

Abstract
In survival analysis, a competing risk is an event whose occurrence precludes the occurrence of the primary event of interest. Outcomes in medical research are frequently subject to competing risks. In survival analysis, there are 2 key questions that can be addressed using competing risk regression models: first, which covariates affect the rate at which events occur, and second, which covariates affect the probability of an event occurring over time. The cause‐specific hazard model estimates the effect of covariates on the rate at which events occur in subjects who are currently event‐free. Subdistribution hazard ratios obtained from the Fine‐Gray model describe the relative effect of covariates on the subdistribution hazard function. Hence, the covariates in this model can also be interpreted as having an effect on the cumulative incidence function or on the probability of events occurring over time. We conducted a review of the use and interpretation of the Fine‐Gray subdistribution hazard model in articles published in the medical literature in 2015. We found that many authors provided an unclear or incorrect interpretation of the regression coefficients associated with this model. An incorrect and inconsistent interpretation of regression coefficients may lead to confusion when comparing results across different studies. Furthermore, an incorrect interpretation of estimated regression coefficients can result in an incorrect understanding about the magnitude of the association between exposure and the incidence of the outcome. The objective of this article is to clarify how these regression coefficients should be reported and to propose suggestions for interpreting these coefficients.
Keywords: competing risks, cumulative incidence function, subdistribution hazard model, survival analysis
1. INTRODUCTION
Survival analysis is concerned with outcomes that occur over time. Two key concepts in survival analysis are the survival function and the hazard function. The survival function, denoted by S(t), is the probability that an individual survives to time t (ie, the probability that an event occurs after time t). The hazard function, denoted by h(t), is the instantaneous rate of the occurrence of the event of interest in subjects who are currently at risk of the event (or for whom the event has not yet occurred). The Kaplan‐Meier method can be used to obtain an estimate of the survival function,1 while the Cox proportional hazards regression model is used to estimate the relative effect of covariates on the hazard function.2 While the regression coefficients from the Cox model describe the relative effect of the covariates on the hazard of the occurrence of the outcome, the following relationship holds:
| (1) |
where S(t| X) denotes the survival function for an individual whose set of covariates is equal to X, S0(t) denotes the baseline survival function (the survival function for a subject whose covariates are all equal to zero), and β denotes the vector of regression coefficients from the Cox model. Thus, there is a direct correspondence between the effect of a covariate on the hazard of the outcome and the effect of a covariate on the incidence of the outcome: If a covariate increases the hazard of the occurrence of the outcome, it also will increase the incidence of the outcome (although the magnitude of the 2 effects can be expected to differ). Thus, making inferences about the direction of the effect of a covariate on the hazard function permits one to make equivalent inferences about the direction of the effect of that covariate on the incidence (or on the probability of the occurrence) of the outcome. This direct correspondence between the effect of a covariate on the hazard function and the effect of the covariate on incidence has allowed authors to be imprecise in their language when interpreting the fitted Cox regression model. Authors have been able to conclude that a given risk factor or covariate increased the risk of an event, without specifying whether risk denotes the hazard of an event (ie, the rate of the occurrence of the event in those still at risk of the event) or the incidence of the event (ie, the probability of the occurrence of the event). Strictly speaking, we would argue that risk refers to probabilities and that one should describe the effect of covariates on the rate at which events occur.
We provide a brief example to which we will return throughout this commentary. The data consist of 16 237 patients hospitalized with heart failure between 1999 and 2005 in the Canadian province of Ontario. The data were collected as part of the EFFECT study.3 These data are described in greater detail in a recent tutorial on methods for the analysis of survival data in the presence of competing risks.4 Subjects were followed for 5 years from the time of hospitalization, and the timing of the occurrence of death (and cause of death) was recorded for each subject. Subjects were censored after 5 years if they had not yet died. Ten thousand two hundred fifteen subjects (62.9%) died within 5 years of hospitalization. Using a Cox proportional hazards model, we regressed the hazard of all‐cause death on patient age and sex. The estimated hazard ratios and associated 95% confidence intervals were 1.54 (1.51‐1.57) for a 10‐year increase in age and 1.18 (1.14‐1.23) for males compared to females. Thus, a 10‐year increase in age was associated with a 54% increase in the rate of all‐cause death. Similarly, the rate of death was 18% higher for males than it was for females. Since the hazard ratio for age is greater than 1, one can also conclude that a 10‐year increase in age is associated with an increase in the incidence of all‐cause death, although one cannot formally quantify the magnitude of this association. Similarly, the incidence of death is higher in males than in females.
In survival analysis, a competing risk is an event whose occurrence precludes the occurrence of the primary event of interest. If the primary outcome of interest is time to death due to cardiovascular causes, then death due to noncardiovascular causes is a competing risk (eg, subjects who die of cancer are no longer at risk of death due to cardiovascular causes).4, 5, 6 In the presence of competing risks, 2 different hazard functions have been defined: the cause‐specific hazard function (formula (2)) and the subdistribution hazard function (formula (3)).4, 5, 6
| (2) |
| (3) |
The cause‐specific hazard function for a given event type is the instantaneous rate of occurrence of the given type of event in subjects who are currently event‐free. The subdistribution hazard function, introduced by Fine and Gray, for a given type of event is defined as the instantaneous rate of occurrence of the given type of event in subjects who have not yet experienced an event of that type.7 Note that for the subdistribution hazard function, we are considering the rate of the event in those subjects who are either currently event‐free or who have previously experienced a competing event. The cause‐specific hazard model estimates the effect of covariates on the cause‐specific hazard function, while the Fine‐Gray subdistribution hazard model estimates the effect of covariates on the subdistribution hazard function.
The cumulative incidence function (CIF) describes the incidence of the occurrence of an event while taking competing risks into account. The subdistribution hazard model has also been described as a CIF regression model. This latter name makes explicit the link between the subdistribution hazard function and the CIF. Thus, the subdistribution hazard model allows one to estimate the effect of covariates on the CIF for the event of interest. In particular, it permits one to recover a relationship similar in form to that described in formula 1:
| (4) |
(where CIF0 denotes the baseline CIF). Thus, if a covariate is associated with an increase in the subdistribution hazard function, it will also be associated with an increase in the incidence of the event. A survey of the medical literature reported in this paper suggests that in the presence of competing risks, clinical researchers may misinterpret hazard ratios from the Fine‐Gray subdistribution hazard model, similar to what often occurs when interpreting the proportional hazards model in the absence of competing risks. This survey further suggests that such issues may arise in part because of the lack of a clear understanding of the relationships of the subdistribution hazard and the cause specific hazard to the CIF: There is a one‐to‐one relationship with the CIF for the subdistribution hazard but not for the cause‐specific hazard.
There are 2 objectives to this commentary. First, to provide guidance on the interpretation of regression coefficients associated with the Fine‐Gray subdistribution hazard model. Second, to review papers published in 2015 in the medical literature that reported using the Fine‐Gray subdistribution hazard model and examine how authors interpreted the regression coefficients associated with the fitted model.
2. INTERPRETING REGRESSION COEFFICIENTS FROM COMPETING RISK REGRESSION MODELS
2.1. Cause‐specific hazard model regression coefficients
The exponentiated regression coefficient from a cause‐specific hazard model denotes the magnitude of the relative change in the cause‐specific hazard function associated with a 1‐unit change in the covariate. Therefore, the cause‐specific hazard ratio denotes the relative change in the instantaneous rate of the occurrence of the primary event in subjects who are currently event‐free. The rate of the occurrence of the event denotes the intensity with which events occur. Thus, the cause‐specific hazard ratio can be interpreted as a rate ratio. When using a cause‐specific hazard model in the presence of competing risks, it is incorrect to infer that a given variable is associated with an increased or decreased incidence of the event of interest, as formula 1 does not hold in the presence of competing risks.5, 6 This is because one must account for the effect of the covariates on the cause‐specific hazard function of each of the different types of events when determining their effect on the CIF for the event of interest.8 On its own, the cause‐specific hazard function is insufficient if the primary focus is on the CIF.
Formally, the CIF for the kth event type is defined as where denotes the cause‐specific hazard function for the kth event type and S(s) denotes the overall survival function for survival free from the occurrence of an event of any type.6 The overall survival function can be evaluated as where denotes the cumulative cause‐specific hazard function for the kth event type.6 Thus, the overall survival function (S(t)) is a function of all of the cause‐specific hazard functions. Accordingly, the CIF for the kth event type is implicitly dependent on all of the cause‐specific hazard functions; it is clear that estimating a single cause‐specific hazard function is insufficient if the focus is on the CIF for the given type of event.
Returning to the empirical example introduced in Section 1, we used a cause‐specific hazard model to regress the hazard of death due to cardiovascular causes on age and sex, treating death due to noncardiovascular causes as a competing risk. The estimated cause‐specific hazard ratios and associated 95% confidence intervals were 1.63 (1.59‐1.68) for a 10‐year increase in age and 1.20 (1.14‐1.27) for males compared to females. Thus, a 10‐year increase in age was associated with a 63% increase in the hazard of cardiovascular death in subjects who were currently alive. Similarly, the hazard of cardiovascular death was 20% higher for males than it was for females. However, unlike in the setting without competing risks (when all‐cause mortality was the outcome), we can make no inferences about the association between age or sex on the incidence of cardiovascular death. Thus, we are restricted to quantifying the magnitude of the association between age or sex and the rate at which cardiovascular death occurs in subjects who are currently alive. We are unable to infer that increasing age or male sex is associated with an increase in the incidence of cardiovascular death. For comparative purposes, the cause‐specific hazard ratios for noncardiovascular death (with cardiovascular death treated as a competing risk) for a 10‐year increase in age and for male sex were 1.42 (1.37‐1.46) and 1.15 (1.08‐1.22), respectively. Thus, increasing age and male sex were associated with an increased rate of noncardiovascular death in those who were currently alive.
2.2. Subdistribution hazard model regression coefficients—effect on the subdistribution hazard function
The exponentiated regression coefficient from a Fine‐Gray subdistribution hazard model denotes the magnitude of the relative change in the subdistribution hazard function associated with a 1‐unit change in the given covariate. Therefore, one is reporting the relative change in the instantaneous rate of the occurrence of the event in those subjects who are event‐free or who have experienced a competing event. In accepting this interpretation, one needs to accept that those who experienced competing events have been “cured” from the primary event of interest and that their being in the risk set after the competing event represents “immortal” time. While such “cure” models have been widely adopted in settings where “cure” is unobservable, in the competing risks set‐up where “cure” (eg, failure from other causes) is observable, some practitioners may find this interpretation difficult to conceptualize. Accordingly, there may be a preference for making inferences about the magnitude of the effects of covariates on the incidence of the outcome.
Using our empirical data, we regressed the subdistribution hazard of cardiovascular death on age and sex. The estimated subdistribution hazard ratios and associated 95% confidence intervals were 1.50 (1.46‐1.54) for a 10‐year increase in age and 1.16 (1.10‐1.22) for males compared to females. Thus, a 10‐year increase in age was associated with a 50% increase in the subdistribution hazard of cardiovascular death. Similarly, the subdistribution hazard of death was 16% higher for males than it was for females. We may interpret this as evidence that a 10‐year increase in age is associated with a 50% increase in the rate of cardiovascular death in subjects who are either event‐free (eg, who are still alive) or who have experienced a competing event (eg, who have died of noncardiovascular causes). For comparative purposes, the subdistribution hazard ratios for noncardiovascular death were 1.20 (1.17‐1.24) for a 10‐year increase in age and 1.09 (1.02‐1.15) for males.
2.3. Subdistribution hazard model regression coefficients—effect on the CIF
An alternative interpretation of the coefficients from a subdistribution hazard model, as noted in Section 1, is to interpret the covariates as having an effect on the incidence of the event (ie, on the CIF). This alternative interpretation may be easier to understand and communicate to nonstatistical audiences. However, this interpretation is not without difficulties. The primary difficulty lies in the interpretation of the numeric value of the subdistribution hazard ratios. It is important to stress that the magnitude of the relative effect of the covariate on the subdistribution hazard function is different from the magnitude of the effect of the covariate on the CIF. This is similar to data without competing risks, where interpreting the hazard ratio in terms of the survival probabilities requires care. One can conclude that if a variable increases the subdistribution hazard function, it will also increase the incidence of the event. However, one cannot infer that the magnitudes of these 2 effects are of the same size, despite being in the same direction (we would note that the same limitation exists for interpreting the coefficients from the Cox model in terms of their effect on cumulative incidence in the absence of competing risks—researchers frequently make the erroneous claim that the magnitude of the estimated hazard ratio denotes the magnitude of the effect on risk or the probability of the occurrence of the event). In our empirical example, the subdistribution hazard ratios for age and male sex were both greater than 1. Thus, we conclude that a 10‐year increase in age is associated with an increase in the incidence of cardiovascular death, while the incidence of cardiovascular death was higher in males than in females. Similarly, we conclude that a 10‐year increase in age is associated with an increase in the incidence of noncardiovascular death, while the incidence of noncardiovascular death was higher in males than in females. However, while we can describe the direction of these associations, we are not able to directly quantify the magnitude of these associations. Despite this limitation, a test of statistical significance of the subdistribution hazard ratio provides a test for the effect of the covariate on the CIF. This is something that is not possible by using the corresponding cause‐specific hazard model. Neither the direction of the cause‐specific hazard ratio nor its statistical significance provides information about the direction or the significance of the association of the covariate with the CIF.8
The regression coefficients from a Fine‐Gray subdistribution hazard model can be indirectly interpreted as the regression coefficients for a complementary log‐log generalized linear model for the CIF similarly to hazard ratios without competing risks.7 Three link functions are used with generalized linear models for binary outcomes: the logit link, the probit link, and the complementary log‐log link (see Table 1).
Table 1.
Generalized linear models for binary outcomes
| Link Function | Transformation of Probability Is A Linear Function of Covariates | |
|---|---|---|
| Logit link |
|
|
| Probit link |
|
|
| Complementary log‐log link | log(− log(1 − p)) = Xβ |
Of these 3, the logistic link function results in regression coefficients with which biostatistical analysts are the most familiar: odds ratios describing the relative effect of the covariates on the odds of the occurrence of the outcome. Unfortunately, regression coefficients from binomial regression models using the other 2 link functions are more challenging to interpret.9 However, the sign of the regression coefficient (positive vs negative) provides information as to whether increases in the covariate are associated with an increase or decrease in the probability of the occurrence of the outcome. Thus, a positive regression coefficient indicates that a 1‐unit change in the variable is associated with an increase in the incidence of the outcome. However, the magnitude of a regression coefficient does not, on its own, provide information about the magnitude of the increase or decrease in the probability of the occurrence of the outcome over time. Instead, the estimated regression coefficients can be used to compute the probability of the occurrence of the event. As has been stressed previously, this holds true for the standard proportional hazards model in the absence of competing risks: The direction of the hazard ratio denotes the direction of the effect of a given covariate on incidence, but not the magnitude of the effect.
While the magnitude of the estimated regression coefficient does not provide information on the magnitude of the effect of the covariate on the incidence of the outcome, the fact that the coefficients can be seen as arising from a complementary log‐log model for the CIF does mean that one can make statements about the relative magnitudes of the effects of different covariates on the incidence of the same outcome (this is because, in the absence of competing risks, the log‐log model for the survival function of the event time results is a proportional hazards model for the hazard function. A similar result can be established with competing risks when assuming a log‐log model for 1 − F 1 [where F 1 denotes the CIF for events of type 1]. As the subdistribution hazard equals {dF 1(t|X)/dt}/{1 −F 1(t|X)}, one may replace the numerator and denominator with their equivalents under the log‐log model. Upon simplification, this yields a proportional hazards model for the subdistribution hazard, analogous to what is obtained in the absence of competing risks). If one covariate has a larger regression coefficient than that of a second covariate, then the magnitude of the effect of the first covariate on the incidence of the outcome will be greater than the magnitude of the effect of the second covariate on the incidence of the outcome (see Appendix A for derivation). Thus, in our case study, the hazard ratio for cardiovascular death for a 10‐year increase in age is 1.50, while the hazard ratio for males is 1.16. Thus, a 10‐year increase in age has a greater effect on the incidence of cardiovascular death than does male sex compared to female sex. Furthermore, male sex is associated with an increase in the incidence of cardiovascular death that is equivalent to that associated with an increase in age of 3.6 years.
Unfortunately, one cannot make conclusions about the relative magnitudes of the effect of the same covariate on the incidence of different outcomes by comparing the relative magnitudes of the subdistribution hazard ratios. Since the baseline CIF differs between the different types of events, one is not able to conclude that because the subdistribution hazard ratio for a given covariate is larger in the first subdistribution hazard model than it is in the second subdistribution hazard model, that the effect of the covariate on the incidence of the first type of event is greater than on the incidence of the second type of event. In our empirical example, the subdistribution hazard ratio for a 10‐year increase in age was 1.50 for cardiovascular death and 1.20 for noncardiovascular death. However, we cannot infer that a 10‐year increase in age increases the incidence of cardiovascular death to a greater extent than it increases the incidence of noncardiovascular death. For similar reasons, a comparison of the relative magnitude of the subdistribution hazard ratios for the same type of event between different studies does not permit one to make conclusions about the relative magnitude of the effect of the covariate on the incidence of the outcome in the different studies.
When the probability of an event is low, then the logistic link function and the complementary log‐log link function are very similar.9 In particular, when the probability is less than 0.1, then these 2 link functions are almost indistinguishable, while when the probability is between 0.1 and 0.2, differences between them are very small (Figure 1). Thus, in settings in which the probability of the occurrence of the event is low over meaningful durations of follow‐up, the coefficients from a subdistribution hazard model can be interpreted as odds ratios for the CIF. Thus, if the subdistribution hazard ratio is equal to 2, one can infer that a 1‐unit increase is associated with an approximate doubling of the odds of the occurrence of the event in settings in which the cumulative incidence of events is less than 0.20 over meaningful durations of follow‐up.
Figure 1.
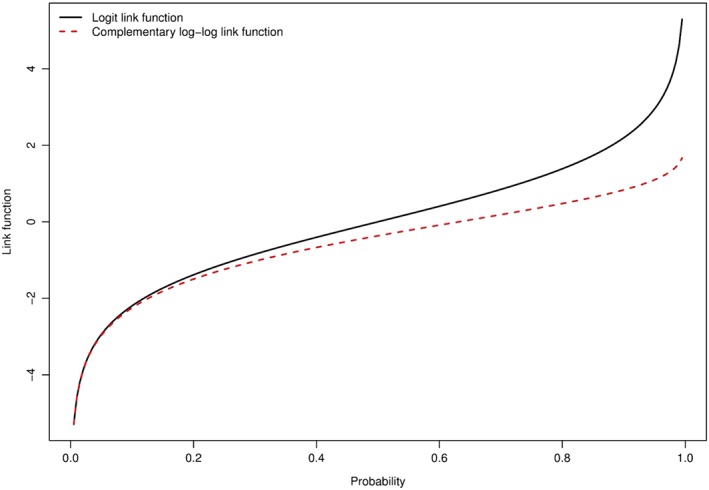
Comparison of logit and complementary log‐log link functions [Colour figure can be viewed at wileyonlinelibrary.com]
3. LITERATURE REVIEW OF THE USE OF THE FINE‐GRAY SUBDISTRIBUTION HAZARD MODEL
In the previous section, we discussed the interpretation of regression coefficients from competing risk regression models. In this section, we report on a literature review that examined how authors in the medical literature interpreted the estimated coefficients from subdistribution hazard models. We searched the PubMed database (https://www.ncbi.nlm.nih.gov/pubmed) on November 1, 2016, using the following search strategy: (“subdistribution hazard”[All Fields] OR “Fine‐Gray”[All Fields]) AND (“2015/01/01”[PDAT] : “2015/12/31”[PDAT]) to identify papers published in 2015 that used the Fine‐Gray subdistribution hazard model.
The search process identified 64 papers. Of these, we excluded 8 methodologically oriented publications and one additional paper because it did not use the Fine‐Gray subdistribution hazard model. We examined the remaining 55 papers to see how the authors interpreted the regression coefficients arising from the Fine‐Gray subdistribution hazard model.
Five (9%) papers interpreted the covariates as having an effect on the subdistribution hazard function. Strictly speaking, it is correct to infer that covariates with a regression coefficient that is statistically significantly different from zero have an effect on the subdistribution hazard function. However, as noted above, this interpretation may be nonintuitive or difficult for some to understand, as it describes the rate of the occurrence of events in subjects who have not yet experienced the event of interest (but who may have experienced a competing event). Twenty‐four (44%) papers described the model covariates as having an effect on risk. While the term “risk” is often used without clarifying the meaning of the term, we interpret risk as meaning the probability of the occurrence of the event (cf. relative risk is the ratio of 2 probabilities). As noted previously, the direction of the effect of the covariate on risk (incidence) will be in the same direction as its effect on the subdistribution hazard function. However, the magnitude of the 2 effects need not coincide. Eleven (20%) papers described the covariates as having an effect on the incidence of the outcome. As stated previously, the subdistribution hazard model allows one to determine the effect of covariates on the CIF. However, as previously stated, the estimated hazard ratio determines the direction of the effect on incidence, but not the magnitude of the effect on incidence. Seven (13%) papers described the covariates as having an effect on the rate of the outcome. This interpretation is correct only with a caveat: that one is determining the rate of the outcome in those subjects who have not experienced the given outcome (but who may have experienced a competing event and who thus contribute immortal time). If the focus is on rates, authors may be better served by using the cause‐specific hazard model, which models the effect of covariates on the rate of the outcome in subjects who are event‐free (and thus who have not experienced any type of event). Rates may be of greater interest when the study has an etiological focus, while risks may be of greater interest when the focus is on estimating patient prognosis and predicting patient outcome (eg, to inform the clinical management of patients).5 Two papers (4%) described the covariates as having an effect on the time to the occurrence of the event.
When interpreting the numerical value of the estimated regression coefficients, 4 (7%) papers described it as denoting the relative increase in incidence due to the covariate. Thus, if the subdistribution hazard ratio was equal to 2, this was interpreted by the authors as meaning that the covariate was associated with a twofold increase in the incidence of the event. One (2%) paper made a similar interpretation about the magnitude of the effect of the covariate on the risk of the event. This is an incorrect interpretation of the magnitude of the subdistribution hazard ratio. The direction of the subdistribution hazard ratio describes the direction of the effect of the covariate on the risk or incidence of the outcome, but not the magnitude of this effect. When the event of interest is relatively infrequent, this subdistribution hazard ratio is approximately the effect on the risk of the event.
The subdistribution hazard model is also referred to as a CIF regression model because of the link between the subdistribution hazard and the effect on the incidence of the outcome. The reporting of a CIF provides context in which to interpret the direction of the estimated regression coefficients from the associated Fine‐Gray regression model. Because of this link, we examined whether studies that used the Fine‐Gray model also reported CIFs in the published paper. Of the 55 studies, 44 (80%) displayed at least one CIF curve.
4. DISCUSSION
The Fine‐Gray subdistribution hazard model is increasingly being used for the analysis of time‐to‐event outcomes in the presence of competing events. The natural interpretation of the subdistribution hazard ratios arising from a fitted subdistribution hazard is the relative change in the subdistribution hazard function. Thus, the associated hazard ratios denote the relative change in the rate of the occurrence of the events in subjects who have not yet experienced the event of interest (but who may have experienced a competing event). Due to the risk set containing subjects who have failed due to a competing event and whose continued existence in the risk set can be construed as representing “immortal time,” this interpretation may not appeal to some investigators and analysts.
We have highlighted that in the subdistribution hazard model, the covariates can be thought of as having an effect on the CIF. However, it is important to note that magnitude of the subdistribution hazard ratio does not, strictly speaking, convey the magnitude of the effect of the covariate on the CIF. This error in interpretation appears to occur moderately frequently in the medical literature. In a study examining cardiovascular disease risk in a cohort of breast cancer survivors, the authors estimated a subdistribution hazard ratio of 1.19 for the comparison of right‐sided radiation therapy compared to left‐sided radiation therapy after mastectomy.10 The authors interpreted this as right‐sided radiation therapy increasing the cumulative incidence 1.19‐fold (p 1066), which is only approximately correct. Similarly, in a study examining the effect of hyponatremia on the incidence of cardiovascular events in peritoneal dialysis patients, the authors estimated a subdistribution hazard ratio of 2.31.11 The authors interpreted this as meaning that patients with hyponatremia had a 2.31‐fold higher risk of cardiovascular events (p 4/10). Similar examples can be found elsewhere in the literature.12, 13, 14 We suggest that when reporting the effect of a covariate on the incidence of the primary outcome, that the analyst and authors either restrict themselves to discussing the direction of the effect or be careful to note that the quantification of the magnitude of the effect on the cumulative incidence is only approximately correct using the subdistribution hazard ratios.
While some would argue that the material presented in this article is well known to statisticians, we think that such an assessment is overly optimistic. We agree that the correct interpretation of the coefficients from the subdistribution hazard model should be well‐understood by specialists in the analysis of survival data. However, not all analysts who use the method are necessarily specialists in the analysis of survival data. Despite the Fine‐Gray model being introduced nearly 20 years ago, we would argue that its use has not permeated the literature, nor are applied analysts as familiar with it as they are with other regression methods. Furthermore, as our review of the medical literature indicated, even when it is being used, the resultant model may be misinterpreted.
The current review was based on published articles that reported the use of a Fine‐Gray subdistribution hazard regression model. We focused on how authors interpreted the hazard ratios associated with this regression model. We would like to stress that the presence of competing risks does not automatically imply that the Fine‐Gray subdistribution hazard model is the most appropriate regression model. Lau et al suggest that there are 2 broad rationales for fitting a regression model: The first is for etiological reasons (eg, is a given risk factor or characteristic associated with the rate of the occurrence of the outcome in subjects who are currently event‐free), while the second is for prognostic reasons (eg, what is an individual's probability of experiencing the outcome within a given duration of time).5 Lau et al suggest that the cause‐specific hazard model is more appropriate for addressing etiological questions, while the Fine‐Gray model is more appropriate for addressing questions around incidence and prognosis. Both we and Wolbers et al have echoed this assertion.4, 15 Thus, if the research objective is to derive a model for predicting the probability of the occurrence of outcomes over time, then a subdistribution hazard model would be appropriate.16, 17 Failure to use the Fine‐Gray model for such a research objective can result in estimates of the probability of the occurrence of the outcome that are biased upwards.17 When analyzing survival data in which competing risks are present, rather than beginning with a predetermined type of regression model, the investigator and analyst should begin by carefully formulating the research question and then selecting the model that is most appropriate for addressing the formulated question. In many instances, particularly in epidemiological research, the most appropriate model will be the cause‐specific hazard model. However, in settings in which it is important to make inferences about the effect of covariates on the incidence of the outcome, then the Fine‐Gray model will be the most appropriate model. Some authors have suggested that to develop a greater understanding of the relationship between covariates and outcomes, that both cause‐specific and subdistribution hazard models be fit, for both the primary outcome and for the competing events.8 When doing so, the principal message of the current study is that the regression coefficients from the subdistribution hazard model must be interpreted correctly.
We recently published a review of how competing risks were addressed in reports of randomized controlled trials (RCTs) published in 4 leading general medical journals.18 In this previous review, we estimated that 77.5% of RCTs with a time‐to‐event outcome were potentially susceptible to competing risks. Amongst those studies that were potentially susceptible to competing risks, we examined whether the statistical methods used were appropriate for the analysis of competing risks survival data. We found that of those studies potentially susceptible to competing risks, 77.4% reported the results of a Kaplan‐Meier survival analysis, while only 16.1% reported using CIFs to estimate the incidence of the outcome over time in the presence of competing risks. We concluded our previous review of reported analyses in RCTs with recommendations for analyzing RCTs in the presence of competing risks. The objective of the current review is different from that of our earlier review. The focus of the current review was to examine how authors interpreted the hazard ratios arising from a Fine‐Gray subdistribution hazard model. We were not interested in the appropriateness of the fitted model, but rather in how the resultant model was interpreted. As such, the current article makes the important distinction between rates and risks or probabilities.
The key message of this paper for applied analysts and clinical researchers is that there is not an exact link between the subdistribution hazard ratio and relative changes in the CIF except for settings in which the event of interest is rare. The direction of the subdistribution hazard ratio denotes the direction but does not directly provide the magnitude of the effect of the covariate on the CIF. Care is needed when attempting to make statements about the magnitude of the covariate effects on the CIF using the subdistribution hazard ratios, as such statements are at best only approximately correct. Furthermore, the relative magnitudes of different covariates from the same subdistribution hazard model allow one to make inferences about the relative magnitudes of the effects of the covariates on the incidence of the given type of event.
FUNDING SOURCES
This study was supported by the Institute for Clinical Evaluative Sciences (ICES), which is funded by an annual grant from the Ontario Ministry of Health and Long‐Term Care (MOHLTC). The opinions, results, and conclusions reported in this paper are those of the authors and are independent from the funding sources. No endorsement by ICES or the Ontario MOHLTC is intended or should be inferred. This research was supported by an operating grant from the Canadian Institutes of Health Research (CIHR; MOP 86508). Dr Austin was supported by Career Investigator awards from the Heart and Stroke Foundation. The Enhanced Feedback for Effective Cardiac Treatment (EFFECT) data used in the study was funded by a CIHR Team Grant in Cardiovascular Outcomes Research (Grants CTP 79847 and CRT43823).
APPENDIX A. COMPLEMENTARY LOG‐LOG MODEL FOR THE CIF—RELATIVE EFFECTS OF DIFFERENT COVARIATES
A.1.
Let us assume that we have a complementary log‐log model for the CIF with 2 covariates:
log(− log(1 − p)) = α0 + α1X1 + α2X2, where p denotes the probability that the event of interest occurs prior to time t (we suppress the dependence on t to simplify the notation).
Then we have that
The above probability of the event occurring prior to time t is conditional on X 1 and X 2.
The probability of the event occurring given that X1 = x1 + 1 is equal to
.
The relative incidence of the event prior to time t for a subject with X1 = x1 + 1 compared to a subject with X1 = x1 (but holding X 2 fixed at x 2) is equal to
.
We replace the common term in the numerator and denominator by B for simplicity. Thus, we have that the relative incidence is equal to . Now, the quantity in the denominator is a probability and is thus between 0 and 1. Therefore, we have that B is also between 0 and 1.
Similarly, the relative incidence of the event prior to time t for a subject with X2 = x2 + 1 compared to a subject with X2 = x2 (but holding X 1 fixed at x 1) is equal to .
Now, if the regression coefficient for X 1 is greater than the regression coefficient for X 2, we have that
Thus, if the first regression coefficient is larger than the second regression coefficient, the relative change in the incidence of the outcome associated with a 1‐unit change in X 1 is greater than the relative change in the incidence of the outcome associated with a 1‐unit change in X2.
Austin PC, Fine JP. Practical recommendations for reporting Fine‐Gray model analyses for competing risk data. Statistics in Medicine. 2017;36:4391–4400. https://doi.org/10.1002/sim.7501
REFERENCES
- 1. Kaplan EL, Meier P. Nonparametric estimation from incomplete observations. J Am Stat Assoc. 1958;53:457‐481. [Google Scholar]
- 2. Cox D. Regression models and life tables (with discussion). J Royal Stat Soc ‐ Series B. 1972;34:187‐220. [Google Scholar]
- 3. Tu JV, Donovan LR, Lee DS, et al. Effectiveness of public report cards for improving the quality of cardiac care: the EFFECT study: a randomized trial. JAMA. 2009;302(21):2330‐2337. [DOI] [PubMed] [Google Scholar]
- 4. Austin PC, Lee DS, Fine JP. Introduction to the analysis of survival data in the presence of competing risks. Circulation. 2016;133:601‐609. https://doi.org/10.1161/CIRCULATIONAHA [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Lau B, Cole SR, Gange SJ. Competing risk regression models for epidemiologic data. Am J Epidemiol. 2009;170(2):244‐256. https://doi.org/10.1093/aje/kwp107 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Putter H, Fiocco M, Geskus RB. Tutorial in biostatistics: competing risks and multi‐state models. Stat Med. 2007;26(11):2389‐2430. https://doi.org/10.1002/sim.2712 [DOI] [PubMed] [Google Scholar]
- 7. Fine JP, Gray RJ. A proportional hazards model for the subdistribution of a competing risk. J Am Stat Assoc. 1999;94:496‐509. [Google Scholar]
- 8. Latouche A, Allignol A, Beyersmann J, Labopin M, Fine JP. A competing risks analysis should report results on all cause‐specific hazards and cumulative incidence functions. J Clin Epidemiol. 2013;66(6):648‐653. [DOI] [PubMed] [Google Scholar]
- 9. McCullagh N, Nelder JA. Generalized Linear Models. London: Chapman & Hall; 1989. [Google Scholar]
- 10. Boekel NB, Schaapveld M, Gietema JA, et al. Cardiovascular disease risk in a large, population‐based cohort of breast cancer survivors. Int J Radiat Oncol Biol Phys. 2016;94(5):1061‐1072. https://doi.org/10.1016/j.ijrobp.2015.11.040 [DOI] [PubMed] [Google Scholar]
- 11. Kim HW, Ryu GW, Park CH, et al. Hyponatremia predicts new‐onset cardiovascular events in peritoneal dialysis patients. PLoS One. 2015;10(6): e0129480. DOI: https://doi.org/10.1371/journal.pone.0129480 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Han K, Pintilie M, Lipscombe LL, Lega IC, Milosevic MF, Fyles AW. Association between metformin use and mortality after cervical cancer in older women with diabetes. Cancer Epidemiol Biomarkers Prev. 2016;25(3):507‐512. https://doi.org/10.1158/1055‐9965.EPI‐15‐1008 [DOI] [PubMed] [Google Scholar]
- 13. Bai AD, Showler A, Burry L, et al. Impact of infectious disease consultation on quality of care, mortality, and length of stay in Staphylococcus aureus bacteremia: results from a large multicenter cohort study. Clin Infect Dis. 2015;60(10):1451‐1461. https://doi.org/10.1093/cid/civ120 [DOI] [PubMed] [Google Scholar]
- 14. Feinstein L, Edmonds A, Okitolonda V, et al. Implementation and operational research: maternal combination antiretroviral therapy is associated with improved retention of HIV‐exposed infants in Kinshasa, Democratic Republic of Congo. J Acquir Immune Defic Syndr. 2015;69(3):e93‐e99. https://doi.org/10.1097/QAI.0000000000000644 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15. Wolbers M, Koller MT, Stel VS, et al. Competing risks analyses: objectives and approaches. Eur Heart J. 2014;35(42):2936‐2941. https://doi.org/10.1093/eurheartj/ehu131 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Austin PC, Lee DS, D'Agostino RB, Fine JP. Developing points‐based risk‐scoring systems in the presence of competing risks. Stat Med. 2016;35(22):4056‐4072. https://doi.org/10.1002/sim.6994 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Wolbers M, Koller MT, Witteman JC, Steyerberg EW. Prognostic models with competing risks: methods and application to coronary risk prediction. Epidemiology. 2009;20(4):555‐561. [DOI] [PubMed] [Google Scholar]
- 18. Austin PC, Fine JP. Accounting for competing risks in randomized controlled trials: a review and recommendations for improvement. Stat Med. 2017;36(8):1203‐1209. https://doi.org/10.1002/sim.7215 [DOI] [PMC free article] [PubMed] [Google Scholar]