

Abstract
Tikhonov regularization is the most commonly used method for extracting distance distributions from experimental double electron-electron resonance (DEER) spectroscopy data. This method requires the selection of a regularization parameter, α, and a regularization operator, L. We analyze the performance of a large set of α selection methods and several regularization operators, using a test set of over half a million synthetic noisy DEER traces. These are generated from distance distributions obtained from in silico double labeling of a protein crystal structure of T4 lysozyme with the spin label MTSSL. We compare the methods and operators based on their ability to recover the model distance distributions from the noisy time traces. The results indicate that several α selection methods perform quite well, among them the Akaike information criterion and the generalized cross validation with either the first- or second-derivative operator. They perform significantly better than currently utilized L-curve methods.
Keywords: inverse problem, Tikhonov regularization, DEER, PELDOR, penalized least-squares
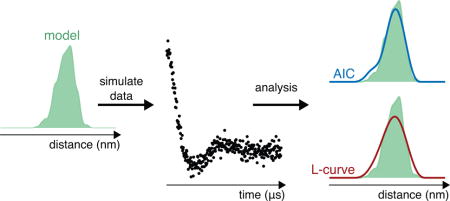
Graphical abstract
1. Introduction
Double electron-electron resonance (DEER) spectroscopy, also called pulsed electron-electron double resonance (PELDOR) spectroscopy, measures the magnetic dipolar coupling between two or more paramagnetic centers, such as spin labels attached to proteins [1–3]. DEER data analysis usually involves the removal of a background signal followed by a transformation of the oscillatory time-domain signal into a distance-domain probability distribution function describing the distances between nearby paramagnetic centers (1.5-10 nm).
There exist several different approaches for extracting distance distributions from DEER data: Tikhonov regularization [4–7], Gaussian mixture models [8–10], Tikhonov regularization post-processed with Gaussians [11, 12], Tikhonov regularization combined with maximum entropy [13], Bayesian inference (based upon Tikhonov regularization) [14], regularization by limiting the number of points in the distance domain [15], wavelet denoising [16], truncated singular-value decomposition [6, 17], and neural networks [18]. Among them, Tikhonov regularization is the most widely employed method.
In this paper, we are concerned with the determination of optimal settings for Tikhonov regularization. This involves the choice of a regularization operator L and of a value for the regularization parameter α. An optimal choice of L and α ensures good distance distribution recovery and prevents overfitting the data; a bad choice causes poor recovery and either under- or overfitting to the data. There are several operators to choose from, and many methods are available for selecting α, each based on a defensible rationale. However, they vary greatly both in terms of theoretical justification and empirical track record. Therefore, the selection of the method/operator combination ought to be based on a thorough comparison of their performance for a practically relevant benchmark set of data analysis problems.
Tikhonov regularization was introduced to NMR for de-Pake-ing [19], for the extraction of internuclear distances from dipolar time-domain signals such as those from REDOR [20], for the determination of orientational distributions from 2H NMR data [21, 22], and relaxation rate distributions [23, 24]. These approaches used the self-consistent method for selecting α, as introduced and implemented in the program FTIKREG [25, 26]. In the context of extracting distance distributions from DEER data, Tikhonov regularization was initally mentioned in 2002 [27, 28], and first applications appeared in 2004 [4, 5]. In these papers, the regularization parameter was selected manually or using FTIKREG. A thorough paper examining Tikhonov regularization and introducing the use of the L-curve maximum-curvature criterion appeared in 2005 [6]. A different L-curve method, the minimum-radius criterion, was introduced in 2006 in the program DeerAnalysis [7] and is used in its current release (2016).
Despite the long history and the widespread use of Tikhonov regularization for DEER data analysis, there has been no systematic assessment and efficiency comparison of regularization operators and regularization parameter selection methods. This is what we present here. We evaluate a large number of regularization parameter selection methods and three regularization operators with respect to their performance against a large set of synthetic DEER time-domain data derived from model distributions obtained by in silico spin labeling of a PDB crystal stucture of T4 lysozyme. We examine and compare all methods by their efficiency in recovering the underlying model distributions. The results indicate that the performance of the methods varies significantly, and that there are methods that perform better than the currently employed L-curve α selection methods.
The paper is structured as follows. Section 2 summarizes the principles of Tikhonov regularization for DEER and introduces the necessary notation. Section 3 explains the construction and characteristics of the large test set of distance distributions and associated synthetic DEER time-domain traces. Section 4 describes the assessment methodology. Section 5 presents the results and discusses benefits and drawbacks of various methods in light of these results. The paper ends with recommendations regarding the preferred methods. Mathematical details of the various regularization parameter selection methods are listed in the Appendix.
2. DEER and Tikhonov regularization
DEER measures the electron spin echo intensity V as a function of the position in time of one or more pump pulses, t. For dilute samples of doubly-labelled proteins or complexes, V is a product of an overall amplitude, V0, a modulation function due to intra-complex coupling, F, and a background modulation function due to the interaction between spins on different complexes, B:
| (1) |
λ is the modulation depth parameter related to the excitation efficiency of the DEER experiment. When utilizing Tikhonov regularization, a background model is typically fitted to V(t)/V0 and divided out, yielding the isolated intra-complex modulation function S(t) after scaling by λ. S(t) is normalized such that S(0) = 1 in the noise-free limit.
In the absence of orientation selection, exchange coupling, differential relaxation, and multi-spin effects, S(t) is related to the distance distribution between the two spins on the complex, P(r), by
| (2) |
where
| (3) |
and . P(r) integrates to one: .
When S is discretized as an nt-element vector with elements Si = S(ti), and P as an nr-element vector with elements Pi = P(ri), the integral transformation from P to S is represented by the matrix-vector multiplication
| (4) |
where K is the nt × nr kernel matrix. Its elements are Kij = K(ti, rj) · Δr, with the distance increment Δr. Usually, nr is set equal to nt.
The matrix K is close to singular, and the calculation of the inverse of KTK—needed to obtain P from S in an ordinary least-squares fitting procedure—is very inaccurate. To enable the solution, Tikhonov regularization is used:
| (5) |
This is a form of penalized least-squares fitting. The first term is the least-squares term capturing the misfit between the model KP and the data S. The second term penalizes for unwanted properties of the solution P and depends on a specific form for the regularization operator L and a specific value for the regularization parameter α. The fit is constrained by the requirement that all elements of P be non-negative (P ≥ 0). The subscripts in PαL indicate that the solution depends on the particular choices of α and L.
L defines the criterion by which P should be penalized. Physically reasonable distance distributions between spin labels on proteins are smooth on a tenths-of-nanometer scale. Three L choices are possible that all encourage smoothness and penalize roughness of P, in one sense or another. The second derivative, represented by the (nr−2) × nr second-order difference matrix
| (6) |
penalizes sharp turns in the distribution, which arise from sharp peaks. The first derivative, represented by the (nr − 1) × nr first-order difference matrix
| (7) |
penalizes steep slopes, which are also associated with sharp peaks. Note that the matrices defined in Eqs. (6) and (7) do not contain Δr. Lastly, the nr × nr identity matrix L0 = I can be used. It penalizes tall peaks, which tend to be narrow due to the overall normalization of P.
The value of α determines the balance between the two terms in Eq. (5). Large α values lead to oversmoothing of P and a poor fit to the time-domain data S, while small α values lead to unrealistically spiky distributions (undersmoothing) and overfitting of the data. Therefore, a proper choice of α is essential. A large number of α selection methods are described in the literature, and we include many of them in our performance analysis. They are described in the Appendix.
The optimal values of both α and L, αopt and Lopt, are the ones which together best recover the underlying true distribution P0, i.e. the ones for which the model recovery error (mre), defined as
| (8) |
is minimal. For synthetic data, as used in this study, this error and thereby αopt and Lopt can be determined, since P0 is given. However, in experimental practice P0 is not known, and one has to resort to other methods to choose a form for L and a value for α.
3. The test set
In order to test α selection methods and regularization operators on DEER data from practically relevant distance distributions, we numerically generated a large set of synthetic noisy DEER time-domain signals based on a crystal structure of T4 lysozyme (PDB ID 2LZM, 1.7 Å resolution); its structure is shown in Fig. 1. We use this protein since it is currently one of the most thoroughly investigated proteins by DEER and other EPR techniques [29–37] and is of a size commensurate with the typical DEER distance range of 1.5 to 6 nm. We in silico labeled the 2LZM protein structure with the nitroxide spin label MTSSL which is to date, by a wide margin, the most commonly used label for DEER. In this section, we detail the construction of the test set.
Figure 1.
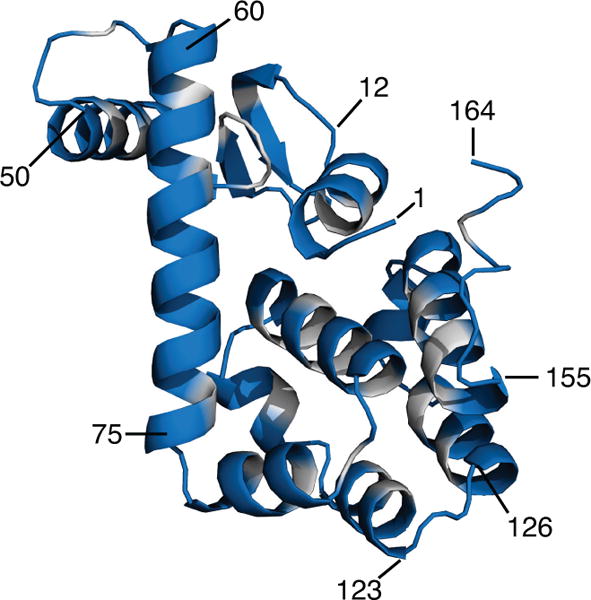
Crystal structure of T4 lysozyme (164 residues, PDB 2LZM, 1.7 Å resolution). Residues with low predicted labeling probabilities that were excluded from the test set are shown in grey. Several residues are labeled as guides to the eye.
3.1 Construction of model distributions
Using scripts based on MMM 2017.1 [38–40] with the default 216-member rotamer library R1A_298K_UFF_216_r1_CASD for MTSSL at ambient temperature, we calculated rotamer distributions for all 164 sites on the protein. For each site, this yielded co-ordinates of the mid-points of the N-O bonds of all 216 rotamers and their associated populations, as well as the site partition function. In order to keep the test set realistic, we eliminated all sites with low predicted labelling probability (partition function smaller than 0.05), leaving 129 sites. These sites are indicated in Fig. 1.
For each of the resulting 8256 site pairs, we calculated the associated model distance distribution, consisting of a sum of Gaussian lineshapes, with centers corresponding to the inter-rotamer distances, intensities corresponding to the products of the respective populations, and with a uniform full width at half maximum (FWHM) of 0.15 nm to account for structural heterogeneity around the energy minimum of each rotamer due to librational motion [38]. Each distribution was discretized with a high resolution of Δr = 0.005 nm, corresponding to 1/30 of the FWHM. To keep the test set experimentally realistic, we discarded all distributions with more than 5% integrated population below 1.7 nm. This guarantees that there is no population below 1.5 nm. Site pairs with population at such short distances are always avoided in experimental studies in order to avoid potential distortions due to exchange coupling and incomplete excitation.
This procedure resulted in a set of 5622 model distance distributions. Their properties are summarized in Fig. 2. The distribution modes (location of the distribution maxima) range from 1.7 to 6.1 nm, and the inter-quartile ranges (iqr; range of central 50% integrated population) are between 0.09 and 1.1 nm wide. Long, short, narrow, wide, unimodal, multimodal, symmetric, and skewed distributions are all well-represented in the test set. Skewness is relatively evenly distributed across both the mode and iqr. The number of significant peaks is evenly distributed across modal distance, but there is a positive correlation between iqr and number of peaks. Fig. 3 shows several representative example distributions.
Figure 2.
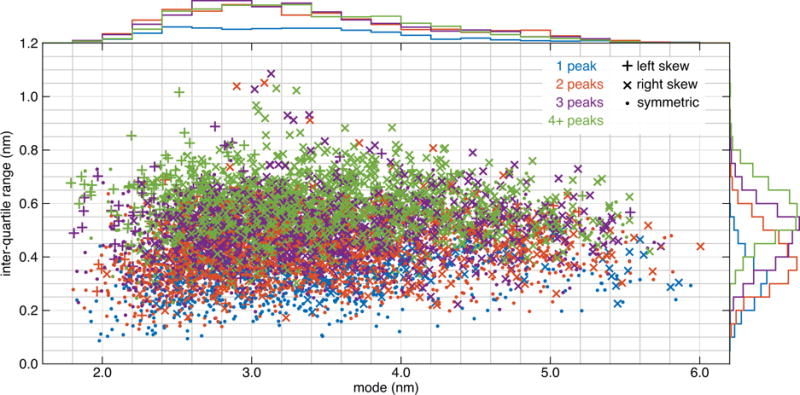
Summary statistics of the 5622 model DEER distance distributions derived from the crystal structure of T4 lysozyme (PDB 2LZM). The inter-quartile range (iqr) of r is plotted vs the mode of r for each distribution. Color indicates the number of peaks (significant maxima), and the symbol indicates the type and degree of skew. The histogram colors correspond to the number of peaks.
Figure 3.
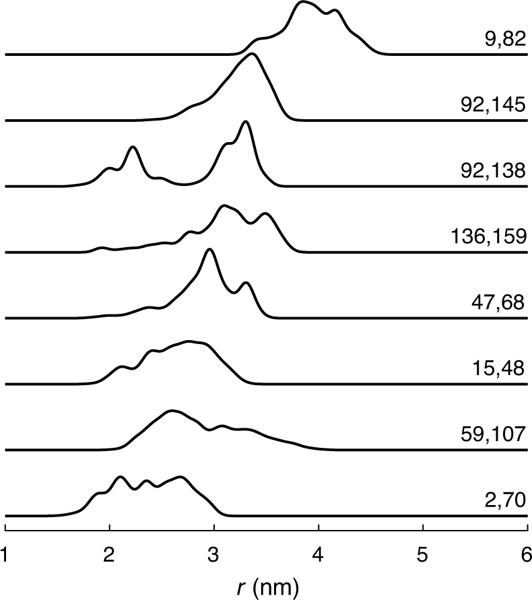
Examples of distance distributions calculated via in silico double labeling of the 2LZM structure of T4 lysozyme with MTSSL. The site pairs corresponding to each distribution are listed in the figure.
An alternative strategy of constructing a test set would be to generate completely artificial distributions without reference to a protein where the center, width, multi-modality, and skewness is varied either systematically or randomly. However, such a test set will be less experimentally relevant. Figure 2 shows that the structure-based test set used here covers a sufficiently diverse range of distribution centers, widths, and shapes.
3.2 Generation of time-domain traces
Each model distribution was used to generate a set of time-domain traces S with varying maximum evolution times tmax, time increments Δt, noise levels σ, and noise realizations, subject to the constraints that: (1) each S must be long enough to permit accurate recovery of the longest distances in the corresponding P, and (2) that the sampling rate must be high enough to recover the shortest distances. The starting time for all time traces was set to tmin = 0. We used multiple values of tmax and Δt for each model distribution in order to be able to assess whether or not any α selection methods display uneven performance with respect to these parameters.
To choose a set of appropriate tmax for a given distribution, we take as an upper limit tmm = 3T⊥,95, where T⊥,95 is the period corresponding to the perpendicular-orientation dipolar frequency of the 95-percentile distance, i.e., T⊥,95 = (r95/nm)3/(52 MHz). The factor 3 prolongs the time in order to completely capture the long-distance tail of the distribution, which has the lowest frequencies. With this, we choose the set of tmax according to the following procedure: if tmm > 6.4 μs, then tmax is 6.4 and 3.2 μs; if 3.2 μs < tmm < 6.4 μs, then tmax is 3.2 and 1.6 μs; if 1.6 μs < tmm < 3.2 μs, then tmax is 1.6 and 0.8 μs; if 0.8 μs < tmm < 1.6 μs, then tmax is 0.8 μs; and if tmm < 0.8 μs, then tmax is 0.4 μs. Figure 4 shows an example distribution for which tmm = 2.36 μs, hence tmax is 1.6 and 0.8 μs. Note that even the shorter tmax value of 0.8 μs is long enough to accommodate a full oscillation of period T⊥,95 = 0.786 μs.
Figure 4.
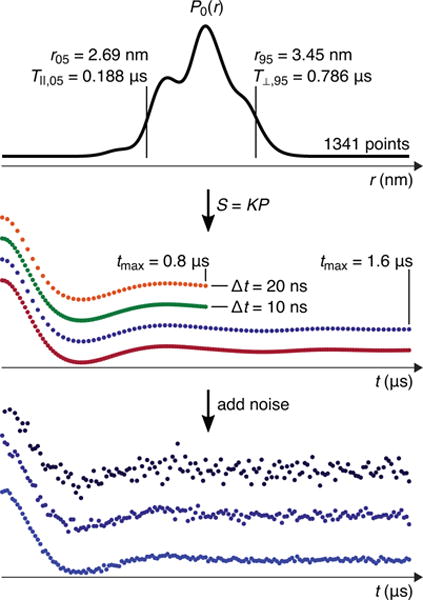
Generation of time traces (S(t)) from a distance distribution. Top panel: the model distribution (for labeled residues 112 and 143). In this case, 3T⊥,95 = 2.36 μs, so tmax was set to 1.6 and 0.8 μs in accordance with the rules given in Section 3. T‖,05/6 = 31.3 ns, so Δt was set to 10 and 20 ns. Middle panel: the four resulting time-domain traces generated using Eq. (4). Bottom panel: three noisy realizations with σ = 0.1, 0.05, and 0.02 for the 3rd (dark blue) trace in the middle panel. A total of 120 noisy time-domain traces were generated from this particular distribution.
To find a reasonable set of time increments Δt for each distribution, we first determined the longest allowable increment, Δtmax, that correctly samples all frequencies in the signal. This is dictated by the highest dipolar frequency in the time-domain signal, which corresponds to the shortest distance in the distribution. We use the period T‖,05 of the parallel-orientation dipolar frequency corresponding to the 5-percentile distance. According to the Nyquist theorem, Δtmax must be less than T‖,05/2 to avoid frequency aliasing. To capture the short-distance tail of the distribution and to obtain enough time-domain points to achieve reasonable distance resolution in the Tikhonov fits in all cases, we chose Δtmax = T‖,05/6. This resulted in values from 8 ns to 280 ns. Δtmax now guides the choice of Δt: If Δtmax > 200 ns, then Δt is 50, 100, and 200 ns; if 100 ns < Δtmax < 200 ns, then Δt is 20, 50, and 100 ns; if 50 ns < Δtmax < 100 ns, then Δt is 10, 20, and 50 ns; if 20 ns < Δtmax < 50 ns, then Δt is 10 and 20 ns; if 10 ns < Δtmax < 20 ns, then Δt is 10 ns; and if Δtmax < 10 ns, then Δt is 5 ns. For the example distribution in Fig. 4, Δtmax = T‖,05/6 = 31.3 ns, so Δt was set to 10 and 20 ns.
To generate the noise-free time trace for a particular combination of tmin, tmax, and Δt (with nt = 33, 41, 65, 81, 129, 161, 321, or 641 points), we used in Eq. (4) the high-resolution model distribution (n0 = 1341 points) and generated the nt-element time trace using an nt × n0 kernel matrix. Therefore, the model distributions used for this forward modeling have a higher resolution than the ones obtained via Tikhonov regularization (Eq. (5)) of the simulated noisy data, with nr = nt. This avoids circular reasoning and committing the “inverse crime” [41, 42]. Fig. 4 shows the synthetic time-domain traces resulting from the above rules for an example distribution.
The combinations of Δt, tmin, and tmax resulted in a total of 20701 noise-free time-domain traces with between 33 and 641 points. A few traces with fewer than 33 points were thrown out, since such short traces are not acquired in practice.
Finally, we generated 30 noisy traces from each noise-free trace. We utilized uncorrelated Gaussian noise [14] with standard deviations σ = 0.02, 0.05, and 0.1. These noise levels span the range typically obtained experimentally for proteins. In experimental settings, the background removal step typically increases the magnitude of the noise at the end of the S(t) trace relative to the start. This effect is more pronounced for steeper background functions and can be negligible for shallower ones. We did not attempt to simulate this characteristic of the data. For each noise level, m = 10 noise realizations were generated using a random-number generator. For reproducibility, seeds for the random-number generator are stored as part of the test set.
Altogether, with these selections for tmax, Δt, σ, and m, the 5622 model distributions P0 resulted in 621030 noisy time-domain traces S. These constitute the final test data set.
4. Performance evaluation
For each of the traces in the test set, we use 60 different variants of α selection methods to determine an appropriate regularization parameter value αsel and the associated Tikhonov solution. Mathematical details of the methods are given in the Appendix. Each method is referred to via a short acronym, which is listed in Table 1. We evaluate each α selection method for each of the three regularization operators L (identity, first derivative, and second derivative). Thus, we examine Tikhonov regularization along both its degrees of freedom (L and α), with a total of 180 approaches.
Table 1.
List of abbreviations for regularization parameter selection methods. To indicate the use of unconstrained P(r) in a method, the suffix ‘u’ is appended to the abbreviation. If a tuning parameter is used, its value is appended as well.
| Acronym | Full name |
|---|---|
|
| |
| AIC | Akaike information criterion |
| AICC | corrected Akaike information criterion |
| BIC | Bayesian information criterion |
| BP | balancing principle |
| CV | leave-one-out cross validation |
| DP | discrepancy principle |
| EE | extrapolated error |
| GCV | generalized cross validation |
| GML | generalized maximum-likelihood |
| hBP | hardened balancing principle |
| ICOMP | information complexity criterion |
| LC | L-curve, maximum curvature |
| LR | L-curve, minimum radius |
| LR2 | L-curve, minimum radius 2 |
| MCL | Mallows’ CL |
| mGCV | modified generalized cross validation |
| NCP | normalized cumulative periodogram |
| QO | quasi-optimality criterion |
| rGCV | robust generalized cross validation |
| RM | residual method |
| SC | self-consistency method |
| srGCV | strong robust generalized cross validation |
| tDP | transformed discrepancy principle |
Each method determines α by minimizing or thresholding some cost function over α. To search for these points, we use an α range from 10−3 to 103 with 61 points on a logarithmic scale, i.e. 10 points per decade (1 dB increments). All methods require the data S as input and need to calculate PαL over the entire α range for each L. For this, PαL can be determined with or without the constraint P ≥ 0 in Eq. (5), and we test both variants in all cases. Several methods require knowledge of the time-domain noise standard deviation, σ. The cost functions of a few methods are equipped with a tuning or scaling parameter that can be adjusted to increase stability.
The analysis procedure also requires the choice of a distance range and resolution for PαL. We use a range of 1.0 nm to 7.0 nm for all cases. These limits encompass the full ranges of all model distributions in the test set. The number of points in the distance domain, nr, is determined separately for each case and is set equal to the number of points in the time-domain trace, nt.
Since the goal of analyzing the time-domain data is to reveal the underlying model distribution, we base our performance evaluation of the various selection methods not on α (which is a nuisance parameter whose numerical value is physically irrelevant), but on the model recovery error defined in Eq. (8). It quantifies how close the calculated Tikhonov solution, PαL, for a given α and L is to the model distribution P0. This error is generally non-zero, since noise in the data and the fundamental ill-posedness of the problem prevent full recovery of the model from the data, no matter which α and L are used. As the actual performance measure, we use the inefficiency [43]
| (9) |
with . This measure relates the model recovery error for a given L and the particular α value chosen by a selection method to the smallest possible model recovery error, obtainable with αopt and Lopt. This error, and the associated optimal solution Popt are found by minimizing the mre as a function of α and L. The inefficiency equals 1 when PαL = Popt and is greater otherwise. The closer the inefficiency is to 1, the better the method.
5. Results and discussion
5.1 Histograms
Figure 5 shows an overview of the calculated inefficiencies for all 621030 time traces, 60 α selection methods, and three regularization operators. Each histogram shows the distribution of inefficiencies for a particular combination of method and operator. The methods are sorted by increasing 75th-percentile inefficiency from top left to bottom right. There is a wide range of performances. Most methods in the top row achieve low inefficiencies that are sharply peaked at 1. Methods shown lower down have a propensity towards worse inefficiencies. The high-inefficiency tails of the histograms are not shown, but are protracted in many cases, indicating a not insignificant failure rate for those methods. It is apparent from the histograms that the L0 operator, shown in blue, tends to perform worse than the others for the same method, except for some with overall bad performance. For most methods, L1 and L2 appear to give similar results.
Figure 5.
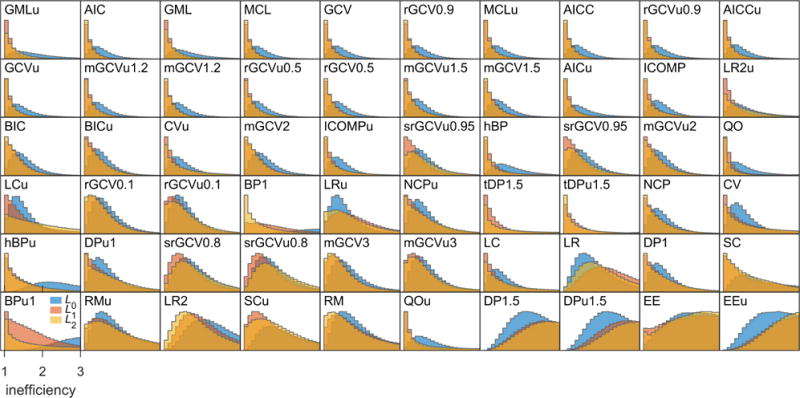
Inefficiency distributions for each α selection method (indicated by their acronyms) and regularization operator (color-coded). The panels are arranged from top left to bottom right in increasing order of lowest 75th-percentile inefficiency among L0, L1, and L2. For each histogram, only the part with inefficiency ≤ 3 is shown, and the often prolonged tails are not visible. The histograms are scaled such that the maxima in all panels are identical.
5.2 Performance comparison
To compare the method/operator combinations more quantitatively, we use the 99th percentile from each inefficiency histogram as the metric. This stringent choice is motivated by the consideration that a method/operator combination can be deemed good and safe if it delivers overall low inefficiencies with negligible risk of large inefficiencies (i.e. severe under- or over-smoothing). Figure 6 shows the results. There is a group of methods that perform similarly well, leading to small 99th-percentile inefficiencies just above 2. Mallows’ CL (MCL), the Akaike information criterion (AIC) and the generalized cross validation (GCV) perform equally well with L1 and L2, whereas the generalized maximum likelihood method and its unconstrained variant (GML and GMLu) perform well only with L1. L0 is the worst-performing operator for these top methods. The methods ranking below this top group are parameterized modifications of GCV and AIC. Since they are inferior to their parent methods, they can be disregarded. Currently, the most commonly applied α selection methods are based on the L-curve. The results show that the L-curve methods LC, LCu, LR, LRu, LR2, LR2u are not competitive with the top group. Their overall tendency is to oversmooth. Similarly, the SC and SCu methods display elevated inefficiency for DEER. The computational cost of all methods is essentially identical, since it is dominated by the solution of the Tikhonov minimization problem for each α.
Figure 6.
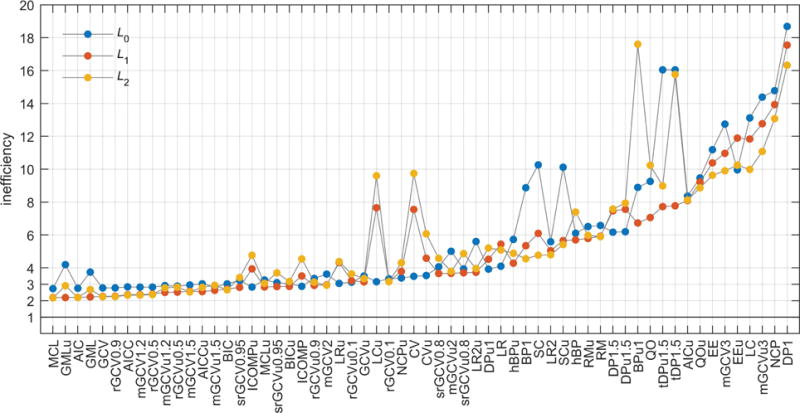
Performance comparison of all combinations of α selection methods and regularization operators, based on their 99th-percentile inefficiency. The methods are sorted based on best 99th-percentile inefficiency among L0, L1, and L2. The gray lines serves as guides to the eye.
5.3 Sensitivity to metric
The performance comparison shown in Fig. 6 is based on our particular choice of metric, the 99th percentile of the ratio of rmsds, defined in Eq. (9). Varying the percentile to 90, 75, or 50 does not significantly affect the composition of the top group, although it affects the detailed rankings (see SI). Altering the definition of inefficiency in Eq. (9) by using the difference instead of the ratio, or by using the maximum absolute deviation (mad) instead of the rmsd, yields similar results (see SI). Therefore, we conclude that the identity of the top methods is insensitive towards the particular choice of ranking metric, and that our assessment procedure is overall robust.
5.4 Sensitivity to data characteristics
To check for uneven performance for certain subsets of the test set, we examined the performance across noise level, the ratio of iqr to mode (a measure of the damping rate of oscillations in S), number of points, and number of modal periods, using the 99th percentile rmsd ratio inefficiency metric. The breakdowns are available in the SI. For all values of these variables, MCL, AIC, GCV, GML, and GMLu are usually within 5% of the optimal method/operator combination and never deviate by more than 11%. The specific rankings vary between subsets, but actual performance changes to such a small degree that this is not significant. The conclusions reached above regarding the three operators generalize to the subsets considered in the SI. In addition to poor performance relative to L1 and L2, L0 also displays much higher variation in performance across test subsets. Several variations on GCV (mGCV, mGCVu, rGCV, and rGCVu) with varied tuning parameter values, as well as AICC, come within 10% of the best case for many of the test subsets. However, none display sufficient consistency or quality of performance to surpass MCL, AIC, GCV, GML, or GMLu.
Since there is no correlation between the performance of any top method and these subset characteristics, the results are therefore likely to be applicable to situations with different relative representations of distance distribution characteristics, such as other spin labels or proteins with more β sheets than T4 lysozyme.
5.5 Method choice
The performance differences among the top method/operator combinations are so small that we cannot identify one as an evident best choice. However, additional considerations can provide some guidance. MCL requires the time-domain noise variance σ2 as an input. An under- or overestimation of σ2, which is likely in experimental settings, will affect the performance and likely degrade it. GML and GMLu depend on a thresholding value to remove eigenvalues close to zero, and the choice of this value can affect the performance. In contrast, AIC and GCV do not require a priori knowledge of σ2 nor do they depend on thresholding or tuning parameters. Therefore, the parameter-free AIC and GCV methods with either L1 or L2 appear to be the simplest, best, and safest choices for practical applications.
Due to the diversity of distribution shapes and time traces, and due to the wide range of inefficiencies, it is impossible to visualize method performances with a few sample datasets. Nevertheless, for the sake of illustration, Figure 7 shows the relative performance of LR2u, GCV, and AIC for a typical test dataset. This example is typical in these sense that the inefficiency of each method is very close to the method’s median inefficiency. The figure shows that the L-curve has a tendency to oversmooth, and that AIC and GCV perform similarly well. Fig. S1 in the Supplementary Material illustrates the uncertainty in the extracted P(r) based on these α selection methods, quantified using Bayesian inference [14].
Figure 7.
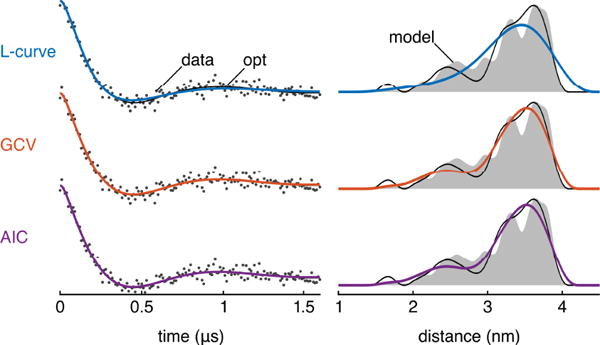
Example case comparing the LR2u L-curve, GCV, and AIC methods (dataset 115333). For this particular test case, each method features an inefficiency very close to that method’s overall median inefficiency (LR2u 1.38, GCV 1.09, AIC 1.09). Left column: the simulated data are shown as grey dots, the Tikhonov fit with optimum α is shown as a black line, and the Tikhonov fits for LR2u, GCV, and AIC are shown as blue, orange, and purple lines, respectively. Right column: the model P is shown in grey, the Tikhonov solution for P with optimum α is shown as a black line, and the Tikhonov Ps for LR2u, GCV, and AIC are shown as blue, orange, and purple lines, respectively. In all cases, the L2 operator was used.
6. Conclusions
Our performance analysis of a large number of regularization parameter selection methods over a large set of protein-based synthetic DEER data indicates that there are several method/operator combinations that perform equally well. Among these, the Akaike information criterion (AIC) and the generalized cross validation (GCV) are preferable, as they are parameter-free and do not require accurate knowledge of the noise level. They work equally well with the first- and second-derivative operator, but not with the identity. L-curve methods, some of which are currently widely employed, perform distinctly worse.
The structure-based test set developed in this work is useful beyond Tikhonov regularization, as it can be used to assess the performance of other existing analysis methods (truncated singular-value decomposition, Gaussian mixture models) and of any new solution approaches.
Supplementary Material
Acknowledgments
This work was supported by the National Science Foundation with grant CHE-1452967 (S.S.) and by the National Institutes of Health with grants R01 EY010329 (S.S.) and T32 GM008268 (T.H.E.). This work was further facilitated though the use of advanced computational, storage, and networking infrastructure provided by the Hyak super-computer system funded by the STF at the University of Washington.
Appendix A. Selection methods
Here, we summarize all α selection methods included in this study and give the expressions necessary to implement them. Further details about the methods can be found in the cited statistics literature.
Most methods are derived assuming an unconstrained Tikhonov regularization, i.e. without the P ≥ 0 constraint in Eq. (5). In this case, the solution PαL can be expressed in closed form as
| (10) |
For the physically relevant constrained problem (with P ≥ 0), a closed-form solution is not possible, and we obtain PαL via an iterative optimization algorithm [44]. In either case, once PαL is obtained, the time-domain fit is
| (11) |
We apply each method described below in two ways, one using the unconstrained solutions and one using the constrained solutions. The methods are referred to by short acronyms (see Table 1). A suffix ’u’ is appended to the method acronym when unconstrained PαL are used. In addition, if the method contains a tuning or scaling parameter, then its value is appended to the acronym as well.
L-Curve methods (LC, LR, LR2)
Several methods select α based on heuristic considerations about a parametric log-log plot of the Tikhonov penalty term, η = ‖LPαL‖, against the residual norm, ρ = ‖S − SαL‖, as a function of α [45, 46]. Such a plot shows a monotonically decaying η(ρ) and is called the L-curve since it tends to form a characteristic “L” shape with a visual corner. The optimal value for α is considered to correspond to this corner, since it intuitively represents a reasonable balance between the fitting error ρ and the regularization error η. The corner is not a mathematically defined quantity, therefore different operational definitions of locating this corner exist.
One of them is the maximum-curvature method (LC) [46]. It selects the α corresponding to the point of maximum (positive) curvature of the L-curve, given by
| (12) |
where , , and the primes indicate derivatives with respect to lg α or α. This method picks the global maximum of the curvature, even though there can be several local maxima.
Another possible definition of corner is the point closest to the lower left corner of the L-curve plot [45]. DeerAnalysis uses one implementation of this idea [7]. The two coordinates and are evaluated over a range of α values and then rescaled to the interval [0,1]. The corner is determined as the location on the L-curve that is closest to the origin in these rescaled coordinates:
| (13) |
The results from this method depend on the α range. We refer to this method as the minimum-radius method and use two variants of it. In the first one (LR), we use the same α range as for all other methods (10−3 to 103), and in the other one (LR2), we employ the same α range as DeerAnalysis2016. The latter extends from the largest generalized singular eigenvalue of K and L, smax, to a value csmax with c = 16ε · 106 ·· 2σ/0.0025, where ε ≈ 2.2 · 10−16 and σ is the noise level. In order to keep the range large enough, we limit c to ≤ 10−6.
Cross validation (CV, GCV, mGCVc, rGCVγ, srGCVγ)
We use several methods based on the idea of cross validation. Leave-one-out cross validation (CV) [47, 48] is conceptually the simplest of them. For a given α, it minimizes the total prediction error, which is obtained as the sum of the prediction errors for each individual data point. For that, a single data point is excluded and a fit to the remaining data is calculated. That fit is judged based upon its ability to reproduce the excluded data point. By repeating the method for each data point, the total prediction error is obtained, and the α value is selected that minimizes it. This procedure can be condensed into the following expression:
| (14) |
with the α-dependent influence matrix .
Generalized cross validation (GCV) [49, 50] is very similar to leave-one-out cross validation, but the diagonal matrix element HαL(i, i) in the denominator is replaced by the average of all diagonal elements, rendering the method more stable. The expression simplifies to
| (15) |
The modified GCV (mGCVc) [51, 52] method is a simple tunable modification to GCV intended to stabilize the method further.
| (16) |
with the tuning parameter c ≥ 1. We use this with c = 1.2, 1.5, 2, and 3, to test a range of stabilizations.
The robust GCV (rGCVγ) method [53, 54] is also designed to exhibit greater stability than the GCV method. It is given by
| (17) |
with the tuning parameter γ ≤ 1. With γ = 1, the method reduces to GCV. As γ gets smaller, the method becomes increasingly stable and less likely to undersmooth. We examine γ values of 0.1, 0.5, and 0.9, with increasing contributions from the second term.
Strong robust GCV (srGCVγ) [55] is another tunable modification to GCV that is based on stronger statistical arguments than rGCV. It selects α via
| (18) |
with γ ≥ 1. Like rGCV, with γ = 1, the method reduces to GCV. We use γ values of 0.8 and 0.95.
Quasi-optimality (QO)
This criterion, from Tikhonov and coworkers [56–58], selects α such that a small change in α from that selected value has minimal effects on the resulting PαL:
| (19) |
The underlying rationale is that the model recovery error is flat at its minimum.
Discrepancy principle (DPτ)
This principle [59–61] is predicated upon the idea that the root-mean-square residual, , should be on the order of the noise standard deviation in the data, σ. It requires a priori knowledge of σ. The value for α is selected as the largest value such that
| (20) |
where τ is a safety factor ≥ 1 to guard against under-smoothing in the case σ is underestimated. We use this principle with τ = 1 and 1.5.
The transformed discrepancy principle (tDPτ) [62–64] performs the comparison in the distance domain, choosing the largest α that satisfies
| (21) |
where . We use τ = 1.5.
Balancing principle (BP, hBP)
The balancing principle (BP) [65, 66] balances the propagated noise error with the unknown model recovery error. Using
| (22) |
and , it selects αsel as the largest α value that satisfies B(α) ≤ 1. The hardened balancing principle (hBP) [66] selects α using
| (23) |
Residual method (RM)
This method [43, 67] determines α by minimizing a scaled norm of the residual vector
| (24) |
where B = KT (I − HαL). The scaling penalizes under-smoothing.
Self-consistency method (SC)
This method [25, 26], utilized in FTIKREG, seeks to minimize the sum of the estimated model recovery error and the propagated data noise variance.
| (25) |
This expression is valid for the unconstrained case. In order to include the non-negativity constraint, further steps are necessary. First, αsel for the unconstrained case is determined. Next, the constrained solution is determined using this α value and the indices q of the active non-negativity constraints are stored. Finally, the columns of K and L with indices q are removed and Eq. (25) is re-evaluated.
Generalized maximum likelihood (GML)
This method [68] selects the α that maximizes the likelihood (or, equivalently, minimizes the negative log-likelihood) and is given by
| (26) |
where detnz(·) indicates the product of the non-zero eigen-values, and m is the their number. To account for numerical errors, we treat all eigenvalues with magnitude below 10−8 as zero.
Extrapolated error (EE)
This method [69–71] minimizes an estimate of the regularization error via
| (27) |
Normalized cumulative periodogram (NCP)
This method [72–74] is based on the idea that the power spectrum of the residuals should match the power spectrum of the noise. The unscaled power spectrum (periodogram) for a given α is a vector p with elements
| (28) |
where k = 1, …, nt, dft refers to the discrete Fourier transform. The normalized cumulative periodogram is an (nt − 1)-element vector c with elements
| (29) |
where ‖…‖1 is the ℓ1 norm (sum of absolute values). The zero-frequency component, p1, is omitted. c represents the integrated power spectrum of the residuals. The α value is selected that minimizes the deviation between c and the integrated power spectrum cnoise expected for the noise:
| (30) |
where cnoise is a (nt − 1)-element vector, with elements cnoise,i = i/(nt − 1) for white noise.
Mallows’ CL (MCL)
This method [75] minimizes an approximation to the model recovery error, derived under the assumption of unconstrained regularization and uncorrelated Gaussian noise.
| (31) |
This requires the knowledge of the noise level σ.
Information-theoretical criteria (AIC, AICC, BIC, ICOMP)
In the context of information theory [76, 77], the set of PαL is regarded as a set of candidate models, and criteria have been developed that select a parsimonious model that balances a small fitting error with a low model complexity. The general expression is
| (32) |
where the second term is a measure of model complexity, which decreases with increasing α. The term tr(HαL) can be regarded as the effective number of free parameters in the model. The constant c depends on the particular criterion: c = 2 for the Akaike information criterion (AIC) [78], c = 2nt/(nt − tr(HαL) −1) for the corrected AIC (AICC) [79, 80], and c = ln(nt) for the Bayesian information criterion (BIC) [81]. The information complexity criterion (ICOMP) [82, 83] is yet another information-theoretical procedure and is given by
| (33) |
where and are the arithmetic and geometric means of the singular values of (KTK + α2LTL)−1. The last term penalizes for interdependence among model parameters. In contrast to the other information-theoretical criteria, this one requires knowledge of the noise level σ.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Supplementary material
The online supplementary material contains (a) tables of relative performance based on different metrics and percentiles, including breakdowns into subsets based on data characteristics, (b) Bayesian uncertainty analysis for the test case in Fig. 7. The complete set of synthetic model distributions and test time-domain traces is freely available for download from the University of Washington ResearchWorks public repository at http://hdl.handle.net/1773/40984.
References
- 1.Milov AD, Salikhov KM, Shchirov MD. Application of the double resonance method to electron spin echo in a study of the spatial distribution of paramagnetic centers in solids. Fiz Tverd Tela. 1981;23:975–982. [Google Scholar]
- 2.Milov AD, Ponomarev AB, Tsvetkov YuD. Electron-electron double resonance in electron spin echo: Model biradical systems and the sensitized photolysis of decalin. Chem Phys Lett. 1984;110:67–72. [Google Scholar]
- 3.Larsen RG, Singel DJ. Double electron-electron resonance spin-echo modulation: Spectroscopic measurement of electron spin pair separations in orientationally disordered solids. J Chem Phys. 1993;98:5134–5146. [Google Scholar]
- 4.Bowman MK, Maryasov AG, Kim N, DeRose VJ. Visualization of distance distributions from pulse double electron-electron resonance data. Appl Magn Reson. 2004;26:23–39. [Google Scholar]
- 5.Jeschke G, Panek G, Godt A, Bender A, Paulsen H. Data analysis procedures for pulse ELDOR measurements of broad distance distributions. Appl Magn Reson. 2004;26:223–244. [Google Scholar]
- 6.Chiang Y-W, Borbat PB, Freed JH. The determination of pair distance distributions by pulsed ESR using Tikhonov regularization. J Magn Reson. 2005;172:279–295. doi: 10.1016/j.jmr.2004.10.012. [DOI] [PubMed] [Google Scholar]
- 7.Jeschke G, Chechik V, Ionita P, Godt A, Zimmermann H, Banjam J, Timmel CR, Hilger D, Jung H. DeerAnalysis2006: a comprehensive software package for analyzing pulsed ELDOR data. Appl Magn Reson. 2006;30:473–498. [Google Scholar]
- 8.Sen KI, Logan TM, Fajer PG. Protein dyanmics and monomer-monomer interactions in AntR activation by electron paramagnetic resonance and double electron-electron resonance. Biochemistry. 2007;46:11639–11649. doi: 10.1021/bi700859p. [DOI] [PubMed] [Google Scholar]
- 9.Brandon S, Beth AH, Hustedt EJ. The global analysis of DEER data. J Magn Reson. 2012;218:93–104. doi: 10.1016/j.jmr.2012.03.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Stein RA, Beth AH, Hustedt EJ. A straightforward approach to the analysis of Double Electron-Electron Resonance data. Methods Enzymol. 2015;563:531–567. doi: 10.1016/bs.mie.2015.07.031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Blackburn ME, Veloro AM, Fanucci GE. Monitoring inhibitor-induced conformational population shifts in HIV-1 protease by pulsed EPR spectroscopy. Biochemistry. 2009;48:8765–8767. doi: 10.1021/bi901201q. [DOI] [PubMed] [Google Scholar]
- 12.Casey TM, Fanucci GE. Spin labeling and Double Electron-Electron Resonance (DEER) to Deconstruct Conformational Ensembles of HIV Protease. Method Enzymol. 2015;564:153–187. doi: 10.1016/bs.mie.2015.07.019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Chiang Y-W, Borbat PP, Freed JH. Maximum entropy: A complement to Tikhonov regularization for determination of pair distance distributions by pulsed ESR. J Magn Reson. 2005;177:184–196. doi: 10.1016/j.jmr.2005.07.021. [DOI] [PubMed] [Google Scholar]
- 14.Edwards TH, Stoll SA. Bayesian approach to quantifying uncertainty from experimental noise in DEER spectroscopy. J Magn Reson. 2016;270:87–97. doi: 10.1016/j.jmr.2016.06.021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Dzuba SA. The determination of pair-distance distribution by double electron–electron resonance: regularization by the length of distance discretization with Monte Carlo calculations. J Magn Reson. 2016;269:113–119. doi: 10.1016/j.jmr.2016.06.001. [DOI] [PubMed] [Google Scholar]
- 16.Srivastava M, Georgieva ER, Freed JH. A New Wavelet Denoising Method for Experimental Time-Domain Signals: Pulse Dipolar Electron Spin Resonance. J Phys Chem A. 2017;121:2452–2465. doi: 10.1021/acs.jpca.7b00183. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Srivastava M, Freed JH. Singular Value Decomposition Method to determine Distance Distributions in Pulsed Dipolar Electron Spin Resonance. J Phys Chem Lett. 2017;8:5648–5655. doi: 10.1021/acs.jpclett.7b02379. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Kuprov I. Deep neural network processing of DEER data. The 50th Annual International Meeting of the Electron Spin Resonance Group of the Royal Society of Chemistry. 2017 [Google Scholar]
- 19.Schäfer H, Mäder B, Volke F. De-Pake-ing of NMR powder spectra by nonnegative least-squares analysis with Tikhonov regularization. J Magn Reson A. 1995;116:145–149. [Google Scholar]
- 20.Vogt FG, Aurentz DJ, Mueller KT. Determination of internuclear distances from solid-state nuclear magnetic resonance: Dipolar transforms and regularization methods. Mol Phys. 1998;95:907–919. [Google Scholar]
- 21.Schäfer H, Mädler B, Sternin E. Determination of Orientational Order Parameters from 2H NMR Spectra of Magnetically Partially Oriented Lipid Bilayers. Biophys J. 1998;74:1007–1014. doi: 10.1016/S0006-3495(98)74025-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Winterhalter J, Maier D, Grabowski DA, Honerkamp J. Determination of orientational distributions from 2H NMR data by a regularization method. J Chem Phys. 1999;110:4035–4046. [Google Scholar]
- 23.Schäfer H, Sternin E. Inverse ill-posed problems in experimental data analysis in physics. Phys Can. 1997;53:77–85. [Google Scholar]
- 24.Sternin E. Use of Inverse Theory Algorithms in the Analysis of Biomembrane NMR Data. Method Mol Bio. 2007;400:103–125. doi: 10.1007/978-1-59745-519-0_8. [DOI] [PubMed] [Google Scholar]
- 25.Honerkamp J, Weese J. Tikhonovs regularization method for ill-posed problems. Continuum Mech Thermodyn. 1990;2:17–30. [Google Scholar]
- 26.Weese J. A reliable and fast method for the solution of Fredholm integral equations of the first kind based on Tikhonov regularization. Comput Phys Commun. 1992;69:99–111. [Google Scholar]
- 27.Jeschke G, Koch A, Jonas U, Godt A. Direct Conversion of EPR Dipolar Time Evolution Data to Distance Distributions. J Magn Reson. 2002;155:72–82. doi: 10.1006/jmre.2001.2498. [DOI] [PubMed] [Google Scholar]
- 28.Jeschke G. Distance Measurements in the Nanometer Range by Pulse EPR. Chem Phys Chem. 2002;3:927–932. doi: 10.1002/1439-7641(20021115)3:11<927::AID-CPHC927>3.0.CO;2-Q. [DOI] [PubMed] [Google Scholar]
- 29.Mchaourab HS, Kálai T, Hideg K, Hubbell WL. Motion of spin-labeled side chains in T4 lysozyme: Effect of side chain structure. Biochemistry. 1999;38:2947–2955. doi: 10.1021/bi9826310. [DOI] [PubMed] [Google Scholar]
- 30.Langen R, Oh KJ, Cascio D, Hubbell WL. Crystal structures of spin labeled T4 lysozyme mutants: Implications for the interpretation of EPR spectra in terms of structure. Biochemistry. 2000;39:8396–8405. doi: 10.1021/bi000604f. [DOI] [PubMed] [Google Scholar]
- 31.Columbus L, Kálai T, Jekö J, Hideg K, Hubbell WL. Molecular motion of spin labeled side chains in α-helices: Analysis by variation of side chain structure. Biochemistry. 2001;40:3828–3846. doi: 10.1021/bi002645h. [DOI] [PubMed] [Google Scholar]
- 32.Liang Z, Lou Y, Freed JH, Columbus L, Hubbell WL. A multifrequency electron spin resonance study of T4 lysozyme dynamics using the slowly relaxing local structure model. J Phys Chem B. 2004;108:17649–17659. [Google Scholar]
- 33.Jacobsen K, Oga S, Hubbell WL, Risse T. Determination of the orientation of T4 lysozyme vectorially bound to a planar-supported lipid bilayer using site-directed spin labeling. Biophys J. 2005;88:4351–4365. doi: 10.1529/biophysj.105.059725. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Altenbach C, Froncisz W, Hemker R, Mchaourab H, Hubbell WL. Accessibility of nitroxide side chains: Absolute Heisenberg exchange rates from power saturation EPR. Biophys J. 2005;89:2103–2112. doi: 10.1529/biophysj.105.059063. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Pyka J, Ilnicki J, Altenbach C, Hubbell WL, Froncisz W. Accessibility and dynamics of nitroxide side chains in T4 lysozyme measured by saturation recovery EPR. Biophys J. 2005;89:2059–2068. doi: 10.1529/biophysj.105.059055. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Lopez CJ, Yang Z, Altenbach C, Hubbell WL. Conformational selection and adaptation to ligand binding in T4 lysozyme cavity mutants. Proc Natl Acad Sci USA. 2013;110:E4306–E4315. doi: 10.1073/pnas.1318754110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Lerch MT, López CJ, Yang Z, Kreitman MJ, Horwitz J, Hubbell WL. Structure-relaxation mechanism for the response of T4 lysozyme cavity mutants to hydrostatic pressure. Proc Natl Acad Sci USA. 2015;112:E2437–E2446. doi: 10.1073/pnas.1506505112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Polyhach Y, Bordignon E, Jeschke G. Rotamer libraries of spin labelled cysteines for protein studies. Phys Chem Chem Phys. 2011;13:2356–2366. doi: 10.1039/c0cp01865a. [DOI] [PubMed] [Google Scholar]
- 39.Polyhach Y, Jeschke G. Prediction of favourable sites for spin labelling of proteins. Spectrosc Int J. 2010;24:651–659. [Google Scholar]
- 40.Jeschke G. MMM: A toolbox for integrative structure modeling. Prot Sci. 2018;27:76–85. doi: 10.1002/pro.3269. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Kaipio J, Somersalo E. Statistical and Computational Inverse Problems. Springer; 2005. [Google Scholar]
- 42.Kaipio J, Somersalo E. Statistical inverse problems: Discretization, model reduction and inverse crimes. J Comput Appl Math. 2007;198:493–504. [Google Scholar]
- 43.Bauer F, Lukas MA. Comparing parameter choice methods for regularization of ill-posed problems. Math Comput Simulat. 2011;81:1795–1841. [Google Scholar]
- 44.Bro R, de Jong S. A fast non-negativity-constrained least squares algorithm. J Chemometr. 1997;11:393–401. [Google Scholar]
- 45.Hansen PC, O’Leary DP. The use of the L-curve in the regularization of discrete ill-posed problems. SIAM J Sci Comp. 1993;14:1487–1503. [Google Scholar]
- 46.Hansen PC. The L-Curve and its use in the numerical treatment of inverse problems. In: Johnston P, editor. Advances in Computational Bioengineering: Computational Inverse Problems in Electrocardiology. WIT Press; 2000. pp. 119–142. [Google Scholar]
- 47.Wahba G. Spline Models for Observational Data. SIAM; 2007. [Google Scholar]
- 48.Hansen PC. Discrete Inverse Problems: Insight and Algorithms. SIAM; 2010. [Google Scholar]
- 49.Wahba G. Practical approximate solutions to linear operator equations when the data are noisy. SIAM J Numer Anal. 1977;14:651–667. [Google Scholar]
- 50.Golub GH, Heath M, Wahba G. Generalized cross-validation as a method for choosing a good ridge parameter. Technometrics. 1979;21:215–223. [Google Scholar]
- 51.Cummins DJ, Filloon TG, Nychka D. Confidence intervals for nonparametric curve estimates: toward more uniform pointwise coverage. J Am Stat Assoc. 2001;96:233–246. [Google Scholar]
- 52.Vio R, Ma P, Zhong W, Nagy J, Tenorio L, Wamsteker W. Estimation of regularization parameters in multiple-image deblur-ring. Astron Astrophys. 2004;423:1179–1186. [Google Scholar]
- 53.Lukas MA. Robust generalized cross-validation for choosing the regularization parameter. Inverse Probl. 2006;22:1883–1902. [Google Scholar]
- 54.Robinson T, Moyeed R. Making robust the cross-validatory choice of smoothing parameter in spline smoothing regression. Stat Theory Methods. 1989;18:523–539. [Google Scholar]
- 55.Lukas MA. Strong robust generalized cross-validation for choosing the regularization parameter. Inverse Probl. 2008;24 [Google Scholar]
- 56.Tikhonov A, Glasko V. Use of the regularization method in non-linear problems. USSR Comput Math Math Phys. 1965;5:93–107. [Google Scholar]
- 57.Tikhonov A, Arsenin V. Solutions of Ill-Posed Problems. Wiley; New York: 1977. [Google Scholar]
- 58.Hofmann B. Regularization of Applied Inverse and Ill-Posed Problems. Teubner; Leipzig: 1986. [Google Scholar]
- 59.Phillips DL. A technique for the numerical solution of certain integral equations of the first kind. J Assoc Comput Mach. 1962;9:84–97. [Google Scholar]
- 60.Morozov VA. On the solution of functional equations by the method of regularization. Soviet Math Dokl. 1966;7:414–417. [Google Scholar]
- 61.Morozov VA. Methods for Solving Incorrectly Posed Problems. Springer-Verlag; New York: 1984. [Google Scholar]
- 62.Raus T. An a posteriori choice of the regularization parameter in case of approximately given error bound of data. Acta et Comment Univ Tartuensis. 1990;913:73–87. [Google Scholar]
- 63.Raus T. About regularization parameter choice in case of approximately given error bounds of data. Acta et Comment Univ Tartuensis. 1992;937:77–89. [Google Scholar]
- 64.Hämarik U, Raus T. On the choice of the regularization parameter in ill-posed problems with approximately given noise level of data. J Inverse Ill-Posed Probl. 2006;14:251–266. [Google Scholar]
- 65.Lepskij O. On a problem of adaptive estimation in gaussian white noise. Theor Probab Appl. 1990;35:454–466. [Google Scholar]
- 66.Bauer F. Some considerations concerning regularization and parameter choice algorithms. Inverse Probl. 2007;23:837–858. [Google Scholar]
- 67.Bauer F, Mathé P. Parameter choice methods using minimization schemes. J Complexity. 2011;27:68–85. [Google Scholar]
- 68.Wahba G. A comparison of gcv and gml for choosing the smoothing parameter in the generalized spline smoothing problem. Ann Stat. 1985;13:1378–1402. [Google Scholar]
- 69.Auchmuty G. A posteriori error estimates for linear equations. Numer Math. 1992;61:1–6. [Google Scholar]
- 70.Brezinski C, Rodriguez G, Seatzu S. Error estimates for linear systems with applications to regularization. Numer Algorithms. 2008;49:85–104. [Google Scholar]
- 71.Brezinski C, Rodriguez G, Seatzu S. Error estimates for the regularization of least squares problems. Numer Algorithms. 2009;51:61–76. [Google Scholar]
- 72.Hansen PC, Kilmer ME, Kjeldsen RH. Exploiting residual information in the parameter choice for discrete ill-posed problems. BIT. 2006;46:41–59. [Google Scholar]
- 73.Rust BW. Parameter selection for constrained solutions to ill-posed problems. Comput Sci Stat. 2000;32:333–347. [Google Scholar]
- 74.Rust BW, O’Leary DP. Residual periodograms for choosing regularization parameters for ill-posed problems. Inverse Probl. 2008;24:034005. [Google Scholar]
- 75.Mallows CL. Some comments on CP. Technometrics. 1973;15:1–6. [Google Scholar]
- 76.Burnham KP, Anderson DR. Model Selection and Multimodel Inference. Springer; 2002. [Google Scholar]
- 77.Zhang Y, Li R, Tsai C-L. Regularization parameter selections via generalized information criterion. J Am Stat Assoc. 2010;105:312–323. doi: 10.1198/jasa.2009.tm08013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Akaike H. A new look at the statistical model identification. IEEE T Automat Contr. 1974;19:716–723. [Google Scholar]
- 79.Sugiura N. Further analysis of the data by Akaike’s information criterion and the finite corrections. Commun Stat Theor M. 1978;A7:13–26. [Google Scholar]
- 80.Hurvich CM, Tsai C-L. Regression and time series model selection in small samples. Biometrika. 1989;76:297–307. [Google Scholar]
- 81.Schwarz G. Estimating the dimension of a model. Ann Stat. 1978;6:461–464. [Google Scholar]
- 82.Bozgodan H. Akaike’s information criterion and recent developments in information complexity. J Math Psychol. 2000;44:62–91. doi: 10.1006/jmps.1999.1277. [DOI] [PubMed] [Google Scholar]
- 83.Urmanov AM, Gribok AV, Bozdogan H, Hines JW, Uhrig RE. Information complexity-based regularization parameter selection for solution of ill conditioned inverse problems. Inverse Probl. 2002;18:L1–L9. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.