

Abstract
Deep clustering is the first method to handle general audio separation scenarios with multiple sources of the same type and an arbitrary number of sources, performing impressively in speaker-independent speech separation tasks. However, little is known about its effectiveness in other challenging situations such as music source separation. Contrary to conventional networks that directly estimate the source signals, deep clustering generates an embedding for each time-frequency bin, and separates sources by clustering the bins in the embedding space. We show that deep clustering outperforms conventional networks on a singing voice separation task, in both matched and mismatched conditions, even though conventional networks have the advantage of end-to-end training for best signal approximation, presumably because its more flexible objective engenders better regularization. Since the strengths of deep clustering and conventional network architectures appear complementary, we explore combining them in a single hybrid network trained via an approach akin to multi-task learning. Remarkably, the combination significantly outperforms either of its components.
Index Terms: Deep clustering, Singing voice separation, Music separation, Deep learning
1. INTRODUCTION
Monaural music source separation has been the focus of many research efforts for over a decade. This task aims at separating a music recording into several tracks where each track corresponds to a single instrument. A related goal is to design algorithms that can separate vocals and accompaniment, where all the instruments are considered as one source. Music source separation algorithms have been successfully used for predominant pitch tracking [1], accompaniment generation for Karaoke systems [2], or singer identification [3].
Despite these advances, a system that can successfully generalize to different music datasets has thus far remained unachievable, due to the tremendous variability of music recordings, for example in terms of genre or types of instruments used. Unsupervised methods, such as those based on computational auditory scene analysis (CASA) [4], source/filter modeling [5], or low-rank and sparse modeling [6], have difficulty in capturing the dynamics of the vocals and instruments, while supervised methods, such as those based on non-negative matrix factorization (NMF) [7], F0-based estimation [8], or Bayesian modeling [9], suffer from generalization and processing speed issues.
Recently, deep learning has found many successful applications in audio source separation. Conventional regression-based networks try to infer the source signals directly, often by inferring time-frequency (T-F) masks to be applied to the T-F representation of the mixture so as to recover the original sources. These mask-inference networks have been shown to produce superior results compared to the traditional approaches in singing voice separation [10]. These networks are a natural choice when the sources can be characterized as belonging to distinct classes.
Another promising approach designed for more general situations is the so-called deep clustering framework [11]. Deep clustering has been applied very successfully to the task of single-channel speaker-independent speech separation [11]. Because it uses of pairwise affinities as separation criterion, deep clustering can handle mixtures with multiple sources from the same type, and an arbitrary number of sources. Such difficult conditions are endemic to music separation.
In this study, we explore the use of both deep clustering and conventional mask-inference networks to separate the singing voice from the accompaniment, grouping all the instruments as one source and the vocals as another. The singing voice separation task that we consider here is amenable to class based separation, and would not seem to require the extra flexibility in terms of source types and number of sources that deep clustering would provide. However, in addition to opening up the potential to apply to more general settings, the additional flexibility of deep clustering may have some benefits in terms of regularization. Whereas conventional mask-inference approaches only focus on increasing the separation between sources, the deep clustering objective also reduces within-source variance in the internal representation, which could be beneficial for generalization. In recent work it has been shown that forcing deep network activations to cluster well can improve the resulting test performance [12]. To investigate these potential benefits, we develop a two-headed “Chimera” network with both a deep clustering head and a mask-inference head attached to the same network body. Each head has its own objective, but the whole hybrid network is trained in a joint fashion akin to multi-task training. Our findings show that the addition of the deep clustering criterion greatly improves upon the performance of the mask-inference network.
2. MODEL DESCRIPTION
2.1. Deep clustering
Deep clustering operates according to the assumption that the T-F representation of the mixed signal can be partitioned into multiple sets, depending on which source is dominant (i.e., its power is the largest among all sources) in a given bin. A deep clustering network takes features of the acoustic signal as input, and assigns a D-dimensional embedding to each T-F bin. The network is trained to encourage the embeddings of T-F bins dominated by the same source to be similar to each other, and the embeddings of T-F bins dominated by different sources to be different. Note that the concept of “source” shall be defined according to the task at hand: for example, one speaker per source for speaker separation, all vocals in one source versus all other instruments in another source for singing voice separation, etc. A T-F mask for separating each source can then be estimated by clustering the T-F embeddings [13].
The training target is derived from a label indicator matrix Y ∈ ℝTF×C, where T denotes the number of frames, F the feature dimension, and C the number of sources in the input mixture x, such that Yi,j = 1 if T-F bin i = (t, f) is dominated by source j, and Yi,j = 0 otherwise. We can construct a binary affinity matrix A = YYT, which represents the assignment of the sources in a permutation independent way: Ai,j = 1 if i and j are dominated by the same source, and Ai,j = 0 if they are not. The network estimates an embedding matrix V ∈ ℝTF×D, where D is the embedding dimension. The corresponding estimated affinity matrix is then defined as  = VVT. The cost function for the network is
| (1) |
Although the matrices A and  are typically very large, their low-rank structure can be exploited to decrease the computational complexity [11].
At test time, a clustering algorithm such as K-means is applied to the embeddings V to generate a cluster assignment matrix, which is used as a binary T-F mask applied to the mixture to estimate the T-F representation of each source.
2.2. Multi-task learning and Chimera networks
Whereas the deep clustering objective function has been shown to enable the training of neural networks for challenging source separation problems, a disadvantage of deep clustering is that the post-clustering process needed to generate the mask and recover the sources is not part of the original objective function. On the other hand, for mask-inference networks, the objective function minimized during training is directly related to the signal recovery quality. We seek to combine the benefits of both approaches in a strategy reminiscent of multi-task learning, except that here both approaches address the same separation task.
In [11] and [13], the typical structure of a deep clustering network is to have multiple stacked recurrent layers (e.g., BLSTMs) yielding an N-dimensional vector at the top layer, followed by a fully-connected linear layer. For each frame t, this layer outputs a D-dimensional vector for each of the F frequencies, resulting in a F × D representation Zt. To form the embeddings, Z then passes through a tanh non-linearity, and unit-length normalization independently for each T-F bin. Concatenating across time results in the TF × D embedding matrix V as used in Eq. 1.
We extend this architecture in order to create a two-headed network, which we refer as “Chimera” network, with one head outputting embeddings as in a deep clustering network, and the other head outputting a soft mask, as in a mask-inference network. The new mask-inference head is obtained starting with Z, and passing it through F fully-connected D × C mask estimation layers (e.g., softmax), one for each frequency, resulting in C masks M(c), one for each source. The structure of the Chimera network is illustrated in Figure 1.
Fig. 1.
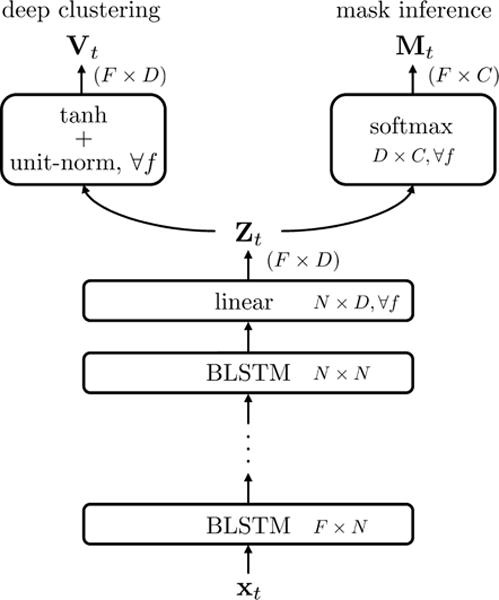
Structure of the Chimera network.
The body of the network, up to the layer outputting Z, can be trained with each head separately. For the deep clustering head, we use the objective ℒDC. For the mask-inference head, we can use a classical magnitude spectrum approximation (MSA) objective [6, 14, 15], defined as:
| (2) |
where R(c) denotes the magnitude of the T-F representation for the c-th clean source and S that of the mixture. Although this objective function makes sense intuitively, one caveat is that the mixture magnitude S may be smaller than that of a given source R(c) due to destructive interference. In this case, M(c), which is between 0 and 1, cannot bring the estimate close to R(c). As a remedy, we consider an alternative objective, denoted as masked magnitude spectrum approximation (mMSA), which approximates R(c) as the output of a masking operation on the mixture using a reference mask O(c), such that O(c) ⊙ S ≈ R(c), for source c:
| (3) |
Note that this is equivalent to a weighted mask approximation objective, using the mixture magnitude as the weights.
We can also define a global objective for the whole network as
| (4) |
where α ∈ [0, 1] controls the importance between the two objectives, and the objective ℒMI for the mask inference head is either ℒMSA or ℒmMSA. Note that here we divide ℒDC by TF because the objective for deep clustering calculates the pair-wise loss for each of the (TF)2 pairs of T-F bins, while the spectrum approximation objective calculates end-to-end loss on the TF time-frequency bins. For α = 1, only the deep clustering head gets trained together with the body, resulting in a deep clustering network. For α = 0, only the mask-inference head gets trained together with the body, resulting in a mask-inference network.
At test time, if both heads have been trained, either can be used. The mask-inference head directly outputs the T-F masks, while the deep clustering head outputs embeddings on which we perform clustering using, e.g., K-means.
3. EVALUATION AND DISCUSSION
3.1. Datasets
For training and evaluation purposes, we built a remixed version of the DSD100 dataset for SiSEC [16], which we refer to as DSD100-remix. For evaluation only, we also report results on two other datasets: the hidden iKala dataset for the MIREX submission, and the public iKala dataset for our newly proposed models.
The DSD100 dataset includes synthesized mixtures and the corresponding original sources from 100 professionally produced and mixed songs. To build the training and validation sets of DSD100-remix, we use the DSD100 development set (50 songs). We design a simple energy-level-based detector [17] to remove silent parts in both the vocal and accompaniment tracks, so that the vocals and accompaniment fully overlap in the generated mixtures. After that, we downsample the tracks from 44.1 kHz to 16 kHz to reduce computational cost, and then randomly mix the vocals and accompaniment together at 0 dB SNR, creating a 15 h training set and a 0.5 h validation set. We build the evaluation set of DSD100-remix from the DSD100 test set using a similar procedure, generating 50 pieces (one for each song) of fully-overlapped recordings with 30 seconds length each.
The input feature we use is calculated by the short-time Fourier transform (STFT) with 512-point window size and 128-point hop size. We use a 150-dimension mel-filterbank to reduce the input feature dimension. First-order delta of the mel-filterbank spectrogram is concatenated into the input feature. We used the ideal binary mask calculated on the mel-filterbank spectrogram as the target Y matrix.
3.2. System architecture
The Chimera network’s body is comprised of 4 bi-directional long-short term memory (BLSTM) layers with 500 hidden units in each layer, followed by a linear fully-connected layer with a D-dimension vector output for each of the frame’s F = 150 T-F bins. Here, we use D = 20 because it produced the best performance in a speech separation task [11]. In the mask-inference head, we set C = 2 for the singing voice separation task, and use softmax as the non-linearity. We use the rmsprop algorithm [18] as optimizer and select the network with the lowest loss on the validation set.
At test time, we split the signal into fixed-length segments, on which we run the network independently. We also tried running the network on the full input feature sequence, as in [11], but this lead to worse performance, probably due to the mismatch in context size between the training and test time. The mask-inference head of the network directly generates T-F masks. For deep clustering, the masks are obtained by applying K-means on the embeddings for the whole signal. We apply the mask for each source to the mel-filterbank spectrogram of the input, and recover the source using an inverse mel-filterbank transform and inverse-STFT with the mixture phase, followed by upsampling.
3.3. Results for the MIREX submission
We first report on the system submitted to the Singing Voice Separation task of the Music Information Retrieval Evaluation eXchange (MIREX 2016) [19]. That system only contains the deep clustering part, which corresponds to α = 1 in the hybrid system. In the MIREX system, dropout layers with probability 0.2 were added between each feed-forward connection, and sequence-wise batch normalization [20] was applied in the input-to-hidden transformation in each BLSTM layer. Similarly to [13], we also applied a curriculum learning strategy [21], where we first train the network on segments of 100 frames, then train on segments of 500 frames. As distinguishing between vocals and accompaniment was part of the task, we used a crude rule-based approach: the mask whose total number of nonzero entries in the low frequency range (< 200 Hz) is more than a half is used as the accompaniment mask, and the other as the vocals mask.
The hidden iKala dataset has been used as the evaluation dataset throughout MIREX 2014-2016, so we can report, as shown in Table 1, the results from the past three years, comparing the best two systems in each year’s competition to our submitted system for 2016. The official MIREX results are reported in terms of global normalized SDR (GNSDR), global SIR (GSIR), global SAR (GSAR) [22].
Table 1.
Evaluation metrics for different systems in MIREX 2014-2016 on the hidden iKala dataset. V denotes vocals and M music.
Due to time limitations at the time of the MIREX submission, we submitted a system that we had trained using the DSD100-remix dataset described in Section 3.1. However, as mentioned in the MIREX description, the DSD100 dataset is different from both the hidden and public parts of the iKala dataset [22]. Nonetheless, our system not only won the 1st place in MIREX 2016 but also outperformed the best systems from past years, even without training on the better-matched public iKala dataset, showing the efficacy of deep clustering for robust music separation. Note that the hidden iKala dataset is unavailable to the public, and it is thus unfortunately impossible to evaluate here what the performance of our system would be when trained on the public iKala data.
3.4. Results for the proposed hybrid system
We now turn to the results using the Chimera networks. During the training phase, we use 100 frames of input features to form fixed duration segments. We train the Chimera network in three different regimes: a pure deep clustering regime (DC, α = 1), a pure mask-inference regime (MI, α = 0), and a hybrid regime (CHIα, 0 < α < 1). All networks are trained from random initialization, and no training tricks mentioned above for the MIREX system are added. We report results on the DSD100-remix test set, which is matched to the training data, and the public iKala dataset, which is not.
By design, deep clustering provides one output for each source, and the sequence of the separation result is random. Therefore, the scores are computed by using the best permutation between references and estimates at the file level. Table 2 shows the results with the MSA objective in the MI head. We compute the source-to-distortion ratio (SDR), defined as scale-invariant SNR [13], for each test example, and report the length-weighted average over each test set of the improvement of SDR in the estimate with respect to that in the mixture (SDRi).
Table 2.
SDRi (dB) on the DSD100-remix and the public iKala datasets. The suffix after CHIα denotes which head of the Chimera network is used for generating the masks.
| DSD100-remix | iKala | |||
|---|---|---|---|---|
|
| ||||
| V | M | V | M | |
|
| ||||
| DC | 4.9 | 7.2 | 6.1 | 10.0 |
|
| ||||
| MI | 4.8 | 6.7 | 5.2 | 8.9 |
|
| ||||
| CHI0.1-DC | 4.8 | 7.2 | 6.0 | 9.7 |
| CHI0.1-MI | 5.5 | 7.8 | 6.4 | 10.5 |
| CHI0.5-DC | 4.7 | 7.1 | 5.9 | 9.9 |
| CHI0.5-MI | 5.5 | 7.8 | 6.3 | 10.5 |
As can be seen in the results, MI performs competitively with DC on DSD100-remix, however DC performs significantly better on the public iKala data. This shows the better generalization and robustness of the deep clustering method in cases where the test and training set are not matched. The best performance is achieved by CHIα-MI, the MI head of the Chimera network. Interestingly, the performance of the DC head does not change significantly for the values of α tested. This suggests that joint training with the deep clustering objective allows the body of the network to learn a more powerful representation than using the mask-inference objective alone; this representation is then best exploited by the mask-inference head thanks to its signal approximation objective.
We now look at the influence of the objective used in the MI head. For the mMSA objective, we use the Wiener like mask [15] since it is shown to have best performance among oracle masks computed from source magnitudes. As shown in Table 3, training a hybrid CHI0.1 network using the mMSA objective leads to slightly better MI performance overall compared to MSA. We also consider varying the embedding dimension D, and find that reducing it from D = 20 to D = 10 leads to further improvements. Because the output of the linear layer Zt has dimension F × D, decreasing D also leaves room to increase the number of frequency bins F.
Table 3.
SDRi (dB) on the DSD100-remix and the public iKala datasets with various objectives in the MI head and embedding dimensions D.
| DSD100-remix | iKala | ||||
|---|---|---|---|---|---|
|
| |||||
| ℒMI | D | V | M | V | M |
|
| |||||
| MSA | 20 | 5.5 | 7.8 | 6.4 | 10.5 |
| mMSA | 20 | 5.4 | 7.8 | 6.5 | 10.7 |
| mMSA | 10 | 5.5 | 7.9 | 6.6 | 10.8 |
Table 4 shows the results for various input features. We design various features by varying the sampling rate, the window/hop size in the STFT, and the dimension of the mel-frequency filterbanks. All networks are trained in the same hybrid regime as above, with the mMSA objective in the MI head and an embedding dimension D = 10. For simplicity, we do not concatenate first-order deltas into the input feature. We can learn from the results that higher sampling rate, larger STFT window size STFT, and more mel-frequency bins result in better performance.
Table 4.
SDRi (dB) on the DSD100-remix and the public iKala datasets with various input features.
| DSD100-remix | iKala | |||
|---|---|---|---|---|
|
| ||||
| V | M | V | M | |
|
| ||||
| 16k-1024-256-mel150 | 5.5 | 7.9 | 6.6 | 10.6 |
| 16k-1024-256-mel200 | 5.5 | 7.9 | 6.9 | 10.9 |
| 22k-1024-256-mel200 | 5.9 | 7.9 | 7.2 | 10.7 |
| 22k-2048-512-mel300 | 6.1 | 8.1 | 7.4 | 11.0 |
4. CONCLUSION
In this paper, we investigated the effectiveness of a deep clustering model on the task of singing voice separation. Although deep clustering was originally designed for separating speech mixtures, we showed that this framework is also suitable for separating sources in music signals. Moreover, by jointly optimizing deep clustering with a classical mask-inference network, the new hybrid network outperformed both the plain deep clustering network and the mask-inference network. Experimental results confirmed the robustness of the hybrid approach in mismatched conditions.
Audio examples are available at [24].
Fig. 2.
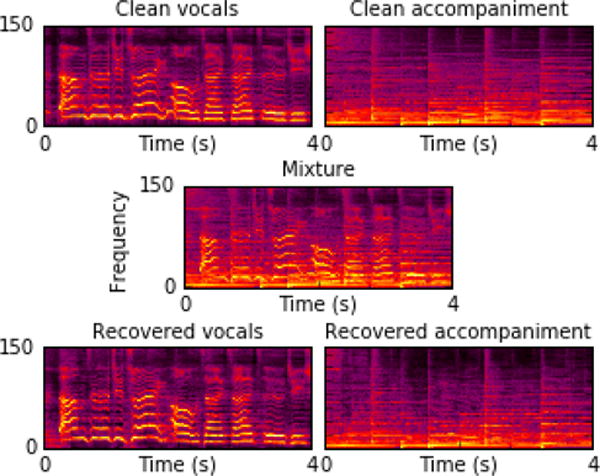
Example of separation results for a 4-second excerpt from file 45378_chorus in the public iKala dataset.
Acknowledgments
The work of Yi Luo, Zhuo Chen, and Nima Mesgarani was funded by a grant from the National Institute of Health, NIDCD, DC014279, National Science Foundation CAREER Award, and the Pew Charitable Trusts.
References
- 1.Fan Zhe-Cheng, Jang Jyh-Shing Roger, Lu Chung-Li. Singing voice separation and pitch extraction from monaural polyphonic audio music via DNN and adaptive pitch tracking. Proc IEEE International Conference on Multimedia Big Data (BigMM) IEEE. 2016:178–185. [Google Scholar]
- 2.Tachibana Hideyuki, Mizuno Yu, Ono Nobutaka, Sagayama Shigeki. A real-time audio-to-audio karaoke generation system for monaural recordings based on singing voice suppression and key conversion techniques. Journal of Information Processing. 2016;24(3):470–482. [Google Scholar]
- 3.Berenzweig Adam L, Ellis Daniel PW, Lawrence Steve. Proc AES 22nd International Conference: Virtual, Synthetic, and Entertainment Audio. Audio Engineering Society; 2002. Using voice segments to improve artist classification of music. [Google Scholar]
- 4.Li Yipeng, Wang DeLiang. Separation of singing voice from music accompaniment for monaural recordings. IEEE Transactions on Audio, Speech, and Language Processing. 2007;15(4):1475–1487. [Google Scholar]
- 5.Durrieu Jean-Louis, Richard Gaël, David Bertrand, Févotte Cédric. Source/filter model for unsupervised main melody extraction from polyphonic audio signals. IEEE Transactions on Audio, Speech, and Language Processing. 2010;18(3):564–575. [Google Scholar]
- 6.Huang Po-Sen, Chen Scott Deeann, Smaragdis Paris, Hasegawa-Johnson Mark. Singing-voice separation from monaural recordings using robust principal component analysis. Proc ICASSP. 2012:57–60. [Google Scholar]
- 7.Sprechmann Pablo, Bronstein Alexander M, Sapiro Guillermo. Real-time online singing voice separation from monaural recordings using robust low-rank modeling. ISMIR. 2012:67–72. [Google Scholar]
- 8.Hsu Chao-Ling, Jang Jyh-Shing Roger. On the improvement of singing voice separation for monaural recordings using the MIR-1K dataset. IEEE Transactions on Audio, Speech, and Language Processing. 2010;18(2):310–319. [Google Scholar]
- 9.Yang Po-Kai, Hsu Chung-Chien, Chien Jen-Tzung. Bayesian singing-voice separation. Proc ISMIR. 2014:507–512. [Google Scholar]
- 10.Huang Po-Sen, Kim Minje, Hasegawa-Johnson Mark, Smaragdis Paris. Singing-voice separation from monaural recordings using deep recurrent neural networks. Proc ISMIR. 2014:477–482. [Google Scholar]
- 11.Hershey John R, Chen Zhuo, Roux Jonathan Le, Watanabe Shinji. Deep clustering: Discriminative embeddings for segmentation and separation. Proc ICASSP. 2016:31–35. [Google Scholar]
- 12.Liao Renjie, Schwing Alex, Zemel Richard, Urtasun Raquel. Learning deep parsimonious representations. Advances in Neural Information Processing Systems. 2016:5076–5084. [Google Scholar]
- 13.Isik Yusuf, Roux Jonathan Le, Chen Zhuo, Watanabe Shinji, Hershey John R. Single-channel multi-speaker separation using deep clustering. Proc Interspeech. 2016 [Google Scholar]
- 14.Weninger Felix, Roux Jonathan Le, Hershey John R, Schuller Björn. Discriminatively trained recurrent neural networks for single-channel speech separation. Proc IEEE GlobalSIP 2014 Symposium on Machine Learning Applications in Speech Processing. 2014 Dec; [Google Scholar]
- 15.Erdogan Hakan, Hershey John R, Watanabe Shinji, Roux Jonathan Le. Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks. Proc ICASSP. 2015:708–712. [Google Scholar]
- 16.SiSEC 2016 Professionally produced music recordings task. https://sisec.inria.fr/home/2016-professionally-produced-music-recordings/, accessed: 2016-09-11.
- 17.Ramirez Javier, Górriz Juan Manuel, Segura José Carlos. Voice activity detection. fundamentals and speech recognition system robustness. INTECH Open Access Publisher; 2007. [Google Scholar]
- 18.Tieleman Tijmen, Hinton Geoffrey. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning. 2012;4(2) [Google Scholar]
- 19.MIREX 2016: Singing Voice Separation Results. http://www.music-ir.org/mirex/wiki/2016:Singing_Voice_Separation_Results, accessed: 2016-09-11.
- 20.Laurent César, Pereyra Gabriel, Brakel Philémon, Zhang Ying, Bengio Yoshua. Batch normalized recurrent neural networks. 2015 arXiv preprint arXiv:1510.01378. [Google Scholar]
- 21.Bengio Yoshua, Louradour Jérôme, Collobert Ronan, Weston Jason. Curriculum learning. Proc ICML. 2009:41–48. [Google Scholar]
- 22.MIREX 2016: Singing Voice Separation Task. http://www.music-ir.org/mirex/wiki/2016:Singing_Voice_Separation, accessed: 2016-09-11.
- 23.Ikemiya Yukara, Itoyama Katsutoshi, Yoshii Kazuyoshi. Singing voice separation and vocal f0 estimation based on mutual combination of robust principal component analysis and subharmonic summation. 2016 arXiv preprint arXiv:1604.00192. [Google Scholar]
- 24.Audio examples for chimera network. http://naplab.ee.columbia.edu/ivs.html.