

Abstract
Methods have been developed for Mendelian randomization that can obtain consistent causal estimates while relaxing the instrumental variable assumptions. These include multivariable Mendelian randomization, in which a genetic variant may be associated with multiple risk factors so long as any association with the outcome is via the measured risk factors (measured pleiotropy), and the MR‐Egger (Mendelian randomization‐Egger) method, in which a genetic variant may be directly associated with the outcome not via the risk factor of interest, so long as the direct effects of the variants on the outcome are uncorrelated with their associations with the risk factor (unmeasured pleiotropy). In this paper, we extend the MR‐Egger method to a multivariable setting to correct for both measured and unmeasured pleiotropy. We show, through theoretical arguments and a simulation study, that the multivariable MR‐Egger method has advantages over its univariable counterpart in terms of plausibility of the assumption needed for consistent causal estimation and power to detect a causal effect when this assumption is satisfied. The methods are compared in an applied analysis to investigate the causal effect of high‐density lipoprotein cholesterol on coronary heart disease risk. The multivariable MR‐Egger method will be useful to analyse high‐dimensional data in situations where the risk factors are highly related and it is difficult to find genetic variants specifically associated with the risk factor of interest (multivariable by design), and as a sensitivity analysis when the genetic variants are known to have pleiotropic effects on measured risk factors.
Keywords: invalid instruments, Mendelian randomization, MR‐Egger, multivariable, pleiotropy
1. INTRODUCTION
Mendelian randomization (MR) uses genetic variants as instrumental variables to estimate the causal effect of a risk factor on an outcome using observational data.1, 2 Increases in the scale of genome‐wide association studies have led to large numbers of genetic variants that are associated with candidate risk factors being discovered.3 If the variants explain additional variability in the risk factor then using multiple variants in a MR analysis will increase power to detect a causal effect.4, 5 A pleiotropic genetic variant is associated with multiple risk factors; such a variant is not a valid instrumental variable and its inclusion in an (univariable) MR analysis may result in biased causal estimates and inappropriate inferences.6 As more variants are used in an MR analysis, the chance of including a pleiotropic variant increases.
For some sets of risk factors, including lipid fractions, several risk factors have common genetic predictors. Although such genetic variants are pleiotropic, they can be used to estimate causal effects in a multivariable MR framework.7 In multivariable MR, the instrumental variable assumptions are extended to allow a genetic variant to be associated with multiple risk factors, provided all associated risk factors are included in the analysis. Alternatively, when genetic variants are suspected to violate the instrumental variable assumptions through unknown pleiotropic pathways, methods have been developed to estimate consistent causal effects under weaker assumptions. These include the weighted median and MR‐Egger methods.8, 9 The extension of MR‐Egger to a multivariable setting has been implemented by Helgadottir et al as part of a sensitivity analysis in their applied work investigating the effect of lipid fractions on coronary heart disease (CHD) risk.10 However, there remains several methodological issues relating to the implementation of the method, and the assumptions required.
In this paper, we expand univariable MR‐Egger to the multivariable setting. In Section 2, we introduce the conventional and MR‐Egger methods in both univariable and multivariable contexts. We provide an example analysis using published data on lipid fractions and CHD risk (Section 3), and compare results from the different MR methods in a simulation study (Section 4). Finally (Section 5), we discuss the results of the paper and the implications for applied practice. Software code for implementing all of the methods used in this paper is provided in the Web Appendix.
2. METHODS
Initially, we consider the causal effect of a risk factor X on an outcome Y using genetic variants G j(j=1,…,J) that are assumed to be uncorrelated (not in linkage disequilibrium). Then, we expand to consider multiple risk factors X 1,X 2,…,X K. Increasingly, MR investigations are implemented using summarized data from consortia to leverage their large sample sizes, thereby improving the precision of causal estimates.11 We therefore assume that summarized data are available on the associations of each genetic variant with the risk factor (or with each risk factor for the multivariable setting) and with the outcome: the beta‐coefficients ( ) and their standard errors ( ) from univariable regression on each variant G j in turn. We additionally assume that the associations of genetic variants with the risk factor and the outcome, and the causal effect of the risk factor on the outcome, are linear and homogeneous across the population; these assumptions are discussed in detail elsewhere.12 To distinguish between the parameters from the different methods considered, we use the following subscript notation: UI (“univariable inverse variance weighted (IVW)”); UE (“univariable MR‐Egger”); MI (“multivariable IVW”); and ME (“multivariable MR‐Egger”).
2.1. Univariable Mendelian randomization
In a univariable MR analysis, each genetic variant must satisfy the following criteria to be a valid instrumental variable (IV):
IV1: The variant is associated with the risk factor X,
IV2: The variant is independent of all confounders U of the risk factor‐outcome association, and
IV3: The variant is independent of the outcome Y conditional on the risk factor X and confounders U.13
These assumptions imply that the genetic variant should not have an effect on the outcome except via the risk factor. Under linearity assumptions, the association between the genetic variant and the outcome can be decomposed into an indirect effect via the risk factor and a direct effect:
| (1) |
where θ is the causal effect of the risk factor on the outcome. Genetic variant j is pleiotropic if α j≠0, and α j is the direct effect of the genetic variant on the outcome. Figure 1 contains a direct effect α j via an independent pathway, which violates the IV3 assumption.
Figure 1.
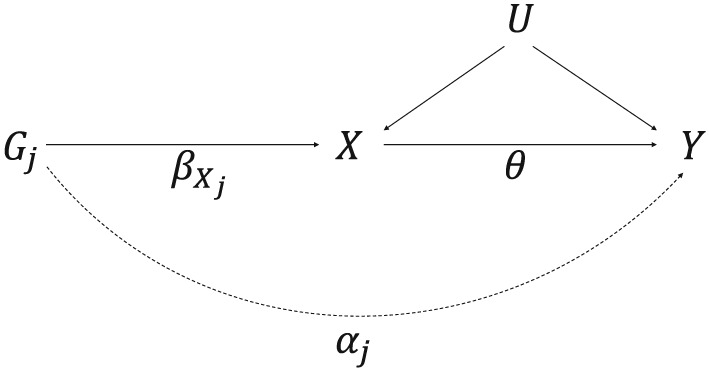
Causal directed acyclic graph illustrating univariable Mendelian randomization assumptions with potential violation of IV3 by a pleiotropic effect indicated by a dotted line. The genetic effect of G j on X is , the direct (pleiotropic) effect of G j on Y via an independent pathway is α j (representing the potential violation of the IV3 assumption), and the causal effect of the risk factor X on the outcome Y is θ. U represents the set of variables that confound the association between X and Y
With a single genetic variant, G 1 say, the causal estimate is .14 This is a consistent estimate of the causal effect θ when α 1=0. With multiple genetic variants, the inverse‐variance weighted (IVW) estimate is the weighted average of these causal estimates,15 using the inverse of their approximate variances as weights:
| (2) |
This estimate can also be obtained from individual‐level data using the 2‐stage least squares method.16 Alternatively, the causal effect of the risk factor on the outcome can be estimated using a weighted linear regression of the genetic association estimates,17 with the intercept set to zero:
| (3) |
The above weighted regression model, where the residual standard error is set to one, is equivalent to performing a fixed‐effect meta‐analysis of the variant‐specific causal estimates.18 Under a multiplicative random effects model, the residual standard error can be greater than one, allowing for heterogeneity in the causal estimates. The point estimate from the fixed and random effect models will be the same, but the standard error of the causal effect from the multiplicative random effects model will be larger if there is heterogeneity between the causal estimates. Throughout this paper, we apply a multiplicative random effects model to all the analyses.
The MR‐Egger estimate is obtained using the same regression model as Equation 2, but allowing the intercept to be estimated9:
| (4) |
If the genetic variants are not pleiotropic, then the intercept term should tend to zero as the sample size increases, and the MR‐Egger estimate ( ) and the IVW estimate ( ) are both consistent estimates of the causal effect. Additionally, if the genetic variants are pleiotropic but the direct effects α (bold symbols represent vectors across the j genetic variants) are independent of the associations of the variants with the risk factor β X (known as the InSIDE assumption—Instrument Strength Independent of Direct Effect), then the MR‐Egger estimate will be a consistent estimate of θ.9, 19
Under the InSIDE assumption, the intercept term can be interpreted as an estimate of the average direct effect of the genetic variants.8 If the average direct effect is zero (referred to as “balanced pleiotropy”), and the InSIDE assumption is satisfied, the intercept term should tend to zero as the sample size increases, and the MR‐Egger estimate ( ) and the IVW estimate ( ) are both consistent estimates of the causal effect. If the intercept term differs from zero, then either the InSIDE assumption is violated or the average direct effect differs from zero (referred to as “directional pleiotropy”); this is a test of the validity of the instrumental variable assumptions (the MR‐Egger intercept test).
2.2. Multivariable Mendelian randomization
In a multivariable MR analysis, each genetic variant must satisfy the following criteria:
IV1(M): The variant is associated with at least one of the risk factors X k,
IV2(M): The variant is independent of all confounders U of each of the risk factor‐outcome associations, and
IV3(M): The variant is independent of the outcome Y conditional on the risk factors X k and confounders U.7
Now, the association of the genetic variants with the outcome can be decomposed into indirect effects via each of the risk factors and a residual direct effect . Assuming there are 3 risk factors and all relationships are linear:
| (5) |
where θ k is the causal effect of the risk factor k on the outcome (Figure 2). We assume that the risk factors do not have causal effects on each other; we later relax this assumption and allow for causal effects between the risk factors.
Figure 2.
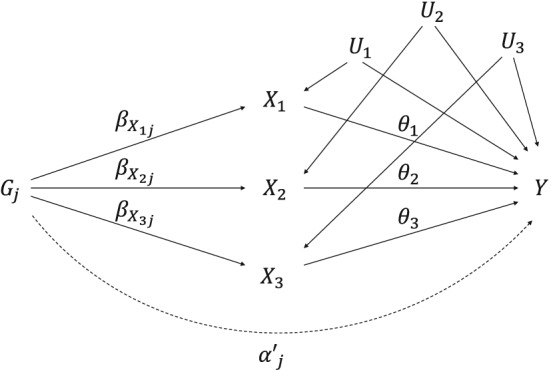
Causal directed acyclic graph illustrating multivariable Mendelian randomization assumptions for a set of genetic variants G j, 3 risk factors X 1, X 2, and X 3, and outcome Y. The genetic effect of G j on X k is , the direct (pleiotropic) effect of G j on Y is , and the causal effect of the risk factor X k on the outcome Y is θ k. U k represents the set of variables that confound the associations between X k and Y
As in the univariable setting, causal estimates of the effect of each risk factor on the outcome can be obtained from individual‐level data using the 2‐stage least squares method.7 The same estimates can also be obtained using multivariable weighted linear regression of the genetic association estimates, with the intercept set to zero (referred to as the multivariable IVW method)20:
| (6) |
We propose the natural extension to multivariable MR‐Egger using the same regression model but allowing the intercept to be estimated:
| (7) |
2.3. Assumptions for multivariable MR‐Egger
We assume that the causal effect of risk factor 1 (θ 1) is of interest and provide the assumptions necessary for the MR‐Egger estimate of θ 1 to be consistent. If all of the causal effects are to be interpreted, then these assumptions must apply for each risk factor.
If the parameters are independent of the parameters for all k=2,3,…,K, then the InSIDE assumption for multivariable MR‐Egger is satisfied if the direct effects of the genetic variants are independent of . More formally, we require:
| (8) |
for the estimate of θ 1 from multivariable MR‐Egger to be consistent. If the InSIDE assumption is satisfied, then the weighted covariance of and ( )) will tend to zero as the number of genetic variants J tends to infinity. The estimate of θ 1 from multivariable MR‐Egger when the parameters are independent of for all k=2,3,…,K is
| (9) |
which is equal to θ 1 if the InSIDE assumption is satisfied, where covw and varw represent the weighted covariance and weighted variance using the inverse‐variance weights :
| (10) |
If the parameters are correlated with at least one of the sets of parameters (k=2,3,…,K), then the InSIDE assumption is required to hold for and for all of the parameters that are correlated with . More formally, we require:
| (11) |
For example, if k=2, and is correlated with , we require both of the weighted covariances of with and to be zero to produce a consistent estimate of θ 1. The estimate of θ 1 from multivariable MR‐Egger with 2 risk factors where and are correlated is
| (12) |
which is equal to θ 1 if the InSIDE assumption holds with respect to and . As more risk factors with correlated sets of association parameters with are included in the multivariable MR‐Egger model, additional terms will be added to the bias term in Equation 12, and the InSIDE assumption must hold for these additional risk factors to obtain a consistent estimate of θ 1.
The variance of the multivariable MR‐Egger estimate will be heavily influenced by the denominator in the bias term of Equation 12. As and become more highly correlated, the standard error of the causal estimate will increase, and in some circumstances, the estimate from multivariable MR‐Egger will be less precise than the estimate from univariable MR‐Egger. The precision of the causal estimates from multivariable MR‐Egger and univariable MR‐Egger is discussed further in the Web Appendix.
2.4. Advantages of multivariable MR‐Egger and comparison with univariable MR‐Egger
The bias for the causal estimate from univariable MR‐Egger depends on the weighted covariance between α and , where
| (13) |
The expression in Equation 13 follows from the multivariable framework outlined in Equation 5, where the direct effect for univariable MR‐Egger has been decomposed into the residual direct effect of multivariable MR‐Egger and the indirect effects via each risk factor. The residual direct effect will be altered with each additional risk factor included in the multivariable MR‐Egger model. If these additional risk factors are causally associated with the outcome (θ k≠0), then will consist of fewer components. It seems likely that the InSIDE assumption would be easier to satisfy for multivariable MR‐Egger than its univariable counterpart as the direct effect for univariable MR‐Egger consists of unmeasured and measured pleiotropy.
If the parameters are independent of the parameters for all k=2,3,…,K, then the second term in Equation 13 (the measured direct effect) does not contribute to the value of . Under this scenario, bias for the univariable and multivariable MR‐Egger estimates depends on the same covariance term . As a consequence, the estimates of the causal effects from univariable MR‐Egger and multivariable MR‐Egger will be asymptotically the same. In this case, multivariable MR‐Egger may improve precision of the causal estimate but will not affect the asymptotic bias.
When the parameters are correlated with at least one of the sets of parameters for k=2,3,…,K, the second term in Equation 13 now contributes to the value of . The InSIDE assumption for univariable MR‐Egger will therefore be automatically violated as the weighted covariance between α and will not equal zero, resulting in biased causal estimates of θ 1. If the InSIDE assumption holds for multivariable MR‐Egger, and are included in the analysis model, then will still be a consistent estimate of θ 1. Hence, in this case, multivariable MR‐Egger should result in reduced bias compared with univariable MR‐Egger.
2.5. Orientation of the genetic variants
Genetic associations represent the average change in the risk factor or the outcome per additional copy of the reference allele. There is no biological rationale why associations should be expressed with respect to either the major (wildtype) or the minor (variant) allele. In the univariable and multivariable IVW methods, the estimate is not affected by the choice of orientation, as the intercept is fixed at zero. However, in the univariable and multivariable MR‐Egger methods, changing the orientation of the variant affects the intercept term and the causal estimate as the orientation affects the definition of the pleiotropy terms α j and . Consequently, for each choice of orientation, there is a different version of the InSIDE assumption.
To ensure that the MR‐Egger analysis does not depend on the reported reference alleles, Bowden et al suggested the genetic variants in univariable MR‐Egger be orientated so the direction of association with the risk factor is either positive for all variants or negative for all variants.9 However, this may not be possible for multivariable MR‐Egger as the same reference allele must be used for associations with each risk factor and with the outcome. We suggest that the variants should be orientated with respect to their associations with the risk factor of primary interest, although we would recommend a sensitivity analysis considering different orientations if multiple risk factors are of interest. If the genetic variants are all valid instruments, then directional pleiotropy should not be detected with respect to any orientation.
3. EXAMPLE: CAUSAL EFFECT OF HDL‐C ON CHD RISK
The effects of high‐density lipoprotein cholesterol (HDL‐C), low‐density lipoprotein cholesterol (LDL‐C), and triglycerides on the risk of coronary heart disease (CHD) have been investigated by numerous MR studies.21 For HDL‐C, univariable MR suggested a causally protective role against CHD risk, whereas univariable MR‐Egger provided no evidence of a causal effect and the test for directional pleiotropy was statistically significant at the 5% level.8 A null causal effect for HDL‐C was also reported from a multivariable MR analysis that included LDL‐C and triglycerides using the multivariable IVW method,7 although a small but protective causal effect was estimated in a further multivariable MR analysis using a wider range of 185 genetic variants.22
We investigate the causal effect of HDL‐C on CHD risk further using the multivariable MR‐Egger method. We consider the 185 genetic variants having known association with at least one of HDL‐C, LDL‐C, and triglycerides at GWAS significance in 188 578 participants reported by the Global Lipids Genetics Consortium.23 The point estimates for the associations between these genetic variants and lipids were taken from Do et al.24 The CARDIoGRAMplusC4D consortium consisting of 60 801 cases and 123 504 controls was used to obtain the estimates of the association between the variants and CHD risk.25 The IVW and MR‐Egger methods were applied to the data under univariable and multivariable frameworks as described in Section 2. For the univariable IVW and MR‐Egger methods, the models were fitted using 2 sets of variants: firstly using all 185 variants; and secondly using all variants associated with HDL‐C at GWAS level of significance. The genetic variants were orientated with respect to the risk increasing allele for HDL‐C. These analyses differ from those provided in Burgess et al and Do et al as they use summarized data from different versions of the CARDIoGRAMplusC4D study22, 24; here, we use associations from the 2015 data release.25
The univariable IVW method suggested a significant protective effect of HDL‐C for both sets of variants with a causal odds ratio of 0.88 (95% CI: 0.80‐0.97) for all variants (Table 1). This estimate attenuated to the null in the univariable MR‐Egger method (0.98, 95% CI: 0.87‐1.11) with evidence of directional pleiotropy (P‐value = 0.004). The causal odds ratios from multivariable IVW (0.96, 95% CI: 0.89‐1.05) and multivariable MR‐Egger (1.04, 95% CI: 0.94‐1.14) had opposite directions of association, with both analyses indicating that HDL‐C is not causally associated with CHD risk. The significant result for directional pleiotropy in the multivariable MR‐Egger method suggests that LDL‐C and triglycerides do not fully explain the direct effects of the genetic variants on the outcome, suggesting that there is still residual pleiotropy via other unmeasured risk factors.
Table 1.
Log causal odds ratios (95% confidence intervals) for coronary heart disease per standard deviation increase in HDL‐C, with 2‐sided P‐values. Estimates of the intercept are given in univariable and multivariable MR‐Egger
| Causal Estimate | MR‐Egger Intercept Test | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| (CI) |
|
P‐value |
|
|
P‐value | ||||
| Univariable IVW | |||||||||
| All variants | −0.130 (−0.227, −0.033) | 0.049 | 0.009 | ‐ | ‐ | ‐ | |||
| Reduced set of variantsa | −0.114 (−0.211, −0.017) | 0.049 | 0.022 | ‐ | ‐ | ‐ | |||
| Univariable MR‐Egger | |||||||||
| All variants | −0.016 (−0.138, 0.106) | 0.062 | 0.800 | −0.007 | 0.002 | 0.004 | |||
| Reduced set of variantsa | 0.067 (−0.070, 0.204) | 0.069 | 0.332 | −0.012 | 0.004 | 0.001 | |||
| Multivariable IVW | −0.039 (−0.123, 0.045) | 0.042 | 0.359 | ‐ | ‐ | ‐ | |||
| Multivariable MR‐Egger | 0.036 (−0.063, 0.134) | 0.050 | 0.477 | −0.005 | 0.002 | 0.008 | |||
Abbreviations: CI, confidence interval; HDL‐C, high‐density lipoprotein cholesterol; IVW, inverse‐variance weighted; MR, Mendelian randomization; SE, standard error.
a95 variants associated with HDL‐C at a genome‐wide level of significance (P‐value<5×10−8).
3.1. Varying the orientation of the genetic variants
As a sensitivity analysis, the multivariable MR‐Egger method was reperformed with the genetic variants orientated with respect to the risk increasing alleles for LDL‐C and triglycerides.
The causal estimates for HDL‐C, LDL‐C, and triglycerides from multivariable MR‐Egger when the variants were orientated with respect to HDL‐C, LDL‐C or triglycerides are presented in Table 2. Estimates of the MR‐Egger intercept are also provided for the three models. To allow for comparisons between the multivariable methods, the causal estimates from multivariable IVW are included in Table 2. The causal estimates in bold follow the recommendation outlined in Section 2.5 that the genetic variants should be orientated with respect to the risk factor‐increasing allele for the risk factor of interest.
Table 2.
Causal log odds ratios (95% confidence intervals) for coronary heart disease per standard deviation increase in HDL‐C, LDL‐C, and triglycerides from multivariable IVW and multivariable MR‐Egger. Estimates from multivariable MR‐Egger are presented from 3 models where the reference allele is the risk increasing allele for HDL‐C, LDL‐C, or triglycerides. Estimates of the intercept are given for multivariable MR‐Egger
| Causal Estimates | MR‐Egger Intercept | |||||||
|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
|||||
| Multivariable IVW | −0.039 (−0.123, 0.045) | 0.375 (0.292, 0.457) | 0.173 (0.063, 0.283) | ‐ | ||||
| Multivariable MR‐Egger | ||||||||
| Orientation with respect toa: | ||||||||
| HDL‐C | 0.036 (−0.063, 0.134) | 0.378 (0.297, 0.458) | 0.136 (0.024, 0.247) | −0.005 (−0.009, −0.001) | ||||
| LDL‐C | −0.034 (−0.118, 0.049) | 0.420 (0.318, 0.522) | 0.194 (0.081, 0.308) | −0.003 (−0.007, 0.001) | ||||
| TG | −0.018 (−0.102, 0.066) | 0.350 (0.267, 0.433) | 0.083 (−0.045, 0.211) | 0.005 (0.001, 0.009) | ||||
Abbreviations: HDL‐C, high‐density lipoprotein cholesterol; LDL‐C, low‐density lipoprotein cholesterol; MR, Mendelian randomization; TG, triglycerides.
aAlleles orientated for all genetic associations with respect to the risk increasing allele for HDL‐C, LDL‐C, or triglycerides.
All of the causal odds ratios for HDL‐C from the multivariable MR‐Egger models indicated that HDL‐C is not causally associated with CHD risk. Significant adverse effects of LDL‐C on CHD risk were reported from the multivariable IVW (1.45, 95% CI: 1.34‐1.58) and multivariable MR‐Egger (1.52, 95% CI: 1.37‐1.69) methods. Orientating the variants with respect to the risk increasing alleles for HDL‐C and triglycerides had little impact on the causal estimates for LDL‐C from multivariable MR‐Egger. The multivariable IVW method suggested a significant adverse effect of triglycerides on CHD risk with a causal odds ratio of 1.19 (95% CI: 1.07, 1.33), this estimate was attenuated to the null in the multivariable MR‐Egger method (1.09, 95% CI: 0.96, 1.23). The causal odds ratios for triglycerides remained significant, however, when the variants were orientated with respect to HDL‐C and LDL‐C in the multivariable MR‐Egger models.
Since the orientation of the genetic variants affects the interpretation of the direct effect, and the definition of the InSIDE assumption, the MR‐Egger intercept will vary between different orientations. In this example, the MR‐Egger intercept differed from zero when the variants were orientated with respect to HDL‐C and triglycerides, yet there was no evidence of directional pleiotropy or the InSIDE assumption being violated when the variants were orientated with respect to LDL‐C.
4. SIMULATION STUDY
To assess the merits of using multivariable MR‐Egger over multivariable IVW and univariable MR‐Egger in realistic settings, we perform a simulation study. Univariable and multivariable MR‐Egger will be compared with respect to the consistency of the causal estimates and statistical power to detect the causal effect. The setup of the simulation study corresponds to the applied example in Section 3 and will be considered under 2 broad scenarios: (1) are generated independently for all k=1,2,…,K; and (2) are correlated for all k=1,2,…,K.
We simulated summarized level data for 185 genetic variants indexed by j=1,2,…,J for 3 risk factors (X 1, X 2, X 3) and an outcome Y from the following data‐generating model:
| (14) |
The primary objective was to estimate θ 1, with the causal effects set to: θ 1=0(null causal effect) or θ 1=0.3(positive causal effect); θ 2=0.1; and θ 3=−0.3. The data were simulated to consider the following four scenarios:
No pleiotropy ( for all j), InSIDE assumption automatically satisfied;
Balanced pleiotropy (μ=0), InSIDE assumption satisfied;
Directional pleiotropy (μ=0.01,0.05 or 0.1), InSIDE assumption satisfied;
Directional pleiotropy (μ=0.01,0.05 or 0.1), InSIDE assumption violated.
When the InSIDE assumption for multivariable MR‐Egger was satisfied, and were drawn from independent distributions, and when it was violated, they were drawn from a multivariate normal distribution with . The above 4 scenarios were applied to the simulated data when were generated independently for all k, with the parameters in the covariance matrix set to: ; ; ; and ρ 12=ρ 13=ρ 23=0. The 4 scenarios were repeated when were correlated for all k(ρ 12=0.2, ρ 13=−0.3, ρ 23=0.1). The mean F‐statistics were greater than 200 and I 2 statistics greater than 99% in each scenario; values are provided in Web Tables A1 and A2. In total, data were simulated for 32 different choices of parameters.
To ensure the direction of association between G j and X 1 was the same for all j variants, the absolute value of the genetic associations with X 1( ) were used to generate (Equation (14)). It was assumed that (for all k) and had the same reference allele and the genetic variants were uncorrelated. The multivariable IVW, univariable MR‐Egger, and multivariable MR‐Egger methods were applied to the simulated datasets. The weights for the multivariable IVW and multivariable MR‐Egger are given by Equation 15, while Equation 16 contains the weights for univariable MR‐Egger:
| (15) |
| (16) |
4.1. Results
The results from the simulation study using 10 000 simulated datasets are presented in Table 3 ( generated independently) and Table 4 ( correlated). For each scenario, the mean estimate, the mean standard error, and the statistical power to detect a null or positive causal effect at a nominal 5% significance level are presented in Tables 3 and 4 for the multivariable IVW, univariable MR‐Egger, and multivariable MR‐Egger methods. For univariable and multivariable MR‐Egger, the statistical power of the MR‐Egger intercept test is also provided.
In scenarios 1 and 2 (no and balanced pleiotropy), estimates from all methods were unbiased, and those from the multivariable IVW method were the most precise. In scenarios 3 and 4 (directional pleiotropy), estimates from the multivariable IVW method were biased, with the magnitude of bias increasing as the average value of increased from 0.01 to 0.1. In scenario 3 (InSIDE satisfied), estimates from the univariable and multivariable MR‐Egger methods were unbiased, whereas in scenario 4 (InSIDE violated), they were biased. Although the causal estimates for both multivariable IVW and multivariable MR‐Egger were biased under scenario 4, the magnitude of bias was less for multivariable MR‐Egger, with the exception of when was generated from . Precision and power to detect a causal effect were always better for the multivariable MR‐Egger method than univariable MR‐Egger, although the univariable MR‐Egger method detected directional pleiotropy more often. The average value of had no impact on the degree of bias for univariable or multivariable MR‐Egger.
Bias for the multivariable IVW method was present in scenarios 3 and 4 only, as in the independently generated setting. In this setting, the InSIDE assumption for univariable MR‐Egger was violated for all 4 scenarios, resulting in biased point estimates of θ 1. However, the multivariable InSIDE assumption was satisfied for scenarios 1, 2, and 3, and so causal estimates from multivariable MR‐Egger were unbiased. When the multivariable InSIDE assumption was violated (scenario 4) the estimates from multivariable MR‐Egger were biased, yet the magnitude of bias was less compared with univariable MR‐Egger as .
Table 3.
Performance of multivariable IVW, univariable MR‐Egger, and multivariable MR‐Egger with respect to for a null (θ 1=0) and positive (θ 1=0.3) causal effect where are generated independently for all k. All tests were performed at the 5% level of significance
| Multivariable IVW | Univariable MR‐Egger | Multivariable MR‐Egger | ||||||
|---|---|---|---|---|---|---|---|---|
| Mean | Power, | Mean | Power, % | Mean | Power, % | |||
| (mean SE) | % | (mean SE) | Intercept | Causal | (mean SE) | Intercept | Causal | |
| Null causal effect: θ1=0 | ||||||||
| 1. No pleiotropy, InSIDE satisfied | ||||||||
| 0.000 (0.045) | 3.8 | −0.002 (0.158) | 9.1 | 4.7 | 0.000 (0.084) | 3.7 | 4.1 | |
| 2. Balanced pleiotropy, InSIDE satisfied | ||||||||
| (0,0.004) | ‐0.001 (0.100) | 4.7 | −0.001 (0.187) | 7.8 | 4.7 | 0.000 (0.165) | 4.6 | 4.6 |
| 3. Directional pleiotropy, InSIDE satisfied | ||||||||
| (0.01,0.004) | 0.041 (0.100) | 6.7 | −0.003 (0.187) | 12.2 | 4.3 | −0.002 (0.165) | 5.9 | 4.5 |
| (0.05,0.004) | 0.210 (0.100) | 55.3 | 0.002 (0.187) | 49.2 | 4.6 | 0.002 (0.166) | 36.3 | 4.6 |
| (0.1,0.004) | 0.417 (0.102) | 97.4 | 0.000 (0.187) | 91.6 | 4.3 | 0.001 (0.165) | 88.0 | 4.6 |
| 4. Directional pleiotropy, InSIDE violated | ||||||||
| (0.01,0.004) | 0.074 (0.100) | 12.3 | 0.089 (0.187) | 6.7 | 7.6 | 0.088 (0.165) | 4.3 | 8.4 |
| (0.05,0.004) | 0.240 (0.100) | 67.2 | 0.089 (0.187) | 34.1 | 7.8 | 0.088 (0.165) | 21.1 | 8.8 |
| (0.1,0.004) | 0.450 (0.101) | 98.6 | 0.088 (0.187) | 84.1 | 7.6 | 0.088 (0.165) | 78.7 | 8.7 |
| Positive causal effect: θ1=0.3 | ||||||||
| 1. No pleiotropy, InSIDE satisfied | ||||||||
| 0.300 (0.044) | 98.9 | 0.300 (0.157) | 9.3 | 50.1 | 0.300 (0.084) | 4.3 | 87.3 | |
| 2. Balanced pleiotropy, InSIDE satisfied | ||||||||
| (0,0.004) | 0.301 (0.100) | 84.6 | 0.303 (0.187) | 7.5 | 38.2 | 0.302 (0.166) | 4.9 | 46.4 |
| 3. Directional pleiotropy, InSIDE satisfied | ||||||||
| (0.01,0.004) | 0.343 (0.100) | 91.5 | 0.300 (0.187) | 12.8 | 36.8 | 0.299 (0.165) | 6.0 | 45.8 |
| (0.05,0.004) | 0.509 (0.100) | 99.7 | 0.300 (0.188) | 50.6 | 37.3 | 0.299 (0.166) | 37.1 | 46.1 |
| (0.1,0.004) | 0.716 (0.102) | 100.0 | 0.300 (0.187) | 91.1 | 37.1 | 0.299 (0.166) | 87.9 | 46.1 |
| 4. Directional pleiotropy, InSIDE violated | ||||||||
| (0.01,0.004) | 0.374 (0.099) | 94.3 | 0.390 (0.187) | 6.6 | 56.4 | 0.389 (0.165) | 4.6 | 65.8 |
| (0.05,0.004) | 0.539 (0.100) | 99.8 | 0.388 (0.187) | 34.4 | 55.6 | 0.387 (0.165) | 21.5 | 65.5 |
| (0.1,0.004) | 0.747 (0.101) | 100.0 | 0.383 (0.187) | 84.7 | 55.1 | 0.384 (0.165) | 78.3 | 65.2 |
Abbreviations: InSIDE, Instrument Strength Independent of Direct Effect; IVW, inverse‐variance weighted; MR, Mendelian randomization; SE, standard error.
Table 4.
Performance of multivariable IVW, univariable MR‐Egger, and multivariable MR‐Egger with being correlated for all k
| Multivariable IVW | Univariable MR‐Egger | Multivariable MR‐Egger | ||||||
|---|---|---|---|---|---|---|---|---|
| Mean | Power, | Mean | Power, % | Mean | Power, % | |||
| (mean SE) | % | (mean SE) | Intercept | Causal | (mean SE) | Intercept | Causal | |
| Null causal effect: θ1=0 | ||||||||
| 1. No pleiotropy, InSIDE satisfied | ||||||||
| 0.000 (0.047) | 4.0 | 0.099 (0.157) | 4.3 | 10.1 | 0.000 (0.086) | 4.4 | 4.6 | |
| 2. Balanced pleiotropy, InSIDE satisfied | ||||||||
| (0,0.004) | −0.001 (0.104) | 4.7 | 0.093 (0.187) | 4.5 | 7.4 | −0.003 (0.169) | 4.6 | 4.4 |
| 3. Directional pleiotropy, InSIDE satisfied | ||||||||
| (0.01,0.004) | 0.043 (0.104) | 7.0 | 0.099 (0.187) | 5.8 | 8.0 | 0.001 (0.169) | 5.9 | 4.8 |
| (0.05,0.004) | 0.213 (0.105) | 52.7 | 0.095 (0.187) | 33.3 | 7.6 | 0.000 (0.169) | 37.2 | 4.5 |
| (0.1,0.004) | 0.426 (0.107) | 96.3 | 0.096 (0.187) | 84.5 | 7.6 | −0.001 (0.169) | 89.2 | 4.6 |
| 4. Directional pleiotropy, InSIDE violated | ||||||||
| (0.01,0.004) | 0.062 (0.104) | 9.5 | 0.184 (0.187) | 4.6 | 17.9 | 0.078 (0.169) | 4.7 | 7.6 |
| (0.05,0.004) | 0.235 (0.104) | 62.1 | 0.187 (0.187) | 20.5 | 18.3 | 0.082 (0.169) | 22.3 | 7.5 |
| (0.1,0.004) | 0.448 (0.106) | 97.9 | 0.181 (0.187) | 73.3 | 17.8 | 0.077 (0.169) | 80.3 | 7.2 |
| Positive causal effect: θ1=0.3 | ||||||||
| 1. No pleiotropy, InSIDE satisfied | ||||||||
| 0.300 (0.047) | 98.7 | 0.395 (0.158) | 4.4 | 70.8 | 0.299 (0.087) | 3.9 | 86.2 | |
| 2. Balanced pleiotropy, InSIDE satisfied | ||||||||
| (0,0.004) | 0.300 (0.104) | 81.5 | 0.399 (0.187) | 4.4 | 58.0 | 0.301 (0.169) | 4.6 | 44.4 |
| 3. Directional pleiotropy, InSIDE satisfied | ||||||||
| (0.01,0.004) | 0.342 (0.104) | 89.4 | 0.395 (0.187) | 6.4 | 57.4 | 0.301 (0.169) | 5.9 | 44.4 |
| (0.05,0.004) | 0.513 (0.105) | 99.4 | 0.394 (0.187) | 33.0 | 57.4 | 0.296 (0.169) | 38.0 | 43.4 |
| (0.1,0.004) | 0.729 (0.107) | 100.0 | 0.400 (0.187) | 83.5 | 58.2 | 0.304 (0.169) | 88.6 | 45.5 |
| 4. Directional pleiotropy, InSIDE violated | ||||||||
| (0.01,0.004) | 0.365 (0.104) | 92.1 | 0.489 (0.187) | 4.2 | 74.0 | 0.382 (0.169) | 4.6 | 63.2 |
| (0.05,0.004) | 0.535 (0.104) | 99.7 | 0.486 (0.187) | 20.3 | 72.9 | 0.382 (0.169) | 21.1 | 63.2 |
| (0.1,0.004) | 0.749 (0.106) | 100.0 | 0.488 (0.187) | 72.5 | 73.4 | 0.381 (0.169) | 79.6 | 62.8 |
Abbreviations: InSIDE, Instrument Strength Independent of Direct Effect; IVW, inverse‐variance weighted; MR, Mendelian randomization; SE, standard error.
4.2. Causal relationships between the risk factors
The simulations performed in Section 4.1 assumed that the effect of each risk factor on the outcome is not mediated through another risk factor. There may be circumstances where causal relationships between risk factors are biologically plausible. Burgess et al illustrated that the multivariable IVW method estimates the direct causal effects (θ k) of each risk factor on the outcome, irrespective of whether causal relationships between the risk factors exist.7
In the applied example of the paper, there may also be deterministic dependencies between the risk factors. LDL‐C is rarely measured directly but is estimated from measurements of total cholesterol, triglycerides, and HDL‐C via the Friedewald equation as total cholesterol minus HDL‐C minus 0.2 times triglycerides (assuming all measurements in mg/dL).26 It has previously been shown that the coefficient for LDL‐C is the same as the coefficient for non‐HDL‐C (calculated as total cholesterol minus HDL‐C) in a regression model including HDL‐C and triglycerides (see Appendix 2 in the paper by Di Angelantonio et al).27 However, the coefficient for triglycerides will change, as the non‐HDL‐C measure contains more triglycerides than the LDL‐C measure. Hence, in the case that there are deterministic relationships between the risk factors, effect estimates may change as the choice of risk factors varies due to their interpretation as direct effects conditional on other risk factors in the regression model.
We performed additional simulations to investigate the behaviour of the multivariable MR‐Egger method when X 2 is causally dependent on X 1, and the causal effect of X 1 on X 2 is γ (Figure 3). The total causal effect of X 1 on Y is θ 1+γ θ 2, consisting of the direct effect (θ 1) and the indirect effect via X 2(γ θ 2). See the Web Appendix for more details on the data generating model.
Figure 3.
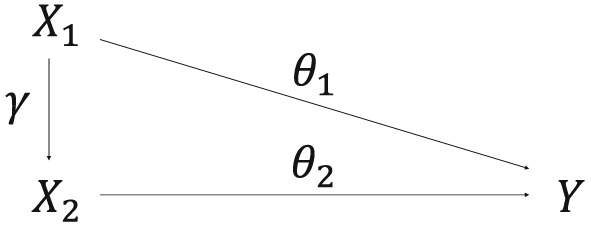
Causal directed acyclic graph illustrating the causal relationships between the 2 risk factors X 1 and X 2, and outcome Y. The causal effect of X 1 on X 2 is γ, and the direct causal effect of the risk factor X k on the outcome Y is θ k. The total causal effect of X 1 on Y is θ 1+γ θ 2, consisting of the direct effect (θ 1) and the indirect effect via X 2 (γ θ 2). U k represents the set of variables that confound the associations between X k and Y
4.2.1. Results
The results from the additional simulations are provided in Web Table A3 and Web Table A4. In scenarios where there was no bias in the original set of simulations, the multivariable IVW and multivariable MR‐Egger methods consistently estimated the direct effect of X 1 on Y(θ 1), while the univariable MR‐Egger method consistently estimated the total causal effect of X 1 on Y(θ 1+γ θ 2). Compared to the results in Section 4.1 precision and power to detect a causal effect were reduced for the multivariable IVW and multivariable MR‐Egger methods. This reduction in power was anticipated since the multivariable models condition on the mediator along a causal pathway, which is known to decrease power to detect a causal effect.28
5. DISCUSSION
In this paper, we have extended univariable MR‐Egger to the multivariable setting and outlined the assumptions required to obtain consistent causal estimates in the presence of directional pleiotropy. Multivariable MR‐Egger should be viewed as a sensitivity analysis to provide robustness against both measured and unmeasured pleiotropy and to strengthen the evidence from the original MR analysis. If the causal estimate from multivariable MR‐Egger is substantially different from the estimate obtained in the original analysis, then further investigation into the causal finding and the potential for pleiotropy is required.
The simulation study has highlighted the benefits of using multivariable MR‐Egger over its univariable counterpart. This is particularly true when the associations of the genetic variants with the risk factor of interest are associated with genetic associations with at least one of the risk factors (measured pleiotropy). Under this scenario, the InSIDE assumption for univariable MR‐Egger is likely to be violated, leading to biased causal estimates. Multivariable MR‐Egger will, however, produce consistent causal estimates if the InSIDE assumption for multivariable MR‐Egger is satisfied. Although the estimates from univariable and multivariable MR‐Egger are asymptotically the same when genetic associations with each risk factor are all independent, multivariable MR‐Egger should also have greater power to detect a causal effect when the InSIDE assumption is satisfied. Given these advantages, and the sensitivity of the multivariable IVW method to directional pleiotropy, we believe that multivariable MR‐Egger should be considered as an important sensitivity analysis for a MR study.
5.1. Multivariable by design, or multivariable as a sensitivity analysis?
There are 2 possible scenarios where multivariable MR‐Egger may be used as a sensitivity analysis: either the primary analysis is considered to be multivariable by design, or a multivariable framework is only considered as part of the sensitivity analysis. The first case should be motivated by biological evidence where the set of risk factors are known to be associated with common genetic variants, such as lipid fractions. Under this scenario, multivariable IVW should be used as the primary analysis method with multivariable MR‐Egger providing robustness against directional pleiotropy as a sensitivity analysis.
In the second scenario, where there is a lack of biological evidence to suggest a multivariable framework, univariable IVW would generally be considered as the primary analysis method and univariable MR‐Egger as the main sensitivity analysis. However, if the genetic variants are associated with other risk factors, multivariable MR‐Egger could also be used as a sensitivity analysis as its assumptions are more likely to be satisfied and it may have greater power to detect a causal effect than univariable MR‐Egger. An example of the use of multivariable MR as a sensitivity analysis is an MR study on plasma urate concentrations and CHD risk.29 To account for measured and unmeasured pleiotropic associations of the genetic variants, the authors performed the multivariable IVW and univariable MR‐Egger methods as sensitivity analyses. This investigation may have benefited from performing the multivariable MR‐Egger method to simultaneously account for both measured and unmeasured pleiotropic associations.
5.2. InSIDE assumption and orientation of genetic variants
The validity of multivariable MR‐Egger and its ability to estimate consistent causal effects is dependent upon the InSIDE assumption being satisfied. While it is not possible to determine whether the InSIDE assumption has been violated, we believe it is more likely to hold for multivariable MR‐Egger then univariable MR‐Egger. When the βX 1 parameters are associated with at least one of the sets of parameters for k=2,3,…,K, the InSIDE assumption for univariable MR‐Egger is automatically violated and causal estimates from the method will be inconsistent. The direct effects of the genetic variants on the outcome will consist of fewer components for multivariable MR‐Egger compared to its univariable counterpart, making it more plausible that the InSIDE assumption will hold for multivariable MR‐Egger.
The recommendation of orientating the genetic variants in multivariable MR‐Egger to the risk factor‐increasing or risk factor‐decreasing allele for the risk factor of interest may be considered arbitrary. While we accept this limitation, we would argue that it brings consistency to the results. This recommendation may result in the analysis being performed up to K times to obtain the causal estimates for all K risk factors. The orientation of the genetic variants will also affect the interpretation of the direct effect, thereby altering the InSIDE assumption. This may result in the MR‐Egger intercept estimate varying between different orientations. This was seen in the applied example where the intercept term was non‐significant when the alleles were orientated with respect to LDL‐C, and significant when orientated with respect to HDL‐C and trigclyercides.
5.3. Linearity and homogeneity assumptions
Throughout this paper, we have assumed linearity and homogeneity (no effect modification) of the causal effects of the risk factors on the outcome, and of the associations between the genetic variants with the risk factors and with the outcome. If the assumptions of linearity and homogeneity are violated then the methods discussed in this paper still provide a valid test for the null hypothesis of whether the risk factor is causally associated with the outcome.12 The causal estimate, however, would not have a literal interpretation if the assumptions were violated.30 Although linearity and homogeneity are strong assumptions, the effect of genetic variants on the risk factor and outcome tend to be limited to a small range, which may make the assumptions of linearity and homogeneity more reasonable in an MR analysis.
The multivariable models have assumed that the risk factors do not have causal effects on each other. The additional simulation study has illustrated that the multivariable MR‐Egger method estimates the direct causal effects of the risk factors on the outcome, irrespective of whether the risk factors are causally related. There was, however, a reduction in precision and power to detect the causal effect for multivariable MR‐Egger when a causal relationship between the risk factors was present. Conversely, univariable MR‐Egger will produce consistent causal estimates of the total effect if the InSIDE assumption for univariable MR‐Egger is satisfied.
5.4. Implication for future research
The paper by Helgadottir et al highlights the importance and need to develop sensitivity analyses for multivariable MR.10 This is particularly relevant given the recent advances in high‐throughput phenotyping which has led to the introduction of “‐omics” data such as metabolomics, genomics, and proteomics.31 Genome‐wide analyses of high‐dimensional “‐omics” data are becoming more popular,32, 33 yet few MR analyses have been performed using these datasets.21 As summarized data from large consortia become more accessible, the opportunities to use MR on high‐dimensional datasets will only increase. Methods such as multivariable MR‐Egger will be valuable to investigate the causal effects of multiple related phenotypes with shared genetic predictors.
Bowden et al have shown that uncertainty in the associations between the genetic variants and the risk factor in univariable MR‐Egger can lead to attenuation towards the null when a causal effect exists between the risk factor and the outcome.34 This attenuation is approximately equal to the I 2 statistic from meta‐analysis of the weighted associations with the exposure , with standard errors .34 Since the mean I 2 statistics for the simulation study in this paper were close to 100%, there was no substantial bias in the causal estimates due to uncertainty in the genetic associations for either the univariable or multivariable MR‐Egger methods. However, it is unclear whether uncertainty in the genetic associations with the risk factors would always lead to the attenuation of the causal estimates for the multivariable MR‐Egger method. Further research is required to investigate this.
Throughout the paper, we have assumed that the genetic variants are uncorrelated (not in linkage disequilibrium). This assumption, and the requirement for further methodological development, is discussed in the Web Appendix.
Supporting information
SIM_7492‐Sup‐0001‐Rees_appendix.pdf
ACKNOWLEDGEMENTS
Jessica Rees is supported by the British Heart Foundation (grant number FS/14/59/31282). Stephen Burgess is supported by Sir Henry Dale Fellowship jointly funded by the Wellcome Trust and the Royal Society (Grant Number 204623/Z/16/Z).
Rees JMB, Wood AM, Burgess S. Extending the MR‐Egger method for multivariable Mendelian randomization to correct for both measured and unmeasured pleiotropy. Statistics in Medicine. 2017;36:4705–4718. https://doi.org/10.1002/sim.7492
REFERENCES
- 1. Smith GD, Ebrahim S. Mendelian randomization: Can genetic epidemiology contribute to understanding environmental determinants of disease? Int J Epidemiol. 2003;32(1):1‐22. [DOI] [PubMed] [Google Scholar]
- 2. Lawlor DA, Harbord RM, Sterne JA, Timpson N, Davey Smith G. Mendelian randomization: Using genes as instruments for making causal inferences in epidemiology. Stat Med. 2008;27(8):1133‐1163. [DOI] [PubMed] [Google Scholar]
- 3. Sleiman PM, Grant SF. Mendelian randomization in the era of genomewide association studies. Clin Chem. 2010;56(5):723‐728. [DOI] [PubMed] [Google Scholar]
- 4. Brion MJ, Shakhbazov K, Visscher PM. Calculating statistical power in Mendelian randomization studies. Int J Epidemiol. 2013;42(5):1497‐1501. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Freeman G, Cowling BJ, Schooling CM. Power and sample size calculations for Mendelian randomization studies using one genetic instrument. Int J Epidemiol. 2013;42(4):1157‐1163. [DOI] [PubMed] [Google Scholar]
- 6. Burgess S, Thompson SG. Use of allele scores as instrumental variables for Mendelian randomization. Int J Epidemiol. 2013;42(4):1134‐1144. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Burgess S, Thompson SG. Multivariable Mendelian randomization: The use of pleiotropic genetic variants to estimate causal effects. Am J Epidemiol. 2015;181(4):251‐260. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Bowden J, Davey Smith G, Haycock PC, Burgess S. Consistent estimation in mendelian randomization with some invalid instruments using a weighted median estimator. Genet Epidemiol. 2016;40(4):304‐314. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Bowden J, Davey Smith G, Burgess S. Mendelian randomization with invalid instruments: Effect estimation and bias detection through Egger regression. Int J Epidemiol. 2015;44(2):512‐525. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Helgadottir A, Gretarsdottir S, Thorleifsson G, et al. Variants with large effects on blood lipids and the role of cholesterol and triglycerides in coronary disease. Nat Genet. 2016;48(6):634‐639. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Burgess S, Scott RA, Timpson NJ, Davey Smith G, Thompson SG. Using published data in Mendelian randomization: A blueprint for efficient identification of causal risk factors. Eur J Epidemiol. 2015;30(7):543‐552. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Burgess S, Dudbridge F, Thompson SG. Combining information on multiple instrumental variables in Mendelian randomization: Comparison of allele score and summarized data methods. Stat Med. 2016;35(11):1880‐1906. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Greenland S. An introduction to instrumental variables for epidemiologists. Int J Epidemiol. 2000;29(4):722‐729. [DOI] [PubMed] [Google Scholar]
- 14. Didelez V, Sheehan N. Mendelian randomization as an instrumental variable approach to causal inference. Stat Methods Med Res. 2007;16(4):309‐330. [DOI] [PubMed] [Google Scholar]
- 15. Johnson T. Efficient calculation for multi‐SNP genetic risk scores, The Comprehensive R Archive Network; 2013. http://cran.r‐project.org/web/packages/gtx/vignettes/ashg2012.pdf. Accessed June 14, 2016.
- 16. Angrist JD, Imbens GW. Two‐stage least squares estimation of average causal effects in models with variable treatment intensity. J Am Stat Assoc. 1995;90(430):431‐442. [Google Scholar]
- 17. Burgess S, Butterworth A, Thompson SG. Mendelian randomization analysis with multiple genetic variants using summarized data. Genet Epidemiol. 2013;37(7):658‐665. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Thompson SG, Sharp SJ. Explaining heterogeneity in meta‐analysis: A comparison of methods. Stat Med. 1999;18(20):2693‐2708. [DOI] [PubMed] [Google Scholar]
- 19. Kolesár M, Chetty R, Friedman J, Glaeser E, Imbens G. Identification and inference with many invalid instruments. J Bus Econ Stat. 2015;33(4):474‐484. http://doi.org.10.1080/07350015.2014.978175 [Google Scholar]
- 20. Burgess S, Dudbridge F, Thompson SG. Re: “Multivariable Mendelian randomization: The use of pleiotropic genetic variants to estimate causal effects". Am J Epidemiol. 2015;181(4):290‐291. [DOI] [PubMed] [Google Scholar]
- 21. Burgess S, Harshfield E. Mendelian randomization to assess causal effects of blood lipids on coronary heart disease: Lessons from the past and applications to the future. Curr Opin Endocrinol Diabetes. 2016;23(2):124‐130. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Burgess S, Freitag DF, Khan H, Gorman DN, Thompson SG. Using multivariable Mendelian randomization to disentangle the causal effects of lipid fractions. PLoS One. 2014;9(10):e108891. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Willer CJ, Schmidt EM, Sengupta S, et al. Discovery and refinement of loci associated with lipid levels. Nat Genet. 2013;45(11):1274‐1283. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Do R, Willer CJ, Schmidt EM, et al. Common variants associated with plasma triglycerides and risk for coronary artery disease. Nat Genet. 2013;45(11):1345‐1352. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Nikpay M, Goel A, Won HH, et al. A comprehensive 1,000 Genomes‐based genome‐wide association meta‐analysis of coronary artery disease. Nat Genet. 2015;47(10):1121‐1130. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Friedewald WT, Levy RI, Fredrickson DS. Estimation of the concentration of low‐density lipoprotein cholesterol in plasma, without use of the preparative ultracentrifuge. Clin Chem. 1972;18(6):499‐502. [PubMed] [Google Scholar]
- 27. Di Angelantonio E, Sarwar N, Perry P, et al. Major lipids, apolipoproteins, and risk of vascular disease. JAMA. 2009;302(18):1993‐2000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Fritz MS, Mackinnon DP. Required sample size to detect the mediated effect. Psychol Sci. 2007;18(3):233‐239. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. White J, Sofat R, Hemani G, et al. Plasma urate concentration and risk of coronary heart disease: A Mendelian randomisation analysis. Lancet Diabetes Endocrinol. 2016;4(4):327‐336. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30. Burgess S, Butterworth AS, Thompson JR. Beyond Mendelian randomization: How to interpret evidence of shared genetic predictors. J Clin Epidemiol. 2016;69:208‐216. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31. Relton CL, Davey Smith G. Is epidemiology ready for epigenetics? Int J Epidemiol. 2012;41(1):5‐9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Suhre K, Raffler J, Kastenmuller G. Biochemical insights from population studies with genetics and metabolomics. Arch Biochem Biophys. 2016;589:168‐176. [DOI] [PubMed] [Google Scholar]
- 33. Kastenmuller G, Raffler J, Gieger C, Suhre K. Genetics of human metabolism: An update. Hum Mol Genet. 2015;24(R1):R93‐R101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Bowden J, Del Greco MF, Minelli C, Davey Smith G, Sheehan NA, Thompson JR. Assessing the suitability of summary data for two‐sample Mendelian randomization analyses using MR‐Egger regression: The role of the I2 statistic. Int J Epidemiol. 2016;45(6):1961‐1974. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
SIM_7492‐Sup‐0001‐Rees_appendix.pdf