

Abstract
The advent of the digital pathology has introduced new avenues of diagnostic medicine. Among them, crowdsourcing has attracted researchers’ attention in the recent years, allowing them to engage thousands of untrained individuals in research and diagnosis. While there exist several articles in this regard, prior works have not collectively documented them. We, therefore, aim to review the applications of crowdsourcing in human pathology in a semi-systematic manner. We first, introduce a novel method to do a systematic search of the literature. Utilizing this method, we, then, collect hundreds of articles and screen them against a predefined set of criteria. Furthermore, we crowdsource part of the screening process, to examine another potential application of crowdsourcing. Finally, we review the selected articles and characterize the prior uses of crowdsourcing in pathology.
Keywords: Citizen science, crowdsourcing, pathology, systematic search
INTRODUCTION
In 2006, the term “crowdsourcing” was coined by Howe[1] to describe an open call for outsourcing tasks, usually done by an employee or an agent, to a large group of people. Although this term was introduced only a decade ago, the concept was utilized centuries ago in 1714, when the Britain's Parliament offered a prize in the form of an open call to find a method to identify the longitudinal position of a ship.[2] The advent of the Internet and prevalence of mobile devices provided a convenient channel for reaching out the crowd and recruiting participants and boosted the growth of crowdsourcing applications. Today, the term crowdsourcing is usually used for only online open calls, and several platforms exist which offer services for this purpose. In this paper, we review the articles which have used crowdsourcing in a human pathology related study.
Crowdsourcing is now in widespread use, covering a varied domain of studies from classifying galaxies,[3] to increase situational awareness for disaster response and recovery.[4] Applications of crowdsourcing are not limited to controlled researches, for example, the Ushahidi-Haiti project (i.e., Mission “4636”) gathered more than 80,000 text messages from on-site users regarding the local situation and needs after the 2010 Haiti earthquake. A large number of these texts were translated into English using a crowdsourcing approach and were sent to the first responders to perform emergency activities.[5]
Health research and medical science have increasingly utilized crowdsourcing in the recent years. In 2013, Ranard et al.[6] reviewed the applications of crowdsourcing in the health research. They identified four types of crowdsourcing tasks in the reviewed articles: problem-solving, data processing, monitoring, and surveying. They concluded that crowdsourcing could effectively improve the quality, decrease the cost, and increase the speed of a project. They also discussed that current efforts lack a standardized guideline to collected well-defined metrics, which hurts the clarity and comparability of methodologies.
Good and Su,[7] explored the bioinformatics community and studied how crowdsourcing is utilized in different contexts. They divided crowdsourcing tasks into two major groups: microtasks, and megatasks. They classified methods found in the literature for crowdsourcing microtasks by the incentives used to recruit the participants: altruism for volunteers (i.e., citizen scientists), fun in casual games (i.e., games with a purpose[8]), money in commercial platforms (e.g., Amazon mechanical turk [AMT]), obligation in workflow sequestration (e.g., ReCAPTCHA[9]), and learning in education (i.e., incorporating crowdsourcing in the curriculum of courses[10]). Regarding megatasks, authors mentioned two possible forms: hard games (e.g., Foldit[11] and EteRNA[12]), and open innovation contests (e.g., DREAM challenges[13]). They distinguish casual games and hard games according to the incentive for the gamers, which is engagement in repetitive tasks (referred as “grinding”) for casual games, and engagement with a difficult challenge in hard games.
The rich literature regarding applications of crowdsourcing in health and medical sciences indicates that it is a promising tool for researchers. However, each field of medicine has its unique requirements, limitations, and opportunities. In this study, we aim to review the applications of crowdsourcing only in pathology. We define a method to conduct a systematic search of the literature and then filter the articles step by step like the recommended procedure in a systematic review.
BACKGROUND
A 60% drop in academic pathology in the UK between 2000 and 2012,[14] and a predicted 35% drop in the ratio of pathologists to the population in the US between 2010 and 2030[15] are evidence that pathology is facing a severe lack of workforce resources.[14] Automated methods and machine learning are promising methods to automate routine scoring and evaluations[16,17,18,19,20] However, reducing the workload for pathologists, and development and training of these methods require a large amount of validated datasets which are currently not widely available.[14] Crowdsourcing, not only may generate the required data for training these algorithms but also can be effectively used to outsource tedious but relatively simple tasks to the crowd, especially in low-resourced areas. For instance, a pathologist is required to check 1000 of red blood cell (RBC) images for an accurate malaria diagnosis. This becomes a severe bottleneck because majority of malaria cases are reported in low-resourced locations, such as in Africa.[21] Crowdsourcing can be used to filter out most of the RBC images (i.e., those which are obviously clean/infected) and leave the experts with a handful of images to make a final diagnosis. Crowdsourcing can also be helpful in pathology research, where thousands of tissue samples should be scored. In this case, since the results do not directly affect patients, researchers can tolerate a higher but known level of error introduced by the crowd and consider it in their results.
In 2013, Ranard et al.[6] performed a systematic review on three major literature search engines, namely PubMed, Embase, and CINAHL, exploring the applications of crowdsourcing in health research. At that time, they found only 21 articles meeting their criteria, which was surprisingly small. Among the selected articles, only three were classified as pathology related researches. Inspired by this prior work, we aim to review applications of crowdsourcing specifically in human pathology. Since the prior review in 2013, encompassed pathology research, our review is beneficial only if there is substantial number of relevant articles published after 2013. To assess this issue, we searched the mentioned three search engines using the same Boolean expression as Ranard et al. and inspected the number of returned results over time. Figure 1 shows that the cumulative number of articles returned from search engines for the Boolean expression used by Ranard et al. has experienced exponential growth. Results show that 1126, 1105, and 112 were returned from PubMed, Embase, and CINAHL, respectively, in 2016, compared to only 265, 343, and 36 in 2013. This almost three-fold increase clearly necessitates conducting a new review on this subject. However, to limit our scope of review, we only consider pathology related articles from the broader health and medicine research topic.
Figure 1.
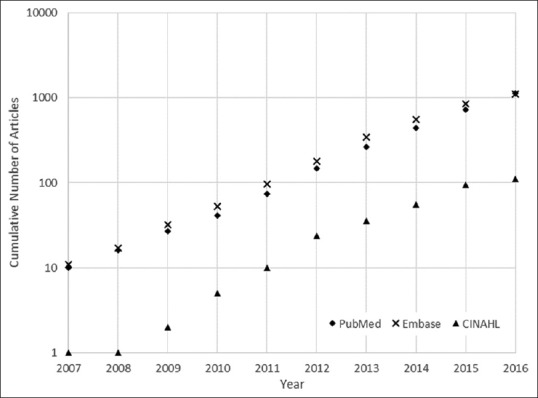
Cumulative number of articles returned from different search engines for Boolean expression used in Ranard et al[6] for crowdsourcing and citizen science research
METHODOLOGY
Definitions
Crowdsourcing
We define crowdsourcing as an online open call to outsource a defined task to the crowd. Our definition, therefore, excludes surveying the crowd for information about themselves (e.g., their own general health) and experts soliciting opinions from other experts. We also exclude competitions and challenges, where participants are most likely teams of experts. It should be noted that our definition suits the purpose of this review and is not recommended to be used otherwise.
Pathology
We define pathology according to its MeSH term definition: “A specialty concerned with the nature and cause of disease as expressed by changes in cellular or tissue structure and function caused by the disease process.[22]” Furthermore, we only consider articles related to human pathology.
Search strategy
Following Ranard et al.,[6] we decided to search PubMed, Embase, and CINAHL for the relevant literature. To perform a systematic search, we needed to carefully construct a Boolean expression which would return articles likely to be related to both crowdsourcing and pathology. To find literature related to crowdsourcing we use the same Boolean string defined by Ranard et al.:
cr_expression = ‘crowdsourc* OR “crowd source” OR “crowd sourcing” OR “crowd sourced” OR “citizen science” OR “citizen scientist” OR “citizen scientists”’ Equation (1)
However, to find the results related to pathology, we used a more rigorous approach to define a Boolean expression. It is important to note that adding “OR (pathology)” to cr_expression from Equation 1, is not sufficient, as there might be crowdsourcing papers which are closely related to the field of pathology but the term “pathology” does not appear in their abstracts or titles. Therefore, we expand our Boolean expression by adding terms which their inclusion in an article is likely to be an indication of relevance to pathology.
Let's define P (pathology | w), as the probability that a document containing word w is related to pathology. We want to rank all the candidate words per this value and include those with relatively higher ranks in our search Boolean. To calculate this probability for each a word, using the Bayes’ theorem is helpful:
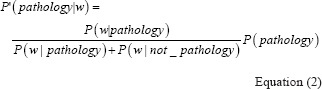
Where P (w|pathology) is the probability that w exists in an article related to pathology, P (w|not_pathology) is the probability that w exists in an article not related to pathology, and P (pathology) is the probability that a given article is related to pathology. Since P (pathology) is constant for all the candidate words, its value does not change our ranking, and therefore we drop this value and define P'(pathology | w) as:
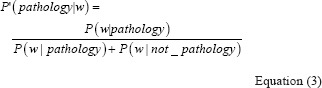
We need text corpuses of article abstracts to extract a set of candidate words and calculate the probabilities in Equation 3 for this set. Let's call the text corpus of pathology related articles as the P-Corpus, and the corpus containing articles not related to pathology as the N-Corpus. With this definition, we have:
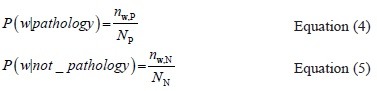
Where nw, P and nw, N are the number of documents containing w in the P-Corpus and N-Corpus, respectively. Np and NN are the total numbers of documents in the P-Corpus and N-Corpus, respectively. We can now select the top n words with larger values of P'(pathology | wi) and construct a Boolean expression for searching pathology related articles as:
p_expression = ‘w1 OR w2 OR w3 OR … wn’ Equation (6)
To limit our results to those articles which meet the conditions imposed by both cr_expression and p_expression we combine them with an AND:
final_expression = (cr_expression) AND (p_expression) Equation (7)
We used final_expression as defined by Equation 7 for our searches in PubMed, Embase, and CINAHL.
Selection criteria
Articles returned for the constructed Boolean expression were included in our review only if they met all the conditions defined below:
Majorly written in English
Representing a primary research (i.e., not a review paper, editorial note, etc.)
Published in a peer-reviewed journal
Not a duplicate article
Related to human pathology
Using crowdsourcing as part of the study.
Excluded papers therefore were, those not meeting at least one of the criteria mentioned above, those which were falsely filtered out (false negatives), those which did not contain any of the keywords used in our Boolean expression in the title or abstract.
Literature informed search
As the final step in our search strategy, we performed a literature informed search, based on the articles which met our selection criteria. In this step, we reviewed the references of each selected article, articles authored by the first author of a selected article, and articles cited a selected article. We then included those which met our selection criteria in this study.
Extracted information
We reviewed articles which passed our multi-stage screening and extracted following information from each one: Research field, study objective, study outcome, crowdsourced task, length of crowdsourcing, whether a tutorial was used, crowdsourcing platform, task load per participant, recruiting and advertisement channel, whether a monetary incentive was used, data validation and performance assessment technique, whether a screening step was included, total task size, crowd size, crowd age, and crowd geographic location. We also looked for other crowd demographics such as ethnicity, language, and education. However, none of the selected articles included this information.
RESULTS
Search terms selection
We developed Python tools to implement the search strategy explained in the previous sections. We utilized the Entrez Programming Utilities to query PubMed and build our two corpuses. To build our P-Corpus, we downloaded all the 172,723 abstracts published in 2016 and returned from PubMed for the search term “pathology.” To build the N-Corpus, we needed to query PubMed and download the abstracts which do not contain the word “pathology.” However, since at least one inclusive word should be present in the PubMed search Boolean, we added the generic term “university” to our expression and used “university NOT (pathology)” as the Boolean search term. Furthermore, we downloaded only the first 1000 results returned for each month in 2016, in this case. This strategy avoided downloading an unnecessarily large number of articles and ensured that we have a uniform sample of abstracts over the year. We made a text corpus of these 12,000 abstracts and used it as our N-Corpus.
Before calculating the probability values, we removed all the stop-words for the English language present in the Natural Language Toolkit Python package from both corpuses. Stop-words are the most common words in a language (e.g., “the,” “at,” “is,” etc., for English). These words are often removed in some natural language processing techniques (e.g., bag-of-words) as their presence in a text document usually do not give us any useful information. The probability of finding a stop-word in a document is almost certain, and therefore the information conveyed, but this presence is close to zero. Since our final goal was deriving search terms, we did not use stemming. Stemming is a process where words are reduced to their word stem or root. For example, words such as “pathology,” “pathologies,” and “pathological” can all be reduced to a common root such as “patholog.” We did not find this technique to be useful for our purpose.
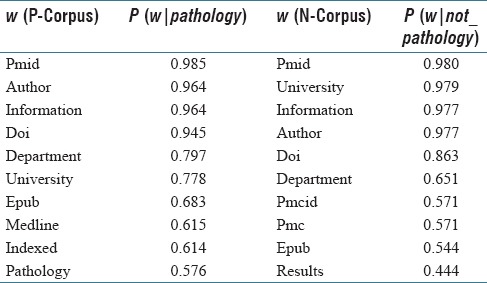
We calculated the probability values for 403,929 words found in the P-Corpus and 96,675 words found in the N-Corpus. Table 1 shows the top 15 words and the values of P (w|pathology) or P (w|not_pathology) for them. As can be seen, the most frequent words in each corpus, are not informative. This is expected according to the definition of P (w|pathology) or P (w|not_pathology). However, we will show that ranking words per their P (pathology | w) values results in a meaningful set of words.
Table 1.
Ten most probable words in P-Corpus and N-Corpus
We filtered out all the words with P (w|pathology) <0.05 and considered the rest of the words in the P-Corpus as the candidate words (434 words in total). We then, calculated the value of P (pathology | w) for these candidates and included those with P (pathology | w) >0.70 in our set of “pathology related words.” This resulted in 61 words. However, we reviewed these words and manually removed 18 words, which we believed are not closely enough related to pathology, despite ranking high by our methodology (e.g., “diagnostic,” “therapeutic,” “expression,” etc.). We also removed five plural words “cells,” “tumors,” “tissues,” “genes,” and “mice” and only kept their singular forms. Table 2 shows the final 38 pathology related words that we included in our Boolean search. We constructed our p_expression using the words given in this table. Figure 2 illustrates this set in a words cloud.
Table 2.
Selected set of pathology related words
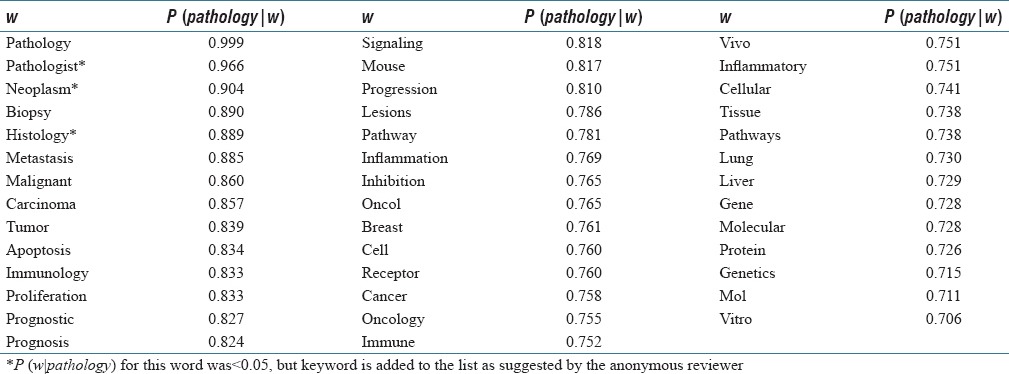
Figure 2.

Word cloud of the pathology related words. Size of each world shows how likely it will return a pathology related article
Search results
We searched PubMed, Embase, and CINAHL on April 14, 2017, using our Boolean search string, final_expression, as defined by Equation 7. This resulted in collecting 726 articles, which were reduced to 487 after removing the duplicates. We then performed a multi-stage screening to identify those articles which met our selection criteria. In the first step, we removed nonprimary articles (i.e., abstracts, editorials, reviews, etc.), articles in other languages, and those which were obviously not pathology or health-related. The first screening step left 129 articles in our cohort.
In the second step, we crowdsourced the review process through an online platform (Qualtrics.com). A simple question was asked like: “Is this article related to human pathology: A crowd-sourcing approach for the construction of …? (1) Yes, (2) Not Sure, (3) No.” The title of the article was hyperlinked to the abstract of the paper on the publisher's website. Questions were presented to the participants in a random order. We placed a screening question in the beginning of the experiment: “Are you a medical doctor/student? (1) Yes, (2) No”, and only the participants who answered “Yes” were able to continue. A second question asked if the participant is a pathologist or a pathology resident. Those who reviewed more than 15 papers, were promised to be acknowledged in our paper. All participants agreed to use their answers in this study.
We recruited participants through social media namely Facebook, LinkedIn and Twitter. The experiment was live during May 2017. A total of 31 participants passed our screening question, and 4 participants claimed to be pathologists/pathology residents. The maximum and minimum numbers of the reviewed article per participant were 105 and 1, respectively. A total number of 640 answers were collected, where 244, 116, and 280 answers were “Yes,” “Not Sure,” and “No,” respectively. We ignored “Not Sure” answers, as if the participant did not see the corresponding question. The maximum number of collected answers for a single article was 8 and the minimum number was 2. There were 5 articles with only 2 answers: A “Yes” and a “No.” We directly included them in the next screening stage for further review, as it was not possible to derive a conclusion based on the crowdsourcing results in those cases. A total of 68 articles with 50% or more “Yes” answers qualified to the next stage. We finally, added 10 articles to the final screening stage, for which there were <50% of “Yes” answers, but at least 1 pathologist has marked the articles as related to pathology. Therefore, a total number of 83 articles passed our crowdsourcing screening stage.
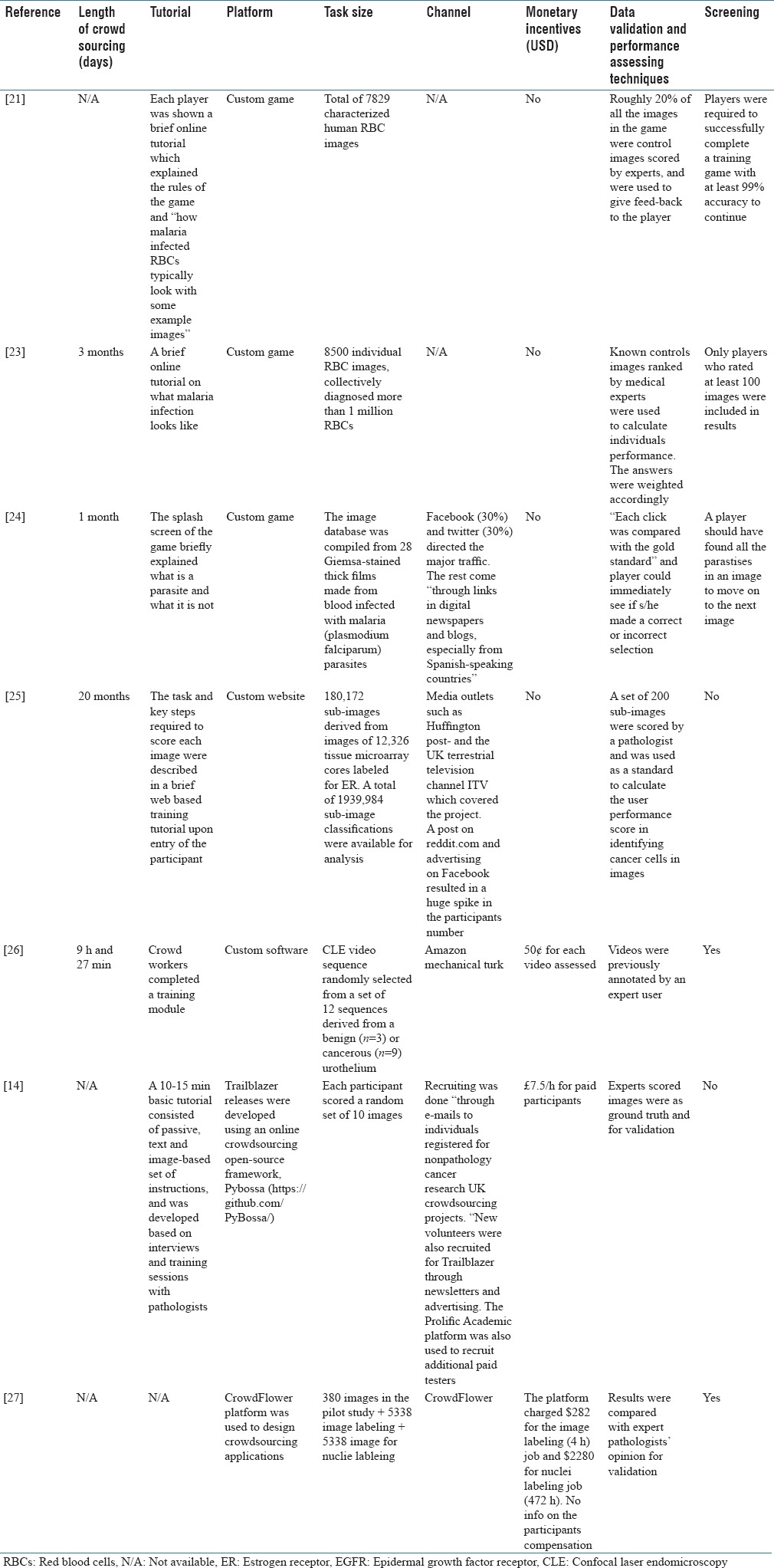
In the final screening step, we read the full texts of 83 remaining articles to select those which met our selection criteria. The focus in this step was identifying articles which use crowdsourcing as defined in our study and are related to human pathology. Only six articles met all our selection criteria at the end. The literature informed searched added one more article to this set. Figure 3 shows the selection flow in a Sankey diagram (Sankey Diagram Generator by Dénes Csala, based on the Sankey plugin for D3 by Mike Bostock; https://sankey.csaladen.es; 2014). We reviewed the final seven articles,[14,21,23,24,25,26,27] and extracted their information which is discussed in the next section.
Figure 3.
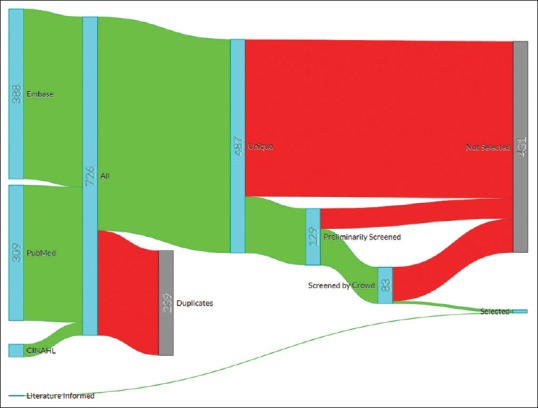
Sankey diagram of the selection flow. Red represents “filtered out” flow and green represents “filtered in” flow
Reviewed articles
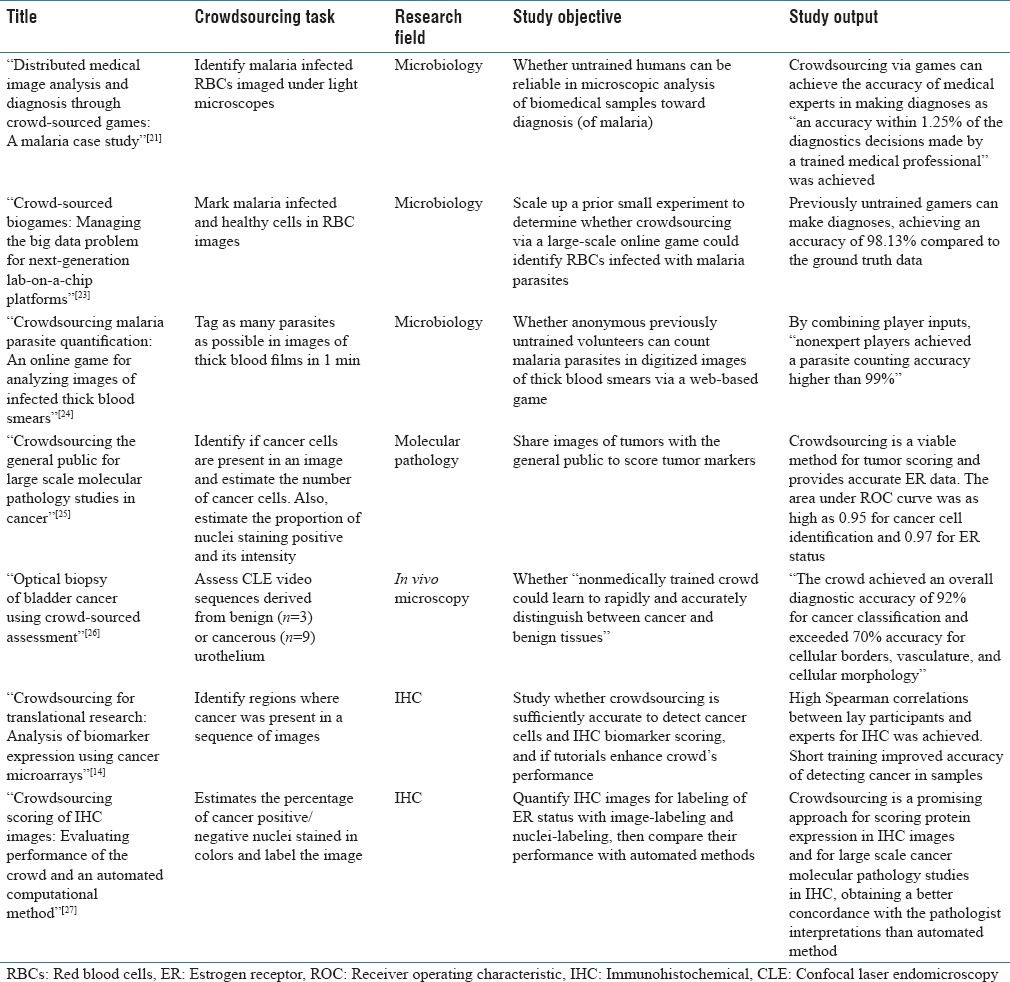
The crowdsourced task in all the articles in our cohort was image analysis. Among the selected seven articles, three were related to malaria diagnoses,[21,23,24] and four to cancer diagnoses.[14,25,26,27] Four topics were covered by the articles: microbiology, immunohistochemistry (IHC), molecular pathology, and in-vivo microscopy. Table 3 summarizes the scope of each article.
Table 3.
Articles summary
Microbiology
Three of seven articles were classified under the topic microbiology.[21,23,24] All three articles were related to malaria diagnosis in RBC images and all used a custom game as the crowdsourcing platform. Mavandadi et al.[21] designed a game to let untrained gamers identify malaria-infected RBCs in images under light microscopes. They demonstrated with 31 of participants that crowdsourcing through games can achieve the accuracy of medical experts in making diagnoses. Later, they scaled up their experiment[23] with over 2000 of untrained gamers and achieved the same conclusion as before. In an independent experiment, Luengo-Oroz et al.[24] tested whether untrained volunteers can count malaria parasites in digitized images of thick blood smears. They conducted experiment through a Web-based game and over 6000 participants, concluding that nonexpert players may achieve an accuracy higher than 99% in a parasite counting.
Molecular pathology
Molecular pathology covered only one article.[25] Authors in this study let the public score tumor images and concluded that crowdsourcing is a viable method for tumor scoring. They also shared their complete data set under the creative commons license[28] which can be invaluable for other researchers to conduct further research on the results.
In-vivo microscopy
One of the articles[26] was a crowdsourcing research on the relatively new field of in-vivo microscopy. The researchers in this article studied whether untrained crowd could rapidly be trained to accurately distinguish between cancer and benign tissues. They achieved a high level of diagnostic accuracy, validating they hypothesis.
Immunohistochemistry
IHC was the main topic of two papers. In the first article,[14] researchers showed that crowdsourcing is sufficiently accurate to detect cancer cells and IHC biomarker scoring. In the second article,[27] authors found crowdsourcing as a promising approach for scoring protein expression in IHC images and for large-scale cancer molecular pathology studies in IHC. They further compared the results achieved by crowdsourcing to automated methods and showed that using crowdsourcing obtains a better concordance with the pathologist interpretations.
Logistics of crowdsourcing
Four articles reported the length of active crowdsourcing period which ranged from 9.5 h[26] to 20 months.[25] Six articles reported having a tutorial to train the participants on the subject before performing the required task. One article specifically studied the effect of tutorial on the performance of the crowd and reported an increase in the accuracy of detecting cancer in images.[14] Three articles used custom games to gamify the crowdsourcing process, and the rest designed a website using open source or commercial frameworks.
Five articles reported the method of recruiting, where CrowdFlower and AMT each were used in one article. Two studies used the newsletter, blogs, and social media (e.g., Facebook). One article recruited its participants, using direct E-mails. In three cases, monetary incentives were given to participants, and one article claimed that participants receiving monetary incentives are more reliable.[14]
All seven articles validated the crowdsourcing results by comparison to experts’ opinion. Two studies used previously scored images to give feedback to the participants while performing the task. This enabled participants to evaluate themselves on the go and possibly improve their performance. Five articles used a method for screening the participants and included the results only from those who passed the screening. For example, one article required participants to score at least 99% on the training session to be able to continue.[21] Table 4 summarizes the logistics of crowdsourcing in all seven studies.
Table 4.
Logistics of crowdsourcing
Crowd characteristics
All seven papers reported the crowd size, however, in one case, only the number of participants in sub-experiments were reported. The crowd sized varied from only 31 to almost 100,000. The average task load was reported in three articles and ranged from 6 images to 9394 images per user. The age range of the crowd was reported in one article and geographic location in two. No further information on the demographics of the crowd was available. The characteristics of the crowd in each article is shown in Table 5.
Table 5.
Characteristics of the crowd

DISCUSSION
To the best of our knowledge, this is the first study to review applications of crowdsourcing in human pathology. The number of articles which applied crowdsourcing in a pathology related study and met our other selection criteria (journal article, etc.) was surprisingly small at only seven. Despite widespread application of crowdsourcing in practical situations in other research areas, all the reviewed articles in this study applied crowdsourcing in a research setting. While medical applications of crowdsourcing need special attention, considering the possible privacy issues and the level of required accuracy, it is about time to see nonresearch applications of crowdsourcing in pathology. It is important to note that our results do not include all the possible articles. Gray literature, conference papers, articles not indexed in our selected search engines are among those articles which are ignored in our study.
Researchers (Mavandadi et al.) suggested that one way to involve untrained participants in making medical diagnoses is to let them filter the data for a medical expert. For example, in resource-poor areas, RBC images can be reviewed by a large crowd, and an expert can only view those samples with higher uncertainty in results. Therefore, crowdsourcing in pathology needs a generic framework to efficiently combine crowds’ and experts’ opinions. Tavakkol et al.[29] introduced a framework based on the entropy of crowdsourced messages to maximize the information gain under limited interpretation resources. Such a framework can be adapted in medical and pathology researches.
Demographics of the crowd such as age, education, and language may have a significant effect on the results and therefore should be an essential part of any study. However, among the seven reviewed articles only two articles reported information, although minimally, about the demographics of the crowd. This finding is in agreement with Ranard et al.[6] This might be due to the limitations in the current available crowdsourcing platforms and channels, where most of the time demographics of the crowd are not available and thus cannot be stored.
All the reviewed articles concluded that their initial hypotheses were valid and crowdsourcing is a viable approach to perform certain assumed tasks. While these studies help to promote crowdsourcing in pathology, they do not help understanding the limitations of this approach. For instance, an essential question in using crowdsourcing in diagnoses is the possible complications that may occur regarding patient's privacy. Furthermore, tasks which need highly skilled experts cannot be crowdsourced, and further studies are necessary to determine the threshold where crowdsourcing is not an option anymore.
As expected from the nature of the research field, the main crowdsourced task in all the selected articles was image analysis. However, several types of images such as gross, histological, cytological, immunohistochemical, etc., are used for diagnosis in pathology. This variety raises a question regarding the effects of type of imagery in the performance and limitations of crowdsourcing. For example, the analyzing gross images may not be as entertaining as stained images for the crowd, which in turn may limit our ability to gamify this process. Furthermore, the difficulty level of detecting abnormalities in images may change according to the type of the image, making crowdsourcing more suitable for a certain type. Since each of the selected articles studied only a certain type of imagery, further studies are necessary to perform a comparative analysis on the influence of the type of pathological images on the logistics and performance of crowdsourcing.
One of the reviewed articles[27] compared the results of crowdsourcing with automated methods and concluded that the crowd did a better job. However, computer vision techniques and digital pathology are continuously experiencing advances. The question is if there will be a time that automated methods will surpass the crowd in every aspect, and what the estimated time for such an event might be. If automated methods eventually, and in the next few years, will outperform the crowd in all pathology related tasks, is there any reason to keep crowdsourcing in our toolbox? Some researchers suggest that crowdsourcing can be used to generate data for training automated methods. Furthermore, researchers believe that there is a social impact in crowdsourcing which cannot be ignored. For example, a single prior research[25] engaged about 100,000 individuals in scoring breast cancer tissue samples, which inevitably increases the awareness of this crowd regarding the global issue of breast cancer.
CONCLUSION
We introduced a novel method to effectively construct a Boolean expression for the systematic literature search. This method can be used by other researchers in systematic reviews, decreasing the subjectivity of defining a Boolean expression. Utilizing this methodology, we collected potentially related articles to applications of crowdsourcing in human pathology. Furthermore, we, ourselves, used crowdsourcing to review the collected articles and decrease the number of potential articles. After screening the candidates against our selection criteria, we only found seven articles. We believe that the pathology is well-suited for outsourcing some of the reparative but simple tasks to the crowd, and therefore such a small number of relevant papers was surprising. Finally, we observed that all the related articles used the crowd for image analysis in one of the following areas: Microbiology, molecular pathology, in-vivo microscopy, and IHC.
Financial support and sponsorship
Nil.
Conflicts of interest
There are no conflicts of interest.
Acknowledgment
We specially thank medical doctors Fardad Masoumi and Scott Jafarian who were generous with their times and reviewed over 100 articles in our crowdsourcing stage. We also thank all the participants, especially, medical doctors Amir Mohammad Pirmoazen, Amir Alishahi Tabriz, Negar Haghighi, Ali Gharibi, Aditya Keerthi Rayapureddy, Faridokht Khorram, Nelli S. Lakis, Mohammad Nargesi, and Marco Vergine for their assistance in reviewing articles and participating in our crowdsourcing open call.
Footnotes
Available FREE in open access from: http://www.jpathinformatics.org/text.asp?2018/9/1/2/225493
REFERENCES
- 1.Howe J. The rise of crowdsourcing. Wired Mag. 2006;14:1–4. [Google Scholar]
- 2.Sobel D. USA: Bloomsbury Publishing; 2007. Longitude: The True Story of A Lone Genius who Solved the Greatest Scientific Problem of his Time. [Google Scholar]
- 3.Lintott C, Schawinski K, Bamford S, Slosar A, Land K, Thomas D, et al. Galaxy Zoo 1: Data release of morphological classifications for nearly 900 000 galaxies. Mon Not R Astron Soc. 2010;410:166–78. [Google Scholar]
- 4.To H, Tavakkol S, Kim SH, Shahabi C. On Acquisition and Analysis of Visual Data for Crowdsourcing Disaster Response. 2016 [Google Scholar]
- 5.Morrow N, Mock N, Papendieck A, Kocmich N. Independent evaluation of the Ushahidi Haiti project. Dev Inf Syst Int. 2011;8:2011. [Google Scholar]
- 6.Ranard BL, Ha YP, Meisel ZF, Asch DA, Hill SS, Becker LB, et al. Crowdsourcing – Harnessing the masses to advance health and medicine, a systematic review. J Gen Intern Med. 2014;29:187–203. doi: 10.1007/s11606-013-2536-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Good BM, Su AI. Crowdsourcing for bioinformatics. Bioinformatics. 2013;29:1925–33. doi: 10.1093/bioinformatics/btt333. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Ahn LV, Dabbish L. Designing games with a purpose. Commun ACM. 2008;51:58–67. [Google Scholar]
- 9.von Ahn L, Maurer B, McMillen C, Abraham D, Blum M. ReCAPTCHA: Human-based character recognition via web security measures. Science. 2008;321:1465–8. doi: 10.1126/science.1160379. [DOI] [PubMed] [Google Scholar]
- 10.Hingamp P, Brochier C, Talla E, Gautheret D, Thieffry D, Herrmann C, et al. Metagenome annotation using a distributed grid of undergraduate students. PLoS Biol. 2008;6:296. doi: 10.1371/journal.pbio.0060296. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Cooper S, Khatib F, Treuille A, Barbero J, Lee J, Beenen M, et al. Predicting protein structures with a multiplayer online game. Nature. 2010;466:756–60. doi: 10.1038/nature09304. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Lee J, Kladwang W, Lee M, Cantu D, Azizyan M, Kim H, et al. RNA design rules from a massive open laboratory. Proc Natl Acad Sci U S A. 2014;111:2122–7. doi: 10.1073/pnas.1313039111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Marbach D, Costello JC, Küffner R, Vega NM, Prill RJ, Camacho DM, et al. Wisdom of crowds for robust gene network inference. Nat Methods. 2012;9:796–804. doi: 10.1038/nmeth.2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Lawson J, Robinson-Vyas RJ, McQuillan JP, Paterson A, Christie S, Kidza-Griffiths M, et al. Crowdsourcing for translational research: Analysis of biomarker expression using cancer microarrays. Br J Cancer. 2017;116:237–45. doi: 10.1038/bjc.2016.404. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Robboy SJ, Weintraub S, Horvath AE, Jensen BW, Alexander CB, Fody EP, et al. Pathologist workforce in the United States: I. Development of a predictive model to examine factors influencing supply. Arch Pathol Lab Med. 2013;137:1723–32. doi: 10.5858/arpa.2013-0200-OA. [DOI] [PubMed] [Google Scholar]
- 16.BenTaieb A, Nosrati MS, Li-Chang H, Huntsman D, Hamarneh G. Clinically-inspired automatic classification of ovarian carcinoma subtypes. J Pathol Inform. 2016;7:28. doi: 10.4103/2153-3539.186899. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Oikawa K, Saito A, Kiyuna T, Graf HP, Cosatto E, Kuroda M, et al. Pathological diagnosis of gastric cancers with a novel computerized analysis system. J Pathol Inform. 2017;8:5. doi: 10.4103/2153-3539.201114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Bar Y, Diamant I, Wolf L, Greenspan H. Deep learning with non-medical training used for chest pathology identification. Proc SPIE. 2015:9414. doi: 10.1117/12.2083124. [Google Scholar]
- 19.Janowczyk A, Madabhushi A. Deep learning for digital pathology image analysis: A comprehensive tutorial with selected use cases. J Pathol Inform. 2016;7:29. doi: 10.4103/2153-3539.186902. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Mohammed EA, Mohamed MM, Far BH, Naugler C. Peripheral blood smear image analysis: A comprehensive review. J Pathol Inform. 2014;5:9. doi: 10.4103/2153-3539.129442. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Mavandadi S, Dimitrov S, Feng S, Yu F, Sikora U, Yaglidere O, et al. Distributed medical image analysis and diagnosis through crowd-sourced games: A malaria case study. PLoS One. 2012;7:37245. doi: 10.1371/journal.pone.0037245. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Pathology – MeSH. National Center for Biotechnology Information. [Last acceseed on 2017 Mar 16]. Available from: https://www.ncbi.nlm.nih.gov/mesh/68010336 .
- 23.Mavandadi S, Dimitrov S, Feng S, Yu F, Yu R, Sikora U, et al. Crowd-sourced bioGames: Managing the big data problem for next-generation lab-on-a-chip platforms. Lab Chip. 2012;12:4102–6. doi: 10.1039/c2lc40614d. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Luengo-Oroz MA, Arranz A, Frean J. Crowdsourcing malaria parasite quantification: An online game for analyzing images of infected thick blood smears. J Med Internet Res. 2012;14:e167. doi: 10.2196/jmir.2338. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Candido Dos Reis FJ, Lynn S, Ali HR, Eccles D, Hanby A, Provenzano E, et al. Crowdsourcing the general public for large scale molecular pathology studies in cancer. EBioMedicine. 2015;2:681–9. doi: 10.1016/j.ebiom.2015.05.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Chen SP, Kirsch S, Zlatev DV, Chang T, Comstock B, Lendvay TS, et al. Optical biopsy of bladder cancer using crowd-sourced assessment. Jama Surg. 2016;151:90–3. doi: 10.1001/jamasurg.2015.3121. [DOI] [PubMed] [Google Scholar]
- 27.Irshad H, Oh EY, Schmolze D, Quintana LM, Collins L, Tamimi RM, et al. Crowdsourcing scoring of immunohistochemistry images: Evaluating performance of the crowd and an automated computational method. Sci Rep. 2017;7:43286. doi: 10.1038/srep43286. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Candido Dos Reis FJ, Lynn S, Ali HR, Eccles D, Hanby A, Provenzano E, et al. “Research data supporting ‘Crowdsourcing the General Public for Large Scale Molecular Pathology Studies in Cancer.'” [Online] [Last accessed on 2017 Dec 21]. Available from: http://www.repository.cam.ac.uk/handle/1810/247569 . [DOI] [PMC free article] [PubMed]
- 29.Tavakkol S, To H, Kim SH, Lynett P, Shahabi C. 2016. An Entropy-Based Framework for Efficient Post-Disaster Assessment Based on Crowdsourced Data. In: Proceedings of the Second ACM SIGSPATIAL International Workshop on the Use of GIS in Emergency Management; p. 13. [Google Scholar]