

Abstract
A widely discussed paradigm for brain-computer interface (BCI) is the motor imagery task using noninvasive electroencephalography (EEG) modality. It often requires long training session for collecting a large amount of EEG data which makes user exhausted. One of the approaches to shorten this session is utilizing the instances from past users to train the learner for the novel user. In this work, direct transferring from past users is investigated and applied to multiclass motor imagery BCI. Then, active learning (AL) driven informative instance transfer learning has been attempted for multiclass BCI. Informative instance transfer shows better performance than direct instance transfer which reaches the benchmark using a reduced amount of training data (49% less) in cases of 6 out of 9 subjects. However, none of these methods has superior performance for all subjects in general. To get a generic transfer learning framework for BCI, an optimal ensemble of informative and direct transfer methods is designed and applied. The optimized ensemble outperforms both direct and informative transfer method for all subjects except one in BCI competition IV multiclass motor imagery dataset. It achieves the benchmark performance for 8 out of 9 subjects using average 75% less training data. Thus, the requirement of large training data for the new user is reduced to a significant amount.
1. Introduction
Brain-computer interface (BCI) is a system that establishes a communication channel between the brain and control devices without using the neuromuscular system of human body [1].
One of the noninvasive modalities of BCI is electroencephalography (EEG). BCI uses different types of EEG control signal from the external scalp of the brain. Some of the control signals used in BCI are visual evoked potential (VEP), P300 evoked potential, slow cortical potential (SCP), and sensory-motor rhythms (SMR) [2]. SMR can be modulated by actual as well as imagery motor task by user [3, 4]. Thus, SMRs are used in BCI as the control signal for translating motor task (hand and foot movement) [5] and referred to as motor imagery- (MI-) BCI. Hence, MI-BCIs are used for supporting patients with spinal cord injury and stroke [6–8]. MI-based BCI system possesses some drawbacks such as lack of robustness, complex setup, and long calibration time [1, 9, 10].
Generally, it is recommended to use at least five times more training data per class than the features [11, 12]. Channel-frequency-time information makes the feature vector of EEG signal very high-dimensional [13, 14]. These high-dimensional features necessitate the requirement for a large number of EEG epochs to be collected to train the classifier [15, 16]. But, EEG data acquisition is a lengthy and exhaustive task for the user. For motor imagery purpose, it is sometimes a day-long process [10, 16]. EEG signals recorded from the scalp are very subjective. It varies from one subject to another for same tasks. Even, it differs for same subject in different sessions [4]. Consequently, each individual has to go through this long data collection process in each attempt of using the system. It is most likely that long calibration time for a user has become one of the bottlenecks of BCI system. Calibration time reduction approaches reported in literatures also reflect the scenario well [17–22].
If labeled samples for certain tasks are available from other users, these samples can be used for a new user. The objective is to utilize the knowledge from data spaces of past users to learn predictive function for a new user. This process of knowledge and information conveying from other domain is known as transfer learning (TL) [23].
TL has been applied for BCI in two types: domain adaptation and rules or knowledge sharing [24]. Some of the domain adaptation approaches are subject invariant common space [18, 19, 25–28], common stationary subspace transfer [29–31], conditional and marginal distribution adaptation [32, 33], and subject-to-subject adaptation [34]. Rule adaptation or sharing prior learning to learn new user prediction function has been attempted in [20, 26, 28, 35]. Active transfer learning (ATL) approach was proposed and implemented by Wu et al. in [36] for VEP based BCI. In their work, actively learned samples from the domain of new coming subject were combined with the samples of historical subjects. QBC was used as active learning method to select samples from the subject-specific domain. The authors used all samples from other subjects directly without any adaptation or selection. An improved version of ATL was proposed and implemented for binary MI-based BCI in our preliminary work [37, 38]. Both works implemented ATL on binary classification. In [36], authors did it for target and nontarget VEP while our preliminary work was done on left-hand and right-hand motor imagery classification with two different feature extraction processes in sequence. Since instances are transferred directly from the source to target domain, it is named as direct transfer with active learning (DTAL). DTAL needs to be investigated for multiclass BCI. Instead of direct transfer, an informative and functional subdomain transfer from source to target also needs to be introduced in DTAL. In addition to finding actively learned samples from target domain (in DTAL), active learning based on most uncertain samples from the source to target domain is introduced in this work. To serve these purposes, the following attempts are made in this paper:
Multiclass direct transfer with active learning (mDTAL) is formulated and implemented. It is the multiclass extension of active transfer learning proposed in [36] for motor imagery BCI (Section 3.1).
Then, aligned instance transfer is introduced for multiclass MI-based BCI (Section 3.2).
After that, informative instances transfer framework is formulated and implemented with and without aligned subspace. Here, multiclass entropy as uncertainty criterion is applied in the source to target domain transfer (Section 3.3).
To address the subject-dependent performance variation of different methods, a generic optimized weighted ensemble of all proposed methods is constructed and applied (Section 3.4).
The main goal of this work is to develop an informative transfer learning framework for MI-BCI which is expected to perform better than direct transfer (mDTAL).
The rest of the paper is organized as follows: Section 2 will describe the concept of different terms and methods which are used for further algorithm's development. Section 3 will describe developed multiclass frameworks and optimized ensemble method. Section 4 will describe experimental setup. Then, Section 5 will analyze and discuss the results. Finally, Section 6 will conclude the paper with the scope of future improvement.
2. Methods
2.1. Transfer Learning (TL)
At first, we need to define some terms to state our problem in the scope of transfer learning.
Domain. A domain D consists of {χ, P(X)}. Here χ is features of n dimension (x1, x2,…, xn) and P(X) means marginal distribution. So, DS = DT means PS(X) = PT(X) and χS = χT. Similarly, DS ≠ DT means PS(X) ≠ PT(X) or/and χS ≠ χT [23].
Task. T = {Y, f(·)}, where Y is set of all class label and f(·) is prediction function which is trained on {X, Y}. From probabilistic view point, f(·) will give conditional probability P(Y∣X). So TS ≠ TT means YS ≠ YT or /and PS(Y∣X) ≠ PT(Y∣X) [23].
Transfer Learning [23]. Given a source domain DS and learning task TS, a target domain DT, and learning task TT, transfer learning aims to help improve the learning of the target predictive function fT(·) on DT using the knowledge in DS and TS, where DS ≠ DT or TS ≠ TT.
Dataset of EEG epochs from a new user is the target domain. EEG epochs with the label from past users are source domain. Same feature extraction method has been applied for both target and source EEG epochs. So, it can be implied that χT = χS. Same types of classes are labeled for imagery EEG epochs in both source and target domain. It implies that YT = YS. But, different subjects neural responses to same motor imagery action have different characteristics. As a result, marginal distribution and conditional distribution are different for source and target domain [33]. That means PS(X) ≠ PT(X) and PS(Y∣X) ≠ PT(Y∣X).
So, samples from source domain cannot represent the target domain correctly. Hence, it needs to get some subdomain from source efficiently which is related mostly to the target domain. The aim of TL is to learn a target prediction function f(XT) → YT so that expected error on DT is as low as possible while PS(X) ≠ PT(X) and PS(Y∣X) ≠ PT(Y∣X).
In this paper, our approach is to select the most informative instances from source domains with the help of few samples of the target domain. Then, we will add them to target domain samples to train a classifier for predicting the label of independent test data of target domain.
2.2. Active Learning (AL)
Active learning method queries for unlabeled samples which have most uncertainty [40]. Trained hypothesis on labeled samples gets confused over some unlabeled samples. These samples are more close to decision line. So, labeling these uncertain samples will accelerate learning process of the model. Hence, these samples carry more information than other certain samples (Figure 1). In this work, active learning method is applied to two ends. At first, query by committee is applied to select the most informative samples from target domain.
Figure 1.
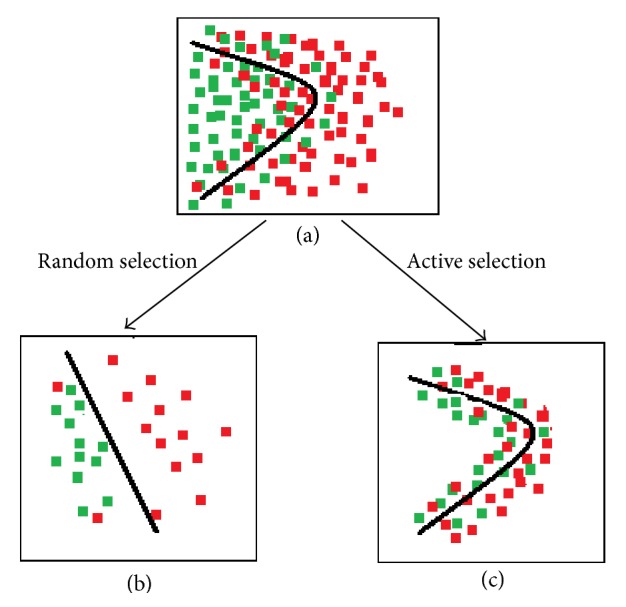
Visual presentation of AL. (a) 2D presentation of binary class dataset with expected decision boundary. (b) Learned decision line on randomly selected samples. (c) Learned decision line on actively selected samples which is more close to expected line.
Then, entropy is applied as uncertainty measure to select informative samples from the source domain.
Query by Committee (QBC) [41]. A hypothesis is a kind of particular set of parameters that tuned on some training set and it can make the prediction over new data. Hypothesis space is all possible set of hypotheses. Version space is a subset of these hypotheses which are consistent with the labeled training set L (Figure 2). Consistent means that the member of version space can make a correct prediction on all instances of L. One of the aims of AL is to select instances which can narrow down this version space. It will make the process of learning target prediction function more precise with fewer labeled instances.
Figure 2.
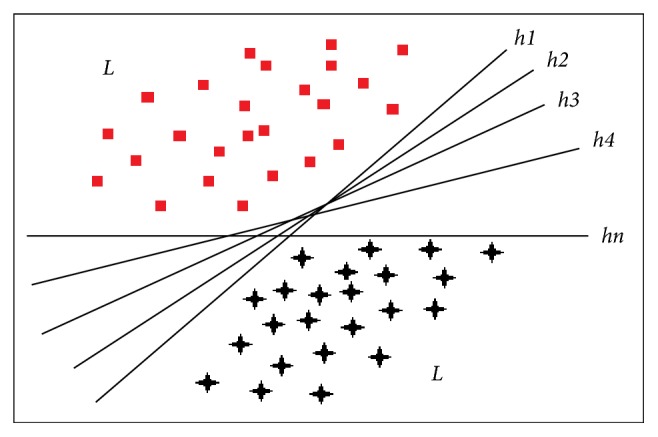
Illustration of linear version space. Each hypothesis in version space is consistent on L (labeled training set). Each of them represents different regions of version space.
QBC maintains a committee of hypothesis (version space) C = {C0, C1, C2,…, CM} (Figure 2). Each member of this committee is trained on labeled data L and represents a candidate hypothesis (h1, h2,…, hn). Then, each member of committee votes for unlabeled samples about their label. The instances attaining the most disagreement about label among the members are considered as the most informative. In analytical perspective, QBC implementation has two steps:
Construction of committee of hypotheses which depict various regions of version space from specific to general (Figure 2)
Quantification of disagreement among the members of the committee.
In this work, linear discriminant analysis (LDA) is our learning model. This model gives negative decision score for one class and positive for others. So, decision boundary ideally is zero scoreline. It is unlikely to get extreme negative (−1) at the same time extreme positive (+1) score for a single sample. Certain instances will have the extreme sum of decision score for which most of the members are agreed. But, uncertain instances will not have the extreme score for any class. It makes the absolute value of the sum of the score for all classes close to zero. In case of LDA, ensemble sum of decision score close to zero represents more disagreement among the members. So, instances attaining the lowest absolute value of the algebraic sum of decision scores from members of the committee are the most informative.
Entropy. Entropy is the amount of information to encode a distribution [42]. It is used as the measurement of uncertainty. For binary classification, entropy enforces us towards posterior probability 0.5. For multiclass, entropy yields a central confusing area of posterior probability. It considers probability distributions for all classes.
| (1) |
Here, Pθ(yc∣xi) is the predicted probability of ith sample xi for class yc by the model θ. nC is the number of classes.
2.3. Feature Extraction: Common Spatial Pattern (CSP)
This method maximizes the variance for one task and minimizes the variance for other task. Therefore, it yields to generate discriminating features of two classes for EEG classification [43–45]. Let us consider that Xi ∈ Rch×t is the ith single-trial bandpass EEG signal and Z ∈ Rch×t is the spatially filtered signal with CSP projection matrix A ∈ Rch×ch. Here, ch is the number of channels and t is the number of time points in single-trial bandpass EEG epoch.
| (2) |
Δ1 and Δ2 are the covariance matrixes of EEG signals X for two classes which can be obtained by
| (3) |
Here, IY is the set of indices of trials corresponding to class Y and nY is the total number of trials from class Y. A is the transformation matrix satisfying below optimization.
| (4) |
This CSP filter matrix A can be obtained by solving
| (5) |
Here, D is a diagonal matrix and it contains eigenvalues.
Generally, m first and m last rows of A (represented by A∗ ∈ Rc×2m) make the spatial filtered signal Z∗ [46]:
| (6) |
Finally, logarithm of variance of Z will give the feature vector F.
| (7) |
This CSP is for binary class. We have used four one vs rest binary CSP for four classes implementation [44].
2.4. Linear Discriminant Analysis (LDA)
LDA is simple and fast to compute [47, 48] which is very successfully paired with CSP feature extraction for MI-based BCI. For binary classification, it deals with two scatter matrixes Sw and Sb which are named as within-class and between-class scatter. Sw and Sb are defined as follows:
| (8) |
| (9) |
Here, ωi denotes the mean vector of ith class and ω denotes the total mean vector. k and n are number of classes and total number of samples, respectively. Objective is set to find matrix G for transformation such that it can ensure maximization of between-class and minimization of within-class scatter. In this work, four one vs rest LDA classifiers are used for 4-class classification.
| (10) |
Decision score is calculated by
| (11) |
Here, b is the bias value and sign of f(x) will give the class label.
3. Algorithms
3.1. Multiclass Direct Transfer with Active Learning (mDTAL)
Multiclass extension of direct transfer learning with active learning or ATL [36] is formulated for MI-based BCI. CSP is used for feature extraction combined with LDA classifier since this combination is very successful for MI-based BCI [16, 46]. For mDTAL, we have considered one vs rest approach [49, 50] in three sections of this algorithm (Figure 3):
One vs rest method for QBC while selecting most active samples from target domain
One vs rest CSP filter in feature extraction part
One vs rest method for LDA training and testing part.
Figure 3.

Multiclass direct transfer with active learning (mDTAL). Here, n is the number of samples to be selected from each class of new subject.
Stepwise process of mDTAL algorithm is described as follows.
Algorithm: mDTAL
Step 1 . —
Start with randomly chosen Nl labeled samples with equal class proportion and Nu unlabeled instances from target domain. M number of other subjects with Nm labeled instances from mth subject are available. Nt independent test samples of new subject are given for performance evaluation.
Step 2 . —
Train classifier C0 using Nl samples. Then, C0 will calculate the decision score for each class of Nu samples as Du0.
Step 3 . —
Train combined classifier Cm using Nl ∪ Nm combined training samples.
Step 4 . —
Get 10-fold cross-validation accuracy am on Nl ∪ Nm training samples. Repeat Steps 2 and 3 for all historic subjects.
Step 5 . —
Get ensemble weighted average decision score for each class on Nu using the following equation:
(12) Here, Dum is decision score calculated using classifier Cm on unlabeled samples Nu. For Du0, weight has been assigned as 1 to give subject-specific classifier higher priority over combined classifier. Similarly, ensemble weighted average decision score for test data set Nt is also calculated as follows:
(13) It is the ultimate output of the algorithm in each iteration.
Step 6 . —
Linear classifier LDA has the negative score for one class and positive for other. So, decision score close to zero represents more uncertainty than others. Equation (12) calculates ensemble decision score of the M + 1 number of models or a committee of models. Unlabeled samples getting lowest or close to zero absolute decision score are more likely to learn decision boundary than others. Considering multiclass, Du(:, c) gives decision score for class c vs rest. So, the lowest absolute decision score of Du(:, c) will give most uncertain samples near class c vs rest boundary as follows (Figure 6):
(14) Here, c = 1,2,…, nC (number of class) and n is number of samples to be selected from each class (Figure 3).
Figure 6.
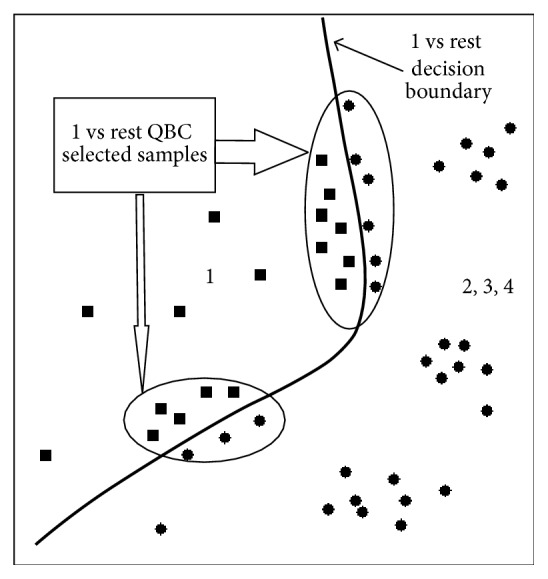
One versus rest presentation of QBC for multiclass.
Step 7 . —
All selected unlabeled subject-specific samples Sc are queried for label. Then this newly labeled samples are added to Nl and removed from Nu. Steps 2to 7 are repeated until maximum number of iteration.
3.2. Multiclass Aligned Instance Transfer with Active Learning (AITAL)
There is no adaptation or selection from historic subjects in mDTAL method. Rather, it directly transfers all labeled samples from historic subjects. But, all samples from historic subjects may not be compatible with the domain of new subject. As a result, it may yield to negative transfer effect [51]. So, the idea is to transfer samples which are aligned with new subject decision boundary (Figure 4). Subject-specific model C0 classifies some samples accurately from historic subjects. It can be assumed that these accurately classified samples agree with the decision boundary of target domain classifier C0. So, these samples are considered as being aligned with target domain.
Figure 4.

Multiclass aligned instance transfer with active learning (AITAL).
AITAL is similar to mDTAL algorithm except Step 3 where it will not take all of Nm samples from mth historic subject. Instead, it will take Nm′ aligned samples (see (15)) from mth historic subject which are determined by subject-specific model C0 (Figure 4).
| (15) |
Here, L0m is the label for samples from mth historic subjects which are predicted by subject-specific classifier C0. Y is the true class label for these samples.
3.3. Most Informative Instance Transfer with Active Learning (MIITAL)
According to active learning query method, samples lying close to decision boundary are more likely uncertain to be predicted. It makes uncertain samples more informative to learn decision boundary than that of other samples. If informative samples from historic subjects are transferred to learn classifier for new user, it will be more effective. In this work, entropy of instances are used as the quantification of information carried by these samples. Entropy can be calculated by
| (16) |
Here, Pθ(yc∣xi) is probability of samples xi to be in class yc which is determined by classifier C0 and represented as model θ.
For this work, we consider four one vs rest entropy calculation. Our goal is to find uncertain samples which are close to each one vs rest decision line. Ideally, samples having 50 : 50 probability ratio are most uncertain and have maximum entropy. We consider samples with probability ratio equal or more than 60 : 40 for this work. It yields to transfer samples that have entropy equal or greater than 0.29228 according to (16). This entropy limit is named information limit or cut-off (l).
There are two combinations of this algorithm:
-
(i)Transfer aligned and most informative samples (most informative and aligned instances transfer with AL (MIAITAL)) (Figure 5):
(17) -
(ii)Transfer most informative samples and ignore whether it is aligned or not (most informative instances transfer with AL (MIITAL) (Figure 5)):
(18)
Algorithm of MIAITAL or MIITAL is the same as mDTAL except Step 3. In Step 3, MIAITAL or MIITAL will take Nm′ according to (17) and (18) in place of Nm.
Figure 5.

Multiclass most informative and aligned informative instance transfer with active learning (MIAITAL). Shaded box is obsolete for MIITAL.
MIAITAL attempts to transfer most informative samples which are perfectly classified by classifier from previous iteration, whereas MIITAL attempts to transfer most informative samples (determined by entropy) and ignores alignment of those informative samples (Figure 5).
3.4. Optimized Ensemble for Multiclass Actively Learned Space Transfer
EEG epochs due to various motor imagery actions are not stable. So, finding prominent features followed by learning classifier does not always yield the expected result. As a result, performance is not generic for all subjects; it is subject-dependent. Some methods perform well for some subjects while not very good for others. The ensemble of different methods can give a general and steady performance for all subjects. An optimized weighted ensemble is proposed to serve the purpose (Figure 7).
Figure 7.

Optimized weighted ensemble of mDTAL, AITAL, MIAITAL, and MIITAL.
Some arbitrary weight (say W) is assigned for each class in each method. Then, these weights are optimized for minimum loss on a validation set. Loss function for nth subject is as follows:
| (19) |
Here, the validation set V is 10 percent of the subject-specific training set and is randomly chosen from that data set. The initial value of weight W is some random value in the range of [0,1]. Then, W is optimized by the genetic algorithm using the loss function from (19). Ensemble decision-making probability on test set T using optimized W is then obtained by
| (20) |
Here, Pmc is probability generated by mth method for class c and Wmc is optimized weight for corresponding class c and method m.
4. Experiment Setup
4.1. Experimental Data
Algorithms described in Section 3 are implemented for BCI competition IV dataset 2A [39]. This dataset consists of 9 subjects. In this dataset, each subject performs four types of motor imagery action for left hand, right hand, both feet, and tongue movement. Data is recorded in two sessions for each subject. In each session, a subject performs 72 trials per class which turns into 288 in total.
In each session, there are approximately 5 minutes of electrooculogram (EOG) recording keeping eyes open, close, and moving. Then, it is followed by the run of trials (Figure 8(a)). Each subject was facing a computer screen which was showing different indication guideline to the subject. Each single-trial starts (t = 0 s) with a fixation cross on the screen in front of the subject. After 2 seconds (t = 2 s), a cue appeared on the screen indicating arrow with the desired movement sign (left hand, right hand, foot, and tongue). After 1.25 seconds of cue appearing, subject starts to imagine the motor action and continues until t = 6 s. A short break (black screen) is given until next trial starts (Figure 8(b)). EEG epoch of 2 seconds after 0.5 seconds of cue appearing is taken as training data. 22 channels (Ag/AgCl) are used for EEG signal recording and other three monopolar electrodes are used for EOG recording. The montage of the electrode was according to the international 10-20 system. Both of the EEG and EOG channels were sampled 250 Hz. After that, they had been filtered using 0.5 Hz to 100 Hz ranged bandpass filter. A 50 Hz notch filter was also enabled during recording to omit the line noise. The sensitivity of the amplifier was set to 100 uV and 1 mV for EEG and EOG recording, respectively.
Figure 8.

(a) Timing for one session [39]. (b) Timing for a single trial [39]. (c) Baseline method.
4.2. Data Preprocessing and EOG Correction
Linear EOG correction method [52] is applied for artefact correction on raw EEG signals. β rhythms (12–30 Hz) of EEG signals are desynchronized with real movement or motor imagery [53]. μ rhythms (8–12 Hz) of EEG signals related to motor actions and sometimes correlate with β rhythms [54, 55]. For this reason, corrected EEG signal is bandpass filtered using casual Chebyshev Type II filter between 8 Hz and 32 Hz. After that, CSP is applied and features are extracted according to (6) and (7). Here, m is set to 2 for A∗ in (6). So, 4 features are obtained from each EEG epoch.
4.3. Experiment and Simulation
For all method, first session of each subject is used as training set and second session is used as test set.
For comparison purpose, a baseline method is also implemented. In baseline method, the full training set of the respective subject is used to train LDA classifier. No sample from other users is used. After applying data preprocessing as described in Section 4.2, four one vs rest LDA classifiers are trained. These models are applied to predict label for respective independent test session (Figure 8(c)).
The accuracy achieved by this baseline method is the benchmark performance by an individual user. The purpose of other methods in this work is to achieve this performance using a reduced amount of training samples. This baseline process is followed for each internal model training and testing phase of other algorithms. As benchmark performance is a static value and does not depend on the iterative increment of subjective training samples, it is a straight line parallel to the horizontal axis.
Other methods in this work are iterative where samples from the new subject are added in training pool iteratively. Each subject is considered as the new user (target) while other 8 subjects are considered to be past users (source). Each simulation starts with 40 random samples (Nl in Step 1 of mDTAL algorithm) with equal class distribution from the target domain. Then, 2 samples per class (n in (14)) are added in each iteration until 20 iterations (maximum number of iteration in Step 7 of Section 3). So, maximum 200 subjective samples for each subject is added at final iteration. This amount of training samples from the new user is good enough to observe whether the new subject can reach the benchmark using a lower amount of training samples. For this reason, the maximum number of iterations is set to 20. This whole simulation is repeated 20 times for each subject to negate random starting samples effect. Then, the average of ten repeats in each iteration is taken as the performance of that iteration.
Only first session of each historical subjects is taken as source domain because label for the second session was kept closed in BCI competition IV. Training samples from the first session of target subject are added iteratively and the classification performance in each iteration is computed on the independent second session of the target subject.
5. Results and Discussion
The performance of proposed methods in this work is evaluated based on the following two criteria: first, investigation to find whether the method has reached the maximum baseline performance; second, the number of subjects for which intended method reaches the maximum baseline performance. Direct transfer method (mDTAL) is the multiclass extension of active transfer learning [36] for motor imagery BCI. Proposed informative space transfer algorithms (AITAL, MIAITAL, and MIITAL) will be compared with mDTAL based on the evaluation criteria mentioned above. Figure 9 presents the accuracy of all methods for comparison. The following observations can be drawn out from this result based on the above-mentioned evaluation criteria:
mDTAL method fails to achieve the baseline performance except for subject A03, A06, and A08. But, it is showing gradual increment in accuracy as the training data from target domain increased. In mDTAL method, all samples from source domain are transferred to the target domain directly. The results reflect that, due to high variability among subjects, there is a high chance of completely different types of domain transfer in direct transfer method.
AITAL method reaches the baseline for subjects A01, A02, A03, and A06. It depicts that transferring solely aligned information does not always yield to transfer of discriminative features transformation. Widely sparse distribution may be aligned but might not have much information for target domain learning process. Moreover, aligned samples are not ensured to be equal in class distribution. So, there is a high possibility of introducing class-imbalance into the combined domain (source + target).
MIITAL and MIAITAL transfer most informative samples in each iteration. Both of them reach baseline or close to baseline for subjects A01, A02, A03, A06, A08, and A09. MIITAL shows better performance than MIAITAL. The reason behind this is that MIITAL emphasizes only on information carried out by samples while MIAITAL requires both informative and aligned samples. Some of the informative samples may not be aligned. These nonaligned informative samples with higher entropy are excluded in MIAITAL but are included in MIITAL. Thus, MIITAL outperforms MIAITAL with more informative samples.
Figure 9.

Performance of mDTAL, AITAL, MIITAL, MIAITAL, and optimized ensemble method on BCI competition IV dataset 2A. Accuracy is along the y-axis and the number of subject-specific training samples is along the x-axis.
From above observation, it is clear that informative transfer approaches (MIITAL and MIAITAL) have reached the baseline for six out of nine subjects while direct transfer (mDTAL) reaches baseline only for three out of nine subjects. It implies that informative subspace transferring enables the new subject to achieve the baseline performance with a reduced number of training data for more number of subjects compared with direct transfer methods. Table 1 shows the number of subject-specific training samples required to reach baseline or close to baseline. It also implies that MIITAL method reaches baseline or close to baseline using average 49% less subject-specific data for 6 out of 9 subjects.
Table 1.
Number of samples to reach baseline for different methods.
| Sub | Base | MIITAL | Reduction by MIITAL | Optimized | Reduction by optimized |
|---|---|---|---|---|---|
| A01 | 288 | 180 | 37.5% | 40 | 86% |
| A02 | 288 | 180 | 37.5% | 90 | 68.75% |
| A03 | 288 | 140 | 51.4% | 40 | 86% |
| A04 | 288 | × | × | × | × |
| A05 | 288 | × | × | 120 | 58% |
| A06 | 288 | 170 | 41% | 40 | 86% |
| A07 | 288 | × | × | 100 | 65.3% |
| A08 | 288 | 60 | 79% | 40 | 86% |
| A09 | 288 | 150 | 48% | 70 | 75.7% |
|
| |||||
| Mean | 288 | 49% | 76.56% | ||
∗×: baseline cannot be reached.
Though informative instance transfer achieves better performance for most of the subjects, this is not a generic outcome for all subjects. Subject A05 and subject A07 are much closer to baseline, but they do not reach it. Exceptionally, subject A04 is very far from the expected line for all the methods. To find a generic solution for all subjects, an optimized weighted ensemble of the proposed four methods is applied (Figure 7). Performance of optimized weighted ensemble method is shown in Figure 9 (solid black line).
Optimized ensemble of all methods achieves the baseline and sometimes better than baseline with less amount of subject-specific samples for 8 out of 9 subjects. As per results in Table 1, optimized ensemble method reaches the baseline or close to baseline using average 75.5% less subject-specific training samples for 8 out of 9 subjects.
To get a generic view irrespective of subjects, mean of the accuracy of all subjects is presented in Figure 10. It shows that proposed informative transfer learning methods MIITAL and MIAITAL are performing always better than that of direct transfer (mDTAL). It infers that informative transfer has advantages over the direct transfer. However, mean performance of both algorithms is behind the baseline performance by 4-5%. On the other hand, mean of the optimized ensemble is much closer to mean baseline of all subjects (differs by only 1-2%). Subjective combination adaptation would have yielded better results in comparison to the optimized ensemble of the methods. However, this will be considered in a future study.
Figure 10.
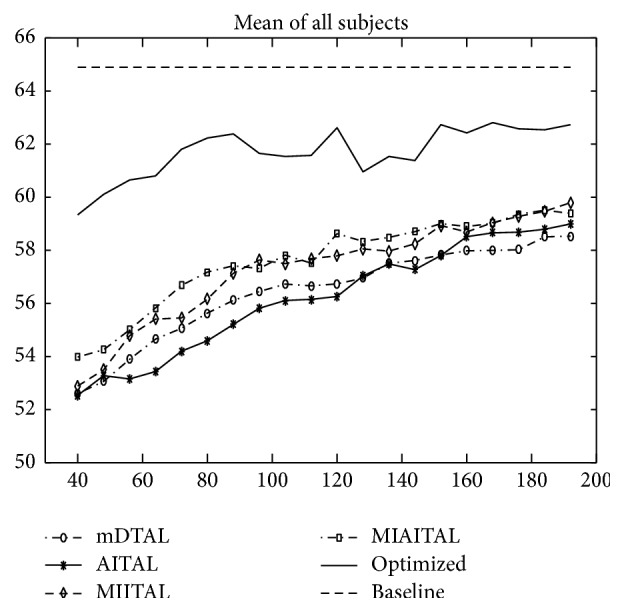
Mean performance of all subjects for mDTAL, AITAL, MIITAL, MIAITAL, and optimized ensemble methods. Accuracy is along the y-axis and number of training samples added from the new subject is along the x-axis.
Another observation is that subject A04 has no improvement by all these methods. Any of the methods used in this study is unable to improve the performance of subject A04. This can be due to the fact that EEG response of some subjects have complete dissimilarity with others [55]. When a completely dissimilar subspace is transferred and combined with the target subject (A04), it does not much effect towards the improvement of predictive function for the target domain. A remedy for this issue could be achieved by clustering closely related subject [28]. Closely related subjects or domains form a cluster. Nonrelated or dissimilar subjects are excluded from this cluster. Then, informative subspace from this close group or cluster can make the transfer more effective. For EEG epochs consisting large number of channels, EEG channels selection could be a better addition for robustification [56–60].
Presented results infer that a single method is working well for some subjects and not up to the mark for others. It implies that performance of proposed TL methods is subject-dependent. Automatic selection of the best approach for a subject is an open question to be investigated. One of the possible causes behind the performance variation is CSP applied for extracting features from a broad range of μ and β rhythms (8–32 Hz). Subjective frequency ranges can be yielded into better feature extraction and selection [49]. Incorporating this subject adaptive frequency ranges will ensure feature transfer from subjective range. Thus, it will lead to better features transfer into proposed TL algorithm. One concerning matter is the mean baseline performance of multiclass BCI that is not up to the mark. Advance feature extraction and learning algorithm could be applied to raise up this baseline which leads to subsequent incorporation into MIITAL and consequent performance raise of the MIITAL algorithm.
In summary, this paper presents two slightly different informative subspace transfer frameworks (MIAITAL and MIITAL) on multiclass BCI. Though MIITAL has achieved the expected result for a good number of subjects, still it is lagging behind the baseline in general. The optimized ensemble of these methods has overcome the gap. The primary goal of this work is to investigate the functionality of informative subspace transferring over the direct transfer for multiclass BCI. Though it succeeded for most of the subjects, there are many scopes to improve in the proposed framework. Secondary goal is to find comparatively better informative transfer approach. From empirical results, it is clear that MIITAL is serving the purpose better than MIAITAL.
6. Conclusion
In this work, we applied direct transfer learning with active learning on multiclass motor imagery BCI. To improve the performance, an informative instances transfer framework is proposed. Its key advantage compared with direct transfer methods is transferring informative instances that narrow down the search spaces more precisely around the decision line. Hence, it reduced training data significantly for most of the subjects (6 out of 9). A generic optimized ensemble of proposed methods is also implemented. It has achieved expected accuracy with fewer subject-specific samples (using average 75% less training samples) for 8 out of 9 subjects. Results achieved in this paper point out some directions for future work as well. Subject adaptive method selection could give a more fine-tuned performance. Cluster base transfer combined with informative transferring could also lead to better performance for the underperforming subject. Another scope is filtering subject and subspace based on distribution similarity. Domain adaptation based on marginal and conditional distribution could introduce more generalize adaptation in the proposed TL framework. All these improvements can reduce the calibration effort remarkably and lead us towards a generic TL framework for BCI application.
Conflicts of Interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
References
- 1.Wolpaw J. R., Wolpaw E. W. Preface. Brain-Computer Interfaces: Principles and Practice. 2012 doi: 10.1093/acprof:oso/9780195388855.002.0005. [DOI] [Google Scholar]
- 2.Nicolas-Alonso L. F., Gomez-Gil J. Brain computer interfaces, a review. Sensors. 2012;12(2):1211–1279. doi: 10.3390/s120201211. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Pfurtscheller G., Neuper C., Flotzinger D., Pregenzer M. EEG-based discrimination between imagination of right and left hand movement. Electroencephalography and Clinical Neurophysiology. 1997;103(6):642–651. doi: 10.1016/S0013-4694(97)00080-1. [DOI] [PubMed] [Google Scholar]
- 4.Pfurtscheller G., da Silva F. H. L. Event-related EEG/MEG synchronization and desynchronization: basic principles. Clinical Neurophysiology. 1999;110(11):1842–1857. doi: 10.1016/S1388-2457(99)00141-8. [DOI] [PubMed] [Google Scholar]
- 5.Scherer R., Schloegl A., Lee F., Bischof H., Janša J., Pfurtscheller G. The self-paced graz brain-computer interface: Methods and applications. Computational Intelligence and Neuroscience. 2007;2007 doi: 10.1155/2007/79826.79826 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Silvoni S., Ramos-Murguialday A., Cavinato M., et al. Brain-computer interface in stroke: a review of progress. Clinical EEG and Neuroscience. 2011;42(4):245–252. doi: 10.1177/155005941104200410. [DOI] [PubMed] [Google Scholar]
- 7.Pfurtscheller G., Müller-Putz G. R., Scherer R., Neuper C. Rehabilitation with brain-computer interface systems. The Computer Journal. 2008;41(10):58–65. doi: 10.1109/MC.2008.432. [DOI] [Google Scholar]
- 8.Ang K. K., Guan C. Brain-computer interface in stroke rehabilitation. Journal of Computing Science and Engineering. 2013;7(2):139–146. doi: 10.5626/jcse.2013.7.2.139. [DOI] [Google Scholar]
- 9.Blankertz B., Tangermann M., Vidaurre C., et al. The Berlin brain-computer interface: non-medical uses of BCI technology. Frontiers in Neuroscience. 2010;4, article 198 doi: 10.3389/fnins.2010.00198. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Van Erp J. B. F., Lotte F., Tangermann M. Brain-computer interfaces: beyond medical applications. The Computer Journal. 2012;45(4):26–34. doi: 10.1109/mc.2012.107. [DOI] [Google Scholar]
- 11.Jain A. K., Chandrasekaran B. 39 Dimensionality and sample size considerations in pattern recognition practice. Handbook of Statistics. 1982;2:835–855. doi: 10.1016/S0169-7161(82)02042-2. [DOI] [Google Scholar]
- 12.Raudys S. J., Jain A. K. Small sample size effects in statistical pattern recognition: recommendations for practitioners. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1991;13(3):252–264. doi: 10.1109/34.75512. [DOI] [Google Scholar]
- 13.Hettiarachchi I. T., Nguyen T. T., Nahavandi S. Motor imagery data classification for BCI application using wavelet packet feature extraction. Proceedings of the the International Conference on Neural Information Processing; 2014; Springer; pp. 519–526. [Google Scholar]
- 14.Hettiarachchi I. T., Nguyen T. T., Nahavandi S. Multivariate adaptive autoregressive modeling and Kalman filtering for motor imagery BCI. Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, SMC 2015; October 2015; Hong Kong. pp. 3164–3168. [DOI] [Google Scholar]
- 15.Jain A. K., Duin R. P. W., Mao J. Statistical pattern recognition: a review. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2000;22(1):4–37. doi: 10.1109/34.824819. [DOI] [Google Scholar]
- 16.Blankertz B., Dornhege G., Krauledat M., Müller K.-R., Curio G. The non-invasive Berlin brain-computer interface: fast acquisition of effective performance in untrained subjects. NeuroImage. 2007;37(2):539–550. doi: 10.1016/j.neuroimage.2007.01.051. [DOI] [PubMed] [Google Scholar]
- 17.Krauledat M., Schröder M., Blankertz B., Müller K.-R. Reducing calibration time for brain-computer interfaces: A clustering approach. Proceedings of the 20th Annual Conference on Neural Information Processing Systems, NIPS 2006; December 2006; can. pp. 753–760. [Google Scholar]
- 18.Krauledat M., Tangermann M., Blankertz B., Müller K.-R. Towards zero training for brain-computer interfacing. PLoS ONE. 2008;3(8) doi: 10.1371/journal.pone.0002967.e2967 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Fazli S., Popescu F., Danóczy M., Blankertz B., Müller K.-R., Grozea C. Subject-independent mental state classification in single trials. Neural Networks. 2009;22(9):1305–1312. doi: 10.1016/j.neunet.2009.06.003. [DOI] [PubMed] [Google Scholar]
- 20.Alamgir M., Grosse-Wentrup M., Altun Y. Multitask learning for brain-computer interfaces. Proceedings of the International Conference on Artificial Intelligence and Statistics; 2010; pp. 17–24. [Google Scholar]
- 21.Tu W., Sun S. A subject transfer framework for EEG classification. Neurocomputing. 2012;82:109–116. doi: 10.1016/j.neucom.2011.10.024. [DOI] [Google Scholar]
- 22.Lotte F. Signal processing approaches to minimize or suppress calibration time in oscillatory activity-based brain-computer interfaces. Proceedings of the IEEE. 2015;103(6):871–890. doi: 10.1109/JPROC.2015.2404941. [DOI] [Google Scholar]
- 23.Pan S. J., Yang Q. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering. 2010;22(10):1345–1359. doi: 10.1109/tkde.2009.191. [DOI] [Google Scholar]
- 24.Jayaram V., Alamgir M., Altun Y., Scholkopf B., Grosse-Wentrup M. Transfer Learning in Brain-Computer Interfaces. IEEE Computational Intelligence Magazine. 2016;11(1):20–31. doi: 10.1109/MCI.2015.2501545. [DOI] [Google Scholar]
- 25.Kang H., Nam Y., Choi S. Composite common spatial pattern for subject-to-subject transfer. IEEE Signal Processing Letters. 2009;16(8):683–686. doi: 10.1109/LSP.2009.2022557. [DOI] [Google Scholar]
- 26.Kang H., Choi S. Bayesian common spatial patterns for multi-subject EEG classification. Neural Networks. 2014;57:39–50. doi: 10.1016/j.neunet.2014.05.012. [DOI] [PubMed] [Google Scholar]
- 27.Lotte F., Guan C. Regularizing common spatial patterns to improve BCI designs: unified theory and new algorithms. IEEE Transactions on Biomedical Engineering. 2011;58(2):355–362. doi: 10.1109/tbme.2010.2082539. [DOI] [PubMed] [Google Scholar]
- 28.Devlaminck D., Wyns B., Grosse-Wentrup M., Otte G., Santens P. Multisubject learning for common spatial patterns in motor-imagery BCI. Computational Intelligence and Neuroscience. 2011;2011 doi: 10.1155/2011/217987.217987 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Samek W., Meinecke F. C., Muller K. Transferring subspaces between subjects in brain—computer interfacing. IEEE Transactions on Biomedical Engineering. 2013;60(8):2289–2298. doi: 10.1109/TBME.2013.2253608. [DOI] [PubMed] [Google Scholar]
- 30.Samek W., Vidaurre C., Müller K.-R., Kawanabe M. Stationary common spatial patterns for brain-computer interfacing. Journal of Neural Engineering. 2012;9(2) doi: 10.1088/1741-2560/9/2/026013.026013 [DOI] [PubMed] [Google Scholar]
- 31.von Bünau P., Meinecke F. C., Király F., Müller K.-R. Finding stationary subspaces in multivariate time series. Physical Review Letters. 2009;103(21) doi: 10.1103/physrevlett.103.214101.214101 [DOI] [PubMed] [Google Scholar]
- 32.Long M., Wang J., Ding G., Pan S. J., Yu P. S. Adaptation regularization: A general framework for transfer learning. IEEE Transactions on Knowledge and Data Engineering. 2014;26(5):1076–1089. doi: 10.1109/TKDE.2013.111. [DOI] [Google Scholar]
- 33.Wu D., Lawhern V. J., Lance B. J. Reducing Offline BCI Calibration Effort Using Weighted Adaptation Regularization with Source Domain Selection. Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, SMC 2015; October 2015; Hong Kong. pp. 3209–3216. [DOI] [Google Scholar]
- 34.Arvaneh M., Robertson I., Ward T. E. Subject-to-subject adaptation to reduce calibration time in motor imagery-based brain-computer interface. Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBC 2014; August 2014; USA. pp. 6501–6504. [DOI] [PubMed] [Google Scholar]
- 35.Samek W., Kawanabe M., Muller K.-R. Divergence-based framework for common spatial patterns algorithms. IEEE Reviews in Biomedical Engineering. 2014;7:50–72. doi: 10.1109/RBME.2013.2290621. [DOI] [PubMed] [Google Scholar]
- 36.Wu D., Lance B., Lawhern V. Transfer learning and active transfer learning for reducing calibration data in single-trial classification of visually-evoked potentials. Proceedings of the 2014 IEEE International Conference on Systems, Man and Cybernetics - SMC; October 2014; San Diego, CA, USA. pp. 2801–2807. [DOI] [Google Scholar]
- 37.Hossain I., Khosravi A., Nahavandhi S. Active transfer learning and selective instance transfer with active learning for motor imagery based BCI. Proceedings of the 2016 International Joint Conference on Neural Networks, IJCNN 2016; July 2016; Canada. pp. 4048–4055. [DOI] [Google Scholar]
- 38.Hossain I., Khosravi A., Hettiarachchi I. T., Nahavandhi S. Informative instance transfer learning with subject specific frequency responses for motor imagery brain computer interface. Proceedings of the 2017 IEEE International Conference on Systems, Man and Cybernetics (SMC); October 2017; Banff, AB. pp. 252–257. [DOI] [Google Scholar]
- 39.Brunner C., Leeb R., Müller-Putz G., Schlögl A., Pfurtscheller G. Bci competition 2008–graz data set a, Institute for Knowledge Discovery (Laboratory of Brain-Computer Interfaces) Vol. 16. Graz University of Technology; 2008. [Google Scholar]
- 40.Settles B. Active Learning Literature Survey. Vol. 52. Madison, Wis, USA: University of Wisconsin; 2010. [Google Scholar]
- 41.Seung H. S., Opper M., Sompolinsky H. Query by committee. Proceedings of the 5th Annual ACM Workshop on Computational Learning Theory; July 1992; ACM; pp. 287–294. [Google Scholar]
- 42.Shannon C. E., Weaver W. The Mathematical Theory of Communication. Urbana, Ill, USA: The University of Illinois Press; 1949. [Google Scholar]
- 43.Ramoser H., Müller-Gerking J., Pfurtscheller G. Optimal spatial filtering of single trial EEG during imagined hand movement. IEEE Transactions on Neural Systems and Rehabilitation Engineering. 2000;8(4):441–446. doi: 10.1109/86.895946. [DOI] [PubMed] [Google Scholar]
- 44.Müller-Gerking J., Pfurtscheller G., Flyvbjerg H. Designing optimal spatial filters for single-trial EEG classification in a movement task. Clinical Neurophysiology. 1999;110(5):787–798. doi: 10.1016/S1388-2457(98)00038-8. [DOI] [PubMed] [Google Scholar]
- 45.Nguyen T., Hettiarachchi I., Khosravi A., Salaken S. M., Bhatti A., Nahavandi S. Multiclass EEG data classification using fuzzy systems. Proceedings of the 2017 IEEE International Conference on Fuzzy Systems, FUZZ 2017; July 2017; Italy. [DOI] [Google Scholar]
- 46.Blankertz B., Tomioka R., Lemm S., Kawanabe M., Müller K.-R. Optimizing spatial filters for robust EEG single-trial analysis. IEEE Signal Processing Magazine. 2008;25(1):41–56. doi: 10.1109/MSP.2008.4408441. [DOI] [Google Scholar]
- 47.Fisher R. A. The use of multiple measurements in taxonomic problems. Annals of Eugenics. 1936;7:179–188. doi: 10.1111/j.1469-1809.1936.tb02137.x. [DOI] [Google Scholar]
- 48.Ye J., Janardan R., Li Q. Two-dimensional linear discriminant analysis. Advances in Neural Information Processing Systems. 2005;17:1569–1576. [Google Scholar]
- 49.Ang K. K., Chin Z. Y., Wang C., Guan C., Zhang H. Filter bank common spatial pattern algorithm on BCI competition IV datasets 2a and 2b. Frontiers in Neuroscience. 2012;6, article 39:9. doi: 10.3389/fnins.2012.00039. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Dornhege G., Blankertz B., Curio G., Müller K.-R. Increase information transfer rates in BCI by CSP extension to multi-class. Proceedings of the 17th Annual Conference on Neural Information Processing Systems, NIPS 2003; December 2003; can. [Google Scholar]
- 51.Rosenstein M. T., Marx Z., Kaelbling L. P., Dietterich T. G. To transfer or not to transfer. NIPS 2005 Workshop on Inductive Transfer: 10 Years Later. 2005;2:p. 7. [Google Scholar]
- 52.Schlögl A., Keinrath C., Zimmermann D., Scherer R., Leeb R., Pfurtscheller G. A fully automated correction method of EOG artifacts in EEG recordings. Clinical Neurophysiology. 2007;118(1):98–104. doi: 10.1016/j.clinph.2006.09.003. [DOI] [PubMed] [Google Scholar]
- 53.Pfurtscheller G., Neuper C. Motor imagery and direct brain-computer communication. Proceedings of the IEEE. 2001;89(7):1123–1134. doi: 10.1109/5.939829. [DOI] [Google Scholar]
- 54.Pineda J. A. The functional significance of mu rhythms: translating ‘seeing’ and ‘hearing’ into ‘doing’. Brain Research Reviews. 2005;50(1):57–68. doi: 10.1016/j.brainresrev.2005.04.005. [DOI] [PubMed] [Google Scholar]
- 55.Pfurtscheller G., Brunner C., Schlögl A., Lopes da Silva F. H. Mu rhythm (de)synchronization and EEG single-trial classification of different motor imagery tasks. NeuroImage. 2006;31(1):153–159. doi: 10.1016/j.neuroimage.2005.12.003. [DOI] [PubMed] [Google Scholar]
- 56.Ghaemi A., Rashedi E., Pourrahimi A. M., Kamandar M., Rahdari F. Automatic channel selection in EEG signals for classification of left or right hand movement in Brain Computer Interfaces using improved binary gravitation search algorithm. Biomedical Signal Processing and Control. 2017;33:109–118. doi: 10.1016/j.bspc.2016.11.018. [DOI] [Google Scholar]
- 57.Park S., Kim J., Sim K. EEG electrode selection method based on BPSO with channel impact factor for acquisition of significant brain signal. Optik - International Journal for Light and Electron Optics. 2018;155:89–96. doi: 10.1016/j.ijleo.2017.10.085. [DOI] [Google Scholar]
- 58.Zhang C., Deng X., Tang Y., Wang G., Li D. Optimization of electrode electroencephalography channel selection based on UPS-EMOA algorithm. Journal of Medical Imaging and Health Informatics. 2017;7(5):1093–1098. doi: 10.1166/jmihi.2017.2142. [DOI] [Google Scholar]
- 59.Franklin Alex Joseph A., Govindaraju C. Channel selection using glow swarm optimization and its application in line of sight secure communication. Cluster Computing. doi: 10.1007/s10586-017-1177-9. [DOI] [Google Scholar]
- 60.Yang J., Singh H., Hines E. L. Channel selection and classification of electroencephalogram signals: an artificial neural network and genetic algorithm-based approach. Artificial Intelligence in Medicine. 2012;55(2):117–126. doi: 10.1016/j.artmed.2012.02.001. [DOI] [PubMed] [Google Scholar]