

Abstract
The incubation period for typhoid, polio, measles, leukemia and many other diseases follows a right-skewed, approximately lognormal distribution. Although this pattern was discovered more than sixty years ago, it remains an open question to explain its ubiquity. Here, we propose an explanation based on evolutionary dynamics on graphs. For simple models of a mutant or pathogen invading a network-structured population of healthy cells, we show that skewed distributions of incubation periods emerge for a wide range of assumptions about invader fitness, competition dynamics, and network structure. The skewness stems from stochastic mechanisms associated with two classic problems in probability theory: the coupon collector and the random walk. Unlike previous explanations that rely crucially on heterogeneity, our results hold even for homogeneous populations. Thus, we predict that two equally healthy individuals subjected to equal doses of equally pathogenic agents may, by chance alone, show remarkably different time courses of disease.
Research organism: Human
eLife digest
When one child goes to school with a throat infection, many of his or her classmates will often start to come down with a sore throat after two or three days. A few of the children will get sick sooner, the very next day, while others may take about a week. As such, there is a distribution of incubation periods – the time from exposure to illness – across the children in the class.
When plotted on a graph, the distribution of incubation periods is not the normal bell curve. Rather the curve looks lopsided, with a long tail on the right. Plotting the logarithms of the incubation periods, however, rather than the incubation periods themselves, does give a normal distribution. As such, statisticians refer to this kind of curve as a “lognormal distribution". Remarkably, many other, completely unrelated, diseases – like typhoid fever or bladder cancer – also have approximately lognormal distributions of incubation periods. This raised the question: why do such different diseases show such a similar curve?
Working with a simple mathematical model in which chance plays a key role, Ottino-Löffler et al. calculate how long it takes for a bacterial infection or cancer cell to take over a network of healthy cells. The model explains why a lognormal-like distribution of incubation periods, modeled as takeover times, is so ubiquitous. It emerges from the random dynamics of the incubation process itself, as the disease-causing microbe or mutant cancer cell competes with the cells of the host.
Intuitively, this new analysis builds on insights from the “coupon collector’s problem”: a classical problem in mathematics that describes the situation where a person collects items like baseball cards, stamps, or cartoon monsters in a videogame. If a random item arrives every day, and the collector’s luck is bad, they may have to wait a long time to collect those last few items. Similarly, in the model of Ottino-Löffler et al., the takeover time is dominated by dramatic slowdowns near the start or end of the infection process. These effects lead to an approximately lognormal distribution, with long waits, as seen in so many diseases.
Ottino-Löffler et al. do not anticipate that their findings will have direct benefits for medicine or public health. Instead, they believe their results could help to advance basic research in the fields of epidemiology, evolutionary biology and cancer research. The findings might also make an impact outside biology. The term “contagion” has now become a familiar metaphor for the spread of everything from computer viruses to bank failures. This model sheds light on how long it takes for a contagion to take over a network, for a variety of idealized networks and spreading processes.
Introduction
The discovery that incubation periods tend to follow right-skewed distributions originally came from epidemiological investigations of incidents in which many people were simultaneously and inadvertently exposed to a pathogen. For example, at a church dinner in Hanford, California on March 17, 1914, ninety-three individuals became infected with typhoid fever after eating contaminated spaghetti prepared by an asymptomatic carrier known to posterity as Mrs. X. Using the known time of exposure and onset of symptoms for the 93 cases, Sawyer, 1914 found that the incubation periods ranged from 3 to 29 days, with a mode of only 6 days and a distribution that was strongly skewed to the right. Similar results were later found for other infectious diseases. Surveying the literature in 1950, Sartwell noted a striking pattern: the incubation periods of diseases as diverse as streptococcal sore throat (Sartwell, 1950) (Figure 1a), measles (Stillerman and Thalhimer, 1944), polio, malaria, chicken pox, and the common cold were all, to a good approximation, lognormally distributed (Sartwell, 1950). On a time scale of years instead of days, the incubation periods for bladder cancer (Goldblatt, 1949) (Figure 1b), skin cancer, radiation-induced leukemia, and other cancers were also found to be approximately lognormally distributed (Armenian and Lilienfeld, 1974).
Figure 1. Frequency distributions of incubation periods for two diseases.
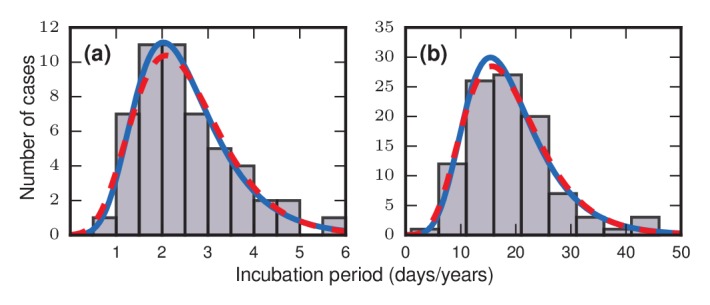
Data redrawn from historic examples. Dashed red curves are noncentral lognormal distributions. Solid blue curves are Gumbel distributions, predicted by the theory developed here. Both sets of curves were fitted via the method of moments. (a) Data from an outbreak of food-borne streptococcal sore throat, reported in 1950 (Sartwell, 1950). Time is measured in units of days. (b) Data from a 1949 study of bladder tumors among workers following occupational exposure to a carcinogen in a dye plant (Goldblatt, 1949). Time is measured in units of years.
Two natural questions arise: Why should incubation periods be distributed at all, and why should they be distributed in the same way for different diseases? Previous explanations rest on the presumed heterogeneity of the host, the pathogen, or the dose (Sartwell, 1950; Nishiura, 2007; Horner and Samsa, 1992). To see how this works, return to the typhoid outbreak at the Hanford church dinner (Sawyer, 1914). Every person who ate that spaghetti presumably had a different level of overall health and immune function, and every plate of spaghetti was likely contaminated with a different dose and possibly even strain of typhoid.
Suppose the typhoid bacteria proliferated exponentially fast within the hosts and triggered symptoms when they reached a fixed threshold. Then, if the bacterial dose, growth rate, or triggering threshold were normally distributed across the hosts, one can show that the resulting distribution of incubation periods would have been either exactly or approximately lognormal (see Results, ‘Influence of heterogeneity’). On the other hand, there is counter-evidence that lognormal distributions can occur even if some of these sources of heterogeneity are lacking. For example, Sartwell, 1950 reanalyzed data from a study (Bodian et al., 1949) in which identical doses and strains of polio virus were injected into the brains of hundreds of rhesus monkeys. The incubation period, defined as the time from inoculation to the onset of paralysis, was still found to be approximately lognormally distributed, even though the route of infection and the viral dose and strain were held constant. Moreover, the lognormal distributions commonly observed for human diseases have a particular shape, with a dispersion factor (Sartwell, 1950) around , which previous models cannot explain without special parameter tuning. (See Box 1 for the definition of dispersion factors.)
Box 1.
Dispersion factors.
The Dispersion Factor of a distribution or dataset is defined to be its geometric standard deviation. Or more explicitly, given a positive dataset , it is , where
We measure this quantity for multiple reasons. While is a dimensionful quantity, is dimensionless. Secondly, is the maximum likelihood estimator for the scale parameter of an unshifted lognormal distribution. Moreover, this is the quantity Sartwell used to describe the variability of incubation periods (Sartwell, 1950), so it is a useful point of comparison.
Here, we propose a new explanation for the skewed distribution of incubation periods. Instead of heterogeneity, it relies on the stochastic dynamics of the incubation process, as the pathogen invades, multiplies, and competes with itself and the cells of the host in a structured network topology. The theory predicts that under a broad range of circumstances, incubation periods should follow a right-skewed distribution that resembles a lognormal, but is actually a Gumbel, one of the universal extreme value distributions (Kotz and Nadarajah, 2000). Heterogeneity is not required, but it is allowed; it does not qualitatively alter our results when included.
Results
Mathematical Model
We model the incubation process using the formalism of evolutionary graph theory (Lieberman et al., 2005; Nowak, 2006; Ohtsuki et al., 2006; Ashcroft et al., 2015). A network of nodes is used to represent an environment within a host where a pathogenic agent, such as a harmful bacterium or a cancer cell, is invading and reproducing. The network could represent several plausible biological scenarios, for example the intestinal microbiome, where harmful typhoid bacteria are competing against a benign resident population of gut flora in a mixing system (modeled as a complete graph); or it could represent mutated leukemic stem-cells vying for space against healthy hematopoietic stem cells within the well-organized three-dimensional bone marrow space (modeled as a 3D lattice); or a flat epithelial sheet with an early squamous cancer compromising and invading nearby healthy cells (modeled as a 2D lattice). For the sake of generality, we will refer to the two types of agents as healthy residents and harmful invaders.
While Sartwell’s law has been applied to many different types of diseases with diverse etiologies, the model we propose makes the most sense for asexually reproducing invaders, like cancer cells or bacteria. Viruses, on the other hand, often reproduce with a ‘one-to-many’ dynamic, which is not faithfully captured in this model. So, while the general phenomenon of network invasion seems to apply to viruses as well, the model in its present form is not well suited to describe their dynamics.
Considering asexually reproducing and competing invaders, then, we choose to model the invasion dynamics as a Moran process (Moran, 1958; Williams and Bjerknes, 1972; Lieberman et al., 2005; Nowak, 2006). Invaders are assigned a relative fitness (suggestively called the carcinogenic advantage by Williams and Bjerknes, 1972). The fitness of residents is normalized to 1. We consider two versions of the Moran process. In the Birth-death (Bd) version (Figure 2a), a random node is chosen, with probability proportional to its fitness. It gives birth to a single offspring. Then, one of its neighbors is chosen uniformly at random to die and is replaced by the offspring (Figure 2b). We also consider Death-birth (Db) updates (Figure 2c,d). In this version of the model, a node is randomly selected for death, with probability proportional to ; then a copy of a uniformly random neighbor replaces it. To test the robustness of our results, we study both versions of the Moran model on various networks: complete graphs, star graphs, Erdős-Rényi random graphs, one-, two-, and three-dimensional lattices, and small-world, scale-free, and -regular networks. We also vary the invader fitness and the model criterion for the onset of symptoms. These extensions are presented in the Materials and methods, Figures 5, 6. Box 2 discusses other variants of the Moran model. Here we focus on the simplest cases to elucidate the basic mechanisms.
Figure 2. Evolutionary update rules.
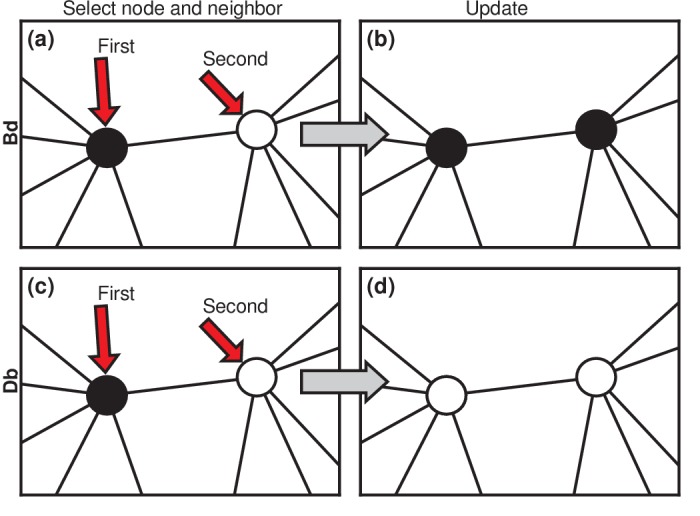
(a) In the Birth-death (Bd) update rule, a node anywhere in the network is selected at random, with probability proportional to its fitness, and one of its neighbors is selected at random, uniformly. (b) The neighbor takes on the type of the first node. In biological terms, one can interpret this rule in two ways: either the first node transforms the second; or it gives birth to an identical offspring that replaces the second. (c) In the Death-birth (Db) update rule, a node is selected at random to die, with probability inversely proportional to its fitness, and one of its neighbors is selected at random, uniformly, to give birth to one offspring. (d) The first node is replaced by the offspring of the second.
Box 2.
Nomenclature for the Moran model.
There are many distinct variations on the basic Moran model, but the six most popular all consist of a two-step update. The first step selects a node over the entire population, whereas the second step selects a neighboring node from the neighbors of the first.
However, the content of each step can vary from one model to another. For example, the selection in each step can occur in a fitness-weighted fashion. Also, the node in the first step can be interpreted as either giving birth, or dying.
To avoid confusion, we use standard abbreviations to distinguish the different models, as illustrated by the table below. The order of letters indicates the order of the steps, and the capitalization denotes which steps have a fitness dependence. For example, dB refers to the update rule where the first step uniformly selects a node from the entire population to die, and then one of its neighbors is selected, with probability proportional to fitness, to replace it.
In this paper, we focus exclusively on Bd and Db. Although much the same analysis could be done on any of the other update rules, these two were showcased due to their relative popularity and simplicity.
| Step order | Fitness-step first | Fitness-step second | Both fitness-steps |
|---|---|---|---|
| Birth first | Bd | bD | BD |
| Death first | Db | dB | DB |
Our simulations start with a single invader placed at a random node in a network of otherwise healthy residents. The update rule is applied at discrete time steps. In the long run, either the invaders replace all the residents, or vice versa. If symptoms are triggered when the entire network has been taken over by invaders, then the incubation period is the number of time steps between the introduction of the invader and its fixation. On the other hand, if the invaders die out and the healthy cells take over, then the process is stopped and no observable symptoms manifest. Later, in the paper, we consider a generalization from complete to partial takeovers, but for now the incubation period will refer to a complete takeover.
Our notion of time in this model is linked directly to the biology of invasion of a reproducing asexual pathogen that divides and replaces other cells sequentially. Instead of considering divisions as a rate, and therefore linking the dynamics to real time, we consider time steps to be individual division events. This is more akin to the standard methods of modeling chemical interactions, as in the Gillespie algorithm (Gillespie, 1977). This focus on the biology of the individual pathogen (or cancer cell) also provides a simple explanation for how diseases with very different natural histories can have the same analytic distribution of incubation time. As each different disease would have a different characteristic mean doubling time, while the shape of the distributions might be the same, the physical time taken would scale with the characteristic proliferation time. Future iterations of this model could consider deriving an exact scaling between physical time and this biological event-based updating of time.
Infinitely fit invaders
First, consider what happens if the invaders have infinite fitness () in the Birth-death model. While an exaggeration, this case is instructive and is a reasonable approximation for aggressive cancers and infections. In this limit, the dynamics simplify enormously: only the invaders reproduce. But because they give birth and replace their neighbors blindly, they waste time whenever they compete between themselves and one invader replaces another. These random self-replacements slow down the incubation process, and make it highly variable. In fact, the level of in-fighting is what determines the incubation period in this case. Beyond fitness, the topology of the network matters too. For low-dimensional networks, exemplified by a two-dimensional lattice (Figure 3a , red circles), the growth rate of the invader population remains roughly constant as takeover occurs. This leads to a normal distribution of incubation periods (Figure 3a, red circles; and see Methods and Materials, ‘Birth-death, other solvable networks’). However, on very high-dimensional networks like the complete graph (Figure 3a, blue circles), the distribution becomes right skewed. Intuitively, this happens because every invader now has a chance of replacing any healthy node or any other invader. It is as if at every time step a candidate node for replacement gets blindly drawn from a bag, relabeled as an invader, and returned to the bag. At the start of the incubation process, almost every draw adds another invader to the population and the infection progresses rapidly. But near the end, it will take many, many draws to blindly fish out the last remaining healthy node, as needed to terminate the incubation period. This slowing-down phenomenon near the end should feel familiar to anyone who has tried to complete a collection of baseball cards, stamps, or coupons, since they are all manifestations of the coupon collector's problem, a well-studied concept in probability theory (Pósfai, 2010; Feller, 1968; Erdős and Rényi, 1961). Because of those frustratingly long waits to collect the final healthy node, the incubation period distribution gets skewed to the right. In the infinite- limit (see Methods and Materials, ‘Birth-death, complete graph’), the coupon collector’s process returns a Gumbel distribution, which resembles a lognormal and can be mistaken for it (Read, 1998). Indeed, when a Gumbel and a lognormal are fit to the same real data, as in Figure 1, it is hard to tell them apart. All this analysis can easily be repeated for the Death-birth model with minimal changes.
Figure 3. Network topology and invader fitness shape the distribution of incubation periods.
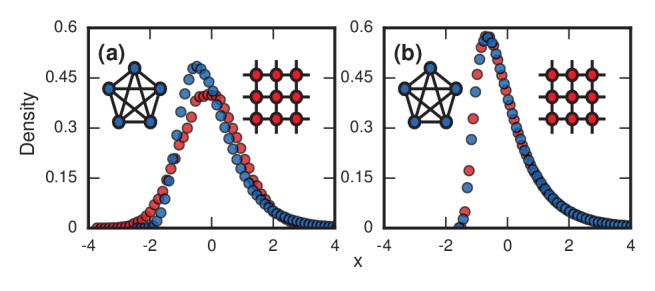
Plots show simulated distributions of incubation periods, defined here as invader fixation times. Starting from a single invader at a random node, the state of the network was updated by Birth-death dynamics on both a complete graph and a two-dimensional (2D) lattice. Results for the Death-birth update rule (not shown) are identical. All distributions are normalized to have zero mean and unit variance. (a) Infinitely fit invader. For invader fitness , the distribution is right-skewed for a complete graph (blue symbols). It approaches a Gumbel distribution as , where is the number of nodes in the network. In contrast, for a 2D lattice (red symbols) the incubation periods are normally distributed. The difference is that a coupon collection mechanism operates in the complete graph and in lattices of sufficiently high dimension ; this mechanism causes the right skew. Simulations used repetitions on a complete graph of nodes, and repetitions for a 2D lattice of nodes. (b) Neutrally fit invader. Distributions of incubation periods are shown for invader fitness , using repetitions on a complete graph of nodes (blue symbols), and repetitions for a 2D lattice of nodes (red symbols). Similar right-skewed distributions occur for both networks, caused by a conditioned random walk mechanism.
Neutrally fit invaders
At the other extreme, suppose the invaders have no selective advantage (). Then a different stochastic mechanism skews the distribution of incubation periods to the right (Figure 3b and Methods and Materials, ‘Random Walk Skewness’). For many networks, the dynamics reduce to an unbiased random walk on the number of invaders, with waiting times at each population level. There are two absorbing states, corresponding to both 0 and invaders for the two kinds of fixation. However, we only care about random walks that successfully hit , as these represent disease processes that manifest symptoms, so we must always condition on its success. This demands that the invader experience early success and growth, pushing it away from probable extinction. This conditioning introduces a bias that makes short incubation times probable, but long walks may still occasionally occur, driving the mean time above the median. In short, a conditioned random walk will introduce a right skew in the distribution of incubation periods. This effect holds for both high- and low-dimensional networks (Figure 3b), and for Birth-death and Death-birth dynamics.
Testing robustness to update rule and truncation
Right-skewed distributions typically persist in the face of various perturbations to the model, but some perturbations can turn them into normal distributions. For example, suppose we allow symptoms to occur when invaders take over only a fraction of the whole network. This is a reasonable consideration as leukemic cells need not take over all the bone marrow before leukemia becomes evident, nor does typhoid need to overwhelm all the cells in the microbiome before causing fever; indeed it is likely far fewer in both cases. Figure 4 contrasts what happens for Birth-death and Death-birth dynamics under these assumptions. When , the Gumbel distribution of Figure 3a persists for (Figure 4a), but turns into a normal distribution (Baum and Billingsley, 1965) when (Figure 4b) or (Figure 4c). Yet under Death-birth dynamics, the distribution stays Gumbel for all nonzero values of (Figure 4d,e,f). The fact that birth-death dynamics returns a normal for whereas Death-birth still returns a Gumbel can be rationalized via various convergence theorems (Baum and Billingsley, 1965; Ottino-Löffler et al., 2017; Pósfai, 2010). However, the fact that similar update rules behave so differently under a reasonable perturbation should caution us to be mindful of our choice of models.
Figure 4. Testing robustness.

The plots show how the distribution of incubation periods does or does not change when we modify the assumed update rules and criterion for the onset of symptoms. Both Birth-death (Bd) and Death-birth (Db) dynamics were simulated on a complete graph of nodes, using a infinite invader fitness. Incubation periods are now defined as times needed for invaders to take over a fraction of the whole network. All distributions are normalized to have zero mean and unit variance. Data points are color-coded according to the nature of the distribution: blue indicates a Gumbel distribution, and red indicates a normal distribution. (a) The distribution of times till invader fixation () under Birth-death dynamics. The Gumbel distribution of Figure 3a persists. (b) When is reduced to 0.9, the incubation periods under Birth-death dynamics become normally distributed instead of skewed. (c) When is reduced to 0.1, the incubation period distribution remains normally distributed. By contrast, Death-birth dynamics are insensitive to this modification: the Gumbel distribution persists not only for (d) but even for (e) and (f) . The difference in sensitivity between the two types of dynamics can be explained intuitively by when the slowest part of the coupon collection process occurs. For Death-birth dynamics, it occurs near the beginning of the invasion, when it takes a long time to randomly select one of the few available invaders to give birth. Since the slow part of coupon collection occurs near the beginning, it is insensitive to the end-condition . In contrast, the slow part occurs near the end of the invasion for Birth-death dynamics (when residents are scarce), and hence gets truncated when , giving rise to a normal instead of a right-skewed distribution.
Influence of heterogeneity
Historically, the distribution of incubation periods has been ascribed to heterogeneity (Sartwell, 1950; Nishiura, 2007; Horner and Samsa, 1992) in the fitness (growth rate, say) or dose of the pathogen, or in host factors like immune response. To see how these potential sources of heterogeneity could account for the skewed and approximately lognormal distribution of incubation periods, consider a pathogen growing exponentially with rate from an initial population , so that its population at time is given by . If an immune response or other detectable symptoms are triggered when reaches a threshold population , then the incubation time satisfies . Solving for yields
| (1) |
So if either the threshold or the inoculum are normally distributed across the host population, the incubation period will be lognormally distributed. Likewise, but in a more qualitative sense, a normal distribution of pathogen growth rates will also produce a skewed distribution that resembles a lognormal (Nishiura, 2007). However, if there is no randomness in any of those sources, this model predicts a single deterministic value of for the incubation period.
In contrast, the stochastic model proposed here does not need these sources of heterogeneity to produce right-skewed distributions. But if they happen to be present, as they likely are for many real diseases, our model can accommodate them. Indeed, when any of the three sources of heterogeneity are included in our model, they only serve to make the predicted distributions even more right-skewed, as we now show.
First, to emulate the heterogeneity of the strength of the pathogen, we assume heterogeneity in the parameter (which, in our model, governs the fitness of the invading cells relative to those of the host). In particular we randomly draw a different in each simulation, to simulate different hosts being infected with different pathogenic strains. The resulting distribution of invader fixation times depends on the distribution of the ’s, but our investigations demonstrate they consistently produce right-skewed distributions (Figure 5a).
Figure 5. Robustness to heterogeneity.
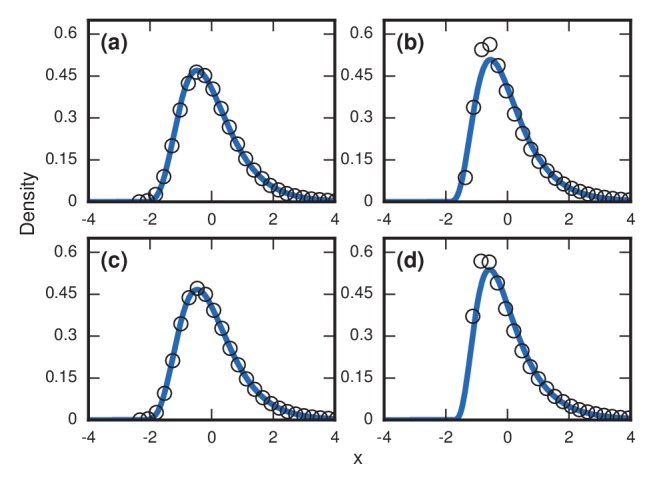
Simulated, fitted, and normalized distributions of incubation periods for birth-death dynamics on a complete graph of nodes. Unless stated otherwise, each simulation used an invader fitness of , measured times till complete takeover (), and started from an initial dose of 1 invader. Runs where the dosage was not smaller than the truncation point were rejected. The blue curves indicate noncentral lognormals fitted via the method of moments. (a) Heterogeneous fitness of invader. Every run used a different selected from a Gamma distribution with a shape parameter of 10. (b) Heterogeneity of host response. Instead of waiting until all residents had been replaced by invaders, every run used a different truncation point uniformly selected from . (c) Heterogeneity of dosage. Every run had a different starting population drawn from a Poisson of mean 10 and a shift of 1. (d) Heterogeneity of invader fitness, host response, and dosage. Every run used an drawn from Gamma(10), a truncation point drawn from Uniform(0,1), and a dosage drawn from Poisson(10)+1.
Second, to emulate the heterogeneity of host factors like immune response, we allow variability in the parameter , which quantifies the fraction of the network that needs to be invaded before symptoms appear. Let denote the time it takes for of the original resident nodes to be replaced by invaders. If we draw randomly from some distribution, then essentially each host has a different threshold at which symptoms appear. In contrast to Figure 4b, where we saw that repeated simulations for a host population with a single, fixed, deterministic can cause skewed distributions to turn into normal distributions, that is no longer the case when heterogeneity is included, as Figure 5b indicates. In fact, the heterogeneity actually causes even more right-skew than before.
Third, emulating variable doses is also straightforward. Instead of always starting with a single invader cell, we choose the initial number of invaders according to some distribution. Again, this modification does not remove the right-skewed behavior established in the Moran model (Figure 5c).
Finally, we can apply all these sources of heterogeneity at once, and remain with a right-skewed distribution (Figure 5d). In summary, although our main results were obtained by analyzing stochastic models of homogeneous host and pathogen populations, allowing for heterogeneity makes the predicted right-skewed distributions more, not less, prominent.
Discussion
The evolutionary dynamical model presented here is intended to mimic the within-host development of certain cancers and bacterial infections. It is not well suited to the dynamics of viruses. Thus, explaining why Sartwell's law also holds for so many viral diseases remains an open question.
Our model suggests two basic mechanisms underlie the observed right-skewed, approximately lognormal distributions of incubation periods. When the fitness of the pathogen is high, the skew comes from coupon collection; when the pathogen fitness is neutral or low, the skew comes from conditioned random walks; and at intermediate fitnesses, a combination of the two creates skew. Neither of these effects demand any heterogeneity from the invader or the host. However, the model can accommodate such heterogeneity, either by having the invader fitness be randomly drawn, or by having symptoms occur when a random fraction of the host network has been invaded. Our simulations show that both sources of heterogeneity only exaggerate the level of right-skewness we would have seen without them (See Results,‘Influence of heterogeneity’, Figure 5).
Beyond accounting qualitatively for the distributions of incubation periods, our model accounts for a quantitative feature that has never been explained before. As shown in Methods and Materials, Table 1, the distributions generated by highly fit pathogens and mutants are predicted to have dispersion factors (also known as geometric standard deviations; see Box 1) of about , close to the actual values of observed for various infectious diseases (Sartwell, 1950;Sartwell, 1966;Nishiura, 2007). Moreover, the model also helps to explain why so few infectious diseases yield dispersion factors greater than 1.5. Such high dispersion factors arise only for , corresponding to pathogens or mutants that are only slightly more fit than the resident populations against which they are competing.
Table 1. Model dispersion factors.
Dispersion factors (geometric standard deviations, see Box 1) for the simulated distributions of incubation periods shown in Figures 6,7,8 , for different networks and invader fitness levels . Errors represent 95% confidence intervals. Due to finite size effects, the dispersion factors exceed 1 for 1D and 2D lattices with (they should approach one as ). Dispersion factors for the case are larger than for the case, but are more uniform for different network topologies.
| Network | ||
|---|---|---|
| Complete | ||
| Star | ||
| 1D Lattice | ||
| 2D Lattice | ||
| 3D Lattice | ||
| Erdős-Rényi | ||
| Small-World | ||
| k-Regular | ||
| Scale-Free |
On the other hand, it is tempting to speculate that this regime of nearly neutral fitness may be more relevant to cancer development. While it is likely that tumor cells late in the disease process have much higher fitness than healthy cells secondary to continued selection (Scott and Marusyk, 2017), there is ample evidence that most cancers have long latency periods, for example in genetic data from pancreatic cancers (Yachida et al., 2010). One could speculate that during this early period, which accounts for the majority of the cancer’s time in the patient, the fitness is nearly neutral. For the cancer data reviewed by (Armenian and Lilienfeld, 1974), the observed distributions typically had dispersion factors around . In our model, these high dispersion factors tend to arise when the invader is only slightly more fit than residents. This is also consistent with the suggestion of (Williams and Bjerknes, 1972); the shape of tumors in the model most closely resembled that of real tumors when the fitness of the invaders was only slightly above neutral.
In 1546, Fracastorii, 1930 described the incubation of rabies after a bite from an rabid dog as ‘stealthy, slow, and gradual.’ Today, nearly five centuries later, the dynamics of incubation processes remain stealthy and slow to yield their secrets. We have tried to shed light on their patterns of variability with the help of a new conceptual tool, evolutionary graph theory. This approach provides a possible solution to the longstanding question of why so many disparate diseases show such similarly-shaped distributions of incubation periods. What remains is to quantify the dynamics of incubation processes experimentally with high-resolution measurements in time and space.
Aside from their possible application to incubation processes, our results also shed light on a broader theoretical question in evolutionary dynamics: when a mutant invades a structured population of residents, how does the distribution of mutant fixation times depend on the network structure of the population? Early work in evolutionary graph theory (Lieberman et al., 2005; Nowak, 2006; Ohtsuki et al., 2006) concentrated on the network’s impact on the probability of mutant fixation and the mean time to fixation. More recent studies have gone beyond the mean time to consider the full distribution of fixation times (Ashcroft et al., 2015), as we have also done here. We hope that our exact results for disparate topologies and dynamics will stimulate further investigations of these important questions in evolutionary biology.
Materials and methods
Here we describe the model and our analytical and numerical results in further detail. We also test the robustness of our claims with respect to relaxation of the various assumptions in the model. See the Appendix for complete proofs of analytical results.
Birth-death, complete graph
The population of cells is represented by a network of nodes. Edges between nodes indicate which cells can potentially interact with each other. There are two types of cells: harmful invaders with fitness , and healthy residents with fitness 1. All simulations are initialized with a single invader placed at a random node.
The Moran Birth-death (Bd) update rule has two steps. First, a node is randomly selected out of the total population, with probability proportional to its fitness. Second, a neighbor of the first node is chosen, uniformly at random, and takes on the type of the first node.
In a complete graph, all nodes are adjacent. Therefore, the probability of adding a new invader, given there are currently invaders, is
In the limit of infinite fitness, , the first term approaches one and we get
and the probability of the invader population ever decreasing is 0. So the time to invader fixation is sum of all the transition times for . These transition times can be calculated as follows. For the population to take steps to go from to invaders, nothing must have happened for steps before advancing on the ’th step. The probability of this happening is exactly
In other words, the time to add a new invader is exactly a geometric random variable. Therefore, the total fixation time is just
This random variable describes a process identical to that of the coupon collector’s problem (Pósfai, 2010; Feller, 1968). In both, we have a collection of nodes, and draw a random one with replacement at each time step. If we pick a healthy node, we relabel it and toss it back, and repeat until there are no healthy nodes left. By adapting classic results (Erdős and Rényi, 1961; Baum and Billingsley, 1965), we show in the Appendix that it is straightforward to find the asymptotic distribution of as gets large. To normalize this distribution, note that its mean is . Then we find
| (2) |
Here is the Euler-Mascheroni constant, denotes convergence in distribution, and a Gumbel() random variable has a density given by
| (3) |
This prediction for the normalized distribution of the incubation period agrees with simulations on large networks (Figure 6a).
Figure 6. Network dependence of incubation periods.

Distributions of invader fixation times, normalized to have zero mean and unit variance, are shown for infinite- Birth-death dynamics on various networks. Open circles show simulation results. Curves show analytical predictions: blue curves are Gumbels, red are normals, and pink is an intermediate distribution. Insets show schematics of networks. (a) The distribution of fixation times for a complete graph on nodes, for runs. Distribution normalized according to analytically calculated mean and standard deviation. Curve shows a Gumbel distribution. (b) The Gumbel distribution of fixation times for a star graph with spokes, for runs. Distribution normalized according to analytically calculated mean and standard deviation. (c) Normal distribution of fixation times for a 1D ring on nodes, for runs. Distribution normalized according to analytically calculated mean and standard deviation. (d) Normal distribution of fixation times for a 2D lattice of nodes, for runs. Distribution normalized according to empirically calculated mean and standard deviation. (e) The distribution of fixation times for a 3D lattice of nodes, for runs. Distribution normalized according to empirically calculated mean and standard deviation. The predicted distribution is the result of an approximating sum of exponential random variables under repetitions. (f) The distribution of fixation times for an Erdős-Rényi random graph on nodes with an edge probability of . Distribution normalized according to empirically calculated mean and standard deviation.
A Gumbel distribution of incubation periods has previously been obtained for a variant of this model. Instead of working with the large- limit of a complete graph, it assumed a continuous-time birth-death model of an invading microbial population whose dynamics were governed by differential equations (Williams, 1965).
Birth-death, other solvable networks
The analysis of the finite- complete graph sets up an important framework that can be applied to more complicated networks. For example, in the Appendix we prove that the distribution of fixation times for a star network also converges to a Gumbel for , specifically:
| (4) |
This prediction matches simulations (Figure 6b).
The same framework also applies to a one-dimensional (1D) ring lattice, but instead of using the coupon-collector framework, we need to cite the Lindeberg-Feller central limit theorem (Durrett, 1991). As shown in the Appendix, this gives us
| (5) |
This prediction agrees with simulations (Figure 6c).
For a two-dimensional square lattice, it is more difficult to produce analytical results that are both rigorous and exact. But by making an approximation based on the geometry of the lattice, and using the fact that the population growth rate is proportional to its surface area (see the Appendix, ”Normally distributed fixation times for 2D lattice’), we can make a non-rigorous analytical guess about the distribution of the fixation times . Via these arguments, and given and , we predict
| (6) |
Despite the approximation, this prediction works well (Figure 6d).
By similar arguments, we predict that lattices of dimension have right-skewed asymptotic distributions of fixation times. Specifically, given , we predict
| (7) |
where is the Riemann zeta function. The methods used to derive that can also be used to create approximate finite-size distributions for the lattices (Figure 6e).
In particular, we predict positive skew for all and for the skew to increase monotonically with dimension (see the Appendix). Meanwhile, both 1D and 2D lattices have normal asymptotic distributions, and therefore no skew. This establishes as a critical dimension in these dynamics, transitioning from zero skew to positive skew.
Incidentally, these arguments also suggest that appropriate infinite-dimensional networks will asymptotically have a Gumbel distribution. This is numerically true for the Erdős-Rényi random graph (Figure 6f).
For more complex networks, such as the Watts-Strogatz small-world network, the -regular random graph, and the Barabasi-Albert scale-free network, we currently lack theory to predict the asymptotic distributions analytically. However, numerical simulations produce simulations that are all well-approximated by a noncentral lognormal, obeying Sartwell’s law (Sartwell, 1950) (Figure 7a,c,e).
Figure 7. Complex networks.

Simulated and fitted distributions of invader fixation times for Birth-death dynamics on small-world, scale-free, and -regular networks. All distributions were normalized to have mean zero and unit variance. The curves indicate non-central lognormals fitted to the first three moments of the data. All distributions are the result of simulations. The figures in the top row ((a), (b), (c)) used invader fitness , whereas the figures in the bottom row ((d), (e), (f)) used neutral fitness . (a) Newman-Watts-Strogatz small-world ring network with shortcut probability of on . (b) Random 3-regular graph on nodes. (c) Barabasi-Albert scale-free network with a minimum degree of 3 and nodes. (d) Newman-Watts-Strogatz small-world ring network with shortcut probability of on nodes. (e) Random 3-regular graph on nodes. (f) Barabasi-Albert scale-free network with a minimum degree of 3 and nodes.
Table 1 shows that geometric standard deviations of the incubation period distributions for all of these networks fall around , in agreement with the dispersion factors of observed for many infectious diseases (Sartwell, 1950; Horner and Samsa, 1992).
Random walk skewness
So far we have focused on infinitely fit invaders (). Now we consider the opposite extreme, where invaders have nearly neutral fitness () relative to the residents. We will show that right-skewed distributions of incubation periods occur in this limit as well, but for a completely different reason than coupon collection.
The analysis is again simplest for the complete graph, so we return to that case. As before, the probability of an invader replacing a resident in the next time step is
Similarly, the probability of an invader being replaced by a resident in the next time step is
So the probability of the next replacement adding a new invader is
This defines a random walk with drift on the invader population.
Only a special subset of these walks are relevant to the computation of the incubation period distribution. For the incubation period to be well-defined, the invader population must not go extinct. Therefore, we need to condition on the fact that the invader population hits before it ever hits 0. For the limiting case , corresponding to a perfectly neutral invader, we can show with martingale methods that the resulting distribution of incubation periods will be strongly skewed to the right as gets large (see the Appendix). This is to be expected: there are only a few ways to walk from one to quickly, while there are many ways to have a long, meandering excursion before finally getting there.
The variance from this conditioned random walk process tends to drown out the effects of network topology. The distribution of incubation periods ends up looking similar for diverse networks (Figure 8), including complex networks (Figure 7b,d,f). So even though no coupon collection happens at low finesses , the effect of the conditioned random walk is more than enough to generate right-skewed distributions of incubation periods. In fact, this conditioned random walk mechanism at low produces an even higher dispersion factor () than coupon collection does at high (see Table 1).
Figure 8. Neutrally fit invader .

Simulated and fitted distributions of invader fixation times are shown for Birth-death dynamics on various networks. All distributions were normalized to have mean zero and unit variance. The curves indicate noncentral lognormals fitted via the method of moments. (a) Complete graph on nodes, for runs. (b) Star graph with spokes, for runs. (c) One-dimensional ring on nodes, for runs. (d) Two-dimensional lattice on nodes, for runs. (e) Three-dimensional lattice on nodes for runs. (f) Erdős-Rényi random graph on nodes with an edge probability of .
Influence of non-static population
In many diseases, it is unlikely that the total network size would remain constant in time. For example, targeted radiation and chemotherapy leads to a loss of mass in both the tumor and the substrate tissue. Depending on the specific physical case, the population levels of invaders and residents can have many nontrivial time dependencies. As a first-order examination of the effects of time-varying populations, three simple cases were considered on the complete graph for the intermediate fitness of . As a baseline, the distribution for a constant population was measured in Figure 9a.
Figure 9. Robustness to population variability.
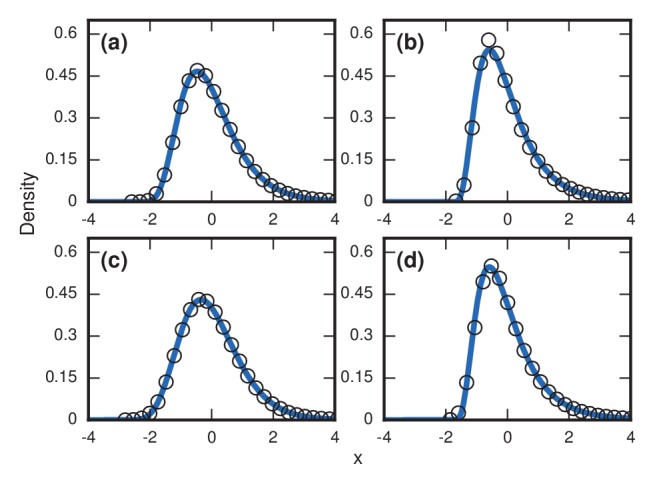
Simulated, fitted, and normalized distributions of incubation periods for Birth-death dynamics on a complete graph that initially has nodes. Invader fitness is set at . The blue curves indicate noncentral lognormals fitted via the method of moments. (a) Constant total population. (b) Growing population. At every time step, there is a constant 1/chance that a new resident node will appear. The new node is adjacent to all preexisting nodes. (c) Shrinking population. At every time step, there is a constant 1/chance that a random resident node will be removed. (d) Randomly varying population. At every time step, a resident node is either added or removed from the population, both events occurring with probability 1/2.
We considered a case when the resident population was growing. At every time step, a new resident node was added with probability , which was chosen so that takeover would happen in finite time. Even still, the majority of the run will be spent when the resident population is small, with takeovers and new additions occurring at a roughly even pace. This led to an accentuated level of right skew in Figure 9b.
We then considered a case where the resident population was constantly shrinking. Again, the probability of change was every time step, but this time it decreased the resident population by 1. While there is still a visible right skew in Figure 9c, it was somewhat lessened due to the global shrinkage speeding up the coupon collecting process.
Finally, we considered a randomly varying resident population. Here, the resident population increases or decreases by one every time step, each with probability 1/2. This random-walking population level also leads to an extreme level of skew in Figure 9d.
Acknowledgements
We thank David Aldous, Rick Durrett, Remco van der Hofstad, Lionel Levine, Piet Van Mieghem, and Steve Schiff for comments.
Appendix 1
Agreement of geometric and exponential variables I
Proposition: Suppose we have a family of sequences , with for all and , where may depend on . Define to be a geometric random variable with distribution
for . Further, let be an exponential random variable with distribution
for . Given some function such that and
| (8) |
and given , , and , then
| (9) |
The symbol “” means the ratio of characteristic functions goes to one as gets large. That is, the random variables on both sides converge to each other in distribution as gets large.
Proof: The proof of this claim simply involves calculating the characteristic functions and taking a limit. We have presented the details elsewhere (Ottino-Löffler et al., 2017).
Agreement of geometric and exponential variables II
Proposition: Given the setup in the previous proposition, define and . If
| (10) |
then
| (11) |
Proof: Our first goal is to show that
We do this by using the proposition in ‘Agreement of geometric and exponential variables I’, substituting for . First we check that Equation (8) is satisfied. Notice that
by hypothesis. Hence
But notice that
Therefore, the proposition is proven.
Condition for normality
Proposition: Let , define and let . If
| (12) |
then
| (13) |
Proof: Apply the Lindeberg-Feller central limit theorem (Durrett, 1991) to the random variables
By construction, , and . So in order to apply the theorem (and thereby get our desired result), we simply need satisfy the Lindeberg condition for any , as given by
Notice that implies
By hypothesis, the right hand side will eventually be less than 0, meaning that eventually will be impossible. So if we define , then we know that
So for large enough , we have
By hypothesis, grows without bound, so the term will be dominant. Therefore, there is some constant such that we can create the upper bound
From here, we can apply the hypothesis to get
Thus the Lindeberg condition holds. Therefore, by applying the theorem, we conclude that
Normally distributed fixation times for 1D lattice
Let us start with a one-dimensional (1D) ring of nodes, with exactly one invader at the start. Under infinite- Birth-death (Bd) dynamics, a uniform random invader gives birth at every time step and replaces one of its neighbors, also uniformly at random.
Because of the simple topology of the ring, the growing chain of invaders will always advance from the left or right ends. This means that if there are currently invaders, then the probability of a new invader being added in this time step is exactly given by
for , where we have defined .
The probability of spending exactly time steps at invaders is given by the odds of doing nothing for exactly steps and then advancing at the last step, and so is given by . In other words, the time spent with invaders is given by the geometric random variable . Therefore the total fixation time is given by .
By applying the results of section ‘Agreement of geometric and exponential variables II’, we can switch to using exponential random variables. From here we wish to apply results from section ‘Condition for normality’, so we need to check if converges to zero, given . Using asymptotics and a constant , we find
This lets us cite our proposition, and conclude that the fixation time is asymptotically distributed as a normal, with
Gumbel distributed fixation times for star graph
Next consider the infinite- Bd dynamics on a star graph. This network consists of one ‘hub’ node and ‘spoke’ nodes, with edges exclusively between the hub and spokes. We will place the initial invader at the hub, since starting from a spoke is a trivial perturbation off of that.
Now, given that of the spokes are invaders, then the odds of another one turning into an invader in one time step is simply the odds of choosing the hub from the set of all invaders, times the probability of replacing an existing healthy spoke. So
for . As before, the fixation time is the sum of geometric random variables . However, it is easy to use section ‘Agreement of geometric and exponential variables II’ to show that the total fixation time is well approximated by the sum of exponential random variables given we normalize by . So we know
| (14) |
The crux of finding the limiting distribution of is noticing that for large . The sequence corresponds to the well-known coupon collector’s problem (see main text). Imagine a child trying to complete a collection of cards by buying one random card each week. The probability of getting a new card the first week is 1; the probability of getting a new card after the first has been collected is ; the probability of getting another new card after two cards have been collected is ; and so on until the probability of getting the last card is .
The time to complete this collection (which is also well approximated by the sum of exponentials) has been the subject of much historical study. In fact, an exact distribution for in the limit of large is known (Ottino-Löffler et al., 2017; Pósfai, 2010; Feller, 1968; Erdős and Rényi, 1961; Baum and Billingsley, 1965; Rubin and Zidek, 1965), and is given in normalized form by
| (15) |
where is the Euler-Mascheroni constant.
Therefore, if we can connect our fixation time to the coupon collector’s time , we would know its distribution. We do so by taking the ratio of their respective characteristic functions, using their respective approximations as exponential random variables. Letting , we find a characteristic function
for our fixation time, and
for the coupon collector’s time.
Taking the ratio gives
Taking the Taylor expansion of the logarithm for , we can substitute in an appropriate function which gets small as gets large. Thus
The first sum is bounded above in norm by a constant times , so the first term goes to zero as gets large. Similarly, the second term goes to zero quickly, meaning that . Hence
| (16) |
Using Equation (16) to connect Equation (14) to Equation (15), we find
| (17) |
as desired.
Normally distributed fixation times for 2D lattice
We wish to find the limiting distribution of fixation times of infinite- Bd growth on a -dimensional square lattice, assuming periodic boundaries. We will eventually focus on the two-dimensional (2D) lattice, but let us set up every case for right now.
Unlike the previous cases, the probability of adding a new invader always depends on the exact configuration of the existing invaders. So we can no longer define exact values for that describe the fixation time as a simple sum of random variables.
But even though we do not know the exact shape of the invader cluster, the simple network structure can motivate a reasonable approximation. In particular, given a sufficiently smooth and convex volume in a -dimensional lattice, we should expect the volume to have a surface area proportional to , where .
Assuming this to be true, recall the basic dynamics of infinite- Bd with nodes and invaders. First, we uniformly select one node out of the population of invaders, which is always a probability of 1/per node. Then we replace one of the invader’s neighbors, uniformly at random. However, only invaders on the surface of the cluster even have a chance at replacing a healthy node!
Given sufficient regularity of the boundary of the cluster, this means that the probability of an invader replacing a healthy node is proportional to
Using this logic, we expect the probability of adding an invader to go as at the start. However, remember we have a periodic lattice, so using as the surface area of the cluster stops being true halfway through, and using the smaller healthy cluster’s volume is a better approximation. In other words, the surface area grows as at the start when the cluster begins forming, and shrinks as at the end when there are only a few healthy cells left.
This intuitive reasoning suggests that the ‘true’ probability of adding a new invader, given that there are already of them, should be roughly proportional to
| (18) |
The fact that we only estimated up to proportionality is adequate, because when we use section ‘Agreement of geometric and exponential variables II’, any multiplicative factors will just be absorbed by the variance anyway when we write down the normalized distribution.
The case of is special, so let us plug in and where appropriate. This gives
Now use section ‘Agreement of geometric and exponential variables II’. Skip ahead to defining to be the sum of exponential random variables, and split the sum in half. Thus
We assume is even without loss of generality.
First, we show that is normally distributed using the section ‘Condition for normality’. To use this result, we first need to calculate . This is exactly
Therefore, we have
as , so the first condition is satisfied.
Next, we need to show that a certain sum of exponentials converges to zero. In particular, for any , we examine
We can make the bound and , so
Therefore as gets large. So the second condition is satisfied. Therefore, is distributed according to a normal.
However, we need to do the same to . So let us estimate the variance of this second contribution. Letting we get
So for large , we obtain the following bound:
Therefore,
This satisfies the first condition from section ‘Condition for normality’.
To satisfy the second condition, we again fix some arbitrary and calculate a certain sum of exponentials. By calculating and choosing careful bounds, we get
This sum can be approximated from above by an appropriate integral:
Therefore, as gets large. This satisfies the second condition in section ‘Condition for normality’, meaning that we now know that is distributed as a normal.
Since the sum of normal variables returns a normal variable, this means that is also normal. Hence, we expect for the fixation time of infinite- Bd on a 2D lattice to be distributed as a normal, like the 1D ring lattice but, as we will now show, unlike .
Non-normality for
Here, we wish to find the limiting distribution of fixation times of infinite- Bd growth on a -dimensional square lattice, assuming periodic boundaries. Right now, we will look only at , since and are special cases.
We did the bulk of the setup for this case in section ‘Normally distributed fixation times for 2D lattice’, so we have the approximate probabilities of adding an invader to be given by
as before. And again, we define the ‘approximate’ fixation time to be the sum of the exponential random variables . Splitting the sum into a front and back half gives
But even with such aggressive approximations, we cannot present a closed form for the distribution of . However, we can still calculate an important quantity: the skew of the distribution.
Since we use section ‘Agreement of geometric and exponential variables II’, let us skip to defining to be the sum of exponential random variables, and split the sum in half, as we did with the 2D lattice. Thus
We assume is even without loss of generality.
First, let us find which half contributes more variance. Bound Var() as
We similarly approximate Var(, setting and finding
Since , only the first term survives as gets large, so
| (19) |
where is the usual Riemann zeta function. Notice that for .
To use both these variances, recall the skewness summation formulation: if we have random variables with variances and skews , then their sum has a skewness of
| (20) |
So this means that
as . Here, we have used the fact that has a finite skew (actually, it is easy to use section ‘Condition for normality’ to show that is distributed as a normal, and thus has zero skew.) Hence the asymptotic skew of is just the asymptotic skew of .
We can calculate the skew of by reusing Equation (20), this time on the exponential variables defining . Therefore
By Equation (19), the denominator limits to . Meanwhile, the numerator looks like
The first term in the parentheses converges to , whereas the rest of the terms converge to 0. Combining the numerator and denominator gives us the conclusion that the skew for the full distribution is given by
| (21) |
Recall that , so the denominator diverges for and both then numerator and denominator diverge for . However, since this expression for is monotone increasing in for , every dimension will attain a unique skew, and therefore a unique limiting distribution. Moreover, if we take , then , and therefore the skew becomes , which is exactly the skew for a Gumbel distribution, supporting our assertion that high-dimensional systems attain higher skews.
For the purposes of estimating the distributions at finite , it is convenient to use the random variable
where
Since the second half of the dynamics contribute the majority of the variance, we should expect this to provide a reasonable approximation of .
Asymptotic skew of conditioned random walk
When for Bd dynamics on the complete graph, the number of invaders becomes very flexible. In fact, the probability of adding an invader on any time step is exactly equal to the probability of removing an invader, so
Hence the probability that the next event increases the number of invaders is always 1/2. This means that, if we ignore the waiting times, the population of invaders obeys a simple random walk on the values with 0 and acting as absorbing states. So we can understand the times required to take over the network by understanding these simple dynamics. To set up the analysis, let denote the number of invaders after population changes. Therefore
where , each with probability 1/2. We will use the wait-omitted time in this section as a first-order approximation of the true takeover time. This way, the present analysis is generalizable to most networks. Moreover, scaling and numerical arguments based on the results here can show that the bulk of the final distribution is defined by this random-walk process.
Although we always start at , we only care about the invader takeover result because that is the only case for which disease symptoms would be manifested. Let us define the stopping time
which records the first time the random walk hits the value . Given that the invader population cannot go negative or above , the walk’s stopping time is
In the main text, we cared only about the conditioned random walk times and whether they tended to be right skewed. So we now study the first few conditional moments
for .
It isn’t hard to set up a linear recurrence relation to find the probability of hitting 0 or . In fact, if the state of the walk is at , then the probability of hitting is exactly
This is a useful fact for simulation; instead of directly simulating and discarding all the cases that hit 0, we can directly simulate the conditioned random walk. If we define
and treat it as a Markov chain, then we can easily calculate the transition probabilities. By applying Bayes’s law,
While this speeds up simulations by a good deal in certain cases, it is not particularly useful for quantifying the distribution of the random walk times themselves.
To identify the moments of , we will want to apply results from martingale theory in general, and optional stopping in particular. To start, define the random variable
We are going to want this to be a martingale. Let’s define to be the sigma field consisting of all information from the first steps of the random walk. Therefore, , since we cannot predict the direction of the next step. However, we do know that , because the steps will always be size 1, regardless of our ignorance. Putting this together gives
So well-approximates its future, meaning that it is a proper martingale.
Thank to this, we can cite an optional stopping theorem (Durrett, 1991). So we expect the expectation of this variable to be the same at the stopping time as at the start, so
| (22) |
Since we start at and , the left hand side trivially gives
However, the right hand side gives something a bit more complicated, since we need to condition on the possible endpoints, remembering we start at . So
Thus we have now calculated both sides of Equation (22), meaning that we now have a value for the first moment of time of the conditioned random walk, given by
The procedure to find the next two moments is not too substantially different: just repeat the same steps of verification and evaluation on ’s siblings
These two martingales reveal the next two moments, which are given by
This is all we need to compute the asymptotic skew of the conditioned fixation times. In the limit of large , only the dominant terms of each will survive. The ’s cancel out in this limit, leading to a constant given by
The conclusion is that in the limit of large , the skew of the distribution of fixation times for a conditioned random walk will always be positive. Therefore, we expect right-skewed distributions to be typical for the limit of Birth-death dynamics.
Funding Statement
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Contributor Information
Steven H Strogatz, Email: strogatz@cornell.edu.
Ben Cooper, Mahidol Oxford Tropical Medicine Research Unit, Thailand.
Funding Information
This paper was supported by the following grants:
National Science Foundation DMS-1513179 to Steven H Strogatz.
National Institutes of Health Loan Repayment Grant to Jacob G Scott.
National Science Foundation Graduate Student Fellowship DGE-1650441 to Bertrand Ottino-Loffler.
National Science Foundation CCF-1522054 to Steven H Strogatz.
Additional information
Competing interests
No competing interests declared.
Author contributions
Conceptualization, Resources, Supervision, Funding acquisition, Investigation, Project administration, Writing—review and editing, Provided mathematical background, designed the study and wrote the manuscript.
Conceptualization, Software, Formal analysis, Investigation, Visualization, Methodology, Writing—original draft, Writing—review and editing, Provided mathematical analysis and simulations, designed the study and wrote the manuscript.
Conceptualization, Supervision, Investigation, Methodology, Writing—review and editing, Provided biomedical background, designed the study and wrote the manuscript.
Additional files
References
- Armenian HK, Lilienfeld AM. The distribution of incubation periods of neoplastic diseases. American Journal of Epidemiology. 1974;99:92–100. doi: 10.1093/oxfordjournals.aje.a121599. [DOI] [PubMed] [Google Scholar]
- Ashcroft P, Traulsen A, Galla T. When the mean is not enough: Calculating fixation time distributions in birth-death processes. Physical Review E. 2015;92:042154. doi: 10.1103/PhysRevE.92.042154. [DOI] [PubMed] [Google Scholar]
- Baum LE, Billingsley P. Asymptotic distributions for the coupon collector's problem. The Annals of Mathematical Statistics. 1965;36:1835–1839. doi: 10.1214/aoms/1177699813. [DOI] [Google Scholar]
- Bodian D, Morgan IM, Howe HA. Differentiation of types of poliomyelitis viruses III. The grouping of fourteen strains Into three basic immunological types. American Journal of Hygiene. 1949;49:234–245. [PubMed] [Google Scholar]
- Durrett R. Probability: Theory and Examples. Belmont: Brooks/Cole; 1991. [Google Scholar]
- Erdős P, Rényi A. On a classical problem of probability theory. Publication of The Mathematical Institute of the Hungarian Academy of Sciences. 1961;6:215–220. [Google Scholar]
- Feller W. An Introduction to Probability Theory and Its Applications: Volume I. New York: John Wiley & Sons; 1968. [Google Scholar]
- Fracastorii H. De Contagione et Contagiosis Morbis et Eorum Curatione, Libri III. GP Putnam and Sons; 1930. [Google Scholar]
- Gillespie DT. Exact stochastic simulation of coupled chemical reactions. The Journal of Physical Chemistry. 1977;81:2340–2361. doi: 10.1021/j100540a008. [DOI] [Google Scholar]
- Goldblatt MW. Vesical tumours induced by chemical compounds. Occupational and Environmental Medicine. 1949;6:65–81. doi: 10.1136/oem.6.2.65. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Horner RD, Samsa G. Criteria for the use of Sartwell's incubation period model to study chronic diseases with uncertain etiology. Journal of Clinical Epidemiology. 1992;45:1071–1080. doi: 10.1016/0895-4356(92)90147-F. [DOI] [PubMed] [Google Scholar]
- Kotz S, Nadarajah S. Extreme Value Distributions: Theory and Applications. World Scientific; 2000. [Google Scholar]
- Lieberman E, Hauert C, Nowak MA. Evolutionary dynamics on graphs. Nature. 2005;433:312–316. doi: 10.1038/nature03204. [DOI] [PubMed] [Google Scholar]
- Moran PAP. The effect of selection in a haploid genetic population. Mathematical Proceedings of the Cambridge Philosophical Society. 1958;54:463–467. doi: 10.1017/S0305004100003017. [DOI] [Google Scholar]
- Nishiura H. Early efforts in modeling the incubation period of infectious diseases with an acute course of illness. Emerging Themes in Epidemiology. 2007;4:2. doi: 10.1186/1742-7622-4-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nowak MA. Evolutionary Dynamics: Exploring the Equations of Life. Harvard University Press; 2006. [Google Scholar]
- Ohtsuki H, Hauert C, Lieberman E, Nowak MA. A simple rule for the evolution of cooperation on graphs and social networks. Nature. 2006;441:502–505. doi: 10.1038/nature04605. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ottino-Löffler B, Scott JG, Strogatz SH. Takeover times for a simple model of network infection. Physical Review E. 2017;96:012313. doi: 10.1103/PhysRevE.96.012313. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pósfai A. Approximation theorems related to the coupon collector’s problem. arXiv. 2010 https://arxiv.org/abs/1006.3531
- Read K. A lognormal approximation for the collector’s problem. The American Statistician. 1998;52:175–180. [Google Scholar]
- Rubin H, Zidek J. A Waiting Time Distribution Arising From the Coupon Collector’s Problem. Stanford, United States: Department of Statistics, Stanford University; 1965. [Google Scholar]
- Sartwell PE. The distribution of incubation periods of infectious disease. American Journal of Hygiene. 1950;51:310–318. doi: 10.1093/oxfordjournals.aje.a119397. [DOI] [PubMed] [Google Scholar]
- Sartwell PE. The incubation period and the dynamics of infectious disease. American Journal of Epidemiology. 1966;83:204–216. doi: 10.1093/oxfordjournals.aje.a120576. [DOI] [PubMed] [Google Scholar]
- Sawyer WA. Ninety-three persons infected by a typhoid carrier at a public dinner. Journal of the American Medical Association. 1914;LXIII:1537–1542. doi: 10.1001/jama.1914.02570180023005. [DOI] [Google Scholar]
- Scott J, Marusyk A. Somatic clonal evolution: A selection-centric perspective. Biochimica et Biophysica Acta (BBA) - Reviews on Cancer. 2017;1867:139–150. doi: 10.1016/j.bbcan.2017.01.006. [DOI] [PubMed] [Google Scholar]
- Stillerman M, Thalhimer W. Attack rate and incubation period of measles: significance of age and of conditions of exposure. American Journal of Diseases of Children. 1944;67:15–21. doi: 10.1001/archpedi.1944.02020010022002. [DOI] [Google Scholar]
- Williams T, Bjerknes R. Stochastic model for abnormal clone spread through epithelial basal layer. Nature. 1972;236:19–21. doi: 10.1038/236019a0. [DOI] [PubMed] [Google Scholar]
- Williams T. The basic birth-death model for microbial infections. Journal of the Royal Statistical Society. Series B . 1965;27:338–360. [Google Scholar]
- Yachida S, Jones S, Bozic I, Antal T, Leary R, Fu B, Kamiyama M, Hruban RH, Eshleman JR, Nowak MA, Velculescu VE, Kinzler KW, Vogelstein B, Iacobuzio-Donahue CA. Distant metastasis occurs late during the genetic evolution of pancreatic cancer. Nature. 2010;467:1114. doi: 10.1038/nature09515. [DOI] [PMC free article] [PubMed] [Google Scholar]