

Abstract
Background
One of the most successful approaches to develop new small molecule therapeutics has been to start from a validated druggable protein target. However, only a small subset of potentially druggable targets has attracted significant research and development resources. The Illuminating the Druggable Genome (IDG) project develops resources to catalyze the development of likely targetable, yet currently understudied prospective drug targets. A central component of the IDG program is a comprehensive knowledge resource of the druggable genome.
Results
As part of that effort, we have developed a framework to integrate, navigate, and analyze drug discovery data based on formalized and standardized classifications and annotations of druggable protein targets, the Drug Target Ontology (DTO). DTO was constructed by extensive curation and consolidation of various resources. DTO classifies the four major drug target protein families, GPCRs, kinases, ion channels and nuclear receptors, based on phylogenecity, function, target development level, disease association, tissue expression, chemical ligand and substrate characteristics, and target-family specific characteristics. The formal ontology was built using a new software tool to auto-generate most axioms from a database while supporting manual knowledge acquisition. A modular, hierarchical implementation facilitate ontology development and maintenance and makes use of various external ontologies, thus integrating the DTO into the ecosystem of biomedical ontologies. As a formal OWL-DL ontology, DTO contains asserted and inferred axioms. Modeling data from the Library of Integrated Network-based Cellular Signatures (LINCS) program illustrates the potential of DTO for contextual data integration and nuanced definition of important drug target characteristics. DTO has been implemented in the IDG user interface Portal, Pharos and the TIN-X explorer of protein target disease relationships.
Conclusions
DTO was built based on the need for a formal semantic model for druggable targets including various related information such as protein, gene, protein domain, protein structure, binding site, small molecule drug, mechanism of action, protein tissue localization, disease association, and many other types of information. DTO will further facilitate the otherwise challenging integration and formal linking to biological assays, phenotypes, disease models, drug poly-pharmacology, binding kinetics and many other processes, functions and qualities that are at the core of drug discovery. The first version of DTO is publically available via the website http://drugtargetontology.org/, Github (http://github.com/DrugTargetOntology/DTO), and the NCBO Bioportal (http://bioportal.bioontology.org/ontologies/DTO). The long-term goal of DTO is to provide such an integrative framework and to populate the ontology with this information as a community resource.
Electronic supplementary material
The online version of this article (10.1186/s13326-017-0161-x) contains supplementary material, which is available to authorized users.
Background
The development and approval of novel small molecule therapeutics (drugs) is highly complex and exceedingly resource intensive, being estimated at over one billion dollars for a new FDA approved drug. The primary reason for attrition in clinical trials is the lack of efficacy, which has been associated with poor or biased target selection [1]. Although the drug target mechanism of action is not required for FDA approval, a target-based mechanistic understanding of diseases and drug action is highly desirable and a preferred approach of drug development in the pharmaceutical industry. Following the advent of the Human Genome, several research groups in academia as well as industry have focused on “the druggable genome” i.e. the subsets of genes in the human genome that express proteins that have the ability to bind drug-like small molecules [2]. The researchers have estimated the number of druggable targets ranging from few hundreds to several thousands [3]. Furthermore, it has been suggested by several analyses that only a small fraction of likely relevant druggable targets are extensively studied, leaving a potentially huge treasure trove of promising, yet understudied (“dark”) drug targets to be explored by pharmaceutical companies and academic drug discovery researchers. Not only is there ambiguity about the number of the druggable targets, but there is also a need of systematic characterization and annotation of the druggable genome. A few research groups have made efforts to address these issues and have indeed developed several useful resources, e.g. IUPHAR/BPS Guide to PHARMACOLOGY (GtoPdb/IUPHAR) [4], PANTHER [5], Therapeutic Target Database (TTD) [6], Potential Drug Target Database (PDTD) [7], covering important aspects of the drug targets. However, to the best of our knowledge, a publically available structured knowledge resource of drug target classifications and relevant annotations for the most important protein families, one that facilitates querying, data integration, re-use, and analysis does not currently exist. Content in the above-mentioned databases is scattered and in some cases inconsistent and duplicated, complicating data integration and analysis.
The Illuminating the Druggable Genome (IDG) project (http://targetcentral.ws/) has the goal to identify and prioritize new prospective drug targets among likely targetable, yet currently poorly or not at all annotated proteins; and by doing so to catalyze the development of novel drugs with new mechanisms of action. Data compiled and analyzed by the IDG Knowledge Management Center (IDG-KMC) shows that the globally marketed drugs stem from only 3% of the human proteome. These results also suggest that the substantial knowledge deficit for understudied drug targets may be due to an uneven distribution of information and resources [8].
In the context of the IDG program we have been developing the Drug Target Ontology (DTO). Formal ontologies have been quite useful to facilitate harmonization, integration, and analysis of diverse data in the biomedical and other domains. DTO integrates and harmonizes knowledge of the most important druggable protein families: kinases, GPCRs, ion channels and nuclear hormone receptors. DTO content was curated from several resources and the literature, and includes detailed hierarchical classifications of proteins and genes, tissue localization, disease association, drug target development level, protein domain information, ligands, substrates, and other types of relevant information. DTO content sources were chosen by domain experts based on relevance, coverage and completeness of the information available through them. Most resources had been peer reviewed (references are included in the respective sections), published and were therefore considered reliable. DTO is aimed towards the drug discovery and clinical communities and was built to align with other ontologies including BioAssay Ontology (BAO) [9–11] and GPCR Ontology [12]. By providing a semantic framework of diverse information related to druggable proteins, DTO facilitates the otherwise challenging integration and formal linking of heterogeneous and diverse data important for drug discovery. DTO is particularly relevant for big data, systems-level models of diseases and drug action as well as precision medicine. The long-term goal of DTO is to provide such an integrative framework and to populate the ontology with this information as a community resource. Here we describe the development, content, architecture, modeling and use of the DTO. DTO has already been implemented in end-user software tools to facilitate the browsing [11] and navigation of drug target data [13].
Methods
Drug target data curation and classification
DTO places special emphasis on the four protein families that are central to the NIH IDG initiative: non-olfactory GPCRs (oGPCRs), Kinases, Ion Channels and Nuclear Receptors. The classifications and annotations of these four protein families were extracted, aggregated, harmonized, and manually curated from various resources as described below, and further enriched using the recent research literature. Proteins and their classification and annotations were aligned with the Target Central Resource Databases (TCRD) database [11] developed by the IDG project (http://targetcentral.ws/ProteinFam). In particular, the Target Development Level (TDL) classification was obtained from the TCRD database.
Kinase classification
Kinases have been classified primarily into protein and non-protein kinases. Protein kinases have been further classified into several groups, families, subfamilies. Non-protein kinases have been classified in several groups, based on the type of substrates (lipid, carbohydrate, nucleoside, other small molecule, etc.). Classification information has been extracted and curated from various resources e.g. UniProt, ChEMBL, PhosphoSitePlus® (PSP) [14], Sugen Kinase website (http://www.kinase.com/web/current/), and the literature, and was organized manually, consolidated and checked for consistency. Kinase substrates were manually curated from UniProt and the literature. Pseudokinases, which lack key functional residues and are (to current knowledge) not catalytically active, were annotated based on the Sugen kinase domain sequences and the literature.
Ion-channel classification
Ion channels have been classified primarily into family, subfamily, sub-subfamily. Most of the information has been taken from the Transporter Classification Database (http://www.tcdb.org/) [15], UniProt and several linked databases therein. The classification is based on both the phylogenetic and functional information. Additional information regarding the gating mechanism (voltage gated, ligand gated, etc.), transported ions, protein structural and topological information has also been captured and included as separate annotations. Moreover, the transported ions, such as chloride, sodium, etc. have been mapped to the “Chemical entity” of the ChEBI reference database [16].
GPCR classification
GPCRs have been classified based on phylogenetic, functional and the endogenous ligand information. The primary classification included class, group, family, and subfamily. Most of the information has been taken from the GPCR.org classification and had been updated using various sources e.g. IUPHAR [4], ChEMBL, UniProt and also from our earlier GPCR ontology [12]. Furthermore, the information for the specific endogenous ligands for each protein has been extracted from IUPHAR and has been integrated with the classification. The information about the GPCR ligand and ligand type (lipid, peptide, etc.) has also been included and has been mapped manually to the “Chemical entity” of the ChEBI reference database.
Nuclear receptor classification
This information has been adopted directly from IUPHAR.
External DTO modules and mapping
Proteins mapped to UniProt. Genes were classified identical to proteins (above) and mapped to Entrez gene. The external modules incorporated into DTO were extracted from the Disease Ontology (DOID) [17], BRENDA Tissue Ontology (BTO) [18], UBERON [19], the ontology of Chemical Entities of Biological Interest (ChEBI) [20], and Protein Ontology (PRO) [21]. Data about over 1000 cell lines from the LINCS project [22] were integrated and mapped to diseases and tissues. Gene/protein–disease [23] and protein–tissue associations [24] were obtained from the JensenLab at Novo Nordisk Foundation Center for Protein Research. Mapping between UBERON and BRENDA to integrate the tissue associations of cell lines and proteins was retrieved from the NCBO BioPortal [25, 26] and manually cross-checked. Target Development Level (TDL) were obtained from TCRD and included as separate annotation for all protein families.
Drug target ontology (DTO) development
Ontology modeling
While curators stored all classification and annotation data into various spreadsheets, ontologists created the ontological model to link the metadata obtained from those spreadsheets, and to create the descriptive logic axioms to define ontology classes using a semi-automated workflow. Finalizing and optimizing the ontology model or design pattern required iterative processes of intensive discussions, modeling refinement, voting, and approval among domain experts, data curators, IT developers, and ontologists. Once ontologists proposed a conceptual ontology model, the selection of the most robust ontology model was guided by simple criteria: correct representation of domain content, minimize the number of relations to link all metadata, avoid contradiction with existing domain knowledge representation ontologies, such as the OBO ontologies. For example, in our conceptual model, the relations among organ, tissue, cell lines and anatomical entity were adopted and refined from the UBERON and CLO ontologies. Some relations such as the shortcut relations between protein and associated disease or tissue were created specifically for DTO, which was a compromise for accommodating the large amount of data in DTO. Approval process of accepting a model proposal was driven by our domain experts with contributing data curators, IT developers, and ontologists. The voting process was rather informal; however, the model had to be agreed by all the parties involved in the ontology development: domain experts, data curators, IT developers, and ontologists. Once the most fit ontology model was chosen, this piece of modeling was used as template for a java tool (described below) to generate all the OWL files by using above mentioned data annotation spreadsheets as input.
Modularization approach
DTO was built with an extended modular architecture based on the modular architecture designed and implemented for BAO [9]. The modularization strategy developed previously was a layered architecture and used the modeling primitives, vocabularies, modules and axioms. Most significantly, DTO’s modular architecture includes an additional layer to the modularization process by automating the creation of basic subsumption hierarchies and select axioms such as the axioms for disease and tissue associations. Three types of files are used in the modular architecture: vocabulary files, module files, and combined files, such as DTO_core and DTO_complete. Vocabularies only contain concepts (classes with subsumption only). Module layers enable combining vocabularies in flexible ways to create desired ontology structures or subsets. Finally, in the combined files axioms are added to the vocabularies to formally define the various concepts to allow logical inferences. Classes and relationships are imported (directly or indirectly) from module and/or vocabulary files [9]. The external third-party ontologies were extracted using the OWL API or OntoFox [27].
OntoJOG tool
To streamline the building process, a Java tool (OntoJOG) was developed to automatically create the OWL module files, vocabulary files as components of the whole ontology. OntoJOG takes a flat CSV or TSV data file and loads it as a table either into a temporary SQLite database or a permanent MySQL database. This table is then used as a reference for creating and generating the OWL files as well as several relationship tables. The relationship tables and the final OWL files are generated based on a CSV mapping file that generates the commands for the OntoJOG to perform and the various options for those commands. The commands from the mapping file are read in two passes to ensure everything is added correctly. In the first pass, all classes and their annotations are inserted into the relationship tables and are assigned IDs as necessary, and in the second pass all axioms and relationships between classes are created. After this process is completed an optional reparenting phase is executed before each module of the ontology is generated into its own OWL vocabulary files with an accompanying module file containing the relationships for the given vocabulary files.
Finally, the ontology was thoroughly reviewed, tested and validated by developers, domain experts, and users in the IDG-KMC.
Data quality control
Several steps of Quality Control (QC) at different stages in the development process of the ontology were implemented. First, data extracted from external resources is checked for consistency against that original source by the lead data curator. Depending on how the data was extracted (APIs, download of files) this involves different scripts, but in all cases thorough manual expert review. Secondly, while developers load curated data into a local staging database, another QC step is taking place to assure data integrity during the loading process. Thirdly, as soon as the auto-ontology building using OntoJOG finishes, reasoning over the whole ontology checks for consistency of the logical definitions and the ontology itself. In a fourth QC step, the ontologist runs several SPARQL queries against the ontology to retrieve the data and arrange them in a format that can directly be compared to the original datasets; any discrepancies are flagged and resolved between the lead curator, developer and ontologist. Fifth, for each new ontology build, an automated script reads all DTO vocabulary and module files and compares them to the previous version. This script generates reports with all new (not present in the previous version), deleted (not present in current version) and changed classes and properties based on their URIs and labels. These reports are reviewed by curators and ontologists and any expected differences among versions are resolved. Sixth and finally, the ontology is loaded into Protégé and carefully manually reviewed by curators and ontologists. In order to audit the QC process, all the development versions are stored at a private GitHub repository owned by our lab. Only when data is in 100% consistency with original datasets and all QC steps are completed and passed, the ontology is released to the designated public GitHub repository.
DTO visualization
Data visualization is important, especially with the increasing complexity of the data. Ontology visualization, correspondingly, has an appealing potential to help to browse and comprehend the structures of ontologies. A number of ontology visualization tools have been developed and applied as information retrieval aids, such as OntoGraf, OWLViz as part of the Ontology development tool Protégé, and OntoSphere3D [28] among others. Further, studies and reviews on different visualization tools, e.g. [29, 30] and [31], have been published by comparing each tool’s performances. Preference of visualization models depends on the type and query context of the visualized network and also on users’ needs.
Data-Drive Document (D3) is a relatively novel representation-transparent and dynamic approach to visualize data on the web. It is a modern interactive visualization tool available as a JavaScript library [29]. By selectively binding input data to arbitrary document elements, D3.js enables direct inspection and manipulation of a native representation. The D3.js JavaScript library gained popularity as a generic framework based on widely accepted web standards such as SVG, JavaScript, HTML5 and CSS.
Consequently, we use the D3.js library for the interactive visualization of our DTO as part of the Neo4J graphical database solution.
DTO and BAO integration to model LINCS data
The Library of Network-Based Cellular Signatures (LINCS) program has been generating a reference “library” of molecular signatures, such as changes in gene expression and other cellular phenotypes that occur when cells are exposed to a variety of perturbing agents. One of the LINCS screening assays is a biochemical kinase profiling assay that measures drug binding using a panel of ~440 recombinant purified kinases, namely, KINOMEscan assay. The HMS LINCS Center has collected 165 KINOMEscan datasets in order to analyze the drug-target interaction. All these LINCS KINOMEscan data were originally retrieved from Harvard Medical School (HMS) LINCS DB (http://lincs.hms.harvard.edu/db/). KINOMEscan data was curated by domain experts to map to both Pfam domains, and corresponding Kinases. Unique KINOMEscan domains and annotations, including domain descriptions, IDs, names, gene symbols, phosphorylation status, and mutations were curated from different sources, including the HMS LINCS DB, DiscoverX KINOMEscan® assay list [32], Pfam (http://pfam.xfam.org/), and our previous modeling efforts of the entire human Kinome (publication in preparation). The kinase domain classification into group, family, etc. was the same as described above (kinase classification). Gatekeeper and hinge residues were assigned based on structural alignment of existing kinase domain crystal structures and structural models of the human kinome and sequence alignment with the full kinase protein referenced by UniProt accession in the DTO. Pfam accession number and names were obtained from Pfam [33]. The protocol and the KINOMEscan curated target metadata table were analyzed by ontologists to create kinase domain drug target ontology model.
Ontology source access and license
The official DTO website is publicly available at http://drugtargetontology.org/, where it can be visualized and searched. The DTO is an open source project, and released under a Creative Commons 3.0 License. The source code including the development and release versions are freely available at the URL: http://github.com/DrugTargetOntology/DTO . DTO is also published at the NCBO BioPortal (http://bioportal.bioontology.org/ontologies/DTO).
Results
In what follows, the italic font represents terms, classes, relations, or axioms used in the ontology.
Drug targets definition and classification
Different communities have been using the term “drug target” ambiguously with no formal generally accepted definition. The DTO project develops a formal semantic model for drug targets including various related information such as protein, gene, protein domain, protein structure, binding site, small molecule drug, mechanism of action, protein tissue localization, disease associations, and many other types of information.
The IDG project defined ‘drug target’ as “a native (gene product) protein or protein complex that physically interacts with a therapeutic drug (with some binding affinity) and where this physical interaction is (at least partially) the cause of a (detectable) clinical effect”. DTO defined a DTO specific term “drug target role”. The text definition of “drug target role” is “a role played by a material entity, such as native (gene product) protein, protein complex, microorganism, DNA, etc., that physically interacts with a therapeutic or prophylactic drug (with some binding affinity) and where this physical interaction is (at least partially) the cause of a (detectable) clinical effect.”
At the current phase, DTO focuses on protein targets. DTO provides various asserted and inferred hierarchies to classify drug targets. Below we describe the most relevant ones.
Target development level (TDL)
The IDG classified proteins into four levels with respect to the depth of investigation from a clinical, biological and chemical standpoint (http://targetcentral.ws/) [8]:
T clin are proteins targeted by approved drugs as they exert their mode of action [3]. The Tclin proteins are designated drug targets under the context of IDG.
T chem are proteins that can specifically be manipulated with small molecules better than bioactivity cutoff values (30 nM for kinases, 100 nM for GPCRs and NRs, 10 uM for ICs, and 1 uM for other target classes), which lack approved small molecule or biologic drugs. In some cases, targets have been manually migrated to Tchem through human curation, based on small molecule activities from sources other than ChEMBL or DrugCentral [34].
T bio are proteins that do not satisfy the Tclin or Tchem criteria, which are annotated with a Gene Ontology Molecular Function or Biological Process with an Experimental Evidence code, or targets with confirmed OMIM phenotype(s), or do not satisfy the Tdark criteria detailed in 4).
T dark refers to proteins that have been described at the sequence level and have very few associated studies. They do not have any known drug or small molecule activities that satisfy the activity thresholds detailed in 2), lack OMIM and GO terms that would match Tbio criteria, and meet at least two of the following conditions:
A PubMed text-mining score < 5 [23]
<= 3 Gene RIFs [35]
<= 50 Antibodies available per Antibodypedia (http://antibodypedia.com)
Functional and phylogenetic classification
DTO proteins have been classified into various categories based on their structural (sequence/domains) or functional similarity. A high-level summary of the classifications for Kinases, Ion Channels, GPCRs and Nuclear Receptors is shown in Fig. 1. It should be noted that, as indicated above, the classification information has been extracted from various database and literature resources. The classification is subject to continuous updating for greater accuracy, and enriching the DTO using the most recent information as it becomes available. The present classification of the four protein families is briefly discussed below:
Fig. 1.
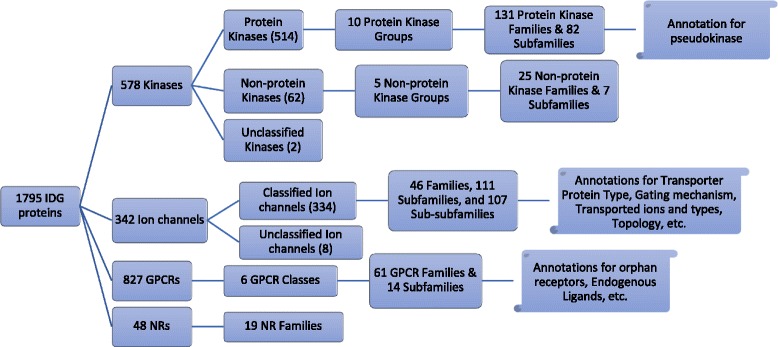
Overview of protein classification hierarchies for Kinase, Ion Channel, GPCR, and NR protein families. Note that several other relevant target annotations have been incorporated into DTO
Most of the 578 kinases covered in the current version of DTO are protein kinases. These 514 PKs are categorized into 10 groups that are further sub-categorized in 131 families and 82 subfamilies. A representative classification hierarchy for MAPK1 is:
Kinase > Protein Kinase > CMGC group > MAPK family > ERK subfamily > Mitogen-activated Protein Kinase 1.
The 62 non-protein kinases are categorized in 5 groups depending on the substrate that is phosphorylated by these proteins. These 5 groups are further sub-categorized in 25 families and 7 subfamilies. There are two kinases that haven’t been categorized yet into any of the above types or groups.
The 334 Ion channel proteins (out of 342 covered in the current version of DTO) are categorized into 46 families, 111 subfamilies, and 107 sub-subfamilies.
Similarly, the 827 GPCRs covered in the current version of DTO are categorized into 6 classes, 61 families and 14 subfamilies. The additional information whether any receptor has a known endogenous ligand or is currently “orphan” is mapped with the individual proteins. Finally, the 48 nuclear hormone receptors are categorized into 19 NR families.
Disease- and tissue-based classification
Target-disease associations and tissue expressions were obtained from the DISEASES [23]and TISSUES [24] databases (see Methods). Examples of such classifications are available as inferences in DTO (see below section 3.3.2).
Additional annotations and classifications
In addition to the phylogenetic classification of the proteins, there are several relevant properties associated with them as additional annotations. For example, there are 46 PKs that have been annotated as pseudokinases [36]. For ion channels, important properties, like transporter protein type, transported ion(s), gating mechanism, etc. have been associated with the individual proteins. The gating mechanism refers to the information regarding the factors that control the opening and closing of the ion channels. The important mechanisms include voltage-gated, ligand-gated, temperature-gated, mechanically-gated, etc. Similarly, for the GPCRs, the additional information whether any receptor has a known endogenous ligand or is currently “orphan” is mapped with the individual proteins. Current version of DTO has approximately 255 receptors that have information available regarding the endogenous ligands.
The analysis of drug target protein classification along with such relevant information associated through separate annotations may lead to interesting inferences.
Chemical classifications
Known GPCR ligands and IC transported ions were categorized by chemical properties and mapped to ChEBI (see Methods). For example, depending upon their chemical structure and properties, these known endogenous ligands for GPCRs have been categorized in seven types, namely, amine, amino acid, carboxylic acid, lipid, peptide, nucleoside and nucleotide. Similarly, the ions transported by the ion channel proteins and ion types (anion/cation) have been mapped to ChEBI. These annotations together with mappings of substrates and ligands to the proteins enable inferred classification of the proteins based on their chemical properties (see below).
DTO ontology implementation and modeling
Drug discovery target knowledge model of the DTO
The first version of the DTO includes detailed target classification and annotations for the four IDG protein families. Each protein is related to four types of entities: gene, related disease, related tissue or organ, and target development level. The conceptual model of DTO is illustrated as a linked diagram with nodes and edges. Nodes represent the classes in the DTO, and edges represent the ontological relations between classes. As shown in Fig. 2, GPCRs, kinases, ICs and NRs are types of proteins. GPCR binds GPCR ligands, and IC transports ions. Most GPCR ligands and ion are types of chemical entity from ChEBI. Each protein has a target development level (TDL), i.e., Tclin, Tchem, Tbio and Tdark. The protein is linked to gene by ‘has gene template’ relation. The gene is associated with disease based on evidence from the DISEASES database. The protein is also associated with some organ, tissue, or cell line using some evidence from TISSUES database. The full DTO contains many more annotations and classifications available at http://drugtargetontology.org/ .
Fig. 2.
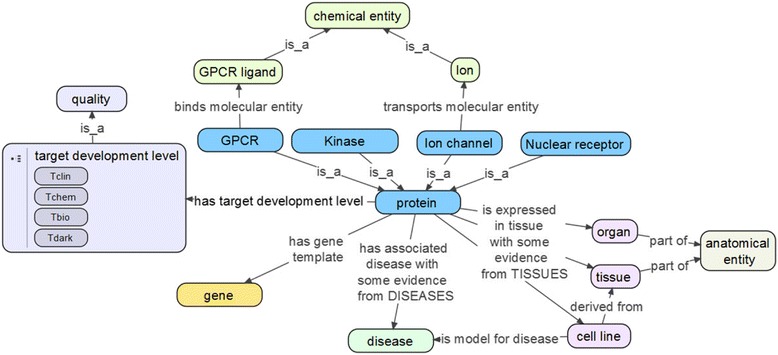
Conceptual high-level model of DTO. Including the main DTO (high-level) classes
DTO is implemented in OWL2-DL to enable further classification by inference reasoning and SPARQL queries. The current version of DTO contains >13,000 classes and >220,000 axioms. The DTO contains 827 GPCRs, 572 kinase, 342 ion channels (ICs), and 48 NRs.
Modular implementation of the DTO combining auto-generated and expert axioms
In DTO, each of the four drug target families has two vocabulary files of gene and protein, respectively; other DTO-native categories were created as separate vocabulary files. Additional vocabulary files include quality, role, properties, and cell line classes and subclasses. A vocabulary file contains entities of a class, which only contains “is-a” hierarchies. For example, the GPCR gene vocabulary contains only GPCR gene list and its curated classification. DTO core imports all the DTO vocabulary files of four families, including genes and proteins, and necessary axioms were added. Finally, DTO core was imported into the DTO complete file, which includes other vocabulary files and external files. External ontologies used in DTO include: BTO, CHEBI, DOID, UBERON, Cell Line Ontology (CLO), Protein Ontology (PRO), Relations Ontology (RO) and Basic Formal Ontology (BFO). The DTO core and DTO external are imported into the DTO module with auto-generated axioms, which links entities from different vocabulary files. Besides the programmatically generated vocabularies and modules, DTO also contains manually generated vocabularies and modules, as shown in Fig. 3.
Fig. 3.
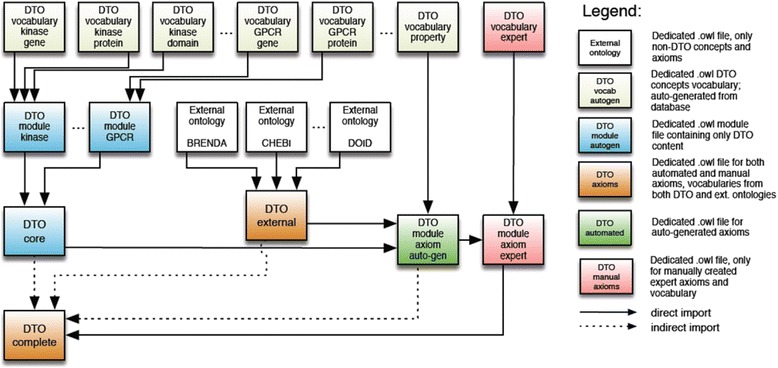
Illustration of the DTO modular architecture
This modularization approach significantly simplifies the maintenance of the ontology contents, especially when the ontology is large in size. If the gene or protein list changes, only the vocabulary file and the specific module file need to be updated instead of the whole ontology. In addition, external and internal resources are maintained separately. This design facilitates automated content updates from external resources including axioms generated using the above-mentioned Java tool OntoJOG without the need to re-generate manually axiomized domain knowledge, which can be very resource intensive, by simply separating them into two layers.
DTO to infer biologically and chemically relevant target classes
Chemically relevant target classes inferred by DTO
In addition to detailed asserted target classifications, DTO incorporates various other annotations including GPCR endogenous ligands for GPCRs, transported ions for ICs, gating mechanism for ICs, or pseudokinases. Endogenous GPCR ligands were manually mapped to ChEBI and classified by chemical category such as amine, lipid, peptide, etc. As ligands relate to receptor properties, GPCRs are typically classified based on their ligands; however, the ligand-based classification is orthogonal to the classification based on class A, B, C, adhesion, etc. and it changes as new ligands are deorphanized.
In DTO we therefore infer the ligand-based receptor, for example aminergic GPCR, lipidergic GPCR, peptidic GPCR, and orphan GPCR, which are of particular interest, by defining their logical equivalent as follows:
aminergic GPCR ≡ GPCR and (‘binds molecular entity’ some amine);
lipidergic GPCR ≡ GPCR and (‘binds molecular entity’ some lipid);
peptidic GPCR ≡ GPCR and (‘binds molecular entity’ some peptide);
orphan GPCR ≡ GPCR and (not (‘binds molecular entity’ some ‘GPCR ligand’)).
An example for 5-hydroxytryptamine receptor is shown in Fig. 4; the receptor is inferred as aminergic receptor based on its endogenous ligand.
Fig. 4.
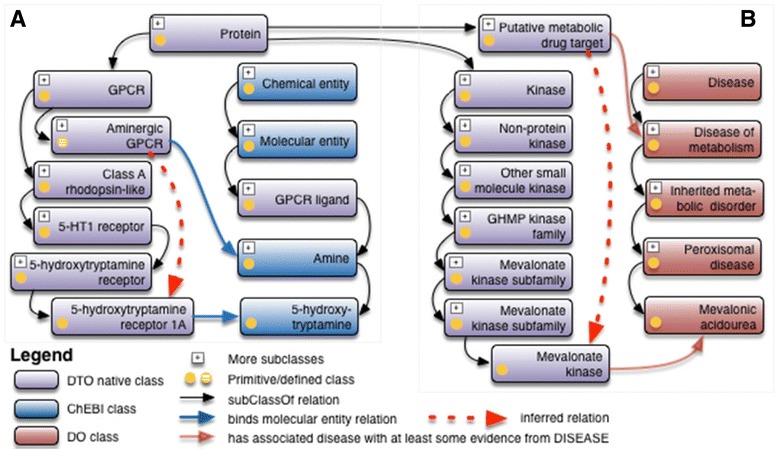
Inferred classifications in DTO. a 5-hydroxytryptamine receptor as an aminergic receptor based on its endogenous ligand, b mevalonate kinase as a putative metabolic drug target
DTO has classified 39 aminergic GPCR, 37 lipidergic GPCR, 119 peptide GPCR and 582 orphan GPCR.
Disease relevant target classes inferred by DTO
In a similar way, we categorized important disease targets by inference based on the protein - disease association, which were modeled as ‘strong’, ‘at least some’, or ‘at least weak’ evidence using subsumption. For example, DTO uses the following hierarchical relations to declare the relation between a protein and the associated disease extracted from the DISEASES database.
has associated disease with at least weak evidence from DISEASES
- has associated disease with at least some evidence from DISEASES
- has associated disease with strong evidence from DISEASES
In the DISEASES database, the associated disease and protein are measured by a Z-Score [23]. In DTO, the “at least weak evidence” is translated as a Z-Score between zero and 2.4; the “some evidence” is translated as a Z-Score between 2.5 and 3.5; and the “strong evidence” is translated as a Z-Score between 3.6 and 5.
This allows querying or inferring proteins for a disease of interest by evidence. Diseases related targets were defined using following axioms (as illustrative as examples):
Putative infectious disease targets ≡ Protein and (‘has associated disease with strong evidence from DISEASES’ some ‘disease of metabolism’);
Putative infectious disease targets ≡ Protein and (‘has associated disease with strong evidence from DISEASES’ some ‘disease by infectious agent’);
Putative mental health disease targets ≡ Protein and (‘has associated disease with strong evidence from DISEASES’ some ‘developmental disorder of mental health’)
We created such inference examples in DTO, including 29 metabolic disease targets, 36 mental health disease targets, and 1 infectious disease target.
Modeling and integration of Kinase data from the LINCS project
The Library of Network-Based Cellular Signatures (LINCS, http://lincsproject.org/) program has a systems biology focus. This project has been generating a reference “library” of molecular signatures, such as changes in gene expression and other cellular phenotypes that occur when cells are exposed to a variety of perturbing agents. The project also builds computational tools for data integration, access, and analysis. Dimensions of LINCS signatures include the biological model system (cell type), the perturbation (e.g. small molecules) and the assays that generate diverse phenotypic profiles. LINCS aims to create a full data matrix by coordinating cell types and perturbations as well as informatics and analytics tools. We have processed various LINCS datasets, which are available at the LINCS Data Portal (http://lincsportal.ccs.miami.edu/) [37]. LINCS data standards [22] are the foundation of LINCS data integration and analysis. We have previously illustrated how integrated LINCS data can be used to characterize drug action [38]; among those, KINOME-wide drug profiling datasets.
We have annotated the KINOMEscan domains data generated from HMS LINCS KINOMEscan dataset. The annotation includes domains descriptions, names, gene symbols, phosphorylation status, and mutations. To integrate this information into DTO, we built a kinase domain module following the modularization approach described in section 2.2.
We started with an example scenario given by domain expert shown below:
ABL1 is a tyrosine-protein kinase with UNIPROT ID P00519 (human). The sequence itself is 1131 AA long.
The KINOMEscan domain named “ABL1” is a part of the protein (AA Start/Stop S229/K512) containing the “Pkinase-Tyr” domain (pFam accession PF07714.14, AA Start/Stop I242/F493).
The KINOMEscan domain named “ABL1(F317I)-nonphosphorylated” is the same part of the protein (AA Start/Stop S229/K512) with a mutation at position 317 in which the wild type Phe is mutated into Ile. pFam (accession PF07714.14) identifies the same domain. In addition, it is annotated as nonphosphorylated (see below).
The KINOMEscan domain named “ABL1(F317I)-phosphorylated” is the same protein, but instead of nonphosphorylated it is phosphorylated (see below).
In this scenario, there are four major ontological considerations or relations that need to be considered when building an ontology module (Fig. 5).
Fig. 5.

Relations between protein, kinase domain, mutated kinase domain, phosphorylated kinase domain, and pfam domains in the DTO
Kinase domain and kinase protein
DTO uses the “has part” relation to link the kinase protein and kinase domain, which reflects the biological reality that the kinase domain is a part of the full protein.
Kinase domain variations: Mutated kinase domain and phosphorylated kinase domain
A mutated kinase domain relates to its wild type kinase domain by simply using “is mutated form of” relation. Both, phosphorylated and nonphosphorylated forms of a kinase domain are children of a kinase domain from which they were modified to their current phosphorylation forms. Since the KINOMEscan assay does not provide the specific phosphorylation position information, the definition of a phosphorylated form of a kinase domain, either mutated or wild-type, is generally constituted using an ad-hoc axiom: has part some “phosphorylated residue”. Note that “phosphorylated residue” (MOD_00696) is an external class imported from Protein Modification Ontology (MOD).
Pfam domain mapping to kinase domain and its variations
DTO data curators / domain experts have mapped all kinase domains (including their variations) to Pfam families using sequence level data. This information was captured by using “map to pfam domain” relation, which links a kinase domain to a pfam domain.
Figure 5 shows how in DTO the above scenario is modeled by connecting ABL1 Kinase domain with ABL1 protein using relation is part of, as well as how kinase domain relates to Pfam domain using map to pfam domain relation. In this scenario, all the variations of ABL1 kinase domain are mapped to the same Pfam domain.
Kinase gatekeeper and mutated amino acid residues
The kinase gatekeeper position is an important recognition and selectivity element for small molecule binding. One of the mechanisms by which cancers evade kinase drug therapy is by mutation of key amino acids in the kinase domain. Often the gatekeeper is mutated. Located in the ATP binding pocket of protein kinases, the gatekeeper residue has been shown to influence selectivity and sensitivity to a wide range of small molecule inhibitors. Kinases that possess a small side chain at this position (Thr, Ala, or Gly) are readily targeted by structurally diverse classes of inhibitors, whereas kinases that possess a larger residue at this position are broadly resistant [39].
DTO includes a “gatekeeper role” to define residues annotated as gatekeeper. In the case of ABL1 kinase domain, the THR74 within the ABL1 kinase domain is identified as a gatekeeper by the data curator / domain expert. This gatekeeper residue is further mapped to the 315th residue located in the whole ABL1 kinase amino acid sequence. DTO defines a term: THR315 in ABL1 kinase domain with an axiom of “has role some gatekeeper role”. With an equivalence definition of term “gatekeeper residue” as anything that satisfied the condition of “has role some gatekeeper role”, DTO can group all the gatekeeper residues in this KINOMEscan dataset (Fig. 6).
Fig. 6.
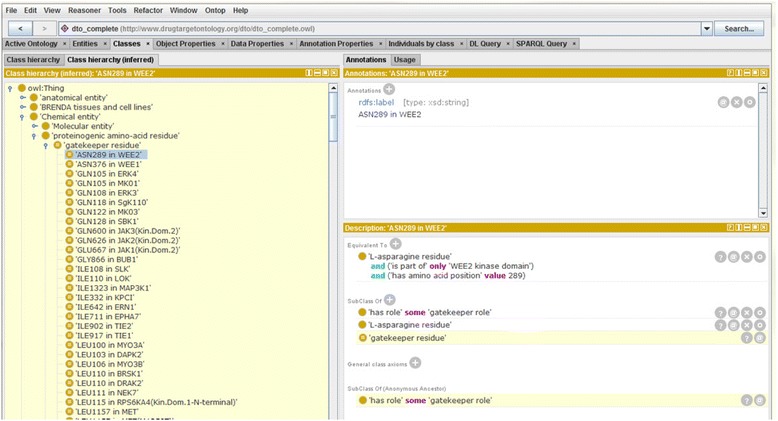
Protégé screen shot shows the inferred subclasses of gatekeeper residue
DTO shines light on Tdark proteins
With integrated information about drug targets available in DTO, it is possible, for example to query information for Tdark kinases for which data in LINCS is available. Kinases in the LINCS KINOMEscan assay were annotated by their (kinase) domain, phosphorylation status, gatekeeper residue and mutations as explained above. To illustrate this integration, we conducted a simple SPARQL query to identify Tdark (kinase) proteins that have a gatekeeper annotation in DTO.
The SPARQL query we use to search DTO are as following:
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX dto: <http://www.drugtargetontology.org/dto/>
select? subject? subject_label? p_label? tdl_label.
Where {.
?subject rdfs:subClassOf? s1 .
?s1 owl:onProperty <http://purl.obolibrary.org/obo/RO_0000087>; owl:someValuesFrom dto:DTO_00000002 .
?subject rdfs:label?subject_label .
?subject owl:equivalentClass?s2 .
?s2 owl:intersectionOf?list .
?list rdf:rest*/rdf:first? l .
?l owl:onProperty dto:DTO_90000020; owl:allValuesFrom? k .
?k rdfs:subClassOf* dto:DTO_61000000 .
?k rdfs:subClassOf?s3 .
?s3 owl:onProperty dto:DTO_90000020; owl:someValuesFrom?p .
?p rdfs:subClassOf* <http://purl.obolibrary.org/obo/PR_000000001> .
?p rdfs:label?p_label .
?p rdfs:subClassOf?s4 .
?s4 owl:onProperty<http://www.drugtargetontology.org/dto/DTO_91000020>; owl:someValuesFrom?TDL .
?TDL rdfs:label?tdl_label.
}
We found in total 378 (kinase) proteins containing gatekeeper residue annotations. Of those 378 proteins, one (Serine/threonine-protein kinase NEK10) is a Tdark protein, two (Mitogen-activated protein kinase 4 and Serine/threonine-protein kinase WNK1) are Tbio proteins, 320 are Tchem proteins, and 54 are Tclin proteins (Additional file 1: Table S1). We then could look for the associated disease and tissue expression information in DTO. For example, the Serine/threonine-protein kinase NEK10 (Tdark), which contains the gatekeeper residue Thr301, is associated with breast cancer by “weak evidence”, and expressed in liver, testis, trachea with “strong evidence”. This way, DTO provides rich information to prioritize proteins for further study, linked directly to KINOMEscan results via the LINCS Data Portal.
Integration of DTO in software applications
DTO visualization
The drug target ontology consists of >13,000 classes and >122,000 links. Our visualization has two options: a) a static pure ontology viewer starting with the top-level concepts featured by a collapsible tree layout (mainly for browsing concepts) and b) a dynamic search and view page where a search-by-class user interface is combined with a collapsible force layout for a deeper exploration. Figure 7 shows an excerpt of an interactive visualization of the DTO. Users can search for classes, alter the visualization by showing siblings, zoom in/out, and alter the figure by moving classes within the graph for better visualization.
Fig. 7.
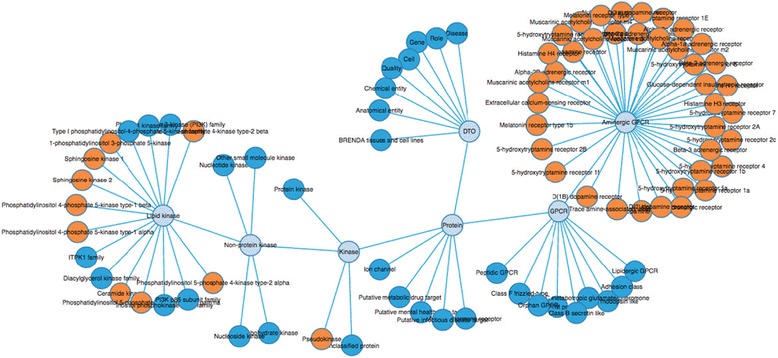
An excerpt of an interactive visualization of the DTO. The viewer is available at http://drugtargetontology.org/
Pharos: The IDG web portal
Pharos is the front-end Web Portal of the IDG project (http://pharos.nih.gov). Pharos was designed and built to encourage “serendipitous browsing” of a wide range of protein drug target information curated and aggregated from a multitude of resources [11]. Via a variety of user interface elements to search, browse and visualize drug target information, Pharos can help researchers to identify and prioritize drug targets based on a variety of criteria. The DTO is an integral part of Pharos; its user interface has been designed to integrate DTO at multiple levels of detail. At the highest level, the user can get a bird’s-eye view of the target landscape in terms of the development level through the interactive DTO circle packing visualization (http://pharos.nih.gov/dto); see Fig. 8. For any suitable set of targets (e.g., as a result of searching and/or filtering), Pharos also provides an interactive sunbrust visualization of the DTO as a convenient way to help the user navigate the target hierarchy. At the most specific level, each appropriate target record is annotated with the full DTO path in form of a breadcrumb. This not only gives the user context but also allows the user to easily navigate up and down the target hierarchy with minimal effort.
Fig. 8.
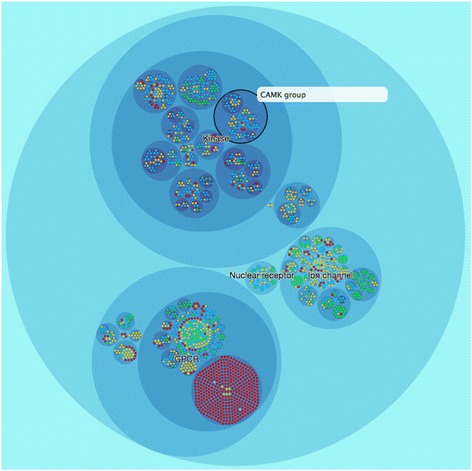
Visualization of the drug target ontology: using the circle packing layout available in the D3 visualization framework
Tin-X: Target importance and novelty explorer
TIN-X is a specialized, user-friendly Web-based tool to explore the relationship between proteins and diseases (http://newdrugtargets.org/) extracted from the scientific literature [13]. TIN-X supports searching and browsing across proteins and disease based on ontological classifications. DTO is used to organize proteins and content can be explored using the DTO hierarchy.
Discussion
The IDG program is a systematic effort to prioritize understudied, yet likely druggable protein targets for the development of chemical probes and drug discovery entry points [3]. DTO covers proteins as prospective druggable targets. Druggability can be considered from a structural point of view, i.e. proteins to which small molecules can bind. This structural druggability is implicit in the selection of the IDG target families, GPCRs, kinases, ion channels and nuclear receptors for which there exist a large number of small molecule binders. Another aspect of druggability is the ability to induce a therapeutic benefit by modulating the biological function of the protein that the drug binds to. Establishing and prioritizing this functional druggability is one of the main goals of the IDG project. DTO includes knowledge of protein disease association and the target development level for all proteins as a foundation to formally describe drug mechanisms of actions. DTO provides a framework and formal classification based on function and phylogenetics, rich annotations of (protein) drug targets along with other chemical, biological, and clinical classifications and relations to diseases and tissue expression. This may facilitate the rational and systematic development of novel small molecule drugs by integrating mechanism of action (drug targets) with disease models, mechanisms, and phenotypes. DTO is already used in the Target Central Resource Database (TCRD - http://juniper.health.unm.edu/tcrd), the IDG main portal Pharos (http://pharos.nih.gov/) and the Target Importance and Novelty eXplorer (TIN-X - http://newdrugtargets.org/) to prioritize drug targets by novelty and importance. The search and visualization uses the inferred DTO model, including the inferred classes described in this report.
We have illustrated how DTO and other ontologies are used to annotate, categorize and integrate knowledge about kinases, including nuanced target information of profiling data generated in the LINCS project. By doing so, DTO facilitates contextual data integration, for example considering the kinase domain or the full protein, phosphorylation status or even information important for small molecule binding, such as gatekeeper residues and point mutations. As we develop DTO and other resources, we will facilitate the otherwise challenging integration and formal linking of biochemical and cell-based assays, phenotypes, disease models, omics data, drug targets and drug poly-pharmacology, binding sites, kinetics and many other processes, functions and qualities that are at the core of drug discovery. In the era of big data, systems-level models for diseases and drug action, and personalized medicine, it is a critical requirement to harmonize and integrate these various sources of information.
The development of DTO also provided an example of building a large dataset ontology that can easily be extended and integrated with other resources. This is facilitated by our modularization approach. The modular architecture allows the developers create terms in a more systematic way by creating manageable and contained components. For example, DTO vocabularies are created as separate files by the OntoJOG java tool. Vocabulary files contain only classes and subsumption relations; the files are subsequently combined (imported) into the DTO core module. A similar, separate module is created of classes from external ontologies; thus, cleanly separating responsibilities of ontology maintenance while providing a seamless integrated product for the users. OntoJOG auto-generated axioms import these vocabulary modules. The manual (expert-created) more complex axioms are layered on top. This way, when an existing data resources is updated, one only needs to update the corresponding auto-created file, e.g. the kinase vocabulary, or target-disease associations from the DISEASES database. Updating of the auto-generated modules (including axioms) does not overwrite expert-created, more complex axioms, which formalize knowledge that cannot easily be maintained in a relational database. Separating domain-specific vocabularies also improves maintenance by multiple specialized curators and may improve future crowd-based development and maintenance. The modular design also makes it simpler to use DTO content in related projects such as LINCS or BAO. Last but not least, the modular architecture facilitates different “flavors” of DTO by incorporating upper-level ontologies, such as BFO or SUMO, via specific mapping (axiom) files; different DTO flavors can be useful for different user groups, e.g. a native version for typical end users of software products (such as Pharos or TinX) or a BFO version for ontologists who develop more expansive, integrated and consistent knowledge models.
Several drug target-related resources have been developed, such as the ChEMBL Drug Target Slim [40], where GO annotations are available for drug targets in ChEMBL. Protein Ontology recently enhanced the protein annotation with pathway information and phosphorylation sites information [41]. Comprehensive FDA-approved drug and target information is available in DrugCentral, http://drugcentral.org/ [34]. The Open Targets Partnership between pharmaceutical companies and the EBI (http://www.opentargets.org/) is a complementary project with similarities to IDG. It developed the Open Target Validation Platform (//www.targetvalidation.org/) [42]. Both, IDG and Open Target make use of ontologies for data standardization and integration. Although there is significant overlap in the content integrated by both projects, there is currently little coordination with respect to data standards including ontologies and data representation. For example, Open Target uses the Experimental Factor Ontology (EFO) [43] to annotate diseases whereas IDG and the DTO uses DOID, primarily because of its use in DISEASES. Ongoing ontology mapping efforts will remedy these challenges. As DTO evolves, we aim to include additional content sources and ontologies to support integrative drug discovery and target validation efforts via a semantic drug target framework.
Conclusions
DTO was built based on the need for a formal semantic model for druggable targets including various related information such as protein, gene, protein domain, protein structure, binding site, small molecule drug, mechanism of action, protein tissue localization, disease association, and many other types of information. DTO will further facilitate the challenging integration and formal linking to biological assays, phenotypes, disease models, drug poly-pharmacology, binding kinetics and many other processes, functions and qualities that are at the core of drug discovery. The first version of DTO is publically available via the website http://drugtargetontology.org/, Github (http://github.com/DrugTargetOntology/DTO), and the NCBO Bioportal (http//bioportal.bioontology.org/ontologies/DTO). The long-term goal of DTO is to provide such an integrative framework and to populate the ontology with this information as a community resource.
Acknowledgements
We acknowledge resources from the Center for Computational Science (CCS) at the University of Miami.
Funding
This work was supported by grants U54CA189205 (Illuminating the Druggable Genome Knowledge Management Center, IDG-KMC) and U54HL127624 (BD2K LINCS Data Coordination and Integration Center, DCIC). The IDG-KMC (http://targetcentral.ws/) is a component of the Illuminating the Druggable Genome (IDG) project (http://commonfund.nih.gov/idg) awarded by the NCI. The BD2K LINC DCIC is awarded by the National Heart, Lung, and Blood Institute through funds provided by the trans-NIH Library of Integrated Network-based Cellular Signatures (LINCS) Program (http://www.lincsproject.org/) and the trans-NIH Big Da-ta to Knowledge (BD2K) initiative (http://datascience.nih.gov/bd2k). Both IDG and LINCS are NIH Common Fund projects.
Availability of data and materials
All materials related to this paper are stored and publicly available on GitHub, at: https://github.com/DrugTargetOntology. The DTO is distributed under an open source license.
Abbreviations
- BFO
Basic Formal Ontology
- BTO
BRENDA Tissue Ontology
- ChEBI
Chemical Entities of Biological Interest
- CLO
Cell Line Ontology
- DOID
Disease Ontology
- DTO
Drug Target Ontology
- GPCRs
G-protein-coupled receptors
- IC
Ion Channel
- IDG
Illuminating the Druggable Genome
- IDG-KMC
IDG Knowledge Management Center
- IUPHAR
International Union of Basic and Clinical Pharmacology
- LINCS
The Library of Network-Based Cellular Signatures
- NR
Nuclear Receptor
- PRO
Protein Ontology
- QC
Quality Control
- RO
Relations Ontology
- TCRD
Target Central Resource Databases
- TDL
Target Development Level
- UBERON
Uber Anatomy Ontology
Additional file
SPARQL query results to identify kinase domains in the KINOMEscan assay with gatekeeper annotations. Shown are TDL classification, DTO ID, kinase domain description, and protein name. (XLSX 28 kb)
Authors’ contributions
YL: ontology development and implementation; SM: content curation and annotation; HKM: ontology modularization and implementation; JPT: software and database tools to build the ontology; DV: kinase domain annotation, DTO curation; MF: kinase domain module, integration with LINCS data; AK: database schema and software tools to build ontology; DTN: implementation of DTO in Pharos, UI design and implementation; LJJ: integration of DISEASES and TISSUES into DTO; RG: Pharos UI design and DTO implementation; SLM: IDG database and synchronization to DTO; OU: development and implementation of DTL; VS: LINCS data processing and annotation; JD: DTO visualizer, web-interface and backend; NN: DTO database and software tools; CC: DTO website and processes; CM: software design; UV: ontology modeling and visualization; JJY: implementation of DTO in TIN-X, UI design; CGB: TDL development, TIN-X DTO integration; TO: DTL classification and annotation, UI design, content curation, project coordination; SCS: envisioned DTO, ontology development and implementation, content curation, database and software design, project coordination. YL, SM and SCS wrote the manuscript; HKM, DTN, RG, UV, TO contributed to writing the manuscript; all co-authors approve the manuscript.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Footnotes
Electronic supplementary material
The online version of this article (10.1186/s13326-017-0161-x) contains supplementary material, which is available to authorized users.
Contributor Information
Tudor I. Oprea, Email: toprea@salud.unm.edu
Stephan C. Schürer, Email: sschurer@miami.edu
References
- 1.Jones LH, Bunnage ME. Applications of chemogenomic library screening in drug discovery. Nat Rev Drug Discov. 2017;16(4):285-96. [DOI] [PubMed]
- 2.Russ AP, Lampel S. The druggable genome: an update. Drug Discov Today. 2005;10(23–24):1607–1610. doi: 10.1016/S1359-6446(05)03666-4. [DOI] [PubMed] [Google Scholar]
- 3.Santos R, Ursu O, Gaulton A, Bento AP, Donadi RS, Bologa CG, Karlsson A, Al-Lazikani B, Hersey A, Oprea TI, et al. A comprehensive map of molecular drug targets. Nat Rev Drug Discov. 2017;16(1):19–34. doi: 10.1038/nrd.2016.230. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Southan C, Sharman JL, Benson HE, Faccenda E, Pawson AJ, Alexander SP, Buneman OP, Davenport AP, McGrath JC, Peters JA, et al. The IUPHAR/BPS guide to PHARMACOLOGY in 2016: towards curated quantitative interactions between 1300 protein targets and 6000 ligands. Nucleic Acids Res. 2016;44(D1):D1054–D1068. doi: 10.1093/nar/gkv1037. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Mi H, Poudel S, Muruganujan A, Casagrande JT, Thomas PD. PANTHER version 10: expanded protein families and functions, and analysis tools. Nucleic Acids Res. 2016;44(D1):D336–D342. doi: 10.1093/nar/gkv1194. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Qin C, Zhang C, Zhu F, Xu F, Chen SY, Zhang P, Li YH, Yang SY, Wei YQ, Tao L, et al. Therapeutic target database update 2014: a resource for targeted therapeutics. Nucleic Acids Res. 2014;42(Database issue):D1118–D1123. doi: 10.1093/nar/gkt1129. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Gao Z, Li H, Zhang H, Liu X, Kang L, Luo X, Zhu W, Chen K, Wang X, Jiang H. PDTD: a web-accessible protein database for drug target identification. BMC Bioinf. 2008;9:104. doi: 10.1186/1471-2105-9-104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Unexplored opportunities in the druggable human genome [http://www.nature.com/nrd/posters/druggablegenome/index.html]. Accessed Mar 2017.
- 9.Abeyruwan S, Vempati UD, Kucuk-McGinty H, Visser U, Koleti A, Mir A, Sakurai K, Chung C, Bittker JA, Clemons PA, et al. Evolving BioAssay ontology (BAO): modularization, integration and applications. J Biomed Semantics. 2014;5(Suppl 1 Proceedings of the Bio-Ontologies Spec Interest G):S5. doi: 10.1186/2041-1480-5-S1-S5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Vempati UD, Przydzial MJ, Chung C, Abeyruwan S, Mir A, Sakurai K, Visser U, Lemmon VP, Schurer SC. Formalization, annotation and analysis of diverse drug and probe screening assay datasets using the BioAssay ontology (BAO) PLoS One. 2012;7(11):e49198. doi: 10.1371/journal.pone.0049198. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Nguyen DT, Mathias S, Bologa C, Brunak S, Fernandez N, Gaulton A, Hersey A, Holmes J, Jensen LJ, Karlsson A, et al. Pharos: collating protein information to shed light on the druggable genome. Nucleic Acids Res. 2017;45(D1):D995–D1002. doi: 10.1093/nar/gkw1072. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Przydzial MJ, Bhhatarai B, Koleti A, Vempati U, Schurer SC. GPCR ontology: development and application of a G protein-coupled receptor pharmacology knowledge framework. Bioinformatics. 2013;29(24):3211–3219. doi: 10.1093/bioinformatics/btt565. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Cannon DC, Yang JJ, Mathias SL, Ursu O, Mani S, Waller A, Schurer SC, Jensen LJ, Sklar LA, Bologa CG, et al. TIN-X: Target Importance and Novelty Explorer. Bioinformatics. 2017;33(16):2601–3. [DOI] [PMC free article] [PubMed]
- 14.Hornbeck PV, Zhang B, Murray B, Kornhauser JM, Latham V, Skrzypek E. PhosphoSitePlus, 2014: mutations, PTMs and recalibrations. Nucleic Acids Res. 2015;43(Database issue):D512–D520. doi: 10.1093/nar/gku1267. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Saier MH, Jr, Reddy VS, Tsu BV, Ahmed MS, Li C, Moreno-Hagelsieb G. The transporter classification database (TCDB): recent advances. Nucleic Acids Res. 2016;44(D1):D372–D379. doi: 10.1093/nar/gkv1103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Hastings J, de Matos P, Dekker A, Ennis M, Harsha B, Kale N, Muthukrishnan V, Owen G, Turner S, Williams M et al: The ChEBI reference database and ontology for biologically relevant chemistry: enhancements for 2013. Nucleic Acids Res 2013, 41(Database issue):D456-D463. [DOI] [PMC free article] [PubMed]
- 17.Kibbe WA, Arze C, Felix V, Mitraka E, Bolton E, Fu G, Mungall CJ, Binder JX, Malone J, Vasant D, et al. Disease ontology 2015 update: an expanded and updated database of human diseases for linking biomedical knowledge through disease data. Nucleic Acids Res. 2015;43(Database issue):D1071–D1078. doi: 10.1093/nar/gku1011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Gremse M, Chang A, Schomburg I, Grote A, Scheer M, Ebeling C, Schomburg D. The BRENDA tissue ontology (BTO): the first all-integrating ontology of all organisms for enzyme sources. Nucleic Acids Res. 2011;39(Database issue):D507–D513. doi: 10.1093/nar/gkq968. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Haendel MA, Balhoff JP, Bastian FB, Blackburn DC, Blake JA, Bradford Y, Comte A, Dahdul WM, Dececchi TA, Druzinsky RE, et al. Unification of multi-species vertebrate anatomy ontologies for comparative biology in Uberon. J Biomed Semantics. 2014;5:21. doi: 10.1186/2041-1480-5-21. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Hastings J, Owen G, Dekker A, Ennis M, Kale N, Muthukrishnan V, Turner S, Swainston N, Mendes P, Steinbeck C. ChEBI in 2016: improved services and an expanding collection of metabolites. Nucleic Acids Res. 2016;44(D1):D1214–D1219. doi: 10.1093/nar/gkv1031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Natale DA, Arighi CN, Blake JA, Bult CJ, Christie KR, Cowart J, D'Eustachio P, Diehl AD, Drabkin HJ, Helfer O, et al. Protein ontology: a controlled structured network of protein entities. Nucleic Acids Res. 2014;42(Database issue):D415–D421. doi: 10.1093/nar/gkt1173. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Vempati UD, Chung C, Mader C, Koleti A, Datar N, Vidovic D, Wrobel D, Erickson S, Muhlich JL, Berriz G, et al. Metadata standard and data exchange specifications to describe, model, and integrate complex and diverse high-throughput screening data from the library of integrated network-based cellular signatures (LINCS) J Biomol Screen. 2014;19(5):803–816. doi: 10.1177/1087057114522514. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Pletscher-Frankild S, Palleja A, Tsafou K, Binder JX, Jensen LJ. DISEASES: text mining and data integration of disease-gene associations. Methods. 2015;74:83–89. doi: 10.1016/j.ymeth.2014.11.020. [DOI] [PubMed] [Google Scholar]
- 24.Santos A, Tsafou K, Stolte C, Pletscher-Frankild S, O'Donoghue SI, Jensen LJ. Comprehensive comparison of large-scale tissue expression datasets. PeerJ. 2015;3:e1054. doi: 10.7717/peerj.1054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Salvadores M, Alexander PR, Musen MA, Noy NF. BioPortal as a dataset of linked biomedical Ontologies and terminologies in RDF. Semant Web. 2013;4(3):277–284. [PMC free article] [PubMed] [Google Scholar]
- 26.Whetzel PL, Noy NF, Shah NH, Alexander PR, Nyulas C, Tudorache T, Musen MA. BioPortal: enhanced functionality via new web services from the National Center for biomedical ontology to access and use ontologies in software applications. Nucleic Acids Res. 2011;39(Web Server issue):W541–W545. doi: 10.1093/nar/gkr469. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Xiang Z, Courtot M, Brinkman RR, Ruttenberg A, He Y. OntoFox: web-based support for ontology reuse. BMC Res Notes. 2010;3:175. doi: 10.1186/1756-0500-3-175. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Bosca A, Bonino D. OntoSphere3D: A Multidimensional Visualization Tool for Ontologies. In: 17th International Workshop on Database and Expert Systems Applications (DEXA'06): 4–8 Sept. 2006 2006; 2006: 339–343.
- 29.Bostock M, Ogievetsky V, Heer J. D<sup>3</sup> data-driven documents. IEEE Trans Vis Comput Graph. 2011;17(12):2301–2309. doi: 10.1109/TVCG.2011.185. [DOI] [PubMed] [Google Scholar]
- 30.Ramakrishnan S, Vijayan A. A study on development of cognitive support features in recent ontology visualization tools. Artif Intell Rev. 2014;41(4):595–623. doi: 10.1007/s10462-012-9326-2. [DOI] [Google Scholar]
- 31.Sivakumar R, Arivoli PV, Sri AVVM: Ontology Visualization Protégé Tools – a Review. In: 2011; 2011.
- 32.Jacoby E, Tresadern G, Bembenek S, Wroblowski B, Buyck C, Neefs JM, Rassokhin D, Poncelet A, Hunt J, van Vlijmen H. Extending kinome coverage by analysis of kinase inhibitor broad profiling data. Drug Discov Today. 2015;20(6):652-8. [DOI] [PubMed]
- 33.Coggill P, Finn RD, Bateman A. Identifying protein domains with the Pfam database. Curr Protoc Bioinformatics. 2008;Chapter 2:Unit 2 5. doi: 10.1002/0471250953.bi0205s23. [DOI] [PubMed] [Google Scholar]
- 34.Ursu O, Holmes J, Knockel J, Bologa CG, Yang JJ, Mathias SL, Nelson SJ, Oprea TI. DrugCentral: online drug compendium. Nucleic Acids Res 2017, 45(D1):D932-D939; http://drugcentral.org/ [DOI] [PMC free article] [PubMed]
- 35.Mitchell JA, Aronson AR, Mork JG, Folk LC, Humphrey SM, Ward JM. Gene indexing: characterization and analysis of NLM's GeneRIFs. AMIA Annu Symp Proc. 2003:460–4. [PMC free article] [PubMed]
- 36.Fabbro D, Cowan-Jacob SW, Moebitz H. Ten things you should know about protein kinases: IUPHAR review 14. Br J Pharmacol. 2015;172(11):2675–2700. doi: 10.1111/bph.13096. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Koleti A, Terryn R, Stathias V, Chung C, Cooper DJ, Turner JP, Vidović D, Forlin M, Kelley TT, D’Urso A, Allen BK, Torre D, Jagodnik KM, Wang L, Jenkins SL, Mader C, Niu W, Fazel M, Mahi N, Pilarczyk M, Clark N, Shamsaei B, Meller J, Vasiliauskas J, Reichard, J, Medvedovic M, Ma’ayan A, Pillai A, Schürer SC. Data Portal for the Library of Integrated Network-based Cellular Signatures (LINCS) Program: Integrated Access to Diverse Large-scale Cellular Perturbation Response Data. Nucleic Acids Res. doi: 10.1093/nar/gkx1063. [DOI] [PMC free article] [PubMed]
- 38.Vidovic D, Koleti A, Schurer SC. Large-scale integration of small molecule-induced genome-wide transcriptional responses, Kinome-wide binding affinities and cell-growth inhibition profiles reveal global trends characterizing systems-level drug action. Front Genet. 2014;5:342. doi: 10.3389/fgene.2014.00342. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Gibbons DL, Pricl S, Kantarjian H, Cortes J, Quintas-Cardama A. The rise and fall of gatekeeper mutations? The BCR-ABL1 T315I paradigm. Cancer. 2012;118(2):293–299. doi: 10.1002/cncr.26225. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Mutowo P, Bento AP, Dedman N, Gaulton A, Hersey A, Lomax J, Overington JP. A drug target slim: using gene ontology and gene ontology annotations to navigate protein-ligand target space in ChEMBL. J Biomed Semantics. 2016;7(1):59. doi: 10.1186/s13326-016-0102-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Natale DA, Arighi CN, Blake JA, Bona J, Chen C, Chen SC, Christie KR, Cowart J, D'Eustachio P, Diehl AD, et al. Protein ontology (PRO): enhancing and scaling up the representation of protein entities. Nucleic Acids Res. 2017;45(D1):D339–D346. doi: 10.1093/nar/gkw1075. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Koscielny G, An P, Carvalho-Silva D, Cham JA, Fumis L, Gasparyan R, Hasan S, Karamanis N, Maguire M, Papa E, et al. Open targets: a platform for therapeutic target identification and validation. Nucleic Acids Res. 2017;45(D1):D985–D994. doi: 10.1093/nar/gkw1055. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Malone J, Holloway E, Adamusiak T, Kapushesky M, Zheng J, Kolesnikov N, Zhukova A, Brazma A, Parkinson H. Modeling sample variables with an experimental factor ontology. Bioinformatics. 2010;26(8):1112–1118. doi: 10.1093/bioinformatics/btq099. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
All materials related to this paper are stored and publicly available on GitHub, at: https://github.com/DrugTargetOntology. The DTO is distributed under an open source license.