

Abstract
Purpose
To develop generic optimization strategies for image reconstruction using graphical processing units (GPUs) in magnetic resonance imaging (MRI) and to exemplarily report on our experience with a highly accelerated implementation of the nonlinear inversion (NLINV) algorithm for dynamic MRI with high frame rates.
Methods
The NLINV algorithm is optimized and ported to run on a multi-GPU single-node server. The algorithm is mapped to multiple GPUs by decomposing the data domain along the channel dimension. Furthermore, the algorithm is decomposed along the temporal domain by relaxing a temporal regularization constraint, allowing the algorithm to work on multiple frames in parallel. Finally, an autotuning method is presented that is capable of combining different decomposition variants to achieve optimal algorithm performance in different imaging scenarios.
Results
The algorithm is successfully ported to a multi-GPU system and allows online image reconstruction with high frame rates. Real-time reconstruction with low latency and frame rates up to 30 frames per second is demonstrated.
Conclusion
Novel parallel decomposition methods are presented which are applicable to many iterative algorithms for dynamic MRI. Using these methods to parallelize the NLINV algorithm on multiple GPUs, it is possible to achieve online image reconstruction with high frame rates.
1. Introduction
Accelerators such as graphical processing units (GPUs) or other multicore vector coprocessors are well-suited for achieving fast algorithm run times when applied to reconstruction problems in medical imaging [1] including computed tomography [2], positron emission tomography [3], and ultrasound [4]. This is because respective algorithms usually apply a massive number of the same independent operations on pixels, voxels, bins, or sampling points. The situation maps well to many-core vector coprocessors and their large number of wide floating-point units that are capable of executing operations on wide vectors in parallel. The memory bandwidth of accelerators is roughly one order of magnitude greater than that of central processing units; they are optimized for parallel throughput instead of latency of a single instruction stream.
Recent advances in magnetic resonance imaging (MRI) pose new challenges to the implementations of associated algorithms in order to keep data acquisition and reconstruction times on par. While acquisition times decrease dramatically as in real-time MRI, at the same time the data grows in size when using up to 64 or even 128 independent receiver channels on modern MRI systems. In addition, new modalities such as model-based reconstructions for (dynamic) parametric mapping increase the computational complexity of reconstruction algorithms because they in general involve iterative solutions to nonlinear inverse problems. As a consequence, accelerators are increasingly used to overcome these challenges [5–13].
Accelerators outperform main processors (CPUs) in all important operations during MRI reconstruction including interpolation [14], filtering [15], and basic linear algebra [16]. The central operation of most MRI reconstruction algorithms is the Fourier transform. Figure 1 shows the performance of the three FFT libraries cuFFT, clFFT, and FFTW [17]. The accelerator libraries cuFFT and clFFT outperform the CPU library FFTW. Consequently, accelerators outperform CPUs for MRI reconstruction, if the algorithm is based on the Fourier transform and if the ratio of computation to data transfer favours computation. Accelerator and CPU typically form distributed memory systems. Figure 2 shows the memory transfer speed for two different PCIe 3.0 systems in dependence of the data transfer size. The amount of computation assigned to an accelerator and the transfer size have a huge impact on the overall performance of the algorithm, which needs to be taken into account when implementing accelerated algorithms for image reconstruction. Another limiting factor for the use of accelerators in MRI is the restricted amount of memory available. Nevertheless, the on-board memory of accelerators increased in recent years and the newest generation of accelerators is equipped with acceptable amounts of memory (compare Table 1).
Figure 1.
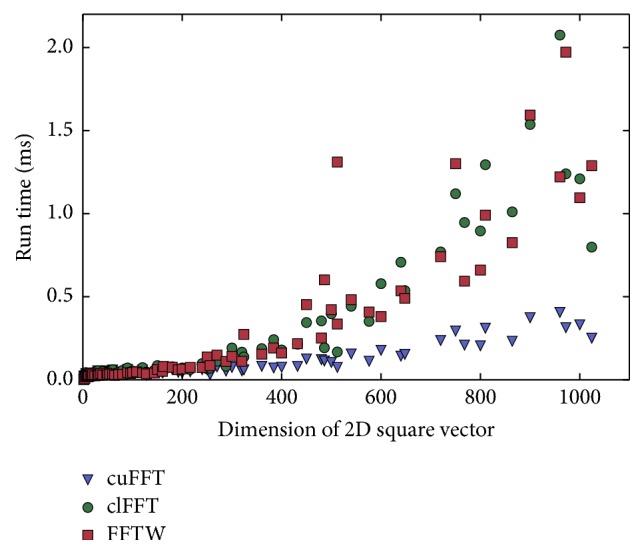
Run time (i.e., minimal wall-clock time in ms) measurement of a single-precision 2D squared complex-to-complex out-of-place Fourier transform of FFTW, clFFT, and cuFFT libraries. clFFT and cuFFT benchmarks were obtained for NVIDIA GeForce Titan Black; the FFTW benchmark was obtained for Intel Xeon E5-2650 utilizing 8 threads. FFTW is initialized with FFTW_MEASURE. The clFFT library has only limited support for mixed radix FFTs and achieves good performance for power of 2 FFTs only.
Figure 2.
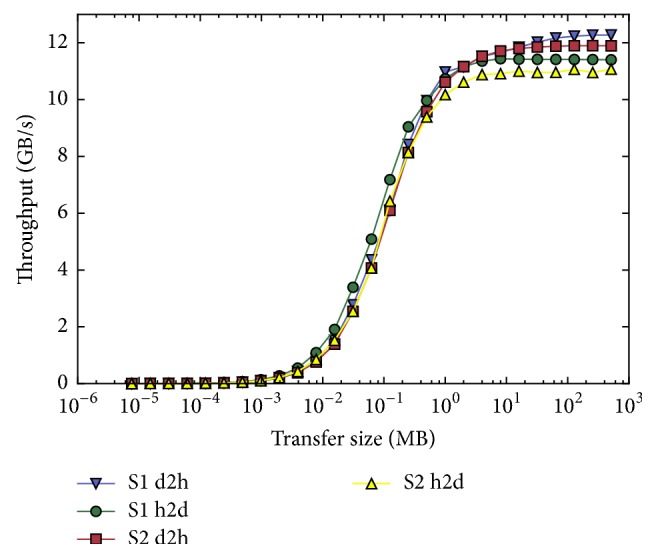
Throughput of Supermicro (S1) and Tyan (S2) 8x PCIe 3.0 systems: device-to-host and host-to-device transfer of nonpageable (pinned) memory with junk sizes between 8 bytes and 1 GB.
Table 1.
Memory, memory bandwidth, and single-precision performance of high performance computing (HPC) and consumer accelerators (source: Wikipedia).
| Vendor | Model | HPC | Memory | Bandwidth | Performance |
|---|---|---|---|---|---|
| NVIDIA | K40 | yes | 12 GB | 288 GB/s | 4.29 TFLOPS |
| NVIDIA | Titan Black | no | 6 GB | 336 GB/s | 5.12 TFLOPS |
| AMD | FirePro W9100 | yes | 16 GB | 320 GB/s | 5.24 TFLOPS |
| AMD | Radeon R9 290X | no | 6 GB | 320 GB/s | 5.63 TFLOPS |
| Intel | Xeon Phi 7120 | yes | 16 GB | 352 GB/s | 2.40 TFLOPS |
In this paper, we summarize our experience in developing a low-latency online reconstruction system for real-time MRI over the last eight years. While some of the described techniques have already been reported previously, this article for the first time explains all technical aspects of the complete multi-GPU implementation of the advanced iterative reconstruction algorithm and adds further background information and analysis. Although we focus on the specific application of real-time MRI, many of the techniques developed for this project can be applied to similar tomographic reconstruction problems. In particular, we describe strategies for optimal choice of the grid size for a convolution-based nonuniform FFT, novel parallelization schemes using temporal and spatial decomposition, and automatic tuning of parameters.
2. Theory
2.1. Real-Time MRI
Diagnostic imaging in real time represents a most demanding acquisition and reconstruction problem for MRI. In principle, the data acquisition refers to the recording of a large number of different radiofrequency signals in the time domain which are spatially encoded with the use of magnetic field gradients. The resulting dataset represents the k-space (or Fourier space) of the image. MRI acquisition times are determined by the number of different encodings needed for high-quality image reconstruction multiplied by the time required for recording a single MRI signal, that is, the so-called repetition time TR. While TR values could efficiently be reduced from seconds to milliseconds by the invention of low-flip angle gradient-echo MRI sequences, for example, see [18] for an early dynamic application, a further speed-up by reducing the number of encodings was limited by the properties of the Fourier transform which for insufficient coverage of k-space causes image blurring and/or aliasing artifacts. Reliable and robust improvements in acquisition speed by typically a factor of two were first achieved when parallel MRI techniques [19, 20] were introduced. These methods compensate for the loss of spatial information due to data undersampling by simultaneously acquiring multiple datasets with different receiver coils. In fact, when such multicoil arrangements are positioned around the desired field-of-view, for example, a head or thorax, each coil provides a dataset with a unique spatial sensitivity profile and thus complementary information. This redundancy may be exploited to recover the image from moderately undersampled k-space data and thus accelerate the scan.
Parallel MRI indeed was the first concept which changed the MRI reconstruction from a two-dimensional FFT to the solution of an inverse problem. To keep mathematics simple and computations fast, however, commercially available implementations turned the true nonlinear inverse problem, which emerges because the signal model contains the product of the desired complex image and all coil sensitivity profiles (i.e., complex images in themselves), into a linear inverse problem. This is accomplished by first determining the coil sensitivities with the use of a prescan or by performing a low-resolution Fourier transform reconstruction of acquisitions with full sampling in the center of k-space and undersampling only in outer regions.
Recent advances towards real-time MRI with so far unsurpassed spatiotemporal resolution and image quality [21] were therefore only possible by combining suitable acquisition techniques with an adequate image reconstruction. Crucial elements include the use of (i) rapid low-flip angle gradient-echo sequences, (ii) spatial encodings with radial rather than Cartesian trajectories, (iii) different (i.e., complementary) sets of spokes in successive frames of a dynamic acquisition (see Figure 3) [22], (iv) extreme data undersampling for each frame, (v) an image reconstruction algorithm (NLINV) that solves the nonlinear inverse problem (see below), and (vi) temporal regularization to the preceding frame which constrains the ill-conditioned numerical problem with physically plausible a priori knowledge. Real-time MRI with NLINV reconstruction achieves a temporal resolution of 10 to 40 ms per frame (i.e., 25 to 100 frames per second) depending on the actual application (e.g., anatomic imaging at different spatial resolutions or quantitative blood flow studies); for a recent review of cardiovascular applications, see [23].
Figure 3.
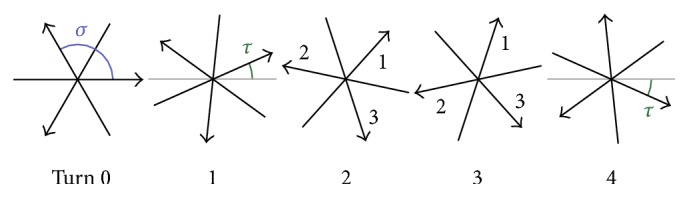
Schematic acquisition scheme for real-time MRI with U = 5 different sets of spokes, K = 3, σ = 2π/K, and τ = 2π/(KU).
The spatial encoding scheme is comprised of U different sets (turns) of K spokes. All U sets of spokes taken together cover the k-space uniformly. Figure 3 illustrates the real-time MRI encoding scheme.
2.2. Image Reconstruction with NLINV
If the receive coil sensitivities in parallel MRI are known, the image recovery emerges as a linear inverse problem which can efficiently be solved using iterative methods. In practice, however, static sensitivities are obtained through extrapolation and, even more importantly, in a dynamic in vivo setting they change due to coupling with the conductive tissue: this situation applies to a human subject during any type of movement (e.g., breathing or cardiac-related processes) or when dynamically scanning different planes and orientations (e.g., during real-time monitoring of minimally invasive procedures).
In such situations, extrapolating static sensitivities is not sufficient. The sensitivities have to be jointly estimated together with the image, yielding an inverse reconstruction problem that is nonlinear and ill-posed. For real-time MRI, both the dynamic changes during a physiologic process and the need for extremely undersampled datasets (e.g., by a factor of 20) inevitably lead to a nonlinear inverse problem.
A powerful solution to this problem is the regularized nonlinear inverse reconstruction algorithm [24]. NLINV formulates the image reconstruction as a nonlinear least-squares problem
| (1) |
The nonlinear forward operator F = ℱ∘C maps the combined vector x of the unknown complex-valued image ρ and all coil sensitivities cj (i.e., complex-valued images in themselves) to the data. C multiplies the image with the sensitivities to obtain individual coil images cjρ and ℱ then predicts the k-space data using a nonuniform Fourier transform for all coil elements j = 1,…, J (this nonuniform FFT is implemented here with a uniform FFT and convolution with the PSF [25], which is especially advantageous for implementation on a GPU [9]). The data fidelity term quantifies the difference between this predicted data and the measured data in the least-squares sense, while the additional regularization term addresses the ill-posedness of the reconstruction problem. Here, W is a weighting matrix in the Fourier domain which characterizes the spatial smoothness of the coil sensitivities and does not change the image component of x. For dynamic imaging, temporal regularization to the immediately preceding frame xprev, which exploits the temporal continuity of a human movement or physiologic process, allows for a remarkably high degree of data undersampling or image acceleration [21].
In the following, the main steps of an efficient numerical implementation are described; for further details, see [9, 21]. First, a change of variables and is done to improve the conditioning of the reconstruction problem. Starting from an initial guess x0, the numerical problem is then solved using the iteratively regularized Gauss-Newton method (IRGNM), which uses the following linear update rule:
| (2) |
Here, denotes the derivative of at and its adjoint. In each of the M Newton steps, this linear system of equations is solved using the method of conjugate gradients (CG). The main operation in a matrix-free implementation is the repeated application of the operator
| (3) |
with
| (4) |
The star ⋆ means complex conjugation. ℱb and Wb are the blocks of the block-diagonal operations ℱ and W which operate on a single channel. Because the nonuniform Fourier transform is paired with its adjoint, it can be implemented efficiently as a truncated convolution with a point-spread function using two applications of an FFT algorithm on a twofold oversampled grid [25]. W is implemented using one FFT followed by the application of a diagonal weighting matrix. Thus, a single iteration requires 4 applications of an FFT algorithm per channel, several pixelwise complex multiplications and additions, and one pixel-by-pixel reduction across all channels (∑j=1J). A flowchart can be found in Figure 4.
Figure 4.

Flowchart of the operator . The implementation of the weighting matrix W−1 and its adjoint W−H applies a diagonal weighting matrix DW−1 and a forward or inverse fast Fourier transform (FFT, iFFT) for each channel. The derivative of the multiplication of the image ρ and the coil sensitivities cj and its adjoint are composed of pointwise multiplication (∗), addition (+), and summation (∑) operations. The combination of the nonuniform Fourier transform and its adjoint ℱHℱ is implemented as a convolution with the point-spread function, consisting of a mask (msk) restricting the oversampled grid to the field of view, application of fast Fourier transform and its inverse, and a pointwise multiplication with the convolution kernel (P). Padding (pad) and cropping (crop) operations are used to reduce computational cost in the overall iterative algorithm.
The NLINV algorithm is an iterative algorithm consisting of operators F, , and as well as the conjugate-gradient method. Depending on the imaging scenario, the number of Newton steps is fixed to 6 to 10. F is only computed once per Newton step. and are applied in each conjugate-gradient iteration. Each operator applies a 2D FFT twice on per-channel data. F computes a scalar product once; the conjugate gradient method contains two scalar products over all channel data. Furthermore each operator applies between 4 and 6 elementwise operations and contains a summation over channel data. The performance of the Fourier transform dominates the run time of a single inner-loop iteration of the algorithm and it has to be applied 4 times in each inner loop.
If 10 channels are assumed, 6 Newton steps are computed (yielding roughly 50 conjugate-gradient iterations); 10∗4∗50 = 2000 2D Fourier transformations must be applied to compute a single image. If data is acquired at a frame rate of 30 fps, the reconstruction system must be able to apply 60000 2D Fourier transforms per second.
3. Optimization Methods and Results
The following section outlines several steps undertaken to move a prototype implementation of the NLINV algorithm to a highly accelerated implementation for use in an online reconstruction pipeline. The original implementation in C utilizes the CUDA framework and is capable of reconstructing at speeds of 1 to 5 fps on a single GPU. A typical clinical scenario in real-time MRI is cardiac imaging where a rate of 30 per second is necessary. To incorporate real-time heart examination in a clinical work-flow, the image reconstruction algorithm must perform accordingly.
The optimization techniques are classified into two categories. The first category encompasses platform independent optimization procedures that reduce the overall computational cost of the algorithm by reducing vector sizes while maintaining image quality. In the second category, the algorithm is modified to take advantage of the multi-GPU computer platform by channel decomposition, temporal decomposition, and tuning of the two techniques to yield best performance for a given imaging scenario.
All benchmark results show the minimum wall-clock time of a number of runs. For microbenchmarks, hundreds of runs were performed. For full reconstruction benchmarks, tens of runs were performed. The speed-up S is defined as the quotient of the old wall-clock time told over the new time tnew
| (5) |
and parallel efficiency E is defined as
| (6) |
with Sp representing the speed-up achieved when using p accelerators over 1. Perfect efficiency is achieved when Sp = p or E = 1; sublinear speed-up is measured if Sp < p and E < 1.
If not stated otherwise, all benchmarks were obtained on a Supermicro SuperServer 4027GR-TR system with PCIe 3.0, 2x Intel Xeon Ivy Bridge-EP E5-2650 main processors, 8x NVIDIA Titan Black (Kepler GK110) accelerators with 6 GB graphics memory each, and 128 GB main system memory. Custom GPU power cables were fabricated for the Supermicro system to support consumer-grade accelerators. The CUDA run time environment version was 6.5 with GPU driver version 346.46. The operating system used was Ubuntu 14.04. The combined single-precision performance of the eight GPUs in this system approaches 41 TFLOPS and the combined memory bandwidth is 2688 Gb/s. For a comparison of the performances of some accelerators available at the time of writing of the article, see Table 1.
3.1. Real-Time Pipeline
The real-time NLINV reconstruction algorithm is part of a larger signal processing pipeline that can be decomposed into several stages:
Datasource: reading of input data into memory
Preprocessing: interpolating data acquired with a non-Cartesian trajectory onto a rectangular grid, correcting for gradient delays as well as performing the channel compression; this stage contains a calibration phase that calculates the channel compression transform matrix and estimates the gradient delay
Reconstruction: the NLINV algorithm, reconstructing each image
Postprocessing: cropping of the image to the measured field of view, calculation of phase-difference image (in case of phase-contrast flow MRI), and applying temporal and spatial filters
Datasink: writing of resulting image to output.
Real-time MRI datasets with high temporal resolution typically contain several hundreds of frames even when covering only a few seconds of imaging. For this reason, it is beneficial to parallelize the pipeline at the level of these functional stages: each stage can work on a different frame, or, in other words, different frames are processed by different stages of the pipeline in parallel. The implementation of such a pipeline follows the actor model [26] where each pipeline stage is one (or multiple, see temporal decomposition in Section 3.3) actor, receiving input data from the previous stage as message and passing results to the following stage as a different message. The first actor and the last actor only produce (datasource) and receive (datasink) messages, respectively.
Figure 5 shows the NLINV pipeline for reconstructing 10 frames. The pipeline has a prologue and an epilogue of 4 frames (number of pipeline stages minus one) where full parallel reconstruction is not possible because the pipeline is filling up or emptying.
Figure 5.
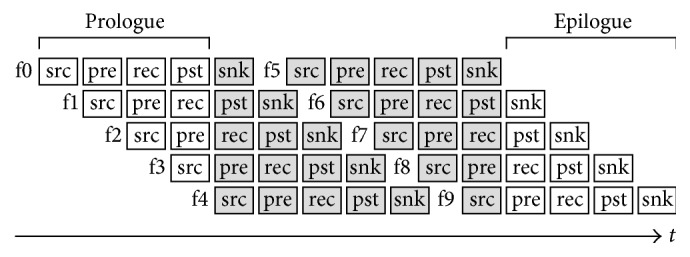
The NLINV reconstruction pipeline consists of 5 stages: datasource (src), preprocessing (pre), reconstruction (rec), postprocessing (pst) and datasink (snk). New frames (f0 through f9) enter the pipeline through the datasource and leave the pipeline through the datasink. A filled pipeline processes 5 frames at the same time by using 5 threads, one for each pipeline stage.
3.2. Computational Cost Reduction
The most compute-intensive part of the NLINV algorithm is the application of the Fourier transform. NLINV applies the Fourier transform multiple times in each iteration. Fast execution of the Fourier transform has thus a major impact on the overall run time of the algorithm. The FFT library cuFFT [27] of the hardware vendor is used. Plotting the performance of the FFT libraries against the input vector size does not yield a linear function, but shows significant fluctuation (compare Figure 6). The algorithm performs better for vector sizes which are factorizable by small prime numbers, with the smallest prime numbers yielding the best results.
Figure 6.
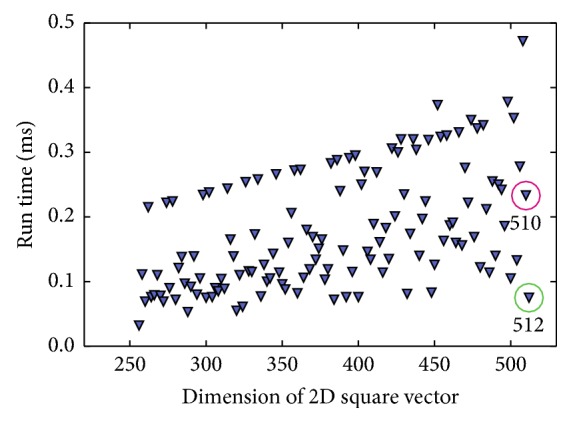
Run time in ms of a single-precision 2D complex-to-complex out-of-place squared Fourier transform calculated using cuFFT. The plot shows run times as a function of vector size and highlights the run time difference between a 5102 vector (red) and 5122 vector (green). The plotted data ranges from 2562 to 5122.
The grid oversampling ratio defines the ratio of grid sample locations G over the side length of the output image N. The ratio between N and G includes an inherent factor of 2 that exists as the convolution with the point-spread function requires twofold oversampling. An additional factor γ can be set to values between 1 and 2 to prevent aliasing artifacts for situations where the operator chooses a field of view smaller than the object size. The relationship of N to G is thus defined as
| (7) |
In the following, only γ is specified. It is found that considering the constraints of the FFT algorithm when choosing γ can yield calculation speed-ups. A lookup table is generated that maps grid size to FFT performance by benchmarking the Fourier transform algorithm for all relevant input sizes. This lookup table is generated for different accelerator generations as well as for new versions of the FFT library. The grid oversampling ratio is adjusted according to the highest measured FFT performance with a minimum oversampling ratio of γ ≥ 1.4. Table 2 shows the speed-up when comparing to a fixed oversampling ratio of 1.5. Figure 6 is a graphical representation of the lookup table that is used to select optimal grid sizes. It highlights the run time difference between two very similar vector sizes of 5102 (2∗3∗5∗17) and 5122 (29).
Table 2.
Reconstruction times in fps for various image sizes with side length N and fixed versus variable oversampling ratio γ. For some input sizes, 1.5 is the optimal value (N = 128, N = 144); for other sizes, the number of grid sample locations must be increased to yield a speed-up (N = 160, N = 170). For a third group of image sizes (N = 256), the optimal FFT size increases the size of the data to a degree that the speed-up is reduced or even nullified by additional overhead. For each test case, 200 frames were reconstructed using 1 accelerator.
| N | Fixed γ = 1.5 | Optimal γ ≥ 1.4 | S | |||
|---|---|---|---|---|---|---|
| G | fps | γ | G | fps | ||
| 128 | 384 | 8.1 | 1.5 | 384 | 8.3 | 1.02 |
| 144 | 432 | 2.5 | 1.5 | 432 | 2.5 | 1.00 |
| 160 | 480 | 4.4 | 1.51875 | 486 | 5.0 | 1.25 |
| 170 | 510 | 2.5 | 1.50588 | 512 | 5.8 | 2.32 |
| 256 | 768 | 2.4 | 1.53125 | 784 | 2.4 | 1.00 |
The NLINV algorithm estimates not only the spin-density map ρ, but also the coil sensitivity profiles cj. The regularization term added to the Gauss-Newton solver constrains the cj coil sensitivity profiles to a few low-frequency components. It is thus possible to not store the entire vector cj, but to reduce its size to (1/4)2 of the original. The number of grid sample locations G is thus reduced to Gc = ⌊(1/4)G⌋ for the coil sensitivity profiles cj. Whenever the original size is required, the vector is padded with zeroes. Figure 7 shows a typical weighting function in 1D as applied to cj and the cut-off that is not stored after this optimization. This saves computing time as functions applied on cj have to compute less. For this technique to yield a speed-up, the computation time saved must exceed the time required to crop and pad the vectors. Table 3 shows the speed-up achieved by this optimization for various data sizes.
Figure 7.
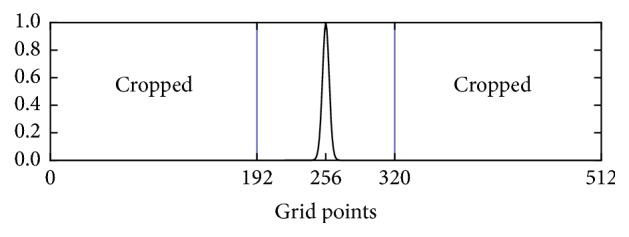
The k-space weight function (1 + 880|k|2)16 with −0.5 < kx, ky < 0.5 is plotted in 1D for a grid size of 5122 with cropping to 25% of the original. The lowest frequency is at the center.
Table 3.
Speed-up S by cropping the 2D vector of size length N of coil sensitivity profiles by a factor of (1/4)2.
| N | G c = G | Reduced Gc = ⌊(1/4)G⌋ | S | ||
|---|---|---|---|---|---|
| G c | fps | G c | fps | ||
| 128 | 384 | 18.1 | 96 | 25.8 | 1.43 |
| 144 | 432 | 10.1 | 108 | 13.0 | 1.29 |
| 160 | 486 | 11.9 | 121 | 17.9 | 1.50 |
| 170 | 512 | 13.4 | 128 | 20.1 | 1.50 |
| 256 | 784 | 6.1 | 196 | 9.7 | 1.59 |
3.3. High-Level Parallelization with Autotuning
In parallel MRI, the reconstruction problem can be partitioned across the domain of multiple receive channels used for signal reception [10]. The measured data yj, corresponding coil sensitivity maps cj, and associated intermediate variables can be assigned to different accelerators A. The image ρ has to be duplicated on all accelerators. The sum ∑jJcj⋆tj is partitioned across accelerators according to
| (8) |
where Ja is the subset of channels assigned to accelerator a. This summation amounts to an all-reduce operation, since all accelerators require the computed updates to ρ. An alternative decomposition would require communication between GPUs within the FFT operation which is not feasible for the typical vector dimensions in this problem. The resulting speed-up from this parallel decomposition originates from the fact that the FFT of all channels can be computed in parallel. With only one accelerator, all J Fourier transforms have to be computed by a single accelerator with a batch size equal to J. A batched FFT computes multiple FFTs of the same size and type on multiple blocks of memory either in parallel or in a sequential manner. With multiple accelerators, J is divided by the number of accelerators A. This is illustrated in Table 4 depicting the computation time of Fourier transforms of 10 2D vectors of various side lengths N for different numbers of GPUs.
Table 4.
Computation time t in μs and parallel efficiency E of the Fourier transform of 10 2D vectors of side length N calculated using the cuFFT batched mode.
| N | 1 GPU | 2 GPUs | 3 GPUs | 4 GPUs | |||
|---|---|---|---|---|---|---|---|
| t | t | E | t | E | t | E | |
| 384 | 429 | 230 | 0.93 | 189 | 0.76 | 152 | 0.71 |
| 432 | 532 | 280 | 0.95 | 228 | 0.78 | 178 | 0.75 |
| 486 | 730 | 387 | 0.94 | 320 | 0.76 | 251 | 0.73 |
| 512 | 555 | 288 | 0.96 | 233 | 0.79 | 179 | 0.78 |
| 784 | 1699 | 865 | 0.98 | 697 | 0.81 | 529 | 0.80 |
The parallel efficiency of distributing a batched FFT across devices decreases from two to three and four accelerators, because an accelerator can compute multiple 2D FFTs at the same time. In addition, the NLINV implementation uses 10 compressed channels which cannot be divided by 3 or 4 with no remainder.
Furthermore, the speed-up is reduced by the communication overhead of calculating ∑a=1A which increases with the number of accelerators. Table 5 shows the reconstruction speed and speed-up for differently sized datasets and varying number of accelerators. To reduce the communication overhead, a peer-to-peer communication technique is employed that allows accelerators to directly access memory of neighbouring accelerators. This is only possible, if accelerators share a PCIe domain. The Supermicro system has 2 PCIe domains that each connect 4 accelerators. The maximum effective number of accelerators that different channels are assigned to is therefore 4.
Table 5.
Image reconstruction speed (fps), relative speed-up Srel, and overall speed-up Sov for different numbers of GPUs and differently sized datasets.
| N | 1 GPU | 2 GPUs | 3 GPUs | 4 GPUs | S ov | |||
|---|---|---|---|---|---|---|---|---|
| fps | fps | S rel | fps | S rel | fps | S rel | ||
| 128 | 8.3 | 13.1 | 1.6 | 13.5 | 1.0 | 13.8 | 1.0 | 1.7 |
| 144 | 2.5 | 3.9 | 1.6 | 4.1 | 1.0 | 4.2 | 1.0 | 1.7 |
| 160 | 5.0 | 8.3 | 1.6 | 8.7 | 1.1 | 9.1 | 1.0 | 1.8 |
| 170 | 6.0 | 9.6 | 1.6 | 10.1 | 1.0 | 10.1 | 1.0 | 1.7 |
| 256 | 2.4 | 3.8 | 1.6 | 4.5 | 1.2 | 4.7 | 1.1 | 2.0 |
Because the parallel efficiency of the channel decomposition is limited, investigations focused on decomposing the problem along the temporal domain which results in reconstructions of multiple frames at the same time. The standard formulation of the NLINV algorithm prohibits a problem decomposition along the temporal domain. Frame n must strictly follow frame n − 1 as xn−1 serves as starting and iterative regularization value for xn. While maintaining the necessary temporal order, a slight relaxation of the temporal regularization constraint allows for the reconstruction of multiple frames at the same time. The following scheme ensures that the difference in the results of in-order and out-of-order image reconstruction remains minimal. The first frame n = 0 is defined with ρ set to unity and cj set to zero. The function h maps frame n for each n > 0 and Newton step m to initialization and regularizations values xh(n, m):
| (9) |
Due to the complementary data acquisition pattern for sequential frames, the initial frames are of poor quality. The first l images of a series are thus reconstructed in a strict in-order sequence. This allows the algorithm to reach the best image quality in the shortest amount of time. From frame l + 1 on, frames may be reconstructed in parallel. Initialization and regularization values are chosen to be the most recent available frame within the range [n − o, n − 1]. The only exception is regularization values in the last Newton step m = M − 1, where xn−1 must be used for regularization. The algorithm thus waits for frame n − 1 to be computed before proceeding to the last Newton step (compare Figure 8). Experimental validation shows that the best match of in-order and out-of-order processing while maintaining a speed-up can be achieved by setting l to the number of turns and o to roughly half the number of turns in the interleaved sampling scheme.
Figure 8.
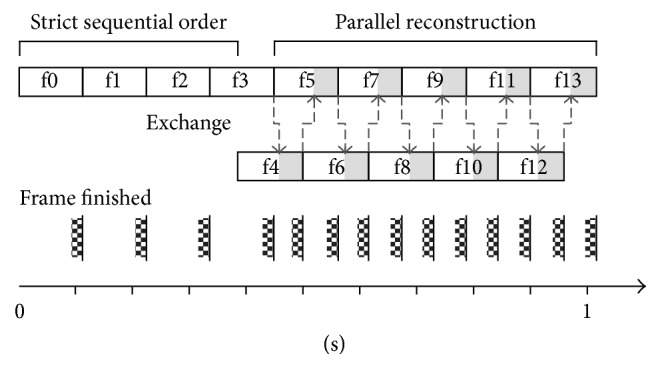
Temporal decomposition when reconstructing 14 frames. The first 4 frames are reconstructed in strict sequential order, while following images are reconstructed by two threads in parallel. Data is exchanged between threads for the last iteration (i.e., Newton step, grey segment) of each frame. This last iterative calculation takes the longest time as the CG algorithm requires more time to solve the system of equations. The frame rate is almost doubled by parallel reconstruction in this example.
Channel decomposition and temporal decomposition can be applied for different imaging situations in different ways. Depending on the acquisition and reconstruction parameters, the number of reconstruction threads T (temporal decomposition) and the number of accelerators per reconstruction thread A (channel decomposition) can be adjusted. A prerequisite to this method is that all (T, A) settings yield the same image quality. The parameters Pacqu and Preco that have the most impact on image reconstruction speed include
the imaging mode: single-slice anatomy, multislice anatomy, and phase-contrast flow,
the data size which depends on the field of view and the chosen resolution,
the number of frames acquired,
the number of virtual channels used.
The number of parameters and the ever-evolving measurement protocols in a research setting make it difficult to come up with a model that maps the set of acquisition and reconstruction parameters to the optimal set of parallelization parameters (Pacqu, Preco) → (T, A). Therefore, an autotuning mechanism is employed: The algorithm measures its own run time R and stores its performance along with all acquisition, reconstruction, and parallelization parameters in a database (Pacqu, Preco) → (T, A) → R. For a given set of (Pacqu and Preco), the autotuning mechanism can select all recorded run times R, sort them, and select the set of parallelization parameters (T, A) that yields the best performance.
The autotuning has an optional learning mode to populate the database with varying parallelization parameters (T, A). If the learning mode is active, the algorithm searches the database for matching performance data and chooses parallelization arguments that do not yet exist in the database. The search space for (T, A) is limited; there are only 16 sets of arguments for the 8-fold GPU reconstruction system used here. The reason for this is the restriction of the channel decomposition stage to the size of the PCIe domain due to peer-to-peer memory access. If A = 1 then T = [1,2, 3,4, 5,6, 7,8], if A = 2, then T = [1,2, 3,4], and if A = [3,4] then T = [1,2]. Table 6 shows an excerpt from the autotuning database.
Table 6.
Autotuning for reconstructing single-slice, dual-slice, and phase-contrast flow MRI acquisitions. N = 160 for all datasets results in a grid size of 4862.
| Single-slice anatomic MRI | ||||||
|---|---|---|---|---|---|---|
| Worst configuration | Best configuration | |||||
| Frames | Threads | GPUs/thread | Fps | Threads | GPUs/thread | Fps |
| 5 | 2 | 4 | 1.9 | 1 | 2 | 3.7 |
| 10 | 2 | 4 | 3.0 | 1 | 2 | 5.0 |
| 25 | 1 | 1 | 4.7 | 2 | 2 | 7.7 |
| 50 | 1 | 1 | 4.9 | 3 | 2 | 11.0 |
| 200 | 1 | 1 | 4.9 | 3 | 2 | 18.1 |
|
| ||||||
| Dual-slice anatomic MRI | ||||||
| Worst configuration | Best configuration | |||||
| Frames | Threads | GPUs/thread | Fps | Threads | GPUs/thread | Fps |
|
| ||||||
| 5 | 2 | 4 | 3.2 | 2 | 1 | 5.9 |
| 10 | 1 | 1 | 4.6 | 2 | 2 | 8.0 |
| 25 | 1 | 1 | 5.0 | 4 | 2 | 12.3 |
| 50 | 1 | 1 | 5.1 | 4 | 2 | 18.4 |
| 200 | 1 | 1 | 5.1 | 4 | 2 | 28.1 |
|
| ||||||
| Phase-contrast flow MRI | ||||||
| Worst configuration | Best configuration | |||||
| Frames | Threads | GPUs/thread | Fps | Threads | GPUs/thread | Fps |
|
| ||||||
| 5 | 2 | 4 | 1.6 | 2 | 1 | 2.6 |
| 10 | 1 | 1 | 1.8 | 2 | 2 | 3.6 |
| 25 | 1 | 1 | 1.9 | 4 | 2 | 5.8 |
| 50 | 1 | 1 | 1.9 | 4 | 2 | 7.5 |
| 200 | 1 | 1 | 1.9 | 4 | 2 | 10.7 |
In a clinical setting, all relevant protocols may undergo a learning phase populating the database and covering the entire search space. This can be done in a setup phase to ensure optimal run times for all clinical scans. The algorithm is also capable of sorting acquisition and reconstruction parameters. This allows the autotuning mechanism to find good (T, A) parameters for new measurement protocols it has never seen before.
4. Discussion
This work describes the successful development of a highly parallelized implementation of the NLINV algorithm for real-time MRI where dynamic image series are reconstructed, displayed, and stored with little or almost no delay. The computationally demanding iterative algorithm for dynamic MRI was decomposed and mapped to massive parallel hardware. This implementation is deployed to several research groups and represents a cornerstone for the evaluation of the clinical relevance of a variety of real-time MRI applications, mainly in the field of cardiac MRI [23, 28], quantitative phase-contrast flow MRI [29, 30], and novel fields such as oropharyngeal functions during swallowing [31], speaking [32], and brass playing [33].
As examples, Supplementary Videos 1 and 2 show T1-weighted radial FLASH MRI acquisitions at 33.32 ms acquisition time (TR = 1.96 ms, 17 radial spokes covering k-space) of a human heart in a short-axis view and midsagittal tongue movements of an elite horn player, respectively. The cardiac example employed a 256 × 256 mm3 field of view, 1.6 mm in-plane resolution (6 mm slice thickness), and N = 160 data samples per spoke (i.e., grid size) which resulted in a slightly delayed reconstruction speed of about 22 fps versus 30 fps acquisition speed. In contrast, the horn study yielded real-time reconstruction speed of 30 fps because of a slightly smaller 192 × 192 mm3 field of view at 1.4 mm in-plane resolution (8 mm slice thickness) and only N = 136 samples per spoke.
Some of the optimization methods discussed here are specific to real-time MRI algorithms, but the majority of techniques translate well to other MRI applications or even to other medical imaging modalities. Functional decomposition can be employed in any signal or image processing pipeline that is built on multiple processing units like multicore CPUs, heterogeneous systems, or distributed systems comprised of FPGAs, digital signal processors, microprocessors, ASICs, and so on. Autotuning is another generic technique that can be useful in many other applications: if an algorithm implementation exposes parallelization parameters (number of threads, number of GPUs, distribution ratios, etc.), it can be tuned for each imaging scenario and each platform individually. The grid size optimization technique can also be universally employed: if an algorithm allows choosing the data size (within certain boundaries) due to regridding or interpolation, the grid size should be chosen such that the following processing steps exhibit optimal performance. This is valuable, if the following processing steps do not exhibit linear performance such as specific FFT implementations.
5. Conclusion
Novel parallel decomposition methods are presented which are applicable to many iterative algorithms for dynamic MRI. Using these methods to parallelize the NLINV algorithm on multiple GPUs, it is possible to achieve online image reconstruction with high frame rates. For suitable parameters choices, real-time reconstruction can be achieved.
Acknowledgments
The authors acknowledge the support by the German Research Foundation and the Open Access Publication Funds of Göttingen University.
Conflicts of Interest
Martin Uecker and Jens Frahm hold a patent about the real-time MRI acquisition and reconstruction technique discussed here. All other authors declare that they have no conflicts of interest.
Supplementary Materials
Video S1: T1-weighted radial FLASH MRI acquisitions with NLINV reconstruction at 33.32 ms acquisition time (TR = 1.96 ms, 17 radial spokes) of a human heart in a short-axis view (256 × 256 mm3 field of view, 1.6 mm in-plane resolution, and 6 mm slice thickness).
Video S2: T1-weighted radial FLASH MRI acquisitions with NLINV reconstruction at 33.32 ms acquisition time (TR = 1.96 ms, 17 radial spokes) of midsagittal tongue movements of an elite horn player (192 × 192 mm3 field of view at 1.4 mm in-plane resolution, and 8 mm slice thickness).
References
- 1.Eklund A., Dufort P., Forsberg D., LaConte S. M. Medical image processing on the GPU—Past, present and future. Medical Image Analysis. 2013;17(8):1073–1094. doi: 10.1016/j.media.2013.05.008. [DOI] [PubMed] [Google Scholar]
- 2.Scherl H., Keck B., Kowarschik M., Hornegger J. Fast GPU-based CT reconstruction using the Common Unified Device Architecture (CUDA). Proceedings of the IEEE Nuclear Science Symposium, Medical Imaging Conference; November 2007; Honolulu, Hawaii, USA. pp. 4464–4466. [DOI] [Google Scholar]
- 3.Schaetz S., Kucera M. Integration of gpgpu methods into a pet reconstruction system. Proceedings of the 9th IASTED International Conference on Parallel and Distributed Computing and Networks, PDCN 2010; February 2010; aut. pp. 49–58. [Google Scholar]
- 4.Dai Y., Tian J., Dong D., Yan G., Zheng H. Real-time visualized freehand 3D ultrasound reconstruction based on GPU. IEEE Transactions on Information Technology in Biomedicine. 2010;14(6):1338–1345. doi: 10.1109/TITB.2010.2072993. [DOI] [PubMed] [Google Scholar]
- 5.Stone S. S., Haldar J. P., Tsao S. C., Hwu W.-M. W., Sutton B. P., Liang Z.-P. Accelerating advanced MRI reconstructions on GPUs. Journal of Parallel and Distributed Computing. 2008;68(10):1307–1318. doi: 10.1016/j.jpdc.2008.05.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Hansen M. S., Atkinson D., Sorensen T. S. Cartesian SENSE and k-t SENSE reconstruction using commodity graphics hardware. Magnetic Resonance in Medicine. 2008;59(3):463–468. doi: 10.1002/mrm.21523. [DOI] [PubMed] [Google Scholar]
- 7.Gai J., Obeid N., Holtrop J. L., et al. More IMPATIENT: A gridding-accelerated Toeplitz-based strategy for non-Cartesian high-resolution 3D MRI on GPUs. Journal of Parallel and Distributed Computing. 2013;73(5):686–697. doi: 10.1016/j.jpdc.2013.01.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Sorensen T. S., Atkinson D., Schaeffter T., Hansen M. S. Real-time reconstruction of sensitivity encoded radial magnetic resonance imaging using a graphics processing unit. IEEE Transactions on Medical Imaging. 2009;28(12):1974–1985. doi: 10.1109/TMI.2009.2027118. [DOI] [PubMed] [Google Scholar]
- 9.Uecker M., Zhang S., Frahm J. Nonlinear inverse reconstruction for real-time MRI of the human heart using undersampled radial FLASH. Magnetic Resonance in Medicine. 2010;63(6):1456–1462. doi: 10.1002/mrm.22453. [DOI] [PubMed] [Google Scholar]
- 10.Schaetz S., Uecker M. Algorithms and Architectures for Parallel Processing. Vol. 7439. Berlin, Heidelberg: Springer Berlin Heidelberg; 2012. A Multi-GPU Programming Library for Real-Time Applications; pp. 114–128. (Lecture Notes in Computer Science). [DOI] [Google Scholar]
- 11.Murphy M., Alley M., Demmel J., Keutzer K., Vasanawala S., Lustig M. Fast l1-SPIRiT Compressed Sensing Parallel Imaging MRI: Scalable Parallel Implementation and Clinically Feasible Runtime. IEEE Transactions on Medical Imaging. 2012;31(6):1250–1262. doi: 10.1109/TMI.2012.2188039. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Smith D. S., Gore J. C., Yankeelov T. E., Welch E. B. Real-time compressive sensing MRI reconstruction using GPU computing and split Bregman methods. International Journal of Biomedical Imaging. 2012;2012 doi: 10.1155/2012/864827.864827 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Uecker M., Ong F., Tamir J. I., et al. Berkeley Advanced Reconstruction Toolbox. Proceedings of the International Society for Magnetic Resonance in Medicine; 2015; Toronto; p. p. 24863. [Google Scholar]
- 14.Gregerson A. Implementing fast MRI gridding on GPUs via CUDA. NVidia Whitepaper. 2008 http://cn.nvidia.com/docs/IO/47905/ECE757_Project_Report_Gregerson.pdf. [Google Scholar]
- 15.Liu J., Huang K., Zhang D., et al. Non-local means denoising algorithm accelerated by GPU. Proceedings of the Sixth International Symposium on Multispectral Image Processing and Pattern Recognition; Yichang, China. p. p. 749711. [DOI] [Google Scholar]
- 16.Volkov V., Demmel J. W. Benchmarking GPUs to tune dense linear algebra. Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC '08); November 2008; pp. 31:1–31:11. [DOI] [Google Scholar]
- 17.Frigo M., Johnson S. G. FFTW: an adaptive software architecture for the FFT. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing; May 1998; IEEE. pp. 1381–1384. [Google Scholar]
- 18.Frahm J., Haase A., Matthaei D. Rapid NMR imaging of dynamic processes using the FLASII technique. Magnetic Resonance in Medicine. 1986;3(2):321–327. doi: 10.1002/mrm.1910030217. [DOI] [PubMed] [Google Scholar]
- 19.Sodickson D. K., Manning W. J. Simultaneous acquisition of spatial harmonics (SMASH): fast imaging with radiofrequency coil arrays. Magnetic Resonance in Medicine. 1997;38(4):591–603. doi: 10.1002/mrm.1910380414. [DOI] [PubMed] [Google Scholar]
- 20.Pruessmann K. P., Weiger M., Scheidegger M. B., Boesiger P. SENSE: sensitivity encoding for fast MRI. Magnetic Resonance in Medicine. 1999;42(5):952–962. doi: 10.1002/(sici)1522-2594(199911)42:5<952::aid-mrm16>3.0.co;2-s. [DOI] [PubMed] [Google Scholar]
- 21.Uecker M., Zhang S., Voit D., Karaus A., Merboldt K.-D., Frahm J. Real-time MRI at a resolution of 20 ms. NMR in Biomedicine. 2010;23(8):986–994. doi: 10.1002/nbm.1585. [DOI] [PubMed] [Google Scholar]
- 22.Zhang S., Block K. T., Frahm J. Magnetic resonance imaging in real time: Advances using radial FLASH. Journal of Magnetic Resonance Imaging. 2010;31(1):101–109. doi: 10.1002/jmri.21987. [DOI] [PubMed] [Google Scholar]
- 23.Zhang S., Joseph A. A., Voit D., et al. Real-time magnetic resonance imaging of cardiac function and flow - recent progress. Quantitative Imaging in Medicine and Surgery. 2014;4(5):p. 313. doi: 10.3978/j.issn.2223-4292.2014.06.03. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Uecker M., Hohage T., Block K. T., Frahm J. Image reconstruction by regularized nonlinear inversion - Joint estimation of coil sensitivities and image content. Magnetic Resonance in Medicine. 2008;60(3):674–682. doi: 10.1002/mrm.21691. [DOI] [PubMed] [Google Scholar]
- 25.Wajer F., Pruessmann K. Proceedings of the International Society for Magnetic Resonance in Medicine. 2001. Major speedup of reconstruction for sensitivity encoding with arbitrary trajectories; p. p. 767. [Google Scholar]
- 26.Greif I. Semantics of communicating parallel processes [Ph.D. thesis] Massachusetts Institute of Technology; 1975. [Google Scholar]
- 27.Nvidia. cuFFT library. 2010. http://docs.nvidia.com/cuda/cufft/ [Google Scholar]
- 28.Zhang S., Uecker M., Voit D., Merboldt K.-D., Frahm J. Real-time cardiac MRI at high temporal resolution: radial FLASH with nonlinear inverse reconstruction. Journal of Cardiovascular Magnetic Resonance. 2010;12:p. 39. doi: 10.1186/1532-429X-12-39. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Joseph A. A., Merboldt K.-D., Voit D., et al. Real-time phase-contrast MRI of cardiovascular blood flow using undersampled radial fast low-angle shot and nonlinear inverse reconstruction. NMR in Biomedicine. 2012;25(7):917–924. doi: 10.1002/nbm.1812. [DOI] [PubMed] [Google Scholar]
- 30.Untenberger M., Tan Z., Voit D., et al. Advances in real-time phase-contrast flow MRI using asymmetric radial gradient echoes. Magnetic Resonance in Medicine. 2016;75(5):1901–1908. doi: 10.1002/mrm.25696. [DOI] [PubMed] [Google Scholar]
- 31.Zhang S., Joseph A. A., Gross L., Ghadimi M., Frahm J., Beham A. W. Diagnosis of Gastroesophageal Reflux Disease Using Real-time Magnetic Resonance Imaging. Scientific Reports. 2015;5 doi: 10.1038/srep12112.12112 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Niebergall A., Zhang S., Kunay E., et al. Real-time MRI of speaking at a resolution of 33 ms: Undersampled radial FLASH with nonlinear inverse reconstruction. Magnetic Resonance in Medicine. 2013;69(2):477–485. doi: 10.1002/mrm.24276. [DOI] [PubMed] [Google Scholar]
- 33.Iltis P. W., Schoonderwaldt E., Zhang S., Frahm J., Altenmüller E. Real-time MRI comparisons of brass players: A methodological pilot study. Human Movement Science. 2015;42:132–145. doi: 10.1016/j.humov.2015.04.013. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Video S1: T1-weighted radial FLASH MRI acquisitions with NLINV reconstruction at 33.32 ms acquisition time (TR = 1.96 ms, 17 radial spokes) of a human heart in a short-axis view (256 × 256 mm3 field of view, 1.6 mm in-plane resolution, and 6 mm slice thickness).
Video S2: T1-weighted radial FLASH MRI acquisitions with NLINV reconstruction at 33.32 ms acquisition time (TR = 1.96 ms, 17 radial spokes) of midsagittal tongue movements of an elite horn player (192 × 192 mm3 field of view at 1.4 mm in-plane resolution, and 8 mm slice thickness).