

Abstract
Background
With the rapid adoption of electronic health records (EHRs), it is desirable to harvest information and knowledge from EHRs to support automated systems at the point of care and to enable secondary use of EHRs for clinical and translational research. One critical component used to facilitate the secondary use of EHR data is the information extraction (IE) task, which automatically extracts and encodes clinical information from text.
Objectives
In this literature review, we present a review of recent published research on clinical information extraction (IE) applications.
Methods
A literature search was conducted for articles published from January 2009 to September 2016 based on Ovid MEDLINE In-Process & Other Non-Indexed Citations, Ovid MEDLINE, Ovid EMBASE, Scopus, Web of Science, and ACM Digital Library.
Results
A total of 1,917 publications were identified for title and abstract screening. Of these publications, 263 articles were selected and discussed in this review in terms of publication venues and data sources, clinical IE tools, methods, and applications (including disease areas, drug-related studies, and clinical workflow optimizations).
Conclusions
Clinical IE has been used for a wide range of applications, however, there is a considerable gap between clinical studies using EHR data and studies using clinical IE. This study enabled us to gain a more concrete understanding of the gap and to provide potential solutions to bridge this gap.
Keywords: information extraction, natural language processing, application, clinical notes, electronic health records
Graphical abstract
1 Introduction
With the rapid adoption of electronic health records (EHRs), it is desirable to harvest information and knowledge from EHRs to support automated systems at the point of care and to enable secondary use of EHRs for clinical and translational research. Following the Health Information Technology for Economic and Clinical Health Act (HITECH Act) legislation in 2009, many health care institutions adopted EHRs, and the number of studies using EHRs has increased dramatically [1]. For example, Ellsworth et al [2] conducted a review to evaluate methodological and reporting trends in the usability of EHRs; Goldstein et al [3] evaluated the state of EHR-based risk prediction modeling through a systematic review of clinical prediction studies using EHR data.
However, much of the EHR data is in free-text form [4]. Compared to structured data, free text is a more natural and expressive method to document clinical events and facilitate communication among the care team in the health care environment. One critical component to facilitate the use of EHR data for clinical decision support, quality improvement, or clinical and translation research is the information extraction (IE) task, which automatically extracts and encodes clinical information from text. In the general domain, IE is commonly recognized as a specialized area in empirical natural language processing (NLP) and refers to the automatic extraction of concepts, entities, and events, as well as their relations and associated attributes from free text [5–7]. Most IE systems are expert-based systems that consist of patterns defining lexical, syntactic, and semantic constraints. An IE application generally involves one or more of the following subtasks: concept or named entity recognition that identifies concept mentions or entity names from text (e.g., person names or locations) [8], coreference resolution that associates mentions or names referring to the same entity [9], and relation extraction that identifies relations between concepts, entities, and attributes (e.g., person-affiliation and organization-location) [10].
NLP focuses on “developing computational models for understanding natural language” [11]. An NLP system can include syntactic processing modules (e.g., tokenization, sentence detection, Part-of-Speech tagging) and/or semantic processing modules (e.g., named entity recognition, concept identification, relation extraction, anaphoric resolution). An IE application is an NLP system with semantic processing modules for extracting predefined types of information from text. In the clinical domain, researchers have used NLP systems to identify clinical syndromes and common biomedical concepts from radiology reports [12], discharge summaries [13], problem lists [14], nursing documentation [15], and medical education documents [16]. Different NLP systems have been developed and utilized to extract events and clinical concepts from text, including MedLEE [17], MetaMap [18], KnowledgeMap [19], cTAKES [20], HiTEX [21], and MedTagger [22]. Success stories in applying these tools have been reported widely [23–34].
A review done by Spyns [35] looked at NLP research in the clinical domain in 1996 and Meystre et al [11] conducted a review of studies published from 1995 to 2008. Other reviews focus on NLP in a specific clinical area. For example, Yim et al [36] provided the potential applications of NLP in cancer-case identification, staging, and outcomes quantification; Pons et al [37] took a close look at NLP methods and tools that support practical applications in radiology. This review focuses on research published after 2009 regarding clinical IE applications.
Another motivation for our review is to gain a concrete understanding of the under-utilization of NLP in EHR-based clinical research. Figure 1 shows the number of publications retrieved from PubMed using the keywords “electronic health records” in comparison with “natural language processing” from the year 2002 through 2015. We can observe that 1) there were fewer NLP-related publications than EHR-related publications and 2) EHR-related publications increased exponentially from 2009 to 2015, while NLP-related publications increased only moderately. One possible reason is federal incentives for EHR adoption (e.g., HITECH Act), which accelerated the progression of publications about EHR. Having said that, we consider that clinical IE has not been widely utilized in the clinical research community despite the growing availability of open-source IE tools. The under-utilization of IE in clinical studies is in part due to the fact that traditional statistical programmers or study coordinators may not have the NLP competency to extract this evidence from text. Through this literature review, we hope to gain some insights and develop strategies to improve the utilization of NLP in the clinical domain.
Figure 1.
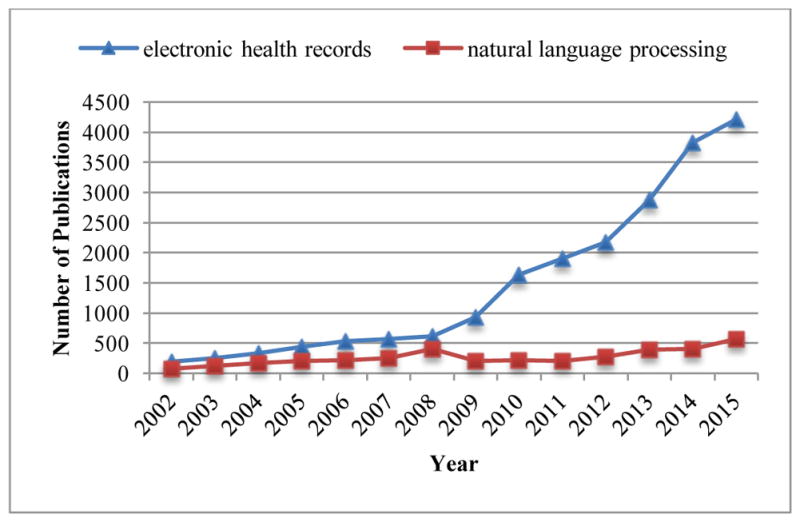
The number of natural language processing (NLP)-related articles compared to the number of electronic health record (EHR) articles from 2002 through 2015.
2 Methods
We followed the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) [38] guidelines to conduct our review.
2.1 Data Sources and Search Strategies
We conducted a comprehensive search of several databases for articles from January 1, 2009, to September 6, 2016. The databases included Ovid MEDLINE In-Process & Other Non-Indexed Citations, Ovid MEDLINE, Ovid EMBASE, Scopus, Web of Science, and ACM Digital Library. We included articles written in English and excluded those in the form of editorial, review, erratum, letter, note, or comment. The search strategy was designed and conducted by an experienced librarian. The selected keywords and the associations between these keywords were identical for searches in each database: (clinical OR clinic OR electronic health record OR electronic health records) AND (information extraction OR named entity extraction OR named entity recognition OR coreference resolution OR relation extraction OR text mining OR natural language processing) AND (NOT information retrieval). The search strings were carefully designed to be exhaustive and effective for each database and are provided in the Appendix.
2.2 Article Selection
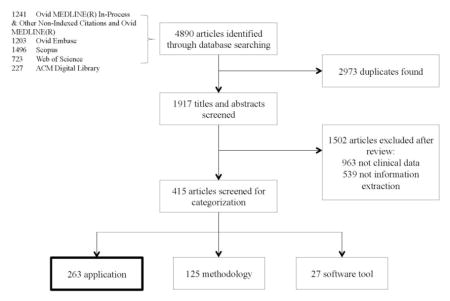
The search strategy retrieved 1,917 articles after removing duplicates. Nine reviewers (Y.W., L.W., M.R.M., S.M., F.S., N.A., S.L., Y.Z., S.M.) independently screened the titles and abstracts of these articles (each reviewer was given around 210 articles). Articles were excluded based on two criteria: 1) if they were overall unrelated to IE or 2) if they did not use clinical narratives written in English. After this screening process, 415 studies were considered for subsequent categorization. According to the main focus of those studies, one reviewer (Y.W.) categorized each article into one of three categories: 1) application, 2) methodology, or 3) software tool. Eventually, 263 articles were identified as IE application studies, 125 articles focused on proposing new IE methodologies, and 27 articles were about releasing new software tools. In this review, we focus on the 263 articles about clinical IE applications. Thus, those 263 studies underwent full-text review, performed by the same nine reviewers. A flow chart of this article selection process is shown in Figure 2.
Figure 2.

Article selection flow chart.
3 Results
In the first analysis, we analyzed the publication venues of the 263 included studies and their data sources. Since clinical IE is an interdisciplinary field of medicine and computer science, publication venues indicate the research communities that have NLP competency to leverage IE techniques. Since developing clinical NLP talent is difficult in large part due to the limited availability of clinical data needed, we provided analysis of data sources used in clinical IE research and the accessibility of these data sources. We hope to provide insight into addressing the data challenge in this domain. Next, we summarized the clinical IE tools and prevalent methods. We provided a list of clinical IE tools used in the 263 articles, an overview of their characteristics (what tools were used for what specific task), and their licenses (are they publically available or not). In addition, the methodologies prevalently adopted in clinical IE were demonstrated. Finally, we described the practical IE applications in the clinical domain, including disease areas that have been studied, drug-related studies, and utility of IE for optimizing clinical workflow. In the statistics presented below, each individual topic is reported. As a result, a single paper, for example, can be counted multiple times if it contains a discussion of multiple IE tools. The details of the included publications and review summaries are provided in the supplementary material.
3.1 Publication Venues and Data Sources
3.1.1 Publication Venues
The 263 articles were published in 117 unique venues, comprising 94 journals and 23 conferences. We manually categorized the publication venues into three categories: 1) clinical medicine, 2) informatics, and 3) computer science. The categorization process is summarized in Figure 3, and Figure 4 shows the number of included studies in each category.
Figure 3.

Categorization of publication venues.
Figure 4.

Distribution of included studies, stratified by category and year (from January 1, 2009, to September 6, 2016).
We observed that the number of journal articles in the categories of clinical medicine and informatics are much larger than the number of conference articles in these categories; those findings were shown to be inversed in the category of computer science. Though the number of publications from informatics journals is smaller compared to clinical medicine journals, it shows that there are more informatics conference publications than other conference publications. The reason might be that informatics conferences recruit more regular papers (e.g., The American Medical Informatics Association (AMIA) Annual Symposium) while abstracts are more common in clinical medicine conferences. Overall, clinical medicine journals are the most popular venues for IE application publications.
Papers in the clinical medicine category are published in a variety of clinical-specific journals, such as Arthritis & Rheumatism. Publications in informatics are mostly published in two venues: 1) Journal of the American Medical Informatics Association (n=26, n denotes the number of publications hereafter) and 2) AMIA Annual Symposium Proceedings/AMIA Symposium (n=24). In Figure 4, we observe a generally increasing trend of IE publications, except for the years 2014 and 2016 (due to the partial-year retrieval). This might be due to the World Congress on Medical and Health Informatics occurring bi-annually (MedInfo, odd year only, n=13). We note that the MedInfo proceedings are published as special issues in Studies in Health Technology and Informatics, which is categorized as clinical medicine journal. Figure 4 also shows an increasing attention and demand in the application of IE techniques in both the clinical research and informatics communities. Interestingly, although IE is a traditional research topic in computer science, only one computer science journal and a few computer science conferences (e.g., International Conference of the Italian Association for Artificial Intelligence, International Conference on System Sciences) are found. Overall, the top five publication venues having the largest number of publications are: 1) Journal of the American Medical Informatics Association (n=26), 2) AMIA Annual Symposium Proceedings/AMIA Symposium (n=24), 3) Pharmacoepidemiology and Drug Safety (n=16), 4) Studies in Health Technology and Informatics (n=13), and 5) Journal of Biomedical Informatics (n=10). The results suggest that only a small portion of papers in JAMIA and AMIA focus on the use of NLP tools for clinical applications. This may be partially due to the tendency of the academic informatics community to prefer innovations in methodology rather than research reporting the use of informatics tools. It may also be due to the dependency and the lack of clear distinction of NLP with relevant fields, such as data mining and knowledge management on text data.
3.1.2 Data Sources
The majority of the 263 studies were conducted in the United States (n=236), while others were conducted in Canada (n=9), United Kingdom (n=5), Australia (n=3), and other countries. Among the 236 US studies, 163 used only clinical documents and 56 used both clinical documents and structured EHR data, such as International Statistical Classification of Diseases, Ninth Revision (ICD-9) codes (n=25). We found that other resources were also used in conjunction with clinical data, such as biomedical literature (n=3) and health-related websites (n=2).
Table 1 shows the number of papers with diverse types of clinical documents being used. Here, we classify clinical documents into two main categories, clinical notes and diagnostic reports. Clinical notes refer to documentation of a patient’s visit with a health care provider, which may include the patient’s medical/social history and physical examination, clinical observations, summaries of diagnostic and therapeutic procedures, plan of treatment, and instructions to the patients which can be telephonic or electronic interactions with the patient. Diagnostic reports refer to the reports provided by diagnostic services, such as laboratory reports, radiology reports, and pathology reports. We counted the number of publications according to their mentions of note types in the papers and listed the most frequently used note types with brief descriptions for clinical notes and diagnostic reports in Table 1. Most of the studies were conducted by the following institutions: US Department of Veterans Affairs (VA) (n=34), Mayo Clinic (n=12), Vanderbilt University (n=8), Humedica (n=7), and Kaiser Permanente (n=7), either within individual institutions or through collaboration across multiple institutions.
Table 1.
The most frequently used note types for clinical notes (top 5) and diagnostic reports (top 3) and the corresponding brief descriptions and number of papers in the included publications.
| Note Type | Brief Description | No. of Papers | |
|---|---|---|---|
| Clinical notes | Discharge summaries | A document that describes the outcome of a patient’s hospitalization, disposition, and provisions for follow-up care. | 26 |
| Progress notes | A document that describes a patient’s clinical status or achievements during the course of a hospitalization or over the course of outpatient care. | 15 | |
| Admission notes | A document that describes a patient’s status (including history and physical examination findings), reasons why the patient is being admitted for inpatient care to a hospital or other facility, and the initial instructions for that patient’s care. | 9 | |
| Operative notes | A document that describes the details of a surgery. | 5 | |
| Primary care notes | A document that describes the details of an outpatient during a primary care. | 3 | |
| Diagnostic reports | Radiology reports | Results of radiological scans and X-ray images of various parts of the patient’s body and specific organs. | 43 |
| Pathology reports | Results of pathological examinations of tissue samples and tissues of organs removed during surgical procedures. | 22 | |
| Colonoscopy reports | Results of a colonoscopy. | 4 |
We summarized the time range of clinical data utilized in those studies and found that the time period ranged from 1987 through 2015. We counted the number of studies using the data in each specific year and these results are shown in Figure 5. The average time span of the clinical data used in the selected papers was 6.77 years. A rapid growth of data can be observed since 1995, and the amount of data utilized in those studies reached a peak in 2009. A large quantity of EHR data became available after 2009. However, Figure 5 implies that these data have not been adequately utilized by clinical IE studies.
Figure 5.

The distribution of studies in terms of clinical narrative data utilized per year.
Note that clinical documents in individual institutions are not accessible to external researchers without collaborative projects, and only a few EHR data sets are accessible to external researchers. Here, we introduce four important clinical text corpora. The first is the i2b2 NLP Challenges data (n=14), where fully de-identified notes from the Research Patient Data Repository at Partners HealthCare were created for a series of NLP challenges, 1,500 notes of which have been released. In order to access these notes, one needs to register at the i2b2 website (https://www.i2b2.org/NLP/DataSets/) and submit a proposal which is then reviewed by the i2b2 organizers. The second is MIMIC II (n=2) [39], a data set consisting of EHR data for over 40,000 de-identified intensive care unit stays at the Beth Israel Deaconess Medical Center, including clinical notes, discharge summaries, radiology reports, laboratory results, and structured clinical data. Physiologic time series are accessible publicly (https://physionet.org/physiobank/database/mimic2db/), and clinical data are accessible with a data use agreement (see http://physionet.org/mimic2/mimic2_access.shtml). The third corpus is MTsamples, which is a large collection of publicly available transcribed medical reports (http://www.mtsamples.com/). It contains sample transcription reports, provided by various transcriptionists for many specialties and different work types, and thus the accuracy and quality of the notes is not guaranteed [40]. Finally, the THYME corpus [41] contains de-identified clinical, pathology, and radiology records for a large number of patients, focusing on brain and colon cancer from a large healthcare practice (Mayo Clinic). It also provides NLP annotations, created by annotators and adjudicators at the University of Colorado at Boulder and Boston Harvard Children’s Medical Center, including temporal entity and relation, coreference, and UMLS named entity. It is available to researchers involved in NLP research under a data use agreement with Mayo Clinic (see https://github.com/stylerw/thymedata and https://clear.colorado.edu/TemporalWiki/index.php/Main_Page).
3.2 Implementations
In the next section, we briefly report the frameworks, tools, and toolkits being utilized in the selected publication. The second part summarizes two main categories of methods being used for clinical IE: rule-based and machine learning. These two areas were analyzed separately so readers can explore them based on their interests. Finally, we introduce the efforts of clinical IE-related NLP shared tasks in the community.
3.2.1 Clinical Information Extraction Tools
The clinical IE tools used in the 263 studies included are summarized in Table 2. The most frequently used tools for IE in the clinical domain are cTAKES [20] (n=26), MetaMap [18] (n=12), and MedLEE [17] (n=10). cTAKES, developed by Mayo Clinic and later transitioned to an Apache project, is the most commonly used tool. It is built upon multiple Apache open-source projects, the Apache Unstructured Information Management Architecture (UIMA) framework [42] and the Apache OpenNLP toolkit [43]. It contains several analysis engines for various linguistics and clinical tasks, such as sentence detection, tokenization, part-of-speech tagging, concept detection, and normalization. cTAKES has been adopted for identification of patient phenotype cohorts [28, 44–54], smoking status extraction [55–58], genome-wide association studies [30], extraction of adverse drug events [59], detection of medication discrepancies [60], temporal relation discovery [61], risk stratification [25], and risk factor identification [62] from EHRs. MetaMap was developed by the National Library of Medicine (NLM) with the goal of mapping biomedical text to the Unified Medical Language System (UMLS) Metathesaurus, or vice versa. It was originally developed to improve biomedical text retrieval of MEDLINE/PubMed citations. Later, MetaMap’s ability was improved to process clinical text [63], which is reflected by the large number of studies using MetaMap for clinical IE tasks. In the included studies, MetaMap has been used for phenotype extraction [31, 64–69], assessment of emergency department use [27, 70], drug-disease treatment relationships [71], fragment recognition in clinical documents [72], and extraction of patient-related attributes [73]. MedLEE is one of the earliest clinical NLP systems developed and is mostly used for pharmacovigilance [26, 74, 75] and pharmacoepidemiology [76, 77].
Table 2.
IE frameworks, tools and toolkits used in the included publications.
| Name | Description | License | Website | No. of Papers |
|---|---|---|---|---|
| Frameworks | ||||
| UIMA | Software framework for the analysis of unstructured contents like: text, video and audio data | Apache | https://uima.apache.org/ | 31 |
| GATE | Java-based open-source software for various NLP tasks such as information extraction and semantic annotation | GNU Lesser General Public License | https://gate.ac.uk/ | 5 |
| Protégé | Open-source ontology editor and framework for building intelligent systems | MIT License | http://protege.stanford.edu/ | 1 |
| Tools | ||||
| cTAKES | Open-source NLP system based on UIMA framework for extraction of information from electronic health records unstructured clinical text | Apache | http://ctakes.apache.org/ | 26 |
| MetaMap | National Institutes of Health (NIH)-developed NLP tool that maps biomedical text to UMLS concepts | UMLS Metathesaurus | https://metamap.nlm.nih.gov/ | 12 |
| MedLEE | NLP system that extracts, structures, and encodes clinical information from narrative clinical notes | NLP International for commercial use | http://zellig.cpmc.columbia.edu/medlee/ | 10 |
| KnowledgeMap Concept Indexer (KMCI) | NLP system that identifies biomedical concepts and maps them to UMLS concepts | Vanderbilt License | https://medschool.vanderbilt.edu/cpm/center-precision-medicine-blog/kmci-knowledgemap-concept-indexer | 4 |
| HITEx | Open-source NLP tool built on top of the GATE framework for various tasks such as principal diagnoses extraction and smoking status extraction | i2b2 Software License Agreement | https://www.i2b2.org/software/projects/hitex/hitex_manual.html | 4 |
| MedEx | NLP tool used to recognize drug names, dose, route, and frequency from free-text clinical records | Apache | https://medschool.vanderbilt.edu/cpm/center-precision-medicine-blog/medex-tool-finding-medication-information | 4 |
| MedTagger | Open-source NLP pipeline based on UIMA framework for indexing based on dictionaries, information extraction, and machine learning–based named entity recognition from clinical text | Apache | http://ohnlp.org/index.php/MedTagger | 3 |
| ARC | Automated retrieval console (ARC) is an open- source NLP pipeline that converts unstructured text to structured data such as Systematized Nomenclature of Medicine – Clinical Terms (SNOMED CT) or UMLS codes | Apache | http://blulab.chpc.utah.edu/content/arc-automated-retrieval-console | 2 |
| Medtex | Clinical NLP software that extracts meaningful information from narrative text to facilitate clinical staff in decision-making process | No license information available | https://aehrc.com/research/projects/medical-free-text-retrieval-and-analytics/#medtex | 2 |
| CLAMP | NLP software system based on UIMA framework for clinical language annotation, modeling, processing and machine learning | Software Research License | https://sbmi.uth.edu/ccb/resources/clamp.htm | 1 |
| MedXN | A tool to extract comprehensive medication information from clinical narratives and normalize it to RxNorm | Apache | http://ohnlp.org/index.php/MedXN | 1 |
| MedTime | A tool to extract temporal information from clinical narratives and normalize it to the TIMEX3 standard | GNU General Public License | http://ohnlp.org/index.php/MedTime | 1 |
| PredMED | NLP application developed by IBM to extract full prescriptions from narrative clinical notes | Commercial | 1 | |
| SAS Text Miner | A plug-in for SAS Enterprise Miner environment provides tools that enable you to extract information from a collection of text documents and uncover the themes and concepts that are concealed in them. | Commercial | 1 | |
| Toolkits | ||||
| WEKA | Open source toolkit that contains various machine learning algorithms for data-mining tasks | GNU General Public License | http://www.cs.waikato.ac.nz/ml/weka/ | 5 |
| MALLET | Java-based package for various NLP tasks such as document classification, information extraction, and topic modeling | Common Public License | http://mallet.cs.umass.edu/ | 4 |
| OpenNLP | Open-source machine learning toolkit for processing of natural language text | Apache | https://opennlp.apache.org/ | 1 |
| NLTK | Python-based NLP toolkit for natural language text | Apache | http://www.nltk.org/ | 1 |
| SPLAT | Statistical parsing and linguistic analysis toolkit (SPLAT) is a linguistic analysis toolkit for natural language developed by Microsoft research | Commercial | https://www.microsoft.com/en-us/research/project/msr-splat/ | 1 |
Other tools focus more on one specific task. For example, GATE [78, 79], NLTK [80], and OpenNLP [81] are typically used for various NLP preprocessing tasks, such as sentence boundary detection, tokenization, and part-of-speech (POS) tagging; MedEx [7] focuses on extracting drug names and doses; MALLET [82] and WEKA [83] are used for IE tasks that leverage machine learning algorithms, such as classification, clustering, and topic modeling; and Protégé [84] is a tool that has been frequently used for ontology building. Note that the tools summarized in this review are from the 263 application articles and that many IE tools, such as TextHunter [85], Patrick et al’s cascaded IE tool [86], KneeTex [87], Textractor [88], and NOBLE [89], in the 27 tool articles and the 125 methodology articles (many of them are participant systems in shared tasks) are not included in this review and subject to a future study.
3.2.2 Methods for Clinical Information Extraction
Approaches to clinical IE can be roughly divided into two main categories: rule-based and machine learning. Rule-based IE systems primarily consist of rules and an interpreter to apply the rules. A rule is usually a pattern of properties that need to be fulfilled by a position in the document. A common form of the rule is a regular expression that uses a sequence of characters to define a search pattern. Among the included 263 articles, 171 (65%) used rule-based IE systems. For example, Savova et al [51] used regular expressions to identify peripheral arterial disease (PAD). A positive PAD was extracted if the pre-defined patterns were matched (e.g., “severe atherosclerosis” where “severe” was from a list of modifiers associated with positive PAD evidence and “atherosclerosis” was from a dictionary tailored to the specific task of PAD discovery). Another form of the rule is logic. Sohn and Savova [57] developed a set of logic rules to improve smoking status classification. In their approach, they first extracted smoking status for each sentence and then utilized precedence logic rules to determine a document-level smoking status. Current smoker has the highest precedence, followed by past smoker, smoker, non-smoker, and unknown (e.g., if current smoker was extracted from any sentence in a document, then the document was labeled as current smoker). The final patient-level smoking status was based on similar logic rules (e.g., if there is a current smoker document but no past smoker document belonging to a patient, then the patient was assigned as a current smoker). A clinical IE system is often composed of many rules that are written by a human-knowledge engineer. The rule could be developed through two means, manual knowledge engineering (78 studies) and leveraging knowledge bases (53 studies), or a hybrid system (40 studies). Manual knowledge engineering can be time consuming and requires collaboration with physicians. It is usually very accurate, since it is based on physicians’ knowledge and experience. Sohn, Savova, and colleagues [51] provide examples of successful applications. A knowledge base is a computerized database system that stores complex structured information, such as UMLS (medical concepts), phenome-wide association studies (PheWAS) [90] (disease-gene relations), and DrugBank [91] (drug-gene relations). For example, Martinez et al [69] mapped phrases into UMLS medical concepts by MetaMap; Hassanpour and Langlotz [53] used RadLex, a controlled lexicon for radiology terminology, to identify semantic classes for terms in radiology reports; and Elkin et al [92] coded signs, symptoms, diseases, and other findings of influenza from encounter notes into Systematized Nomenclature of Medicine – Clinical Terms (SNOMED CT) medical terminology.
Machine learning–based IE approaches have gained much more interest due to their efficiency and effectiveness [93–95], particularly their success in many shared tasks [96]. Among the 263 included studies, 61 articles have illustrations on using machine learning algorithms. Some articles included different machine learning approaches for evaluation purposes. We took all of those approaches into consideration and counted their frequency of appearance and listed the six most frequently used methods in Table 3. Support Vector Machine (SVM) is the most frequently employed method by researchers. Barrett et al [97] integrated feature-based classification (SVM) and template-based extraction for IE from clinical text. Roberts et al [94] proposed an approach to use SVM with various features to extract anatomic sites of appendicitis-related findings. Sarker et al [98] proposed an automatic text classification approach for detecting adverse drug reaction using SVM. Himes et al [99] conducted a study to classify chronic obstructive pulmonary disease with SVM among asthma patients recorded in the electronic medical record. Logistic regression (LR) is mostly used for entity and relation detections. For example, Chen et al [100] applied LR to detect geriatric competency exposures from students’ clinical notes; and Rochefort et al [101] used multivariate LR to detect events with adverse relations from EHRs. Conditional random field (CRF) is another widely used method in many papers for the purpose of entity detection. For example, Deleger et al [23] used CRF to extract Pediatric Appendicitis Score (PAS) elements from clinical notes; and Li et al [60] used it to detect medication names and attributes from clinical notes for automated medication discrepancy detection. Based on our observation, many machine learning algorithms leveraged outputs from IE as features. For example, Yadav et al [102] used IE tools to extract medical word features and then utilized those features as input for a decision tree to classify emergency department computed tomography imaging reports. Some researchers compared different machine learning approaches in one paper for the purpose of performance comparison. For example, to better identify patients with depression in free-text clinical documents, Zhou et al [86] compared SVM, Generalized nearest neighbor (NNge), Repeated Incremental Pruning to Produce Error Propositional Rule (RIPPER), and DT for performance evaluation, and found that DT and NNge yielded the best F-measure with high confidence, while RIPPER outperformed other approaches with intermediate confidence.
Table 3.
The most frequently used machine learning methods (top 6) and the corresponding number of papers in the included publications.
| Method | No. of Papers |
|---|---|
| Support Vector Machine (SVM) | 26 |
| Logistic regression (LR) | 11 |
| Conditional random field (CRF) | 9 |
| Decision Tree (DT) | 8 |
| Naïve Bayes (NB) | 6 |
| Random Forest (RF) | 4 |
3.2.3 Clinical IE-related NLP Shared Tasks
Multiple clinical NLP shared tasks have leveraged community efforts for methodology advancement. Though we have categorized most studies resulting from those shared tasks as methodology publications, we would like to briefly describe those shared tasks due to their significant impact on the clinical NLP research. Table 4 summarizes the most recognizable clinical IE-related NLP shared tasks in the community.
Table 4.
Clinical IE-related NLP shared tasks.
| Shared Task | Year | Brief Description | No. of Partici pants | Best Participant Performance (F-measure) | Website |
|---|---|---|---|---|---|
| i2b2 de-identification and smoking challenge [103, 104] | 2006 | Automatic de-identification of personal health information and identification of patient smoking status. | 15 | De-identification: 0.98; Smoking identification: 0.90. | https://www.i2b2.org/NLP/DataSets/ |
| i2b2 obesity challenge [105] | 2008 | Identification of obesity and its co- morbidities. | 30 | 0.9773 | |
| i2b2 medication challenge [106] | 2009 | Identification of medications, their dosages, modes (routes) of administration, frequencies, durations, and reasons for administration in discharge summaries. | 20 | Durations identification: 0.525; Reason identification: 0.459. | |
| i2b2 relations challenge [107] | 2010 | Concept extraction, assertion classification and relation classification. | 30 | Concept extraction: 0.852; Assertion and relation classification: 0.936. | |
| i2b2 coreference challenge [108] | 2011 | Coreference resolution. | 20 | 0.827 | |
| i2b2 temporal relations challenge [109] | 2012 | Extraction of temporal relations in clinical records including three specific tasks: clinically significant events, temporal expressions and temporal relations. | 18 | Event: 0.92; Temporal expression: 0.90; Temporal relation: 0.69. | |
| i2b2 de-identification and heart disease risk factors challenge [110, 111] | 2014 | Automatic de-identification and identification of medical risk factors related to coronary artery disease in the narratives of longitudinal medical records of diabetic patients. | 10 | De-identification: 0.9586; Risk factor: 0.9276. | |
| CLEF eHealth shared task 1 [112] | 2013 | Named entity recognition in clinical notes. | 22 | 0.75 | https://sites.google.com/site/shareclefehealth/ |
| CLEF eHealth shared task 2 [113] | 2014 | Normalization of acronyms or abbreviations. | 10 | Task 2a: 0.868 (accuracy); Task 2b: 0.576 (F-measure). | https://sites.google.com/site/clefehealth2014/task-2 |
| CLEF eHealth shared task 1b [114] | 2015 | Clinical named entity recognition from French medical text. | 7 | Plain entity recognition: 0.756; Normalized entity recognition: 0.711; Entity normalization: 0.872. | https://sites.google.com/site/clefehealth2015/task-1/task-1b |
| CLEF eHealth shared task 2 [115] | 2016 | Clinical named entity recognition from French medical text. | 7 | Plain entity recognition: 0.702; Normalized entity recognition: 0.529; Entity normalization: 0.524. | https://sites.google.com/site/clefehealth2016/task-2 |
| SemEval task 9 [116] | 2013 | Extraction of drug-drug interactions from biomedical texts. | 14 | Recognition of drugs: 0.715; Extraction of drug-drug interactions: 0.651. | https://www.cs.york.ac.uk/semeval-2013/task9.html |
| SemEval task 7 [117] | 2014 | Identification and normalization of diseases and disorders in clinical reports. | 21 | Identification: 0.813; Normalization: 0.741 (accuracy). | http://alt.qcri.org/semeval2014/task7/index.php?id=task-description |
| SemEval task 14 [118] | 2015 | Named entity recognition and template slot filling for clinical texts. | 16 | Named entity recognition: 0.757; Template slot filling: 0.886 (accuracy); Disorder recognition and template slot filling: 0.808 (accuracy). | http://alt.qcri.org/semeval2015/task14/ |
| SemEval task 12 [119] | 2016 | Temporal information extraction from clinical texts including time expression identification, event expression identification and temporal relation identification. | 14 | Time expression identification: 0.795; Event expression identification: 0.903; Temporal relation identification: 0.573. | http://alt.qcri.org/semeval2016/task12/ |
3.3 Applications of Clinical Information Extraction
In this section, we summarize the application of clinical IE in terms of disease study areas, drug-related study areas, and clinical workflow optimization.
3.3.1 Disease Study Areas
IE for phenotyping accounted for a large portion of the studies. Among 263 papers, 135 focused on IE of 88 unique diseases or conditions from clinical notes, pathology reports, or radiology reports. For further analysis, we used ICD-9 to categorize diseases, as shown in Table 5. Our findings showed that the neoplasms category was the most studied disease area (e.g., hepatocellular cancer [120] and colorectal cancer [121]), followed by diseases of the circulatory system (e.g., heart failure [122] and peripheral arterial disease [51]), diseases of the digestive system (e.g., pancreatic cyst [123] and celiac disease [124]), diseases of the nervous system (e.g., headache [125], endocrine, nutritional, and metabolic diseases), and immunity disorders (e.g., diabetes mellitus [126]).
Table 5.
Application areas of clinical IE and the corresponding number of publications.
| Application Areas | No. of Papers |
|---|---|
| Disease study areas | |
| Neoplasms | 27 |
| Diseases of the circulatory system | 23 |
| Diseases of the digestive system | 12 |
| Diseases of the nervous system | 12 |
| Endocrine, nutritional and metabolic diseases, and immunity disorders | 12 |
| Mental disorders | 12 |
| Diseases of the respiratory system | 11 |
| Injury and poisoning | 8 |
| Diseases of the musculoskeletal system and connective tissue | 6 |
| Symptoms, signs, and ill-defined conditions | 5 |
| Infectious and parasitic diseases | 3 |
| Diseases of the genitourinary system | 2 |
| Diseases of the blood and blood-forming organs | 1 |
| External causes of injury and supplemental classification | 1 |
| Drug-related studies | |
| Adverse drug reaction | 3 |
| Medication extraction | 9 |
| Drug exposure | 2 |
| Drug-treatment classification | 1 |
| Dosage extraction | 3 |
| Clinical workflow optimization | |
| Adverse events | 5 |
| Quality control | 8 |
| Patient management | 6 |
| Measurement value extraction | 8 |
The included IE studies involved 14 disease categories among a total of 19 ICD-9 categories. Five disease areas were not covered in these studies (i.e., diseases of the sense organs; complications of pregnancy, childbirth, and the puerperium; congenital anomalies; certain conditions originating in the perinatal period; and external causes of injury and supplemental classification). Recent studies showed a research trend to look further into refined diseases with specific features (e.g., drug-resistant pediatric epilepsy [127], severe early-onset childhood obesity [49], non-severe hypoglycemic events [128], and neuropsychiatric disorder [129]). This research trend reflects the fact that IE techniques could play an important role when exact ICD-9 codes are not available for data extraction. IE has been used to identify patients having rare diseases with no specific ICD-9 diagnosis codes, such as acquired hemophilia [130]. The most frequently studied individual diseases (focused by more than 5 papers) were cancer, venous thromboembolism, PAD, and diabetes mellitus.
Various aspects of malignancy have been extensively focused, including identifying specific cancer type [131] or molecular testing data in a specific cancer type [132], cancer recurrence [44], diagnosis, primary site, laterality, histological type/grade, metastasis site/status [133], cancer metastases [134], and cancer stage [135]. Mehrabi et al [131] developed a rule-based natural language processing (NLP) system to identify patients with a family history of pancreatic cancer. This study showed consistent precision across the institutions ranging from 0.889 in the Indiana University (IU) dataset to 0.878 in the Mayo Clinic dataset. Customizing the algorithm to Mayo Clinic data, the precision increased to 0.881. Carrell et al [44] developed an NLP system using cTAKES to process clinical notes for women with early-stage breast cancer to identify whether recurrences were diagnosed and if so, the timing of these diagnoses. The NLP system correctly identified 0.92 of recurrences with 0.96 specificity. Farrugia et al. proposed an NLP solution for which preliminary results of correctly identifying primary tumor stream, metastases, and recurrence are up to 0.973 [134]. Nguyen et al [133] used Medtex to automatically extract cancer data and achieved an overall recall of 0.78, precision of 0.83, and F-measure of 0.80 over seven categories, namely, basis of diagnosis, primary site, laterality, histological, histological grade, metastasis site, and metastatic status. Warner et al [135] developed an NLP algorithm to extract cancer staging information from narrative clinical notes. The study looked at the four stages of lung cancer patients and showed that the algorithm was able to calculate the exact stage of 0.72 of patients.
To extract venous thromboembolism, Tian et al [136] used unigrams, bigrams, and list of negation modifiers to develop rules for identifying if a sentence from clinical reports refers to positive case of deep vein thrombosis (DVT) or Pulmonary embolism, and NLP achieved 0.94 sensitivity, 0.96 specificity and 0.73 PPV for DVT. McPeek Hinz et al [137] tried to capture both acute and historical cases of thromboembolic disease using a general purpose NLP algorithm, and obtained a positive predictive value of 0.847 and sensitivity of 0.953 for an F-measure of 0.897.
For PAD, Savova et al [51] used cTAKES to identify four groups of PAD patients, positive, negative, probable and unknown based on radiology reports, and the positive predictive value was in the high 90’s. Duke et al [138] implemented an NLP system to improve identification of PAD patients from EHR. The results showed that using unstructured data is able to identify more PAD patients compared to structured data. The NLP system was able to identify 98% of PAD patients in their dataset but when only structured data was used only 22% of PAD patients were captured. The NLP system developed by Afzal et al [139] ascertained PAD status from clinical notes with sensitivity (0.96), positive predictive value (0.92), negative predictive value (0.99), and specificity (0.98).
Currently extraction of diabetes from clinical text can achieve a performance score of over 0.95. For example, Wei et al [140] combined NLP, a machine learning algorithm (e.g., SVM), and ontology (SNOMED-CT) for the automatic identification of patients with Type 2 Diabetes Mellitus, achieving an F-measure of above 0.950.
3.3.2 Drug-related Studies
Out of 263 papers in our collection, 17 used IE for drug-related studies. Table 5 shows our categorization of drug-related studies and the number of papers in each category. In this section, we review papers in each category and highlight their novelties.
3.3.2.1 Drug-named Entity Recognition
One of the main components in drug-related studies is identifying drug names in clinical notes. Most of these studies used a rule-based keyword search approach. MedEx, developed by Xu et al [141], has been applied in several studies, such as the application in [142]. MedEx is a rule-based system that extracts medication name, strength, route, and frequency. The system was evaluated on 50 discharge summaries, and an F-measure of 0.93 was reported. Sohn et al [143] studied semantic and context patterns for describing medication information in clinical notes. They analyzed two different corpora: 159 clinical notes from Mayo Clinic and 253 discharge summaries from the i2b2 shared task. They illustrated that 12 semantic patterns cover 95% of medication mentions. Zheng et al [144] developed an NLP system to extract mentions of aspirin use and dosage information from clinical notes. The system had several components, including sentence splitting, tokenization, part-of-speech tagging, etc. To identify the mentions, the system used a keyword search plus a word-sense disambiguation component. The authors trained the systems on 2,949 notes and evaluated it on 5,339 notes. The system achieved 0.955 sensitivity and 0.989 specificity.
3.3.2.2 Dosage Information Extraction
A few drug-related studies focused on extracting dosage information from clinical notes. Xu et al [145] extended MedEx to extract dosage information from clinical notes and then calculated daily doses of medications. They tested the system for tacrolimus medication on four data sets and reported precision in the range of 0.90 to 1.0 and a recall rate of 0.81 to 1.0. In another study, Xu et al [24] evaluated MedEx in an automating data-extraction process for pharmacogenetic studies. The study used a cohort of patients with a stable warfarin dose. They evaluated the system on 500 physician-annotated sentences and achieved 0.997 recall and 0.908 precision. The extracted information was used to study the association between the dose of warfarin and genetic variants.
3.3.2.3 Adverse Drug Reaction Detection
We identified three research studies on extracting adverse drug reactions (ADRs) from clinical notes. Wang et al [75] conducted the first study to use unstructured data in EHR for identifying an ADR. In this study, the authors used MedLEE to identify medication entities and events. They considered co-occurrences of entities and events as indications of ADR. The system evaluated for seven drug classes and their known ADRs; the authors reported 0.75 recall and 0.31 precision. Sohn et al [59] developed two systems, a rule-based system to discover individual adverse effects and causative drug relationships, and a hybrid system of machine learning (C4.5-based decision tree) and a rule-based system to tag sentences containing adverse effects. They evaluated the system in the domain of psychiatry and psychology and reported 0.80 F-measure for the rule-based system and 0.75 for the hybrid system. Haerian et al [26] studied ADRs from another perspective, confounders. They designed and implemented an NLP system to identify cases in which the event is due to a patient’s disease rather than a drug. They evaluated the system for two ADRs, rhabdomyolysis and agranulocytosis, and reported 0.938 sensitivity and 0.918 specificity.
Conclusions from these studies show that ADR identification is a complex task and needs more sophisticated systems. Nevertheless, the mentioned systems could assist experts in the process of manual review of ADR identification.
3.3.2.4 Drug Exposure Extraction
Liu et al [146] and Feng et al [147] developed NLP systems to determine patient drug exposure histories. The former system, which is a hybrid system of NLP and machine learning, first identifies drug names and then drug events. While detecting drug events, the system labels drug mentions with an “on” or “stop” label. Finally, the system models drug exposure for a patient based on temporal information for each drug. The authors evaluated the system for warfarin exposure and reported 0.87 precision and 0.79 recall. The latter system used NLP to identify drug exposure histories for patients exposed to multiple statin dosages.
3.3.3 Clinical Workflow Optimization
Many studies leveraged clinical IE to improve and optimize clinical workflow. Table 5 lists four categories of clinical workflow and the number of papers in each category. In this section, we review papers in each category and highlight their novelties.
3.3.3.1 Adverse Event Detection
Adverse events (AEs) are injuries caused by medical management rather than the underlying condition of the patient. Automated IE tools have been developed to detect AEs. Rochefort et al [101] utilized rules to detect AEs of 1) hospital-acquired pneumonias, 2) central venous catheter–associated bloodstream infections, and 3) in-hospital falls. Receiver operating characteristic (ROC) was used to find the optimal threshold for detection of AEs based on values of blood cell counts, abnormal ventilator settings, or elevated body temperature. In another of their studies [148], Rochefort and colleagues used similar techniques to detect three highly prevalent AEs in elderly patients: 1) DVT, 2) pulmonary embolism (PE), and 3) pneumonia. Zhang et al [149] extracted information on adverse reactions to statins from a combination of structured EHR entries. Hazlehurst et al [150] used an NLP software, MediClass, to detect vaccine AEs based on concepts, terms, and rules. Baer et al [151] developed Vaccine Adverse Event Text Mining (VaeTM) to extract features about AEs, including diagnosis and cause of death, from clinical notes. They found that the clinical conclusion from VaeTM agreed with the full text in 93% of cases, even though 74% of words were reduced.
3.3.3.2 Quality Control
Inappropriate emergency department (ED) usage increases the workload of emergency care services due to the fact that patients with non-urgent problems make up a substantial proportion of ED visits. Using IE to automatically identify inappropriate ED caseloads could accurately predict inappropriate use. In two studies [27, 70], researchers used GATE- and MetaMap-extracted biopsychosocial concepts from the primary care records of patients and studied their relationship to inappropriate use of ED visits. The study [27] extracted over 38 thousand distinct UMLS codes from 13,836 patients’ primary records; and the codes of mental health and pain were associated with inappropriate ED room use with statistical significance (p < 0.001). It showed the feasibility of using IE to reduce inappropriate ED usage. Tamang et al [152] utilized rules to detect unplanned care in EHRs, such as emergency care, unplanned inpatient care, and a trip to an outpatient urgent care center, in order to reduce these unplanned care episodes.
Researchers from UCLA conducted quality assessment of radiologic interpretations using, as a reference, other clinical information, such as pathology reports [153]. They developed a rule-based system to automatically extract patient medical data and characterize concordance between clinical sources, and showed the application of IE tools to facilitate health care quality improvement.
The increased use of imaging has resulted in repeated imaging examinations [154]. Ip et al [155] utilized GATE [78] to extract imaging recommendations from radiology reports and quantify repeat imaging rates in patients. Since ADR is an important quality metric for colonoscopy performance, a few studies showed the application of IE tools in automatically extracting components to calculate ADR. Mehrotra and Harkema [156] developed an IE tool to measure published colonoscopy quality indicators from major gastroenterology societies, including documentation of cecal landmarks and bowel preparation quality. Raju et al [157, 158] developed an NLP program to identify adenomas and sessile serrated adenomas from pathology reports for reporting ADR. Gawron et al [159] developed a flexible, portable IE tool—QUINCE—to accurately extract pathology results associated with colonoscopies, which is useful for reporting ADRs across institutions and health care systems.
3.3.3.3 Patient Management
Popejoy et al [15] described a care coordination ontology that was built to identify and extract care coordination activities from nursing notes and show how these activities can be quantified. Activities include communication and/or management of elderly patient needs. The study by Gundlapalli et al [160] aimed to detect homeless status using free-text Veterans Affairs (VA) EHRs. In this study, a total of 356 concepts about risk factors among the homeless population were categorized into eight categories, including direct evidence, “doubling up,” mentions of mental health diagnoses, etc.
Arranging and documenting follow-up appointments prior to patient dismissal is important in patient care. Information contained in the dismissal record is beneficial for performance measurement to support quality improvement activities and quality-related research. Ruud et al [161] used the SAS text mining tool (SAS Text Miner) [162] to extract date, time, physician, and location information of follow-up appointment arrangements from 6,481 free-text dismissal records at Mayo Clinic. The SAS Text Miner tool automatically extracts words and phrases and labels them as “terms.” This is used to facilitate the IE process of dismissal records. The total annotation time can be reduced from 43 hours to 14 hours. Were et al [163] evaluated the Regenstrief EXtracion (REX) tool to extract follow-up provider information from free-text discharge summaries at two hospitals. Comparing three physician reviewers showed that the tool was beneficial at extracting follow-up provider information.
3.3.3.4 Measurement Values Extraction
Rubin et al [164] used GATE framework to identify device mentions in portable chest radiography reports and to extract the information, indicating whether the device was removed or remained present. The aim was to study complications, such as infections that could be related to the presence and length of time that devices were present. Hao et al [165] developed a tool called Valx to extract and normalize numeric laboratory test expressions from clinical texts and evaluated them using clinical trial eligibility criteria text. Garvin et al [166, 167] used regular expressions in UIMA to extract left ventricular ejection fraction value, which is a key clinical component of heart failure quality measure, from echocardiogram reports, and achieved accurate results. Meystre et al [168] developed a system called CHIEF, which was also based on the UMIA framework, to extract congestive heart failure (CHF) treatment performance measures, such as left ventricular function mentions and values, CHF medications, and documented reasons for a patient not receiving these medications, from clinical notes in a Veterans Health Administration project, and achieved high recall (>0.990) and good precision (0.960–0.978).
4 Discussion
Observing that clinical IE has been underutilized for clinical and translational research, we have systematically reviewed the literature published between 2009 and 2016 in this study. Our review indicates that clinical IE has been used for a wide range of applications, but there is a considerable gap between clinical studies using EHR data and studies using clinical IE. This study enabled us to gain a more concrete understanding of underlying reasons for this gap.
First, NLP experts trained in the general domain have limited exposure to EHR data as well as limited experience in collaborating with clinicians. Few clinical data sets are available in the public domain due to the Health Insurance Portability and Accountability Act (HIPAA) privacy rule and institutional concerns [169]. Our review showed that the majority of clinical IE publications are from a handful of health care institutions, usually with a strong informatics team (including NLP experts). The development of clinical IE solutions often requires NLP experts to work closely with clinicians who can provide the necessary domain knowledge. However, even with the availability of some EHR data sets to the general community accessible with a data-use agreement (e.g., i2b2 and MIMIC II), they are still underutilized.
Second, as an applied domain, clinical NLP has been dominated by rule-based approaches, which is considerably different from the general NLP community. We demonstrated that more than 60% of the studies in this review used only rule-based IE systems. However, in the academic NLP research domain (as opposed to the applied or commercial NLP domain), rule-based IE is widely considered obsolete, and statistical machine learning models dominate the research. For example, Chiticariu et al [170] examined 177 research papers in four best NLP conference proceedings (NLP, EMNLP, ACL, and NAACL) from 2003 through 2012 and found that only 6 papers relied solely on rules. The skew of clinical IE toward rule-based approaches is very similar to the situation of commercial IE products in the general NLP application domain (as opposed to the specialized clinical NLP domain). Chiticariu and colleagues [170] also conducted an industry survey on 54 different IE products in the general domain and found that only one-third of the vendors relied entirely on machine learning. The systems developed by large vendors, such as IBM, SAP, and Microsoft, are completely rule-based. Like these commercial products in the general domain, clinical IE systems greatly value rule-based approaches due to their interpretability to clinicians. In addition, rule-based IE can incorporate domain knowledge from knowledge bases or experts, which is essential for clinical applications. We found that seven machine learning algorithms were applied on four NLP subtasks in 15 studies, and 16 machine learning algorithms were adopted on classification and regression tasks in 64 studies. Most machine learning methods were used for data prediction (e.g., chronic obstructive pulmonary disease prediction [99]), estimation (e.g., lesion malignancy estimation [171]), and association mining (e.g., association between deep vein thrombosis and pulmonary embolism [172]), while only a small group of them were applied directly to NLP tasks (e.g., tumor information extraction [67] and smoking status extraction [55]). Deep learning [173], the prevalent representation-learning method, has not been utilized in the 263 included studies. Nevertheless, there are over 2,800 deep-learning publications in the Scopus database in the year 2015 alone. This is again partially due to the limited availability of clinical data sets to researchers. Other reasons include the challenge of interpretability of machine learning methods [174] and the difficulty of correcting specific errors reported by end users (compared to rule-based approaches, which can trivially modify rules correct specific errors). Efforts, such as organizing shared tasks to release clinical text data, are needed to encourage more NLP researchers to contribute to clinical NLP research.
Additionally, the portability and generalizability of clinical IE systems are still limited, partially due to the lack of access to EHRs across institutions to train the systems, and partially due to the lack of standardization. Rule-based IE systems require handcrafted IE rules, while machine learning–based IE systems require a set of manually annotated examples. The resultant IE systems may lack portability, primarily due to the sublanguage difference across heterogeneous sources. One potential solution to this lack of portability is to adopt advanced IE techniques, such as bootstrapping or distant supervision, to build portable and generalizable IE systems [175–179]. These techniques take advantage of a large amount of raw corpus, information redundancy across multiple sources, and existing knowledge bases to automatically or semi-automatically acquire IE knowledge. For example, we can generate raw annotated examples by utilizing an information redundancy across multiple sources and known relationships recorded in knowledge bases. Additionally, most IE tasks are defined without standard information models (a model defining a representation of concepts and the relationships, constraints, rules, and operations to specify data semantics) or value sets (typically used to represent the possible values of a coded data element in an information model), which also limit their portability and generalizability.
We believe the above issues could be alleviated through the training of NLP experts with cross-disciplinary experience, the adoption of standard information models and value sets to improve the interoperability of NLP systems and downstream applications, and collaboration among multiple institutions to advance privacy-preserving data analysis models. Training NLP experts with cross-disciplinary experience is critical to the biomedical informatics community, amplified by the area’s interdisciplinary nature. Most NLP courses in informatics training focus on state-of-the-art NLP techniques, while our review demonstrates the widespread use of rule-based NLP systems for real-world practice and clinical research. It may imply an opportunity in informatics training to distinguish academic informatics from applied informatics. Even machine learning-based NLP systems achieve the state-of-the-art performance, however, it is difficult for clinicians and clinical researchers to participate in the system development process.
Standardizing semantics involves two components: 1) information models and 2) value sets. Information models generally specify data semantics and define the representation of entities or concepts, relationships, constraints, rules, and operations, while value sets specify permissible values. The adoption of standards will improve the interoperability of NLP systems and, therefore, facilitate the use of NLP for EHR-based studies. A potential solution is to leverage an international consensus information model, such as the Clinical Information Modeling Initiative (CIMI), and use the compositional grammar for SNOMED-CT concepts in Health Level Seven International (HL7) as standard representations. There are a few existing efforts focusing on sharing clinical data of a group of patients. For example, the clinical e-science framework (CLEF) [180], a UK MRC–sponsored project, aims to establish policies and infrastructure for clinical data sharing of cancer patients to enable the next generation of integrated clinical and bioscience research. However, no prior effort exists for privacy-preserving computing (PPC) on NLP artifacts with distributional information [181, 182]. PPC strategies could combine different forms provided by different data resources within the topic of privacy restrictions. A primary issue of leveraging this technique is building a PPC infrastructure. Advanced PPC infrastructure, such as integrating Data for Analysis, Anonymization, and SHaring (iDASH) [183], may be a viable option. Through existing collaborating efforts or building and leveraging this privacy-preserving computing infrastructure, it will become more prevalent to use EHR data for structuring of clinical narratives and supporting the extraction of clinical information for downstream applications.
This review has examined the last 8 years of clinical information extraction applications literature. There are a few limitations in this review. First, this study may have missed relevant articles published after September 7, 2016. Second, the review is limited to articles written in the English language. Articles written in other languages would also provide valuable information. Third, the search strings and databases selected in this review might not be sufficient and might have introduced bias into the review. Fourth, the articles utilizing clinical narratives from non-EHR systems, such as clinical trials [184], are not considered in this review. Finally, the 27 articles about releasing new IE tools and 125 methodology articles are not included in this literature review and will be the focus of future work.
Supplementary Material
Highlights.
A literature review for clinical information extraction applications.
1,1917 publications were identified for title and abstract screening.
263 publications were fully reviewed in terms of publication venues and data sources, clinical IE tools, methods, and applications.
Understand gap between clinical studies using EHR data and studies using clinical IE, and provide potential solutions to bridge the gap.
Acknowledgments
Funding
This work was made possible by NIGMS R01GM102282, NCATS U01TR002062, NLM R01LM11934, and NIBIB R01EB19403.
Appendix A: Search Strategy
A.1 Ovid
Database(s): Embase 1988 to 2016 Week 36, Ovid MEDLINE(R) In-Process & Other Non-Indexed Citations and Ovid MEDLINE(R) 1946 to Present
Search Strategy:
| No. | Searches | Results |
|---|---|---|
| 1 | (clinic or clinical or “electronic health record” or “electronic health records”).mp. | 10,297,015 |
| 2 | (“coreference resolution” or “co-reference resolution” or “information extraction” or “named entity extraction” or “named entity recognition” or “natural language processing” or “relation extraction” or “text mining”).mp. | 10,981 |
| 3 | “information retrieval”.mp. | 29,773 |
| 4 | (1 and 2) not 3 | 3,245 |
| 5 | limit 4 to English language | 3,204 |
| 6 | limit 5 to yr=“2009 -Current” | 2,480 |
| 7 | limit 6 to (editorial or erratum or letter or note or comment) [Limit not valid in Embase, Ovid MEDLINE(R), Ovid MEDLINE(R) In-Process; records were retained] | 36 |
| 8 | 6 not 7 | 2,444 |
| 9 | remove duplicates from 8 | 1,651 |
A.2 Scopus
| 1 | TITLE-ABS-KEY(clinic OR clinical OR “electronic health record” OR “electronic health records”) |
| 2 | TITLE-ABS-KEY(“coreference resolution” OR “co-reference resolution” OR “information extraction” OR “named entity extraction” OR “named entity recognition” OR “natural language processing” OR “relation extraction” OR “text mining”) |
| 3 | TITLE-ABS-KEY(“information retrieval”) |
| 4 | PUBYEAR AFT 2008 AND LANGUAGE(english) |
| 5 | (1 and 2 and 4) and not 3 |
| 6 | DOCTYPE(le) OR DOCTYPE(ed) OR DOCTYPE(bk) OR DOCTYPE(er) OR DOCTYPE(no) OR DOCTYPE(sh) |
| 7 | 5 and not 6 |
| 8 | PMID(0*) OR PMID(1*) OR PMID(2*) OR PMID(3*) OR PMID(4*) OR PMID(5*) OR PMID(6*) OR PMID(7*) OR PMID(8*) OR PMID(9*) |
| 9 | 7 and not 8 |
A.3 Web of Science
1 TOPIC: (clinic OR clinical OR “electronic health record” OR “electronic health records”) AND TOPIC: (“coreference resolution” OR “co-reference resolution” OR “information extraction” OR “named entity extraction” OR “named entity recognition” OR “natural language processing” OR “relation extraction” OR “text mining”) AND LANGUAGE: (English) AND DOCUMENT TYPES: (Article OR Abstract of Published Item OR Book OR Book Chapter OR Meeting Abstract OR Proceedings Paper OR Review) Indexes=SCI-EXPANDED Timespan=2009–2016
| 2 | TS=(“information retrieval”) |
| 3 | 1 NOT 2 |
| 4 | PMID=(0* or 1* or 2* or 3* or 4* or 5* or 6* or 7* or 8* or 9*) |
| 5 | 3 NOT 4 |
A.4 ACM Digital Library
+clinic +”information extraction” -”information retrieval” +clinical +”information extraction” -”information retrieval” +”electronic health record” +”information extraction” -”information retrieval” +”electronic health records” +”information extraction” -”information retrieval” +clinic +”coreference resolution” -”information retrieval” +clinical +” coreference resolution” -”information retrieval” +”electronic health record” +” coreference resolution” -”information retrieval” +”electronic health records” +” coreference resolution” -”information retrieval” +clinic +”co-reference resolution” -”information retrieval” +clinical +”co-reference resolution” -”information retrieval” +”electronic health record” +”co-reference resolution” -”information retrieval” +”electronic health records” +”co-reference resolution” -”information retrieval” +clinic +”named entity extraction” -”information retrieval” +clinical +”named entity extraction” -”information retrieval” +”electronic health record” +”named entity extraction” -”information retrieval” +”electronic health records” +”named entity extraction” -”information retrieval” +clinic +”named entity recognition” -”information retrieval” +clinical +”named entity recognition” -”information retrieval” +”electronic health record” +”named entity recognition” -”information retrieval” +”electronic health records” +”named entity recognition” -”information retrieval” +clinic +”natural language processing” -”information retrieval” +clinical +”natural language processing” -”information retrieval “ +”electronic health record” +”natural language processing” -”information retrieval” +”electronic health records” +”natural language processing” -”information retrieval” +clinic +”relation extraction” -”information retrieval” +clinical +”relation extraction” -”information retrieval “ +”electronic health record” +”relation extraction” -”information retrieval” +”electronic health records” +”relation extraction” -”information retrieval” +clinic +”text mining” -”information retrieval” +clinical +”text mining” -”information retrieval “ +”electronic health record” +”text mining” -”information retrieval” +”electronic health records” +”text mining” -”information retrieval” All limited from 2009 to present.
Footnotes
Competing Interests
None.
Contributors
Y.W.: conceptualized, designed, and wrote the study; designed the analysis of clinical workflow optimization. L.W.: analyzed the data; designed disease areas; edited the manuscript. M.R.M.: analyzed the data; designed drug-related studies; edited the manuscript. S.M.: analyzed the data; designed data sources; edited the manuscript. F.S.: analyzed the data; designed machine learning methods; edited the manuscript. N.A.: analyzed the data; designed clinical IE tools; edited the manuscript. S.L.: analyzed the data; designed publication venues; edited the manuscript. Y.Z.: analyzed the data. S.M.: analyzed the data. S.S.: edited the manuscript. H.L: conceptualized, designed, and edited the manuscript.
Conflict statement
We have nothing to disclose.
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- 1.Blumenthal D. Launching hitech. New England Journal of Medicine. 2010;362:382–5. doi: 10.1056/NEJMp0912825. [DOI] [PubMed] [Google Scholar]
- 2.Ellsworth MA, Dziadzko M, O’Horo JC, Farrell AM, Zhang J, Herasevich V. An appraisal of published usability evaluations of electronic health records via systematic review. J Am Med Inform Assoc. 2017;24:218–26. doi: 10.1093/jamia/ocw046. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Goldstein BA, Navar AM, Pencina MJ, Ioannidis J. Opportunities and challenges in developing risk prediction models with electronic health records data: a systematic review. J Am Med Inform Assoc. 2017;24:198–208. doi: 10.1093/jamia/ocw042. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Jensen K, Soguero-Ruiz C, Mikalsen KO, Lindsetmo R-O, Kouskoumvekaki I, Girolami M, et al. Analysis of free text in electronic health records for identification of cancer patient trajectories. Scientific Reports. 2017:7. doi: 10.1038/srep46226. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Sarawagi S. Information extraction. Foundations and Trends® in Databases. 2008;1:261–377. [Google Scholar]
- 6.Small SG, Medsker L. Review of information extraction technologies and applications. Neural computing and applications. 2014;25:533–48. [Google Scholar]
- 7.Cowie J, Lehnert W. Information extraction. Communications of the ACM. 1996;39:80–91. [Google Scholar]
- 8.Nadeau D, Sekine S. A survey of named entity recognition and classification. Lingvisticae Investigationes. 2007;30:3–26. [Google Scholar]
- 9.Lee H, Peirsman Y, Chang A, Chambers N, Surdeanu M, Jurafsky D. Stanford’s multi-pass sieve coreference resolution system at the CoNLL-2011 shared task. Proceedings of the Fifteenth Conference on Computational Natural Language Learning: Shared Task: Association for Computational Linguistics; 2011; pp. 28–34. [Google Scholar]
- 10.Bach N, Badaskar S. Literature review for Language and Statistics II. 2007. A review of relation extraction. [Google Scholar]
- 11.Meystre SM, Savova GK, Kipper-Schuler KC, Hurdle JF. Extracting information from textual documents in the electronic health record: a review of recent research. Yearb Med Inform. 2008;35:44. [PubMed] [Google Scholar]
- 12.Flynn RWV, Macdonald TM, Schembri N, Murray GD, Doney ASF. Automated data capture from free-text radiology reports to enhance accuracy of hospital inpatient stroke codes. Pharmacoepidemiology and Drug Safety. 2010;19:843–7. doi: 10.1002/pds.1981. [DOI] [PubMed] [Google Scholar]
- 13.Yang H, Spasic I, Keane JA, Nenadic G. A text mining approach to the prediction of disease status from clinical discharge summaries. J Am Med Inform Assoc. 2009;16:596–600. doi: 10.1197/jamia.M3096. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Kung R, Ma A, Dever JB, Vadivelu J, Cherk E, Koola JD, et al. A natural language processing alogrithm for identification of patients with cirrhosis from electronic medical records. Gastroenterology. 2015;(1):S1071–S2. [Google Scholar]
- 15.Popejoy LL, Khalilia MA, Popescu M, Galambos C, Lyons V, Rantz M, et al. Quantifying care coordination using natural language processing and domain-specific ontology. J Am Med Inform Assoc. 2015;22:e93–103. doi: 10.1136/amiajnl-2014-002702. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Di Marco C, Bray P, Covvey HD, Cowan DD, Di Ciccio V, Hovy E, et al. Authoring and generation of individualized patient education materials. AMIA Annual Symposium Proceedings: American Medical Informatics Association; 2006; p. 195. [PMC free article] [PubMed] [Google Scholar]
- 17.Friedman C, Alderson PO, Austin JH, Cimino JJ, Johnson SB. A general natural-language text processor for clinical radiology. J Am Med Inform Assoc. 1994;1:161–74. doi: 10.1136/jamia.1994.95236146. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Aronson AR, Lang F-M. An overview of MetaMap: historical perspective and recent advances. J Am Med Inform Assoc. 2010;17:229–36. doi: 10.1136/jamia.2009.002733. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Denny JC, Irani PR, Wehbe FH, Smithers JD, Spickard A., III . The KnowledgeMap project: development of a concept-based medical school curriculum database. AMIA; Citeseer: 2003. [PMC free article] [PubMed] [Google Scholar]
- 20.Savova GK, Masanz JJ, Ogren PV, Zheng J, Sohn S, Kipper-Schuler KC, et al. Mayo clinical Text Analysis and Knowledge Extraction System (cTAKES): architecture, component evaluation and applications. J Am Med Inform Assoc. 2010;17:507–13. doi: 10.1136/jamia.2009.001560. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Goryachev S, Sordo M, Zeng QT. A suite of natural language processing tools developed for the I2B2 project. AMIA Annual Symposium Proceedings: American Medical Informatics Association; 2006; p. 931. [PMC free article] [PubMed] [Google Scholar]
- 22.Liu H, Bielinski SJ, Sohn S, Murphy S, Wagholikar KB, Jonnalagadda SR, et al. An information extraction framework for cohort identification using electronic health records. AMIA Summits Transl Sci Proc. 2013;2013:149–53. [PMC free article] [PubMed] [Google Scholar]
- 23.Denny JC, Ritchie MD, Basford MA, Pulley JM, Bastarache L, Brown-Gentry K, et al. PheWAS: demonstrating the feasibility of a phenome-wide scan to discover gene–disease associations. Bioinformatics. 2010;26:1205–10. doi: 10.1093/bioinformatics/btq126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Xu H, Jiang M, Oetjens M, Bowton EA, Ramirez AH, Jeff JM, et al. Facilitating pharmacogenetic studies using electronic health records and natural-language processing: a case study of warfarin. J Am Med Inform Assoc. 2011;18:387–91. doi: 10.1136/amiajnl-2011-000208. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Deleger L, Brodzinski H, Zhai H, Li Q, Lingren T, Kirkendall ES, et al. Developing and evaluating an automated appendicitis risk stratification algorithm for pediatric patients in the emergency department. J Am Med Inform Assoc. 2013;20:e212–20. doi: 10.1136/amiajnl-2013-001962. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Haerian K, Varn D, Vaidya S, Ena L, Chase HS, Friedman C. Detection of pharmacovigilance-related adverse events using electronic health records and automated methods. Clin Pharmacol Ther. 2012;92:228–34. doi: 10.1038/clpt.2012.54. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.St-Maurice J, Kuo MH. Analyzing primary care data to characterize inappropriate emergency room use. Stud Health Technol Inform. 2012;180:990–4. [PubMed] [Google Scholar]
- 28.Kumar V, Liao K, Cheng SC, Yu S, Kartoun U, Brettman A, et al. Natural language processing improves phenotypic accuracy in an electronic medical record cohort of type 2 diabetes and cardiovascular disease. Journal of the American College of Cardiology. 2014;(1):A1359. [Google Scholar]
- 29.Patel R, Lloyd T, Jackson R, Ball M, Shetty H, Broadbent M, et al. Mood instability is a common feature of mental health disorders and is associated with poor clinical outcomes. BMJ Open. 2015;5:e007504. doi: 10.1136/bmjopen-2014-007504. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Kullo IJ, Fan J, Pathak J, Savova GK, Ali Z, Chute CG. Leveraging informatics for genetic studies: use of the electronic medical record to enable a genome-wide association study of peripheral arterial disease. J Am Med Inform Assoc. 2010;17:568–74. doi: 10.1136/jamia.2010.004366. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Davis K, Staes C, Duncan J, Igo S, Facelli JC. Identification of pneumonia and influenza deaths using the Death Certificate Pipeline. BMC Med Inf Decis Mak. 2012;12:37. doi: 10.1186/1472-6947-12-37. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Wi C-I, Sohn S, Rolfes MC, Seabright A, Ryu E, Voge G, et al. Application of a Natural Language Processing Algorithm to Asthma Ascertainment: An Automated Chart Review. American Journal of Respiratory And Critical Care Medicine. 2017 doi: 10.1164/rccm.201610-2006OC. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Afzal N, Sohn S, Abram S, Scott CG, Chaudhry R, Liu H, et al. Mining peripheral arterial disease cases from narrative clinical notes using natural language processing. Journal of Vascular Surgery. 2017;65:1753–61. doi: 10.1016/j.jvs.2016.11.031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Sohn S, Ye Z, Liu H, Chute CG, Kullo IJ. Identifying abdominal aortic aneurysm cases and controls using natural language processing of radiology reports. AMIA Summits Transl Sci Proc. 2013;2013:249. [PMC free article] [PubMed] [Google Scholar]
- 35.Spyns P. Natural language processing. Methods Inf Med. 1996;35:285–301. [PubMed] [Google Scholar]
- 36.Yim W-w, Yetisgen M, Harris WP, Kwan SW. Natural language processing in oncology: a review. JAMA Oncol. 2016;2:797–804. doi: 10.1001/jamaoncol.2016.0213. [DOI] [PubMed] [Google Scholar]
- 37.Pons E, Braun LM, Hunink MM, Kors JA. Natural language processing in radiology: a systematic review. Radiology. 2016;279:329–43. doi: 10.1148/radiol.16142770. [DOI] [PubMed] [Google Scholar]
- 38.Moher D, Liberati A, Tetzlaff J, Altman DG, Group P. Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. PLoS med. 2009;6:e1000097. doi: 10.1371/journal.pmed.1000097. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Saeed M, Villarroel M, Reisner AT, Clifford G, Lehman L-W, Moody G, et al. Multiparameter Intelligent Monitoring in Intensive Care II (MIMIC-II): a public-access intensive care unit database. Critical care medicine. 2011;39:952. doi: 10.1097/CCM.0b013e31820a92c6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Gøeg KR, Elberg PB. Global applicability of a local physical examination template. Scandinavian Conference on Health Informatics 2012; October 2–3; Linköping. Sverige: Linköping University Electronic Press; 2012. pp. 1–7. [Google Scholar]
- 41.Styler WF, IV, Bethard S, Finan S, Palmer M, Pradhan S, de Groen PC, et al. Temporal annotation in the clinical domain. Transactions of the Association for Computational Linguistics. 2014;2:143–54. [PMC free article] [PubMed] [Google Scholar]
- 42.Ferrucci D, Lally A. UIMA: an architectural approach to unstructured information processing in the corporate research environment. Nat Lang Eng. 2004;10:327–48. [Google Scholar]
- 43.Baldridge J. The opennlp project. 2005 URL: http://opennlpapacheorg/indexhtml.
- 44.Carrell DS, Halgrim S, Tran D-T, Buist DSM, Chubak J, Chapman WW, et al. Using natural language processing to improve efficiency of manual chart abstraction in research: the case of breast cancer recurrence. Am J Epidemiol. 2014;179:749–58. doi: 10.1093/aje/kwt441. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Wei W-Q, Tao C, Jiang G, Chute CG. A high throughput semantic concept frequency based approach for patient identification: a case study using type 2 diabetes mellitus clinical notes. AMIA Annu Symp Proc. 2010;2010:857–61. [PMC free article] [PubMed] [Google Scholar]
- 46.Lin C, Karlson EW, Dligach D, Ramirez MP, Miller TA, Mo H, et al. Automatic identification of methotrexate-induced liver toxicity in patients with rheumatoid arthritis from the electronic medical record. J Am Med Inform Assoc. 2015;22:e151–61. doi: 10.1136/amiajnl-2014-002642. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Hamid H, Fodeh S, Lizama GA, Czlapinski R, Pugh MJ, LaFrance W, et al. Validating a natural language processing tool to exclude psychogenic non-epileptic seizures in electronic medical record based epilepsy research. Epilepsy Currents. 2014;14:279. doi: 10.1016/j.yebeh.2013.09.025. [DOI] [PubMed] [Google Scholar]
- 48.Xia Z, Secor E, Chibnik LB, Bove RM, Cheng S, Chitnis T, et al. Modeling disease severity in multiple sclerosis using electronic health records. PLoS ONE. 2013;8:e78927. doi: 10.1371/journal.pone.0078927. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Lingren T, Thaker V, Brady C, Namjou B, Kennebeck S, Bickel J, et al. Developing an Algorithm to Detect Early Childhood Obesity in Two Tertiary Pediatric Medical Centers. Appl Clin Inform. 2016;7:693–706. doi: 10.4338/ACI-2016-01-RA-0015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Mehrabi S, Schmidt CM, Waters JA, Beesley C, Krishnan A, Kesterson J, et al. An efficient pancreatic cyst identification methodology using natural language processing. Stud Health Technol Inform. 2013;192:822–6. [PubMed] [Google Scholar]
- 51.Savova GK, Fan J, Ye Z, Murphy SP, Zheng J, Chute CG, et al. Discovering peripheral arterial disease cases from radiology notes using natural language processing. AMIA Annu Symp Proc. 2010;2010:722–6. [PMC free article] [PubMed] [Google Scholar]
- 52.Cui L, Bozorgi A, Lhatoo SD, Zhang G-Q, Sahoo SS. EpiDEA: extracting structured epilepsy and seizure information from patient discharge summaries for cohort identification. AMIA Annu Symp Proc. 2012;2012:1191–200. [PMC free article] [PubMed] [Google Scholar]
- 53.Hassanpour S, Langlotz CP. Information extraction from multi-institutional radiology reports. Artif Intell Med. 2016;66:29–39. doi: 10.1016/j.artmed.2015.09.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Pathak J, Hall-Flavin DK, Biernacka JM, Jenkins GD, Bruce KT, Murphy SP, et al. Using electronic health records driven phenotyping for major depressive disorder. Biol Psychiatry. 2014;(1):343S. [Google Scholar]
- 55.Liu M, Shah A, Jiang M, Peterson NB, Dai Q, Aldrich MC, et al. A study of transportability of an existing smoking status detection module across institutions. AMIA Annu Symp Proc. 2012;2012:577–86. [PMC free article] [PubMed] [Google Scholar]
- 56.Khor R, Yip W, Bressel M, Rose W, Duchesne G, Foroudi F. Automated smoking status extraction from free text: Adapting a system for use in the Australian context. Journal of Medical Imaging and Radiation Oncology. 2013;57:148. [Google Scholar]
- 57.Sohn S, Savova GK. Mayo clinic smoking status classification system: extensions and improvements. AMIA Annu Symp Proc. 2009;2009:619–23. [PMC free article] [PubMed] [Google Scholar]
- 58.Khor R, Yip W-K, Bressel M, Rose W, Duchesne G, Foroudi F. Practical implementation of an existing smoking detection pipeline and reduced support vector machine training corpus requirements. J Am Med Inform Assoc. 2014;21:27–30. doi: 10.1136/amiajnl-2013-002090. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Sohn S, Kocher J-PA, Chute CG, Savova GK. Drug side effect extraction from clinical narratives of psychiatry and psychology patients. J Am Med Inform Assoc. 2011;18(Suppl 1):i144–9. doi: 10.1136/amiajnl-2011-000351. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Li Q, Spooner SA, Kaiser M, Lingren N, Robbins J, Lingren T, et al. An end-to-end hybrid algorithm for automated medication discrepancy detection. BMC Med Inf Decis Mak. 2015;15:37. doi: 10.1186/s12911-015-0160-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Lin C, Dligach D, Miller TA, Bethard S, Savova GK. Multilayered temporal modeling for the clinical domain. J Am Med Inform Assoc. 2016;23:387–95. doi: 10.1093/jamia/ocv113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Khalifa A, Meystre S. Adapting existing natural language processing resources for cardiovascular risk factors identification in clinical notes. J Biomed Inform. 2015;58(Suppl):S128–32. doi: 10.1016/j.jbi.2015.08.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Aronson AR, Mork JG, Névéol A, Shooshan SE, Demner-Fushman D. Methodology for creating UMLS content views appropriate for biomedical natural language processing. AMIA. 2008 [PMC free article] [PubMed] [Google Scholar]
- 64.Yetisgen-Yildiz M, Bejan CA, Vanderwende L, Xia F, Evans HL, Wurfel MM. Automated tools for phenotype extraction from medical records. AMIA Summits Transl Sci Proc. 2013;2013:283. [PubMed] [Google Scholar]
- 65.Bejan CA, Xia F, Vanderwende L, Wurfel MM, Yetisgen-Yildiz M. Pneumonia identification using statistical feature selection. J Am Med Inform Assoc. 2012;19:817–23. doi: 10.1136/amiajnl-2011-000752. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Gundlapalli AV, Redd A, Carter M, Divita G, Shen S, Palmer M, et al. Validating a strategy for psychosocial phenotyping using a large corpus of clinical text. J Am Med Inform Assoc. 2013;20:e355–64. doi: 10.1136/amiajnl-2013-001946. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Yim W-W, Denman T, Kwan SW, Yetisgen M. Tumor information extraction in radiology reports for hepatocellular carcinoma patients. AMIA Summits Transl Sci Proc. 2016;2016:455–64. [PMC free article] [PubMed] [Google Scholar]
- 68.Sevenster M, Buurman J, Liu P, Peters JF, Chang PJ. Natural Language Processing Techniques for Extracting and Categorizing Finding Measurements in Narrative Radiology Reports. Appl Clin Inform. 2015;6:600–110. doi: 10.4338/ACI-2014-11-RA-0110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Martinez D, Ananda-Rajah MR, Suominen H, Slavin MA, Thursky KA, Cavedon L. Automatic detection of patients with invasive fungal disease from free-text computed tomography (CT) scans. J Biomed Inform. 2015;53:251–60. doi: 10.1016/j.jbi.2014.11.009. [DOI] [PubMed] [Google Scholar]
- 70.St-Maurice J, Kuo MH, Gooch P. A proof of concept for assessing emergency room use with primary care data and natural language processing. Methods Inf Med. 2013;52:33–42. doi: 10.3414/ME12-01-0012. [DOI] [PubMed] [Google Scholar]
- 71.Khare R, Li J, Lu Z. LabeledIn: cataloging labeled indications for human drugs. J Biomed Inform. 2014;52:448–56. doi: 10.1016/j.jbi.2014.08.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Thorne C, Cardillo E, Eccher C, Montali M, Calvanese D. Process fragment recognition in clinical documents. 13th International Conference of the Italian Association for Artificial Intelligence, AI*IA 2013. Turin2013; pp. 227–38. [Google Scholar]
- 73.Zhu H, Ni Y, Cai P, Qiu Z, Cao F. Automatic extracting of patient-related attributes: disease, age, gender and race. Stud Health Technol Inform. 2012;180:589–93. [PubMed] [Google Scholar]
- 74.Wang X, Hripcsak G, Friedman C. Characterizing environmental and phenotypic associations using information theory and electronic health records. BMC Bioinformatics. 2009;10(Suppl 9):S13. doi: 10.1186/1471-2105-10-S9-S13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Wang X, Hripcsak G, Markatou M, Friedman C. Active computerized pharmacovigilance using natural language processing, statistics, and electronic health records: a feasibility study. J Am Med Inform Assoc. 2009;16:328–37. doi: 10.1197/jamia.M3028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Salmasian H, Freedberg DE, Abrams JA, Friedman C. An automated tool for detecting medication overuse based on the electronic health records. Pharmacoepidemiol Drug Saf. 2013;22:183–9. doi: 10.1002/pds.3387. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Kamauu AWC, Petratos G, Amey A, Bechtel P, Dine D. Extracting meaningful, searchable and discrete data from unstructured medical text. Pharmacoepidemiology and Drug Safety. 2010;19:S75. [Google Scholar]
- 78.Cunningham H, Maynard D, Bontcheva K, Tablan V. GATE: an architecture for development of robust HLT applications. Proceedings of the 40th annual meeting on association for computational linguistics: Association for Computational Linguistics; 2002; pp. 168–75. [Google Scholar]
- 79.Cunningham H, Tablan V, Roberts A, Bontcheva K. Getting more out of biomedical documents with GATE’s full lifecycle open source text analytics. PLoS Comput Biol. 2013;9:e1002854. doi: 10.1371/journal.pcbi.1002854. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.Bird S. NLTK: the natural language toolkit. Proceedings of the COLING/ACL on Interactive presentation sessions: Association for Computational Linguistics; 2006; pp. 69–72. [Google Scholar]
- 81.Morton T, Kottmann J, Baldridge J, Bierner G. Opennlp: A java-based nlp toolkit. 2005. [Google Scholar]
- 82.McCallum AK. Mallet: A machine learning for language toolkit. 2002. [Google Scholar]
- 83.Holmes G, Donkin A, Witten IH. Weka: A machine learning workbench. Intelligent Information Systems, 1994 Proceedings of the 1994 Second Australian and New Zealand Conference on: IEEE; 1994; pp. 357–61. [Google Scholar]
- 84.Musen MA. The Protégé project: A look back and a look forward. AI matters. 2015;1:4–12. doi: 10.1145/2757001.2757003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.Ball M, Patel R, Hayes RD, Dobson RJ, Stewart R. TextHunter–A User Friendly Tool for Extracting Generic Concepts from Free Text in Clinical Research. AMIA Annual Symposium Proceedings: American Medical Informatics Association; 2014; p. 729. [PMC free article] [PubMed] [Google Scholar]
- 86.Patrick JD, Nguyen DH, Wang Y, Li M. A knowledge discovery and reuse pipeline for information extraction in clinical notes. J Am Med Inform Assoc. 2011;18:574–9. doi: 10.1136/amiajnl-2011-000302. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87.Spasić I, Zhao B, Jones CB, Button K. KneeTex: an ontology–driven system for information extraction from MRI reports. J Biomed Semantics. 2015;6:34. doi: 10.1186/s13326-015-0033-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88.Meystre SM, Thibault J, Shen S, Hurdle JF, South BR. Textractor: a hybrid system for medications and reason for their prescription extraction from clinical text documents. J Am Med Inform Assoc. 2010;17:559–62. doi: 10.1136/jamia.2010.004028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89.Tseytlin E, Mitchell K, Legowski E, Corrigan J, Chavan G, Jacobson RS. NOBLE–Flexible concept recognition for large-scale biomedical natural language processing. BMC Bioinformatics. 2016;17:32. doi: 10.1186/s12859-015-0871-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 90.Hebbring SJ. The challenges, advantages and future of phenome-wide association studies. Immunology. 2014;141:157–65. doi: 10.1111/imm.12195. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 91.Law V, Knox C, Djoumbou Y, Jewison T, Guo AC, Liu Y, et al. DrugBank 4.0: shedding new light on drug metabolism. Nucleic Acids Res. 2014;42:D1091–D7. doi: 10.1093/nar/gkt1068. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 92.Elkin PL, Froehling DA, Wahner-Roedler DL, Brown SH, Bailey KR. Comparison of natural language processing biosurveillance methods for identifying influenza from encounter notes. Ann Intern Med. 2012;156:11–8. doi: 10.7326/0003-4819-156-1-201201030-00003. [DOI] [PubMed] [Google Scholar]
- 93.Horng S, Sontag DA, Shapiro NI, Nathanson LA. Machine learning algorithms can identify patients who will benefit from targeted sepsis decision support. Ann Emerg Med. 2012;(1):S121. [Google Scholar]
- 94.Roberts K, Rink B, Harabagiu SM, Scheuermann RH, Toomay S, Browning T, et al. A machine learning approach for identifying anatomical locations of actionable findings in radiology reports. AMIA Annu Symp Proc. 2012;2012:779–88. [PMC free article] [PubMed] [Google Scholar]
- 95.Zheng C, Rashid N, Cheetham TC, Wu YL, Levy GD. Using natural language processing and machine learning to identify gout flares from electronic clinical notes. Arthritis and Rheumatism. 2013;65:S856–S7. doi: 10.1002/acr.22324. [DOI] [PubMed] [Google Scholar]
- 96.Kluegl P, Toepfer M, Beck P-D, Fette G, Puppe F. UIMA Ruta: Rapid development of rule-based information extraction applications. Nat Lang Eng. 2016;22:1–40. [Google Scholar]
- 97.Barrett N, Weber-Jahnke JH, Thai V. Engineering natural language processing solutions for structured information from clinical text: extracting sentinel events from palliative care consult letters. Stud Health Technol Inform. 2013;192:594–8. [PubMed] [Google Scholar]
- 98.Sarker A, Gonzalez G. Portable automatic text classification for adverse drug reaction detection via multi-corpus training. J Biomed Inform. 2015;53:196–207. doi: 10.1016/j.jbi.2014.11.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 99.Himes BE, Dai Y, Kohane IS, Weiss ST, Ramoni MF. Prediction of chronic obstructive pulmonary disease (COPD) in asthma patients using electronic medical records. J Am Med Inform Assoc. 2009;16:371–9. doi: 10.1197/jamia.M2846. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 100.Chen Y, Wrenn J, Xu H, Spickard A, 3rd, Habermann R, Powers J, et al. Automated Assessment of Medical Students’ Clinical Exposures according to AAMC Geriatric Competencies. AMIA Annu Symp Proc. 2014;2014:375–84. [PMC free article] [PubMed] [Google Scholar]
- 101.Rochefort CM, Buckeridge DL, Forster AJ. Accuracy of using automated methods for detecting adverse events from electronic health record data: a research protocol. Implement Sci. 2015;10:5. doi: 10.1186/s13012-014-0197-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 102.Yadav K, Sarioglu E, Smith M, Choi H-A. Automated outcome classification of emergency department computed tomography imaging reports. Acad Emerg Med. 2013;20:848–54. doi: 10.1111/acem.12174. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 103.Uzuner Ö, Luo Y, Szolovits P. Evaluating the state-of-the-art in automatic de-identification. J Am Med Inform Assoc. 2007;14:550–63. doi: 10.1197/jamia.M2444. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 104.Uzuner Ö, Goldstein I, Luo Y, Kohane I. Identifying patient smoking status from medical discharge records. J Am Med Inform Assoc. 2008;15:14–24. doi: 10.1197/jamia.M2408. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 105.Uzuner O. Recognizing obesity and comorbidities in sparse data. J Am Med Inform Assoc. 2009;16:561–70. doi: 10.1197/jamia.M3115. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 106.Uzuner O, Solti I, Cadag E. Extracting medication information from clinical text. J Am Med Inform Assoc. 2010;17:514–8. doi: 10.1136/jamia.2010.003947. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 107.Uzuner O, South BR, Shen S, DuVall SL. 2010 i2b2/VA challenge on concepts, assertions, and relations in clinical text. J Am Med Inform Assoc. 2011;18:552–6. doi: 10.1136/amiajnl-2011-000203. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 108.Uzuner O, Bodnari A, Shen S, Forbush T, Pestian J, South BR. Evaluating the state of the art in coreference resolution for electronic medical records. J Am Med Inform Assoc. 2012;19:786–91. doi: 10.1136/amiajnl-2011-000784. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 109.Sun W, Rumshisky A, Uzuner O. Evaluating temporal relations in clinical text: 2012 i2b2 Challenge. J Am Med Inform Assoc. 2013;20:806–13. doi: 10.1136/amiajnl-2013-001628. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 110.Stubbs A, Kotfila C, Xu H, Uzuner O. Identifying risk factors for heart disease over time: Overview of 2014 i2b2/UTHealth shared task Track 2. J Biomed Inform. 2015;58(Suppl):S67–77. doi: 10.1016/j.jbi.2015.07.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 111.Stubbs A, Kotfila C, Uzuner Ö. Automated systems for the de-identification of longitudinal clinical narratives: Overview of 2014 i2b2/UTHealth shared task Track 1. J Biomed Inform. 2015;58:S11–S9. doi: 10.1016/j.jbi.2015.06.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 112.Pradhan S, Elhadad N, South BR, Martinez D, Christensen LM, Vogel A, et al. CLEF (Working Notes) 2013. Task 1: ShARe/CLEF eHealth Evaluation Lab 2013. [Google Scholar]
- 113.Kelly L, Goeuriot L, Suominen H, Schreck T, Leroy G, Mowery DL, et al. Overview of the share/clef ehealth evaluation lab 2014. International Conference of the Cross-Language Evaluation Forum for European Languages; Springer; 2014. pp. 172–91. [Google Scholar]
- 114.Goeuriot L, Kelly L, Suominen H, Hanlen L, Névéol A, Grouin C, et al. Overview of the CLEF eHealth evaluation lab 2015. International Conference of the Cross-Language Evaluation Forum for European Languages; Springer; 2015. pp. 429–43. [Google Scholar]
- 115.Kelly L, Goeuriot L, Suominen H, Névéol A, Palotti J, Zuccon G. Overview of the CLEF eHealth evaluation lab 2016. International Conference of the Cross-Language Evaluation Forum for European Languages; Springer; 2016. pp. 255–66. [Google Scholar]
- 116.Segura-Bedmar I, Martínez P, Zazo MH. Semeval-2013 task 9: Extraction of drug-drug interactions from biomedical texts (ddiextraction 2013). Second Joint Conference on Lexical and Computational Semantics (* SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013); 2013; pp. 341–50. [Google Scholar]
- 117.Pradhan S, Elhadad N, Chapman WW, Manandhar S, Savova G. SemEval@ COLING. 2014. SemEval-2014 Task 7: Analysis of Clinical Text; pp. 54–62. [Google Scholar]
- 118.Elhadad N, Pradhan S, Gorman SL, Manandhar S, Chapman WW, Savova GK. SemEval-2015 Task 14: Analysis of Clinical Text. SemEval@ NAACL-HLT. 2015:303–10. [Google Scholar]
- 119.Bethard S, Savova G, Chen W-T, Derczynski L, Pustejovsky J, Verhagen M. Semeval-2016 task 12: Clinical tempeval. Proceedings of SemEval. 2016:1052–62. [Google Scholar]
- 120.Sada Y, Hou J, Richardson P, El-Serag H, Davila J. Validation of Case Finding Algorithms for Hepatocellular Cancer From Administrative Data and Electronic Health Records Using Natural Language Processing. Med Care. 2016;54:e9–14. doi: 10.1097/MLR.0b013e3182a30373. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 121.Xu H, Fu Z, Shah A, Chen Y, Peterson NB, Chen Q, et al. Extracting and integrating data from entire electronic health records for detecting colorectal cancer cases. AMIA Annu Symp Proc. 2011;2011:1564–72. [PMC free article] [PubMed] [Google Scholar]
- 122.Kim Y, Garvin J, Heavirland J, Meystre SM. Improving heart failure information extraction by domain adaptation. Stud Health Technol Inform. 2013;192:185–9. [PubMed] [Google Scholar]
- 123.Roch AM, Mehrabi S, Krishnan A, Schmidt HE, Kesterson J, Beesley C, et al. Automated pancreatic cyst screening using natural language processing: A new tool in the early detection of pancreatic cancer. Hpb. 2015;17:447–53. doi: 10.1111/hpb.12375. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 124.Ludvigsson JF, Pathak J, Murphy S, Durski M, Kirsch PS, Chute CG, et al. Use of computerized algorithm to identify individuals in need of testing for celiac disease. J Am Med Inform Assoc. 2013;20:e306–10. doi: 10.1136/amiajnl-2013-001924. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 125.Sances G, Larizza C, Gabetta M, Bucalo M, Guaschino E, Milani G, et al. Application of bioinformatics in headache: The I2B2-pavia project. Journal of Headache and Pain. 2010;11:S134–S5. [Google Scholar]
- 126.Graystone A, Bhatia R, Davies R, McClinton S. Validation of the DM reporter text mining application for evaluating the management of high risk populations with diabetes. Diabetes Conference: 70th Scientific Sessions of the American Diabetes Association Orlando, FL United States Conference Start; 2010. [Google Scholar]
- 127.Cohen KB, Glass B, Greiner HM, Holland-Bouley K, Standridge S, Arya R, et al. Methodological Issues in Predicting Pediatric Epilepsy Surgery Candidates Through Natural Language Processing and Machine Learning. Biomed. 2016;8:11–8. doi: 10.4137/BII.S38308. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 128.Nunes AP, Yang J, Tunceli K, Kurtyka K, Radican L, Engel SS, et al. Interim results on the relationship between mild-moderate and severe hypoglycaemia and cardiovascular disease in a cohort of sulfonylurea users. Diabetologia. 2015;(1):S62. [Google Scholar]
- 129.Lyalina S, Percha B, LePendu P, Iyer SV, Altman RB, Shah NH. Identifying phenotypic signatures of neuropsychiatric disorders from electronic medical records. J Am Med Inform Assoc. 2013;20:e297–305. doi: 10.1136/amiajnl-2013-001933. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 130.Wang M, Cyhaniuk A, Cooper DL, Iyer NN. Identification of persons with acquired hemophilia in a large electronic health record database. Blood. 2015;126(23):3271. doi: 10.2147/JBM.S136060. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 131.Mehrabi S, Krishnan A, Roch AM, Schmidt H, Li D, Kesterson J, et al. Identification of Patients with Family History of Pancreatic Cancer--Investigation of an NLP System Portability. Stud Health Technol Inform. 2015;216:604–8. [PMC free article] [PubMed] [Google Scholar]
- 132.Hirst C, Hill J, Khosla S, Schweikert K, Senerchia C, Kitzmann K, et al. The application of natural language processing (NLP) technology to enrich electronic medical records (EMRS) for outcomes research in oncology. Value in Health. 2014;17(3):A6. [Google Scholar]
- 133.Nguyen AN, Moore J, O’Dwyer J, Philpot S. Assessing the Utility of Automatic Cancer Registry Notifications Data Extraction from Free-Text Pathology Reports. AMIA Annu Symp Proc. 2015;2015:953–62. [PMC free article] [PubMed] [Google Scholar]
- 134.Farrugia H, Marr G, Giles G. Implementing a natural language processing solution to capture cancer stage and recurrence. Journal of Medical Imaging and Radiation Oncology. 2012;56:5. [Google Scholar]
- 135.Warner JL, Levy MA, Neuss MN, Warner JL, Levy MA, Neuss MN. ReCAP: Feasibility and Accuracy of Extracting Cancer Stage Information From Narrative Electronic Health Record Data. J Oncol Pract. 2016;12:157–8. e69–7. doi: 10.1200/JOP.2015.004622. [DOI] [PubMed] [Google Scholar]
- 136.Tian Z, Sun S, Eguale T, Rochefort C. Automated extraction of VTE events from narrative radiology reports in electronic health records: A validation study. Pharmacoepidemiology and Drug Safety. 2015;24:166. doi: 10.1097/MLR.0000000000000346. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 137.McPeek Hinz ER, Bastarache L, Denny JC. A natural language processing algorithm to define a venous thromboembolism phenotype. AMIA Annu Symp Proc. 2013;2013:975–83. [PMC free article] [PubMed] [Google Scholar]
- 138.Duke J, Chase M, Poznanski-Ring N, Martin J, Fuhr R, Chatterjee A, et al. Natural language processing to improve identification of peripheral arterial disease in electronic health data. Journal of the American College of Cardiology. 2016;(1):2280. [Google Scholar]
- 139.Afzal N, Sohn S, Abram S, Liu H, Kullo IJ, Arruda-Olson AM. Identifying peripheral arterial disease cases using natural language processing of clinical notes. 3rd IEEE EMBS International Conference on Biomedical and Health Informatics, BHI; 2016; Institute of Electrical and Electronics Engineers Inc; 2016. pp. 126–31. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 140.Rao A, Ehrenfeld JM, Peterfreund R, Zalis M, Harris M. Automated analysis of free text electronic medical records to identify patients with specific medical diagnoses. Anesthesia and Analgesia Conference; 2011; p. 112. [Google Scholar]
- 141.Xu H, Stenner SP, Doan S, Johnson KB, Waitman LR, Denny JC. MedEx: a medication information extraction system for clinical narratives. J Am Med Inform Assoc. 2010;17:19–24. doi: 10.1197/jamia.M3378. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 142.Xu H, Aldrich MC, Chen Q, Liu H, Peterson NB, Dai Q, et al. Validating drug repurposing signals using electronic health records: a case study of metformin associated with reduced cancer mortality. J Am Med Inform Assoc. 2015;22:179–91. doi: 10.1136/amiajnl-2014-002649. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 143.Sohn S, Clark C, Halgrim SR, Murphy SP, Jonnalagadda SR, Wagholikar KB, et al. Analysis of cross-institutional medication description patterns in clinical narratives. Biomed. 2013;6:7–16. doi: 10.4137/BII.S11634. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 144.Zheng C, Rashid N, Koblick R, An J. Medication Extraction from Electronic Clinical Notes in an Integrated Health System: A Study on Aspirin Use in Patients with Nonvalvular Atrial Fibrillation. Clin Ther. 2015;37:2048–58. e2. doi: 10.1016/j.clinthera.2015.07.002. [DOI] [PubMed] [Google Scholar]
- 145.Xu H, Doan S, Birdwell KA, Cowan JD, Vincz AJ, Haas DW, et al. An automated approach to calculating the daily dose of tacrolimus in electronic health records. AMIA Summits Transl Sci Proc. 2010;2010:71–5. [PMC free article] [PubMed] [Google Scholar]
- 146.Liu M, Jiang M, Kawai VK, Stein CM, Roden DM, Denny JC, et al. Modeling drug exposure data in electronic medical records: an application to warfarin. AMIA Annu Symp Proc. 2011;2011:815–23. [PMC free article] [PubMed] [Google Scholar]
- 147.Feng Q, Waitara MS, Jiang L, Xu H, Jiang M, McCarty CA, et al. Dose-response curves extracted from electronic medical records identify sort-1 as a novel genetic predictor of statin potency (ED50) Clinical Pharmacology and Therapeutics. 2012;91:S48–S9. [Google Scholar]
- 148.Rochefort C, Verma A, Eguale T, Buckeridge D. Surveillance of adverse events in elderly patients: A study on the accuracy of applying natural language processing techniques to electronic health record data. European Geriatric Medicine. 2015;6:S15. [Google Scholar]
- 149.Zhang H, Plutzky J, Skentzos S, Morrison F, Mar P, Shubina M, et al. Epidemiology of adverse reaction to statins in routine care settings. Endocrine Reviews Conference: 94th Annual Meeting and Expo of the Endocrine Society, ENDO; 2012; p. 33. [Google Scholar]
- 150.Hazlehurst B, Naleway A, Mullooly J. Detecting possible vaccine adverse events in clinical notes of the electronic medical record. Vaccine. 2009;27:2077–83. doi: 10.1016/j.vaccine.2009.01.105. [DOI] [PubMed] [Google Scholar]
- 151.Baer B, Nguyen M, Woo EJ, Winiecki S, Scott J, Martin D, et al. Can Natural Language Processing Improve the Efficiency of Vaccine Adverse Event Report Review? Methods Inf Med. 2016;55:144–50. doi: 10.3414/ME14-01-0066. [DOI] [PubMed] [Google Scholar]
- 152.Tamang S, Patel MI, Blayney DW, Kuznetsov J, Finlayson SG, Vetteth Y, et al. Detecting unplanned care from clinician notes in electronic health records. J Oncol Pract. 2015;11:e313–9. doi: 10.1200/JOP.2014.002741. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 153.Hsu W, Han SX, Arnold CW, Bui AA, Enzmann DR. A data-driven approach for quality assessment of radiologic interpretations. J Am Med Inform Assoc. 2016;23:e152–6. doi: 10.1093/jamia/ocv161. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 154.Smith-Bindman R, Miglioretti DL, Larson EB. Rising use of diagnostic medical imaging in a large integrated health system. Health Affairs. 2008;27:1491–502. doi: 10.1377/hlthaff.27.6.1491. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 155.Ip IK, Mortele KJ, Prevedello LM, Khorasani R. Repeat abdominal imaging examinations in a tertiary care hospital. American Journal of Medicine. 2012;125:155–61. doi: 10.1016/j.amjmed.2011.03.031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 156.Mehrotra A, Harkema H. Development and validation of a natural language processing computer program to measure the quality of colonoscopy. J Gen Intern Med. 2011;26:S339–S40. [Google Scholar]
- 157.Raju GS, Ross WA, Lum P, Lynch PM, Slack RS, Miller E, et al. Natural language processing (NLP) as an alternative to manual reporting of colonoscopy quality metrics. Gastrointest Endosc. 2014;(1):AB116–AB7. doi: 10.1016/j.gie.2015.01.049. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 158.Raju GS, Lum PJ, Slack RS, Thirumurthi S, Lynch PM, Miller E, et al. Natural language processing as an alternative to manual reporting of colonoscopy quality metrics. Gastrointest Endosc. 2015;82:512–9. doi: 10.1016/j.gie.2015.01.049. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 159.Gawron AJ, Pacheco JA, Scuba B, Chapman W, Kaltenbach T, Thompson WK. Quality improvement natural language processing colonoscopy evaluation tool (QUINCE): A flexible, portable tool to extract pathology results for colonoscopy quality reporting. Gastroenterology. 2016;(1):S637. [Google Scholar]
- 160.Gundlapalli AV, Carter ME, Divita G, Shen S, Palmer M, South B, et al. Extracting Concepts Related to Homelessness from the Free Text of VA Electronic Medical Records. AMIA Annu Symp Proc. 2014;2014:589–98. [PMC free article] [PubMed] [Google Scholar]
- 161.Ruud KL, Johnson MG, Liesinger JT, Grafft CA, Naessens JM. Automated detection of follow-up appointments using text mining of discharge records. Int J Qual Health Care. 2010;22:229–35. doi: 10.1093/intqhc/mzq012. [DOI] [PubMed] [Google Scholar]
- 162.Abell M. SAS Text Miner: CreateSpace Independent Publishing Platform. 2014 [Google Scholar]
- 163.Were MC, Gorbachev S, Cadwallader J, Kesterson J, Li X, Overhage JM, et al. Natural language processing to extract follow-up provider information from hospital discharge summaries. AMIA Annu Symp Proc. 2010;2010:872–6. [PMC free article] [PubMed] [Google Scholar]
- 164.Rubin D, Wang D, Chambers DA, Chambers JG, South BR, Goldstein MK. Natural language processing for lines and devices in portable chest x-rays. AMIA Annu Symp Proc. 2010;2010:692–6. [PMC free article] [PubMed] [Google Scholar]
- 165.Hao T, Liu H, Weng C. Valx: A System for Extracting and Structuring Numeric Lab Test Comparison Statements from Text. Methods Inf Med. 2016;55:266–75. doi: 10.3414/ME15-01-0112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 166.Garvin JH, Elkin PL, Shen S, Brown S, Trusko B, Wang E, et al. Automated quality measurement in Department of the Veterans Affairs discharge instructions for patients with congestive heart failure. J Healthc Qual. 2013;35:16–24. doi: 10.1111/j.1945-1474.2011.195.x. [DOI] [PubMed] [Google Scholar]
- 167.Garvin JH, DuVall SL, South BR, Bray BE, Bolton D, Heavirland J, et al. Automated extraction of ejection fraction for quality measurement using regular expressions in Unstructured Information Management Architecture (UIMA) for heart failure. J Am Med Inform Assoc. 2012;19:859–66. doi: 10.1136/amiajnl-2011-000535. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 168.Meystre SM, Kim Y, Gobbel GT, Matheny ME, Redd A, Bray BE, et al. Congestive heart failure information extraction framework for automated treatment performance measures assessment. J Am Med Inform Assoc. 2016;24:e40–e6. doi: 10.1093/jamia/ocw097. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 169.Friedman C, Rindflesch TC, Corn M. Natural language processing: state of the art and prospects for significant progress, a workshop sponsored by the National Library of Medicine. J Biomed Inform. 2013;46:765–73. doi: 10.1016/j.jbi.2013.06.004. [DOI] [PubMed] [Google Scholar]
- 170.Chiticariu L, Li Y, Reiss FR. Rule-based information extraction is dead! long live rule-based information extraction systems! EMNLP. 2013:827–32. [Google Scholar]
- 171.Bozkurt S, Gimenez F, Burnside ES, Gulkesen KH, Rubin DL. Using automatically extracted information from mammography reports for decision-support. J Biomed Inform. 2016;62:224–31. doi: 10.1016/j.jbi.2016.07.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 172.Rochefort CM, Verma AD, Eguale T, Lee TC, Buckeridge DL. A novel method of adverse event detection can accurately identify venous thromboembolisms (VTEs) from narrative electronic health record data. J Am Med Inform Assoc. 2015;22:155–65. doi: 10.1136/amiajnl-2014-002768. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 173.LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521:436–44. doi: 10.1038/nature14539. [DOI] [PubMed] [Google Scholar]
- 174.Vellido A, Martín-Guerrero JD, Lisboa PJ. Making machine learning models interpretable. ESANN. 2012:163–72. [Google Scholar]
- 175.Riloff E, Wiebe J, Wilson T. Learning subjective nouns using extraction pattern bootstrapping. Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003-Volume 4: Association for Computational Linguistics; 2003; pp. 25–32. [Google Scholar]
- 176.Riloff E, Jones R. Learning dictionaries for information extraction by multi-level bootstrapping. AAAI/IAAI. 1999:474–9. [Google Scholar]
- 177.Mintz M, Bills S, Snow R, Jurafsky D. Distant supervision for relation extraction without labeled data. Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2-Volume 2: Association for Computational Linguistics; 2009; pp. 1003–11. [Google Scholar]
- 178.Takamatsu S, Sato I, Nakagawa H. Reducing wrong labels in distant supervision for relation extraction. Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1: Association for Computational Linguistics; 2012; pp. 721–9. [Google Scholar]
- 179.Weld DS, Hoffmann R, Wu F. Using wikipedia to bootstrap open information extraction. ACM SIGMOD Record. 2009;37:62–8. [Google Scholar]
- 180.Kalra D, Singleton P, Milan J, Mackay J, Detmer D, Rector A, et al. Security and confidentiality approach for the Clinical E-Science Framework (CLEF) Methods Inf Med. 2004;44:193–7. [PubMed] [Google Scholar]
- 181.Malik MB, Ghazi MA, Ali R. Privacy preserving data mining techniques: current scenario and future prospects. Computer and Communication Technology (ICCCT), 2012 Third International Conference on: IEEE; 2012; pp. 26–32. [Google Scholar]
- 182.Gardner J, Xiong L. An integrated framework for de-identifying unstructured medical data. Data Knowl Eng. 2009;68:1441–51. [Google Scholar]
- 183.Ohno-Machado L, Bafna V, Boxwala AA, Chapman BE, Chapman WW, Chaudhuri K, et al. iDASH: integrating data for analysis, anonymization, and sharing. J Am Med Inform Assoc. 2012;19:196–201. doi: 10.1136/amiajnl-2011-000538. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 184.Weng C, Wu X, Luo Z, Boland MR, Theodoratos D, Johnson SB. EliXR: an approach to eligibility criteria extraction and representation. J Am Med Inform Assoc. 2011;18:i116–i24. doi: 10.1136/amiajnl-2011-000321. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.