

Abstract
This paper describes Gaussian process regression (GPR) models presented in predictive model markup language (PMML). PMML is an extensible-markup-language (XML) -based standard language used to represent data-mining and predictive analytic models, as well as pre- and post-processed data. The previous PMML version, PMML 4.2, did not provide capabilities for representing probabilistic (stochastic) machine-learning algorithms that are widely used for constructing predictive models taking the associated uncertainties into consideration. The newly released PMML version 4.3, which includes the GPR model, provides new features: confidence bounds and distribution for the predictive estimations. Both features are needed to establish the foundation for uncertainty quantification analysis. Among various probabilistic machine-learning algorithms, GPR has been widely used for approximating a target function because of its capability of representing complex input and output relationships without predefining a set of basis functions, and predicting a target output with uncertainty quantification. GPR is being employed to various manufacturing data-analytics applications, which necessitates representing this model in a standardized form for easy and rapid employment. In this paper, we present a GPR model and its representation in PMML. Furthermore, we demonstrate a prototype using a real data set in the manufacturing domain.
Keywords: predictive model markup language (PMML), Gaussian process regression, predictive analytics, data mining, standards, XML
Introduction
The last decade has seen an explosion in the application and research of machine learning [1] across different industries. The number of data sources, computing environments, and machine-learning tools continues to increase. Continuous improvements in sensor technologies, data-acquisition systems, and data-mining, and big data-analytics techniques allow the industries to effectively and efficiently collect large, rapid, and diverse volumes of data and get valuable insights from this data. The manufacturing industry, which is vital to all economies, is one of the domains experiencing a never-seen increase in available data collected from each stage of the product life cycle (design, production, and post-production). The availability of a large volume of data has given strong impetus to data-driven decision-making.
Given the specific nature of manufacturing systems being dynamic, uncertain, and complex, to overcome some of major challenges of manufacturing systems, valid candidates are machine-learning techniques [2]. These data-driven approaches are able to find highly complex and non-linear patterns in data of different types and sources and transform raw data to feature spaces, so-called models, which are then applied for prediction [3], detection and classification [4,5], or forecasting [6] of a quantity of interest (QoI) for a specific problem of the manufacturing process or system. A prediction model must be capable of providing a quantification of the uncertainty associated with the prediction for informed decision-making. However, a majority of the existing statistical techniques provide point predictions [3–6] without considering that predictions can be affected by uncertainties in the model parameters and input data. Bhinge et al. [7] and Park et al. [8] used the Gaussian process (GP) to build a nonlinear regression model that predicts the energy usage of a milling machine. The GP models represent the complex relationship between the input machining parameters and output energy consumption, and construct a prediction function for the energy consumption with confidence bounds [7,8]. Using the similar data set collected at the UC Berkeley Mechanical Engineering Machine Shop [9], Ak et al. [10] built an empirical prediction model using an ensemble neural networks (NNs) approach to estimate the energy consumption for a computer numerical control (CNC) milling machine tool. In addition to pure data-driven techniques, Nannapaneni et al. [11] proposed a hybrid framework using Bayesian networks to aggregate the uncertainty from multiple sources for the purpose of uncertainty quantification (UQ) in the prediction of performance of a manufacturing process. The mathematical equations are used to calculate the conditional probability relationships between parent and child nodes in the network. The work focuses on both data and model uncertainties. The proposed uncertainty-evaluation methodology is demonstrated using two manufacturing processes: welding and injection molding.
For the manufacturing industry, in addition to the need for continuous development of the advanced analytics techniques, open standards, communication protocols, or best practices are also needed to effectively and consistently deploy methodologies and technologies to assess process performance [12]. In this context, the rapid growth of data analytics and the ever-increasing complexity of machine-learning models have made the development and adoption of predictive model standards a necessity. There are evolving data-analytics standards that support computational modeling (e.g., data analytics and simulation) and lay foundations for modeling and integrating manufacturing systems and related services for continuous improvement within the enterprise [12]. To be widely adopted, these standards must support a wide range of machine-learning models, including non-parametric probabilistic models such as Gaussian process regression (GPR).
The predictive model markup language (PMML) is a de facto standard used to represent data-mining and predictive analytic models [13–16]. It is developed by the Data Mining Group (DMG), a consortium of commercial and open-source data-mining companies, and is supported by many statistical tools, such as R [14], ADAPA [16], SAS [17], and Python [18]. PMML is an XML-based language; thus, all PMML documents must conform to the XML standard and the structure of the PMML is defined by an XML schema [13–15]. The schema describes the general structure of PMML documents, as well as model-specific elements. The PMML standard can be used to represent both predictive and descriptive models, as well as pre-processing and post-processing transformations. Users can easily share the analytic models represented in PMML between different PMML-compliant applications. The models can be exchanged freely between computing environments, promoting interoperability across programming languages, and physical devices. One can train a model in a local computing environment, express the trained model as a PMML document, and then deploy the PMML document to a scoring engine to perform predictions for a new unseen data set. In addition to PMML, there exists similar standards, such as portable format for analytics (PFA) [13], which is an emerging standard for statistical models and data-transformation engines.
Although the previous PMML version, PMML 4.2, covers many data-mining algorithms, it does not provide capabilities for representing probabilistic machine-learning algorithms such as GPR, Bayesian (belief) networks, and probabilistic support vector machines that are widely used for constructing predictive models with uncertainty quantification capability. It is worth mentioning that PMML 4.2 [13] represents Naïve Bayes models that are considered as a special case of a two-level Bayesian network. Naïve Bayes models are used as a classification model not as a regression model [19]. A major disadvantage of Naïve Bayes models is that it makes a strong assumption that the input variables are conditionally independent, given the output [19], and do not provide the uncertainty quantification capabilities that we mentioned previously. In this paper, we focus on GPR model and present the GPR PMML schema. We also present a prototype to generate a GPR PMML representation using a real data set in the manufacturing domain.
The previous PMML 4.2 standard only supports parametric regression models, such as general regression, neural networks, and tree regression. The parametric regression models specify the type of basis functions that will be used to approximate a target function and optimize the parameters that best fits the model to the data. As a result, such models' representability strongly depends on the selected basis function and provides only a point estimation for an unknown target input. As a nonparametric probabilistic regression, GPR, however, is a regression model based on nonparametric Bayesian statistics [20]. It predicts the target function value in the form of posterior distribution computed by combining a prior distribution on the target function and likelihood (noise) model. GPR uses a Gaussian process (GP) as a prior to describe the distribution on the target function (i.e., the latent function values) and Gaussian likelihood to represent the noise distribution. When a GP prior is used with Gaussian likelihood, the posterior distribution on the unknown target function value can be analytically represented as a Gaussian distribution, which provides an estimated mean value and uncertainty in the predicted value. One special characteristic of a GPR model is that it does not use any predefined set of basis functions but uses training data points to represent the structure of the target function. Therefore, a GPR model can represent complex input and output relationships with a small number of hyper-parameters. Because of its ability to quantify uncertainty in the predictive model, GPR has received increased attention in the machine-learning community over the past decade. The GPR algorithm has been applied to many fields, including manufacturing, robotics, music rendering, and others [7,8,21,22]. Note that GPR can also be used for classification by converting the repression output to class probability [23]. In this paper, we focus on regression application and its representation in PMML.
The purpose of this paper is to illustrate the use of the standard PMML representation of a GPR model for an advanced manufacturing application, in this case, for energy prediction on part machining. Furthermore, a MATLAB-based interpreter has been developed to import and export the GPR PMML models. The paper is organized as follows. The next section briefly introduces the basic concepts of GPR. Following that, the GPR PMML schema is introduced. An example using manufacturing data from a numerical control (NC) milling machine is demonstrated in the next main section. Finally, the last section concludes the paper with a brief summary and discussion for future work.
Theory of Gaussian Process Regression (GPR)
GPR approximates an unknown target function y = f(x) in a probabilistic manner. Given a data set Dn = {(xi, yi)|i = 1, …, n} with n samples, x1:n = (x1, …, xn) and y1:n = (y1, …, yn) denote the inputs and the corresponding (possibly noisy) output observations, respectively. The goal of GPR is to construct a posterior distribution p(fnew|Dn) on the function value fnew = f(xnew) corresponding to an unseen target input xnew. The prediction is given as a probability distribution rather than a point estimate, quantifying uncertainty in the target value. A detailed description of GPR can be found in Refs 20 and 23. The basic steps for training a GPR model and then performing prediction (or scoring) is summarized as shown in Fig. 1, which also shows the organization of this section.
Fig. 1.

Flow chart showing GPR training and scoring procedure.
Training Procedure
GPR uses GP as a prior to describe the distribution on the target function f(x). In GPR, the function values f1:n = (f1, …, fn) corresponding to the input x1:n = (x1, …, xn) are treated as random variables, where fi ≔ f(xi). GP is defined as a collection of random variables (stochastic process), any finite number of which is assumed to be jointly Gaussian distributed. GP can fully describe the distribution over an unknown function f(x) by its mean function m(x) = E[f(x)] and a kernel function k(x, x′) that approximates the covariance E[(f(x) − m(x))(f(x′) − m(x′))]. The kernel (covariance) function represents a geometrical distance measure assuming that the more closely located inputs would be more correlated in terms of their function values. That is, the prior on the function values is represented as:
| (1) |
where:
m(·) = a mean function capturing the overall trend in the target function value, and
k(·, ·) = a kernel function used to approximate the covariance.
In GPR, the kernel (covariance) function describes the structure of the target function. Thus, the type of kernel function k(x, x′) used to build a GPR model and its parameters can strongly affect the overall representability of the GPR model and impact the accuracy of the prediction model. A wide variety of kernel functions can be used [23]; for example, the linear kernel, the polynomial kernel, the squared exponential kernel, which are included in the current PMML standard. As an example, Eq 2 shows the automatic relevance determination (ARD) squared exponential covariance function [7,8,23], which is widely used in many applications. However, the Matern (covariance) kernel function, which has received considerable attention, is not included in the current PMML representation. The function requires the evaluation of the gamma function to estimate the covariance between two points [23]; it is expected to include the case in the near future:
| (2) |
The ARD kernel function is described by the parameters, γ and λ. The term γ is referred to as the signal variance that quantifies the overall magnitude of the covariance value. The parameter vector λ = (λ1, …λi, …, λm) is referred to as the characteristic length scales that quantify the relevancy of the input features in , where m defines the number of input variables, for predicting the response y. A large length scale λi indicates weak relevance for the corresponding input feature xi and vice versa.
Likelihood of Observations
The latent random variables (or a random vector) f1:n needs to be inferred from the observation y1:n = (y1, …, yn). Each observed value is assumed to contain some random noise εi, such that yi = f(xi) + εi. Different likelihood functions can be used to model the random noise term. It is common to assume that the noise term εi is independent and identically distributed Gaussian, in which case the likelihood function becomes:
| (3) |
where:
= the noise variance and quantifies the level of noise that exists in the response yi = f(xi) + εi.
The Gaussian likelihood function is used because it guarantees that the posterior can also be expressed as a Gaussian distribution. Including the noise model, the covariance function is parameterized (i.e., defined) by the hyper-parameters jointly denoted by θ = (σε, γ, λ) for the case of the squared exponential covariance function as shown in Eq 2.
Hyper-Parameter Optimization
The marginal distribution of the observations can be computed as:
| (4) |
When the GP prior and Gaussian likelihood function are used, the marginal distribution is also Gaussian. One attractive property of the GP model is that it provides an analytical closed form expression for the marginal likelihood of the data (with the unknown latent function being “marginalized” out). The marginal log-likelihood for the training data set Dn = {(xi, yi)|i = 1, …, n} can be expressed as [20,23]:
| (5) |
where:
K = the covariance (kernel) matrix whose (i, j)th entry is Kij = k(xi, xj).
Then, the hyper-parameters for the noise model and the kernel function are determined as ones maximizing the marginal log-likelihood of the training data Dn = {(xi, yi)|i = 1, …, n} as:
| (6) |
As long as the kernel function is differentiable with respect to its hyper-parameters θ, the marginal likelihood can be differentiated and optimized by various off-the-shelf mathematical programming tools.
Scoring Procedure: Computing the Posterior Distribution of the Target Function Value
After optimizing the model hyper-parameters, the GPR model is referred to as “trained.” The model is fully characterized by the prior, the likelihood function, the hyper-parameters, and the training data set. Let us denote a newly observed input xnew:
The (hidden) function value f(xnew), denoted here as fnew, for the new input xnew and the observed outputs y1:n = {y1, …, yn} follow a multivariate Gaussian distribution:
| (7) |
where:
kT = (k(x1, xnew), …, k(xn, xnew)).
The posterior distribution on the response fnew for the newly observed (and previously unseen) input xnew given the historical data Dn = {(xi, yi)|i = 1,…, n} can then be expressed as a 1D Gaussian distribution:
| (8) |
| (9) |
fnew ∼ N(μ(xnew|Dn), σ2(xnew|Dn)) with the mean and variance functions expressed, respectively, as [20,23]:
Here, μ(xnew|Dn) and σ2(xnew|Dn) can be used as the scoring functions for evaluating, respectively, the mean and variance of the hidden function output fnew corresponding to the input data xnew.
As long as the kernel function is differentiable with respect to its hyper-parameters θ, the marginal likelihood can be differentiated and optimized by various off-the-shelf mathematical programming tools, such as GPML [24], PyGP [25], Scikit-learn [26], and GPy [27].
GPR-PMML Schema
PMML provides an open standard for representing data-mining and predictive models, thus the models can be transferred easily from one environment to another. Once a machine-learning model has been trained in an environment like MATLAB, Python, or R, it can be saved as a PMML file. The PMML file can then be moved to a production environment, such as an embedded system or a cloud server. The code in the production environment can import the PMML file, and use it to generate predictions for new unseen data points. It is important to note that PMML does not control the way that the model is trained, it is purely a standardized way to represent the trained model.
Fig. 2 shows the general structure of a PMML document, which includes four basic elements, namely, header, data dictionary, data transformation, and the data-mining or predictive model [13]. The Header element provides a general description of the PMML document, including name, version, timestamp, copyright, and other relevant information for the model-development environment. The DataDictionary element contains the data fields and their types, as well as the admissible values for the input data. The data transformation is performed via the TransformationDictionary or LocalTransformations element that describes the mapping of the data, if necessary, into a form usable by the mining or predictive model. PMML defines various data transformations such as normalization, discretization, etc. [13]. The last element in the general structure contains the definition and description of the predictive model. The element is chosen among a list (called MODEL-ELEMENT) of models defined in PMML. To represent the GPR models, it is required to choose the GaussianProcessModel element that includes the optimal hyper-parameters and the training data set. For detailed explanations of PMML structure and each element within the structure, we refer the reader to Refs 13–16 and 28.
Fig. 2.

The structure and contents of a GPR PMML file adapted from Ref 14.
Our discussion focuses on the description of the GPR model defined in PMML. As a non-parametric model, GPR requires a training data set to fully characterize the model [20,23,29]. The term non-parametric implies an infinite-dimensional parameter space that the number and nature of the parameters are flexible and not fixed in advance [29,30]. Therefore, all of the training data must be included in the PMML document along with the other model parameters. The list of information required to characterize the GPR model includes:
The training inputs x1:n = (x1, …, xn) and the corresponding outputs y1:n = (y1, …, yn).
The type of a kernel function k(·, ·) used to describe the underlying structure of the target function.
The hyper-parameters for the specified kernel function and the noise variance representing the error magnitude in the output.
The PMML standard for the GPR model thus includes the description of the model, the kernel type and its hyper-parameters, and the training data set.
The current PMML only focuses on the case where the mean function in Eq 1 is zero, i.e., m(x) = 0, for two reasons. First, using zero mean function, m(x) = 0, simplifies the learning and prediction procedures without compromising its representability. Second, a mean function m(x) can be represented by other parametric models, such as generalized linear regression, thus it can be expressed using the parametric models already included in the PMML standard. Integrating the regression models into current PMML GPR schema would be desirable in the future.
Gaussianprocessmodel Element
A GPR model is represented by a GaussianProcessModel element defined in the XML schema, which contains all the necessary information to fully characterize the model. Fig. 3 shows the attributes that can be added to the GaussianProcessModel element, and the elements, which can be nested within the GaussianProcessModel element. Some of the attributes in the GaussianProcessModel are optional. The optional attributes are used to provide additional metadata about the model, such as the optimization algorithm used to optimize the hyper-parameters. The attributes defined are as follows:
modelName specifies the name of the GPR model.
functionName specifies whether the model type is “classification” or “regression.”
optimizer specifies the optimization algorithm used in training the Gaussian process model.
isScorable specifies whether the model is complete, and can actually be used to generate predictions.
Fig. 3.

PMML schema of Gaussian process regression model.
The schema also defines the elements that can be nested within the Gaussian-ProcessModel element. The LocalTransformations element is used to define any mathematical transformation applied to the input or output values of the model. The GaussianProcessModel element must contain one of the four possible kernel elements, RadialBasisKernel, ARDSquaredExponentialKernel, AbsoluteExponentialKernel, and GeneralizedExponentialKernel, as shown in the schema (see Fig. 3). As an example, the ARDSquaredExponentialKernel element is described in the next section. The TrainingInstances element contains the training data, and is described in the section following that.
Kernel Element
The GaussianProcessModel element must contain a single kernel element, which defines the type of kernel used in the model. For example, the ARD squared exponential kernel function defined in Eq 2 is represented in the PMML schema as shown in Fig. 4.
Fig. 4.

ARDSquaredExponentialKernel element schema.
The ARD squared exponential kernel is characterized by the covariance magnitude, γ, the length-scale vector, λ, and the noise variance, . The covariance magnitude and the noise variance are stored as numerical attributes on the kernel element. The length-scale vector is represented as an Array element, nested inside the kernel element. Fig. 5 shows the schema for the nested length-scale element.
Fig. 5.

Length-scale (lambda) element schema.
Traininginstances Element
For GPR, the training data is required to fully characterize the model. The training data is included in the TrainingInstances element. The schema for the TrainingInstances element is defined in the PMML 4.2 standard [13] and is repeated here for the sake of clarity, as shown in Fig. 6. The training data can be represented as either an InlineTable or TableLocator element. The InlineTable element allows training data to be included directly into the PMML document. The InstanceFields element is used to specify the fields that are included in the training data. Data contained in an external table can be referenced using a TableLocator element.
Fig. 6.

TrainingInstances element schema [13].
Application of GPR PMML to Predict Milling Machine Energy Consumption
This section discusses how an energy-prediction model for a milling machine is stored according to the PMML standard for GPR, using a specifically developed MATLAB package [31]. A MATLAB package is developed to save generic GPR models to a file in the PMML format. Specifically, a GPR energy model is trained using real energy-consumption data obtained from a Mori Seiki NVD 1500DCG 3-axis milling machine at the UC Berkeley Mechanical Engineering Machine Shop [9], and the model is in the PMML format. The saved model can be used to predict energy consumption when machining a new part as well to determine the best tool path for machining a part with minimal energy [7,8]. The scoring (or the prediction) procedure using the GPR PMML file is illustrated.
Energy-Prediction Model
Machine-learning techniques have been applied to various applications in manufacturing domain [2]; one of them is monitoring and optimizing the energy efficiency of the manufacturing processes, which has become a priority in the manufacturing industry. Advanced monitoring and operation strategies of machine tools will improve energy usage in manufacturing. The first step toward developing such strategies is to understand the energy-consumption pattern of machine tools and manufacturing operations. These strategies can enable the development of energy-prediction models to determine how different operational strategies influence the energy-consumption pattern of a machine tool and to derive an optimal strategy to select efficient operations for machining a part.
Herein, a GPR model is developed to predict the energy consumption of the milling machine as a function of the operating (machine) parameters. Whereas this case study used face milling as a demonstrative example, the same technique has shown to be applicable to other milling operations [7,8]. The experimental design, setup, and data-processing techniques used for generating the data sets for this study have been previously described by Bhinge et al. [7]. A total of 196 face milling experiments for machining parts using the milling machine were conducted. The data sets were obtained using different operating parameters, including feed rate, spindle speed, and depth of cut. Each operation within the data sets refers to a single NC block. The energy consumption, E ∈ ℝ, for each NC block, was obtained by numerically integrating the power time series recorded over the duration of the block.
In this study, the output parameter, y, is defined as the energy consumption per unit length. Furthermore, the input features employed are defined as follows:
x1 ∈ ℝ feed rate: the velocity at which the tool is fed.
x2 ∈ ℝ spindle speed: rotational speed of the tool.
x3 ∈ ℝ depth of cut: depth of material that the tool is removing.
x4 ∈ {1, 2, 3, 4} active cutting direction: (1 is for x-axis, 2 for y-axis, 3 for z-axis, and 4 for x-y axes).
x5 ∈ {1, 2, 3} cutting strategy: the method for removing material (1 is for conventional, 2 for climbing, and 3 for both).
For this example, we choose to use all of the measured input features, and subsequently define the input feature vector, x = {x1, …, x5}. We assume that the output y = f(x) + ε is measured with noise . The ARD squared exponential kernel is used as the covariance function. Furthermore, we assume the mean function from the prior (see Eq 1) to be a zero function.
The GPR model is used to generate energy density predictions ŷi for a new set of operating conditions xi. Let Dtrain denote the training data set containing the input feature data and the output parameter data. Each new prediction ŷi is represented by a mean energy density function μ(xi|Dtrain) and associated standard deviation function σ(xi|Dtrain). We can then estimate the energy consumption Êi and the corresponding standard deviation Si on the estimated energy-consumption value as:
| (10) |
| (11) |
Details on developing the GPR model have been reported in Refs 7, 8, 20, and 23.
Representing the Model Using PMML
In a real application, it is likely that the same GPR model will be used to generate predictions in multiple different computing environments. Using the PMML schema described in this work, it is possible to communicate the GPR model in a standard way to different PMML-compliant scoring engines. Thus, one can train the model in one computing environment, and then communicate the model to multiple other environments using the GPR PMML format.
A MATLAB package [31] is developed to consume and produce GPR PMML documents. The package is made up of four main modules: a PMML parser, PMML generator, GPR core, and GPR interface. The PMML parser is designed to extract important information from a PMML file, such as the kernel type and hyper-parameters. The PMML generator provides a way to generate a PMML representation of a GPR model. The GPR core provides the mathematical logic for training GPR models and scoring new observations, relying on the scoring and optimization algorithms provided by the Gaussian process for machine-learning (GPML) toolbox [24]. The GPR interface provides a clean object-orientated interface to the PMML generator, PMML parser, and GPR core.
The package provides a simple way to save trained GPR models to PMML. Given the kernel type, likelihood function, optimized hyper-parameters, and training data, the package generates a valid PMML representation of the GPR model. Internally, the package uses the JAXP extensible markup language parser [32] to generate the PMML file, according to the schema described in this document. The package also provides a way to load a GPR model from a PMML file and then generate predictions for a new data point, xnew. The JAXP parser is used to extract the kernel type, likelihood function, hyper-parameters, and training data from the PMML file. This information is then used to calculate μ(xnew|Dn) and σ(xnew|Dn) as described previously.
For our study, the MATLAB package [31] is installed on two separate computers, both of which are connected to the Internet. Hereafter, we will refer to the first computer as the training environment and the second computer as the testing environment. The milling machine data set is randomly divided into a training set Dtrain and testing set Dtest with the ratio of training to testing points set to 7:3. A GPR model is trained in the training environment using Dtrain, and saved in the PMML format using the previously described MATLAB package. As shown in Fig. 7, the PMML file is transferred to the testing environment via an Internet connection. The trained GPR model parameters are loaded from the PMML file using the MATLAB package. The PMML file contains the optimized hyper-parameters, kernel function type, training data, variable names, and PMML version number. The optional copyright attribute is included in the PMML header element. A new set of energy-consumption predictions, Êtest, is generated from the PMML file in the testing environment. An abbreviated version of the PMML file corresponding to the case study, i.e., energy-prediction model, is shown for reference in Fig. 8. Note that most of the training data has been omitted for brevity.
Fig. 7.

Example of training and testing flow using PMML to persist GPR model.
Fig. 8.

PMML file representing the energy-consumption model.
Fig. 9 shows the energy consumption predicted by the model stored in the PMML file. As shown in Fig. 10 the GPR model provides a good estimation of the energy consumption of the milling machine on the test data set. Because of the standardized nature of PMML, the predicted energy consumption is independent from the computing platform/tool.
Fig. 9.
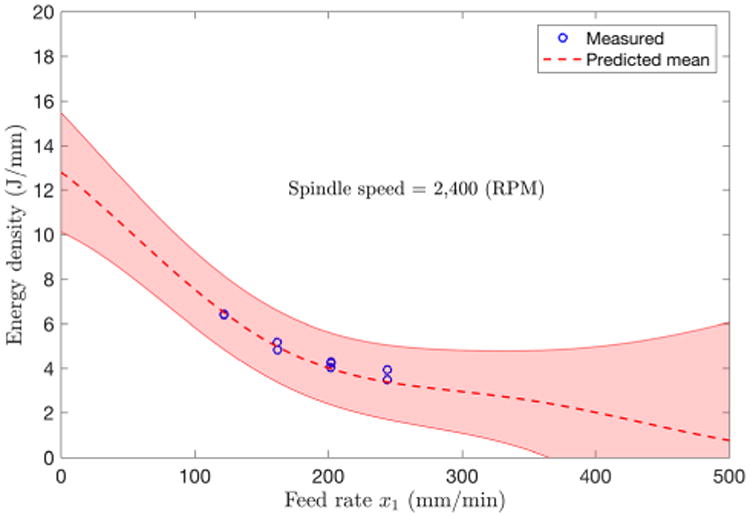
Predicted energy-consumption density for generic test parts machined using face milling, y-direction cut, 2,400 rpm spindle speed, conventional cutting strategy, and 1-mm cut depth. The shaded area shows one-standard deviation bounds for the prediction.
Fig. 10.

Predicted mean energy consumption for face milling operations using the GPR, compared to the actual energy consumption of the machine.
Discussion and Conclusion
This study presents PMML representation of Gaussian process regression (GPR) model and a prototype to generate GPR PMML representation using a real data set. GP is a stochastic process that is capable of modeling the complex relationship between the input and output variables, and constructing a prediction function with confidence bounds. Estimation of confidence bounds for future values provides more information about the predictions and thus plays an important role in risk-informed decision-making. The newly released PMML version 4.3, which includes the Gaussian process model, provides this capability.
In the PMML v4.3, the GaussianProcessRegression element is defined to represent a trained GPR Model. An XML schema of the GPR model is provided to assist in parsing and validating of GPR models. We have demonstrated that a GPR model for the energy consumption of a milling machine can be structured in the PMML file format using a purposely built MATLAB software package [31]. The development of an abstraction layer on the GPR PMML file format makes it trivial to convert existing GPR models to valid PMML. The standardized PMML file format ensures that transferring the model from one environment to another is reliable and straightforward.
For the case of GP regression, a prediction on a target input is represented by a posterior distribution that can be expressed in a closed form using the parameters optimized and the training data. For classification, however, the prediction cannot be represented using analytical expression, because the output of the regression needs to be converted to a probability using a squashing function, i.e., sigmoid function. To predict the probability of output class, it is required to approximate the inference procedure and this complicates the scoring procedure of classification tasks. In addition, the current PMML GPR model can be extended so that it can represent multi-output GP regression models, which is similar to representing a parametric regression model for a vector output. To represent a multi-output regression model, the PMML will include a more generalized kernel function that can represent the covariance in the same type of output as well as the covariance in the different output values.
The current PMML GPR standard assumes that the size of training data is moderate. One of the drawbacks of the GP is that it is not sparse and uses the whole set of samples or features information to perform the prediction. Thus, the GPR PMML standard requires that all of the training data points are stored in the PMML file along with the model parameters. This can cause excessively large PMML file size and slow load time. When the size of training data is large, approximated methods for training and prediction are required [33]. There have been recent rapid developments in efficient approximation techniques for Gaussian processes. To reduce the computational and storage requirements, approximated GP regression approaches, such as stochastic variational inference for Gaussian Process models [33], Gaussian Process mixture model [34], local GP [19,35], and sparse GP [35–39] have been proposed. In most cases, these methods reduce the computational demand when training and scoring from GPR models, making them very favorable [40]. Future work could investigate the representation of local or sparse GPR models in the PMML format.
One promising application of the PMML format is its ability to train models in a powerful computing environment like the Google Compute Engine [40,41], and then transfer those models to a personal computer or embedded device for scoring. The development of a GPR PMML scoring machine in a low-level language such as C would allow GPR PMML models to be evaluated on embedded devices. This would provide a simple standardized framework to develop smart sensors and devices.
Acknowledgments
Disclaimer: The work described in this paper is funded in part by the National Institute of Standards and Technology (NIST) cooperative agreement with Stanford University, Grant No. 70NANB12H273, and is supported by National Institute of Standards and Technology's Foreign Guest Researcher Program. The writers acknowledge the support of the late Prof. David Dornfeld and Mr. Raunak Bhinge of the Laboratory for Manufacturing and Sustainability at UC Berkeley, United States, in collecting, preparing, and providing machine operation data. Certain commercial systems are identified in this paper. Such identification does not imply recommendation or endorsement by NIST; nor does it imply that the products identified are necessarily the best available for the purpose.
References
- 1.Jordan MI, Mitchell TM. Machine Learning: Trends, Perspectives and Prospects. Science. 2015;349(6245):255–260. doi: 10.1126/science.aaa8415. http://dx.doi.org/10.1126/science.aaa8415. [DOI] [PubMed] [Google Scholar]
- 2.Wuest T, Weimer D, Irgens C, Thoben KD. Machine Learning in Manufacturing: Advantages, Challenges, and Applications. Prod Manuf Res Open Access J. 2016;4(1):23–45. [Google Scholar]
- 3.Suresh PVS, Venkateswara Rao P, Deshmukh SG. A Genetic Algorithmic Approach for Optimization of Surface Roughness Prediction Model. Int J Mach Tools Manuf. 2002;42(6):675–680. http://dx.doi.org/10.1016/S0890-6955(02)00005-6. [Google Scholar]
- 4.Ghosh N, Ravi YB, Patra A, Mukhopadhyay S, Paul S, Mohanty AR, Chattopadhyay AB. Estimation of Tool Wear During CNC Milling Using Neural Network-Based Sensor Fusion. Mech Syst Signal Proc. 2007;21(1):466–479. http://dx.doi.org/10.1016/j.ymssp.2005.10.010. [Google Scholar]
- 5.Jihong Y, Lee J. Degradation Assessment and Fault Modes Classification Using Logistic Regression. J Manuf Sci Eng. 2005;127(4):912–914. http://dx.doi.org/10.1115/1.1962019. [Google Scholar]
- 6.Carbonneau R, Laframboise K, Vahidov R. Application of Machine Learning Techniques for Supply Chain Demand Forecasting. Eur J Oper Res. 2008;184(3):1140–1154. http://dx.doi.org/10.1016/j.ejor.2006.12.004. [Google Scholar]
- 7.Bhinge R, Biswas N, Dornfeld D, Park J, Law KH, Helu M, Rachuri S. presented at the IEEE International Conference on Big Data, Bethesda, MD. IEEE, Piscataway; NJ: Oct 27–30, 2014. An Intelligent Machine Monitoring System for Energy Prediction Using a Gaussian Process Regression; pp. 978–986. [Google Scholar]
- 8.Park J, Law KH, Bhinge R, Biswas N, Srinivasan A, Dornfeld D, Helu M, Rachuri S. presented at the ASME 2015 International Manufacturing Science and Engineering Conference (MSEC2015), Charlotte, NC. ASME; New York: Jul 8–12, 2015. A Generalized Data-Driven Energy Prediction Model With Uncertainty for a Milling Machine Tool Using Gaussian Process. [Google Scholar]
- 9.Bhinge R. LMAS Database. [Last accessed 17 Jan 2017]; http://web.archive.org/web/20170117185446/http://lmas.berkeley.edu/raunak.html.
- 10.Ak R, Helu M, Rachuri S. presented at the ASME 2015 International Design Engineering Technical Conferences & Computers Information in Engineering Conference (IDETC/CIE), Boston, MA. ASME; New York: Aug 2–5, 2015. Ensemble Neural Network Model for Predicting the Energy Consumption of a Milling Machine. [Google Scholar]
- 11.Nannapaneni S, Sankaran M, Rachuri S. Performance Evaluation of a Manufacturing Process Under Uncertainty Using Bayesian Networks. J Cleaner Prod. 2016;113:947–959. http://dx.doi.org/10.1016/j.jclepro.2015.12.003. [Google Scholar]
- 12.Lyons K, Bock C, Shao G, Ak R. Standards Supporting Simulations of Smart Manufacturing Systems. presented at the 2016 Winter Simulation Conference; Arlington, VA. Dec 11–14 2016. [Google Scholar]
- 13.The Predictive Model Markup Language (PMML) 4.2, by the Data Mining Group (DMG) [Last accessed 17 Jan 2017]; http://web.archive.org/web/20170117185024/http://dmg.org.
- 14.Guazzelli A, Zeller M, Lin WC, Williams G. PMML: An Open Standard for Sharing Models. R J. 2009;1:60–65. [Google Scholar]
- 15.Guazzelli A. What Is PMML? Explore the Power of Predictive Analytics and Open Standards. IBM developerWorks; Raleigh-Durham, NC: 2010. pp. 1–10. [Google Scholar]
- 16.Guazzelli A, Stathatos K, Zeller M. Efficient Deployment of Predictive Analytics Through Open Standards and Cloud Computing. ACM SIGKDD Explor Newsl. 2009;11(1):32–38. [Google Scholar]
- 17.SAS; Cary, NC: 2011. [Last accessed 17 Jan 2017]. Getting Started With SAS Enterprise Miner 7.1. http://web.archive.org/web/20170117190308/http://support.sas.com/documentation. [Google Scholar]
- 18.Python Software Foundation; Wilmington, DE: [Last accessed 17 Jan 2017]. Python. http://web.archive.org/web/20170117185932/https://www.python.org. [Google Scholar]
- 19.Mitchell TM. Machine Learning. Vol. 1997. McGraw-Hill; New York: 1997. Bayesian Learning; pp. 154–200. [Google Scholar]
- 20.Rasmussen CE. Advanced Lectures on Machine Learning. Vol. 2004. Springer; Berlin: 2004. Gaussian Processes in Machine Learning; pp. 63–71. [Google Scholar]
- 21.Nguyen-Tuong D, Peters JR, Seeger M. presented at the 22nd Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada. Advances in Neural Information Processing Systems 21, NIPS Foundation; La Jolla, CA: Dec 8–10, 2008. Local Gaussian Process Regression for Real Time Online Model Learning; pp. 1193–1200. [Google Scholar]
- 22.Teramura K, Hideharu O, Yuusaku T, Shimpei M, Shin-ichi M. presented at the International Conference on Music Perception and Cognition (ICMPC 10) Vol. 2008. The University of Washington School of Music (Seattle); Sapporo, Japan: Aug 23–27, 2010. Gaussian Process Regression for Rendering Music Performance; pp. 167–172. [Google Scholar]
- 23.Rasmussen CE, Williams CKI. Gaussian Processes for Machine Learning. MIT Press; Cambridge, MA: 2006. [Google Scholar]
- 24.Rasmussen CE, Nickisch H. Gaussian Processes for Machine Learning (GPML) Toolbox. J Mach Learn Res. 2010;11:3011–3015. [Google Scholar]
- 25.Google. Python Software Foundation; Wilmington, DE: [Last accessed 17 Jan 2017]. Scikit-Learn, Machine Learning in Python. http://web.archive.org/web/20170117190447/http://sci-kit-learn.org/stable. [Google Scholar]
- 26.Stegle O, Zwiessele M, Fusi N. Python Software Foundation; Wilmington, DE: [Last accessed 12 Dec 2016]. Python Package for Gaussian Process Regression in Python. http://web.archive.org/web/20170117190637/https://pypi.python.org/pypi/pygp. [Google Scholar]
- 27.Sheffield Machine Learning Group, University of Sheffield; Sheffield, UK: [Last accessed 12 Dec 2016]. GPy. http://web.archive.org/web/20170117191110/https://sheffieldml.github.io/GPy. [Google Scholar]
- 28.Guazzelli A, Lin WC, Jena T. PMML in Action: Unleashing the Power of Open Standards for Data Mining and Predictive Analytics. 2nd. Create-Space; Paramount, CA: 2012. [Google Scholar]
- 29.Orbanz P, Teh YW. Encyclopedia of Machine Learning. Springer; New York: 2011. Bayesian Nonparametric Models; pp. 81–89. [Google Scholar]
- 30.Murphy KP. Machine Learning: A Probabilistic Perspective. MIT Press; Cambridge, MA: 2012. p. 16. [Google Scholar]
- 31.Ferguson M, Park J. Gaussian Process Regression PMML Package for MATLAB. [Last accessed 30 June 2016]; http://web.archive.org/web/20170117190801/https://github.com/maxkferg/matlab-pmml.
- 32.Suttor J, Walsh N, Kawaguchi K. Technical Report. Sun Microsystems; Santa Clara, CA: 2004. JSR 206 Java API for XML Processing (JAXP) 1.3; pp. 1–252. [Google Scholar]
- 33.Hensman J, Nicolo F, Lawrence ND. Gaussian Processes for Big Data. presented at the Proceedings of the Twenty-Ninth Conference on Uncertainty in Artificial Intelligence (UAI2013); Sept. 26 2013. [Google Scholar]
- 34.Shi JQ, Murray-Smith R, Titterington DM. Hierarchical Gaussian Process Mixtures for Regression. Stat Comput. 2005;15(1):31–41. http://dx.doi.org/10.1007/s11222-005-4787-7. [Google Scholar]
- 35.Snelson E, Zoubin G. presented at the 11th International Conference on Artificial Intelligence and Statistics. Vol. 11. San Juan, Puerto Rico: AISTATS; Mar 21–24, 2007. Local and Global Sparse Gaussian Process Approximation; pp. 524–531. [Google Scholar]
- 36.Snelson E, Ghahramani Z. presented at the Neural Information Processing Systems 2005 Conference, Vancouver, British Columbia. Neural Information Processing Systems (NIPS); La Jolla, CA: Dec 5–8, 2005. Sparse Gaussian Processes Using Pseudo-Inputs; pp. 1257–1264. [Google Scholar]
- 37.Quiñonero-Candela J, Rasmussen CE. A Unifying View of Sparse Approximate Gaussian Process Regression. J Mach Learn Res. 2005;6:1939–1959. [Google Scholar]
- 38.Titsias MK. presented at the 12th International Conference on Artificial Intelligence and Statistics, 2009. Vol. 12. Montreal, Canada: Jun 14–18, 2009. Variational Learning of Inducing Variables in Sparse Gaussian Processes; pp. 567–574. [Google Scholar]
- 39.Ranganathan A, Yang MH, Ho J. Online Sparse Gaussian Process Regression and Its Applications. IEEE Trans Image Proc. 2011;20(2):391–404. doi: 10.1109/TIP.2010.2066984. http://dx.doi.org/10.1109/TIP.2010.2066984. [DOI] [PubMed] [Google Scholar]
- 40.Cohen M, Hurley K, Newson P. O'Reilly Media. Sebastopol, CA: 2015. Google Compute Engine. [Google Scholar]
- 41.Ferguson M, Law K, Bhinge R, Lee YST, Park J. presented at the IEEE International Conference on Big Data, Dec 5–8, 2016, Washington, DC. IEEE; Piscataway, NJ: Evaluation of a PMML-Based GPR Scoring Engine on a Cloud Platform and Microcomputer Board for Smart Manufacturing; pp. 1–10. [Google Scholar]