

Summary
Central to the organization of behavior is the ability to predict the values of outcomes to guide choices. The accuracy of such predictions is honed by a teaching signal that indicates how incorrect a prediction was (‘reward prediction error’, RPE). In several reinforcement learning contexts such as Pavlovian conditioning and decisions guided by reward history, this RPE signal is provided by midbrain dopamine neurons. In many situations, however, the stimuli predictive of outcomes are perceptually ambiguous. Perceptual uncertainty is known to influences choices, but it has been unclear whether or how dopamine neurons factor it into their teaching signal. To cope with uncertainty, we extended a reinforcement learning model with a belief state about the perceptually ambiguous stimulus; this model generates an estimate of the probability of choice correctness, termed decision confidence. We show that dopamine responses in monkeys performing a perceptually ambiguous decision task comply with the model’s predictions. Consequently, dopamine responses did not simply reflect a stimulus’ average expected reward value, but were predictive of the trial-to-trial fluctuations in perceptual accuracy. These confidence-dependent dopamine responses emerged prior to monkeys’ choice initiation raising the possibility that dopamine impacts impeding decisions, in addition to encoding a post-decision teaching signal. Finally, by manipulating reward size, we found that dopamine neurons reflect both the upcoming reward size and the confidence in achieving it. Together, our results show that dopamine responses convey teaching signals that are also appropriate for perceptual decisions.
eTOC Blurb
Lak et al show that dopamine neuron responses during a visual decision task comply with predictions of a reinforcement learning model with a belief state signaling confidence. The results reveal that dopamine neurons encode teaching signals appropriate for learning perceptual decisions and respond early enough to impact impeding decisions.
Introduction
In the struggle of life animals survive by following a simple dictum: win big and win often [1]. Finding bigger wins (e.g. more food reward) and more likely wins is particularly challenging when these are not available in their nearby environment. In these situations a process of trial and error is required to selectively reinforce the most successful actions. Inspired by the study of animal behavior, a machine learning approach called reinforcement learning provides a rigorous framework to understand how to select winning behaviors. The key to reinforcement learning is adjusting the expected reward values associated with each behavior based on the outcomes of one’s actions. These adjustments to reward values are based on the discrepancy between the received and predicted value, referred to as the reward prediction error [2]. There is a great deal understood about the neural mechanisms underlying reinforcement learning and it is well established that midbrain dopamine neurons broadcast reward prediction error signals [3–6]. Here we address whether dopamine neurons provide appropriate prediction error signals when there is ambiguity in the cues that predict rewards.
Computing reward prediction error, by definition, requires predicting the value of impending outcomes. Such value prediction relies on different sources of information and correspondingly distinct processes as dictated by the behavioral context. In one context, distinct, unambiguous cues that predict different reward outcomes are used to guide decisions. Because there is no uncertainty in identifying the cues, the accuracy of outcome predictions is limited instead by potentially complex, probabilistic reward payoff contingencies. Thus the expected value of each decision can be estimated based on the experienced outcomes associated with the cues. These estimates can be produced by classic reinforcement learning algorithms [2]. In the context of ambiguous stimuli requiring perceptual decisions, animals face an additional challenge, because reward history alone can only provide an inaccurate estimate of upcoming outcome value. Rather, estimating the value of the choice requires an evaluation of the immediate percept and the decision process to compute the probability that the choice will be correct [7–9]. Thus, reward history-guided and perceptual decisions, despite having fundamental similarities, differ in the computations required for reward prediction and hence prediction error estimation.
The phasic activity of dopamine neurons has been the subject of many studies, a few employing choice behaviors and many using simple Pavlovian conditioning tasks [10, 11]. The results of these studies can be chiefly summarized as showing that dopamine responses encode prediction error, consistent with the temporal difference reinforcement learning (TDRL) algorithm [3–6, 12–23]. In contrast to this large body of literature characterizing how reward history determines dopamine responses, dopamine neurons have been rarely studied in perceptual decision tasks [24, 25]. Observations from these studies revealed that dopamine neurons exhibit temporally-extended responses during the perceptual choice and that they can reflect subjective sensory experiences, rather than physical stimulus intensity [24, 25].
To understand dopamine neuron responses in perceptual decision making, we constructed a reinforcement learning model that incorporated a belief state to infer the trial-by-trial probability of choice correctness, reflecting the confidence in the decision. We compared dopamine neuronal responses recorded during a visual decision task to predictions of our model. These analyses enable us to show that dopamine prediction errors can reflect decision confidence in addition to reward magnitude and these signals emerge even before the behavioral manifestation of choice.
Results
Previously, Nomoto and colleagues studied midbrain dopamine neurons in a perceptual decision task [24]. Here we reexamined these neuronal responses in an attempt to identify signatures of prediction errors based on the value of a perceptual decision that requires an on-line estimate of the probability of choice correctness. The behavioral task and monkeys’ performance have been described previously [24] and explained in the Supplemental Experimental Procedures. Briefly, two Japanese macaques performed a two-alternative forced-choice reaction time task (Figure 1A, see Figure S1A). In each trial, monkeys were presented with a random dot motion visual stimulus and were trained to move their gaze to one of two targets based on the direction of motion and receive juice reward for their correct choices. Choice difficulty was adjusted by varying the coherence of dots pseudo-randomly from trial to trial. Across blocks of varying lengths, one motion direction was associated with a large reward magnitude while the other one was associated with a small reward. Animals could categorize easy (high coherence) stimuli almost perfectly but were challenged with more difficult (low coherence) stimuli (Figure S1B). Moreover, due to the asymmetric reward schedule, when presented with low coherence stimuli, animals showed bias toward the direction associated with the larger reward (Figure S1B, C).
Figure 1. Predictions of a temporal difference learning model that incorporates a belief state.
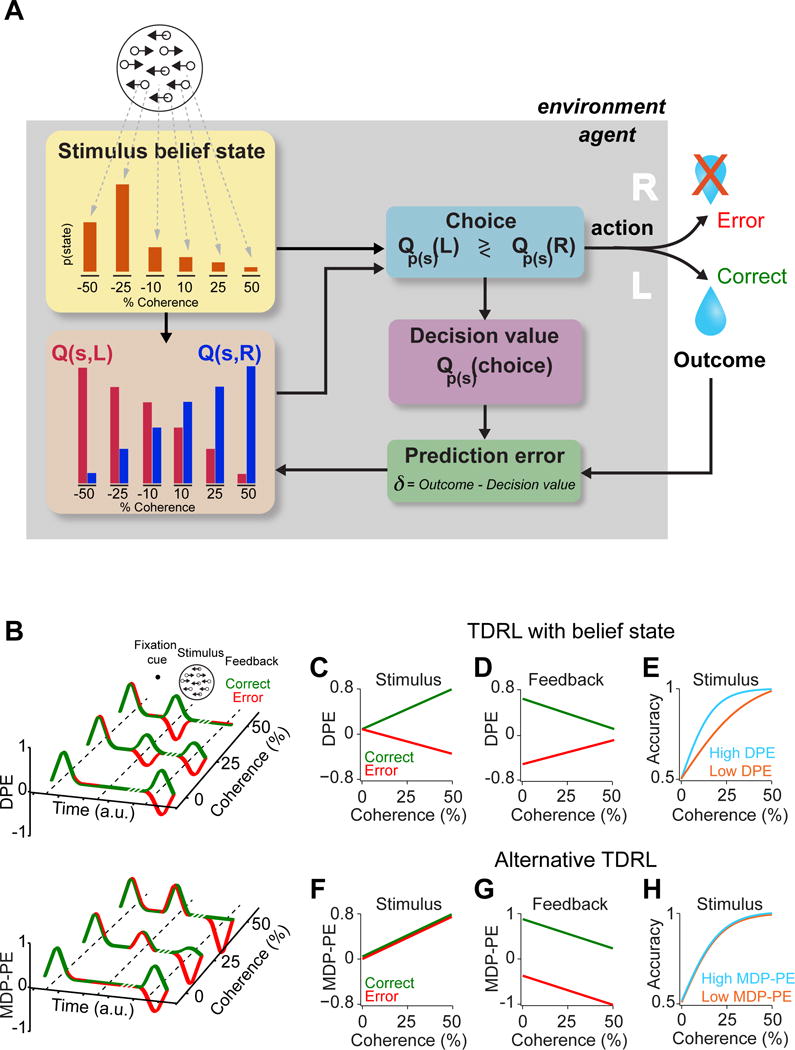
(A) Schematic of a TDRL model incorporating a belief state for performing the random dot motion discrimination task (see Experimental Procedures and Figure S1). Having observed a noisy readout of the motion stimulus , the model forms a belief, denoted by , representing the probability distribution over all motion stimulus states, sm (red bars, for simplicity only six states are shown in the panel). The model also stores the values of taking a left or right action, given each possible state Q(sm, L) and Q(sm, R), respectively. On each trial, the value of left and right decisions are computed: and . The choice is made by comparing and . The reward expectation associated with the choice (i.e. decision value) is . Upon receiving the outcome (small, large or no reward) the model computes the prediction error, δm, the difference between the received reward size and the decision value. This prediction error, together with the belief state, is then used to update Q(sm, L) and Q(sm, R), which are used in the subsequent trials.
(B) Schematic of prediction error function of the TDRL model with belief state (top) and the alternative TDRL model (bottom), as a function of stimulus difficulty and decision outcomes (i.e. correct or error). DPE refers to decision value prediction errors for the model with a belief state, while MDP-PE stands for Markov Decision Process prediction error of the model without belief state. Unlike the model without the belief state, prediction errors at the time of stimulus in the model with the belief state reflect the decision outcome. Note that since some stimuli predict below average reward rates, the resulting prediction errors at the motion stimulus state can be negative.
(C–E) Properties of the TDRL model with belief state. The plots are from a model run with asymmetric reward sizes and in order to isolate the effect of belief on the model behavior, only trials with a choice toward the large-reward side are shown. Note that decision values depend on both belief and the reward size, hence for large-reward choices, DPEs take on slight positive values even for stimuli with close to zero coherence. See Figure S2 for additional predictions of this model.
(C) DPEs at the time of stimulus show dependency on both stimulus coherence and decision outcome. These prediction errors reflect subjective belief about the choice correctness.
(D) Model’s DPEs at the time of the outcome feedback. These prediction errors reflect the difference between the value of obtained reward and the values predicted at stimulus time, shown in (C).
(E) The model’s psychometric curves plotted separately for high and low DPEs at the time of stimulus (above and below 75th percentile, respectively). Trials with larger DPEs for the same stimulus coherence predict increased choice accuracy.
(F–H) as in (C–E) for a TDRL model without belief state. Note that both TDRL model with belief state and the alternative TDRL model have qualitatively similar predictions when only correct trials are taken into account. Thus, for comparing the two models, it is essential to include both correct and error trials. See Figure S2 for schematic of this model. See also Figures S1 and S2.
A reinforcement learning model incorporating perceptual uncertainty
To examine whether the activity of dopamine neurons reflect the value of a perceptual decision, we constructed a computational model (Figure 1A). A reinforcement model for our behavioral task needs to deal with the perceptual ambiguity inherent in the random dot stimulus as well as keep track of the history of rewards delivered after left and right choices. The phasic responses of dopamine neurons in tasks in which reward values are based on prior experience are well captured by a standard temporal difference reinforcement learning (TDRL) model [3, 26]. For tasks involving noisy sensory information, variants of the TDRL based on partially observable Markov decision process (POMDP) have been proposed [27–30]. POMDPs capture the intuitive notion that under perceptual uncertainty a decision maker faces an additional obstacle beyond stimulus-reward association, the need to make an estimate of the true state of the environment based on the current perceptual experience. This estimate is referred to as the ‘belief state’ [29, 30], and can be used to infer the probability that the choice will turn out to be correct, i.e. decision confidence. POMDP-based TDRL incorporates this belief into the computation of state values from which a choice can be made and a prediction error can be generated.
Having received a motion stimulus, sm, the model represents a noisy estimate of it, sampled from a normal distribution with constant variance and mean given by the true stimulus, . In a Bayesian framework, a subject’s belief about the stimulus is not limited to a single estimated value but comprises a belief distribution over all possible values of sm, given by . Assuming that the subject’s prior is Assuming that the subject’s prior is that stimuli are uniformly delivered, the belief state distribution will also be Gaussian with the same variance as the sensory noise distribution, and mean given by , (Figure 1A). The model also stores the values of taking a left (L) or right (R) action, given each possible state sm : Q(sm, L) and Q(sm, R), respectively. On each trial, the value of left and right choices are computed as the expected values of these Q-values, given the belief state . That is and , where 〈.〉p denotes the expectation operator. Thus Q-values integrate both past rewards as well as the currently computed belief. The choice is computed by comparing and . When the rewards for correct choices are equal across sides, then the only factor contributing to the choice is the current sensory signal. However, when rewards are unequal then choices are biased toward the larger value side in proportion to their relative size. The reward expectation associated with the choice (i.e. decision value) is given by . Upon receiving the outcome (small, large or no reward) the model computes the prediction error, δm, the difference between the received reward size and the decision value, which incorporates both past rewards and the subjective belief about the accuracy of the current choice. This prediction error is then used to update Q(sm, L) and Q(sm, R), which are used to make decisions in subsequent trials. Therefore, by employing a belief state, the POMPD-based TDRL model can represent the trial-by-trial probability that the choice will turn out to be correct. Therefore, our main model introduces a case in which reward predictions (and hence prediction errors) are computed based on the same state inference process used by the decision making system.
The alternative model reflects a scenario in which dopamine neurons do not have access to perceptual uncertainty contributing to the current choice. Instead, dopamine neurons’ value predictions and prediction error computations are informed by an independent sensory stream (see Figure S2A and Experimental Procedures). By comparing these two models, we identified several distinct features of prediction error signals computed solely based on reward history from those that additionally have access to the perceptual uncertainty underlying the choice process.
We refer to the prediction errors of the first model as decision value prediction errors (DPE), because these incorporate information about the current decision process. This is in contrast to prediction errors produced by the alternative model, which we refer to as the Markov Decision Process MDP prediction error (MDP-PE) that does not have direct access to the sensory evidence underling choice computation.
To test the novel features of prediction errors in our belief state-dependent TDRL model, we wanted to isolate the contribution of the belief computation by first considering only large-reward trials (i.e. trials in which the model chose the side with the large reward). Following training, the model with the belief state produces three task-related prediction error responses (Figure 1B, top panel). First, there is a prediction error evoked by the fixation cue, the earliest predictor of a potential reward. This signal is uniform across all trial types and is proportional to the average value of a trial. Second, the model generates another prediction error when the stimulus is presented. This signal encodes the difference between the value of the current decision and the average value of a trial (indicated by the fixation cue) and can thus take on positive or negatives values. Finally, the model generates a prediction error at the moment of feedback signaling the deviation between the actual and the predicted outcome, i.e. the decision value at the stimulus time. The alternative TDRL model also generates three task-related prediction errors (Figure 1B, bottom panel). Similar to the TDRL model with the belief state, prediction errors evoked by the fixation cue are uniform across trials. However, the prediction errors to stimuli and feedback are different from those generated by the alternative model in several ways (Figure 1B, cf. Figure 1C–E with Figure 1F–H).
First, prediction errors generated by TDRL model with the belief state are distinct for correct and error outcomes (Figure 1C, D). At the time of the stimulus and outcome, prediction errors of the model with belief state reflect both stimulus difficulty as well as the upcoming outcome, thus qualitatively differing from those generated by the alternative model, which only reflect stimulus difficulty (Figure 1F, G). Second, the magnitude of prediction error at the time of the stimulus is predictive of decision accuracy (Figure 1E and H, see Figure S2C); decisions in trials with high prediction errors have greater accuracy for the same stimulus difficulty (Figure 1E), in sharp contrast with the alternative model (Figure 1H).
Next we sought to clarify the critical features of the belief-state model that lead to these distinct predictions. For optimal decision making, keeping track of the full belief distribution, , is necessary in general [31]. However, in a two alternative choice task with binary feedback (reward or no reward), after a decision is made, the relevant features of belief state distribution can be summarized as a confidence statistic. Decision confidence, in a statistical sense, is defined as the probability that the chosen action turns out to be the correct action, given the sensory evidence. This can be formalized as p(correct|choice, percept), where percept, the internal representation of the stimulus, is specified by the belief state. In our model, this quantity can be determined by computing the probability that the correct action corresponding to different stimulus states is the same as the chosen action (see Experimental Procedure). When computed for different stimulus difficulties and plotted separately for correct and incorrect trials, the pattern of computed p(correct|choice, percept) closely resembled the prediction error pattern of our belief-based TDRL model (Figure 2A, cf. Figure 1C–D). This indicates that the prediction errors generated by the model with a belief state are mathematically equivalent to decision confidence. Note that keeping track of the entire belief distribution, while important for optimal behavior in non-stationary environments, is not necessary for our behavioral task. Because of the stationarity typical of laboratory decision tasks, a reduced version of our model that uses the mean of the belief state to assign a single state to the motion stimulus, without keeping track of the full distribution could also account for our data (see Figure S2B and Experimental Procedure). In summary, when the model incorporates information about the current decision process, after learning, it contains the knowledge about the relationship between quality of internal evidence and the expected outcome of the decision, in other words, decision confidence.
Figure 2. Prediction errors of the TDRL model with belief state reflect decision confidence.
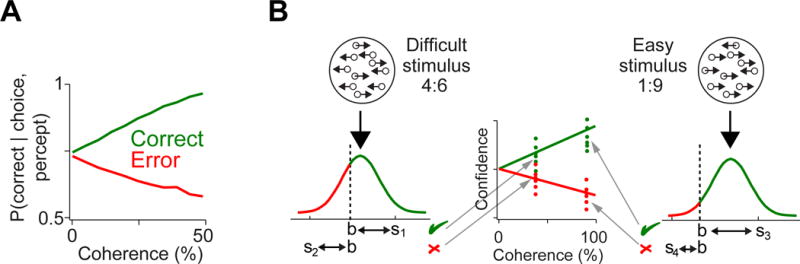
(A) The pattern of estimated decision confidence. The simulation of p(correct|choice, percept) in this model shown as a function of stimulus coherence separately for correct and error choices (see Experimental Procedure). Note the similarity of these patterns with prediction errors in the belief-state TDRL model (cf. the panel with Figure 1C).
(B) Signal detection theory-inspired intuition illustrating the model’s predictions. For the same external stimulus, the distance between a percept s and the decision boundary b differs across trials (compare s1 and s2 for the difficult stimulus example and s3 and s4 for the easy stimulus example) leading to different confidence estimates (distance between the percept s, and the boundary b), as shown in the middle panel.
The signature predictions of the TDRL model with the belief state (Figure 1C) can be intuitively understood using a signal detection theory inspired approach to decision confidence. Here, confidence reflects the distance between the internal representation of the stimulus (percept), and decision boundary, b, or more precisely confidence is a calibrated function of this distance, c = fc|perfect − b|, as shown previously [32]. Figure 2B illustrates how the stimulus and boundary configurations that could lead to a given choice offer an intuition behind model predictions. For correct choices, distance between stimulus distribution and the boundary increases as the stimulus becomes easier. For error choices, which happen when a stimulus is perceived to be on the wrong side of the boundary, the distance between stimulus sample and boundary tends to be smaller for easy stimuli because the overlapping region of the stimulus distribution is smaller. Thus, although errors are less frequent for easy stimuli, when they occur, the distance from the stimulus sample to the boundary is small, and hence confidence is low.
Responses of dopamine neurons reflect decision confidence
Next we analyzed the activity of 75 dopamine neurons recorded while monkeys performed the perceptual decision task (Supplemental Experimental Procedures) [24]. We first limited our analysis to trials in which animals chose the large-reward side, which enabled us to isolate the contribution of the perceptual decision process independent of reward size. The responses of these neurons closely matched the prediction errors produced by our model with a belief state. Figure 3A and B show responses of an example dopamine neuron and neuronal population aligned to the stimulus and feedback tone (see Figure S3A–C for responses to the fixation cue), and separated based on the trial outcome. After stimulus onset, the early responses (until ~200 ms) were uniform, and only later components (~200–500ms) reflected stimulus coherence [24]. These later responses increased with stimulus coherence for correct choices (Linear regression on single neurons, 67/75 positive and 5/75 negative slope, P < 0.01, 3/75 not significant) and decreased for error choices (Linear regression on single neurons: 33/75 with negative and 5/75 positive slope, P < 0.01, 37/75 not significant), consistent with the DPEs of the model with belief state (cf. Figure 1C with Figure 3C and D). Note that analyzing dopamine responses using a longer temporal window (60–600 ms after the stimulus onset) displayed very similar response patterns (Figure S3D). Responses to the feedback tone also showed graded sensitivity to both the stimulus coherence and the animal’s choice similar to the DPE signals (cf. Figure 1D with Figure 3C and D; Linear regression on single neurons for correct trials: 53/75 with positive, 8/75 with negative slope, P < 0.01, 14/75 not significant; Linear regression on single neurons for error trials: 27/75 with negative, 14/75 with positive slope, P < 0.01, 34/75 not significant). To further quantify when this choice outcome-selectivity (difference between correct and error trials) arose in individual neurons, we used receiver operating characteristic (ROC) analysis and computed area under ROC curve (AUC) in sliding time windows (Experimental Procedures). Figure 3B shows that the majority of neurons showed outcome-selective responses to the stimulus and feedback (61/75 and 66/75 neurons, for responses to the stimulus and feedback tone, respectively, permutation test on sliding ROCs, P < 0.001). These results suggest that during perceptual decisions, dopamine responses do not simply reflect the average value of the perceptually ambiguous stimulus but are also predictive of the trial-to-trial fluctuations in decision outcome.
Figure 3. Dopamine responses reflect both stimulus difficulty and choice.
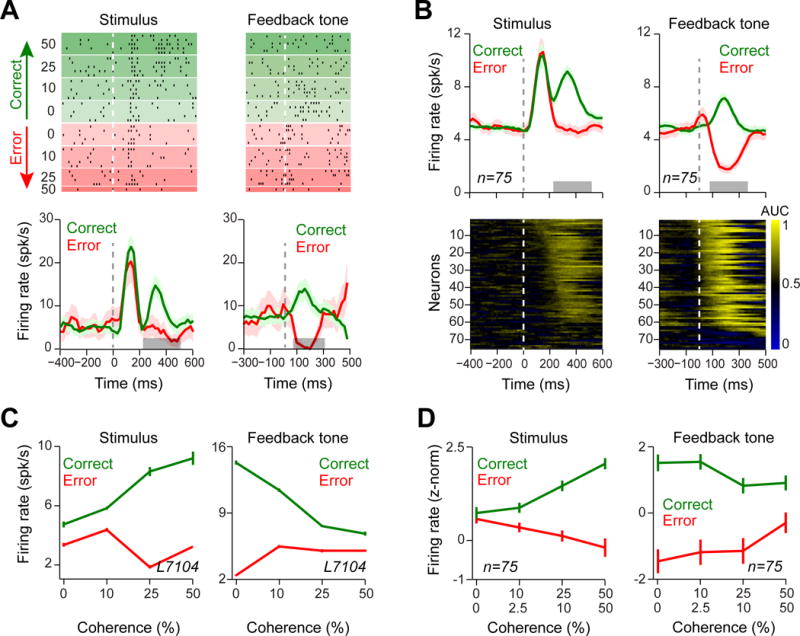
(A) Top panels: Raster plots of an example dopamine neuron aligned to stimulus onset and feedback tone onset, which indicated the trial outcome (correct or error). For error trials of low stimulus coherence and all correct trials, only a fraction of trials (randomly selected) is shown. Bottom panels: pre-stimulus time histograms (PSTHs) of the example neuron aligned to different task events. In the PSTHs, trials with different stimulus difficulties were collapsed. Horizontal gray bars indicate temporal windows used for analyses in (C). For illustration purposes, in all figures, we treat stimuli of equal coherence together, regardless of motion direction. To isolate the effect of decision confidence on neuronal responses, only trials in which the monkey made a saccade to the large-reward side were included in all panels of this figure. See Figure S3 for neuronal responses to the fixation cue. Unless otherwise stated, in all figures error bars are s.e.m. across trials or neurons (for single neuron examples and population, respectively).
(B) Top panels: PSTHs of dopamine population (averaged across 75 neurons recorded in two monkeys) aligned to different task events. Trials with different stimulus difficulties were collapsed. Horizontal gray bars indicate temporal windows used for analyses in (D). Bottom panels: Running area under ROC curve (AUC) for each neuron aligned to different events (see Experimental Procedures). The AUCs significantly larger than 0.5 indicate larger dopamine responses in correct trial compared to the error trials. For illustration, AUCs in each panel are sorted based on the time of the first of three consecutive significant analysis time steps (P < 0.001).
(C) The average responses of the example dopamine neuron at the time of stimulus and feedback tone. These neuronal responses resembled the DPE of the TDRL model shown in Figure 1C and D.
(D) The population dopamine responses at the time of stimulus and feedback tone. These neuronal responses resembled the DPE of the TDRL model shown in Figure 1c and d and differed markedly from prediction errors of the alternative TDRL model shown in Figure 1F and G. See also Figure S3.
Confidence-dependent dopamine responses arise prior to observed choice
We next considered the time course of choice outcome-selectivity in relation to saccade initiation, which is the earliest observable measure of choice commitment (Figure 4A and B). We found that the difference in dopamine responses between correct and error choices emerged considerably before action initiation (Figure 4A, Mann-Whitney U test on responses during 300 ms before saccade onset: 33/75 neurons with larger pre-saccadic activity for correct compared to error trials, P < 0.05; sliding ROC analysis with permutation test: 45/75 neurons extending up to 300 ms before the saccade onset, P < 0.001). Thus, outcome-selective dopamine responses begin even before the behavioral manifestation of choice commitment.
Figure 4. Dopamine activity predicts choice accuracy prior to behavioral response.
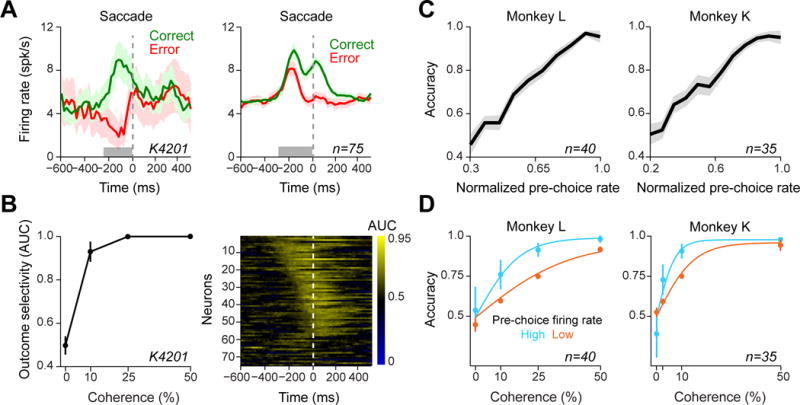
(A) PSTH of an example neuron and the entire neuronal population aligned to saccade onset (i.e. the time in which the animal gaze left the central fixation). In the PSTHs, trials with different stimulus difficulties were collapsed. Horizontal gray bars indicate temporal windows used for analyses in B–D. Only choices towards the large-reward size were included in all panels of this figure.
(B) Left: Area under ROC curve (AUC) for the example neuron measured from pre-saccade dopamine responses (during 250 ms prior to saccade initiation). At each stimulus coherence neuronal responses in correct and error trials were used to compute AUC. Right: running AUC for all neurons aligned to the saccade onset. For this analysis, trials from all tested coherence levels were collapsed and running AUC for each neuron was measured by comparing neuronal responses in each time bin of correct and error trials.
(C) Choice accuracy as a function of dopamine pre-saccade responses (measured for each neuron from responses during 300 ms before saccade initiation).
(D) Animals’ psychometric curves separated based on the pre-saccade dopamine responses (below and above 75th percentile, respectively). See also Figure S4.
Our model further predicts that dopamine signals should be predictive of choice accuracy (Figure 1E and H, see Figure S2C). We found that the graded levels of pre-choice dopamine responses (during the 300 ms before saccade onset) predicted the accuracy of monkeys (Figure 4C, Linear regression on single neurons: 58/75 with positive and 1/75 with negative slope, P < 0.01, 16/75 not significant). Moreover, this predictive property of responses should go beyond what can be inferred from stimulus difficulty alone, such that trials with larger prediction errors should have increased accuracy for the same stimulus difficulty (Figure 1E). To test this, we separated trials based on the rate of the pre-choice dopamine activity (below versus above 75 percentile) and found that monkeys’ psychometric slopes were significantly greater when dopamine activity was high (Figure 4D, Mann-Whitney U test on session-by-session slopes of the psychometric functions: Monkey L: p = 1.99 × 10−6, Monkey K: p = 0.002; Mann-Whitney U test on individual data points, p < 0.05 in both monkeys). We next considered the possibility that this difference in performance is due to different durations of sensory evidence integration. There was no difference in reaction times for a given stimulus difficulty for high and low pre-choice dopamine activity (Figure S4A, p > 0.1; Mann-Whitney U test) and the difference in psychometric slopes (Figure 4D) held even when we only considered high or low reaction times (median split, p < 0.01 in both monkeys). These analyses exclude the possibility that dopamine firing simply indexes reaction times and thus the accuracy differences observed are a direct consequence of differential sensory evidence integration. In contrast to this choice-predictive phasic dopamine activity, separating trials based on the pre-stimulus tonic activity or phasic activity to the fixation cue did not reveal correlations with perceptual accuracy (P > 0.1 in both monkeys, Mann-Whitney U test, Figure S4B–C). Theoretical accounts as well as pharmacological studies in humans suggested that the tonic levels of dopamine correlate with factors such as average reward rate that reflect response vigor ([33, 34], but see [35] for pre-trial dopamine action potentials). In our data the tonic firing of dopamine neurons before trial initiation does not correlate with decision accuracy.
Dopamine responses integrate decision confidence and reward size
Until now, we focused on the large-reward side trials to isolate the contribution of the perceptual decision process to prediction error signals. Next, we investigated how the neuronal representation of decision confidence interacts with reward size. Therefore, we evaluated our model predictions after including both small- and large-reward trials (Experimental Procedures), and similarly, examined neuronal responses in all trials irrespective of the reward size. DPEs computed by the TDRL model with the belief state jointly reflected confidence estimates and expected reward size (Figure 5A). When rewards associated with left and right choices differ, and , are updated to reflect these rewards whereas the belief state, , continues to reflect the trial-by-trial probability that sensory categorization will turn out to be correct. Because decision value represents the product of these variables, it jointly reflects reward size as well as the confidence in obtaining it. Therefore, DPEs should reflect both reward and confidence predictions. To test this directly we asked whether the population of dopamine neurons that showed confidence-dependent responses (61/75 neurons quantified with the sliding ROC analysis, Figure 3B), do so mainly irrespective of the expected reward size. We separated dopamine responses to the stimulus and feedback tone based on the saccade direction (i.e. towards the side associated with small or large reward) and trial outcome (error or correct). The population neuronal responses were modulated by both decision confidence and reward size, resembling the DPE predictions (cf. Figure 5A and B) and showed marked differences from the prediction of a conventional TDRL model (Figure S5).
Figure 5. Dopamine responses reflect both decision confidence and reward size.
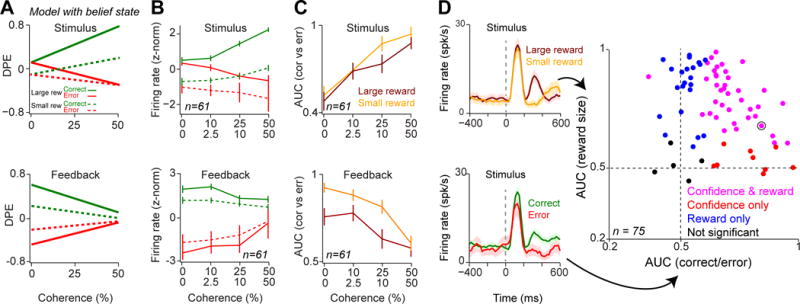
(A) Prediction errors of a TDRL model with belief state trained on an asymmetric reward schedule. Unlike Figure 1C–D, here all trials irrespective of reward size were included. See Figure S5 for analogous plots from a TDRL model that does not include a belief-state.
(B) Population dopamine responses at the time of stimulus and feedback tone separated based on the reward size condition (small/large reward) as well as decision outcome (error/correct). Unlike Figure 3 and 4, all trials (irrespective of reward size condition) were included in all panels of this figure.
(C) Average AUCs of dopamine responses to stimulus and feedback tone for different reward conditions. The AUC of each individual neuron at each stimulus coherence level was measured by comparing neuronal responses in correct and error trials and were then averaged across neurons. For both small and large reward conditions neuronal AUCs increased at the time of stimulus (left) and decreased at the feedback time (right), as a function of stimulus coherence. These results remained statistically significant even when responses of all recorded cells are taken into account (Linear regression of population AUCs onto stimulus coherence; stimulus time: P = 0.03 and P = 0.000006, reward time: P = 0.04 and P = 0.007 for small and large reward conditions, respectively).
(D) Left: PSTHs of example dopamine neuron (same neuron shown in Figure 3) separated based on the upcoming reward size (i.e. reward size associated with the saccade direction, top panel) or based on the upcoming outcome (correct/error, bottom panel). These responses were used to measure area under ROC curve shown on the right. Right: scatter plot of AUCs measured for each neuron quantifying reward size coding and decision confidence coding for each individual neuron. For each neuron, the statistical significance was estimated using permutation test (see Experimental Procedures). Circled point indicates the example neuron shown on the left panels. See also Figure S5.
Next we sought to isolate the effect of decision confidence on dopamine responses irrespective of reward size. Therefore, we quantified the differences in responses between correct and errors trials by computing the area under the ROC curve (AUC). Confidence encoding predicts that the difference between cue-driven correct and error response increases with increasing stimulus coherence (Figure 5A), and hence the AUC measure should capture this trend [32]. Indeed, at the time of stimulus, AUC measures for both small and large reward conditions showed a significant positive relation with stimulus coherence (Figure 5C; linear regression of population AUC onto stimulus coherence: P < 0.001 for both small and large reward conditions). Similarly, at the time of feedback, AUCs for both reward conditions showed a significant inverse relation with stimulus coherence (Linear regression of population AUC onto stimulus coherence: P < 0.001 for both small and large reward conditions). Thus, for both small and large reward conditions, dopamine responses showed stronger outcome sensitivity (larger AUC) as stimulus coherence increased.
Finally, we examined the extent to which stimulus-driven responses reflected both decision confidence and reward size for each neuron. To quantify confidence and reward encoding independently, we compared the difference between responses for correct vs. error trials and for large vs. small reward trials using ROC analysis (Figure 5D, left panels). The majority of neurons encoded both decision confidence as well as upcoming reward size with similar strength (Figure 5D, right panel, ROC analysis with permutation test in 39/75 neurons, P < 0.01), while a fraction of neurons reflected only one variable reliably (9/75 outcome selective only, 22/75 reward size selective only, ROC analysis with permutation test, P < 0.01; for the sake of comparison a fixed time window, 220–500 ms, was used after the stimulus although the time course of encoding across neurons is variable, Figure 3B, 4B). Interestingly, neurons which only showed outcome selectively (9/75 neurons) did so while monkeys showed clear behavioral sensitivity to reward size manipulation in these sessions (P < 0.01, Mann-Whitney U test on estimated psychometric bias). Together, these analyses indicate that dopamine neurons compute prediction errors by taking into account both the expected reward size as well as the subjective belief about the correctness of a perceptual choice.
Discussion
Taken together our analyses reveal a close correspondence between the phasic activity of dopamine neurons during a perceptual decision task and a reinforcement learning model extended with a belief state. In Bayesian decision theory belief states serve as estimates of the uncertain true states [29]. Specifically, in our model the role of the belief state is to represent the uncertainty arising from a perceptually ambiguous stimulus and enables a prediction about the probability that the stimulus categorization will be correct. In our decision task, this state inference process is equivalent to a computation of statistical decision confidence [9], as our analyses revealed (Figure 2a). In fact, the distinctive signatures of our belief-state-dependent TDRL model (Figure 1C–E, see Figure S2C), that are qualitatively different from a TDRL without belief-state (Figure 1F–H), are precisely those that have been used to identify decision confidence in the orbitofrontal and pulvinar neuronal responses as well as rodent and human confidence-reporting behavior [8, 32, 36, 37]. These similarities support the hypothesis that dopamine prediction error signals incorporate estimates of decision confidence during perceptual decision making. We emphasize that in our task monkeys were not trained to report their decision confidence, thus our results do not imply a neuronal correlate of confidence reporting behavior but rather reveal the neuronal representation of a signal that is consistent with the computation of decision confidence. In other words, we use the term confidence in a statistical sense, i.e. the probability that a choice is correct given the evidence [9, 31], and show that an RL model that reflects this computation accounts for dopamine responses under perceptual uncertainty.
Dopaminergic integration of decision confidence and reward value signals
Our perceptual decision task with an asymmetric reward schedule allowed us to dissociate two information sources for computing expected rewards and prediction errors: trial-by-trial estimates of reward probability and the history-dependent estimates of reward size. Thus, while our findings are fully consistent with the notion that dopamine responses reflect reward expectation, they reveal how reward expectations are formed based on uncertain sensory evidence. From this standpoint, our results agree with previous findings that dopamine responses integrate across all relevant reward dimensions to encode the subjective expected value of future rewards [21].
A previous study, using a vibrotactile detection task, showed that dopamine responses can vary with perceptual reports rather than stimulus physical parameters [25]. Dopamine responses for correct detection trials increased with stimulus intensity but not for missed stimuli, suggesting that perceptual uncertainty might influence dopamine response. However, that study did not test the relationship between choice accuracy and dopamine activity, thus the relationship of those data to prediction errors requiring belief state computation remain unclear. In addition, in that study choice reports were delayed, unlike in our reaction time task that enabled us to observe pre-choice responses that were predictive of performance. Thus, without taking a computational approach, it remained unclear what type of computations might underlie those observations and also how they could be related to dopamine prediction error responses observed in reward history-guided tasks. The asymmetric reward schedule in the task allowed us to examine dopamine responses in relation to the computations underlying confidence and demonstrate that dopamine neurons perform confidence estimation simultaneously with reward size-dependent prediction error signaling. We suggest that dopamine responses in the vibrotactile detection task [25] can also be explained by our computational framework incorporating belief states, given that correct detection responses increase with increasing confidence in the sensory percept [38].
In another related study, Matsumoto and Takada [39] explored dopamine neuronal responses in a delayed match-to-sample visual search task and suggested that they reflected the monkey’s subjective judgment of success. Examining these neuronal responses in light of a model that estimates confidence in visual search success might reveal signatures of confidence coding in that study as well.
A unified framework for understanding dopamine in perceptual and reward history-guided tasks
From a computational perspective, it is straightforward to see that computing decision confidence is necessary for estimating the trial-by-trial value of a perceptual decision, which can be combined with reinforcement-based expected reward value for computing prediction errors. Therefore, our results are a natural extension of the well-established framework according to which dopamine neurons carry reward prediction signals. Reward prediction errors have been mostly studied in reward history-guided tasks where past outcomes are sufficient to compute the value of upcoming reward [3–6, 12, 14–16, 18–22]. Our findings thus provide an instance of a computational framework in which both reward history-guided and perceptual choices can be studied. Consistent with predictions of this framework, dopamine prediction errors reflected both past rewards as well as immediate belief about the outcome of sensory categorization, supporting the view that these neurons access a wider range of computations than previously thought [15, 16, 39, 40]. From this perspective, these results can serve as a bridge between reward history-guided and perceptually-guided decision making, which while both integral components of decisions in natural settings, have been mostly studied in isolation (but see [41–44]).
We note that explaining our neuronal responses does not require incorporating an explicit confidence variable into the RL framework. RL models without any explicit confidence computation, such as our POMDP model implementations, could account for the observed neuronal responses, as long as prediction errors are computed in relation to value predictions that are based on the sensory evidence used for the choice computation. While such models do not incorporate any explicit confidence variable, their prediction errors reflect the p(correct|choice, percept), i.e. decision confidence, as our simulation indicated (Figure 2A, see Experimental Procedure). Another related issue is that, while keeping track of the full belief state is necessary for efficient choice computation and updating in a non-stationary environment, keeping track of the first moment of the belief state is sufficient for explaining our neuronal data (Figure S2B). Nevertheless, we favor the POMDP model that includes a full belief state for several reasons. Optimal processing in the face of perceptual uncertainty requires that sensory stimuli should be probabilistically represented. By representing the stimulus as a distribution, POMDPs offer the normative framework to cope with such uncertainty. This comes at the cost of only one additional variable, the belief state, but no additional parameters. As a consequence, this framework can be broadly applied. For instance, beliefs might have a non-Gaussian distribution, when Bayesian inference is used and the belief state is influenced by not only the external stimulus, but also by the statistics of the environment as reflected the Bayesian prior.
A previous modeling study suggested a neuronal network implementation of POMDP framework, focusing primarily on the computational reasons behind the extended time course of dopamine, as well as prediction errors in perceptual decision tasks of the type described here [30]. The model we developed is based on fundamentally similar ideas from machine learning for introducing perceptual ambiguity into the RL framework. Our approach was to generate several diagnostic predictions of the model, those that contrast it with a TDRL without a belief state, and test them against the activity of dopamine neurons. This approach enabled us to demonstrate that the main computational requirement necessary to account for dopamine responses under perceptual uncertainty is decision confidence. Statistical confidence explains the relation between the dopamine prediction errors, stimulus coherence and animal’s choice (Figure 3). This analysis also provides evidence against the interpretation that the difference in dopamine activity in correct/error trials reflects an attentional process, rather than decision confidence, because trials with different dopamine responses lead to different slopes of the psychometric function but comparable lapse rates (Figure 4). Finally, our model identifies the contribution of both reward size and confidence in shaping dopamine responses (Figure 5). As mentioned, the diagnostic predictions of our model do not depend on the specific way confidence is computed: confidence estimates based on the belief state of a POMDP or explicit confidence signals generated using frameworks such as evidence accumulation [7] or attractor models [45], when incorporated into a RL model, would yield similar predictions (Figure 2). Confidence models based on evidence accumulation have proven useful for explaining how neuronal responses in parietal cortex evolve over time to represent decision confidence [7]. In our implementation, we assumed that confidence estimation occurs as a discrete processing step, which appears consistent with the transient nature of dopamine responses observed here. Nevertheless it will be interesting to evaluate models where confidence estimation unfolds across time [7].
Implications for decision making
It is generally believed that dopamine neurons do not have a direct role in computing immediate decisions [14]. Rather, decisions are generated elsewhere in the brain and conveyed to the dopamine system, where a prediction error is computed in relation to an already prepared or completed choice, which helps guide future choices. The fact that dopamine responses reflect both reward size and subjective belief in receiving the reward suggest that they can act as a teaching signal for a both reward history-guided and perceptual decisions[46]. Moreover, dopamine responses begin to predict the decision outcome rapidly (~200 ms) after the stimulus onset, and well before (~200 ms) the earliest behavioral manifestation of choice commitment (i.e. saccade initiation). This time course is comparable to choice and confidence-dependent activity that appears around 200–300 ms after stimulus onset during random dots task in monkeys’ parietal cortex and dorsal pulvinar [7, 36], suggesting that the observed dopamine signals might be received from other brain regions involved in the perceptual choice process such as the caudate nucleus [47]. This time course suggests that prediction error signals reflect the evolving decision process. Given the dense dopaminergic projections to brain regions involved in decision making [48], the early dopamine prediction errors might even be able to influence the current choice computation, for instance by modulating the gain of evidence accumulation [49]. Alternatively, pre-decision dopamine responses do not impact choices directly but other aspects of immediate behavior such as the willingness to complete the trial [50]. In conclusion, our results formally extend the prediction error coding framework of dopamine neurons into the perceptual decision making domain and suggest that dopamine broadcasts prior to choice commitment may influence the on-going decision process.
Experimental Procedures
Animal care and surgical procedures were in accordance with the U.S. National Institutes of Health Guide for the Care and Use of Laboratory Animals and with Tamagawa University guidelines for the use and care of laboratory animals in research.
Temporal difference reinforcement learning models
We used two variants of the temporal difference reinforcement learning (TDRL) model to simulate dopamine neuronal activity: a TDRL model incorporating a belief state that deals with the uncertainty it faces when performing the perceptual decision making and a TDRL model that did not have access to this belief state (‘alternative TDRL’). The basic features of the model implementation that were common among the model variants are described in the Supplemental Experimental Procedure.
We simulated the sequence of behavioral events in each trial as states, s. For our task, these states are ‘initial, ‘fixation cue’, ‘motion stimulus’, ‘feedback and ‘end’, denoted as si, sfc, sm, sfb, se. In each state, the agent performs an action, a, observes an outcome and transits to the next state.
TDRL model with the belief state
Here we use a partially observable Markov decision processes (POMDP) formalism to deal with the uncertainty inherent in the random dot stimulus. Apart from ‘motion stimulus’ state, all other states are defined as fully observable and thus the same as in the previous section.
For the case of ‘motion stimulus’ state, due to the noisy nature of the stimulus, the agent has an imperfect knowledge about the true underlying state and represents it in a probabilistic manner. Motion stimuli ranged from −50% to 50% (50% of dots moving to left and right, respectively). We used a discrete form of these stimuli (21 different levels of motion coherence), i.e. −50%, −45% …, 0, …, 45%, 50%, corresponding to motion stimulus states sm. We assume that due to the uncertainty inherent in the random dot stimulus, in each trial, subject does not directly observe sm but an internal noisy estimate of it which, in each trial, is sampled from a normal distribution with constant variance σ2 around the true stimulus; that is . A subject’s belief about the stimulus comprises a belief distribution over all possible values of sm; this distribution can be denoted by . In our implementation, we discretized this belief distribution and truncated it to values between −50% and 50%.
The Q-values of actions left and right for each state sm are denoted as Q(sm, L) and Q(sm, R), respectively. For each motion coherence state ranging from −50% to 50%, the model learns and updates the Q-values of choosing left or right.
Under this setting, given a belief , the net value of actions L and R are computable as the expected values of Q(sm, L) and Q(sm, R) under the belief state, :
| Eq. 1 |
For action selection, we assume that the animal just chooses the action that has the highest value. That is .
Upon observing the stimulus and selecting a choice, the prediction error is computed as:
| Eq. 2 |
where Vfc is the expected value of reward during fixation cue presentation:
| Eq. 3 |
When the agent occupies the fixation cue state, the belief is a uniform distribution.
After performing action a and receiving the reward feedback R, the prediction error is
| Eq. 4 |
Based on this prediction error the Q-value of action a will be updated as:
| Eq. 5 |
where α is the learning rate.
Following learning, the prediction errors at different states of the task exhibit the patterns plotted in Figure 1B–E.
Model prediction errors and decision confidence
We now show by simulation that, in the context of our task, the probability that the choice turns out to be correct given the sensory evidence, i.e. the decision confidence, is qualitatively equivalent to prediction error at the motion stimulus state, δm.
In order to compute decision confidence, p(correct|a, percept), we first compute, for each possible motion coherence, sm, whether the choice a that was made on the basis of is the same as the choice that would have been made on the basis of sm. In other words, if the choice that would have been made on the basis of sm (i.e., by comparing Q(sm, R) and Q(sm, L) was the same as a, that choice is considered correct, and otherwise incorrect:
| Eq. 6 |
Having defined choice correctness for each possible sm, we define confidence as the expected value of choice correctness, under the belief distribution :
| Eq. 7 |
where 〈.〉p is the expectation operator under the distribution p. In other words:
| Eq. 8 |
Simulation of this equation indicates that, in our TDRL model with the belief state prediction errors reflect the probability that the choice will turn out to be correct, and thus implicitly reflect decision confidence (Figure 2A).
Note that tracking the full belief distribution, as normatively prescribed for efficient choice in more complex tasks requiring Bayesian updating, is not essential for our behavioral task. A reduced version of our POMDP model that uses the mean of the belief state to assign a single state, , to the motion stimulus and arrive at a choice by comparing and results in prediction error patterns similar to those of our full POMDP model (see Figure S2B).
To isolate the effect of decision confidence on model prediction errors, in Figure 1, we illustrate predictions of the model only in trials for which the agent choses the large reward side. To investigate the effect of decision confidence and reward size, in Figure 5, we illustrate the predictions of the model in all trials, independent of the reward size.
The alternative model
The alternative model introduces a case in which the dopamine system does not have direct access to the sensory evidence used for the decision process. In this model, the decision making system assign one state, , to the motion stimulus and makes the choice by comparing and . Since the dopamine system does not have direct access to the sensory evidence used for choice, it assigns another state, , to the motion stimulus, which could be identical to different from the one used for choice, . The dopamine system uses the largest of and for prediction error computation at the motion stimulus and feedback states (Figure S2A). As such, in this model, the state inference and choice computation are identical to the reduced POMDP (Figure S2B) but the model reflects the situation that the dopamine system does not have access to the sensory evidence used for choice.
Figure 1, illustrates predictions of the alternative model only in large-reward trials and Figure S5 illustrates the predictions of the model in all trials, independent of the reward size.
Analysis of the neuronal data
We analyzed only the trials in which the monkey made directional choices and thus we excluded trials in which the monkey broke fixation before the onset of the random dot motion stimuli. For analyses shown in Figure 3 and 4, we only included trials in which animals made a saccade towards large-reward side. This enabled us to isolate the neuronal representation of decision confidence independent of reward size. For analysis shown in Figure 5, we included all trials regardless of saccade direction, which allowed us to examine the effect of decision confidence and reward size on dopamine neuronal responses. Because testing predictions of our model requires both correct and error trials, in all our analysis, we included both types of trials.
All data analyses and modeling were performed using custom-made software coded with Matlab (MathWorks). Supplemental Experimental Procedure includes details of statistical analyses on neuronal responses.
Supplementary Material
Highlights.
Reinforcement learning model with belief state to cope with perceptual uncertainty
Model provides unified account of dopamine in perceptual and reward-guided choices
Dopamine can act as a teaching signal during perceptual decision making as well
Dopamine signals decision confidence prior to behavioral manifestation of choice
Acknowledgments
We are grateful for Drs. Naoshige Uchida, Uri Livneh and Brett Mensh for comments on a previous version of this manuscript and the anonymous reviewers for constructive suggestions. This work was supported by Sir Henry Wellcome Trust Postdoctoral Fellowship (106101/Z/14/Z) to A.L., by grants from the Swartz Foundations and the National Institute of Mental Health (National Institutes of Health) grant R01MH097061 to A.K.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Author Contributions
K.N. and M.S. designed and performed the experiment. A.L. and A.K. analyzed the data. A.L. and A.K. conceptualized the findings. A.L., M.K and A.K. constructed the models. A.L. and A.K. wrote the manuscript with comments from other authors.
Supplemental Information
Supplemental Information includes Supplemental Experimental Procedures and 5 figures
References
- 1.Poole S. ‘Winning, winning, winning’: the genius of The Donald’s Trumpspeak. The Guardian. 2016 Mar 4; [Google Scholar]
- 2.Sutton RS, Barto AG. Reinforcement Learning: An Introduction. MIT press; 1998. [Google Scholar]
- 3.Schultz W, Dayan P, Montague PR. A neural substrate of prediction and reward. Science. 1997;275:1593–1599. doi: 10.1126/science.275.5306.1593. [DOI] [PubMed] [Google Scholar]
- 4.Bayer HM, Glimcher PW. Midbrain Dopamine Neurons Encode a Quantitative Reward Prediction Error Signal. Neuron. 2005;47:129–141. doi: 10.1016/j.neuron.2005.05.020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Nakahara H, Itoh H, Kawagoe R, Takikawa Y, Hikosaka O. Dopamine Neurons Can Represent Context-Dependent Prediction Error. Neuron. 2004;41:269–280. doi: 10.1016/s0896-6273(03)00869-9. [DOI] [PubMed] [Google Scholar]
- 6.Cohen JY, Haesler S, Vong L, Lowell BB, Uchida N. Neuron-type-specific signals for reward and punishment in the ventral tegmental area. Nature. 2012;482:85–88. doi: 10.1038/nature10754. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Kiani R, Shadlen MN. Representation of Confidence Associated with a Decision by Neurons in the Parietal Cortex. Science. 2009;324:759–764. doi: 10.1126/science.1169405. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Kepecs A, Uchida N, Zariwala HA, Mainen ZF. Neural correlates, computation and behavioural impact of decision confidence. Nature. 2008;455:227–231. doi: 10.1038/nature07200. [DOI] [PubMed] [Google Scholar]
- 9.Hangya B, Sanders JI, Kepecs A. A Mathematical Framework for Statistical Decision Confidence. Neural Comput. 2016;28:1840–1858. doi: 10.1162/NECO_a_00864. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Schultz W. Predictive reward signal of dopamine neurons. J Neurophysiol. 1998;80:1–27. doi: 10.1152/jn.1998.80.1.1. [DOI] [PubMed] [Google Scholar]
- 11.Bromberg-Martin ES, Matsumoto M, Hikosaka O. Dopamine in Motivational Control: Rewarding, Aversive, and Alerting. Neuron. 2010;68:815–834. doi: 10.1016/j.neuron.2010.11.022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Tobler PN, Fiorillo CD, Schultz W. Adaptive Coding of Reward Value by Dopamine Neurons. Science. 2005;307:1642–1645. doi: 10.1126/science.1105370. [DOI] [PubMed] [Google Scholar]
- 13.Daw ND, Doya K. The computational neurobiology of learning and reward. Curr Opin Neurobiol. 2006;16:199–204. doi: 10.1016/j.conb.2006.03.006. [DOI] [PubMed] [Google Scholar]
- 14.Morris G, Nevet A, Arkadir D, Vaadia E, Bergman H. Midbrain dopamine neurons encode decisions for future action. Nat Neurosci. 2006;9:1057–1063. doi: 10.1038/nn1743. [DOI] [PubMed] [Google Scholar]
- 15.Bromberg-Martin ES, Matsumoto M, Hong S, Hikosaka O. A Pallidus-Habenula-Dopamine Pathway Signals Inferred Stimulus Values. J Neurophysiol. 2010;104:1068–1076. doi: 10.1152/jn.00158.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Takahashi YK, Roesch MR, Wilson RC, Toreson K, O’Donnell P, Niv Y, Schoenbaum G. Expectancy-related changes in firing of dopamine neurons depend on orbitofrontal cortex. Nat Neurosci. 2011;14:1590–1597. doi: 10.1038/nn.2957. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Lee D, Seo H, Jung MW. Neural Basis of Reinforcement Learning and Decision Making. Annu Rev Neurosci. 2012;35:287–308. doi: 10.1146/annurev-neuro-062111-150512. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Bouret S, Ravel S, Richmond BJ. Complementary neural correlates of motivation in dopaminergic and noradrenergic neurons of monkeys. Front Behav Neurosci. 2012;6:40. doi: 10.3389/fnbeh.2012.00040. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Fiorillo CD. Two dimensions of value: dopamine neurons represent reward but not aversiveness. Science. 2013;341:546–549. doi: 10.1126/science.1238699. [DOI] [PubMed] [Google Scholar]
- 20.Steinberg EE, Keiflin R, Boivin JR, Witten IB, Deisseroth K, Janak PH. A causal link between prediction errors, dopamine neurons and learning. Nat Neurosci. 2013;16:966–973. doi: 10.1038/nn.3413. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Lak A, Stauffer WR, Schultz W. Dopamine prediction error responses integrate subjective value from different reward dimensions. Proc Natl Acad Sci U S A. 2014;111:2343–2348. doi: 10.1073/pnas.1321596111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Stauffer WR, Lak A, Schultz W. Dopamine reward prediction error responses reflect marginal utility. Curr Biol. 2014;24:2491–2500. doi: 10.1016/j.cub.2014.08.064. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Lak A, Stauffer WR, Schultz W. Dopamine neurons learn relative chosen value from probabilistic rewards. Elife. 2016;5:e18044. doi: 10.7554/eLife.18044. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Nomoto K, Schultz W, Watanabe T, Sakagami M. Temporally Extended Dopamine Responses to Perceptually Demanding Reward-Predictive Stimuli. J Neurosci. 2010;30:10692–10702. doi: 10.1523/JNEUROSCI.4828-09.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.de Lafuente V, Romo R. Dopamine neurons code subjective sensory experience and uncertainty of perceptual decisions. Proc Natl Acad Sci U S A. 2011;108:19767–19771. doi: 10.1073/pnas.1117636108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Montague PR, Dayan P, Sejnowski TJ. A framework for mesencephalic dopamine systems based on predictive Hebbian learning. J Neurosci. 1996;16:1936–1947. doi: 10.1523/JNEUROSCI.16-05-01936.1996. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Kakade S, Dayan P. Dopamine: generalization and bonuses. Neural Netw. 2002;15:549–559. doi: 10.1016/s0893-6080(02)00048-5. [DOI] [PubMed] [Google Scholar]
- 28.Daw ND, Courville AC, Touretzky DS. Representation and timing in theories of the dopamine system. Neural Comput. 2006;18:1637–1677. doi: 10.1162/neco.2006.18.7.1637. [DOI] [PubMed] [Google Scholar]
- 29.Dayan P, Daw ND. Decision theory, reinforcement learning, and the brain. Cogn Affect Behav Neurosci. 2008;8:429–453. doi: 10.3758/CABN.8.4.429. [DOI] [PubMed] [Google Scholar]
- 30.Rao RPN. Decision Making Under Uncertainty: A Neural Model Based on Partially Observable Markov Decision Processes. Front Comput Neurosci. 2010;4:146. doi: 10.3389/fncom.2010.00146. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Pouget A, Drugowitsch J, Kepecs A. Confidence and certainty: distinct probabilistic quantities for different goals. Nat Neurosci. 2016;19:366–374. doi: 10.1038/nn.4240. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Lak A, Costa GM, Romberg E, Mainen ZF, Koulakov A, Kepecs A. Orbitofrontal cortex is required for optimal waiting based on decision confidence. Neuron. 2014;84:190–201. doi: 10.1016/j.neuron.2014.08.039. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Niv Y, Daw ND, Joel D, Dayan P. Tonic dopamine: opportunity costs and the control of response vigor. Psychopharmacology (Berl) 2007;191:507–520. doi: 10.1007/s00213-006-0502-4. [DOI] [PubMed] [Google Scholar]
- 34.Beierholm U, Guitart-Masip M, Economides M, Chowdhury R, Duzel E, Dolan R, Dayan P. Dopamine modulates reward-related vigor. Neuropsychopharmacology. 2013;38:1495–1503. doi: 10.1038/npp.2013.48. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Cohen JY, Amoroso MW, Uchida N. Serotonergic neurons signal reward and punishment on multiple timescales. Elife. 2015;4:e06346. doi: 10.7554/eLife.06346. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Komura Y, Nikkuni A, Hirashima N, Uetake T, Miyamoto A. Responses of pulvinar neurons reflect a subject’s confidence in visual categorization. Nat Neurosci. 2013;16:749–755. doi: 10.1038/nn.3393. [DOI] [PubMed] [Google Scholar]
- 37.Sanders JI, Hangya B, Kepecs A. Signatures of a Statistical Computation in the Human Sense of Confidence. Neuron. 2016;90:499–506. doi: 10.1016/j.neuron.2016.03.025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Hangya B, Ranade SP, Lorenc M, Kepecs A. Central Cholinergic Neurons Are Rapidly Recruited by Reinforcement Feedback. Cell. 2015;162:1155–1168. doi: 10.1016/j.cell.2015.07.057. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Matsumoto M, Takada M. Distinct representations of cognitive and motivational signals in midbrain dopamine neurons. Neuron. 2013;79:1011–1024. doi: 10.1016/j.neuron.2013.07.002. [DOI] [PubMed] [Google Scholar]
- 40.Sadacca BF, Jones JL, Schoenbaum G. Midbrain dopamine neurons compute inferred and cached value prediction errors in a common framework. Elife. 2016;5:e13665. doi: 10.7554/eLife.13665. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Whiteley L, Sahani M. Implicit knowledge of visual uncertainty guides decisions with asymmetric outcomes. J Vis. 2008;8(2):1–15. doi: 10.1167/8.3.2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Teichert T, Ferrera VP. Suboptimal integration of reward magnitude and prior reward likelihood in categorical decisions by monkeys. Front Neurosci. 2010;4:186. doi: 10.3389/fnins.2010.00186. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Rorie AE, Gao J, McClelland JL, Newsome WT. Integration of sensory and reward information during perceptual decision-making in lateral intraparietal cortex (LIP) of the macaque monkey. Plos One. 2010;5:e9308. doi: 10.1371/journal.pone.0009308. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Summerfield C, Tsetsos K. Building Bridges between Perceptual and Economic Decision-Making: Neural and Computational Mechanisms. Front Neurosci. 2012;6:70. doi: 10.3389/fnins.2012.00070. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Rolls ET, Grabenhorst F, Deco G. Decision-Making, Errors, and Confidence in the Brain. J Neurophysiol. 2010;104:2359–2374. doi: 10.1152/jn.00571.2010. [DOI] [PubMed] [Google Scholar]
- 46.Ding L, Gold JI. The basal ganglia’s contributions to perceptual decision making. Neuron. 2013;79:640–649. doi: 10.1016/j.neuron.2013.07.042. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Ding L, Gold JI. Caudate Encodes Multiple Computations for Perceptual Decisions. J Neurosci. 2010;30:15747–15759. doi: 10.1523/JNEUROSCI.2894-10.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Lewis DA, Melchitzky DS, Sesack SR, Whitehead RE, Auh S, Sampson A. Dopamine transporter immunoreactivity in monkey cerebral cortex: regional, laminar, and ultrastructural localization. J Comp Neurol. 2001;432:119–136. doi: 10.1002/cne.1092. [DOI] [PubMed] [Google Scholar]
- 49.Lloyd K, Dayan P. Tamping Ramping: Algorithmic, Implementational, and Computational Explanations of Phasic Dopamine Signals in the Accumbens. PLoS Comput Biol. 2015;11:e1004622. doi: 10.1371/journal.pcbi.1004622. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Hamid AA, Pettibone JR, Mabrouk OS, Hetrick VL, Schmidt R, Vander Weele CM, Kennedy RT, Aragona BJ, Berke JD. Mesolimbic dopamine signals the value of work. Nat Neurosci. 2016;19:117–126. doi: 10.1038/nn.4173. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.