

Abstract
Background
A wide range of diseases show some degree of clustering in families; family history is therefore an important aspect for clinicians when making risk predictions. Familial aggregation is often quantified in terms of a familial relative risk (FRR), and although at first glance this measure may seem simple and intuitive as an average risk prediction, its implications are not straightforward.
Methods
We use two statistical models for the distribution of disease risk in a population: a dichotomous risk model that gives an intuitive understanding of the implication of a given FRR, and a continuous risk model that facilitates a more detailed computation of the inequalities in disease risk. Published estimates of FRRs are used to produce Lorenz curves and Gini indices that quantifies the inequalities in risk for a range of diseases.
Results
We demonstrate that even a moderate familial association in disease risk implies a very large difference in risk between individuals in the population. We give examples of diseases for which this is likely to be true, and we further demonstrate the relationship between the point estimates of FRRs and the distribution of risk in the population.
Conclusions
The variation in risk for several severe diseases may be larger than the variation in income in many countries. The implications of familial risk estimates should be recognized by epidemiologists and clinicians.
Keywords: Familial relative risk, Inequality, Lorenz curve, Gini index, Familial association
Background
An important factor in the prediction of disease risk is the family history of disease, as the presence of such a history indicates that the patient has some underlying susceptibility. If few risk factors for a disease are known, but a familial association is observed, assessing family history of disease is one of the simplest and most cost-effective tools for risk prediction. However, the concept of familial risk is not as simple as it appears. Indeed, relatives may have an increased risk of disease due to genetic, epigenetic, common environmental/behavioral factors, or a combination of these. Very often these underlying determinants are unknown. Despite improved clinical health registries and the rapid development of genetic research methodology, observed factors explain only a minor proportion of the variation in disease risk within a given population [1]. For example, having a BRCA mutation increases the risk of breast cancer dramatically, but can explain only a minor proportion of all breast cancers [2]. Similarly, an underlying, unobserved heterogeneity in risk is likely to be important for many diseases [1].
This failure to explain the causes of complex diseases is currently a matter of debate. For example, the impact of chance per se in cancer development has been heavily discussed after being sparked by Tomasetti and Vogelstein, who implied that a large proportion of cancers are simply due to ’bad luck’ [3, 4]. When the causes of a disease are unknown, studying its familial aggregation may help us understand how the risk is distributed in the population due to both observed and unobserved factors. This is not only important from a scientific point of view; it can also reveal the consequences of having an affected relative. In practice, this information may be important for genetic counseling and for follow-up of individuals with a family history of disease [5].
Familial associations are often quantified in terms of familial relative risks (FRRs). Generally, the FRR denotes the risk of disease when a family member is affected compared to the risk level in the general population. Specific types of familial relationships, like first-degree relatives, parent-child, or siblings might also be of interest. A familial association has been demonstrated in a wide range of diseases. In the last decades, FRRs for virtually all cancers have become readily available in the literature [6]. For breast, colon, and prostate cancer, the risk has been reported to double when a family member (first-degree relative) has the disease [6–9], and the risk further increases if several family members are affected. Furthermore, several autoimmune and neurodegenerative diseases also have a substantial familial association [10, 11]. Therefore, understanding the information that is carried by an FRR is becoming increasingly important.
Fundamentally, we can assume two different points of view when studying familial associations. One view consists of focusing on observed familial associations in incidence, e.g., measured as the FRR, which can be calculated immediately from the data. The other focuses on how the risk varies between families, i.e., rather than consider summary measures like the FRR in isolation, we can investigate how the disease risk is distributed across families in the population. Indeed, it is logical that a familial association of disease risk implies a variation between individuals in a population. However, the connection between these two views is not immediate or intuitively easy. It is generally under-appreciated that a risk factor that is correlated within a family has to be very strong to produce even a moderate familial association in disease risk [12–14]. In the present study, we will use different models to illustrate various possible, potentially surprising, relationships between these two views.
First, we will study a simple dichotomous risk model, by dividing the population into two distinct risk groups. All members of a family (e.g., a group of siblings) belongs to the same risk group. This model provides simple, yet informative illustrations of the relationship between observed familial risk and actual differences in disease risk. If FRRs are available for both one and two affected family members, then the actual relative risk between the two risk strata, as well as the size of both of these strata, can be calculated. Next, we will study a slightly more detailed model, using a continuous distribution for the risk of developing disease. This facilitates the computation of Lorenz curves and Gini coefficients, which are well established methods for measuring inequality in wealth in economics. Finally, we discuss the issues highlighted in the paper, and their implications.
Methods
Dichotomous risk model
In the dichotomous risk model, we will consider a population that is divided into two groups: a high-risk group and a low-risk group. The risk is assumed to be the same for all individuals in the same group, and all individuals from the same family belongs to the same risk group. Thus, the type of familial relationship is not considered here. This is a simplification, but provides convenient and illustrative examples.
The probabilities of belonging to the high- and low-risk groups are q and 1−q, respectively. The risk of acquiring a disease, say within a given age, is ph and pl within these two groups. The individual relative risk (IRR), comparing a high-risk individual with a low-risk individual is IRR=ph/pl.
The FRR is calculated by considering two people from the same family. That is, assuming one family member acquired the disease at a given age, we may calculate the probability that the other family member will acquire the same disease by the same age. This probability is then divided by the average risk of disease:
| 1 |
This formula can be expanded to include a larger family, whose members might have different disease statuses. For a family with three members, assuming two have acquired the disease, the FRR is calculated as
| 2 |
Both FRR1 and FRR2 depend on the IRR and the size of the risk groups (q). However, given the IRR, the FRRs are independent of the actual disease risks in each group, ph and pl.
Continuous risk model
A more detailed description of the risk distribution can be obtained by considering a risk that varies continuously in the population. Let P be the probability of acquiring a disease for a given person over a given time interval (say that the disease occurs before a certain age). This probability is a random variable in that 1) we let P vary between families, but assume it is identical for members of the same family; 2) P accounts for all variability in risk between families, hence individuals from the same family are independent given the family’s risk level. Define E[P] as the expected value of P, i.e., the mean risk of acquiring the disease. Thus the risk of acquiring the disease if one family member is affected is calculated as
Here, E[P2] is the mean risk of two individuals from the same family acquiring the disease over a given time interval. By dividing by the mean risk of acquiring the disease, E[P], the FRR is found as
| 3 |
where CV is the coefficient of variation of P [1, 15, 16]. Since Ps distribution is nonnegative, even a moderate value of CV implies a skewed distribution.
In the examples to come, we will assume a beta distribution for P [17], which is a very flexible family of distributions. The density on [0,1] is given by
where B(α,β) is the beta function. The expectation of the distribution is given by
| 4 |
The squared coefficient of variation is given as
| 5 |
We wish to measure and understand the skewness of the distribution, that is, how (un)evenly the risk is distributed across the population. For this, we use published estimates of FRRs and the life-time risks of the diseases in question, and plug them into Expressions (3), (4) and (5).
The Lorenz curve highlights the inequality in risk
In parallel to epidemiological studies of the distribution of disease risk, economic studies have a strong interest in the distribution of wealth. In economic studies, the Lorenz curve and the Gini index are important measures. The Lorenz curve often represents the percentage of income in the population earned by a certain cumulative percentage of the population. If the Lorenz curve is a straight diagonal line, it represents perfect equality in income. The Gini index is calculated as the area between the theoretical perfect equality line and the actual Lorenz curve (which is usually less than 0.5), multiplied by two. Thus, if the Gini index is 0, there is a perfect equality in income. Despite its usefulness, the Lorenz curve has been much less used in epidemiological studies [18]. In studies of disease, the Lorenz curve displays the expected proportion of disease burden carried by the X% at lowest risk. Intuitively, in a medical setting the Gini index denotes the deviation from equality in risk, i.e., the Gini index is equal to 0 if all families have the same disease risk, and the index is 1 if only one family is at risk. That is, the larger the Gini index, the larger the deviation from equality.
Results
Dichotomous risk model: Moderate FRRs can imply large differences in risk
Small high-risk groups produce large FRRs
Figure 1a shows both FRR1 and FRR2 plotted against the IRR in a situation where only q=1% of the population belongs to the high-risk group, and the IRR varies from 1 to 20. In this situation, the FRRs are much lower than all the IRR values. Assuming one affected family member, a doubling of the FRR requires an IRR of 12.2. Assuming two affected family members leads to a better correspondence between the FRR and IRR, but the IRR still has to be larger than 5 to produce a doubling of the FRR. It is perhaps more natural to consider the IRR as a function of the FRR, since the latter is observable in practice. Such a plot is given in Fig. 1b, in which the discrepancies between the two relative risks when one or two family members are affected are even more pronounced.
Fig. 1.
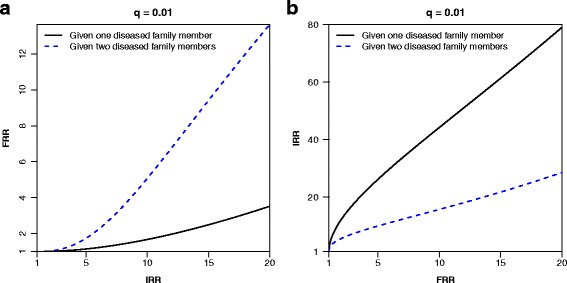
a The familial relative risk (FRR) as a function of the individual relative risk (IRR) defined in terms of the dichotomous model in Expression (1) and (2), assuming one or two diseased family members, respectively. b The IRR as a function of the FRR. 1% of the population belong to the high-risk group (q=0.1) in both panels
Figure 1 revealed two important characteristics. First, the FRR can be substantially different from the IRR. Closely related to this example, Peto et al. described a mendelian context with a 10-fold increase in the disease risk among carriers of a dominant genotype (i.e. an IRR=10), but having a sibling with the disease only doubled the risk (i.e. a FRR=2) [19]. Second, the FRR depends strongly on the number of affected family members, in particular for rare diseases. One example is testicular cancer, for which the FRR is 6 given one affected brother, and increases to almost 22 given two affected brothers [20]. Intuitively, if the disease is rare, having an increasing number of affected family members will increase the likelihood of the family actually belonging to the (small) high-risk group of the population. Notably, the FRR would be reduced if there were additional disease free members in the family. For rare diseases, however, the main determinant of the FRR is the number of affected family members, as has been shown for testicular cancer [20].
FRRs may be misleading for common diseases.
Figure 2a and b display the relationship between the FRR and the IRR when q=0.5. That is, when we assume that 50% of the population belong to the high-risk group. FRRs assuming one or two affected family members are below 2 irrespective of the size of the IRR. This is caused by the fact that the disease appears quite frequently in the population, therefore having a family member with disease does not provide much information on whether the family is at high or low risk. Although having more affected family members will increase this likelihood, Fig. 2a and b show that this increase is not necessarily substantial. Figure 2c and d show a situation in which the high-risk group accounts for 80% of the population (q=0.8), i.e., a minority of 20% has lower disease risk. The FRR does not exceed 1.25 in this situation, irrespective of the size of the IRR.
Fig. 2.
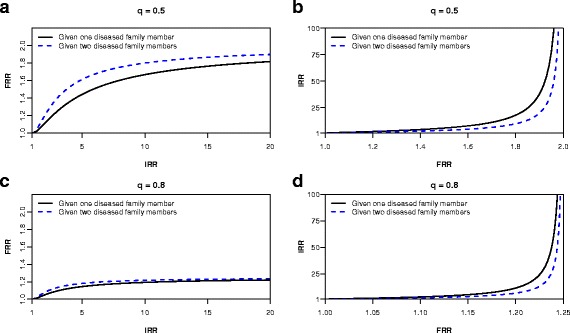
a, c) The familial relative risk (FRR) as a function of the individual relative risk (IRR) defined in terms of the dichotomous model in Expression (1) and (2), assuming one or two diseased family members, respectively. b, d) The IRR as a function of the FRR. 50% (q=0.5) and 80% (q=0.8) of the population belong to the high-risk group in panels a, b) and c, d), respectively
Figure 3 presents the relationships between FRRs, assuming one or two affected family members, and the proportion of high-risk individuals q, given an IRR=20. The curves peak at very low values of q, illustrating a better correspondence between the FRR and the IRR when the high-risk group is small. The plots of the IRR in terms of the FRR (Figs. 1b, 2b, and 2d) clearly illustrated that considering the FRR alone can give a very misleading impression of the true risk distribution in the population, especially for common diseases.
Fig. 3.
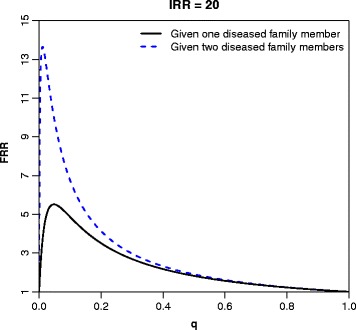
The familial relative risk (FRR) as a function of the proportion, q, of the population belonging to the high-risk group defined in terms of the dichotomous model in Expression (1) and (2), assuming one or two diseased family members, respectively. The individual relative risk (IRR) is 20
Inferences based on published FRRs
For several diseases, estimates of both FRR1 and FRR2 are available in the literature. Expressions 1 and 2 can then be solved to find both the corresponding IRR and high-risk proportion, q. In Table 1, these values are given for seven selected cancers. For testicular cancer, the FRR1=5.9 and FRR2=21.7 translate into a high-risk group consisting of 1% of the population, which has 30.6 times the risk of the remaining 99% of the population. For breast cancer, FRR1=1.8 and FRR2=2.9 implies that the 10% of the population that make up the high-risk group has on average 5.2 times the risk of developing the cancer compared with the remaining 90%. In the dichotomous model, the IRR represents the ratio of the average risk in the two groups. This is a crude simplification, but Table 1 illustrates that it may be possible to gain useful information on how risk is distributed in a population, even when assuming a dichotomous model. However, rather than being dichotomous, the real risk distribution is likely continuous and skewed [1].
Table 1.
Expressions 1 and 2 solved for the individual relative risk (IRR) and the high-risk proportion q, according to the familial relative risks (FRRs) given one (FRR1) and two (FRR2) affected relatives
| Cancer | Familial relationship studied | FRR 1 | FRR 2 | ⇒ | IRR | q |
|---|---|---|---|---|---|---|
| Testicular cancer [20] | Brothers | 5.88 | 21.71 | ⇒ | 30.6 | 0.010 |
| Prostate cancer [51] | Brothers | 2.96 | 7.71 | ⇒ | 12.2 | 0.027 |
| Colorectal cancer [52] | Siblings | 2.25 | 4.25 a | ⇒ | 7.4 | 0.067 |
| Melanoma [53] | FDRs | 1.9 | 4.7 a | ⇒ | 8.2 | 0.025 |
| Breast cancer [25] | Women FDRs | 1.80 | 2.93 | ⇒ | 5.2 | 0.10 |
| Hodgkin’s lymphoma [54] | FDRs | 6 | 13 a | ⇒ | 22.6 | 0.030 |
| Non-medullary thyroid cancer [55] | FDRs | 3.1 | 23.2 a | ⇒ | 34.2 | 0.0022 |
Abbreviations: FRR: Familial relative risk; IRR: Individual relative risk; FDR: First degree relative
a ≥ 2 siblings/FDRs is used in the reference
Estimates for FRR1 and FRR2 are taken from the indicated reference (the level of accuracy given in the reference is used)
Continuous risk model: Large inequalities in individual risk are likely
The results from the dichotomous model gave an intuitive understanding of the challenges of handling familial risks. However, in real life, the individual risk may often vary continuously across the population. This reflects the fact that the individual risk of most diseases is caused by a combination of several inherited and environmental factors.
The risk of severe diseases varies more than income in the USA
Parkinson’s disease has a complex etiology, and many factors, both heritable and non-heritable, could contribute to disease risk. We therefore consider the risk to vary continuously across the population. The life-time risk of Parkinson’s disease is approximately 1% (i.e. E[ P]=0.01) and the FRR has been estimated at 2.3 [11]. We assume that the beta distribution can describe the risk distribution, and use the approach described above to make inferences about its shape. Solving Eqs. (3), (4) and (5), α=0.75 and β=74 are obtained. The corresponding Lorenz curve is shown in Fig. 4a, and the Gini index equals 0.55, which implies a very large variation in individual risk. This is further demonstrated in Fig. 4b, which shows a Manhattan-type skyscraper landscape, with a large variation in the height of the columns. These heights are simulations from the distribution and resemble the disease risk of different families.
Fig. 4.

The Lorenz curve (a) and 400 samples (b) from a beta distribution resulting from a familial relative risk of 2.3 and E[P]=0.01, representing Parkinson’s disease
For Parkinson’s disease, the large variation in risk is not obvious from its moderate FRR. Indeed, many severe cancers could share similar patterns. For example, in the USA, cancer of the pancreas (life-time risk of 1.5% and a FRR of 2.19), leukemias (life-time risk of 0.96% and a FRR of 2.01), and cancer of the stomach (life-time risk of 1.78% and a FRR of 1.92) all show these features [21, 22], producing Gini indexes of 0.54, 0.50 and 0.49, respectively.
A further increased FRR would imply an even more skewed risk distribution for the same level of life-time risk. In Fig. 5, we display the risk distribution and the Lorenz curves when the lifetime risk is E[ P]=1%, for different FRRs. In this scenario, even a moderate FRR of 1.5 implies a distribution that is considerably skewed; the Lorenz curve corresponds to a Gini index of 0.37, and the 10% with the highest risk accounts for 26% of the diagnoses. Increasing the FRR to 6 yields a Gini index of 0.80, and the 10% with the highest risk accounts for 65% of the diseased. The latter example is similar to testicular cancer, which has a reported FRR of 5.88 and a life-time risk of 0.9% [20, 23].
Fig. 5.
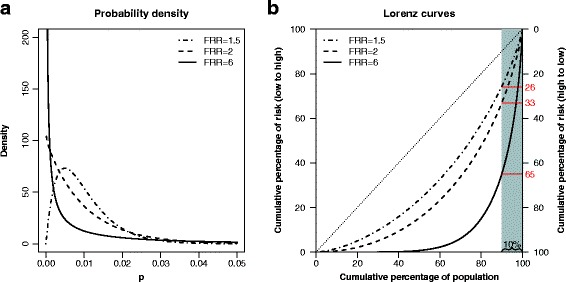
The distribution (a) of a beta distributed variable P, and its corresponding Lorenz curve (b), for three selected familial relative risks (FRRs). The expected value of P is set to 0.01. The 10% at highest risk (shaded area) account for 26%, 33%, and 65% of the diagnoses in the three scenarios, respectively
Breast cancer has a reported life-time risk of 12% and a FRR of 1.8 [24, 25], which renders a Gini index of 0.47. The 10% with highest risk accounts for 30% of the diagnoses, and the mean risk in that 10% is 6.2 times the mean risk in the remaining 90%. This is similar to what was found in Table 1 and to hypothesized risk distributions for breast cancer [2, 26].
More common diseases may also have a considerable variation in risk. For example, diabetes type 2 has a life-time risk of more than 30% in the USA [27] and is estimated to have a FRR of 2.24 [28]. This yields a Gini index of 0.60, again implying a strong heterogeneity in the risk of the disease that is not reflected by the moderate FRR. For this example, it is also intuitive: We know that several risk factors, e.g., body weight, physical inactivity and particularly genetic factors, are unequally distributed between families. Evaluating such factors clearly gives a better indication of the disease risk than the FRR.
As an interesting comparison, the Gini index for income distributions in the Scandinavian countries ranges from 0.25 to 0.27, in the USA it is 0.45, while Lesotho tops the list at 0.63 [29]. In other words, all the diseases mentioned above show a variation in individual risk that is larger than the variation in income in the USA.
Extreme risk in the highest percentile
The results from the dichotomous risk model and the graph in Fig. 3 suggested that large FRRs tend to be found for rare diseases. Diabetes type 1 has a prevalence of about 0.2% among Americans under 20 years of age and an FRR=12 among singleton siblings [30]. Diabetes type 1 occurs when the immune system targets the insulin producing cells in the pancreas. This processes occurs in genetically susceptible individuals, but it is postulated that environmental effects, such as viral infections, could contribute to developing the disease. If we consider the risk of developing diabetes to be E[ P]=0.2%, we obtain a Gini index of 0.89. In our model, 25% of the individuals with disease would belong to a group of high-risk families comprising only 1% of the total population. The median risk among this 1% of high-risk families would be more than 10,000 times higher than the 99% remaining population.
Discussion
Even when a familial disease association is modest, the variation in individual risk could be substantial. Using simple statistical models we have shown relationships between the FRR and the IRR that are intuitively surprising. Even familial disease risks that are apparently modest, like the doubling of risk in relatives of patients with breast cancer or colon cancer, imply large variations in risk between families [31, 32]. It is important that clinicians and epidemiologists are able to recognize the consequences of these relationships. In particular, even if an FRR is modest, some families would have a remarkably larger risk of developing the disease than others. In fact, the risk distribution may be more skewed than the income distributions of many countries. This points to a fundamental, and to a large extent unexplained, variation in risk. This variation occurs due to genetic predispositions, but also environmental, and various other sources of variation, including more unspecific, random variation [1]. Importantly, this unexplained variation in risk may lead to considerable selection bias in observational studies [33, 34]. Estimates of FRRs may actually be used to adjust for this bias, e.g., in Cox proportional hazards models [35].
Using FRRs for counseling is tempting when other tools for predicting individual risks, such as genetic tests or biomarkers, are lacking. It could also be tempting to use FRRs to aid in targeted screening [6, 36]. For example, many countries use family history of colorectal cancer in screening recommendations today [37]. However, the quantifications of familial associations are often crude, sometimes limited to one number for a given familial relationship. We emphasize that this FRR could be deceiving, even for relatively rare diseases. A correct interpretation of the FRR is therefore crucial. Individuals could suffer from unnecessary worry and testing if the FRR is misinterpreted. On the other hand, we could also fail to identify high-risk individuals by putting too much confidence on moderate FRRs, which are often population averages. In reality, FRRs vary continuously along a number of parameters. The number of affected family members is of obvious importance, but the number of healthy members may also provide important information. Furthermore, the aspect of time is essential. The ages at which family members acquire a disease (or remains disease free) is crucial to determining the level of risk. Taking these aspects into account is possible, e.g., by using methods from survival analysis that provides the opportunity to make risk predictions based on the family history of specific individuals [16, 20, 38]. These detailed FRRs could be more useful for individualized risk predictions, and could thus contribute to targeted screening as well as help focus preventive efforts.
Estimated FRRs from epidemiological studies are often taken at face value in other biomedical disciplines. For example, these estimates are frequently used as reference values in genome-wide association studies (GWAS’) [39–42], in which the proportion of the FRRs that can be attributed to specific, or all known risk alleles are frequently reported. However, methods for estimating FRRs may vary in their complexity. Thus, the proportion of the FRR explained in GWAS’ is dependent on the methods used in the epidemiological studies they base their reference on. A review of the genetics of type 1 diabetes stated that 34 susceptibility loci explained 60% of the variation in risk, based on an estimated FRR reference value of 15 [43]. The review was criticized for using this reference value as it was estimated in a period when risk was lower than it is presently, and it was suggested that 12 was a better estimate [44]. Applying this reference value changed the explained variance to 75%. The criticism was sound, but alternative methods for estimating the FRR might have produced different (or more detailed) estimates [16, 20, 38]. Rather than focusing on a single estimate of the FRR, investigating the sensitivity to different methods and measures of association seems like a good practice. Furthermore, the FRR encompasses much more than merely genetic inheritance. If all susceptibility alleles could be identified, they would not explain 100% of the familial risk. Also, a gene with a strong impact on disease susceptibility might only explain a minor fraction of the FRR, depending on the magnitude of the FRR and the population frequency of the allele [45]. Hence, it is not clear what information that is provided by this measure (proportion of FRR explained), and it seems difficult to compare it across different diseases.
Interpreting familial risks can be challenging, especially when relating them to heredity. Even if a mutation gives a high life-time risk of, say 50%, half of the high-risk individuals would not be expected to develop the disease. Furthermore, the mutation would only be passed on to half of the individuals in the next generation, on average. Consequently, many cancers diagnosed in genetically predisposed individuals would appear to be sporadic (i.e., occurring in individuals without a family history). Such an argument has been used to suggest that the majority of hereditary, early-onset breast cancers appears sporadically in the population [46]. In a recent study, Cremers et al. found that the same single-nucleotide polymorphisms (SNPs) were associated with an increased risk of both hereditary (defined as three cancers in first-degree relatives) and sporadic prostate cancer, and concluded that “hereditary prostate cancer most probably is merely an accumulation of sporadic prostate cancers” [47]. Although that might be the case, it is possible to draw the opposite conclusion; that sporadic cancers are, in fact, also inherited. This underscores the fact that relating the FRR to heredity is not straightforward. If assessing the degree of heritability is the aim, one should look to other types of studies, e.g., to twin studies [48, 49]. However, the large variation in risk implied by even a moderate familial risk is unlikely to be explained by environmental risk factors correlated in families [12, 13, 50].
Conclusions
We have seen that the interpretation of the FRR depends on the context. First, the life-time prevalence of the disease is important. The specific definition of the FRR, in particular the familial relationships that are studied, may also be crucial. Even if a precise definition of the FRR is given, it may be estimated in several different ways. If the FRR is calculated to perform risk predictions and genetic counseling, a detailed FRR based on individual characteristics (i.e. familial histories) is desirable. In any case, we have shown that even simple FRRs, averaged over the population, can reveal important information on how the risk is distributed in the population. Even a moderate FRR may imply a very skewed risk distribution.
Acknowledgements
We would like to thank Steinar Tretli and Tom Grotmol at the Cancer Registry of Norway for valuable discussions and comments on an earlier version of the manuscript.
Funding
This work was partially supported by the Norwegian Cancer Society, grant number 4493570, the Nordic Cancer Union, grant number 186031, and the Norwegian Research Council, grant number NFR239956/F20..
Availability of data and materials
Calculations were performed based on estimates available in the references given in the text.
Abbreviations
- CV
Coefficient of variation
- FRR
Familial relative risk
- GWAS
Genome-wide association study
- IRR
Individual relative risk
- SNP
Single-nucleotide polymorphism
Authors’ contributions
All authors (MV, MJS and OOA) contributed to the conception of the study, the drafting of the manuscript, revising the manuscript for important intellectual content. All authors read and approved the final manuscript..
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Morten Valberg, Email: morten.valberg@medisin.uio.no.
Mats Julius Stensrud, Email: m.j.stensrud@medisin.uio.no.
Odd O. Aalen, Email: o.o.aalen@medisin.uio.no
References
- 1.Aalen OO, Valberg M, Grotmol T, Tretli S. Understanding variation in disease risk: the elusive concept of frailty. Int J Epidemiol. 2014;44:1408–21. doi: 10.1093/ije/dyu192. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Balmain A, Gray J, Ponder B. The genetics and genomics of cancer. Nat Genet. 2003;33:238–44. doi: 10.1038/ng1107. [DOI] [PubMed] [Google Scholar]
- 3.Tomasetti C, Vogelstein B. Variation in cancer risk among tissues can be explained by the number of stem cell divisions. Science. 2015;347(6217):78–81. doi: 10.1126/science.1260825. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Stensrud MJ, Strohmaier S, Valberg M, Aalen OO. Can chance cause cancer? A causal consideration. Eur J Cancer. 2017;75:83–5. doi: 10.1016/j.ejca.2016.12.022. [DOI] [PubMed] [Google Scholar]
- 5.Riley BD, Culver JO, Skrzynia C, Senter LA, Peters JA, Costalas JW, et al. Essential elements of genetic cancer risk assessment, counseling, and testing: updated recommendations of the National Society of Genetic Counselors. J Genet Counsel. 2012;21(2):151–61. doi: 10.1007/s10897-011-9462-x. [DOI] [PubMed] [Google Scholar]
- 6.Frank C, Fallah M, Sundquist J, Hemminki A, Hemminki K. Population Landscape of Familial Cancer. Sci Rep. 2015;5:12891. doi: 10.1038/srep12891. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Jasperson KW, Tuohy TM, Neklason DW, Burt RW. Hereditary and familial colon cancer. Gastroenterology. 2010;138(6):2044–58. doi: 10.1053/j.gastro.2010.01.054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Ripperger T, Gadzicki D, Meindl A, Schlegelberger B. Breast cancer susceptibility: current knowledge and implications for genetic counselling. Eur J Hum Genet. 2009;17(6):722–31. doi: 10.1038/ejhg.2008.212. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Johns L, Houlston R. A systematic review and meta-analysis of familial prostate cancer risk. BJU Int. 2003;91(9):789–94. doi: 10.1046/j.1464-410X.2003.04232.x. [DOI] [PubMed] [Google Scholar]
- 10.Hemminki K, Li X, Sundquist J, Sundquist K. Familial risks for amyotrophic lateral sclerosis and autoimmune diseases. Neurogenetics. 2009;10(2):111. doi: 10.1007/s10048-008-0164-y. [DOI] [PubMed] [Google Scholar]
- 11.Marder K, Tang MX, Mejia H, Alfaro B, Cote L, Louis E, et al. Risk of Parkinson’s disease among first-degree relatives A community-based study. Neurology. 1996;47(1):155–60. doi: 10.1212/WNL.47.1.155. [DOI] [PubMed] [Google Scholar]
- 12.Khoury MJ, Beaty TH, Kung-Yee L. Can familial aggregation of disease be explained by familial aggregation of environmental risk factors? Am J Epidemiol. 1988;127(3):674–83. doi: 10.1093/oxfordjournals.aje.a114842. [DOI] [PubMed] [Google Scholar]
- 13.Aalen OO. Modelling the influence of risk factors on familial aggregation of disease. Biometrics. 1991;47(3):933–45. doi: 10.2307/2532650. [DOI] [PubMed] [Google Scholar]
- 14.Hopper JL, Carlin JB. Familial aggregation of a disease consequent upon correlation between relatives in a risk factor measured on a continuous scale. Am J Epidemiol. 1992;136(9):1138–47. doi: 10.1093/oxfordjournals.aje.a116580. [DOI] [PubMed] [Google Scholar]
- 15.Moger TA, Aalen OO, Heimdal K, Gjessing HK. Analysis of testicular cancer data using a frailty model with familial dependence. Stat Med. 2004;23(4):617–32. doi: 10.1002/sim.1614. [DOI] [PubMed] [Google Scholar]
- 16.Aalen OO, Borgan Ø, Gjessing HK. Survival and Event History Analysis: A Process Point of View. New York: Springer; 2008. [Google Scholar]
- 17.Smith C. Recurrence risks for multifactorial inheritance. Am J Hum Genet. 1971;23(6):578. [PMC free article] [PubMed] [Google Scholar]
- 18.Mauguen A, Begg CB. Using the Lorenz curve to characterize risk predictiveness and etiologic heterogeneity. Epidemiology. 2016;27(4):531–7. doi: 10.1097/EDE.0000000000000499. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Peto J. Genetic predisposition to cancer. In: Cairns J, Lyon JL, Skolnick M, editors. Banbury Report 4: Cancer Incidence in defined populations. Cold Spring Harbor: Cold Spring Harbor Laboratory; 1980. [Google Scholar]
- 20.Valberg M, Grotmol T, Tretli S, Veierød MB, Moger TA, Aalen OO. A hierarchical frailty model for familial testicular germ-cell tumors. Am J Epidemiol. 2014;179(4):499–506. doi: 10.1093/aje/kwt267. [DOI] [PubMed] [Google Scholar]
- 21.Howlader N, Noone AM, Krapcho M, editors. SEER Cancer Statistics Review, 1975-2008, based on November 2010 SEER data submission. Bethesda: National Cancer Institute; 2011. [Google Scholar]
- 22.Frank C, Fallah M, Ji J, Sundquist J, Hemminki K. The population impact of familial cancer, a major cause of cancer. Int J Cancer. 2014;134(8):1899–906. doi: 10.1002/ijc.28510. [DOI] [PubMed] [Google Scholar]
- 23.Cancer Registry of Norway . Cancer in Norway 2015 - Cancer incidence, mortality, survival and prevalence in Norway. Oslo: Cancer Registry of Norway; 2016. [Google Scholar]
- 24.DeSantis CE, Fedewa SA, Goding Sauer A, Kramer JL, Smith RA, Jemal A. Breast cancer statistics, 2015: Convergence of incidence rates between black and white women. CA: Cancer J Clin. 2016;66(1):31–42. doi: 10.3322/caac.21320. [DOI] [PubMed] [Google Scholar]
- 25.Collaborative Group on Hormonal Factors in Breast Cancer and others Familial breast cancer: collaborative reanalysis of individual data from 52 epidemiological studies including 58 209 women with breast cancer and 101 986 women without the disease. Lancet. 2001;358(9291):1389–99. doi: 10.1016/S0140-6736(01)06524-2. [DOI] [PubMed] [Google Scholar]
- 26.Chatterjee N, Shi J, García-Closas M. Developing and evaluating polygenic risk prediction models for stratified disease prevention. Nat Rev Genet. 2016;17(7):392–406. doi: 10.1038/nrg.2016.27. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Narayan KV, Boyle JP, Thompson TJ, Sorensen SW, Williamson DF. Lifetime risk for diabetes mellitus in the United States. Jama. 2003;290(14):1884–90. doi: 10.1001/jama.290.14.1884. [DOI] [PubMed] [Google Scholar]
- 28.Weires M, Tausch B, Haug P, Edwards C, Wetter T, Cannon-Albright L. Familiality of diabetes mellitus. Exp Clin Endocr Diab. 2007;115(10):634–40. doi: 10.1055/s-2007-984443. [DOI] [PubMed] [Google Scholar]
- 29.CIA World Factbook. https://www.cia.gov/library/Publications/the-world-factbook/rankorder/2172rank.html. Accessed 20 Feb 2017.
- 30.Hemminki K, Li X, Sundquist J, Sundquist K. Familial association between type 1 diabetes and other autoimmune and related diseases. Diabetologia. 2009;52(9):1820–8. doi: 10.1007/s00125-009-1427-3. [DOI] [PubMed] [Google Scholar]
- 31.Byrnes GB, Southey MC, Hopper JL. Are the so-called low penetrance breast cancer genes, ATM, BRIP1, PALB2 and CHEK2, high risk for women with strong family histories. Breast Cancer Res. 2008;10(3):208. doi: 10.1186/bcr2099. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Hopper JL. Disease-specific prospective family study cohorts enriched for familial risk. Epidemiol Perspect Innov. 2011;8(1):2. doi: 10.1186/1742-5573-8-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Stensrud MJ, Valberg M, Røysland K, Aalen OO. Exploring Selection Bias by Causal Frailty Models: The Magnitude Matters. Epidemiology. 2017;28(3):379–86. doi: 10.1097/EDE.0000000000000621. [DOI] [PubMed] [Google Scholar]
- 34.Stensrud MJ, Valberg M, Aalen OO. Can Collider Bias Explain Paradoxical Associations? Epidemiology. 2017;28(4):e39–40. doi: 10.1097/EDE.0000000000000653. [DOI] [PubMed] [Google Scholar]
- 35.Stensrud MJ. Handling survival bias in proportional hazards models: A frailty approach. arXiv preprint arXiv:170106014. 2017.
- 36.Hemminki K, Fallah M, Hemminki A. Collection and use of family history in oncology clinics. J Clin Oncol. 2014;32(29):3344–5. doi: 10.1200/JCO.2014.56.4336. [DOI] [PubMed] [Google Scholar]
- 37.Win AK, Ouakrim DA, Jenkins MA. Cancer Forum. vol. 38. Australia: Cancer Council Australia; 2014. Risk profiling: familial colorectal cancer. [Google Scholar]
- 38.Moger TA, Haugen M, Yip BH, Gjessing HK, Borgan Ø. A hierarchical frailty model applied to two-generation melanoma data. Lifetime Data Anal. 2011;17(3):445–60. doi: 10.1007/s10985-010-9188-3. [DOI] [PubMed] [Google Scholar]
- 39.Houlston RS, Webb E, Broderick P, Pittman AM, Di Bernardo MC, Lubbe S, et al. Meta-analysis of genome-wide association data identifies four new susceptibility loci for colorectal cancer. Nat Genet. 2008;40(12):1426–35. doi: 10.1038/ng.262. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Houlston R, Ford D. Genetics of coeliac disease. QJM-Mon J Assoc Phys. 1996;89(10):737–44. doi: 10.1093/qjmed/89.10.737. [DOI] [PubMed] [Google Scholar]
- 41.Cox A, Dunning AM, Garcia-Closas M, Balasubramanian S, Reed MW, Pooley KA, et al. A common coding variant in CASP8 is associated with breast cancer risk. Nat Genet. 2007;39(3):352–8. doi: 10.1038/ng1981. [DOI] [PubMed] [Google Scholar]
- 42.Witte JS, Visscher PM, Wray NR. The contribution of genetic variants to disease depends on the ruler. Nat Rev Genet. 2014;15(11):765–76. doi: 10.1038/nrg3786. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Polychronakos C, Li Q. Understanding type 1 diabetes through genetics: advances and prospects. Nat Rev Genet. 2011;12(11):781–92. doi: 10.1038/nrg3069. [DOI] [PubMed] [Google Scholar]
- 44.Hemminki K. Familial risk and familial survival in prostate cancer. World J Urol. 2012;30(2):143–8. doi: 10.1007/s00345-011-0801-1. [DOI] [PubMed] [Google Scholar]
- 45.Rybicki BA, Elston RC. The relationship between the sibling recurrence-risk ratio and genotype relative risk. Am J Hum Genet. 2000;66(2):593–604. doi: 10.1086/302778. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Cui J, Hopper JL. Why are the majority of hereditary cases of early-onset breast cancer sporadic? A simulation study. Cancer Epidemiol Biomarkers Prev. 2000;9(8):805–12. [PubMed] [Google Scholar]
- 47.Cremers RG, Galesloot TE, Aben KK, van Oort IM, Vasen HF, Vermeulen SH, et al. Known susceptibility SNPs for sporadic prostate cancer show a similar association with “hereditary” prostate cancer. Prostate. 2015;75(5):474–83. doi: 10.1002/pros.22933. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Mucci LA, Hjelmborg JB, Harris JR, Czene K, Havelick DJ, Scheike T, et al. Familial Risk and Heritability of Cancer Among Twins in Nordic Countries. JAMA. 2016;315(1):68–76. doi: 10.1001/jama.2015.17703. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Stensrud MJ, Valberg M. Inequality in genetic cancer risk suggests bad genes rather than bad luck. Nat Commun. 2017;8:1165. doi: 10.1038/s41467-017-01284-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Risch N. The genetic epidemiology of cancer: Interpreting family and twin studies and their implications for molecular genetic approaches. Cancer Epidemiol Biomarkers Prev. 2001;10(7):733–41. [PubMed] [Google Scholar]
- 51.Brandt A, Bermejo JL, Sundquist J, Hemminki K. Age-specific risk of incident prostate cancer and risk of death from prostate cancer defined by the number of affected family members. Eur Urol. 2010;58(2):275–80. doi: 10.1016/j.eururo.2010.02.002. [DOI] [PubMed] [Google Scholar]
- 52.Johns LE, Houlston RS. A systematic review and meta-analysis of familial colorectal cancer risk. Am J Gastroenterol. 2001;96(10):2992–3003. doi: 10.1111/j.1572-0241.2001.04677.x. [DOI] [PubMed] [Google Scholar]
- 53.Fallah M, Pukkala E, Sundquist K, Tretli S, Olsen JH, Tryggvadottir L, et al. Familial melanoma by histology and age: joint data from five Nordic countries. Eur J Cancer. 2014;50(6):1176–83. doi: 10.1016/j.ejca.2013.12.023. [DOI] [PubMed] [Google Scholar]
- 54.Kharazmi E, Fallah M, Pukkala E, Olsen JH, Tryggvadottir L, Sundquist K, et al.Risk of familial classical Hodgkin lymphoma by relationship, histology, age, and sex: A joint study from five Nordic countries. Blood. 2015. 10.1182/blood-2015-04-639781. [DOI] [PubMed]
- 55.Fallah M, Pukkala E, Tryggvadottir L, Olsen JH, Tretli S, Sundquist K, et al. Risk of thyroid cancer in first-degree relatives of patients with non-medullary thyroid cancer by histology type and age at diagnosis: a joint study from five Nordic countries. J Med Genet. 2013. 10.1136/jmedgenet-2012-101412. [DOI] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Calculations were performed based on estimates available in the references given in the text.