

Abstract
BLANC is a link-based coreference evaluation metric for measuring the quality of coreference systems on gold mentions. This paper extends the original BLANC (“BLANC-gold” henceforth) to system mentions, removing the gold mention assumption. The proposed BLANC falls back seamlessly to the original one if system mentions are identical to gold mentions, and it is shown to strongly correlate with existing metrics on the 2011 and 2012 CoNLL data.
1 Introduction
Coreference resolution aims at identifying natural language expressions (or mentions) that refer to the same entity. It entails partitioning (often imperfect) mentions into equivalence classes. A critically important problem is how to measure the quality of a coreference resolution system. Many evaluation metrics have been proposed in the past two decades, including the MUC measure (Vilain et al., 1995), B-cubed (Bagga and Baldwin, 1998), CEAF (Luo, 2005) and, more recently, BLANC-gold (Recasens and Hovy, 2011). B-cubed and CEAF treat entities as sets of mentions and measure the agreement between key (or gold standard) entities and response (or system-generated) entities, while MUC and BLANC-gold are link-based.
In particular, MUC measures the degree of agreement between key coreference links (i.e., links among mentions within entities) and response coreference links, while non-coreference links (i.e., links formed by mentions from different entities) are not explicitly taken into account. This leads to a phenomenon where coreference systems outputting large entities are scored more favorably than those outputting small entities (Luo, 2005). BLANC (Recasens and Hovy, 2011), on the other hand, considers both coreference links and non-coreference links. It calculates recall, precision and F-measure separately on coreference and non-coreference links in the usual way, and defines the overall recall, precision and F-measure as the mean of the respective measures for coreference and non-coreference links.
The BLANC-gold metric was developed with the assumption that response mentions and key mentions are identical. In reality, however, mentions need to be detected from natural language text and the result is, more often than not, imperfect: some key mentions may be missing in the response, and some response mentions may be spurious—so-called “twinless” mentions by Stoyanov et al. (2009). Therefore, the identical-mention-set assumption limits BLANC-gold’s applicability when gold mentions are not available, or when one wants to have a single score measuring both the quality of mention detection and coreference resolution. The goal of this paper is to extend the BLANC-gold metric to imperfect response mentions.
We first briefly review the original definition of BLANC, and rewrite its definition using set notation. We then argue that the gold-mention assumption in Recasens and Hovy (2011) can be lifted without changing the original definition. In fact, the proposed BLANC metric subsumes the original one in that its value is identical to the original one when response mentions are identical to key mentions.
The rest of the paper is organized as follows. We introduce the notions used in this paper in Section 2. We then present the original BLANC-gold in Section 3 using the set notation defined in Section 2. This paves the way to generalize it to imperfect system mentions, which is presented in Section 4. The proposed BLANC is applied to the CoNLL 2011 and 2012 shared task participants, and the scores and its correlations with existing metrics are shown in Section 5.
2 Notations
To facilitate the presentation, we define the notations used in the paper.
We use key to refer to gold standard mentions or entities, and response to refer to system mentions or entities. The collection of key entities is denoted by , where ki is the ith key entity; accordingly, is the set of response entities, and rj is the jth response entity. We assume that mentions in {ki} and {rj} are unique; in other words, there is no duplicate mention.
Let Ck(i) and Cr(j) be the set of coreference links formed by mentions in ki and rj:
As can be seen, a link is an undirected edge between two mentions, and it can be equivalently represented by a pair of mentions. Note that when an entity consists of a single mention, its coreference link set is empty.
Let Nk(i, j) (i ≠ j) be key non-coreference links formed between mentions in ki and those in kj, and let Nr(i, j) (i ≠ j) be response non-coreference links formed between mentions in ri and those in rj, respectively:
Note that the non-coreference link set is empty when all mentions are in the same entity.
We use the same letter and subscription without the index in parentheses to denote the union of sets, e.g.,
We use Tk = Ck ∪ Nk and Tr = Cr ∪ Nr to denote the total set of key links and total set of response links, respectively. Clearly, Ck and Nk form a partition of Tk since Ck ∩ Nk = ∅, Tk = Ck ∪ Nk. Likewise, Cr and Nr form a partition of Tr.
We say that a key link l1 ∈ Tk equals a response link l2 ∈ Tr if and only if the pair of mentions from which the links are formed are identical. We write l1 = l2 if two links are equal. It is easy to see that the gold mention assumption—same set of response mentions as the set of key mentions—can be equivalently stated as Tk = Tr (this does not necessarily mean that Ck = Cr or Nk = Nr).
We also use | · | to denote the size of a set.
3 Original BLANC
BLANC-gold is adapted from Rand Index (Rand, 1971), a metric for clustering objects. Rand Index is defined as the ratio between the number of correct within-cluster links plus the number of correct cross-cluster links, and the total number of links.
When Tk = Tr, Rand Index can be applied directly since coreference resolution reduces to a clustering problem where mentions are partitioned into clusters (entities):
| (1) |
In practice, though, the simple-minded adoption of Rand Index is not satisfactory since the number of non-coreference links often overwhelms that of coreference links (Recasens and Hovy, 2011), or, |Nk| ≫ |Ck| and |Nr| ≫ |Cr|. Rand Index, if used without modification, would not be sensitive to changes of coreference links.
BLANC-gold solves this problem by averaging the F-measure computed over coreference links and the F-measure over non-coreference links. Using the notations in Section 2, the recall, precision, and F-measure on coreference links are:
| (2) |
| (3) |
| (4) |
Similarly, the recall, precision, and F-measure on non-coreference links are computed as:
| (5) |
| (6) |
| (7) |
Finally, the BLANC-gold metric is the arithmetic average of and :
| (8) |
Superscriptg in these equations highlights the fact that they are meant for coreference systems with gold mentions.
Eqn. (8) indicates that BLANC-gold assigns equal weight to , the F-measure from coreference links, and , the F-measure from non-coreference links. This avoids the problem that |Nk| ≫ |Ck| and |Nr| ≫ |Cr|, should the original Rand Index be used.
In Eqn. (2) – (3) and Eqn. (5) – (6), denominators are written as a sum of disjoint subsets so they can be related to the contingency table in (Recasens and Hovy, 2011). Under the assumption that Tk = Tr, it is clear that Ck = (Ck ∩ Cr) ∪ (Ck ∩ Nr), Cr = (Ck ∩ Cr) ∪ (Nk ∩ Cr), and so on.
4 BLANC for Imperfect Response Mentions
Under the assumption that the key and response mention sets are identical (which implies that Tk = Tr), Equations (2) to (7) make sense. For example, Rc is the ratio of the number of correct coreference links over the number of key coreference links; Pc is the ratio of the number of correct coreference links over the number of response coreference links, and so on.
However, when response mentions are not identical to key mentions, a key coreference link may not appear in either Cr or Nr, so Equations (2) to (7) cannot be applied directly to systems with imperfect mentions. For instance, if the key entities are {a, b, c} {d, e}; and the response entities are {b, c} {e, f, g}, then the key coreference link (a, b) is not seen on the response side; similarly, it is possible that a response link does not appear on the key side either: (c, f) and (f, g) are not in the key in the above example.
To account for missing or spurious links, we observe that
Ck \ Tr are key coreference links missing in the response;
Nk \ Tr are key non-coreference links missing in the response;
Cr \ Tk are response coreference links missing in the key;
Nr \ Tk are response non-coreference links missing in the key,
and we propose to extend the coreference F-measure and non-coreference F-measure as follows. Coreference recall, precision and F-measure are changed to:
| (9) |
| (10) |
| (11) |
Non-coreference recall, precision and F-measure are changed to:
| (12) |
| (13) |
| (14) |
The proposed BLANC continues to be the arithmetic average of Fc and Fn:
| (15) |
We observe that the definition of the proposed BLANC, Equ. (9)–(14) subsume the BLANC-gold (2) to (7) due to the following proposition: If Tk = Tr, then BLANC = BLANC(g).
Proof
We only need to show that , , , and . We prove the first one (the other proofs are similar and elided due to space limitations). Since Tk = Tr and Ck ⊂ Tk, we have Ck ⊂ Tr; thus Ck \ Tr = ∅, and |Ck ∩ Tr| = 0. This establishes that .
Indeed, since Ck is a union of three disjoint subsets: Ck = (Ck ∩ Cr) ∪ (Ck ∩ Nr) ∪ (Ck \ Tr), and Rc can be unified as . Unification for other component recalls and precisions can be done similarly. So the final definition of BLANC can be succinctly stated as:
| (16) |
| (17) |
| (18) |
| (19) |
4.1 Boundary Cases
Care has to be taken when counts of the BLANC definition are 0. This can happen when all key (or response) mentions are in one cluster or are all singletons: the former case will lead to Nk = ∅ (or Nr = ∅); the latter will lead to Ck = ∅ (or Cr = ∅). Observe that as long as |Ck| + |Cr| > 0, Fc in (18) is well-defined; as long as |Nk| + |Nr| > 0, Fn in (18) is well-defined. So we only need to augment the BLANC definition for the following cases:
If Ck = Cr = ∅ and Nk = Nr = ∅, then BLANC = I(Mk = Mr), where I(·) is an indicator function whose value is 1 if its argument is true, and 0 otherwise. Mk and Mr are the key and response mention set. This can happen when a document has no more than one mention and there is no link.
If Ck = Cr = ∅ and |Nk| + |Nr| > 0, then BLANC = Fn. This is the case where the key and response side has only entities consisting of singleton mentions. Since there is no coreference link, BLANC reduces to the non-coreference F-measure Fn.
If Nk = Nr = ∅ and |Ck| + |Cr| > 0, then BLANC = Fc. This is the case where all mentions in the key and response are in one entity. Since there is no non-coreference link, BLANC reduces to the coreference F-measure Fc.
4.2 Toy Examples
We walk through a few examples and show how BLANC is calculated in detail. In all the examples below, each lower-case letter represents a mention; mentions in an entity are closed in {}; two letters in () represent a link.
Example 1
Key entities are {abc} and {d}; response entities are {bc} and {de}. Obviously,
Therefore, , , and , , , , , . Finally, .
Example 2
Key entity is {a}; response entity is {b}. This is boundary case (1): BLANC = 0.
Example 3
Key entities are {a}{b}{c}; response entities are {a}{b}{d}. This is boundary case (2): there are no coreference links. Since
we have
So .
Example 4
Key entity is {abc}; response entity is {bc}. This is boundary case (3): there are no non-coreference links. Since
we have
So .
5 Results
5.1 CoNLL-2011/12
We have updated the publicly available CoNLL coreference scorer1 with the proposed BLANC, and used it to compute the proposed BLANC scores for all the CoNLL 2011 (Pradhan et al., 2011) and 2012 (Pradhan et al., 2012) participants in the official track, where participants had to automatically predict the mentions. Tables 1 and 2 report the updated results.2
Table 1.
The proposed BLANC scores of the CoNLL-2011 shared task participants.
| Participant | R | P | BLANC |
|---|---|---|---|
| lee | 50.23 | 49.28 | 48.84 |
| sapena | 40.68 | 49.05 | 44.47 |
| nugues | 47.83 | 44.22 | 45.95 |
| chang | 44.71 | 47.48 | 45.49 |
| stoyanov | 49.37 | 29.80 | 34.58 |
| santos | 46.74 | 37.33 | 41.33 |
| song | 36.88 | 39.69 | 30.92 |
| sobha | 35.42 | 39.56 | 36.31 |
| yang | 47.95 | 29.12 | 36.09 |
| charton | 42.32 | 31.54 | 35.65 |
| hao | 45.41 | 32.75 | 36.98 |
| zhou | 29.93 | 45.58 | 34.95 |
| kobdani | 32.29 | 33.01 | 32.57 |
| xinxin | 36.83 | 34.39 | 35.02 |
| kummerfeld | 34.84 | 29.53 | 30.98 |
| zhang | 30.10 | 43.96 | 35.71 |
| zhekova | 26.40 | 15.32 | 15.37 |
| irwin | 3.62 | 28.28 | 6.28 |
Table 2.
The proposed BLANC scores of the CoNLL-2012 shared task participants.
| Participant | R | P | BLANC |
|---|---|---|---|
| Language: Arabic | |||
|
| |||
| fernandes | 33.43 | 44.66 | 37.99 |
| bjorkelund | 32.65 | 45.47 | 37.93 |
| uryupina | 31.62 | 35.26 | 33.02 |
| stamborg | 32.59 | 36.92 | 34.50 |
| chen | 31.81 | 31.52 | 30.82 |
| zhekova | 11.04 | 62.58 | 18.51 |
| li | 4.60 | 56.63 | 8.42 |
|
| |||
| Language: English | |||
|
| |||
| fernandes | 54.91 | 63.66 | 58.75 |
| martschat | 52.00 | 58.84 | 55.04 |
| bjorkelund | 52.01 | 59.55 | 55.42 |
| chang | 52.85 | 55.03 | 53.86 |
| chen | 50.52 | 56.82 | 52.87 |
| chunyang | 51.19 | 55.47 | 52.65 |
| stamborg | 54.39 | 54.88 | 54.42 |
| yuan | 50.58 | 54.29 | 52.11 |
| xu | 45.99 | 54.59 | 46.47 |
| shou | 49.55 | 52.46 | 50.44 |
| uryupina | 44.15 | 48.89 | 46.04 |
| songyang | 40.60 | 50.85 | 45.10 |
| zhekova | 41.46 | 33.13 | 34.80 |
| xinxin | 44.39 | 32.79 | 36.54 |
| li | 25.17 | 52.96 | 31.85 |
|
| |||
| Language: Chinese | |||
|
| |||
| chen | 48.45 | 62.44 | 54.10 |
| yuan | 53.15 | 40.75 | 43.20 |
| bjorkelund | 47.58 | 45.93 | 44.22 |
| xu | 44.11 | 36.45 | 38.45 |
| fernandes | 42.36 | 61.72 | 49.63 |
| stamborg | 39.60 | 55.12 | 45.89 |
| uryupina | 33.44 | 56.01 | 41.88 |
| martschat | 27.24 | 62.33 | 37.89 |
| chunyang | 37.43 | 36.18 | 36.77 |
| xinxin | 36.46 | 39.79 | 37.85 |
| li | 21.61 | 62.94 | 30.37 |
| chang | 18.74 | 40.76 | 25.68 |
| zhekova | 21.50 | 37.18 | 22.89 |
5.2 Correlation with Other Measures
Figure 1 shows how the proposed BLANC measure works when compared with existing metrics such as MUC, B-cubed and CEAF, using the BLANC and F1 scores. The proposed BLANC is highly positively correlated with the other measures along R, P and F1 (Table 3), showing that BLANC is able to capture most entity-based similarities measured by B-cubed and CEAF. However, the CoNLL data sets come from OntoNotes (Hovy et al., 2006), where singleton entities are not annotated, and BLANC has a wider dynamic range on data sets with singletons (Recasens and Hovy, 2011). So the correlations will likely be lower on data sets with singleton entities.
Figure 1.
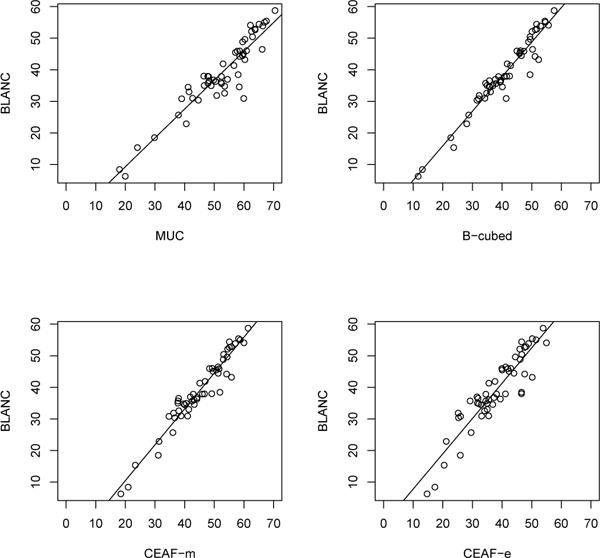
Correlation plot between the proposed BLANC and the other measures based on the CoNLL 2011/2012 results. All values are F1 scores.
Table 3.
Pearson’s r correlation coefficients between the proposed BLANC and the other coreference measures based on the CoNLL 2011/2012 results. All p-values are significant at < 0.001.
| R | P | F1 | |
|---|---|---|---|
| MUC | 0.975 | 0.844 | 0.935 |
| B-cubed | 0.981 | 0.942 | 0.966 |
| CEAF-m | 0.941 | 0.923 | 0.966 |
| CEAF-e | 0.797 | 0.781 | 0.919 |
6 Conclusion
The original BLANC-gold (Recasens and Hovy, 2011) requires that system mentions be identical to gold mentions, which limits the metric’s utility since detected system mentions often have missing key mentions or spurious mentions. The proposed BLANC is free from this assumption, and we have shown that it subsumes the original BLANC-gold. Since BLANC works on imperfect system mentions, we have used it to score the CoNLL 2011 and 2012 coreference systems. The BLANC scores show strong correlation with existing metrics, especially B-cubed and CEAF-m.
Acknowledgments
We would like to thank the three anonymous reviewers for their invaluable suggestions for improving the paper. This work was partially supported by grants R01LM10090 from the National Library of Medicine.
Footnotes
The order is kept the same as in Pradhan et al. (2011) and Pradhan et al. (2012) for easy comparison.
Contributor Information
Xiaoqiang Luo, Google Inc., 111 8th Ave, New York, NY 10011.
Sameer Pradhan, Harvard Medical School, 300 Longwood Ave., Boston, MA 02115.
Marta Recasens, Google Inc., 1600 Amphitheatre Pkwy, Mountain View, CA 94043.
Eduard Hovy, Carnegie Mellon University, 5000 Forbes Ave., Pittsburgh, PA 15213.
References
- Bagga Amit, Baldwin Breck. Proceedings of the Linguistic Coreference Workshop at The First International Conference on Language Resources and Evaluation (LREC’98) 1998. Algorithms for scoring coreference chains; pp. 563–566. [Google Scholar]
- Hovy Eduard, Marcus Mitchell, Palmer Martha, Ramshaw Lance, Weischedel Ralph. Proceedings of the Human Language Technology Conference of the NAACL, Companion Volume: Short Papers. New York City, USA: Association for Computational Linguistics; 2006. Jun, OntoNotes: The 90% solution; pp. 57–60. [Google Scholar]
- Luo Xiaoqiang. Proc of Human Language Technology (HLT)/Empirical Methods in Natural Language Processing (EMNLP) 2005. On coreference resolution performance metrics. [Google Scholar]
- Pradhan Sameer, Ramshaw Lance, Marcus Mitchell, Palmer Martha, Weischedel Ralph, Xue Nianwen. Proceedings of the Fifteenth Conference on Computational Natural Language Learning: Shared Task. Portland, Oregon, USA: Association for Computational Linguistics; 2011. Jun, CoNLL-2011 shared task: Modeling unrestricted coreference in OntoNotes; pp. 1–27. [Google Scholar]
- Pradhan Sameer, Moschitti Alessandro, Xue Nianwen, Uryupina Olga, Zhang Yuchen. Joint Conference on EMNLP and CoNLL – Shared Task. Jeju Island, Korea: Association for Computational Linguistics; 2012. Jul, CoNLL-2012 shared task: Modeling multilingual unrestricted coreference in OntoNotes; pp. 1–40. [Google Scholar]
- Rand WM. Objective criteria for the evaluation of clustering methods. Journal of the American Statistical Association. 1971;66(336):846–850. [Google Scholar]
- Recasens M, Hovy E. BLANC: Implementing the Rand index for coreference evaluation. Natural Language Engineering. 2011;17:485–510. 10. [Google Scholar]
- Stoyanov Veselin, Gilbert Nathan, Cardie Claire, Riloff Ellen. Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2 – Volume 2. Stroudsburg, PA, USA: Association for Computational Linguistics; 2009. Conundrums in noun phrase coreference resolution: Making sense of the state-of-the-art; pp. 656–664. ACL ’09. [Google Scholar]
- Vilain M, Burger J, Aberdeen J, Connolly D, Hirschman L. In Proc of MUC6. 1995. A model-theoretic coreference scoring scheme; pp. 45–52. [Google Scholar]