

Abstract
Sequential stream segregation by cochlear implant (CI) listeners was investigated using a temporal delay detection task composed of a sequence of regularly presented bursts of pulses on a single electrode (B) interleaved with an irregular sequence (A) presented on a different electrode. In half of the trials, a delay was added to the last burst of the regular B sequence, and the listeners were asked to detect this delay. As a jitter was added to the period between consecutive A bursts, time judgments between the A and B sequences provided an unreliable cue to perform the task. Thus, the segregation of the A and B sequences should improve performance. In Experiment 1, the electrode separation and the sequence duration were varied to clarify whether place cues help CI listeners to voluntarily segregate sounds and whether a two-stream percept needs time to build up. Results suggested that place cues can facilitate the segregation of sequential sounds if enough time is provided to build up a two-stream percept. In Experiment 2, the duration of the sequence was fixed, and only the electrode separation was varied to estimate the fission boundary. Most listeners were able to segregate the sounds for separations of three or more electrodes, and some listeners could segregate sounds coming from adjacent electrodes.
Keywords: auditory streaming, cochlear implant, auditory perception
Introduction
Cochlear implants (CIs) can substantially improve the ability of severely hearing-impaired listeners to understand speech in quiet. However, listening to music or a single voice in a crowded room is still challenging for most CI users (e.g., Nelson, Jin, Carney, & Nelson, 2003; Stickney, Zeng, Litovsky, & Assmann, 2004). In such situations, sounds from multiple sources compose a complex acoustic waveform. Therefore, to hear out an individual source, for example, a specific speaker, the auditory system needs to separate this mixture into perceptually meaningful auditory objects (e.g., a speaker, a car, or a violin). This process of object formation is known as auditory scene analysis (Bregman, 1990). Two main processes have been described in auditory scene analysis: auditory stream integration, also named fusion, and auditory stream segregation, also named fission. When different sounds are perceived as a single auditory object, they are considered to be integrated. Conversely, when different sounds are perceived as separate auditory objects, they are considered to be segregated. The perceptual organization of sounds includes grouping of both simultaneous (e.g., Micheyl & Oxenham, 2010a) and sequential (e.g., Moore & Gockel, 2012) components of the auditory scene. Bregman (1990) made a distinction between primitive versus schema-based stream segregation. Primitive, or obligatory, stream segregation is a process considered to be driven exclusively by the acoustic characteristics of the stimuli and typically assumed to be involuntary and preattentive. Schema-based, or voluntary, stream segregation represents instead a process where attention influences perception and where the listener actively attempts to segregate the sounds.
To study integration and segregation of sequentially presented sounds, an auditory streaming paradigm has been proposed, where listeners are presented with sequences of triplets (ABA) with A and B representing narrowband sounds (typically pure tones) at different frequencies (Bregman, 1990; van Noorden, 1975). When the A and B sounds are fused into a single stream, the sequence is perceived to have a galloping rhythm. Conversely, when the tones are perceived as being segregated, the galloping rhythm vanishes, and the A and B tones are perceived as two different monotonous streams. In normal-hearing (NH) listeners, low presentation rates or small frequency differences promote the integration of the A and B tones, whereas high presentation rates or large frequency differences promote segregation (Bregman, 1990; van Noorden, 1975). The percept of the tone sequence may change over time, with an increasing probability of a segregated percept with increasing exposure time of the sequence. This phenomenon, commonly referred to as the build-up of stream segregation, has often been investigated under either integration-promoting listening instructions (Roberts, Glasberg, & Moore, 2008; Thompson, Carlyon, & Cusack, 2011) or neutral listening instructions (e.g., Anstis & Saida, 1985; Bregman, 1978; van Noorden, 1975). The build-up effect has also been reported by Micheyl, Carlyon, Cusack, and Moore (2005) and Nie and Nelson (2015) when listeners were encouraged to segregate the sounds, even though it might be more likely to occur under integration-promoting instructions (Micheyl & Oxenham, 2010b). van Noorden (1975) observed that listeners could either fuse or segregate the sounds for intermediate frequency separations of the A and B sounds. Based on these results, van Noorden defined the fission boundary (FB) as the smallest frequency difference at which segregation can occur and the temporal coherence boundary (TCB) as the largest frequency separation at which the sounds can be perceived as integrated. Thus, the TCB can be considered as the limit for obligatory stream segregation and the FB as the limit for voluntary stream segregation.
Auditory stream segregation abilities can be assessed by asking the listener to report whether a particular sound sequence was fused or segregated. In this subjective approach, the listener typically undergoes some training to distinguish the one-stream and the two-stream percepts. An alternative approach has been to measure the performance of the listener in a given task (e.g., a signal detection or discrimination task) that is affected by the integration or segregation of the sounds. Because this approach does not rely on subjective reports of perceived segregation, it has been referred to as an objective psychophysical measure of integration and segregation of sounds (Micheyl & Oxenham, 2010b).
Current CI stimulation strategies convey acoustic information mainly through place cues, with different frequency bands stimulating different electrodes (e.g., Zeng, Rebscher, Harrison, Sun, & Feng, 2008). However, it is not known to what extent CI listeners can make use of electrode separation cues to segregate sounds. Findings from previous studies have been contradictory. Some studies found similar trends as in NH listeners (Böckmann-Barthel, Deike, Brechmann, Ziese, & Verhey, 2014; Chatterjee, Sarampalis, & Oba, 2006; Hong & Turner, 2006; Tejani, Schvartz-Leyzac, & Chatterjee, 2017), whereas other studies did not find any effect of the sequence duration or the tone presentation rate (Cooper & Roberts, 2007, 2009), which are well documented in studies with NH listeners (Bregman, 1990; Moore & Gockel, 2012; van Noorden, 1975). Thus, it has been suggested that CI listeners might experience some aspects of stream segregation as a function of electrode separation but might not be able to experience all aspects of full stream segregation (Chatterjee et al., 2006; Cooper & Roberts, 2007, 2009; Hong & Turner, 2006; Tejani et al., 2017).
Previous studies assessing auditory streaming abilities of CI listeners as a function of place cues have made use of both subjective (Böckmann-Barthel et al., 2014; Chatterjee et al., 2006; Cooper & Roberts, 2007) and objective measures (Cooper & Roberts, 2009; Hong & Turner, 2006; Tejani et al., 2017). The subjective measures require the listener to be able to experience both fused and segregated percepts. It is unclear whether CI listeners can experience both fused and segregated percepts during their training sessions, and thus, results from the subjective measures could reflect electrode discrimination instead of perceived segregation (Cooper & Roberts, 2007).
Most of the objective studies assessing streaming abilities of CI listeners used the irregular rhythm detection task (Cusack & Roberts, 2000; Roberts, Glasberg, & Moore, 2002). In this task, listeners are presented with sequences of alternating A and B tones. In some of the sequences, the timing between A and B sounds is kept constant throughout, while in other sequences, the B tones are gradually delayed along the sequence. Listeners are asked to decide if a given sequence has an irregular rhythm. Because the detection of rhythm changes is more difficult when the A and B sounds fall in separate streams (e.g., Micheyl & Oxenham 2010b, 2010; van Noorden, 1975), the integration of the streams improves the performance in the detection task. Studies using the irregular rhythm detection task with CI listeners (Cooper & Roberts, 2009; Hong & Turner, 2006; Tejani et al., 2017) observed better performance for small rather than large electrode separations. However, the results also presented substantial nonmonotonicities (Tejani et al., 2017), and a build-up effect of streaming was not found (Cooper & Roberts, 2009). The irregular rhythm detection task has one confounding factor: Several studies have suggested that temporal gap detection abilities in CI listeners worsen when the gap markers are presented from different electrodes (e.g., Hanekom & Shannon, 1998; van Wieringen & Wouters, 1999) or with different pulse rates (e.g., Chatterjee, Fu, & Shannon, 1998). Thus, a worsening of the detection performance on the irregular rhythm detection task might not be solely due to stream segregation (Cooper & Roberts, 2009; Hong & Turner, 2006; Tejani et al., 2017).
While the irregular rhythm detection task has been used to assess obligatory stream integration abilities and the TCB, voluntary stream segregation has received less attention. In one experiment, Cooper and Roberts (2009) assessed the effect of electrode separation on the ability to segregate a simple melody from interleaved distractor notes. The task was facilitated by the segregation of the streams and, thus, assessed voluntary segregation. They observed that CI listeners were not able to identify the target melody in the presence of the interleaved distractors without loudness cues, regardless of the electrode range of the distractors relative to the melody. The sequences used by Cooper and Roberts (2009) had a fixed duration of 2.2 s. It is therefore unclear whether the poor performance in the task was due to poor voluntary stream segregation abilities or due to too short sequences, assuming that CI listeners might need more time to build up a two-stream percept even in a segregation-promoting paradigm.
The present study investigated voluntary stream segregation abilities in CI listeners as a function of place cues. Rhythm detection performance was measured in a paradigm where the listeners were required to make within-stream time judgments in the presence of a temporally irregular distractor stream. Thus, the task became easier if the listeners could segregate the target from the distractor. This paradigm has previously been used with NH listeners (Micheyl & Oxenham, 2010b; Nie & Nelson, 2015; Nie, Zhang, & Nelson, 2014) but not yet considered in studies with CI listeners. While in the irregular rhythm detection task (Cusack & Roberts, 2000) the integration of the streams improves performance, in the present study, the segregation of the streams should facilitate detection performance. Thus, the gap detection confounding factor of the irregular rhythm detection task is here avoided by encouraging the listeners to perform within-channel temporal judgments. In Experiment 1, the electrode separation and the sequence duration were varied to clarify (a) whether place cues help CI listeners to voluntarily segregate sounds and (b) whether a two-stream percept needs some time to build up. Experiment 2 combined measurements at three extra electrode separations in a subset of the listeners with an ideal observer (IO) model to estimate the minimum electrode separation needed to segregate the streams.
Experiment 1: Exploring the Contribution of Place Cues to Voluntary Stream Segregation
Rationale
Experiment 1 aimed to determine whether place cues can help CI listeners to voluntarily segregate sequential sounds and whether this segregation occurs instantaneously or if it needs some time to build up. Streaming abilities of CI listeners were assessed in a rhythm detection task. The paradigm was inspired by Micheyl et al. (2005) and Micheyl & Oxenham (2010b) and has previously been used by Nie et al. (2014) and Nie and Nelson (2015) to assess voluntary stream segregation abilities of NH listeners. In this paradigm, the listeners are asked to detect a small delay applied to the last sound of the sequence. The rhythm detection task is facilitated by the segregation of the streams. Thus, if place cues help CI listeners to segregate the A and B streams, better performance should be achieved for larger electrode separations between the streams. Conversely, if place cues do not contribute to the segregation of the streams, the performance in the rhythm detection task should not depend on the electrode separation between the streams. Furthermore, the presence of a build-up effect should result in better performance for the longer sequences, whereas the lack of such build-up should lead to similar performance for short and long sequences. The better performance for the longer sequences could also reflect the longer time to focus on the steady rhythm of the target stream in the long sequence. Thus, rhythm detection performance was also measured for the long and short sequences in the absence of the distractor stream, to quantify the effect of sequence duration on the task when no stream segregation is necessary.
Methods
Listeners
Nine Cochlear CI listeners (six female and three male) participated in this experiment. The listeners were aged between 19 and 78 years (M: 48 years, SD: 25 years; see Table 1) and had no residual hearing in their implanted ear. All listeners were bilateral except listener 7 who was bimodal. For listener 7, the contralateral ear was unaided and blocked with an ear plug during the experiments. All listeners provided informed consent prior to the study, and all experiments were approved by the Science-Ethics Committee for the Capital Region of Denmark (reference H-16036391).
Table 1.
Relevant Information About CI Listeners.
| Listener | Age | Gender | Onset of deafness | Implant (ear) | Years of experience | Experiment 1 | Experiment 2 |
|---|---|---|---|---|---|---|---|
| 1 | 19 | F | Prelingual | CI24RE (right) | 16 | Yes | No |
| 2 | 21 | F | Prelingual | CI24R (right) | 14 | Yes | No |
| 3 | 21 | M | Prelingual | CI24RE (right) | 9 | Yes | Yes |
| 4 | 74 | F | Postlingual | CI24R (left) | 13 | Yes | Yes |
| 5 | 73 | M | Postlingual | CI24RE (right) | 3 | Yes | Yes |
| 6 | 64 | F | Perilingual | CI24R (right) | 15 | Yes | Yes |
| 7 | 78 | M | Postlingual | CI24RE (right) | 3 | Yes | No |
| 8 | 61 | F | Perilingual | CI24RE (right) | 3 | Yes | Yes |
| 9 | 21 | F | Prelingual | CI24RE (left) | 16 | Yes | Yes |
Note. CI = cochlear implant; F = female; M = male.
Stimuli and conditions
The stimulation paradigm is illustrated in Figure 1, where different panels represent different conditions. A sequence of regularly presented bursts of pulses on a single electrode (B) was interleaved with an irregular sequence presented on a different electrode (A). In half of the trials, a small temporal delay (Δt) was added to the last burst of the regular B sequence, the target stream. The listeners were asked to indicate after each trial whether or not the last sound of the sequence was delayed. A jitter was added to the period between consecutive bursts of the A sequence, the distractor stream, making time judgments between successive A and B sounds an unreliable cue for performing the task. Therefore, to optimize performance, the listener needs to compare the time interval between the last two B sounds with those between previous B sounds. Thus, the task becomes easier if the A and B sequences fall into different streams (Micheyl & Oxenham, 2010b; Nie et al., 2014; Nie & Nelson, 2015), encouraging the listener to segregate the streams.
Figure 1.

Graphical representation of the experimental paradigm. The onset-to-onset interval is represented by T and the delay of the last B sound by Δt. The electrode separation between A and B sounds varied across conditions.
Two sequence durations were tested (Figure 1). The long sequence consisted of 12 AB pairs and the short sequence of 4 AB pairs, resulting in a nominal duration of 3.96 and 1.24 s, respectively, when no Δt was present. All sequences started with the distractor stream (A). The target stream (B) was always played through electrode 11,1 located at the midpoint of the array, with an onset-to-onset interval of 340 ms. The distractor stream (A) was played through either electrode 12 or 19 depending on the condition, leading to an electrode separation between target and distractor of either one or eight electrodes in the apical direction. This choice aimed to make the listening task more pleasant for the listeners by avoiding basal, high-pitch electrodes. The onset-to-onset interval of the distractor stream varied for each presentation, having a nominal duration of 340 ms ± 220 ms jitter. The jitter values were uniformly distributed. Consecutive A and B sounds were always separated by a minimum interval of 10 ms.
Each A and B sound consisted of a 50-ms biphasic pulse burst presented with a fixed rate of 900 pulses per second (pps) in monopolar mode. Each biphasic pulse had a phase width of 25 µs and phase gap of 8 µs. The stimuli were presented through the Nucleus Implant Communicator research interface (NIC v2, Cochlear Limited, Sydney).
Rhythm detection performance for the long and short sequences was also measured without the distractor stream. These conditions were significantly easier than the test conditions, and thus, a different (shorter) Δt value was used to avoid ceiling effects. Because listener 2 was not available for the control condition, no control data were available for this listener.
For each combination of electrode separation and sequence duration, 60 presentations of the delayed sequence and 60 presentations of the non-delayed sequence were used to calculate the listener’s sensitivity (d′) to the delayed target.
Loudness balancing
Loudness has been found to be an effective cue for sound segregation of CI listeners (e.g., Cooper & Roberts, 2009; Marozeau, Innes-Brown, & Blamey, 2013). The stimuli were therefore loudness-balanced in this experiment. Categorical loudness scaling was performed for each electrode using an 11-step attribute scale ranging from off (Attribute 0) to too loud (Attribute 10). The intensity of the pulse train was increased in steps of 1.6 dB until the listener could perceive a just noticeable sound (Attribute 1). The intensity of the pulse train was further increased with a step size of 0.8 dB until the sound became comfortable but soft (Attribute 5). Finally, a step size of 0.3 dB was used until the sound became loud but comfortable (Attribute 7) and then decreased again until the most comfortable level (MCL) was reached (Attribute 6).
Once all electrodes were set at MCL, each pair of target and distractor electrodes (i.e., 11/12 and 11/19) were loudness matched by the listener using a simple user interface, which allowed the increase and decrease of the distractor sound intensity in steps of 0.15, 0.3, or 0.45 dB. The loudness matching of the electrode pairs was performed in the beginning of each session. The level of the loudness-balanced stimuli did not markedly change for the different sessions.
Delay (Δt) adjustment procedure
Individual Δt values were used in this study. Δt values were chosen such that all listeners would be equally sensitive to the delayed target in a given condition. The long sequence with the largest electrode separation (12 AB pairs with the distractor stream played at electrode 19) was used for the individual adjustment of Δt. The sensitivity to the delayed target was measured for four different delays: 5, 40, 80, and 120 ms or 5, 30, 60, 90 ms (listener 9) based on 30 presentations of each delayed sequence and 30 presentations of the non-delayed sequences. The four Δt values were presented in random order. A sigmoid function bounded between 0 and 4.7 was fitted to the data of each listener using the MATLAB fitting toolbox. The individual Δt was defined as the delay leading to a signal sensitivity of d′ = 2. Individual Δt values were always smaller than the 110 ms jitter applied to each A sound (see Table 2).
Table 2.
Individual Δt Values as Obtained From the Delay Adjustment Procedure.
| Listener | Δt (ms) for d′ = 2 | Δt (ms) for control condition, d′ = 3 |
|---|---|---|
| 1 | 40 | 30 |
| 2 | 70 | – |
| 3 | 52 | 35 |
| 4 | 45 | 35 |
| 5 | 35 | 32 |
| 6 | 80 | 55 |
| 7 | 80 | 80 |
| 8 | 60 | 28 |
| 9 | 35 | 30 |
The same delay adjustment procedure was used to find the individual Δt values to be used in the control conditions. In this case, the long sequence without distractor stream with delays of 5, 20, 40, and 60 ms was used to fit the psychometric function. The delay leading to d′ = 3 was chosen as Δt for the control condition (see Table 2). This d′ value was chosen to keep the control conditions relatively easy while avoiding ceiling effects.
Procedure
The experiments took place in a double-walled, sound-attenuating booth at the Technical University of Denmark and were organized in two sessions, each lasting 2 h including short breaks. The first session included a brief description of the task, the loudness balancing of the different electrodes, training for the rhythm detection task, and the delay adjustment procedures. All four conditions as well as the two control conditions were tested in the second session.
A one-interval, two-alternative, forced-choice procedure was used, where the listeners were asked to report whether a given sequence contained a delayed target or not. A one-interval task was chosen instead of a two- or three-interval paradigm to minimize the attentional effort required to perform the task (Nie & Nelson, 2015).
Listeners were familiarized with the rhythm detection task by listening to the target stream in the absence of any distractor sound. They were asked to report whether the sequence of target sounds was regular (non-delayed) or irregular (delayed). Once the task was clear, the distractor stream was introduced from electrode 19 (i.e., a large electrode separation) at a soft (but audible) level. Listeners were asked to perform the task while ignoring the distractor sounds. The level of the distractor stream increased progressively until both target and distractor sounds were presented at the listener’s MCL. The training procedure was repeated with the distractor presented at electrode 12 (i.e., a small electrode separation). The duration of the training varied across listeners, ranging between 10 to 20 min.
Eight different sequences were presented to the listeners, resulting from the combination of two possible distractor electrodes (12 or 19), two sequence durations (4 and 12 AB pairs), and two different Δt values (delayed or non-delayed). Short and long sequences were presented in different blocks. In each block, each of the four possible sequences was repeated 12 times in pseudorandom order, ensuring that the distractor electrode alternated from one sequence to the next one. Thus, the first sound of each sequence alternated between electrode 12 and 19, contributing to the resetting of the build-up of a two-stream percept after each presentation (Roberts et al., 2008). Each block was repeated five times in a random order.
The control conditions were tested in four blocks (two with long sequences and two with short sequences) containing 30 repetitions of the delayed and 30 repetitions of the non-delayed sequences. The control blocks were randomly presented at the beginning or at the end of either session.
Statistical analysis
Unless otherwise specified, statistical inference was performed by fitting a mixed-effects linear model to the computed d′ scores. The experimental factors (i.e., electrode separation, sequence duration, and their interaction) were treated as fixed effects terms, whereas listener-related effects were treated as random effects. The model was implemented in R using the lme4 library (Bates, Mächler, Bolker, & Walker, 2014), and the model selection was carried out with the lmerTest library (Kuznetsova, Christensen, & Brockhoff, 2017) following the backward selection approach based on stepwise deletion of model terms with high p values (Kuznetsova, Christensen, Bavay, & Brockhoff, 2015). The p values for the fixed effects were calculated from F tests based on Sattethwaite’s approximation of denominator degrees of freedom, and the p values for the random effects were calculated based on likelihood ratio tests (Kuznetsova et al., 2015). Post hoc analysis was performed through contrasts of least-square means using the lsmeans library (Lenth, 2016) and the lme4 model object. The p values were corrected for multiple comparisons using the Tukey method.
Results
The individual results from Experiment 1 are shown in Figure 2, where each panel represents one listener. The sensitivity to the delayed B sound is plotted for each electrode separation and for the control condition with black circles representing the long sequence and gray triangles representing the short sequence.
Figure 2.
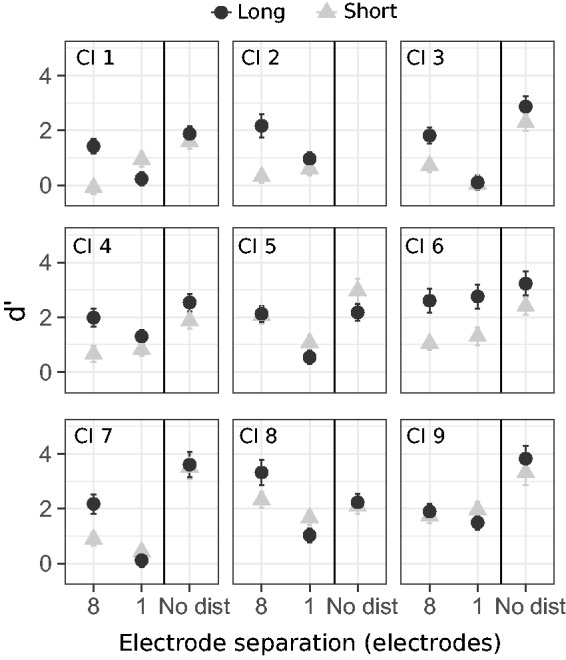
Individual sensitivity to the delayed tone (d′) for each electrode separation and sequence duration. Error bars represent the standard errors of the d′ estimates.
Figure 3 shows the results from Experiment 1. Figure 3(a) shows d′ scores for all combinations of sequence duration and distractor electrode. Figure 3(b) shows the individual difference between d′ scores in the long and short sequences, for each distractor electrode. Figure 3(c) shows the individual difference between d′ scores obtained when the distractor and the target were separated by one and eight electrodes, for each sequence duration. The significance of the statistical contrasts is illustrated with asterisks. Both sequence duration, F(1, 7.94) = 7.214, p = .028, distractor electrode, F(2, 7.85) = 16.348, p = .002, and their interaction, F(2, 15.18) = 17.503, p < .001, were found to be significant factors in the statistical model.
Figure 3.

(a) Sensitivity to the delayed tone (d′) for each condition. (b) Individual differences in d′ between the long and short sequences for the different electrode separations and the control condition. (c) Individual differences in d′ achieved when the distractor and the target were separated by one and eight electrodes for each sequence duration.
Figure 3(a) and (c) show that for the long sequence, greater d′ scores were obtained when the electrode separation between distractor and target was eight electrodes rather than one, t(19.23) = 4.439, p = .003, difference estimate = 1.221, implying that CI listeners benefitted from the larger target-distractor electrode separation to perform the task. Conversely, the distractor electrode did not significantly affect d′ scores in the short sequence, t(19.23) = 0.333, p = .999, difference estimate = 0.091.
Figure 3(a) and (b) show a significant difference in d′ scores between the long and short sequences when distractor and target streams were separated by eight electrodes, t(14.49) = 5.311, p = .001, difference estimate = 1.096. No significant difference was observed when the distractor and the target streams were separated by one electrode, t(14.49) = −0.160, p = 1.000, difference estimate = −0.033, or for the control condition, t(15.79) = 1.588, p = .533, difference estimate = 0.341.
Discussion
Experiment 1 investigated if electrode separation promotes voluntary stream segregation and whether a segregated percept needs time to build up in a segregation-promoting paradigm. The detection performance was assumed to improve if the listeners would perceptually segregate the A and B sequences. Thus, greater d′ scores represent higher likelihood for a segregated percept.
Earlier studies that considered temporal tasks to assess streaming abilities of CI listeners reported a large variability in their results (Cooper & Roberts, 2009; Hong & Turner, 2006; Tejani et al., 2017). Such variability is likely to represent differences in both streaming abilities as well as temporal discrimination abilities across subjects. In an attempt to minimize the variability due to individual differences in temporal discrimination abilities, Δt was adjusted for each listener. Despite this individual adjustment of the task difficulty, the results still varied considerably across listeners (Figures 2 and 3).
Greater d′ scores were observed, overall, for the large than for the small electrode separation between the target and the distractor stream. Thus, a large electrode separation facilitated the detection task, suggesting that CI listeners were able to make use of place cues to segregate the A and B sequences. This finding is consistent with reports from previous studies (e.g., Chatterjee et al., 2006; Hong & Turner, 2006; Tejani et al., 2017). However, this was only observed for the long sequence and not for the short one, in which d′ scores did not depend on the electrode separation (Figure 3(a) and (c)). The build-up process of a two-stream percept has been widely reported for NH listeners, both in obligatory (Roberts et al., 2008; Thompson et al., 2011) and voluntary stream segregation (Micheyl et al., 2005; Nie & Nelson, 2015). Presumably, the short sequence in the present study was not long enough to allow such build-up process to occur in the CI listeners. The results from the no-distractor condition demonstrated that detecting the delay on the B sequence per se was not affected by the sequence duration. Thus, the greater d′ scores achieved for the large rather than for the short electrode separation in the long sequence are likely to represent the build-up of a two-stream percept. The results from Experiment 1 suggest that a similar build-up process is experienced by both NH and CI listeners during voluntary stream segregation. This is consistent with the findings from Böckmann-Barthel et al. (2014), who investigated the time course of stream segregation in CI listeners as a function of frequency separation and found similar trends in CI and NH listeners. In that study, the listeners directly reported their percept without any specific instructions encouraging integration or segregation of the sounds. Thus, it is possible that the reports from the CI listeners reflected pitch or electrode discrimination instead of stream segregation (Chatterjee et al., 2006; Cooper & Roberts, 2007). Such uncertainty was avoided in the present study by using a detection task that specifically promotes segregation.
Cooper and Roberts (2009) did not find an effect of electrode separation on voluntary stream segregation performance in CI listeners. However, their sequences had a fixed duration of 2.2 s. This is longer than the short sequence (1.24 s) and shorter than the long sequence (3.96 s) used in the present study. Thus, the results from the present study suggest that CI listeners need between about 1.2 and 4 s to build up a two-stream percept when place cues are provided through a segregation-promoting paradigm. In the study of Cooper and Roberts (2009), such build-up effect could have been significantly reduced by introducing large loudness differences between the streams, which has been shown to be a strong cue for stream segregation in CI listeners (Marozeau et al., 2013). In their study, CI listeners performed near-chance level in the absence of loudness cues but could segregate the target sounds when the distractor sounds were attenuated by at least 50% of the listener’s dynamic range. In the present study, CI listeners required shorter Δt values to avoid ceiling effects in the absence of the distractor stream. This implies that performance in the rhythm detection task was substantially affected by the presence of a distractor stream even when the electrode separation between the target and the distractor was as large as eight electrodes. Thus, even though CI listeners seem to be able to achieve a segregated percept and exhibit a similar build-up process as the one reported for NH listeners, it is likely that they need longer time to achieve a fully segregated percept when only place cues are provided.
The results reported in the present study are similar to the ones obtained by Nie and Nelson (2015) who used a similar segregation-promoting paradigm to investigate the effect of spectral separation and sequence duration on stream segregation in NH listeners. They found a significant interaction between the sequence duration and the spectral separation between the A and B sounds. A corresponding interaction between electrode separation and sequence duration was found here for CI listeners. Tejani et al. (2017) made use of the irregular rhythm detection task (Cusack & Roberts, 2000) to assess obligatory stream segregation abilities of both NH and CI listeners. Despite the variability of the CI group, the results showed similar trends for both NH and CI listeners, with no significant differences between the groups. The similarity in the trends observed in both groups supports the idea that CI listeners and NH listeners might experience both voluntary and obligatory stream segregation in a similar way.
Experiment 2: Estimating the Fission Boundary
Rationale
Experiment 2 investigated how large the electrode separation needs to be for segregation to occur using a subset of the listeners from Experiment 1. The same rhythm detection task as in Experiment 1 was used. However, the sequence duration was fixed at 3.96 s (long sequence in Experiment 1), and only the electrode separation was varied.
The rhythm detection task used in Experiments 1 and 2 encouraged the listeners to focus on the temporally regular B sounds and ignore the jittered A sounds. However, the distribution of possible onset-to-onset gaps between the last A and B sounds was shifted by +Δt in the delayed with respect to the non-delayed sequences, providing the listeners with an extra cue to perform the task. As a result, listeners could achieve above chance performance even when unable to segregate the streams. Due to the individual adjustment of Δt, the d′ reflecting chance level performance varied across listeners. In Experiment 2, an IO model was used to establish the upper limit of performance for each listener when the streams were assumed to be perceived as fused.
Methods
The methods used in Experiment 2 are identical to those used in Experiment 1, unless otherwise stated.
Listeners
Six CI listeners (four female and two male) participated in this experiment. The listeners were 21 to 74 years old (M: 52 years, SD: 23 years; see Table 1) and had no residual hearing in their implanted ear.
Stimuli and conditions
Five electrode separations were tested with a sequence duration of 12 AB pairs, leading to a nominal duration of 3.96 s. The target stream (B) was always played through electrode 11, and the distractor stream (A) was played through electrode 11 (no difference condition), 12, 14, 16, or 19 depending on the condition. Each pulse burst was presented at a rate of 900 pps. As in Experiment 1, an additional delay (Δt) was sometimes added before the last burst of the target stream (see Table 2).
Procedure
The first session comprised a brief explanation of the task, the loudness balancing, and some of the blocks from the rhythm detection task. The remaining blocks as well as the no-difference condition were tested in the second session. Ten different sequences were presented to the listeners, resulting from the combination of five possible distractor electrodes (11, 12, 14, 16, or 19) and two different Δt values (delayed or non-delayed). The distractor electrodes 12, 14, 16, and 19 were presented in pseudorandom order, ensuring that the different distractor electrodes were used in consecutive sequences. Distractor electrode 11 was tested on a separate block.
IO model
An IO model was used to simulate the best possible performance that listeners could achieve if the delay between the last A and B sounds was the only available cue. The model categorized individual trials as delayed or non-delayed by evaluating the gap between the last A and B sounds of a given sequence and comparing it with the nominal gap between consecutive A and B sounds (i.e., 170 ms). A given trial was categorized as delayed if the gap between the last A and B sounds was larger than the nominal gap. Otherwise, the trial was categorized as non-delayed. Because Δt values were adjusted individually, the probability of giving a correct answer when fusing the A and B streams (chance level) was different for each listener. Thus, the gap between the last A and B sounds of each presentation was stored for each listener and condition and used as input to the IO model. The IO model generated a d′ estimate for each listener and condition. Segregation was considered to occur when CI listeners’ performance was significantly better than the one achieved by the IO model.
Statistical analysis
A mixed-effects linear model was fitted to the d′ scores. The electrode separation and data type (listener’s data or IO model prediction) were treated as fixed effects terms, whereas listener-related effects were treated as random effects (correlated random intercept and slope). Statistical contrasts between the individual listener’s data and their respective IO model predictions were performed using t tests with the mean and standard error from each d′ estimate. The resulting p values were adjusted for multiple comparisons for controlling the false discovery rate (Benjamini & Hochberg, 1995).
Results
Figure 4 shows the individual results from Experiment 2. For each listener, the d′ scores are shown for each target-distractor electrode separation. The experimental data are indicated by the black-filled circles. Estimates from the IO model are indicated by the gray triangles. Adjusted p values resulting from the statistical contrast between the achieved d′ scores and the IO model predictions are indicated with asterisks.
Figure 4.

Individual sensitivity (d′) scores to the delayed tone for each electrode separation (black circles, solid line) as well as the corresponding ideal observer model prediction (gray triangles, dashed line). Error bars represent the standard errors of the d′ estimates. A statistically significant difference between the IO model predictions and the listener’s data is indicated by one asterisk if .05 > p > .01, two asterisks if .01 > p > .001, and three asterisks if p < .001.
IO = ideal observer.
Sensitivity scores generally increased for larger electrode separations between the A and B sequences. On average, listeners required a minimum separation of 2.8 electrodes to obtain significantly larger d′ scores than those from the IO model. However, a large variability was observed across listeners: While listeners 4, 6, and 9 obtained significantly larger d′ scores than the IO model when the A and B sequences were separated by one or more electrodes, listeners 5 and 8 required a minimum separation of three electrodes, and listener 3 could only obtain larger d′ scores than the IO model for a separation of eight electrodes. None of the listeners achieved significantly larger d′ scores than those predicted by the IO model (Figure 4) for the no difference condition.
Table 3 summarizes the results from the statistical contrast between d′ scores obtained by CI listeners and those predicted by the IO model, based on the lsmeans estimates obtained from the mixed-effects linear model. Both electrode separation, F(4, 40) = 12. 810, p < .001, data type, F(1, 5) = 33.496, p = .002, and their interaction, F(4, 40) = 13.083, p < .001, were found to be significant factors in the statistical model. Listeners’ d′ scores were significantly larger than those obtained with the IO model for a separation of three or more electrodes between the A and B streams.
Table 3.
Summary of the Statistical Contrast Between d′ Scores Obtained by CI Listeners and IO Model for Each Electrode Separation.
| Electrode separation | Difference estimate | t ratio | p |
|---|---|---|---|
| 0 | 0.220 | 0.932 | .992 |
| 1 | 0.619 | 2.627 | .290 |
| 3 | 1.147 | 4.870 | .007 |
| 5 | 1.645 | 6.984 | <.001 |
| 8 | 1.574 | 6.683 | <.001 |
Note. Statistical contrasts were performed on the lsmeans estimates from the mixed-effects linear model for each data type and electrode separation (df = 13.83). IO = ideal observer; CI = cochlear implant.
Figure 5 contains d′ scores from all listeners (dark gray boxes) and the corresponding IO model estimates (light gray boxes). The d′ scores from the listeners increased monotonically with the electrode separation between the A and B sounds, possibly reaching a plateau at a separation of five electrodes. The IO model predictions were rather constant across the different electrode separations, although they showed some variability both across the different electrode separations and across listeners. The variability across electrode separations reflects the limited number of observations used for calculating the d′ (60 observations of the delayed and 60 observations of the non-delayed sequences) because the IO model predictions were solely based on the gap between the last A and B sounds and did not depend on the electrode separation between the A and B sequences. Instead, the variability across listeners reflects the use of individual Δt values in this experiment. The IO model predictions were related to Δt because larger Δt values increased the difference between the distributions of possible gaps between the last A and B sounds of the delayed and non-delayed sequences. Thus, the larger was Δt, the larger was the predicted d′.
Figure 5.

Sensitivity (d′) scores to the delayed tone for each electrode separation. Data from the CI listeners are plotted in dark gray and predictions from the ideal observer model in light gray.
IO = ideal observer; CI = cochlear implant.
Discussion
Experiment 2 combined measurements of performance using the rhythm detection task from Experiment 1 and predictions from an IO model to estimate the minimum electrode separation needed to segregate the streams. Consistent with the results from Experiment 1, greater d′ scores were achieved for larger electrode separations, demonstrating that a larger electrode separation facilitated the segregation of the sounds. Moreover, all CI listeners achieved significantly greater d′ scores than those predicted by the IO model, indicating that all listeners were able to achieve a segregated percept.
Böckmann-Barthel et al. (2014) made use of direct reports of perception from CI listeners to assess the role of place cues on stream segregation. Even though their study did not aim to estimate the FB, they reported an ambiguous percept for a frequency separation of six semitones between the A and the B sounds and suggested that a separation of two to three electrodes might be needed by CI listeners to segregate the sounds. With a similar paradigm as Böckmann-Barthel et al. (2014), Chatterjee et al. (2006) and Cooper and Roberts (2007) found little or no evidence for ambiguous percepts. The results from these studies indicated the proportion of time where listeners reported a two-stream percept, and thus, they might be influenced by how listeners were instructed to perform the task. Ultimately, if listeners are uncertain about what to listen for, they might report pitch or electrode discrimination instead of segregation (Chatterjee et al., 2006; Cooper & Roberts, 2007). The results from Experiment 2, where the FB was assessed through a rhythm detection task, support the hypothesis of Böckmann-Barthel et al. (2014). Three out of six listeners were able to segregate the sounds when they were presented from adjacent electrodes, and all (but one) listeners were able to experience a segregated percept with a separation of three electrodes.
Temporal perception has been found to be similar in CI and NH listeners (e.g., Moore & Glasberg, 1988; Shannon, 1989, 1992), and previous studies have demonstrated that CI listeners are able to make use of temporal cues to segregate sounds (e.g., Duran, Collins, & Throckmorton, 2012; Hong & Turner, 2009). Temporal regularity and predictive processing are known to influence the representation of auditory objects, with irregular sounds being more likely to be segregated (for a review, see Bendixen, 2014). In the present study, the distractor stream was always temporally irregular, possibly contributing to the segregation process. The temporal regularity properties of the streams were kept constant across conditions; therefore, it cannot account for the improvement in performance observed for the larger electrode separation. Nie et al. (2014) observed that listeners were able to segregate sequential sounds under attentive listening even when only temporal regularity cues were present. In the present study, none of the CI listeners achieved significantly larger d′ scores than those predicted by the IO model for the no difference condition, where both A and B streams were presented through the same electrode and with identical pulse rate. Thus, even though the temporal irregularity of the distractor stream may contribute to the segregation process both in NH and in CI listeners (e.g., Nie et al., 2014; Rajendran, Harper, Willmore, Hartmann, & Schnupp, 2013), in the present study, this cue was not found to be strong enough to elicit a segregated percept. Instead, place cues were the dominant cue used by CI listeners to segregate the streams.
Overall Summary and Conclusion
The present study assessed the effect of place cues on voluntary stream segregation in CI listeners. The results from Experiment 1 suggest that CI listeners can make use of place cues to voluntarily segregate sounds. Moreover, a build-up process similar to that reported in NH listeners was observed. In Experiment 2, all (but one) listeners were able to segregate the sounds for electrode separations of three electrodes, with some listeners being able to segregate sounds coming from adjacent electrodes. Experiment 2 also validated the use of the rhythm detection task to assess the effect of electrode separation on stream segregation in the presence of temporal regularity cues because temporal regularity was not salient enough to elicit a segregated percept in the absence of place cues. Altogether, place cues seem to play an important role for the segregation of sounds, allowing CI listeners to segregate sequentially presented sounds. However, these findings are based on a relatively simple paradigm and should not be extrapolated to more complex and realistic scenarios without further investigation. It is possible that the limitations experienced by CI listeners in complex listening scenarios, such as speech intelligibility in a noisy environment, arise from the degraded frequency resolution. Current sound coding strategies result in a wide range of electrodes being active most of the time, which might limit the place information available to the listener (e.g., Tejani et al., 2017).
Acknowledgments
We would like to thank the two anonymous reviewers for the helpful and constructive comments on an earlier version of the article, Per B. Brockhoff and Alexandra Kuznetsova for their help and guidance with the statistical analysis of the data, and our colleagues from the Hearing Systems Group for valuable comments and stimulating discussions. The research equipment was provided by Cochlear Ltd.
Note
In the Cochlear electrode array, electrode 1 is the most basal electrode and electrode 22 the most apical one.
Authors’ Note
The data presented here are publicly available at http://doi.org/10.5281/zenodo.890790
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Oticon Centre of Excellence for Hearing and Speech Sciences (CHeSS) and the Carlsberg Foundation.
References
- Anstis S. M., Saida S. (1985) Adaptation to auditory streaming of frequency-modulated tones. Journal of Experimental Psychology: Human Perception and Performance 11: 257–271. doi:10.1037/0096-1523.11.3.257. [Google Scholar]
- Bates D., Mächler M., Bolker B., Walker S. (2014) Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67(1): 1–48. doi:10.18637/jss.v067.i01. [Google Scholar]
- Benjamini Y., Hochberg Y. (1995) Controlling the false discovery rate: A practical and powerful approach to multiple testing. Journal of the Royal Statistical Society. Series B 57: 289–300. [Google Scholar]
- Bendixen A. (2014) Predictability effects in auditory scene analysis: A review. Frontiers in Neuroscience 8: 1–16. doi:10.3389/fnins.2014.00060. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Böckmann-Barthel M., Deike S., Brechmann A., Ziese M., Verhey J. L. (2014) Time course of auditory streaming: Do CI users differ from normal-hearing listeners? Frontiers in Psychology 5: 775 doi:10.3389/fpsyg.2014.00775. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bregman A. S. (1978) Auditory streaming is cumulative. Journal of Experimental Psychology: Human Perception and Performance 4: 380–387. doi:10.1037/0096-1523.4.3.380. [DOI] [PubMed] [Google Scholar]
- Bregman A. S. (1990) Auditory scene analysis: The perceptual organization of sound, Cambridge, MA: The MIT Press. [Google Scholar]
- Chatterjee M., Fu Q. J., Shannon R. V. (1998) Within-channel gap detection using dissimilar markers in cochlear implant listeners. Journal of the Acoustical Society of America 103: 2515–2519. doi:10.1121/1.422772. [DOI] [PubMed] [Google Scholar]
- Chatterjee M., Sarampalis A., Oba S. I. (2006) Auditory stream segregation with cochlear implants: A preliminary report. Hearing Research 222: 100–107. doi:10.1016/j.heares.2006.09.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cooper H. R., Roberts B. (2007) Auditory stream segregation of tone sequences in cochlear implant listeners. Hearing Research 225: 11–24. doi:10.1016/j.heares.2006.11.010. [DOI] [PubMed] [Google Scholar]
- Cooper H. R., Roberts B. (2009) Auditory stream segregation in cochlear implant listeners: Measures based on temporal discrimination and interleaved melody recognition. Journal of the Acoustical Society of America 126: 1975–1987. doi:10.1121/1.3203210. [DOI] [PubMed] [Google Scholar]
- Cusack R., Roberts B. (2000) Effects of differences in timbre on sequential grouping. Perception & Psychophysics 62: 1112–1120. doi:10.3758/BF03212092. [DOI] [PubMed] [Google Scholar]
- Duran S. I., Collins L. M., Throckmorton C. S. (2012) Stream segregation on a single electrode as a function of pulse rate in cochlear implant listeners. Journal of the Acoustical Society of America 132: 3849–3855. doi:10.1121/1.4764875. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hanekom J. J., Shannon R. V. (1998) Gap detection as a measure of electrode interaction in cochlear implants. Journal of the Acoustical Society of America 104: 2372–2384. doi:10.1121/1.423772. [DOI] [PubMed] [Google Scholar]
- Hong R. S., Turner C. W. (2006) Pure-tone auditory stream segregation and speech perception in noise in cochlear implant recipients. Journal of the Acoustical Society of America 120: 360–374. doi:10.1121/1.2204450. [DOI] [PubMed] [Google Scholar]
- Hong R. S., Turner C. W. (2009) Sequential stream segregation using temporal periodicity cues in cochlear implant recipients. Journal of the Acoustical Society of America 126: 291–299. doi:10.1121/1.3140592. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kuznetsova, A., Brockhoff, P. B. and Christensen, R. H. B (2017). lmerTest package: tests in linear mixed effects models. Journal of Statistical Software, 82, 1–26. doi: 10.18637/jss.v082.i13.
- Kuznetsova, A., Christensen, R. H. B., & Brockhoff, P. B. (2013). lmerTest: Tests for random and fixed effects for linear mixed effect models (lmer objects of lme4 package).
- Lenth R. V. (2016) Least-squares means: The {R} package {lsmeans}. Journal of Statistical Software 69: 1–33. doi:10.18637/jss.v069.i01. [Google Scholar]
- Marozeau J., Innes-Brown H., Blamey P. (2013) The acoustic and perceptual cues in melody segregation for listeners with a cochlear implant. Frontiers in Psychology 4: 1–11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Micheyl C., Carlyon R. P., Cusack R., Moore B. C. J. (2005) Performance measures of auditory organization. In: Pressnitzer D., Cheveigné A. de, McAdams S., Collet L. (eds) Auditory signal processing: Physiology, psychoacoustics, and models, New York, NY: Springer, pp. 203–211. [Google Scholar]
- Micheyl C., Oxenham A. J. (2010. a) Pitch, harmonicity and concurrent sound segregation: Psychoacoustical and neurophysiological findings. Hearing Research 266: 36–51. doi:10.1016/j.heares.2009.09.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Micheyl C., Oxenham A. J. (2010. b) Objective and subjective psychophysical measures of auditory stream integration and segregation. JARO – Journal of the Association for Research in Otolaryngology 11: 709–724. doi:10.1007/s10162-010-0227-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moore B. C., Glasberg B. R. (1988) Gap detection with sinusoids and noise in normal, impaired, and electrically stimulated ears. Journal of the Acoustical Society of America 83: 1093–1101. doi:10.1121/1.396054. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Gockel H. E. (2012) Properties of auditory stream formation. Philosophical Transactions of the Royal Society B: Biological Sciences 367: 919–931. doi:10.1098/rstb.2011.0355. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nelson P. B., Jin S.-H., Carney A. E., Nelson D. A. (2003) Understanding speech in modulated interference: Cochlear implant users and normal-hearing listeners. Journal of the Acoustical Society of America 113: 961–968. doi:10.1121/1.1531983. [DOI] [PubMed] [Google Scholar]
- Nie Y., Nelson P. (2015) Auditory stream segregation using amplitude modulated bandpass noise. Journal of the Acoustical Society of America 127: 1809 doi:10.1121/1.3384104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nie Y., Zhang Y., Nelson P. B. (2014) Auditory stream segregation using bandpass noises: Evidence from event-related potentials. Frontiers in Neuroscience 8: 1–12. doi:10.3389/fnins.2014.00277. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rajendran V. G., Harper N. S., Willmore B. D., Hartmann W. M., Schnupp J. W. H. (2013) Temporal predictability as a grouping cue in the perception of auditory streams. Journal of the Acoustical Society of America 134: EL98 doi:10.1121/1.4811161. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roberts B., Glasberg B. R., Moore B. C. J. (2002) Primitive stream segregation of tone sequences without differences in fundamental frequency or passband. Journal of the Acoustical Society of America 112: 2074–2085. doi:10.1121/1.1508784. [DOI] [PubMed] [Google Scholar]
- Roberts B., Glasberg B. R., Moore B. C. J. (2008) Effects of the build-up and resetting of auditory stream segregation on temporal discrimination. Journal of Experimental Psychology: Human Perception and Performance 34: 992–1006. doi:10.1037/0096-1523.34.4.992. [DOI] [PubMed] [Google Scholar]
- Shannon R. V. (1989) Detection of gaps in sinusoids and pulse trains by patients with cochlear implants. Journal of the Acoustical Society of America 85: 2587–2592. doi:10.1121/1.397753. [DOI] [PubMed] [Google Scholar]
- Shannon R. V. (1992) Temporal modulation transfer functions in patients with cochlear implants. Journal of the Acoustical Society of America 91: 2156–2164. doi:10.1121/1.403807. [DOI] [PubMed] [Google Scholar]
- Stickney G. S., Zeng F.-G., Litovsky R., Assmann P. (2004) Cochlear implant speech recognition with speech maskers. Journal of the Acoustical Society of America 116: 1081–1091. doi:10.1121/1.1772399. [DOI] [PubMed] [Google Scholar]
- Tejani V. D., Schvartz-Leyzac K. C., Chatterjee M. (2017) Sequential stream segregation in normally-hearing and cochlear-implant listeners. Journal of the Acoustical Society of America 141: 50–64. doi:10.1121/1.4973516. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thompson S. K., Carlyon R. P., Cusack R. (2011) An objective measurement of the build-up of auditory streaming and of its modulation by attention. Journal of Experimental Psychology: Human Perception and Performance 37: 1253–1262. doi:10.1037/a0021925. [DOI] [PubMed] [Google Scholar]
- van Noorden, L. P. A. S. (1975). Temporal coherence in the perception of tone sequences, PhD dissertation, Institute for Perception Research, Eindhoven, The Netherlands.
- van Wieringen A., Wouters J. (1999) Gap detection in single- and multiple-channel stimuli by LAURA cochlear implantees. Journal of the Acoustical Society of America 106: 1925–1939. doi:10.1121/1.427941. [DOI] [PubMed] [Google Scholar]
- Zeng F. G., Rebscher S., Harrison W., Sun X., Feng H. (2008) Cochlear implants: System design, integration, and evaluation. IEEE Reviews in Biomedical Engineering 1: 115–142. doi:10.1109/RBME.2008.2008250. [DOI] [PMC free article] [PubMed] [Google Scholar]