

Abstract
Measuring temporal discounting through the use of intertemporal choice tasks is now the gold standard method for quantifying human choice impulsivity (impatience) in neuroscience, psychology, behavioral economics, public health and computational psychiatry. A recent area of growing interest is individual differences in discounting levels, as these may predispose to (or protect from) mental health disorders, addictive behaviors, and other diseases. At the same time, more and more studies have been dedicated to the quantification of individual attitudes towards risk, which have been measured in many clinical and non-clinical populations using closely related techniques. Economists have pointed to interactions between measurements of time preferences and risk preferences that may distort estimations of the discount rate. However, although becoming standard practice in economics, discount rates and risk preferences are rarely measured simultaneously in the same subjects in other fields, and the magnitude of the imposed distortion is unknown in the assessment of individual differences. Here, we show that standard models of temporal discounting —such as a hyperbolic discounting model widely present in the literature which fails to account for risk attitudes in the estimation of discount rates— result in a large and systematic pattern of bias in estimated discounting parameters. This can lead to the spurious attribution of differences in impulsivity between individuals when in fact differences in risk attitudes account for observed behavioral differences. We advance a model which, when applied to standard choice tasks typically used in psychology and neuroscience, provides both a better fit to the data and successfully de-correlates risk and impulsivity parameters. This results in measures that are more accurate and thus of greater utility to the many fields interested in individual differences in impulsivity.
Introduction
Time preference, or the preference of typical humans for immediate over delayed rewards, has long been a subject of study in economics, finance, neuroscience, and psychology. Temporal discounting describes this preference mathematically by quantifying how the subjective value of a payoff decreases as the time to its receipt increases. This delay-dependent decrease in subjective value is captured in models with diverse functional forms, with time preference typically summarized as a discount rate or discount parameter. The two most widely used functional forms are the exponential and the hyperbolic classes of models. Exponential discounting is derived from economic theory and assumes a constant rate of discounting at every time period. Hyperbolic forms are favored in psychology and neuroscience, as they can fit empirical data better [1, 2], exhibiting steeper discounting for near-future outcomes and shallower discounting of far-future payoffs, an inconsistency referred to as “present bias” [3]. More recently, psychologists have related this time preference to the multidimensional construct of impulsivity [4, 5]. Scholars of impulsivity have converged to a taxonomy that divides it into action and choice impulsivity, and officially consider the measurement of discounting as a quantitative assessment of the latter [6]. We note that for economics, impulsivity is not directly equated to elevated discounting. For this field, when discounting is constant (such as in exponential discounting) the discount rate reflects consistent impatient preferences. By contrast, in hyperbolic discounting the discount parameter may reflect inconsistencies in these preferences (present bias) and therefore reflect what economists consider impulsivity. In this paper, we attempt to reconcile these insights from economics and bring them to the attention of fields like psychology, neuroscience, and psychiatry.
With hundreds of publications a year focused on delay discounting, these measurements have now been performed on a wide variety of healthy and clinical populations under many different conditions. Examples of the prevalence of this measure in the literature include large studies and meta-analyses in healthy volunteers [7–13], as well as case-control studies in a variety of patient populations with substance use disorders [14–16], anorexia [17], obesity [18], personality disorders [19], ADHD [20], and anxiety [21–23]. Adding to this growing literature, several groups have investigated the neural basis of temporal discounting [24–29] and others have explored the effect of behavioral or neural manipulations on temporal discounting in healthy volunteers [30–33].
In parallel to using measures of temporal discounting to assess impulsivity, there has been growing interest in the quantitative assessment of risk attitudes by measuring formal risk preferences, that is, an individual’s general proneness to or avoidance of risky prospects, in a wide array of populations [34–37]. In expected utility theory and many other cardinal economic theories of choice, risk attitude is associated with the curvature of the utility function. This function can be interpreted as the mapping from the objective amount of a good (or money) to the subjective value derived from obtaining it. In these theories, this function is related to choices over probabilistic outcomes [38, 39]. When a subject’s utility function is linear, she chooses between lotteries as if maximizing expected value (choosing the option for which the product of the value of the prize and its probability is highest); this is often referred to as risk neutrality. When the utility function is concave, subjects are risk averse; when it is convex, subjects are risk seeking. Many studies have concluded that there is great diversity in risk preference and that risk attitudes are affected by age, context and even physiological states like menstrual cycle phase [40–45].
More recently, economists have examined how risk attitudes might introduce possible confounds to the empirical measurement of discount rates [46–48]. The key ideas in this literature are: first, that because the future is inherently uncertain, risk attitude must play a role when evaluating future prospects irrespective of their time preferences [49, 50]; and second, that the preference for smaller-sooner rewards may be driven by either impatience (what in psychology is considered the “choice impulsivity” dimension of impulsivity) or by diminishing marginal utility as captured by nonlinearities in the utility function [51, 52]. Although accounting for risk preferences when estimating discount rates is of growing importance in the economics and management fields, with few exceptions [26, 53], it is not a practice that has fully impacted studies in the neuroscience and psychology fields, even when both types of preferences are measured in the same individual. Further, because in economics the focus is rarely on the employment of these measures for the study of individual differences, the size of the impact of risk preference on individual discount rate estimates has not been well characterized.
In this study, we investigated how individuals’ risk attitudes bias the estimation of their discount rates. As our goal is to propose this methodology to the fields that do not already employ it, we used simple standard binary choice tasks widely used in the psychology and neuroscience literature [24, 25, 54, 55] in a real-world non-expert sample. We hypothesized that a procedure that estimated individual subject temporal discounting rates, but that also incorporated independently estimated risk attitude parameters, would outperform standard (economic) tools for estimating temporal discounting rates. We found that in our community sample of subjects, where there was a wide diversity of individual risk preferences, our approach showed superior performance in capturing individual intertemporal choice behavior. Unlike previous studies that employed similar methods but that focused on population-level discount rate estimates, here we focused on individually estimated parameters. We found that the standard approach introduces a systematic pattern of bias that distorts individual discount rate estimates. We conclude that ignoring individuals’ risk attitudes when measuring temporal discount rates can significantly impact interpretations about their degree of choice impulsivity.
Materials and methods
Subjects
All participants gave written informed consent in accordance with the procedures of the University Committee on Activities Involving Human Subjects of New York University and the Institutional Review Board of the New York University School of Medicine, which approved this study. We recruited 56 medically healthy participants (11 women) from the general community (via flyers, internet advertisement and word-of mouth) without significant history of substance use or psychiatric illness. Subjects’ demographic information including average education level, income level, employment and race and ethnicity breakdown is presented in Table 1.
Table 1. Sample demographics.
| Gender (% males) | 73.3% |
| Age (years) | 44.04 (12.4) |
| Nonverbal I.Q. | 91 (2.5) |
| Education (years) | 13.8 (2.0) |
| Unemployed (%) | 14% |
| Income (monthly $) | 1770.49 (263.73) |
| Race (% C—% AA) | 47.6—52.4 |
| Ethnicity (% Hispanic) | 14.3 |
Values are presented as mean (± 1 standard deviation) unless they are percentages. Race is divided into Caucasian (C) and African American (AA). No other races were present in our sample. Ethnicity is divided into Hispanic and non-Hispanic. The education and income of our sample match median education level and personal income level adjusted for educational attainment in the United States.
Session description
After collecting pertinent contact and demographic information, subjects completed the intertemporal choice task and the risk task. The order of the tasks was randomized across subjects and sessions. Both tasks were computerized (Psychtoolbox for MatLab and e-prime 2.0) and were completed in a private testing room. Subjects were given extensive instructions as well as some practice trials to ensure they understood the tasks fully before beginning. Subjects completed 2 sessions separated by at least one week.
Risk attitude (RA) task
The task consisted of 64 lottery choices in the gain domain. Each trial involved a choice between a fixed amount of money ($5 for sure) and a lottery with the probability level associated with winning a (usually higher) amount changing from trial to trial. Each lottery had two possible outcomes: $v or $0. The exact amounts of v were: $5, $6, $7, $8, $9, $10, $12, $14, $16, $18, $20, $23, $26, $30, $34, $39, $44, $50, $57, and $66. We used three winning probabilities, p, 25%, 50%, and 75%. In this case, each lottery can be fully described by v and p. Each amount v was presented with each probability level once in random order over 4 blocks of 16 trials. In addition, 4 “catch” trials were included at the start of each block. These trials always presented a choice between $5 for sure vs. 50% chance of $4 or $0. Thus, these trials in addition to trials that offered risky lotteries where v was $5 (10 in total), allowed us to assess the frequency of first order stochastic dominance violations, that is, whether subjects chose the objectively worse of the two options. We considered two or more of such violations as evidence that we could not reliably model subjects’ choices with a monotonic utility function. Both the fixed $5 and the lottery were presented side by side on the screen. Subjects were told that each lottery image represents a physical paper bag that contains 100 poker chips, some red and some blue. Subjects were told the precise number of red and blue chips in the bag by explicitly showing the number and by coloring parts of the image according to the proportion of red and blue chips.
Intertemporal choice (ITC) task
The task was a two alternative forced choice task consisting of 102 trials that presented two options, one monetary reward to be received on that day and one monetary reward to be received with variable delay (in days). On each trial, both the fixed immediate and delayed options were presented side by side on the screen. The range of rewards across both periods went from $2 to $66. The immediate reward was either $2, $5 or $15, and the delayed reward was always a larger amount in the following increment levels: for trials with $2 immediate reward, +$5, +$10, +$20, +$40, +$64; for trials with $5 immediate reward, +$5, +$10, +$20, +$40, +$60; and for trials with $15 immediate reward, +$5, +$10, +$20, +$40, +$50. The actual delayed alternative presented was the result of the exact given increment level or plus or minus $1. Possible delays were 5, 10, 30, 60, 90, 120 and 150 days. The actual delay presented corresponded to the stated delays in days or plus or minus one day. For example, one of the trials was a choice between $5 today and $66 in 89 days. The selected choice set allowed for a very distributed investigation of the space to ensure our ability to estimate very high or very low discount rates with equivalent precision.
Incentive compatibility and payment
We compensated subject participation with a $10 fee and a bonus. At the end of the session, one choice from either the ITC or RA task was randomly selected to determine this bonus. This ensures that subjects’ decisions were incentive compatible: they do not know which choice will count so their best strategy is to treat each one as if it were the one that counts. Payment for both the participation fee and the bonus was made via money order in the following way: subjects received a code via a text message to their phone on the day the payment was due, to prevent against subjects forgetting payments, to claim their bonus at their convenience. Critically, because all payments were made this way we introduced no differences in the transaction costs for different types of payments (participation fee, RA task payment, ITC immediate payment or ITC delayed payment). For ITC delayed payments, subjects received the code on the date corresponding to the delay for that chosen option.
RA task analysis
To quantify technical risk attitude for each session, we used a power utility model to fit the choice data from the RA task as we have described previously [40, 41, 43, 54, 56]. In this model, the utility (U) of each option (safe or lottery) is given by:
| (1) |
where v is the dollar amount, p is the probability of winning, and α is the curvature of the utility function which serves as a subject-specific measure of technical risk attitude. A subject whose α = 1 has a linear utility function and is thus risk neutral. A subject whose α > 1 has a convex utility function and is thus risk-seeking (reflecting a tolerance of risk and uncertainty). A subject whose α < 1 has a concave utility function and is thus risk-averse (reflecting a distaste for risk and uncertainty). Using maximum likelihood estimation in MATLAB, we fit a single logistic function to the trial-by-trial choice data of each subject:
| (2) |
where Pr is the probability that the subject chose the lottery option on a given trial, Usafe and Ulottery are the utilities (subjective values) of the safe and lottery options, respectively, and γ is the slope of the logistic function, which is a second subject-specific parameter. The parameter γ captures the stochasticity (as it is related to the randomness of the choice data).
ITC task analysis
We applied four models to quantify subject time preferences. The first model was a non-normative hyperbolic discounting model [57], which assumes an underlying linear utility. We call this model Linear utility Hyperbolic discounting (LH) for ease of reference in the text. In this model, the utility (U) of each option (immediate or delayed) is given by:
| (3) |
where v is the dollar amount of the option, d is the delay to the delivery of v (which is 0 for the immediate option), and κ is the discount parameter which serves as a subject-specific measure of impulsivity. The second model was a non-normative hyperbolic discounting model that took into account the curvature of the utility function as estimated by Eq (1), captured in the parameter α. We call this model Nonlinear utility Hyperbolic discounting (NLH) for ease of reference in the text. In this model, the utility (U) of each option is given by:
| (4) |
The third model was a normative exponential discounting model which assumes an underlying linear utility. We call this model Linear utility Exponential discounting (LE) for ease of reference in the text. In this model, the utility (U) of each option is given by:
| (5) |
The fourth model was a normative exponential discounting model that took into account the curvature of the utility function again by using α. We call this model Nonlinear utility Exponential discounting (NLE) for ease of reference in the text. In this model, the utility (U) of each option is given by:
| (6) |
Using maximum likelihood estimation in MATLAB, we fit a single logistic function to the trial-by-trial choice data of each subject:
| (7) |
where Pr is the probability that the subject chose the delayed option on a given trial, Uimmediate and Udelayed are the utilities (subjective values) of the immediate and delayed options, respectively, and β is the slope of the logistic function, which is another subject-specific parameter. The parameter β captures the stochasticity (as it is related to the randomness of the choice data).
Model comparison
The models were evaluated by comparison of their cross-validated log likelihoods: we computed the log likelihood by leave-one-out cross-validation, fitting the model to the data from all the trials except for one. This process was repeated iteratively for each of the trials and the likelihoods were added to compute the final log likelihood. We chose this leave-one-out method to avoid discarding too much data from the estimation process as there were no replicates of the trials and the indifference point location could be hard to resolve for some sessions (see S1 Fig for a description and rationale of the choice set.)
Results
By design, our subjects exhibited a wide demographic diversity and were representative of the general urban population (see Table 1). None of our subjects were students or had any advanced knowledge of finance or previous experience with the type of tasks used in this study. Subjects performed two decision-making tasks during each session, an intertemporal choice (ITC) task and a risk attitude (RA) task (see Fig 1A). We recruited 56 subjects to complete 2 identical testing sessions to allow us to assess test-retest reliability. We found that for our tools and subject sample, reliability was high (intraclass correlation coefficient for risk attitude and discount parameters r > 0.54, p < 0.05). For our analyses, we excluded any sessions for which the goodness-of-fit (R2) for the risk attitude parameter estimation was lower than 0.4. We also excluded sessions in which subjects always selected one of the options in the ITC task as this makes it impossible to resolve their indifference point with our choice set. After these exclusions, we analyzed a total of 78 sessions (2 sessions for each of 39 subjects). In most of the following analyses, each session is regarded as a separate data point. Since we do not perform group comparisons between subjects (all comparisons are of different model fits within subjects), we note that there are no statistical implications from treating the data in this manner.
Fig 1. RA and ITC task design.
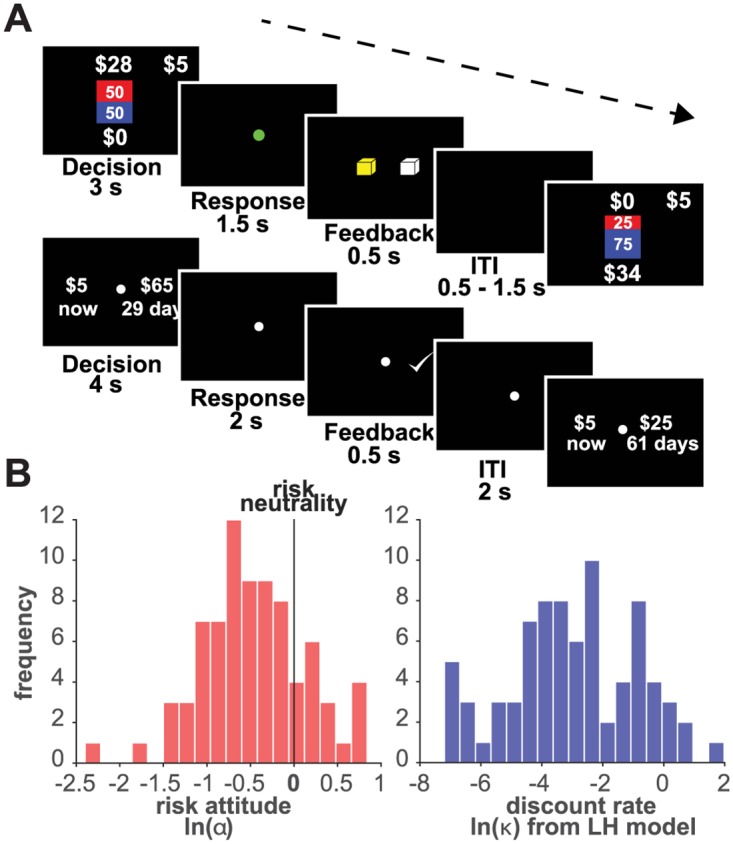
A (top): RA task design, the safe and lottery options are simultaneously displayed during the decision phase. A green dot cues the response time. A yellow square provides feedback on the choice entered. A variable inter-trial interval (ITI) follows. A (bottom): ITC task design, the immediate and delayed options simultaneously displayed during the decision phase. The offer disappears and a white dot cues the response time. A white check mark provides feedback on the choice entered. A variable ITI ensues. For a description of the choice set (see S1A and S1B Fig). B (left): distribution of natural logarithm of risk attitude parameter (ln(α)) across all subjects and all sessions. B (right): distribution of natural logarithm of discount parameter (ln(κ)) estimated from the LH model across all subjects and all sessions.
Diversity in risk preferences
We found that our sample exhibited very diverse risk preferences. We fit the power utility model shown in Eq (1) to the RA task choice data from each session using the softmax decision rule in Eq (2). We estimated a subject and session-specific RA parameter (α). This parameter ranged from 0.1 to 2.173, as shown in Fig 1B (note that values in those distributions are natural log-transformed). The average RA parameter (α) was 0.7508, and the median was 0.6087. Note that although on average our sample exhibited risk aversion (α < 1), individual risk preferences were heterogenous: there was a wide range of α values with many subjects deviating far from risk neutrality (α = 1, or 0 in the log space shown in Fig 1B).
Diversity in time preferences
To evaluate the diversity of time preferences in our sample, we first ignored risk preferences and estimated discount parameters using standard methods (effectively assuming risk neutrality in all subjects.) To do so, we fit the “Linear utility Hyperbolic discounting” model (LH) shown in Eq (3) to each session’s ITC choice data using the softmax decision rule in Eq (7). We estimated a subject and session-specific ITC discount parameter (κ). The distribution of subject discount parameters is shown in Fig 1B (note that values in those distributions are natural log-transformed). Values ranged from 0.001 (equivalent to the discounting of 2.9% of the reward’s value after a delay of one month) to 6.4 (equivalent to the discounting of 99.5% of the reward’s value after one month). The mean κ was 0.3139 and the median was 0.0499 (equivalent to the loss of 60% of the reward’s value after one month).
Taking risk preferences into account improves the fit to ITC choice data
We used maximum-likelihood estimation to fit four different models to each individual session ITC choice data: two hyperbolic discounting models and two exponential discounting models. We focused on these two classes of models because they are the most prevalent in the literature. Exponential discounting provides a normative account of discounting grounded in discounted utility theory. Hyperbolic discounting often provides a better fit to behavioral human and animal data [3, 58]. Of the two hyperbolic models, one did not take risk attitude into account (assumed a linear utility function, LH) as in Eq (3) and the other (NLH) used the estimated risk attitude (the utility function curvature parameter α from Eq (1)) as in Eq (4). Similarly, for the exponential type, one model assumed a linear utility function (LE) as in Eq (5), and the other (NLE) used the α as shown in Eq (6). To evaluate these four models, we compared their cross-validated log likelihoods (LL). Note that all four models have the same number of free parameters because the α parameter in the models that incorporated a risk attitude estimate (NLH and NLE) was fixed, taken from the maximum likelihood estimation procedure performed on independent data from the RA task (Eq (1)). We employed cross-validation to avoid over-fitting by iteratively fitting the model on all trials but one and computing the log likelihood of the model for the left-out trial (see Materials and methods section).
We found that the LL was higher for the model that included an independent estimate of risk when estimating a hyperbolic discount parameter (NLH) than for the model that did not (LH), for the majority of the sessions in our data set (Fig 2A). Similarly, we found that the model that included an independent estimate of risk when estimating an exponential discount parameter (NLE) had a higher LL than did a model that omitted this term (LE) for the majority of the sessions in our data set (Fig 2B). Interestingly, the two models that included an estimate of risk attitude (NLH and NLE) performed similarly well, suggesting that in our data goodness-of-fit does not rely on exponential or hyperbolic assumptions (Fig 2C). AIC and BIC scores were also compared and yielded similar results to our cross-validated LL comparison (see S2 Fig). We note that for both the hyperbolic and exponential forms, the advantage in goodness-of-fit of the models that account for risk (NLH relative to LH and NLE relative to LE) was correlated with the discount parameter. However, this correlation was not only carried by outliers as the rank-ordered Spearman coefficient was significant, rho = 0.5, p < 0.001 for the exponential form and rho = 0.52, p < 0.001 for the hyperbolic form. This means that the advantage of NLE and NLH was not only true for impatient outliers.
Fig 2. Model comparison.
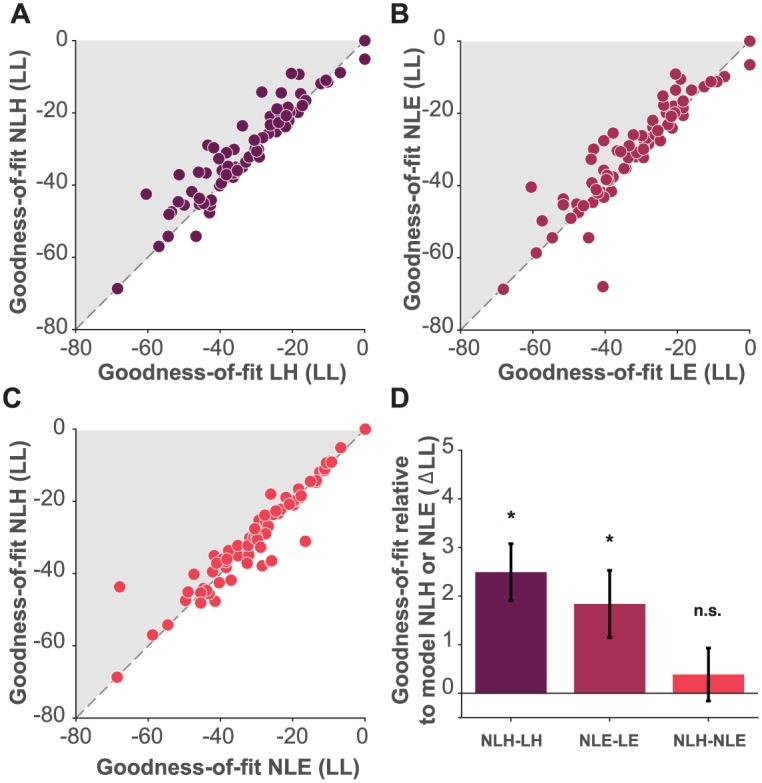
A: cross-validated log likelihood (LL) comparison of model LH against model NLH. Each dot corresponds to data from a single subject’s session. B: LL comparison of model LE against model NLE. Panel C, LL comparison of model NLE against model NLH. Shaded areas for panels A and B correspond to sessions for which the nonlinear utility models fit the data better than the linear utility models. C: Shaded area corresponds to sessions for which the NLH model fit the data better than the NLE model. D: average difference in LL across all sessions between model NLH and model LH (dark color), between model NLE and model LE (intermediate color) and, between model NLH and model NLE (light color), black bars indicate S.E.M.
To evaluate the overall performance of the models, we computed the average difference in LL across all sessions and subjects of the LH, LE, and NLE models relative to the LL of the NLH and NLE models (Fig 2D and for all possible comparisons between models see S3 Fig). Across all the data, the risk-incorporating models (NLH and NLE) show overall significantly superior performance than models that did not include risk (LH and LE). The difference in goodness-of-fit between NLH and NLE was not significant. However, when we simulated data generated from each model, NLE proved to be less distinguishable from the other models than NLH (see S2 Fig); the NLE model fits were equally good for data generated from NLE itself as for data generated from other models, whereas NLH fits were significantly better for data generated from NLH itself and not from the other models. We therefore focus on the NLH model’s superiority for the rest of our analyses.
Failing to measure risk attitude systematically deviates estimates of discount parameter
Having established that model NLH provides a better account of the data than models that do not incorporate risk attitude, we next examined the magnitude and direction of the misestimation when risk preference was ignored. We compared the individual discount parameter estimates (κ) obtained from model LH (the most commonly used model in the psychology literature) and those obtained with model NLH. We found that the two discount parameter estimates indeed differed for most of our subjects (Fig 3A): for the large majority of subject sessions the discount parameter from model LH was higher than the discount parameter from model NLH. We next tested whether the difference in estimated discount parameters depended systematically on risk preference (captured by the α parameter). We simulated 100 data sets using our NLH model with values for the risk parameter samples drawn from a uniform distribution within the range of our RA task choice set. This allowed us to cover the space of α fully, given that in our sample (as in most reported studied subjects in the literature) most subjects are risk averse (α < 1). We observed that the difference in discount parameter estimates obtained for these synthetic data sets (κ from LH—κ from NLH) led to a systematic shift in the estimated discount parameter as a function of the risk preference parameter (α) (see gray points in Fig 3B).
Fig 3. A systematic bias in discount parameters.
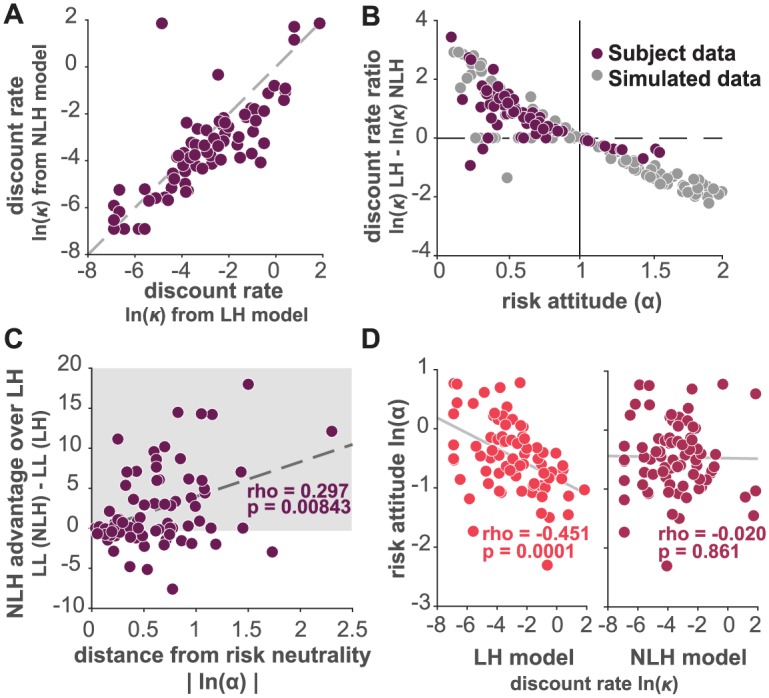
A: comparison of estimated discount parameters from model LH against model NLH for each subject’s sessions presented as natural logarithm of discount parameter (ln(κ)). B: discount parameter bias computed as difference between the natural log of estimated parameters from model LH against model NLH (ln(κ)LH − ln(κ)NLH), plotted as a function of the corresponding risk attitude parameter (α), dark dots represent data from each of our subjects’ sessions, gray dots represent simulated data. C: difference of goodness of fit (LL from NLH—LL from LH) between NLH and LH model as a function of the absolute value of the natural logarithm of α (|ln(α)|), risk neutrality here is 0 and any value above 0 is either risk averse or risk seeking. Spearman correlation: rho = 0.297, p < 0.01. Shaded area corresponds to the sessions for which model NLH fit the data better than model LH. D: correlation between the natural logarithm of the risk attitude parameter (ln(α)) and the natural logarithm of the discount parameter and model NLH (dark color).
We also computed the difference in discount parameter estimates from both models for our subject data and saw the same trend we observed for simulated data (see dark points in Fig 3B): When the α parameter is less than 1 (risk aversion) the κ parameter estimated by LH is higher than that of NLH. Thus, the standard method employed by most studies leads erroneously to the conclusion that risk-averse individuals are more impulsive than they really are. Conversely, when the α parameter is higher than 1 (risk tolerant) the κ parameter estimated by LH is lower than that of NLH: risk-seeking individuals appear to be less impulsive than they really are. Logically, when α = 1 NLH and LH converge to the same functional form and the discount parameter estimates are identical. Further, the larger the deviation from risk neutrality, the more model NLH outperforms LH, suggesting that any individuals with non-neutral risk preferences are much better captured by our model NLH (Fig 3C).
Importantly, the NLH model also resulted in the orthogonalization of the risk attitude parameter α and the discount parameter κ, while α and κ derived from model LH were significantly negatively correlated (Fig 3D). For model LH, the Pearson correlation coefficient was r = -0.451, p = 0.0001. Conversely, the correlation between α and the κ derived from model NLH was not significant (Pearson’s r = -0.02, p = 0.861). Taken together, these results show that the NLH model yields a discount parameter that is not only more precise but also allows for κ and α to reflect distinct aspects of decision-making rather than being conflated as is the case with estimates derived from the traditional model LH.
Discussion
We show here that 1) a temporal discounting model that incorporates an individual out-of-sample estimate for risk attitude outperforms models that assume risk neutrality (Fig 2), and 2) that failing to incorporate this risk attitude estimate leads to systematically biased discount parameters that entangle risk attitude and choice impulsivity (as in Fig 3); risk-averse subjects appear more impulsive than they are.
The finding that risk attitude interacts with intertemporal preference is not unexpected. Recent advances in economic research focusing on time preferences have been prompted by the potential confounding influence of non-linear utility upon estimates of discount parameter [59]. Studies devoted to this issue have applied either joint elicitation techniques of the kind used in our study (where risk preferences and time preferences are estimated from separate choice tasks) or methods where both utility and discounting are elicited from intertemporal choices [60, 61]. There is still no theoretical consensus among economists on the correct interpretation of the relationship between utility for risk and instantaneous utility for time [62] and, for some, subjective valuation of temporal payoffs may differ from that of risky ones [60, 63–65], but see [66]. However, from an empirical point of view, our study contributes to the growing number of reports that indicate there is a systematic bias in the discount parameter estimates when risk attitude is ignored. This dependence can be observed even in simple and widely employed binary choice tasks and at the individual subject level.
While we recapitulate the results reported by previous studies coming from economics and finance, the novel contribution of our work lies in two keys aspects: First, unlike previous studies we do not aggregate the subject data and estimate a single group parameter for the entire sample. Instead, we capitalize on the diversity of individual preferences by independently estimating a risk aversion parameter and a discount parameter for each subject’s session. This diversity is the result of our rich community sample which is representative of the average urban dweller. With some notable exceptions [51], the majority of previous studies on this topic have been performed with expert samples such as economics or finance students, which may lack the diversity in demographics that would allow for inferences about how these decisions are made by typical people. If not enough variance in risk preferences is achieved in the studied sample, it is possible the effect of risk may not be fully observable. We found wide variability in parametric risk attitudes in our sample, despite the mean not being much different from what has been previously reported in the literature. Furthermore, we simulated data with higher risk-seeking preferences to explore what the bias in the discount parameter would be in that direction. Although not often seen in healthy volunteers, risk-seeking behavior is more prevalent in psychiatric conditions [67–72], making this bias relevant for these types of studies. Second, we employed widely used binary choice tasks that can easily be completed by any subject and do not require any explicit knowledge of finance. We believe this is important if these assessments are to be deployed across different types of populations, including those without any higher education (in our sample the average education level is 13.8 years, see Table 1) and without any sophisticated understanding of interest rates and finance in general.
To establish whether the diversity in risk preferences has implications for how well models of temporal discounting fit individual subject choice data, we compared four models that are used in this growing literature. Two of these models assume that subjects are risk neutral: the linear hyperbolic (LH) and exponential (LE) models. The two other models incorporate subject-specific risk attitudes, that is, the curvature of the individual’s utility function. The LH model is the most widely used in the psychology and neuroscience literature to parametrically investigate discounting as a measure of impulsivity. It has been shown to fit behavioral data better than the normative exponential (LE) alternative, which often fails to fit especially highly impulsive subjects’ data. The superiority of LH over LE has usually been linked to the fact that subjects exhibit a “present bias”, that is, the tendency to give stronger weight to payoffs that are closer to the present time when considering trade-offs between two future moments. As such, subjects’ preferences have been reported to be better modeled by a hyperbolic rather than an exponential decay function. We recapitulated that result in our sample but found that our NLH model fit the intertemporal data better than both LH and LE across most of our subjects and sessions, suggesting taking risk into account is important regardless of where one sits in the exponential versus hyperbolic debate. Interestingly, NLH and NLE had similar performance. Consistent with previous studies [51], accounting for risk in the exponential form (NLE) resulted in a significantly better fit than the hyperbolic form that did not (LH) (see S3 Fig), which suggests that discounting becomes more constant when risk is considered. However, NLE seems to be a less precise model at distinguishing between LE and NLE generated data, while our model NLH was more specific (Fig 2 and S2 Fig). This means that NLE is too flexible, fitting data equally well even when it comes from different generative models. By contrast, NLH was a more selective model, a feature that may be more desirable for fields such as neuroscience that seek the true (neural) generative mechanism behind the behavior exhibited by the decision maker.
We have shown that ignoring risk attitude results in a systematic bias in the discount parameter estimates (Fig 3). For a large range of α values close to 1, LH and NLH do not perform differently, but the more risk averse or the more risk-seeking an individual, the more our approach outperforms the traditional approach. One clear implication of using the LH model in subjects that exhibit widely varying risk attitudes is that discount parameter estimates may be biased. We showed that when subjects are risk averse, the LH model returns a higher κ estimate value than NLH and conversely, when subjects are risk-seeking, LH underestimates the discount parameter. If one were comparing risk-averse individuals (e.g., the average healthy person) to less risk averse individuals (e.g., problem gamblers) the standard approach might lead to conclusions about differences in choice impulsivity between these groups that might be (perhaps better) explained by differences in risk attitude. Some studies have already begun to suggest that reported differences in discount rates between substance users and controls may be inflated by the use of the LH model [73]. This could also prove relevant for the comparison between patients with anxiety disorders (who have been reported to be highly risk-averse [74]) and healthy controls.
Of particular interest to us is the fact that investigations into the neural correlates of utility (or subjective value) and of intertemporal choice have also shown that the shape of this function is important when computing discounted subjective value [26]. We found that the NLH model not only fits behavioral data better but also is the most specific model (see S2 Fig), suggesting that the NLH model could be the best approximation to the brain’s generating model, a question that remains to be tested in future studies. This is relevant for any study that attempts to tie time preference behavior to neural activity. For instance, it has been suggested that temporal discounting could provide a behavioral marker for psychiatric diagnosis and prognosis [75, 76]. Transforming neural measurements of temporal discounting into a valid biomarker of clinical utility for psychiatry supposes that it accurately measures the intended biological and behavioral process [77, 78]. Our study shows that incorporating risk attitude is critical to delineating this process with precision.
As shown in Fig 2 (and S3 Fig) we found a clear benefit of taking risk preferences into account. While several psychiatric disorders are characterized by exhibiting extreme attitudes toward taking risks, most clinical studies that have examined impulsivity in these populations have not simultaneously assessed risk preference and have not done so in an incentive-compatible manner. For example, an implication of doing so could be that differences in discounting could be underestimated if in fact there are larger differences in risk preferences, e.g. if the control sample is significantly more risk averse than the clinical sample. Similarly, differences in risk preferences could be interpreted as differences in discounting. A few psychological studies in problem gamblers and alcoholics have performed both measures of temporal and probability discounting [79, 80]. Although these studies employ tasks very similar to our RA task for the estimation of probability discounting rates, they have not explicitly resolved the curvature of the utility function and therefore have not corrected for it in their estimation of discount rates. This would prove fairly easy to do using the methodology we propose here. The impact of ignoring risk preferences may reach beyond studies of clinical populations. In the social decision-making field for example, studies have suggested that discounting may be related to lack of cooperation [81] and to the willingness to punish other free-riders and non-cooperators [82, 83]. However, few of these studies have controlled for risk preferences, which may be important given that these seem to also correlate with individuals’ willingness to cooperate [84].
Temporal discounting is considered to be one of the many dimensions of the impulsivity personality construct. In the psychology literature, risk-seeking aspects of personality are often included in descriptions of impulsivity but there have been many attempts to separate these dimensions. Our approach results in the decorrelation of risk preference and time preference parameters (Fig 3) and allows for these parameters to reflect different aspects of decision-making and personality. We believe this separation could result in discount parameter estimates that may be more meaningful than those obtained using traditional methods. We propose a methodology that better resolves individual estimates of impulsivity and that could be easily incorporated in the growing literature on impulsivity by researchers interested in individual differences and behavioral phenotyping in clinical samples.
Supporting information
A) Visualization of the ITC task trial space. Each dot is a trial composed of an offered immediate (no delay) monetary amount, a larger monetary amount to be delivered with a delay, and the delay to its delivery (in days). Shaded plains correspond to trials where the immediate monetary amount is the same, B) The same trial space displaying the choices made by an example subject. Blue dots correspond to the trials where the subject chose the immediate payment option and pink dots correspond to the trials where the subject chose the delayed payment. The boundary between pink and blue dots reflects the location of the indifference points in the space. Shaded plains correspond to trials where the immediate monetary amount is the same.
(TIF)
Synthetic datasets were generated from each of the four models, LH, NLH, LE and NLE and then fitted with each model. Each cell in this matrix represents: AIC Fitted model—AIC True model. This difference equals 0 when the data generated from a model is fit with the same generative model. The larger the difference the worse the fitted model’s performance with respect to the generative model. Model LH is not a very discriminative model, models LE and NLE are especially bad a discriminating between each other. Out of the four models, model NLH is the most discriminative and the only that is significantly superior in goodness-of-fit to all other ones.
(TIF)
Cells indicate medians and 95% CI of bootstrapped log likelihood (LL) score differences. A positive median (in red) indicates that the model in the corresponding row had a higher score (better fit) than the model in the corresponding column.
(TIF)
Acknowledgments
The authors wish to acknowledge Jeff Dennison, John Messinger, Adelya Urmanche and Yuqi Yan for their help with the majority of the data collection. They would also like to thank Jan Zimmermann, Christopher Steverson and Will Adler for their invaluable input in analysis and interpretation. S.L.G. was supported by a fellowship from the U.S. Fulbright Commission and the Colombian government. A.B.K. was supported by a Ruth L. Kirschstein National Service Award (NRSA) from the National Institute on Drug Abuse (F32DA039648). This project was supported by a National Institute on Drug Abuse grant (5R01DA038063).
Data Availability
The data set and code can be found on figshare: https://doi.org/10.6084/m9.figshare.5768340.v1.
Funding Statement
PWG received a grant from the National Institute on Drug Abuse, https://www.drugabuse.gov/, number:5R01DA038063; ABK received the Ruth L. Kirschstein National Service Award (NRSA) from the National Institute on Drug Abuse, https://www.drugabuse.gov/, number:F32DA039648; SLG received a grant from the US-Colombian Fulbright Commission, http://www.fulbright.edu.co/, (no number). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1. Myerson J, Green L. Discounting of delayed rewards: Models of individual choice. Journal of the Experimental Analysis of Behavior. 1995;64(3):263–276. doi: 10.1901/jeab.1995.64-263 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Benhabib J, Bisin A, Schotter A. Present-bias, quasi-hyperbolic discounting, and fixed costs. Games and Economic Behavior. 2010;69(2):205–223. doi: 10.1016/j.geb.2009.11.003 [Google Scholar]
- 3. Green L, Fristoe N, Myerson J. Temporal discounting and preference reversals in choice between delayed outcomes. Psychonomic Bulletin & Review. 1994;1(3):383–389. doi: 10.3758/BF03213979 [DOI] [PubMed] [Google Scholar]
- 4. Baumann AA, Odum AL. Impulsivity, risk taking, and timing. Behav Processes. 2012;90(3):408–14. doi: 10.1016/j.beproc.2012.04.005 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Stevens JR. The Many Faces of Impulsivity In: Impulsivity. Nebraska Symposium on Motivation. Springer, Cham; 2017. p. 1–6. Available from: https://link.springer.com/chapter/10.1007/978-3-319-51721-6_1 [PubMed] [Google Scholar]
- 6. Hamilton KR, Mitchell MR, Wing VC, Balodis IM, Bickel WK, Fillmore M, et al. Choice impulsivity: Definitions, measurement issues, and clinical implications. Personality Disorders. 2015;6(2):182–198. doi: 10.1037/per0000099 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Silverman IW. Gender Differences in Delay of Gratification: A Meta-Analysis. Sex Roles. 2003;49(9-10):451–463. doi: 10.1023/A:1025872421115 [Google Scholar]
- 8. de Wit H, Flory JD, Acheson A, McCloskey M, Manuck SB. IQ and nonplanning impulsivity are independently associated with delay discounting in middle-aged adults. Personality and Individual Differences. 2007;42(1):111–121. doi: 10.1016/j.paid.2006.06.026 [Google Scholar]
- 9. Steel P. The nature of procrastination: A meta-analytic and theoretical review of quintessential self-regulatory failure. Psychological Bulletin. 2007;133(1):65–94. doi: 10.1037/0033-2909.133.1.65 [DOI] [PubMed] [Google Scholar]
- 10. Cross CP, Copping LT, Campbell A. Sex differences in impulsivity: A meta-analysis. Psychological Bulletin. 2011;137(1):97–130. doi: 10.1037/a0021591 [DOI] [PubMed] [Google Scholar]
- 11. Fields SA, Lange K, Ramos A, Thamotharan S, Rassu F. The relationship between stress and delay discounting: a meta-analytic review. Behavioural Pharmacology. 2014; p. 1 doi: 10.1097/FBP.0000000000000044 [DOI] [PubMed] [Google Scholar]
- 12. Wesley MJ, Bickel WK. Remember the future II: meta-analyses and functional overlap of working memory and delay discounting. Biol Psychiatry. 2014;75(6):435–48. doi: 10.1016/j.biopsych.2013.08.008 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Perales JC, Verdejo-Garcia A, Moya M, Lozano O, Perez-Garcia M. Bright and dark sides of impulsivity: performance of women with high and low trait impulsivity on neuropsychological tasks. Journal of Clinical and Experimental Neuropsychology. 2009;31(8):927–944. doi: 10.1080/13803390902758793 [DOI] [PubMed] [Google Scholar]
- 14. Amlung M, Vedelago L, Acker J, Balodis I, MacKillop J. Steep delay discounting and addictive behavior: a meta-analysis of continuous associations. Addiction. 2017;112(1):51–62. doi: 10.1111/add.13535 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15. Contreras-Rodríguez O, Albein-Urios N, Vilar-López R, Perales JC, Martínez-Gonzalez JM, Fernández-Serrano MJ, et al. Increased corticolimbic connectivity in cocaine dependence versus pathological gambling is associated with drug severity and emotion-related impulsivity. Addiction Biology. 2016;21(3):709–718. doi: 10.1111/adb.12242 [DOI] [PubMed] [Google Scholar]
- 16. Contreras-Rodríguez O, Albein-Urios N, Perales JC, Martínez-Gonzalez JM, Vilar-López R, Fernández-Serrano MJ, et al. Cocaine-specific neuroplasticity in the ventral striatum network is linked to delay discounting and drug relapse. Addiction (Abingdon, England). 2015;110(12):1953–1962. doi: 10.1111/add.13076 [DOI] [PubMed] [Google Scholar]
- 17. Steinglass JE, Figner B, Berkowitz S, Simpson HB, Weber EU, Walsh BT. Increased Capacity to Delay Reward in Anorexia Nervosa. Journal of the International Neuropsychological Society. 2012;18(4):773–780. doi: 10.1017/S1355617712000446 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Amlung M, Petker T, Jackson J, Balodis I, MacKillop J. Steep discounting of delayed monetary and food rewards in obesity: a meta-analysis. Psychological Medicine. 2016;46(11):2423–2434. doi: 10.1017/S0033291716000866 [DOI] [PubMed] [Google Scholar]
- 19. Andrade LF, Riven L, Petry NM. Associations between Antisocial Personality Disorder and Sex on Discounting Rates. The Psychological Record. 2014;64(4):639–644. doi: 10.1007/s40732-014-0085-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Jackson JNS, MacKillop J. Attention-Deficit/Hyperactivity Disorder and Monetary Delay Discounting: A Meta-Analysis of Case-Control Studies. Biological Psychiatry: Cognitive Neuroscience and Neuroimaging. 2016;1(4):316–325. doi: 10.1016/j.bpsc.2016.01.007 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Bickel WK, Jarmolowicz DP, Mueller ET, Koffarnus MN, Gatchalian KM. Excessive discounting of delayed reinforcers as a trans-disease process contributing to addiction and other disease-related vulnerabilities: Emerging evidence. Pharmacology & Therapeutics. 2012;134(3):287–297. doi: 10.1016/j.pharmthera.2012.02.004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Story GW, Vlaev I, Seymour B, Darzi A, Dolan RJ. Does temporal discounting explain unhealthy behavior? A systematic review and reinforcement learning perspective. Front Behav Neurosci. 2014;8:76 doi: 10.3389/fnbeh.2014.00076 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Steinglass JE, Lempert KM, Choo TH, Kimeldorf MB, Wall M, Walsh BT, et al. Temporal discounting across three psychiatric disorders: Anorexia nervosa, obsessive compulsive disorder, and social anxiety disorder. Depression and Anxiety. 2016; p. 1–11. doi: 10.1002/da.22586 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Kable JW, Glimcher PW. The neural correlates of subjective value during intertemporal choice. Nat Neurosci. 2007;10(12):1625–33. doi: 10.1038/nn2007 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. McClure SM, Laibson DI, Loewenstein G, Cohen JD. Separate neural systems value immediate and delayed monetary rewards. Science. 2004;306(5695):503–7. doi: 10.1126/science.1100907 [DOI] [PubMed] [Google Scholar]
- 26. Pine A, Seymour B, Roiser JP, Bossaerts P, Friston KJ, Curran HV, et al. Encoding of marginal utility across time in the human brain. J Neurosci. 2009;29(30):9575–81. doi: 10.1523/JNEUROSCI.1126-09.2009 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Peters J, Büchel C. The neural mechanisms of inter-temporal decision-making: understanding variability. Trends Cogn Sci. 2011;15(5):227–39. doi: 10.1016/j.tics.2011.03.002 [DOI] [PubMed] [Google Scholar]
- 28. Sripada CS, Gonzalez R, Phan KL, Liberzon I. The neural correlates of intertemporal decision-making: contributions of subjective value, stimulus type, and trait impulsivity. Hum Brain Mapp. 2011;32(10):1637–48. doi: 10.1002/hbm.21136 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Volkow ND, Baler RD. NOW vs LATER brain circuits: implications for obesity and addiction. Trends in Neurosciences. 2015;38(6):345–352. doi: 10.1016/j.tins.2015.04.002 [DOI] [PubMed] [Google Scholar]
- 30. Cho SS, Ko JH, Pellecchia G, Van Eimeren T, Cilia R, Strafella AP. Continuous theta burst stimulation of right dorsolateral prefrontal cortex induces changes in impulsivity level. Brain Stimulation. 2010;3(3):170–176. doi: 10.1016/j.brs.2009.10.002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31. Figner B, Knoch D, Johnson EJ, Krosch AR, Lisanby SH, Fehr E, et al. Lateral prefrontal cortex and self-control in intertemporal choice. Nature Neuroscience. 2010;13(5):538–539. doi: 10.1038/nn.2516 [DOI] [PubMed] [Google Scholar]
- 32. Koffarnus MN, Jarmolowicz DP, Mueller ET, Bickel WK. Changing delay discounting in the light of the competing neurobehavioral decision systems theory: a review. J Exp Anal Behav. 2013;99(1):32–57. doi: 10.1002/jeab.2 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Pickens CL, Airavaara M, Theberge F, Fanous S, Hope BT, Shaham Y. Neurobiology of the incubation of drug craving. Trends Neurosci. 2011;34(8):411–20. doi: 10.1016/j.tins.2011.06.001 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Cardenas JC, Carpenter J. Risk attitudes and economic well-being in Latin America. Journal of Development Economics. 2013;103:52–61. doi: 10.1016/j.jdeveco.2013.01.008 [Google Scholar]
- 35. Kimball MS, Sahm CR, Shapiro MD. Risk Preferences in the PSID: Individual Imputations and Family Covariation. The American economic review. 2009;99(2):363–368. doi: 10.1257/aer.99.2.363 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36. Reyna VF, Farley F. Risk and Rationality in Adolescent Decision Making: Implications for Theory, Practice, and Public Policy. Psychological Science in the Public Interest. 2006;7(1):1–44. doi: 10.1111/j.1529-1006.2006.00026.x [DOI] [PubMed] [Google Scholar]
- 37. von Gaudecker HM, van Soest A, Wengstrom E. Heterogeneity in Risky Choice Behavior in a Broad Population. American Economic Review. 2011;101(2):664–694. doi: 10.1257/aer.101.2.664 [Google Scholar]
- 38. Neumann Jv, Morgenstern O. Theory of Games and Economic Behavior (2007 Commemorative Edition). Princeton University Press; 1944. [Google Scholar]
- 39. Kahneman D, Tversky A. Prospect Theory: An Analysis of Decision under Risk. Econometrica. 1979;47(2):263–291. doi: 10.2307/1914185 [Google Scholar]
- 40. Gilaie-Dotan S, Tymula A, Cooper N, Kable JW, Glimcher PW, Levy I. Neuroanatomy Predicts Individual Risk Attitudes. Journal of Neuroscience. 2014;34(37):12394–12401. doi: 10.1523/JNEUROSCI.1600-14.2014 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41. Grubb MA, Tymula A, Gilaie-Dotan S, Glimcher PW, Levy I. Neuroanatomy accounts for age-related changes in risk preferences. Nature Communications. 2016;7:13822 doi: 10.1038/ncomms13822 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42. Holt CA, Laury, Susan K. Risk Aversion and Incentive Effects. American Economic Review. 2002;92(5):1644–1655. doi: 10.1257/000282802762024700 [Google Scholar]
- 43. Lazzaro SC, Rutledge RB, Burghart DR, Glimcher PW. The Impact of Menstrual Cycle Phase on Economic Choice and Rationality. PLoS ONE. 2016;11(1):e0144080 doi: 10.1371/journal.pone.0144080 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44. Levy I, Snell J, Nelson AJ, Rustichini A, Glimcher PW. Neural representation of subjective value under risk and ambiguity. J Neurophysiol. 2010;103(2):1036–47. doi: 10.1152/jn.00853.2009 [DOI] [PubMed] [Google Scholar]
- 45. Tymula A, Belmaker LAR, Ruderman L, Glimcher PW, Levy I. Like cognitive function, decision making across the life span shows profound age-related changes. Proceedings of the National Academy of Sciences. 2013;110(42):17143–17148. doi: 10.1073/pnas.1309909110 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46. Chapman GB. Temporal discounting and utility for health and money. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1996;22(3):771–791. doi: 10.1037/0278-7393.22.3.771 [DOI] [PubMed] [Google Scholar]
- 47. Frederick S, Loewenstein G, O’Donoghue T. Time Discounting and Time Preference: A Critical Review. Journal of Economic Literature. 2002;40(2):351–401. doi: 10.1257/002205102320161311 [Google Scholar]
- 48. Loewenstein G, Prelec D. Anomalies in Intertemporal Choice: Evidence and an Interpretation. The Quarterly Journal of Economics. 1992;107(2):573–597. doi: 10.2307/2118482 [Google Scholar]
- 49.Epper T, Fehr-Duda H. The missing link: Unifying risk taking and time discounting. Department of Economics—University of Zurich; 2012. 096. Available from: https://ideas.repec.org/p/zur/econwp/096.html
- 50. Halevy Y. Strotz Meets Allais: Diminishing Impatience and the Certainty Effect. American Economic Review. 2008;98(3):1145–1162. doi: 10.1257/aer.98.3.1145 [Google Scholar]
- 51. Andersen S, Harrison GW, Lau MI, Rutström EE. Eliciting Risk and Time Preferences. Econometrica. 2008;76(3):583–618. doi: 10.1111/j.1468-0262.2008.00848.x [Google Scholar]
- 52. Ferecatu A, Önçüler A. Heterogeneous risk and time preferences. Journal of Risk and Uncertainty. 2016; p. 1–28. doi: 10.1007/s11166-016-9243-x [Google Scholar]
- 53. Killeen PR. Models of ADHD: Five ways smaller sooner is better. Journal of Neuroscience Methods. 2015;252:2–13. doi: 10.1016/j.jneumeth.2015.01.011 [DOI] [PubMed] [Google Scholar]
- 54. Levy I, Rosenberg Belmaker L, Manson K, Tymula A, Glimcher PW. Measuring the subjective value of risky and ambiguous options using experimental economics and functional MRI methods. Journal of Visualized Experiments: JoVE. 2012;(67):e3724 doi: 10.3791/3724 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55. Weber EU, Johnson EJ, Milch KF, Chang H, Brodscholl JC, Goldstein DG. Asymmetric Discounting in Intertemporal Choice: A Query-Theory Account. Psychological Science. 2007;18(6):516–523. doi: 10.1111/j.1467-9280.2007.01932.x [DOI] [PubMed] [Google Scholar]
- 56. Levy DJ, Thavikulwat AC, Glimcher PW. State dependent valuation: the effect of deprivation on risk preferences. PLoS ONE. 2013;8(1):e53978 doi: 10.1371/journal.pone.0053978 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57. Mazur JE. An adjusting procedure for studying delayed reinforcement In: Commons ML, Mazur JE, Nevin JA, Rachlin H, editors. The Effect of Delay and of Intervening Events on Reinforcement Value, Quantitative Analyses of Behavior. Hillsdale, New Jersey: Erlbaum; 1987. p. 55–73. [Google Scholar]
- 58. Ainslie GW. Impulse control in pigeons. J Exp Anal Behav. 1974;21(3):485–9. doi: 10.1901/jeab.1974.21-485 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59. Cheung SL. Recent developments in the experimental elicitation of time preference. Journal of Behavioral and Experimental Finance. 2016;11:1–8. doi: 10.1016/j.jbef.2016.04.001 [Google Scholar]
- 60. Abdellaoui M, Bleichrodt H, l’Haridon O, Paraschiv C. Is There One Unifying Concept of Utility?An Experimental Comparison of Utility Under Risk and Utility Over Time. Management Science. 2013;59(9):2153–2169. doi: 10.1287/mnsc.1120.1690 [Google Scholar]
- 61. Andreoni J, Sprenger C. Estimating Time Preferences from Convex Budgets. American Economic Review. 2012;102(7):3333–3356. doi: 10.1257/aer.102.7.3333 [Google Scholar]
- 62. Attema AE, Bleichrodt H, Gao Y, Huang Z, Wakker PP. Measuring Discounting without Measuring Utility. American Economic Review. 2016;106(6):1476–1494. doi: 10.1257/aer.20150208 [Google Scholar]
- 63. Andreoni J, Sprenger C. Risk Preferences Are Not Time Preferences. American Economic Review. 2012;102(7):3357–3376. doi: 10.1257/aer.102.7.3357 [Google Scholar]
- 64.Cheung SL. Eliciting utility curvature and time preference. University of Sydney, School of Economics; 2015. 2015-01. Available from: https://ideas.repec.org/p/syd/wpaper/2015-01.html
- 65. Luckman A, Donkin C, Newell BR. People Wait Longer when the Alternative is Risky: The Relation Between Preferences in Risky and Inter-temporal Choice. Journal of Behavioral Decision Making. 2017; p. n/a–n/a. doi: 10.1002/bdm.2025 [Google Scholar]
- 66. Luckman A, Donkin C, Newell BR. Can a single model account for both risky choices and inter-temporal choices? Testing the assumptions underlying models of risky inter-temporal choice. Psychonomic Bulletin & Review. 2017; p. 1–8. doi: 10.3758/s13423-017-1330-8 [DOI] [PubMed] [Google Scholar]
- 67. Paulus MP. Decision-making dysfunctions in psychiatry–altered homeostatic processing? Science (New York, NY). 2007;318(5850):602–606. doi: 10.1126/science.1142997 [DOI] [PubMed] [Google Scholar]
- 68. Schutter DJLG, Bokhoven Iv, Vanderschuren LJMJ, Lochman JE, Matthys W. Risky Decision Making in Substance Dependent Adolescents with a Disruptive Behavior Disorder. Journal of Abnormal Child Psychology. 2011;39(3):333–339. doi: 10.1007/s10802-010-9475-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69. Matthies S, Philipsen A, Svaldi J. Risky decision making in adults with ADHD. Journal of Behavior Therapy and Experimental Psychiatry. 2012;43(3):938–946. doi: 10.1016/j.jbtep.2012.02.002 [DOI] [PubMed] [Google Scholar]
- 70. Verdejo-Garcia A, Chong TTJ, Stout JC, Yücel M, London ED. Stages of dysfunctional decision-making in addiction. Pharmacology Biochemistry and Behavior. 2017; doi: 10.1016/j.pbb.2017.02.003 [DOI] [PubMed] [Google Scholar]
- 71. Fishbein DH, Eldreth DL, Hyde C, Matochik JA, London ED, Contoreggi C, et al. Risky decision making and the anterior cingulate cortex in abstinent drug abusers and nonusers. Cognitive Brain Research. 2005;23(1):119–136. doi: 10.1016/j.cogbrainres.2004.12.010 [DOI] [PubMed] [Google Scholar]
- 72. Euteneuer F, Schaefer F, Stuermer R, Boucsein W, Timmermann L, Barbe MT, et al. Dissociation of decision-making under ambiguity and decision-making under risk in patients with Parkinson’s disease: a neuropsychological and psychophysiological study. Neuropsychologia. 2009;47(13):2882–2890. doi: 10.1016/j.neuropsychologia.2009.06.014 [DOI] [PubMed] [Google Scholar]
- 73. Gu L, Lim KO, Specker SM, Raymond N, MacDonald AW III. Valuation Bias of Reward in Long-Term Cocaine Users: The specificity of decision-making biases in cocaine addiction. Acta Psychopathologica. 2015;1(1). [Google Scholar]
- 74. Hartley CA, Phelps EA. Anxiety and Decision-Making. Biological psychiatry. 2012;72(2). doi: 10.1016/j.biopsych.2011.12.027 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75. Bickel WK, Koffarnus MN, Moody L, Wilson AG. The behavioral- and neuro-economic process of temporal discounting: A candidate behavioral marker of addiction. Neuropharmacology. 2014;76 Pt B:518–27. doi: 10.1016/j.neuropharm.2013.06.013 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76. Story GW, Moutoussis M, Dolan RJ. A Computational Analysis of Aberrant Delay Discounting in Psychiatric Disorders. Frontiers in Psychology. 2016;6 doi: 10.3389/fpsyg.2015.01948 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77. Abi-Dargham A, Horga G. The search for imaging biomarkers in psychiatric disorders. Nature Medicine. 2016;22(11):1248–1255. doi: 10.1038/nm.4190 [DOI] [PubMed] [Google Scholar]
- 78. Ahn WY, Busemeyer JR. Challenges and promises for translating computational tools into clinical practice. Current Opinion in Behavioral Sciences. 2016;11:1–7. doi: 10.1016/j.cobeha.2016.02.001 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79. Miedl SF, Peters J, Büchel C. Altered Neural Reward Representations in Pathological Gamblers Revealed by Delay and Probability Discounting. Archives of General Psychiatry. 2012;69(2):177–186. doi: 10.1001/archgenpsychiatry.2011.1552 [DOI] [PubMed] [Google Scholar]
- 80. Richards JB, Zhang L, Mitchell SH, de Wit H. Delay or probability discounting in a model of impulsive behavior: effect of alcohol. Journal of the Experimental Analysis of Behavior. 1999;71(2):121–143. doi: 10.1901/jeab.1999.71-121 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 81. Curry OS, Price ME, Price JG. Patience is a virtue: Cooperative people have lower discount rates. Personality and Individual Differences. 2008;44(3):780–785. doi: 10.1016/j.paid.2007.09.023 [Google Scholar]
- 82. Crockett MJ, Clark L, Lieberman MD, Tabibnia G, Robbins TW. Impulsive choice and altruistic punishment are correlated and increase in tandem with serotonin depletion. Emotion (Washington, DC). 2010;10(6):855–862. doi: 10.1037/a0019861 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83. Espín AM, Brañas-Garza P, Herrmann B, Gamella JF. Patient and impatient punishers of free-riders. Proceedings of the Royal Society of London B: Biological Sciences. 2012;279(1749):4923–4928. doi: 10.1098/rspb.2012.2043 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84. Espín AM, Exadaktylos F, Herrmann B, Brañas-Garza P. Short- and long-run goals in ultimatum bargaining: impatience predicts spite-based behavior. Frontiers in Behavioral Neuroscience. 2015;9 doi: 10.3389/fnbeh.2015.00214 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
A) Visualization of the ITC task trial space. Each dot is a trial composed of an offered immediate (no delay) monetary amount, a larger monetary amount to be delivered with a delay, and the delay to its delivery (in days). Shaded plains correspond to trials where the immediate monetary amount is the same, B) The same trial space displaying the choices made by an example subject. Blue dots correspond to the trials where the subject chose the immediate payment option and pink dots correspond to the trials where the subject chose the delayed payment. The boundary between pink and blue dots reflects the location of the indifference points in the space. Shaded plains correspond to trials where the immediate monetary amount is the same.
(TIF)
Synthetic datasets were generated from each of the four models, LH, NLH, LE and NLE and then fitted with each model. Each cell in this matrix represents: AIC Fitted model—AIC True model. This difference equals 0 when the data generated from a model is fit with the same generative model. The larger the difference the worse the fitted model’s performance with respect to the generative model. Model LH is not a very discriminative model, models LE and NLE are especially bad a discriminating between each other. Out of the four models, model NLH is the most discriminative and the only that is significantly superior in goodness-of-fit to all other ones.
(TIF)
Cells indicate medians and 95% CI of bootstrapped log likelihood (LL) score differences. A positive median (in red) indicates that the model in the corresponding row had a higher score (better fit) than the model in the corresponding column.
(TIF)
Data Availability Statement
The data set and code can be found on figshare: https://doi.org/10.6084/m9.figshare.5768340.v1.