

Abstract
Background
Application Programming Interfaces (APIs) are now widely used to distribute biological data. And many popular biological APIs developed by many different research teams have adopted Javascript Object Notation (JSON) as their primary data format. While usage of a common data format offers significant advantages, that alone is not sufficient for rich integrative queries across APIs.
Results
Here, we have implemented JSON for Linking Data (JSON-LD) technology on the BioThings APIs that we have developed, MyGene.info, MyVariant.info and MyChem.info. JSON-LD provides a standard way to add semantic context to the existing JSON data structure, for the purpose of enhancing the interoperability between APIs. We demonstrated several use cases that were facilitated by semantic annotations using JSON-LD, including simpler and more precise query capabilities as well as API cross-linking.
Conclusions
We believe that this pattern offers a generalizable solution for interoperability of APIs in the life sciences.
Electronic supplementary material
The online version of this article (10.1186/s12859-018-2041-5) contains supplementary material, which is available to authorized users.
Keywords: API, JSON-LD, API interoperability, Knowledge discovery, Semantic web, Linking APIs
Background
Recent developments in biological research have yielded a flood of data and knowledge about various biological entities, e.g. diseases, drugs, genes, variants, proteins and pathways. One key challenge that the scientific community faces is the large-scale integration of annotation information for each biological entity type, which is often fragmented across multiple databases. For example, ClinVar [1], dbSNP [2], and CADD [3] all contain useful and distinct information on human genetic variants. When filtering variants identified in a genome sequencing study, for example, large-scale integration of these variant data would greatly improve the efficiency of the data analysis. Moreover, a more important and sophisticated challenge would be to link data across multiple biological entities. For example, fields like systems chemical biology, which studies the effect of drugs on the whole biological system, requires the integration and cross-linking of data across from multiple domains, including genes, pathways, drugs as well as diseases [4].
Javascript Object Notation (JSON) is designed to be a lightweight, language-independent data interchange format that is easy to parse and generate. Over the past decade, JSON has been widely adopted in RESTful APIs. Previously, we have developed three biomedical APIs, MyGene.info [5, 6], MyVariant.info [7] and MyChem.info [8], that integrate public resources for annotations of genes, genetic variants and chemicals respectively. These three services collectively serve over six million requests every month from thousands of unique users. The underlying design and implementation of these systems are not specific to genes, variants or chemicals, but rather can be easily adapted to develop other entity-specific APIs for other biomedical data types such as diseases, pathways, species, genomes, domains and interactions.
A key challenge of Web API development is the semantic interoperability of data exposed by APIs. This challenge comes from the heterogeneity of biological entities (from variants to diseases), the variety of their data models and the scarcity of explicit data descriptions. Previously, there were efforts both within and outside the life science domain trying to achieve integration and interoperability among web resources. For example, SADI [9] is a framework that registers Web-based services so that they can be easily detected for the processing of data in the Web. Moreover, SA-REST [10] also proposed to add additional metadata to REST API descriptions. However, these existing technologies focus on either Web APIs with XML output or annotating APIs in XML format, which are not suitable for JSON-based APIs. Considering the wide adoption of JSON in current REST API development, precise semantic alignment of individual JSON-based APIs would enable powerful integrative queries that span multiple web services, entity types, and biological domains.
JSON for Linking Data (JSON-LD) has been a W3C (World Wide Web Consortium) recommendation since 2014 to promote interoperability among JSON-based web services [11]. JSON-LD offers a simple method to express semantically-precise Linked Data in JSON. It has been designed to be simple to implement, concise, backward-compatible, and human readable. JSON-LD as an official W3C standard has been well accepted and adopted, especially within the Internet of Things community [12]. While JSON-based web services are quite common among biomedical resources, the use of JSON-LD has not yet been extensively explored.
Here, we present our implementation and application of JSON-LD technology to biomedical APIs. We first implemented JSON-LD into three of the BioThings APIs we have developed, MyGene.info, MyVariant.info and MyChem.info. We then demonstrated its application by showing how it could be utilized to make data-structure neutral queries, to perform data discrepancy checks, to cross-link BioThings APIs as well as to integrate BioThings APIs into the linked data cloud. We believe that this work describes a generalizable pattern for stitching together individual APIs into a network of linked web services.
Results
Adding semantics to JSON document
JSON was specifically designed as a lightweight, language-independent data interchange format that is easy to parse and generate. However, the convenience and simplicity of JSON comes at a price, one of which is lack of namespace or semantics support.
Consider a scenario in which two biological data providers both created a key called “accession number” in their JSON document. One group used it to refer to a UniProt [13] accession number, while another group used it to refer to a ClinVar accession number. While a knowledgeable scientist can usually determine the intended usage, defining the semantics programmatically and automatically is much more difficult. It would be extremely useful for JSON documents to be “self-describing” in the sense that providers can explicitly define the semantic meaning of each key.
For the BioThings APIs, we solved this issue by implementing JSON-LD. Each API specifies a JSON-LD context (Fig. 1), which itself is a JSON document and can provide a Universal Resource Identifier (URI) mapping for each key in the output JSON document. The use of URIs provides consistency when specifying subjects and objects. In our implementation, we used identifiers.org as the default URI repository. Identifiers.org [14] focuses on providing URIs for the scientific resources, especially in the life science domain. For example, a key for “rsid”, which is the ID adopted by dbSNP database to represent a variant, could be assigned to the URI (“http://identifiers.org/dbsnp/”). Accessing this URI via HTTP shows a page with more detailed information about rsids. Importantly, a data consumer can be confident that two APIs that reference the same URI are referring to the exact same concept.
Fig. 1.

A simplified version of JSON-LD context for MyVariant.info. In this JSON-LD context, selected keys from the response document of MyVariant.info API are mapped to identifiers.org URIs. The complete version can be found at: http://myvariant.info/context/context.json
Making data-structure neutral queries by URI
By using JSON-LD to define semantics in JSON documents, we found that JSON-LD could standardize and simplify the way we make queries in RESTful APIs. Most APIs are developed and maintained independently by different groups. And in most cases, API developers use different data representations and query syntax. Thus, a user has to read the API documentation and figure out the data structure and query syntax every time they need to handle a new API, which can be very time-consuming. For example, a user who would like to fetch the linked OMIM [15] disease IDs for a specific variant in MyVariant.info must first consult the JSON data schema, which would define the JSON field path of the OMIM ID (“clinvar.rcv.conditions.identifiers.omim”). Moreover, as services evolve, API developers often introduce incompatible changes in data structure between different versions, which would require API users to update their client code in order to properly handle the new JSON schema.
In contrast, an API that provides a JSON-LD context can be queried based on concept URIs in a way that is completely independent of the JSON data structure. Therefore, we adapted our biothings_client Python client [16] to use the JSON-LD context to translate data-structure neutral URIs into specific field locations within the JSON document[17]. In the example above, a user can simply query by the URI for OMIM ID (“http://identifiers.org/omim/”) without necessarily having to know the data source (ClinVar) and object structure. This pattern is demonstrated in Additional file 1. Although BioThings APIs are used in this demonstration, the JSON-LD processing procedure can be generalized to any JSON-based API that provides a JSON-LD context.
Data discrepancy check
Variant annotation is a crucial part of the next genome sequencing data analysis. Incorrect annotations can cause researchers both to overlook potentially pathogenic DNA variants and to dilute interesting variants in a pool of false positives. Looking for discrepancies in data between different resources can be one way to assess data quality.
A typical data discrepancy check procedure would first require the user to identify which data sources contain common data fields or identifiers (e.g. that dbNSFP and dbSNP both contain information about rsid). In addition, the user has to understand the query syntax and data structure of MyVariant.info in order to retrieve the data field from each data resource. JSON-LD, on the other hand, would greatly simplify the process by providing the semantic context of each data key. As shown in Additional file 2, we performed a data discrepancy check based only on the JSON-LD context file. We were able to quantify the extent of differences in annotation of over 424 million variants from multiple variant annotation databases, including ClinVar (2017–04 release), dbSNP (version 150), and dbNSFP (version 3.4a) [18]. Of the 424 million variants in MyVariant.info, we found 10,842 unique variants that had different rsids reported across the resources that were imported (Additional file 3). Because each rsid can be unambiguously mapped to a unique genome location, this analysis clearly reveals some database-specific discrepancies [19] (Additional file 4).
In addition to quality control, JSON-LD can also be utilized to conduct discovery-oriented queries. For example, we queried for variants with a high degree of variability in allele frequency in African populations as reported by 1000 genomes [20], ESP [21], and ExAC [22], a query that was greatly simplified by normalization to a common URI. We found 84 variants for which the reported allele frequency varied by more than 50% (Additional file 5), a list that could be notable for studying different selective pressures among African sub-populations.
Facilitate API cross linking
When JSON-LD contexts are used, annotating data between genes, variants and drugs can be seamlessly integrated together. For example, consider a use case where an upstream analysis identified two missense variants (“chr6:g.26093141G > A” and “chr12:g.111351981C > T” in hg19 genome assembly) related to a rare Mendelian disease. If an analyst wanted to obtain genes which the variant might affect as well as available drugs targeting these affected genes, he would have to query multiple BioThings APIs, e.g. MyGene.info which contains WikiPathways information, MyVariant.info which contains variant annotation information, as well as MyChem.info which contains drug annotation information. Thus, a typical workflow would involve the following steps (Fig. 2):
Query MyVariant.info to retrieve the annotation objects for variant “chr6:g.26093141G > A” and “chr12:g.111351981C > T”.
Parse the annotation objects to get the NCBI Gene IDs related to these variants from the dbsnp.gene.geneid field, which are “3077” and “4633”.
Query MyGene.info to retrieve the annotation objects for NCBI Gene “3077” and “4633”.
Parse the annotation objects to get the WikiPathways [23] IDs related to each gene from the pathway.wikipathways.id field.
Query MyGene.info again to retrieve annotation objects related to the WikiPathways IDs from step d.
Parse the query results to retrieve all UniProt IDs related to these WikiPathways IDs.
Query MyChem.info to retrieve the drug objects associated to the target proteins, using the UniProt IDs found in step f.
Fig. 2.

Typical workflow for finding treatments related to a rare Mendelian disease using multiple BioThings APIs. An upstream analysis first identified some variants related to a rare Mendelian disease. Next, the analyst wanted information about genes where these variants are located (step a, b). Then, from the genes, the analyst would like to know all the pathway information where these genes are involved (step c, d). Furthermore, the analyst would also like to know other genes involved in these pathways (step e, f). Finally, the analyst wanted to obtain information about all available treatment options (e.g. drugs) available targeting all these genes obtained in the previous steps (step g)
To perform this workflow, traditionally, users must first manually inspect the output or the documentation of MyGene.info, MyVariant.info and MyChem.info to identify the relevant JSON keys (e.g. dbsnp.gene.geneid and pathway.wikipathways.id).
An alternative approach utilizing JSON-LD greatly simplified the protocol (Fig. 3). We first created a BioThings API Registry that was constructed from the JSON-LD context files of all BioThings APIs [19]. The registry records information about the input and output type for each API (expressed as URIs) as well as the query syntax for each endpoint of BioThings APIs (as shown in Additional file 6). This registry was then used to help locate the right API to use when input/output type is specified. JSON-LD, on the other hand, could be utilized to construct the API query and extract the output from the JSON document. As demonstrated in Additional file 7, users no longer need to have any prior knowledge of API input and output data structures. It only requires the user to specify the URI for the input type (e.g. http://identifiers.org/ncbigene/) and the target output type (e.g. http://identifiers.org/wikipathways/). We implemented a Python function IdListHandler, as shown in the demo code, which automatically scans through the JSON-LD contexts provided from a list of APIs, currently demonstrated by our existing BioThings API (MyGene.info, MyVariant.info and MyChem.info). IdListHandler then selects the API which is able to perform the task and automatically executes the queries to return the desired output. As we are expanding the scope of BioThings API to cover additional biomedical entities (e.g. diseases, phenotypes), the power of this approach will continue to grow. Moreover, since the JSON-LD context can be provided by a third-party, not just the API providers, the mechanism we described here can be further extended to cross-link even broader scope of biomedical APIs.
Fig. 3.
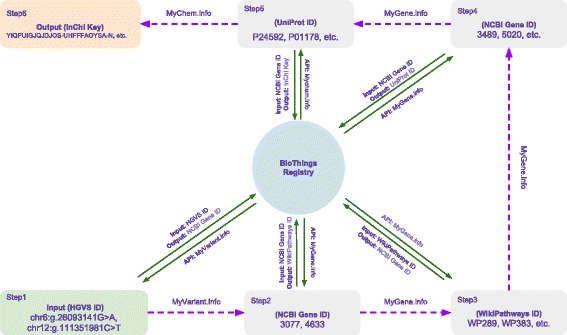
Workflow of using JSON-LD and BioThings API Registry to perform complex queries. By combining JSON-LD and BioThings API Registry, the Python function IdListHandler is able to select the API which is able to perform the task and automatically executes the queries to return the desired output. Users could easily get a list of drug candidates related to a rare Mendelian disease by the following path: HGVS ID → NCBI Gene ID → WikiPathways ID → NCBI Gene ID → UniProt ID → Drug InChI Key. It only requires the user to specify the input/output type at each step
Easy conversion to RDF
The Resource Description Framework (RDF) [24] has been widely used to describe, publish and link data in the life science domain. It generates a series of “triples” consisting of a subject, predicate and object.
A number of biomedical resources provide RDF to facilitate relationship exploration, such as Bio2RDF [25], Monarch [26], and Open PHACTS [27]. Since JSON-LD is simply a JSON-based representation of Linked Data, it is programmatically simple to export JSON-LD data into RDF for integration with other RDF-based resources (demonstrated in Additional file 8). JSON-LD offers a convenient method by which bioinformatics web services (like MyGene.info, MyVariant.info and MyChem.info) can be integrated with the network of Linked Data.
Discussion
The biomedical research community has seen a proliferation of web services in recent years. These services have become a primary route for the bioinformatics community to disseminate and consume data and analysis methods. Individually, these web services are very useful components of our informatics ecosystem. Nevertheless, there is growing appreciation that creating an integrated network of APIs would be an even more powerful resource that is greater than the sum of its parts.
Here, we demonstrate that JSON-LD is one technical solution for integration of web-based APIs. JSON-LD offers many advantages -- that it builds on the widely-used JSON data exchange format, that it itself is a W3C standard, and that it offers the potential of decoupling the authoring of semantic context from the serving of data. In fact, several biomedical tool providers have already introduced JSON-LD in their APIs, including Monarch Initiative [26], CEDAR [28], and UniProt [29].
Nevertheless, two key challenges remain before achieving broader adoption and the ability to address more complex biomedical use cases. First, there needs to be greater standardization of URIs for biological concepts. In addition to identifiers.org, other entities like health-lifesci.schema.org [30] and Bio2RDF provide URIs for biologically-relevant entities. As we generalize our approach to handle more complex biological concepts and relationships, we expect more specialized ontologies, such as RO [31] and SIO [32], to be adopted for API annotations. Second, a mechanism for expressing in a structured format the semantic nature between concepts and the provenance of such relationships would expand the richness of possible queries in a JSON-LD ecosystem, which could potentially be solved by the development of PROV-JSONLD [33].
The ultimate goal of the project is to extend the pattern described here beyond BioThings APIs and build a connected API ecosystem. This requires the integration of standards and technologies including OpenAPI specifications [34], which provides standardized descriptions for REST APIs, as well as EDAM [35], which provides an ontology of bioinformatics operations, types of data, etc. We also participated in the smartAPI project [36], which could serve as a formal mechanism to incorporate JSON-LD based semantic annotations into the OpenAPI based specifications, in order to generalize our approach to even broader range of the biological APIs.
Conclusions
We believe that the proof-of-concept presented here demonstrates that the JSON-LD pattern already has useful applications, and that adoption of this pattern would greatly expand the interoperability of biomedical web services.
Methods
URI repository
In our implementation, we used http://identifiers.org as the default URI repository. It is a URI repository specifically focused on the life science domain, currently maintained by The European Bioinformatics Institute. And it provides clean and reliable permanent URIs for most of the biological ID types used in BioThings APIs.
Creating JSON-LD context
JSON-LD context for each BioThings API is created by mapping each individual field name to a URI. For example, a field named “dbsnp.rsid” in MyVariant.info is mapped to http://identifiers.org/dbsnp/. Example BioThings API context could be found at http://myvariant.info/context/context.json.
API cross-linking
API cross-linking is made possible through the combination of BioThings API Registry and JSON-LD transformation.
BioThings API Registry records information about the input and output type accepted as well as the query syntax for each endpoint of BioThings APIs. It is utilized to find the right API given input and output type specified by the user.
JSON-LD transformation is performed using PyLD python package (version 0.7.2) [36]. When a JSON document is retrieved along with its JSON-LD context, JSON-LD transformation will convert the JSON document into N-Quads format where each value is mapped to an URI. Through N-Quads output, we can then extract the desired output data.
RDF transformation
RDF transformation is performed using PyLD python package (version 0.7.2) [37]. It is demonstrated using a Jupyter Notebook stored in GitHub (Additional file 8).
Additional files
A Jupyter Notebook demonstration of how to Make Data-structure Neutral Queries by URI. (HTML 256 kb)
A Jupyter Notebook demonstration of how to perform data discrepancy check using JSON-LD. (HTML 263 kb)
Table listings 10,842 unique variants that had different rsids reported across the resources recorded in MyVariant.info. (CSV 658 kb)
Figure showing an example of data discrepancy for rsid between different sources. Data discrepancy for rsid between different sources, e.g. dbNSFP, dbSNP and mutDB. The default assembly used in dbNSFP is hg38. And the hg19 genomic positions provided by dbNSFP were lifted over from its hg38 positions, which is corresponding to a different rsid (“rs542852754”) in this case from the one dbSNP provides (“rs7182058”). This suggests an error caused in the liftover process. (EPS 139 kb)
Table listing 84 variants for which the reported allele frequency varied by more than 50% across the resources recorded in MyVariant.info. (CSV 40 kb)
A Jupyter Notebook demonstration of BioThings API registry. (HTML 249 kb)
A Jupyter Notebook demonstration of how to cross-link BioThings APIs in order to perform complex queries across APIs. (HTML 270 kb)
A Jupyter Notebook demonstration of how to convert a JSON document from MyVariant.info into RDF using JSON-LD. (HTML 248 kb)
Acknowledgements
Not applicable.
Funding
This work was supported by the US National Institute of Health (https://www.nih.gov/) grant U01HG008473 to CW. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Availability of data and materials
The information for data, workflows and scripts used in the paper is available under an Apache software license at https://github.com/biothings/JSON-LD_BioThings_API_DEMO. This repo has also been deposited to Zenodo (https://zenodo.org/) with the assigned DOI: 10.5281/zenodo.1039892.
Abbreviations
- API
Application Programming Interfaces
- JSON
Javascript Object Notation
- JSON-LD
JSON for Linked Data
- RDF
Resource Description Framework
- URI
Universal Resource Identifier
Authors’ contributions
AIS, CW and JX conceived and designed the methodology. JX, SL, CA and JA performed the implementation and data analysis. GT coordinated the project outreach. JX wrote the paper, edited by AIS and CW. The work was supervised by AIS and CW. All authors read and approved the final manuscript.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Footnotes
Electronic supplementary material
The online version of this article (10.1186/s12859-018-2041-5) contains supplementary material, which is available to authorized users.
Contributor Information
Jiwen Xin, Email: kevinxin@scripps.edu.
Cyrus Afrasiabi, Email: cyrus@scripps.edu.
Sebastien Lelong, Email: slelong@scripps.edu.
Julee Adesara, Email: julee.soni87@gmail.com.
Ginger Tsueng, Email: gtsueng@scripps.edu.
Andrew I. Su, Email: asu@scripps.edu
Chunlei Wu, Email: cwu@scripps.edu.
References
- 1.Landrum MJ, Lee JM, Benson M, Brown G, Chao C, Chitipiralla S, et al. ClinVar: public archive of interpretations of clinically relevant variants. Nucleic Acids Res. 2016;44:D862–D868. doi: 10.1093/nar/gkv1222. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Sherry ST. dbSNP: the NCBI database of genetic variation. Nucleic Acids Res. 2001;29:308–311. doi: 10.1093/nar/29.1.308. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Kircher M, Witten DM, Jain P, O’Roak BJ, Cooper GM, Shendure J. A general framework for estimating the relative pathogenicity of human genetic variants. Nat Genet. 2014;46:310–315. doi: 10.1038/ng.2892. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Kinnings SL, Liu N, Buchmeier N, Tonge PJ, Xie L, Bourne PE. Drug discovery using chemical systems biology: repositioning the safe medicine Comtan to treat multi-drug and extensively drug resistant tuberculosis. PLoS Comput Biol. 2009;5:e1000423. doi: 10.1371/journal.pcbi.1000423. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.MyGene.info. MyGene.info. http://mygene.info/. Accessed 2 Nov 2017.
- 6.Xin J, Mark A, Afrasiabi C, Tsueng G, Juchler M, Gopal N, et al. High-performance web services for querying gene and variant annotation. Genome Biol. 2016;17:91. doi: 10.1186/s13059-016-0953-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.MyVariant.info. MyVariant.info. http://myvariant.info/. Accessed 2 Nov 2017.
- 8.MyChem.info Chemical/Drug Query v1 API. API Documentation. http://mychem.info/. Accessed 2 Nov 2017.
- 9.Wilkinson MD, Vandervalk B, McCarthy L. The Semantic Automated Discovery and Integration (SADI) Web service Design-Pattern. API and Reference Implementation. J Biomed Semantics. 2011;2:8. doi: 10.1186/2041-1480-2-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Lathem J, Gomadam K, Sheth AP. SA-REST and (S)mashups : Adding Semantics to RESTful Services. In: International Conference on Semantic Computing (ICSC 2007). 2007. 10.1109/icosc.2007.4338383.
- 11.JSON-LD - JSON for Linking Data. http://json-ld.org. Accessed 2 Nov 2017.
- 12.Su X, Riekki J, Nurminen JK, Nieminen J, Koskimies M. Adding semantics to internet of things. Concurr Comput. 2014;27:1844–1860. doi: 10.1002/cpe.3203. [DOI] [Google Scholar]
- 13.UniProt Consortium. Reorganizing the protein space at the Universal Protein Resource (UniProt). Nucleic Acids Res. 2012;40 Database issue:D71–5. [DOI] [PMC free article] [PubMed]
- 14.EMBL-EBI. Identifiers.org < EMBL-EBI. http://identifiers.org/. Accessed 2 Nov 2017.
- 15.OMIM - Online Mendelian Inheritance in Man. https://omim.org. Accessed 2 Nov 2017.
- 16.biothings. biothings/biothings_client.py. GitHub. https://github.com/biothings/biothings_client.py. Accessed 2 Nov 2017.
- 17.biothings-client 0.1.1 : Python Package Index. https://pypi.python.org/pypi/biothings-client/0.1.1. Accessed 2 Nov 2017.
- 18.Liu X, Wu C, Li C, Boerwinkle E. dbNSFP v3.0: A One-Stop Database of Functional Predictions and Annotations for Human Nonsynonymous and Splice-Site SNVs. Hum Mutat. 2016;37:235–241. doi: 10.1002/humu.22932. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.biothings. biothings/JSON-LD_BioThings_API_DEMO. GitHub. https://github.com/biothings/JSON-LD_BioThings_API_DEMO/blob/master/supplement/rsid_discrepancy_example.json. Accessed 2 Nov 2017.
- 20.1000 Genomes Project Consortium. Auton A, Brooks LD, Durbin RM, Garrison EP, Kang HM, et al. A global reference for human genetic variation. Nature. 2015;526:68–74. doi: 10.1038/nature15393. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Exome Variant Server. http://evs.gs.washington.edu/. Accessed 2 Nov 2017.
- 22.Lek M, Karczewski KJ, Minikel EV, Samocha KE, Banks E, Fennell T, et al. Analysis of protein-coding genetic variation in 60,706 humans. Nature. 2016;536:285–291. doi: 10.1038/nature19057. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Kutmon M, Riutta A, Nunes N, Hanspers K, Willighagen EL, Bohler A, et al. WikiPathways: capturing the full diversity of pathway knowledge. Nucleic Acids Res. 2016;44:D488–D494. doi: 10.1093/nar/gkv1024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.RDF - Semantic Web Standards. https://www.w3.org/RDF/. Accessed 2 Nov 2017.
- 25.Belleau F, Nolin M-A, Tourigny N, Rigault P, Morissette J. Bio2RDF: towards a mashup to build bioinformatics knowledge systems. J Biomed Inform. 2008;41:706–716. doi: 10.1016/j.jbi.2008.03.004. [DOI] [PubMed] [Google Scholar]
- 26.McMurry JA, Köhler S, Washington NL, Balhoff JP, Borromeo C, Brush M, et al. Navigating the Phenotype Frontier: The Monarch Initiative. Genetics. 2016;203:1491–1495. doi: 10.1534/genetics.116.188870. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Harland L. Open PHACTS: A Semantic Knowledge Infrastructure for Public and Commercial Drug Discovery Research. In: Lecture Notes in Computer Science; 2012. pp. 1–7. [Google Scholar]
- 28.Musen MA, Bean CA, Cheung K-H, Dumontier M, Durante KA, Gevaert O, et al. The center for expanded data annotation and retrieval. J Am Med Inform Assoc. 2015;22:1148–1152. doi: 10.1093/jamia/ocv048. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.The UniProt Consortium UniProt: the universal protein knowledgebase. Nucleic Acids Res. 2017;45:D158–D169. doi: 10.1093/nar/gkw1099. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Home - health-lifesci.schema.org. http://health-lifesci.schema.org/. Accessed 2 Nov 2017.
- 31.Smith B, Ashburner M, Rosse C, Bard J, Bug W, Ceusters W, et al. The OBO Foundry: coordinated evolution of ontologies to support biomedical data integration. Nat Biotechnol. 2007;25:1251–1255. doi: 10.1038/nbt1346. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Dumontier M, Baker CJ, Baran J, Callahan A, Chepelev L, Cruz-Toledo J, et al. The Semanticscience Integrated Ontology (SIO) for biomedical research and knowledge discovery. Journal of biomedical semantics. 2014;5:14. doi: 10.1186/2041-1480-5-14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Huynh TD, Michaelides DT, Moreau L. PROV-JSONLD: A JSON and Linked Data Representation for Provenance. In: Lecture Notes in Computer Science; 2016. [Google Scholar]
- 34.Home. Open API Initiative. https://www.openapis.org/. Accessed 2 Nov 2017.
- 35.Ison J, Kalas M, Jonassen I, Bolser D, Uludag M, McWilliam H, et al. EDAM: an ontology of bioinformatics operations, types of data and identifiers, topics and formats. Bioinformatics. 2013;29:1325–1332. doi: 10.1093/bioinformatics/btt113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Zaveri A, Dastgheib S, Wu C, Whetzel T, Verborgh R, Avillach P, et al. smartAPI: Towards a More Intelligent Network of Web APIs. 2017. pp. 154–169. [Google Scholar]
- 37.digitalbazaar. digitalbazaar/pyld. GitHub. https://github.com/digitalbazaar/pyld. Accessed 2 Nov 2017.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
A Jupyter Notebook demonstration of how to Make Data-structure Neutral Queries by URI. (HTML 256 kb)
A Jupyter Notebook demonstration of how to perform data discrepancy check using JSON-LD. (HTML 263 kb)
Table listings 10,842 unique variants that had different rsids reported across the resources recorded in MyVariant.info. (CSV 658 kb)
Figure showing an example of data discrepancy for rsid between different sources. Data discrepancy for rsid between different sources, e.g. dbNSFP, dbSNP and mutDB. The default assembly used in dbNSFP is hg38. And the hg19 genomic positions provided by dbNSFP were lifted over from its hg38 positions, which is corresponding to a different rsid (“rs542852754”) in this case from the one dbSNP provides (“rs7182058”). This suggests an error caused in the liftover process. (EPS 139 kb)
Table listing 84 variants for which the reported allele frequency varied by more than 50% across the resources recorded in MyVariant.info. (CSV 40 kb)
A Jupyter Notebook demonstration of BioThings API registry. (HTML 249 kb)
A Jupyter Notebook demonstration of how to cross-link BioThings APIs in order to perform complex queries across APIs. (HTML 270 kb)
A Jupyter Notebook demonstration of how to convert a JSON document from MyVariant.info into RDF using JSON-LD. (HTML 248 kb)
Data Availability Statement
The information for data, workflows and scripts used in the paper is available under an Apache software license at https://github.com/biothings/JSON-LD_BioThings_API_DEMO. This repo has also been deposited to Zenodo (https://zenodo.org/) with the assigned DOI: 10.5281/zenodo.1039892.