

Abstract
Many public health interventions provide benefits that extend beyond their direct recipients and impact people in close physical or social proximity who did not directly receive the intervention themselves. A classic example of this phenomenon is the herd protection provided by many vaccines. If these ‘spillover effects’ (i.e. ‘herd effects’) are present in the same direction as the effects on the intended recipients, studies that only estimate direct effects on recipients will likely underestimate the full public health benefits of the intervention. Causal inference assumptions for spillover parameters have been articulated in the vaccine literature, but many studies measuring spillovers of other types of public health interventions have not drawn upon that literature. In conjunction with a systematic review we conducted of spillovers of public health interventions delivered in low- and middle-income countries, we classified the most widely used spillover parameters reported in the empirical literature into a standard notation. General classes of spillover parameters include: cluster-level spillovers; spillovers conditional on treatment or outcome density, distance or the number of treated social network links; and vaccine efficacy parameters related to spillovers. We draw on high quality empirical examples to illustrate each of these parameters. We describe study designs to estimate spillovers and assumptions required to make causal inferences about spillovers. We aim to advance and encourage methods for spillover estimation and reporting by standardizing spillover parameter nomenclature and articulating the causal inference assumptions required to estimate spillovers.
Keywords: Spillover effects, indirect effects, herd effects, herd immunity, diffusion, externalities, interference
Introduction
Public health interventions may benefit those in close physical or social proximity to intervention recipients who do not receive the intervention themselves. When such ‘spillovers’ are present in the same direction as direct effects on recipients, direct effects alone do not capture the full health impact and cost-effectiveness of an intervention. Most epidemiological studies measuring spillover effects have evaluated herd effects of vaccines,1,2 but spillovers are theoretically possible for numerous other interventions that could alter disease transmission or change health behaviours. Spillovers have increasingly been measured for other interventions, particularly in economics, since evidence of spillovers can support the case for scaling up or subsidizing an intervention.3,4 However, to date, discussion of methods for estimating spillover effects and identifying them within a causal inference framework has largely remained confined to the vaccine literature,5–14 with few articles extending methods to studies of other interventions.15–18
Here we define spillover parameters using standardized notation and discuss causal inference assumptions for spillovers using non-technical language to provide an accessible introduction for epidemiologists. In conjunction with a systematic review we conducted on health spillovers of interventions in low- and middle-income countries,19 we classified types of spillovers to make their similarities and differences more transparent. By standardizing spillover parameter definitions and articulating causal inference assumptions for spillovers, we aim to advance methods for spillover study design, estimation and reporting.
Types of spillover parameters
We describe six classes of spillover parameters that were most common in our systematic review.19 We present individual-level counterfactual definitions of spillover effects in Box 1; the Supplement (available as Supplementary data at IJE online) contains average spillover effects as well as identification assumptions for each parameter. For simplicity we discuss spillovers among untreated individuals; however, spillover effects may also occur among the treated (Box 1). For example, HIV vaccine candidates provide imperfect protection to vaccinated individuals, but protection has been shown to increase as immunization coverage increases, due to reductions in transmission resulting from herd effects.20 We define spillover parameters in the context of ‘intention-to-treat’ analyses, which estimate the true causal effect of interventions with high adherence. Inferences about spillovers are more complicated when there is imperfect adherence (e.g. in ‘per-protocol’ analyses),16 and a formal discussion of that setting is beyond the scope of this paper.
Box 1. Spillover parameter definitions
Here, we provide definitions of individual-level average spillover effects using counterfactual notation. The Supplement (available at IJE online) includes additional details and identification assumptions. Figures cited below provide visual representations of each parameter.
We present the first three types of parameters in a two-stage randomized trial in which the treatment regimen is defined such that at least one individual in a treated cluster receives treatment (α1), and in control clusters, all individuals are allocated to control (α0). Let Yij(a) be the potential outcome for individual j in cluster i, where ai denotes a vector of treatment assignments for individuals in cluster i. The individual potential outcome averaging over different configurations of ai is (α, a) and is a function of the treatment regimen (α) and the individual’s treatment assignment (a).
Cluster-level spillover effects (Figure 1)
Cluster-level spillover effect:
This parameter compares the mean potential outcome of an individual assigned to control in a treatment cluster with treatment regimen α1 with their mean potential outcome if they were assigned to control in a cluster assigned to control (α0).
Direct effect:
This parameter compares the mean potential outcome of an individual assigned to treatment in a treatment cluster with treatment regimen α1 with their mean potential outcome if they were assigned to control in a cluster with treatment α1.
Total effect:
This parameter compares the mean potential outcome of an individual assigned to treatment in a treatment cluster with treatment regimen α1 their mean potential outcome if they were assigned to control in a cluster assigned to control (α0).
Overall effect:
This parameter compares the mean potential outcome across individuals in a cluster with treatment regimen α1 with their mean potential outcome had the cluster been assigned to control (α0).
Distance-based spillover effects (Figure 2)
Spillover effect conditional on distance to clusters (Figure 2a):
This parameter compares the mean potential outcome for individuals at distance k from a cluster with treatment regimen α1 with the mean potential outcome at distance k from a cluster with treatment regimen α0 (all individuals assigned to control).
Spillover effect conditional on distance between clusters (Figure 2b):
This parameter compares the mean potential outcome of individuals in control clusters with treatment regimen β0 within distance k of treatment clusters with treatment regimen α1 with those in clusters assigned to control with treatment regimen β0 within distance k of control clusters with treatment regimen α0.
Spillover effect conditional on treatment density (Figure 3)
Define pi as the proportion of individuals allocated to treatment in treatment clusters. In a two-stage randomized trial, in the first stage, clusters are randomly assigned to receive a certain proportion of treatment (E[ai] = pi), including clusters with pi = 0. In the second stage, individuals are randomized to treatment (pi > 0) or control (pi = 0) in clusters.
This parameter compares the mean potential outcome of an individual assigned to control in clusters with different proportions of individuals assigned to treatment (pi vs. pi′, where pi ≠ pi′).
Social network spillover effect (Figure 4)
This parameter can be estimated as a trial that randomizes treatment to egos (the initially enrolled subjects) and compares the mean outcomes of alters (the persons socially connected to the egos) in the treatment vs control group. For this parameter, we define the potential outcome for alter j as Yj(a1, a0), which is a function the treatment assignment of the ego (a1) and the treatment assignment of the alter (a0).
This parameter compares the mean potential outcome among an untreated alter socially connected to a treated ego (Yj (a1 = 1, a0 = 0)) with their mean potential outcome if they were connected to an untreated ego (Yj (a1 = 0, a0 = 0)).
Vaccine efficacy for infectiousness (Figure 5)
This parameter is typically estimated in studies that enrol households with an infected individual (a ‘case’) and at least one uninfected individual (a ‘susceptible’). S is the outcome for the primary household case; Y is the outcome for the susceptible individual; and A is the treatment assignment for the case.
The parameter compares the secondary attack rate among uninfected susceptible individuals in households with a vaccinated case with the rate among those in households with unvaccinated cases. Identification of this parameter requires assumptions that complicate the presentation of causal parameters, so we define a statistical parameter here and provide a causal parameter definition in the Supplement. The parameter is labelled ‘VE’ to be consistent with how it is presented in the vaccine literature.
To make causal inferences, investigators typically invoke the Stable Unit Treatment Value Assumption (SUTVA),22 which states that an individual’s potential outcome is not affected by the treatment assignment of other individuals in the population. This is also known as the assumption of no interference.23 SUTVA does not hold when spillovers are present because an individual’s potential outcome depends on their own treatment assignment and the treatment assignment of other individuals connected to them. The most common and theoretically tractable method to make causal inferences about spillover effects is by making the ‘partial interference’ assumption,24 which states that there are no spillovers between clusters of individuals but allows for spillovers among individuals within the same cluster.24 This assumption underpins the validity of many cluster-randomized trials. Studies can minimize spillovers between clusters by including buffer zones between clusters, as is common in cluster-randomized trials.25–27
Studies that assume no spillovers (i.e. that SUTVA holds) typically index counterfactuals only by an individual’s own treatment assignment (e.g. Ya could indicate the potential outcome for a person with treatment assignment A = a). Under the partial interference assumption, the treatment assignment of each individual (j) in each cluster (i) can be summarized in a vector of treatments for n individuals: Ai ≡ (Ai1,…, ). Similarly, Ai,-j ≡ Ai1,…, Aij-1, Aij+1,…, denotes the vector of treatments for individuals in cluster i for all individuals except for individual j.Ai can be considered a random treatment allocation regimen, and is the set of all possible treatment allocation regimens for ni individuals (the set of values that Ai can assume). Specific regimens within can be denoted by α, the parameterization of the distribution of Ai for i = 1,…, N. For example, α1 may include a scenario in which half of all individuals in a cluster are allocated to treatment and half are allocated to control, and α0 may include a scenario in which all individuals in a cluster are allocated to control. In the following sections, we define individual-level average causal effects; see the Supplement for individual-level and group-level causal effects (available as Supplementary data at IJE online).
Cluster-level spillovers
Causal cluster-level spillover effects can be measured in a two-stage randomized trial9 in which treatment is randomized to independent clusters in the first stage, and in the second stage, individuals within treatment clusters are assigned to treatment or control (Figure 1). This is sometimes referred to as a double-randomized trial.11 The cluster-level spillover effect may be defined as the difference in mean outcomes among untreated individuals in treated clusters and the outcomes among individuals in control clusters.5,6,8,9 We provide the definition of this parameter from Hudgens and Halloran8 and Tchetgen Tchetgen.10 We present this and the parameters in subsequent sections on the additive scale. To be consistent with the causal inference literature,10 we reverse the order of treatment and control contrasts from those in Hudgens and Halloran,8 which subtract potential outcomes for those assigned to treatment from those assigned to control.
Figure 1.

Cluster-level spillover effects. This spillover parameter can be estimated in a two-stage randomized trial in which clusters are randomly allocated to treatment or control and then individuals within treatment clusters are randomly allocated to treatment or control. The direct effect compares potential outcomes of individuals allocated to treatment in treatment clusters to the potential outcomes of individuals allocated to control in treatment clusters. The cluster-level spillover effect compares potential outcomes of individuals allocated to control in treatment clusters to those of individuals in control clusters. The total effect compares the potential outcomes of individuals allocated to treatment in treatment clusters to those of individuals allocated to control in control clusters. The overall effect compares the potential outcomes of all individuals in clusters allocated to treatment to those of all individuals in clusters allocated to control.
Let Yij(ai) be the potential outcome for individual j in cluster i, where ai denotes a vector of treatment assignments for individuals in cluster i. Let ai,-j be the vector of treatment for all individuals in cluster i except individual j. The potential outcome in this parameter, Yij(ai,-j, aij), is a function of the individual’s own treatment assignment (aij) and the treatment assignment of other individuals (ai,-j) in the cluster. In treatment clusters, the treatment regimen (α1) is defined such that at least one individual receives treatment, and in control clusters, all individuals are allocated to control (α0). The treatment vector ai can vary for a given treatment regimen α. Thus, the individual potential outcome averaging over different configurations of ai for a given α (i.e. averaging over all possible treatment regimens) is defined as:
| (1) |
We assume that the proportion of individuals assigned to treatment (α1) is the same among all treated clusters. A cluster-level spillover effect measures spillovers that occur among untreated individuals in a cluster that received treatment. This effect can be defined as:
| (2) |
This parameter compares the mean potential outcome of an individual assigned to control in a treatment cluster with treatment regimen α1 with their mean potential outcome if they were assigned to control in a cluster assigned to control (α0). For example, Chong et al. estimated cluster-level spillovers by randomly assigning schools to receive a sexual health education programme and then randomly assigning the programme to classrooms within intervention schools; they compared sexual health knowledge among children in control classrooms in intervention schools with that of children in control schools (Table 1, Example 1).28
Table 1.
Examples of empirical studies estimating different spillover parameters
| Example | Study design | Spillover parameter | Intervention | Outcome | Spillover group | Comparison group |
|---|---|---|---|---|---|---|
| 1. Chong et al., 2013 | Double-randomized trial | Cluster-level spillover (Figure 1) | School-based sexual health education programme | Knowledge and attitudes about sexually transmitted infections and safe sex practices | Children in schools that received the programme but in classrooms that did not receive the programme | Children in schools that did not receive the programme |
| 2. Banerjee et al., 2010 | Cluster-randomized trial | Distance-based spillover (Figure 2) | Immunization campaign with and without incentives | Vaccination | Individuals in randomly selected, untreated villages within 6 km of villages randomized to treatment | Individuals in villages randomized to control |
| 3. Hawley et al., 2003 | Cluster-randomized trial | Distance-based spillover (Figure 2) | Insecticide-treated nets | Malaria, anaemia, child mortality | Untreated compounds 0–299 m, 300–599m and 600–899 m from treated compounds | Untreated compounds ≥ 900 m from treated compounds |
| 4. Miguel and Kremer, 2004 | Cluster-randomized trial | Spillovers conditional on treatment density (Figure 3) | School-based deworming | Soil-transmitted helminth infection | Untreated students at schools for which some pupils were treated at schools within 0–3 km and 4–6 km | Untreated students at schools for which no pupils were treated at schools within 0–3 km and 4–6 km |
| 5. German et al., 2012 | Randomized trial | Social network spillover (Figure 4) | Peer network intervention | Depression | Peers of individuals randomized to treatment | Peers of individuals randomized to control |
| 6. Préziosi and Halloran, 2003 | Secondary attack rate study | Vaccine efficacy for infectiousness (Figure 5) | Pertussis vaccine | Pertussis | Susceptibles living in households with treated cases | Susceptibles living in households with untreated cases |
There are several related parameters that can also be estimated in a two-stage randomized trial (Figure 1). Direct effects compare the mean potential outcome of a treated individual in a treated cluster with treatment regimen α1 with their mean potential outcome if they were assigned to control in the same cluster (); total effects compare the mean potential outcome of a treated individual in a treated cluster with treatment regimen α1 with their mean potential outcome if they were assigned to control in control clusters (); and overall effects compare the mean outcome of all individuals in treated clusters with treatment regimen α1 with the mean outcome had the cluster been assigned to control () (see complete definitions in the Supplement, available as Supplementary data at IJE online). The direct effect defined in the spillover literature differs from other definitions in the causal mediation literature (effect of an exposure through no intermediate variables).29 Similarly, in the spillover literature, the term ‘indirect effect’ is frequently used to describe spillover effects–in the mediation literature, an ‘indirect effect’ is the part of an intervention’s effect that is mediated through intermediate variables.
Cluster-level spillovers can be measured in studies that enrol clusters of any size. They are relatively convenient to estimate in studies with small- to medium-size clusters when the treatment status of most individuals in the cluster is known. Cluster-level spillover parameters often condition on other variables, such as eligibility to receive an intervention. For example, a comparison of outcomes among ineligible individuals in the treatment group with ineligible individuals in the control group estimates a cluster-level spillover effect (Figure 1).30–37
Distance-based spillovers
Spillovers can be measured as a function of distance from treated individuals or clusters. We introduce two parameters: one conditional on individuals’ distance to clusters, and one conditional on distance between clusters. The first parameter measures spillover effects among individuals located a certain distance from the boundary of treatment and control clusters (Figure 2a). We define Yij(ai | Ki = k) as the potential outcome for individual j residing within distance k from cluster i, with treatment vector ai. The individual average potential outcome (α | Ki = k) is a function of the treatment regimen (α) and the individual’s distance to the nearest study cluster (k). Let α1 be a treatment regimen in which at least one individual per cluster is allocated to treatment. Again, we assume that the treatment regimen is uniform (i.e. α1 does not vary) among treated clusters. The spillover effect conditional on distance to treated clusters can be defined as:
| (3) |
Figure 2.

Distance-based spillover effects. (a) Spillover effects conditional on distance to clusters can also be estimated in a two-stage randomized trial. This parameter compares the potential outcomes of untreated individuals within distance k of treated clusters to those of untreated individuals within distance k of control clusters. (b) Spillover effects conditional on distance between clusters can be estimated in a two-stage randomized trial. In the first stage, a study pair-matches clusters separated by distance k and then randomly allocates each pair to treatment or control. In the second stage, the study randomly selects one member from each pair to be the “primary” cluster; in the treated pairs, the primary cluster is assigned to treatment and the other cluster is assigned to control. Individuals in clusters assigned to treatment are randomly assigned to treatment or control. This parameter compares potential outcomes of individuals allocated to control in secondary clusters within distance k of treated clusters to those of individuals allocated to control in secondary clusters within distance k of control clusters.
This parameter compares the mean potential outcome of an individual distance k from a cluster with treatment regimen α1 (at least one individual allocated to treatment per cluster) with their mean potential outcome at distance k from a cluster with treatment regimen α0 (all individuals assigned to control). Studies estimating this parameter must ensure control clusters are at a distance from treatment clusters beyond which the intervention has an effect. Hawley et al. estimated a similar parameter in a re-analysis of a cluster-randomized trial to measure spillovers of insecticide-treated nets on malaria and other outcomes over different distances.38 They compared individuals assigned to control clusters who were 0–299 m, 300–599 m and 600–899 m with those who were ≥ 900 m from the nearest individual in a treated cluster (Table 1, Example 3).
Spillover effects can also be measured as a function of distance between clusters using a pair-matched, two-stage design (Figure 2b). This parameter differs from the previous one because the individuals used to measure spillover effects reside in separate clusters rather than in the areas around the boundaries of the treatment clusters. To measure this type of spillover effect, first a study pair-matches clusters separated by distance k and then randomly allocates each pair to treatment or control. Second, the study randomly selects one member from each pair to be the ‘primary’ cluster; in the treated pairs, the primary cluster is assigned to treatment and the other cluster is assigned to control. In practice, the pairs of control clusters may be reduced to a single control cluster unless the second is needed to achieve sufficient statistical efficiency. Individuals in clusters assigned to treatment are randomly assigned to treatment or control. Let ai be the treatment vector for primary clusters and bi be the treatment vector for secondary clusters. Let Yij(ai, bi | Ki = k) be the potential outcome for individual j in secondary cluster i with treatment vector bi within distance Ki = k from a primary cluster with treatment vector ai. We define α as the treatment regimen for primary clusters and β as the treatment regimen for secondary clusters. The individual potential outcome averaging over different configurations of ai and bi for a given α and β is (α, β | Ki = k). The spillover effect conditional on distance between clusters may be defined as:
| (4) |
This parameter compares the mean potential outcome of a control individual in a secondary control cluster (β0) within distance Ki = k of a treatment cluster with treatment regimen α1 with their mean potential outcome if they were assigned to a secondary control cluster (β0) within distance Ki = k of a primary control cluster (α0). Banerjee et al. conducted a study with a design similar to this to measure spillovers of a vaccine promotion campaign with and without subsidies (Table 1, Example 2).39 They assigned clusters to treatment or control and then enrolled clusters within 6 km of treated clusters to measure spillovers. Their design assumes that clusters within 6 km of treatment clusters (the study’s spillover clusters) had similar baseline characteristics to control clusters; since spillover clusters were not included in the randomization, it is possible that there were systematic differences between spillover and control clusters, which could have confounded results.
Spillovers conditional on treatment density
We have defined spillover parameters with counterfactuals indexed by a vector of treatment assignments (ai). In some cases, spillovers are a function not of the precise allocation of treatment to specific individuals, but instead of summaries of ai, such as the proportion of those that get treatment (pi). Thus, we can represent the model of the counterfactual distribution as Yij(pi, a) = f(pi,a), where f is a function of individual-level treatment assignment and low-dimensional summaries of treatment assignment among individuals in cluster i. Designs such as a two-stage randomized study can be tailored to estimate such effects. For instance, in the first stage, clusters are randomly assigned to receive a certain proportion of treatment (E[ai] = pi), and some clusters are assigned to pi = 0. In the second stage, individuals are randomized to treatment or control in clusters with pi > 0 (Figure 3).8,10,13 We can define counterfactuals for individual j in cluster i as, which is indexed by two scalars: the individual treatment assignment (aij) and the average proportion treated (pi). The spillover effect among untreated individuals (aij = 0) conditional on treatment density is then:
| (5) |
Figure 3.

Spillover effects conditional on treatment density. Spillover effects conditional on treatment density can be estimated in a two-stage randomized design that randomly allocates clusters to treatment or control and then randomly allocates individuals in treatment clusters to treatment or control. This parameter compares potential outcomes of untreated individuals in clusters allocated to treatment proportion p to those of untreated individuals in clusters allocated to a different treatment proportion p’. For example, in this figure, the treatment proportion within 30m of untreated individuals varies. This parameter compares potential outcomes of untreated individuals in clusters with treatment proportion 50% and 90% to those of untreated individuals in clusters with 0% of individuals allocated to treatment (i.e. control clusters).
In a two-stage randomized trial, this parameter compares the mean potential outcomes of an individual assigned to control in clusters with different proportions of individuals assigned to treatment (pi vs. pi′). This is equivalent to the cluster-level spillover effect on untreated individuals within the cluster (Equation 2), except for the simplifying assumption that the counterfactual is only a function of a summary of ai,, namely pi. This effect can also be estimated among treated individuals (see the Supplement for details, available as Supplementary data at IJE online). Miguel and Kremer estimated this parameter in a cluster-randomized trial of a school-based deworming programme in Kenya.3 They compared outcomes among children in untreated schools in areas with varying levels of density of treated children (Table 1, Example 4).3 This class of parameters can also be estimated by conditioning on the proportion of treated social network nodes within a given social distance metric of each untreated individual. For example, a study of a school-based deworming programme in Kenya estimated whether child deworming was associated with the number of social links to parents whose children received deworming at school.40 Causal interpretation of this type of parameter requires that treatment be randomized to individuals within the social network rather than to individuals within a specific geographical area.
Social network spillovers
Social networks can be used to measure spillovers as a function of social proximity. A variety of designs can be employed to estimate different social network effects. For example, causal spillovers through social networks can be measured in a design that randomizes treatment to egos (the initially enrolled subjects) and compares the mean outcomes of alters (the persons socially connected to the egos) in the treatment vs control group (Figure 4). Counterfactuals in this design are a function of a joint treatment (a1, a0), where the treatment assignment for the ego is a1, and the treatment assignment for the alter is a0. The potential outcome for the alter j connected to the ego with treatment a1 is Yj (a1, a0). The social network spillover effect may be defined as:
| (6) |
Figure 4.

Social network spillover effects. Social network spillover effects can be estimated in a study that randomizes treatment to egos (the initially enrolled subject) and compares the mean outcomes of alters (the person socially connected to the ego) in the treatment vs. control group.
This parameter compares mean outcomes among untreated alters socially connected to treated egos with their mean potential outcome had the egos been untreated. It is distinct from a parameter conditioning on treatment density among social network links (above) because it focuses on alters socially connected to specific egos, isolating the spillover effect through individual peer-to-peer connections. German et al. estimated this parameter in a randomized study that evaluated spillover effects of a peer network intervention. They compared depression scores among peers of treated vs control participants (Table 1, Example 5).41
Alternative parameters can be defined to estimate spillover effects through social networks. For example, spillover effects can be estimated for certain types of social ties (e.g. direct friends, social ties in the community, village members)42 or based on which type of social ties were targeted for intervention (e.g. villagers with the most social ties, nominated friends).43 We presented social network spillovers among the untreated, but they can also be estimated among the treated by comparing counterfactual outcomes among treated alters connected to treated vs untreated egos. Many other types of social network spillover parameters have been described, and an overview of social network effects has been provided by Vanderweele and An.44 We have described estimation of social network spillover effects in an individually randomized trial, but other study designs can be used to estimate spillover effects through social networks. For instance, Christakis et al. measured the spread of obesity45 and smoking46 through social networks in a large cohort study. Stochastic, actor-oriented models can also be used to estimate spillover effects in networks;47,48 these models allow individuals to change their behaviour status and/or social ties at each time point and require strong assumptions.44
When estimating social network spillover effects, both observational and randomized designs face unique threats to validity. First, socially connected individuals may have correlated outcomes and may inhabit the same environment, leading to environmental confounding.49–53 Second, an individual may sever a social tie based on their present outcome status as a result of homophily, which may bias estimates of spillover effects.51 A randomized design can minimize homophily by randomizing individuals to peers in their social network, such as a room-mate, to ensure that potential confounders are balanced within ego and alter pairs.54
Spillovers conditional on exposure to infection
Epidemiologists studying vaccines have developed parameters that condition on exposure to infected individuals to measure whether vaccines reduce transmission to uninfected individuals.6,9,12,55–58 These parameters are typically estimated in studies that enrol households with an infected individual (a ‘case’) and at least one uninfected individual (a ‘susceptible’). The vaccine efficacy for the infectiousness parameter (also referred to as the ‘infectiousness effect’59) is a type of spillover parameter that compares the secondary attack rate among uninfected susceptible individuals in households with a vaccinated case, with the rate among those in households with unvaccinated cases (Figure 5; Table 1, Example 6).
Figure 5.
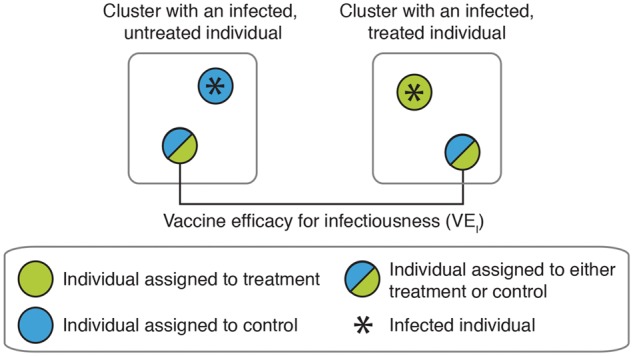
Vaccine efficacy for infectiousness. This parameter is typically estimated in studies that enroll households with an infected individual (a “case”) and at least one uninfected individual (a “susceptible“). The parameter compares the secondary attack rate among uninfected susceptible individuals in households with a vaccinated case to the rate among those in households with unvaccinated cases. Susceptibles may be either vaccinated or unvaccinated.
Conditioning on post-treatment outcome status can introduce selection bias because individuals who become infected may be systematically different from those who do not.6 Under standard causal inference assumptions this parameter is not identifiable;58 to identify this parameter, relatively strong additional assumptions are required.58–60 For example, one must assume that susceptibles are only exposed to infection in their household, i.e. that household members interact with each other but not with other households.6 Because these additional assumptions complicate the presentation of causal parameters, we define a parameter below that does not use counterfactuals (i.e. a statistical parameter); see the Supplement for a causal definition (available as Supplementary data at IJE online).
Let S be the outcome for the primary household case, Y be the outcome for the susceptible individual, and A be the treatment assignment for the case. The vaccine efficacy for infectiousness (VE) on the additive scale is:
| (7) |
We present this parameter on the additive scale for consistency with other parameters, but it is most often estimated as a reduction in the relative risk [(1-RR) x 100%]. These parameters are similar to the cluster-level spillover effect (Equation 2) but condition on outcome status instead of treatment status. Préziosi and Halloran measured this parameter in a household secondary attack rate study of pertussis vaccination by comparing outcomes among susceptibles in households with vaccinated cases with those in households with unvaccinated cases.61
Designing studies to measure spillovers
In this section we discuss spillover study designs. Box 2 summarizes recommendations throughout this section.
Box 2. Recommendations for designing studies to estimate spillover effects
| Importance of theory |
|
| Causal inferences about spillovers |
|
| Pre-specifying analyses |
|
Causal inferences about spillovers
Confounding of spillover effect estimates
Estimates of spillover effects will be confounded if there are factors associated with untreated individuals’ exposure to treatment and outcomes that are not controlled for. A two-stage randomized trial is ideal for estimating cluster-level spillovers, distance-based spillovers and spillovers conditional on treatment density, because it minimizes systematic differences other than treatment assignment between treated and untreated individuals in the treatment and control arms. Individually randomized trials can generate internally valid spillover estimates for certain parameters, such as social network spillover effects, if they ensure that there is sufficient physical or social distance between untreated individuals so that some individuals can serve as a valid counterfactual. For observational studies, strategies such as propensity scores,62 inverse probability weighting,13,63–65 matching in the design stage,66–68 regression discontinuity69,70 and instrumental variables28,29 can increase comparability between untreated individuals in proximity to treated individuals and untreated individuals not in proximity to treated individuals that serve as a control group. For example, cluster-randomized trials can measure cluster-level spillovers by matching individuals who were ineligible for treatment in treated clusters to similar individuals in control clusters and comparing outcomes.73 However, this approach only ensures comparability on measured covariates, so unmeasured confounding may remain, and matching could potentially reduce the study’s external validity.74 We note that some of these methods, such as regression discontinuity, have yet to be applied to estimation of spillover effects; to do so would require an extension of current theory, which is appropriate for total and overall effects.
Spillover effects conditional on distance can be confounded by factors that affect whether untreated individuals live near treated individuals and as well as their outcomes. Two-stage randomized designs (Figure 2) minimize this form of confounding by balancing the distribution of treatment across space. In observational studies, investigators can select comparison areas with similar geographical features to treatment areas to minimize confounding. Sensitivity analyses can estimate the extent of possible bias in studies with unmeasured confounding or studies that randomize treatment but condition on a post-treatment variable, such as the presence of an infected case in a household, which can also lead to bias.52
Violations of SUTVA and the partial interference assumption
SUTVA is one of the core assumptions required to make causal inferences; but when spillovers occur, the assumption can be relaxed to allow for spillovers within but not between clusters (partial interference)24 (Figure 6a). Two-stage randomized designs can reasonably assume partial interference, but the assumption is difficult to assert in individually randomized studies unless enrolled individuals are separated by a large physical or social distance. In cluster-randomized trials, when interventions affect outcomes in the control clusters (‘contamination’), the partial interference assumption is violated (Figure 6b). In this case, spillover effects can generally be considered lower bounds of the true spillover effect under the assumption that the effect of treatment in the control group is less than or equal to its effect in the treatment group. However, if contamination causes re-composition of treatment and control units that alters transmission dynamics, treatment effects may be biased away from the null. Estimates will also be biased when spillovers occur in multiple directions—untreated individuals affect treated individuals’ outcomes and treated individuals affect untreated individuals’ outcomes (Figure 6c). For example, in a trial that randomizes improved latrines to a subset of households in a village, environmental contamination resulting from use of unimproved latrines by non-recipients may spread enteric infections to latrine recipients, diluting benefits from improved latrines.
Figure 6.

Schematic of spillovers within and between clusters. (a) The partial interference assumption states that there are no spillovers between clusters of individuals but allows for spillovers among individuals within the same cluster. (b) When an intervention affects individuals in a cluster assigned to control, this is often referred to as “contamination” in the cluster-randomized trial literature. This is an example of a violation of the partial interference assumption depicted in (a). (c) Spillovers may occur in multiple directions: individuals assigned to treatment may influence potential outcomes of individuals assigned to control and vice versa. When such multi-dimensional effects occur, causal inference becomes complicated.
To assess possible violations of SUTVA and the partial interference assumption, investigators can conduct Fisher’s permutation test of no effect, which assumes every study unit has the same outcome under all treatment assignments; in a cluster-randomized study, if the null hypothesis is true, there is no effect of intervention and there are no spillovers between clusters.75–77 In some cases nothing can be done to prevent spillovers between individuals or clusters–a violation of the partial interference assumption. Recent efforts have explored causal inference in this setting, which is referred to as ‘general interference’. These studies have described statistical approaches and developed software packages78 for analyzing network data in which individuals are not considered independent.17,64,79–90
Causal epidemiological effects vs biological effects
Another consideration in estimating spillover effects is that the causal estimates from an epidemiological study may not be equivalent to the biological effects of intervention, even in a randomized trial.91 Comparing the quantities estimated in challenge studies vs epidemiological studies of vaccines illustrates this difference. The biological effect of a vaccine is the reduction in risk associated with exposure to a specific volume of inoculum. Challenge studies estimate this effect by comparing risk among individuals randomly assigned to receive a known quantity of inoculum or a placebo.91 On the other hand, epidemiological studies cannot control the level of exposure to pathogens targeted by vaccines;6 as a result, they produce estimates that are a function of the level of population mixing and frequency of exposure to illness, both of which are typically unknown. Because most trials do not condition on the level of exposure to infection, their causal estimates will differ from the biological effect for interventions that produce spillovers. In addition, spillover and total effects estimated in trials with differing levels of baseline transmission are not directly comparable.91 These principles may apply to studies of interventions other than vaccines, even if analogous biological effects cannot be estimated through challenge studies. For example, in a study led by German et al. of a peer network intervention to reduce depression,41 peers of study participants were recruited to measure spillovers, but the level of social contact between peers was not controlled by the investigator; estimates of spillover effects were a function of the extent and type of social contact between peers, which may vary across populations.
Importance of theory
Spillover estimates will be most meaningful when the theory about how the intervention diffuses through a population informs the parameter choice and study design. For example, to measure spillovers of an intervention that aims to reduce HIV transmission, social network spillovers are likely to provide information that is more useful for public health intervention than distance-based spillovers since transmission occurs through sexual contact. For spillovers of behaviour change interventions, network92 and diffusion theory93,94 may inform how intervention effects diffuse over geographical areas or through social networks and whether spillovers occur evenly across a population or more strongly within subgroups. Interventions that diffuse through communication between individuals over great distances may cause spillovers over large geographical areas, even if no contact is made in person. If so, measuring spillovers through social networks is more appropriate than measuring spillovers through physical proximity since the latter may fail to capture the full spillover effect.
The strength of theory to support spillovers may inform design and analysis choices when estimating spillovers. When the causal mechanism for spillovers is not strongly grounded in theory, we encourage investigators to use a design that can effectively minimize confounding (e.g. two-stage randomization in Figure 1). However, for certain interventions such as vaccines, the biological mechanism for reducing pathogen transmission is often sufficiently clear for observational studies to provide strong inference about vaccine spillovers.9 In some cases, even if theory to support spillovers is strong, statistical models are required to make inferences about spillovers; this may occur if there is limited variation in treatment status within levels of confounders. Statistical models can yield biased estimates if they are mis-specified or if they extrapolate beyond the observed data, so model-based estimates should always be considered carefully in light of their potential assumptions and limitations.
Individual- vs group-level measurements
Spillovers can be estimated in studies that measure outcomes either in individuals or in groups. Two-stage randomized studies and other cluster-randomized studies produce individual-outcome level data. Studies have commonly attempted to measure spillover effects by assessing how rates of illness among untreated individuals change with the proportion of individuals treated in different areas, using group-level data from trials or observational studies.95–102 Studies with individual-level outcome measurements typically have the strongest inference because they are better able to control for both individual-level and group-level confounders, whereas group-level studies can only control for the latter. Despite these drawbacks, group-level measurements can be useful for hypothesis generation when individual-level measurements are not available.
Measuring spillovers within geographic areas
Certain types of spillovers, such as spillovers conditional on treatment density and distance-based spillovers, measure intervention coverage and outcomes within specific geographical areas (e.g. neighbourhoods). Spillover estimates are likely to be very sensitive to the way areas are defined.103 The size or shape of the area may determine whether spillovers are detected. Pre-specification of area definition before looking at outcomes prevents investigators from selectively using a definition that provides the most favourable result. Ideally, area definition is based on the hypothesized strength and scale of spillovers. For example, when spillover effects are expected to be weak, measurement is best within small areas where spillovers are most likely to be detected. Expected transmission dynamics may also inform area definition: a study of the cholera vaccine measured spillovers associated with immunization coverage near a shared water source, where cholera transmission was hypothesized to be the strongest.97
Power calculations for spillovers
Typically, spillover effects are smaller than total or overall effects of interventions, so larger sample sizes are needed in order to detect them. We recommend that investigators conduct power calculations in the study design phase, to assess whether statistical power will be sufficient to detect spillovers. Several studies have provided sample size formulas to estimate spillovers using randomized designs and variants of them.9,16 For non-standard study designs, simulations can be used to estimate statistical power.78
Pre-specifying spillovers
We encourage investigators who plan to measure spillovers to pre-specify the specific spillover parameter(s), the scale at which spillovers are expected, and the hypothesized mechanism(s) of spillover be estimated in a study protocol. Pre-specification reduces the chance that the spillover parameters selected are those that detect positive spillovers, whether intentionally or not.105 It also reduces the chance of publication bias.106,107 We also encourage investigators to use the terms ‘spillovers’ or ‘indirect effects’ to refer to spillovers in protocols and manuscripts, because these are the most commonly used terms in the literature, and they provide a direct link to the theoretical literature on this topic.
Summary
We have defined different types of spillover effects relevant to a wide range of interventions using standardized notation to encourage estimation and reporting of spillovers by a broad range of investigators. We have also provided a general introduction to assumptions required to make causal inferences about spillover effects. Rigorous definition and study of spillover effects will improve the accuracy of estimates of the population-level impact and cost-effectiveness of interventions that have benefits beyond direct recipients.
Supplementary Data
Supplementary data are available at IJE online.
Conflict of interest: None declared.
Supplementary Material
References
- 1. Fine PE. Herd immunity: history, theory, practice. Epidemiol Rev 1993;15:265–302. [DOI] [PubMed] [Google Scholar]
- 2. John TJ, Samuel R. Herd immunity and herd effect: new insights and definitions. Eur J Epidemiol 2000;16:601–06. [DOI] [PubMed] [Google Scholar]
- 3. Miguel E, Kremer M. Worms: identifying impacts on education and health in the presence of treatment externalities. Econometrica 2004;72:159–217. [Google Scholar]
- 4. Banerjee A, Chandrasekhar AG, Duflo E, Jackson MO. The diffusion of microfinance. Science 2013;341:1236498. [DOI] [PubMed] [Google Scholar]
- 5. Halloran ME, Struchiner CJ. Study designs for dependent happenings. Epidemiology 1991;2:331–38. [DOI] [PubMed] [Google Scholar]
- 6. Halloran ME, Struchiner CJ. Causal inference in infectious diseases. Epidemiology 1995;6:142–51. [DOI] [PubMed] [Google Scholar]
- 7. Longini IM, Sagatelian K, Rida WN, Halloran ME. Optimal vaccine trial design when estimating vaccine efficacy for susceptibility and infectiousness from multiple populations. Stat Med 1998;17:1121–36. [DOI] [PubMed] [Google Scholar]
- 8. Hudgens MG, Halloran ME. Toward causal inference with interference. J Am Stat Assoc 2008;103:832–42. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Halloran E, Longini IM Jr, Struchiner CJ. Design and Analysis of Vaccine Studies. New York, NY: Springer, 2010. [Google Scholar]
- 10. VanderWeele TJ, Tchetgen Tchetgen EJ. Effect partitioning under interference in two-stage randomized vaccine trials. Stat Probab Lett 2011;81:861–69. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Clemens J, Shin S, Ali M. New approaches to the assessment of vaccine herd protection in clinical trials. Lancet Infect Dis 2011;11:482–87. [DOI] [PubMed] [Google Scholar]
- 12. VanderWeele T, Tchetgen Tchetgen E, Halloran M. Components of the indirect effect in vaccine trials: identification of contagion and infectiousness effects. Epidemiology 2012;23:751–61. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Tchetgen EJT, VanderWeele TJ. On causal inference in the presence of interference. Stat Methods Med Res 2012;21:55–75. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Halloran ME. The minicommunity design to assess indirect effects of vaccination. Epidemiol Methods 2012;1:83–105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15. Angelucci M, Maro VD. Program Evaluation and Spillover Effects. J Dev Effectiveness 2016;8(1). [Google Scholar]
- 16. Baird S, Bohren A, McIntosh C, Ozler B. Designing Experiments to Measure Spillover Effects. PIER Working Paper No. 14–006; 2014. http://ssrn.com/abstract=2402749 or http://dx.doi.org/10.2139/ssrn.2402749 (9 June 2017, date last accessed). [Google Scholar]
- 17. Bowers J, Fredrickson MM, Panagopoulos C. Reasoning about interference between units: a general framework. Polit Anal 2013;21(1):97–124. [Google Scholar]
- 18. Sinclair B, McConnell M, Green DP. Detecting spillover effects: Design and analysis of multilevel experiments. Am J Polit Sci 2012;56:1055–69. [Google Scholar]
- 19. Benjamin-Chung J, Abedin J, Berger D, et al. Spillover effects on health outcomes in low- and middle-income countries: a systematic review. Int J Epidemiol 2017;46:1251–76. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Anderson R, Garnett G. Low-efficacy HIV vaccines: potential for community-based intervention programmemes. Lancet 1996;348:1010–13. [DOI] [PubMed] [Google Scholar]
- 21. Little RJ, Rubin DB. Causal effects in clinical and epidemiological studies via potential outcomes: concepts and analytical approaches. Annu Rev Public Health 2000;21:121–45. [DOI] [PubMed] [Google Scholar]
- 22. Rubin D. Comment: Neyman (1923) and causal inference in experiments and observational studies. Stat Sci 1990;5:472–80. [Google Scholar]
- 23. Cox DR. Planning of Experiments. Oxford, UK: Wiley, 1958. [Google Scholar]
- 24. Sobel ME. What do randomized studies of housing mobility demonstrate? J Am Stat Assoc. 2006;101:1398–407. [Google Scholar]
- 25. Campbell MJ, Donner A, Klar N. Developments in cluster randomized trials and statistics in medicine. Stat Med 2007;26:2–19. [DOI] [PubMed] [Google Scholar]
- 26. Hayes RJ, Moulton LH. Cluster Randomised Trials. Abingdon, UK: Taylor & Francis, 2009. [Google Scholar]
- 27. Donner A, Klar N. Design and Analysis of Cluster Randomization Trials in Health Research. Hoboken, NJ: Wiley, 2010. [Google Scholar]
- 28. Chong A, Gonzalez-Navarro M, Karlan D, Valdivia M. Effectiveness and Spillovers of Online Sex Education: Evidence from a Randomized Evaluation in Colombian Public Schools. Cambridge, MA: National Bureau of Economic Research, 2013. [Google Scholar]
- 29. Robins JM, Greenland S. Identifiability and exchangeability for direct and indirect effects. Epidemiology 1992;3:143–55. [DOI] [PubMed] [Google Scholar]
- 30. Avitabile C. Spillover Effects in Healthcare Programmes: Evidence on Social Norms and Information Sharing. Washington, DC: Inter-American Development Bank, 2012. [Google Scholar]
- 31. Buttenheim A, Alderman H, Friedman J. Impact evaluation of school feeding programmes in Lao People’s Democratic Republic. J Dev Eff 2011;3:520–42. [Google Scholar]
- 32. Contreras D, Maitra P. Health Spillover Effects of a Conditional Cash Transfer Programme. 2012. http://www.buseco.monash.edu.au/eco/research/papers/2013/4413healthcontrerasmaitra.pdf (9 June 2017, date last accessed). [Google Scholar]
- 33. Fitzsimons E, Malde B, Mesnard A, Vera-Hernández M. Household Responses to Information on Child Nutrition: Experimental Evidence From Malawi. 2012. http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2034133 (9 June 2017, date last accessed). [Google Scholar]
- 34. Handa S, Huerta M-C, Perez R, Straffon B. Poverty, Inequality, and Spillover in Mexico’s Education, Health, and Nutrition Programme. 2001. http://agris.fao.org/agris-search/search.do?recordID=US2012205787 (9 June 2017, date last accessed). [Google Scholar]
- 35. House JI, Ayele B, Porco TC, et al. Assessment of herd protection against trachoma due to repeated mass antibiotic distributions: a cluster-randomised trial. Lancet 2009;373:1111–18. [DOI] [PubMed] [Google Scholar]
- 36. Kazianga H, de Walque D, Alderman H. School feeding Programs and the nutrition of siblings: evidence from a randomized trial in rural Burkina Faso. Oklahoma State University, Department of Economics and Legal Studies in Business, 2009. [Google Scholar]
- 37. Ribas RP, Soares FV, Teixeira CG, Silva E, Hirata GI. Externality and Behavioural Change Effects of a Non-Randomised CCT Programmeme: Heterogeneous Impact on the Demand for Health and Education. Brasilia: International Policy Centre for Inclusive Growth, 2011. [Google Scholar]
- 38. Banerjee AV, Duflo E, Glennerster R, Kothari D. Improving immunisation coverage in rural India: clustered randomised controlled evaluation of immunisation campaigns with and without incentives. BMJ 2010;340:c2220. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39. Hawley WA, Phillips-Howard PA, Kuile FOT, et al. Community-wide effects of permethrin-treated bed nets on child mortality and malaria morbidity in Western Kenya. Am J Trop Med Hyg 2003;68(Suppl 4):121–27. [PubMed] [Google Scholar]
- 40. Kremer M, Miguel E. The illusion of sustainability. Q J Econ 2007;122:1007–65. [Google Scholar]
- 41. German D, Sutcliffe CG, Sirirojn B, et al. Unanticipated effect of a randomized peer network intervention on depressive symptoms among young methamphetamine users in Thailand. J Community Psychol 2012;40:799–813. [Google Scholar]
- 42. Shakya HB, Christakis NA, Fowler JH. Social network predictors of latrine ownership. Am J Public Health 2014;104:5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43. Kim DA, Hwong AR, Stafford D, et al. Social network targeting to maximise population behaviour change: a cluster randomised controlled trial. Lancet 2015;386:145–53. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44. Vanderweele T, An W. Social networks and causal inference. Handbook of Causal Analysis for Social Research New York, NY: Springer, 2013. [Google Scholar]
- 45. Christakis NA, Fowler JH. The spread of obesity in a large social network over 32 years. N Engl J Med 2007;357:370–79. [DOI] [PubMed] [Google Scholar]
- 46. Christakis NA, Fowler JH. The collective dynamics of smoking in a large social network. N Engl J Med 2008;358:2249–58. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47. Snijders TAB. The statistical evaluation of social network dynamics. Sociol Methodol 2001;31:361–95. [Google Scholar]
- 48. Snijders TA. Models for longitudinal network data. In: Carrington PJ, Scott J, Wasserman S (eds). Models and Methods in Social Network Analysis. New York: Cambridge, 2005, pp.215–47. [Google Scholar]
- 49. Cohen-Cole E, Fletcher JM. Detecting implausible social network effects in acne, height, and headaches: longitudinal analysis. BMJ 2008;337:a2533. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50. Lyons R. The spread of evidence-poor medicine via flawed social-network analysis. Stat Polit Policy. 2011;2:1. [Google Scholar]
- 51. Noel H, Nyhan B. The ‘unfriending’ problem: The consequences of homophily in friendship retention for causal estimates of social influence. Soc Netw 2011;33:211–18. [Google Scholar]
- 52. VanderWeele TJ. Sensitivity analysis for contagion effects in social networks. Sociol Methods Res. 2011;40:240–55. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53. VanderWeele TJ, Ogburn EL, Tchetgen Tchetgen JE. Why and when ‘flawed’ social network analyses still yield valid tests of no contagion. Stat Polit Policy 2012;3:1–11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54. Sacerdote B. Peer effects with random assignment: results for Dartmouth Roommates. Q J Econ 2001;116:681–704. [Google Scholar]
- 55. Longini IM, Koopman JS, Haber M, Cotsonis GA. Statistical inference for infectious diseases risk-specific household and community transmission parameters. Am J Epidemiol 1988;128:845–59. [DOI] [PubMed] [Google Scholar]
- 56. Halloran ME, Haber M, Longini IM Jr, Struchiner CJ. Direct and indirect effects in vaccine efficacy and effectiveness. Am J Epidemiol. 1991;133(4):323–331. [DOI] [PubMed] [Google Scholar]
- 57. Halloran ME, Struchiner CJ, Longini IM. Study designs for evaluating different efficacy and effectiveness aspects of vaccines. Am J Epidemiol 1997;146:789–803. [DOI] [PubMed] [Google Scholar]
- 58. Hudgens MG, Halloran ME. Causal vaccine effects on binary postinfection outcomes. J Am Stat Assoc 2006;101:51–64. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59. VanderWeele TJ, Tchetgen Tchetgen EJ. Bounding the infectiousness effect in vaccine trials. Epidemiology 2011;22:686–93. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60. Halloran ME, Hudgens MG. Causal inference for vaccine effects on infectiousness. Int J Biostat 2012;8:2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61. Préziosi M-P, Halloran ME. Effects of pertussis vaccination on transmission: vaccine efficacy for infectiousness. Vaccine.2003;21:1853–61. [DOI] [PubMed] [Google Scholar]
- 62. Hong G, Raudenbush SW. Effects of kindergarten retention policy on children’s cognitive growth in reading and mathematics. Educ Eval Policy Anal 2005;27:205–24. [Google Scholar]
- 63. Perez-Heydrich C, Hudgens MG, Halloran ME, Clemens JD, Ali M, Emch ME. Assessing effects of cholera vaccination in the presence of interference. Biometrics 2014;70:731–44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64. Liu L, Hudgens MG, Becker-Dreps S. On inverse probability-weighted estimators in the presence of interference. Biometrika 2016;103:829–42. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65. Lundin M, Karlsson M. Estimation of causal effects in observational studies with interference between units. Stat Methods Appl 2014;23:417–33. [Google Scholar]
- 66. Rosenbaum PR, Rubin DB. The central role of the propensity score in observational studies for causal effects. Biometrika 1983;70:41–55. [Google Scholar]
- 67. Rosenbaum PR, Rubin DB. The bias due to incomplete matching. Biometrics 1985;41:103–16. [PubMed] [Google Scholar]
- 68. Diamond A, Sekhon JS. Genetic matching for estimating causal effects: a general multivariate matching method for achieving balance in observational studies. Rev Econ Stat 2013;95:932–45. [Google Scholar]
- 69. Bor J, Moscoe E, Mutevedzi P, Newell M-L, Bärnighausen T. Regression discontinuity designs in epidemiology. Epidemiology 2014;25:729–37. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70. Imbens G, Lemieux T. Regression Discontinuity Designs: A Guide to Practice. Cambridge, MA: National Bureau for Economic Research, 2007. [Google Scholar]
- 71. Angrist JD, Imbens GW, Rubin DB. Identification of causal effects using instrumental variables. J Am Stat Assoc 1996;91:444–55. [Google Scholar]
- 72. Greenland S. An introduction to instrumental variables for epidemiologists. Int J Epidemiol 2000;29:722–29. [DOI] [PubMed] [Google Scholar]
- 73. Janssens W. Measuring Externalities in Programme Evaluation. Tinbergen Institute Discussion Paper. Amsterdam: Tinbergen Institute, 2005. [Google Scholar]
- 74. Freemantle N, Marston L, Walters K, Wood J, Reynolds MR, Petersen I. Making inferences on treatment effects from real world data: propensity scores, confounding by indication, and other perils for the unwary in observational research. BMJ 2013;347:f6409. [DOI] [PubMed] [Google Scholar]
- 75. Fisher R. Statistical Methods for Research Workers. Edinburgh, UK: Oliver and Boyd, 1925. [Google Scholar]
- 76. Arnold BF, Null C, Luby SP, et al. Cluster-randomised controlled trials of individual and combined water, sanitation, hygiene and nutritional interventions in rural Bangladesh and Kenya: the WASH Benefits study design and rationale. BMJ Open 2013;3:e003476. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77. WASH Benefits Bangladesh Primary Outcome Analysis Plan Update. 2016. https://osf.io/63mna/ (9 June 2017, date last accessed).
- 78. Sofrygin O, van der Laan MJ. Targeted Maximum Likelihood Estimation for Networks. 2015. Report No.: R package version 0.1. https://github.com/osofr/tmlenet (9 June 2017, date last accessed). [Google Scholar]
- 79. Rosenbaum PR. Interference between units in randomized experiments. J Am Stat Assoc 2007;102:191–200. [Google Scholar]
- 80. Aral S, Walker D. Identifying social influence in networks using randomized experiments. IEEE Intell Syst 2011;26:91–96. [Google Scholar]
- 81. Toulis P, Kao E. Estimation of Causal Peer Influence Effects. 2013. http://www.jmlr.org/proceedings/papers/v28/toulis13.html (10 January 2017, date last accessed). [Google Scholar]
- 82. Ugander J, Karrer B, Backstrom L, Kleinberg J. Graph Cluster Randomization: Network Exposure to Multiple Universes. 2013. https://arxiv.org/abs/1305.6979 (9 June 2017, date last accessed). [Google Scholar]
- 83. Eckles D, Karrer B, Ugander J. Design and analysis of experiments in networks: Reducing bias from interference. 2014. https://arxiv.org/abs/1404.7530 (9 June 2017, date last accessed). [Google Scholar]
- 84. Walker D, Muchnik L. Design of randomized experiments in networks. Proc IEEE 2014;102:1940–51. [Google Scholar]
- 85. van der Laan MJ. Causal inference for a population of causally connected units. J Causal Infer 2014;2:13–74. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86. Aral S, Walker D. Tie strength, embeddedness, and social influence: a large-scale networked experiment. Manag Sci 2014;60:1352–70. [Google Scholar]
- 87. Aronow PM, Samii C. Estimating Average Causal Effects Under Interference Between Units. 2015. https://arxiv.org/abs/1305.6156 (9 June 2017, date last accessed). [Google Scholar]
- 88. Sofrygin O, van der Laan MJ. Semi-parametric estimation and inference for the mean outcome of the single time-point intervention in a causally connected population. J Causal Inference. 2017;5:35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89. Choi D. Estimation of monotone treatment effects in network experiments. J Am Stat Assoc In press. [Google Scholar]
- 90. Basse GW, Airoldi EM. Optimal Model-Assisted Design of Experiments for Network Correlated Outcomes Suggests New Notions of Network Balance. 2016. https://arxiv.org/abs/1507.00803(9 June 2017, date last accessed). [Google Scholar]
- 91. Struchiner CJ, Halloran ME. Randomization and baseline transmission in vaccine field trials. Epidemiol Amp Infect 2007;135:181–94. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 92. Valente T. Network interventions. Science 2012;337:49–53. [DOI] [PubMed] [Google Scholar]
- 93. Rogers EM. Diffusion of Innovations. 4th ednn New York, NJ: Simon and Schuster, 2010. [Google Scholar]
- 94. Greenberg MR. The diffusion of public health innovations. Am J Public Health 2006;96:209–10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95. Ali M, Sur D, You YA, et al. Herd protection by a bivalent-killed-whole-cell oral cholera vaccine in the slums of Kolkata, India. Clin Infect Dis 2013;56:1123–31. [DOI] [PubMed] [Google Scholar]
- 96. Chen W-J, Moulton LH, Saha SK, Mahmud AA, Arifeen SE, Baqui AH. Estimation of the herd protection of Haemophilus influenzae type b conjugate vaccine against radiologically confirmed pneumonia in children under 2 years old in Dhaka, Bangladesh. Vaccine. 2014;32:944–48. [DOI] [PubMed] [Google Scholar]
- 97. Emch M, Ali M, Root ED, Yunus M. Spatial and environmental connectivity analysis in a cholera vaccine trial. Soc Sci Med 2009;68:631–37. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 98. Haile M, Tadesse Z, Gebreselassie S, et al. The association between latrine use and trachoma: a secondary cohort analysis from a randomized clinical trial. Am J Trop Med Hyg 2013;89:717–20. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 99. Huq A, Yunus M, Sohel SS, et al. Simple sari cloth filtration of water is sustainable and continues to protect villagers from cholera in Matlab, Bangladesh. mBio.2010;1:e00034–10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 100. Khatib AM, Ali M, von Seidlein L, et al. Effectiveness of an oral cholera vaccine in Zanzibar: findings from a mass vaccination campaign and observational cohort study. Lancet Infect Dis 2012;12:837–44. [DOI] [PubMed] [Google Scholar]
- 101. Root ED, Giebultowicz S, Ali M, Yunus M, Emch M. The role of vaccine coverage within social networks in cholera vaccine efficacy. PLoS One 2011;6:e22971. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 102. Root ED, Lucero M, Nohynek H, et al. Distance to health services affects local-level vaccine efficacy for pneumococcal conjugate vaccine (PCV) among rural Filipino children. Proc Natl Acad Sci U S A 2014;111:3520–25. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 103. Openshaw S. Ecological fallacies and the analysis of areal census data. Environ Plann A 1984;16:17–31. [DOI] [PubMed] [Google Scholar]
- 104. Arnold BF, Hogan DR, Colford JM, Hubbard AE. Simulation methods to estimate design power: an overview for applied research. BMC Med Res Methodol 2011;11:94. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 105. Miguel E, Camerer C, Casey K, et al. Promoting transparency in social science research. Science 2014;343:30–31. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 106. Ioannidis JPA, Munafò MR, Fusar-Poli P, Nosek BA, David SP. Publication and other reporting biases in cognitive sciences: detection, prevalence, and prevention. Trends Cogn Sci 2014;18:235–41. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 107. Dal-Ré R, Ioannidis JP, Bracken MB, et al. Making prospective registration of observational research a reality. Sci Transl Med 2014;6:224. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.