

Summary
How the size of micron-scale cellular structures like the mitotic spindle, cytoskeletal filaments, the nucleus, the nucleolus and other non-membrane bound organelles is controlled despite a constant turnover of their constituent parts is a central problem in biology. Experiments have implicated the limiting-pool mechanism: structures grow by stochastic addition of molecular subunits from a finite pool until the rates of subunit addition and removal are balanced, producing a structure of well-defined size. Here, we consider these dynamics when multiple filamentous structures are assembled stochastically from a shared pool of subunits. Using analytical calculations and computer simulations, we show that robust size control can be achieved when only one filament is assembled at a time. When multiple filaments compete for monomers, filament lengths exhibit large fluctuations. These results extend to three-dimensional structures and reveal the physical limitations of the limiting pool mechanism of size-control when multiple organelles are assembled from a shared pool of subunits.
Keywords: Size control, Organelle size, Master equation, Cytoskeleton filaments, Self-assembly
Graphical abstract
Introduction
Cells consist of organelles and other large structures whose size is often matched to the size of the cell. A classic example of this is the scaling of the size of the mitotic spindle with the size of the cell in a developing embryo (Goehring and Hyman, 2012). How organelles and other micron-sized structures within the cell are assembled and maintained to have a specific size is still not well understood.
A simple idea, which seems to provide the answer in several cases, is that the cell maintains a limiting pool of a diffusible molecular component that is required for assembling the structure. In such a case, size control is simply achieved by the structure growing until the limiting pool is depleted to the point when the rates of assembly and disassembly of the structure are matched.
The idea that a limiting pool plays a major role in size control was the subject of a recent review that summarized the experimental evidence for this mechanism in the assembly of diverse structures such as centrosomes, flagella, and the nucleus (Goehring and Hyman, 2012). In addition, a recent in vitro study used a microfluidic system to encapsulate cytoplasm from Xenopus egg extracts in small droplets and showed that spindle size is proportional to the droplet volume, thereby suggesting that the amount of cytoplasmic material controls the size (Good et al., 2013). Furthermore, another study showed inverse scaling of the size of nucleoli with nuclear size in a developing C. elegans embryo in conditions when the number of nucleoli components in the nucleoplasm was fixed, also consistent with the limiting pool mechanism (Weber and Brangwynne, 2015).
The key idea of the limiting pool mechanism of size control is that assembly slows down as the free subunit pool is depleted and the size of the assembling structure increases. When the rate of assembly of the structure matches disassembly, the cytoplasmic (“free”) pool of the limiting component reaches the so-called critical concentration, which is equal to the dissociation constant of the assembly reaction. At this point the structure being assembled reaches a well-defined size. This is the expected assembly dynamics for a single structure, however, what happens to these dynamics when multiple structures are assembled from a shared limiting pool? In this case, once the critical concentration is established, the molecular component that is limiting could stochastically transfer from one to another structure with no change to the free concentration of this component, therefore incurring no free-energy penalty. Notably, additional size control mechanisms can impose a free energy penalty for such an exchange. In this paper, we study the implications of limiting pool mechanism on the size-control of multiples structures growing from a shared pool of diffusing components, when such additional size control mechanisms are absent.
Although the key ideas of our theoretical study can be extended to three dimensional structures like nucleoli (Weber and Brangwynne, 2015), we focus here on the filamentous structures that comprise the cytoskeleton. Filamentous structures are a particularly good model system for investigating questions relating to size control because “size” can be simply defined by the length of the filament. Most cytoskeletal structures are composed of actin filaments and microtubules, which in turn are composed of actin monomers and tubulin dimers. These subunits undergo constant turnover as they are stochastically added and removed from the structure, yet the structures themselves can be maintained at a precise size. This is important since large changes in structure size can produce significant deviations from its normal physiological functions. For example, in yeast cells intracellular transport is disrupted if actin cables overgrow and buckle (Chesarone-Cataldo et al., 2011). In addition, experiments have shown that when filamentous structures are cut to a smaller size, they often grow back to their physiological length suggesting that the length is under tight control (Marshall et al., 2005).
In some instances, multiple filamentous structures, made from a shared pool of actin monomers or tubulin dimers, coexist within the cell’s cytoplasm. For example, actin cables and actin patches in yeast are made up of actin monomers. They have different size, shape, and function, yet they coexist in the same cytoplasm while exchanging actin monomers from an apparently common pool (Michelot and Drubin, 2011). This observation raises the question, how are such diverse structures assembled and maintained from a common pool of subunits?
Here, we consider the stochastic assembly of multiple filamentous structures from a common and limited pool of subunits with a specific focus on the length fluctuations of these assembled structures. We assumed the simple scenario when the limiting components are the building blocks of the filamentous structures being assembled and have no other effect on the length of the filaments. From this simple, analytically tractable model of stochastic assembly we derive general conclusions about the limiting pool mechanism, and describe its limitations in controlling the sizes of multiple structures within the cell.
Notably, this approach purposefully considers the limiting monomer pool to be the only mechanism by which filament length is controlled. Cognizant of the fact that in cells multiple size-regulating mechanisms might be at play, we contend that the simple, limiting pool mechanism discussed here is a useful “null hypothesis” against which experimental data can be analyzed (Marshall, 2016). To the extent that the detailed quantitative predictions of the limiting pool mechanism are not borne out by experiments (that is, the null hypothesis can be rejected based on quantitative measurements), one can be confident that other size control mechanisms are at play.
Results
We consider the limiting pool mechanism of size control in the context of a simple model where filaments grow from a fixed number of nucleating centers within the cell by stochastic addition of diffusing monomers. Monomers, whose number in the cell is fixed, also stochastically dissociate from the filament. The number of filaments is fixed by the number of nucleating centers, which can be a single protein or a protein complex, and which aid in the formation of the filament. An example is provided by formins which help assemble filamentous actin structures. Formins bind to the barbed end of an actin filament and capture (profilin bound) actin monomers from solution, which are then incorporated into the growing filament (see Figure 1A). Note that the model we consider is a significant departure from textbook examples of stochastic filament assembly where every monomer in solution can serve as the site of new filament assembly. In our case filament assembly occurs only from nucleating centers.
Figure 1. Growth of a filament from a single nucleating center and two nucleating centers in the presence of a limiting pool of monomers.
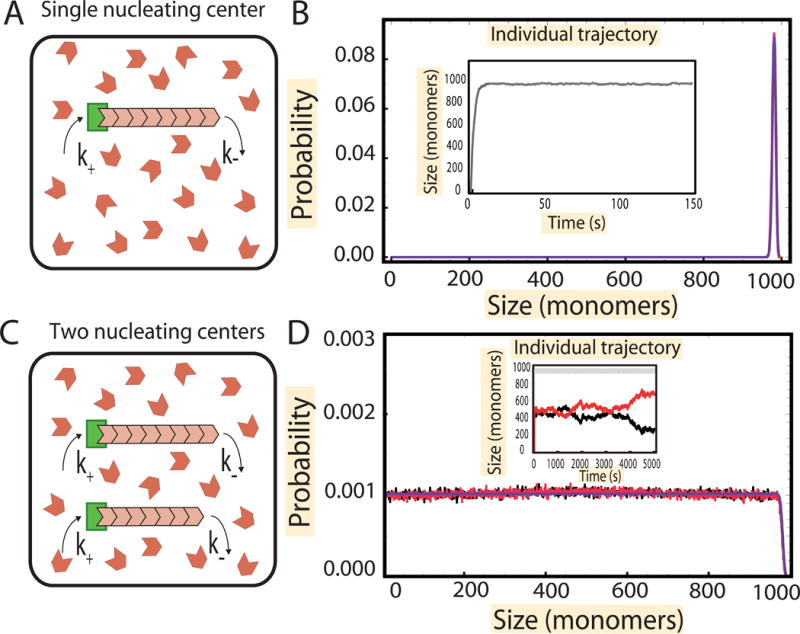
(A) Schematic showing the growth of a single filament (pink) from a single nucleating center (green) in a pool of monomers (in red). (B) (Inset) Numerical simulation of the growth trajectory of a single filament from the nucleating center (gray). After a fast growth phase, the size attains a steady state. By considering several such trajectories, we compute the probability distribution of filament lengths numerically, and a peaked distribution of size is obtained (in red). The parameters used for simulations are , k− = 10 s−1 and N = 1000, where Nfree is the number of free monomers in solution and is equal to N − l where l is the length of the filament in monomers. The simulation results are compared with the analytical results (blue) obtained in STAR Methods, section “Exact solutions of filament distributions”. (C) Schematic showing the growth of filaments (pink) from two nucleating centers (green) in a pool of monomers (in red). (D) (Inset) Numerical simulation of the growth trajectory of the two individual filaments (red and black) and the sum of their lengths (gray). After an initial growth phase where the two filaments grow roughly in unison and the total length of the two filaments reaches steady state, we observe anti-correlated fluctuations in the individual lengths. These fluctuations lead to individual filaments having a uniform distribution of lengths (red and black) in simulations; we compare these to results obtained analytically (blue) in STAR Methods, section “Gamma function representation of two filaments”. The parameters used for simulations are k− = 10 s−1 and N = 1000, where Nfree is the number of free monomers in solution and is equal to N − l1 − l2, where l1 and l2 are the lengths of the two filaments.
We consider three different scenarios, one when there is a single nucleating center in a cell which contains a fixed number of monomers, the case of two identical nucleating centers, and of two distinct nucleating centers, which differ in the rates at which they incorporate monomers. An example of inequivalent nucleators is provided by the two different formins Bni1 and Bnr1 in budding yeast, which assemble actin filaments at different rates (Buttery et al., 2007). Later in this section, we turn our attention to the case of many filaments and also discuss how our results carry over to the case when three dimensional structures are assembled from a limiting pool.
A limiting-pool of monomers assembles into a single filament of a well-defined length
First we consider the case of a single nucleating center, where a single filament is assembled by the addition and dissociation of monomers. The total number of monomers in the cell, N, is fixed, and each monomer can associate to a filament with assembly rate k+, which is proportional to the number of free monomers in the cell. Hence, for a single filament, its assembly rate starts off as but as the filament grows, it decreases to k′+(N − l), where l is the length of the filament in units of monomers. Note that the rate constant k′+ is obtained by taking the second order rate constant for monomer addition, which has units M−1s−1, and multiplying it by the volume of the cytoplasm within which the free monomers diffuse. The rate of assembly is thus length dependent, and assuming a constant monomer dissociation rate, k−, it leads to a peaked distribution of filament lengths (Figure 1B).
To describe the dynamics of an individual filament, we model the growth and decay of the filament using the master equation formalism. The key quantity to compute is the probability, p(l, t), that the filament has a length l (measured here in units of monomers) at time t. The master equation describes the evolution of p(l, t) in time, by taking into account all the possible changes of the state (length) of filament that can occur in a small time interval Δt. The master equation for a single filament is (for l > 0)
| (1) |
We compute the steady-state distribution of filament lengths by setting the left-hand side of the equation to zero and omit the time variable in p(l) to indicate the steady state nature of the distribution. We use detailed balance equations , to obtain (See section “Exact solutions of filament distributions” in STAR Methods), where is a dimensionless dissociation constant for the chemical reaction of a monomer binding to filament (equal to the dissociation constant multiplied with the cell volume). For example, for actin cables in yeast cells we estimate κd ~ 104 and N ~ 2 × 105, using the measured concentration of actin in yeast (~ 10μM) (Johnston et al., 2015), the typical volume of a yeast cell (~ 40μm3) (Philips and Milo, 2015) and the measured rates of association (11.6 μM−1 s−1) and dissociation (1.4 s−1) for binding of actin monomers to actin filaments (Pollard, 1986) (See section “Estimates for actin cables in yeast” in STAR Methods for the calculations). The mean and standard deviation of the distribution are given by N − κd and , respectively. This distribution is very peaked, and the same is true for the distribution of free monomers, which in fact is very close to Poisson (See STAR Methods, “Main inferences and estimates” section). Notably, the typical length of the filament is essentially given by the number of available monomers unless k′+ and k_ are fine-tuned to be close in value (See STAR Methods, section “Fraction of monomers in filaments”).
We used stochastic simulations to analyze the time evolution of the length distribution. We start with a filament of zero length growing from a single nucleating center and then follow the growth trajectory of the length of the filament in time as monomers attach and fall off. After some time, we observe the filament reaching a steady state (see Figure 1B inset), when the length distribution of the filaments no longer changes with time. The distribution extracted from these simulations matches the analytic results. The time scale over which the steady state is reached is of order 1/k′+, which can be understood as the time it takes N monomers to be taken up from the pool at a rate k′+ N (see Box 1 and STAR Methods, section “Growth time scale τg” for a more precise calculation).
Box 1. Experimental tests of the limiting-pool mechanism.
Our study makes several predictions that can be used to test the limiting pool mechanism. In case of a single filamentous structure assembled from a pool of monomers, the steady state distribution of filament length (STAR Methods, Section “Main inferences and estimates”) can be tested in experiments in which the total number of monomers is tuned. This can be achieved, for example, by using the microfluidic approach described in (Good et al., 2013). We observe that the mean length (N − κd) of the filament depends on the total number of monomers whereas the variance (κd) does not. This result can be used as a stringent test of the limiting-pool mechanism of size control.
Furthermore, if there are multiple identical structures being made from a common pool of monomers, we predict the existence of anti-correlated fluctuations of individual filament lengths over time. For the two filament case, we predicted that these fluctuations will be observed at time scales of order N2/k−, which can also be tuned by controlling the total number of monomers. An experiment with two inequivalent filaments assembling from a common monomer pool should also reveal the time scale of order N, during which the slower assembling filament loses the monomers it quickly accumulated in the initial growth phase.
One example where in vivo experiments can be used to test our predictions for the case of filaments is provided by fission yeast cells. These cells have two different types of actin structures, namely cables and patches which are assembled by different nucleating factors (formins and the Arp2/3 complex, respectively) (Rotty et al., 2015; Suarez et al., 2015). Recently it was shown that it is possible reduce the number of patches in yeast cells by over-expressing profilin, which is an actin-binding protein that has two specific effects on assembly: it significantly favors the formation of cables by increasing the assembly rates of formin-nucleated filaments and it inhibits Arp 2/3 mediated branching and hence represses the formation of patches (Rotty et al., 2015; Suarez et al., 2015). Thus, by regulating the level of profilin either formin or Arp 2/3 generated structures will take up most of the available pool of actin monomers. This observation is consistent with our calculations since we find that when two structures are competing for the same subunit pool the one that assembles faster takes up practically all subunits. Still, further experiments need to be performed in which size distributions of different structures are measured to quantitatively test predictions of the limiting monomer pool model.
Predictions of the limiting pool mechanism for the case of assembly of three-dimensional structures could be tested in C.elegans early embryo cells, where two nucleoli are assembled from a shared pool of nucleoli particles. These nucleoli grow equally in size up until cell division (~ about 20 minutes) (Weber and Brangwynne, 2015). Measurements of the nucleoli size and how they scale with the size of the nucleus are consistent with predictions of the limiting pool mechanism (Weber and Brangwynne, 2015). Experiments have also revealed that during the assembly phase the size (volume) of the nucleolus grows with time to the fourth power (Berry et al., 2015). This measurement is inconsistent with the assumption of size-independent rates k′+ and k−, and also with the assumption that the rates grow in proportion to the radius of the nucleolus, presumably due to the active role played by transcription of rRNA. Regardless, in steady state we still expect the assembly and disassembly rates to be balanced, and therefore we predict the same diffusive dynamics and large fluctuations of the sizes of individual nucleoli, as long as the limiting pool mechanism alone is responsible for their size control. Specifically, we predict that in cells engineered to have longer cell cycles one should observe the predicted large, anti-correlated fluctuations in individual nucleoli sizes.
Time scales of assembly
In the Results section, we discussed different time scales associated with growth of filaments from identical nucleating centers, i.e., growth and diffusion timescales and their dependence on the number of monomers in the pool. One can use those calculations to estimate timescales in the case where multiple actin cables are made from a common pool of actin monomers in the mother compartment of a budding yeast cell. Using previously published numbers for cell volume (Philips) and rates of association and dissociation of monomers to actin filaments (Pollard, 1986), we estimate k′+ = 5 × 10−3 1/s. Given that the observed number of actin cables is about ten we predict that the growth phase lasts for less than a minute, assuming that there are no additional length control mechanisms at play. (See STAR Methods, sections “Growth time scale τg” and “Estimates for actin cables in yeast” for details.)
In contrast, we estimate the diffusion time scale to span several days (STAR Methods, Section “Diffusion time scale τd”). In other words, we should never observe order-N2 fluctuations in cable lengths on the time scale of live-cell experiments, given a division time of about 90 minutes. Note that for this estimate, we assume that all the actin in the mother compartment of the budding yeast cells are used to make cables. This is a reasonable assumption as these cells have very few or no patches in their mother compartment. A substantially smaller number of actin monomers in cables could bring down the estimate of the diffusion time scale considerably due to the N2 dependence of this time scale.
Of course, there could be other reasons why large length fluctuations of cables are not observed in live cell experiments: other length-control mechanisms could be at play, which may reduce length fluctuations, and even lead the system to an altogether different steady state. Indeed, several actin and formin binding proteins have been shown to play an important role in controlling cable length (Chesarone-Cataldo et al., 2011; Mohapatra et al., 2015, 2016).
Two equivalent filaments assembling from a common limiting pool of monomers leads to large, anti-correlated fluctuations in their lengths
Next we turn to the case of assembly of multiple filamentous structures competing for a common, limited pool of monomers. We begin by considering the simplest case of two identical nucleating centers that are growing one filament each (Figure 1C). The results obtained in this simple case are also found in the more general many-filament case, which is described in detail in the STAR Methods.
In the case of two identical nucleating centers, each of the two filaments adds a monomer to it at the same rate k′+. Therefore, the assembly rate of filaments starts off as k′+N, however as the two filaments grow, it decreases to k′+(N − l1 − l2), where l1 and l2 are the lengths of the two filaments in units of monomers. The rate of dissociation (k−) of monomers is assumed to be identical for both filaments.
Since there are now two filaments in the cell, we characterize the state of the system with a joint probability distribution p(l1, l2, t), which satisfies the master equation
| (2) |
At steady state, and the joint probability distribution takes on the product form , which is a textbook result from queueing theory (Kelly, 1979) (see “Exact solutions of filament distributions” section in STAR Methods). Here is once again the dimensionless dissociation constant. The distribution of lengths for a single filament, i.e., p1(l1) and p2(l2), can be obtained from the joint distribution by summing over all possible lengths of the other filament (l2 and l1, respectively); we perform these calculations explicitly in sections “Equal nucleating centers” and “Gamma function representation of two filaments” of the STAR Methods.
An approximate formula for the distribution of lengths for a single filament in steady state can be derived from a simple argument, which also sheds light on the physics of the problem. In steady state the average number of free monomers left in solution is κd, and the distribution of free monomers is very close to Poisson with standard deviation , implying that it is very narrowly concentrated around its mean κd. (The Poisson approximation to the free monomer pool was previously derived (Hu and Othmer, 2011) by assuming that the probability of a filament having zero length is zero; we rigorously justify this approximation in STAR Methods, section “Equal nucleating centers”.) Hence, the total number of assembled monomers, i.e., the sum of the lengths of the two filaments, is to an excellent approximation a constant N − κd. Furthermore, monomers diffuse from one filament to another with equal rates (k−/2; see STAR Methods, section “Diffusion time scale τd”, for the derivation) independent of the lengths of individual filaments. Therefore, every possible configuration of filament lengths that satisfies l1 + l2 = N − κd is equally likely. The number of such configurations is N − κd + 1, implying that the probability distribution for a single filament is
| (3) |
i.e., it is uniform on the interval (0, N − κd). This approximation is very accurate except in a very narrow interval of lengths of order when l1 is close to N − κd, where it decays rapidly to zero. This effect is due to the Gaussian fluctuations of the free monomer pool around its mean. This simple argument can be further extended to an arbitrary number of filaments and is validated by our exact calculations (see STAR Methods, section “Equal nucleating centers”).
We also used stochastic simulations to investigate individual growth trajectories for the two filaments and compared the results to our analytical steady-state distributions p1(l1) and p2(l2) (Figure 1D). Once again, we follow the stochastic trajectory in time of the length of each individual filament. Initially, both filaments grow in unison (subject to small fluctuations) until their combined length reaches the steady state total length N − κd. After this rapid growth period the individual trajectories of the filaments diverge, as one grows the other shrinks (Figure 1D inset). These anti-correlated fluctuations in length persist indefinitely and eventually become of order N − κd. At the same time the length distributions for each filament, p1(l1) and p2(l2), settle into their steady state values, Equation 3.
These dynamics are illustrated in Figure 2, where we plot p1(l1, t) obtained from stochastic simulations. At first the mean filament length increases until the free monomer pool (or equivalently the total filament length) reaches its steady state (black curves). The time scale for this is of order 1/(2k′+), same as in the case of a single filament. After that, we observe the widening of the distribution at constant mean (blue curve) which eventually becomes uniform (red curve) at the longest times, of order N2/k− (STAR Methods, section “Diffusion time scale τd”). Thus, we reach the somewhat surprising conclusion that the limiting-pool mechanism does not control length in the case of two structures competing for the same monomers. In fact, this remains true even when the additional processes of catastrophe and rescues (to simulate microtubules undergoing dynamic instability) were included in our simulation analysis (Figure S1).
Figure 2. Evolution of probability for individual filament lengths in the case of identical nucleating centers.
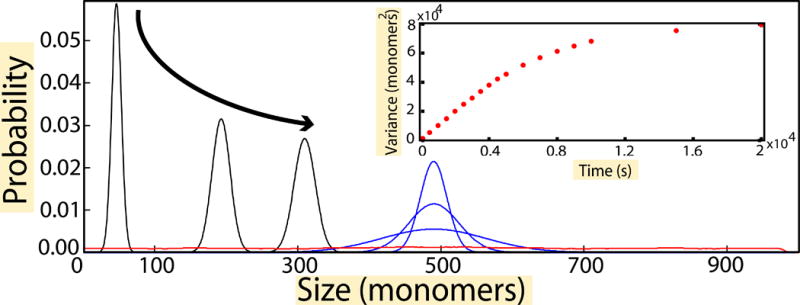
In the initial growth phase (black), the distribution of individual filament lengths starts off as a peaked distribution whose mean increases, until the total length reaches a steady state. The growth phase is followed by the slow phase of monomers swapping which leads to anti-correlated fluctuations are seen in the individual trajectories, which is translated into the increase in the width of the filament length distributions while the mean stays unchanged (blue). The final, steady state distribution (red) is flat. (Inset) Plot of variance of the distribution (σ2) vs. time of simulation. The variance initially increases linearly with time, but later saturates. Time was varied from 0 – 20000 s in steps of 100 s. From the slope of the linear part plot of, we find a diffusion constant D = 5 monomer2/s using the relation σ2= 2Dt. The parameters used for simulations were , k− = 10 s−1, N = 1000 and Nfree = N − l1 − l2, is the number of free monomers in solution and l1 and l2 are the lengths of the two filaments.
Once the total length of the two filaments has reached a steady state, any monomer that comes off a filament is rapidly taken up by one or the other filament. This is a consequence of the fact that in steady state the total number of monomers in the two filaments is narrowly distributed around its mean value. We therefore expect individual filament lengths to exhibit diffusive dynamics. We demonstrate this explicitly in the inset to Figure 2 where the variance, σ2, of the length distribution of an individual filament is seen to increase linearly with time until it eventually saturates. Given the diffusional law σ2 = 2Dt the initial slope of the σ2 curve in Figure 2 inset gives the diffusion constant D. The diffusion constant can be computed by taking into account that when the total length reaches steady state monomers exchange between the two filaments with the rate k−. A detailed analysis of all possible exchange processes while accounting for their probabilities leads to the exact result D = k−/2 (STAR Methods, section “Diffusion time scale τd”), which we also checked with stochastic simulations.
Two inequivalent filaments assembling from a common limiting pool of monomers results in only one filament having a well-defined length
Next, we consider the case of two nucleating centers with different assembly rates for filaments in a common pool of monomers (see Figure 3A). As in the example of two different formins in yeast, monomers are stochastically added to the two filaments at different rates: k′1,+ and k′2,+. These rates start as k′1,+N and k′2,+N but as the two filaments grow they decrease to k′1,+(N − (l1 + l2)) and k′2,+(N − (l1 + l2)) respectively, where l1 and l2 are the individual lengths of the two filaments in units of monomers. The rate of dissociation, k−, of monomers is assumed identical for both filaments.
Figure 3. Growth of filaments from two inequivalent nucleating centers in a limiting pool of monomers.
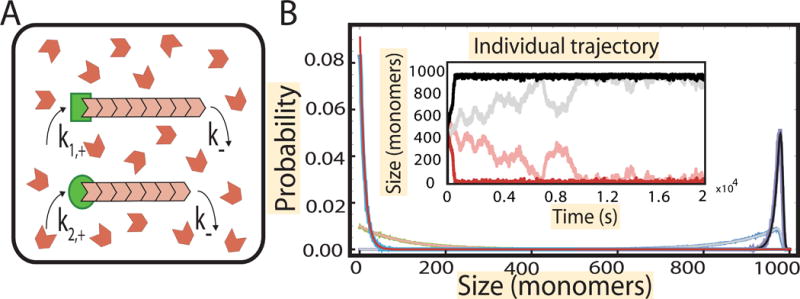
(A) Schematic showing the growth of filaments (pink) from two distinct nucleating centers (green) in a pool of monomers (in red). (B) (Inset) Numerical simulation of the growth trajectory of the filaments from the nucleating centers. Shown are trajectories for 10% difference in assembly rate (dark) and 1% difference (light). After a growth phase, where both filaments accrue monomers, the faster growing filaments attains a steady state by taking up most of the free monomers, while the slower filament shrinks. The faster growing filament attains a peaked distribution of size (black) and the slower one attains a geometric distribution (red). The parameters used are , , , k− = 10 s−1, N = 1000 and Nfree = N − l1 − l2, is the number of free monomers in solution and l1 and l2 are the lengths of the two filaments. The simulations are overlaid on the results obtained analytically (blue and green) in STAR Methods, section “Gamma function representation of two filaments”.
As before, the joint probability distribution p(l1, l1, t), satisfies a master equation, but now with different assembly rates for the two filaments, namely
| (4) |
The steady state joint distribution of filament lengths is again given by a product form, from which the distribution of lengths of each individual filament can be computed. The exact calculation is in the STAR Methods (section “Unequal nucleating centers”) and here we provide a simple intuitive argument.
For concreteness, let us assume that the assembly rate of first filament is larger than the second, i.e., k′1,+ > k′2,+ (or equivalently, , using for the dimensionless dissociation constants). Then over a long period of time, a larger number of monomers will join the first, fast assembling filament. Since the detachments rates are the same, the first filament will accumulate most of the monomers. Hence, p1(0) ≈ 0, implying that average rate of monomers leaving the first filament is k−(1 − p1(0)) ≈ k_. Next, by equating this rate to the rate at which monomers attach to the first filament, i.e., k′1,+ × (average number of free monomers), we find that the average number of free monomers is , and, as in the case of equivalent filaments, we expect the steady-state distribution of the number of free monomers to be Poisson. From this result, we can derive the distribution of lengths for the second, slower growing filament from the detailed balance equations , which leads to the conclusion that the lengths for the second filament are distributed geometrically, i.e., . Then the first filament is virtually unaffected by the presence of the second and the distribution of its lengths is peaked, as in the case of a single filament. The approximate average length of the first and the second filament are given by and , respectively (STAR Methods, section “Unequal nucleating centers”).
Once again, to develop intuition about the assembly dynamics we used stochastic simulations to follow the growth of the two filaments from the two nucleating centers each starting from zero length (Figure 3B, inset). Just like in the case of equal nucleating centers, we observe that there is an initial, fast growth phase which occurs over a time of the order . After the growth phase, we observe that filament with a higher assembly rate grows to a steady state characterized by a large length, whereas the other filament shrinks to zero. When the two assembly rates are close in magnitude then we find anti-correlated fluctuations of lengths similar to what we observed in the case of identical nucleating centers. These fluctuations happen over a time scale , i.e., over a time that is of order N, and eventually subside as the system settles into a steady state with practically all monomers taken up by the faster growing filament. This is illustrated in the plots of steady-state length distributions for the two filaments, where for the fast-assembling filament we observe a distribution sharply peaked around the mean while the slower assembling filament is characterized by a geometric distribution of filament lengths peaked at zero; see Figure 3B. We find wider distributions when the assembly rates are numerically close to each other, which results from the increased fluctuations of the filament lengths. Comparison of the analytical solution of Equation 4 for p1(l1) and p2(l2) (see STAR Methods, section “Unequal nucleating centers”) to the simulation data serves as a stringent test of the simulation procedure (Figure 3B).
To summarize, when considering two nucleating centers with different rates of filament assembly, the one with the higher rate wins and assembles a filament of well-defined length, while the other filament does not stably form.
Assembly of many filaments
Thus far we have only considered two filamentous structures competing for the same pool of monomers. In cells, though, it is common to observe multiple structures made from the same pool of monomers. For example, the number of actin cables in budding yeast is about ten or so, while the number of actin patches is of order ten to a hundred.
The key results described for two filamentous structures readily carry over to the case of multiple filaments. More specifically, for any finite number of filaments starting at zero length, growth of all filaments is strongly favored in the initial phase of assembly, and all the filaments quickly reach lengths of order N (the total number of monomers) over a time scale which is independent of N. Then, in case of inequivalent assembly rates, the slower growing filaments gradually lose monomers and diminish in length to a small, geometrically distributed length. The duration of this phase is of order N. Furthermore, at the end of this phase practically all the monomers are taken up by the fast-growing filaments, and the number of free monomers approaches a Poisson distribution with a mean equal to the smallest (dimensionless) dissociation constant among all the filaments. This then implies that the total number of monomers assembled into the fast-growing filaments will have a well-defined size characterized by a peaked distribution. The lengths of individual fast-growing filaments then undergo protracted diffusive dynamics on time scales of the order N2. These dynamics are generated by the stochastic swapping of monomers between individual filaments, and eventually lead to a broad, power-law distribution of filament lengths in steady state. Notably, we find that if the number of fast growing filaments is of the order of N, then in the limit of large N the resulting length distribution is geometric (see STAR Methods, section “Equal nucleating centers” for a detailed calculation for this case). This theoretical result might provide a link between two recent experiments on mitotic spindles, one which showed that the spindle size is controlled by a limiting pool mechanism (Good et al., 2013) and the other that found that individual microtubule lengths within the spindle are geometrically distributed (Brugués et al., 2012).
To illustrate our general results regarding assembly of many filaments from a common pool of monomers we show in Figure 4 the different phases of assembly using an example of six filaments with three growing at the same, fast rate and three taking up monomers more slowly. (See section “Aggregate distribution of multiple filaments” in STAR Methods for detailed calculations pertaining to the multi-filament case.)
Figure 4. Growth dynamics of multiple filaments from two types of inequivalent nucleating centers.
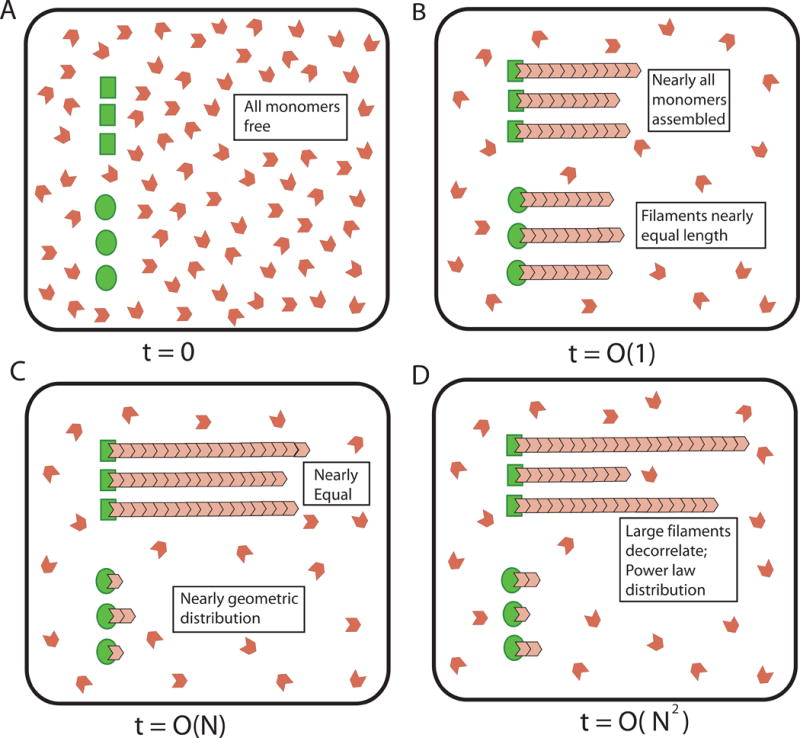
(A) Schematic showing six nucleating centers in a pool of monomers where the first three nucleate filaments that grow at a high association rate k′h,+ and the remaining three at a slower rate k′s,+ (k′h,+ > k′s,+); all filaments disassemble with the same rate k−. (B) After a rapid assembly phase lasting approximately 1/(3(k′h,+ + k′s,+)), the fast and slow growing filaments reach the average length of Nk′h,+/(3(k′h,+ + k′s,+)), and Nk′s,+/(3(k′h,+ + k′s,+)), respectively. (C) After this rapid assembly phase, the slower growing filaments slowly decrease to nearly zero length over a period of time of order , where is the (dimensionless) dissociation constant for the slow growing filaments. At the end of this phase, the three slow growing filaments are geometrically distributed with parameter , the free monomer pool approaches a Poisson distribution with mean , and nearly all the monomers, , are taken by the fast growing filaments, and are equally distributed among them. (D) Finally, the sizes of the three largest filaments decorrelate on a slow, diffusion time scale which is of order N2, during which the monomers randomly exchange between these large filaments.
Assembly of three dimensional structures
From the preceding analysis, we see that assembling multiple filamentous structures from a shared, limiting pool of monomers does not lead to precise size control of individual structures without additional control mechanisms. This stems from the inherent reversibility of the assembly process once steady state is reached. At steady state exchange of subunits between different structures results in structures with either very small, exponentially distributed sizes, or large sizes whose variability is described by a power-law distribution. Since the key ingredient for this result to hold, namely the reversibility of stochastic assembly, is not limited to one-dimensional filamentous structures, equivalent phenomena are expected to occur for three-dimensional structures assembled from a common and limiting pool of subunits.
In the case of multiple three-dimensional structures being assembled from a shared pool of subunits, the total mass (or equivalently, the total number of assembled subunits) of the structures will reach a well-defined value once the assembly rate and the disassembly rates are balanced, and the pool of free subunits reaches the critical concentration. As in the case of filamentous structures, the masses of individual structures will be broadly distributed.
To demonstrate this explicitly we have done stochastic simulations of assembly of two identical three-dimensional structure from a finite pool of subunits. The three-dimensional nature of the structures is reflected in our choice of assembly and disassembly rates, which are both proportional to the radius of the growing structures (Berg and Purcell, 1977). As in the case of assembling filaments, the assembly rate diminishes as the structures grow and the free monomer pool is depleted. As before we find that after an initial, fast growth phase the system tends to a steady state in which individual masses undergo diffusive dynamics and leading to a mass distribution which is broad (Figure S2).
Discussion
The limiting pool mechanism of size control has been implicated in the assembly of a number of different cellular structures in different cell types (Goehring and Hyman, 2012). In order to understand the quantitative features of this general size-control mechanism we considered a simple model of stochastic growth of filamentous structures from a limiting pool of diffusing monomers, where the number of filaments is determined by the number of nucleating centers at which they assemble. While we found that the limiting-pool mechanism is able to precisely control the length of a single filament, it is unable to control individual filament lengths when multiple filaments are assembled from the same monomer pool, even when additional processes of catastrophe and rescues were included (Figure S1). At steady state exchange of monomers between different filaments results in structures with either very small, exponentially distributed lengths, or large lengths whose variability is described by a power-law distribution. Since the key ingredient for this result to hold, namely the reversibility of stochastic assembly, is not limited to one-dimensional filamentous structures, equivalent phenomena are expected to occur for three-dimensional structures assembled from a common and limiting pool of subunits (Figure S2). We suggest that when in vivo observations demonstrate that size control of multiple structures is precise, mechanisms beyond the limiting pool must contribute to this precision (See Box 1).
One of the consequences of our study is that a limiting pool mechanism by itself is unable to make steady-state structures of different and well defined sizes. Our analysis describes the limitations associated with the limiting-pool mechanism and underlines the necessity for the cell to invest in additional mechanisms to control size. In fact, there are other length-sensing mechanisms that have been reported in the filament literature (Andrianantoandro and Pollard, 2006; Chesarone-Cataldo et al., 2011; Gardner et al., 2011; Marshall et al., 2005; Mohapatra et al., 2015, 2016; Varga et al., 2006). In these studies specific proteins have been identified as being critical to length-control, and found to either modulate the assembly or the disassembly rate of cytoskeletal filaments in a length dependent fashion (Mohapatra et al., 2016). Such size sensing mechanisms might play a role in assembling three dimensional structures as well. For example, an autocatalytic reaction at the core was recently proposed to play a critical role in controlling the sizes of centrosomes (Zwicker et al., 2014), which could provide an additional feedback of centrosome size to the assembly rate. An interesting question is whether such size sensing mechanism exist in other three dimensional structures like the nucleoli, where only the limiting pool has been implicated as the only size control mechanism thus far (Weber and Brangwynne, 2015) (See Box 1).
In summary, the limiting-pool mechanism of size control can produce a single structure of a well-defined size. On the other hand, this mechanism is unable to maintain multiple structures that have a well-defined size, which assemble from a common pool of subunits. Cells can get around this problem by using additional size-regulatory mechanisms (Mohapatra et al., 2016). Quantitative experiments that measure the size and assembly dynamics of intracellular structures, and how they vary with different parameters, like the total amount of the limiting subunit or the size of the chamber within which they are assembled, are needed to quantitatively define the role of the limiting-pool mechanism in regulating size. Such experiments can also help uncover general design principles of how cells regulate the sizes of their organelles.
STAR Methods
In the STAR Methods, we provide the computation and rigorous justification of several results from the manuscript. First, in section “Heuristic derivation of filament distributions”, we present an intuitive derivation of the approximate filament distributions for a general number of equal and unequal nucleating centers; see sections “Equal nucleating centers”, “Unequal nucleating centers” and “General case”. Even though our derivation is heuristic, it leads to explicit and accurate approximations for the range of parameters that are relevant in biology. The accuracy of these approximate solutions in this section is further rigorously validated in section “Exact solutions of filament distributions”. For a general number of filaments with inequivalent assembly rates, our results show that in steady state there can be at most one filament with well-defined length of order N, while all the other filaments are very small O(1); we use O(x) to denote a quantity that is of the order of x. Furthermore, any scenarios that grow multiple filaments of order N yield highly variable lengths whose standard deviation is about the same as the mean.
Section “Time dynamics” describes the time dynamics of our system. We show that filaments undergo three phases, namely the growth, linear adjustment and diffusion ones. The growth phase is relatively quick of the order τg = O(1), and at the end of this phase all filaments have length of the order O(N). After this phase, in the case of unequal assembly rates, the system will undergo a linear adjustment phase τa = O(N), during which the filaments with smaller assembly rates will decrease to nearly zero and will have geometric distributions. Next, if at the end of this phase there are multiple filaments with the highest assembly rate, they will converge to steady state through a slower diffusion time scale τd = O(N2). During this phase, the dissociated monomers will randomly transfer between the longest filaments, which will result in their steady state distribution being a power law. In order to estimate the diffusion time scale, we also compute the diffusion constant.
In the section “Main inferences and estimates”, we briefly summarize our results and make a number of additional inferences that are relevant for biology. We discuss the fraction of monomers in filamentous form, as well as provide explicit expressions for the filament mean and variance under different growth conditions. In addition, we briefly outline our results on time dynamics of the finite monomer pool mechanism.
In section “Exact solutions of filament distributions”, using Queueing Theory arguments (Anselmi et al., 2013), we show that the exact solution to our model admits an explicit representation up to a multiplicative normalization constant. However, the computation of the normalization constant in this solution requires a prohibitively large summation of the order O(Nf), where N is the number of monomers and f is the number of filaments. In addition, even if one were capable of computing the sums, they provide little, if any, insight into the problem. To alleviate these issues, we develop intuitive and explicit representations of the filament distributions in terms of auxiliary random variables in section “Equal nucleating centers”. In addition to being computationally efficient, these explicit representations readily provide a rigorous justification for our heuristic approximations from section “Heuristic derivation of filament distributions”. Furthermore, for 2 nucleating centers, we present computationally suitable representation for the solutions in the section “Gamma function representations of 2 filaments”, which are used in Figure 1D and Figure 3 as comparison to the stochastic simulations.
Finally, in section “Aggregate distribution of multiple filaments”, we derive the aggregate distributions, both for the case of equivalent and inequivalent nucleating centers.
Heuristic derivation of filament distributions
Here, we provide an intuitive derivation of the filament distributions. The accuracy of the derived distributions will be validated through the exact calculations in the following section.
Let N be the total number of monomers and f ≥ 1 be the number of filaments. Next, we use l1, l2, …, lf, to denote the number of assembled monomers in filaments 1, 2, …, f, respectively. Each monomer has a rate k′i,+, 1 ≤ i ≤ f to assemble to filament i, and can disassemble one monomer at a time with disassembly rates kj,−, 1 ≤ j ≤ f. In addition, we assume that kj,− = k−, i.e., all filaments disassemble at the same rate. Furthermore, let , 1 ≤ i ≤ f, be the corresponding dissociation constants, and since they are chemical constants, they do not scale with N. Let p(l1, l2, …, lf) be the steady state probability that lengths of filaments 1, 2, …, f, are equal to l1, l2, …, lf, respectively.
Equal nucleating centers:
We assume that κd ≪ N, i.e., the dissociation constant is not too large, otherwise most monomers would be free in steady state. Hence, when N is large and f ≪ N, the probability of a filament having zero length is negligible. Therefore, the rate at which monomers join the free monomer pool is approximately fk_. Let M be the number of free monomers in steady state. Now, when the number of free monomers is M = m, the rate at which monomers leave the monomer pool is mfk′+. By equating the rates in and out of state M = m, we obtain that the distribution of free monomers satisfies approximately
| (1) |
This balance equation readily yields a Poisson distribution, i.e., . Note that the preceding derivation is exact for the case of f =1, i.e., in this case the number of free monomers is truncated Poisson; see section “Exact solutions of filament distributions”. Otherwise, the Poisson distribution is an approximation, albeit a good one, since the rate at which monomers join the pool can be smaller than fk− at the boundary when some filaments have zero length. The rest of the derivation assumes f ≥ 2.
Next, when κd is relatively large, but still κd ≪ N, due to the Central Limit Theorem1, M is very concentrated around its mean, 〈M〉 ≈ κd, i.e., M ≈ κd. Therefore the total number of assembled monomers is approximately constant, i.e., l1 + ⋯+ lf ≈ N − κd. Furthermore, monomers diffuse from one filament to others with equal rates (k−/f, see section “Diffusion time scale τd”) independent of the lengths of individual filaments, and therefore, all states l1 + ⋯+ lf ≈ N − κd are equally likely; the number of configurations satisfying the preceding equation is . Now, if we are interested in the filament distribution, say filament 1, then the remaining filaments satisfy l2 + ⋯+ lf ≈ N − κd − l1, and the number of these configurations is . Therefore, when f ≪ N − κd, and l1 < N − κd,
| (2) |
and p(l1) ≈ 0, for l1 > N − κd. For f = 2, this expression is uniform, i.e., in interval (0, N − κd), and p(l1) ≈ 0 outside of it.
The preceding derivation assumes that f is a fixed constant, which does not scale with N. Now, we consider the case when the number of filaments f is of the same order as N, i.e., when in the limit as N grows to infinity, the ratio (N − κd)/(N − κd + f) ≈ N/(N + f) → ϕ, 0 < ϕ < 1. Interestingly, in this case, the preceding power law distribution becomes geometric with parameter ϕ. Namely, for any constant l1, after canceling the common terms in the fraction of two binomial coefficients in Equation 2, we obtain
Next, since l1 is fixed, i.e. l1 ≪ f, l1 ≪ N, and κd is a chemical constant that doesn’t scale with N the preceding fraction further simplifies to
and hence the distribution of lengths is geometric.
Unequal nucleating centers:
Let us assume that all ki,− = k_, , and that f is finite, i.e., it doesn’t scale with N. Then, over a long period of time, a considerably larger number of monomers will join the first filament than any other filament. Hence, since the detachment rates are all the same, the first filament tends to accumulate most of the monomers, i.e., it gets considerably larger than other filaments. Therefore, in steady state p1(0) ≈ 0. This implies that the rate at which monomers leave the first filament is k−(1 − p1(0)) ≈ k_, and the average rate at which monomers are attaching to the first filament is 〈M〉k′1,+. Then, due to rate conservation, 〈M〉k′1,+ ≈ k_, yielding . Now that we know the average number of monomers 〈M〉, we can compute pi(0), i ≥ 2, from 〈M〉k′i,+ = k_(1 − pi(0)), which gives . Furthermore, the distribution of filament i ≥ 2 satisfies, for l > 1, pi(l)k_ ≈ 〈M〉k′i,+ pi(l − 1), implying that pi(l) is geometric, i.e.,
| (3) |
For the free monomer pool, the rate at which the monomers are arriving to the pool is
| (4) |
and, when M = m, the rate at which monomers are leaving the pool is m(k′1,+ + k′2,+ + … + k′f,+). Therefore, by equating these rates, we derive an approximate balance equation
| (5) |
resulting in M being approximately Poisson with a mean . Finally, L1 can be computed from N − M − L2 − …− Lf. From this we can see that, L1 = O(N), i.e., the first filament takes most of the monomers.
For f = 2, the distribution of first filament is peaked and second filament is geometric, i.e.,
General case:
Here, we consider a general scenario where f1 filaments are growing at a fast rate with dissociation constant , and the remaining f2 = f − f1 are growing at slower rates; the total number of filaments f is finite, as in the preceding subsection. Again, we show that the limiting-pool mechanism can grow at most one filament of the cell size, O(N), with a well-defined length, i.e., peaked filament distribution.
The same arguments as in the preceding section can show that each of the f2 filaments will have geometrically distributed and independent lengths. Hence, the total sum of filaments, S2, in the slower growing group will have a peaked distribution since the sum of independent geometric variables is peaked. In fact, as f2 increases, the distribution of S2 will approach the Gaussian, and it will be highly centered around its mean. Therefore, the aggregate distribution of all the fast growing filaments will be highly concentrated around its mean ; note that accounts for the average number of free monomers in steady state. Thus, the total number of assembled monomers in the fast growing group will be approximately constant in steady state ; note that this group of filaments will grab nearly all monomers. Hence, if f1 = 1, the first filament will have a well-defined length, i.e., peaked distribution, of order O(N).
However, if f1 ≥ 2, the monomers in the first group will, similarly as in the derivation of Equation 2, assume any of the equally likely configurations that satisfy , whose number is . Hence, if we are interested in a single filament distribution from this group, say filament 1, then the remaining filaments satisfy and the number of these configurations is . Therefore, by dividing the preceding binomial expressions, when , and , one derives that the distribution of a single fast growing filament is a power law
| (6) |
Note that for f1 = f (f2 = 〈S2〉 = 0), the preceding distribution coincides with the previously derived in Equation 2 for of section “Equal nucleating centers”.
Overall, regardless of the number of filaments, there can be at most one filament of order N with well-defined size, i.e., peaked distribution.
Time dynamics
In this section we show that the filament time dynamics occurs on three times scales of the order O(1), O(N) and O(N2), respectively. First, they go through a quick growth phase where all filaments reach size O(N) in time ; see section “Growth time scale τg” in STAR methods. Then, in case of inequivalent filaments, they undergo a linear adjustment phase of the order τg = O(N), as described in section “Adjustment time scale τa for inequivalent filaments”. In this phase filament dynamics can be thought of as diffusion with drift. Finally, in case of two or more fastest growing filaments, they will start performing a random walk until they reach steady state, which will occur at a slower diffusion time scale τd ≈N2/(2D), where D is the diffusion constant; see section “Diffusion time scale τd”. We provide an expression for the diffusion constant D in section “Calculation of diffusion constant D”.
Growth time scale τg
Initially when the filaments start to assemble, there is a strong tendency for them to grow. In this section, we will estimate this growth time scale. To this end, assume f filaments that are growing in a pool of N monomers with possible different association rates and equal dissociation constant k−. Now, let us consider a continuous limit, where monomers are treated as fluid. Hence, during the initial phase while all li(t) > 0, the continuous (fluid) amount of free monomers m(t) satisfies
| (7) |
from which one easily computes, using the initial value m(0) = N,
| (8) |
From this equation we see that the monomer pool is quickly reduced to a small fraction of N in time
| (9) |
Next, when all filaments grow at the same rate , we immediately obtain by symmetry the continuum approximation for the individual filament lengths
| (10) |
Hence, in the case of equal assembly rates, all filaments will quickly grow to length (N − κd)/f in time . More specifically, the time required for a filament to get very close to (N − κd)/f, say 90%(N − κd)/f is given by log (10)/ , i.e., .
Using , for actin cables in budding yeast cells (see “Estimates for actin cables in yeast” section in STAR Methods for more details), and typical number of cables, i.e. f = 10, we find , i.e. less than a minute.
After this initial growth phase, in case that all assembly rates are equal, the filaments will undergo a random diffusion, which is described in section “Diffusion time scale τd” in STAR Methods. On the other hand, if some of the association rates are different, there will be a linear adjustment period that we describe in the next section.
Adjustment time scale τa for inequivalent filaments
In this section, we study the filament time dynamics when some of the assembly rates are different. It is convenient to denote the sum of all the association rates as . Then, the individual filament lengths satisfy
| (11) |
which by replacing Equation 8 from the preceding section and using integration, yields
| (12) |
The preceding equation remains true initially while all filament lengths li(t) > 0. From this equation we see that, after a quick growth phase of the order , the individual filaments will reach approximately lengths , and then, those with assembly rates smaller than the average assembly rate, i.e. , will linearly decrease until one of them reaches zero. At that time, say , we exclude the filaments whose length is zero, and repeat the preceding calculations with the remaining filaments and initial values equal to , . We repeat these calculations for as long as there are filaments that linearly decrease to zero. There can be at most f − 1 such linear adjustment times, and since each time is of the order N, the entire adjustment time in the general case will be τa = O(N).
Now, in the case of two inequivalent filaments with , the preceding analysis, for all t such that l2(t) > 0, specializes to
| (13) |
and
| (14) |
| (15) |
As in the preceding general case, after the initial growth , the filaments will reach the respective lengths and , i.e., both filaments will be of order N. After that, they will go through an adjustment phase τa, during which the second filament will linearly decrease to zero and the first will grow to include nearly all N. We can compute τa, by using Equation 14 and setting l2(τa) = 0; hence, by ignoring the small exponential term in Equation 14, τa results from solving the linear equation, which produces
| (16) |
When and are close, this adjustment time will be very large, but will still scale linearly in N; one could think of this phase as diffusion with a small drift .
Therefore, at the end of this adjustment phase, we have
| (17) |
Finally, for t > τa, there will be a very small correction in size, such that and .while l2(t) = 0. This will occur very quickly in time .
Diffusion time scale τd
In case of two or more fast growing filaments, after the preceding growth and linear adjustment phases are completed, these large filaments will perform a random diffusion until they reach the steady state in diffusion time τd. The diffusion constant for this random walk is D = (f − 1)k−/f, which will be computed in the following section. In order to reach the steady state, the filaments need to cover at least the total average filament length (N − κd), which will happen in time of the order τd ≈ N2/(2D) = N2/k_.
If we take into account the estimated in vivo rate of disassembly (see “Estimates for actin cables in yeast” section in STAR Methods), τd ~ several days. In other words, it is impossible to see fluctuations in the time scale of experiments. The fraction of F-actin to G-actin in cells and the fraction of F-actin in patches are not well characterized and could contribute to an error to the estimate. But, at the same time, the fact that we do not see the fluctuations in minutes could hint that there are additional length control mechanisms at play and the cables are not determined just by the limited pool of actin monomers.
Calculation of diffusion constant D
As noted earlier, in this section we will provide further arguments that the filament lengths perform a random walk in steady state for the case of equal nucleating centers, and compute its diffusion constant D. Consider the steady state time dynamics of Li(t), where Li(t) is the length of filament i at time t, and let all assembly and disassembly rates be equal k′i,+ = k′+ and k′i,− = k′−, respectively.
Using the analysis from the preceding sections (for finite f), we know that the number of free monomers M in steady state is approximately Poisson with mean κd and standard deviation , implying when κd ≫ 1, that . This and L1 + ⋯ + Lf = N − M yield for 1 ≪ κd ≪ N,
| (18) |
Thus, the filaments perform a random walk in steady state in a close proximity of the hyperplane
| (19) |
and the number of free monomers is very close to
| (20) |
Next, let us pick an interval of time T, such that 1/(fk′+) ≪ T ≪ N2. Now, consider the first filament L1. Then, in interval (0, T), a Poisson number of monomers with mean Tk_ leaves L1. Each of these monomers is delayed in the free monomer pool an exponential amount of time with mean 1/(fk′+), and then it rejoins one of the filaments. Note that the randomly delayed Poisson process is again Poisson with the same rate k−. After passing through the free monomer pool, each of the monomers will rejoin one of the filaments with probability 1/f. Hence, Tk_/f of these monomers will return to the first filament. Therefore, the net number of monomers that leaves the first filament is approximately Poisson with equal mean and variance given by .
On the other hand, the f − 1 filaments Li, 2 ≤ i ≤ f, will contribute an independent Poisson number of monomers of mean . Since these contributions are independent and Poisson, their total sum is Poisson with mean and variance equal to .
Thus, by summing the preceding variances for the total number of monomers that leave and arrive, we obtain, for 1 ≪ T ≪ N2, that
| (21) |
As we can see, the net average number of monomers that leave and arrive to a filament is zero. Hence, the only mechanism with which the filaments change their lengths and approach the steady state is by performing a random walk/diffusion in the proximity of L1 + L2 + ⋯ Lf ≈ N − κd hyper-plane. This will happen very slowly, in time τd = O(N2); see the preceding section. After the system reaches the steady state, this random walk will continue indefinitely.
For f = 2, the variance is Tk_ and consequently the diffusion constant D is k_/2.
Main inferences and estimates
In this section, we briefly summarize our results and make a number of additional inferences that are relevant for biology.
Fraction of monomers in filaments
From section “Heuristic derivation of filament distributions” we see that the number of free monomers M for finite f is closely approximated by the Poisson distribution with mean (recall k′+ is the assembly rate per monomer and k− is the rate of removal of monomers); note that, in the case of unequal nucleating centers, κd is the smallest disassociation constant. Hence, the mean number of assembled monomers in all filaments is given by N − κd, where N is the total number of monomers. The fraction of monomers in filamentous form relative to the total pool of monomers is given by . Typically the initial rate of assembly, Nk′+ is much faster than the rate of disassembly k− (Example: In actin, k′+ = 11.6 μM−1s−1 and k− = 1.4 s−1 (Pollard, 1986) at the barbed end of the filament); then this ratio determines the ratio of free monomers at steady state, which will be very small.
From limiting pool mechanism, most of the monomers are going to be in the filaments. In order to obtain a different fraction of monomers in the filamentous form, k′+ and k− will have to be fine-tuned. Such fine-tuning is not seen very often in biology, and cells probably get by this situation by having additional length control mechanisms.
Steady state properties in case of equal nucleating centers
From the approximate expression (Equation 2) for the distribution, or by symmetry, one easily computes an intuitively expected mean filament length , i.e., the average filament lengths are equal. However, the filament distribution is flat with a very high variance/standard deviation. To compute the variance/standard deviation, we obtain 〈L〉2 ≈ (N − κd)2/(f(f + 1)) using (Equation 2), and combine it with the preceding expression for the mean
| (22) |
We see, maybe somewhat surprisingly, that the standard deviation is of the same order as N and the mean. In the case of f = 2, the distribution is entirely flat, i.e., uniform in interval (0, N − κd)
| (23) |
and p(l) ≈ 0 outside of it. The mean of this distribution is (N − κd)/2 and the standard deviation is .
Interestingly, when the number of filaments scale with N, i.e., N/(N + f) → ϕ, 0 < ϕ < 1, the preceding power law distribution turns into geometric with parameter ϕ.
Steady state properties in case of unequal nucleating centers
Let us first consider f = 2 that are growing in two unequal nucleating centers. The distribution of first filament is peaked and second filament is geometric, i.e., . The approximate average lengths of the first and second filament are respectively given by
| (24) |
The one with higher assembly rates always takes up most of the monomers, leaving not much for the other one. In addition, the average length of the first filament increases with N, while the second one remains constant. Furthermore, their variances are given by
| (25) |
Here, both variances remain constant as N increases. In either case, it is impossible to obtain multiple peaked distributions of individual filaments with just finite monomer pool. We need additional size-control mechanisms to achieve that.
Finally, if two groups of finitely many filaments f1, f2 are growing, where the first group has higher assembly rate , and the second group slower rate , , then the second group will have f2 geometrically distributed filaments. Hence, the expected total number of monomers in the second group will be , and the first group will have . Similarly as in the case of two filaments, the variance of each group remains constant as N increases. The first group will grab almost all the monomers, and in the case of a single filament, f1 = 1, its length will be well defined.
However, in case of multiple large filaments, f1 ≥ 2, they will have a power law distribution given in Equation 6, with the standard deviation of the same order as the mean, similarly as in Equation 22.
Overall, we show that in general there can be at most one large filament with well-defined size, and thus, additional size-control mechanisms may be needed to achieve multiple filaments of order N.
Time dynamics of the finite monomer pool mechanism
Here, we briefly summarize the main results on the time dynamics of the free monomer pool. As shown in section 2, the filaments undergo three phases, namely the growth, linear adjustment and diffusion ones.
Initially, the environment strongly favors assembly which quickly reduces the monomer pool to a small fraction of N i.e., the filament lengths become (N), in time
| (26) |
At the end of this phase, each filament will grow to the order N size
| (27) |
After that, in the case of unequal assembly rates, the system will undergo a linear adjustment phase for a period of time τa = O(N), during which the filaments with smaller assembly rates will reduce to nearly zero, and their dissociated monomers will be taken up by the fastest growing filaments. The filaments will follow the dynamics given by Equation 12 until one of them reaches the boundary value of zero length. This will happen in time (N). After this time, we exclude the filament of zero length, and study the dynamics of the remaining filaments until all of those with lower assembly rates reach zero.
For example, if there are six filaments, out of which three are assembled at a higher rate , and the other three at a slower rate , . Then, the slower growing filaments will be reduced to zero at time
| (28) |
which can be computed by setting Equation 12 to zero for the slowest growing filament(s).
Following the linear adjustment period, in case of more than one fastest growing filament, e.g., 3 in the preceding example, the largest filaments will approach the steady state through a slow diffusion time scale of the order τd = O(N2). During this phase, the dissociated monomers will randomly diffuse between the fast growing filaments, leading to the flat, power law, distribution in steady state.
Estimates for actin cables in yeast
Now, we will use previously known experimental numbers to estimate the total amount of actin proteins N and the dissociation constant κd for actin cables in budding yeast.
Cables consist of a few actin filaments bundled together. These cables are polymerized by a few formins, and hence the assembly rate of cables are about 10 times more than that of single filaments, i.e. (Pollard, 1986; Yu et al., 2011). Dividing this rate by, 40 μm3, the average volume of an yeast cell (Philips), we get .
Also cables are degraded in about a minute (Goode et al., 2015) so considering a few (~3) filaments per cross section, 4 microns per filament, and 400 monomers per micron of a cable, we estimate a k− ≈ 60 s−1. Hence κd,cables≈ 104. Also, budding yeast contains about 10μM free actin (Johnston et al., 2015), which translates to N ≈ 2 × 105 actin proteins.
Exact solutions of filament distributions
In this section we derive the exact expressions for the filament distributions. In addition, at the end of each subsection, we demonstrate how these exact expressions yield the explicit approximations from section “Heuristic derivation of filament distributions”.
Let N be the total number of monomers and f ≥ 1 be the number of filaments. Recall, we use l1, l2, …, lf, to denote the number of assembled monomers in filaments 1,2, …, f, respectively. Each monomer has a rate , 1 ≤ i ≤ f, of assembly to filament i. Here, we consider that each filament disassembles one monomer at a time with disassembly rates kj,−, 1 ≤ j ≤ f. Furthermore, let , 1 ≤ i ≤ f, be the corresponding dissociation constants, and let p(l1, l2, …, lf) be the steady state probability that lengths of filaments 1,2, …, f are equal to l1, l2, …, lf, respectively. This model falls into the framework of Queueing Theory presented in (Kelly, 1979), and thus, admits a solution given by
| (29) |
where 0 = (0,0,…,0) and p(0) is the normalization constant obtained from Σp(·) = 1. One can also check that Equation 29 is a solution by simply substituting it in the detailed balance equations. In addition, this is the unique solution since this Markov chain is aperiodic, irreducible and finite.
For f = 1, one can easily compute the normalization constant, and derive the filament distribution
| (30) |
where is the regularized Gamma function. Note that the steady state distribution of filament lengths can be computed exactly by using the detailed balance equations , to obtain , where . Typically in cells N ≫ κd, and the normalization constant p(0) is numerically indistingushable from e−κd, yielding the following simple formula for filament distribution , which is reported in the main text and plotted in Figure 1B for specific parameters. However, the derivation for single filament does not scale for general f since the number of summands grows as O(Nf). To alleviate this problem, in the following two subsections we derive a more intuitive representation for the filament distributions using the auxiliary random variable. To illustrate the idea for f = 1, we can define an auxiliary Poisson random variable M(κd) with mean κd. Then the preceding solution can be represented as
| (31) |
and the number of free monomers can be shown to be truncated Poisson
| (32) |
Here, it can be readily seen that P[M(κd) ≤ N] is numerically indistinguishable from 1 when κd ≪ N, implying that the number of free monomers is effectively Poisson, and the filament length is N − M. This probabilistic representation is essential for the derivations for general f ≥ 2 in the following subsections, as well as the rigorous justifications of our heuristic derivations from section “Heuristic derivation of filament distributions”. Due to the inherent complexity of computing Equation 29, which requires O(Nf) operations, a number of approximate techniques have been developed in prior studies for this and related models. These prior techniques relied on integral/transform methods, as well as the algebraic computation with special type of scaling; see (Anselmi et al., 2013) and the references therein. In contrast to the prior techniques, our probabilistic approach appears to be new, and it readily yields explicit approximations for the quantities and range of parameters that are relevant in biology.
Equal nucleating centers:
We start with a few probabilistic identities that will be used in our derivations. Let X be an integer valued random variable taking random values in {0,1,2..} and define an indicator/step function 1[x ≤ n] = 1 is x ≤ n, and 1[x ≤ n] = 0, otherwise. With this notation, for any function f(x), we can be conveniently represent the truncated expected value as
| (33) |
Also, it will be convenient to write the number of combinations by defining (n)k = n(n − 1)(n − 2)…(n − k + 1), k ≥ 1 with (n)0 = 1. With this notation,
| (34) |
Normalization constant
Starting with Equation 29 and Σp(n) = 1, or κdN e−κd Σ p(n) = κdN e−κd, we derive
| (35) |
where in the last equality, we have used Equations 33 and 34. Note that M(κd) is a Poisson random variable with mean κd. We introduced the notation M(κd) to differentiate it from the free monomer pool M, which is only approximately Poisson. In addition, in the third equality, we have used that the number of nonnegative solutions to is .
Filament distributions
Next, let 0i denote a vector with i zeros, and let p(0f, N) denotes explicitly the normalization constant for a problem with f filaments and N monomers. Then it is easy to see that the length distribution for one filament is given by
| (36) |
Hence, by combining the preceding expression with Equation 29, we obtain
| (37) |
Free monomer distribution
Similarly, we can easily derive the distribution of free monomers
| (38) |
Now, we can show how the heuristic approximations from the preceding section follow from these exact results.
Approximation
Assume first that the number of filaments f is finite, i.e., it doesn’t scale with N. Since M(κd) is Poisson, its mean and standard deviation are κd and , respectively. Hence, when κd ≫ 1, M(κd) is very close to its mean, i.e., it is unlikely to deviate from it more than two standard deviations . Therefore, when 1 ≪ κd ≪ N, we can approximate M(κd) ≈ κd, P[M(κd) ≤ N] ≈ 1 and P[M(κd) ≤ N − l] ≈ 1[l ≤ N − κd], to obtain
| (39) |
,i.e., p(l) has approximately polynomial shape in interval (0, N − κd), and p(l) ≈ 0 outside of it. On the other hand, when f is large, i.e., of the order of N, similar reasoning leads to a rigorous justification of the geometric approximation from the end of section “Equal nucleating centers”. Here, one has to be more careful in unwinding the numerator and denominator in Equation 37 since they will consist of a large number of products. However, when l is finite, the numerator and denominator in Equation 37 differ only in a finite number of l terms, and we only need to limit these. To this end, we use the fact that κd is a finite constant, i.e., κd/N → 0 as N grows, implying P[M(κd) ≤ εN] ≈ 1 for any small ε > 0 and N sufficiently large. Hence, for ε small and N large enough, Equation 37 simplifies to
Regarding the free monomer pool, when f is finite, and m ≪ N, then N + f − 1 − m ≈ N, and Equation 38 simplifies to
| (40) |
This also provides a rigorous justification for the previously derived Poisson approximation in Equation 3.
Unequal nucleating centers:
Before proceeding with the derivations, let us observe that the following analysis can be easily extended to include the case when a group of filaments grow at the fastest assembly rate, i.e., . However, we omit this extension since it further complicates the notation, and just discuss it heuristically in sections “General case” and “Aggregate distribution of multiple filaments”.
If X1, X2, …, are independent random variables taking values in non negative integers, then
| (41) |
| (42) |
Normalization constant
As before, let be a Poisson random variable with mean and , 2 ≤ i ≤ f, geometric random variables with parameters . Note that we introduce the notation to denote a true geometric variable, and differentiate it from the filament length Li, which will only be approximately geometric. Furthermore, we assume that and are independent. Next,
| (43) |
where in last two inequalities, we used Equations 41 and 42; this gives a compact representation for p(0), namely,
| (44) |
Length distribution for the first filament
Using the above expression, we can evaluate the length distribution for the first filament
| (45) |
For the length distribution of the other filaments, 2 ≤ i ≤f we compute
| (46) |
Free monomer distribution
By following exactly the same steps one can easily derive the exact distribution for the free monomer pool
| (47) |
Approximations
Again, we will show how these exact results lead to the justification for the heuristic derivation in the preceding section. Assume that f is finite, , and with (f−1)C ≪ N, then for N large and ,
| (48) |
The numerator in Equation 46 can be also written as
| (49) |
Hence, we can simplify Equation 45 to
| (50) |
i.e., the length of the first filament is approximately equal in distribution
| (51) |
Furthermore, when , Equations 46, 48 and 49, yield for i ≥ 2
| (52) |
i.e., . Hence, the other filaments are approximately geometric. Finally, the equation for the free monomer distribution, when in addition m ≪ N − (f − 1)C, is approximately Poisson
| (53) |
Thus the average filament lengths and average number of free monomers are given by , and . As noted earlier, in this scenario, 〈L1〉 = O(N) and 〈Li〉 = O(1), i ≥ 2, i.e., the first filament takes approximately all the monomers.
Gamma function representation of two filaments
In this section, we represent our analytical results in terms of the regularized Gamma function, Q(n, κd), that is more suitable for numerical evaluation. Note that Q(n, κd), for integer n is equivalent to the cumulative Poisson distribution function, i.e.,
| (54) |
where is the incomplete Gamma function. Now, we will represent the distributions from Equations 37, 45, and 46 in terms of for Q(m, κd) for f = 2.
Equal nucleating centers:
Observe that for f = 2, the Expression 37 reduces to
| (55) |
Next, by using 〈1[M(κd) ≤ N]〉 = P[M(κd) ≤ n] = Q(n + 1, κd) and
| (56) |
in the preceding expression for p(l), we obtain
| (57) |
Unequal nucleating centers:
Now for f = 2, the expressions in Equations 45 and 46 reduce to
| (58) |
and
| (59) |
First, we derive a regularized gamma function representation for the denominator
| (60) |
Next, the numerator in can be represented as
| (61) |
Hence, by replacing the preceding expressions in the formula for p1(l) and rearranging the terms, we obtain
| (62) |
and similarly, using
| (63) |
we obtain
| (64) |
Note that we used Equations 57, 62 and 64 to verify our simulation results in Figure 1D and Figure 3.
Aggregate distribution of multiple filaments
While in this paper, we primarily focus on the individual filament distributions, it may be of some interest to compute the aggregate distribution for all assembled monomers in a group of filaments. To this end, consider a similar situation as in Section “General case”, where two groups of finitely many filaments f1 ≥ 2 and f2 ≥ 2 are growing with dissociation constants and , respectively; f1 + f2 = f. Let filaments L1, ⋯, , be part of the first nucleating center, and , ⋯, Lf, part of the second. Then the total number of assembled monomers in each nucleating center is respectively given by and , respectively. Here, we provide a heuristic derivation for the aggregate distribution. This can be validated using the same type of exact calculations as in section “Exact solutions of filament distributions”. To avoid repetitions, we avoid these calculations.
Equal assembly rates:
By using the same heuristic arguments as in section “Equal nucleating centers”, we can easily compute, for 1 ≤ s ≤ N − κd
| (65) |
i.e., S1 has Beta distribution on interval (0, N − κd) with parameters (f1, f2), which can be somewhat pointy. The mean and standard deviation are given by
| (66) |
We can see that the standard deviation is relatively smaller as compared to the single filament case, e.g., when f1 = f2, , which comes from averaging. However, it is still very large and of the same order as the mean.
Unequal assembly rates:
Recall from section “General case” that all filaments in the second group are independent and geometrically distributed with parameter , which easily implies that the means and variances are given by
| (67) |
| (68) |
Note that only the first structure can grow with N, while the second remains constant. Furthermore, the distribution of S2 is given by a negative Binomial
| (69) |
which is a pointy distribution that approaches the Gaussian as f2 increases.
Simulation protocol
We used stochastic simulations to solve the master equations in Equations 1, 2 and 4 in the main text. We start with a filament of zero length and then follow the stochastic trajectory of the filament. In the simulation, the state of the system is characterized by the filament length. In one step of the simulation we choose one of the set of all possible transitions from the current state of the system to the next. The transitions are chosen at random according to their relative weight, which is proportional to the rate of the transition. Once a particular transition is chosen the system is updated to a new state, which becomes the new current state. The time elapsed between two consecutive transitions is drawn from an exponential distribution, the rate parameter of which equals the sum of all the rates of allowed transitions. This process is repeated for a long enough time such that the length of the cable reaches steady state. We obtain many such trajectories of a single filament and then compute the steady state distributions of filament lengths.
Supplementary Material
Acknowledgments
We wish to thank Rob Phillips, Bruce Goode, Wallace Marshall, Stephanie Weber, David Kovar, Seham Ebrahim, Fred Chang and Nenad Pavin for many stimulating discussions. This work was supported by the National Science Foundation through grants DMR-1206146 and MRSEC-1420382 (J.K., L.M. and D.H.), Boehringer Ingelheim Funds, Arthur Klorfein Scholarship and Fellowship Fund, Mountain Memorial Fund Scholarship, Howard A. Schneiderman Endowed Scholarship (T.J.L.). We are grateful to the Burroughs-Wellcome Fund for its support of the Physiology Course at the Marine Biological Laboratory, where part of the work on this paper was done.
Footnotes
Author Contributions
L.M., T.J.L., D.H., P.R.J. and J.K. designed the study, did the calculations, and wrote the paper. Simulation were conducted by L.M. T.J.L. and D.H.
M can be viewed as sum of n independent Poisson variables with mean κd/n since the sum of independent Poisson variables is also Poisson; hence, when κd is large, M is approximately Gaussian.
References
- Andrianantoandro E, Pollard TD. Mechanism of actin filament turnover by severing and nucleation at different concentrations of ADF/cofilin. Mol Cell. 2006;24:13–23. doi: 10.1016/j.molcel.2006.08.006. [DOI] [PubMed] [Google Scholar]
- Anselmi J, D’Auria B, Walton N. Closed Queueing Networks Under Congestion: Nonbottleneck Independence and Bottleneck Convergence. Math Oper Res. 2013;38:469–491. [Google Scholar]
- Berg HC, Purcell EM. Physics of chemoreception. Biophys J. 1977;20:193–219. doi: 10.1016/S0006-3495(77)85544-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Berry J, Weber SC, Vaidya N, Haataja M, Brangwynne CP. RNA transcription modulates phase transition-driven nuclear body assembly. Proc Natl Acad Sci U S A. 2015;112:E5237–5245. doi: 10.1073/pnas.1509317112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brugués J, Nuzzo V, Mazur E, Needleman DJ. Nucleation and Transport Organize Microtubules in Metaphase Spindles. Cell. 2012;149:554–564. doi: 10.1016/j.cell.2012.03.027. [DOI] [PubMed] [Google Scholar]
- Buttery SM, Yoshida S, Pellman D. Yeast formins Bni1 and Bnr1 utilize different modes of cortical interaction during the assembly of actin cables. Mol Biol Cell. 2007;18:1826–1838. doi: 10.1091/mbc.E06-09-0820. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chesarone-Cataldo M, Guérin C, Yu JH, Wedlich-Soldner R, Blanchoin L, Goode BL. The myosin passenger protein Smy1 controls actin cable structure and dynamics by acting as a formin damper. Dev Cell. 2011;21:217–230. doi: 10.1016/j.devcel.2011.07.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gardner MK, Zanic M, Gell C, Bormuth V, Howard J. Depolymerizing kinesins Kip3 and MCAK shape cellular microtubule architecture by differential control of catastrophe. Cell. 2011;147:1092–1103. doi: 10.1016/j.cell.2011.10.037. [DOI] [PubMed] [Google Scholar]
- Goehring NW, Hyman AA. Organelle growth control through limiting pools of cytoplasmic components. Curr Biol CB. 2012;22:R330–339. doi: 10.1016/j.cub.2012.03.046. [DOI] [PubMed] [Google Scholar]
- Good MC, Vahey MD, Skandarajah A, Fletcher DA, Heald R. Cytoplasmic volume modulates spindle size during embryogenesis. Science. 2013;342:856–860. doi: 10.1126/science.1243147. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goode BL, Eskin JA, Wendland B. Actin and Endocytosis in Budding Yeast. Genetics. 2015;199:315–358. doi: 10.1534/genetics.112.145540. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hu J, Othmer HG. A theoretical analysis of filament length fluctuations in actin and other polymers. J Math Biol. 2011;63:1001–1049. doi: 10.1007/s00285-010-0400-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Johnston AB, Collins A, Goode BL. High-speed depolymerization at actin filament ends jointly catalysed by Twinfilin and Srv2/CAP. Nat Cell Biol. 2015;17:1504–1511. doi: 10.1038/ncb3252. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kelly FP. Reversibility and stochastic networks. J. Wiley; 1979. [Google Scholar]
- Marshall WF. Cell Geometry: How Cells Count and Measure Size. Annu Rev Biophys. 2016;45:49–64. doi: 10.1146/annurev-biophys-062215-010905. [DOI] [PubMed] [Google Scholar]
- Marshall WF, Qin H, Brenni MR, Rosenbaum JL. Flagellar Length Control System: Testing a Simple Model Based on Intraflagellar Transport and Turnover. Mol Biol Cell. 2005;16:270–278. doi: 10.1091/mbc.E04-07-0586. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Michelot A, Drubin DG. Building distinct actin filament networks in a common cytoplasm. Curr Biol CB. 2011;21:R560–569. doi: 10.1016/j.cub.2011.06.019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mohapatra L, Goode BL, Kondev J. Antenna Mechanism of Length Control of Actin Cables. PLoS Comput Biol. 2015;11:e1004160. doi: 10.1371/journal.pcbi.1004160. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mohapatra L, Goode BL, Jelenkovic P, Phillips R, Kondev J. Design Principles of Length Control of Cytoskeletal Structures. Annu Rev Biophys. 2016 doi: 10.1146/annurev-biophys-070915-094206. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Philips RM, Milo R. Cell Biology by the Numbers. Garland Science; 2015. [Google Scholar]
- Pollard TD. Rate constants for the reactions of ATP- and ADP-actin with the ends of actin filaments. J Cell Biol. 1986;103:2747–2754. doi: 10.1083/jcb.103.6.2747. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rotty JD, Wu C, Haynes EM, Suarez C, Winkelman JD, Johnson HE, Haugh JM, Kovar DR, Bear JE. Profilin-1 serves as a gatekeeper for actin assembly by Arp2/3-dependent and -independent pathways. Dev Cell. 2015;32:54–67. doi: 10.1016/j.devcel.2014.10.026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Suarez C, Carroll RT, Burke TA, Christensen JR, Bestul AJ, Sees JA, James ML, Sirotkin V, Kovar DR. Profilin regulates F-actin network homeostasis by favoring formin over Arp2/3 complex. Dev Cell. 2015;32:43–53. doi: 10.1016/j.devcel.2014.10.027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Varga V, Helenius J, Tanaka K, Hyman AA, Tanaka TU, Howard J. Yeast kinesin-8 depolymerizes microtubules in a length-dependent manner. Nat Cell Biol. 2006;8:957–962. doi: 10.1038/ncb1462. [DOI] [PubMed] [Google Scholar]
- Weber SC, Brangwynne CP. Inverse Size Scaling of the Nucleolus by a Concentration-Dependent Phase Transition. Curr Biol. 2015;25:641–646. doi: 10.1016/j.cub.2015.01.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilson EB. The cell in development and heredity. New York: Macmillan; 1925. [Google Scholar]
- Yu JH, Crevenna AH, Bettenbühl M, Freisinger T, Wedlich-Söldner R. Cortical actin dynamics driven by formins and myosin V. J Cell Sci. 2011;124:1533–1541. doi: 10.1242/jcs.079038. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.