

Abstract
We introduce an additive partial correlation operator as an extension of partial correlation to the nonlinear setting, and use it to develop a new estimator for nonparametric graphical models. Our graphical models are based on additive conditional independence, a statistical relation that captures the spirit of conditional independence without having to resort to high-dimensional kernels for its estimation. The additive partial correlation operator completely characterizes additive conditional independence, and has the additional advantage of putting marginal variation on appropriate scales when evaluating interdependence, which leads to more accurate statistical inference. We establish the consistency of the proposed estimator. Through simulation experiments and analysis of the DREAM4 Challenge dataset, we demonstrate that our method performs better than existing methods in cases where the Gaussian or copula Gaussian assumption does not hold, and that a more appropriate scaling for our method further enhances its performance.
Keywords: Additive conditional covariance operator, Additive conditional independence, Copula, Gaussian graphical model, Partial correlation, Reproducing kernel
1. Introduction
We propose a new statistical object, the additive partial correlation operator, for estimating nonparametric graphical models. This operator is an extension of the partial correlation coefficient (Muirhead, 2005) to the nonlinear setting. It is akin to the additive conditional covariance operator of Li et al. (2014) but achieves better scaling, leading to enhanced estimation accuracy, when characterizing conditional independence in graphical models.
Let 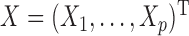 be a
be a 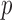 -dimensional random vector. Let
-dimensional random vector. Let
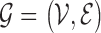 be an undirected
graph, where
be an undirected
graph, where 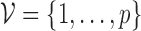 represents the set of vertices
corresponding to
represents the set of vertices
corresponding to 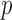 random variables and
random variables and 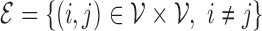 represents the set of undirected
edges. For convenience we assume that
represents the set of undirected
edges. For convenience we assume that 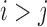 . A common approach to modelling an
undirected graph is to associate separation with conditional independence; that is, node
. A common approach to modelling an
undirected graph is to associate separation with conditional independence; that is, node
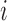 and node
and node 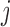 are separated if and only if
are separated if and only if
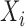 and
and 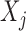 are independent given the rest of
are independent given the rest of
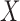 . In symbols,
. In symbols,
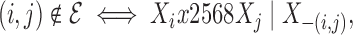 |
(1) |
where 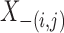 represents
represents
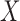 with its
with its 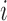 th and
th and 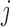 th components removed.
Intuitively, this means that nodes
th components removed.
Intuitively, this means that nodes 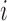 and
and 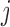 are connected if and
only if, after removing the effects of all the other nodes,
are connected if and
only if, after removing the effects of all the other nodes, 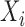 and
and
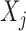 still depend on each other. In other words, nodes
still depend on each other. In other words, nodes
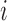 and
and 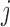 are connected in the graph if and only
if
are connected in the graph if and only
if 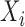 and
and 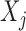 have a direct relation. The
statistical problem is to estimate
have a direct relation. The
statistical problem is to estimate 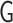 based on a sample of
based on a sample of
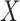 .
.
One of the most commonly used statistical models for (1) is the Gaussian graphical model, which assumes that
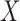 satisfies (1) and is distributed as
satisfies (1) and is distributed as 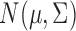 for a nonsingular
covariance matrix
for a nonsingular
covariance matrix 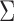 . An appealing property of the multivariate Gaussian
distribution is that conditional independence is completely characterized by the zero
entries of the precision matrix. Specifically, let
. An appealing property of the multivariate Gaussian
distribution is that conditional independence is completely characterized by the zero
entries of the precision matrix. Specifically, let 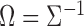 be the precision matrix and
be the precision matrix and 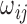 its
its 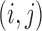 th element. Then
th element. Then
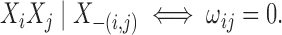 |
(2) |
Thus, under Gaussianity, estimation of
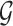 amounts to identifying the zero entries or,
equivalently, the sparsity pattern of the precision matrix
amounts to identifying the zero entries or,
equivalently, the sparsity pattern of the precision matrix 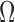 . Many
procedures have been developed to estimate the Gaussian graphical model. For example, Yuan & Lin (2007), Banerjee et al. (2008) and Friedman et al. (2008) considered penalized maximum likelihood estimation with
. Many
procedures have been developed to estimate the Gaussian graphical model. For example, Yuan & Lin (2007), Banerjee et al. (2008) and Friedman et al. (2008) considered penalized maximum likelihood estimation with
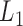 penalties on
penalties on 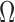 . Based on a
relation between partial correlations and regression coefficients, Meinshausen & Bühlmann (2006) and Peng et al. (2009) proposed to select the neighbours of each node
by solving multiple lasso problems (Tibshirani,
1996). Other recent advances include the work of Bickel & Levina (2008a, b), who used hard thresholding to determine the sparsity pattern, Lam & Fan (2009), who used the smoothly clipped
absolute deviation penalty (Fan & Li,
2001), and Yuan (2010) and Cai et al. (2011), who used the Danzig selector
(Candès & Tao, 2007).
. Based on a
relation between partial correlations and regression coefficients, Meinshausen & Bühlmann (2006) and Peng et al. (2009) proposed to select the neighbours of each node
by solving multiple lasso problems (Tibshirani,
1996). Other recent advances include the work of Bickel & Levina (2008a, b), who used hard thresholding to determine the sparsity pattern, Lam & Fan (2009), who used the smoothly clipped
absolute deviation penalty (Fan & Li,
2001), and Yuan (2010) and Cai et al. (2011), who used the Danzig selector
(Candès & Tao, 2007).
Since Gaussianity could be restrictive in applications, many recent papers have considered
extensions. The challenge is not only to relax Gaussianity but also to preserve the
simplicity of the conditional independence structure imparted by the Gaussian distribution.
One elegant solution is to assume a copula Gaussian model, under which the data can be
transformed marginally to multivariate Gaussianity; see Liu et al. (2009, 2012), Xue & Zou (2012) and Harris & Drton (2013). The copula Gaussian
model preserves the equivalence (2) for
the transformed 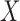 , without requiring the
, without requiring the 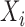 to be marginally
Gaussian. Other work on non-Gaussian graphical models includes Fellinghauer et al. (2013) and Voorman et al. (2014). In their settings, a given node is
associated with its neighbours via either a semiparametric or a nonparametric model.
to be marginally
Gaussian. Other work on non-Gaussian graphical models includes Fellinghauer et al. (2013) and Voorman et al. (2014). In their settings, a given node is
associated with its neighbours via either a semiparametric or a nonparametric model.
Another extension is the additive semigraphoid model of Li et al. (2014), which is based on a new statistical relation called additive conditional independence. By generalizing the precision matrix to the additive precision operator and replacing the conditional independence in (2) by additive conditional independence, Li et al. (2014) showed that the equivalence (2) emerges at the linear operator level, at which no distributional assumption is needed.
The primary motivation for introducing additive conditional independence is to maintain nonparametric flexibility without employing high-dimensional kernels. The distribution of points in a Euclidean space becomes increasingly sparse as the dimension of the space increases. For a kernel estimator in such spaces to be effective, we need to increase the bandwidth; otherwise we may have very few observations within a local ball of radius equal to the bandwidth. Increasing bandwidth, however, also increases bias. Therefore we face the dilemma of either increased bias or lack of data in each local region, a phenomenon known as the curse of dimensionality (Bellman, 1957). To avoid this problem while extracting useful information from high-dimensional data, one must impose some kind of additional structure, such as parametric models, sparsity or linear indices. The structure imposed by additive conditional independence is additivity, which allows us to employ only one-dimensional kernels, thus avoiding high dimensionality. The cost is that the graphical model is no longer characterized by conditional independence. Nonetheless, Li et al. (2014) have shown that additive conditional independence satisfies the semigraphoid axioms (Pearl & Verma, 1987; Pearl et al., 1989), a set of four fundamental properties of conditional independence.
To estimate the additive semigraphoid model, Li et
al. (2014) proposed the additive conditional covariance and additive precision
operators, which extend the conditional covariance and precision matrices and characterize
additive conditional independence without distributional assumptions. In the classical
setting, the conditional covariance 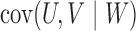 between two
random variables
between two
random variables 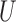 and
and 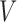 given a third random variable
given a third random variable
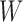 describes the strength of dependence between
describes the strength of dependence between
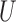 and
and 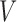 after removing the effect of
after removing the effect of
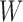 . However, it is confounded by statistical variations in
. However, it is confounded by statistical variations in
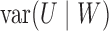 and
and 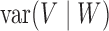 , which have nothing
to do with the conditional dependence. Partial correlation is designed to remove these
effects, so that conditional dependence is retained. The additive partial correlation
operator that we propose serves the same purpose in the nonlinear setting. We will also
propose an estimator of the new operator, and establish its consistency along with that of
the estimator of the additive conditional covariance operator, which was not proved in Li et al. (2014). Based on the additive partial
correlation operator, we develop an estimator for the additive semigraphoid model and
establish the consistency of this procedure.
, which have nothing
to do with the conditional dependence. Partial correlation is designed to remove these
effects, so that conditional dependence is retained. The additive partial correlation
operator that we propose serves the same purpose in the nonlinear setting. We will also
propose an estimator of the new operator, and establish its consistency along with that of
the estimator of the additive conditional covariance operator, which was not proved in Li et al. (2014). Based on the additive partial
correlation operator, we develop an estimator for the additive semigraphoid model and
establish the consistency of this procedure.
All the proofs, as well as some additional propositions and numerical results, are presented in the Supplementary Material.
2. Additive conditional independence and graphical models
2.1. Additive conditional independence
Let 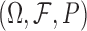 be a probability space,
be a probability space, 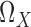 a subset of
a subset of
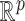 , and
, and 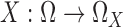 a random
vector. Let
a random
vector. Let 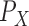 be the distribution of
be the distribution of 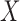 . Let
. Let
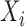 be the
be the 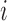 th component of
th component of
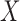 , and let
, and let 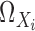 be the support of
be the support of
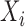 . For a subvector
. For a subvector 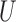 of
of
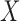 , let
, let 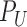 be the distribution of
be the distribution of
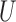 and
and 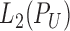 the centred
the centred
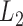 class
class
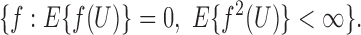 |
We assume that all functions in
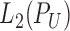 have mean zero, because constants have no bearing on
our construction. Additive conditional independence (Li et al., 2014) was introduced in terms of the
have mean zero, because constants have no bearing on
our construction. Additive conditional independence (Li et al., 2014) was introduced in terms of the 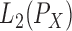 geometry.
Suppose that
geometry.
Suppose that 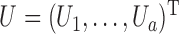 ,
, 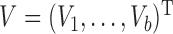 and
and 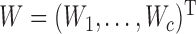 are
subvectors of
are
subvectors of 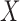 . For a subvector such as
. For a subvector such as 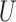 , let
, let
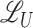 be the additive family formed by functions in each
be the additive family formed by functions in each
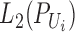 ; that is,
; that is,
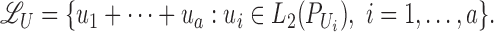 |
Note
that 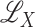 and
and 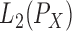 are different: the former
consists of additive functions, while the latter has no such restriction. If
are different: the former
consists of additive functions, while the latter has no such restriction. If
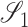 and
and 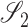 are subspaces of
are subspaces of
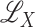 , we write
, we write 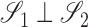 if
if 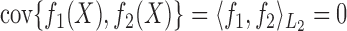 for all
for all 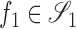 and
and
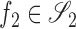 , where
, where 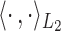 denotes the inner product in
denotes the inner product in 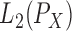 . If
. If 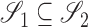 , we denote by
, we denote by  the set of functions
the set of functions 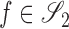 such that
such that 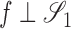 . Also, let
. Also, let 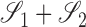 denote the subspace
denote the subspace 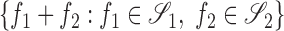 .
.
Definition 1 —
We say that
and
are additively independent conditional on
if and only if
(3) We denote this relation by
.
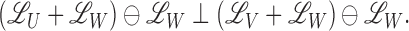
Li et al. (2014) showed that the three-way
relation 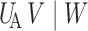 satisfies the four semigraphoid axioms
(Pearl & Verma, 1987; Pearl et al., 1989), which are features
abstracted from probabilistic conditional independence suitable for describing a
graph.
satisfies the four semigraphoid axioms
(Pearl & Verma, 1987; Pearl et al., 1989), which are features
abstracted from probabilistic conditional independence suitable for describing a
graph.
Based on (3), Li et al. (2014) proposed the following graphical model. Let
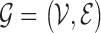 be as defined in §1.
be as defined in §1.
Definition 2 —
We say that
follows an additive semigraphoid model with respect to
if
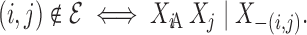
Li et al. (2014) developed theoretical
results and estimation methods for the additive semigraphoid model using the additive
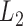 space
space 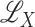 .
.
2.2. Additive reproducing kernel Hilbert spaces
Rather than use 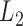 geometry, here we use reproducing kernel Hilbert
space geometry to derive our new operator and related methods. This is mainly because many
asymptotic tools for linear operators have recently been developed in the reproducing
kernel Hilbert space setting (Fukumizu et al.,
2007; Bach, 2008). The advantage of
this alternative formulation will become clear in §4.
Let
geometry, here we use reproducing kernel Hilbert
space geometry to derive our new operator and related methods. This is mainly because many
asymptotic tools for linear operators have recently been developed in the reproducing
kernel Hilbert space setting (Fukumizu et al.,
2007; Bach, 2008). The advantage of
this alternative formulation will become clear in §4.
Let 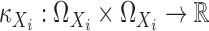 be a
positive-definite kernel. For convenience, we assume
be a
positive-definite kernel. For convenience, we assume 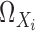 and
and
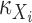 to be the same for all
to be the same for all 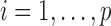 and
write the common kernel function as
and
write the common kernel function as 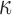 . Let
. Let 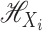 be the reproducing kernel Hilbert space of functions of
be the reproducing kernel Hilbert space of functions of 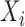 based on the
kernel
based on the
kernel 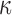 ; that is,
; that is, 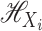 is the space spanned
by
is the space spanned
by 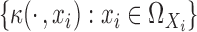 , with its inner product
given by
, with its inner product
given by 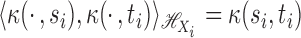 . In our theoretical developments, we require that
all the functions in
. In our theoretical developments, we require that
all the functions in 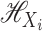 be square-integrable, which is
guaranteed by the following assumption:
be square-integrable, which is
guaranteed by the following assumption:
Assumption 1 —
for
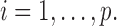
This condition is satisfied by most of the commonly used kernels, including the radial basis function.
Let 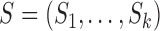 be a subvector of
be a subvector of 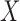 . The additive
reproducing kernel Hilbert space
. The additive
reproducing kernel Hilbert space 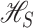 of functions of
of functions of
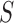 is defined as follows.
is defined as follows.
Definition 3 —
The space
is the direct sum
in the sense that
with inner product
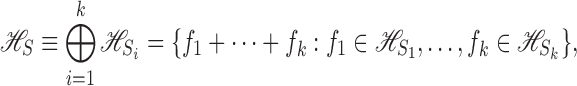
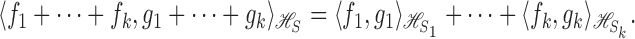
Equivalently, 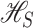 can be viewed as the reproducing kernel Hilbert
space generated by the additive kernel
can be viewed as the reproducing kernel Hilbert
space generated by the additive kernel 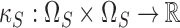 ,
, 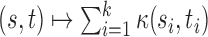 , where
, where 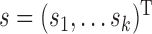 and
and
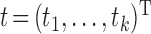 .
.
2.3. Other notation
For two Hilbert spaces 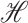 and
and 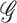 , we let
, we let
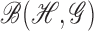 denote the class of all bounded
operators from
denote the class of all bounded
operators from 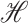 to
to 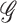 and
and
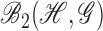 the class of all
Hilbert–Schmidt operators. When
the class of all
Hilbert–Schmidt operators. When 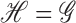 , we denote
these classes simply by
, we denote
these classes simply by 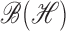 and
and
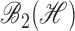 . The symbols
. The symbols  and
and
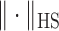 stand for the operator and Hilbert–Schmidt
norms. For
stand for the operator and Hilbert–Schmidt
norms. For 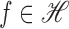 and
and 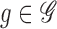 , the tensor product
, the tensor product
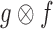 is the mapping
is the mapping 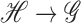 ,
, 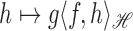 . For two matrices or Euclidean vectors
. For two matrices or Euclidean vectors
 and
and 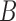 ,
, 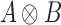 denotes
their Kronecker product. The symbol
denotes
their Kronecker product. The symbol 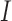 stands for the identity mapping in a
functional space, whereas
stands for the identity mapping in a
functional space, whereas 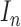 means the
means the 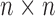 identity
matrix. The symbol
identity
matrix. The symbol 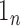 stands for the vector of length
stands for the vector of length
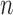 whose entries are all ones. For an operator
whose entries are all ones. For an operator
 ,
, 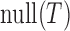 represents the null space of
represents the null space of 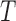 and
and 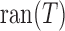 the range of
the range of
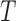 ; that is,
; that is,
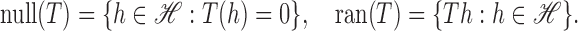 |
Also, 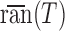 stands for the closure of
stands for the closure of
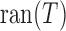 .
.
3. Additive partial covariance operator
3.1. The additive conditional covariance operator
The additive conditional covariance operator was proposed by Li et al. (2014) in terms of the 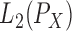 geometry;
here we redefine it in the reproducing kernel Hilbert space geometry.
geometry;
here we redefine it in the reproducing kernel Hilbert space geometry.
For subvectors 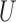 and
and 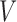 of
of 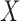 , by the Riesz
representation theorem there exists a unique operator
, by the Riesz
representation theorem there exists a unique operator 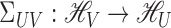 such that (Conway, 1994, p. 31)
such that (Conway, 1994, p. 31)
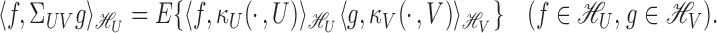 |
We define
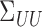 and
and 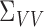 similarly. The nonadditive
versions of these operators were introduced by Baker
(1973) and Fukumizu et al. (2004,
2009). Moreover, by Baker (1973), for any
similarly. The nonadditive
versions of these operators were introduced by Baker
(1973) and Fukumizu et al. (2004,
2009). Moreover, by Baker (1973), for any 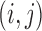 there exists a unique operator
there exists a unique operator
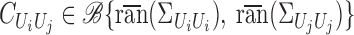 |
such that 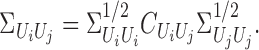 The operator
The operator 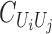 is the
correlation operator between
is the
correlation operator between 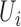 and
and 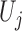 . Let
. Let 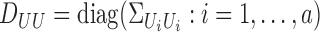 denote the
denote the 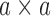 diagonal
matrix of operators whose diagonal entries are the operators
diagonal
matrix of operators whose diagonal entries are the operators 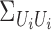 ,
and let
,
and let 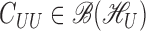 be the
be the
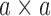 matrix of operators whose
matrix of operators whose 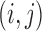 th element is
th element is
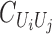 . Then it is obvious that
. Then it is obvious that 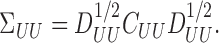 Notice that
Notice that 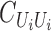 is the identity operator.
Define operators such as
is the identity operator.
Define operators such as 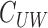 ,
, 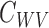 and
and 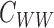 in a similar
way. We make the following assumption about the entries of
in a similar
way. We make the following assumption about the entries of 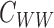 .
.
Assumption 2 —
For
,
is a compact operator.
In the Supplementary Material,
we show that 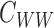 is invertible and its inverse is bounded. We are
now ready to define the additive conditional covariance operator.
is invertible and its inverse is bounded. We are
now ready to define the additive conditional covariance operator.
Definition 4 —
Suppose that Assumptions 1 and 2 hold. Then the operator
is called the additive conditional covariance operator of
given
.
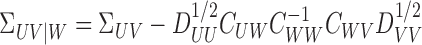
Again, this definition also accommodates operators such as 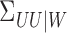 and
and 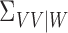 .
.
3.2. The additive partial correlation operator
We now introduce the additive partial correlation operator and establish its population-level properties. A straightforward way to define the additive partial correlation operator might be as
 |
(4) |
but caution
is needed here because 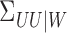 and
and 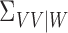 are Hilbert–Schmidt operators and their eigenvalues tend to zero, so that there is no
guarantee that (4) will be
well-defined. The following theorem, which echoes Theorem 1 of Baker (1973), shows that (4) is well-defined under minimal conditions.
are Hilbert–Schmidt operators and their eigenvalues tend to zero, so that there is no
guarantee that (4) will be
well-defined. The following theorem, which echoes Theorem 1 of Baker (1973), shows that (4) is well-defined under minimal conditions.
Theorem 1 —
Suppose that Assumptions 1 and 2 hold. Then there exists a unique operator
such that:
, where
,
, and
denotes the projection onto a subspace
in
;
;
.
Theorem 1 justifies the following definition.
Definition 5 —
Under Assumptions 1 and 2, the operator
in Theorem 1 is called the additive partial correlation operator.
The additive partial correlation operator is defined via a reproducing kernel Hilbert
space, whereas additive conditional independence is characterized via
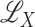 . In the Supplementary Material we show that when the kernel function is
sufficiently rich that it is a characteristic kernel (Fukumizu et al., 2008, 2009), projections onto
. In the Supplementary Material we show that when the kernel function is
sufficiently rich that it is a characteristic kernel (Fukumizu et al., 2008, 2009), projections onto 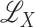 can be well
approximated by elements in reproducing kernel Hilbert spaces. Specifically, this requires
the following assumption.
can be well
approximated by elements in reproducing kernel Hilbert spaces. Specifically, this requires
the following assumption.
Assumption 3 —
Each
is a dense subset of
up to a constant; that is, for each
there is a sequence
in
such that
as
.
We are now ready to state the first main result: one can use the additive conditional covariance or additive partial correlation operator to characterize additive conditional independence.
Theorem 2 —
If Assumptions 1–3 hold, then
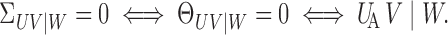
3.3. Estimators
Here we define sample estimators of 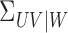 and
and
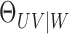 . Let
. Let 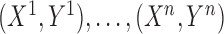 be
independent copies of
be
independent copies of 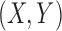 . Let
. Let 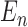 represent the sample average:
represent the sample average:
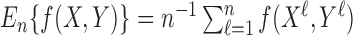 . We define the
estimate of
. We define the
estimate of 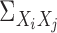 by replacing the expectation with the sample average
by replacing the expectation with the sample average
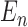 ; that is,
; that is,
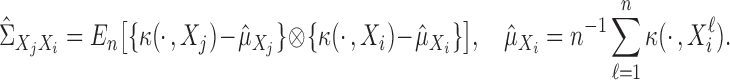 |
Let 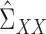 be the
be the
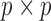 matrix of operators whose
matrix of operators whose 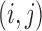 th entry is
th entry is
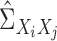 , and let
, and let 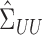 ,
,
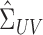 and so forth be the submatrices corresponding to
subvectors
and so forth be the submatrices corresponding to
subvectors 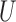 and
and 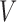 . Let
. Let 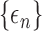 be
a sequence of positive constants converging to zero. We define the estimator of
be
a sequence of positive constants converging to zero. We define the estimator of
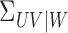 as
as
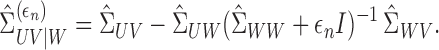 |
(5) |
Let 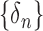 be
another sequence of positive constants converging to zero. We define the estimator of
be
another sequence of positive constants converging to zero. We define the estimator of
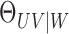 as
as
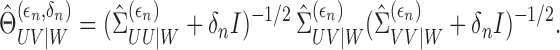 |
(6) |
The tuning parameters
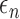 and
and 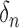 in (5) and (6) play roles similar to that of the penalty in ridge regression (Hoerl & Kennard, 1970). Technically, they
ensure the invertibility of the relevant linear operators and the consistency of the
estimators. In practice, they often bring efficiency gains in high dimensions due to their
shrinkage effects. Interestingly, as we will see in the next section,
in (5) and (6) play roles similar to that of the penalty in ridge regression (Hoerl & Kennard, 1970). Technically, they
ensure the invertibility of the relevant linear operators and the consistency of the
estimators. In practice, they often bring efficiency gains in high dimensions due to their
shrinkage effects. Interestingly, as we will see in the next section,
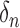 needs to converge to zero more slowly than
needs to converge to zero more slowly than
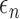 in order for
in order for 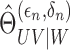 to be consistent.
to be consistent.
4. Consistency and convergence rate
We first establish consistency of 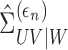 . Besides serving as an intermediate step for proving the
consistency of
. Besides serving as an intermediate step for proving the
consistency of 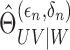 , the consistency of
, the consistency of
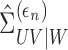 is of interest in its own right, because
it was not proved in Li et al. (2014), where it
was originally proposed under
is of interest in its own right, because
it was not proved in Li et al. (2014), where it
was originally proposed under 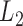 geometry. To derive the convergence rate, we need an
additional assumption.
geometry. To derive the convergence rate, we need an
additional assumption.
Assumption 4 —
There is an operator
such that
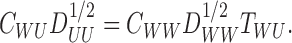
The operator 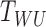 also appeared in Lee et al. (2016), where it was called the regression operator
because it can be written in the form
also appeared in Lee et al. (2016), where it was called the regression operator
because it can be written in the form 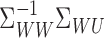 ,
resembling the coefficient vector in linear regression. Assumption 4 is essentially a
smoothness condition: it requires that the main components in the relation between
,
resembling the coefficient vector in linear regression. Assumption 4 is essentially a
smoothness condition: it requires that the main components in the relation between
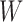 and
and 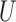 be sufficiently concentrated on the
low-frequency components of the covariance operator
be sufficiently concentrated on the
low-frequency components of the covariance operator 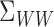 , in the
following sense. If
, in the
following sense. If 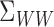 is invertible, then Assumption 4 requires
is invertible, then Assumption 4 requires
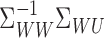 to be a compact operator. Since, under mild
conditions,
to be a compact operator. Since, under mild
conditions, 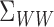 is a Hilbert–Schmidt operator (Fukumizu et al., 2007),
is a Hilbert–Schmidt operator (Fukumizu et al., 2007), 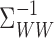 is
an unbounded operator. Intuitively, in order for
is
an unbounded operator. Intuitively, in order for 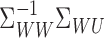 to be compact, the range space of
to be compact, the range space of
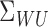 should be sufficiently concentrated on the eigenspaces
of
should be sufficiently concentrated on the eigenspaces
of 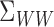 corresponding to its large eigenvalues, or the
low-frequency components. As a simple special case of this scenario, in Lee et al. (2016, Proposition 1) it was shown that
Assumption 4 is satisfied if the range of
corresponding to its large eigenvalues, or the
low-frequency components. As a simple special case of this scenario, in Lee et al. (2016, Proposition 1) it was shown that
Assumption 4 is satisfied if the range of 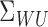 is a finite-dimensional
reducing subspace of
is a finite-dimensional
reducing subspace of 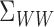 . This is true, for example, when the polynomial
kernel of finite order is used. For kernels inducing infinite-dimensional spaces, Assumption
4 holds if there exist only finitely many eigenfunctions of
. This is true, for example, when the polynomial
kernel of finite order is used. For kernels inducing infinite-dimensional spaces, Assumption
4 holds if there exist only finitely many eigenfunctions of 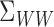 that
carry nontrivial correlations with any function in
that
carry nontrivial correlations with any function in 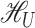 . Of
course, these sufficient conditions can be relaxed with careful examination.
. Of
course, these sufficient conditions can be relaxed with careful examination.
We state the consistency of the additive conditional covariance and additive partial
correlation operators in the following two theorems, which require different rates for the
ridge parameters. For two positive sequences 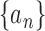 and
and 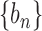 , we write
, we write
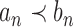 if and only if
if and only if 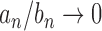 , and
we write
, and
we write 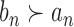 if and only if
if and only if 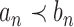 .
.
Theorem 3 —
If Assumptions 1, 2 and 4 are satisfied and
, then
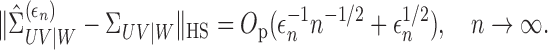
Theorem 4 —
If Assumptions 1, 2 and 4 are satisfied and
(7) then
in probability as
.
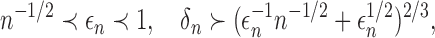
We return now to the estimation of the additive semigraphoid graphical model in Definition 2. The estimators of the additive conditional covariance operator and additive partial correlation operator lead to the following thresholding methods for estimating the additive semigraphoid model:
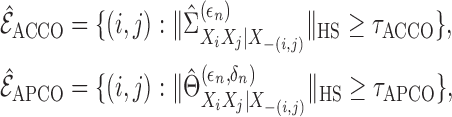 |
where
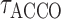 and
and 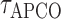 are thresholding
constants for the additive conditional covariance operator and additive partial correlation
operator, respectively. By combining Theorems 2, 3 and 4, it is easy to show that
are thresholding
constants for the additive conditional covariance operator and additive partial correlation
operator, respectively. By combining Theorems 2, 3 and 4, it is easy to show that
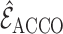 and
and 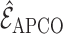 are
consistent estimators of the true edge set
are
consistent estimators of the true edge set 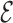 , in the following sense.
, in the following sense.
Theorem 5 —
Suppose that Assumptions 1–4 hold and
satisfies the additive semigraphoid model in Definition 2 with respect to the graph
. Suppose further that
and
are positive sequences satisfying (7). Then, for sufficiently small
and
, as
,
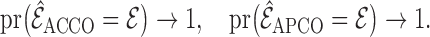
The foregoing asymptotic development is under the assumption that 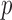 is fixed as
is fixed as
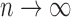 . We believe it should be possible to prove the consistency
in the setting where
. We believe it should be possible to prove the consistency
in the setting where 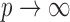 as
as 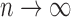 , perhaps along the lines of
Bickel & Levina (2008a, b). We leave this to future research.
, perhaps along the lines of
Bickel & Levina (2008a, b). We leave this to future research.
5. Implementation of estimation of graphical models
5.1. Coordinate representation
The estimators in (5) and (6) are defined in operator form. To
compute them, we need to represent the operators as matrices. In the subsequent
development we describe this process in the context of estimating the graphical models. We
adopt the system of notation for coordinate representation from Horn & Johnson (1985); see also Li et al. (2012). Let 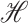 be a
generic
be a
generic 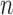 -dimensional Hilbert space with spanning system
-dimensional Hilbert space with spanning system
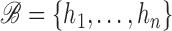 . For any
. For any 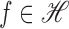 ,
there is a vector
,
there is a vector 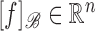 such that
such that
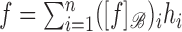 . The vector
. The vector
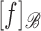 is called the coordinate of
is called the coordinate of 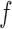 with respect to
with respect to
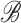 . Suppose that
. Suppose that 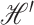 is
another Hilbert space, spanned by
is
another Hilbert space, spanned by 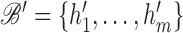 ,
and
,
and 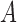 is a linear operator from
is a linear operator from 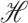 to
to
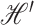 . Then the coordinate of
. Then the coordinate of 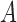 relative to
relative to
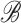 and
and 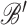 is the matrix
is the matrix
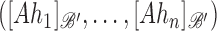 , denoted by
, denoted by
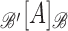 . If
. If  is a
third finite-dimensional Hilbert space, with spanning system
is a
third finite-dimensional Hilbert space, with spanning system  , and
, and
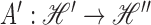 is a linear operator, then
is a linear operator, then
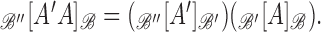 When there is no ambiguity
regarding the spanning system used, we abbreviate
When there is no ambiguity
regarding the spanning system used, we abbreviate 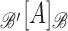 to
to  ,
, 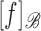 to
to 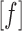 , and so on. One can also show that
, and so on. One can also show that
 for any
for any 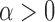 . In the rest of this
section, square brackets
. In the rest of this
section, square brackets  will be reserved exclusively for the
coordinate notation.
will be reserved exclusively for the
coordinate notation.
5.2. Norms of the estimated additive partial correlation operator
For each 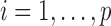 , let
, let 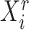 and
and 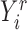 be the
be the
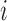 th components of the vectors
th components of the vectors 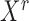 and
and
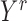 , respectively. Consider the reproducing kernel
Hilbert space
, respectively. Consider the reproducing kernel
Hilbert space
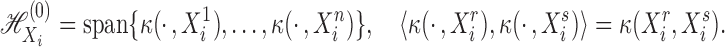 |
Let
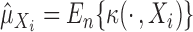 be the Riesz representation
of the linear functional
be the Riesz representation
of the linear functional 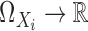 ,
,
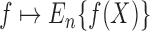 , and let
, and let 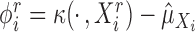 . For our purposes, it suffices to consider the
subspace
. For our purposes, it suffices to consider the
subspace 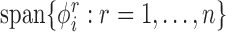 of
of 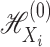 , because it is the range of operators such
as
, because it is the range of operators such
as 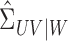 and
and 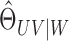 . For this
reason, we define this subspace to be
. For this
reason, we define this subspace to be 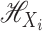 .
.
Let 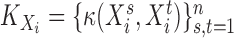 be the Gram kernel matrix. Let
be the Gram kernel matrix. Let
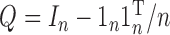 , which is the projection onto the orthogonal
complement of
, which is the projection onto the orthogonal
complement of 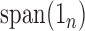 in
in 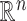 . Let
. Let
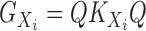 , and let
, and let 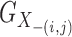 be the
be the
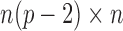 matrix obtained by removing the
matrix obtained by removing the
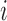 th and
th and 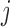 th blocks from the
th blocks from the
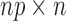 matrix
matrix 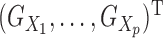 . Let
. Let
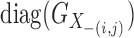 be the
be the 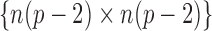 -dimensional block-diagonal matrix whose diagonal
blocks are the
-dimensional block-diagonal matrix whose diagonal
blocks are the  blocks of
blocks of 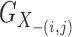 , each
of dimension
, each
of dimension 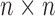 . To avoid complicated notation, throughout this
subsection we write the estimated operators
. To avoid complicated notation, throughout this
subsection we write the estimated operators 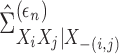 and
and 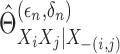 as simply
as simply 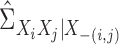 and
and 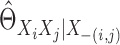 .
.
By straightforward calculations, details of which are given in the Supplementary Material, we have the following coordinate representations:
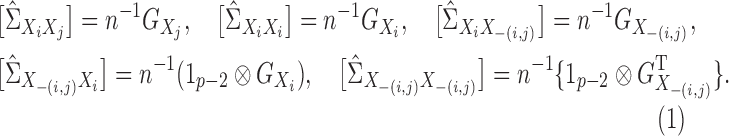 |
(8) |
Let 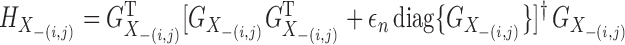 ,
where
,
where 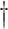 indicates the Moore–Penrose inverse. Therefore,
indicates the Moore–Penrose inverse. Therefore,
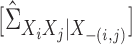 is equal to
is equal to
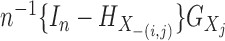 and is denoted by
and is denoted by
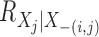 . Similarly,
. Similarly, 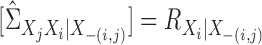 . Then we can compute
. Then we can compute
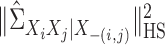 via
via
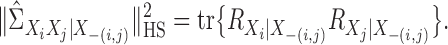 |
(9) |
In the Supplementary Material,
we also derive an explicit formula for calculating 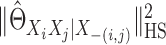 . Let
. Let 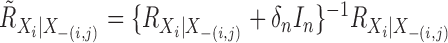 and
and
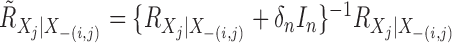 . Then we have
. Then we have
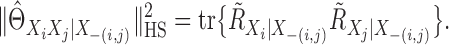 |
(10) |
The following result links the additive partial correlation operator with the partial correlation when a linear kernel is considered.
Corollary 1 —
Let
. Then, as
,
converges in probability to the absolute value of the partial correlation between
and
given
.
5.3. Reduced kernel and generalized crossvalidation
To make our method readily applicable to relatively large networks with thousands of
nodes, we now propose, as alternatives to (9) and (10), simplified
algorithms for estimating 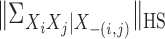 and
and 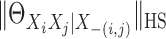 . Lower-frequency
eigenfunctions of kernels often play dominant roles, and the numbers of statistically
significant eigenvalues of kernel matrices are often much smaller than
. Lower-frequency
eigenfunctions of kernels often play dominant roles, and the numbers of statistically
significant eigenvalues of kernel matrices are often much smaller than
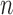 ; see, for example, Lee & Huang (2007) and Chen et al. (2010). By employing only the dominant low-frequency eigenfunctions,
we can greatly reduce the amount of computation without incurring much loss of accuracy.
Let the eigendecomposition of the kernel matrix
; see, for example, Lee & Huang (2007) and Chen et al. (2010). By employing only the dominant low-frequency eigenfunctions,
we can greatly reduce the amount of computation without incurring much loss of accuracy.
Let the eigendecomposition of the kernel matrix 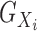 be written
as
be written
as
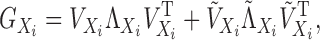 |
(11) |
where 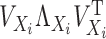 corresponds to the first
corresponds to the first 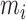 eigenvalues of
eigenvalues of
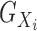 and
and 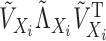 corresponds to the last
corresponds to the last 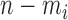 eigenvalues.
Instead of the original bases
eigenvalues.
Instead of the original bases 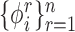 , we now work with
, we now work with
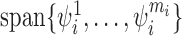 , where
, where
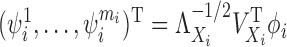 and will be written simply as
and will be written simply as 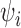 .
.
Let 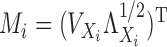 , let
, let 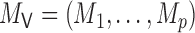 , let
, let 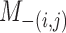 be the matrix obtained by
removing
be the matrix obtained by
removing 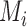 and
and 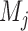 from
from 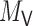 , and
let
, and
let 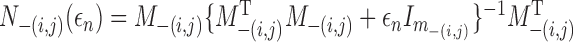 , where
, where 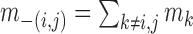 . Using derivations similar to (8) and (10), we find the coordinate representation of the additive conditional
covariance operator with respect to the new basis
. Using derivations similar to (8) and (10), we find the coordinate representation of the additive conditional
covariance operator with respect to the new basis 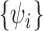 as
as
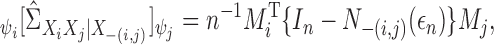 |
(12) |
which is denoted by 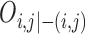 .
Correspondingly, the Hilbert–Schmidt norms of the additive conditional covariance operator
and the additive partial correlation operator can be computed via
.
Correspondingly, the Hilbert–Schmidt norms of the additive conditional covariance operator
and the additive partial correlation operator can be computed via
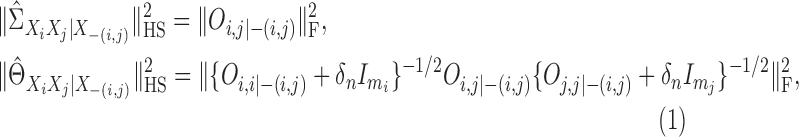 |
(13) |
where
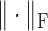 is the Frobenius matrix norm. In (12) we need to invert an
is the Frobenius matrix norm. In (12) we need to invert an
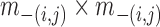 matrix
matrix 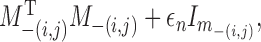 which could be large if
which could be large if
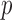 is large. However, as shown in Proposition 4 of Li et al. (2014), calculation of this matrix can
be reduced to the eigendecomposition of an
is large. However, as shown in Proposition 4 of Li et al. (2014), calculation of this matrix can
be reduced to the eigendecomposition of an 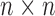 matrix.
matrix.
For the choice of 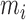 , we follow Fan et al. (2011) and determine it adaptively according to the sample size
, we follow Fan et al. (2011) and determine it adaptively according to the sample size
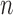 . Specifically, we take
. Specifically, we take
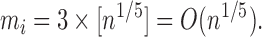 |
(14) |
We use the reduced kernel bases consistently for all the simulations and the real-data analysis in §6. Based on our experience, using the reduced bases not only cuts the computation time substantially but also gives very high accuracy compared with using the full bases.
Next, we introduce a generalized crossvalidation procedure to choose the thresholds
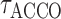 and
and 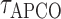 . Our process roughly follows Li et al. (2014). Given
. Our process roughly follows Li et al. (2014). Given 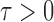 , let
, let
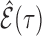 be the estimated graph by either criterion in
(13), and define the neighbours of
node
be the estimated graph by either criterion in
(13), and define the neighbours of
node 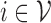 as
as 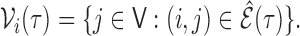 Our strategy is to regress each node on
its neighbours and obtain the residuals; the generalized crossvalidation criterion is then
used to minimize the total prediction error. Specifically,
Our strategy is to regress each node on
its neighbours and obtain the residuals; the generalized crossvalidation criterion is then
used to minimize the total prediction error. Specifically, 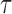 is determined
by minimizing
is determined
by minimizing
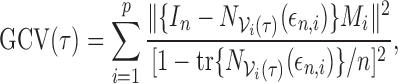 |
(15) |
where the 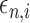 are
chosen differently for each node, as shown in the next subsection.
are
chosen differently for each node, as shown in the next subsection.
5.4. Algorithm
The following algorithm summarizes the estimating procedure for the additive semigraphoid model based on the estimated additive partial correlation operator and the estimated additive conditional covariance operator.
Step 1 —
For each
, standardize
such that
and
.
Step 2 —
Select the kernel
, for example as the radial basis function
where
is the bandwidth parameter. As in Lee et al. (2013), we recommend choosing
via
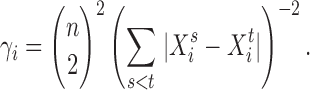
Step 3 —
Use the selected
and
to compute the kernel matrix
, its centred counterpart
, and the eigendecomposition (11) for
. Choose
according to (14).
Step 4 —
Determine the tuning parameters
,
and
to be the fractions of the largest singular values of relevant matrices to be penalized. That is, let
where
denotes the largest singular value of a matrix. The constants
,
and
control the smoothing effects; we fix
and let
and
be
based on a criterion similar to that used in Step 3. Finally, to further simplify the computation, we can approximate
by
.
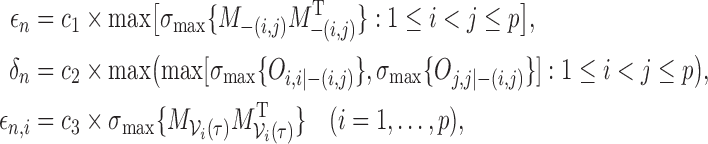
Step 5 —
For each
, calculate
or
using (9) and (10) or their fast versions given in (13).
Step 6 —
Compute the thresholds that minimize (15), and determine the graph using either of the two criteria. For example, if
is the best threshold, then remove
from the edge set
if
.
6. Numerical study
6.1. Additive and high-dimensional settings
By means of simulated examples, we compare the additive partial correlation operator with
the additive conditional covariance operator of Li
et al. (2014) and the methods of Yuan &
Lin (2007), Liu et al. (2009), Fellinghauer et al. (2013) and Voorman et al. (2014). The additive partial
correlation operator is able to identify the graph whose underlying distribution does not
satisfy the Gaussian or copula Gaussian assumption. To demonstrate this feature, we
generate dependent random variables that do not have Gaussian or copula Gaussian
distributions using the structural equation models of Pearl (2009). Specifically, given an edge set
 , we generate
, we generate 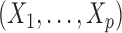 sequentially via
sequentially via
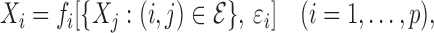 |
where 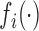 is the
link function and
is the
link function and 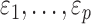 are independent
and identically distributed standard Gaussian variables. If
are independent
and identically distributed standard Gaussian variables. If 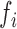 is linear, the
joint distribution is Gaussian; otherwise, the joint distribution may be neither Gaussian
nor copula Gaussian.
is linear, the
joint distribution is Gaussian; otherwise, the joint distribution may be neither Gaussian
nor copula Gaussian.
We consider the following graphical models based on three choices of
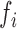 .
.
Model I:
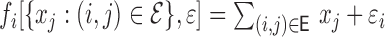 .
. Model II:
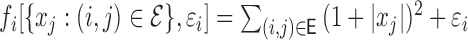 .
. Model III:
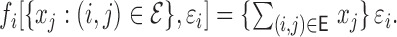
The sample sizes are taken to be 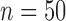 and 100, and the number of nodes
is
and 100, and the number of nodes
is 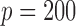 .
.
We use the hub structure to generate the underlying graphs and the corresponding edge
sets 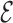 . Hubs are commonly observed in networks such as gene
regulatory networks and citation networks; see Newman (2003). Specifically, given a graph of size
. Hubs are commonly observed in networks such as gene
regulatory networks and citation networks; see Newman (2003). Specifically, given a graph of size 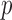 , ten independent
hubs are generated so that each module is of degree
, ten independent
hubs are generated so that each module is of degree 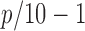 . For each of
the
. For each of
the 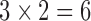 combinations, we generate 100 samples and produce the
averaged receiver operating characteristic curves and the areas under these curves. To
draw the curves, we need to compute the false positive and true positive rates. Suppose
combinations, we generate 100 samples and produce the
averaged receiver operating characteristic curves and the areas under these curves. To
draw the curves, we need to compute the false positive and true positive rates. Suppose
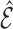 is an estimate of
is an estimate of 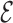 ; then
the formal definitions of these two measures are
; then
the formal definitions of these two measures are
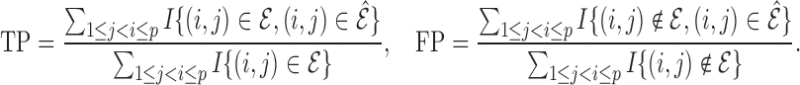 |
(16) |
The receiver operating characteristic curves are plotted in Fig. 1.
Fig. 1.

Receiver operating characteristic curves for different estimators: the additive
partial correlation operator (— —); the additive
conditional covariance operator (black —–); the method of Yuan & Lin (2007) (black - - - -); the method of Liu et al. (2009) (
—); the additive
conditional covariance operator (black —–); the method of Yuan & Lin (2007) (black - - - -); the method of Liu et al. (2009) ( );
the method of Fellinghauer et al. (2013)
(grey ——); and the method of Voorman et al.
(2014) with default basis (grey - - - -). The two middle panels also display
the method of Voorman et al. (2014) with
the correct basis
);
the method of Fellinghauer et al. (2013)
(grey ——); and the method of Voorman et al.
(2014) with default basis (grey - - - -). The two middle panels also display
the method of Voorman et al. (2014) with
the correct basis 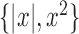 for Model II (grey -
-
for Model II (grey -
- - -). In each panel the horizontal axis shows the
false positive rate and the vertical axis the true positive rate.
- -). In each panel the horizontal axis shows the
false positive rate and the vertical axis the true positive rate.
For all the comparisons in §§6.1 and 6.2, we use the radial basis function for both the
additive conditional covariance and the additive partial correlation operators. For Model
I, we see that the methods of Yuan & Lin
(2007) and Liu et al. (2009) perform
better than the nonparametric methods. This is not surprising as Gaussianity holds under
Model I, and because both methods use the 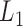 penalty, which is more efficient
than thresholding. Nevertheless, the performance of the additive partial correlation
operator is not far behind. For example, the areas under the receiver operating
characteristic curves for the additive partial correlation operator have an average of
0
penalty, which is more efficient
than thresholding. Nevertheless, the performance of the additive partial correlation
operator is not far behind. For example, the areas under the receiver operating
characteristic curves for the additive partial correlation operator have an average of
0 98 for the two curves in Model I, only slightly smaller
than the average of the areas under the curves for the methods of Yuan & Lin (2007) and Liu et al. (2009), which is 1
98 for the two curves in Model I, only slightly smaller
than the average of the areas under the curves for the methods of Yuan & Lin (2007) and Liu et al. (2009), which is 1 00.
00.
For Models II and III, under which neither Gaussianity nor copula Gaussianity is
satisfied, the methods of Yuan & Lin
(2007) and Liu et al. (2009) do not
perform well. In contrast, both the additive conditional covariance and the additive
partial correlation operators still perform remarkably well. Moreover, the receiver
operating characteristic curves of the additive partial correlation operator are
consistently better than those of the additive conditional covariance operator for Models
I and II and for sample sizes 50 and 100, indicating the benefit of a better scaling by
the additive partial correlation operator. We also observe that the performance of the
method of Fellinghauer et al. (2013) is not
very stable. Since their method is based on random forests, it may be affected by the
curse of dimensionality that a fully nonparametric approach tends to suffer from. The
method of Voorman et al. (2014) is
implemented using the R package (R Development Core
Team, 2016) spacejam, whose default basis is the cubic polynomial. It shows
improvements over the methods of Yuan & Lin
(2007) and Liu et al. (2009), but
does not perform as well as the additive partial correlation operator. To investigate the
effect of the choice of basis on the method of Voorman et al. (2014), we compute its receiver operating characteristic curve
for Model II using the correct basis 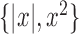 . Notably, this method
with the correct basis performs the best under Model II among all the competing methods.
Results for smaller graphs are presented in the Supplementary Material.
. Notably, this method
with the correct basis performs the best under Model II among all the competing methods.
Results for smaller graphs are presented in the Supplementary Material.
6.2. Nonadditive and low-dimensional settings
We also investigate a setting where the relationships between nodes are nonadditive and the dimension of the graph is relatively low, which favours a fully nonparametric method such as the method of Fellinghauer et al. (2013). Specifically, we consider
Model IV:
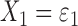 ,
, 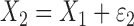 ,
, 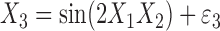 ,
, 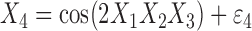 ,
, 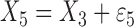 ,
,
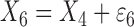 ,
,
where 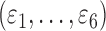 are independent and
identically distributed standard Gaussian variables.
are independent and
identically distributed standard Gaussian variables.
Our goal is to recover the graph determined by the set of conditional independence
relations 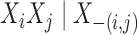 whenever
whenever 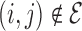 . Under Model IV, the edge set is
. Under Model IV, the edge set is
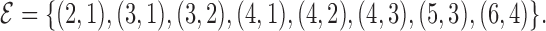 The graphical model based on pairwise conditional independence cannot fully describe the
interdependence in
The graphical model based on pairwise conditional independence cannot fully describe the
interdependence in 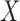 , because it cannot capture three-way or multi-way
conditional dependence. A fully descriptive approach in such situations would be to use a
hypergraph (Lauritzen, 1996, p. 21).
Nevertheless, the pairwise conditional independence graphical model is well-defined and
helps to illustrate the difference between an additive and a fully nonparametric
model.
, because it cannot capture three-way or multi-way
conditional dependence. A fully descriptive approach in such situations would be to use a
hypergraph (Lauritzen, 1996, p. 21).
Nevertheless, the pairwise conditional independence graphical model is well-defined and
helps to illustrate the difference between an additive and a fully nonparametric
model.
Taking 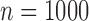 , we compute the receiver operating characteristic
curves for 100 replicates, which are presented in the Supplementary Material. Since the
model is nonlinear, we only compare the additive partial correlation operator with the
additive conditional covariance operator and the methods of Voorman et al. (2014) and Fellinghauer et al. (2013). The method of Fellinghauer et al. (2013) performs the best, because it allows the conditional
expectation of each node to be a nonadditive function of its neighbouring nodes. On the
other hand, the additive partial correlation operator still performs reasonably well. This
indicates that, in spite of its additive formulation, the additive partial correlation
operator is capable of identifying conditional independence even in nonadditive
models.
, we compute the receiver operating characteristic
curves for 100 replicates, which are presented in the Supplementary Material. Since the
model is nonlinear, we only compare the additive partial correlation operator with the
additive conditional covariance operator and the methods of Voorman et al. (2014) and Fellinghauer et al. (2013). The method of Fellinghauer et al. (2013) performs the best, because it allows the conditional
expectation of each node to be a nonadditive function of its neighbouring nodes. On the
other hand, the additive partial correlation operator still performs reasonably well. This
indicates that, in spite of its additive formulation, the additive partial correlation
operator is capable of identifying conditional independence even in nonadditive
models.
6.3. Effects of the choices of kernels, ridge parameters and number of eigenfunctions
In this subsection we study the performance of the additive partial correlation operator
with different choices of kernel. We investigate six types of kernel: the radial basis
function, the rational quadratic kernel with parameters 200 and 400, the linear kernel,
the quadratic kernel, and the Laplacian kernel. The choice of parameters for the rational
quadratic kernel follows Li et al. (2014).
For each model, ten replicates are generated using 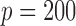 and
and
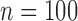 . The averaged receiver operating characteristic
curves for the six kernels are presented in the Supplementary Material. The results suggest that all the nonlinear
kernels give comparable performance across Models I, II and III. As expected, the linear
kernel fails for Models II and III.
. The averaged receiver operating characteristic
curves for the six kernels are presented in the Supplementary Material. The results suggest that all the nonlinear
kernels give comparable performance across Models I, II and III. As expected, the linear
kernel fails for Models II and III.
Next, we investigate the sensitivity of the proposed estimator to the tuning parameters
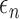 and
and 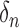 . We take 20 equally spaced
grid points in each of the ranges
. We take 20 equally spaced
grid points in each of the ranges 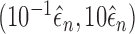 and
and 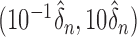 , with
, with 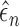 and
and
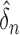 computed via the empirical formulas in §5.4. Then, for each of the
computed via the empirical formulas in §5.4. Then, for each of the 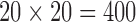 combinations, a receiver operating characteristic curve is produced and its area under the
curve is computed. The means of the areas for Models I, II and III are
0
combinations, a receiver operating characteristic curve is produced and its area under the
curve is computed. The means of the areas for Models I, II and III are
0 995, 0
995, 0 956 and
0
956 and
0 971, respectively, with standard deviations of
0
971, respectively, with standard deviations of
0 004, 0
004, 0 004 and
0
004 and
0 011. These values indicate that the performance of the
proposed estimator is reasonably robust with respect to the choice of tuning parameters.
The actual receiver operating characteristic curves for different combinations of tuning
parameters are plotted in the Supplementary Material.
011. These values indicate that the performance of the
proposed estimator is reasonably robust with respect to the choice of tuning parameters.
The actual receiver operating characteristic curves for different combinations of tuning
parameters are plotted in the Supplementary Material.
We also investigated the effect of using different numbers of eigenfunctions. For each of
Models I–III and with 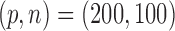 , we increase
, we increase 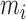 from 1 to
from 1 to
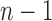 and, for each fixed
and, for each fixed 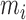 , produce a
receiver operating characteristic curve and compute the area under the curve. The areas
under the curves are reported in the Supplementary Material. The results show that the effect of using a different
number of eigenfunctions varies across the three models, which is to be expected as they
have different complexities. Specifically, a single eigenfunction achieves the largest
area under the curve for the linear model, but for the nonlinear models the optimal areas
are achieved when more eigenfunctions are used. We also see that our choices of
, produce a
receiver operating characteristic curve and compute the area under the curve. The areas
under the curves are reported in the Supplementary Material. The results show that the effect of using a different
number of eigenfunctions varies across the three models, which is to be expected as they
have different complexities. Specifically, a single eigenfunction achieves the largest
area under the curve for the linear model, but for the nonlinear models the optimal areas
are achieved when more eigenfunctions are used. We also see that our choices of
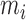 are not far from the best choice for all three
models.
are not far from the best choice for all three
models.
6.4. Exploring the generalized crossvalidation procedure
In this subsection we investigate the performance and computational cost of the generalized crossvalidation procedure introduced in §5.3, and compare it with the method of Voorman et al. (2014) using two different selection criteria: the Akaike information criterion and the Bayesian information criterion. Three measures are used to evaluate the comparisons: the true positive and false positive rates in (16), and a synthetic score defined as
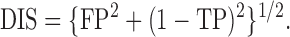 |
(17) |
Table 1 shows the averages of these criteria over 100 replicates using Model III with
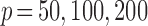 and
and 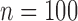 . We omit the
result obtained from the method of Voorman et al.
(2014) using the Bayesian information criterion, because the Akaike information
criterion for the same method always performs better in this setting. Our procedure
consistently picks up the thresholds located around the best scenario. In comparison, the
method of Voorman et al. (2014) with the
Akaike information criterion does not perform as well as our estimator.
. We omit the
result obtained from the method of Voorman et al.
(2014) using the Bayesian information criterion, because the Akaike information
criterion for the same method always performs better in this setting. Our procedure
consistently picks up the thresholds located around the best scenario. In comparison, the
method of Voorman et al. (2014) with the
Akaike information criterion does not perform as well as our estimator.
Table 1.
Comparison of the tuning procedures for (a) the additive partial correlation operator
with generalized crossvalidation and (b) the method of Voorman et al. 2014 with the Akaike information criterion;
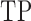 and
and 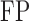
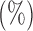 are defined
in (16), and
are defined
in (16), and
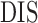 is defined in (17); larger
is defined in (17); larger 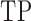 ,
smaller
,
smaller 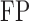 and lower
and lower  indicate better performance
indicate better performance
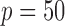
|
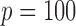
|
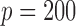
|
|||||||
|---|---|---|---|---|---|---|---|---|---|
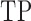
|
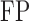
|
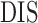
|
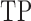
|
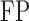
|
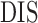
|
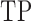
|
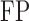
|
|
|
| (a) | 97 1 1 |
10 9 9 |
0 11 11 |
98 1 1 |
17 8 8 |
0 18 18 |
98 7 7 |
22 1 1 |
0 22 22 |
| (b) | 58 8 8 |
24 7 7 |
0 61 61 |
90 0 0 |
71 6 6 |
0 72 72 |
78 6 6 |
51 5 5 |
0 56 56 |
We also compare the computational costs of the two methods in estimating larger networks
with 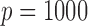 or 5000. For the tuning parameters, 40 grid points
are used for both the additive partial correlation operator and the method of Voorman et al. (2014). The results are reported
in Table 2. With
or 5000. For the tuning parameters, 40 grid points
are used for both the additive partial correlation operator and the method of Voorman et al. (2014). The results are reported
in Table 2. With 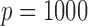 , our
algorithm takes only minutes to complete, and for
, our
algorithm takes only minutes to complete, and for 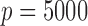 it is still
reasonably efficient. In terms of estimation accuracy, our method has smaller
it is still
reasonably efficient. In terms of estimation accuracy, our method has smaller
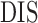 than the method of Voorman et al. (2014). The complexity of the additive partial
correlation operator grows as
than the method of Voorman et al. (2014). The complexity of the additive partial
correlation operator grows as 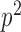 . However, for handling graphs with
thousands of nodes, our method is faster than the regression-based approaches.
. However, for handling graphs with
thousands of nodes, our method is faster than the regression-based approaches.
Table 2.
Comparison of computing times for (a) the additive partial correlation operator with
generalized crossvalidation and (b) the method of Voorman et al.2014 with the Akaike information criterion. All experiments were conducted
on an Intel Xeon E5520 with  GHz CPU
GHz CPU
|
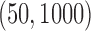
|
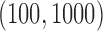
|
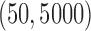
|
|
||||
|---|---|---|---|---|---|---|---|---|
| Minutes |
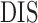
|
Minutes |
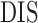
|
Minutes |
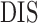
|
Minutes |
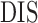
|
|
| (a) | 2 3 3 |
0 35 35 |
8 6 6 |
0 23 23 |
58 4 4 |
0 59 59 |
213 3 3 |
0 54 54 |
| (b) | 47 7 7 |
0 87 87 |
122 8 8 |
0 68 68 |
553 4 4 |
0 97 97 |
1572 8 8 |
0 96 96 |
6.5. Application to the DREAM4 Challenges data
We apply the six methods to a dataset from the DREAM4 Challenges project (Marbach et al., 2010). The goal of this study is
to infer network structure from gene expression data. The topologies of the graphs are
obtained by extracting subgraphs from real biological networks. The gene expression levels
are generated based on a system of ordinary differential equations governing the dynamics
of the biological interactions between the genes. There are five networks of size 100 to
be estimated in this dataset. For each network, we stack up observations from three
different experimental conditions, wild-type, knockdown and knockout, so that the overall
sample size 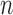 is 201. Then, the estimated graphs are produced using
the additive partial correlation operator, the additive conditional covariance operator of
Li et al. (2014), and the methods of Voorman et al. (2014), Fellinghauer et al. (2013), Yuan & Lin (2007) and Liu et al.
(2009). The areas under the receiver operating characteristic curves are reported
in Table 3, and the actual receiver
operating characteristic curves are displayed in the Supplementary Material. We see that
the additive partial correlation operator consistently performs best among the six
estimators.
is 201. Then, the estimated graphs are produced using
the additive partial correlation operator, the additive conditional covariance operator of
Li et al. (2014), and the methods of Voorman et al. (2014), Fellinghauer et al. (2013), Yuan & Lin (2007) and Liu et al.
(2009). The areas under the receiver operating characteristic curves are reported
in Table 3, and the actual receiver
operating characteristic curves are displayed in the Supplementary Material. We see that
the additive partial correlation operator consistently performs best among the six
estimators.
Table 3.
Areas under the receiver operating characteristic curves for the DREAM4 Challenges dataset, obtained from (a) the additive partial correlation operator, (b) the additive conditional covariance operator, (c) the method of Voorman et al. (2014), (d) the method of Fellinghauer et al. 2013, (e) the method of Liu et al. 2009, (f) the method of Yuan & Lin 2007, and (g) the championship method
| (a) | (b) | (c) | (d) | (e) | (f) | (g) | |
|---|---|---|---|---|---|---|---|
| Network 1 | 0 86 86 |
0 67 67 |
0 79 79 |
0 73 73 |
0 61 61 |
0 74 74 |
0 91 91 |
| Network 2 | 0 81 81 |
0 62 62 |
0 70 70 |
0 64 64 |
0 57 57 |
0 70 70 |
0 81 81 |
| Network 3 | 0 83 83 |
0 70 70 |
0 77 77 |
0 68 68 |
0 64 64 |
0 73 73 |
0 83 83 |
| Network 4 | 0 83 83 |
0 71 71 |
0 76 76 |
0 71 71 |
0 61 61 |
0 72 72 |
0 83 83 |
| Network 5 | 0 77 77 |
0 66 66 |
0 70 70 |
0 73 73 |
0 61 61 |
0 70 70 |
0 75 75 |
The original DREAM4 project was open to public challenges, so it is reasonable to compare our results with those submitted by the participating teams. In column (g) of Table 3 we show the areas under the receiver operating characteristic curves obtained from the method of the championship team. The additive partial correlation operator yields the best areas under the curves for four of the five networks; in particular, it performs better than the method of the championship team for Network 5. As mentioned in Marbach et al. (2010), the best-performing approach used a combination of multiple models, including ordinary differential equations. Our operator replicates the most competitive results without employing any prior information on the model setting, which demonstrates the benefit of relaxing the distributional assumption; moreover, its additive structure does not seem to hamper its accuracy in this application.
7. Concluding remarks
In establishing the consistency of the additive conditional covariance operator and the additive partial correlation operator, we have developed a theoretical framework that is not limited to the current setting; it can be applied to other problems where additive conditional independence and linear operators are involved. Moreover, the idea of characterizing conditional independence by small values of the additive partial correlation operator has ramifications beyond those explored in this paper. For instance, the penalty in the proposed additive partial correlation operator is based on hard thresholding, but other penalties, such as the lasso-type penalties, may be more efficient in dealing with sparsity in the estimation of operators. We leave these extensions and refinements to future research.
Supplementary material
Supplementary material available at Biometrika online includes the proofs of the theoretical results and additional plots for the numerical studies.
Supplementary Material
Acknowledgments
We are grateful to three referees for their constructive comments and helpful suggestions. Bing Li's research was supported in part by the U.S. National Science Foundation; Hongyu Zhao's research was supported in part by both the National Science Foundation and the National Institutes of Health.
References
- Bach F. R. (2008). Consistency of the group lasso and multiple kernel learning. J. Mach. Learn. Res. 9, 1179–225. [Google Scholar]
- Baker C. R. (1973). Joint measures and cross-covariance operators. Trans. Am. Math. Soc. 186, 273–89. [Google Scholar]
- Banerjee O., Ghaoui, El L. & d'Aspremont A. (2008). Model selection through sparse maximum likelihood estimation for multivariate Gaussian or binary data. J. Mach. Learn. Res. 9, 485–516. [Google Scholar]
- Bellman R. E. (1957). Dynamic Programming. Princeton: Princeton University Press. [Google Scholar]
- Bickel P. J. & Levina E. (2008a). Covariance regularization by thresholding. Ann. Statist. 36, 2577–604. [Google Scholar]
- Bickel P. J. & Levina E. (2008b). Regularized estimation of large covariance matrices. Ann. Statist. 36, 199–227. [Google Scholar]
-
Cai T., Liu W. &
Luo X.
(2011). A constrained
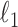 minimization approach to sparse precision matrix estimation. J.
Am. Statist. Assoc. 106,
594–607. [Google Scholar]
minimization approach to sparse precision matrix estimation. J.
Am. Statist. Assoc. 106,
594–607. [Google Scholar] -
Candès E. & Tao T.
(2007). The Dantzig selector: Statistical estimation when
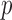 is much larger than
is much larger than 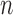 .
Ann. Statist. 35,
2313–51. [Google Scholar]
.
Ann. Statist. 35,
2313–51. [Google Scholar] - Chen P.-C., Lee K.-Y., Lee T.-J., Lee Y.-J. & Huang S.-Y. (2010). Multiclass support vector classification via coding and regression. Neurocomputing 73, 1501–12. [Google Scholar]
- Conway J. B. (1994). A Course in Functional Analysis. New York: Springer, 2nd ed. [Google Scholar]
- Fan J., Feng Y. & Song R. (2011). Nonparametric independence screening in sparse ultra-high-dimensional additive models. J. Am. Statist. Assoc. 106, 544–57. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan J. & Li R. (2001). Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Statist. Assoc. 96, 1348–60. [Google Scholar]
- Fellinghauer B., Bühlmann P., Ryffelb M., Rheinc M. & Reinhardta J. D. (2013). Stable graphical model estimation with random forests for discrete, continuous, and mixed variables. Comp. Statist. Data Anal. 64, 132–52. [Google Scholar]
- Friedman J. H., Hastie T. J. & Tibshirani R. J. (2008). Sparse inverse covariance estimation with the graphical lasso. Biostatistics 9, 432–41. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fukumizu K., Bach F. R. & Gretton A. (2007). Statistical consistency of kernel canonical correlation analysis. J. Mach. Learn. Res. 8, 361–83. [Google Scholar]
- Fukumizu K., Bach F. R. & Jordan M. I. (2004). Dimensionality reduction for supervised learning with reproducing kernel Hilbert spaces. J. Mach. Learn. Res. 5, 73–99. [Google Scholar]
- Fukumizu K., Bach F. R. & Jordan M. I. (2009). Kernel dimension reduction in regression. Ann. Statist. 37, 1871–905. [Google Scholar]
- Fukumizu K., Gretton A., Sun X. & Schölkopf B. (2008). Kernel measures of conditional dependence. Adv. Neural Info. Proces. Syst. 20, 489–96. [Google Scholar]
- Harris N. & Drton M. (2013). PC algorithm for nonparanormal graphical models. J. Mach. Learn. Res. 14, 3365–83. [Google Scholar]
- Hoerl A. E. & Kennard R. W. (1970). Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 12, 55–67. [Google Scholar]
- Horn R. A. & Johnson C. R. (1985). Matrix Analysis. Cambridge: Cambridge University Press. [Google Scholar]
- Lam C. & Fan J. (2009). Sparsistency and rates of convergence in large covariance matrix estimation. Ann. Statist. 37, 4254–78. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lauritzen S. L. (1996). Graphical Models. Oxford: Oxford University Press. [Google Scholar]
- Lee K.-Y., Li B. & Chiaromonte F. (2013). A general theory for nonlinear sufficient dimension reduction: Formulation and estimation. Ann. Statist. 41, 221–49. [Google Scholar]
- Lee K.-Y., Li B. & Zhao H. (2016). Variable selection via additive conditional independence. J. R. Statist. Soc. B to appear, doi:10.1111/rssb.12150.
- Lee Y.-J. & Huang S.-Y. (2007). Reduced support vector machines: A statistical theory. IEEE Trans. Neural Networks 18, 1–13. [DOI] [PubMed] [Google Scholar]
- Li B., Chun H. & Zhao H. (2012). Sparse estimation of conditional graphical models with application to gene networks. J. Am. Statist. Assoc. 107, 152–67. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li B., Chun H. & Zhao H. (2014). On an additive semi-graphoid model for statistical networks with application to pathway analysis. J. Am. Statist. Assoc. 109, 1188–204. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu H., Han F., Yuan M., Lafferty J. & Wasserman L. (2012). High-dimensional semiparametric Gaussian copula graphical models. Ann. Statist. 40, 2293–326. [Google Scholar]
- Liu H., Lafferty J. & Wasserman L. (2009). The nonparanormal: Semiparametric estimation of high dimensional undirected graphs. J. Mach. Learn. Res. 10, 2295–328. [PMC free article] [PubMed] [Google Scholar]
- Marbach D., Prill R. J., Schaffter T., Mattiussi C., Floreano D. & Stolovitzky G. (2010). Revealing strengths and weaknesses of methods for gene network inference. Proc. Nat. Acad. Sci. 107, 6286–91. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Meinshausen N. & Bühlmann P. (2006). High-dimensional graphs and variable selection with the lasso. Ann. Statist. 34, 1436–62. [Google Scholar]
- Muirhead R. J. (2005). Aspects of Multivariate Statistical Theory. New York: Wiley, 2nd ed. [Google Scholar]
- Newman M. (2003). The structure and function of complex networks. SIAM Rev. 45, 167–256. [Google Scholar]
- Pearl J. (2009). Causality: Models, Reasoning and Inference. Cambridge: Cambridge University Press, 2nd ed. [Google Scholar]
- Pearl J., Geiger D. & Verma T. (1989). Conditional independence and its representations. Kybernetika 25, 33–44. [Google Scholar]
- Pearl J. & Verma T. (1987). The logic of representing dependencies by directed graphs. In Proceedings of the Sixth National Conference on Artificial Intelligence, vol. 1. AAAI Press, pp. 374–9.
- Peng J., Wang P., Zhou N. & Zhu J. (2009). Partial correlation estimation by joint sparse regression models. J. Am. Statist. Assoc. 104, 735–46. [DOI] [PMC free article] [PubMed] [Google Scholar]
- R Development Core Team (2016). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. ISBN 3-900051-07-0. http://www.R-project.org.
- Tibshirani R. J. (1996). Regression shrinkage and selection via the lasso. J. R. Statist. Soc. B 58, 267–88. [Google Scholar]
- Voorman A., Shojaie A. & Witten D. (2014). Graph estimation with joint additive models. Biometrika 101, 85–101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xue L. & Zou H. (2012). Regularized rank-based estimation of high-dimensional nonparanormal graphical models. Ann. Statist. 40, 2541–71. [Google Scholar]
- Yuan M. (2010). High dimensional inverse covariance matrix estimation via linear programming. J. Mach. Learn. Res. 11, 2261–86. [Google Scholar]
- Yuan M. & Lin Y. (2007). Model selection and estimation in the Gaussian graphical model. Biometrika 94, 19–35. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.