

Abstract
Study design
Cross-sectional, observational study.
Background
New health status instruments can be administered by computerized adaptive test (CAT) or short forms (SF). The Prosthetic Limb Users Survey of Mobility (PLUS-M™) is a self-report measure of mobility for prosthesis users with lower limb loss. This study used PLUS-M to examine advantages and disadvantages of CAT and SFs.
Objectives
To compare scores obtained from CAT to scores obtained from fixed-length short forms (7- item and 12-item) in order to provide guidance to researchers and clinicians on how to select the best form of administration for different uses.
Methods
Individuals with lower limb loss completed the PLUS-M by CAT and SFs. Administration time, correlations between the scores, and standard errors were compared.
Results
Scores and SEs from the CAT, 7-item SF, and 12-item SF were highly correlated and all forms of administration were efficient. CAT required less time to administer than either paper or electronic SFs, however time savings were minimal compared to the 7-item SF.
Conclusions
Results indicate that the PLUS-M™ CAT is most efficient and differences in scores between administration methods are minimal. The main advantage of the CAT was more reliable scores at higher levels of mobility compared to SFs.
Background
Instruments developed with modern psychometric methods are no longer static instruments that require the same questions to be administered to the same person. New instruments, called item banks, allow for dynamic administration by computerized adaptive testing (CAT)1 and allow for the items to be tailored to the person. CAT uses an algorithm to choose the next item based on how the respondent answers previous items. Simulation studies found CAT can achieve a reliable score in 4–5 items, and provide more precise scores than fixed length instruments, especially for those very high or very low level of the trait measured (e.g., prosthetic mobility).2–4
A subset of items from item banks are typically called short forms (SF). SFs are fixed-length instruments developed to measure well across the whole range of the trait, or to target high or low trait levels.1 Because SFs administer the same items to all respondents they cannot measure with the same precision as CAT across the whole trait continuum. Advantages of SFs are that they are familiar to respondents and can be administered on paper or by computer. While CATs have several advantages over SFs, they also require a computer and software with a CAT algorithm to administer and score the instrument. Depending on the importance of score precision and efficiency, CAT administration may or may not outweigh the technical and computing requirements needed for its implementation.5
In this study we examined the differences between CAT and SF administration of the Prosthetic Limb Users Survey of Mobility (PLUS-M™). PLUS-M is an item response theory (IRT) based item bank that measures mobility of amputees with lower limb amputation (LLA). One of the advantages of IRT-based item banks like PLUS-M is that regardless of what items are administered or the method of administration (i.e., CAT or SF) chosen, scores are on the same metric and directly comparable. We also compared the performance and efficiency of PLUS-M CAT and two fixed length SFs. While simulation studies3,4 have found CAT to be efficient, the amount of time saved depends on the item bank administered, and to what instrument (e.g., short form) the CAT performance is compared. The purpose of the study was to quantify the differences between SFs and CAT to provide researchers and clinicians with guidance on selecting the most appropriate PLUS-M instrument for their application. We expected that: (1) correlations between PLUS-M CAT and SFs scores from the same individuals would be high; (2) the PLUS-M CAT would require fewer items than the SFs to achieve an accurate score; and (3) PLUS-M CAT would produce more precise scores at the lowest and highest levels of mobility, compared to either SF.
Method
Different methods for administering PLUS-M instruments were evaluated using data collected from two studies. Data from electronic versions of the PLUS-M CAT and SFs were collected as part of a study designed to examine psychometric properties of the PLUS-M item bank (study 1). Data from paper versions of PLUS-M SFs were collected specifically for this analysis (study 2).
Participants
Study 1
Individuals with LLA were recruited from multiple clinical sites across the U.S. Recruitment methods included print media and direct recruitment from clinics or research registries. Study participants were eligible if they: (1) were 18 years of age or older; (2) could read, write, and understand spoken English; (3) had a unilateral leg amputation (i.e., at or above the ankle and below the hip) that was the result of trauma, dysvascular complications, tumor, or infection; (4) regularly used a prosthesis for the previous 6 months or more; (5) were a patient at a participating recruitment site and were scheduled to receive a replacement prosthesis or major prosthetic component likely to affect mobility (i.e., prosthetic socket or microprocessor-controlled prosthetic knee).
Study 2
Individuals with LLA were recruited through a registry of people interested in participating in research. Study participants were eligible to participate in study 2 if they met criteria 1–4 from study 1.
Procedures
Study 1
Participants in study 1 completed an electronic survey on a tablet computer (Apple Ipad 2; Cupertino, CA) during a visit to their prosthetics clinic. The survey included demographic and amputation-related questions, in addition to PLUS-M items. Participants in this study completed both the PLUS-M CAT and SFs using the Assessment Center, an online research management tool that enables researchers to create study-specific websites for securely capturing participant data.6 Administration time was recorded electronically for all items.
Study 2
Participants in study 2 completed a paper survey that was mailed to their home. Participants were randomly assigned to complete the 7-item SF (SF-7) or the 12-item SF (SF-12). The survey included demographic and amputation-related questions, in addition to the PLUS-M instrument. Participants were mailed a packet containing instructions and a paper survey in a sealed envelope, and instructed not to open the envelope until contacted by study staff. During a scheduled phone call, participants opened and completed the survey while study staff recorded the time. In addition, time required by researchers to score SFs (e.g., reading scoring instructions and calculating T-scores) was measured. All procedures for study 1 and study 2 were approved by a University of Washington institutional review board and all participants provided informed consent.
Measures
Demographic and amputation-related information
Participants provided information about their amputation including amputation etiology, level, and age at and time since amputation. Participants also responded to questions about their age, gender, education, ethnicity, and employment.
PLUS-M
The PLUS-M is a self-report measure of mobility of adults with LLA who use prosthesis.7, 8 The PLUS-M item bank includes 44 items calibrated to an IRT model. The PLUS-M CAT and SFs use items from the item bank and all scores are on the same T-score metric and directly comparable. SF-7 and SF-12 were developed to measure a broad range of mobility. All items of the SF-7 are included in the SF-12. A PLUS-M score of 50 (SD=10) represents the mean of the development sample.9 All analyses presented were completed using the IRT based T-scores. CAT and SFs are freely available to all users at www.plus-m.org.
CAT administration
Participants in study 1 completed the PLUS-M CAT. The CAT was set to administer the same first item (i.e., “are you able to keep up with others when walking?”) to every participant with subsequent items selected based on the participant’s previous responses. IRT analyses rank-order items by difficulty, and the CAT algorithm picks each subsequent item to most closely match the respondent’s reported level of the trait (e.g., mobility in this case). For instance, if a person reports no difficulty keeping up with others, the PLUS-M CAT chooses a more difficult item, like walking up and down steep stairs in a crowded stadium. The algorithm was set to administer a minimum of 4 items and to stop administration when the standard error (SE) associated with the respondent’s score dropped to 3.0 or below, or a maximum of 12 items had been administered. The SE stopping rule was selected as a SE of 3.0 corresponds to a conventional reliability of 90% for an IRT-based T-score.10, 11
SF administration
All participants completed PLUS-M SFs. Study 1 participants completed electronic SF-7 and SF-12, and study 2 participants completed paper SF-7 or SF-12. SFs were scored according to instructions in the PLUS-M users guide.9 Study 2 participants were randomly assigned either the SF-7 or SF-12. Time to complete the SF was recorded by study staff during the phone call with the participant. Responses were double-entered and scored by a SAS algorithm that uses the lookup tables published in the PLUS-M Users Guide.9 Table 1 summarizes the measures and mode of administration for each study.
Table 1.
Summary of mode of administration, measures, and overall study objectives
| Study | Study 1 | Study 2 |
|---|---|---|
| Mode of Survey Administration | Electronic survey on tablet in clinic (timed by Assessment Center) | Paper survey at home (timed by investigator) |
| Measures Administered |
|
|
| Main Objective(s) |
|
|
CAT = Computerized adaptive test, PLUS-M: Prosthetic Limb Users Survey of Mobility, SF = short form
Three research assistants and three clinicians unfamiliar with the SFs were timed while they read the scoring instructions (once each) and calculated scores for ten SFs (i.e., five SF-7 and five SF-12). Manual scoring included summing the individual item scores and converting raw scores to T-scores using the appropriate PLUS-M look-up table.
Analysis
CAT and SF Comparisons
Using study 1 data, performance of the CAT was compared to the SFs using a number of metrics. CAT and SF scores, SEs, and effective ranges of measurement were compared. Effective range of measurement was defined as range for which participants’ scores had a reliability of at least 90%.12 CAT and SF scores from study 1 were correlated using Pearson correlation to examine correspondence, and average score differences were calculated. Finally, we examined the average number of items administered by CAT and calculated the range of scores that typically required CAT administer only 4 items.
Administration Time
Relative efficiency of the PLUS-M instruments was evaluated using administration time as a primary metric. Administration time of the CAT (study 1) and SFs (study 1 and 2) were calculated and compared. Data from participants whose response time was less than 1 second per item were excluded from analyses, in accordance with procedures used in prior studies.13 Administration times for electronically administered SFs and CAT were calculated by summing the response times to each of the individual items. Administration times for the paper SFs were measured directly by study staff during the phone call and were used to calculate average completion times. Administration times that were more than 2.5 SD greater than the average administration time were considered outliers and excluded.14
Results
Participants
One hundred ninety-nine individuals completed the CAT and electronic SFs in study 1 and sixty individuals completed paper SFs (30 each SF) in study 2 (Table 2).
Table 2.
Demographics and amputation related characteristics of study samples
| Study 1
|
Study 2
|
|||
|---|---|---|---|---|
| n | % | n | % | |
| Gender | ||||
| Male | 143 | 71.9% | 46 | 76.7% |
| Female | 56 | 28.1% | 14 | 23.3% |
| Race/Ethnicity | ||||
| Non-Hispanic White | 147 | 73.9% | 56 | 93.3% |
| Others | 49 | 24.6% | 4 | 6.7% |
| Not reported | 3 | 1.5% | 0 | 0.0% |
| Education | ||||
| Some high school | 13 | 6.5% | 1 | 1.7% |
| High school/GED | 51 | 25.6% | 11 | 18.3% |
| Some college/technical degree | 81 | 40.7% | 20 | 33.3% |
| College degree | 36 | 18.1% | 16 | 26.7% |
| Advanced degree | 17 | 8.5% | 12 | 20.0% |
| Not reported | 1 | 0.5% | 0 | 0.0% |
| Employment | ||||
| Employed | 57 | 28.6% | 24 | 40.0% |
| Homemaker | 8 | 4.0% | 0 | 0.0% |
| Retired | 54 | 27.1% | 20 | 33.3% |
| On disability | 66 | 33.2% | 13 | 21.7% |
| Unemployed | 8 | 4.0% | 3 | 5.0% |
| Student | 6 | 3.0% | 0 | 0.0% |
| Amputation Level | ||||
| Ankle disarticulation (Symes) | 4 | 2.0% | 0 | 0.0% |
| Transtibial | 146 | 73.4% | 41 | 68.3% |
| Knee disarticulation | 6 | 3.0% | 1 | 1.7% |
| Transfemoral | 34 | 17.1% | 18 | 30.0% |
| Not reported | 9 | 4.5% | 0 | 0.0% |
| Etiology | ||||
| Trauma | 81 | 40.7% | 36 | 60.0% |
| Dysvascular complications (including diabetes and PVD) | 83 | 41.7% | 9 | 15.0% |
| Cancer or non-malignant tumor | 8 | 4.0% | 4 | 6.7% |
| Infection | 15 | 7.5% | 10 | 16.7% |
| Congenital | 2 | 1.0% | 1 | 1.7% |
| Not reported | 10 | 5.0% | 0 | 0.0% |
|
| ||||
| Mean | SD | Mean | SD | |
|
| ||||
| Age at time of survey (years) | 55.17 | 14.44 | 60.96 | 11 |
| Age at amputation (years) | 44.16 | 19.06 | 41.76 | 17.75 |
| Time since amputation (years) | 11.01 | 13.07 | 19.2 | 16 |
Note. Percentages may not total 100 due to rounding. SD: Standard Deviation. GED: General Educational Development. PVD: Peripheral vascular disease.
CAT and SF Comparisons (Study 1 Electronic Administration)
Score Precision
Average SEs associated with PLUS-M scores from the study 1 sample were 2.7 (SD=0.3) for the CAT; 2.2 (SD=0.5) for the SF-12; and 2.9 (SD=0.5) for the SF-7. Almost all (97%, n=194) CAT scores, 92% of SF-12 scores (183 out of 199), and 70% (n=139) of SF-7 scores achieved a SE less than 3.0. The average score for participants with a SE greater than 3.0 was 64.8 for the CAT (n=5), 62.6 for the SF-12 (n=16), and 59.0 for the SF-7 (n=60).
Figure 1 shows the relationship between SE and PLUS-M instrument scores. Scores with reliability greater than 90% ranged from 23.5 to 69.1 (n=196; 98%) for the CAT; 27.2 to 62.5 (n=191; 96%) for the SF-12; and 34.4 to 55.3 (n=153; 77%) for the SF-7. The SF-7 had the narrowest effective range of measurement, relative to the CAT and SF-12. CAT provided scores with reliability greater than 90% for about a half of participants with highest mobility (n=6 of 13, 46%), while neither SF achieved 90% reliability for scores of 60 or more.
Figure 1.
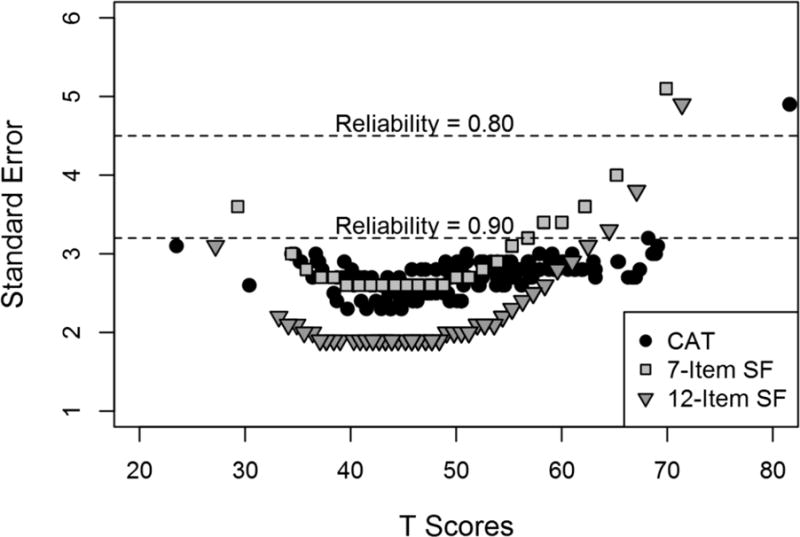
The relationship between standard errors and PLUS-M scores across three administration methods.
Score Differences and Correlations
Mean scores for the CAT, SF-12, and SF-7 were 50.8 (SD=8.6), 50.3 (SD=7.9), and 50.5 (SD=7.7), respectively. Correlations between the CAT and both SFs were 0.90. Correlation between the two SFs was 0.98. Mean differences in scores across the score continuum never exceeded 0.5, which is negligible considering the SD of 10.
Number of Items Administered
On average, the CAT administered 5 items (SD=1.9; range=4–12). About 60% of participants (n=119) responded to the minimum number of items (i.e., 4), 21% (n=41) answered 5 items and 9% (n=17) responded to 6 items before the SE stopping rule was reached. About a third of the participants (n=65) would have met the SE cutoff with only 3 items, but none would have achieved the cutoff with only 2 items. Seven participants completed 12 items, the maximum number administered by the CAT algorithm. The mobility level of these seven participants was either very low or very high, or their responses varied greatly item-to-item. The CAT was most efficient (i.e., needed only 4 items to estimate a reliable score) for participants with scores between 35 and 55 (n=119, average SE=2.6). On average, the CAT algorithm administered 3 items from the SF-12 (range 2 to 6) and 2 items from the SF-7 (range 1 to 4).
Administration Time
Study 1 Electronic Administration
Data from 182 participants (i.e., 1≤ item response time≤ 59.8 seconds) were used to determine the CAT administration time. On average, the CAT took 68.9 seconds to administer and score. Responding to CAT items required an average of 13.8 seconds per item. Similarly, data from 143 participants (i.e., 1 ≤ item response time≤ 48.8 seconds) were used to calculate the SF-12 administration times. Mean time to complete the SF-12 was 124.5 seconds (i.e., 10.4 seconds per item). Data from 154 participants (i.e., 1 ≤ item response time≤ 52.9 seconds) was used to calculate administration time for the SF-7. The mean time to completion for the SF-7 was 82.9 seconds (i.e., 11.9 seconds per item).
Study 2 Paper Administration
Data from 60 participants (i.e., n=30 each for the SF-7 and SF-12) was used to determine paper administration times. On average, participants required 86.2 (SD=37.6) seconds to complete the SF-12 and 73.1 (SD=35.3) seconds to complete the SF-7 on paper. Research assistants and prosthetists (n=6) required, on average, 163 (SD=61.3) seconds to read the scoring instructions. Manually scoring surveys required, on average, 36.6 (SD=15.1) seconds for the SF-7, and 47.5 (SD=21.1) seconds for the SF-12.
Discussion
Overall results indicate that any of the three PLUS-M instruments can be used to accurately assess mobility in people with LLA. As expected, only the CAT achieved reliability greater than 90% for people with scores greater than 60. This finding is consistent with published literature.5, 15 In contrast to our hypothesis, both CAT and SFs achieved acceptable precision at the lower end of mobility, likely due to inclusion of more items targeted to lower mobility levels on SFs.
CAT obtained adequately precise scores in more than half of the study participants (60%) using only four items and a third (33%) would have met the SE cutoff with only three items. The CAT was also more time efficient than either of the SFs. However, administration time saved with the CAT relative to SFs was small because the SFs are also very efficient. It is important to note that CAT times include time for both administration and scoring because scores are automatically generated by the CAT algorithm. Electronically administered SFs in this study required additional scoring time, although it is possible to set up automatic scoring software or algorithms for SFs administered via computer. Scoring paper surveys added an average of 37 and 48 seconds to the overall administration time for SF-7 and SF-12 respectively, making CAT 37–49% more efficient than paper SFs. The study results suggest that when practical, the PLUS-M CAT should be considered in place of SFs when minimizing respondent burden and maximizing score precision is a priority.
Results of this study are similar to previously published studies. Choi et al. used computer simulation to compare CAT and 8-item SF for PROMIS depression and found a correlation of .96 between the CAT and SF score.5 Similar to our study, the CAT was more efficient than the SF, and required only 5 items on average to estimate a reliable score. Fries et al. compared the performance of the 10- and 20-item PROMIS physical function short form with 10-item CAT in 378 people with arthritis. The 10-item CAT outperformed the SFs.16
One benefit of CAT that is not directly explored in this study is the flexibility to modify the CAT administration rules to match specific study requirements.1 Users interested in measuring prosthetic mobility with greater precision could use a PLUS-M CAT stopping rule with a lower SE to achieve a highly reliable score and maximize the likelihood that a smaller treatment effect would be detected. In a clinical setting where efficiency may be more important than score precision, the minimum number of items administered could be set to 2 or 3, or the SE threshold could be relaxed to 3.5 or 4. Such a change would result in fewer items being administered and reduce the overall time of administration.
The need for appropriate computer hardware and software is currently the biggest disadvantage of CAT. At present, CAT administration is not integrated into most electronic survey administration platforms, with notable exceptions like the PROMIS Assessment Center6 and Research Electronic Data Capture (REDCap),17 though these platforms only provide preprogrammed PROMIS instruments at this time. Until CAT is more readily available, fixed-length SFs are excellent alternatives for clinicians and researchers who wish to use IRT-based item banks, like PLUS-M. Paper and pencil or computer administered SFs are often convenient and easy to administer and, in the case of PLUS-M, produced scores that are highly correlated with CAT scores. Although SF scores are generally not as precise as CAT scores at the extremes of the instrument range,5, 16 the PLUS-M SFs in this study provided reliable scores along most of the mobility continuum and therefore can be used with confidence as alternatives to CAT.
A disadvantage of the CAT administration software used to collect data for this study was that stopping rules could not be adjusted to reduce the number of items for respondents at the extremes of the mobility continuum. As a result, people with very low or very high mobility were asked to respond to the maximum number of items. More sophisticated stopping rules would allow the CAT to terminate when items provide little information toward the assessment, even when the SE threshold has not been achieved.18
This study has several limitations related to the sample and methodology used. For both study 1 and 2, a convenience sample was used that may not represent the population of individuals with LLA. Study 2 collected administration times for paper SF by participants’ self-report on the phone. Participants may have read the survey prior to the timed administration, which could have resulted in an under-estimation of response time.
Conclusion
Both PLUS-M CAT and SFs provided reliable scores and were efficient to administer. Users can use convenience and feasibility to choose the version of PLUS-M to administer. While PLUS-M CAT is fastest to administer and provides the most precise scores, especially for those at the higher mobility levels, the gains may not be sufficient to justify the expense of programming CAT.
Clinical Relevance.
Health-related item banks, like the Prosthetic Limb Users Survey of Mobility, can be administered by Computerized Adaptive Testing (CAT) or as fixed-length short forms (SFs). Results of this study will help clinicians and researchers decide whether they should invest in a CAT administration system or whether SFs are more appropriate.
Acknowledgments
Funding:
This research is supported by the National Center for Medical Rehabilitation Research (NCMRR), National Institute of Child and Human Development of the National Institutes of Health [NIH grant number HD-065340]. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health. The contents of this publication were also developed in part under a grant from the National Institute on Disability, Independent Living, and Rehabilitation Research [NIDILRR grant number H133P120002]. NIDILRR is a Center within the Administration for Community Living (ACL), Department of Health and Human Services (HHS). The contents of this publication do not necessarily represent the policy of NIDILRR, ACL, HHS, and you should not assume endorsement by the Federal Government.
Footnotes
Author Contributions:
Authors Hafner and Amtmann contributed to the conception and design of the overall study and provided critical revisions for intellectual content. Authors Kim, Bocel, Chung, Park, and Bamer all contributed to the analyses and interpretation of data while author Salem was in charge of data acquisition and key data cleaning and coding. Authors Kim and Bamer drafted the manuscript with critical input from Bocel, Chung, Park and Salem. Author Hafner obtained funding for the research described in the publication.
Declaration of Conflicting Interests:
The authors declare that there is no conflict of interest.
References
- 1.Cella D, Gershon R, Lai JS, Choi S. The future of outcomes measurement: Item banking, tailored short-forms, and computerized adaptive assessment. Quality of Life Research. 2007;16:133–41. doi: 10.1007/s11136-007-9204-6. [DOI] [PubMed] [Google Scholar]
- 2.Ayala De. R The theory and practice of item response theory. New York, New York: Guildford Press; 2009. [Google Scholar]
- 3.Cook KF, Choi SW, Crane PK, Deyo RA, Johnson KL, Amtmann D. Letting the CAT out of the bag: comparing computer adaptive tests and an 11-item short form of the Roland-Morris Disability Questionnaire. Spine. 2008;33:1378–83. doi: 10.1097/BRS.0b013e3181732acb. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Haley SM, Coster WJ, Andres PL, Kosinski M, Ni P. Score comparability of short forms and computerized adaptive testing: Simulation study with the activity measure for post-acute care. Arch Phys Med Rehabil. 2004;85:661–6. doi: 10.1016/j.apmr.2003.08.097. [DOI] [PubMed] [Google Scholar]
- 5.Choi SW, Reise SP, Pilkonis PA, Hays RD, Cella D. Efficiency of static and computer adaptive short forms compared to full-length measures of depressive symptoms. Qual Life Res. 2010;19:125–36. doi: 10.1007/s11136-009-9560-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Gershon R, Rothrock NE, Hanrahan RT, Jansky LJ, Harniss M, Riley W. The development of a clinical outcomes survey research application: Assessment Center. Qual Life Res. 2010;19:677–85. doi: 10.1007/s11136-010-9634-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Amtmann D, Abrahamson D, Morgan S, et al. The PLUS-M: item bank of mobility for prosthetic limb users. Qual Life Res. 2014;23:39–40. [Google Scholar]
- 8.Hafner B, Morgan S, Askew R. Psychometric evaluation of self-report outcome measures for prosthetic applications. J Rehabil Res Dev. 2016 doi: 10.1682/JRRD.2015.12.0228. (in press) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Prosthetic Limb Users Survey of Mobility (PLUS-M™). Version 1.2 – English. Short Form Users Guide 2015.
- 10.Hung M, Clegg DO, Greene T, Weir C, Saltzman CL. A lower extremity physical function computerized adaptive testing instrument for orthopaedic patients. Foot Ankle Int. 2012;33:326–35. doi: 10.3113/FAI.2012.0326. [DOI] [PubMed] [Google Scholar]
- 11.Jette AM, Haley SM, Ni P, Olarsch S, Moed R. Creating a computer adaptive test version of the late-life function and disability instrument. J Gerontol A Biol Sci Med Sci. 2008;63:1246–56. doi: 10.1093/gerona/63.11.1246. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Lai JS, Cella D, Choi S, et al. How item banks and their application can influence measurement practice in rehabilitation medicine: a PROMIS fatigue item bank example. Arch Phys Med Rehabil. 2011;92:S20–7. doi: 10.1016/j.apmr.2010.08.033. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Amtmann D, Cook KF, Jensen MP, et al. Development of a PROMIS item bank to measure pain interference. Pain. 2010;150:173–82. doi: 10.1016/j.pain.2010.04.025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Havas DA, Glenberg AM, Rinck M. Emotion simulation during language comprehension. Psychon Bull Rev. 2007;14:436–41. doi: 10.3758/bf03194085. [DOI] [PubMed] [Google Scholar]
- 15.Haley SM, Ni P, Hambleton RK, Slavin MD, Jette AM. Computer adaptive testing improved accuracy and precision of scores over random item selection in a physical functioning item bank. Journal of Clinical Epidemiology. 2006;59:1174–82. doi: 10.1016/j.jclinepi.2006.02.010. [DOI] [PubMed] [Google Scholar]
- 16.Fries JF, Cella D, Rose M, Krishnan E, Bruce B. Progress in assessing physical function in arthritis: PROMIS short forms and computerized adaptive testing. The Journal of rheumatology. 2009;36:2061–6. doi: 10.3899/jrheum.090358. [DOI] [PubMed] [Google Scholar]
- 17.Obeid JS, McGraw CA, Minor BL, et al. Procurement of shared data instruments for Research Electronic Data Capture (REDCap) J Biomed Inform. 2013;46:259–65. doi: 10.1016/j.jbi.2012.10.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Choi SW, Grady MW, Dodd BG. A New Stopping Rule for Computerized Adaptive Testing. Educ Psychol Meas. 2010;70:1–17. doi: 10.1177/0013164410387338. [DOI] [PMC free article] [PubMed] [Google Scholar]