected to patent his discoveries and charge royalties on the test.8 They had naively assumed he would put his discoveries into the public domain.9 Citizen sponsors, like any other research sponsors, need well-drafted research agreements if they want to avoid unpleasant surprises. The Canavan families’ greatest contribution to science ultimately may have been that they demonstrated the power of well-organized citizen groups—perhaps, next time, with appropriate consulting and legal support—to instigate high-quality scientific research. Hiring lawyers and scientists is relatively straightforward if a citizen group has money, and money need not always come from external fundraising and donors. A citizen group that controls a critical data resource, coupled with a workable revenue model, may be able to monetize its resource lawfully and on terms ethically acceptable to the group members.
This article introduces consumer-driven data commons, which are institutional arrangements for organizing and enabling citizen research sponsorship. The term “consumer-driven” reflects a conscious decision to avoid terms like “patient-driven” or “patient-centered” that are ubiquitous yet evoke different meanings in the minds of different readers.10 For some, “patient-centered” may refer to research that respects patient preferences, decisions, and outcomes, and “helps people and their caregivers communicate and make informed healthcare decisions, allowing their voices to be heard in assessing the value of healthcare options.”11 Others may view a system as patient-centered if it extends various courtesies to participating individuals, such as sharing progress reports about discoveries made with their data or enabling return of their individual research results.12 Others may associate patient-centered databases with granular consent mechanisms that allow each included individual to opt in or opt out of specific data uses at will, like the patient-controlled electronic health records proposed in the last decade.13 The term “consumer-driven” aims to quash preconceptions of this sort.
The choice of “consumer” rather than “patient” accords with a broad conception that health data include information about people in sickness (when their consumption of healthcare services generates clinical data) and in health (when they may purchase fitness trackers that generate useful information about lifestyle and exposures). This article construes personal health data (PHD) broadly to include data about patients, research participants, and people who use sensor devices or direct-to-consumer testing services (together, consumers). PHD includes traditional sources of health data, such as data from consumers’ encounters with the healthcare system as well as data generated when they consent to participate in clinical research. PHD also may include individually identifiable (or re-identifiable) research results that investigators derive during informational research—research that uses people’s data or biospecimens with or without their consent.14 Increasingly, PHD includes genetic and other diagnostic information that healthy-but-curious consumers purchase directly from commercial test providers, as well as information people generate for themselves using mobile, wearable, and at-home sensing devices. More creepily, PHD also includes data captured passively by the panopticon of algorithms that silently harvest data from online shopping, professional, leisure, and social communication activities.15 Such algorithms may support excruciatingly personal inferences about an individual’s health status—for example, pregnancy—that arouse intense privacy concerns.16 All these data are potential fuel for future biomedical discoveries.
The consumer-driven data commons discussed here would be self-governing communities of individuals, empowered by access to their own data, who come together in a shared effort to create high-valued collective data resources. These data commons are conceptually similar to the “data cooperatives, that enable meaningful and continuous roles of the individuals whose data are at stake” that Effy Vayena and Urs Gasser suggest for genomic research,17 and to “people-powered” science that aims to construct communities to widen participation in science,18 and to the “patient-mediated data sharing” described in a recent report on FDA’s proposed medical device safety surveillance system.19
Consumer-driven data commons differ starkly from the traditional access mechanisms that have successfully supplied data for biomedical research in recent decades. This article explores how these mechanisms, imbedded in major federal research and privacy regulations, enshrine institutional data holders—entities such as hospitals, research institutions, and insurers that store people’s health data—as the prime movers in assembling large-scale data resources for research and public health. They rely on approaches—such as de-identification of data and waivers of informed consent—that are increasingly unworkable going forward. They shower individuals with unwanted, paternalistic protections—such as barriers to access to their own research results—while denying them a voice in what will be done with their data. Consumer-driven data commons also differ from many of the patient-centered data aggregation models put forward as alternatives to letting data holders control the fate of people’s data. One alternative, already noted, is a personally controlled electronic health record with granular individual consent: that is, a scheme in which individuals (or their designated agents) assemble their own health data and then specify, in very granular detail, the particular data uses that would be acceptable to each individual.
In contrast, the consumer-driven data commons proposed here would aggregate data for a group of participating volunteers who, thereafter, would employ processes of collective self-governance to make decisions about how the resulting data resources— in the aggregate, as a collective data set—can be used. The group’s collective decisions, once made, would be binding on all members of the group (at least until a member exited the group), but the decisions would be made by the group members themselves, according to rules and processes they established. This article explores the promise and the challenge of enabling consumer-driven data commons as a mechanism for consenting individuals to assemble large-scale data resources. Twenty-first century science, as discussed below,20 needs large-scale, deeply descriptive, and inclusive data resources. Granular, individual consent can make it difficult to assemble such resources, which require collective action.
There are many competing visions of the public good and how to advance it. This analysis presumes, as its starting point, that the public good is served when health data are accessible for biomedical research, public health studies,21 regulatory science,22 and other activities that generate knowledge to support continuous improvements in wellness and patient care. The goal here is not to debate this vision but rather to assume it and study how competing legal and institutional arrangements for data sharing may promote or hinder the public good and address people’s concerns about privacy and control over their PHD.
1. THE CHALLENGE OF ASSEMBLING DATA RESOURCES FOR PUBLIC GOOD
Consumer-driven data commons have the potential to elevate citizen science from its perceived status as do-it-yourself puttering and transform it into a force for addressing some of the grand scientific challenges of the twenty-first century. These challenges include several programs initiated during the Obama Administration, such as the Precision Medicine23 and Brain Research through Advancing Innovative Neurotechnologies (BRAIN)24 Initiatives and the Cancer Moonshot.25 They also include efforts to clarify the clinical significance of genomic variants and to ensure that modern diagnostics are safe and effective.26 Another major challenge is to develop a “learning health care system”27 that routinely captures data from treatment settings, as well as from people’s experiences as non-patients before and after their healthcare encounters, to glean insights to support continual improvements in wellness and patient care.
These scientific challenges all share a common feature: they require access to very large-scaled data resources—sometimes, data for tens to hundreds of millions of individuals28 (known as “data partners”29 in the nomenclature of the Precision Medicine Initiative). The most valuable data resources are deeply descriptive in the sense of reflecting, for each individual, a rich array of genomic and other diagnostic test results, clinical data, and other available PHD such as data from mobile and wearable health devices that may reflect lifestyle and environmental factors influencing health.30 The data need to be longitudinal in the sense of tracing, as completely as possible, the history of a person’s innate characteristics, factors that may have influenced the person’s health status, diagnoses during spells of illness, treatments, and health outcomes.31
Such data, unfortunately, are inherently identifiable. Access to at least some identifiers is necessary, at least in certain phases of database creation, in order to link each person’s data that is arriving from different data holders, to verify that the data all pertain to the same individual, and to update the person’s existing data with subsequent clinical observations.32 Once the data have been linked together to create a longitudinal record for each individual, the identifiers could be removed if there is no need to add subsequent data about the individual. Even if overt identifiers like names are stripped off after the data are linked together, the resulting assemblage of data— deeply descriptive of each individual—potentially can be re-identified.33 If a dataset contains a rich, multi-parametric description of a person, there may be only one individual in the world for whom all of the parameters are a match. If other, external datasets link a subset of those parameters to the person’s identity, re-identification may be possible.34
For some important types of research, the data resources also need to be highly inclusive, in the sense that most (or even all) people are included in the dataset.35 Inclusive data sets capture rare events and allow them to be studied and avoid consent bias (selection bias).36 Empirical studies suggest that people who consent to having their data used in research may have different medical characteristics than the population at large.37 For example, patients who are sick and have symptoms may feel more motivated than asymptomatic people are to volunteer for studies that explore possible genetic causes of their symptoms. If true, then a cohort of consenting research subjects may over-represent people who carry a specific gene variant and also happen to be ill. The study may reach biased conclusions misstating how often the variant results in actual illness.
Consent bias reportedly was a factor that contributed to a tendency for early studies to overstate the lifetime risk of breast and ovarian cancer in people with certain BRCA genetic mutations.38 Costs of testing were high under the gene patenting doctrine of the day; insurance reimbursement criteria tended to make clinical BRCA testing available only to people with a personal or family history of these cancers; such people also were highly motivated to share their data for use in research.39 As a broader population gains access to BRCA testing, the available data resources are gradually expanding to include more people who have mutations without developing cancer, and lifetime risk estimates are trending downward.40 Getting these numbers right has obvious impact on future patients who face decisions based on their test results.
One possible way to create large, deeply descriptive, inclusive datasets free of consent bias would be to force all citizens to contribute their data, in effect requiring them to pay a “data tax” (an exaction of part of their data) just as we all must pay income taxes. That idea, seemingly, would be repugnant to many, and I do not propose it except to contrast it with a rarely considered policy that this article seeks to advance: Why not get people to want to participate in large-scale, deeply descriptive, inclusive datasets for use in research? Why not make participation interesting and enjoyable, perhaps even fun? Current ethical and regulatory frameworks that govern data access, such as the Common Rule41 and Health Insurance Portability and Accountability Act of 1996 (HIPAA) Privacy Rule42 decisively fail to do this. Have we, as a society, unwittingly embraced a prune-faced framework of bioethics, such that making it fun for people to participate in informational research seems coercive or ethically problematic? If so, how did it come to this and what can we do about it?
The Common Rule and HIPAA Privacy Rule both provide workable pathways to obtain data—if necessary, without consent—for socially important research, public health purposes, and regulatory science.43 But the resulting data uses are not fun—indeed, people often do not know the uses even occurred—and unconsented data access, even when it is legal, will always be controversial.44 Surveys show that “the majority of consumers are positive about health research, and if asked in general terms, support their medical information being made available for research”45—in other words, they see research participation as potentially fun—but they want to be asked before their data are taken and they prefer for their data be de-identified.46 Sadly, as just noted, de-identification may no longer be feasible, and even if it were feasible, it cannot support creation of deeply descriptive, longitudinal data that twenty-first-century science needs.47
The existing regulations, which were designed for clinical research and for small-data informational studies of the past, function well enough and may continue to function, at least for those who are sufficiently well-lawyered to thread the needle of data access. But they do not excite people about becoming partners in the grand scientific challenges of the twenty-first century, which ought to be easy given how fascinating these challenges are. Current regulations sometimes insult the very people whose data investigators want to use, showering individuals with unwanted, paternalistic protections—such as barriers to the return of research results48—while denying them a voice in what will be done with their data. Data partners’ only real “voice” is their right to withhold consent and, in effect, take their data and go home. Even that right can be waived by an Institutional Review Board,49 typically staffed by employees of institutions that wish to use the people’s data and whom the people never chose to represent their interests.50
Most people have no wish to take their data and go home. Surveys suggest that eighty percent of Americans would like to see their data used to generate socially beneficial knowledge.51 They want to participate, but subject to privacy, data security protections, and other terms that are transparent and satisfactory to themselves.52 Consumer-driven data commons are a vehicle for enabling consumers to set and enforce those terms through collective self-governance and to find the voice that ethics and regulatory frameworks consistently deny them.
2. DISTINGUISHING DATA OWNERSHIP, DATA COMMONS, AND THE PUBLIC DOMAIN
There are multiple, viable pathways for developing heath data commons to promote public good, and it will be important for policymakers to have the wisdom to allow them to evolve in parallel during early phases of the effort.
The first major pathway,53 resembling propertization, bestows entitlements (such as specific rights of access, rights to transfer and enter transactions involving data, rights to make managerial decisions about data, or even outright data ownership) on specific parties. It then relies on those parties to enter private transactions to assemble large-scale data resources. The initial endowment of rights can be bestowed various ways: on the individuals to whom the data relate (patients and consumers); on data holders such as hospitals, insurers, research institutions, and manufacturers of medical and wearable devices that store and possess people’s data; on both groups; or on other decision-makers.
A second major pathway is to develop data resources in the public domain54—for example, through legislation or regulations that force entities that hold data to supply it for specific public health or regulatory uses, or by using public funds (e.g., grants or tax incentives) to create data resources under rules that make them openly available for all to use (or for use by a designated group of qualified entities, such as public health officials or biomedical researchers, who are legally authorized to use data on the public’s behalf).
A third pathway is to foster creation of data commons, which are distinct from the other two pathways and can include many different types of commons that may exist simultaneously.55
This section briefly clarifies the relationship among data ownership, data commons, and the public domain.
In 2014, the Health Data Exploration Project surveyed a sample consisting primarily of people who track their PHD and found that 54% believe they own their data; 30% believe they share ownership with the sensor company or service provider that enables collection of their data; 4% believe the service provider owns the data; and only 13% profess indifference.56 Most respondents viewed ownership as important “because it implies a level of control over the fate of [the] data,” and a significant number of people expressed that they have or would like to have control.57 Kish and Topol, in their recent call for patient ownership of data, took the stance that individual ownership serves important personal interests that are not served by rights of access and control58—a contention this article queries further below.59
At the February 2016 Precision Medicine Initiative Summit, President Obama captured many Americans’ sentiments: “I would like to think that if somebody does a test on me or my genes, that that’s mine.”60 He impressed the lawyers in the room by adding, “But that’s not always how we define these issues, right? So there’s some legal issues involved.”61 Indeed. Intense feelings of ownership can exist in the absence of legal ownership. Airline passengers feel strong bonds of ownership to their assigned seats and may experience feelings of trespass if a neighboring passenger encroaches on “their” seat. The legal reality is that airline passengers have no property interest in their assigned seats. They merely have a contract for carriage—a type of service contract—with the airline, which can uphold its end of the bargain by reassigning the passenger to any other seat, however unsatisfactory, on the plane or by placing the passenger on the next flight, with or without a voucher toward a future trip on the airline which, by then, one ardently hopes one shall never have to fly on again. We all “like to think” we own our assigned seats and our health data, but this is irrelevant to whether we do.
Discussions of health data commons occur against the backdrop of these calls for patients to own their health data. Terms like scientific research commons, medical information commons, and genomic data commons have roots in a decades-long analysis of commons in natural resource economics and property theory.62 The scientific and medical communities sometimes refer to “a commons” or “the commons,” apparently to denote a specific, shared data resource, database, or health information infrastructure that would be openly accessible to researchers and clinicians (as if in the public domain), while possibly incorporating respect for individual data ownership.63 These discussions can seem jumbled to traditional commons scholars, who view commons as a multiplicity of possible institutional arrangements64 (that is, “sets of working rules”65 for creating, sharing, using, and sustaining a resource) that exist in the space between66 the two extremes of assigning private property rights to the resource or placing it in the public domain.67 “[T]he knowledge commons is not synonymous with open access” 68 or the public domain, although arrangements that embrace open-access rules are one variety of commons.69
Language is a living, evolving thing and members of the scientific and medical communities are free to define the word “commons” in any way that aids their internal communications. It may facilitate broader cross-fertilization of ideas, however, to link discussions of health data commons to other strands of commons analysis. Professors Frischmann, Madison, and Strandburg70 are modern explicators of the commons analysis identified with Elinor Ostrom and her collaborators in natural resource contexts71 and later adapted to knowledge resources by Charlotte Hess and Elinor Ostrom.72 Key points are that commons do not denote specific resources—such as a fishery, pasture, or health database.73 Commons are not a place or a thing or a resource that people can use.74 Rather, commons are institutional arrangements for managing or governing the production and use of a particular resource—such as a health database— and for addressing social dilemmas that impede sustainable sharing and stewardship of the resource.75
For rivalrous resources, such as a pasture where one group’s use may preclude use by others, the number of simultaneously existing commons is often quite limited; some resources can only support the formation of a single commons arrangement. Informational resources are generally conceived as non-rivalrous, because multiple parties can simultaneously use copies of the same information at the same time. Note, though, that interoperable health data resources are partially rivalrous, because converting data from disparate sources into well-curated, consistent formats that allow particular types of analysis requires a substantial investment of capital and skilled labor.76 These latter resources have supply constraints that may limit the number of competing, simultaneous data uses. Data, in theory, could be used for any number of scientific studies, but unless the data are already in an interoperable format (which American data generally are not),77 there may not be enough skilled data analysts to convert the data into the formats each study requires.
Generally speaking, though, once data are converted into a common data model or other interoperable format, further uses of the converted data are non-rivalrous. Health data resources thus can support the simultaneous existence of multiple health data commons. For example, a group of three hospitals might form a commons to allow limited data sharing among themselves for use in quality improvement activities. Patients of those same hospitals might merge their own data with data from patients who used other hospitals to form a patient-driven commons to compare their experiences as health care consumers. The two commons, operating under different sets of rules for the benefit of distinctly different groups of users, would co-exist and neither would be the commons.
3. THE INEVITABILITY OF SHARED DATA CONTROL
In popular culture, property rights are a venerated symbol of an individual’s right to restrict other people’s access to things that are personally important, such as one’s home or one’s PHD.78 Ownership resonates with a new model of privacy that gained ground in recent years. The traditional view of privacy as secrecy or concealment—as a “right to be let alone”79—grows strained in an age when the Internet and ubiquitous communication technologies foster broad, voluntary sharing of personal information.80 We vomit our personal data into the Universe, but we want the Universe to protect our privacy. To conceal the contradiction, modern theorists embrace a new view of privacy in which concealing one’s secrets “is less relevant than being in control of the distribution and use by others” 81 of the thick data trails people generate and willingly or unwittingly82 disseminate. Presently, “[t]he leading paradigm on the Internet and in the real, or off-line world, conceives of privacy as a personal right to control the use of one’s data.”83 Property rights, it is hoped, may restore our desired control.84
In this debate, the ultimate value of the data ownership metaphor may be its insistence—once property rights are correctly understood—that just and efficient protection of the individual’s interests requires limits to individual consent, a proposition embraced less comfortably, when at all, in the bioethics literature. Proposals for individual data ownership sometimes portray property rights as allowing people to veto any unwanted use of their data.85 This level of control reflects a mythical86 or fairy-tale87 view of the legal protections that ownership provides. In practice, property regimes grant individuals a qualified (non-absolute) right to control the disposition of their assets, but they also protect competing individual and social interests by imposing responsibilities and limitations on ownership.88 Jacqueline Lipton usefully reminds us that ownership actually supplies a bundle of rights, limitations on those rights, and duties89 so that individual and competing interests both receive protection. Margaret Jane Radin sees the two basic functions of property theory as to justify rights and to explain their boundaries.90 As Edella Schlager and Elinor Ostrom point out, in natural resource settings, “all rights have complementary duties.”91
Those seeking absolute control of their PHD should not look to data ownership to give it to them.92 As an example, homeowners enjoy a very robust set of rights but can be forced without consent to pay property taxes or to cede control of some or all of their property. Their control is subject to easements that may allow public utility projects to cross their land or facilitate a neighbor’s access to a landlocked adjacent property. The government has police power to impose duties—such as a requirement for owners to abate hazards or to install sidewalks on their property—that promote public health and safety.93 Failure to comply may draw sanctions up to and including uncompensated seizure of the property.94 Eminent domain, or takings, can force non-consenting owners to cede their property for “public use”95—a broad concept that in modern law includes commercial office parks and other private endeavors that allegedly confer public benefit,96 in addition to more traditional public uses such as highways97—so long as fair compensation is paid.98
The waiver provisions of the HIPAA Privacy Rule and the current (pre-revision) Common Rule strongly resemble the private eminent domain powers that some utility companies enjoy under state laws; any regime of data ownership presumably would incorporate a similar mechanism to ensure access to individuals’ data for research that benefits the public.99 Elsewhere, I have explained why the court-determined fee for a “data taking” would very likely be zero under existing doctrines for assessing takings compensation.100 Thus, patient data ownership would be unlikely to confer ironclad control or even control superior to what people already have.
Scholars point to additional conceptual and practical flaws with data ownership as a tool to protect privacy: The fact that data resources are largely non-rivalrous undermines the economic justification that property rights are necessary to prevent the waste of scarce resources.101 Property and privacy serve fundamentally different interests, with property denoting control in the marketplace over things alienable from the self—things we are willing to part with—whereas privacy denotes control over things entwined with our selfhood.102 Commodifying people’s data is potentially objectionable on both moral and practical grounds.103 Property rights will do little to protect privacy if vulnerable people sell their rights or give them away and, ultimately, things that are owned can nevertheless be stolen. Creating informational property rights is no guarantee that they will function effectively on an ongoing basis; substantial infrastructure and effort may be required to effectuate orderly transfers of “owned” data.104 The list of objections is long.
Despite these flaws, property terminology is familiar to everyone and the ownership metaphor “will likely stick”105 in public discourse about data privacy, even if cooler heads resist pressure to enshrine data ownership as law. There is no real harm in invoking property metaphors, as long as we carefully specify what we conceive ownership to mean.106
Kish and Topol’s recent proposal for patient data ownership, despite its many merits, was not entirely clear what ownership means. They mentioned that “possession is nine-tenths of the law,” suggesting a right of access and personal possession, but did not clarify whether this would be a right of exclusive possession that allows patients to insist that their healthcare providers erase the providers’ copies of their records.107 Kish and Topol also noted that having a title to one’s home creates conditions for trusted exchange, suggesting a right to transfer one’s records to others.108 They listed several conditions to be met: patients should have access to their records anywhere at any time; records should be controlled by the patient or patient’s agent; they should be unique and traceable to a real person; records should be privacy-enabled and secure and have a known provenance that allows them to be traced to the data-holder whence they came.109 These conditions, while useful for purposes of managing data resources, do not all reflect attributes of legal property ownership. Owning one’s home does not guarantee that it is secure against break-ins, for example.
Some proposals liken data ownership to traditional fee simple ownership of a house,110 but there are many alternative models to consider. Data ownership might, for example, resemble co-ownership in which multiple parties have rights of access and use; it could resemble the nonexclusive rights riparian owners have in a river next to their land—that is, a right to use the river but no right to interfere with others’ simultaneous uses such as fishing and navigation;111 or it could work like a copyright that ends after a period of time and allows fair use by others during that time.112
None of the available models of individual data ownership is presently reflected in law. Property law in the United States is set primarily at the state level,113 except in discrete fields (for example, patent law) where a federal framework controls. Several states have enacted laws that grant individuals a property interest in their own genetic information114 and a few more states have considered such legislation,115 although such laws are notoriously vague about what genetic property rights mean.116 In most states, and for most other categories of health information, state law does not directly address who owns a person’s health data.117
A few state court cases have found patients own their medical records under specific circumstances.118 Unfortunately, the pertinent body of state medical records law generally applies in traditional healthcare settings and seemingly does not govern commercial providers of PHD devices and services, such as purveyors of medical and fitness devices. Courts do not recognize an individual property right in personal information such as one’s name, address, and social security number.119 Commercial databases that hold such information are generally treated as the property of the companies that compiled them.120 In a famous case121 where plaintiffs sought to block a company from disclosing their personal information by selling its mailing lists, Vera Bergelson notes an implicit judicial bias “that, to the extent personal information may be viewed as property, that property belongs to the one who collects it.”122 This bias— if it exists—is reminiscent of the ancient res nullius doctrine from natural resource law, which treated assets such as subsurface mineral deposits and wild animals as unowned until somebody discovers and captures (takes possession of) them.123 “Rarely used today, it let private owners stake claims as in the Klondike gold rush.”124
Law does, however, recognize a subtle difference between a data holder’s ownership of a database and its ownership of data that populate the database. “Although it is common for businesses contracting with one another to state that one or another of them ‘owns’ a particular data set, ownership of the contents of a database is a precarious concept in the United States.”125 Database operators have a legal interest in the data in their databases, but this interest is not usually regarded as ownership.126 Information in a database can be owned in the sense of being eligible for trade secret protection, if the operator meets all the other legal requirements (such as maintaining the data’s secrecy) for such protection.127 Copyright law typically does not protect database content, which is in the nature of facts rather than expression, so copyright protection typically extends only to features such as the arrangement of a database rather than to the data itself.128 Even though data holders do not own database content, Marc Rodwin echoes concerns that courts tend to “grant property interests to those who possess that data and preserve the status quo.”129 The status quo is that data are widely scattered in proprietary corporate databases, creating a tragedy of the anticommons that threatens to leave valuable stores of data inaccessible for research and other beneficial uses.130
As for PHD generated outside the traditional healthcare setting, the privacy policies and service contracts of device manufacturers do little to clarify data ownership. Scott Peppet recently surveyed privacy policies of twenty popular consumer sensor devices and found only four that discussed data ownership.131 Three of those four indicated that the device manufacturer, rather than the consumer, owns the data, with some claiming “sole and exclusive” ownership.132 Such assertions of ownership are not necessarily enforceable at law. Suppose a sensor manufacturer asserted, in its privacy policy, that it owns the Eiffel Tower and a consumer purchased and used the sensor with actual or constructive notice of that policy. Neither of those facts would affect ownership of the Eiffel Tower, if neither party had an enforceable claim to it under relevant law. Such policies may, however, deter consumer challenges to a manufacturer’s alleged ownership.
Even without legal ownership, it is fair to say that health data holders enjoy powers tantamount to ownership. The information they hold is “out of circulation even though it is not, strictly speaking, owned”133 and many operators “treat patient data as if it were their private property.”134 “Multiple ownership of different pieces of a patient’s medical history … makes it difficult for anyone to assemble a complete record.”135 The data are siloed.
The reality is that multiple parties have legitimate interests in a person’s health data. Healthcare providers must maintain copies of patient data to comply with medical records laws, to ensure continuity of care during patients’ future visits, and to defend against lawsuits. Insurers need records for auditing, fraud prevention, and state regulatory purposes. Even in theory, exclusive data ownership is unworkable. If data ownership existed, it seemingly would have to be some form of shared ownership.
What might shared data ownership look like? In a different context, Ostrom and Schlager identified a set of entitlements individuals enjoy in shared property regimes for natural resources, such as fisheries.136 These resonate with some of the entitlements people wish to have in relation to their PHD. The list includes “operational-level” entitlements:
-
(1)
a right of access to the resource, and
-
(2)
a right to withdraw products from the resource (e.g., a right to catch fish), corresponding to a right to use data resources.137
A party may—but does not always—have additional “collective-choice” rights, including:
-
(3)
a right of management, which confers the right to participate in decisions about resource uses and the right to improve or transform the resource (such as by adding, deleting, or editing data),
-
(4)
a right of exclusion, which confers the right to participate in decisions about who can access and use the resource and decisions about the appropriate process for approving and enforcing access and use, and
-
(5)
a right of alienation, to transfer the above rights to other people.138
In shared ownership regimes, the individual does not usually enjoy “sole and despotic dominion,”139 such as an unassailable right to consent to, or veto, specific resource uses. Rather, the individual has a voice (voting rights) in a collective decision-making process, and a residual right to exit the collective if its decisions prove unsatisfactory.
4. THE CHALLENGE OF ASSEMBLING LARGE-SCALE DATA RESOURCES
In traditional healthcare and research environments, control of data remains fragmented among multiple data holders (such as physicians, research institutions, hospitals, insurers),140 with another layer of fragmentation at the level of individuals, to the extent their consent is required for data access.141 As tracking and surveillance technologies and direct-to-consumer testing services generate PHD outside traditional healthcare settings, the fragmentation increases, with different data holders operating subject to different legal and regulatory regimes.142 Harnessing data for public good requires transactions to bring the data together. Subpart A of this discussion discusses traditional healthcare and research environments. Subpart B then highlights key differences affecting non-traditional PHD such as self-tracking sensor data.
A. Traditional healthcare and research data
The Common Rule and HIPAA Privacy Rule frequently apply in traditional clinical care and research settings. These regulations endow individuals and data holders with various entitlements,143 somewhat resembling the entitlements Schlager and Ostrom associate with shared resource ownership regimes.144 Note that these are regulatory entitlements, not ownership rights, but they include various rights of access, use, management, exclusion, and alienation and, in some respects, they are “strikingly similar” to a scheme of data ownership.145 By exercising their regulatory entitlements, the parties may be able to free data for use in assembling large-scale data resources for research and public health.
When a data holder stores a person’s data, both parties share control and their interests are not necessarily aligned. Individual consent may not be sufficient to ensure data access. In this respect, assembling data for informational studies is fundamentally different from the problem of enlisting human participants for clinical (interventional) studies. Access to the key resource for interventional research (human beings to study) is properly modeled as a two-party transaction between an individual and a prospective user such as an investigator who desires to involve the individual in the research. The individual has exclusive control over the resource—the individual’s body—to which the prospective user needs access. Assuming the individual has decisional capacity and is willing to consent, the consent is sufficient to ensure access. In contrast, acquiring the key resource for informational research (data) is poorly modeled as a two-party transaction. It often requires three-way transactions among the prospective data user, the data subject, and a data holder that possesses the person’s data. Figure 1 displays four possible solutions to the problem of data access.
Figure 1.
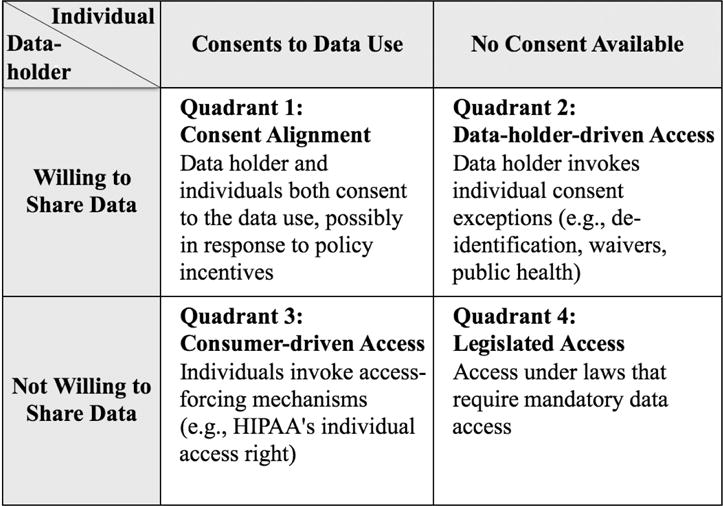
Pathways for Assembling Large-Scale Data Resources
Solution 1: Incentivized consent alignment
In Quadrant 1, data access is unproblematic because there is consent alignment. The individual and the data holder both want to share the individual’s data. Consent alignment sometimes arises naturally, but it also may be possible for policy makers to create incentives for the parties to align.
Incentivized consent alignment has a proven track record in research settings.146 Conditional grants are an effective mechanism. For example, the National Institutes of Health (NIH) and counterpart funding agencies in other nations have encouraged sharing of genomic data by implementing policies that require grantee research institutions to deposit certain data they generate under grants into shared genomic databases.147 If the deposited data are de-identified, individual consent is not required by current regulations.148 If a research project contemplates sharing data in a form that does need individual consent (for example, sharing of data among participating institutions in a multi-site study), consent can be procured at the point when participants consent to the research.
The NIH-funded Precision Medicine Initiative’s million-person cohort is another example of incentivized consent alignment. Data holders and the individual data partners who wish to participate in this exciting project will be asked to consent to its data-sharing terms.149 Publicly funded efforts of this sort can jump-start discovery and pave the way for future efforts. The major drawback is that conditional funding solutions are costly and, amid budgetary constraints, raise concerns about long-term sustainability.150 They are not scalable as a way to develop the data resources ultimately required for twenty-first-century science, which may need to include hundreds of millions of people.151
Consent alignment is more difficult to achieve in clinical and commercial healthcare settings, yet it is potentially critical to the overall effort. These environments hold large stores of clinical health data that are essential for assembling deeply descriptive data resources that link individuals’ phenotypes to their genotypes. Clinical laboratories and healthcare providers have various commercial incentives not to share data that they hold.152 The data-deposit policies of funding agencies like NIH are not binding on these data holders, although many do voluntarily contribute at least some data to shared public data resources like ClinGen/ClinVar.153 Commercial data holders’ reluctance to share data poses an important barrier to the assembly of large-scale, linked data resources, even as surveys show most individuals would be willing to share.154
Policy options for fostering consent alignment—including in clinical and commercial settings—have not been exhausted. Policy-makers should explore approaches for incentivizing consent alignment. Possible approaches include conditioning desirable benefits (as opposed to funding) on data sharing. Commercial data holders may voluntarily agree to share data if a benefit, such as Medicare reimbursement or Food and Drug Administration (FDA) approval of a medical product, depends on it. Such approaches may fail to achieve alignment, however, if individual consent is also required. Incentivizing individual consent, depending on the context, may or may not raise concerns about coercion, so incentives must be thoughtfully designed.
Solution 2: Data-holder-driven access
Consent alignment can fail in two ways, portrayed in Quadrants 2 and 3 of Figure 1. In Quadrant 2, the individual is unwilling to share data or cannot practicably be reached to provide consent and privacy authorization. The data holder is willing to share. Problems of this sort seem destined to occur in the future, if growing awareness of re-identification risks makes individuals wary of consenting to research with their data.
The HIPAA Privacy Rule and Common Rule pragmatically address the situation in Quadrant 2 with an array of individual consent exceptions, exemptions, and definitional loopholes that protect society’s interest in enabling certain important data uses. These exceptions permit, but do not require, a data holder to release data155 and, for that reason, Figure 1 characterizes these pathways as “data-holder-driven” access mechanisms. Data can be freed through these legal pathways, but only if the data holder wants to do so.
For example, the Privacy Rule and Common Rule allow data holders to supply data, without individual consent, for certain public health, regulatory, and judicial uses of data,156 but the regulations do not themselves require data holders to share.157 In one recent study, Institutional Review Boards refused to provide about five percent of the requested medical records for a well-documented, congressionally authorized public health purpose.158 Users that are denied data access must look to other sources of law—such as a court order or provisions of state public health laws that require healthcare providers to report specific types of information—to force data access. HIPAA and the Common Rule do not themselves mandate access for these uses.
The waiver provisions159 of the Privacy Rule and Common Rule have traditionally been an important legal pathway that allows Institutional Review Boards and privacy boards (collectively, IRBs)160 to approve unconsented research uses of data— including, crucially, data with identifiers that can be linked across separate datasets to form longitudinal health records. When IRBs are affiliated with the data holding institution, this effectively allows the data holder to override individual consent. When an external IRB approves a waiver, the data holder may, but is not required to, release the data,161 so discretion still rests with the data holder. Unfortunately, as already noted, data holders do not always wish to share.
The recent amendments to the Common Rule still allow IRBs to waive consent for the use of identifiable data and biospecimens but impose one restriction that does not exist in the current Common Rule: If an individual is asked to grant a broad consent for the use of identifiable data and specimens in unspecified future research and refuses to grant such a consent, IRBs will not subsequently be able approve waivers overriding the person’s expressed refusal.162 If the person has not previously rejected a request for broad consent, IRBs will be able to approve waivers of consent, just as under the current Common Rule.163 This restriction may create incentives for researchers to avoid seeking broad consent for research, when doing so could foreclose future options to seek consent waivers.164
Data-holder-driven data access under HIPAA and the Common Rule has been an important pathway enabling data access for important research and public health uses. It will not suffice, however, as a way to assemble the large-scale, deeply descriptive data resources that the future requires. IRBs may be comfortable concluding that conditions for waiving consent (such as that privacy risks are minimized) are met in the context of a discrete proposed data use. Certifying that these conditions are met is far more difficult, however, in the context of a large-scale data infrastructure that will be widely accessible for many different uses. Moreover, even in past contexts where data-holder-driven access has worked, it has never been uncontroversial. Bioethicists and data subjects criticize its disrespect for the individual’s right of choice.165 Law scholars criticize the democratic illegitimacy, procedural deficiencies, and potential conflicts inherent in using IRBs as the decision-makers to override individual consent.166 Investigators and institutions find it cumbersome to administer.167 There is little to like about this method of access, particularly in contexts such as Precision Medicine that aim to empower patients and research subjects. Something new is needed.
Solution 3: Consumer-driven data access
Consumer-driven access may be the needed alternative. There have been isolated instances, such as the Canavan example discussed in the introduction, where patient advocacy groups took the lead in assembling data resources for research into specific diseases. The question is whether such efforts are scalable: Could they be used to assemble larger data resources for more general use in diverse research contexts, under terms and conditions set via consumer self-governance?
In Quadrant 3 of Figure 1, the individual wishes to share his or her stored data, but this desire is thwarted by an unwilling data holder. The bioethical literature is asymmetrical, evincing concern about unconsented uses of people’s data (Quadrant 2), while largely failing to register ethical objections when data holders or their IRBs block data access for uses of which the individual would have approved (Quadrant 3). The Common Rule exemplifies this asymmetry: it contains multiple consent exceptions168 allowing data holders to share people’s data without their consent in Quadrant 2, but contains no access-forcing mechanism to help data subjects free their data for socially valuable uses in Quadrant 3. This defect may be unintentional, an artifact of cramming three-party data access transactions into the Common Rule’s simplistic two-party model of human-subject enrollment in clinical trials.
The HIPAA Privacy Rule, in contrast, contains an access-forcing mechanism. The Privacy Rule was expressly designed for data transactions (and, in particular, those where a person’s data are held by an institutional or corporate data holder).169 It takes a more symmetrical approach that facilitates data access in Quadrant 3 as well as in Quadrant 2. Section 164.524 of the Privacy Rule grants individuals a right of access to information about themselves that a HIPAA-covered entity holds in its files.170 By exercising this right, individuals can obtain their data171 and then, if they wish, contribute it for research and other uses. Mark Hall once proposed a scheme in which a patient could grant a license to a trusted intermediary, which would exercise the patient’s Section 164.524 access rights to gather the patient’s data from the various HIPAA-covered healthcare organizations that hold portions of the patient’s medical data, assemble the data into a longitudinal record, and then act as the patient’s agent for purposes of negotiating access with researchers and other prospective users in accordance with the patient’s preferences.172 This vision is now set to become reality.
In 2014, the U.S. Department of Health and Human Services (HHS) amended173 the Privacy Rule and the Clinical Laboratory Improvement Amendments of 1988 (CLIA) regulations174 to expand the reach of people’s section 164.524 access right to include information held at HIPAA-covered clinical laboratories.175 Laboratories had not previously been subject to the access right, which applied to other healthcare providers such as hospitals and clinics. The changes became legally effective on October 6, 2014 amid considerable confusion and even disbelief about the apparent scope of the new individual access right. A legal analysis by an NIH-funded working group concluded that at HIPAA-covered laboratories that conduct genomic testing, whether for research or clinical purposes, the accessible dataset includes not just final, interpreted test reports but also underlying genomic data if the laboratory has stored data in a form that is traceable to the requesting consumer.176 Patients who sought to exercise their new rights of access to laboratory-held information after October 2014 sometimes encountered barriers, however, and were not able to access their data.177
The HHS Office for Civil Rights, which administers the Privacy Rule, issued guidance in January and February of 2016 confirming that the Section 164.524 access right applies to underlying genetic variant data generated during genomic sequencing, as well as to finished test reports which typically focus on just a few target variants; that individuals have a right to request their data in machine-readable (electronic) format; and that they can direct the data holder to transfer data to an agent or trusted intermediary of their choosing.178 Consumers now have the power to force HIPAA-covered laboratories to release data from clinical testing.179 Moreover, they also can access data generated at HIPAA-covered research laboratories (such as laboratories embedded in HIPAA-covered academic medical centers).180
The section 164.524 access right was originally conceived as an instrument to enhance privacy protection. In the preamble to the original Privacy Rule in 2000, HHS cited a “well-established principle” that an individual (or designated personal representative) should have “access rights to the data and information in his or her health record”181 and remarked that people’s “confidence in the protection of their information requires that they have the means to know what is contained in their records.”182 More recently, HHS acknowledged that the individual access right has broader importance. In its 2014 rulemaking, HHS described section 164.524 as crucial not merely to enhance privacy protection but also because: (1) it “enable[s] patients to have a more active role in their personal health care decisions”; (2) it is consistent with “certain health reform concepts” including personalized medicine, participatory medicine, disease management and prevention; and (3) it supports HHS’s goals and commitments regarding widespread adoption of electronic health records (EHRs).183 These last two points conceive section 164.524 as an instrument to free data for public good.
The Privacy Rule pits the rights of the individual and the rights of the data holder against one another, and the interplay/tension between the two helps protect the public’s interest in data access. This is far from a perfect access scheme—for example, the data resources available in Quadrant 3 may be marred by selection bias, because these datasets only include individuals who took volitional steps to free their data for research.184 Access is nevertheless broader than under the lopsided framework of the Common Rule.
Solution 4: Mandatory data sharing
This leaves Quadrant 4, the all-too-common situation where neither the data subject nor the data holder is motivated to share data for the public good. Data users have little recourse when this is true. As noted above, the Common Rule and HIPAA Privacy Rule contain no provisions requiring data holders to free data, other than HIPAA’s section 164.524 access right. Authority to force access must come from other sources of law. Legislatures offer a legitimate, democratic mechanism for imposing binding, collective decisions on data holders and individual data subjects who, in Quadrant 4, dissent from a socially beneficial data use. Access-forcing laws are, however, very rare and typically focus on narrow problems where the need for access is compelling (e.g., reporting of child abuse and communicable diseases). They generally do not address the problem of freeing data for research.
Forcing access to data in Quadrant 4 presents difficult legal issues, which may explain lawmakers’ reluctance to require mandatory access. Forcing private-sector data holders to disclose their data may constitute a taking and require “just compensation,”185 if courts recognize the data holders’ asserted ownership of the data (or of the capital they invested to marshal the data and develop their health data infrastructures). A related problem is that creating useful research data resources requires inputs not just of data, but of services (such as to convert data to an interoperable format) that data holders would need to provide.186 The government has little power to force data holders to contribute services,187 even if they could be forced to share their data. The needed services can only be procured by consensual methods, such as entering contracts with the data holders188 or requiring their services as a condition of a grant,189 all of which require funding. Legislatures, when enacting access-forcing laws, would need to provide the necessary funding. This, again, explains why access-forcing legislation is rare. Forced access is a possible solution in specific, narrow contexts, but it is not a solution to the broad problem of assembling the large-scale, deeply descriptive data resources for twenty-first-century science.
B. Special challenges with non-traditional PHD
Even within the category of wearables and other sensors, “the information from two disconnected sensing devices can, when combined, create greater information than that of either device in isolation.”190 An example of this “sensor fusion” is that data on heart rate and respiration, when combined, may support inferences about substance abuse.191 Linking sensor data that reflect lifestyle, exposures, and environment to traditional health and genomic data would be even more powerful, and that is a goal of developing twenty-first-century data resources.
Harnessing non-traditional PHD for public good requires a framework to support multi-party consent transactions, as modeled in Figure 1. Individuals can exercise unilateral control over PHD stored on their own sensor devices, but much of their PHD may be externally stored and subject to full or partial control of a device or sensor manufacturer, service provider, or other data holder (PHD company). PHD companies rarely are bound by the HIPAA Privacy Rule and Common Rule.192 Except where isolated state-law privacy protections apply to them, their privacy and access policies are largely a matter of company policy. Whether data are stored on the device, by the company, or by both depends, of course, on the device, how much storage capacity it has, and on the service contract that accompanies the device. Many companies do act as data holders for their customers and, for many devices, the company is the primary holder of the consumer’s data. There are competing interests: the consumer, the data holder, and the public as represented by researchers and other users who desire access to the data for socially beneficial purposes. Balancing these interests requires a scheme of informed consent, well-tailored consent exceptions, and one or more access-forcing mechanisms.
Many observers think it unlikely that legislators will act to create a privacy and access scheme for PHD companies. Congress has broad power to set rules under the commerce clause193 and presumably could establish rules for PHD companies if it wanted to do so. Yet Congress has refused for many decades to impose a uniform ethical and privacy framework on private-sector (non-publicly-funded) research activities. The Common Rule is mandatory only for research that the federal government funds.194 The Common Rule is an exercise of Congress’s spending power, which regulates by placing strings on gifts of federal funds. PHD companies, firmly rooted in the private sector, are less in the habit of taking federal funds and therefore lack the “hook” that Congress has used to regulate privacy and ethical issues in traditional academic research settings.195
The Federal Trade Commission (FTC) and state attorneys general have jurisdiction to regulate unfair or deceptive business practices and can act, for example, if a PHD company publishes a privacy policy that it later dishonors.196 The recent Wyndham appeal recognized that the FTC has authority to regulate cybersecurity more broadly even if a company has not dishonored a policy it previously published.197 The FTC is actively engaged in efforts to protect consumer information privacy and has published reports and Fair Information Practices to guide Internet and consumer-data companies.198 Congress has not, however, made them mandatory.199
The cautious assumption is that the privacy of, and access to, PHD will continue to be governed largely by company policies and voluntary industry self-regulation. A survey of such policies by Scott Peppet found that some data-holding PHD companies promise not to share consumers’ personally identifying information (PII).200 As with traditional health data, re-identification is a growing concern with sensor data.201 Professor Peppet cites an intelligence source for the proposition that if fitness data reveals the gait at which a person walks, unique identification may be possible.202 PHD companies’ policies tend to be vague when defining PII: Does it merely include consumers’ names and other overt identifiers or is re-identifiable sensor data also PII?203 Companies generally reserve the right to share or sell non-personal information (non-PII) more broadly than PII, but their policies may leave it unclear which data are accessible for research.204 A reasonable expectation for consumers, absent a clear policy to the contrary, is that a company’s promise not to share PII amounts to a promise to strip consumers’ sensor data of overt identifiers before it is shared. Despite the theoretical risk of re-identification, removing overt identifiers affords at least some privacy protection, and consumers still display considerable willingness to have their data shared for research in de-identified form.205
Professor Peppet’s survey found PHD companies’ policies were “likewise inconsistent in the access, modification, and deletion rights they give consumers…. None provided an easy mechanism for exportation of raw sensor data.”206 In contrast to the HIPAA-regulated space, PHD consumers have limited access rights, and their access rights are often indefinite.207 Some companies’ policies allow access to PII but not to non-PII.208 When these terms are vaguely defined—as often happens—the scope of a consumer’s access right may be quite limited. Debjanee Barua et al. found that consumers want to be able to get a copy of their data: “This is the simplest level of control over one’s data—the ability to inspect, manipulate, and store your own information.”209 Often, however, this level of control is not possible.
Legislation or regulations may not be the best or the swiftest way to fix these problems. The PHD industry is responsive to its consumers and its consumers tend to be an educated, empowered group.210 The best path forward may be to educate consumers about appropriate privacy, data security, and access standards; to mobilize consumers to demand such standards; and to develop a system of voluntary certification for PHD companies that makes it easy for consumers to identify those that implement the standards consumers demand. The question of what the standards should be is beyond the scope of this article and, in any event, should be resolved with meaningful input from consumers themselves.
One point, however, is very clear: access and transfer rights, as broad and enforceable as the Privacy Rule’s section 164.524 provides, are a crucial access-forcing mechanism to free data for transfer into consumer-driven data commons. There are costs of providing an access mechanism and many practical issues, such as making sure consumers can access their data in useful formats.211 As with HIPAA’s access right, PHD companies should be able to charge a reasonable, cost-based fee for servicing access requests, but such fees should be subject to rules concerning what the fees can include.212 For FDA-regulated devices, access to one’s own data potentially bears on a device’s safety and effectiveness. FDA should explore whether it has authority to impose minimal consumer access rights on devices the agency regulates.
5. THE NECESSITY OF COLLECTIVE SELF-GOVERNANCE
Discussions of governance of large-scale data commons all too often conflate governance models with system architecture. That is a distraction. The crucial question in governance is not whether to establish a central database versus a federated/distributed data network or a network of networks. Rather, governance is about control relationships: Who gets to decide whose data will be included in a large-scale data resource, the rules of access to the data, the list of permissible uses and terms of use, the privacy and security protections, and the procedures for making such decisions? A consumer-driven data commons is one in which such decisions would be made collectively by the people whose data are involved.
Consumer-driven data commons would grow up alongside—and, if they succeed, possibly replace over time—the data-holder-centric models of the past, which grow increasingly unworkable in the environment of big data, where de-identification is dead. Consumer-driven data commons also will exist alongside consumer-driven access models that rely on granular individual consent to specific data uses. In granular consent models, individuals exercise their access rights to free data from data holders, but there is no collective self-governance of the overall data resource and each individual makes decisions strictly for herself. Granular consent has many merits— such as overcoming people’s initial reluctance to contribute their data—and it is the model the Precision Medicine Initiative apparently is embracing for its initial million-person research cohort.
Long-term, however, granular individual consent has a fatal flaw: the grand scientific challenges of the twenty-first century require collective action to resolve, and granular individual consent fractures the people, limits us and makes us small by robbing us of the capacity for collective action. It consigns us to the state Thomas Hobbes referred to as “the confusion of a disunited multitude,”213 unable to act together to conquer grand challenges. In Hobbes’ scheme, the greater power of a Commonwealth is instituted when a multitude of people come together and covenant “every one with every one,” to create institutions for making collective decisions, so that “every one, as well he that voted for it as he that voted against it” shall embrace decisions made by the “consent of the people assembled,” “in the same manner as if they were his own.”214 Consumer-driven data commons are vehicles for groups of consenting individuals to work together to build more inclusive datasets than their members, acting alone, could offer for scientific use. Members might further enhance the inclusiveness of their data assets through transactions to merge their own data resources with those of other commons-forming groups.
Whatever the possible merits of universal, compulsory contribution of individual PHD, that is not what consumer-driven data commons are about. Rather, they are smaller, self-governing groups of consenting individuals, who have rights to enter and leave the commons on transparent terms that each commons-forming group would itself establish. People would still have a right to consent, but it would be a right to enter, or not enter, a specific commons arrangement. Those choosing to place their data in a consumer-driven commons would, thereafter, have collective choice rights to participate in decisions about how the entire data resource—including the data of all members—can be used. Members could elect to leave the commons, but while members, they would be bound by its collective decisions regarding permissible uses of their data.
As consumer-driven commons groups develop their own rules of access and use, privacy practices, and decision-making processes, they offer a laboratory for modernizing ethical norms to accommodate the age of big data. The existing bioethical norms surrounding informational research were heavily influenced by norms designed for the clinical or interventional research setting.215 The strong norm of individual, protocol-specific informed consent in interventional research has deep roots in the common law notion that unconsented touching of a person’s body constitutes battery. Unauthorized invasions of the human body are “offensive to human dignity”216 and our legal system has long credited “the right of every individual to the possession and control of his own person, free from all restraint or interference of others.”217 But does it follow that touching a person’s data is equivalent to touching the person’s body, so that the same consent norms should apply in informational research?
The clamor for individual data ownership—which is widely misperceived as conferring inviolable individual consent rights— often draws inspiration from John Locke or from the concept of property as an aspect of personhood.218 Yet the Lockean concept that people own their bodies does not imply that they own data about their bodies, just as home ownership does not imply ownership of house-related information, which is widely available to realtors, taxing authorities, building inspectors, and busybodies curious about its square footage, improvements, and market value. People whose workouts generate fitness tracking data undoubtedly have earned “sweat equity” in their PHD under Locke’s labor theory of ownership, but the company that designed and marketed the device and invested effort to capture and store the PHD could assert an equally plausible claim under this theory.219
The personhood theory of ownership recognizes a moral claim to things that are integrally related to one’s self-development and sense of personhood.220 Much—some say too much—has been made of the “tenuous link between personal information and personhood.”221 The “Quantified Self” name of a collaboration of users and makers of self-tracking tools222 and the “Welcome to You” greeting on 23andMe’s web site223 are marketing claims, not ontological claims. Your data are not actually who you are.
Philosopher Charles Taylor bemoans the fact that modern discourse has banished ontological accounts of human worth from the discussion of morality.224 “Ontological accounts have the status of articulations of our moral instincts…. If you want to discriminate more finely what it is about human beings that makes them worthy of respect, you have to call to mind what it is to feel the claim of human suffering, or what is repugnant about injustice, or the awe you feel at the fact of human life.”225 The claim that PHD is integral to selfhood lends credence to Taylor’s alarm about impoverished ontological accounts of the modern Self. Early assertions that genetic information is integral to selfhood226 credited genomic science with a predictive power that, it is now clear, was fanciful. A person’s genome is a “future diary” recorded in a largely foreign language with most of the words inscrutable.
Research and public health uses of data are not directed at reading personal secrets in people’s diaries. As Lawrence Lessig points out, “no one spends money collecting these data to actually learn anything about you. They want to learn about people like you.”227 The variants in one’s genome are interesting to scientists only insofar as the variants are shared by other people and, if they are shared, in what sense can one person “own” them? Genomic testing has been misrepresented as “intensely private” when, in fact, the genome is a public space—perhaps the ultimate public space.228 It is where we go to discover what we have in common with other people.
Ruth Faden et al. acknowledge that the “moral framework for a learning health care system will depart in important respects from contemporary conceptions of clinical and research ethics”229 and may include an obligation for patients to participate in learning activities.230 Faden and her coauthors see this as a bounded obligation that would vary with the level of burden and risk involved.231 While not obligated in risky clinical trials, people may have an ethical duty to contribute their data to studies that can advance useful knowledge while providing reasonable data security.232 Faden et al. suggest that this obligation is justified by a “norm of common purpose … a principle presiding over matters that affect the interests of everyone.”233 “Securing these common interests is a shared social purpose that we cannot as individuals achieve.”234 The notions of common purpose, security common interests, and shared social purpose all bear emphasis, because many of the unsolved mysteries of twenty-first-century biomedicine will require large-scale, collective action to resolve. Whether to proceed with such studies calls for collective, rather than individual, decision-making: Do we, as a group, wish to gain this knowledge or not? If so, then our collective decision whether to proceed, and on what terms, must bind everyone.
Governance “in the sense of binding collective decisions about public affairs”235 is one of a core set of universal concepts—such as giving, lending, reciprocation, and coalition—that anthropologists find to be widely shared across many different cultures and societies, however primitive or advanced they may be.236 People acting in solidarity can reap benefits that autonomous individuals, acting alone, may forfeit, and human populations taken as a whole are greater than the sum of their atomistically autonomous parts. This concept was under-theorized in twentieth-century bioethics. Autonomy-based bioethics disempowers the people it seeks to protect if it precludes collective action on matters of common interest.
As Charles Taylor pointed out in discussing whether it violates individual freedom for the state to install a traffic light at a frequented intersection, thus forcing people to stop: a philosopher could find a violation in this, but most people view their autonomy with a sense of proportion.237 “[I]n such a case it is incorrect to speak of an infringement of freedom: the security and convenience of the walkers are in question, not freedom.”238 The use of data to advance precision medicine implicates patient safety, public health, and the preservation of other people’s lives—not individual freedom. Bioethical principles that support a right of individuals to veto the use of their data for such purposes blur the line between individual autonomy and narcissism.239
Our legal system traditionally employs informed consent when people are making decisions about risk to themselves,240 but not when they make decisions about matters of public safety and welfare. Thus, informed consent is irrelevant when setting the speed limit or levying taxes. There is no opt-in that nullifies the speed limit for individuals who refuse their consent to drive sixty miles per hour. There is no opt-out that sets a general speed limit but allows determined speeders to fill out a form to be excused from it. Decisions about speed limits are confided to elected representatives and, once made, are binding on everyone. Taylor notes that people apply the concept of infringements on freedom “against a background of understanding that certain goals and activities are more significant than others.”241 There is a strong case that decisions to make data available for projects like the Precision Medicine Initiative, the Cancer Moonshot, and the learning healthcare system, while they pose some privacy risk for the individual, are mainly decisions about public safety—and this may be true regardless of whether a study constitutes “research” or “public health” under the traditional and increasingly blurred conceptions of those terms.
There is wide dissensus concerning appropriate policies for data use, and consumer-driven data commons allow people to develop approaches congenial to themselves. Each consumer-driven data commons could establish rights and duties of membership. For example, one commons group might establish a duty for its members to boycott clinical research projects that do not return results to participants, because individuals’ access to their own data is fundamental to sustain a consumer-driven data commons. Another might bestow privileges of membership, such as the privilege of using the collective data resource to inform the interpretation of one’s own genomic test results. Those wishing to derive the benefits of the collective resource would be expected to contribute their own data in return. Bioethical concerns about coercion have enabled free-riders to enjoy the benefits of other people’s research participation without themselves participating. This may have had strong ethical justification in the context of clinical research whether the burdens of participation are great, but is it still appropriate in the context of informational research? Commons-forming consumer groups would parse these ethics for themselves, perhaps engaging external ethics experts to inform their collective decisions.
Consumer-driven commons groups could be organized by the members themselves, by patient advocacy groups, or by commercial entities acting as organizers and trustees to manage people’s collective data according to rules the people themselves would set. Over time, some groups’ rules might have wide appeal, attracting broader membership and amassing larger, more valuable data resources. Assembling and maintaining high-quality data resources is costly and requires external technical, legal, and ethics consultants. To fund these costs and add value to their collective data resources, members of a consumer-driven data commons might agree on acceptable revenue mechanisms to monetize their data assets. Here, consumer-driven commons offer a distinct advantage over traditional, data-holder-driven commons. Data holders face restrictions, such as the Health Information Technology for Economic and Clinical Health, or HITECH, Act’s restrictions on sales of data and allowable fees for data-related services,242 that limit their potential revenue models. Law does not similarly restrict the right of individuals to sell or charge fees for preparation and transmittal of their own data. This difference may be crucial, if it makes consumer-driven data commons more sustainable than the data-holder-driven commons of the past.
The specific content of consumer-driven commons arrangements would be determined by collective agreement of the group members, and therefore could vary widely. The content of these agreements is a topic requiring much further debate and engagement of the scholarly community. The aggregated data resources of a commons-forming group would be a resource shared by the group members and, at a minimum, the group’s agreed set of rules should address the following issues identified by Schlager and Ostrom243:
First, a consumer-driven data commons should have transparent rules that describe “operational-level” entitlements: What rights do members have to access their data that is in the collective data set? What duties do they have to contribute data and to update their data contributions? What uses can they personally make of the collective data set? Should the group appoint a trustee—perhaps a commercial data management service—to manage the day-to-day process of exercising HIPAA access rights to collect members’ data from external data holders? Will it engage consultants to develop a common data model and convert members’ data into a consistent, useful format? Should it appoint an ethics advisory committee to advise it on ethical issues, and what privacy and data security arrangements should it adopt? How will necessary management and consulting services be funded? Will members pay a fee for group membership, or are they willing to charge third-party data users for access to their collective data resources? Do they wish to promote certain data uses, for example, by charging academic users lower fees than they charge commercial users, or by providing cut-rate access to users who commit to place resulting discoveries in the public domain? Do they wish to encourage socially beneficial behaviors among parties who access and use their data, for example, by requiring drug companies that use their data to agree to make drugs available for reasonable, cost-based fees as opposed to whatever the market of desperate patients will bear? What are the rules for new members to enter the group or for existing members to exit?
Second, the group’s agreed rules should describe how it will make decisions and the “collective choice” rights that members will have to participate in those decisions. Will members vote on requests by third parties to access and use their data resources, or will they appoint an elected IRB or panel of scientific experts to assess which data requests reflect high-quality scientific uses that should be allowed? Will individual members have veto rights over certain categories of controversial data use, or will all requests for data access be decided by majority voting? What sort of data use agreements and privacy and security commitments should the group require from all entities that wish to use their data? What is the mechanism for resolving disputes within the group?
A related question, to be decided at a societal level, concerns the role of external law: Should consumer-driven data commons be subject to external regulations that set minimal substantive standards with which all consumer-driven commons must comply, or should the role of law be limited to contractual enforcement of whatever terms group members have agreed, to transparent disclosure of what those terms are, and to supervision to ensure that members can freely enter and exit as promised?
The aim of consumer-driven data commons is to allow consenting groups of individuals to assemble datasets on a meaningful scale, empowering themselves through collective action to exercise greater control over the fate of their data than individuals can achieve acting alone. It is crucial to summarize two things that consumer-driven data commons are not.
First, consumer-driven data commons are not a scheme of compulsory data access. Individuals would remain free to join (or not to join) one or more commons-forming consumer groups, at the individual’s sole discretion. Consumer-driven data commons preserve each individual’s right to consent to research uses of his or her data; however, they move the critical points in the consent process to the moments when individuals decide whether to affiliate with, not affiliate with, remain in, or exit from specific consumer-driven data commons groups. While affiliated with a commons group, the consumer would be bound by whatever data-access rules and decision-making processes its members have collectively agreed. In effect, membership in the group would be equivalent to appointing the group’s decision-making body to act as one’s surrogate for purposes of informed consent to uses of one’s data. However, individuals would have the right to secede from a commons group—on the terms to which the individual agreed when joining the group—if its collective decisions ever became repugnant.
The second important point is that consumer-driven data commons would not necessarily embrace ethical and privacy norms that are radically different from those reflected in the Common Rule and HIPAA Privacy Rule. It is conceivable that a group of commons-forming individuals might determine after careful deliberation that they like the norms of data access reflected in those regulations. If so, they would be free to adopt those norms as the data-access policies of their commons. They might, however, decide to elect (or otherwise choose for themselves) the IRB that will be authorized to make waiver decisions and oversee ethical and privacy protections for their group. They might adopt IRB procedures that make IRB members directly accountable to the people whose data are used, or require them to follow more rigorous due-process protections than the Common Rule provides.
Alternatively, a commons-forming group might decide that it dislikes the Common Rule and Privacy Rule. We sometimes forget that the Common Rule and Privacy Rule were not handed down on stone tablets from a source of ultimate ethical truth. Rather, both regulations set minimal standards. The Common Rule enunciates minimal ethical protections that many federal agencies require researchers to offer to research subjects, in order to be eligible to receive federal funding.244 At no point were research subjects given a direct, meaningful voice in establishing those standards.245 It is possible that individuals, if given the opportunity to do so, might design better ethical and privacy standards, more responsive to the concerns of people whose data are used in research, yet capable of supporting a vibrant research enterprise that benefits us all. Consumer-driven data commons are a mechanism to let consumers try.
The disconnect between survey data (which suggest that eighty percent of Americans feel favorably about letting researchers use their data)246 and enrollment data (which show very few Americans actually consent for their data to be used)247 may be signaling that the Common Rule and Privacy Rule are not what consumers want. Each consumer-driven data commons would be free to enunciate its own ethical, privacy, and data-access policies—the terms on which its members are willing to allow their data to be used. As multiple groups enunciate their policies, there would be a “marketplace” of ethical and privacy policies, which individuals could compare when deciding which consumer-driven data commons they wish to join. Markets are an excellent generator of empirical data: Consumer-driven commons that succeed in enrolling members presumably would have enunciated policies that reflect what people want; those that fail would not have done so. Consumer-driven commons groups could learn from each other. Consumer-driven commons that succeed in sponsoring useful lines of research, on terms satisfactory to their members, would have successfully threaded the needle of balancing privacy and data access—a challenge that the Common Rule and Privacy Rule have chronically failed to meet. Successful consumer-driven data commons might expand and eventually become important drivers of twenty-first-century science.
CONCLUSION
Ubiquitous calls to make large-scale data systems worthy of public trust merely highlight that trust is something one needs when one is not in control. A person traveling by commercial airliner needs to trust the pilot. When driving one’s own car, trust is less necessary: one can judge for oneself whether the driver is sober and competent. Concerns about public trust might recede if the public had a meaningful voice in the governance of informational research and of the massive data systems needed to support it. This Article has proposed consumer-driven data commons as a mechanism to give people a voice.
Current regulations such as the HIPAA Privacy Rule and the Common Rule deny people a voice. The economist Albert O. Hirschman elaborated the distinction between exit and voice in his essay on ways consumers respond when presented with unsatisfactory products.248 Customers can exit—that is, they can stop buying a firm’s products—although exit may not be an effective strategy if consumers are dealing with a monopoly supplier such that no better product is available.249 Alternatively, some consumers voice their discontent, complaining to management in an attempt to force production of better products.250 In Hirschman’s terminology, the Common Rule’s consent right and HIPAA’s authorization right are nothing more than an exit right: people can walk away from informational research if the study objectives are not to their liking or if people distrust the privacy protections IRBs and regulators have arranged for them. An exit right is not the same thing as having a voice with which to negotiate the purposes, terms, and conditions of research that uses one’s sensitive health information.
Twentieth-century bioethics was a top-down affair in which ethics experts and regulators set privacy and ethical standards to protect research subjects, who were portrayed as autonomous but too vulnerable and disorganized to protect themselves.251 Regulations like the Privacy Rule and Common Rule drew on this mindset, and recent revisions to the Common Rule do little to challenge it. These federal regulations conceive individual protection as an exit right (informed consent/authorization) while granting people no real voice in setting the goals of informational research or the privacy and ethical protections they expect. Lacking a voice, people CRexit from research—that is, they exercise their Common Rule, or “CR,” informed consent rights to exit from informational research altogether. This CRexit strategy scarcely advances people’s interests, when surveys show that most Americans would like to see their data used to advance science. Low participation in informational research should be viewed as what it is: a widespread popular rejection of the unsatisfactory, top-down protections afforded by existing regulations.
To fix this problem, citizen science needs to mean more than simply letting people dabble in science projects. It must also embrace the challenge of granting people a greater voice in how science should be done. In the twenty-first century, citizen-led bioethics needs to be an integral part of citizen science.
This paper offers consumer-driven data commons not as a panacea, but as a grand experiment in democratic data self-governance, perhaps worth trying at a time when existing mechanisms of data access seem destined not to meet the challenges that lie ahead. It is fortuitous that new forms of PHD, such as data from mobile and wearable sensing devices, are generally not regulated by the Common Rule and HIPAA Privacy Rule. This regulatory gap offers an opportunity to design a new PHD privacy and access models on a blank slate, perhaps avoiding pitfalls of existing regulations. A major pitfall, till now, has been the tendency of our federal regulations to enshrine a data-holder-centric view, in which data holders assemble large-scale data resources by invoking individual consent exceptions to free data for socially beneficial research on terms, and subject to privacy and security protections, in which the data subjects—the people whose data are used—have no real voice. The goal of consumer-driven data commons is to grant people the voice they have previously been denied and, by doing so, engage citizens more actively in the task of assembling the hundred-million-person and even billion-person cohorts that twenty-first-century science ultimately will require.
Acknowledgments
This research received support from the Robert Wood Johnson Foundation’s Health Data Exploration Project (Kevin Patrick, M.D., M.S., PI) http://hdexplore.calit2.net with additional support from NIH/NHGRI/NCI grants U01HG006507 (GPJ) and U01HG007307-02S2 (GPJ). The author thanks Matthew Bietz, Cinnamon Bloss, Jason Bobe, Andrea Downing, Mary Majumder, Kevin Patrick, Karl Surkan, and Susan Wolf for their helpful insights and comments.
References
- 1.Adam Christopher. Comment to What is the Meaning of ‘Barbarians at the Gate?’. Blurtit; http://references-definitions.blurtit.com/76895/what-is-the-meaning-of-barbarians-at-the-gate [ https://perma.cc/4XWE-JE3E] [Google Scholar]
- 2.Id.
- 3.Madison Michael J. Commons at the Intersection of Peer Production, Citizen Science, and Big Data: Galaxy Zoo. In: Frischmann Brett M, et al., editors. Governing Knowledge Commons. Vol. 209. 2014. p. 215. [Google Scholar]
- 4.Id. at 215, 228–29 (describing the success of Galaxy Zoo, which involved citizen volunteers in the effort of classifying galaxies).
- 5.Federal Policy for the Protection of Human Subjects, 80 Fed. Reg. 53,933, 53,938 (proposed Sept. 8, 2015) (characterizing a shift in research activities to include more informational studies that rely on data and biospecimens, in contrast to clinical studies).
- 6.Greenberg v. Miami Children’s Hosp. Research Inst., 264 F. Supp.2d 1064, 1066–67 (S.D. Fla. 2003).
- 7.Federal Policy for the Protection of Human Subjects, 80 Fed. Reg. at 53,943.
- 8.Greenberg, 264 F. Supp. 2d at 1067.
- 9.Id. at 1068 (“Plaintiffs allege that at no time were they informed that Defendants intended to seek a patent on the research. Nor were they told of Defendants’ intentions to commercialize the fruits of the research … .”).
- 10.See, e.g.; Norquist Grayson. Patient-Driven Research Will Lead to Better Health. Health Aff Blog. 2016 May 19; http://healthaffairs.org/blog/2016/05/19/patient-driven-research-will-lead-to-better-health/[https://perma.cc/3DHS-CHMZ ] describing how the Patient-Centered Outcomes Research Institute PCORI has focused on research that is “patient-driven” and “patient-centered” by “involving patients, caregivers, clinicians, payers, industry, and other health care stakeholders throughout the research process”.
- 11.See, e.g.; Patient-Centered Outcomes Research. PCORI. 2013 Nov. http://www.pcori.org/research-results/patient-centered-outcomes-research [ https://perma.cc/6TZ3-KK6B]
- 12.See, e.g.; Shalowitz David I, Miller Franklin G. Disclosing Individual Results of Clinical Research: Implications of Respect for Participants. JAMA. 2005;294:737, 737–40. doi: 10.1001/jama.294.6.737. discussing the importance of returning individual research results to participants in clinical research. [DOI] [PubMed] [Google Scholar]
- 13.See; Hall Mark A, Schulman Kevin A. Ownership of Medical Information. JAMA. 2009;301:1282, 1283–84. doi: 10.1001/jama.2009.389. (discussing advantages of patient-controlled longitudinal health records and suggesting that one way to foster the development of such records would be to “give patients the rights to sell access to their records, rights that are superior to the property rights held by [entities that currently hold patients’ data]”) [DOI] [PubMed] [Google Scholar]; see also; Hall Mark A. Property, Privacy, and the Pursuit of Interconnected Electronic Medical Records. Iowa L Rev. 2010;95:631, 651. [hereinafter Hall, Property] “[I]f patients were given ownership of their complete medical treatment and health histories, they could license to compilers their rights to that information in a propertized form that could be more fully developed and commercialized.”. [Google Scholar]; see also; Meslin Eric M, Schwartz Peter H. How Bioethics Principles Can Aid Design of Electronic Health Records to Accommodate Patient Granular Control. J Gen Internal Med. 2014;30:S3, S5–6. doi: 10.1007/s11606-014-3062-z. (discussing granular consent) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.See discussion infra at note 43 and accompanying text.
- 15.See generally FRANK PASQUALE, THE BLACK BOX SOCIETY: THE SECRET ALGORITHMS THAT CONTROL MONEY AND INFORMATION (2015) (discussing modern data-mining practices that generate health-related information about consumers). See also Panopticon, THE OXFORD DICTIONARY OF ENGLISH ETYMOLOGY (1966) (“[Jeremy] Bentham’s name for a circular prison in which warders could at all times observe their prisoners … .”)
- 16.Pasquale, supra note 15, at 28–32.
- 17.Vayena Effy, Gasser Urs. Between Openness and Privacy in Genomics. PLOS Med. 2016 Jan 12;13 doi: 10.1371/journal.pmed.1001937. at 1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Charnley Berris. People Powered Science. Constructing Sci Communities. 2015 May 14; https://conscicom.org/2015/05/14/people-powered-science/ [ https://perma.cc/SQS7-HCMP]
- 19.Med Nat’l. Device Evaluation Sys Planning Bd., The National Evaluation System for Health Technology (NEST): Priorities for Effective Early Implementation. 2016;27 https://healthpolicy.duke.edu/sites/default/files/atoms/files/NEST%20Priorities%20for%20Effective%20Early%20Implementation%20September%202016_0.pdf [ https://perma.cc/C52T-LKZ8] [Google Scholar]
- 20.See discussion infra Part 2.
- 21.See; Gostin Lawrence O. Public Health Law. (2d) 2008;4 describing public health as including population-oriented as opposed to patient-specific efforts “to ensure the conditions for people to be healthy” and “to pursue the highest possible level of physical and mental health in the population, consistent with the values of social justice”. [Google Scholar]; Amoroso Paul J, Middaugh John P. Research vs. Public Health Practice: When Does a Study Require IRB Review? Preventive Med. 2003;36:250, 250. doi: 10.1016/s0091-7435(02)00061-0. (offering, as examples public health activities, tracking communicable diseases, investigating disease outbreaks, and collecting personal data to protect public health) [DOI] [PubMed] [Google Scholar]
- 22.See; Advancing Regulatory Science: Moving Regulatory Science Into the 21st Century. FDA; (last updated May 24, 2016), http://www.fda.gov/ScienceResearch/SpecialTopics/RegulatoryScience/default.htm?utm_campaign=Goo [ https://perma.cc/4JW9-E9JW]. [Google Scholar]
- 23.The Precision Medicine Initiative. White House; https://www.whitehouse.gov/precision-medicine [ https://perma.cc/NYH9-7GPV]. [Google Scholar]
- 24.See; BRAIN Initiative. White House; Sept. 2014. https://www.whitehouse.gov/share/brain-initiative [ https://perma.cc/JK2B-8HZP]. [Google Scholar]
- 25.Press Release, White House Office of the Press Sec’y, Fact Sheet: Investing in the National Cancer Moonshot (Feb. 1, 2016), https://www.whitehouse.gov/the-press-office/2016/02/01/fact-sheet-investing-national-cancer-moonshot [https://perma.cc/Y4NY-6YSX].
- 26.See; Public Workshop - Use of Databases for Establishing the Clinical Relevance of Human Genetic Variants. FDA; Nov. 2015. http://www.fda.gov/medicaldevices/newsevents/workshopsconferences/ucm459450.htm [ https://perma.cc/6UPG-RHQD] [Google Scholar]; Evans Barbara J, Burke Wylie, Jarvik Gail P. The FDA and Genomic Tests - Getting Regulation Right. New Eng J Med. 2015;372:2258, 2259. doi: 10.1056/NEJMsr1501194. See also. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Olsen Leighanne, Aisner Dara, Mcginnis J Michael, Inst. of Med. The Learning Healthcare System: Workshop Summary (IOM Roundtable on Evidence-Based Medicine) 2007;3:6. [PubMed] [Google Scholar]
- 28.See generally; Shirts Brian H, et al. Large Numbers of Individuals Are Required to Classify and Define Risk for Rare Variants in Known Cancer Risk Genes. Genetics in Med. 2014 discussing the size of data resources required to draw inferences about the clinical significance of rare genetic variants;16:529. doi: 10.1038/gim.2013.187. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Press Release, White House Office of the Press Sec’y, Fact Sheet: Obama Administration Announces Key Actions to Accelerate Precision Medicine Initiative (Feb. 25, 2016), at https://www.whitehouse.gov/the-press-office/2e [; https://perma.cc/ZBH3-D843].
- 30.Evans Barbara J. Much Ado About Data Ownership. Harv J L & Tech. 2011;25:69, 90. [Google Scholar]
- 31.Id.
- 32.Id. at 93–94. Note that while there are algorithms that can link incoming streams of data that lack identifiers, such linkages are probabilistic. The resulting longitudinal record for an individual may contain errors if incoming data have been erroneously inferred to belong to that individual.
- 33.See; FTC. Protecting Consumer Privacy in an Era of Rapid Change: A Proposed Framework for Businesses and Policymakers. 2010 Dec.35–38 (warning that the distinction between personally identifiable information and non-identifiable information is increasingly irrelevant in light of the potential for data to be re-identified) [Google Scholar]; Ohm Paul. Broken Promises of Privacy: Responding to the Surprising Failure of Anonymization. UCLA L Rev. 2010;57:1701, 1706. (discussing the risks to individual privacy if de-identified data were to be re-identified) [Google Scholar]; Rothstein Mark A. Is Deidentification Sufficient to Protect Health Privacy in Research? Am J Bioethics. 2010;10:3, 5. doi: 10.1080/15265161.2010.494215. “Despite using various measures to deidentify health records, it is possible to reidentify them in a surprisingly large number of cases …”. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.See Ohm, supra note 33, at 1724–25; Rothstein, supra note 33, at 5–6.
- 35.Evans, supra note 30, at 95–96.
- 36.Id.
- 37.See generally; Casarett David, et al. Bioethical Issues in Pharmacoepidemiologic Research. In: Strom Brian L., editor. Pharmacoepidemiology. 4th. Vol. 587. 2005. pp. 593–94. [Google Scholar]; Comm. on Health Research & The Privacy of Health Info.: The Hipaa Privacy Rule, Inst. of Med., Beyond the Hipaa Privacy Rule: Enhancing Privacy, Improving Health Through Research 209–14 (Sharyl J. Nass et al. eds., 2009 [hereinafter IOM, Privacy Report] http://www.nap.edu/catalog/12458.html [https://perma.cc/2PJG-K7SP] (surveying studies of consent and selection bias); Buckley Brian, et al. Selection Bias Resulting from the Requirement for Prior Consent in Observational Research: A Community Cohort of People with Ischaemic Heart Disease. Heart. 2007;93:1116. doi: 10.1136/hrt.2006.111591. [DOI] [PMC free article] [PubMed] [Google Scholar]; El Emam Khaled, et al. A Globally Optimal k-Anonymity Method for the De-Identification of Health Data. J Am Med Informatics Ass’n. 2009;16:670, 670. doi: 10.1197/jamia.M3144. [DOI] [PMC free article] [PubMed] [Google Scholar]; Jacobsen Steven J, et al. Potential Effect of Authorization Bias on Medical Record Research. Mayo Clinic Proc. 1999;74:330. doi: 10.4065/74.4.330. [DOI] [PubMed] [Google Scholar]; Tu Jack V, et al. Impracticability of Informed Consent in the Registry of the Canadian Stroke Network. New Eng J Med. 2004;350:1414. doi: 10.1056/NEJMsa031697. [DOI] [PubMed] [Google Scholar]; Woolf Steven H, et al. Selection Bias from Requiring Patients to Give Consent to Examine Data for Health Services Research. Archives Fam Med. 2000;9:1111. doi: 10.1001/archfami.9.10.1111. [DOI] [PubMed] [Google Scholar]
- 38.Audio Recording: Toby Bloom, Deputy Director, Bioinformatics, N.Y. Genome Ctr., Next Generation Sequencing and Bioinformatics: A Researcher’s Perspective, Remarks at the American Association of Law Schools Annual Conference, BioLaw Section (Jan. 8, 2016, https://soundcloud.com/aals-2/biolaw-co-sponsored-by-law-medicine-and-health-care/s-BDCUD [https://perma.cc/7GES-CSWC]
- 39.Id.
- 40.Id.
- 41.Protection of Human Subjects, 45 C.F.R. pt. 46 (2015). On January 19, 2017, HHS and other Common Rule agencies published a final rule revising the Common Rule. See Federal Policy for the Protection of Human Subjects, 82 Fed. Reg. 7149 (Jan. 19, 2017). These revisions, unless further altered or revised by the incoming Administration, are scheduled to become effective on January 19, 2018. These Common Rule revisions do not address, and in some cases will tend to amplify, the central concerns explored in this Article.
- 42.Health Insurance Portability and Accountability Act of 1996, Pub. L. No. 104-191, 110 Stat. 1936 (2012) (codified as amended in scattered sections of 18, 26, 29 and 42 U.S.C.); see HIPAA Privacy Rule, 45 C.F.R. pts. 160, 164 (2015).
- 43.See Evans, supra note 30, at 82–86 (discussing nonconsensual access pathways under the Privacy Rule and the current Common Rule that will remain in effect through January 19, 2018). See also Protection of Human Subjects, 82 Fed. Reg. at 7150 (noting that the final Common Rule revisions slated to become effective in January 2018 did not adopt restrictive proposals that would have treated research with nonidentified biospecimens as subject to the Common Rule, requiring consent, nor did the final rule adopt the most restrictive proposals relating to consent for identifiable private information and identifiable biospecimens). The final rule will, however, prohibit IRBs from waiving informed consent if individuals have been asked for, and have declined to provide, broad consent to the storage and maintenance for secondary research use of their identifiable private information or identifiable biospecimens. See id. at 7226, 7267 (continuing to allow waivers for unconsented use of identifiable data and biospecimens, even under the revised Common Rule, if broad individual consent has not previously been sought and refused).
- 44.See IOM, Privacy Report, supra note 37, at 81–82 (discussing the results of a survey showing a “majority of respondents were not comfortable with their health information being provided for health research except with notice and express consent”).
- 45.See generally id. at 82; Kish Leonard J, Topol Eric J. Unpatients—Why Patients Should Own Their Medical Data. Nature Biotechnology. 2015;33:921, 921–24. doi: 10.1038/nbt.3340. (discussing individuals’ willingness to participate in research) [DOI] [PubMed] [Google Scholar]; Topol Eric J. The Big Medical Data Miss: Challenges in Establishing an Open Medical Resource. Nature Revs. 2015;16:253. doi: 10.1038/nrg3943. (discussing individuals’ willingness to participate in medical research as long as there are sufficient privacy safeguards). Health Data Exploration Project, Personal Health Data for The Public Good: New Opportunities to Enrich Understanding of Individual and Population Health (2014, http://hdexplore.calit2.net/wp-content/uploads/2015/08/hdx_final_report_small.pdf [ https://perma.cc/229B-B3FB] discussing the willingness of individuals to contribute non-traditional forms of PHD for use in research) [DOI] [PubMed] [Google Scholar]
- 46.IOM, Privacy Report, supra note 37, at 82.
- 47.See supra notes 32–34 and accompanying text.
- 48.See generally; Evans Barbara J. The First Amendment Right to Speak About the Human Genome. U Pa J Const L. 2014;16:549. (discussing and criticizing IRB-imposed restrictions on return of results from research) [PMC free article] [PubMed] [Google Scholar]
- 49.Common Rule Waiver Provision, 45 C.F.R. § 46.116(d) (2015); HIPAA Waiver Provision, 45 C.F.R. § 164.512(i) (2015).
- 50.See; Coleman Carl H. Rationalizing Risk Assessment in Human Subject Research. Ariz L Rev. 2004;46:1, 13–17. discussing procedural informality of the Common Rule. [PubMed] [Google Scholar]
- 51.See Kish & Topol, supra note 45, at 923.
- 52.Id.
- 53.See, e.g., Hall, Property, supra note 13, at 651 (discussing such a scheme).
- 54.See, e.g.; Rodwin Marc A. Patient Data: Property, Privacy & the Public Interest. Am JL & Med. 2010;36:586, 593. doi: 10.1177/009885881003600403. (proposing such a scheme) [DOI] [PubMed] [Google Scholar]
- 55.See discussion infra.
- 56.Health Data Exploration Project, supra note 45, at 12.
- 57.Id.
- 58.Kish & Topol, supra note 45, at 922.
- 59.See discussion infra.
- 60.Newman Lily Hay. Obama Says People Who Give Genetic Samples for Research Should Own the Data, Slate. 2016 Feb 26; http://www.slate.com/blogs/future_tense/2016/02/26/at_precision_medicine_initiative_summit_obama_says_people_own_their_genetic.html [ https://perma.cc/JG72-R7W9]
- 61.Id.
- 62.See, e.g., Elinor Ostrom, Governing The Commons: The Evolution of Institutions for Collective Action (1990 examining natural resource commons); Rose Carol. The Comedy of the Commons: Custom, Commerce, and Inherently Public Property. U Chi L Rev. 1986;53:711. (elaborating the role of commons in property theory more generally) [Google Scholar]
- 63.Cf. Brett M. Frischmann et al., Governing Knowledge Commons, in Governing Knowledge Commons, supra note 2, at 1–3 (describing a wide variety of commons arrangements and emphasizing that “commons does not denote the resources, the community, a place, or a thing”)
- 64.Id.
- 65.Ostrom, supra note 62, at 50–51.
- 66.See; Hess Charlotte, Ostrom Elinor. Introduction: An Overview of the Knowledge Commons. In: Hess Charlotte, Ostrom Elinor., editors. Understanding Knowledge as a Commons: Theory and Practice. Vol. 3. 2011. pp. 4–7. [Google Scholar]
- 67.See Frischmann et al., supra note 63, at 7–8 (contrasting the domain of proprietary rights and the public domain).
- 68.Hess & Ostrom, supra note 66, at 13.
- 69.Id. at 16–18.
- 70.Frischmann et al., supra note 63, at 3.
- 71.See Ostrom, supra note 62.
- 72.Hess & Ostrom, supra note 66.
- 73.Frischmann et al., supra note 63, at 2.
- 74.Id.
- 75.See id. at 3 (“Knowledge commons” refers to “the institutionalized community governance of the sharing and, in some cases, creation, of information, science, knowledge, data, and other types of intellectual and cultural resources.”).
- 76.Evans, supra note 30, at 102–03.
- 77.President’s Council of Advisors on Sci. & Tech., Exec. Off. of the President, Report to the President Realizing the Full Potential of Health Information Technology to Improve Healthcare for Americans: The Path Forward 1, 27, 39 (2010).
- 78.Suter Sonia M. Disentangling Privacy from Property: Toward a Deeper Understanding of Genetic Privacy. Geo Wash L Rev. 2004;72:737, 751. [PubMed] [Google Scholar]
- 79.Warren Samuel D, Brandeis Louis D. The Right to Privacy. Harv L Rev. 1890;4:193, 193. [Google Scholar]
- 80.Bergelson Vera. It’s Personal but Is It Mine? Toward Property Rights in Personal Information. U.C Davis L Rev. 2003;37:379, 401–02. [Google Scholar]; Solove Daniel J. Conceptualizing Privacy. Cal L Rev. 2002;90:1087, 1092–1126. [Google Scholar]
- 81.Bergelson, supra note 80, at 401 (quoting Raymond T. Nimmer, The Law of Computer Technology, ¶ 16.02, at 16–5 (2001)).
- 82.Miller Walter W, Jr, O’Rourke Maureen A. Bankruptcy Law v. Privacy Rights: Which Holds the Trump Card? Hous L Rev. 2001;38:777, 786–87. (discussing transaction-generated data gathered without consumers’ knowledge using “cookies” and related technology) [Google Scholar]
- 83.Schwartz Paul M. Internet Privacy and the State. Conn L Rev. 2000;32:815, 820. [Google Scholar]
- 84.Bergelson, supra note 80, at 401–02.
- 85.See, e.g.; Mell Patricia. Seeking Shade in a Land of Perpetual Sunlight: Privacy as Property in the Electronic Wilderness. Berkeley Tech L.J. 1996;111:26–41. [Google Scholar]
- 86.Evans, supra note 30, at 77.
- 87.Suter, supra note 78, at 804 (citing; Litman Jessica. Information Privacy/Information Property. Stan L Rev. 2000;52:1283, 1297–98. [Google Scholar]
- 88.See Bergelson, supra note 80, at 438; Evans, supra note 30, at 77–82; Lipton Jacqueline. Information Property: Rights and Responsibilities. Fla L Rev. 2004;56:135, 165–75. [Google Scholar]
- 89.Lipton, supra note 88, at 165–75 (emphasis added).
- 90.Radin Margaret Jane. Property and Personhood. Stan L Rev. 1982;34:957, 958. emphasis added. [Google Scholar]
- 91.Schlager Edella, Ostrom Elinor. Property-Rights Regimes and Natural Resources: A Conceptual Analysis. Land Econ. 1992;68:249, 250. [Google Scholar]
- 92.Evans, supra note 30, at 79.
- 93.Hart John F. Land Use Law in the Early Republic and the Original Meaning of the Takings Clause. Nw L Rev. 2000;94:1099, 1102, 1107. (discussing historical uses of the state’s police power to require owners to confer positive externalities on the community) [Google Scholar]
- 94.Merrill Thomas W. The Economics of Public Use. Cornell L Rev. 1986;72:61, 66. [Google Scholar]
- 95.See; Malloy Robin Paul, Smith James Charles. Private Property, Community Development, and Eminent Domain. In: Malloy Robin Paul., editor. Private Property, Community Development, and Eminent Domain. Vol. 1. 2008. p. 8. discussing the public use requirement. [Google Scholar]
- 96.See, e.g., Kelo v. City of New London, 545 U.S. 469 (2005) (holding that the city’s taking of private property for resale and redevelopment as an office park did not violate the Takings Clause); Poletown Neighborhood Council v. City of Detroit, 410 Mich. 894 (1981) (holding that exercise of eminent domain for neighborhood redevelopment was justified because the action was for the public good, irrespective of incidental private gain).
- 97.See; Bell Abraham. Private Takings. U Chi L Rev. 2009;76:517, 522. noting, “public ownership of … property is not a necessary companion to just and efficient takings”. [Google Scholar]
- 98.U.S. Const. amend. V.
- 99.Evans, supra note 30, at 79, 85–86. See supra note 43 for a discussion of how recent revisions to the Common Rule, which are scheduled to become effective on January 18, 2018, will affect the Common Rule’s waiver provisions, if these revisions are implemented by the new Administration.
- 100.Id. at 81.
- 101.Samuelson Pamela. Privacy as Intellectual Property? Stan L Rev. 2000;52:1125, 1138–39. [Google Scholar]
- 102.Suter, supra note 78, at 737.
- 103.Id. at 799–803.
- 104.See Samuelson, supra note 101, at 1136–37, citing; Laudon Kenneth C. Markets and Privacy. Comm ACM. 1996;39:92. See also Litman, supra note 87, at 1297–98; Suter, supra note 78, at 804. [Google Scholar]
- 105.Lipton, supra note 88, at 141.
- 106.Id. at 141–42.
- 107.Kish & Topol, supra note 45, at 922.
- 108.Id. at 922–23.
- 109.Id. at 921–23.
- 110.See, e.g., Mell, supra note 85, at 76.
- 111.Claeys Eric R. Takings, Regulations, and Natural Property Rights. Cornell L Rev. 2003;88:1549, 1575. [Google Scholar]
- 112.Bell, supra note 97, at 540–42.
- 113.Evans, supra note 30, at 73.
- 114.See; Axelrad Seth. Am Soc L Med & Ethics, State Statutes Declaring Genetic Information to be Personal Property. http://www.aslme.org/dna_04/reports/axelrad4.pdf [ https://perma.cc/3DSY-NSX7] (listing statutes of Alaska, Colorado, Florida, and Georgia that recognize individual property rights in genetic information) See also ala Stat Ann § 18.13.010(a)(2) (West 2016); Colo Rev Stat Ann § 10-3-1104.7(1)(a) (West 2016); Fla Stat Ann §760.40(2)(a) (West 2016); Ga Code Ann § 33-54-1(1) (West 2016)
- 115.See, e.g., H.B. 1260, 87th Leg. Assemb., Reg. Sess. (S.D. 2012); H.B. 1220, 84th Leg. Sess. (Tex. 2015); H.B. 2110, 82nd Leg. Sess. (Tex. 2011).
- 116.Wagner Jennifer K, Vorhaus Dan. On Genetic Rights and States: A Look at South Dakota and Around the U.S. Genomics L Rpt. 2012 Mar 20; http://www.genomicslawreport.com/index.php/2012/03/20/on-genetic-rights-and-states-a-look-at-south-dakota-and-around-the-u-s/ [ https://perma.cc/JX9U-NJ97]
- 117.Silverman David L. Data Security Breaches: The State of Notification Laws. Intell Prop & Tech L.J. 2007;19:5, 8. [Google Scholar]
- 118.See; Gindin Susan E. Lost and Found in Cyberspace: Informational Privacy in the Age of the Internet. San Diego L Rev. 1997;34:1153, 1195, n. 231. listing several cases where courts have recognized patients’ ownership of medical records. [Google Scholar]
- 119.DeMarco David A. Understanding Consumer Information Privacy in the Realm of Internet Commerce: Personhood and Pragmatism, Pop-Tarts and Six-Packs. Tex L Rev. 2006;84:1013. [Google Scholar]
- 120.Id. at 1035–36.
- 121.Dwyer v. Am. Express Co., 652 N.E.2d 1351 (Ill. App. Ct. 1995).
- 122.Bergelson, supra note 80, at 412.
- 123.Nullius Res. Bouvier’s Law Dictionary. (6th) 1856 [Google Scholar]
- 124.Evans Barbara J. Mining the Human Genome after Association for Molecular Pathology v. Myriad Genetics. Genetics in Med. 2014;16:504, 505. doi: 10.1038/gim.2013.186. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 125.Silverman, supra note 117, at 8.
- 126.See; Schwartz Paul M. Property, Privacy, and Personal Data. Harv L Rev. 2004;117:2056, 2076–94. discussing conceptual difficulties in applying a regime of property rights to information in databases. [Google Scholar]
- 127.Silverman, supra note 117, at 8.
- 128.Schwartz, supra note 126, at 2092–93.
- 129.Rodwin, supra note 54, at 593.
- 130.Id. at 590–93.
- 131.Peppet Scott R. Regulating the Internet of Things: First Steps Toward Managing Discrimination, Privacy, Security, and Consent. Tex L Rev. 2014;93:85, 145. [Google Scholar]
- 132.Id.
- 133.Hall, Property, supra note 13, at 646.
- 134.Rodwin, supra note 54, at 588.
- 135.Hall, Property, supra note 13, at 647.
- 136.Schlager & Ostrom, supra note 91, at 250–51.
- 137.Id. at 250.
- 138.Id.
- 139.2; Blackstone William. In: Commentaries. Morrison Wayne., editor. Vol. 3. 2001. spelling conformed to modern conventions. [Google Scholar]
- 140.Hall, Property, supra note 13, at 647–48; Rodwin, supra note 54, at 606.
- 141.Rodwin, supra note 54, at 606.
- 142.See discussion infra at subsection B.
- 143.Evans, supra note 30, at 82–86.
- 144.See discussion supra at Part 3.
- 145.Evans, supra note 30, at 82.
- 146.See Jorge L. Contreras, Constructing the Genome Commons, in Governing Knowledge Commons 99, supra note 2, at 112–13 (providing examples of data-sharing policies that correspond to the concept that this Article refers to as incentivized consent alignment).
- 147.Id. (discussing funding agencies’ data-sharing policies); Evans, Burke & Jarvik, supra note 26 (discussing NIH data-deposit policies).
- 148.See 45 C.F.R. § 46.102(f) (2016) (defining “human subject,” for purposes of the Common Rule, in a way that excludes a person whose data is received by an investigator in de-identified form from being a human subject that has a right of informed consent); 45 C.F.R. §164.502(d)(2) (2016) (providing that, for purposes of the HIPAA Privacy Rule, de-identified information is not protected health information that is subject to the Privacy Rule’s provisions, including its individual authorization requirement); Federal Policy for the Protection of Human Subjects, 82 Fed. Reg. 7149, 7260 (Jan. 19, 2017) (providing a definition of “human subject” to be codified at § __.102(e)(1) of the revised Common Rule that will have substantially similar effect).
- 149.Patil DJ, et al. Your Data in Your Hands: Enabling Access to Health Information. Medium. 2016 Mar 10; https://medium.com/@WhiteHouse/your-data-in-your-hands-enabling-access-to-healthinform ation-6fce6da976cb#.60242uv2i [ https://perma.cc/4UQF-NA4P]
- 150.Evans, Burke & Jarvik, supra note 26, at 2261.
- 151.Shirts et al., supra note 15.
- 152.Cook-Deegan Robert, et al. The Next Controversy in Genetic Testing: Clinical Data as Trade Secrets? Eur J Hum Genetics. 2013;21:585, 585. doi: 10.1038/ejhg.2012.217. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 153.Evans, Burke & Jarvik, supra note 26, at 2260.
- 154.See supra note 45.
- 155.See Evans, supra note 30, at 107 n.247.
- 156.See, e.g., 45 C.F.R. § 164.512 (2016) (listing HIPAA exceptions).
- 157.See, e.g., 45 C.F.R. § 46.116(d) (couching the current Common Rule’s waiver provision in permissive language: “An IRB may approve … .”); 45 C.F.R. § 164.512(i) (providing, in the HIPAA waiver provision, that uses and disclosures of a person’s data without authorization pursuant to a waiver are “permitted” — i.e., disclosures are allowed but not required). The IRB of a research institution that wishes to receive data from a data holder can approve a waiver authorizing release of the data without individual consent; see Standards for Privacy of Individually Identifiable Health Information, 65 Fed. Reg. 82,464, 82,695 (Dec. 28, 2000) (codified at 45 C.F.R. pts. 160, 164) (rejecting, in the preamble to the HIPAA Privacy Rule, suggestions that HHS should require IRBs that approve waivers to be independent of the entity conducting the research). Under 45 C.F.R. § 164.512(i), recipient-approved waivers permit the data holder to disclose data but do not require it, so the recipient has no way to force the provision of needed data and services.
- 158.Cutrona Sarah L. Design for Validation of Acute Myocardial Infarction Cases in Mini-Sentinel. Pharmacoepidemiology & Drug Safety. 2012;21:274, 278–79. doi: 10.1002/pds.2314. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 159.See Common Rule Waiver Provision, 45 C.F.R. § 46.116(d) (2015) (describing the waiver provision of the current Common Rule, effective until revisions go into effect on January 18, 2018); Federal Policy for the Protection of Human Subjects, 82 Fed. Reg. 7149, 7267 (Jan. 19, 2017) (replacing the current Common Rule waiver provision with a new provision, to be codified at § __.116(f) of the Common Rule, to be effective January 18, 2018); HIPAA Waiver Provision, 45 C.F.R. § 164.512(i) (2015).
- 160.See 45 C.F.R. §§ 46.103(b), 46.107–108 (describing IRBs: private ethical review panels, often staffed by employees of the data holder or data-using research institution, to which the Common Rule delegates various aspects of research oversight); 45 C.F.R § 164.512(i)(2)(iv) (allowing waivers of consent under the HIPAA Privacy Rule to be approved by either a Common Rule-compliant IRB or by a HIPAA-compliant “privacy panel” that is similar to an IRB).
- 161.See supra note 157.
- 162.See Federal Policy for the Protection of Human Subjects, 82 Fed. Reg. at 7267 (providing, at § __.116(f)(1) of the revised waiver provision, that “[i]f an individual was asked to provide broad consent for the storage, maintenance, and secondary research use of identifiable private information or identifiable biospecimens in accordance with the requirements at paragraph (d) of this section, and refused to consent, an IRB cannot waive consent for the storage, maintenance, or secondary research use of the identifiable private information or identifiable biospecimens.”).
- 163.Id.
- 164.See Federal Policy for the Protection of Human Subjects, 82 Fed. Reg. at 7225 (reporting that some public commenters in the proceedings to revise the Common Rule noted that “investigators would continue to seek consent waivers for secondary use of identifiable private information instead of seeking broad consent.”).
- 165.IOM, Privacy Report, supra note 37.
- 166.Coleman, supra note 50, at 13–27.
- 167.IOM, Privacy Report, supra note 37.
- 168.See supra notes 43–45, 158–59 and accompanying text.
- 169.See HIPAA Privacy Rule, 45 C.F.R. §§ 160.102, 160.103 (2015).
- 170.45 C.F.R. § 164.524 (2015). See also; Evans Barbara J, Dorschner Michael O, Burke Wylie, Jarvik Gail P. Regulatory Changes Raise Troubling Questions for Genomic Testing. Genetics Med. 2014;16:799. doi: 10.1038/gim.2014.127. discussing the scope of this access right at genomic testing laboratories. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 171.Evans, Dorschner, et al., supra note 170, at 799–800.
- 172.Hall, Property, supra note 13, at 650, 660–61.
- 173.CLIA Program and HIPAA Privacy Rule; Patients’ Access to Test Reports, 79 Fed. Reg. 7290 (Feb. 6, 2014) (codified at 42 C.F.R. pt. 493, 45 C.F.R. pt. 164).
- 174.42 C.F.R. pt. 493 (2015).
- 175.79 Fed. Reg. at 7292.
- 176.Evans, Dorschner, et al., supra note 170.
- 177.See, e.g., Press Release, ACLU, ACLU Files Complaint Against Lab that Refuses to Recognize Patients’ Right to Their Own Genetic Information (May 19, 2016), available at https://www.aclu.org/news/aclu-files-complaint-against-lab-refuses-recognize-patients-right-their-own-genetic-information [https://perma.cc/2DK6-G7TJ].
- 178.HHS. Individuals’ Right Under HIPAA to Access Their Health Information. [hereinafter HHS, Access Rights], http://www.hhs.gov/hipaa/for-professionals/privacy/guidance/access/ [ https://perma.cc/9N DA-JTJD].
- 179.Id.
- 180.Id. See also Evans, Dorschner, et al., supra note 170, at 799.
- 181.HHS, Standards for Privacy of Individually Identifiable Health Information: Final Rule, 65 Fed. Reg. 82,462, 82,606 (Dec 28, 2000 to be codified at 45 C.F.R. pts. 160, 164 quoting Am. Soc. for Testing & Materials, Standard Guide for Confidentiality, Privacy, Access and Data Security, Principles for Health Information Including Computer-Based Patient Records, E1869–97, § 11.1.1 2014
- 182.Id. (quoting Nat’l Comm. for Quality Assurance & The Joint Comm’n on Accreditation of Healthcare Orgs., Protecting Personal Health Information: A Framework for Meeting the Challenges in a Managed Care Environment 25 (1998)).).
- 183.CLIA Program and HIPAA Privacy Rule: Patients’ Access to Test Reports, 79 Fed. Reg. 7290, 7290 (Feb. 6, 2014) (codified at 42 C.F.R. pt. 493, 45 C.F.R. pt. 164).
- 184.See supra note 37 and accompanying text (discussing selection bias).
- 185.U.S. Const. amend. V.
- 186.Evans, supra note 30, at 102–03.
- 187.See; Brenner Susan W, Clarke Leo L. Civilians in Cyberwarfare: Conscripts. Vand J Transnat’l L. 2010;43:1011, 1056–57. discussing whether the government can require civilian workers to perform services aimed at protecting against cyberterrorism and finding only one example, during the Revolutionary War, where Congress forced civilians to provide services outside the context of conscripted military service. [Google Scholar]
- 188.See; Kelman Steven J. Contracting. In: Salamon Lester M., editor. The Tools of Government: A Guide to the New Governance. Vol. 282. 2002. pp. 283–85. in. discussing features of contracts through which the government procures products or services for its use; see also Ruth Hoogland DeHoog & Lester M. Salamon Purchase-of-Service Contracting, in The Tools of Government: A Guide to the New Governance 319, supra, at 320 (describing contracts in which the government procures services for delivery to third parties such as beneficiaries of welfare programs) [Google Scholar]
- 189.See; Beam David R, Conlan Timothy J. Grants. The Tools of Government: A Guide to the New Governance. 340 in. supra note 188, at 340–41 (discussing the government’s use of grants to stimulate performance of services) [Google Scholar]
- 190.Peppet, supra note 131, at 93.
- 191.Id.
- 192.IOM, Privacy Report, supra note 37, at 126, 157–59 (“The Privacy Rule does not protect personally identifiable health information that is held or maintained by an organization other than a covered entity.”).
- 193.U.S. Const. art. I, § 8, cl. 3.
- 194.See; Federal Policy for the Protection of Human Subjects. Fed Reg. 80:53,933. (proposed Sept. 8, 2015) (to be codified at 45 C.F.R. pt. 46) (proposing to apply the Common Rule to all clinical trials, regardless of funding source, conducted at institutions that receive public funds). But see Federal Policy for the Protection of Human Subjects, 82 Fed. Reg. 7149, 7150 (Jan. 19, 2017) (noting that the final rule did not implement this proposal and “does not expand the policy to cover clinical trials that are not federally funded.”). [Google Scholar]
- 195.IOM, Privacy Report, supra note 37, at 126.
- 196.DeMarco, supra note 119, at 1040–41.
- 197.FTC v. Wyndham Worldwide Corp., 799 F.3d 236, 259 (3rd Cir. 2015).
- 198.See, e.g., FTC, Internet of Things: Privacy & Security in a Connected World (Jan 2015); FTC, Protecting Consumer Privacy in an Era of Rapid Change: Recommendation for Businesses and Policymakers (Mar 2012)
- 199.DeMarco, supra note 119, at 1040–41.
- 200.Peppet, supra note 131, at 129.
- 201.Id.
- 202.Id.
- 203.Id. at 143–44.
- 204.Id. at 144.
- 205.See supra note 45.
- 206.Peppet, supra note 131, at 145–46 n355.
- 207.Kish & Topol, supra note 45, at 922.
- 208.Peppet, supra note 131, at 144–46.
- 209.Id. at 160.
- 210.Health Data Exploration Project, supra note 45, at 6–7, 32.
- 211.Peppet, supra note 131, at 117–48 (describing the problems associated with data-collecting consumer devices).
- 212.See HHS, Access Rights, supra note 178 (discussing the reasonable cost-based fee).
- 213.Hobbes Thomas. In: Leviathan. Martinich AP, Battiste Brian, editors. Vol. 163. Broadview Press; 2011. rev. ed. removed emphasis in original. [Google Scholar]
- 214.Id. at 162.
- 215.See Institutional Review Boards: Report and Recommendations of the National Commission for the Protection of Human Subjects of Biomedical and Behavioral Research, 43 Fed. Reg. 56,174 (Nov. 30, 1978) (discussing the various types of research considered during development of the Common Rule); see also Evans, supra note 30, at 113–29 (discussing how the Common Rule was adapted and applied in the years after 1980 to address informational research).
- 216.Rochin v. California, 342 U.S. 165, 174 (1952).
- 217.Union Pac. Ry. Co. v. Botsford, 141 U.S. 250, 251 (1891).
- 218.Radin, supra note 90, at 958 n.3.
- 219.See DeMarco, supra note 119, at 1036 (arguing that Locke’s labor-desert theory supports the notion that those who invest to collect data have rights in it).
- 220.Id.
- 221.Id. at 1014.
- 222.About the Quantified Self, Quantified Self, http://quantifiedself.com/about/[https://perma.cc/369C-TWMX].
- 223.23andMe, https://www.23andme.com [https://perma.cc/53DY-S8F3].
- 224.Taylor Charles. Sources of the Self: The Making of the Modern Identity. 1992;5 [Google Scholar]
- 225.Id. at 8.
- 226.See, e.g.; Annas George J. Privacy Rules for DNA Databanks: Protecting Coded ‘Future Diaries’. JAMA. 1993;270:2346. [PubMed] [Google Scholar]
- 227.Lessig Lawrence. Code and Other Laws of Cyberspace. 1999;152 emphasis in original. [Google Scholar]
- 228.Evans, supra note 124, at 505.
- 229.Faden Ruth R, et al. An Ethics Framework for a Learning Health Care System: A Departure from Traditional Research Ethics and Clinical Ethics. Hastings Ctr Rep. 2013;43:S16, S16. doi: 10.1002/hast.134. [DOI] [PubMed] [Google Scholar]
- 230.Id. at S18.
- 231.Id. at S19–20.
- 232.Id. at S23.
- 233.Id.
- 234.Id.
- 235.Green Stuart P. The Universal Grammar of Criminal Law: Basic Concepts of Criminal Law by George P. Fletcher. Mich L Rev. 2000;98:2104, 2112. [Google Scholar]; Brown Donald E. Human Universals. 1991 citing. [Google Scholar]; see also; Kar Robin Bradley. The Deep Structure of Law and Morality. Tex L Rev. 2006;84:877, 885. [Google Scholar]
- 236.Green, supra note 235.
- 237.Taylor Charles. Philosophy and the Human Sciences, 2 Philosophical Papers. 1985;218 noting, “In a philosophical argument, we might call this a restriction of freedom, but not in a serious political debate.”. [Google Scholar]
- 238.Santoro Emilio. Autonomy, Freedom and Rights: A Critique of Liberal Subjectivity. 2003;247 [Google Scholar]
- 239.See Narcissistic Personality Disorder (NPD) Definition, http://www.healthyplace.com/personality-disorders/malignant-self-love/narcissistic-personality-disorder-npd-definition/ [https://perma.cc/FWS7-A6QD] (defining narcissism as “[a] pattern of traits and behaviors which signify infatuation and obsession with one’s self to the exclusion of all others and the egotistic and ruthless pursuit of one’s gratification, dominance and ambition”) (emphasis added).
- 240.3; Feinberg Joel. The Moral Limits of the Criminal Law: Harm to Self. 1986:305–15. [Google Scholar]
- 241.Taylor, supra note 237.
- 242.See Evans, supra note 124 (summarizing these deficiencies).
- 243.See supra notes 139–41 and accompanying text.
- 244.45 C.F.R. §§ 46.101(f), 46.122 (2015).
- 245.See; Singer Eleanor, Levine Felice J. Protection of Human Subjects of Research: Recent Developments and Future Prospects for the Social Sciences. Pub Opinion Q. 2003;67:148. describing all the players involved in developing the standards. [Google Scholar]
- 246.Kish & Topol, supra note 45, at 923.
- 247.There are few reliable statistics indicating how many Americans volunteer their data for informational research. See; Rothstein Mark A. Improve Privacy in Research by Eliminating Informed Consent? IOM Report Misses the Mark. J.L. Med. & Ethics. 2009;37:507, 508. doi: 10.1111/j.1748-720X.2009.00411.x. “It is not known what percentage of potential research subjects decline to participate, for what types of research, and under what consent mechanisms; nor is there evidence of what the effects are on sample accrual or on the statistical power of the research.”. Based on even the most casual inquiries, however, one concludes that the percentage of Americans who actually volunteer their data for biomedical research is far less than the eighty percent who, according to Kish & Topol’s survey data, indicate an interest in doing so. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 248.Hirschman Albert O. Exit, Voice, and Loyalty: Responses to Decline in Firms, Organizations, and States. 1970 [Google Scholar]
- 249.Id. at 4, 26–29.
- 250.Id. at 4.
- 251.Evans Barbara J. Power to the People: Data Citizens in the Age of Precision Medicine. Vand J Ent & Tech L. 2017;19 forthcoming. [PMC free article] [PubMed] [Google Scholar]