

Abstract
Competing risks data often exist within a center in multicenter randomized clinical trials where the treatment effects or baseline risks may vary among centers. In this paper we propose a subdistribution hazard regression model with multivariate frailty to investigate heterogeneity in treatment effects among centers from multicenter clinical trials. For inference, we develop a hierarchical likelihood (or h-likelihood) method, which obviates the need for an intractable integration over the frailty terms. We show that the profile likelihood function derived from the h-likelihood is identical to the partial likelihood, and hence it can be extended to the weighted partial likelihood for the subdistribution hazard frailty models. The proposed method is illustrated with a dataset from a multicenter clinical trial on breast cancer as well as with a simulation study. We also demonstrate how to present heterogeneity in treatment effects among centers by using a confidence interval for the frailty for each individual center and how to perform a statistical test for such heterogeneity using a restricted h-likelihood.
Keywords: Competing risks, Hierarchical likelihood, Multivariate frailty, Random treatment-by-center interaction, Subdistribution hazard
1 Introduction
Competing risks (CR) data arise when an occurrence of an event precludes other type of events from being observed.1 Two broad classes of models for analyzing the CR data have been developed based on Cox’s proportional hazards (PH) models; one is to model the cause-specific hazard of the different event types2 and the other is to model the subhazard (i.e. the hazard function of a subdistribution) for the event of interest3. In particular, the subhazard model by Fine and Gray3, often referred to as the Fine-Gray model, directly associates covariate effects with the cumulative probability of a specific cause of events over time, i.e. the cumulative incidence function (CIF), whereas the cause-specific hazard model associates the covariate effects with the cause-specific hazard function. Therefore, if one is interested in direct statistical inference on the cumulative probability of cause-specific events, Fine-Gray model would be more appropriate.
In this paper we model the subhazard for the CR data from multi-center randomized clinical trials, which are often observed within a cluster (e.g. center). In many applications involving CR data, individual events within a cluster may be correlated due to unobserved shared factors across individuals. The Fine-Gray model, however, takes no account for such correlation, which can be modelled by the frailty (or random effect)4,5. Thus Katsahian et al.6 and Christian7 have extended the Fine-Gray model to a subhazard frailty model with a random center effect only. It would be practically more useful to model heterogeneity in treatment effect among centers as well as the random center effect, where the two random effects might be correlated.8,9 Here the heterogeneity in treatment effect among centers can be modelled as an additive frailty term to a regression coefficient for the baseline treatment effect without heterogeneity.10 In this paper, we extend the standard correlated frailty modelling approach5,10–12 to a subhazard frailty modelling approach to handling the potential heterogeneity in treatment effect in CR data from multi-center clinical trials.
For inference, we develop a hierarchical likelihood (or h-likelihood; Lee and Nelder13) method; it obviates integration itself over the frailty distributions and also gives a statistically efficient estimation procedure for various random-effect models10,13,14. In particular, we show that the profile likelihood function derived from the h-likelihood is identical to the partial likelihood, and hence it can be extended to the weighted partial likelihood for the subdistribution hazard frailty models. The proposed method is illustrated with time-to-event data from a phase III breast cancer trials (B-14) conducted by the National Surgical Adjuvant Breast and Bowel Project (NSABP), which consist of 2,817 patients from 167 centers15,16, as well as a simulation study. We also demonstrate via the practical data set how to present heterogeneity in treatment effect among centers by using a confidence interval17,18 for the frailty for each individual center, not the parameters for the frailty distribution, and how to perform a statistical test for such heterogeneity using a restricted h-likelihood14.
The paper is organized as follows. In Section 2, we propose a formulation of sub-hazard frailty models. In Section 3, we show how the h-likelihood can be extended to the subhazard frailty models, and develop the h-likelihood estimation procedure for fitting the models. A simulation study is conducted to evaluate the performance of the proposed method in Section 4. The new method is illustrated using the breast cancer data set in Section 5. Finally, we discuss our method in Section 6. The technical derivations and additional simulation results are presented in Appendix and Supplementary Material, respectively.
2 Formulation for subhazard frailty models
Suppose that the data consist of censored time-to-event observations collected from q centers (or clusters). We also assume that there are L distinct event types in each center. For subject j of center i, let Tij be the time to the first event and let εij ∈ {1, 2, …, L} be the corresponding cause of event (i = 1,…,q, j = 1,…, ni, n = Σini). Then observable random variables become Yij = min(Tij, Cij) and ξij = I(Tij ≤ Cij)εij, where Cij is the independent censoring time, ξij ∈ {0, 1, 2, …, L} and I(·) is the indicator function. The CIF of events from cause 1 (i.e. εij = 1) is defined by
which represents the probability that an individual will experience an event of Type 1 by time t. The corresponding hazard function of subdistribution (subhazard function) is defined by
For simplicity, in this paper we consider the two event types (L = 1, 2). Thus, ξij ∈ {0, 1, 2} it is 1 for an event of interest, 2 for a competing event and 0 for censoring.
Fine and Gray3 first introduced a way to directly associate the effects of covariates with CIF, which models the subhazard for the event of interest, L = 1. Furthermore, Katsahian et al.6 and Christian7 have extended Fine-Gray model to a subhazard frailty model with only one random component (i.e. random center effect) to analyze multi-center competing risks data.
In this paper we show that, for the purpose of more systematic analysis, the model above needs to be extended to a general subhazard frailty model allowing multiple random components (e.g. random center and random treatment effect) and their correlation, as in Ha et al.10. Here, random treatment effect means random treatment-by-center interaction. In particular, a model allowing for the correlation between random center and random treatment effects can properly account for the heterogeneities from the treatment effect across centers as well as between-center variation.10 Denote by vi = (vi0, vi1, …, vir−1)T an r-dimensional vector of unobserved log-frailties (random effects) associated with the ith (i = 1, …, q) center. Note that in (1), ui = exp(vi) (i.e. vi = log ui) are referred to frailties5,8,10. As described in Fine and Gray3 and Ha et al.19, we assume that given vi, (Tij, εij) and Cij, j = 1, …, ni, are conditionally independent, and that given vi, Cij, j = 1, …, ni, are non-informative about vi. Suppose that we are interested in assessing the effects of covariates on the conditional CIF for cause 1 given the log-frailties vi, defined by F1(t|vi) = Pr(Tij ≤ t, εij = 1|vi). The conditional subhazard function for cause 1 given vi, , is modeled as
| (1) |
where is the unknown baseline subhazard function,
is the linear predictor for the log-hazard, and xij = (xij1, …, xijp)T and zij = (zij1, …, zijr)T are p × 1 and r × 1 covariate vectors corresponding to fixed effects β = (β1, …, βp)T and log-frailties vi, respectively. We assume that the log-frailties vi are independent and follow a multivariate normal distribution, vi ~ Nr(0, Σi(θ)), where the covariance matrix Σi(θ) depends on a vector of unknown parameters θ. The normal distribution has been used for modelling multi-component20 and correlated frailties9.
Model (1) includes some well-known models as special cases. In a multicenter medical study, let vi0 be a random intercept or random center effect that modifies the baseline risk for center i, and let vi1 be associated with the treatment effect, i.e., a random treatment effect (or random treatment-by-center interaction). In (1), if we consider zij = 1 and vi = vi0 for all i, j, this becomes the random center or shared frailty model6,7 with
| (2) |
where for all i. Model (2) can be extended as follows. Let β1 be the main treatment effect associated with the treatment indicator xij1 and let βm (m = 2, …, p) be the fixed effects corresponding to the covariates xijm. Our two random components leads to a bivariate model9,10 with
| (3) |
which is easily derived by taking zij = (1, xij1)T and vi = (vi0, vij1)T in (1). Here, to maintain the invariance of model to parametrization of the treatment effect we allow a general covariance matrix9,14 between vi0 and vi1 within a cluster:
| (4) |
where the correlation is denoted by ρ = σ01/(σ0σ1). The bivariate normal model (3) with (4) is very useful for investigating heterogeneity in the baseline risk and the treatment effect across centers.
3 H-likelihood estimation
In this section we show how to construct systematically the h-likelihood estimation procedure for fitting the semiparametric subhazard frailty model (1). For this, we first show how to construct the h-likelihood, and then propose the estimation procedure. The general case for incomplete (censoring) data is presented here as in Pintilie1 because the proposed method can be directly applied to complete (no censoring) data.
3.1 H-likelihood construction
Let y(k) denotes the kth (k = 1, …, D) smallest distinct event time of Type 1 among the yij’s, where yij is the observed value of Yij and D is the total number of distinct Type 1 events. Let R(k) denotes the risk set at y(k):
Note that as compared to the classical Cox model, the risk set R(k) comprises individuals who have not failed from any cause by y(k) but also those who have previously failed from competing causes.3,6 Since the functional form of baseline subhazard function is unknown, following Breslow’s21 idea and the reformulation (equation (3.4), page 80) used by Fan and Li22 without competing risks, at each yij, the baseline cumulative subhazard function can be written as
where is the subhazard function for cause 1 events at y(k). Let δij = I(ξij = 1) be an event indicator representing whether subject j of center i experiences a Type 1 event. Along the lines of Lee and Nelder13 and Ha et al.19, the hierarchical loglikelihood (h-likelihood) for subhazard frailty models (1) is defined by
| (5) |
where
is the sum of the logarithm of the conditional density function for Yij and δij given vi, i.e. the ordinary log-likelihood for censored survival data given vi, , and
is the logarithm of the density function for vi with parameters , i.e. the log-likelihood for vi, and . Here, , , and d(k) is the number of the events of interest at y(k). As the number of can increase with the number of distinct event times, the function is potentially of high dimension. Accordingly, for estimation of (β, v) Ha et al.19 proposed the use of the profiled h-likelihood h* from which in (5) is eliminated:
| (6) |
where
are solutions of the estimating equations, , for k = 1, …, D. Note here that
with a constant term Σk d(k){log d(k) −1} eliminated, so that h* becomes the penalized partial likelihood (PPL)11,23: see also Appendix C of Ha et al.10. In particular, the first term, , of h* in (6) can be viewed as the log-partial likelihood for the Fine-Gray model given vi, by treating the observed event times yij’s as complete outcomes.
In the case of right censoring under competing risks, Fine and Gray3 developed a weighted score function based on the complete-data partial likelihood. Thus the inverse probability of censoring weighting (IPCW) by Fine and Gray3 can be equally applied to the first term of h* as in Pintilie1,24 and Katsahian et al.6 Accordingly, a weighted partial h-likelihood based on the IPCW is defined by
| (7) |
Here
where
is the weight of subject j of center i at y(k), and Ĝ(·) is the Kaplan-Meier estimate of the survival function for the censoring times. Here, wij = 1 as long as individuals have not failed (i.e. yij ≥ y(k); the first condition of R(k)), whereas wij ≤ 1 and decreasing over time if they failed from Type 2 (i.e. yij ≤ y(k) and εij ≠ 1; the second condition of R(k))1,24. Note that in (7) is an extension of the weighted log-partial likelihood1,24,25 for the Fine-Gray model to the subhazard frailty models (1). We can show that, under the subhazard shared model (2), is also equivalent to the PPL of Katsahian et al.6, by combining R(k) and wij as in (17) of Appendix.
3.2 Estimation procedure
Now, Ha et al.’s10 procedures for standard correlated frailty models without competing risks can be extended to the subhazard model (1) by using in (7). That is, given frailty parameters θ, the maximum h-likelihood (MHL) estimators of τ = (βT, vT)T are obtained by solving the joint estimating equations, . In Appendix we show that given θ, the joint equations lead to Ha and Lee’s26 MHL estimator score equations for τ:
| (8) |
where X and Z are n × p and n × q* model matrices for β and v whose ijth row vectors are and , respectively, W* is the symmetric weight matrix given in (16) of Appendix, and is a q* × q* matrix; q* = q × r and BD(·) denotes a block diagonal matrix. Here w* = W *η+(δ−μ) with η = Xβ+Zv and . Note the terms in both W * and w* are evaluated at given in (16) of Appendix. For the Fine-Gray model3 without frailty, they reduce to a simple form:
We thus see that the estimating equations (8) provide new generalized iterative least squares equations for the Fine-Gray model: see also Ha and Lee26.
For estimation of θ we use the adjusted partial h-likelihood (i.e. restricted h-likelihood14) , given by
| (9) |
where and is an information matrix for τ. Note that is a function of θ only because it has already eliminated τ from and that the additional term in (9) is an adjusted form for such elimination13,14, leading to restricted maximum likelihood (REML) estimator for θ. The REML estimator for θ are obtained by solving iteratively
| (10) |
Note here that
where Σ = BD(Σ1, …, Σq) is the q* × q* block diagonal matrix and . Here, the equations (10) are solved using the Newton-Raphson method with the Hessian matrix, . Note that in implementing (10) we allow the term10,14,26 and that the computations of and follow those of Ha et al.10 using pτ(h*).
The approximated standard-error (SE) estimates for and are obtained from the inverses of the corresponding Hessian matrices, and , respectively.10,14 In particular, Fine and Gray3 proposed a robust/sandwich variance estimator to estimate using an empirical process theory because the martingale properties break down under the Fine-Gray model due to the use of IPCW and thus the standard asymptotic theories are no longer valid. Furthermore, in the subhazard frailty model (2) with one frailty term Katsahian and Boudreau27 presented a robust variance estimator of using Gray’s28 method, estimated from
| (11) |
where τ = (βT, vT)T and . However, the proposed method, , has been also used as a variance estimator in the context of the PPL: see Verweij and Van Houwelingen29 and Therneau et al.12 We investigate the performance of the two variances of by simulation studies in next section. Accordingly, the current estimation procedure can be implemented by replacing the risk indicator matrix in Ha et al.’s10 procedure with a weighted risk indicator matrix (i.e. M in (17) of Appendix) which contains both the weights w and the risk set R used for modelling the subhazard function: see also Ruan and Gray.30 Further quantities (e.g. confidence intervals of frailties) are also directly applied.
In summary, the estimates of τ and θ are obtained by alternating between the two estimating equations (8) and (10) until convergence is achieved10,26. At convergence, we compute the SEs of and . Note that the h-likelihood procedure performs well under any restrictions for cluster size ni such as ni = 1 and unbalanced cases.10,20,31 The equations (8), which estimates all random effects simultaneously from the weighted h-likelihood in (7), may influence the consistency of fixed parameters (β, θ), particularly for a small cluster size ni. However, here the resulting biases decrease quickly as n rather than q increases26,31: see also the simulation results of Section 4. Furthermore, when ni is very small, the biases can be further reduced using the Laplace approximation based on the h-likelihood: see Lee et al.14
For a subhazard shared frailty model (2), the procedures proposed by Katsahian et al.6 and Katsahian and Boudreau27 are based on the PPL11,23. Given frailty parameters θ, the PPL and h-likelihood methods provide the same estimates for β and v. However, the two methods do not yield the same final results for β and v because they give different estimators for θ.10,26 That is, the PPL method ignores the term in solving the estimating equations of θ, given in (10); this leads to an underestimation of the parameters θ, particularly when the cluster size ni is small: see also simulation results by Ha and Lee26 and Christian7.
4 Simulation study
Simulation study is conducted to evaluate the performance of the proposed method under the subhazard frailty models (3) with a general correlation structure (4) by using 1000 replications of simulated data.
The simulated data are generated using a method similar to that of Fine and Gray3 and Katsahian and Boudreau27. We consider two covariates xij = (xij1, xij1)T and a bivariate normal (BN) random effect vi = (vi0, vi1)T with mean 0 and covariance matrix having , and . The conditional subdistribution for Type 1 events given xij and vi is given by
where p = P (εij = 1|xij = (0, 0), vi = (0, 0)) is the proportion of Type 1 events and . Here β11 and β12 are regression parameters for Type 1 events. Thus the conditional distribution function of Tij given a Type 1 event as well as xij and vi is given by
| (12) |
Times to Type 1 event of interest are then generated from the distribution function above (12) using the probability integral transformation, conditional on xij and vi. The conditional subdistribution for Type 2 events is simply obtained by taking P (εij = 2|xij, vi) = 1 − P (εij = 1|xij, vi) and using an exponential distribution with rate for P (Tij ≤ t|εij = 2, xij, vi), where , and β21 and β22 are regression parameters for Type 2 events. Thus the conditional distribution function of Tij given a Type 2 event as well as xij and vi is given by
| (13) |
As before, Type 2 event times (times-to-CR event) are generated from the distribution function (13) using the probability integral transformation.
Following Fine and Gray3 and Katsahian and Boudreau27, we consider the two cases of the true parameter values for p and β:
Case A: (p, β11, β12, β21, β22) = (0.3, 0.5, 0.5, −0.5, 0.5),
Case B: (p, β11, β12, β21, β22) = (0.6, 1, −1, 1, 1).
Following Katsahian and Boudreau27, we also consider the three sample sizes: with n = 200, 400 and 1000, and (q, ni) = (20, 10), (20, 20) and (50, 20). The covariates xij1 are generated from a Bernoulli random variable with probability 0.5 in order to mimic the binary treatment covariate of the multi-center study, and xij2 are from a standard normal distribution. The covariance parameters of the random effects are and σ01 = −0.25, leading to ρ = −0.5. Though not reported here, we found similar results for σ01 = 0.25. Censoring times are generated from a Uniform(a, b) distribution where the values of a and b were empirically selected to achieve the approximate right censoring rate, low (around 25%) and high (around 50%). That is, in Case A we used Uniform(1, 2.6) and Uniform(0.45, 1) for the censoring rates 25% and 50%, respectively, and in Case B we used Uniform(0.2, 1.7) and Uniform(0, 0.7) for the censoring rates 25% and 50%, respectively.
For the 1000 replications we computed the mean, standard deviation (SD), and the mean of the estimated standard errors (denoted by SE1) for and , respectively. The SE1s for and are, respectively, obtained from and . For comparison of standard errors of , we calculated the mean of estimated standard errors (denoted by SE2) using a robust variance formula in (11). All computations were done using SAS/IML. The simulation results are summarized in Table 1.
Table 1.
Case A: (p, β11, β12, β21, β22) = (0.3, 0.5, 0.5, −0.5, 0.5); Simulation results for the estimation of parameters over 1000 replications under the subhazard correlated frailty model
| Censoring | Sample Size | Parameter | True | Mean | SD | SE1 | SE2 | |
|---|---|---|---|---|---|---|---|---|
| 25% |
n = 200 (q = 20, ni = 10) |
β11 | 0.5 | 0.502 | 0.307 | 0.306 | 0.254 | |
| β12 | 0.5 | 0.511 | 0.137 | 0.134 | 0.130 | |||
|
|
0.5 | 0.534 | 0.451 | 0.439 | – | |||
|
|
0.5 | 0.583 | 0.654 | 0.652 | – | |||
| σ01 | −0.25 | −0.285 | 0.471 | 0.438 | – | |||
|
n = 400 (q = 20, ni = 20) |
β11 | 0.5 | 0.487 | 0.245 | 0.238 | 0.179 | ||
| β12 | 0.5 | 0.505 | 0.090 | 0.092 | 0.091 | |||
|
|
0.5 | 0.497 | 0.300 | 0.303 | – | |||
|
|
0.5 | 0.505 | 0.377 | 0.405 | – | |||
| σ01 | −0.25 | −0.245 | 0.286 | 0.284 | – | |||
|
n = 1000 (q = 50, ni = 20) |
β11 | 0.5 | 0.490 | 0.157 | 0.150 | 0.112 | ||
| β12 | 0.5 | 0.497 | 0.056 | 0.058 | 0.057 | |||
|
|
0.5 | 0.492 | 0.191 | 0.182 | – | |||
|
|
0.5 | 0.486 | 0.234 | 0.233 | – | |||
| σ01 | −0.25 | −0.241 | 0.174 | 0.168 | – | |||
| 50% |
n = 200 (q = 20, ni = 10) |
β11 | 0.5 | 0.512 | 0.362 | 0.357 | 0.309 | |
| β12 | 0.5 | 0.515 | 0.164 | 0.159 | 0.156 | |||
|
|
0.5 | 0.550 | 0.539 | 0.558 | – | |||
|
|
0.5 | 0.603 | 0.758 | 0.821 | – | |||
| σ01 | −0.25 | −0.294 | 0.561 | 0.559 | – | |||
|
n = 400 (q = 20, ni = 20) |
β11 | 0.5 | 0.487 | 0.281 | 0.270 | 0.217 | ||
| β12 | 0.5 | 0.503 | 0.109 | 0.110 | 0.108 | |||
|
|
0.5 | 0.487 | 0.342 | 0.352 | – | |||
|
|
0.5 | 0.511 | 0.469 | 0.503 | – | |||
| σ01 | −0.25 | −0.237 | 0.327 | 0.341 | – | |||
|
n = 1000 (q = 50, ni = 20) |
β11 | 0.5 | 0.491 | 0.178 | 0.168 | 0.136 | ||
| β12 | 0.5 | 0.497 | 0.066 | 0.069 | 0.068 | |||
|
|
0.5 | 0.471 | 0.214 | 0.210 | – | |||
|
|
0.5 | 0.466 | 0.287 | 0.286 | – | |||
| σ01 | −0.25 | −0.222 | 0.209 | 0.201 | – |
SE1, mean of estimated standard errors using and for β1 =(β11, β12)T and , respectively, over 1000 simulations;
SE2, mean of estimated standard errors using for β = (β11, β12)T over 1000 simulations; SD, standard deviation of estimates over 1000 simulations, is defined by , where is the estimate of ψ in the ith replication and is the mean of , and ψ = β11, β12, , , or σ01.
Our method overall performs well even when the censoring rate is as high as 50%. In particular, the increase of n or ni, rather than q, reduces bias more effectively: see also Ha and Lee26. In Table 1, the SD is the empirical estimates of , and SE1 and SE2 are the averages of the proposed and robust standard-error estimates for , respectively. Our work well as judged by the very good agreement between SE1 and SD. Similarly, our SE1s for also perform well. On the other hand, the are seriously underestimated even if n increases, but the work well. A possible reason is that the SE2 may be sensitive to the random-effect structures because β11 depends on the random treatment-by-center interaction (vi1) via the same covariates xij1, but β12 does not. The trends in Table 2 are similar to those evident in Table 1. In particular, with a smaller sample as in n = 200 the biases of frailty-parameter estimators are largely reduced, as compared to those in Table 1.
Table 2.
Case B: (p, β11, β12, β21, β22) = (0.6, 1, −1, 1, 1); Simulation results for the estimation of parameters over 1000 replications under the subhazard correlated frailty model
| Censoring | Sample Size | Parameter | True | Mean | SD | SE1 | SE2 | |
|---|---|---|---|---|---|---|---|---|
| 25% |
n = 200 (q = 20, ni = 10) |
β11 | 1 | 1.003 | 0.274 | 0.272 | 0.217 | |
| β12 | −1 | −1.006 | 0.140 | 0.129 | 0.124 | |||
|
|
0.5 | 0.505 | 0.372 | 0.357 | – | |||
|
|
0.5 | 0.520 | 0.472 | 0.493 | – | |||
| σ01 | −0.25 | −0.254 | 0.353 | 0.347 | – | |||
|
n = 400 (q = 20, ni = 20) |
β11 | 1 | 0.991 | 0.215 | 0.217 | 0.152 | ||
| β12 | −1 | −1.004 | 0.093 | 0.088 | 0.087 | |||
|
|
0.5 | 0.490 | 0.265 | 0.259 | – | |||
|
|
0.5 | 0.493 | 0.321 | 0.315 | – | |||
| σ01 | −0.25 | −0.245 | 0.244 | 0.234 | – | |||
|
n = 1000 (q = 50, ni = 20) |
β11 | 1 | 0.983 | 0.145 | 0.137 | 0.095 | ||
| β12 | −1 | −0.999 | 0.057 | 0.056 | 0.054 | |||
|
|
0.5 | 0.486 | 0.166 | 0.160 | – | |||
|
|
0.5 | 0.477 | 0.192 | 0.191 | – | |||
| σ01 | −0.25 | −0.237 | 0.150 | 0.143 | – | |||
| 50% |
n = 200 (q = 20, ni = 10) |
β11 | 1 | 1.011 | 0.335 | 0.330 | 0.278 | |
| β12 | −1 | −1.028 | 0.172 | 0.159 | 0.153 | |||
|
|
0.5 | 0.527 | 0.458 | 0.490 | – | |||
|
|
0.5 | 0.578 | 0.666 | 0.699 | – | |||
| σ01 | −0.25 | −0.279 | 0.477 | 0.486 | – | |||
|
n = 400 (q = 20, ni = 20) |
β11 | 1 | 0.986 | 0.257 | 0.251 | 0.193 | ||
| β12 | −1 | −1.006 | 0.118 | 0.108 | 0.106 | |||
|
|
0.5 | 0.489 | 0.327 | 0.329 | – | |||
|
|
0.5 | 0.518 | 0.411 | 0.449 | – | |||
| σ01 | −0.25 | −0.249 | 0.314 | 0.316 | – | |||
|
n = 1000 (q = 50, ni = 20) |
β11 | 1 | 0.983 | 0.164 | 0.157 | 0.121 | ||
| β12 | −1 | −1.002 | 0.068 | 0.068 | 0.066 | |||
|
|
0.5 | 0.487 | 0.199 | 0.198 | – | |||
|
|
0.5 | 0.478 | 0.248 | 0.249 | – | |||
| σ01 | −0.25 | −0.238 | 0.187 | 0.185 | – |
SE1, mean of estimated standard errors using and for β1 =(β11, β12)T and , respectively, over 1000 simulations;
SE2, mean of estimated standard errors using for β = (β11, β12)T over 1000 simulations; SD, standard deviation of estimates over 1000 simulations, is defined by , where is the estimate of ψ in the ith replication and is the mean of , and ψ = β11, β12, , , or σ01.
In addition, we carried out the simulation studies of Cases A and B above under a subhazard shared frailty mode1 (2) with and . Here, for the censoring and covariate patterns, we follow the schemes of Katsahian and Boudreau27. Furthermore, the performances of likelihood ratio tests (LRT) based on the h-likelihood are evaluated for testing versus , which lies on the boundary of the parameter space. The LRT statistics are calculated as , where is the likelihood value under (i.e. vi0 = 0 for all i). For the purpose, we investigate the nominal level and power of the LRT at the 5% level based on the asymptotic chi-square mixture distribution, which gives critical value 2.71 at 5% level.32 Here ranges from 0, 0.1 to 1. The conclusions obtained are as follows (see also Tables S1 and S2 in Supplementary Material): (i) The trends of the estimates of the fixed parameters(β1, θ) are quite similar to those presented in Table 1, except for the standard errors for . We have found that the results of SE1 and SE2 for are about the same; here xij1 depends on β11, but not the random center effect vi0. (ii) The LRT statistic under is somewhat conservative because the observed size (i.e. the observed rate of rejecting H0 at the 5% level under ) is less than the nominal level 5% as shown in Katsahian and Boudreau27, but it becomes closer to the nominal level 5% with sample size ni or n, especially for the Case B. (iii) The power of all tests increases as and/or n increase. These results indicate that the LRT statistic overall performs well under the shared model (2).
5 A practical example
5.1 The data
We re-examine the data from the B-14 randomized multicenter breast cancer trial conducted by the NSABP15,16. The 2,817 eligible patients from 167 distinct centers were followed up for about 20 years since randomization. The number of patients per center varied from 1 to 241, with a mean of 16.9 and median of 8. The patients were randomized to one of two treatment arms, tamoxifen (1413 patients) or placebo (1404 patients). The average age of patients was 55 and the average tumor size was about 2 centimeters. The aim of this analysis is to investigate the effect of treatment on local or regional recurrence. Here we consider two event types. The first type is local or regional recurrence (Type 1) and the second type is a new primary cancer, distance recurrence or death (Type 2); only the event that occurs firstly is of interest in this analysis, so that the repeated event times are not considered. Table 3 gives the number of first observed event types in this data set; Type 1 is an event of interest (314 patients; 11.15%), Type 2 is an event of competing risk (1303 patients; 46.25%), and no-events until the last follow-up are censoring (1200 patients; 42.60%).
Table 3.
First observed event type by two treatment arms (n = 2817 patients)
| Types of Event | Placebo | Tamoxifen | Total |
|---|---|---|---|
| Type 1: Local or regional recurrence | 205 | 109 | 314 (11.15%) |
| Type 2: Distance recurrence, second primary or death | 671 | 632 | 1303 (46.25%) |
| No event (Censoring) | 537 | 663 | 1200 (42.60%) |
Table 3 also shows the number of first observed event types by two treatment arms. Figure 1 presents the estimated CIFs1 for the two treatment arms. The tamoxifen group has lower CIFs compared to placebo group for both Type 1 and Type 2. For Type 1 the difference of CIFs of two arms seems to be large, whereas for Type 2 it does not. In particular, the estimated probability that a patient of tamoxifen group will experience Type 1 event within ten years after surgery is 5%, while for a patient of placebo group it is 10%.
Figure 1.
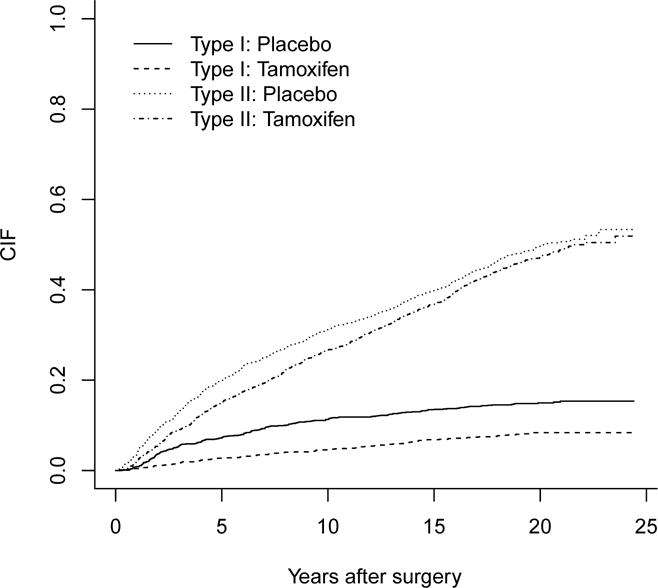
Estimated CIFs for tamoxifen vs placebo for the two types of events in the breast cancer data.
5.2 Analyses using subhazard models
For the data analysis we consider the three covariates of interest: treatment (xij1 is 1 for tamoxifen and 0 for placebo), age (xij2) and tumor size (xij3) as continuous covariates. Let vi0 and vi1 be random center effects and random treatment effects (i.e. random treatment-by-center interaction), respectively. Following Ha et al.10, we consider the three submodels of (1) for the time to Type 1 event, which include the proportional subhazards model without random effects (i.e. Fine-Gray model) and two subhazard frailty models. In other words, we consider the following three models, with ηij allowing two frailty structures (M2 and M3): Here (vi0, vi1) ~ BN means that , and ρ = Corr(vi0, vi1).
M1 (F-G): ηij = β1xij1 + β2xij2 + β3xij3;
M2 (Center): ηij = vi0 + β1xij1 + β2xij2 + β3xij3, with ;
M3 (Corr): ηij = vi0 + (β1 + vi1)xij1 + β2xij2 + β3xij3, with (vi0, vi1) ~ BN,
where ‘F-G’, ‘Center’ and ‘Corr’ indicate Fine-Gray model without frailties, subhazard frailty model with the random center effect vi0 and subhazard correlated frailty model with ρ = Corr(vi0, vi1), respectively. Here M3 ( , , ρ ≠ 0) is our full model and the others are various simplifications of it by assuming null components, i.e. M1 (vi0 = 0, vi1 = 0; , ) and M2 (vi1 = 0; , ). The estimation results are listed in Table 4.
Table 4.
Results for fitting the three subhazard models to Type 1 event of the breast cancer data
| Model | Treatment (SE) |
Age (SE) |
Tumor size (SE) |
(SE) |
(SE) |
(SE) |
|
|
|---|---|---|---|---|---|---|---|---|
| M1 (F-G) | −0.667 (0.119) |
−0.026 (0.005) |
0.082 (0.042) |
– | – | – | 4870.5 | |
| M2 (Center) | −0.672 (0.119) |
−0.026 (0.005) |
0.081 (0.042) |
0.043 (0.051) |
– | – | 4869.4 | |
| M3 (Corr) | −0.658 (0.137) |
−0.026 (0.005) |
0.079 (0.043) |
0.091 (0.026) |
0.249 (0.073) |
−0.108 [−0.721] (0.037) |
4865.7 |
M1, proportional subhazard model (Fine-Gray model) without frailties;
M2, subhazard shared frailty model with random center effect only;
M3, subhazard correlated frailty model with ρ;
and , the variances of random center effect and random treatment-by-center interaction, respectively;
σ01 and ρ, the corresponding covariance and correlation with ρ = σ01/(σ0σ1);
SE, the estimated standard error for regression and frailty parameters;
, restricted h-likelihood in (9).
In all the three subhazard models the two fixed effects (βj, j = 1, 2) are significant, except for β3. In particular, the use of tamoxifen (tamoxifen = 1) significantly reduces the risk of local or regional recurrence (Type 1 event) as compared to patients who receive placebo (placebo= 0). We also observe that overall, there are no substantial changes in the fixed-effects estimates, although the effect of main treatment (β1) becomes slightly weaker due to the increased standard error when the two random components and their correlation are included as in M3. In M2 and M3, the variance components ( and ) indicate the amount of variation between centers in baseline risk (i.e. center effect) and in the treatment effect, respectively. Here, the estimate and SE of are relatively larger than those of , which is also confirmed in Figure 2. Furthermore, the correlated model M3 explains the degree of dependency between the two random components (i.e. the random center effect v0 and the random treatment-by-center interaction v1). The estimate of gives a negative value, indicating that the two predicted random components ( and ) have a negative correlation. In particular, the estimate of β1 in M3 is negative; we see that a decreasing value of vi1 corresponds to a larger treatment effect. Thus, the negative correlation leads to the conclusion that treatment confers more benefit in centers with a higher baseline risk. This is consistent with the findings by Rondeau et al.9 in the context of meta-analysis and by Ha et al.10 in that of multi-center trials.
Figure 2.

Random effects of 167 centers in the breast cancer data (event of interest is Type 1) and their 95% confidence intervals, under subhazard correlated frailty model (M3); (a) random center effects (vi0); (b) random treatment-by-center interaction (i.e. random treatment effects) (vi1); Centers are sorted in increasing order of number of patients.
5.3 Investigating and testing for heterogeneity
We demonstrate how to investigate heterogeneity related to treatment effect over centers using confidence intervals17,18 for frailties of the individual centers. Note that the standard intervals using in (9) can be null due to zero estimation of the variance components, especially for small sample sizes or small variance components.18,33,34 Thus we follow Ha et al.’s18 modification of (9) to deal with such shrinkage issue12 for frailty. That is, for estimation of frailty parameters θ we use a further adjusted likelihood, defined by
| (14) |
which leads to non-negative variance-component estimators. Following Ha et al.18 and (14), the individual (1 − α)-level h-likelihood confidence intervals for the unidimensional components vk of random effects v are of the form
| (15) |
where maximizes the profile h-likelihood in (7), zα/2 is the normal quantile with probability α/2 in the right tail, and are obtained from . In particular, Ha et al.18 have shown via numerical studies that in a general class of frailty models without competing risks, the adjusted h-likelihood interval (15) preserves well the nominal interval. Figure 2 shows the estimates and 95% confidence intervals17,18 for the random effects in the 167 centers using the subhazard correlated model M3. Here, centers are ordered by the number of patients entered. Figures 2(a) and 2(b) give the confidence intervals for the random center effect (vi0) and the random treatment-by-center interaction (vi1), respectively. Overall, the lengths of the intervals are seen to decrease as the number of patients per center increases: see also Vaida and Xu8 and Ha et al.10.
Figure 2(a) indicates overall homogeneity in the baseline risk across 167 centers (i.e. no variation in random center effect). Figure 2(b) also shows there is no substantial variation in the effect of treatment across centers although three centers (148, 164 and 165) among 167 centers noticeably stand out. Note here that the centers (148, 165) and 164 provide the lowest and the highest treatment-by-center interactions, respectively, but that the corresponding three intervals include zero; this indicates there is little treatment-by-center interaction in this data set. Thus, in this multicenter trial there is little variation in the treatment effects across centers and the treatment is shown to be effective, These results suggest that the treatment effect may be generalized to a broader patient population as in the findings by Yamaguchi and Ohashi35 and Ha et al.10
Now, we show this heterogeneity can also be tested via the restricted h-likelihood in (9). Recently, Katsahian and Boudreau27 proposed how to test such heterogeneity (i.e. variation in random center effect) using the PPL method under the subhazard model (M2) with random center effect only. However, the heterogeneities from random treatment-by center interaction as well as random center effect should be simultaneously tested. For this purpose we again consider the three models in Section 5.2. Note that although we report the SEs of the σ2s in Table 4, one should not use them for testing .8, 10 Firstly, the null hypothesis (i.e. no center effect) lies on the boundary of the parameter space. Consider the difference of deviance between two models (M1 and M2). As shown in the simulation study of Section 4, under the null hypothesis this LR test statistic asymptotically follows a chi-square mixture .10,32,36 From Table 4, we obtain the deviance difference between M1 and M2 to be 1.1 (p-value=0.147), indicating that the random center effect is not significant (i.e. ). Furthermore, the difference in deviance between M2 and M3 is 3.7 (p-value=0.106) with an asymptotic statistic37, leading to . Accordingly, we find that there are no substantial variations for the baseline risk and treatment effect over centers, which confirms the homogeneity evident in Figure 2.
6 Discussion
We have shown that the proposed correlated frailty modelling approach based on the h-likelihood provides systematically more informative results for multi-center competing risk data. We have also demonstrated via a practical example how to investigate the heterogeneity related to treatment effect over centers and how to test such heterogeneity.
Our h-likelihood procedure can be also applied for fitting the cause-specific PH frailty models7,38, by using the risk set in the classical Cox model. It would be an interesting comprehensive analysis to compare the inference results from both the sub-hazard and cause-specific frailty models for the Type 1 event in the breast cancer dataset presented in Section 5. We have shown via a simulation study that the LR tests based on the h-likelihood perform well under the subhazard shared frailty model (2) with one frailty parameter only. However, a simulation study under the subhazard frailty model (3) with a general correlation structure (4) might be challenging due to the number of parameters to be dealt with, and hence it would be an interesting future work. Another further work is to investigate the performance of the proposed method via a simulation study when the cluster size ni is random or data-directed unbalanced case10 because in current simulation settings, ni is always fixed and at least 10.
The subhazard frailty models (1) implicitly assume that the frailty effects for the event of interest are independent of those for the other types of events (i.e. competing events). Developing an extended frailty modelling approach to allow a correlation between both events would be an interesting topic for future work.
Supplementary Material
Acknowledgments
Funding
This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (No. 2010-0021165). This work was supported by the National Research Foundation of Korea(NRF) grant funded by the Korea government (MEST) (No. 2011-0030810). Dr. Jeong’s research was supported in part by National Institute of Health (NIH) grants 5-U10-CA69974-09 and 5-U10-CA69651-11.
Appendix: Proof of estimating equations in (8)
The weighted partial h-likelihood in (7) can be expressed as
| (16) |
where hw = ℓ1w + Σiℓ2i and . Here with , and
are solutions of the estimating equations, , for k = 1, …, D. Thus, Ha et al.’s10 procedures for standard correlated frailty models without competing risks can be extended to the subhazard model (1) by using in (16). That is, given frailty parameters θ, the MHL estimators of τ = (βT, vT)T are obtained by solving the joint estimating equations, . Here, the calculations in Ha and Lee26 and Ha et al.10 show that
since ∂hw/∂τ = (∂η/∂τ)(∂hw/∂η) with η = Xβ + Zv = Eτ. Here E = (X, Z), , and δ and μ are the n × 1 vectors of δij’s, and μij’s, respectively. Note that the vector μ can be written as a simple form by using a weighted risk indicator matrix M which contains the weight wij as well as the risk set R(k). Let L be the n×1 vector of Lij’s with . Since and , we have L = MAJ, where M is the n × D weighted-risk indicator matrix whose (ij, k)th element is mij,k, is the D × D diagonal matrix and J is the D × 1 vector with one. This gives μ = W0(MAJ) with W0 = diag{exp(ηij)}. Note here that mij,k are constructed by combining R(k) and wij as in Ruan and Gray30:
| (17) |
This is also equivalent to the weights by Katsahian et al.6 and Katsahian and Boudreau27 because mij,k are equal to one as long as individuals have not failed by time y(k) (i.e. yij ≥ y(k)), and below 1 and decreasing over time if they failed from another type (Type 2) before y(k) (i.e. yij ≤ y(k) and εij ≠ 1), and zero otherwise (e.g. they failed from Type 1 or have been right censored).
Furthermore, using the computation of Ha and Lee26, we have
| (18) |
where W* = W1 − W2, W1 = diag(μ), W2 = (W0M)C−1(W0M)T, is the D × D diagonal matrix, and F = BD(0, U). Following Ha and Lee26 and (18), we can show that given θ, the MHL estimators of τ = (βT, vT)T are obtained from the following score equations:
leading to (8). Here w* = W*η + (δ − μ). Note here that the terms in W* and w* are evaluated at their estimates , where Mk is the kth component vector of M = (M1, …, MD) and ψ is the vector of exp(ηij)’s. This completes the proof.
Footnotes
Conflict of interest statement
The Authors declare that there is no conflict of interest.
Contributor Information
Il Do Ha, Department of Asset Management, Daegu Haany University, Gyeongsan, South Korea.
Nicholos J. Christian, Department of Epidemiology, University of Pittsburgh, Pittsburgh, USA
Jong-Hyeon Jeong, Department of Biostatistics, University of Pittsburgh, Pittsburgh, USA.
Junwoo Park, Department of Statistics, Seoul National University, Seoul, South Korea.
Youngjo Lee, Department of Statistics, Seoul National University, Seoul, South Korea.
References
- 1.Pintilie M. Competing risks: A practical perspective. Wiley; 2006. [Google Scholar]
- 2.Prentice R, Kalbfleisch JD, Peterson AV, Flournoy N, Farewell VT, Breslow NE. The analysis of failure times in the presence of competing risks. Biometrics. 1978;34:541–554. [PubMed] [Google Scholar]
- 3.Fine JP, Gray RJ. A proportional hazards model for the subdistribution of a competing risk. Journal of the American Statstical Association. 1999;94:496–509. [Google Scholar]
- 4.Hougaard P. Analysis of Multivariate Survival Data. New York: Springer; 2000. [Google Scholar]
- 5.Duchateau L, Janssen P. The Frailty Models. New York: Springer; 2008. [Google Scholar]
- 6.Katsahian S, Resche-Rigon M, Chevret S, Porcher R. Analysing multicentre competing risk data with a mixed proportional hazards model for the subdistribution. Statistics in Medicine. 2006;25:4267–4278. doi: 10.1002/sim.2684. [DOI] [PubMed] [Google Scholar]
- 7.Christian NJ. PhD thesis. Department of Biostatistics, University of Pittsburgh; 2011. Hierarchical likelihood inference on clustered competing risk data. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Vaida F, Xu R. Proportional hazards model with random effects. Statistics in Medicine. 2000;19:3309–3324. doi: 10.1002/1097-0258(20001230)19:24<3309::aid-sim825>3.0.co;2-9. [DOI] [PubMed] [Google Scholar]
- 9.Rondeau V, Michiels S, Liquet B, Pignon JP. Investigating trial and treatment heterogeneity in an individual patient data meta-analysis of survival data by means of the penalized maximum likelihood approach. Statistics in Medicine. 2008;27:1894–1910. doi: 10.1002/sim.3161. [DOI] [PubMed] [Google Scholar]
- 10.Ha ID, Sylvester R, Legrand C, MacKenzie G. Frailty modelling for survival data from multi-centre clinical trials. Statistics in Medicine. 2011;30:2144–2159. doi: 10.1002/sim.4250. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Ripatti S, Palmgren J. Estimation of multivariate frailty models using penalized partial likelihood. Biometrics. 2000;56:1016–1022. doi: 10.1111/j.0006-341x.2000.01016.x. [DOI] [PubMed] [Google Scholar]
- 12.Therneau TM, Grambsch PM, Pankratz VS. Penalized survival models and frailty. Journal of Computational and Graphical Statistics. 2003;12:156–175. [Google Scholar]
- 13.Lee Y, Nelder JA. Hierarchical generalized linear models (with discussion) Journal of the Royal Statistical Society, Series B. 1996;58:619–678. [Google Scholar]
- 14.Lee Y, Nelder JA, Pawitan Y. Generalised Linear Models with Random Effects: Unified Analysis via h-Likelihood. Chapman and Hall; 2006. [Google Scholar]
- 15.Fisher B, Costantino J, Redmond C, et al. A randomized clinical trial evaluating tamoxifen in the treatment of patients with node-negative breast cancer who have estrogen receptor-positive tumors. New England Journal of Medicine. 1989;320:479–484. doi: 10.1056/NEJM198902233200802. [DOI] [PubMed] [Google Scholar]
- 16.Fisher B, Dignam J, Bryant J, et al. Five versus more than five years of tamoxifen therapy for breast cancer patients with negative lymph nodes and estrogen receptor- positive tumors. Journal of the National Cancer Institute. 1996;88:1529–1542. doi: 10.1093/jnci/88.21.1529. [DOI] [PubMed] [Google Scholar]
- 17.Lee Y, Nelder JA. Likelihood inference for models with unobservables: another view (with discussion) Statistical Science. 2009;24:255–293. [Google Scholar]
- 18.Ha ID, Vaida F, Lee Y. Interval estimation of random effects in proportional hazards models with frailties. Statistical Methods in Medical Research. 2013 doi: 10.1177/0962280212474059. Published online: 29/January/2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Ha ID, Lee Y, Song JK. Hierarchical likelihood approach for frailty models. Biometrika. 2001;88:233–243. [Google Scholar]
- 20.Ha ID, Lee Y, MacKenzie G. Model selection for multi-component frailty models. Statistics in Medicine. 2007;26:4790–4807. doi: 10.1002/sim.2879. [DOI] [PubMed] [Google Scholar]
- 21.Breslow NE. Discussion of Professor Cox’s paper. Journal of the Royal Statistical Society, Series B. 1972;34:216–217. [Google Scholar]
- 22.Fan J, Li R. Variable selection for Cox’s proportional hazards model and frailty model. The Annals of Statistics. 2002;30:74–99. [Google Scholar]
- 23.McGilchrist C. REML estimation for survival models with frailty. Biometrics. 1993;49:221–225. [PubMed] [Google Scholar]
- 24.Pintilie M. Analysing and interpreting competing risk data. Statistics in Medicine. 2007;26:1360–1367. doi: 10.1002/sim.2655. [DOI] [PubMed] [Google Scholar]
- 25.Kuk D, Varadhan R. Model selection in competing risks regression. Statistics in Medicine. 2013;32:3077–3088. doi: 10.1002/sim.5762. [DOI] [PubMed] [Google Scholar]
- 26.Ha ID, Lee Y. Estimating frailty models via Poisson hierarchical generalized linear models. Journal of Computational and Graphical Statistics. 2003;12:663–681. [Google Scholar]
- 27.Katsahian S, Boudreau C. Estimating and testing for center effects in competing risks. Statistics in Medicine. 2011;30:1608–1617. doi: 10.1002/sim.4132. [DOI] [PubMed] [Google Scholar]
- 28.Gray RJ. Flexible methods for analyzing survival data using splines, with applications to breast cancer prognosis. Journal of the American Statstical Association. 1992;87:942–951. [Google Scholar]
- 29.Verweij JM, Van Houwelingen HC. Penalized likelihood in Cox regression. Statistics in Medicine. 1994;13:2427–2436. doi: 10.1002/sim.4780132307. [DOI] [PubMed] [Google Scholar]
- 30.Ruan PK, Gray RJ. Analyses of cumulative incidence functions via nonparametric multiple imputation. Statistics in Medicine. 2008;27:5709–5724. doi: 10.1002/sim.3402. [DOI] [PubMed] [Google Scholar]
- 31.Ha ID, Noh M, Lee Y. Bias reduction of likelihood estimators in semiparametric frailty models. Scandinavian Journal of Statistics. 2010;37:307–320. [Google Scholar]
- 32.Self SG, Liang KY. Asymptotic properties of maximum likelihood estimators and likelihood ratio tests under nonstandard conditions. Journal of the American Statistical Association. 1987;82:605–610. [Google Scholar]
- 33.Morris CN. Mixed model prediction and small area estimation. Test. 2006;15:72–76. [Google Scholar]
- 34.Li H, Lahiri P. An adjusted maximum likelihood method for solving small area estimation problems. Journal of Multivariate Analysis. 2010;101:882–892. doi: 10.1016/j.jmva.2009.10.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Yamaguchi T, Ohashi Y. Investigating centre effects in a multi-centre clinical trial of superficial bladder cancer. Statistics in Medicine. 1999;18:1961–1971. doi: 10.1002/(sici)1097-0258(19990815)18:15<1961::aid-sim170>3.0.co;2-3. [DOI] [PubMed] [Google Scholar]
- 36.Ha ID, Lee Y. Multilevel mixed linear models for survival data. Lifetime Data Analysis. 2005;11:131–142. doi: 10.1007/s10985-004-5644-2. [DOI] [PubMed] [Google Scholar]
- 37.Verbeke G, Molenberghs G. The use of score test for inference on variance components. Biometrics. 2003;59:254–262. doi: 10.1111/1541-0420.00032. [DOI] [PubMed] [Google Scholar]
- 38.Gorfine M, Hsu L. Frailty-based competing risks model for multivariate survival data. Biometrics. 2011;67:415–426. doi: 10.1111/j.1541-0420.2010.01470.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.