

Abstract
Purpose
This study reports data on vocal fundamental frequency (fo) and the first four formant frequencies (F1, F2, F3, F4) for four vowels produced by speakers in 3 adult-age cohorts, in a test of the null hypothesis that there are no age-related changes in these variables. Participants were 43 men and 53 women between the ages of twenty to ninety-two years.
Results
The most consistent age-related effect was a decrease in fo for women. Significant differences in F1, F2, and F3 were vowel-specific for both sexes. No significant differences were observed for the highest formant F4.
Conclusions
Women experience a significant decrease in fo, which is likely related to menopause. Formant frequencies of the corner vowels change little across several decades of adult life, either because physiological aging has small effects on these variables or because individuals compensate for age-related changes in anatomy and physiology.
Keywords: adult acoustics, aging voice, vowels, fundamental frequency, formants, sex differences
1. Introduction
From infancy through young adulthood, the acoustic signal of speech undergoes substantial change, including marked decreases in both vocal fundamental frequency (fo) and the frequencies of the vowel formants [1]. These developmental changes are accompanied by a sexual dimorphism that is proportionately (i.e., male:female ratio) one of the largest in human development [2]. After adulthood, age-related changes in the acoustic properties of speech and voice are much less marked and conclusions across studies are inconsistent, with some studies showing no effects and others reporting a variety of effects such as a decrease of fo in women [3, 4], an increase of fo in men [3,4], a centralization of formant frequencies [5], a decrease in F1 frequency [6], decreases in all formant frequencies [7], and a sex-vowel interaction in formant frequencies [8].
Because results are not consistent across reports and because the aggregate number of individuals studied is small compared to the general population, it is difficult to draw firm conclusions on the effect of aging on speech acoustics. Even if acoustic changes occur with age, there are uncertainties in the interpretation of age- and sex-related variations. For example, changes in vowel formant frequencies during adulthood have been linked to lengthening of the vocal tract [7, 9], altered dimensions of the back cavity of the vocal tract [10], diachronic or intergenerational phonetic change [11, 12], reduction of articulatory movement [13], and adjustments of lingual articulation [14]. Possibly, two or more of these factors operate in combination to account for age-related acoustic changes in speech, and the combinations may vary among individuals.
Given the diverse results in previous studies, it is difficult at this time to describe a normative lifespan pattern for measures of fo and formant frequencies in vowel production. A normative pattern is needed to inform studies of quality of life during aging [15], to serve as reference data for clinical assessment and treatment [16, 17, 18], to provide information for biometric identification and forensics [19] and speech technologies such as automatic speaker recognition [20]. Most of the relevant research to date has focused on fo and other features of phonation. A much smaller literature has been published on the joint effects of aging on fo and formant frequencies, and most of these reports present data only for F1 and F2, neglecting the higher formants, which may be sensitive to sex differences and alterations in vocal tract geometry.
More generally, little is known about the effects of aging on any aspect of speech production. Smiljanic [21] concluded that, “In contrast to the accumulated knowledge about the perceptual processing difficulties [in aging], very little is known about whether age-related changes impact speech production patterns for older adult talkers and the intelligibility of their speech” (p. EL129). Research to date, though limited, indicates that older adults have reduced speech intelligibility [22], greater impairment of phonological than semantic levels of language production [23], and difficulties with specific articulatory features [24]. Acoustic studies shed light on why intelligibility changes with age. For example, Benjamin [25] concluded that aging affected vowel productions, voice onset time, phoneme segment duration, and speaking rate. Schötz [26] reported age-related changes in speaking rate (segment duration), intensity range, and to a lesser extent, fo and the frequencies of the first two formants. She also noted that the acoustic correlates of aging speech are not the same in men and women. Because multiple acoustic cues underlie speech intelligibility, systematic research is needed to determine which cues, perhaps in various combinations, explain reduced intelligibility. Changes that occur in healthy aging are an important basis for understanding speech and voice disorders associated with health conditions that affect older individuals, such as hearing loss, Parkinson’s disease, dementia, stroke, and cancer [27].
The purpose of this study is test the null hypothesis that there are no age-related changes in fo and the first four formant frequencies (F1, F2, F3, F4) for four vowels produced by speakers in 3 adult age cohorts. Several features of this research are notable. The test words used in this report are from a larger lifespan study of speech acoustics that covers the age range of 4 to 92 years. Constancy of the words across speakers throughout the lifespan facilitates comparisons and reduces variability related to the use of different speech samples across speaker ages. Collection of data for the first four formants, as opposed to just two formants, as has been the case in most studies, provides additional information that may be helpful in explaining age-related changes in formant pattern, for example, by referring to formant-cavity affiliations.
2. Methods
2.1 Participants
Speech recordings were from 96 healthy adult participants (43 male, 53 female), between the ages of 20 to 92 years. All participants met eligibility requirements as native English speakers. Ages were grouped into three cohorts, cohort I consisted of young adults (19 males, 21 females) ages 20 to 30 years, cohort II consisted of middle-aged adults (12 males, 20 females) ages 40 to 60 years, and cohort III consisted of older adults (12 males, 12 females) ages 70 to 92 years. No participant was excluded on the basis of hearing status. Not surprisingly, the majority of participants in cohort III had a hearing loss as determined by self-report or a screening test (9 wore hearing aids).
2.2. Speech sample
The speech stimuli consisted of 20 unique monosyllabic American English words. The words had the syllable structures of consonant-vowel, vowel-consonant, or consonant-vowel-consonant. The words were composed with the four corner vowels in the classic vowel quadrilateral: /i/ (bead, bee, eat, sheep, feet), /u/ (boo, boot, zoo, hoot, shoe), /æ/ (bath, bat, cat, hat, sad), and /ɑ/ (dot, hop, pot, top, hot). For each vowel, two of the stimuli were recorded twice (e.g., bead, eat, bat, hat). The stimuli were designed to collect data over the lifespan and were therefore chosen to be familiar to young children; also, to have high phonological neighborhood density, which reportedly maximizes F1/F2 acoustic vowel space [28].
2.3. Recording protocol
Participants were recorded in a quiet room in either a laboratory or a retirement center. Background noise levels were measured with a Fisher Scientific Sound Level Meter Model 11-661-6A with an A-weighting. The levels varied between 31 to 38 dBA, depending on the recording site. Recordings were made with a Shure-SM48 microphone mounted on a floor stand and attached to a Marantz digital recorder. The microphone was adjusted to each participant’s seated height and positioned at an approximate 15 cm distance from the mouth. The Marantz-PMD660 digital audio recorder digitizes speech at 48 kHz with 16-bit resolution on a SanDisk Ultra II flashcard. To optimize recording level, the Marantz recorder gain was adjusted to 6 to 12 dB below the maximum level on the volume unit (VU) meter. Using a laptop with the TOCS+ Platform program [29] for randomization, the stimuli were presented visually and aurally using pictures with the orthographic word, while playing the recording of an adult male through external speakers. Participants were instructed to repeat the words at a normal loudness level. Two practice words were used at the beginning to adjust recording levels. During recording, stimuli that were mispronounced or considered to be deviant in VU meter reading were repeated and the repeated recording replaced the original productions.
2.4. Acoustic analysis methods
Acoustic analysis were based on methods and criteria developed for the analysis of speech from speakers who represent various combinations of age and sex [30, 31]. The basic steps were as follows: Speech recordings were uploaded to a computer, segmented into separate word files with Praat (version 5.1.31 by Boersma & Weenink) [32], and saved into separate wave files. The vowel portion of each word was analyzed to obtain estimates of fo and the first four formants (F1, F2, F3, F4) using the acoustic analysis software TF32, (Milenkovic 2010) [33]. The frequency of fo was measured with the pitch determination algorithm in TF32. The formant frequencies were estimated with reference to the spectrogram (with overlaid formant tracks determined by LPC) and time-slice spectra from linear prediction coding (LPC) and Fast Fourier Transform (FFT). The LPC and FFT spectra were superimposed to permit comparisons. In cases where the LPC and FFT spectra were not congruent, reference was made to the spectrogram together with adjustments in analysis parameters, especially the number of LPC coefficients. The default setting for TF32 is a 300 Hz bandwidth and 48 dB dynamic range. Both the number of LPC coefficients and the dynamic range were adjusted to achieve optimum results for each speaker. Males were analyzed at 300 Hz, with a dynamic range adjusted between 48–64 dB. Females were analyzed at default settings, however, if formant energy was unclear, bandwidth was adjusted to 350 or 400 Hz and dynamic range could be adjusted as high as 68 dB. These procedures are consistent with general practice and recommendations for formant analysis using LPC and FFT [34, 35, 36, 37]. Because we have observed that the temporal midpoint of the vowel does not always correspond to a formant steady state, we used vowel-specific time points as defined by Derdemezis et al. [31] and similar to criteria used others [38]:]:
Vowel /i/ -- point of highest F2 frequency;
Vowel /u/ -- point of lowest F2 frequency;
Vowel /ɑ/ -- point of least separation of F1 and F2 frequencies;
Vowel /æ/ -- point of most evenly spaced formants, taking care to avoid measurement at a point of decreasing F2-F1 difference which can reflect backing of the vowel.
The value of fo was determined at the same time point as the formant measurements unless this time point occurred during an interval of vocal fry, pitch break, or other deviation from the overall fo contour of the syllable. In such cases, fo was measured at a proximal time point where the value was consistent with the contour of the utterance, as our interest was in the utterance-typical value of fo.
2.5. Data analysis
Acoustic measurements for the cohorts I and II (young adult and middle-aged adults) were completed by 6 raters. One of these 6 raters made acoustic measurements for cohort III (older adults). All measurements for fo and F1–F4 were visually examined for outliers, and unusual measurements were checked for possible data entry errors or other inconsistencies. There were no missing measurements for F1 and F2. However, some measurements could not be made for fo, F3, and F4. The percentage of missing measurements were: fo < 1% missing data, F3 < 1.5% missing data, and F4 < 7% missing data. Since an important goal for this database is to provide normative data for adult age cohorts, outliers that exceeded 2.576 SD from their Age cohort x Sex mean were excluded from this analysis. This ensured that there was a low probability (1%) of excluding data incorrectly, but also guarded against large outliers having undue influence on the age cohort analysis. Outliers removed were less than 1.8% of the total data. To assess reliability, raters’ inter- and intra-rater reliability was measured using the intraclass correlation coefficient (ICC), which can be thought of as the correlation of observations within a subject (with the value 1 being the maximal possible reproducibility of the frequency measurements). Inter-rater reliability was assessed using a two-way random effects model, with the assumption that the raters came from a larger population of possible raters. A random subset of recordings from six participants were measured by all raters. Reliability among the raters was excellent, with ICC values > .96 for all vowels/formants except F1 of /æ/ where ICC was .69 but still considered good reliability. To assess intra-rater reliability for Cohort III, a random sample of six older adults was re-measured by the same rater. Again, reliability was excellent with ICC > .91 for all vowels and formants with the exception of F4 for /i/ where ICC was .714 but still considered very good reliability.
2.6. Statistical methods
All analyses were completed using the Statistical Analysis System (SAS) software (version 9.4 by SAS Institute, Inc., 2013). Mixed effects models were used to compare fundamental frequency and the first four formants across age cohorts. Fixed effects included Sex, Age/cohort, and Sex X Age cohort interaction. A random effect for subject was included in the mixed models to account for the correlation of repeat words from the same subject. Comparisons of interest for males and females were between the following three age cohorts in years: Cohort I (ages 20–30) vs. cohort II (ages 40–60), cohort II vs. cohort III (ages 70–92), and cohort I vs. cohort III. The Bonferroni method was used to adjust p-values to account for multiple comparisons for each model, with a p-value of .05/6 = .0083 indicating significant differences.
3. Results
Findings revealed the expected significant differences by sex for all vowels and all frequencies, fo and all formants, see Table 1. Age cohort differences are displayed in Figures 1 and 2 as well as Tables 1 and 2. Findings revealed significant differences among age cohorts for all vowels for fo, and for /i/, /u/ and /æ/ for F1 and F2. There was a significant Age cohort X Sex interaction for all vowels for fo, for /u/ and /æ/ for F1, and for /æ/ for F3, indicating that the differences among age cohorts varied by sex. Given the interaction, the boxplots in Figures 1 and 2 display the findings separately by speaker sex to display age group/cohort differences more clearly. Table 2 shows the model means (least squares means) for each frequency (fo, F1, F2, F3, F4) by vowel for each sex and age cohort, and indicates significant age cohort differences.
Table 1.
Results of mixed models estimating the effect of sex, age cohort and sex X age cohort interaction on vowel fundamental frequencies and formants.
| Sex | Age cohort | Sex X Age cohort | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
||||||||
| Measure | Vowel | F (1,90) | p-value | F (2,90) | p-value | F (2,90) | p-value | |||
| fo | i | 289.37 | <.0001 | * | 3.96 | 0.0225 | * | 10.84 | <.0001 | * |
| u | 288.44 | <.0001 | * | 4.49 | 0.0138 | * | 9.41 | 0.0002 | * | |
| æ | 242.91 | <.0001 | * | 5.04 | 0.0084 | * | 17.55 | <.0001 | * | |
| ɑ | 274.11 | <.0001 | * | 4.51 | 0.0136 | * | 14.61 | <.0001 | * | |
| F1 | i | 87.75 | <.0001 | * | 4.53 | 0.0134 | * | 1.63 | 0.2010 | |
| u | 41.77 | <.0001 | * | 10.85 | <.0001 | * | 5.72 | 0.0046 | * | |
| æ | 100.10 | <.0001 | * | 9.35 | 0.0002 | * | 4.05 | 0.0207 | * | |
| ɑ | 133.96 | <.0001 | * | 1.11 | 0.3342 | 0.07 | 0.9323 | |||
| F2 | i | 219.36 | <.0001 | * | 3.26 | 0.0430 | * | 0.01 | 0.9924 | |
| u | 27.43 | <.0001 | * | 14.48 | <.0001 | * | 0.50 | 0.6105 | ||
| æ | 155.69 | <.0001 | * | 6.07 | 0.0034 | * | 2.31 | 0.1051 | ||
| ɑ | 96.72 | <.0001 | * | 2.78 | 0.0672 | 0.91 | 0.4052 | |||
| F3 | i | 154.43 | <.0001 | * | 0.97 | 0.3839 | 0.09 | 0.9147 | ||
| u | 165.84 | <.0001 | * | 1.54 | 0.2205 | 2.29 | 0.1069 | |||
| æ | 216.52 | <.0001 | * | 1.26 | 0.2873 | 4.25 | 0.0172 | * | ||
| ɑ | 67.07 | <.0001 | * | 1.14 | 0.3240 | 0.22 | 0.8009 | |||
| F4 | i | 156.51 | <.0001 | * | 0.24 | 0.7842 | 0.02 | 0.9849 | ||
| u | 169.92 | <.0001 | * | 0.79 | 0.4558 | 0.12 | 0.8837 | |||
| æ | 139.79 | <.0001 | * | 1.11 | 0.3336 | 0.20 | 0.8155 | |||
| ɑ | 57.17 | <.0001 | * | 2.23 | 0.1139 | 1.35 | 0.2638 | |||
Fixed effect is significant at p < .05 alpha level.
Figure 1.

Vowel-specific fundamental frequency (fo) for cohort I (young adults), cohort II (middle-aged adults) and cohort III (older adults). Top panel shows the box and whisker plots for women and bottom panel for men. The boxplots show the 25th and 75th percentiles and the dash line represents the mean. The whiskers show the maximum and minimum values excluding outliers. Outlying data (greater than 1.5 times the intra-quartile range above or below the box) are shown as open round symbols. Asterisk denotes significant age cohort differences.
Figure 2.
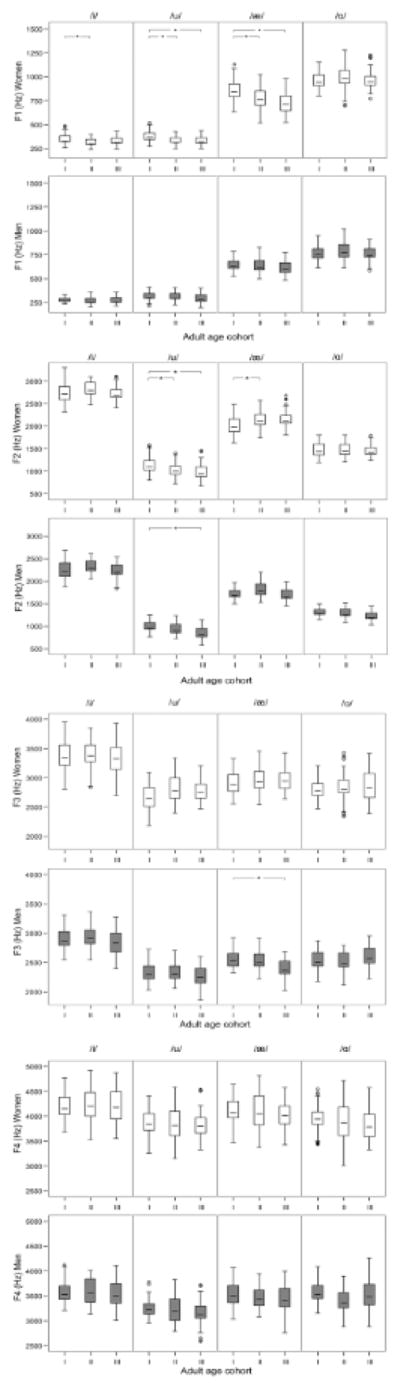
Vowel-specific frequencies (first through fourth formants) for cohort I (young adults), cohort II (middle-aged adults) and cohort III (older adults). Top panel shows the box and whisker plots for women and bottom panel for men. See Figure 1 caption for boxplot information. Asterisk denotes significant age cohort differences.
Table 2.
Least squares means from mixed models for three adult age cohorts for women and men, with indicators for significant differences.
| Female | Male | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|||||||||||
| 20–30 | 40–60 | 70+ | 20–30 | 40–60 | 70+ | |||||||
| Mean (SE) | Mean (SE) | Mean (SE) | Mean (SE) | Mean (SE) | Mean (SE) | |||||||
| fo | i | 212 (4.65) | 1,2 | 177 (4.78) | 1 | 188 (6.16) | 2 | 108 (4.90) | 115 (6.15) | 125 (6.16) | ||
| u | 211 (4.54) | 1,2 | 178 (4.66) | 1 | 187 (6.01) | 2 | 112 (4.79) | 115 (6.00) | 126 (6.02) | |||
| æ | 205 (4.54) | 1,2 | 167 (4.66) | 1 | 166 (6.01) | 2 | 103 (4.78) | 110 (6.00) | 120 (6.01) | |||
| ɑ | 200 (4.31) | 1,2 | 165 (4.42) | 1 | 170 (5.71) | 2 | 102 (4.55) | 108 (5.70) | 119 (5.71) | |||
| F1 | i | 355 (6.54) | 1 | 322 (6.69) | 1 | 332 (8.64) | 282 (6.86) | 274 (8.63) | 276 (8.63) | |||
| u | 386 (6.76) | 1,2 | 335 (6.92) | 1 | 337 (8.92) | 2 | 317 (7.09) | 316 (8.92) | 299 (8.92) | |||
| æ | 865 (16.16) | 1,2 | 783 (16.56) | 1 | 734 (21.39) | 2 | 650 (16.99) | 645 (21.44) | 618 (21.41) | |||
| ɑ | 965 (18.17) | 998 (18.62) | 974 (24.04) | 770 (19.10) | 793 (24.02) | 764 (24.04) | ||||||
| F2 | i | 2761 (35.37) | 2838 (36.25) | 2732 (46.79) | 2250 (37.18) | 2332 (46.79) | 2230 (46.80) | |||||
| u | 1145 (23.36) | 1,2 | 1035 (23.96) | 1 | 994 (30.95) | 2 | 1006 (24.55) | 2 | 946 (30.90) | 867 (30.90) | 2 | |
| æ | 2027 (30.51) | 1 | 2159 (31.27) | 1 | 2163 (40.39) | 1720 (32.08) | 1822 (40.37) | 1704 (40.37) | ||||
| ɑ | 1488 (21.26) | 1496 (21.78) | 1466 (28.13) | 1317 (22.36) | 1300 (28.12) | 1227 (28.13) | ||||||
| F3 | i | 3376 (39.53) | 3403 (40.54) | 3354 (52.27) | 2908 (41.51) | 2944 (52.30) | 2855 (52.42) | |||||
| u | 2682 (35.34) | 2814 (36.22) | 2783 (46.74) | 2338 (37.17) | 2343 (46.74) | 2278 (46.74) | ||||||
| æ | 2918 (31.71) | 2964 (32.53) | 2976 (42.03) | 2567 (33.32) | 2 | 2533 (41.94) | 2406 (41.93) | 2 | ||||
| ɑ | 2815 (35.84) | 2838 (36.72) | 2867 (47.44) | 2539 (37.66) | 2521 (47.42) | 2607 (47.52) | ||||||
| F4 | i | 4195 (51.82) | 4228 (54.54) | 4191 (69.94) | 3573 (54.49) | 3598 (68.60) | 3547 (68.63) | |||||
| u | 3883 (50.17) | 3855 (51.44) | 3838 (66.42) | 3273 (52.90) | 3235 (66.39) | 3170 (66.39) | ||||||
| æ | 4118 (53.11) | 4123 (56.46) | 4051 (70.45) | 3549 (55.88) | 3482 (70.42) | 3430 (70.30) | ||||||
| ɑ | 3975 (53.73) | 3901 (55.16) | 3819 (71.17) | 3567 (56.50) | 3403 (71.08) | 3543 (71.68) | ||||||
Significant difference (p < .0083) between ages 20–30 vs. 40–60.
Significant difference (p < .0083) between ages 20–30 vs. 70+.
As seen in Figure 1 and Table 2, the young adult women in age cohort I had significantly higher fo than middle-aged women in cohort II for all vowels. Differences (cohort I–cohort II) in least square means by vowel were: /i/ 35 Hz, p < .0001; /u/ 34 Hz, p < .0001; /æ/ 38 Hz, p < .0001; /ɑ/ 35 Hz, p < .0001. As seen in Figure 2 and Table 2, women in cohort I had significantly higher F1 than cohort II for /i/ (34 Hz, p = .0005), /u/ (51 Hz, p <.0001), and /æ/ (82 Hz, p = .0006); significantly higher F2 for /u/ (110 Hz, p = .0014) but significantly lower F2 for /æ/ (−133 Hz, p = .0032). The comparison of young adult women in age cohort I to older adult women in cohort III also revealed younger women to have significantly higher fo for all vowels (/i/ 23 Hz, p = .0031; /u/ 24 Hz, p = .0019; /æ/ 39 Hz, p < .0001; /ɑ/ 30 Hz, p < .0001), higher F1 for /u/ (49 Hz, p < .0001) and /æ/ (131 Hz, p < .0001), and higher F2 for /u/ (151 Hz, p = .0002). There were no significant differences between middle-aged women (cohort II) and older women (cohort III) for fo, F1, or F2. In addition, there were no significant differences for F3 and F4 between any of the age cohorts indicating stability of these formant frequencies across age in women.
For men, there were only two significant differences in vowel frequencies between age cohorts. As seen in Figure 2 and Table 2, young adult men (cohort I) had significantly higher F2 than older adult men (cohort III) for /u/ (138 Hz, p = .0007) and significantly higher F3 for /æ/ (162 Hz, p = .0033). There were no significant differences between any of the age cohort comparisons for men for fo, F1, or F4.
Figure 3 displays a comparison of the current F1–F2 data with those of two frequently cited studies of vowel formants, Peterson and Barney (1952) [39] and Hillenbrand, Getty, Clark, and Wheeler (1995) [34]. The current results for men in all age cohorts are nearly congruent with those of Peterson and Barney [39]. The current data for women agree with those of Peterson and Barney [39] for the high vowels but differ somewhat for the low vowels. For both men and women in the present study, there is no indication of centralization or lowering of formant frequencies in the vowel quadrilaterals for any of the age cohorts.
Figure 3.

Average F1–F2 data for each of the three age cohorts superimposed on the F1–F2 acoustic space from Peterson and Barney (1952; P&B)[39] and Hillenbrand et al. (1995; HGC&W)[34]. Top figure shows the data for women and bottom figure for men.
4. Discussion
The results of the present study and previously published studies on vowel formants are compiled in Table 3 which provides an overall view of age-related changes in vowel acoustics. This summary table provides an overview of research and is helpful to determine the extent of agreement across studies. There does not appear to be an invariant pattern of age-related changes. But it should be noted that the aggregate number of research participants in Table 3 is no more than a few hundred, which is hardly sufficient to generalize to the aging population at large. Approximately 42 million people in the U.S.A. were age 65 or older in 2012 [40] and by all projections, the number is increasing as longevity increases. It is almost certainly the case that changes would be observed in some individuals or some groups selected according to criteria such as health status. In this connection, it should be noted that many participants in the published studies probably were self-selected to be relatively healthy, on the assumption that healthy and vigorous individuals are more likely than their less healthy counterparts to volunteer for research studies. Research on a much larger sample is needed to establish the nature of formant changes with aging. Until such an ambitious project is undertaken, the current wisdom is necessarily based on the combination of longitudinal and cross-sectional studies summarized in Table 3. What is clear from this table is that vowel formants do not systematically decrease with age and may not decrease at all in some individuals. Variable results are not surprising given that the studies summarized in Table 3 used different methods (including speech sample, recording equipment, and analysis procedure) and had different criteria for participant selection.
Table 3.
Summary of studies of effects of aging on vowel formants (and fo when included in the study).
| Source | Participants | Change in fo | Change in F1 | Change in F2 |
|---|---|---|---|---|
| Cox & Selent (2015) [43] | 35 men in five age cohorts | Decreased | NA | NA |
| Debruyne & Decoster (1999) [61] | 40 young adults (20 male, 20 female) and 40 older adults (20 male, 20 female) | Increased in men, decreased in women | Decreased in men and women | Decreased in men and women |
| Endres, Bambach, & Flosser (1971) [7] | Longitudinal study of 2 men and 3 women over a time span of 13 to 15 years | Decreased in men and women | Decreased in men and women | Decreased in men and women |
| Linville & Fisher (1985) [14] | 75 women at three age levels (25 to 35, 45 to 55, 70 to 80) | NA | Decreased in women for one vowel studied | -- |
| Fletcher, McAuliffe, Lansford, & Liss (2015) [62] | 149 speakers of New Zealand English (55 males, 94 females), aged between 65 and 90 | NA | No change | No change |
| Harrington, Palethorpe, & Watson (2007) [6] | Longitudinal study of 2 men and 2 women over varying spans of time | Decreased in both men and women | Decreased in both men and women | -- |
| Kaur & Narang (2015) [63] | Unspecified number of women in two age groups | Decreased in women | Decreased in women | Decreased in women |
| Linville & Rens (2001) [9] | NA | Decreased in both men and women | Decreased in women; tended to decrease in men | |
| Mwangi et al. (2009) [64] | One speaker (Queen Elizabeth II) from age 26 to 76 years | Decreased | Decreased | No change |
| Rastatter & Jaques (1990) [5] | 20 young adults (10 men, 10 women; mean age of 21) 20 older adults (10 men, 10 women, mean age of 74) | NA | Varied with vowel for both men and women; apparent centralization | Varied with vowel for both men and women; apparent centralization |
| Reubold, Harrington, & Kleber (2010) [65 | Longitudinal study of 2 men and 3 women over a time span of at least XX years | Decreased in women but one man showed a decrease followed by an increase in old age | Decreased for schwa vowel | No consistent change |
| Scukanec & Petrosino (1991) [10] | 6 young women (mean age of 21) and 3 older women (mean age of 68) | NA | Decreased for 4 vowels studied in women | Decreased for back vowels in women |
| Schötz (2006) [26] | 269 women and 268 men ranging age from 18 to 90 years | In women, decreased until age 50, followed by a slight increase until age group 70, then another decrease; in men, slight decrease until age 50, followed by an increase into old age | F1 decreased in some vowels | No consistent change |
| Sebastian, Babu, Oommen & Ballraj (2012) [66] | 20 men (age range of 60–80) and 20 women (age ranges of 60–80) were divided into 4 age groups (60–64, 65–69, 70–74, and 75–79) with 5 subjects in each group. | Increased in men, decreased in women | No change | No change |
| Torre & Barlow (2009) [3] | 27 young adults (12 men and 15 women, mean age of 25.5) and 59 older adults (27 men and 32 women, mean age of 75) | Increased in men, decreased in women | Decreased for some vowels for men, decreased for all vowels in women | Interacted with sex and vowel |
| Vorperian et al. (present study) | 43 men and 53 women between the ages of 20 and 92 years | Decreased in women | Varied with vowel | Varied with vowel |
| Xue, Jiang, Lin, Glassenberg, & Mueller (1999) [8] | 10 young women (mean age of 40) and 12 older women (mean age of 56) | NA | Decreased in men and women | Varied with vowel |
| Xue & Hao (2003) [67] | 38 young adults (19 men and 19 women, mean age of 22) and 38 older adults (19 men and 19 women, mean ages of 71 and 74, respectively) | NA | Decreased for most vowels in men and women | Decreased depending on vowel in men and women |
The studies listed in Table 3 are those that report vowel formant values with or without data on fo. A much larger literature has accumulated specifically on fo [41, 42]. Although the studies are not in complete agreement, a general conclusion from the preponderance of the data is that fo decreases with age in both men and women, with the larger change occurring in women. The present results point to a significant age-related decrease in fo in women. In contrast, the men had a trend of slight increases in fo between each of the age cohorts but the changes were not statistically significant. Previous studies reporting increased fo in men include: Cox and Selent, (2015)[43], Nishio and Niimi (2008)[44], along with three studies cited in Table 3. Previous studies reporting decreased fo in women include Nishio and Niimi (2008) [44] and several studies cited in Table 3. The results reported for formants are quite variable and the most consistent finding is a reduced F1 frequency, especially in women. The explanation for this finding is uncertain and may be related to articulatory variations rather than aging of the vocal tract tissues. As shown in Figure 3, the women in the present study produced vowels with highly distinctive F1–F2 patterns.
The present study extends previous research by reporting data for the first four formants of the quadrilateral vowels in American English. It was expected that the data for four formants would help to determine the presence of general processes such as vowel tract lengthening (which should result in decreases of all formant frequencies) or centralization (which should result in movement to the centroid of formant space). For both men and women, the frequencies of F3 and F4 were essentially unchanged across the age cohorts. This result agrees with that of Schötz [26], one of the few studies that analyzed higher formants and is notable for the relatively large number of research participants. The lack of an aging effect on the higher formants supports the idea that any changes found for F1 and F2 are related to specific articulatory effects rather than generalized processes such as lengthening of the vocal tract. It is notable that formant frequencies were unaffected in the oldest cohort even though the majority of participants in this group had a hearing loss.
Conclusions on the effects of aging on speech should be drawn with great caution. With this caveat in mind, we offer tentative conclusions as follows: Vowel formant frequencies change little if at all across several decades of adult life, either because physiological aging has small effects on these variables or because individuals compensate for age-related changes in anatomy and physiology. Changes in formant frequencies do not seem to be inevitable with aging. A clinical implication is that normative acoustic data on vowel production by adults do not require substantial age adjustments. A related implication is that if substantial changes are observed in an aging individual, they may indicate pathology but not necessarily so. Regarding fo, studies generally point to a decrease in both sexes, but especially women. The fo changes in women may be related to a number of age-related physiologic changes, including hormonal changes after menopause [45, 46]; decrease in size of the laryngeal muscles, hardening and possible ossification of the laryngeal cartilages [47]; decreased glandular function [49]; and edema, bowing, and/or thickening of the vocal folds [48; 9]. Given that only women showed a significant effect of aging in this study, particularly between cohort I and II and not between cohort II and III, it is likely that hormonal changes explain the decreased fo in women. This explanation is based on the safe assumption that all women in Cohort III were postmenopausal since by age 58 years, 100% of women have reached menopause [50].
A normative standard for vowel formants and derived indices such as vowel space area is important clinically given their use in assessing speech functions and monitoring treatment for various disorders that often are age-related, including acquired dysarthria [51, 52, 53, 54], glossectomy [55, 56], oral or oropharyngeal cancer [57], and individuals in psychological distress or with self-reported symptoms of depression and post-traumatic stress disorder [58, 59].
The present study adds to the gradually accumulating body of data on the effects of aging on the acoustic properties of speech. Progress would be aided considerably by conduct of a much larger study involving hundreds of participants of both sexes participating in a carefully selected set of speech and voice tasks. Ideally, participants would be described by health-related variables to account for differences in health states. This is particularly important given evidence that physiological differences among individuals may become greater with advancing age [60]. A possible outcome of such a study is that the data would indicate the presence of subgroups of individuals who have different patterns of aging effects. Until such a large-scale study is undertaken, the results summarized in Table 3 caution against any sweeping conclusions on the effects of aging on vowel formants.
Acknowledgments
This work was supported by NIH Research Grant R01 DC6282 (MRI and CT Studies of the Developing Vocal Tract, Houri K. Vorperian, Principal Investigator) from the National Institute on Deafness and other Communicative Disorders (NIDCD), and by a core grants P-30 HD03352 and U54 HD090256 from the National Institute of Child Health and Human Development (NICHD) to the Waisman Center for research support (Albee Messing, Principal Investigator). Special thanks to Elaine Romenesko for assistance with acoustic analysis, Alyssa Wild, Daniel Reilly and Emily Reinicke for assistance with data collection; also, Courtney A. Miller and Gabriel S. Jardim for assistance with figure preparation. Portions of this research were presented at the 2016 Motor Speech Conference in Newport Beach, CA.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Contributor Information
Julie Traub Eichhorn, Waisman Center, University of Wisconsin-Madison, 1500 Highland Avenue, Madison Wisconsin 53705.
Raymond D. Kent, Waisman Center, University of Wisconsin-Madison, 1500 Highland Avenue, Madison Wisconsin 53705
Diane Austin, Waisman Center, University of Wisconsin-Madison, 1500 Highland Avenue, Madison Wisconsin 53705.
Houri K. Vorperian, Waisman Center, University of Wisconsin-Madison, 1500 Highland Avenue, Madison Wisconsin 53705.
References
- 1.Vorperian HK, Kent RD. Vowel acoustic space development in children: A synthesis of acoustic and anatomic data. J Speech Lang Hear Res. 2007;50:1510–1545. doi: 10.1044/1092-4388(2007/104). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Rendall D, Kollias S, Ney C, Lloyd P. Pitch (F0) and formant profiles of human vowels and vowel-like baboon grunts: The role of vocalizer body size. J Acoust Soc Am. 1995;117:944–955. doi: 10.1121/1.1848011. [DOI] [PubMed] [Google Scholar]
- 3.Torre P, Barlow JA. Age-related changes in acoustic characteristics of adult speech. J Commun Disord. 2009;42:324–333. doi: 10.1016/j.jcomdis.2009.03.001. [DOI] [PubMed] [Google Scholar]
- 4.Stathopoulos ET, Huber JE, Sussman JE. Changes in acoustic characteristics of the voice across the life span: measures from individuals 4–93 years of age. J Speech Lang Hear Res. 2011;54:1011–1021. doi: 10.1044/1092-4388(2010/10-0036). [DOI] [PubMed] [Google Scholar]
- 5.Rastatter MP, Jacques RD. Formant frequency structure of the aging male and female vocal tract. Folia Phoniatr Logo. 1990;42:312–319. doi: 10.1159/000266088. [DOI] [PubMed] [Google Scholar]
- 6.Harrington J, Palethorpe S, Watson CI. Age-related changes in fundamental frequency and formants: a longitudinal study of four speakers. Interspeech. 2007:2753–2756. [Google Scholar]
- 7.Endres W, Bambach W, Flosser G. Voice spectrograms as a function of age, voice disguise, and voice imitation. J Acoust Soc Am. 1971;49:1842–1848. doi: 10.1121/1.1912589. [DOI] [PubMed] [Google Scholar]
- 8.Xue A, Jiang J, Lin E, Glassenberg R, Mueller PB. Age-related changes in human vocal tract configurations and the effects on speakers’ vowel formant frequencies: a pilot study. Logoped Phoniatr Vocol. 1999;24:132–137. [Google Scholar]
- 9.Linville SE, Rens J. Vocal tract resonance analysis of aging voice using long-term average spectra. J Voice. 2001;15:323–330. doi: 10.1016/S0892-1997(01)00034-0. [DOI] [PubMed] [Google Scholar]
- 10.Scukanec G, Petrosino L, Squibb K. Formant frequency characteristics of children, young adult, and aged female speakers. Percept Mot Skills. 1991;73:203–208. doi: 10.2466/pms.1991.73.1.203. [DOI] [PubMed] [Google Scholar]
- 11.Fox RA, Jacewicz E. Dialect and generational differences in vowel space areas. ExLing. 2010:45–48. [Google Scholar]
- 12.Kim JE, Yoon K. An analysis of the vowel formants of the young versus old speakers in the Buckeye Corpus. Phon Speech Sci. 2012;4:29–35. [Google Scholar]
- 13.Watson PJ, Munson B. A comparison of vowel acoustics between older and younger adults. Proceedings of the 16th International Congress of Phonetic Sciences (ICPhS XVI); Saarbücken, Germany. 2007. [Google Scholar]
- 14.Linville SE, Fisher HB. Acoustic characteristics of women’s voices with advancing age. J Gerontol. 1985;40:324–330. doi: 10.1093/geronj/40.3.324. [DOI] [PubMed] [Google Scholar]
- 15.Verdonck-de Leeuw IM, Mahieu HF. Vocal aging and the impact on daily life: a longitudinal study. J Voice. 2004;18:193–202. doi: 10.1016/j.jvoice.2003.10.002. [DOI] [PubMed] [Google Scholar]
- 16.Johns MM, Arviso LC, Ramadan F. Challenges and opportunities in the management of the aging voice, Otolaryngol. Head Neck Surg. 2011;145:1–6. doi: 10.1177/0194599811404640. [DOI] [PubMed] [Google Scholar]
- 17.Ryan WJ, Burk KW. Perceptual and acoustic correlates of aging in the speech of males. J Commun Disord. 1974;7:181–192. doi: 10.1016/0021-9924(74)90030-6. [DOI] [PubMed] [Google Scholar]
- 18.Sataloff RT, Rosen DC, Hawkshaw M, Spiegel JR. The aging adult voice. J Voice. 1997;11:156–160. doi: 10.1016/s0892-1997(97)80072-0. [DOI] [PubMed] [Google Scholar]
- 19.Lanitis A. A survey of the effects of aging on biometric identity verification. Int J Biom. 2009;2:34–52. [Google Scholar]
- 20.Vipperla R, Renals S, Frankel J. Ageing voices: The effect of changes in voice parameters on ASR performance. EURASIP J Audio Speech Music Proc 2010. 2010;1:525783. [Google Scholar]
- 21.Smiljanic R. Can older adults enhance the intelligibility of their speech? J Acoust Soc Am. 2013;133:129–135. doi: 10.1121/1.4776774. [DOI] [PubMed] [Google Scholar]
- 22.Shuey EM. Intelligibility of older versus younger adults’ CVC productions. J Commun Disord. 1989;22:437–444. doi: 10.1016/0021-9924(89)90036-1. [DOI] [PubMed] [Google Scholar]
- 23.Burke DM, MacKay DG, James LE. Theoretical approaches to language and aging. In: Perfect TJ, Maylor EA, editors. Models of Cognitive Aging. Oxford University Press; Oxford, England: 2000. pp. 204–237. [Google Scholar]
- 24.Bilodeau-Mercure M, Tremblay P. Age differences in sequential speech production: articulatory and physiological factors. J Am Geriatr Soc. 2016;64:e177–e182. doi: 10.1111/jgs.14491. [DOI] [PubMed] [Google Scholar]
- 25.Benjamin BJ. Speech production of normally aging adults. Semin Speech Lang. 1997;18:135–141. doi: 10.1055/s-2008-1064068. [DOI] [PubMed] [Google Scholar]
- 26.Schötz S. Perception, analysis and synthesis of speaker age. Media-Tryck; Lund: 2006. [Google Scholar]
- 27.Yorkston KM, Bourgeois MS, Baylor CR. Communication and aging. Phys Med Rehabil Clin N Am. 2010;21:309–319. doi: 10.1016/j.pmr.2009.12.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Munson B, Solomon N. The effect of phonological neighborhood density on vowel articulation. J Speech Lang Hear Res. 2004;47:1048–1058. doi: 10.1044/1092-4388(2004/078). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Hodge M, Daniels J. Computer software. Vers. Edmonton, Canada: University of Alberta; 2007. TOCS+ Software Platform for Stimulus Presentation and Audio Recording. [Google Scholar]
- 30.Burris C, Vorperian HK, Fourakis M, Kent RD, Bolt DM. Quantitative and descriptive comparison of four acoustic analysis systems: vowel measurements. J Speech Lang Hear Res. 2014;57:26–45. doi: 10.1044/1092-4388(2013/12-0103). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Derdemezis E, Vorperian HK, Kent RD, Fourakis M, Reinicke EL, Bolt DM. Optimizing vowel formant measurements in four acoustic analysis systems for diverse speaker groups. Am J Speech Lang Pathol. 2016;25:335–354. doi: 10.1044/2015_AJSLP-15-0020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Boersma P, Weenink D. Praat. Computer software. Vers 5.1.32. 2010 http://www.fon.hum.uva.nl/praat.
- 33.Milenkovic P. Time-frequency analysis software program for 32-bit Windows. Computer software. Alpha Version 1.2. http://userpages.chorus.net/cspeech/
- 34.Hillenbrand J, Getty LA, Clark MJ, Wheeler K. Acoustic characteristics of American English vowels. J Acoust Soc Am. 1995;97:3099–3111. doi: 10.1121/1.411872. [DOI] [PubMed] [Google Scholar]
- 35.Vallabha GK, Tuller B. Systematic errors in the formant analysis of steady-state vowels. Speech Commun. 2002;38:141–160. [Google Scholar]
- 36.Vallabha G, Tuller B. Choice of filter order in LPC analysis of vowels. In: Slifka J, Manuel S, Matthies M, editors. From sound to sense: 50+ years of discoveries in speech communication [Compact disk] Research Laboratory of Electronics, Massachusetts Institute of Technology; Cambridge, MA: 2004. pp. B148–B163. [Google Scholar]
- 37.Yao Y, Tilsen S, Sprouse RL, Johnson K. Automated measurement of vowel formants in the Buckeye Corpus. Gengo Kenkyu. 138:99–113. [Google Scholar]
- 38.Fletcher AR, McAuliffe MJ, Lansford KL, Liss JM. Assessing vowel centralization in dysarthria: A comparison of methods. J Speech Lang Hear Res. 2017;60:341–354. doi: 10.1044/2016_JSLHR-S-15-0355. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Peterson GE, Barney HL. Control methods used in a study of the vowels. J Acoust Soc Am. 1952;24:175–184. [Google Scholar]
- 40.Ortman JM, Velkoff VA, Hogan H. An aging nation: the older population in the United States. United States Census Bureau, Economics and Statistical Administration, US Department of Commerce; 2014. pp. 25–1140. [Google Scholar]
- 41.Baken RJ, Orlikoff RF. Clinical Measurement of Speech and Voice. Cengage Learning; 2000. [Google Scholar]
- 42.Goy H, Fernandes DN, Pichora-Fuller MK, van Lieshout P. Normative voice data on younger and older adults. J Voice. 2013;27:545–555. doi: 10.1016/j.jvoice.2013.03.002. [DOI] [PubMed] [Google Scholar]
- 43.Cox VO, Selent M. Acoustic and respiratory measures as a function of age in the male voice. J Phon Audiol. 2015;1:105. doi: 10.4172/jpay.1000105. [DOI] [Google Scholar]
- 44.Nishio M, Niimi S. Changes in speaking fundamental frequency characteristics with aging. Folia Phoniatr Logo. 2008;60:120–127. doi: 10.1159/000118510. [DOI] [PubMed] [Google Scholar]
- 45.Abitbol J, Abitbol P, Abitbol B. Sex hormones and the female voice. J Voice. 1999;13:424–446. doi: 10.1016/s0892-1997(99)80048-4. [DOI] [PubMed] [Google Scholar]
- 46.Kadakia S, Carlson D, Sataloff RT. The effect of hormones on the voice. J Sing. 2013;69:571–575. [Google Scholar]
- 47.Kahane JC, Beckford NS. The aging larynx and voice. In: Ripich D, editor. Geriatric communication disorders. Pro-Ed; Austin: 1991. pp. 165–186. [Google Scholar]
- 48.Honjo I, Isshiki N. Laryngoscopic and voice characteristics of aged persons. Arch Otolaryngol. 1980;106:149–150. doi: 10.1001/archotol.1980.00790270013003. [DOI] [PubMed] [Google Scholar]
- 49.Mueller P, Sweeney R, Barbeau L. Acoustic and morphologic study of the senescent voice. Ear Nose Throat J. 1984;63:292–295. [PubMed] [Google Scholar]
- 50.National Center for Health Statistics. Age at menopause United States 1960–1962. 1968. DHEW Publication No. (HSM) 73–1268. [Google Scholar]
- 51.Bang Y, Min K, Sohn YH, Cho SR. Acoustic characteristics of vowel sounds in patients with Parkinson disease. NeuroRehabilitation. 2013;32:649–654. doi: 10.3233/NRE-130887. [DOI] [PubMed] [Google Scholar]
- 52.Kim S, Kim JH, Ko DH. Characteristics of vowel space and speech intelligibility in patients with spastic dysarthria. Commun Sci Disord. 2014;19:352–360. [Google Scholar]
- 53.Turner GS, Tjaden K, Weismer G. The influence of speaking rate on vowel space and speech intelligibility for individuals with amyotrophic lateral sclerosis. J Speech Hear Res. 1995;38:1001–1013. doi: 10.1044/jshr.3805.1001. [DOI] [PubMed] [Google Scholar]
- 54.Weismer G, Jeng JY, Laures JS, Kent RD, Kent JF. Acoustic and intelligibility characteristics of sentence production in neurogenic speech disorders. Folia Phoniatr Logo. 2001;53:1–18. doi: 10.1159/000052649. [DOI] [PubMed] [Google Scholar]
- 55.Kaipa R, Robb MP, O'Beirne GA, Allison RS. Recovery of speech following total glossectomy: An acoustic and perceptual appraisal. Int J Speech Lang Pathol. 2012;14:24–34. doi: 10.3109/17549507.2011.623326. [DOI] [PubMed] [Google Scholar]
- 56.Whitehill TL, Ciocca V, Chan JCT, Samman N. Acoustic analysis of vowels following glossectomy. Clin Linguist Phon. 2006;20:135–140. doi: 10.1080/02699200400026694. [DOI] [PubMed] [Google Scholar]
- 57.De Bruijn MJ, Ten Bosch L, Kuik DJ, Quené H, Langendijk JA, Leemans CR, Verdonck-de Leeuw IM. Objective acoustic-phonetic speech analysis in patients treated for oral or oropharyngeal cancer. Folia Phoniatr Logo. 2009;61:180–187. doi: 10.1159/000219953. [DOI] [PubMed] [Google Scholar]
- 58.Scherer S, Lucas G, Gratch J, Rizzo A, Morency LP. Self-reported symptoms of depression and PTSD are associated with reduced vowel space in screening interviews. IEEE Trans Affect Comput. 2016;7:59–73. doi: 10.1109/TAFFC.2015.2440264. [DOI] [Google Scholar]
- 59.Scherer S, Morency LP, Gratch J, Pestian J. Reduced vowel space is a robust indicator of psychological distress: A cross-corpus analysis. Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on; IEEE; 2015. pp. 4789–4793. [Google Scholar]
- 60.Ramig LO, Ringel RL. Effects of physiological aging on selected acoustic characteristics of voice. J Speech Hear Res. 1983;26:22–30. doi: 10.1044/jshr.2601.22. [DOI] [PubMed] [Google Scholar]
- 61.Debruyne F, Decoster W. Acoustic differences between sustained vowels perceived as young or old. Logoped Phoniatr Vocol. 1999;24:1–5. [Google Scholar]
- 62.Fletcher AR, McAuliffe MJ, Lansford KL, Liss JM. The relationship between speech segment duration and vowel centralization in a group of older speakers. J Acoust Soc Am. 2015;138:2132–2139. doi: 10.1121/1.4930563. [DOI] [PubMed] [Google Scholar]
- 63.Kaur J, Narang V. Variation of pitch and formants in different age group. Int J Multidiscip Res Mod Educ. 2015;1(1):517–521. [Google Scholar]
- 64.Mwangi S, Spiegl W, Hönig F, Haderlein T, Maier A, Nöth E. Effects of vocal aging on fundamental frequency and formants. Proceedings of the International Conference on Acoustics NAG/DAGA; 2009. pp. 1761–1764. [Google Scholar]
- 65.Reubold U, Harrington J, Kleber F. Vocal aging effects on F0 and the first formant: A longitudinal analysis in adult speakers. Speech Commun. 2010;52:638–651. [Google Scholar]
- 66.Sebastian S, Babu S, Oommen NE, Ballraj A. Acoustic measurements of geriatric voice. J Laryngol Voice. 2012;2:81–84. [Google Scholar]
- 67.Xue SA, Hao GJ. Changes in the human vocal tract due to aging and the acoustic correlates of speech production: a pilot study. J Speech Lang Hear Res. 2003;46:689–701. doi: 10.1044/1092-4388(2003/054). [DOI] [PubMed] [Google Scholar]